A Benchmark of Video-Based Clothes-Changing Person Re-Identification
Abstract
Person re-identification (Re-ID) is a classical computer vision task and has achieved great progress so far. Recently, long-term Re-ID with clothes-changing has attracted increasing attention. However, existing methods mainly focus on image-based setting, where richer temporal information is overlooked. In this paper, we focus on the relatively new yet practical problem of clothes-changing video-based person re-identification (CCVReID), which is less studied. We systematically study this problem by simultaneously considering the challenge of the clothes inconsistency issue and the temporal information contained in the video sequence for the person Re-ID problem. Based on this, we develop a two-branch confidence-aware re-ranking framework for handling the CCVReID problem. The proposed framework integrates two branches that consider both the classical appearance features and cloth-free gait features through a confidence-guided re-ranking strategy. This method provides the baseline method for further studies. Also, we build two new benchmark datasets for CCVReID problem, including a large-scale synthetic video dataset and a real-world one, both containing human sequences with various clothing changes. We will release the benchmark and code in this work to the public.
1 Introduction

The past few years have witnessed that person re-identification (Re-ID) has become a very popular topic in the computer vision community, because of its significance in many real-world applications, such as video surveillance, unmanned supermarket, etc. The classical person Re-ID task [51, 27, 52] focuses on the image-based data, in which the clothes of a person also keep unchanged in the dataset. This may limit the information utilization from the video sequence, which is easy to obtain in many real-world application. Also, for the long-period applications, e.g., history criminal retrieval, the assumption of unchanged clothes is not reasonable. This way, two categories of person Re-ID task have been proposed in recent years, i.e., the video-based person Re-ID [33, 30, 11] and the clothes-changing person Re-ID [44, 23, 34, 45]. The former focuses on utilizing the temporal information from the video sequence, and the later aims to extract the clothes-independent appearance features for person identification.
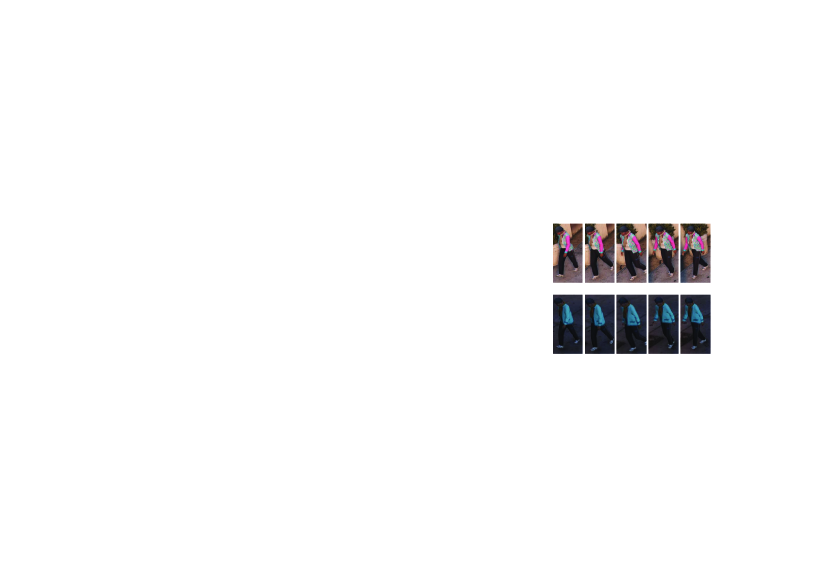
In this paper, we are more interested in studying the video-based clothes-changing person Re-ID problem. This is because the video-based Re-ID is complementary to the clothes-changing Re-ID. Specifically, the (image-based) clothes-changing person Re-ID is very challenging given the very limited information from a single human image, which is dominated by the appearance of the clothes (as seen in Fig. 1(a)). If a video sequence is given, we can obtain more information not related to the clothes, e.g., the human gait (as seen in Fig. 1(b)). However, the video-based clothes-changing person Re-ID problem has not been studied widely. For this problem, only one dataset namely CCVID [16] is publicly available, which is actually built based on a gait recognition dataset [49]. Although clothes-changing is considered, all samples in the dataset are taken from the same camera view, and all identities follows the same designated route. Thus, it can not meet the request of person Re-ID problem, e.g., the various scenes, varied perspectives, abundant samples.
In this work, we propose to build a benchmark to systematically study the Clothes-Changing Video-based Re-ID (CCVReID) problem. For this purpose, the first step is to collect the applicable datasets. Considering the convenience of dataset collection and the huge success in cross-domain person Re-ID [38, 40], we first build a large-scale synthetic dataset for CCVReID. We use a game namely Grand Theft Auto V for data collection, whose character modeling is very realistic. We record the pedestrians for 48 hours in total, from which we obtained contains 9,620 sequences from 333 identities and each identity has 2-37 suits of clothes, with an average of 7. The number of sequences, identities and suits for each person are much larger than previous datasets. Besides, we also build a real dataset including the human sequences with various clothe changes.
We also propose a new baseline for the CCVReID problem. Our basic idea is to take advantage of the clothes-independent appearance feature from each RGB image and the temporal-aware gait feature from the video sequence. Specifically, we first use a video-based Re-ID method [1] and a gait recognition method [3] to extract the appearance and gait features, respectively. We then conduct the inference stage of the Re-ID task that using a query to get the candidate ranking from the gallery, using the appearance and gait representations, respectively. We propose a two-branch ranking fusion framework, containing a candidate relation graph, to combine the ranking lists from these two representations. We also propose a confidence-aware re-weighting strategy to estimate the representation certainty for balancing the two branches. We conduct the experiments on an existing dataset and two new datasets collected in this work. The results verify the effectiveness of our method, which outperforms the methods using the appearance and gait separately, with an obvious margin.
