A Bayesian Composite Risk Approach for Stochastic Optimal Control and Markov Decision Processes
Abstract
Inspired by
Shapiro et al. [63],
we consider a
stochastic optimal control (SOC) and Markov decision process (MDP)
where the risks arising
from epistemic and aleatoric uncertainties are assessed using
Bayesian composite risk (BCR) measures (Qian et al. [52]).
The time dependence of the risk measures allows us to capture
the decision maker’s (DM) dynamic risk preferences
opportunely as increasing information about both uncertainties is obtained. This makes the new BCR-SOC/MDP model more flexible than
conventional risk-averse SOC/MDP models. Unlike
[63] where
the control/action at each episode is
based on
the current state alone,
the new model
allows
the control
to depend on the probability distribution of the epistemic uncertainty, which reflects the fact that in many practical instances the cumulative
information about
epistemic uncertainty often
affects the DM’s belief about
the future aleatoric uncertainty and hence
the DM’s action [67].
The new modeling paradigm incorporates several
existing SOC/MDP models including distributionally robust
SOC/MDP models and Bayes-adaptive MDP models and generates so-called preference robust SOC/MDP models.
Moreover, we derive conditions under which the BCR-SOC/MDP model is well-defined,
demonstrate that finite-horizon BCR-SOC/MDP models can be
solved using dynamic programming techniques,
and extend the discussion to the infinite-horizon case. By using Bellman equations,
we show that under some standard
conditions, asymptotic convergence of the optimal values and optimal actions
as the episodic variable goes to infinity is achieved.
Finally,
we carry out numerical tests on a finite horizon spread betting problem and
an inventory control problem and
show the effectiveness of the proposed model and numerical schemes.
Keywords: Stochastic optimal control, Markov decision process, Bayesian learning , Bayesian composite risk measure
1 Introduction
Stochastic optimal control (SOC) and Markov decision process (MDP) are the fundamental models for sequential decision-making where the outcomes are partly random and partly under the control of a decision maker (DM). In recent years, MDP has become even more popular because of its close relationship to reinforcement learning. In a SOC/MDP, the environment is characterized by a finite or infinite set of states, and the DM’s actions influence the transitions between these states. Each action taken in a given state determines the next state probabilistically, thereby capturing the dynamic and stochastic nature of the environment and the long-term consequences of decisions. SOC/MDP have been applied extensively in diverse fields such as inventory control [51], hydro-thermal planning [22], economics and behavioral ecology [5], among other fields [18].
A critical component of a SOC/MDP model’s validity lies in its ability to characterize uncertainty effectively. The uncertainties addressed by such models can arise from both epistemic uncertainty—that is, arising from limited data availability that affects the estimation of model parameters—and the inherent randomness of the environment, referred to as aleatoric uncertainty [69], which are both inevitable in the real world. Aleatoric uncertainty pertains to the variability in the outcome of an experiment arising from inherently random effects. Consequently, even the most accurate model of this process can only offer probabilities for different outcomes, rather than exact answers. On the other hand, epistemic uncertainty arises from a lack of knowledge about the correct model. In other words, it reflects the ignorance of the DM regarding the epistemic state, rather than the inherent randomness of the system. Unlike uncertainty caused by inherent randomness, epistemic uncertainty can, in principle, be reduced by acquiring additional information. We will review existing SOC/MDP models that address these two types of uncertainty below.
The primary goal of SOC/MDP is to develop a policy that on average minimizes a specified cost function under uncertainty, typically by mapping states to actions. However, this risk-neutral SOC/MDP neglects critical low-probability events with potentially severe consequences. To address this limitation, risk-averse SOC/MDP has been proposed to minimize not only the expected costs but also the variability and associated risks of outcomes. These models typically handle aleatoric uncertainty using a fixed distribution. Early work in this area adopted the expected utility framework, where a convex utility function is adopted to achieve risk aversion [29]. Other studies have explored a static risk-averse SOC/MDP, where a risk measure is applied to the total accumulated cost, e.g., the mean-variance [65, 42], or value-at-risk (VaR) [19]. However, these measures are not coherent, failing to satisfy properties consistent with rational decision-making. Various approaches have emerged [9, 68] within the realm of coherent risk measures. Nonetheless, SOC/MDPs employing a static risk-averse formulation cannot guarantee time-consistent optimal policies, where a current optimal policy may lose its optimality when new realizations emerge. As highlighted in [57], utilizing nested compositions of risk transition mappings at each episode facilitates time-consistent decision-making through dynamic programming solutions. Notable research has explored dynamic formulation on finite and infinite horizons further, including average value-at-risk (AVaR) [3], quantile-based risk measure [33], and entropic risk measure (ERM) [50, 26], respectively.
Although SOC/MDP and their risk-averse variants provide valuable frameworks for decision-making under aleatoric uncertainty, a common practical challenge is the neglect of epistemic uncertainty in model parameters. In addition, the inherent randomness of the environment complicates the task of maintaining the robustness of learned policies against small perturbations in real-world applications ([41]). Distributionally robust optimization (DRO) has emerged as a powerful approach which takes epistemic uncertainty into consideration by constructing an ambiguity set for possible distributions of the environment. Ambiguity sets in DRO can generally be categorized into two main types: moment-based and distance-based. In moment-based DRO [14, 77, 81], the DM has certain information about the moments of the random variable’s distribution. In distance-based DRO, the DM has a known reference distribution and considers a region of uncertainty around it, typically defined by a probability metric such as Kullback-Leibler divergence [49] or Wasserstein distance [20]. This has led to the development of distributionally robust SOC/MDP, as introduced in [44, 31]. Extensive discussions of distributionally robust SOC/MDP can be found in studies such as [43, 76, 82, 60, 84], which usually rely on robust Bellman equations. However, it is essential to note that an inappropriately constructed ambiguity set may lead to an over conservative consideration of epistemic uncertainty, which will generate a policy that performs poorly under far more realistic scenarios than the worst case [79].
The existing SOC/MDP models discussed above highlight an important issue: there is a large middle ground between an optimistic belief in a fixed environment, and a pessimistic focus on worst-case scenarios when dealing with epistemic uncertainty. Further, since both risk-averse SOC/MDP and distributionally robust SOC/MDP operate within the domain of continuous decision-making, the dynamics of certain potential parameters may vary between interaction episodes and remain elusive. When faced with unfamiliar scenarios, the DM is compelled to learn continuously through a single episode of interaction, striving to deduce the underlying model parameters while simultaneously aiming to optimize the objective function (see, [6, 32]). Although relying on point estimates of potential parameters can yield feasible strategies within the current risk-averse SOC/MDP framework, and taking worst-case scenarios of these parameters into consideration can produce feasible strategies in the distributionally robust SOC/MDP framework, the absence of adaptive learning between episodes often results in insufficiently robust or over conservative strategies. This issue highlights a common shortcoming that is inadequately addressed in conventional SOC/MDP models, which assume no prior knowledge and depend solely on learning through repetitive interactions within the same system. These challenges can be addressed effectively through a Bayesian approach to MDP, known as Bayes-adaptive MDP [67]. In Bayes-adaptive MDPs, the DM utilizes prior knowledge expressed as a belief distribution over a range of potential environments, continually updating this belief using Bayes’ rule during engagement with the system [16]. By incorporating Bayesian posterior information instead of concentrating solely on extreme scenarios, the Bayes-adaptive MDP model offers a more balanced and practical approach than distributionally robust SOC/MDP problems where uncertainty plays a critical role. Building on the Bayes-adaptive MDP, a significant body of work [11, 45] enhances our understanding and application of Bayesian approaches in MDP, contributing to a broader landscape of intelligent decision-making systems. In this framework, the posterior distribution is treated as an augmented state, complementing the original physical state, and is updated at each episode based on the observed reward and transition, see [55]. In essence, this Bayesian approach not only enhances a deeper understanding of possible scenarios but also enables a more adaptive and flexible optimization policy.
In conclusion, the risk-averse SOC/MDP model captures low-probability, high-impact events effectively under aleatoric uncertainty, while the Bayes-adaptive MDP model adapts to and delineates epistemic uncertainty robustly through a learning process. These models complement each other, enhancing DM’s management of risk. Therefore, exploring the integration of these models into a risk-averse Bayes-adaptive SOC/MDP framework is essential to capture and manage risks effectively, particularly those involving cognitive uncertainties and the integration of observational data and prior knowledge. However, existing literature on this topic remains sparse, with most studies primarily focusing on optimizing risk measures using finite and discrete states over MDPs such as [64]. In addition, previous studies have predominantly addressed static risk, overlooking the dynamic evolution of risk over time, which is crucial for comprehensive and timely risk assessment [53, 9]. However, in the absence of the nested risk function structure, prior studies such as [46, 30] have demonstrated that optimizing a static risk function can also potentially lead to time-inconsistent behavior. Hence, investigating dynamic risk becomes paramount, especially in the context of risk-averse Bayes-adaptive SOC/MDPs with a continuous state space. In a more recent development, a Bayesian risk MDP (BR-MDP) framework is proposed in [38, 73] to dynamically solve a risk-neutral Bayes-adaptive MDP, whereby some specific coherent risk measures are used to quantify the risk of the expected value of the cost function associated with epistemic uncertainty. To reduce computational challenges, Shapiro et al. [63] proposed a suboptimal episodic Bayesian SOC framework compared to BR-MDP, which is like conventional SOC/MDPs in avoiding the incorporation of the posterior distribution as an augmented state. They demonstrate convergence of the optimal values like that of conventional SOC/MDP models. In this paper, we follow this strand of research by adopting general law invariant risk measures to quantify the risks associated with both epistemic and aleatoric uncertainties and allow the explicit dependence of the optimal policy at each episode on the posterior distribution. The new model provides a more general adaptive framework for risk management of dynamic decision-making.
Building on these insights, it becomes evident that a unified framework integrating risk-averse SOC/MDP, distributionally robust SOC/MDP, and Bayes-adaptive MDPs may help to address the limitations of existing models. Such a framework not only captures the dynamic interplay between epistemic and aleatoric uncertainties but also integrates these uncertainties into objective functions tailored to a wide range of risk preferences. Conventional approaches, while handling specific aspects of uncertainty effectively, often fail to achieve this level of flexibility and comprehensiveness. To leverage fully the Bayesian approach in modeling decision-making under distributional uncertainty, given its suitability for such problems, we adopt a perspective akin to composite risk optimization (CRO). This approach, introduced by [52], has proven effective for static (single-stage) optimization. By extending this approach to dynamic SOC/MDP settings, our research aims to analyze the temporal evolution of risk and its impact on state transitions and decisions, offering a refined strategy for timely, adaptive risk management policies. This perspective offers a robust foundation for unifying the existent SOC/MDP models within a coherent and dynamic framework. The main contributions of this paper can be summarized as follows.
-
•
Modeling. We propose an adaptive SOC/MDP where the risks arising from epistemic and aleatoric uncertainties are assessed by Bayesian composite risk (BCR) measures. Unlike the episodic Bayesian SOC model [63], where the control or action at each episode is based on the current state alone and ignores any future revelation of the randomness process, the BCR-SOC/MDP model allows the action to depend explicitly on the probability distribution of the epistemic uncertainty [67], which reflects the fact that, in many practical situations, accumulated information about epistemic uncertainty can influence the DM’s belief about future aleatoric uncertainty, thereby impacting the DM’s actions. The new modeling paradigm subsumes several existing SOC/MDP models including distributionally robust SOC/MDP models, risk-averse SOC/MDP models, and Bayes-adaptive MDP models and generates so-called preference robust SOC/MDP models. Note that it is well known in the risk neutral setting that SOC and MDP models are equivalent [60]. The equivalence also holds in risk averse setting. We use SOC/MDP instead of merely SOC or MDP as both are used in the literature [38, 57].
-
•
Analysis. We derive conditions under which the BCR-SOC/MDP model is well defined and demonstrate how the BCR-SOC/MDP model can be solved in both the finite and infinite horizon cases. Moreover, we demonstrate, through detailed case studies, the adaptability of the BCR-SOC/MDP model, illustrating its ability to generalize from existing models and be applied to innovative SOC/MDP contexts. By employing a composite risk measure framework, we investigate the fundamental properties of the BCR-SOC/MDP model across both finite and infinite horizons. Further, using Bellman equations, we demonstrate asymptotic convergence of the optimal values as the episodic variable goes to infinity under some standard conditions and provide quantitative evaluations for specific settings. Notably, we show that, as information or data accumulates, the optimal value and optimal policy derived from our infinite-horizon BCR-SOC/MDP model converge on their respective true optimal counterparts under the true SOC/MDP model. We haven’t seen such theoretical guarantees for current risk-averse or distributionally robust SOC/MDP models. We further explore the tractability and probabilistic guarantees of specific models, such as the VaR-Expectation SOC/MDP and the AVaR-AVaR SOC/MDP.
-
•
Applications. We examine performances of the proposed BCR-SOC/MDP models and computational schemes by applying them to two conventional SOC/MDP problems: a finite-horizon spread betting problem and an infinite-horizon inventory control problem. In the spread betting problem, the BCR-SOC/MDP model is more robust and has lower variability than the standard risk-averse and distributionally robust SOC/MDP models, particularly when the number of historical records of market movement is small. In the inventory control problem, the BCR-SOC/MDP framework exhibits convergence of the optimal values and optimal policies to their true counterparts as information on aleatoric uncertainty accumulates, demonstrates its adaptability and dynamic learning capabilities. The preliminary numerical results show the efficiency and effectiveness of the BCR-SOC/MDP model in tackling complex decision-making problems with evolving uncertainties in real-world applications.
The rest of the paper is structured as follows. In Section 2, we revisit some basic notions and results in SOC/MDP and risk measures which are needed throughout the paper. In Section 3, we introduce the BCR-SOC/MDP model and demonstrate how it can subsume some existing SOC/MDP models. In Section 4, we briefly discuss the dynamic programming formulation of finite horizon BCR-SOC/MDP. In Section 5, we establish the existence, uniqueness, and convergence of a stationary optimal policy for the infinite-horizon BCR-SOC/MDP. In Section 6, we present a computationally efficient SAA algorithm for two special cases. Finally, in Section 7, we report numerical test results about the BCR-SOC/MDP model, displaying their superior performance and applicability.
