A Boundary Regression Model for Nested
Named Entity Recognition
Abstract
Recognizing named entities (NEs) is commonly conducted as a classification problem that predicts a class tag for a word or a NE candidate in a sentence. In shallow structures, categorized features are weighted to support the prediction. Recent developments in neural networks have adopted deep structures that map categorized features into continuous representations. This approach unfolds a dense space saturated with high-order abstract semantic information, where the prediction is based on distributed feature representations. In this paper, positions of NEs in a sentence are represented as continuous values. Then, a regression operation is introduced to regress boundaries of NEs in a sentence. Based on boundary regression, we design a boundary regression model to support nested NE recognition. It is a multiobjective learning framework, which simultaneously predicts the classification score of a NE candidate and refine its spatial location in a sentence. It has the advantage to resolve nested NEs and support boundary regression for locating NEs in a sntence. By sharing parameters for predicting and locating, this model enables more potent nonlinear function approximators to enhance model discriminability. Experiments demonstrate state-of-the-art performance for nested NE recognition111Our codes to implement the BR model are available at: https://github.com/wuyuefei3/BR..
I Introduction
Named entity (NE) recognition is often modeled as a sequence labelling task, where a sequence model (e.g., Conditional Random Field (CRF) [30] or Long Short-Term Memory (LSTM) [15]) is adopted to output a maximized labelling sequence. Because sequence models are effective to encode semantic dependencies of a sentence and constraint the structure of a labelling sequence, they have achieved a great success for NE recognition. However, sequence models assume a flattened structure for each input sentence. They are not effective to find nested NEs in a sentence. For example, “Guizhou University” is an organization NE, where “Guizhou” is also a NE indicating the location of the university. In this case, outputting a label sequence cannot resolve the nested structure. Due to the reason that nested structures are effective to represent semantic relationships of entities (e.g., affiliation, ownership, hyponymy), they are widely used in natural languages. For example, in the GENIA corpus and ACE corpus, the nesting ratio is 35.27% and 33.90%, respectively [31, 6].
Span classification is an effective method to recognize nested NEs. It generates NE spans from a sentence in a process known as region proposal, then outputs a class label for each possible NE span. It has two advantages to support nested NE recognition. First, nested NE structure can be resolved as separated NE spans. Second, the classification can be implemented on a span representation, which encode global semantic relevant to a predicated NE. At current, span classification has achieved a great attention. However, many span classification models enumerate all possible NE spans in a sentence, which suffer from a high computing complexity and the data unbalance problem. Therefore, many related work only verify possible NE spans upto a certain length (e.g., [48, 39, 47]), or filter unlikely NE spans with predefined thresholds [42] or NE boundary cues [3, 52]. For example, Chen et al. [3] verify NE spans combined from detected NE boundaries. Lin et al. [25] apply a point network to recognize span boundaries relevant to the head word of a NE mention. The main problem for span classification is that, due to the reason of computation complexity and data imbalance, it is difficult to enumerate all NE candidates in a sentence. If a NE is not enumerated in the region proposal process, it cannot be recognized by span classification.
In our study, we found that there are some similarities between named entity recognition and object detection. For example, named entities in a sentence and objects in an image have similar spatial structures, e.g., flattened, nested and discontinuous [43]. The task to recognize them can be modelled as a span (or region) classification problem. The main difference between named entities and objects is that the former uses a discrete position representations. Because deep neural network has the ability to transform multimodal signals into an abstract semantic space [50], in this paper, we represent positions of NEs as continuous values. Then, a regression operation can be introduced to regress boundaries of NEs for locating NEs in a sentence the same way as detecting object detection in an image.
In this paper, motivated by techniques developed in object detection of computer vision, we generate abstract NE representations from sentence in a region proposal process. The generated NE representations is named as textual bounding boxes (or bounding boxes in short). Every bounding box is annotated with three parameters to indicate its entity type, start position and length in a sentence. Then, instead of predicting the class of a NE candidate, a boundary regression operation is applied to refine its spatial location in a sentence. Based on boundary regression, we design a boundary regression (BR) model to support nested NE recognition. It is a multiobjective learning framework composed of a basic network module, a region proposal module, a classification module and a regression module. The basic network transforms each sentence into abstraction representation. Then, a region proposal network is applied to generate bounding boxes. They are fed into the classification module fro class prediction and regression module for boundary regression. In the training process, in addition to maximizing the confidence scores of a NE, a linear layer is used to minimizes its location offset relative to a true NE.
The BR model simultaneously predicts the classification score of a NE candidate and refine its spatial location in a sentence. The contributions of this paper include the following:
-
1)
Positions of NEs in a sentence are represented as continuous values to support NE boundary regression. It has the advantage to resolve nested NEs and locate NEs with boundary regression operation.
-
2)
A bounding box based multiobjective learning model is designed to support nested NE recognition. It supports simultaneously predicts the class probability and refines spatial locations of NEs in a sentence.
The structure of this paper is organized as follows. Before discussing the details of this model, our motivation is first discussed in Section II. Section III presents the definition of boundary regression and the architecture of the BR model. Experiments are conducted in Section IV, where several issues about the BR model are discussed. Section V introduce related work. Section VI gives the conclusion of this paper.
II Motivation
The motivation of BR model is inspired by techniques developed in object detection in computer vision. From our intuition, a sentence is a one-dimensional linear textual stream, and an image is a two-dimensional pixel patch. They are totally different in external representations. However, in recent years, based on deep neural networks, language and vision can be embedded into a distributed representation and mapped into an abstract semantic space. Therefore, the combination of natural language processing and computer vision has become popular in research communities, e.g., the text retrieval approach in videos [38] and multimodal deep learning [50].
As shown in Figure 1, spatial patterns of entities in sentences and objects in images have similar structures.
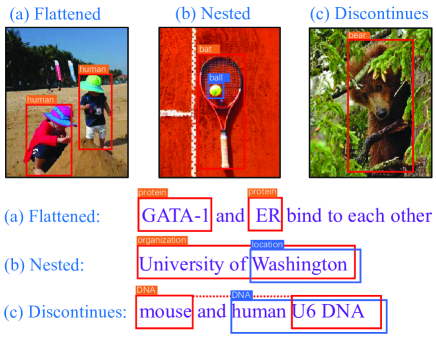
The structures between objects (or entities) can be roughly divided into three categories: flattened, nested and discontinuous [43]. Flattened entities (or objects) are spatially separated from each other. In nested structure, two or more entities or objects are overlapped with each other. The discontinuous structure refers to disclosed objects (or entities). For example, “HEL, KU812 and K562 cells” contains three entities: “HEL cells”, “KU812 cells” and “K562 cells”. The first two NEs are discontinuous. Because the discontinuous structure can be transformed into nested structure [2]. For example, the above examples can be processed as three nested NEs: “HEL, KU812 and K562 cells”, “KU812 and K562 cells” and “K562 cells”. In the paper, we only consider the flattened and nested structures.
Object detection is a fundamental task in computer vision, which classifies regions of an image for predicting locations of objects. In the early stage, the task is implemented in a multistage pipeline, where a region proposal step is applied to select coarse proposals. Another tendency for object detection adopts end-to-end architectures. A deep neural network is first adopted to map an input image into abstract representations known as conv feature maps. Then, proposals are generated from these feature maps. A proposal is an abstract representation of a possible object. Parameters are defined to indicate its location and shape in an image. Finally, a multiobjective learning framework is designed to simultaneously locate objects and predict the class probability.
Motivated by techniques developed in computer vision, we adopt a region proposal network to generate abstract NE representations (referred as bounding boxes). Every bounding box is annotated with three parameters to indicate its entity type, start position and length in a sentence. Then, the spatial locations of NEs are represented as real values. It enables a regression operation for locating NEs in a sentence. The concept to regress boundaries for NE recognition is visualized in Figure 2.
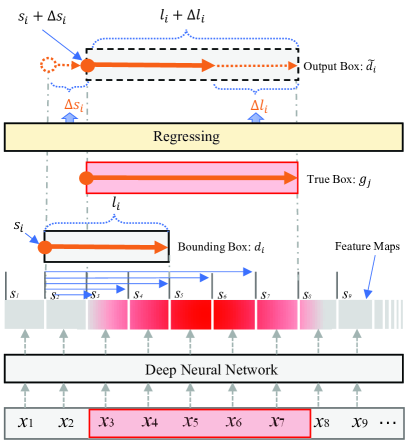
As shown in Figure 2, an input sentence is first mapped into recu feature maps by a deep neural network. The feature maps can be seen as an abstract representation of an input sentence. Every feature map denotes a representation of an NE boundary, which can be bounded with others to generate bounding boxes (an example is shown in Figure 2). Every bounding box has two parameters denoting its position and shape in a sentence. If a bounding box correctly matches to a true NE, the box is referred to as a “ground truth box” (or truth box, e.g., in Figure 2).
