1xN Pattern for Pruning Convolutional
Neural Networks
Abstract
Though network pruning receives popularity in reducing the complexity of convolutional neural networks (CNNs), it remains an open issue to concurrently maintain model accuracy as well as achieve significant speedups on general CPUs. In this paper, we propose a novel 1N pruning pattern to break this limitation. In particular, consecutive N output kernels with the same input channel index are grouped into one block, which serves as a basic pruning granularity of our pruning pattern. Our 1N pattern prunes these blocks considered unimportant. We also provide a workflow of filter rearrangement that first rearranges the weight matrix in the output channel dimension to derive more influential blocks for accuracy improvements and then applies similar rearrangement to the next-layer weights in the input channel dimension to ensure correct convolutional operations. Moreover, the output computation after our 1N pruning can be realized via a parallelized block-wise vectorized operation, leading to significant speedups on general CPUs. The efficacy of our pruning pattern is proved with experiments on ILSVRC-2012. For example, given the pruning rate of 50% and N=4, our pattern obtains about 3.0% improvements over filter pruning in the top-1 accuracy of MobileNet-V2. Meanwhile, it obtains 56.04ms inference savings on Cortex-A7 CPU over weight pruning. Our project is made available at https://github.com/lmbxmu/1xN.
Index Terms:
Network pruning, pruning pattern, CPUs acceleration, CNNs.1 Introduction
Convolutional neural networks (CNNs) have substantially advanced varieties of computer vision tasks [1, 2, 3]. Despite these tremendous success, newly developed networks tend to have more learnable parameters which also mean more floating-point operations (FLOPs). As a result, these CNNs can be rarely run on the general CPUs embedded devices with limited computation power [4]. By pruning the redundancy in CNNs, the emerging network pruning has become a broad consensus in favour of model deployment by both the academia and industries.
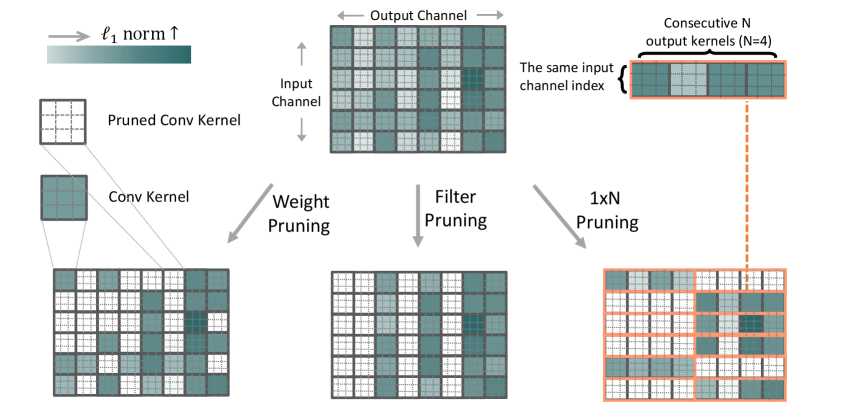
As illustrated in Fig. 1, according to the basic pruning granularity, existing works accomplishing network pruning are categorized into weight pruning and filter pruning. The basic granularity of weight pruning falls into individual weights at any location of the filters or connections between full-connected layers. It essentially sparsifies the network at a fine-grained level and is demonstrated to achieve an extremely high compression rate and high accuracy performance [4, 5, 6]. However, weight pruning receives very limited speed gains since its irregular sparsity barely takes advantage of vector processing architectures such as Single Instruction Multiple Data (SIMD), and poorly utilizes memory buses. In contrast, this increases latency due to the dependent sequences of reads [7]. Recent studies [8, 9, 7, 10] advocate N:M weight pruning where N out of M weights are zeros for every continuous M weights. Currently, this pattern achieves acceleration only in the case of 2:4. Besides, the acceleration is realized on the specially designed sparse Matrix Multiply-Accumulate (MMA) instructions of NVIDIA A100 towards modern single- and multi-GPU workstations, servers, clusters, and even supercomputers [7], making it impossible to be utilized on other types of GPUs, let alone the CPUs-based platforms.
Different from weight pruning, the basic granularity of filter pruning in Fig. 1 consists of the whole filters. It reduces network complexity at a coarse-grained level by removing all weights in a filter. Consequently, the network structure does not change, thus the sparsified network can be well fitted by regular hardware and off-the-shelf basic linear algebra subprograms (BLAS) library to obtain acceleration. Nevertheless, filter pruning only maintains accuracy under moderate sparsity rates. Otherwise, such methods suffer more significant performance degradation than weight pruning methods. For example, a recent study [11] shows that a parameter reduction of ResNet-50 can well retain the accuracy performance of the original network by weight pruning, however, it is only a reduction in filter pruning. Though the research community has developed varieties of techniques [12, 13, 14, 15], recent works [16, 17] demonstrate that the capacity of these techniques for performance improvement is indeed limited if appropriate training settings are given to the previous works.
Above all, how to simultaneously retain the performance and achieve apparent acceleration on mobile and embedded devices becomes a challenging but valuable problem. In this paper, we propose a novel pattern of 1N pruning with its merits in realizing both high-performing accuracy and apparent CPUs acceleration for practical model deployment. Our 1N pattern provides an intermediate granular level for network pruning, which is coarser as compared to the fine-grained weight but finer as compared to the coarse-grained filter. An example of our pruning pattern that satisfies N=4 requirement is shown in Fig. 1: the core distinction of our pruning from existing scenarios [15, 13, 12] lies in that our basic pruning granularity consists of consecutive N output kernels with the same input channel index. In short, we aim to remove these consecutive kernels with smaller norms that are considered less important in literature [12]. Our 1N pruning in this paper follows the typical three-step pipeline of network training, pruning consecutive kernels with smaller norms, and fine-tuning the sparsified one to recover the performance. At the point of the second step, we further propose a workflow of filter rearrangement, which rearranges the weight matrix in the output channel dimension according to the norm of each filter, based on which more influential consecutive kernels with larger norms are observed for accuracy improvements. Then, the next-layer weights are similarly rearranged in the input channel dimension to ensure the same convolutional results. In contrast to earlier developments [18, 19, 20] that also explore removing kernels, we have a stronger requirement of continuity on the N removed kernels, with its benefit in acceleration because these consecutive kernels can be stored continuously in the memory cache and the convolution with the inputs can proceed using a block-wise vectorized operation in parallel as analyzed in Sec. 3.4.