We summarize the main contributions in this work:
-
•
We systematically study a relatively new and practical problem of Clothes-Changing Video-based Re-ID (CCVReID). For this problem, we simultaneously consider the clothes-inconsistent appearance and the temporal information contained in the sequence to complement each other for person Re-ID, which is overlooked previously.
-
•
We develop a preliminary framework for handling the CCVReID problem. The proposed framework integrates two branches that focus on the classical appearance and cloth-free biological features (specifically the gait feature) through a confidence-balanced re-ranking strategy. This method can provide the baseline for further studies.
-
•
We build two new benchmark datasets for the proposed problem, i.e., a large-scale synthetic video dataset and a real-world one, both including the human sequences with various clothe changes.

2 Related Work
Video-based person Re-ID. Video-based person Re-ID aims to extract spatial-temporal features from consecutive frame sequences. To this end, some of existing methods lift image-based Re-ID methods by aggregating multi-frame features through RNNs [33, 30], mean/max pooling [50, 8], and temporal attention [15, 5], etc. Other methods perform concurrent spatial-temporal information modeling via 3D convolution [17, 26] or graph convolution [4]. Despite the fact that a number of works have been done for video-based Re-ID, most of them focus on clothes consistent setting only, which are not applicable to long-term application scenarios.
Clothes-changing person Re-ID.
Image-based clothes-changing person Re-ID has been widely studied in the literature. Several public datasets, e.g., PRCC [44], Celeb-reID [23], LTCC [34], VC-Clothes&Real28 [40], and COCAS [45], have been collected successively to support this task.
Based on these datasets, [23] proposed to use vector-neuron capsules instead of the traditional scalar neurons, to perceive cloth changes of the same person. [28] proposed a Clothing Agnostic Shape Extraction Network (CASE-Net) to shape-based feature representation via adversarial learning and feature disentanglement.
Besides, other works attempted to leverage contour sketch [44], silhouettes [21, 24], face [40], skeletons [34], 3D shape [6], or radio signals [14] to capture clothes-irrelevant features.
Despite the achievement of image-based methods, they are susceptible to the quality of person images, i.e., they are less tolerant to noise due to the limited information contained in a single frame.
Recently, some works [46, 47, 16] have extended clothes-changing person Re-ID to video-based data.
[46] collected a Motion-ReID dataset with clothes-changing, and developed a FIne moTion encoDing (FITD) model based on true motion cues from videos.
[47] collected a Cloth-Varying vIDeo re-ID (CVID-reID) dataset, which contains video tracklets of celebrities posted on the Internet, and proposed to learn hybrid feature representation from image sequences and skeleton sequences.
Furthermore, [16] constructed a Clothes-Changing Video person re-ID (CCVID) dataset from a gait recognition dataset FVG [49], and proposed a Clothes-based Adversarial Loss (CAL) to mine clothes-irrelevant features from the original RGB images.
In the aforementioned datasets, only CCVID [16] dataset is publicly available. However, since the original FVG [49] dataset contains only one view, and the field of view contains only one person that follows designated routes, the CCVID dataset built on that is not suitable for real-world scenarios, where there are usually multiple people who walk in arbitrary directions.
For supporting the CCVReID task, we build two new benchmark datasets of surveillance scenarios in this paper.
Person Re-ID with gait.
Affected by lighting, clothing, view, and other factors, the same person’s appearance features may change a lot, which brings challenges to the Re-ID task. To solve that, [47, 31] attempted to introduce gait to achieve complementarity of appearance and gait features. [24] performed gait prediction and regularization from a single image, which used gait to drive the main Re-ID model to learn cloth-independent features.
However, such methods only consider the fusion of body and face information in a single sample. In the proposed method, in addition to considering this, we also introduce the contextual information among neighbor samples.
Synthetic datasets.
Due to the difficulty of building large-scale datasets in the real world and the cost of extensive manual annotation, synthetic datasets are gaining increasing attention in many computer vision tasks, including pose estimation [12, 20], tracking [12], action recognition [39], and semantic segmentation [35, 32], etc.
For person Re-ID, [2, 38, 40] have introduced synthetic data. Although the PersonX [38] and VC-Clothes [40] dataset involve clothes changing, they are all image-based.
To promote the researches on CCVReID, we construct a large-scale synthetic dataset in this paper.
3 Proposed Method
3.1 Overview
The overall pipeline of the proposed method is illustrated in Fig. 2. Given an image sequence , whose identity label is denoted as , as query, person Re-ID aims to return a ranking list of gallery image sequences where the sequences from the same person, i.e., , can rank top. To this end, this paper proposes a two-branch confidence-aware re-ranking framework. Specifically, given a query and several galleries, we first extract the appearance and gait features. Base on that, we conduct the inference stage to get the initial ranking list and collect top-K candidates for model training. Then, we construct candidate relation graph and use GCN to estimate the confidence for balancing the two branches. Finally, we fuse the confidence-aware re-weighted appearance and gait representations, and re-rank the galleries as the final retrieval result.
3.2 Two-branch Initial Ranking
Two-branch top-K candidates collection. Given a query sequence and a gallery set , where represents the number of gallery sequences, the extracted appearance features can be denotes as and , respectively. Similarly, the gait features can be denoted as and . denotes the appearance feature extraction model with parameters , and denotes the gait model with parameters . Then, we can obtain the ranking list, i.e., , through the appearance features according to the pairwise distance between the query and each gallery , where . In the same way, the ranking list calculated through the gait (biological) features can also be obtained.
Since the value of is usually large, we select -nearest neighbors of the query for subsequent training.
Specifically, we select the top samples of , and supplement the rest with the top samples of . The selected candidates are denoted as .
Candidate relation graph building.
Given the selected samples , we first construct two graphs with respect to appearance and gait features, respectively.
We approximately represent the appearance similarity between the query and sample in by applying min-max normalization to the distance:
| (1) |
where and denote the maximum and minimum values of all with , respectively. The gait similarity can be represented by the same way.