Every box has two parameters to indicate its position () and shape (or length) ()222In this paper, the position parameter () and shape parameter () of an NE are also referred to as location parameters.. The regression operation respectively predicts the position offset and shape offset ( and ) relative to a truth box. Finally, in the output, locations of the recognized NEs are updated as . Because the outputs of a regression operation are continuous values, they are rounded to the nearest word boundary locations.
To design an end-to-end multiobjective learning architecture for boundary regression, we should carefully take the following four issues under consideration:
1) representation: object detection usually uses stacked convolutional layers to map an image into conv feature maps. In language processing, the recurrent (or attention) neural network is more effective in capturing the semantic dependency in a sentence. In this paper, the abstract representations of input sentences are referred to as recu feature maps.
2) region proposal: in the recu feature map, a feature map position can be considered as an abstract representation of a possible entity boundary. It can be bounded with other feature maps to generate bounding boxes. Every bounding box is an abstract representation of an NE candidate labelled with its location information and class category.
3) multiobjective learning: because the recurrent neural network can learn the semantic dependency, a bounding box contains semantic information about the whole sentence. In addition to predicting conditional class probabilities on a bounding box, a linear layer can be stacked to predict its location in a sentence.
4) maximum of overlapping neighbourhoods: in the prediction process, every bounding box will approach a true bounding box. They are overlapped in the neighbourhood of a true bounding box. It is necessary to collect the most likely matched bounding boxes from overlapped bounding boxes.
According to the above discussion, we designed an end-to-end multiobjective learning architecture for boundary regression. The architecture of the BR model is given in the following section.
III Model
In this paper, instead of modelling the NE recognition task as a classification problem, we frame the task as a multiobjective optimization process. In this framework, in addition to outputting discretized entity categories, a regression operation is integrated into a deep network for predicating the location offset of an NE candidate relative to a true NE in a sentence. The structure of the BR model is shown in Figure 3.
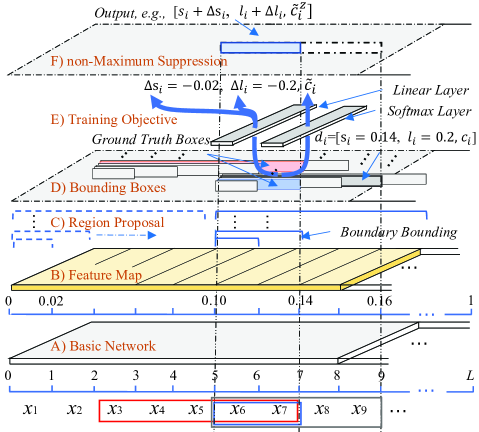
As Figure 3 shows, six specific issues (referred to from A to F) are highlighted in the BR model. They are discussed as follows.
III-A Basic Network
In a neural network model, the values of inputs represent the tense of signals. Therefore, words in a sentence are traditionally represented as high-dimensional one-hot vectors. At current, deep neural network has two advantages to support automatically extracting semantic features from raw inputs: word embedding and feature transformation. Word embedding is applied to map every word into a distributed representation, which encodes semantic information learned from external resources. In feature transformation, many types of neural layers (CNN [21], LSTM [15] or Attention [44]) can be stacked to support designed feature transformation for capturing syntactic and semantic features of a sentence, which avoid the need for manually feature engineering.
For feature extraction, there are two differences between object detection and NE recognition. First, the detection of objects is mainly based on internal features of objects. Therefore, an object moving in an image exerts less influence on the object detection. However, entities have a strong semantic dependency in a sentence. Second, in nested objects, features in the bottom object are blocked by upper objects, which makes challenge for bottom object detection. While nested NEs share the same context in a sentence. It is important to lean dependent features relevant to considered NEs. Therefore, comparing with object detection, encoding semantic dependencies in a sentence is more important for NE recognition. In deep architectures, a recurrent neural network or an attention network is helpful to capture the semantic dependency between words.
In our BR model, we adopted a basic network consisting of an embedding layer and a Bi-LSTM layer. The embedding layer is adopted to map a sentence into a distributed representation, where words (or characters) are embedded into vectors by a lookup table pretrained with unsupervised algorithms. Then, a Bi-LSTM is implemented to encode the semantic dependencies in a sentence. To simplify the region proposal step, we set the length of the input sentence as a fixed number, denoted as . Longer or shorter sentences are trimmed or padded, respectively.
III-B Feature Map
The output of the basic network is denoted as recu feature maps, where a feature map is an abstract token representation of the input. In the BR model, it also denotes as the feature map layer, which represent high-order abstract features of a sentence integrated with dependent semantics between words. In computer vision, images have an invariance property for a zooming operation. Object detection can benefit from multigranularity representations, where the region proposal can be implemented on multiscale feature maps to generate bounding boxes with different scales. In natural language processing, it is difficult to condense a textual sequence into multigranularity representations. At present, for each input sentence, we generate a single recu feature map layer, which can be seen as a high-order abstract representation of an input sentence. Each feature map position corresponds to a possible entity boundary. Because we adopt continuous location representation, the position of feature maps is normalized into the interval to support regression operation.
The feature map layer is mainly applied to support region proposal for generating abstract NE representations. Instead of directly generating NE candidates from a sentence (e.g., Sohrab et al. [39]), generating abstract NEs from the feature map layer can share parameters in the bottom network. It reduces the computational complexity and enables more potent nonlinear function approximators to enhance model discriminability.
III-C Region Proposal
A feature map corresponds to an abstract representation of a possible NE boundary in a sentence. Each feature map can be set as a start position and combined with right feature maps to generate bounding boxes with different lengths. In this paper, for every feature map, we enumerate bounding boxes from left to right. The value is a predefined parameter indicating the longest NE candidate. It is similar to an exhaustive enumeration method, which verifies every possible NE candidate up to a certain length (e.g., Sohrab et al. [39]). The difference is that bounding boxes are referred by their spatial locations in a sentence, which can be used to filter bounding boxes those are unlikely to be a truth box (discussed in Section III-D). It reduces the computational complexity and decreases the influence caused by negative examples.
To show the potential ability of the BR model to locate NEs those are missed in the region proposal process, in this experiment, we also propose an interval enumeration strategy. For every feature map, we enumerate bounding boxes from left to right with lengths [1, 3, 5, 7, 11, 15, 20]333We set the longest length of NEs to be 20. They cover 99.05% of NEs in the Chinese ACE corpus.. In the training process, all ground truth boxes in training data are included to train the classifier. In the testing process, only bounding boxes with lengths [1, 3, 5, 7, 11, 15, 20] are verified. Comparing with exhaustively enumeration with lengths from 1 to 20, the interval enumeration reduces about 65% computational overhead. For convenience, we refer to the BR model with interval enumeration as “BR”. The BR model implemented on exhaustive enumeration is referred to as “BR”.
III-D Bounding Boxes
A bounding box is a high-order abstract representation of a possible NE generated from feature maps by region proposal. Because feature maps are transformed by a basic network which consists of a recurrent neural network or an attention network, each bounding box contains contextual features about a possible NE. Using class labels and location parameters of bonding boxes, a softmax layer and a linear layer can be set to predict their class probabilities and learn the location offset relative to a ground truth box. In the following, we give formal definitions about the bounding box.
Let denote a bounding box set generated from an input sentence . is the size of . Each bounding box has 3 parameters: , and . Parameters and are two real numbers denoting the start position and length of in a sentence, respectively. The end position of can be computed as . Parameter is a one-hot vector representing the entity type of , where is the number of entity types. Therefore, a bounding box can be referred to as a three-tuple . If a bounding box corresponds to a true NE, it is referred to as a ground truth box and represented as .
Bounding boxes are labelled with location parameters. Borrowed from the intersection over union (IoU) developed in computer vision [8], the overlapping ratio between two bounding boxes can be measured by the IoU value.
Let and be a bounding box and a ground truth box, respectively. The IoU value between them is computed as:
| (1) |
where the function represents the range of a bounding box in feature maps. If a bounding box has a large IoU value, it is highly overlapped with a ground truth box. A high overlapping ratio indicates that a bounding box contains adequate contextual features about a true NE, which guarantees learning of the location offset relevant to a truth box. Otherwise, if the IoU value of a bounding box is lower than a predefined threshold, it denotes a false NE. It is used to train a classifier for identifying false NEs.
Let represent the set of all ground truth boxes in . We define two sets as follows:
| (2) |
where is a predefined threshold. is a subset of , where is equal to 1.