We display multiple compression rates using the light-weight MobileNet-V1 [21], -V2 [22], -V3 [23] and large-scale ResNet-50 [2] on the challenging ILSVRC-2012 [24], and compare our 1N pruning with weight pruning and filter pruning. The experiments suggest obvious increasing accuracy performance compared with filter pruning, and apparent inference acceleration compared with weight pruning. For example, given a pruning rate of 50% and N=4, our 1N pattern obtains around 3.0% improvements over filter pruning in the top-1 accuracy of MobileNet-V2 on ImageNet, meanwhile, it obtains 56.04ms inference savings on Cortex-A7 CPU compared to weight pruning which obtains no speedup.
This work addresses the problem of simultaneously maintaining accuracy and achieving general CPU speedups to enable practical model deployment on CPUs-based platforms. The key contributions of this paper include: (1) One novel pattern of 1N for network pruning. (2) A workflow of filter rearrangement for accuracy improvements. (3) Simultaneously maintaining high-performing accuracy and achieving apparent CPUs acceleration.
The remainder of this paper is organized as follows: We briefly discuss some relevant prior works in network pruning in Sec. 2. Then, we present details of our 1N pattern for network pruning in Sec. 3. In Sec. 4, a discussion on the empirical evaluation of our method in comparison with weight pruning and filter pruning is presented. Moreover, a brief discussion on the limitation of this work is given in Sec. 5, laying out some avenues for future research in our 1N pruning pattern. We finally conclude in Sec. 6.
2 Related Work
Traditional network pruning including weight pruning and filter pruning is a classical research topic. We briefly review some related works below.
Weight Pruning. Weight pruning dates back to Optimal Brain Damage [25] and Optimal Brain Surgeon [26], which prune weights based on the Hessian of the loss function. Despite their accuracy retaining, the second-order Hessian needs additional computation cost. Dong et al. [27] restricted the second-order derivatives for a specific layer to enable tractable computation. Han et al. [4] proposed to recursively remove small-weight connectivity and retrain the -regularized subnetwork to derive smaller weight values. Dynamic network surgery [28] performs pruning and splicing on-the-fly. The former compresses the network and the latter recovers the incorrect pruning. The lottery ticket hypothesis [29] randomly initializes a dense network and trains it from scratch. The subnets with high-weight values are extracted, and retrained with the initial weight values of the original dense model. Lin et al. [30] proposed a dynamic allocation of sparsity pattern and incorporated feedback signal to reactivate prematurely pruned weights.
Filter Pruning. The norm of filter weight such as -norm [12] is often considered as an indicator of filter importance. Filters with smaller norms are considered unimportant and removed. He et al. [31] pruned the filter with -norm criterion, but the pruned filters are changeable and endowed with the chance to be recovered during network training. Ding et al. [32] computed the changes in the next layer’s outputs to evaluate the impact of pruning the filters. Lin et al. [33] used the artificial-bee-colony-based evolutionary algorithm to automatically search for the best pruning structure for each layer. He et al. [34] leveraged reinforcement learning to sample many subnetworks from the original CNN for evaluation, and ultimately find the best compressed network. Liu et al. [13] adopted meta-learning to prune redundant filters. It trains a weight-generating meta-network in advance for subnetworks evaluation, and then searches for the best subnetwork.
Discussion. While a variety of approaches for network pruning have been proposed, existing methods fail to either maintain accuracy or achieve apparent speedups on the general CPUs-based platforms. Thus, it is natural for researchers to go further on pruning neural networks. This motivates our search for designing one new pruning pattern that enables general CPUs acceleration as well as maintains accuracy performance.
3 Methodology
In this section, we introduce the intuition of our method and present its implementation details. In order to simplify the explanations, we only talk about the convolutional layers as illustrations. However, our 1N pruning can also be applied to the fully-connected layers since their weights can be regarded as 1 x 1 convolutions.
3.1 Preliminaries
We start with notation definitions. Considering a pre-trained -layer CNN model , we denote its filter set as with , where , , and respectively indicate the number of output channel, input channel, kernel height and kernel width in the -th layer; is the filter set for the -th layer and is the -th filter in the -th layer. For the fully-connected layer, its weight matrix is indeed an exception of and . In order to simplify the explanations, in the following contents, we only talk about the convolutional layers as illustrations.
Network pruning can be implemented by imposing a mask upon . Here is a binary tensor (0 or 1) with its entries indicating the states of network connections, i.e., whether the corresponding weights are pruned or not. Thus, given an expected pruning rate , network pruning is formally expressed as:
| (1) |
where represents the masking operation, measures the importance of its input, and denotes the size of that varies according to the basic pruning granularity. We measure the input importance using the norm of the basic pruning granularity. We find this criterion sufficient, however, other metrics, such as weight gradients [6], activation sparsity [35], can be adopted as well.
Weight Pruning. The studies on weight pruning remove individual weights at any location of . Therefore, each mask in weight pruning has the same shape with of and its size . The specific objective of weight pruning is:
| (2) |
Filter Pruning. The studies on filter pruning remove the entire filter . Thus, each mask in filter pruning has the shape of and . The specific objective of filter pruning is:
| (3) |
In the following, we introduce a novel pattern of 1N pruning, whose basic pruning granularity falls into consecutive N output kernels with the same input channel index. We show that our 1N pruning can be an efficient and effective alternative to simultaneously accelerate the model inference on modern CPUs-based platforms and retain the accuracy performance.
3.2 1N Pruning Pattern
We define the problem of pruning CNNs using our 1N pattern. In order to simplify the explanations, we reformat the representation of as . Note that each element in is a kernel with the shape of , i.e., . Each column stands for a filter and each row consists of these kernels that have the same input channel index of .