The similarity of appearance features between the query and samples in and that of gait features are combined as an initialized similarity matrix , and then embedded into a shared matrix by an encoder. For the appearance graph, the nodes represent all samples, and the features of each node is initialized as the vector of the corresponding row in the matrix . The edges represent the proximity relationship between the samples. If the gait feature is one of the -nearest neighbors of feature , there will be an edge from to , and the edge feature will be defined as the element-wise multiplication of and . In the same way, the gait graph can be constructed.
3.3 Confidence Balanced Re-ranking
Confidence estimation. Based on the appearance and gait graph, we aim to estimate confidence for the appearance/gait feature of each sample, which explicitly represents the reliability of the feature. Inspired by the effectiveness and generalization that GCN has demonstrated in many computer vision applications [42, 18, 36, 41, 10, 43] , we adopt GCN here to explore the latent structural relationships among the candidate samples. The message passing of node in layer can be formulated as
| (2) |
where denotes the feature of node in layer , denotes the weight of the edge from node to node , and denotes the learnable weight matrix of layer . is the set of all nodes that have an edge pointing to node . is an activation function.
After the GCN layer, a linear layer is used to map the node feature into a one-dimensional confidence score, which can be formulated as
| (3) |
where denotes the learnable weight of the linear layer, and denotes the estimated confidence score for node .
Note that the network structure used to extract appearance confidences from the appearance graph and that used to extract gait confidences from the gait graph are the same, while do not share parameters.
The appearance confidence for node can be denoted as and the gait confidence can be denoted as .
Confidence-aware re-ranking.
With the estimated confidence, we propose to adjust the weight of original appearance/gait similarity for each sample in the fusion phase.
The final similarity between the query and the sample in is defined as:
| (4) |
where denotes the vector in the k-th row of matrix , i.e., the initialized node feature, which is mapped into one dimension using a linear layer with weight .
Finally, the revised ranking list can be obtained by descending sort of the final similarities.
Confidence loss.
To guide the learning of the network, we propose the confidence loss by designing pseudo-labels for the confidence.
Specifically, assume the ground-truth label of the sample is . When the identity label of sample equals that of the query, i.e., , the value of is 1, otherwise it is 0.
Given the initial appearance similarity and the ground-truth label of sample , we propose to define the pseudo-label of confidence for appearance feature as
| (5) |
where denotes the symbol of absolute value.
The proof is as follows. Since similarity indicates the relational degree between two samples, i.e., the greater the similarity, the higher the probability that the query and the gallery sample have the same identity label, we define a threshold to represent the prediction results based on similarities. If , we consider the prediction result to be 1. In this case, if is also 1, i.e., the prediction is correct, the value of confidence should be large. Intuitively, the larger the similarity , the larger the confidence should be. Therefore, can be assigned the value of . In contrast, if , i.e., the prediction is wrong, the value of confidence should be small. And the larger the similarity , the smaller the confidence should be. Therefore, can be assigned the value of . The above can be formulated as
| (6) |
Similarly, if , we consider the prediction result to be 0. In this case, if , i.e., the prediction is wrong, the value of confidence should be small. And the smaller the similarity , the smaller the confidence should be. Therefore, can be assigned the value of . In contrast, if , i.e., the prediction is correct, the value of confidence should be large. And the smaller the similarity , the larger the confidence should be. Therefore, can be assigned the value of . The formulation of the above analysis takes the same form as Eq. 6. Further, Eq. 6 can be rewritten as follows:
| (7) |
which is exactly the form of classified discussion of Eq. 5. In the same way, the pseudo-label of confidence for gait feature can be defined as
| (8) |
In the training stage, the designed pseudo-labels and play a role of ground-truths of confidence to guide the confidence estimation. The confidence loss can be formulated as
| (9) |
3.4 Network Setting
Ranking loss. We also consider the widely used triplet ranking loss [19] in person Re-ID:
| (10) |
where denotes the final similarity between the query and the positive sample whose ground-truth label is 1, and denotes that for negative sample whose ground-truth label is 0. and denote the number of positive and negative samples, respectively, with . denotes the margin.
Combining the confidence and ranking loss, the total loss in the training stage can be formulated as .
Implementation Details.
We use SINet [1] proposed for video-based person Re-ID as the appearance model , and GaitSet [3] proposed for gait recognition as the gait model .
For SINet, we directly input RGB sequences for appearance feature extraction. While for GaitSet, we first perform an instance segmentation algorithm HTC [7] to extract silhouettes from RGB sequences, and then input silhouette sequences for gait feature extraction.
SINet and GaitSet are pre-trained on ImageNet [9] and GREW [53], respectively, and then trained on the corresponding CCVReID datasets to get the initial features.
The number of selected samples for training, i.e., , is set to 100.
The ratio of selecting samples from is set to 0.75.
In graph building, following [43], the encoder takes a Multi-Layer Perceptron (MLP) structure, which consists of a linear, BN, PReLU, dropout, and linear layer successively. The dimension of the initialized node feature is 32. The in -nearest neighbors for edge connection is set to 30. In confidence estimation, one GCN layer is used, with the output dimension of 32. The margin in Eq. 10 is set to 0.2. We use Adam [25] algorithm to optimize the model in all experiments.
During the testing phase, given a query, the samples selected for training from gallery are ranked in the top-K according to their final similarities, followed by the rest samples reordered according to the summation of the initial appearance rank in and gait rank in .