In this paper, is referred to as the positive bounding box set, and is referred to as the negative bounding box set. In region proposal, a large number of negative bounding boxes will be generated, which lead to a significant data imbalance problem. This is also computationally expensive. In the training process, we collect and with a ratio of 1:3 for balancing positive and negative samples. This guarantees faster optimization and a stable training process.
Given a bounding box , its relative ground truth box is identified as:
| (3) |
Given a ground truth box , all bounding boxes of satisfying Equation 3 are referred to as . They are the neighbourhoods of . This is formalized as:
| (4) |
It is important to know that, in the training data, all bounding boxes in are labelled with a positive class tag the same as . This labelling strategy is different from the traditional method in which, if the start and end boundaries of an NE candidate are not precisely matched to a true NE, it is labelled with a negative class tag. The reason for this will be discussed in detail in Section III-E. For consistency, in this paper, we use the term “positive box” referring to a bounding box with an IoU value relevant to a ground truth box larger than . The term “truth box” refers to a bounding box, which has a location precisely matched to a real NE.
Based on and Equation 3, can be partitioned into a set . Therefore, is a partition of . If , then . Every bounding box belongs to a .
For convenience, Table I lists the definitions about different bounding box sets. Their roles to support boundary regression will be discussed in the following subsection.
| Symbol | Meaning |
| A bounding box set generated from a sentence ; | |
| The set of all ground truth boxes in ; | |
| The positive bounding box set; | |
| The negative bounding box set; | |
| The neighbourhoods of ; | |
| A partition of ; |
III-E Training Objective
Let and be the normalized position offset and shape offset between and . Given a bounding box , the BR model outputs 3 parameters: , and . and denote the predicted position offset and shape offset of relative to . is a confidence score that reflects the confidence that a box contains a true NE. As Figure 3 shows, and are regressed by a linear layer, while the classification confidence score is predicted by a softmax layer.
For every , the location offset of relates to a ground truth box that is predicted by a linear layer. A characteristic function is defined to indicate that a default box is matched to a relative ground truth box selected by Equation 3. In the training process, the regression operation updates and for the purpose of approaching and , respectively. The location loss can be computed as:
| (5) |
where is the cardinality of . It is used to normalize the weight between . is a robust loss that quantifies the dissimilarity between and . It is less sensitive to outliers [13].
Equation 5 shows that only the positive bounding box set is adopted to compute the location loss. For every ground truth box , its neighbourhoods are used to generate the location loss. This setting is natural because neighbourhoods contain sufficient contextual features about an NE to support boundary regression. On the other hand, negative bounding boxes are far from any ground truth box. Because the vanishing gradient problem, it is difficult to precisely regress their location offsets.
When minimizing the location loss, bounding boxes belonging to will approach the ground truth box . Therefore, all bounding boxes in are given a class tag which is the same as ground truth box .
Confidence loss is a softmax loss over multiple class confidences. It is given as follows:
| (6) |
where , is the confidence score indicating that an example is negative. A key issue about the classification is that the confidence score should be estimated based on NE representations with refined spatial locations in a sentence.
The total loss function combines the location loss and confidence loss:
| (7) |
where is a predefined parameter balancing the weight between the location loss and confidence loss. The training objective is to reduce the total loss of the location offset and class prediction. In the training process, we optimize their locations to improve their matching degree and maximize their confidences.
III-F Non-Maximum Suppression
In the prediction process, the BR model outputs a set of bounding boxes for each input sentence, referred to as . Every box has 3 outputs: , and , respectively indicating the position offset, shape offset and class probability of relative to a truth box. After and are resized as and , an predicated NE can be located as: [, , ]444An example of the output is shown in Figure 3..
The output contains a large number of boxes, but many of them are overlapped. Non-maximum suppression (NMS) is implemented in the prediction process to produce the final decision, which selects truth boxes from overlapped neighbourhoods. The NMS algorithm is shown in Table II.
| Input: , a threshold . |
| Output: recognized NEs. |
| 1: Sort according confidence scores in descending order; |
| 2: While (if is not empty){ |
| 3: Select from ; |
| 4: Delete from ; |
| 5: For , if , delete from ; |
| 6: Add to ; } |
It is a one-dimensional NMS algorithm that selects nested NEs from overlapped positive boxes. The NMS algorithm searches local maximized elements from overlapping neighbourhoods in which a smaller number of high-confidence boxes are collected. The threshold is adopted to control the overlapping ratio between neighbourhoods. In our experiments, the value of is set as 0.6.
IV Experiments
In our experiments, the ACE 2005 corpus [6] and the GENIA corpus [20] are adopted to evaluate the BR model. In order to show the performance of the BR model to recognize flattened NE structure, in Section IV-B, the BR model is also evaluated on the OntoNotes 5.0 [32] and CoNLL 2003 English [35] corpora.
The ACE 2005 corpus is collected from broadcasts, newswires and weblogs. It is the most popular source of evaluation data for NE recognition. The corpus contains three datasets: Chinese, English and Arabic. In this paper, the BR model is mainly evaluated on the ACE Chinese corpus. To show the extensibility of the BR model regarding other languages, it is also evaluated on the ACE English corpus and the GENIA corpus.
The GENIA corpus was collected from biomedical literature. It contains 2,000 abstracts in MEDLINE by PubMed based on three medical subject heading terms: human, blood cells and transcription factors. This dataset contains 36 fine-grained entity categories. In the GENIA corpus, many NEs have discontinuous structure. They are transformed into nested structures by holding the discontinuous NE as a single mention.
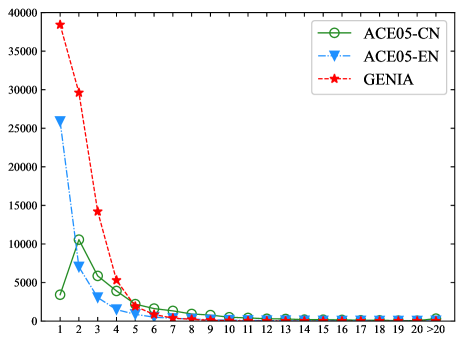
In the ACE Chinese dataset, there are 33,238 NEs in total. The number of NEs in the ACE English dataset is 40,122. The GENIA corpus is annotated with 91,125 NEs. The distributions of NE lengths in the three corpora are shown in Figure 4.
In the basic network, the default length of sentence is 50. Sentences with longer or shorter length are trimmed or padded, respectively. In the total loss function, is used. Two BERTBASE [5] model are tuned by implementing the innermost and outermost NE recognition tasks, respectively. Then, every sentence is encoded into two sequence of vectors by two tuned BERT models, where every word in a sentence is encoded as a concatenated dimensional vector. It is fed into a Bi-LSTM layer, which outputs a dimensional recu feature map. In the training process, word representations are fixed and not subject to further tuning.
In region proposal, two strategy have been introduced: exhaustive enumeration and interval enumeration, which corresponds to two BR models referred to as “BR” and “BR”. The BR model exhaustively enumerates all NEs with length up to 6. We ignore NEs with length larger than 6. In the BR model, we intermittently enumerate bounding boxes from left to right with lengths [1, 3, 5, 7, 11, 15, 20]. To collect the positive bounding box set to train the linear layer, is set as 0.7 and 0.6 for BR and BR, respectively. The quantitative test to set is discussed in Section IV-C1.
In the output layer, a correct NE requires that start and end boundaries of an NE are precisely identified. Because the BR model uses a regression operation to predicate spatial locations of NEs in a sentence, all entity locations are mapped into interval for a smooth learning gradient. Therefore, the output of BR is rounded to the nearest character location.
IV-A Comparison with related work
To show the superiority of our model, we first compare the BR model with related work. It is first evaluated on the Chinese corpus. Then, to show the extensibility of the BR model, the BR model is transformed to the English corpus for further assessment.
IV-A1 Evaluation in the Chinese Corpus
In the Chinese corpus, we first conduct a popular sequence model (Bi-LSTM-CRF) [16]. It consists of an embedding layer, a Bi-LSTM layer, an MLP layer and a CRF layer. The embedding layer and Bi-LSTM layer have the same settings as the basic network of the BR model. We adopt cascading and layering strategies to solve the nesting problem [1]. The layering model proposed by Lin et al. [25] is adopted for comparison.
In the Chinese ACE corpus, BA is a pipeline framework for nested NE recognition that has achieved state-of-the-art performance [3]. The original BA is a “Shallow” model, which uses a CRF model to identify NE boundaries and a maximum entropy model to classify NE candidates. NNBA is a neural network version, where the LSTM-CRF model is adopted to identify NE boundaries, and a multi-LSTM model is adopted to filter NE candidates.
