A cheap data assimilation approach for expensive numerical simulations
Abstract
Using a very cheap Data Assimilation (DA) method, I show an alternative approach to classical DA for numerical climate models which produce a large amount of “big data”. The problematic features of state-of-the-art high resolution Regional Climate Models are highlighted. One of the shortcomings is the sensitivity of such models to the slightly different initial and boundary conditions which could be corrected by assimilating scattered observational data. This method might help to reduce the bias of numerical models based on available observations within the model domain, especially for the time-averaged observations and the long-term simulations.
Keywords: Data Assimilation, statistical models, bias correction, data-model comparison, Optimal Interpolation, Big Data
1 Introduction
The concerns about the climate change require deeper learning about the uncertainties in future predictions of climate system. However, our cutting-age science appears helpless to describe processes which take place beyond the yearly cycle of the climate system. The main question in this regard will be why there is an urgent need for such studies? It is now well known that many of long-term processes (millennial scale) in the climate system may have a large impact on predicting the climate even in shorter time scales (decadal, yearly scales) (Evans et al., 2013; Acevedo, 2015; Fallah, 2015; Acevedo et al., 2016; Latif et al., 2016). According to Lovejoy et al. (2016), the atmosphere shows an extremely changing behaviour “more than 20 orders of magnitude in time and 10 in space: billions of years to milliseconds and tens of thousands of kilometers to millimeters”. There exist several challenging open questions in the field of future climatic change: How variable is the future climate?, What is the probability of
extreme future climate changes?, How would this impact the sea level rise?
1.1 Challenges in long-term climate investigations
Available observational climate data sets are the most accurate source of knowledge about the climate system. However they suffer from ill structural conditions: (i) time span of these data sets are usually less than a century, (ii) they change their accuracy in time (environmental changes in station location, usage of different measuring devices, urbanization), (iii) they change their density in time (more stations are available online in recent years), (iv) more numbers of stations over land than over oceans.
Climate proxy archives (tree ring, coral, sediment and glacial) are alternative, indirect climate observations which posses a recording characteristic (Acevedo, 2015; Jones & Mann, 2004). The best resolved features of climate recorded by proxies are of annual and seasonal cycles. However, the data recording process involved in such observations are very complex, encompassing physical, biological and chemical processes (Evans et al., 2013). Differentiating the climate and human impact on proxies is also a challenging work, for example, in terms of historical drought spells. The difficult challenge of inverting proxy records into climate information is traditionally done in the frame work of statistical modeling. However, multivariate linear regression techniques dominate this area (Acevedo, 2015). On the other hand, even using more sophisticated statistical models is problematic in a way that the overlapping time span between the instrumental records (weather station observations) and the proxy records are too short to train the statistical models. Climate model hindcast may serve as a modeling idea to study the long term climate variability. The climate models create dynamically consistent state of the climate using numerical methods. However, their reconstructed states are very sensible to the initial conditions and the forcing used in the model as well as parametrization schemes used for sub-grid scale processes (small processes which are not physically presented by model).
One of the novel and appealing approaches to reconstruct the past climate is Data Assimilation (DA) which blends the proxy records and the climate models (Evensen, 2003; Hughes et al., 2010; Brönnimann, 2011; Bhend et al., 2012; Hakim et al., 2013; Steiger et al., 2014; Matsikaris et al., 2015; Hakim et al., 2016).
1.2 Challenges of Data Assimilation in climate studies
For a review of DA techniques applied in climate studies (not the weather forecasting), I refer to the works of Acevedo et al. (2016); Steiger & Hakim (2015). Acevedo et al. (2016); Steiger & Hakim (2015); Steiger et al. (2014) showed that the climate models may not have forecasting skills longer than several years. This fact makes the usage of classical DA methods very limited. The models lose their skill shortly after initialization and will evolve freely till the next step where the observations (in form of proxies) are available.
Considering the implementation ramification of DA methods in climate systems, their extremely computational expenses and the short forecasting skill of the models, an alternative DA approach (“off-line” or “no-cycling”) was applied by several scholars (Acevedo et al., 2016; Steiger & Hakim, 2015; Chen et al., 2015; Steiger et al., 2014). To my knowledge, there exists no study which applies such strategies in high resolution Regional Climate Model (RCM) simulations for long term climate studies.