2 Preliminaries
In this section, we revisit some basic notions and results in SOC/MDP and risk measurement that are needed throughout the paper.
2.1 Stochastic optimal control/Markov decision process
By convention (see e.g. [51]), we express a discounted MDP by a 5-tuple , where and denote the state space of the system and the action space respectively, represents the transition probability matrix, with signifying the probability of transition from state to state under action . Earlier research has shown that the state transition equation in the SOC model, coupled with the random variable , determines the transition probability matrix in the MDP model at episode . In particular, the state transition process in the MDP model can be described by the equation , where is a state transition function (see e.g., [38, 60]). Here, is a random vector mapping from probability space with support set . This relationship can be established by setting , where is a realization of such that . Indeed, it is well known in the risk neutral setting, that SOC and MDP models are equivalent ([60]). The cost function quantifies the immediate cost incurred at episode and the parameter represents the discount factor of the cost function. A deterministic Markovian policy, , maps each state in to an action in . The objective of a standard SOC/MDP is to find an optimal policy that minimizes the expected cumulative cost over all initial states , formulated as
| (2.1) |
where denotes the mathematical expectation with respect to (w.r.t. for short) the joint probability distribution of for each fixed policy and represents time horizon. In the case that , (2.1) becomes a SOC/MDP with infinite time horizon. In that case, the discount factor is restricted to taking values over .
2.2 Topology of weak convergence and risk measures
Consider a probability space and an -measurable function , where represents random losses. Let denote the probability measure/distribution 111Throughout the paper, we use the terminologies probability measure and probability distribution interchangeably. on induced by , let denote the cumulative distribution function (cdf) of and be the left quantile function, that is, Let and denote the space of random variables defined over with -th order finite moments . Let denote the space of all probability measures over and
| (2.2) |
In the case when , and in the case when , reduces to the set of all probability measures with and . Note also that iff in that . Define as the linear space of all continuous functions for which there exists a positive constant such that
| (2.3) |
In the case when , is bounded by over . By [85, Proposition 2.1], the Fortet-Mourier metric (see definition in appendix) metricizes the -weak topology on for , denoted by , which is the coarsest topology on for which the mapping defined by
is continuous. A sequence is said to converge -weakly to , written , if it converges with respect to (w.r.t.) . In the case when , it reduces to the usual topology of weak convergence. Recall that a function is called a monetary risk measure if it satisfies: (a) For any , for all implies that , and (b) for any and real number . A monetary risk measure is said to be convex if it also satisfies: (c) for any and . A convex risk measure is said to be coherent if it further satisfies (d) A risk measure is law invariant if for any random variables with the same probability distribution.
Note that in [61], is called value-at-risk (VaR)222In some references, VaR is defined as the quantile function at , see e.g. [54, 1]. Here we follow the definition in [61]., which is a monetary risk measure satisfying positive homogeneity but not convexity. By convention, we denote it by , for a random variable with . Let be a non-negative, non-decreasing function with the normalized property and denote the set of all such . The spectral risk measure of with , is defined as
| (2.4) |
where is called a risk spectrum representing the DM’s risk preference. Obviously plays a role of weighting and is the weighted average loss of . Moreover, by changing variables in the integral (2.4) (setting ), we obtain
| (2.5) |
in which case may be interpreted as a distortion function of probability. Thus SRM is also known as distortion risk measure ([25]) although the latter has a slightly different representation. SRM is introduced by Acerbi [1]. It shows that is a law invariant coherent risk measure. The following example lists a few well-known spectral risk measures in the literature.
Example 1.
By choosing some specific risk spectra, we can recover a number of well-known law invariant coherent risk measures.
- (i)
-
(ii)
Wang’s proportional hazards transform or power distortion [78]. Let where is a parameter. Then
-
(iii)
Gini’s measure [78]. Let where . Then where is an independent copy of .
-
(iv)
Convex combination of expected value and AVaR. Let
for some , where is the indicator function over interval . Then
(2.7)
It may be helpful to note that any law invariant risk measure defined over a non-atomic space can be represented as a risk functional over the space of the probability distributions of the random variables in the space. Specifically, there exists a unique functional such that
| (2.8) |
where is a random variable uniformly distributed over . In the case when is a coherent risk measure and , we have
| (2.9) |
where is the Lipschitz modulus of , denotes the probability distribution of , and denotes the Kantorovich metric (see the definition in the appendix), see the proof of [72, Corollary 4.8]. Moreover, any monetary risk measure is Lipschitz continuous with respect to the Wasserstein distance , that is,
| (2.10) |
see e.g. [74, Lemma 2.1]. The continuity of a risk measure of a random function w.r.t. the parameters of the function is slightly more complicated. The next lemma addresses this.
Lemma 1.
Let be a random variable with support and be a decision vector. Let be a continuous function such that
| (2.11) |
for some positive constants . Let denote the probability distribution of over , and for any fixed , let be a probability measure on induced by . Let for any . Then the following assertions hold.
-
(i)
is continuous in with respect to topology and .
-
(ii)
Let
(2.12) be a spectral risk measure of , where is a risk spectrum. Let be a set of risk spectra. Suppose that there exists a positive number such that and there is a positive constant with such that and is a compact set. Then
| (2.13) |
where is the Wasserstein distance of order . In the special case that is a singleton, is continuous in with respect to topology and .
For any law invariant continuous risk measure , is continuous in with respect to topology and .
In the case that is compact, is continuous in for any law invariant monetary risk measure with respect to topology and , where denotes the weak topology.
2.3 Bayesian composite risk measure
Consider a random variable whose true distribution belongs to a family of parametric distributions, denoted by , where is a vector of parameters. The true probability distribution is associated with an unknown underlying parameter , i.e., for some . To ease the exposition, we consider the case that . All of our results in the forthcoming discussions are applicable to the case when . Since the information on is incomplete, it might be sensible to describe as a random variable with prior distribution from a modeler’s perspective. This distribution may be obtained from partially available information and/or subjective judgment. For each realization of , gives rise to a probability distribution of . In practice, we may not be able to obtain a closed form of , rather we may obtain samples of , denoted by and use them to estimate by maximum likelihood. Alternatively, we may use Bayes’ formula to obtain a posterior distribution of , that is,
| (2.14) |
where is the probability density function (pdf) of associated with , is the likelihood function and is the normalizing factor. As more samples are gathered, converges to the Dirac distribution of at and subsequently the BCR converges to . In this paper, we focus on the latter approach and apply it within the framework of SOC/MDP.
To quantify the risk of (which represents losses), we may adopt a law invariant risk measure, that is, . The notation does not capture the probability distribution of . However, if we use the risk functional defined in (2.8), then equivalently we can write as . Since is a random variable, then is a random function of . There are two ways to quantify the risk of . One is to consider the mean value of with respect to the posterior distribution of , that is, . The other is to adopt a law invariant risk measure to quantify the risk of , that is, . By using the equivalent risk function of , written , we can write as , where denotes the probability distribution of . Unfortunately, this notation is too complex. To ease the exposition, we write for and for even though this notation is not consistent with our previous discussions. We call a Bayesian composite risk (BCR) measure with being the inner risk measure conditional on and being the outer risk measure. This composite framework was proposed by Qian et al. [52]. In a particular case that is a spectral risk measure parameterized by and is the mathematical expectation, the composite risk measure recovers the average randomized spectral risk measure introduced by Li et al. [37]. The next proposition states the definition of well-defined for the BCR.
3 The BCR-SOC/MDP model
In this section, we move on from the conventional SOC/MDP model (2.1) to propose a BCR-SOC/MDP model by adopting BCR to quantify the risk of loss during each episode and discuss its relationship with some existing SOC/MDP models in the literature. Specifically we consider
| s.t. | (3.1b) | ||||
where , , is a random variable with probability density function at episode , the cost function is continuous with respect to and is the policy for action at episode , where denotes the set of all density functions whose corresponding probability distributions are in . Compared to (2.1), the BCR-SOC/MDP model has several new features.
-
(i)
For , the true probability distribution of is unknown, but it is known that it belongs to a family of parametric distributions, written as , where is a random variable with prior distribution , see [63]. In the objective function of the BCR-SOC/MDP model (3.1), we write for at episode to indicate that corresponds to the density function . In the initial episode, the epistemic uncertainty is based on prior data and/or subjective judgment, which leads to a prior distribution over . As the stochastic process is observed, the posterior distribution is updated with the Bayes’ formula:
(3.2) Moreover, instead of using the mean values as in [63], we propose to use law invariant risk measures and to quantify the risks arising from aleatoric uncertainty and epistemic uncertainty respectively during each episode. This is intended to provide a complement to [63] which can be used effectively to deal with the cases where some DMs are risk-averse rather than risk neutral. The time dependence of the risk measures allows us to capture the DM’s dynamic risk preferences as more information about both uncertainties is obtained. This makes the new BCR-SOC/MDP model more flexible than the conventional SOC/MDP model (2.1).
-
(ii)
Unlike [63] where is purely based on the physical state , the policy in the BCR-SOC/MDP model depends not only on but also on the belief , as considered in [38]. This is motivated by the fact that signifies how takes values over and subsequently affects the probability distribution of . If we interpret as the underlying uncertainty that affects the loss function , then may be regarded as the DM’s belief about the prospect of the future market, such as a bull market or bear market, at state . Such belief is accumulated over the decision-making process over the past episodes and affects the DM’s decision at episode . Nevertheless, the above augmented pair of states might bring some computational difficulties as envisaged by Shapiro et al. [63], where the authors propose a so-called episodic Bayesian stochastic optimal control framework to avoid explicit inclusion of as an augmented state. In the forthcoming discussions, we will demonstrate how to overcome the resulting computational difficulties.
-
(iii)
The SOC/MDP model serves as an effective tool to demonstrate various foundational concepts becaues, on the one hand, it can be expressed naturally as a type of stochastic optimal control model [51, 60, 63], and on the other hand, it can be formulated within the multi-stage stochastic programming (MSP) framework [15, 17, 59], by considering with and , as an augmented decision variable. Specifically, the BCR-SOC/MDP model can be reformulated as a risk-averse MSP model in [48] as follows:
(3.3a) s.t. (3.3b) where with being updated according to (3.1b) and the stochastic process . For a detailed example, we refer the readers to [61], which illustrates how the classical inventory model can be adapted to fit the above framework.
To ensure the BCR-SOC/MDP model to be well-defined, we make the following assumption.
Assumption 1.
(a) For , the cost function is continuous, and there exist positive constants such that
| (3.4) |
holds, and
| (3.5) |
(b) For , is a continuous law invariant monetary risk measure such that , and
| (3.6) |
where is a positive constant depending on . (c) The random variables are independent and identically distributed (i.i.d.) with true unknown distribution which belongs to a parametric family of distributions , where for all . (d) The density function is continuous in over . (e) The action space is a compact and convex set.
The following comments about how the specified conditions in the assumption can be satisfied might be helpful. Inequalities (3.4)-(3.5) in Assumption 1 (a) specify the growth conditions of the cost functions in terms of . This type of condition is widely used in stochastic programming, see e.g., [23] and references therein, but it is a new consideration for SOC/MDP models. In the literature of SOC/MDP models, the cost functions are often assumed to be bounded. Here we relax the boundedness condition to cover the case where the dependence of on is non-linear and the support set of can be unbounded. Condition (b) is closely related to (a). In the case where in (3.5), condition (a) subsumes the case that is bounded. By setting , condition (b) will also accommodate this case. We will return to this shortly to show how condition (b) can be satisfied under some specific circumstances. Assumption 1 (c) is the set-up of the BCR-SOC/MDP model. The independence of is usually assumed in SOC/MDP models and holds automatically in many scenarios. Assumption 1 (d) is also satisfied by many probability distributions and is widely used in the literature, see e.g., [63].
Inequality (3.6) in Assumption 1 (b) poses a bound on under the BCR. Since depends on , the upper bound of the BCR depends on . Inequality (3.6) requires the bound to be controllable by . This kind of condition is less intuitive, so we use an example to explain how the condition can be satisfied in some important cases.
Example 2.
Inequality (3.6) holds under the following specific cases.
-
(a)
The support set of , , is bounded. In this case, is bounded by a positive constant .
-
(b)
Both and follow a normal distribution with and . Let . Then
(3.7) Since , then
(3.8) where and the inequality is based on the generalized Minkowski inequality. By applying the inner risk measure to both sides of the inequality, we obtain
(3.9) where and . Since , then
(3.10) By applying the outer risk measure to both sides of the inequality above, we obtain
(3.11) A combination of (3.9)-(3.11) yields
(3.12) where , . By applying (3.7) to the right-hand side of (3.12), we obtain
where and are constants defined as , depending on .
-
(c)
and . Let . Then the posterior distribution can be updated based on as follows:
(3.13) We consider BCR with both the inner and outer risk measures being mathematical expectation. Since , then
and subsequently
Moreover, since , then we have
for . By exploiting (3.13), we obtain
Let
Then
Next, we consider the case where the inner risk measure is . Since , the result follows in a similar manner to the case where . Furthermore, consider the case where the inner risk measure is . Since , the result can be deduced in a similar manner to the case. For the outer risk measures and , similar results hold.
-
(d)
and . By setting the prior distribution , the posterior distribution can be updated based on sample as follows:
(3.14) Consider the case that both the inner and outer risk measures are mathematical expectations. For , the expectation is given by:
For simplicity, we can find constants and such that
Since , we have:
Substituting and into the equation above, we obtain
Using the properties of the Gamma function, we have
Consequently we can establish
where and . Similar results can be established when VaR and AVaR are chosen for the inner and outer risk measures respectively. We omit the details.
We are now ready to address the well-definedness of the BCR-SOC/MDP problem (3.1).