In this experiment, the “Adam” optimizer is adopted. The learning rate, weight decay rate and batch size are set as 0.00005, 0.01 and 30, respectively. Shallow models refer to CRF-based models. In the BR model, we use the same settings as Chen et al. [3] to configure the basic neural network, where the BERT is adopted to initialize word embeddings. These models are implemented with the same data and settings as Chen et al. [3]. The results are shown in Table III.
| Model | P(%) | R(%) | F(%) | |
| Shallow Models | Innermost | 73.60 | 45.50 | 56.32 |
| Outermost | 72.60 | 45.54 | 55.97 | |
| Cascading | 76.52 | 51.80 | 61.80 | |
| Layering | 71.93 | 56.57 | 63.33 | |
| BA [4] | 73.98 | 62.16 | 67.56 | |
| Deep Models | Innermost | 82.00 | 70.70 | 75.93 |
| Outermost | 80.45 | 69.08 | 74.33 | |
| Cascading | 76.96 | 71.39 | 74.07 | |
| Layering [25] | 78.85 | 81.34 | 80.07 | |
| NNBA [3] | 80.49 | 79.46 | 79.97 | |
| BR | 72.35 | 73.71 | 73.02 | |
| BR | 85.95 | 84.39 | 85.16 | |
| Models | GENIA | ACE | |||||
| P(%) | R(%) | F(%) | P(%) | R(%) | F(%) | ||
| Lu et al. [27] | Mention Hypergraphs | 72.5 | 65.2 | 68.7 | 66.3 | 59.2 | 62.5 |
| Katiyar et al. [19] | Neural Hypergraph | 76.7 | 71.1 | 73.8 | 70.6 | 70.4 | 70.5 |
| Ju et al. [18] | Layered-BiLSTM-CRF | 78.5 | 71.3 | 74.7 | 74.2 | 70.3 | 72.2 |
| Wang et al. [45] | Stack-LSTM | 77.0 | 73.3 | 75.1 | 76.8 | 72.3 | 74.5 |
| Lin et al. [25] | Sequence-to-nuggets | 75.8 | 73.9 | 74.8 | 76.2 | 73.6 | 74.9 |
| Xia et al. [47] | MGEPN | - | - | - | 79.0 | 77.3 | 78.2 |
| Fisher et al. [11] | BERT+Merge&Label | - | - | - | 82.7 | 82.1 | 82.4 |
| Shibuya et al. [36] | BERT+FLAIR | 76.3 | 74.7 | 75.5 | 85.94 | 85.69 | 85.82 |
| Strakova et al. [40] | BERT+Seq2Seq | - | - | 78.3 | - | - | 84.33 |
| Wang et al. [46] | BERT+Pyramid | 79.45 | 78.94 | 79.19 | 85.30 | 87.40 | 86.34 |
| Tan et al. [42] | BERT+Boundary | 79.2 | 77.4 | 78.3 | 83.8 | 83.9 | 83.9 |
| Li et al. [24] | BERT+MRC | 85.18 | 81.12 | 83.75 | 87.16 | 86.59 | 86.88 |
| Ours | BR | 80.81 | 77.43 | 79.09 | 86.88 | 84.83 | 85.84 |
| BR | 81.74 | 81.75 | 81.75 | 89.10 | 87.52 | 88.30 | |
In Table III, all deep models outperform shallow models because neural networks can effectively utilize external resources by using a pretrained lookup table and have the advantage of learning abstract features from raw input. In deep models, the performances of innermost and outermost models are heavily influenced by a lower recall rate, which is caused by ignoring nested NEs. The deep cascading model also suffers from poor performance because predicting every entity type by an independent classifier can not make full use of annotated data. The deep layering model is impressive. This model is produced by implementing two independent classifiers that separately recognize the innermost and outermost NEs. It offers higher performance, even outperforming the NNBA model. The reason for the improvement is that, in our experiments, entities with length exceeding 6 are ignored, which decreases the nesting ratio. Most of the nested NEs have two layers, which can be handled appropriately by the layering model. In Table III, the BR model exhibits the best performance.
The Chinese language is hieroglyphic. It contains very little morphological information (e.g., capitalization) to indicate word usage. Because there is a lack of delimitation between words, it is difficult to distinguish monosyllabic words from monosyllabic morphemes. However, Chinese has two distinctive characteristics. First, Chinese characters are shaped similar squares. They are known as square-shaped characters. Their locations are uniform. Second, because the meaning of a Chinese word is usually derived from the characters it contains, every character is informative. Therefore, character representations can effectively capture the syntactic and semantic information of a sentence. The BR model works well on the Chinese corpus.
IV-A2 Evaluation in the English Corpus
In the ACE English corpus and the GENIA corpus, we adopt the same settings as Lu et al. [27] to evaluate the BR model, where the evaluation data are divided according to the proportion 8:1:1 for training, developing and testing. In the GENIA corpus, researchers often report the performance with respect to five NE types (DNA, RNA, protein, cell line and cell type). To compare with existing methods, we generate results for the five NE types.
In Table IV, Lu et al. [27] and Katiyar et al. [19] represent nested NEs as mentioned hypergraphs. Ju et al. [18] feed the output of a BiLSTM-CRF model to another BiLSTM-CRF model. This strategy generates layered labelling sequences. The stack-LSTM [45] uses a forest structure to model nested NEs. Then, a stack-LSTM is implemented to output a set of nested NEs. Sequence-to-nuggets [25] first identifies whether a word is an anchor word of an NE with specific types. Then, a region recognizer is implemented to recognize the range of the NE relative to the anchor word. MGEPN [47] and Merge&Label are pipeline frameworks. They first generate NE candidates. Then, all candidates are further assessed by a classifier. FLAIR [36] extracts entities iteratively from outermost to innermost. Strakova et al. [40] encode an input sentence into a vector representation. Then, a label sequence is directly generated from the sentence representation. Wang et al. [46] use a CNN to condense a sentence into a stacked hidden representation with a pyramid shape, where a layer represents NE candidate representations with different granularity. These models are all nesting-oriented models. Their performances are listed in Table IV.
Table IV shows that the performance of the GENIA corpus is lower than that of the ACE corpus. There are three reasons for this phenomenon. First, the GENIA corpus was annotated with discontinuous NEs. For the example mentioned in Section II, “HEL, KU812 and K562 cells” contains two discontinuous NEs. Second, in the GENIA corpus, nested NEs may occur in a single word. For example, “TCR-ligand” is annotated as an “other_name” entity, where it is nested with a “TCR” protein. Third, a large number of abbreviations are annotated in the GENIA corpus, which brings about a serious feature sparsity problem. Therefore, the performance is lower in the GENIA corpus.
In related work, many models also exhaustively verify every possible NE candidate with length up to 6, e.g., Xu et al. [48], Sohrab et al. [39], Xia [47] and Tan et al. [42]. Because limiting the length of NEs can reduce the influence caused by negative instances, these models achieve higher performance. In comparison with them, the BR model significantly improves the performance. In the testing data, the ratios of NEs with lengths [1, 3, 5, 7, 11, 15, 20] in the ACE English and the GENIA corpora are 79.47% and 58.34%, respectively (the ratio in the ACE Chinese corpus is 39.89%). Therefore, the BR model also achieves competitive performance in the ACE English and the GENIA corpora.
In Table IV, all neural network-based models exhibit higher performance. Especially in the BERT models, the performance is improved considerably. Li et al. [24] present a model based on machine reading comprehension, where manually designed questions are required to encode NE representations. It achieves higher performance with respect to the GENIA corpus. However, because this model benefits from prior knowledge and experience, which essentially introduce descriptive information about the categories, it is rarely used for comparison with related work. In comparison with related work in the English corpus, the BR model also shows competitive performance.