As shown in Fig. 1, we further partition the whole into a collection of smaller blocks. Our partition can be made more precise for an matrix by partitioning into a collection of row-groups, and then further partitioning into a collection of col-groups. Consequently, each block is a 1N matrix including consecutive N output kernels with the same input channel index , namely . Based on this partitioned matrix, the basic pruning granularity of our 1N sparsity falls into these blocks. Thus, the mask, , in our 1N pruning has the shape of and its size . Finally, the specific objective of our 1N pruning is:
| (4) |
Furthermore, we realize that weight pruning and filter pruning are two special cases of our proposed 1N pruning pattern. Specifically, our 1N pruning degenerates to weight pruning subject to N = 1, and . Besides, it further degenerates to filter pruning if . When , our method provides an intermediate granular level for network pruning, since it is coarser as compared to the fine-grained weight pruning but finer as compared to the coarse-grained filter pruning. Many previous researches [18, 19, 20] also explore removing kernels; however, our pruning pattern has a stronger requirement of continuity on the N removed kernels, with its merits in acceleration since these consecutive kernels can be stored continuously in the memory cache and the convolution with the inputs can proceed using a parallelized block-wise vectorized operation as analyzed in Sec. 3.4. Therefore, it is expected that our 1N pruning can offer a better performance than the filter pruning, and also an apparent inference speedup compared to the weight pruning.
As a distinguished difference from weight pruning and filter pruning, pruning kernels provides an intermediate granular level for network sparsity, since it is coarser as compared to the fine-grained weight pruning but finer as compared to the coarse-grained filter pruning.
3.3 Filter Rearrangement
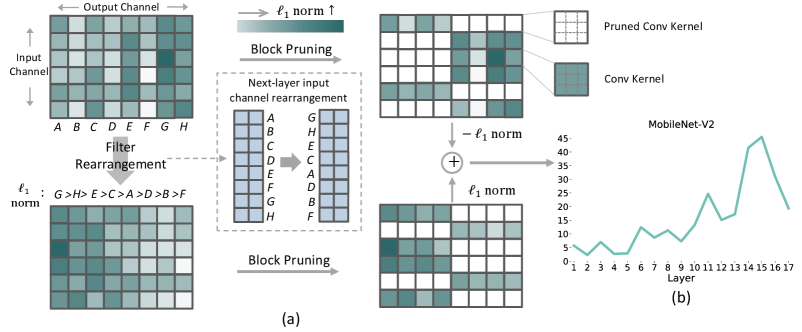
Our 1N pruning in this paper follows the typical three-step pipeline of network training, then pruning consecutive kernels with smaller norms, and fine-tuning the sparse one to recover the performance in the end. At the second pruning step, inspired by [10] which conducts channel permutations to preserve more high-magnitude weights in the N:M weight pruning, we realize that the layout of can be altered to further relieve the pruning impact.
To implement the above process, we propose a workflow of filter rearrangement, whose working principle is shown in Fig. 2. Given the original weight matrix in the top-left of (a), simply applying 1N pruning upon leads to the loss of some kernels with relatively large values of norms in the top-right of (a). We calculate the norm of each filter, i.e., one column in , then rearrange in the output channel dimension according to the calculated filter norm in a decreasing order as shown in the lower-left of (a). The rearranged weight matrix is denoted as to which our 1N pruning is further applied. As a consequence, more kernels with larger norms are preserved after pruning in the lower-right of (a), leading to an overall increasing weight magnitude as verified on MobileNet-V2 of (b). The filter rearrangement requires the outputs to be similarly rearranged as well, so as to maintain the same convolutional results with the next-layer weight matrix. However, frequently rearranging outputs incurs more run-time cost in the inference. Alternatively, we choose to apply a similar rearrangement to the input channel dimension of the next-layer weight matrix as illustrated in the middle of (a), which is accomplished once for all before pruning and thus brings no run-time cost. The effectiveness of filter rearrangement for accuracy improvements is presented in Sec. 4.
Herein, we want to stress the difference of our filter rearrangement against the channel permutation [10]. First, rearranging the columns of is indeed to change the position of each filter in our setting. Second, our goal is to preserve more high-magnitude kernels, while [10] is to preserve more individual high-magnitude weights. Third, we simply accomplish our rearrangement according to the norm of each filter. The implementation details of channel permutations are discussed in another paper [36] where a bounded regressions-based permutation search is proposed to find a high-quality permutation.
Then, Eq. (4) after filter rearrangement is rewritten as:
| (5) |
Note that the maximization of the above objective can be achieved by setting to s the entries of corresponding to these blocks in with their norms within the largest top-, and s otherwise. As a consequence, the pruned weights after applying our 1N pruning pattern is then derived as:
| (6) |
3.4 Encoding and Decoding Efficiency
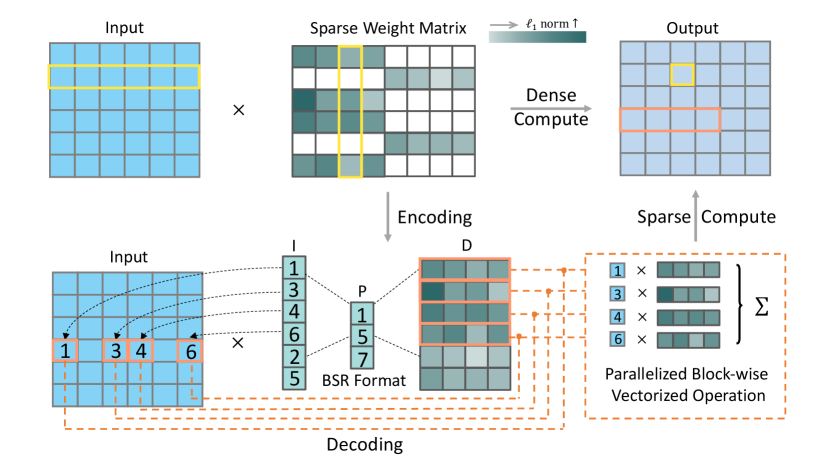
Given the input activation tensor as illustrated in Fig. 3, the output tensor calculated by the standard dense-matrix structure is obtained as:
| (7) |
Considering a sparse matrix, operations using the standard dense-matrix structure bear inefficiency as processing and memory are wasted on a large number of zero-valued elements. Thus, it is of great necessity to take advantage of specialized data structures in order to store and manipulate the sparse matrix. However, the irregular sparse matrix resulting from weight pruning requires a great many of indices to record the positions of the reserved weights. Though Compressed Sparse Row Format (CSR) can be used to save index storage, irregular sparsity barely takes advantage of vector processing architectures and memory buses, resulting in little acceleration and even speed deterioration.