In this study, I will apply an Off-line DA (ODA) approach in a RCM simulation and test the performance of this method. I will present the problematic features of RCMs in simulating the climate and demonstrate the performance of very cheap statistical methods to correct the model’s bias by means of ODA.
2 Data and Methods
2.1 Regional Climate Model
The numerical RCM used in this study is the COSMO-CLM (CCLM) model version cosmo1311085.00clm8 (Asharaf et al., 2012). The horizontal resolution of the simulations is set to 0.44∘ 0.44∘. The full model set-up file is included in the supplementary materials. “The CCLM model is a non-hydrostatic RCM which uses terrain following height coordinates (Rockel et al., 2008), developed from the COSMO model, the current weather forecast model used by the German weather service (DWD)”(Fallah et al., 2016). In order to investigate the sensitivity of RCM to the initial conditions, two sets of simulations are conducted:
-
•
Default (NATURE) simulation: 6 years long simulation over Europe driven by global atmospheric reanalysis data (6 hourly) produced by the European Centre for Medium-Range Weather Forecasts (ECMWF), the so-called ERAInterim (Dee et al., 2011) (initial and boundary conditions are taken from ERAInterim). This run will be used as the “Nature” or “True” state of the climate in the investigations.
-
•
Shifted domain simulation: the same as Default but shifted 4 grid points to the Northwest compared with the Default.
2.1.1 Model’s Skill Metric
The skill of the forecast (or prior) state of the Shifted simulation (without DA) can be measured, by the Root Mean Square Error (RMSE):
| (1) |
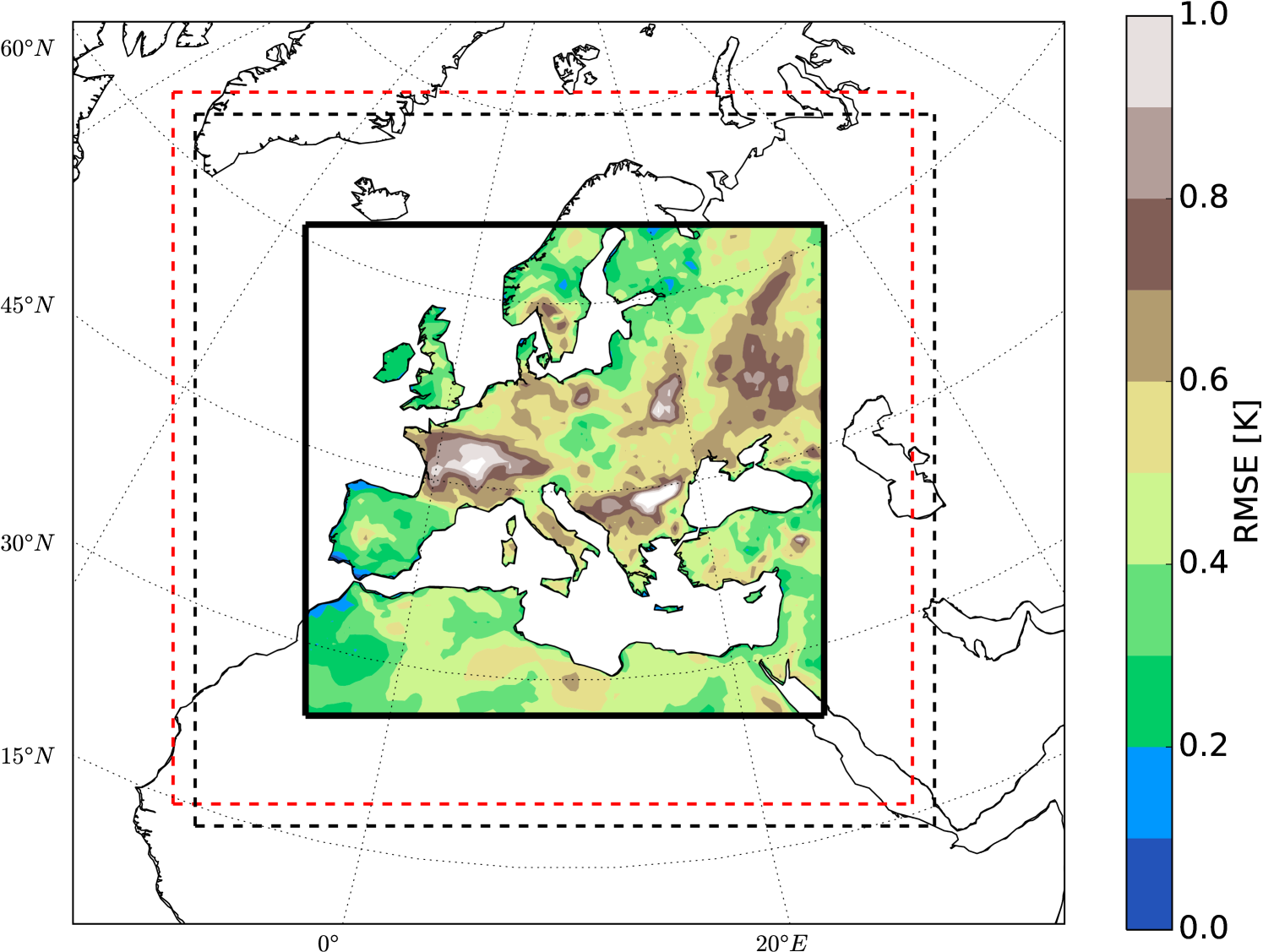
where denotes the time mean operator. Figure 1 shows the monthly near surface temperature (2 meter temperature) RMSE between the Nature and the Shifted simulations over the evaluation domain. For evaluation, the relaxation zone (the region where the boundary data is relaxed in the RCM, here 20 grid points next to the lateral boundaries) is removed. The last year of the simulations is used for validation and the first 5 years are considered as spin-up 111In climate modeling Spin-up is the time considered for any model to reach a quasi equilibrium state.. The 2 meter temperature (T2M) over oceans in CCLM model is interpolated from the driving Model (here ERAInterim) and not calculated by the model. Therefore the RMSEs over oceans are masked out from the analysis and only values over lands are shown.