IV-B Ablation Study
In natural language processing, continuous location representation has not been used denoting to positions of linguistic units in a sentence. Therefore, the regression operation is rarely used to support information extraction. As we known, the BR model is the first attempt to locate linguistic units in a sentence by regression operation. To analyse the mechanism of boundary regression for nested NE recognition, we design a traditional NE classification model named as bounding box classifier (BBC) for comparison. It is generated by omitting the linear layer from the deep architecture in Figure 3. In the output, only a softmax layer is adopted to predict the class probability for every bounding box.
| BBC (0.7) Model | BBC (1.0) Model | BR Model | ||||||||
| TYPE | Number | P(%) | R(%) | F(%) | P(%) | R(%) | F(%) | P(%) | R(%) | F(%) |
| VEH | 499 | 46.15 | 71.32 | 56.04 | 84.87 | 70.62 | 77.09 | 79.36 | 69.93 | 74.34 |
| LOC | 1,277 | 33.33 | 53.09 | 40.95 | 76.11 | 49.81 | 60.21 | 74.88 | 57.45 | 65.02 |
| WEA | 324 | 44.44 | 63.76 | 52.38 | 78.57 | 63.76 | 70.40 | 77.58 | 65.21 | 70.86 |
| GPE | 8,071 | 49.83 | 86.90 | 63.34 | 87.29 | 85.72 | 86.50 | 86.24 | 86.77 | 86.50 |
| PER | 11,351 | 46.21 | 90.65 | 61.22 | 90.79 | 90.16 | 90.48 | 89.81 | 89.96 | 89.88 |
| ORG | 4,837 | 34.68 | 80.81 | 48.53 | 82.56 | 79.46 | 80.98 | 82.79 | 81.19 | 81.98 |
| FAC | 1,194 | 34.56 | 67.33 | 45.67 | 75.22 | 65.33 | 69.93 | 73.25 | 70.91 | 72.06 |
| Total | 27,553 | 43.62 | 84.30 | 57.49 | 87.00 | 83.27 | 85.10 | 85.95 | 84.39 | 85.16 |
In this section, three experiments are conducted to show the usefulness of the regression operation. We first conduct two ablation studies to show the feasibility of boundary regression. In the first experiment, exhaustive enumeration is adopted in region proposal. The BBC model and the BR model are compared to show the ability of BR to refine spatial locations of NEs in a sentence. In the second experiment, the BR model is implemented on intermittently enumerated bounding boxes. The experiment shows the ability of the BR model to locate true NEs from mismatched NE candidates. The BR model is mainly designed to supported nested NE recognition. It also can be used to recognize flattened NEs. Therefore, in the third experiment, we evaluate the BR model on flattened NE recognition. The first experiment and the second experiment are conducted on the ACE Chinese corpus. The third experiment is implemented on two English corpora with flattened NE annotation: the OntoNotes 5.0 [32] corpus and the CoNLL 2003 [35] corpus.
IV-B1 Performance with exhaustive enumeration
In this experiment, we compare the the BR model with two BBC model: BBC (0.7) and BBC (1.0). The BBC (0.7) model is implemented on the same evaluation data as the BR model with to collect positive bounding boxes. In the BBC (1.0) model, is applied. Under this setting, the positive bounding box set and the negative bounding box set can be denoted as: and . It means that every positive bounding box is precisely matched to a true ground truth box. Therefore, the BBC (1.0) model is a traditional classifier implemented on precisely annotated evaluation data.
We implement the BBC model and the BR model with the same data and settings. The result is shown in Table V, where Column “Number” refers to the number of annotated NEs in the corpus. the performance is reported with respect to 7 true entity types. The “Total” denotes to the micro-average on all entity types.
In NE recognition, a correct output requires that both the start and end boundaries are precisely matched to a manually annotated NE. Because the BBC model is a traditional classifier which cannot regress mismatched boundaries, as Table V shows, it suffers from significantly diminished precision caused by mismatched NE boundaries. The BBC (1.0) model is implemented on the evaluation data with , where boundaries of positive bounding boxes are precisely matched to true NEs. The result in Table V shows that, in comparison with the BBC (0.7) model, BBC (1.0) achieves higher performance.
In the BR model, because bounding boxes in have a high overlapping ratio relevant to a ground truth box, they have sufficient semantic features with respect to a true NE for supporting boundary regression. In the prediction process, mismatched boundaries of bounding boxes can approach a ground truth box through the regression operation. In comparison with the BBC (0.7) model, mismatched boundaries can be revised, which considerably improve the performance. The result indicates that the regression operation really regresses boundaries and locates NEs in a sentence.
Comparing the BR model with the BBC (1.0) model, in both the BR model and the BBC (1.0) model, all NEs with length up to 6 have been enumerated and verified. In this condition, in the prediction process of the BR model, approaching to an NE that is already verified is less helpful to improve the performance. However, because the BR model can refine spatial locations of bounding boxes in and share model parameters in the bottom network, a higher recall ratio can be achieved in the BR model, which improve the final performance.
IV-B2 Performance of interval enumeration
In the second experiment, the BBC (1.0) model is compared with the BR, which only verifies bounding boxes with lengths [1, 3, 5, 7, 11, 15, 20] in the testing dataset. The results are listed in Table VI.
| BBC (1.0) Model | BR Model | |||||
| TYPE | P(%) | R(%) | F(%) | P(%) | R(%) | F(%) |
| VEH | 86.53 | 25.42 | 39.30 | 60.60 | 56.49 | 58.47 |
| LOC | 66.66 | 11.65 | 19.84 | 53.99 | 43.55 | 48.21 |
| WEA | 68.96 | 27.39 | 39.21 | 71.66 | 58.90 | 64.66 |
| GPE | 82.34 | 25.17 | 38.56 | 82.65 | 78.87 | 80.72 |
| PER | 91.68 | 44.70 | 60.10 | 80.24 | 79.82 | 80.03 |
| ORG | 82.10 | 32.01 | 46.06 | 70.09 | 65.09 | 67.50 |
| FAC | 77.27 | 20.98 | 33.00 | 61.37 | 54.93 | 57.98 |
| Total | 86.67 | 34.00 | 48.84 | 76.46 | 73.00 | 74.69 |
Because the BBC is a traditional classifier which only assigns a class tag to every NE candidate, it cannot regress NE boundaries for locating possible NEs. Therefore, if a true NE is not enumerated in the testing data, it will be missed by the traditional classifier, which leads to greatly reduced recall. For example, in the ACE Chinese corpus, a sentence “中国要把广西发展为连接西部地区和东南亚的桥梁” (China wants to develop Guangxi into a bridge connecting the western region and Southeast Asia) contains five NEs: “中国” (China), “广西” (Guangxi), “西部地区” (the western region), “西部” (the western), “东南亚” (Southeast Asia), which correspond to five ground truth boxes: [0, 2, GPE]555In this triple, the parameters represent the start position, the length and the type of an NE in a sentence., [4, 2, GPE], [11, 4, LOC], [11, 2, LOC], and [16, 2, GPE]. In the BBC model, only “东南” can be enumerated and verified, which considerably worsens the performance.
In the BR model, suppose a true NE is missed in the region proposal process, if it is overlapped with one or more bounding boxes, the regression operation can refine their spatial locations in a sentence, which enables these boxes approaching the missing true NE. As in the previous example, in the BR model, “西部地区” cannot be enumerated in the testing data, but it is overlapped by at least two bounding boxes: [11, 3, ?] (“西部地”) and [11, 5, ?] (“西部地区和”), where “?” means that the class tag is unknown. Because their IoU values with the truth box [11, 4, LOC] is larger than 0.7 ( ). They contain semantic information about “西部地区”. The softmax layer outputs a high confidence score on “LOC”. More than anything, the offsets which are relevant to the truth box [11, 4, LOC] are learned, which enables the NE “西部地区” to be recognized correctly.
IV-B3 Evaluation in the Flattened Corpus
In this section, the OntoNotes 5.0 [32] and CoNLL 2003 English [35] corpora are employed to evaluate the performance of BR model to recognize NEs with flattened structure. The OntoNotes corpus is collected from a wide variety of sources, e.g., magazine, telephone conversation, newswire, etc. It contains 76,714 sentences and annotated with 18 entity types. The CoNLL corpus consists of 22,137 sentences collected from Reuters newswire articles. It is split into 14,987, 3,466 and 3,684 sentences for training, developing and testing.
The BR model is compared with several SOTA models conducted on the OntoNotes and CoNLL corpora. Ma et al. [29] is a BiLSTM-CNNs-CRF model, which automatically encodes semantic features from words and characters. Ghaddar et al. [12] is also a BiLSTM-CRF model learning lexical features from word and entity type representations. Devlin et al. [5] is the BERT framework, which is effective to learn semantic features from external resources. Li et al. [24] is a model based on machine reading comprehension. Yu et al. [49] uses a biaffine model to encode dependency trees of sentences. Luo et al. [28] is also a BiLSTM model based on hierarchical contextualized representations. The result is shown in Table VII.
| OntoNotes | CoNLL | |||||
| Architecture | P(%) | R(%) | F(%) | P(%) | R(%) | F(%) |
| BiLSTM [29] | 86.04 | 86.53 | 86.28 | - | - | 91.03 |
| BiLSTM [12] | - | - | 87.95 | - | - | 91.37 |
| BERT [5] | 90.01 | 88.35 | 89.16 | - | - | 92.8 |
| MRC [24] | 92.98 | 89.95 | 91.11 | 92.33 | 94.61 | 93.04 |
| Biaffine [49] | 91.1 | 91.5 | 91.3 | 93.7 | 93.3 | 93.5 |
| BiLSTM [28] | - | - | 90.37 | - | - | 93.37 |
| BR | 89.36 | 89.87 | 89.61 | 91.32 | 92.99 | 92.15 |
| BR | 90.94 | 88.81 | 89.86 | 92.89 | 91.86 | 92.37 |
In Table VII, the compared models are all sequence models. There are three of them directly based on the BiLSTM network. Another tree models (the BERT, MRC and Biaffine) also applied BiLSTM as an inner structure for capturing semantic dependencies in a sentence. Because sequence models output a maximized labelling sequence for each input sentence, they are effective to encode syntactic and semantic structures in a sentence. Therefore, in flattened NE recognition, sequence models achieve the best performance.