| Methods | CC | Standard | |||||||
| mAP | R1 | R5 | R10 | mAP | R1 | R5 | R10 | ||
| Video-based w/o clothes-changing | AP3D [17] | 26.7 | 47.1 | 71.5 | 80.2 | 39.1 | 79.4 | 94.3 | 96.9 |
| TCLNet [22] | 30.1 | 48.6 | 72.4 | 81.7 | 43.2 | 84.3 | 95.6 | 97.3 | |
| SINet [1] | 33.0 | 51.0 | 75.5 | 84.6 | 46.5 | 84.4 | 97.4 | 98.6 | |
| Gait recognition | GaitSet [3] | 16.7 | 23.4 | 56.0 | 68.5 | 20.6 | 33.6 | 68.4 | 80.1 |
| GaitPart [13] | 15.9 | 22.4 | 54.7 | 68.8 | 19.2 | 30.4 | 64.7 | 79.3 | |
| GaitGL [29] | 11.7 | 15.6 | 44.3 | 56.7 | 14.5 | 23.5 | 54.1 | 65.4 | |
| Image-based clothes-changing | ReIDCaps-R [23] | 12.2 | 30.0 | 53.5 | 65.1 | 12.9 | 32.2 | 56.0 | 67.0 |
| ReIDCaps-A [23] | 10.2 | 26.0 | 48.6 | 60.4 | 21.2 | 66.8 | 87.1 | 92.1 | |
| Pixel_sampling-R [37] | 13.8 | 29.8 | 57.3 | 68.9 | 21.7 | 57.9 | 81.8 | 88.3 | |
| Pixel_sampling-A [37] | 10.1 | 23.2 | 46.8 | 60.4 | 17.4 | 50.4 | 77.2 | 85.8 | |
| GI-ReID-R [24] | 4.9 | 8.9 | 21.4 | 31.3 | 6.4 | 12.4 | 30.1 | 42.2 | |
| GI-ReID-A [24] | 8.2 | 14.3 | 33.3 | 43.1 | 8.5 | 14.7 | 35.1 | 44.5 | |
| Video-based clothes-changing | CAL [16] | 31.2 | 48.9 | 71.3 | 81.8 | 45.4 | 87.6 | 95.0 | 96.9 |
| Ours | 39.8 | 54.8 | 76.2 | 86.1 | 51.1 | 83.0 | 94.5 | 97.4 | |
4 Datasets
Current works focus little on CCVReID. Of the datasets available for this task, including Motion-ReID [46], CVID-reID [47], and CCVID [16], only CCVID is publicly available. However, as seen in Fig. 3(a), all samples in the CCVID were taken from the same view, i.e., the frontal view, and have clean backgrounds and no occlusion, which is not fully applicable to real-world scenes. Therefore, to advance related researches, we build two new benchmark datasets in this paper, including a large-scale synthetic one named SCCVReID, and a small real one named RCCVReID. We will give a brief introduction in Secs. 4.1 and 4.2.
4.1 The SCCVReID Dataset
Following [12], we collect a large-scale synthetic dataset for CCVReID in surveillance scenarios by exploiting the highly photorealistic video game Grand Theft Auto V. The examples can be seen in Fig. 3(b). We set up 10 surveillance cameras within 5 scenes (2 cameras for each scene) to collect data. After recording the pedestrians for 48 hours in the game at 60 FPS, we use the automatic bounding boxes to crop out RGB sequences of each person. The obtained SCCVReID dataset contains 9,620 sequences from 333 identities and each identity has 2-37 suits of clothes, with an average of 7. Each sequence contains a number of frames ranging between 8 and 165 with an average length of 37. For evaluation, 167 identities with 5,768 sequences are used for training and the rest 166 identities with 3,852 sequences for testing. In the test set, we select the first sequence of each suit of each identity as query. In total, 971 sequences are used as query, and the rest 2,881 as gallery.
4.2 The RCCVReID Dataset
We also collect a real dataset named RCCVReID to support researches on CCVReID, which can be seen in Fig. 3(c). All raw videos were recorded in outdoor scenarios. For each video, we first performed ByteTrack [48] to generate human bounding boxes with unified IDs, and used them to crop out RGB sequences of each identity, which is then split into several short sequences (about 200 frames). After that, we merged the sequences of the same identity from different videos and manually labeled the clothes IDs. In total, 6,948 sequences from 34 identities are obtained. Each identity has 2-9 suits of clothes, with an average of 4. We consider two evaluation settings on this dataset. (1) Due to the small number of identities in RCCVReID, we train the models on the large-scale synthetic dataset SCCVReID and only use RCCVReID for performance evaluation. In this case, 2,133 sequences are used as query, and the rest 4,815 sequences as gallery. (2) Despite the small number of identities, the total sample size is sufficient for training models. Thus, we divide the training and test sets as existing Re-ID datasets do. Specifically, 20 identities with 5,532 sequences are reserved for training, and the remaining 14 identities are used for test. In the test set, 486 sequences are used as query, and the rest 932 sequences as gallery.
5 Experiments
5.1 Datasets and Evaluation Protocol
We perform experiments on three CCVReID datasets, i.e., CCVID [16], SCCVReID, and RCCVReID, to evaluate the proposed method. For evaluation, we focus on two kinds of test settings, i.e., clothes-changing (CC) setting and standard setting. In clothes-changing setting, gallery samples that have the same identity label and clothes label with query are removed, that is, only gallery samples with clothes-changing are considered. While in standard setting, both clothes-consistent and clothes-changing samples are used as gallery to calculate accuracy. Following existing person Re-ID works, we adopt the Rank-1/5/10 (R1/R5/R10) of CMC curve and the mAP (mean average precision) score as the evaluation protocols.