Proof. Let
We begin by considering case. Since , then
Under Assumption 1 (c),
| (3.15) |
By setting , we know by Proposition 1 that is well defined and is continuous in . Repeating the analysis above, we can show by induction that
| (3.16) |
and hence the well-definedness of by virtue of Proposition 1 and continuity in by Lemma 1 for .
The proposition applies to the case where , that is, the BCR-SOC/MDP is a finite-horizon problem. In the case of , we need to assume that is bounded and . The condition is widely used in the literature of infinite horizon SOC/MDP. In the context of Assumption 1, it corresponds to and . Consequently, is bounded by a constant for all , which leads to the well-definedness of BCR-SOC/MDP problem (3.1) with .
3.1 BCR-SOC/MDP vs conventional SOC/MDP models
The proposed BCR-SOC/MDP model subsumes several important SOC/MDP models in the literature. Here we list some of them.
Example 3 (Conventional risk-averse SOC/MDPs).
Conventional risk-averse SOC/MDP models (see e.g. [2, 47, 33]) assume that the transition probability matrix or the distribution for is known. These models can be regarded as a special case of the BCR-SOC/MDP model by setting , where is the Dirac probability measure at . Consequently the posterior distribution remains for all , because of the Bayes’ updating mechanism . The resulting objective function of problem (3.1) can be reformulated as:
| (3.17) |
Moreover, by adopting the inner risk measure as expectation, VaR and AVaR, respectively, the BCR-SOC/MDP model recovers the relevant risk-averse SOC/MDP models in the literature.
Example 4 (Distributionally robust SOC/MDPs).
In the distributionally robust SOC/MDP models (see e.g. [60, 76]), the DM uses partially available information to construct an ambiguity set of transition probability matrices to mitigate the risk arising from incomplete information about the true transition probability matrix for and . The optimal decision is based on the worst expected cost calculated with the ambiguity set of transition matrices. The distributionally robust SOC/MDP models can be recast as BCR-SOC/MDP models.
-
•
The ambiguity set of transition probabilities can equivalently be described by the ambiguity set of the distributions of the random parameters within the BCR-SOC/MDP framework. For instance, if we set the inner risk measure with the mathematical expectation and the outer risk measure with essential supremum () where , then the objective function of problem (3.1) becomes
or equivalently
(3.18) where is the support set of for . As demonstrated in [40], this reformulation is in alignment with distributionally robust SOC/MDP models if we treat as an ambiguity set of . If the inner risk measure is set using a general risk measure instead of the mathematical expectation, the BCR-SOC/MDP model is equivalent to the distributionally robust risk-averse SOC/MDP model proposed in [56]. Moreover, by choosing for outer risk measure , the BCR-SOC/MDP model effectively transforms into a less conservative chance-constrained SOC/MDP form, as proposed in [13]. This BCR-SOC/MDP model can thus be viewed as a distributionally robust SOC/MDP with respect to the Bayesian ambiguity set defined in [24]. Further elaboration on this equivalence will be provided in Section 6.1.
-
•
In view of the robust representation of coherent risk measures, employing some coherent risk measure as the outer risk measure gives our BCR-SOC/MDP framework (3.17) an interpretation aligned with distributionally robust SOC/MDP models concerning the corresponding ambiguity sets. To be consistent with the setting of our article, we refer to [60] for the detailed equivalence between the distributional robust model and the risk-averse model under the premise of parametric family of probability distributions.
Example 5 (Bayes-adaptive MDP).
Like the concept behind BCR-SOC/MDP, the state space of Bayes-adaptive MDPs consists of the physical state space and the posterior distribution space , as introduced in [55]. Specifically, as demonstrated in [8], the objective function of the episodic Bayesian SOC in [63] can be formulated as the following Bayes-adaptive form:
| (3.19) |
Here, satisfying , represents the posterior estimate of the underlying distribution . By setting both the inner risk measure and the outer risk measure as the expectation operators and respectively, the objective function of the BCR-SOC/MDP model reduces to
| (3.20) |
which is equivalent to that of Bayes-adaptive MDP. This can easily be derived by exchanging the order of integrals. Furthermore, the objective function of the BR-MDP in [38]
| (3.21) |
can be derived from the BCR-SOC/MDP model by only setting the inner risk measure as the expectation operator .
3.2 BCR-SOC/MDP with randomized VaR and SRM – a preference robust viewpoint
BCR can be understood as the risk measure of a random risk measure. In decision analytics, is DM’s belief about uncertainty of the state of nature and is a measure of the risk of such uncertainty. The risk measure captures the DM’s risk preference and the uncertainty of makes a random variable. In this subsection, we will use two examples to compare empirical distributions and ambiguity sets, and highlight the importance and practical relevance of the BCR model in real-world problems.
In a data-driven environment, a popular approach is to use samples to derive an estimation of and subsequently an approximation of . However, the approach may not work well when the sample size is small. The next example illustrates this.
Example 6.
Consider an example of predicting the price movement of a stock. The true probability distribution of the stock price increasing is , where signifies the likelihood of an upward movement (stock price increase). When , it means the probability that the stock price will increase is less than 0.5, indicating a generally downward market trend. Let us consider the case where the stock price movement is neutral, i.e., , meaning the probability of an upward movement is 50%. Suppose that we observe the stock price movement over five trading days, resulting in 2 days of price increases (up days) and 3 days of price decreases (down days). In this case, we may deduce that , suggesting a higher probability of a downward movement than the true . This estimate deviates significantly from the true because the sample size is small. Indeed, by using the Binomial distribution, we have
which means that the probability of observing 2 up days and 3 down days with a stock market with a neutral price movement is very close to that of a stock market where . To address the issue, we can use a convex combination , instead of , to evaluate the risk of loss in the market. This concept is used by Li et al. [37, Example 1] in the context of randomized spectral risk measures.
It might be tempting to adopt a robust approach by considering the worst-case probability distribution of from an ambiguity set such as . In that case, we have
which means that the worst-case probability distribution is too conservative for use. This is because is assumed to have equal probability over the range in the robust argument. The simple calculation shows that adopting a distributional form of estimation of which weights the different effects of the values on the distribution of might be more appropriate in the absence of complete information about based on a small sample size of .
We can cope with the above issue from a Bayesian perspective: before observing any data, we assume that no specific information about the true parameter is known by the DM, and thus the DM can consider to be a realization of a random variable following a uniform distribution over the interval [0, 1], i.e., for all . After observing data with 2 up days and 3 down days, we easily derive using Bayes’ formula that the posterior distribution follows a Beta(3,4) distribution, as illustrated in Figure 1.
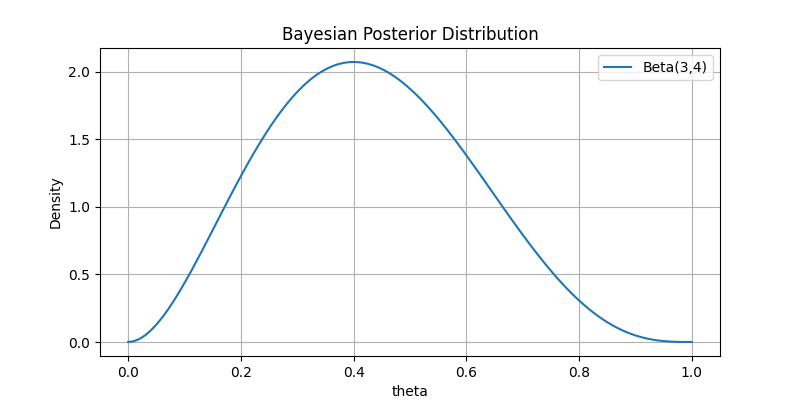
As depicted, in such cases, employing a distribution to randomize allows us to capture the variability in environmental performance more effectively. From a modeling perspective, evaluating under this framework can quantify the DM’s risk preference with respect to the environment through . Therefore, utilizing as the probability distribution of is more reasonable.
It is possible to express BCR-SOC/MDP as a preference robust SOC/MDP under some specific circumstances. To see this, we consider a BCR where for some and . The resulting BCR is
We will show shortly that the BCR may be expressed as an SRM. Assume, for fixed , that there exists a bijective function such that , where is the true probability distribution of . For fixed and , let
| (3.22) |
Then
The right-hand side of the equation above is a spectral risk measure, which can be viewed as the weighted average of the randomized . The next example explains how it may work.
Example 7.
Consider a random variable which follows an exponential distribution parameterized by . It is easy to derive that
Suppose that the true probability distribution of is . By definition, the SRM of is
On the other hand, the BCR of is
By setting , we demonstrate that Thus, by letting risk spectrum
we obtain .
Generalizing from this, we consider a generic law invariant coherent risk measure . We know from [61] that can be represented as
where represents a set of probability density functions.
By adopting a coherent risk measure for the outer risk measure , we have
| (3.23) |
where is the domain of the Fenchel’s conjugate of (see [61, Theorem 6.5]), and is a set of risk spectra corresponding to based on the one-to-one correspondence between and as specified in (3.22). The second term in equation (3.23) can be viewed as distributionally robust formulation of , while the third term of the equation is preference robustness of SRM. The robustness in the former is concerned with the ambiguity of the environmental risk represented by whereas the robustness in the latter is concerned with ambiguity of the DM’s preference (represented by ) associated with the ambiguity in the environmental risk.
Example 8 (Preference robust SOC/MDP).
Let the inner risk measure be and the outer risk measure be a coherent risk measure. In this case, the objective function of the BCR-SOC/MDP model (3.1) becomes
By virtue of (3.23), we can recast the problem as a preference robust SOC/MDP problem:
where , , is a set of risk spectra representing the uncertainty of a DM’s risk attitude at episode . Based on Bayes’ rule, we understand that the updates of can be established by a continuous process of learning and correction. Therefore, in the corresponding preference robust SOC/MDP model, the DM’s ambiguity set of risk attitude also evolves continually as the sample data accumulates.
A similar correspondence between BCR-SOC/MDP and preference robust SOC/MDP can be established when the inner risk measure is and the outer risk measure is a coherent risk measure. In that case, we can derive a representation akin to the Kusuoka’s representation [36], with Kusuoka’s ambiguity set being induced by . All these will lead to another preference robust SOC/MDP model with Kusuoka’s ambiguity set representing DM’s preference uncertainty.
In summary, the examples discussed above show that the BCR-SOC/MDP model displays the breath of its scope and appropriateness for adaptive and self-learning systems within the realm of risk control. Moreover, by judiciously selecting risk measures and configuring posterior distributions, we can align BCR-SOC/MDP models with preference robust SOC/MDP models.
4 Finite-horizon BCR-SOC/MDP
We now turn to discussing numerical methods for solving (3.1). As with the conventional SOC/MDP models, we need to separate the discussions depending on whether and . We begin with the former in this section. The finite horizon BCR-SOC/MDP may be regarded as an extension of the risk-neutral MDP [38]. The key step is to derive dynamic recursive equations. In the literature of SOC/MDP and multistage stochastic programming, this relies heavily on interchangeability and the decomposability of the objective function [60]. However, the BCR-SOC/MDP does not require these conditions. The next proposition states this.
Proposition 3.
By analogy with the analysis in [57], Proposition 3 is evident if we treat the state space and the posterior distribution space together as an augmented state space, see [38] for the latter. In alignment with the discussions in [12, 59], the BCR-SOC/MDP formulation (3.1) emphasizes the critical aspect of time consistency within the nested risk function framework. Thus, for the proposed BCR-SOC/MDP model with a finite horizon, we can recursively solve it using a dynamic programming solution procedure such as that outlined in Algorithm 1. We will discuss the details of solving the Bellman equations (4.1a)-(4.1b) in Section 6.
| (4.4a) | |||||
| s.t. | (4.4b) | ||||
A key step in Algorithm 1 is to solve problem (4.4) for all . This is implementable in practice only when is a discrete set with finite elements. Moreover, it is often difficult to obtain a closed form of the objective function when is continuously distributed. All these mean that the algorithm is conceptual as it stands. We will return to the issues in Section 6. Another issue is the convexity of problem (4.4). We need to ensure that this is a convex program so that is an optimal solution. It is sufficient to ensure that is convex in . We address this below. The following assumption is required.
Assumption 2.
For all , and are jointly convex with respect to .
By comparison with the assumptions in the existing literature (e.g., [22, 63]), Assumption 2 is mild. In these works and in many practical applications, it is typically assumed that is affine. Note that the convexity of is required to ensure that problem (4.1b) is convex which will facilitate numerical solution of the problem. The next proposition states the convexity of problem (4.1b).
Proposition 4.
Let Assumptions 1 and 2 hold. If and are convex risk measures for each episode , then the following assertions hold.
-
(i)
Problem (4.1b) is a convex program.
-
(ii)
If, in addition, and are Lipschitz continuous in uniformly for all and with modulus and , respectively, then is Lipschtz continuous in , i.e.,
(4.5) for , where .
-
(iii)
If, further, and are Lipschitz continuous in uniformly for all and , then is Lipschtz continuous in , i.e.,
(4.6) for .
Proof. Part (i). Due to Assumption 1 (e), it suffices to show that is jointly convex in . Under Assumption 2, the function is jointly convex provided that is convex in . This is because the BCR is convex and monotone since and are convex risk measures. In what follows, we use backward induction to derive convexity of in . Observe that . Thus, the conclusion holds at episode . Assuming that the convexity holds for episodes from to , we demonstrate the convexity at episode . This is evident from (4.1b) in that is convex in and hence is jointly convex in .
Part (ii). We also use backward induction to establish Lipschitz continuity of in . At episode , the Lipschtz continuity is evident since . Assuming that the Lipschtz continuity holds from episodes to , we demonstrate that the Lipschitz continuity also holds at episode . Under the hypothesis of the induction, is Lipschtz continuous in with modulus . For any ,
Thus
A similar conclusion can be derived by swapping the positions of and . Therefore, we have
This deduction confirms by mathematical induction that the Lipschitz continuity property holds for all episodes.
Part (iii). For any , we have:
for .