Comparing the BR model with sequence models, the BR model can be seen as a span classification model, which applied a regression operation to refine spatial locations of NEs in a sentence. Because the classification is based on enumerated spans, due to the reason of the vanishing gradient problem, it is weak to encode long-distance semantic dependencies in a sentence for flattened NEs. Even so, as Table VII shows, the BR model also achieves competitive performance in flattened NE recognition.
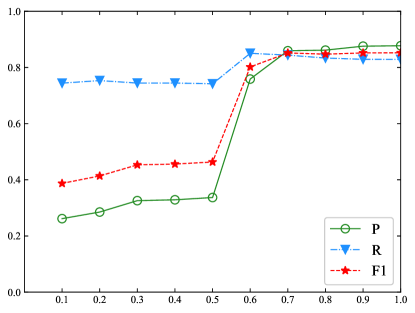
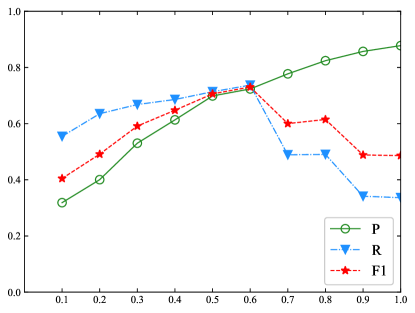
IV-C Influence of Model Parameters
Because the IoU value and the NMS algorithm are influential on the BR model, in this section, we conduct experiments to analyse the influences of IoU and NMS.
IV-C1 Influence of IoU
In Equation 2, a predefined parameter is adopted to divide the training data into positive bounding box set and negative bounding box set . Every bounding box in has a high overlapping ratio with a true bounding box. The overlap enables each bounding box to contain semantic features about a truth box, which are used to train the linear layer. This is the key to supporting boundary regression. As Equation 5 shows, the location loss is computed from , which aggregates all position offsets between each bounding box and its relevant ground truth bounding box. Therefore, the IoU value directly determine the number of bounding boxes used for computing the location loss.
This experiment is conduced to analyse the influence of IoU value on the final performance. Because cannot be used to collect positive bounding boxes, the value is initialized from 0.1 to 1.0 with step size 0.1. The result is shown in Figure 5.
In both the BR model and the BR model, if has a small value, contains many bounding boxes with small overlapping ratios relevant to a true NE. In these bounding boxes, there are insufficient semantic features with respect to a true NE. The regression operation cannot guarantee appropriately learning of the location offset, which worsens the performance. The result indicates that a bounding box far from any truth box is less helpful for boundary regression.
The BR model achieves high performance when is approximately 0.7. After , the output of the BR model exhibits stable performance. The reason for the phenomenon is that, when the value of is large enough, contains almost exclusively enumerated ground truth boxes. As Equation 5 reveals, the influence of regression is weakened. On the other hand, because the BR model verifies every NE candidate with length from 1 to 6, in this condition, the BR model is almost degenerated into a traditional classification model. Its performance is heavily dependent upon the output of the softmax layer.
In the BR model, the highest performance is achieved when is approximately 0.6. When the value of exceeds 0.6, the performance is considerably diminished. In the BR model, a large means that contains a smaller number of positive bounding boxes. Their boundaries are almost precisely matched with ground truth boxes. In particular, when , only contains grounding truth boxes. As Equation 5 shows, in the training process, the location loss is always zero. Therefore, the linear layer cannot be trained appropriately.
IV-C2 Influence of NMS
In the testing process, the BR model adopts an one-dimensional NMS algorithm to select true bounding boxes from the output (as Table II shows). The NMS algorithm is originally designed to support object detection in computer vision, where a rectangle is adopted to frame an object. One difference between object detection and entity recognition is that, when detecting an object, a rectangle is permitted to have mutual overlap with the reference object. On the other hand, recognizing an NE requires that both start and end boundaries of an NE should be precisely matched. In this experiment, we study the influence of NMS on the nested NE recognition. The result is shown in Figure 6.
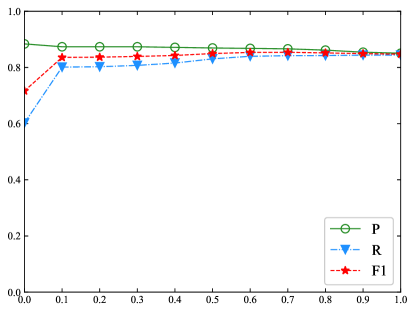
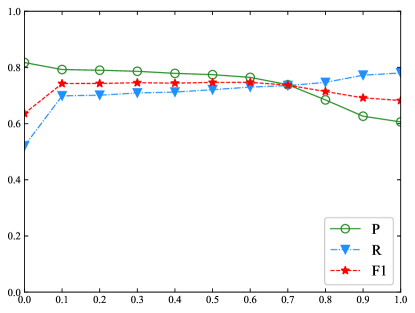
The results show that leads to the lowest recall because many bounding boxes are discarded. When , enlarging slowly improves the performance. Because bounding boxes belonging to a true NE are closely overlapped, if the is not large enough, enlarging exerts little influence on the performance. Therefore, a stable performance is achieved when takes value from 0.1 to 0.6. The BR models achieve the best performance around . Comparing the BR model with the BR model, the performance of the BR model is decreased when . The reason for this is that the BR exhaustively enumerates all NE candidates with length up to 6. The output contains a large number of bounding boxes which have precisely matched boundaries.
In the NE recognition task, identifying an NE heavily depends on its contextual features. Therefore, highly overlapped bounding boxes may refer to different true NEs, which will be discarded when . This problem can be avoided by setting . In the BR model, the performance of is the same as disabling the NMS algorithm. In this setting, only fully overlapped bounding boxes are considered and erased as redundant boxes. Because many bounding boxes are remained even they have high overlapping ratio, this setting has a higher recall. However, it worsens the precision. As shown in Figure 6(b), leads to a poor F1 score.
IV-D Time Complexity of Boundary Regression
In object detection of computer vision, compared with multistage pipeline models (e.g., R-CNN [14]), an end-to-end framework is hailed due to the superiority of high speed (e.g., Faster R-NN [34]). The reason for this is that the background of an image is learned in a single pass in the training process. It is shared by all proposed regions in an image.
To show the time complexity of boundary regression, in this experiment, we compare our model with those of Zheng et al. [52] and Wang et al. [46]. Zheng et al. [52] present a boundary-aware neural model which detects entity boundaries. Boundary-relevant regions are then utilized to predict entity categorical labels. The boundary detection and region prediction share the same bidirectional LSTM for feature extraction. Wang et al. [46] present a pyramid-shaped model stacked with neural layers. This model directly implements NE span prediction. Therefore, it has a higher speed.
In this experiment, we implement these models on the ACE English corpus with the same data split, settings and GPU platform. The times required to train these models are shown in Figure 7, where the height of the histograms represents the time cost in seconds.
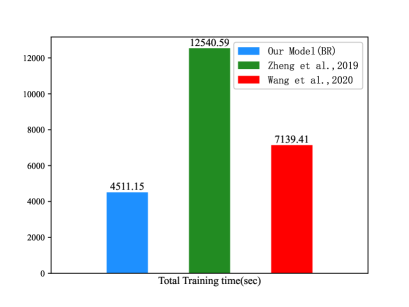
In comparison with them, boundary regression achieves the least time complexity. The BR model has two characteristics which support high speed recognition. First, feature maps are generated from a basic network. They are shared by all bounding boxes in a sentence. In fact, all bounding boxes are mutually overlapped. They are parts of feature maps, which considerably reduce model parameters. Second, every bounding box has location parameters. Therefore, in the learning process, the IoU value can be adopted to filter negative bounding boxes. This strategy is effective to reduce the time complexity.