| Methods | Only test | With train | |||||||
| CC | Standard | CC | Standard | ||||||
| mAP | R1 | mAP | R1 | mAP | R1 | mAP | R1 | ||
| Video-based w/o clothes-changing | AP3D [17] | 9.2 | 16.6 | 30.0 | 85.3 | 21.0 | 20.2 | 62.7 | 94.9 |
| TCLNet [22] | 12.0 | 20.2 | 37.3 | 95.6 | 22.6 | 28.0 | 62.3 | 95.7 | |
| SINet [1] | 8.2 | 15.2 | 29.8 | 86.9 | 23.8 | 31.9 | 67.3 | 96.7 | |
| Gait recognition | GaitSet [3] | 6.3 | 13.0 | 16.5 | 66.5 | 16.4 | 26.5 | 43.2 | 84.4 |
| GaitPart [13] | 6.5 | 14.6 | 16.3 | 64.2 | 15.6 | 23.7 | 37.4 | 77.4 | |
| GaitGL [29] | 5.0 | 10.6 | 10.1 | 44.6 | 18.7 | 31.1 | 45.3 | 87.9 | |
| Image-based clothes-changing | ReIDCaps-R [23] | 7.3 | 13.2 | 25.5 | 85.0 | 18.0 | 22.0 | 56.1 | 95.5 |
| ReIDCaps-A [23] | 8.2 | 14.3 | 29.8 | 90.8 | 21.6 | 29.6 | 62.4 | 97.3 | |
| Pixel_sampling-R [37] | 4.5 | 4.5 | 9.1 | 14.6 | 21.3 | 27.2 | 55.3 | 87.4 | |
| Pixel_sampling-A [37] | 6.0 | 11.7 | 20.7 | 74.5 | 17.9 | 17.7 | 58.0 | 92.2 | |
| GI-ReID-R [24] | 4.5 | 3.9 | 9.9 | 18.7 | 11.5 | 9.1 | 31.8 | 44.0 | |
| GI-ReID-A [24] | 5.2 | 5.7 | 11.9 | 21.8 | 14.1 | 11.5 | 37.6 | 53.5 | |
| Video-based clothes-changing | CAL [16] | 13.0 | 20.9 | 40.3 | 96.3 | 26.0 | 31.5 | 68.1 | 99.2 |
| Ours | 14.5 | 25.7 | 43.1 | 95.8 | 33.9 | 46.7 | 72.3 | 99.4 | |
| Methods | CC | Standard | |||
| mAP | R1 | mAP | R1 | ||
| VReID | AP3D [17] | 69.4 | 75.5 | 71.7 | 77.0 |
| TCLNet [22] | 71.2 | 77.1 | 73.3 | 78.3 | |
| SINet [1] | 77.8 | 81.1 | 82.4 | 85.6 | |
| GR | GaitSet [3] | 62.6 | 72.7 | 69.2 | 77.6 |
| GaitPart [13] | 60.1 | 73.1 | 67.0 | 79.9 | |
| GaitGL [29] | 69.0 | 82.1 | 75.4 | 88.1 | |
| CCIReID | ReIDCaps-R [23] | 45.9 | 54.2 | 49.8 | 58.6 |
| ReIDCaps-A [23] | 46.2 | 50.1 | 49.9 | 52.5 | |
| Pixel_sampling-R [37] | 42.4 | 52.5 | 48.0 | 58.2 | |
| Pixel_sampling-A [37] | 50.4 | 57.3 | 55.7 | 62.9 | |
| GI-ReID-R [24] | 17.6 | 17.3 | 21.3 | 23.1 | |
| GI-ReID-A [24] | 27.3 | 27.8 | 31.7 | 34.7 | |
| CCVReID | CAL [16] | 81.7 | 83.8 | 83.2 | 84.5 |
| Ours | 84.5 | 88.1 | 87.1 | 89.7 | |
5.2 Comparison with State-of-the-art Methods
Since there are few works to explore CCVReID task, we compare our method with four kinds of methods for a comprehensive evaluation: 1) video-based person Re-ID methods that do not involve clothes-changing, including AP3D [17], TCLNet [22], and SINet [1], 2) gait recognition methods, including GaitSet [3], GaitPart [13], and GaitGL [29], 3) image-based clothes-changing methods, including ReIDCaps [23], Pixel_sampling [37], and GI-ReID [24], 4) video-based clothes-changing method CAL [16].
Note that image-based methods receive a single frame as input, we report the results under two different settings of such methods, i.e., randomly select a frame for feature extraction (denoted with suffix ”-R”), and extract the features of all frames and take the average as the final feature (denoted with suffix ”-A”).
Results on SCCVReID.
As shown in Tab. 1, compared with image-based methods, video-based Re-ID and gait recognition methods achieve better performance, which indicates the importance of spatio-temporal information in improving the accuracy of Re-ID.
Besides, our method achieves the best performance under CC setting.
Compared with CAL [16], our method improves the mAP and R1 by more than 8.6% and 5.9%, respectively.
However, it is observed that under standard setting, our method is lower than SINet [1] in R1, R5, and R10.
Intuitively, this can be attributed to the low accuracy of the gait features.
While gait information can assist in identification when appearance information is unreliable, i.e., with clothes-changing, it may also introduce certain interference when appearance information are reliable, i.e., with clothes-consistent.
Despite this, our method achieve the best mAP under this setting, that is, our method allows the highest average ranking for all gallery samples with the same identity as the query.
Results on RCCVReID.
We compare our method with state-of-the-art methods under two evaluation settings, i.e., use SCCVReID for training and use RCCVReID only for testing, or use RCCVReID for both training and testing.
The results are shown in Tab. 2.
Note that the only test setting can be considered as cross-domain CCVReID, evaluating the generalization ability of the models.
Under both evaluation settings, our method achieves the best mAP and R1 under CC setting, and the best mAP under standard setting, which are consistent with the results on SCCVReID.
Results on CCVID.
As seen in Tab. 3, our method outperforms all the other methods by a large margin on all evaluation protocols.
Since CCVID is built based on gait recognition dataset, the extracted gait features are relatively more discriminative.
Thus, the drop in R1 under standard setting caused by the interference of low-quality gait features does not exist here.
5.3 Ablation Study
In this section, we conduct a series of ablation experiments on SCCVReID to verify each design of our method.