Weight pruning leads to an irregular sparse matrix, therefore, a large number of indices are needed to record the positions of the reserved weights. To save the index storage, the relative Compressed Sparse Row (CSR) format is usually adopted [4, 37], which encodes each index by the relative distance (i.e., the number of zeros) between two adjacent non-zero weights. Besides, a decoding process is needed to select the corresponding activations for the reserved weights. The main drawback of irregular pruning is that decoding one index requires a search over the whole activation vector, thus it brings little acceleration, even speed degradation.
In contrast, due to the requirement of continuity on the N removed kernels, our pruning pattern results in a sparse matrix with constant-sized blocks. This good property brings two merits: First, the constant-sized blocks are by nature more easily encoded by Block Compressed Sparse Row Format (BSR) [38] to save non-zero elements in with significantly less storage for the indices. Second, the output tensor is derived using a block-wise vectorized operation in parallel to achieve an apparent speedup. Specifically, as illustrated in Fig. 3, the pruned weight matrix in our 1N pruning is encoded by BSR into three components: , and , where is the number of non-zero blocks in . The matrix, , and vector, , contain non-zero blocks and their row indices in , respectively. We form by firstly stacking up non-zero blocks within the same col-group of , and concatenating the stacked ones across different col-groups. The vector records the row index of each block item in . The -th element of the vector encodes the start row index of the -th col-group in . The last element of is a fictitious index, which is always equal to . Attributed to the block storage format of , we can calculate in a block-wise manner during decoding as follows:
| (8) |
| N=2 (%) | N=4 (%) | N=8 (%) | N=16 (%) | N=32 (%) | ||||||
| Top-1 | Top-5 | Top-1 | Top-5 | Top-1 | Top-5 | Top-1 | Top-5 | Top-1 | Top-5 | |
| w/o Rearrange | 69.900 | 89.296 | 69.521 | 88.920 | 69.206 | 88.608 | 68.971 | 88.399 | 68.431 | 88.315 |
| Rearrange | 70.233 | 89.417 | 69.579 | 88.944 | 69.372 | 88.862 | 69.352 | 88.708 | 68.762 | 88.425 |
| ResNet-50 (%) | MobileNet-V2 (%) | |||
|---|---|---|---|---|
| Top-1 | Top-5 | Top-1 | Top-5 | |
| 1N (N=4) | 76.506 | 93.238 | 69.706 | 89.165 |
| kernel (random) | 74.834 | 92.178 | 68.615 | 88.434 |
| kernel () | 75.370 | 92.582 | 69.514 | 89.012 |
With proper index vectors and , we can directly fetch these activations corresponding to non-zero weights for the output computation, through which we avoid a complete involvement of the whole activation tensor as with the dense-matrix structure. Besides, the block storage format of also allows fast row data access since each block is stored continuously in the memory. Besides, the block-wise vectorized operation in Eq. (8) can be implemented extremely fast as the multiplication between input item and each entry of can proceed in parallel. Thus, our 1N pruning enables apparent acceleration on the general CPUs-based devices. To ensure end-to-end execution efficiency, we utilize the optimizing compiler TVM [39] to enable optimal code generation. And based on Eq. (8), we use Ansor [40] for automated tensor program generation to search best sparse convolution implementation.
4 Experiments
4.1 Implementation Settings
For fair comparison, similar to our 1N pruning, we re-implement the compared baselines of weight pruning and filter pruning using norm as the importance evaluation. Besides, given the expected pruning rate , we simply remove per-layer weights/filters/blocks with their corresponding norms within the smallest top-. All experiments are performed using the pre-trained light-weight MobileNet-V1 [21], -V2 [22], -V3 [23] and large-scale ResNet-50 [2] on ILSVRC-2012 [24] that contains over million images for training and validation images from classes. After pruning, we fine-tune the sparse models for 90 epochs on two NVIDIA V100 GPUs with the settings: Stochastic Gradient Descent (SGD) optimizer with a momentum of 0.9, weight decay of 4e-5 for MobileNets and 1e-4 for ResNet-50, and initial learning rate of 0.1 with a cosine annealing. The data augmentation includes random cropping and horizontal flipping.
4.2 Ablation Study
We first analyze the influence of filter rearrangement in Sec. 3.3. Table I compares the performance of our 1N pruning for pruning MobileNet-V2 with and without filter rearrangement. The pruning rate is set to . As can be seen, rearranging filters consistently enhances the accuracy performance in both the top-1 and top-5, even with various block size (N). For example, the top-1 classification accuracy of pruned MobileNet-V2 with 116 pruning is increased by (69.352% with and 68.971% without filter rearrangement). To dive into a deeper analysis, by rearranging the weight matrix in the output channel dimension, more blocks with larger norms are preserved after applying our 1N as validated in Fig. 2(b). These results well validate the effectiveness of filter rearrangement in boosting the performance of pruned models.
We continue the study on our consecutive kernel removal. Recall that consecutive N output kernels with the same input channel index are grouped into one block and our 1N removes these blocks with a smaller norm. In Table II, we compare our consecutive kernel removal with two variants including (1) removing kernels randomly and (2) removing kernels with smaller magnitudes. From these results in Table II, we can see that removing random kernels performs worse than removing smaller magnitude kernels, indicating the importance of preserving larger magnitude weights. Our stronger constraint of block-level magnitude leads to performance increase compared with the kernel-level magnitude. Also, our 1N merits in its acceleration since the consecutive kernels can be stored continuously in the memory cache. Moreover, the convolution with the inputs can proceed using a parallelized block-wise vectorized operation as analyzed in Sec. 3.4 and verified in the following Sec. 4.3.