5 Infinite-horizon BCR-SOC/MDP
In this section, we move on to discuss the BCR-SOC/MDP problem (3.1) with infinite-horizon, i.e., . We start with the following assumption.
Assumption 3.
Consider problem (3.1). (a) The transition dynamics are time-invariant, i.e., and for all . (b) For all , the absolute value of the cost function is bounded by a constant . (c) The discount factor .
Under Assumption 3, we can formulate the BCR-SOC/MDP model (3.1) as follows:
| (5.1a) | |||||
| s.t. | (5.1c) | ||||
We use to denote the optimal value of problem (5.1). Given the boundness of the cost function , it follows that the value function is also bounded, i.e.,
5.1 Bellman equation and optimality
It is challenging to solve the infinite-horizon BCR-SOC/MDP problem (5.1). A standard approach is to use the Bellman equation to develop an iterative scheme analogous to those used in the existing SOC/MDP models (e.g., [22, 63, 82]). We begin by defining the Bellman equation of (5.1).
Definition 1 (Deterministic Bellman operator).
Let denote the space of real-valued bounded measurable functions on . For any value function , define the deterministic operator as follows:
| (5.2) |
and operator for a given :
| (5.3) |
The dynamic programming formulation integrated into the Bellman operator ensures that risk factors are effectively incorporated into the decision-making process. This approach accounts systematically for both epistemic and aleatoric uncertainties, which are crucial when determining the optimal policy at each decision point. In the Bellman equation presented above, the random variable serves as a general representation of the stochastic input in each decision episode. This simplification helps to maintain the recursive structure of the model without the need to explicitly track time indices for the random variables.
Model (5.1) and the Bellman equation (5.2) assume deterministic policies, but the rationale behind this set-up has not yet been explained fully. The next lemma states that optimizing over randomized policies is essentially equivalent to optimizing over deterministic ones. The latter will simplify the decision problem and improve computational efficiency.
Lemma 2.
The deterministic Bellman operator is equivalent to the random Bellman operator, i.e.,
where denotes the set of all randomized policies.
Proof. Denote an arbitrary randomized policy by . For any value function , we have
Hence,
The reverse is straightforward, as a deterministic policy is a special case of a randomized policy.
The proof leverages an arbitrary randomized policy to demonstrate that the deterministic Bellman operator indeed corresponds to the random Bellman operator, thereby justifying our focus on deterministic policies. This simplification, however, does not preclude the extension of our analysis to randomized policies. In what follows, we demonstrate that the optimal value function of BCR-SOC/MDP problem (5.1) is the unique fixed point of operator . Specifically,
| (5.4) |
To this end, we derive an intermediate result to ensure that the Bellman operators defined in Definition 1 are monotonic and contractive.
Lemma 3 (Monotonicity and contraction).
-
(i)
Both and are monotonic, i.e., implies that and .
-
(ii)
For any measurable functions and , ,
(5.5) and
(5.6) where is the sup-norm under probability measure and is the sup-norm under probability measure .
-
(iii)
The operators and are contractive with respect to the norm. That is, for any bounded value functions , we have
Proof. Part (i). By definition
If two value functions and satisfy for all and , then we can deduce given the monotonicity of the composite risk measure. The same argument applies to .
Part (ii). The inequalities are known as non-expansive properties of a risk measure satisfying translation invariance, see (2.10).
Part (iii). For any , there exists a deterministic policy , such that for any ,
Consequently, we have
Since an arbitrarily small can be chosen, this implies that . Switching the positions of and , we obtain the desired result for . The proof of is analogous to that for .
We are now ready to present the main result of this section which states the existence of a unique solution to Bellman equation (5.4) and the solution coinciding with the optimal value of the infinite BCR-SOC/MDP (5.1).
Theorem 1.
Consider Bellman equation (5.4). The following assertions hold.
Proof. Part (i). Since is contractive, the existence and uniqueness of the optimal function follows directly from the Banach fixed-point theorem. We prove the other two arguments below. Consider any policy such that
| (5.7) |
Such a policy always exists since we can choose such that . By applying iteratively to both sides of (5.7) and invoking the monotonicity property from Lemma 3, we deduce that for all . Here, represents the accumulated risk value over a finite horizon with the stationary policy and the terminal value function . Specifically,
As tends to infinity, the sequence at right-hand side converges to the value function under the policy . Since is defined as the minimum over all such policies, then .
Next, consider a finite horizon BCR-SOC/MDP with the risk value at last episode defined as . It follows that:
Therefore, we can deduce
By setting and , we have
Let be an upper bound on , we have
As , the left-hand side of the inequality converges to the value function under the policy . The infimum over all policy is bounded from below by , leading to the conclusion that .
Part (ii). To begin, with the definition of , for any horizon , state , and policy , we have that
Therefore,
Given the monotone property of Bellman operator , forms a nondecreasing sequence which implies that
Hence, to complete the proof, it only remains to show that . Consider any policy such that . By iterating this inequality, for all and , we obtain:
Letting , it follows that for all ,
Therefore, combining this result with Part (i) of Theorem 1, we conclude that satisfies the Bellman equation .
5.2 Asymptotic convergence
Let be defined as in Theorem 1 and be defined in Section 2. Define
| (5.8) |
and
| (5.9) |
For , let be defined as in (5.1c). Define
| (5.10) |
and
| (5.11) |
In this section, we investigate the convergence of to and to as . The rationale behind the convergence analysis is that in the infinite-horizon Markov decision making process, the DM and the environment interact continuously, allowing the DM to acquire gradually an infinite amount of information about the true environment (represented by the true probability distribution of ). As information or data accumulates, the DM’s understanding of the environment improves continuously, diminishing the uncertainty of . This raises a question as to whether the optimal value and the optimal policy , obtained from solving the BCR-SOC/MDP model (5.1), converge to their respective true optimal counterparts, and as the data set expands. The first step is to derive weak convergence of to . To this end, we need the following assumption.
Assumption 4.
Let and denote the posterior mean and variance with respect to . As tends to infinity, and almost surely (a.s.).
This assumption indicates that as the sequence expands with the increase of , more observations of are gathered. Consequently, the Bayesian posterior distribution will increasingly concentrate around , eventually reducing to a Dirac function centered at . The following example illustrates that this assumption is reasonable.
Example 9.
Consider the inventory control problem, as proposed in [38]. Based on experience and relevant expertise, a warehouse manager believes that the customer demand follows a Poisson distribution with parameter . The prior distribution is modeled as a distribution, which, because of its conjugate nature with respect to the Poisson distribution, ensures that the posterior distribution of remains within the Gamma distribution family with updated parameters . Here, , and . Therefore, the posterior mean and variance can easily be calculated as
By the law of large numbers, a.s. under the true distribution . From this, it follows immediately that and almost surely, thereby satisfying Assumption 4. Further, since the convergence rate of is , we have
which verifies the conditions required in Theorem 3 presented below.
Proposition 5.
In [63], this result is called Bayesian consistency, see Assumption 3.2 there. As shown in [27], it follows by Markov’s inequality that
| (5.13) |
Therefore, the Bayesian consistency as stated in (5.12) is achieved under Assumption 4.
Lemma 4.
Under Assumption 4, converges weakly to the Dirac measure , i.e.,
| (5.14) |
for any bounded and continuous function . Moreover, converges to as goes to infinity.
Proof. The result is similar to [62, Lemma 3.2], here we give a proof for completeness. For any , decompose the integral as follows:
| (5.15) |
Since is continuous, for any , there exists an such that for all and , . Consequently, we have
Since , this implies
| (5.16) |
On the other hand, since is bounded, then there exists a constant such that for all . Together with (5.12), we have
| (5.17) |
as . Combining (5.15)-(5.17), we obtain
Since can be arbitrarily small, and the second term tends to as , we establish (5.14) as desired. Moreover, since converges to weakly and by Lemma 1 is continuous in , we conclude that converges to as goes to infinity.
5.2.1 Qualitative convergence
We are now ready to address qualitative asymptotic convergence of optimal values and optimal policies defined in (5.10) and (5.11).
Theorem 2.
Let and be defined as in (5.10) and (5.8), let and be the associated optimal policies defined as in (5.11) and (5.9). Under Assumptions 1, 3 and 4, the following assertions hold.
-
(i)
converges to uniformly w.r.t. as , i.e., for any , there exists a such that for all ,
(5.18) -
(ii)
For each fixed , converges to the set a.s. as . Moreover, if is a singleton, then converges to almost surely.
Proof. Part (i). It suffices to show the uniform convergence of the right-hand side of (5.10). By definition,
| (5.19) | ||||
The third inequality follows by defining and applying Lemma 4 directly. Letting , we obtain that converges uniformly to .
Part (ii). The result here is similar to that of [63, Proposition 3.2], we provide a proof for completeness due to the adoption of BCR in our model. By Part (i),
Thus, for any , there exists a such that for all ,
By the definition of ,
Thus, we can derive
Define the lower level set:
Then . By the convexity of the objective function and the compactness and convexity of the action set, we deduce that for any , the set of the optimal actions, , is nonempty and bounded. Consider a decreasing sequence , it is evident that . Thus the intersection is contained in the topological closure of .
Assume for the sake of contradiction that the convergence does not hold. Then we can find a bounded sequence such that for any . Let be an accumulation point of the sequence. Then
for any , and hence
i.e., . However, this contradicts the assumption that . Consequently, the distance from to the topological closure of converges to zero almost surely, and therefore the distance from to converges to zero as well. The conclusion is straightforward when is a singleton.
The theorem shows uniform convergence of to and point-wise convergence of the optimal policies, which are similar to the convergence results in [63, Propositions 3.1-3.2]. We include a proof as the conventional SOC/MDPs and the episodic Bayesian SOC model [63] focus on a risk-neutral objective function under fixed environment parameters, whereas the BCR-SOC/MDP model (5.1) introduces additional complexity by incorporating epistemic uncertainty about parameter estimation and its impact on both the policy and value function. Moreover, since the BCR does not usually preserve linearity, we need to make sure the specific details of the convergence of the Bellman optimal value function and policy work through. Note also that the asymptotic convergence is short of quantifying for the prescribed precision . In the next section, we will present some quantitative convergence results when the BCR takes a specific form.
5.2.2 Quantitative convergence
From Theorem 2, we can see that the convergence of the optimal values and optimal policies depends heavily on the convergence of to . Under some special circumstances, convergence of the latter may be quantified by the mean and variance of . This raises a question as to whether the convergence of the optimal values and optimal policies can be quantified in terms of the convergence of the mean and variance of . In this subsection, we address this. To this end, we need the following generic technical condition.
Assumption 5.
Let and The inner risk measure is Lipschitz continuous on , i.e., there exist constants and such that
| (5.20) |
The next proposition states how the assumption may be satisfied.
Proposition 6.
Suppose the total variation (TV) distance [66] between and satisfies the following condition:
| (5.21) |
where is a constant. Then, there exists a constant such that
| (5.22) |
if one of the following conditions hold: (i) The inner risk measure is a coherent risk measure taking a parametric form as:
| (5.23) |
where is a non-empty closed convex subset of , and is jointly convex with respect to . For every , the function is nondecreasing and positive homogeneous in . (ii) The diameter of is finite and the inner risk measure is a robust SRM as .
Proof. Part (i). By definition
where the second last inequality follows from the assumption on , which guarantees the existence of a constant such that . By setting and , we can draw the conclusion.
Part (ii). Denote and . Then by definition, we have
Thus, by setting and , we can draw the conclusion using part (ii) of Lemma 1.
The assumption about TV distance in Proposition 6 is satisfied by a number of important parametric probability distributions including exponential, gamma and mixed normal distributions under some moderate conditions. The condition of part (i) in Proposition 6 is commonly used in the literature, such as in [22, 61, 33]. It encompasses a variety of risk measures including AVaR, -divergence risk measure, -norm risk measure and -norm risk measure.
Theorem 3.
Let Assumptions 4 and 5 hold. If there exist positive constants and such that
| (5.24) |
then the following assertions hold.
-
(i)
If the outer risk measure is chosen with , then
(5.25) for all
-
(ii)
If the outer risk measure is chosen with , then
(5.26) Furthermore, if the outer risk measure is chosen with robust SRM , then
(5.27) -
(iii)
If the outer risk measure is chosen with , then
(5.28)
Before providing a proof, it might be helpful to comment on the conditions and results of the theorem. Unlike Theorem 2, Theorem 3 explicitly quantifies the convergence by providing a worst-case upper bound for the optimal value functions uniformly with respect to risk measures. This is achieved by strengthening Assumption 4 with an additional condition (5.24) about the rate of convergence of and , which means that as episode increases, both the posterior variance and bias decrease at a rate of . As shown in [21], under standard statistical assumptions, both and typically converge at a rate of , corresponding to , see Example 9. With the convergence rate of and , we can establish the rate of convergence of the optimal value function from Theorem 3 under some specific BCRs.
-
•
If the outer risk measure is chosen with , , and robust SRM, the convergence rate of to is .
-
•
If the outer risk measure is chosen with , the convergence rate of to is .
Moreover, Part (i) of the theorem provides a supplement to Part (iii). Specifically, when , we have the inequality , demonstrating that the convergence rate for can be as fast as that of .
Proof. Part (i). By the definitions of and in Assumption 4, we have
| (5.29) |
Since , then by (5.20), we have
| (5.30) |
By Hölder inequality,
| (5.31) |
Part (ii) Under Assumption 5, it follows from (5.13) that
For the specified in the definition of , let . Then the inequality above can equivalently be written as
| (5.32) |
Let and be the probability distribution of . Then (5.32) implies
| (5.33) |
By the definition of VaR, this implies
Thus, we obtain that
Similar to the proof of (LABEL:4.18), we can conclude that
Thus the proof for is completed. Similar result can be deduced by the definition of .
Part (iii). Similar to the proof of Part (ii), we have
By setting , we can obtain
| (5.34) |
Let
and
Then, for all , we have
The second last inequality results from the boundedness of the cost function. In combination with (LABEL:4.18), we can conclude that
which completes the proof for .