2.2 Optimal Interpolation
Prior to describing the DA methodology, I give a brief review of the Optimal Interpolation (OI) method (for the full review see Gandin (1966); Barth et al. (2008)). OI or “objective analysis” or “kriging” is one of the most commonly used and fairly simple DA methods applied since 1970s. The unknown state of the climate is the vector which has to be estimated based on the available observations (). Given the state vector , the state on observations’ location is obtained by an interpolation method (here nearest neighbor). This operation is noted as matrix and the state at the observations’ location as . The ultimate goal is to find the nearest state to the “True” state of the climate () the so-called Analysis () given the observation () and background (first guess). The background and observation can be written as :
| (2) |
| (3) |
where and denote the observation and background errors, respectively.
2.2.1 Assumptions in OI method
In the applied OI scheme here, it is assumed that the background and observations are unbiased:
| (4) |
| (5) |
Other hypotheses are that the information about the observation and background errors are known (prior knowledge) and they are independent:
| (6) |
| (7) |
| (8) |
2.2.2 Analysis (posterior)
The OI scheme is considered as the Best Linear Unbiased Estimator (BLUE) of the . BLUE has the following characteristics:
-
1.
It is linear for and
-
2.
It is not biased:
(9) -
3.
It has the lowest error variance (optimal error variance).
The unbiased linear equation between and can be written as :
| (10) |
where K is the “Kalman gain” matrix. Equation 10 can be written as :
| (11) |
Thus the error covariance of the Analysis will be:
| (12) |
The trace of matrix indicates the error covariance of the analysis:
| (13) | |||
Given that the total error variance of Analysis has its minimum value, a small will not modify the total variance:
| (14) | |||
Given that the is arbitrary, the Kalman gain is :
| (15) |
Finally, the error covariance of the BLUE is given by:
| (16) | |||
In the scheme used here, is parametrized as following:
| (17) |
Where the is the error variance and the correlation length (or scanning radius). The number of influential observations which contribute to each grid point has also to be given as the input variable.