IV-E Visualization of Boundary Regression
For a better understanding of boundary regression and investigating more details of the BR model, in the follows, we present a visualization about boundary regression.
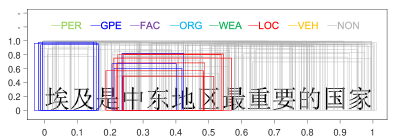
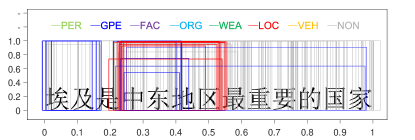
A sentence “埃及是中东地区最重要的国家”666It can be translated as: “Egypt is the most important country in the Middle East area”. is selected from the testing data. It contains four nested NEs: “埃及” (Egypt, GPE), “中东地区最重要的国家” (the most important country in the Middle East area, GPE), “中东地区” (the Middle East area, LOC), and “中东” (the Middle East, GPE). A bounding box is denoted by 3 parameters , and , which represent the starting position of the box, the length of the box and the class probability of the box, respectively. To visualize bounding boxes, a bounding box is drawn as a rectangle. The horizontal ordinate represents the boundary positions of the bounding boxes in a sentence, which are normalized to . The vertical coordinate represents the classification confidence score. The colours of the bounding box represent NE types. To generate bounding boxes, the selected sentence is predicted by a pre-trained BR model. All outputted bounding boxes are collected and drawn with respect to the sentence. The result is shown in Figure 8.
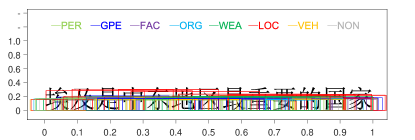
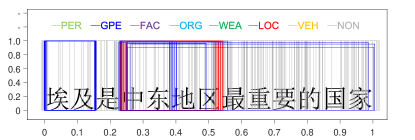
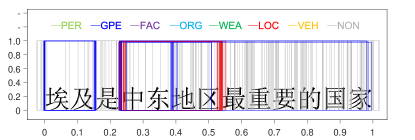
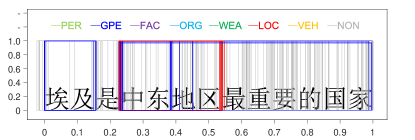
In Figure 8(a), bounding boxes were predicted by the BR model without training (0 iterations). From Figure 8(b) to Figure 8(f), the BR model is trained with different rounds (denoted in the titles of subfigures). Because the regression operation may output negative values for parameters and , we filter bounding boxes with or (beyond the sentence range).
In Figure 8(a), there is no tendency between bounding boxes. They are distributed evenly across the whole sentence and all NE types. In Figure 8(b), the BR model is implemented on the training data in only one round. One interesting phenomenon is that red bounding boxes and blue bounding boxes are grouped around NEs quickly. Furthermore, other true entity types are appropriately depressed. From Figure 8(c) to Figure 8(f), when the number of iterations is increased, there are two tendencies in bounding boxes. First, the BR model becomes more confident in the entity type prediction, which increases the classification confidence of the bounding boxes. Second, the locations of bounding boxes are approaching the true NEs. This indicates that the regression operation to locate NEs is feasible.
Overlapped bounding boxes are the key to solving the nested NE problem. Figure 8(f) shows that nested NEs are distinguished appropriately. We have tracked several bounding boxes and found that bounding boxes do not approach true NEs smoothly and directly. There are some oscillations between them. In the training process, a bounding box may match the true NE perfectly, while moving away in the next iteration. However, in accordance with the increase in the number of training steps, the oscillation tends toward stability.
V Related Work
Because the BR model is motivated by object detection from computer vision, in the following, we divide the related work into two parts: object detection and NE recognition.
Object detection is implemented in a multistage pipeline in the early stage. A typical object detection model is often composed of three stages: segmentation, feature extraction and classification. Segmentation is implemented to generate possible object locations for prediction. Generic algorithms (e.g., selective search) are often adopted to avoid exhaustive searching. Feature extraction is implemented to extract higher-order abstract features from raw input images. The output of this process is often denoted as feature maps. The feature extraction process can be encapsulated as a basic network truncated from a standard architecture for high-quality image classification, including the VGG-16 network [37], GoogLeNet [41], etc. Finally, an output layer (e.g., a linear SVM or a softmax layer) is used to predict confidence scores for each proposed region.
End-to-end object detection models can be optimized globally and share computation between inputs. These models are often similar in the feature extraction layer and output layer, where a basic network is adopted to generate conv feature maps, and two fully connected layers synchronously output class probabilities and object locations. The main difference is the strategy to generate the region proposal. For example, Faster R-NN adopts anchor boxes to generate region proposals per feature map [34]. Erhan et al. [7] use a single deep neural network to generate a small number of bounding boxes. Redomon et al. [33] divide an image into grids associated with a number of bounding boxes. Liu et al. [26] use a basic network that maps an image into multiple feature maps for generating default boxes with different aspect ratios and scales.
In the field of NE recognition, neural networks have also received great attention. Early models usually adopt a sequence model to output flattened NEs (e.g., LSTM, Bi-LSTM or Bi-LSTM-CNN). To handle the nesting problem, the sequence model is redesigned. It has three variants: the layering, cascading and joint models [1]. Parsing trees are also widely used to represent nested NEs in a tree structure [10]. For example, Finkel et al. [9] use internal and structural information of parsing trees to flatten nested NEs. Zhang et al. [51] adopted a transition-based parser. Jie et al. [17] tried to capture the global dependency of a parsing tree.
Recently, many models have been designed to recognize nested NEs directly. Lu et al. [27] resolve nested NEs into a hypergraph representation. Xu et al. [48] and Sohrab et al. [39] verify every possible fragment up to a certain length. Wang et al. [45] map a sentence with nested mentions to a designated forest. Ju et al. [18] proposed an iterative method that implements a sequence model in the output of a previous model. Lin et al. [25] propose a head-driven structure. Li et al. [22] combined outputs of a Bi-LSTM-CRF network with another Bi-LSTM network. Strakova et al. [40] proposed a sequence-to-sequence model. Zheng et al. [52] proposed an end-to-end boundary-aware neural model. In Chen et al. [4], a boundary assembling (BA) model is designed to recognize nested NEs. The BA model identifies NE boundaries, assembles them into NE candidates, and picks the most likely ones. For a broad understanding of the NER problem, the interested reader can refer to the survey paper [23] for deep neural network based NE recognition.
VI Conclusion and Future Work
In this paper, we proposed a boundary regression model for nested NE recognition. The BR model can be seen as a framework to support nested NE recognition. In Section III-B, we divide the BR model into two modules: “perceptional module” and “cognitive module”. In the perceptional module”, various deep architectures can be designed to extract high order abstract features from raw inputs. In cognitive module, instead of bounding boxes, abstract NE representations can be defined with other position and shape parameters. These issues are left as our future work. For enumerating NE candidates, new strategies can be designed to support region proposal. These issues are left as our future work. They are also open for researchers who are interested in this work.
VII Acknowledgment
This work is supported by the Joint Funds of the National Natural Science Foundation of China (Nos. 62166007, 62050194, and 62037001, 62066007, 62066008, 61721002), the National Natural Science Foundation of China under Grant No. U1836205, and the Key Projects of Science and Technology of Guizhou Province under Grant No. [2020]1Z055.
References
- [1] Beatrice Alex, Barry Haddow, and Claire Grover. Recognising nested named entities in biomedical text. In Proceedings of the BioNLP ’07, pages 65–72. ACL, 2007.
- [2] Yanping Chen, Ying Hu, Yijing Li, Ruizhang Huang, Yongbin Qin, Yuefei Wu, Qinghua Zheng, and Ping Chen. A boundary assembling method for nested biomedical named entity recognition. IEEE Access, 8:214141–214152, 2020.
- [3] Yanping Chen, Yuefei Wu, Yongbin Qin, Ying Hu, Zeyu Wang, Ruizhang Huang, Xinyu Cheng, and Ping Chen. Recognizing nested named entity based on the neural network boundary assembling model. IEEE IS, 2019.
- [4] Yanping Chen, Qinghua Zheng, and Ping Chen. A boundary assembling method for chinese entity-mention recognition. IEEE IS, 30(6):50–58, 2015.
- [5] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805, 2018.
- [6] George R Doddington, Alexis Mitchell, Mark A Przybocki, Lance A Ramshaw, Stephanie Strassel, and Ralph M Weischedel. The automatic content extraction (ace) program-tasks, data, and evaluation. In LREC, volume 2, pages 837–840, 2004.