5.3 Algorithms for value iterations and policy iterations
Having examined the theoretical properties of the proposed infinite-horizon BCR-SOC/MDP problem, we now consider its solution. This subsection introduces two algorithms for computing the unique value function within the infinite-horizon BCR-SOC/MDP framework. Both algorithms are inspired by the dynamic programming equation embodying a risk-averse adaptation of the usual value iteration and policy iteration methods applied in standard SOC/MDPs (see [4, 28] for details).
In the BCR-SOC/MDP model, the introduction of risk-averse characteristics requires adjustments to the conventional value iteration algorithm to accommodate the new dynamic programming equations. The core of these adjustments lies in integrating the impact of risk measures on decision-making during the value function update process. Building on the framework of the conventional value iteration algorithm, we propose a value iteration algorithm tailored for BCR-SOC/MDP, as detailed in Algorithm 2, which aims to approximate with and meanwhile identify the corresponding -optimal policy .
| (5.35) |
The main component of Algorithm 2 is Steps 2-7 which are designed to obtain an approximate optimal value function of problem (5.1). As in Algorithm 1, this requires the set to be a finite discrete set. Once an approximate optimal value function is obtained, we solve problem (5.35) to obtain an approximate optimal policy in Step 9. This kind of algorithm is well known in the literature of infinite horizon MDP, see [51]. The convergence of such algorithms is also well documented. In the next theorem, we give a statement of convergence of the algorithm for self-containedness resulting from the BCR structure.
Theorem 4.
Let the sequence be generated by Algorithm 2. Then
-
(i)
converges linearly to the unique value function at a rate of . Further, the initialization ensures a non-decreasing sequence . Conversely, the initialization results in a non-increasing sequence .
-
(ii)
The policy derived in Algorithm 2 is -optimal, i.e.,
Proof. Part (i). Leveraging Lemma 3, it is evident that the sequence converges linearly to , as demonstrated by:
Starting with leads to . The monotonicity of , as established in Lemma 3, ensures that
for all . Conversely, initiating with implies that . This reasoning concludes that for all .
Part (ii). We begin by noting that
| (5.36) |
We dissect the first term of the right-hand side of (5.36) as follows:
The first equation is because is the fixed point of and the second equation is satisfied since according to Algorithm 2. Thus we can infer
Further examining the second term of the right-hand side of (5.36) leads to the following recursive deduction:
Therefore, we conclude from the above two inequalities and (5.36) that whenever
it follows that .
Algorithm 2 is about an iterative process of value function. Once a satisfactory approximate value function is obtained, we solve a single program (5.35) to obtain an approximate optimal policy. It is also possible to carry out policy iterations. Unlike value iterations, policy iterations refine policies directly. This kind of approach is also known in the literature of MDP [57]. Algorithm 3 describes the process.
| (5.37) |
| (5.38) |
The next theorem states the convergence of Algorithm 3.
Theorem 5.
The sequence of value functions generated by Algorithm 3 is non-increasing and converges linearly to the unique value function at a rate of .
Proof. Equations (5.37)–(5.38) can be expressed concisely as:
respectively. Therefore, we can deduce that
from which we can obtain
because of the monotonicity of the operator . As , we can conclude that converges to by applying Lemma 3 and Banach fixed-point theorem. Therefore,
| (5.39) |
Thus, we have established the non-increasing property of the sequence . Recall that , we deduce from (5.39) that
As a result of the contraction property of , we can conclude that
Hence, the sequence converges linearly to at a rate of .
Remark 1.
Suppose is finite, there exist only finitely policies. Then Algorithm 3 must terminate after a finite number of iterations because of the non-increasing property of sequence . That is, for all we have , and are optimal policies, and is the optimal value function.
In summary, both Algorithm 2 and Algorithm 3 are pivotal in navigating the solution complexities of BCR-SOC/MDPs, each offering distinct advantages in the quest for optimal policies. The transition from approximating value functions to directly refining policies encapsulates a comprehensive approach to addressing BCR-SOC/MDPs, marking a significant advance in the field of Bayes-adaptive risk-averse SOC/MDP methods.
6 Sample average approximation of the BCR-SOC/MDPs
In Algorithms 1-3, we respectively outline how to solve BCR-SOC/MDP (3.1) in the finite horizon case and BCR-SOC/MDP (5.1) in the infinite horizon case. A key step in Algorithms 1 and 2 is to solve the BCR minimization problem. When either or or both are continuously distributed, these problems are not tractable because either a closed form of the objective function cannot be obtained or calculating multiple integrals is prohibitively expensive. This motivates us to adopt the sample average approximation (SAA) approach to discretize the probability distributions in the first place. The same issue exists in Algorithm 3. We begin by considering the general BCR minimization problem as follows:
| (6.1a) | |||||
| s.t. | (6.1b) | ||||
for a predetermined value function . In this section, we discuss how an appropriate SAA method can be implemented when the inner and outer risk measures take specific risk measures such as VaR and AVaR.
6.1 The VaR-Expectation case
In Example 4, we explained how BCR-SOC/MDPs can be derived under the distributionally robust SOC/MDP framework by setting the outer risk measure as with . In this section, we revisit the problem but with a general :
| (6.2a) | |||||
| s.t. | (6.2b) | ||||
In this formulation, the objective is to minimize the -quantile of the expected costs . This approach is less conservative than a DRO problem
| (6.3) |
as demonstrated in [52].
Further, problem (6.2) can be reformulated as a chance-constrained minimization problem:
| () | ||||
This reformulation provides a probabilistic interpretation of the -quantile constraint, aligning it with Bayesian decision-making. Specifically, by treating as a function of , the chance constraint in () can be understood as Bayesian posterior feasibility, as defined in [24]. Thus, problem () can be equivalently reformulated as a DRO problem with a Bayesian ambiguity set, as proposed in [24].
Below, we discuss how to use SAA to discretize (6.2). To this end, let , be iid random variables having posterior distribution . Analogous to [39, 52], we can formulate the sample average approximation of () as:
| () | ||||
| s.t. | ||||
where , are auxiliary variables taking integer values , stands for the largest integer value below and is a large positive constant exceeding
The next proposition states convergence of the problem () to its true counterpart () in terms of the optimal value.
Proposition 7.
Proof. By Theorem 3 in [39], we can deduce that with probability at least for all . Moreover, following a similar argument to the proof of [39, Theorem 10], we can show that a feasible solution to the problem
| (6.6) | ||||
| s.t. | ||||
is also a feasible solution to problem with probability at least for all . Thus, the optimal value of problem (6.6) can be written as . This means that when the solution to problem (6.6) is feasible for problem , it holds that . The conclusion follows as .
Note that in (6.4), the sample size depends on the logarithm of and , which means increases very slowly when and are driven to . Indeed, the numerical experiments in [39] show that the bounds in Proposition 7 are over conservative, potentially allowing for a smaller in practice. Note also that when does not have a closed-form and the dimension of is large, we need to use sample average to approximate . Consequently, problem () can be approximated further by the following MINLP:
| () | ||||
| s.t. | ||||
where are i.i.d. samples generated from for . Denote the optimal value of problem () by . The next proposition states that lies in a neighborhood of with a high probability when the sample size is sufficiently large.
Proposition 8.
Suppose: (a) there exists a measurable function such that
| (6.7) |
for all , and , (b) the moment generating function of is finite valued in a neighborhood of 0. Define
where and are positive constants corresponding to the given objective function and distribution . Then with probability at least , we have
| (6.8) |
for all .
Proof. Proposition 2 in [70] demonstrates that a feasible solution for problem () is also feasible for the problem:
| (6.9) | ||||
| s.t. | ||||
with probability at least for all . Observe that the optimal value of problem (6.9) is . Therefore, if a feasible solution to problem () is also a feasible solution to problem , then we have . Likewise a feasible solution to the following problem
| (6.10) | ||||
| s.t. | ||||
is also feasible for problem () with probability at least when . The optimal value of problem (6.10) is given by . Therefore, when the feasible solution to problem (6.10) is feasible for problem (), it holds that .
The assumptions (a) and (b) in Proposition 8 can easily be satisfied, and its justification can be found in part (iii) of Proposition 4. From the numerical perspective, we can conveniently use packages such as BARON to solve moderately-sized problems () and (). By combining Propositions 7 and 8, we are ready to state the main result of this section.
6.2 The VaR-AVaR case
We now discuss the case when the outer risk measure and the inner risk measure in the BCR minimization problem are set with VaR and AVaR respectively:
| (6.11) | ||||
| s.t. |
This kind of model is used to minimize the highest risk value with preference that occurs with a probability less than or equal to a predefined threshold and can also be interpreted within the framework of a Bayesian DRO problem. Since it is often difficult to derive a closed-form expression for , we may consider the sample average approximation of the problem. However, accurately evaluating SAA requires a large sample size when and are close to . Meanwhile, directly substituting with in model (6.11) results in a large mixed integer program, posing significant computational challenges. To address these issues, we relax the outer risk measure VaR to its closest convex upper bound AVaR, resulting in a convex program which can be solved efficiently using a wide range of algorithms. Specifically, under this setting, we propose an algorithm to solve the following optimization problem within the BCR-SOC/MDP framework:
| (6.12) | |||
By exploiting Rockafellar-Uryasev’s reformulation of in [54] as an optimization problem, we can rewrite problem (6.12) as
| () |
and applying SAA to the latter
| (6.13) |
we can obtain sample average approximation of problem ():
| () | ||||
| s.t. | ||||
where represents the vector with all components being ones. By regarding problem () as a AVaR-constrained problem, we can use another SAA to approximate the AVaR in the constraints:
| () | ||||
| s.t. | ||||
where denotes an auxiliary variable and are i.i.d. samples generated from for . Because of the convexity as demonstrated in Proposition 4, problem () is a convex optimization problem with a linear objective function, which can be solved efficiently even for large-scale problems.
Next, we examine the necessary sample sizes and for a specified precision of the optimal value. Denote the optimal values of () and () by and , respectively. Regarding , it has been proven in [61, Corollary 5.19] that under certain conditions, the next proposition holds.
Proposition 9.
Suppose that for all , , is Lipschtiz continuous with respect to with a Lipschitz constant . Let , and
where is a constant. Then the optimal solution of problem () lies in the -neighborhood of that of problem () with probability for all . Moreover, the optimal value of problem () lies in the -neighborhood of that of problem () with probability for all .
As for the selection of , we give the following proposition.
Proposition 10.
Suppose: (a) there exists a measurable function such that
for all , and ; (b) the moment generating function of is finite in a neighborhood of 0. Let , ,
where and are constants associated with a given objective function and distribution . Then with probability at least ,
| (6.14) |
for all .
Proof. Proposition 3 in [70] states that with probability at least , a feasible solution to problem () is also feasible for the problem:
| (6.15) | ||||
| s.t. | ||||
for all . Note that the optimal value of problem (6.15) equals . Thus, if a feasible solution to problem () is feasible for problem (6.15), then . Likewise a feasible solution to the problem
| (6.16) | ||||
| s.t. | ||||
is also feasible for problem (6.15) with probability at least for all . The optimal value of problem (6.16) is . Thus, when the feasible solution to problem (6.16) is feasible for problem (6.15), we have .
Theorem 7.
The sample sizes established in Propositions 9 and 10 could be large. In practice, various strategies may be employed to accelerate the solution process. For example, [83] shows that smoothing the AVaR can improve computational efficiency significantly, potentially speeding up the solution process by several multiples.
7 Numerical results
In this section, we evaluate the performance of proposed BCR-SOC/MDP models and algorithms by applying them to a finite-horizon spread betting problem and an infinite-horizon inventory control problem. All the experiments are carried out on a 64-bit PC with 12 GB of RAM and a 3.20 GHz processor.
We choose the following SOC/MDP models for comparison.
-
•
BCR-SOC/MDP: for the exact dynamic programming method and value iterations, Algorithm 1 and Algorithm 2, we need to discretize the augmented state into a fine grid with a step size of 0.1. We consider two variants in our experiment: the VaR-Expectation BCR-SOC/MDP and the AVaR-AVaR BCR-SOC/MDP, as discussed in Section 6.
-
•
Risk-averse SOC/MDP (RA-SOC/MDP) presented in [7]: we derive a maximal likelihood estimation (MLE) from the observations of and solve the corresponding risk-averse SOC/MDP using the estimated distribution . For comparability with the risk-averse Bayes-adaptive MDP (AVaR-AVaR case), we adopt the AVaR as the risk measure.
-
•
Standard SOC/MDP: for comparability with the risk-averse Bayes-adaptive MDP (VaR-Expectation case), we adopt the expectation operator as the objective function. Likewise, we use the MLE estimator to estimate the true distribution parameter.
- •
-
•
Distributionally robust SOC/MDP (DR-SOC/MDP) presented in [82, 38]: since prior probabilistic information to construct the ambiguity set might not be available from the dataset directly, we simulate samples of from the posterior distribution to construct the ambiguity set, and derive the optimal policy that minimizes the expected cost under the worst-case scenario of .
Each method will be used to derive the optimal policy from the same sample set, and the performance of the resulting policy will then be tested on a real system, specifically, a SOC/MDP with the true parameter . Below are detailed descriptions of the problems and the tests.
7.1 Finite horizon spread betting problem
In this subsection, we consider a spread betting problem varied from Birge et al. [6]. In spread betting markets, market makers (e.g., bookmakers) quote a spread line for the outcome of an uncertain event, and participants (bettors) bet on whether the outcome will exceed or fall below the spread line based on their own judgment and experience. A typical example is in sports betting, where the bookmaker sets a point spread for a specific match or game. Bettors then bet on whether the outcome will be greater (favorite wins by more than the spread) or smaller (favorite does not win by more than the spread) than the set spread line. Birge et al. [6] consider the market maker’s decision-making process on setting spread line such that the total expected profit is maximized over a specified time horizon.
Here, we focus on a risk-averse bettor’s optimal decision-making problem where the bettor aims to minimize the long-term risk of random losses by dynamically adjusting the bet size and learning about the market’s movements over time. To model this dynamic decision-making process, we apply the BCR-SOC/MDP model to the informed bettor’s decision problem in [6]. The setup is specified as follows.