| MobileNet (p = 50%) | ResNet-50 (p = 50%) | |||||||||
| V1 (%) | V2 (%) | V3-small (%) | V3-large (%) | (%) | ||||||
| Top-1 | Top-5 | Top-1 | Top-5 | Top-1 | Top-5 | Top-1 | Top-5 | Top-1 | Top-5 | |
| Origin | 71.154 | 89.834 | 71.737 | 90.452 | 67.225 | 87.351 | 74.280 | 91.928 | 77.008 | 93.654 |
| Weight Pruning | 70.764 | 89.592 | 71.146 | 89.872 | 66.376 | 86.868 | 72.897 | 91.093 | 77.088 | 93.614 |
| Filter Pruning | 65.348 | 86.264 | 66.730 | 87.190 | 59.054 | 81.743 | 69.137 | 89.097 | 75.382 | 92.518 |
| 12 Pattern (Ours) | 70.281 | 89.370 | 70.233 | 89.417 | 65.380 | 86.060 | 72.120 | 90.677 | 76.654 | 93.466 |
| 14 Pattern (Ours) | 70.052 | 89.056 | 69.706 | 89.165 | 64.465 | 85.495 | 71.935 | 90.458 | 76.506 | 93.238 |
| 18 Pattern (Ours) | 69.908 | 89.027 | 69.372 | 88.862 | 64.101 | 85.274 | 71.478 | 90.163 | 76.146 | 93.134 |
| 116 Pattern (Ours) | 69.559 | 88.933 | 69.352 | 88.708 | 63.126 | 84.203 | 71.112 | 90.129 | 76.254 | 93.084 |
| 132 Pattern (Ours) | 69.541 | 88.801 | 68.762 | 88.425 | 62.881 | 83.982 | 70.769 | 89.696 | 75.960 | 92.950 |
4.3 Performance Comparison
In this section, we compare the performance of our proposed 1N pruning with traditional weight pruning and filter pruning. We show that the advantages of pruning pattern are reflected from two perspectives: ) maintaining better accuracy than filter pruning, and ) achieving apparent CPUs acceleration compared to weight pruning.
(a) MobileNet-V2
(b) ResNet-50
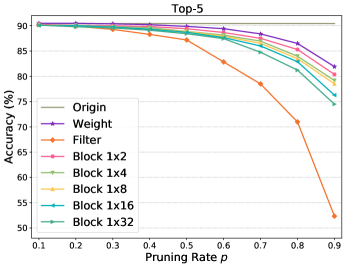
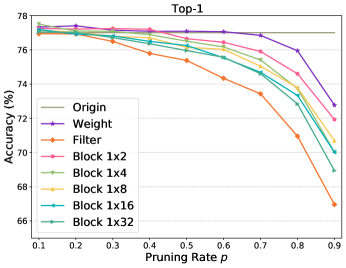
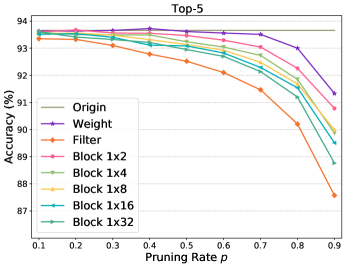
Accuracy Performance. We first study the performance of 1N sparsity across different networks. Table III displays the pruning results of our 1N pruning and existing weight pruning and filter pruning using MobileNet-V1/-V2/-V3 with the pruning rate set to . Table III shows that filter pruning suffers the most performance degradation of , , , and when pruning MobileNet-V1, V2, V3-small and V3-large, respectively. Such severe performance losses are attributed to its coarse-grained pruning granularity. Consequently, the poor performance barricades the using of filter pruning in practical model deployment. In contrast, due to its fine-grained pruning granularity, weight pruning presents the best performance with top-1 accuracy losses of , , , and when pruning MobileNet-V1, V2, V3-small and V3-large, respectively. Despite its ability to maintain high accuracy, weight pruning achieves rare acceleration as analyzed in the following. The poor speedup also disables the using of filter pruning. With respect to our proposed 1N pruning, we have two observations: ) our method well boosts the performance of filter pruning regardless of the block size N. Taking MobileNet-V2 as an example, our 14 pruning achieves top-1 accuracy, significantly better than of filter pruning. Though it is slightly poorer than of weight pruning, our 14 pruning obtains an apparent speedup as detailed in the following context. ) The performance of 1N pruning degenerates as the block size N increases. The rationale behind this is that a larger N indicates coarser pruning. As analyzed in Sec. 3.2, our 1N pruning degenerates to weight pruning with a small N and filter pruning with a large N.
Table III also provides the performance comparison when using ResNet-50 as the network backbone with the pruning rate . We can observe similar phenomena to MobileNets that filter pruning suffers the most performance drops and weight pruning presents best performance while our 1N provides a trade-off. Besides, our performance decreases as the block size N increases.
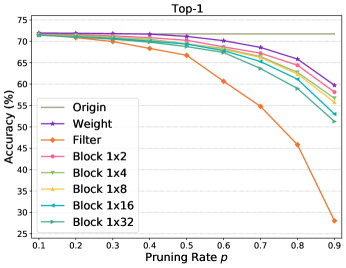
Fig. 4 further shows the performance comparison when applying different pruning rates to sparsifying MobileNet-V2 and ResNet-50. We can see that the increasing pruning rate results in decreasing accuracy performance for all methods. However, filter pruning degrades drastically if . In contrary, our pruning pattern maintains a similar decreasing tendency and close performance to weight pruning even if the pruning rate is very high111The raw data for plotting Fig. 4 can be found from our project at https://github.com/lmbxmu/1xN..
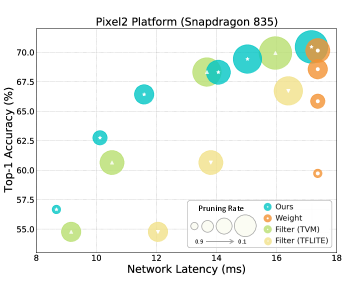
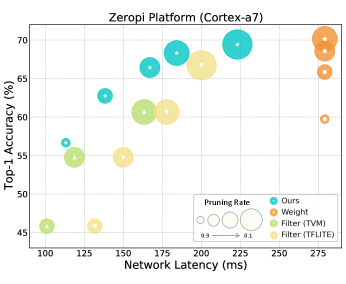
CPUs Acceleration. Fig. 5 presents the experimental results, which are conducted to further explore the acceleration capacity of different methods on CPUs-based platforms. In Sec. 3.4, we adopt TVM [39] to compile the pruned model of our pruning pattern. For fair comparison, we also consider TVM compiler for weight pruning and filter pruning. Besides, additional experiments by TFLite compiler [41] are also presented for weight pruning and filter pruning. After model compiling, we respectively deploy the sparse models to obtain network latencies on the mobile platform of Pixel2 equipped with a Snapdragon 835 CPU and the embedded platform of Zeropi equipped with a Cortex-a7 CPU.