The effectiveness of proposed method.
To verify the effectiveness of the proposed method, we compare it with different fusion framework in Tab. 4.
The top 2 rows report the performance of using appearance and gait features solely, respectively.
The third row report the performance when the initial appearance and gait similarity are directly summed for re-ranking.
SEF [43] is the inspiration for this paper. Differently, SEF considers the appearance (gait) features only when building appearance (gait) graph, and uses GCN to directly predict the final similarity.
The results show that all fusion strategies bring an improvement in accuracy under CC setting and mAP under standard setting, while a certain drop in R1 under standard setting.
The main reason for that has been discussed in Sec. 5.2.
However, compared to the other two fusion strategies, our method obtains the highest improvement under clothes-changing setting and the least drop of R1 under standard setting, which indicates the superiority of our method.
| CC | Standard | |||
|---|---|---|---|---|
| mAP | R1 | mAP | R1 | |
| App only | 33.0 | 51.0 | 46.5 | 84.4 |
| Gait only | 18.7 | 28.1 | 23.3 | 38.0 |
| Direct summation | 36.4 | 50.2 | 48.7 | 81.7 |
| SEF [43] | 38.8 | 50.6 | 47.2 | 67.1 |
| Ours w pseudo-label (Oracle) | 69.4 | 97.2 | 75.2 | 99.6 |
| Ours w/o appConf | 39.4 | 53.6 | 50.7 | 81.7 |
| Ours w/o gaitConf | 39.2 | 52.6 | 50.8 | 82.3 |
| Ours | 39.8 | 54.8 | 51.1 | 83.0 |
The effectiveness of confidence loss.
To evaluate the effectiveness of the proposed confidence loss, We first list the accuracy obtained by calculating the final similarity using designed pseudo-label of confidence.
As shown in Tab. 4, compared with the simple summation of similarities, our model with pseudo-label, i.e., the ground-truth of confidence, improves 33.0% on mAP and 47.0% on R1 under CC setting, 26.5% on mAP and 17.9% on R1 under standard setting.
The results demonstrate the validity of the designed pseudo-label of confidence, which can be regarded as the oracle of the proposed confidence-aware method.
We also compare our method with and without appearance/gait confidence loss. In Tab. 4, we can observe that removing the confidence loss of both the appearance and gait branch causes a certain degradation under both clothes-changing and standard setting.
This demonstrates that the proposed loss can effectively supervise the learning of confidence.
Discussion of two-branch framework.
We conduct ablation experiments to verify each branch of the proposed framework in Tab. 5.
We discuss three settings of confidence: 1) the confidence are output by the network, which is represented by . 2) the confidence is fixed to 0, that is, the original similarity is not used to calculate the final similarity, only the other branch is considered. However, in this case, the original similarity is not completely neglected, since the information has been implicitly included in the linear layer.
3) the confidence is fixed to 1, that is, the original similarity is used to calculate the final similarity without weight adjustment.
From the comparison between the first and second rows, the third and fourth rows, we can see that the model with confidence set to 1 outperforms the model with confidence set to 0. That shows that the importance of the original similarity in the re-ranking stage.
From the comparison between the top 4 rows and the fifth to the eighth rows, we can see that the model with confidence fixed for one branch outperforms the model with confidence fixed for both branches. Also, the model without confidence fixed achieves the best performance (the last row), which fully proves the superiority of the proposed network for confidence learning.
Besides, we compare the models with and without linear layer (the last 2 rows).
The results show that with addition of the linear layer, the performance of model is improved.
| AppConf | GaitConf | Linear | CC | Standard | ||
|---|---|---|---|---|---|---|
| mAP | R1 | mAP | R1 | |||
| 0 | 38.4 | 51.7 | 50.5 | 82.7 | ||
| 1 | 38.7 | 52.3 | 50.9 | 83.8 | ||
| 0 | 37.6 | 52.1 | 49.8 | 83.0 | ||
| 1 | 37.6 | 52.2 | 50.0 | 84.3 | ||
| 0 | 0 | 36.5 | 50.9 | 49.1 | 82.3 | |
| 0 | 1 | 36.3 | 49.2 | 48.3 | 76.7 | |
| 1 | 0 | 36.5 | 50.7 | 49.0 | 81.1 | |
| 1 | 1 | 36.6 | 50.8 | 49.2 | 82.1 | |
| 38.9 | 52.7 | 50.7 | 83.2 | |||
| 39.8 | 54.8 | 51.1 | 83.0 | |||
| CC | Standard | |||
|---|---|---|---|---|
| mAP | R1 | mAP | R1 | |
| 32.4 | 50.3 | 41.9 | 77.2 | |
| 36.6 | 53.1 | 48.0 | 81.2 | |
| 38.0 | 52.7 | 49.5 | 82.9 | |
| (Ours) | 39.8 | 54.8 | 51.1 | 83.0 |
| 39.2 | 53.2 | 50.9 | 82.4 | |
Discussion of candidates collection. The parameter controls the contribution of initial appearance and gait ranking list when selecting training samples. As shown in Tab. 6, we observe that as the value of increases, the accuracy under both the settings show a trend of first increasing and then decreasing. The model achieves the best performance when . This means that the optimal neighbors collection strategy is to select most of the samples based on more reliable appearance features, while samples with similar gait features to the query are also considered.
6 Conclusion
In this paper, we have focused on a less studied yet and practical problem of video-based person re-identification with clothes-changing (CCVReID). For this problem, we propose a two-branch confidence-aware re-ranking framework, which fuse the appearance and gait features that have been re-weighted by confidence, for final re-ranking. We also design confidence pseudo-labels to supervise confidence learning. Besides, we build two new benchmarks for CCVReID problem, including a large-scale synthetic one and a real-world one. With the above efforts, we hope to promote the researches on this practical topic.