-
(i)
Market movement . The spread market is a betting market on a specific event, where the outcome of the event is represented by a continuous random variable with cdf at episode . The bookmaker sets a spread line for each bet at episode . The corresponding spread market movement is a binary random variable, where: represents the event that the outcome of exceeds and otherwise. In practice, the probability is unknown to bettors and must be estimated over time. For simplicity, we assume that the market maker maintains a constant probability for the event , denoted as , for all bets. This may be understood as the market maker striving to control the spread line such that the probability of the event exceeding the spread remains constant over time. The assumption means that the market maker would maintain a fixed probability for market movements by adjusting according to the distribution of . In the case that , the market maker remains indifferent to the outcome of the bets in each run, avoiding significant exposure to either side of the bet.
-
(ii)
Wealth . The bettor’s cumulative wealth at episode , representing the bettor’s account balance. Wealth is updated at each episode based on the trades and the spread market scenarios.
-
(iii)
Belief . The bettor’s belief (or estimate) of the spread market activity level . The belief about spread market movements is updated based on the spread market feedback after the trade observation, reflecting the evolving understanding of the spread market state over time. A typical prior for here is the Beta prior since the posterior is also a Beta distribution (see [21]).
-
(iv)
Position Size . At each episode , the bettor chooses the position size , which represents the amount of money to bet. The bettor can bet on the event (i.e., the outcome exceeds the spread line). The position size is determined by the bettor’s policy , which depends on the bettor’s current wealth and belief about the market state . In this model, the bettor cannot bet more than the bettor’s available wealth, so the stake must satisfy the constraint , ensuring that the bettor does not wager more than they have.
-
(v)
Loss function and state transition function . The loss at episode is defined as the negative profit from the trade. Specifically, the loss function is defined as:
where denotes the commission rate (a value between 0 and 1) charged by the market maker, and is an indicator function that takes the value of 1 if and 0 otherwise. The net profit for the bettor is calculated as follows. If the bettor wins (i.e., ), the effective profit is reduced by the commission: . If the bettor loses (i.e., ), then the net loss is , and no commission is applied. The cumulative wealth of the bettor at episode , , can then be defined as .
The BCR-SOC/MDP formulation of the above spread betting problem can be formulated as:
| s.t. | ||||
The well-definedness of this problem can be verified using the expressions of loss function, state transition function as well as the boundedness of . In the numerical tests, the initial wealth is set with . The true parameter is defined as , with the support set of the parameter being . The bettor engages in a series of episodes, selecting the betting size from the action space at each episode. We set and for the outer and inner risk parameters, respectively. The commission rate . The dataset for this problem comprises historical market movement records of size . To reduce the effect of random sampling, we repeat each test with 100 simulations, each of which employs an independent dataset. Table 1 displays the average CPU time (in seconds) required to determine the optimal betting policy, as well as the mean and variance of the actual performance of the optimal policy across the 100 simulations with different sample sizes . Figure 2 visualizes the histogram of actual performances for the BCR-SOC/MDP with -, incorporating different combinations of risk levels: and .
| Approach | time(s) | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| mean | variance | mean | variance | mean | variance | mean | variance | ||
| Bayes-adaptive MDP (-) | 165.11 | -9.94 | 5.79 | -10.48 | 4.37 | -11.51 | 2.59 | -13.61 | 1.32 |
| Standard SOC/MDP | 1.08 | -7.85 | 7.63 | -8.07 | 6.79 | -10.78 | 4.29 | -13.07 | 2.66 |
| BCR-SOC/MDP (-) | 172.63 | -11.12 | 4.17 | -11.66 | 3.02 | -12.44 | 1.05 | -13.92 | 0.25 |
| RA-SOC/MDP | 1.15 | -7.29 | 6.33 | -7.76 | 5.97 | -10.02 | 3.57 | -12.36 | 2.48 |
| BCR-SOC/MDP (-) | 224.37 | -10.09 | 4.95 | -10.63 | 3.74 | -11.79 | 1.80 | -13.78 | 1.07 |
| DR-SOC/MDP | 1.84 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |

-
•
Compared to the standard SOC/MDP and RA-SOC/MDP, the BCR-SOC/MDP model exhibits better robustness in terms of the mean and variance across different BCR measures (e.g., -, - and -). Unlike the methods that depend solely on the point estimate , our approach utilizes the distribution to capture the uncertainty in effectively, significantly enhancing the stability of the optimal policy for both small and large sample sizes. Moreover, the DR-SOC/MDP tends to be over conservative, as it always considers the worst-case scenario from the set of all possible market uncertainties, resulting in zero variance in actual performance. In particular, even in situations where the probability of winning at is high, the DM under DR-SOC/MDP model refrains from betting because of its conservative nature.
-
•
As the sample size increases, the uncertainty corresponding to the model parameter diminishes. Consequently, the performances of all SOC/MDP models improve consistently, with variance monotonically decreasing. The tendency is underpinned by the convergence of both the posterior distribution and the MLE estimator to the true parameter as the sample size increases. Eventually, every model converges to the SOC/MDP model with respect to the true parameter in terms of optimal values and optimal policies.
-
•
In the Bayes-adaptive MDP models (e.g. [38, 55]), we tend to use the augmented pair of the original physical state and the posterior distribution to obtain the optimal value function and policy. Utilizing dynamic programming techniques, we discretize the continuous state, resulting in an exceedingly large augmented state space. As a result of this brute-force approach the computational time for BCR-SOC/MDP model is considerably higher than that of conventional SOC/MDP formulations which involve only a single discrete state physical space .
-
•
In Figure 2, the risk levels and reflect the bettor’s risk preferences towards the epistemic and aleatoric uncertainties, respectively. With lower values of and , the DM tends to adopt a more conservative policy, typically choosing not to bet. Consequently, this conservative stance causes the distribution of actual performance to shift toward the right. However, the risk preferences characterized by and diverge in specific aspects. A lower indicates a bettor’s increased concern over losses in extreme environment, signifying a preference for avoiding such outcomes. As decreases, the optimal decisions under BCR-SOC/MDP model closely resemble those of the DR-SOC/MDP approach, resulting in more conservative choices. Conversely, a lower directly signifies a bettor’s aversion to losses, demonstrating prudence and a preference for minimal potential losses. Thus, as decreases, the bettor focuses more on the losses with respect to worst-case irrespective of the environmental parameter , steering the BCR-SOC/MDP model towards the robust SOC/MDP model. This invariably leads to more cautious decisions. Moreover, compared to the risk level , exerts a stronger influence on the conservativeness of the outcomes. This is because, while the outer conservatism ensures that losses maintain a degree of randomness even in the worst environment, the inner conservatism compels the bettor to directly consider the most adverse scenario.
7.2 Infinite horizon inventory control problem
Having demonstrated the reasonability and efficiency of the proposed BCR-SOC/MDP model compared with typical SOC/MDP models in the literature, in this subsection, we mainly apply the proposed infinite horizon BCR-SOC/MDP model to the inventory control problem with a discount factor .
Inventory models have numerous real-world applications, including healthcare systems, electric energy storage systems, and more (see [58, 75] and the references therein). In inventory management, the problem typically involves deciding the order quantity required in each episode to fulfill customer demand while minimizing costs. The goal of the inventory manager is to manage the trade-offs between ordering costs, holding costs, and penalty costs associated with stockouts, while dynamically adjusting orders based on inventory levels and the uncertainty of future demand. A typical risk-averse inventory control problem aims to minimize long-term costs by dynamically adjusting order quantities and updating beliefs about future demand.
To model this dynamic decision-making process using the BCR-SOC/MDP framework, we define the following parameters and assumptions:
-
(i)
Customer demand . The random variable represents the demand for goods at episode . We assume that the demand follows a Poisson distribution with an unknown parameter [61].
-
(ii)
Inventory level . The inventory level at episode , denoted by , represents the quantity of goods available in stock at that episode. Inventory is updated at each episode based on the decision made by the inventory manager (the order quantity) and the actual demand observed during that episode.
-
(iii)
Belief . The inventory manager’s belief about the demand distribution at episode , denoted by , represents the manager’s knowledge of the likelihood of various demand amounts. A typical prior for here is the Gamma prior since the posterior is also a Gamma distribution (see also [21]).
-
(iv)
Order quantity . The order quantity at episode , denoted by , represents the amount of goods the inventory manager decides to order. This decision is determined by the manager’s policy , which depends on the current inventory level and the inventory manager’s belief about the demand distribution.
-
(v)
Cost function and state transition function . The cost at episode is defined as
where
and are unit order cost, penalty cost for unfulfilling a unit demand, and unit holding cost for excess inventory, respectively. The inventory level can then be defined as .
Under the BCR-SOC/MDP framework, the infinite horizon inventory control problem can be formulated as:
| (7.2a) | ||||
| s.t. | (7.2b) | |||
The classical stationary inventory control problem corresponding to the true distribution can be described in BCR-SOC/MDP form as follows:
| (7.3) | ||||
| s.t. |
As demonstrated in [63], the optimal policy for problem (7.3) is the base-stock policy , where with being the cdf of the random demand and . Thus, for , the optimal value of (7.3) is given by:
| (7.4) |
With this analytical expression, we can compute the true optimal value functions with and , respectively, as benchmarks for standard SOC/MDP and risk-averse SOC/MDP to demonstrate the convergence of the BCR-SOC/MDP models corresponding to - and - with respect to the value functions.
In this inventory control problem, we set . The unit cost for ordering is , the unit holding cost is , and the penalty for unmet demand is set at . For the BCR-SOC/MDP model, we set the outer risk parameter and the inner risk parameter . To facilitate comparison with other MDP models, we examine the performance of the model with different true parameter values . Figure 3 depicts the performance when the learned policy is deployed in various environments with the demand following different Poisson distributions. To illustrate the convergence of optimal value function, we use Algorithm 2 to find the unique optimal value function of the Bellman equation corresponding to (7.2a). Then, we generate sample sequences across different episodes , compute and obtain the corresponding optimal value . The procedure is replicated 100 times to ensure robustness, and the results are shown in Figures 4 and 5. Specifically, we plot boxplot of the sup-norm of the gap between the estimation and the true optimal value , which is calculated as . Moreover, we also use line chart to show the average and standard deviation of the sup-norm of the gap between the estimated value and the true optimal value across different episodes, providing insights into the robustness and variability of the estimation process. We can make the following observations from Figures 3, 4 and 5.