2.3 Observation System Simulation Experiment (OSSE)
Models contain systematic errors which may have diverse origins (dynamical core, parametrization, initialization). DA schemes are also based on simplified hypotheses and are imperfect (e.g., here the Gaussian parametrization for ). All these sources of errors may also interact with one another in a way that tracing the source of problem may be impossible. In recent studies (Acevedo, 2015; Acevedo et al., 2016) these error sources are neglected by using a simplified numerical experiment called OSSE.
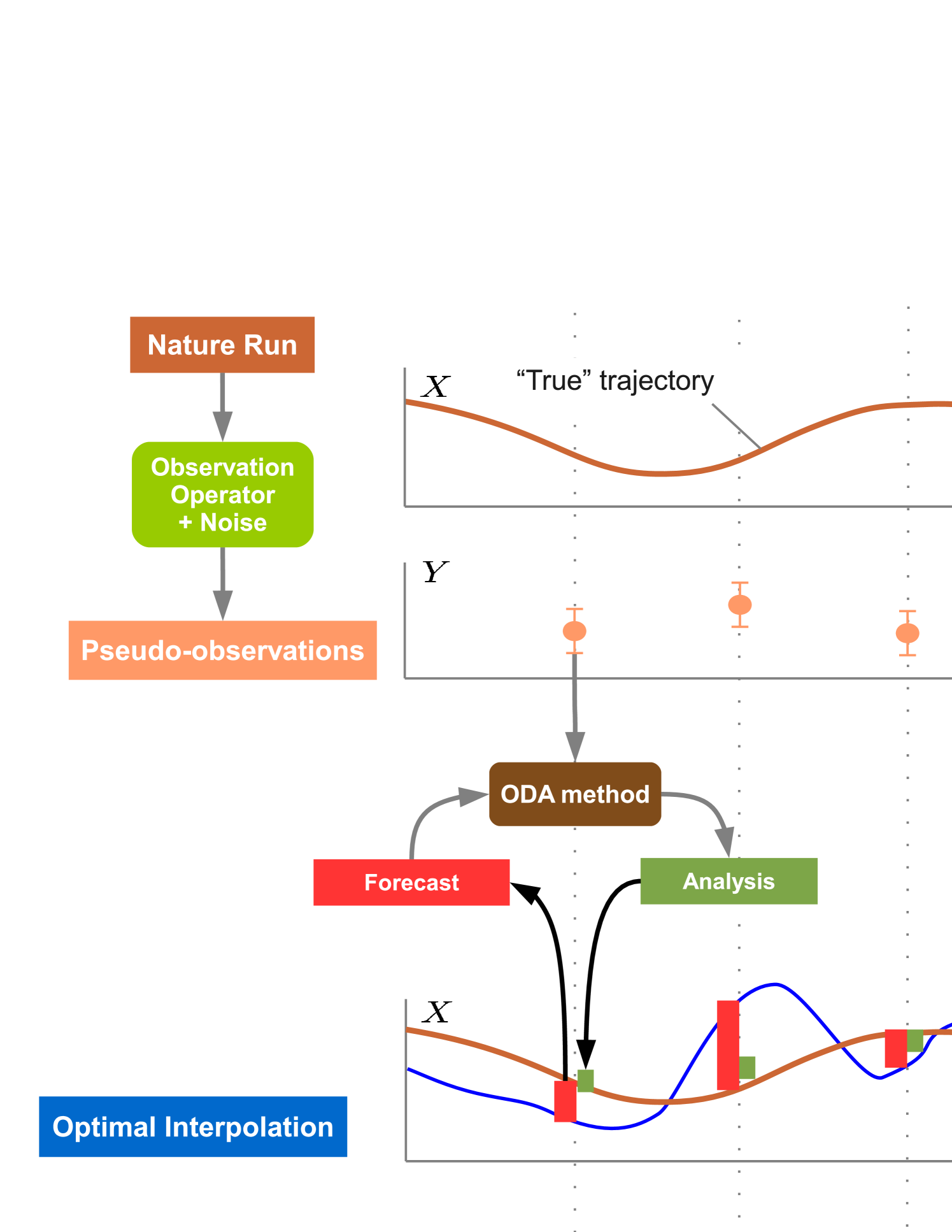
The OSSE used in this study is described by the schematic shown in Figure 2. First the NATURE model simulation (“true” run) is conducted as the final prediction target. Then using the output from NATURE run and adding random draws from a White Noise distribution (with and ), the pseudo-observations are created which are interpolated over the observations’ location. And finally, applying the OI scheme on the new forecast (Shifted) run, the observationally constrained run is obtained by assimilating the noisy observations.