From Fig. 5, we observe no speedup from weight pruning, despite its ability to preserve good performance. As analyzed in Sec. 1, weight pruning leads to irregular sparsity that hardly utilizes the vector processing architectures and memory buses. Thus, weight pruning often results in little acceleration and even speed deterioration. Filter pruning leads to the most significant speedups since it does not modify the network structure, so that the pruned network can be well fitted by regular hardware to achieve acceleration. Nevertheless, the severe performance degradation disables the using of filter pruning in the model deployment. In contrast, our 1N (N=4) pruning achieves noticeable latency reductions across various pruning rates such as ms inference savings on Cortex-A7 CPU over weight pruning when , while maintaining comparable top-1 accuracy performance. Compared with weight pruning and filter pruning, our 1N pruning shows a better capacity of keeping a trade-off between latency and performance.
5 Limitations
First, our filter rearrangement using norms of filters does not always guarantee maximizing magnitude. Though it does not seem to have happened in the experiments, opportunity exists that lower-magnitude kernels are retained. The approach to cluster large values as in [42] has no this issue. However, we observe a similar performance of the cluster against our rearrangement. We adopt the norm based rearrangement since it is much easier to implement.
Second, though our 1N is originally proposed for CNNs, we observe rare speedups on recurrent neural networks (RNNs) compared to these RNNs acceleration [43, 44]. Nevertheless, we are making efforts to break this limitation and expecting that our method can be well generalized to a wider variety of networks in the near future.
Third, this paper misses comparisons to many studies that also explore an intermediate pruning granularity [45, 18, 46, 42], most of which only report the theoretical acceleration in their papers. In our deployment, we find most of them fail to obtain practical acceleration, or only reach few CPU speedups in a pruning rate of over 90% [45]. Currently, we are not sure if something is wrong in our implementation of these methods. Our future work will focus on this topic to show that our method is worth building on.
Fourth, we do not introduce a new pruning criterion but use the norm as our measure to reflect the importance of these consecutive kernels. This is because we find that existing pruning criteria show similar performance if fair training settings are given, which is also discussed in [16, 17]. Thus, we focus on designing a new pruning pattern. However, it is unclear if a specialized pruning criterion exists in our 1N pattern. We will continue excavating this issue.
6 Conclusion
We introduce a novel 1N pruning pattern to simultaneously maintain model accuracy and achieve significant speedups on general CPUs. Unlike previous approaches that prune the individual weights or the whole filters, we design a pruning pattern that supports network pruning by removing consecutive N output kernels with the same input channel index. To preserve more influential kernels, we propose a workflow of filter rearrangement that rearranges the weight matrix in the output channel dimension and applies similar rearrangement to the next-layer weight matrix in the input channel dimension. Our pruning pattern leads to a sparse matrix with constant-sized blocks enabling the computation outputs by using a parallelized block-wise vectorized operation. The experiments on the MobileNets/ResNet-50 and CPUs embedded hardware platforms demonstrate the efficacy of our approach.
Acknowledgments
This work was supported by the National Science Fund for Distinguished Young Scholars (No. 62025603), the National Natural Science Foundation of China (No. U21B2037, No. 62176222, No. 62176223, No. 62176226, No. 62072386, No. 62072387, No. 62072389, and No. 62002305), Guangdong Basic and Applied Basic Research Foundation (No. 2019B1515120049), and the Natural Science Foundation of Fujian Province of China (No. 2021J01002).
References
- [1] Y. Sun, Y. Chen, X. Wang, and X. Tang, “Deep learning face representation by joint identification-verification,” in Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), 2014, pp. 1988–1996.
- [2] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2016, pp. 770–778.
- [3] Y. Kim, Y. Jernite, D. Sontag, and A. M. Rush, “Character-aware neural language models,” in Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), 2016, pp. 2741–2749.
- [4] S. Han, J. Pool, J. Tran, and W. Dally, “Learning both weights and connections for efficient neural network,” in Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), 2015, pp. 1135–1143.
- [5] U. Evci, T. Gale, J. Menick, P. S. Castro, and E. Elsen, “Rigging the lottery: Making all tickets winners,” in Proceedings of the International Conference on Machine Learning (ICML), 2020, pp. 2943–2952.
- [6] P. Molchanov, S. Tyree, T. Karras, T. Aila, and J. Kautz, “Pruning convolutional neural networks for resource efficient inference,” in Proceedings of the International Conference on Learning Representations (ICLR), 2017.
- [7] J. Choquette, W. Gandhi, O. Giroux, N. Stam, and R. Krashinsky, “Nvidia a100 tensor core gpu: Performance and innovation,” IEEE Micro, vol. 41, no. 02, pp. 29–35, 2021.
- [8] A. Zhou, Y. Ma, J. Zhu, J. Liu, Z. Zhang, K. Yuan, W. Sun, and H. Li, “Learning n:m fine-grained structured sparse neural networks from scratch,” in Proceedings of the International Conference on Learning Representation (ICLR), 2021.
- [9] I. Hubara, B. Chmiel, M. Island, R. Banner, S. Naor, and D. Soudry, “Accelerated sparse neural training: A provable and efficient method to find n: M transposable masks,” arXiv preprint arXiv:2102.08124, 2021.
- [10] A. Mishra, J. A. Latorre, J. Pool, D. Stosic, D. Stosic, G. Venkatesh, C. Yu, and P. Micikevicius, “Accelerating sparse deep neural networks,” arXiv preprint arXiv:2104.08378, 2021.
- [11] A. Renda, J. Frankle, and M. Carbin, “Comparing rewinding and fine-tuning in neural network pruning,” in Proceedings of the International Conference on Learning Representation (ICLR), 2020.
- [12] H. Li, A. Kadav, I. Durdanovic, H. Samet, and H. P. Graf, “Pruning filters for efficient convnets,” in Proceedings of the International Conference on Learning Representations (ICLR), 2016.
- [13] Z. Liu, H. Mu, X. Zhang, Z. Guo, X. Yang, K.-T. Cheng, and J. Sun, “Metapruning: Meta learning for automatic neural network channel pruning,” in Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2019, pp. 3296–3305.