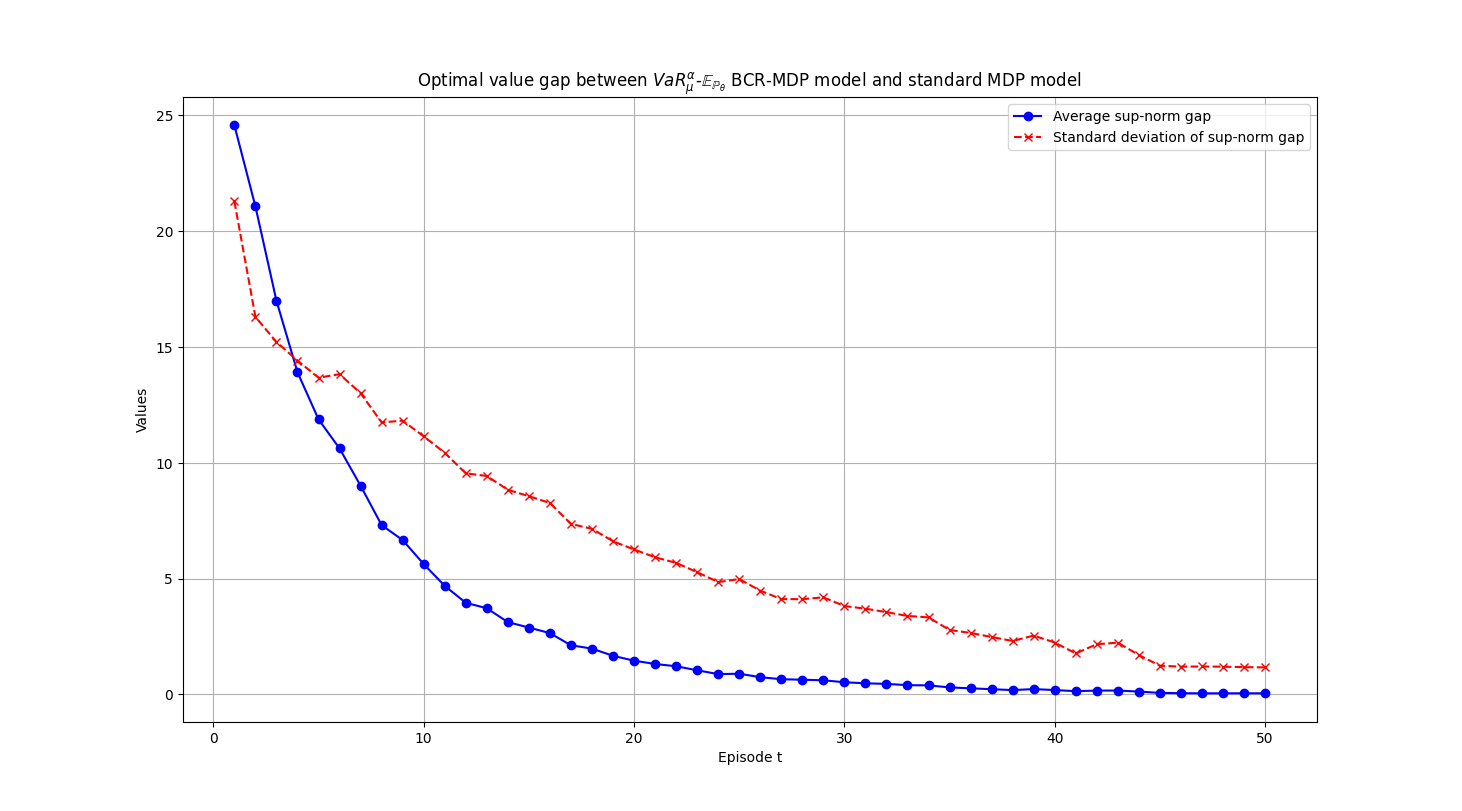
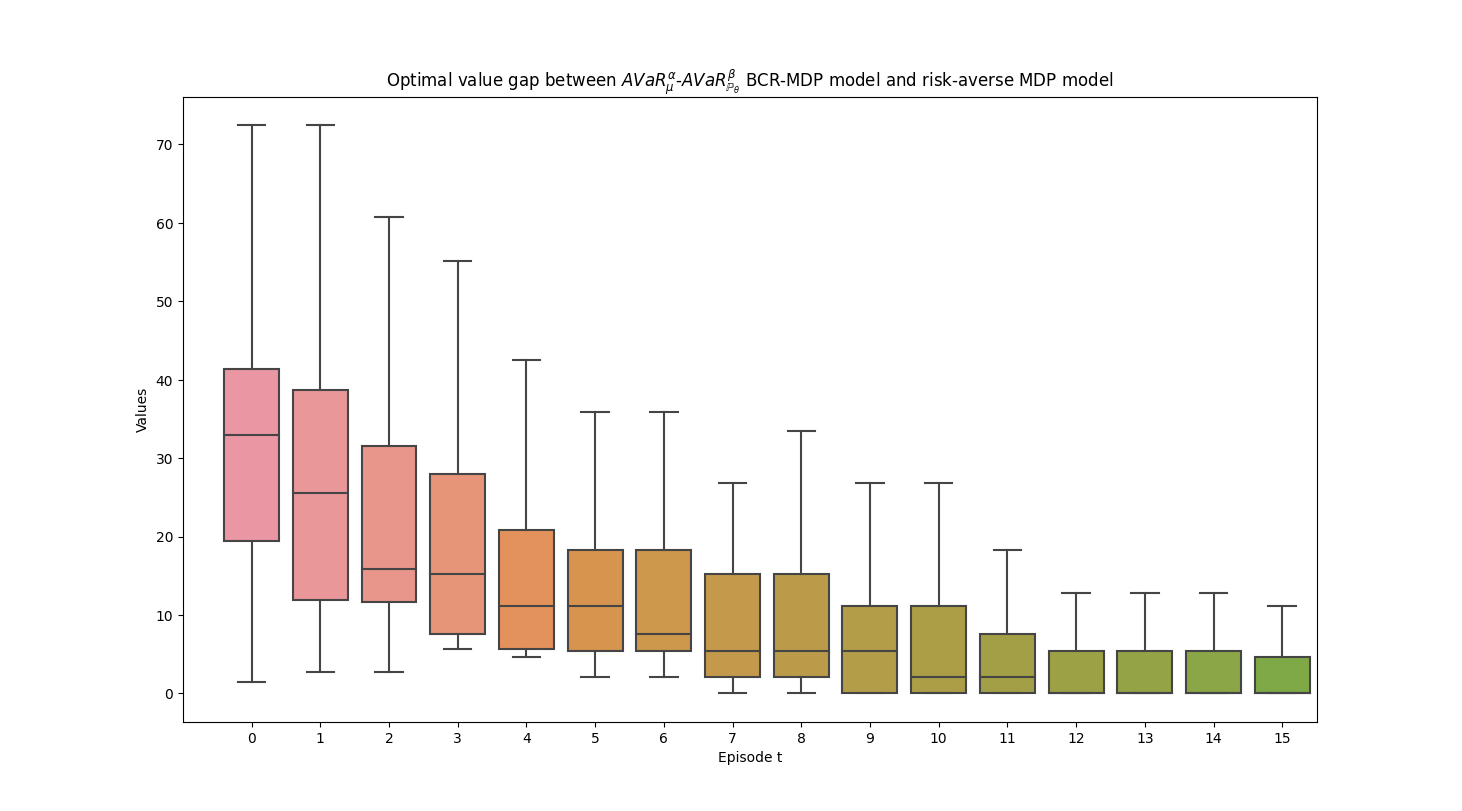
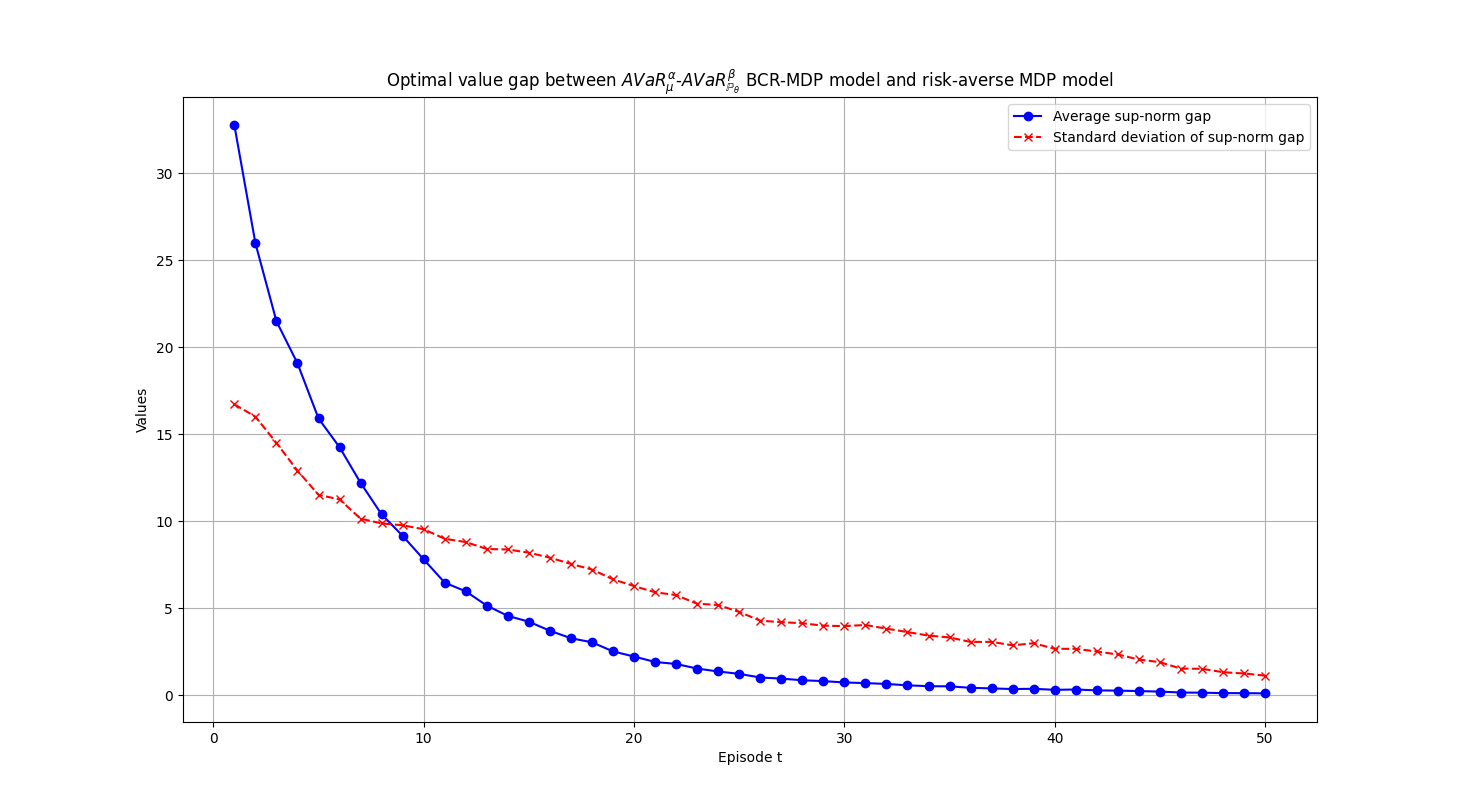
-
•
The BCR-SOC/MDP model outperforms the standard SOC/MDP and RA-SOC/MDP models in diverse environments and various BCR measures, such as -, - and -. Moreover, when compared to the risk-neutral Bayes-adaptive SOC/MDP model, BCR-SOC/MDP models incorporating risk-averse preferences achieve a lower optimal cost value in more adversarial scenarios (e.g., when the Poisson parameter is less than 10), emphasizing their robustness and adaptability to a wide range of challenging environments.
-
•
The mean, median and the range of the super-norm all decrease to as increases, which means that the optimal value functions of all - and - BCR-SOC/MDP models display uniform convergence as envisaged by the theoretical results. From the boxplots in Figures 4 and 5, we observe that the convergence rate of the optimal value functions corresponding to the - case is slower than that of the - BCR-SOC/MDP model, which is consistent with the conclusion in Theorem 3. Moreover, the line charts in Figures 4 and 5 show that, compared to the - BCR-SOC/MDP model, the - BCR-SOC/MDP model exhibits smaller variability in the sup-norm gap, reflecting the more robust characteristics of the latter risk-averse attitude with respect to the value function.
-
•
As the episode increases, the elements of the stochastic process increase, and the optimal value function corresponding to state converges exponentially to the optimal value of the true model as converges. This manifests the significance and characteristics of Bayes-adaptive MDPs. Specifically, the epistemic uncertainty gradually diminishes as the DM continuously observes/learns about the environment. Consequently, the DM’s understanding of the environment becomes more precise, driving the gap of the optimal values to zero. Likewise, the variability of the gap reduces to zero. By contrast, for a standard SOC/MDP or risk-averse SOC/MDP, once the model is established, the optimal value function remains fixed and does not change over time. Specifically, once an MLE estimator is derived for the standard or risk-averse SOC/MDP, the corresponding optimal value function takes a similar form to that in (7.4), with being replaced by . Consequently, for any episode , the optimal value functions for the estimated SOC/MDP models remain fixed, which explains that these models do not adaptively learn in response to dynamic change of the environment.
8 Concluding remarks
In this paper, we introduce a BCR-SOC/MDP model which subsumes a range of existing SOC/MDP models and relates to preference robust SOC/MDP models. By comparison with [63], the new model exhibits adaptive learning capabilities and ensures robustness against the inherent parameter randomness. In the finite-horizon case, we derive some important properties of the BCR-SOC/MDP model. In the infinite-horizon case, we derive some basic properties and demonstrate the model’s adaptability by showing that as the number of episodes increases, the optimal value functions and optimal policies almost surely converge to those of the true underlying problem. We also propose SAA-type algorithms tailored for solving the BCR-SOC/MDP model under specific composite risk measures and examine the robustness and adaptability of the model through numerical experiments. The theoretical analyses and numerical results show that the monetary risk measure, especially the Value at Risk (VaR), robust spectral risk measure (SRM) and average VaR, also exhibits convergence properties, prompting an examination of how to relax the conditions to encompass a broader range of risk measures.
There are a few aspects that we may take from this work for more in-depth exploration. First, the relationship between the BCR-SOC/MDP and preference-robust SOC/MDP models. We have indicated in Section 3.2 that a relationship between the two models may be established. It might be interesting to investigate the fine details of the relationship between distributionally robustness and preference robustness in the dynamic setting given that both are fundamentally related to DM’s dynamic risk preferences. Moreover, the BCR-SOC/MDP framework may potentially provide a more convenient avenue for solving multistage randomized preference-robust optimization problems [80]. Second, because of the complex structure of the Bayesian composite risk measure and the posterior distributions in the augmented state space, this paper does not explore SDDP-type methods for solving the problem as in [62]. It might be worth discussing SDDP for solving the proposed model at least under some specific cases given the known effectiveness of SDDP approach. Third, in practical application of the BCR-SOC/MDP model, particularly in data-driven problems, samples are often drawn from empirical data which might contain some noise. In that case, it might be relevant to investigate whether the proposed models are stable against perturbations in the uncertainty data in terms of both optimal values and optimal policies. Stability results for conventional SOC/MDP models have been derived by Kern et al. [35], and it would be valuable to explore whether similar stability results can be established for the BCR-SOC/MDP model. Finally, the numerical tests were carried out with two conventional SOC/MDP problems. It will be much more interesting if we can find new applications particularly related to online decision making. We leave all these avenues for future research.
Declarations
-
•
This project is supported by the National Key R&D Program of China (2022YFA1004000, 2022YFA1004001), National Natural Science Foundation of China (11991023) and CUHK start-up grant.
Acknowledgments
We would like to thank Alex Shapiro and Zhiyao Yang for a number of valuable discussions during preparation of this work.
reference
- [1] C. Acerbi, Spectral measures of risk: A coherent representation of subjective risk aversion, Journal of Banking & Finance, 26 (2002), pp. 1505–1518.
- [2] M. Ahmadi, U. Rosolia, M. D. Ingham, R. M. Murray, and A. D. Ames, Constrained risk-averse Markov decision processes, in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 35, 2021, pp. 11718–11725.
- [3] N. Bäuerle and J. Ott, Markov decision processes with average-value-at-risk criteria, Mathematical Methods of Operations Research, 74 (2011), pp. 361–379.
- [4] R. E. Bellman and S. E. Dreyfus, Applied Dynamic Programming, vol. 2050, Princeton University Press, 2015.
- [5] D. Bertsekas, Dynamic Programming and Optimal Control: Volume I, Athena scientific, 2012.
- [6] J. R. Birge, Y. Feng, N. B. Keskin, and A. Schultz, Dynamic learning and market making in spread betting markets with informed bettors, Operations Research, 69 (2021), pp. 1746–1766.
- [7] S. Carpin, Y.-L. Chow, and M. Pavone, Risk aversion in finite Markov decision processes using total cost criteria and average value at risk, in 2016 IEEE International Conference on Robotics and Automation (ICRA), IEEE, 2016, pp. 335–342.
- [8] Z. Chen and W. Ma, A Bayesian approach to data-driven multi-stage stochastic optimization, Journal of Global Optimization, 90 (2024), pp. 401–428.