3 Results
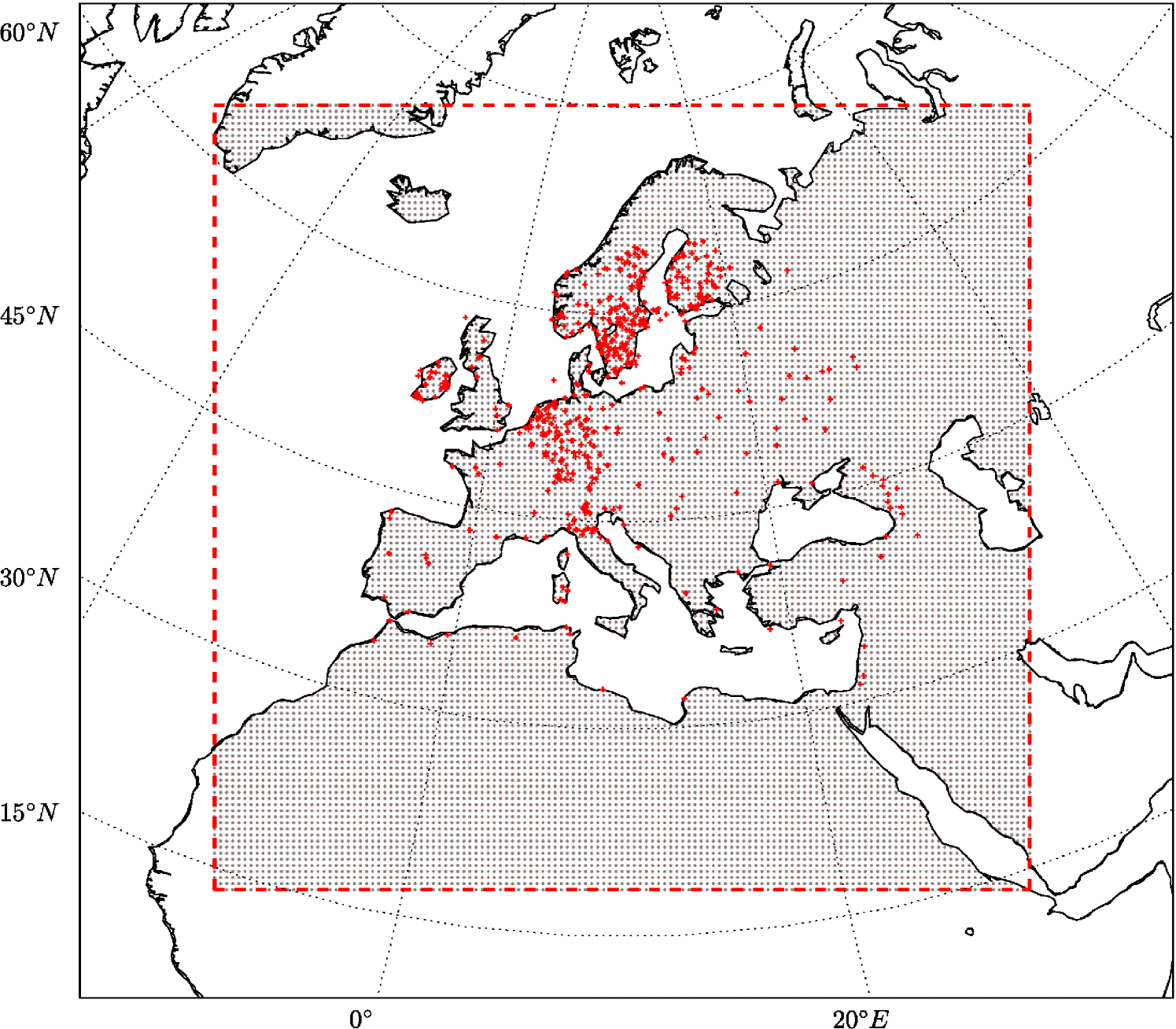
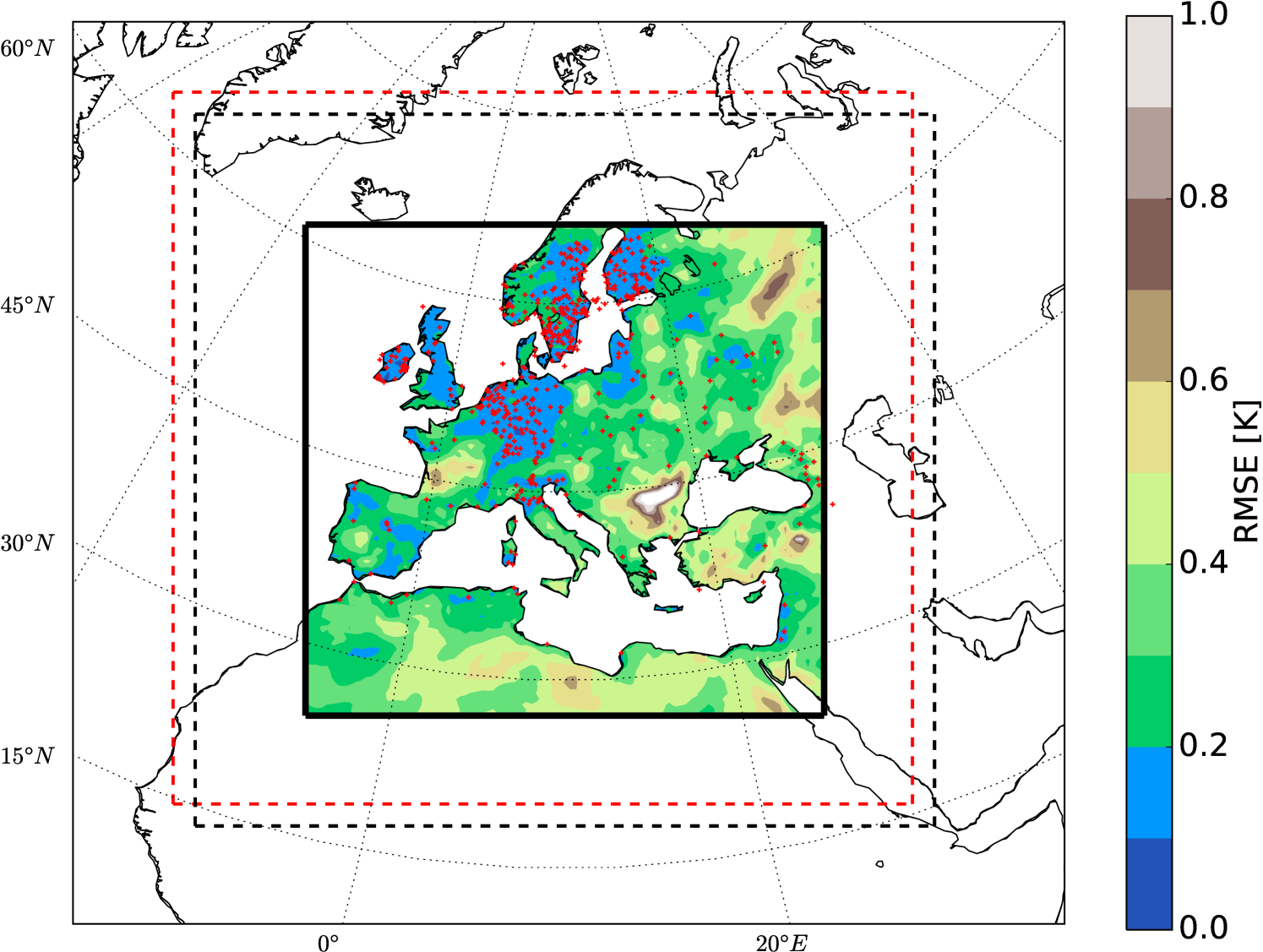
Comparing the two simulations exhibits that a slight change in the initial conditions of a RCM leads to large values (more than in monthly values) of internal variability in the model forecast (Fig.1). This feature has to be considered cautiously when conduction long-term climate simulations using RCMs, especially for the future climate projections. Here, I will show that the OI can significantly reduce the bias of the model forecast by assimilating the pseudo-observations. The product of the OI is called analysis, hereafter. Knowing the “True” state of the climate (NATURE run), the the error variance can be estimated. The location of 500 random meteorological stations of the “ENSEMBLES daily gridded observational dataset for precipitation, temperature and sea level pressure in Europe called E-OBS” (Haylock et al., 2008) are used in this study to create the pseudo-observation data (Fig.3).