References
- [1] Shutao Bai, Bingpeng Ma, Hong Chang, Rui Huang, and Xilin Chen. Salient-to-broad transition for video person re-identification. In CVPR, pages 7339–7348, 2022.
- [2] Slawomir Bak, Peter Carr, and Jean-Francois Lalonde. Domain adaptation through synthesis for unsupervised person re-identification. In ECCV, pages 189–205, 2018.
- [3] Hanqing Chao, Kun Wang, Yiwei He, Junping Zhang, and Jianfeng Feng. Gaitset: Cross-view gait recognition through utilizing gait as a deep set. 44(7):3467–3478, 2021.
- [4] Di Chen, Andreas Doering, Shanshan Zhang, Jian Yang, Juergen Gall, and Bernt Schiele. Keypoint message passing for video-based person re-identification. In AAAI, volume 36, pages 239–247, 2022.
- [5] Dapeng Chen, Hongsheng Li, Tong Xiao, Shuai Yi, and Xiaogang Wang. Video person re-identification with competitive snippet-similarity aggregation and co-attentive snippet embedding. In CVPR, pages 1169–1178, 2018.
- [6] Jiaxing Chen, Xinyang Jiang, Fudong Wang, Jun Zhang, Feng Zheng, Xing Sun, and Wei-Shi Zheng. Learning 3d shape feature for texture-insensitive person re-identification. In CVPR, pages 8146–8155, 2021.
- [7] Kai Chen, Jiangmiao Pang, Jiaqi Wang, Yu Xiong, Xiaoxiao Li, Shuyang Sun, Wansen Feng, Ziwei Liu, Jianping Shi, Wanli Ouyang, et al. Hybrid task cascade for instance segmentation. In CVPR, pages 4974–4983, 2019.
- [8] Dahjung Chung, Khalid Tahboub, and Edward J Delp. A two stream siamese convolutional neural network for person re-identification. In CVPR, pages 1983–1991, 2017.
- [9] Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In CVPR, pages 248–255. Ieee, 2009.
- [10] Naina Dhingra, George Chogovadze, and Andreas Kunz. Border-seggcn: improving semantic segmentation by refining the border outline using graph convolutional network. In ICCV, pages 865–875, 2021.
- [11] Chanho Eom, Geon Lee, Junghyup Lee, and Bumsub Ham. Video-based person re-identification with spatial and temporal memory networks. In ICCV, pages 12036–12045, 2021.
- [12] Matteo Fabbri, Fabio Lanzi, Simone Calderara, Andrea Palazzi, Roberto Vezzani, and Rita Cucchiara. Learning to detect and track visible and occluded body joints in a virtual world. In ECCV, pages 430–446, 2018.
- [13] Chao Fan, Yunjie Peng, Chunshui Cao, Xu Liu, Saihui Hou, Jiannan Chi, Yongzhen Huang, Qing Li, and Zhiqiang He. Gaitpart: Temporal part-based model for gait recognition. In CVPR, pages 14225–14233, 2020.
- [14] Lijie Fan, Tianhong Li, Rongyao Fang, Rumen Hristov, Yuan Yuan, and Dina Katabi. Learning longterm representations for person re-identification using radio signals. In CVPR, pages 10699–10709, 2020.
- [15] Yang Fu, Xiaoyang Wang, Yunchao Wei, and Thomas Huang. Sta: Spatial-temporal attention for large-scale video-based person re-identification. In AAAI, volume 33, pages 8287–8294, 2019.
- [16] Xinqian Gu, Hong Chang, Bingpeng Ma, Shutao Bai, Shiguang Shan, and Xilin Chen. Clothes-changing person re-identification with rgb modality only. In CVPR, pages 1060–1069, 2022.
- [17] Xinqian Gu, Hong Chang, Bingpeng Ma, Hongkai Zhang, and Xilin Chen. Appearance-preserving 3d convolution for video-based person re-identification. In ECCV, pages 228–243. Springer, 2020.
- [18] Will Hamilton, Zhitao Ying, and Jure Leskovec. Inductive representation learning on large graphs. In NeurIPS, 2017.
- [19] Alexander Hermans, Lucas Beyer, and Bastian Leibe. In defense of the triplet loss for person re-identification. arXiv preprint arXiv:1703.07737, 2017.
- [20] David T Hoffmann, Dimitrios Tzionas, Michael J Black, and Siyu Tang. Learning to train with synthetic humans. In GCPR, pages 609–623. Springer, 2019.
- [21] Peixian Hong, Tao Wu, Ancong Wu, Xintong Han, and Wei-Shi Zheng. Fine-grained shape-appearance mutual learning for cloth-changing person re-identification. In CVPR, pages 10513–10522, 2021.
- [22] Ruibing Hou, Hong Chang, Bingpeng Ma, Shiguang Shan, and Xilin Chen. Temporal complementary learning for video person re-identification. In ECCV, pages 388–405. Springer, 2020.
- [23] Yan Huang, Jingsong Xu, Qiang Wu, Yi Zhong, Peng Zhang, and Zhaoxiang Zhang. Beyond scalar neuron: Adopting vector-neuron capsules for long-term person re-identification. IEEE TCSVT, 30(10):3459–3471, 2019.
- [24] Xin Jin, Tianyu He, Kecheng Zheng, Zhiheng Yin, Xu Shen, Zhen Huang, Ruoyu Feng, Jianqiang Huang, Zhibo Chen, and Xian-Sheng Hua. Cloth-changing person re-identification from a single image with gait prediction and regularization. In CVPR, pages 14278–14287, 2022.
- [25] Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. In ICLR, 2015.
- [26] Jianing Li, Shiliang Zhang, and Tiejun Huang. Multi-scale 3d convolution network for video based person re-identification. In AAAI, volume 33, pages 8618–8625, 2019.