- [14] S. Guo, Y. Wang, Q. Li, and J. Yan, “Dmcp: Differentiable markov channel pruning for neural networks,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020, pp. 1539–1547.
- [15] M. Lin, R. Ji, Y. Wang, Y. Zhang, B. Zhang, Y. Tian, and L. Shao, “Hrank: Filter pruning using high-rank feature map,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020, pp. 1529–1538.
- [16] Z. Liu, M. Sun, T. Zhou, G. Huang, and T. Darrell, “Rethinking the value of network pruning,” in Proceedings of the International Conference on Learning Representations (ICLR), 2019.
- [17] D. H. Le and B.-S. Hua, “Network pruning that matters: A case study on retraining variants,” in Proceedings of the International Conference on Learning Representations (ICLR), 2021.
- [18] H. Mao, S. Han, J. Pool, W. Li, X. Liu, Y. Wang, and W. J. Dally, “Exploring the granularity of sparsity in convolutional neural networks,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshop (CVPRW), 2017, pp. 13–20.
- [19] M. Wortsman, A. Farhadi, and M. Rastegari, “Discovering neural wirings,” in Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), 2019, pp. 2684–2694.
- [20] S. Xie, A. Kirillov, R. Girshick, and K. He, “Exploring randomly wired neural networks for image recognition,” in Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2019, pp. 1284–1293.
- [21] A. G. Howard, M. Zhu, B. Chen, D. Kalenichenko, W. Wang, T. Weyand, M. Andreetto, and H. Adam, “Mobilenets: Efficient convolutional neural networks for mobile vision applications,” arXiv preprint arXiv:1704.04861, 2017.
- [22] M. Sandler, A. Howard, M. Zhu, A. Zhmoginov, and L.-C. Chen, “Mobilenetv2: Inverted residuals and linear bottlenecks,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2018, pp. 4510–4520.
- [23] A. Howard, M. Sandler, G. Chu, L.-C. Chen, B. Chen, M. Tan, W. Wang, Y. Zhu, R. Pang, V. Vasudevan et al., “Searching for mobilenetv3,” in Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2019, pp. 1314–1324.
- [24] J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, “Imagenet: A large-scale hierarchical image database,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2009, pp. 248–255.
- [25] Y. LeCun, J. Denker, and S. Solla, “Optimal brain damage,” in Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), 1989, pp. 598–605.
- [26] B. Hassibi and D. Stork, “Second order derivatives for network pruning: Optimal brain surgeon,” in Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), 1992, pp. 164–171.
- [27] X. Dong, S. Chen, and S. Pan, “Learning to prune deep neural networks via layer-wise optimal brain surgeon,” in Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), 2017, pp. 4860–4874.
- [28] Y. Guo, A. Yao, and Y. Chen, “Dynamic network surgery for efficient dnns,” in Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), 2016, pp. 1379–1387.
- [29] J. Frankle and M. Carbin, “The lottery ticket hypothesis: Finding sparse, trainable neural networks,” in Proceedings of the International Conference on Learning Representations (ICLR), 2019.
- [30] T. Lin, S. U. Stich, L. Barba, D. Dmitriev, and M. Jaggi, “Dynamic model pruning with feedback,” in Proceedings of the International Conference on Learning Representations (ICLR), 2020.
- [31] Y. He, G. Kang, X. Dong, Y. Fu, and Y. Yang, “Soft filter pruning for accelerating deep convolutional neural networks,” in Proceedings of the International Joint Conference on Artificial Intelligence (IJCAI), 2018, pp. 2234–2240.
- [32] X. Ding, G. Ding, Y. Guo, J. Han, and C. Yan, “Approximated oracle filter pruning for destructive cnn width optimization,” in Proceedings of the International Conference on Machine Learning (ICML), 2019, pp. 1607–1616.
- [33] M. Lin, R. Ji, Y. Zhang, B. Zhang, Y. Wu, and Y. Tian, “Channel pruning via automatic structure search,” in Proceedings of the International Joint Conference on Artificial Intelligence (IJCAI), 2020, pp. 673–679.
- [34] Y. He, J. Lin, Z. Liu, H. Wang, L.-J. Li, and S. Han, “Amc: Automl for model compression and acceleration on mobile devices,” in Proceedings of the European Conference on Computer Vision (ECCV), 2018, pp. 784–800.
- [35] D. Molchanov, A. Ashukha, and D. Vetrov, “Variational dropout sparsifies deep neural networks,” in Proceedings of the International Conference on Machine Learning (ICML), 2017, pp. 2498–2507.
- [36] J. Pool and C. Yu, “Channel permutations for n: m sparsity,” in Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), 2021, pp. 13 316–13 327.
- [37] S. Han, H. Mao, and W. J. Dally, “Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding,” in Proceedings of the International Conference on Learning Representations (ICLR), 2016.
- [38] R. Shahnaz and A. Usman, “Blocked-based sparse matrix-vector multiplication on distributed memory parallel computers.” The International Arab Journal of Information Technology (IAJIT), vol. 8, no. 2, pp. 130–136, 2011.
- [39] T. Chen, T. Moreau, Z. Jiang, L. Zheng, E. Yan, H. Shen, M. Cowan, L. Wang, Y. Hu, L. Ceze et al., “Tvm: An automated end-to-end optimizing compiler for deep learning,” in Symposium on Operating Systems Design and Implementation (OSDI), 2018, pp. 578–594.
- [40] L. Zheng, C. Jia, M. Sun, Z. Wu, C. H. Yu, A. Haj-Ali, Y. Wang, J. Yang, D. Zhuo, K. Sen et al., “Ansor: Generating high-performance tensor programs for deep learning,” in Symposium on Operating Systems Design and Implementation (OSDI), 2020, pp. 863–879.
- [41] “Google llc. tensorflow lite,” https://www.tensorflow.org/lite, [Online Accessed, 2019].
- [42] Y. Ji, L. Liang, L. Deng, Y. Zhang, Y. Zhang, and Y. Xie, “Tetris: Tile-matching the tremendous irregular sparsity,” in Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), vol. 31, 2018, pp. 4115–4125.
- [43] S. Narang, E. Undersander, and G. Diamos, “Block-sparse recurrent neural networks,” arXiv preprint arXiv:1711.02782, 2017.