- [9] Y. Chow, A. Tamar, S. Mannor, and M. Pavone, Risk-sensitive and robust decision-making: a CVaR optimization approach, Advances in Neural Information Processing Systems, 28 (2015).
- [10] M. Claus, Advancing Stability Analysis of Mean-risk Stochastic programs: Bilevel and Two-stage Models, PhD thesis, Dissertation, Duisburg, Essen, Universität Duisburg-Essen, 2016.
- [11] R. Dearden, N. Friedman, and D. Andre, Model-based Bayesian exploration, arXiv preprint arXiv:1301.6690, (2013).
- [12] E. Delage and D. A. Iancu, Robust multistage decision making, in The operations research revolution, INFORMS, 2015, pp. 20–46.
- [13] E. Delage and S. Mannor, Percentile optimization for Markov decision processes with parameter uncertainty, Operations Research, 58 (2010), pp. 203–213.
- [14] E. Delage and Y. Ye, Distributionally robust optimization under moment uncertainty with application to data-driven problems, Operations Research, 58 (2010), pp. 595–612.
- [15] P. Dommel and A. Pichler, Foundations of Multistage Stochastic Programming, arXiv preprint arXiv:2102.07464, (2021).
- [16] M. O. Duff, Optimal Learning: Computational procedures for Bayes-adaptive Markov Decision Processes, University of Massachusetts Amherst, 2002.
- [17] J. Dupačová and K. Sladkỳ, Comparison of multistage stochastic programs with recourse and stochastic dynamic programs with discrete time, ZAMM-Journal of Applied Mathematics and Mechanics, 82 (2002), pp. 753–765.
- [18] E. A. Feinberg and A. Shwartz, Handbook of Markov Decision Processes: Methods and Applications, vol. 40, Springer Science & Business Media, 2012.
- [19] J. A. Filar, D. Krass, and K. W. Ross, Percentile performance criteria for limiting average Markov decision processes, IEEE Transactions on Automatic Control, 40 (1995), pp. 2–10.
- [20] R. Gao and A. Kleywegt, Distributionally robust stochastic optimization with Wasserstein distance, Mathematics of Operations Research, 48 (2023), pp. 603–655.
- [21] A. Gelman, J. Carlin, H. Stern, D. Dunson, A. Vehtari, and D. Rubin, Bayesian Data Analysis, Third Edition, Chapman & Hall/CRC Texts in Statistical Science, Taylor & Francis, 2013.
- [22] V. Guigues, A. Shapiro, and Y. Cheng, Risk-averse stochastic optimal control: an efficiently computable statistical upper bound, Operations Research Letters, 51 (2023), pp. 393–400.
- [23] S. Guo and H. Xu, Robust spectral risk optimization when the subjective risk aversion is ambiguous: a moment-type approach, Mathematical Programming, 194 (2022), pp. 305–340.
- [24] V. Gupta, Near-optimal bayesian ambiguity sets for distributionally robust optimization, Management Science, 65 (2019), pp. 4242–4260.
- [25] H. Gzyl and S. Mayoral, On a relationship between distorted and spectral risk measures., (2008).
- [26] J. L. Hau, M. Petrik, and M. Ghavamzadeh, Entropic risk optimization in discounted MDPs, in International Conference on Artificial Intelligence and Statistics, PMLR, 2023, pp. 47–76.
- [27] L. Hong and R. Martin, A review of Bayesian asymptotics in general insurance applications, European Actuarial Journal, 7 (2017), pp. 231–255.
- [28] R. A. Howard, Dynamic Programming and Markov Processes, John Wiley, 1960.
- [29] R. A. Howard and J. E. Matheson, Risk-sensitive Markov decision processes, Management Science, 18 (1972), pp. 356–369.
- [30] D. A. Iancu, M. Petrik, and D. Subramanian, Tight approximations of dynamic risk measures, Mathematics of Operations Research, 40 (2015), pp. 655–682.
- [31] G. N. Iyengar, Robust dynamic programming, Mathematics of Operations Research, 30 (2005), pp. 257–280.
- [32] D. Jalota and Y. Ye, Stochastic online fisher markets: Static pricing limits and adaptive enhancements, Operations Research, (2024).
- [33] D. R. Jiang and W. B. Powell, Risk-averse approximate dynamic programming with quantile-based risk measures, Mathematics of Operations Research, 43 (2018), pp. 554–579.
- [34] L. V. Kantorovich and S. Rubinshtein, On a space of totally additive functions, Vestnik of the St. Petersburg University: Mathematics, 13 (1958), pp. 52–59.
- [35] P. Kern, A. Simroth, and H. Zähle, First-order sensitivity of the optimal value in a Markov decision model with respect to deviations in the transition probability function, Mathematical Methods of Operations Research, 92 (2020), pp. 165–197.
- [36] S. Kusuoka, On law invariant coherent risk measures, Advances in mathematical economics, (2001), pp. 83–95.
- [37] M. Li, X. Tong, and H. Xu, Randomization of spectral risk measure and distributional robustness, arXiv preprint arXiv:2212.08871, (2022).
- [38] Y. Lin, Y. Ren, and E. Zhou, Bayesian risk Markov decision processes, Advances in Neural Information Processing Systems, 35 (2022), pp. 17430–17442.
- [39] J. Luedtke and S. Ahmed, A sample approximation approach for optimization with probabilistic constraints, SIAM Journal on Optimization, 19 (2008), pp. 674–699.
- [40] W. Ma and Z. Chen, Multi-stage distributionally robust convex stochastic optimization with Bayesian-type ambiguity sets, Mathematical Methods of Operations Research, 100 (2024), pp. 553–600.
- [41] S. Mannor, D. Simester, P. Sun, and J. N. Tsitsiklis, Bias and variance in value function estimation, in Proceedings of the twenty-first International Conference on Machine learning, 2004, p. 72.
- [42] S. Mannor and J. Tsitsiklis, Mean-variance optimization in Markov decision processes, arXiv preprint arXiv:1104.5601, (2011).
- [43] S. Mannor and H. Xu, Data-driven methods for Markov decision problems with parameter uncertainty, in Operations Research & Management Science in the Age of Analytics, INFORMS, 2019, pp. 101–129.
- [44] A. Nilim and L. El Ghaoui, Robust control of Markov decision processes with uncertain transition matrices, Operations Research, 53 (2005), pp. 780–798.
- [45] I. Osband, D. Russo, and B. Van Roy, (More) efficient reinforcement learning via posterior sampling, Advances in Neural Information Processing Systems, 26 (2013).
- [46] T. Osogami and T. Morimura, Time-consistency of optimization problems, in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 26, 2012, pp. 1945–1953.
- [47] M. Petrik and D. Subramanian, An approximate solution method for large risk-averse Markov decision processes, arXiv preprint arXiv:1210.4901, (2012).
- [48] G. C. Pflug and A. Pichler, Multistage Stochastic Optimization, vol. 1104, Springer, 2014.
- [49] A. B. Philpott, V. L. de Matos, and L. Kapelevich, Distributionally robust SDDP, Computational Management Science, 15 (2018), pp. 431–454.
- [50] A. Pichler and R. Schlotter, Risk-averse optimal control in continuous time by nesting risk measures, Mathematics of Operations Research, 48 (2023), pp. 1657–1678.
- [51] M. L. Puterman, Markov Decision Processes: Discrete Stochastic Dynamic Programming, John Wiley & Sons, 2014.
- [52] P. Qian, Z. Wang, and Z. Wen, A composite risk measure framework for decision making under uncertainty, Journal of the Operations Research Society of China, 7 (2019), pp. 43–68.
- [53] M. Rigter, B. Lacerda, and N. Hawes, Risk-averse Bayes-adaptive reinforcement learning, Advances in Neural Information Processing Systems, 34 (2021), pp. 1142–1154.
- [54] R. T. Rockafellar, S. Uryasev, et al., Optimization of conditional value-at-risk, Journal of risk, 2 (2000), pp. 21–42.
- [55] S. Ross, J. Pineau, B. Chaib-draa, and P. Kreitmann, A Bayesian approach for learning and planning in partially observable Markov decision processes., Journal of Machine Learning Research, 12 (2011).
- [56] H. Ruan, Z. Chen, and C. P. Ho, Risk-averse MDPs under reward ambiguity, arXiv preprint arXiv:2301.01045, (2023).
- [57] A. Ruszczyński, Risk-averse dynamic programming for Markov decision processes, Mathematical Programming, 125 (2010), pp. 235–261.
- [58] E. Saha and P. K. Ray, Modelling and analysis of inventory management systems in healthcare: A review and reflections, Computers & Industrial Engineering, 137 (2019), p. 106051.
- [59] A. Shapiro, Tutorial on risk neutral, distributionally robust and risk averse multistage stochastic programming, European Journal of Operational Research, 288 (2021), pp. 1–13.
- [60] A. Shapiro, Distributionally robust modeling of optimal control, Operations Research Letters, 50 (2022), pp. 561–567.
- [61] A. Shapiro, D. Dentcheva, and A. Ruszczynski, Lectures on Stochastic Programming: Modeling and Theory, SIAM, 2021.
- [62] A. Shapiro, E. Zhou, and Y. Lin, Bayesian distributionally robust optimization, SIAM Journal on Optimization, 33 (2023), pp. 1279–1304.
- [63] A. Shapiro, E. Zhou, Y. Lin, and Y. Wang, Episodic Bayesian optimal control with unknown randomness distributions, arXiv preprint arXiv:2308.08478, (2023).
- [64] A. Sharma, J. Harrison, M. Tsao, and M. Pavone, Robust and adaptive planning under model uncertainty, in Proceedings of the international conference on automated planning and scheduling, vol. 29, 2019, pp. 410–418.
- [65] M. Sniedovich, A variance-constrained reservoir control problem, Water Resources Research, 16 (1980), pp. 271–274.
- [66] H. Strasser, Mathematical Theory of Statistics: Statistical Experiments and Asymptotic Decision Theory, vol. 7, Walter de Gruyter, 1985.
- [67] M. Strens, A Bayesian framework for reinforcement learning, in ICML, 2000, pp. 943–950.
- [68] A. Tamar, Y. Chow, M. Ghavamzadeh, and S. Mannor, Sequential decision making with coherent risk, IEEE Transactions on Automatic Control, 62 (2016), pp. 3323–3338.
- [69] H. Wang, L. He, R. Gao, and F. Calmon, Aleatoric and epistemic discrimination: Fundamental limits of fairness interventions, Advances in Neural Information Processing Systems, 36 (2024).
- [70] W. Wang and S. Ahmed, Sample average approximation of expected value constrained stochastic programs, Operations Research Letters, 36 (2008), pp. 515–519.
- [71] W. Wang and H. Xu, Robust spectral risk optimization when information on risk spectrum is incomplete, SIAM Journal on Optimization, 30 (2020), pp. 3198–3229.
- [72] W. Wang, H. Xu, and T. Ma, Quantitative statistical robustness for tail-dependent law invariant risk measures, Quantitative Finance, 21 (2021), pp. 1669–1685.
- [73] Y. Wang and E. Zhou, Bayesian risk-averse Q-Learning with streaming observations, arXiv preprint arXiv:2305.11300, (2023).
- [74] S. Weber, Distribution-invariant risk measures, information, and dynamic consistency, Mathematical Finance: An International Journal of Mathematics, Statistics and Financial Economics, 16 (2006), pp. 419–441.
- [75] T. Weitzel and C. H. Glock, Energy management for stationary electric energy storage systems: A systematic literature review, European Journal of Operational Research, 264 (2018), pp. 582–606.
- [76] W. Wiesemann, D. Kuhn, and B. Rustem, Robust Markov decision processes, Mathematics of Operations Research, 38 (2013), pp. 153–183.
- [77] W. Wiesemann, D. Kuhn, and M. Sim, Distributionally robust convex optimization, Operations Research, 62 (2014), pp. 1358–1376.
- [78] D. Wozabal, Robustifying convex risk measures for linear portfolios: A nonparametric approach, Operations Research, 62 (2014), pp. 1302–1315.
- [79] D. Wu, H. Zhu, and E. Zhou, A Bayesian risk approach to data-driven stochastic optimization: Formulations and asymptotics, SIAM Journal on Optimization, 28 (2018), pp. 1588–1612.
- [80] Q. Wu, H. Xu, and H. Zheng, Multistage Robust Average Randomized Spectral Risk Optimization, arXiv preprint arXiv:2409.00892, (2024).
- [81] H. Xu, Y. Liu, and H. Sun, Distributionally robust optimization with matrix moment constraints: Lagrange duality and cutting plane methods, Mathematical Programming, 169 (2018), pp. 489–529.
- [82] H. Xu and S. Mannor, Distributionally robust Markov decision processes, Advances in Neural Information Processing Systems, 23 (2010).
- [83] H. Xu and D. Zhang, Smooth sample average approximation of stationary points in nonsmooth stochastic optimization and applications, Mathematical Programming, 119 (2009), pp. 371–401.
- [84] I. Yang, Wasserstein distributionally robust stochastic control: A data-driven approach, IEEE Transactions on Automatic Control, 66 (2020), pp. 3863–3870.
- [85] S. Zhang, H. Xu, and H. Sun, Statistical Robustness of Kernel Learning Estimator with Respect to Data Perturbation, arXiv preprint arXiv:2406.10555, (2024).
9 Appendix
Definition 2 (Fortet-Mourier metric).
Let
| (9.1) |
be the set of locally Lipschitz continuous functions of growth order , where denotes some norm on , for all , and describes the growth of the local Lipschitz constants. The -th order Fortet-Mourier metric over is defined by
| (9.2) |
In the case when , it reduces to Kantorovich metric, in which case we denote the distance by .
Definition 3 (Wasserstein distance/ metric).
For probability measures and , the Wasserstein distance/ metric of order is
| (9.3) |
where is among all probability measure with marginals and , i.e.,
| (9.4) |
One of the main results concerning the Wasserstein distance is the Kantorovich–Rubinstein Theorem ([34]), which establishes a relationship between the Kantorovich metric of two probability measures and the Wasserstein distance when , i.e.,
| (9.5) |