- [27] Wei Li, Rui Zhao, Tong Xiao, and Xiaogang Wang. Deepreid: Deep filter pairing neural network for person re-identification. In CVPR, pages 152–159, 2014.
- [28] Yu-Jhe Li, Xinshuo Weng, and Kris M Kitani. Learning shape representations for person re-identification under clothing change. In WACV, pages 2432–2441, 2021.
- [29] Beibei Lin, Shunli Zhang, and Xin Yu. Gait recognition via effective global-local feature representation and local temporal aggregation. In ICCV, pages 14648–14656, 2021.
- [30] Yiheng Liu, Zhenxun Yuan, Wengang Zhou, and Houqiang Li. Spatial and temporal mutual promotion for video-based person re-identification. In AAAI, volume 33, pages 8786–8793, 2019.
- [31] Xiaoyan Lu, Xinde Li, Weijie Sheng, and Shuzhi Sam Ge. Long-term person re-identification based on appearance and gait feature fusion under covariate changes. Processes, 10(4):770, 2022.
- [32] John McCormac, Ankur Handa, Stefan Leutenegger, and Andrew J Davison. Scenenet rgb-d: Can 5m synthetic images beat generic imagenet pre-training on indoor segmentation? In ICCV, pages 2678–2687, 2017.
- [33] Niall McLaughlin, Jesus Martinez Del Rincon, and Paul Miller. Recurrent convolutional network for video-based person re-identification. In CVPR, pages 1325–1334, 2016.
- [34] Xuelin Qian, Wenxuan Wang, Li Zhang, Fangrui Zhu, Yanwei Fu, Tao Xiang, Yu-Gang Jiang, and Xiangyang Xue. Long-term cloth-changing person re-identification. In ACCV, 2020.
- [35] German Ros, Laura Sellart, Joanna Materzynska, David Vazquez, and Antonio M Lopez. The synthia dataset: A large collection of synthetic images for semantic segmentation of urban scenes. In CVPR, pages 3234–3243, 2016.
- [36] Lei Shi, Yifan Zhang, Jian Cheng, and Hanqing Lu. Two-stream adaptive graph convolutional networks for skeleton-based action recognition. In CVPR, pages 12026–12035, 2019.
- [37] Xiujun Shu, Ge Li, Xiao Wang, Weijian Ruan, and Qi Tian. Semantic-guided pixel sampling for cloth-changing person re-identification. IEEE Sign. Process. Letters, 28:1365–1369, 2021.
- [38] Xiaoxiao Sun and Liang Zheng. Dissecting person re-identification from the viewpoint of viewpoint. In CVPR, pages 608–617, 2019.
- [39] Gül Varol, Ivan Laptev, Cordelia Schmid, and Andrew Zisserman. Synthetic humans for action recognition from unseen viewpoints. IJCV, 129(7):2264–2287, 2021.
- [40] Fangbin Wan, Yang Wu, Xuelin Qian, Yixiong Chen, and Yanwei Fu. When person re-identification meets changing clothes. In CVPRW, pages 830–831, 2020.
- [41] Likai Wang, Jinyan Chen, and Yuxin Liu. Frame-level refinement networks for skeleton-based gait recognition. CVIU, 222:103500, 2022.
- [42] Max Welling and Thomas N Kipf. Semi-supervised classification with graph convolutional networks. In ICLR, 2017.
- [43] Qiaokang Xie, Zhenbo Lu, Wengang Zhou, and Houqiang Li. Improving person re-identification with multi-cue similarity embedding and propagation. IEEE TMM, 2022.
- [44] Qize Yang, Ancong Wu, and Wei-Shi Zheng. Person re-identification by contour sketch under moderate clothing change. 43(6):2029–2046, 2019.
- [45] Shijie Yu, Shihua Li, Dapeng Chen, Rui Zhao, Junjie Yan, and Yu Qiao. Cocas: A large-scale clothes changing person dataset for re-identification. In CVPR, pages 3400–3409, 2020.
- [46] Peng Zhang, Qiang Wu, Jingsong Xu, and Jian Zhang. Long-term person re-identification using true motion from videos. In WACV, pages 494–502, 2018.
- [47] Peng Zhang, Jingsong Xu, Qiang Wu, Yan Huang, and Xianye Ben. Learning spatial-temporal representations over walking tracklet for long-term person re-identification in the wild. IEEE TMM, 23:3562–3576, 2020.
- [48] Yifu Zhang, Peize Sun, Yi Jiang, Dongdong Yu, Fucheng Weng, Zehuan Yuan, Ping Luo, Wenyu Liu, and Xinggang Wang. Bytetrack: Multi-object tracking by associating every detection box. In ECCV, pages 1–21. Springer, 2022.
- [49] Ziyuan Zhang, Luan Tran, Xi Yin, Yousef Atoum, Xiaoming Liu, Jian Wan, and Nanxin Wang. Gait recognition via disentangled representation learning. In CVPR, pages 4710–4719, 2019.
- [50] Liang Zheng, Zhi Bie, Yifan Sun, Jingdong Wang, Chi Su, Shengjin Wang, and Qi Tian. Mars: A video benchmark for large-scale person re-identification. In ECCV, pages 868–884, 2016.
- [51] Liang Zheng, Liyue Shen, Lu Tian, Shengjin Wang, Jingdong Wang, and Qi Tian. Scalable person re-identification: A benchmark. In ICCV, pages 1116–1124, 2015.
- [52] Zhedong Zheng, Liang Zheng, and Yi Yang. Unlabeled samples generated by gan improve the person re-identification baseline in vitro. In ICCV, pages 3754–3762, 2017.
- [53] Zheng Zhu, Xianda Guo, Tian Yang, Junjie Huang, Jiankang Deng, Guan Huang, Dalong Du, Jiwen Lu, and Jie Zhou. Gait recognition in the wild: A benchmark. In ICCV, pages 14789–14799, 2021.