- [7] Dumitru Erhan, Christian Szegedy, Alexander Toshev, and Dragomir Anguelov. Scalable object detection using deep neural networks. In Proceedings of the CVPR ’14, pages 2147–2154, 2014.
- [8] Mark Everingham, Luc Van Gool, Christopher KI Williams, John Winn, and Andrew Zisserman. The pascal visual object classes (voc) challenge. International journal of computer vision, 88(2):303–338, 2010.
- [9] Jenny Rose Finkel and Christopher D Manning. Joint parsing and named entity recognition. In Proceedings of the HLT-NAACL ’09, pages 326–334. ACL, 2009.
- [10] Jenny Rose Finkel and Christopher D Manning. Nested named entity recognition. In Proceedings of the EMNLP ’09, pages 141–150. ACL, 2009.
- [11] Joseph Fisher and Andreas Vlachos. Merge and label: A novel neural network architecture for nested ner. arXiv preprint arXiv:1907.00464, 2019.
- [12] Abbas Ghaddar and Philippe Langlais. Robust lexical features for improved neural network named-entity recognition. arXiv preprint arXiv:1806.03489, 2018.
- [13] Ross Girshick. Fast r-cnn. In Proceedings of the ICCV ’15, pages 1440–1448, 2015.
- [14] Ross Girshick, Jeff Donahue, Trevor Darrell, and Jitendra Malik. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the CVPR ‘14, pages 580–587, 2014.
- [15] Sepp Hochreiter and Jürgen Schmidhuber. Long short-term memory. Neural computation, 9(8):1735–1780, 1997.
- [16] Zhiheng Huang, Wei Xu, and Kai Yu. Bidirectional lstm-crf models for sequence tagging. arXiv preprint arXiv:1508.01991, 2015.
- [17] Zhanming Jie, Aldrian Obaja Muis, and Wei Lu. Efficient dependency-guided named entity recognition. In Proceedings of the AAAI ’17, pages 3457–3465, 2017.
- [18] Meizh Ju, Makoto Miwa, and Sophia Ananiadou. A neural layered model for nested named entity recognition. In Proceedings of the NAACL-HLT ’19, pages 1446–1459, 2018.
- [19] Arzoo Katiyar and Claire Cardie. Nested named entity recognition revisited. In Proceedings of the NAACL-HLT ’18, pages 861–871, 2018.
- [20] J-D Kim, Tomoko Ohta, Yuka Tateisi, and Jun’ichi Tsujii. Genia corpus—a semantically annotated corpus for bio-textmining. In Bioinformatics, pages 180–182, 2003.
- [21] Yoon Kim. Convolutional neural networks for sentence classification. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 1746–1751, 2014.
- [22] Fei Li, Meishan Zhang, Bo Tian, Bo Chen, Guohong Fu, and Donghong Ji. Recognizing irregular entities in biomedical text via deep neural networks. Pattern Recognition Letters, 2017.
- [23] Jing Li, Aixin Sun, Jianglei Han, and Chenliang Li. A survey on deep learning for named entity recognition. IEEE Transactions on Knowledge and Data Engineering, 2020.
- [24] Xiaoya Li, Jingrong Feng, Yuxian Meng, Qinghong Han, Fei Wu, and Jiwei Li. A unified mrc framework for named entity recognition. In Proceedings of the ACL ‘20, pages 5849–5858, 2020.
- [25] Hongyu Lin, Yaojie Lu, Xianpei Han, and Le Sun. Sequence-to-nuggets: Nested entity mention detection via anchor-region networks. In Proceedings of the ACL ’19, page 5182—5192, 2019.
- [26] Wei Liu, Dragomir Anguelov, Dumitru Erhan, Christian Szegedy, Scott Reed, Cheng-Yang Fu, and Alexander C Berg. Ssd: Single shot multibox detector. In Proceedings of the ECCV ’16, pages 21–37. Springer, 2016.
- [27] Wei Lu and Dan Roth. Joint mention extraction and classification with mention hypergraphs. In Proceedings of the EMNLP ’15, pages 857–867, 2015.
- [28] Ying Luo, Fengshun Xiao, and Hai Zhao. Hierarchical contextualized representation for named entity recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 34, pages 8441–8448, 2020.
- [29] Xuezhe Ma and Eduard Hovy. End-to-end sequence labeling via bi-directional lstm-cnns-crf. arXiv preprint arXiv:1603.01354, 2016.
- [30] Andrew McCallum and Wei Li. Early results for named entity recognition with conditional random fields, feature induction and web-enhanced lexicons. In Proceedings of the HLT-NAAC ’03, pages 188–191. ACL, 2003.
- [31] Tomoko Ohta, Yuka Tateisi, and Jin-Dong Kim. The genia corpus: An annotated research abstract corpus in molecular biology domain. In Proceedings of the HLT ’02, pages 82–86. Morgan Kaufmann Publishers Inc., 2002.
- [32] Sameer Pradhan, Alessandro Moschitti, Nianwen Xue, Hwee Tou Ng, Anders Björkelund, Olga Uryupina, Yuchen Zhang, and Zhi Zhong. Towards robust linguistic analysis using ontonotes. In Proceedings of the CoNLL ’13, pages 143–152, 2013.
- [33] Joseph Redmon, Santosh Divvala, Ross Girshick, and Ali Farhadi. You only look once: Unified, real-time object detection. In Proceedings of the CVPR ’16, pages 779–788, 2016.
- [34] Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun. Faster r-cnn: Towards real-time object detection with region proposal networks. In roceedings of the NIPS ’15, pages 91–99, 2015.
- [35] Erik F Sang and Fien De Meulder. Introduction to the conll-2003 shared task: Language-independent named entity recognition. Proceedings of the CoNLL ’03, 2003.
- [36] Takashi Shibuya and Eduard Hovy. Nested named entity recognition via second-best sequence learning and decoding. arXiv preprint arXiv:1909.02250, 2019.
- [37] Karen Simonyan and Andrew Zisserman. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556, 2014.
- [38] Josef Sivic and Andrew Zisserman. Video google: A text retrieval approach to object matching in videos. In null, page 1470. IEEE, 2003.
- [39] Mohammad Golam Sohrab and Makoto Miwa. Deep exhaustive model for nested named entity recognition. In Proceedings of the EMNLP ’18, pages 2843–2849, 2018.
- [40] Jana Straková, Milan Straka, and Jan Hajič. Neural architectures for nested ner through linearization. arXiv preprint arXiv:1908.06926, 2019.
- [41] Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, and Andrew Rabinovich. Going deeper with convolutions. In Proceedings of the CVPR ’15, pages 1–9, 2015.
- [42] Chuanqi Tan, Wei Qiu, Mosha Chen, Rui Wang, and Fei Huang. Boundary enhanced neural span classification for nested named entity recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 34, pages 9016–9023, 2020.
- [43] Jasper RR Uijlings, Koen EA Van De Sande, Theo Gevers, and Arnold WM Smeulders. Selective search for object recognition. International journal of computer vision, 104(2):154–171, 2013.
- [44] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. In Advances in neural information processing systems, pages 5998–6008, 2017.
- [45] Bailin Wang, Wei Lu, Yu Wang, and Hongxia Jin. A neural transition-based model for nested mention recognition. arXiv preprint arXiv:1810.01808, 2018.
- [46] Jue Wang, Lidan Shou, Ke Chen, and Gang Chen. Pyramid: A layered model for nested named entity recognition. In Proceedings of the ACL ‘20, pages 5918–5928, 2020.
- [47] Congying Xia, Chenwei Zhang, Tao Yang, Yaliang Li, Nan Du, Xian Wu, Wei Fan, Fenglong Ma, and Philip Yu. Multi-grained named entity recognition. arXiv preprint arXiv:1906.08449, 2019.
- [48] Mingbin Xu and Hui Jiang. A fofe-based local detection approach for named entity recognition and mention detection. arXiv preprint arXiv:1611.00801, 2016.
- [49] Juntao Yu, Bernd Bohnet, and Massimo Poesio. Named entity recognition as dependency parsing. arXiv preprint arXiv:2005.07150, 2020.
- [50] Chao Zhang, Zichao Yang, Xiaodong He, and Li Deng. Multimodal intelligence: Representation learning, information fusion, and applications. arXiv preprint arXiv:1911.03977, 2019.
- [51] Xiantao Zhang, Dongchen Li, and Xihong Wu. Parsing named entity as syntactic structure. In Proceedings of the ISCA ’14, 2014.
- [52] Changmeng Zheng, Yi Cai, Jingyun Xu, Ho-fung Leung, and Guandong Xu. A boundary-aware neural model for nested named entity recognition. In Proceedings of the EMNLP-IJCNLP ’19, pages 357–366, 2019.