- [44] N. Kalchbrenner, E. Elsen, K. Simonyan, S. Noury, N. Casagrande, E. Lockhart, F. Stimberg, A. Oord, S. Dieleman, and K. Kavukcuoglu, “Efficient neural audio synthesis,” in Proceedings of the International Conference on Machine Learning (ICML), 2018, pp. 2410–2419.
- [45] E. Elsen, M. Dukhan, T. Gale, and K. Simonyan, “Fast sparse convnets,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020, pp. 14 629–14 638.
- [46] D. T. Vooturi, D. Mudigere, and S. Avancha, “Hierarchical block sparse neural networks,” arXiv preprint arXiv:1808.03420, 2018.
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/a3890dd0-7c48-4ebf-9bf1-a49953042c2e/mbl.jpg) |
Mingbao Lin finished his M.S.-Ph.D. study and obtained the Ph.D. degree in intelligence science and technology from Xiamen University, Xiamen, China, in 2022. Earlier, he received the B.S. degree from Fuzhou University, Fuzhou, China, in 2016. He is currently a senior researcher with the Tencent Youtu Lab, Shanghai, China. His publications on top-tier conferences/journals include IEEE TPAMI, IJCV, IEEE TIP, IEEE TNNLS, CVPR, NeurIPS, AAAI, IJCAI, ACM MM and so on. His current research interest is to develop efficient vision model, as well as information retrieval. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/a3890dd0-7c48-4ebf-9bf1-a49953042c2e/yxz.png) |
Yuxin Zhang received the B.E. degree in Computer Science, School of Informatics, Xiamen University, Xiamen, China, in 2020. He is currently pursuing the B.S. degree with Xiamen University, China. His research interests include computer vision and neural network compression & acceleration. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/a3890dd0-7c48-4ebf-9bf1-a49953042c2e/ycl.jpg) |
Yuchao Li received the M.S. degree in Computer Science, School of Information Science and Engineering, Xiamen University, Xiamen, China, in 2020. He is currently working toward the algorithm engineer in Alibaba. His research interests include computer vision and neural network compression and acceleration. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/a3890dd0-7c48-4ebf-9bf1-a49953042c2e/bhc.jpg) |
Bohong Chen received the B.E. degree in Computer Science, School of Informatics, Xiamen University, Xiamen, China, in 2020. He is currently working toward the master’s degree from Xiamen University, China. His research interests include computer vision, and neural network compression & acceleration. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/a3890dd0-7c48-4ebf-9bf1-a49953042c2e/fc.png) |
Fei Chao (Member, IEEE) received the B.Sc. degree in mechanical engineering from the Fuzhou University, Fuzhou, China, in 2004, the M.Sc. degree with distinction in computer science from the University of Wales, Aberystwyth, U.K., in 2005, and the Ph.D. degree in robotics from the Aberystwyth University, Wales, U.K., in 2009. He is currently an Associate Professor with the School of Informatics, Xiamen University, Xiamen, China. He has authored/co-authored more than 50 peer-reviewed journal and conference papers. His current research interests include developmental robotics, machine learning, and optimization algorithms. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/a3890dd0-7c48-4ebf-9bf1-a49953042c2e/mdw.jpg) |
Mengdi Wang received the Ph.D. degree in Electronic Engineering, from Tsinghua University, Beijing, China, in 2017. She is currently working in Alibaba Group. Her research interests include efficient deep learning computing, model compression and neural architecture search. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/a3890dd0-7c48-4ebf-9bf1-a49953042c2e/sl.jpg) |
Shen Li received his M.S. degree in Control Science and Engineering, Zhejiang University, Hangzhou, China, in 2013. He is currently working as Algorithm Expert at Platform of AI, Alibaba Cloud. His research interests include deep learning model compression and acceleration. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/a3890dd0-7c48-4ebf-9bf1-a49953042c2e/yht.jpg) |
Yonghong Tian (Fellow, IEEE) is currently a Boya Distinguished Professor with the Department of Computer Science and Technology, Peking University, China. His research interests include neuromorphic vision, brain-inspired computation and multimedia big data. He is the author or coauthor of over 200 technical articles in refereed journals such as IEEE TPAMI/TNNLS/TIP/TMM/TCSVT/TKDE/TPDS, ACM CSUR/TOIS/TOMM and conferences such as NeurIPS/CVPR/ICCV/AAAI/ACMMM/WWW. Prof. Tian was/is an Associate Editor of IEEE TCSVT (2018.1-), IEEE TMM (2014.8-2018.8), IEEE Multimedia Mag. (2018.1-), and IEEE Access (2017.1-). He co-initiated IEEE Int’l Conf. on Multimedia Big Data (BigMM) and served as the TPC Co-chair of BigMM 2015, and aslo served as the Technical Program Co-chair of IEEE ICME 2015, IEEE ISM 2015 and IEEE MIPR 2018/2019, and General Co-chair of IEEE MIPR 2020 and ICME2021. He is the steering member of IEEE ICME (2018-) and IEEE BigMM (2015-), and is a TPC Member of more than ten conferences such as CVPR, ICCV, ACM KDD, AAAI, ACM MM and ECCV. He was the recipient of the Chinese National Science Foundation for Distinguished Young Scholars in 2018, two National Science and Technology Awards and three ministerial-level awards in China, and obtained the 2015 EURASIP Best Paper Award for Journal on Image and Video Processing, and the best paper award of IEEE BigMM 2018. He is a senior member of IEEE, CIE and CCF, a member of ACM. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/a3890dd0-7c48-4ebf-9bf1-a49953042c2e/rrj.jpg) |
Rongrong Ji (Senior Member, IEEE) is currently a Professor and the Director of the Intelligent Multimedia Technology Laboratory, and the Dean Assistant with the School of Information Science and Engineering, Xiamen University, Xiamen, China. His work mainly focuses on innovative technologies for multimedia signal processing, computer vision, and pattern recognition, with over 100 papers published in international journals and conferences. He is a member of the ACM. He was a recipient of the ACM Multimedia Best Paper Award and the Best Thesis Award of Harbin Institute of Technology. He serves as an Associate/Guest Editor for international journals and magazines such as Neurocomputing, Signal Processing, Multimedia Tools and Applications, the IEEE Multimedia Magazine, and the Multimedia Systems. He also serves as program committee member for several Tier- international conferences. |