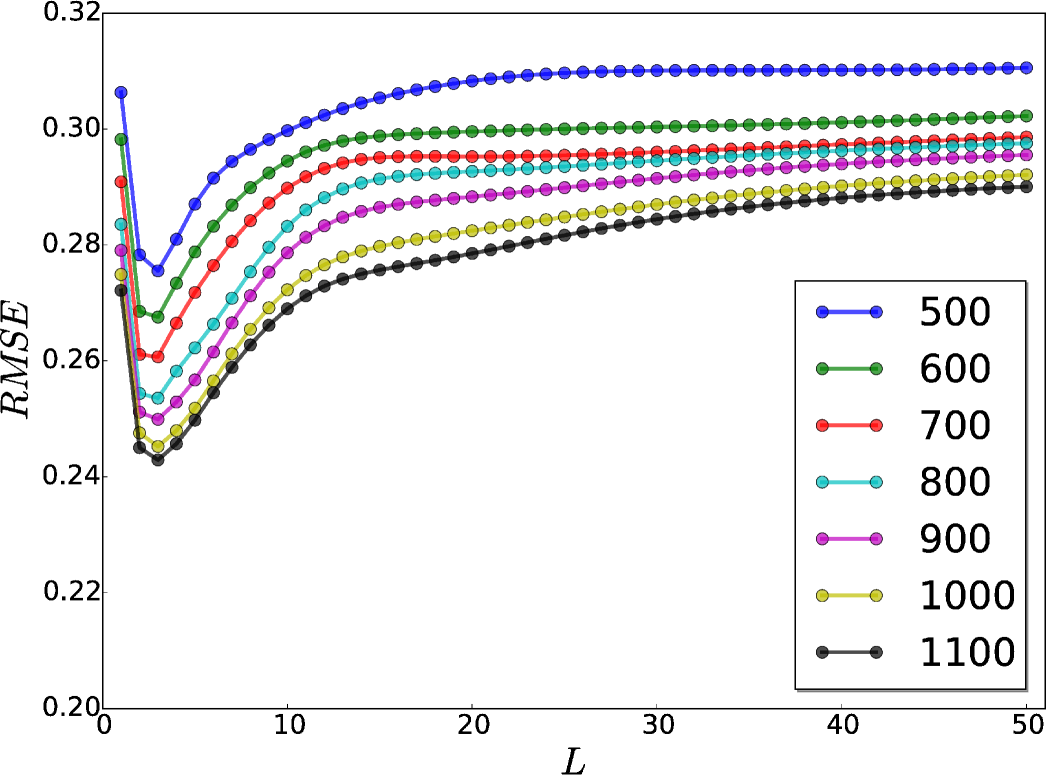
In order to find the optimal correlation length (), I have calculated the mean RMSE for the whole evaluation domain with several different correlation lengths () as well as with different number of observations (). Figure 4 shows that the more the number of assimilated observations the lower the RMSE values are. The RMSE values show a minimum at correlation length of 3 (3 150 ) independent to the number of observations. Therefore, for this study the correlation length of three have been chosen. For long-term time smoothing (here I used monthly averaged temperatures), e.g., yearly or decadal time-averaging, the correlation length will increase (Chen et al., 2015) accordingly.
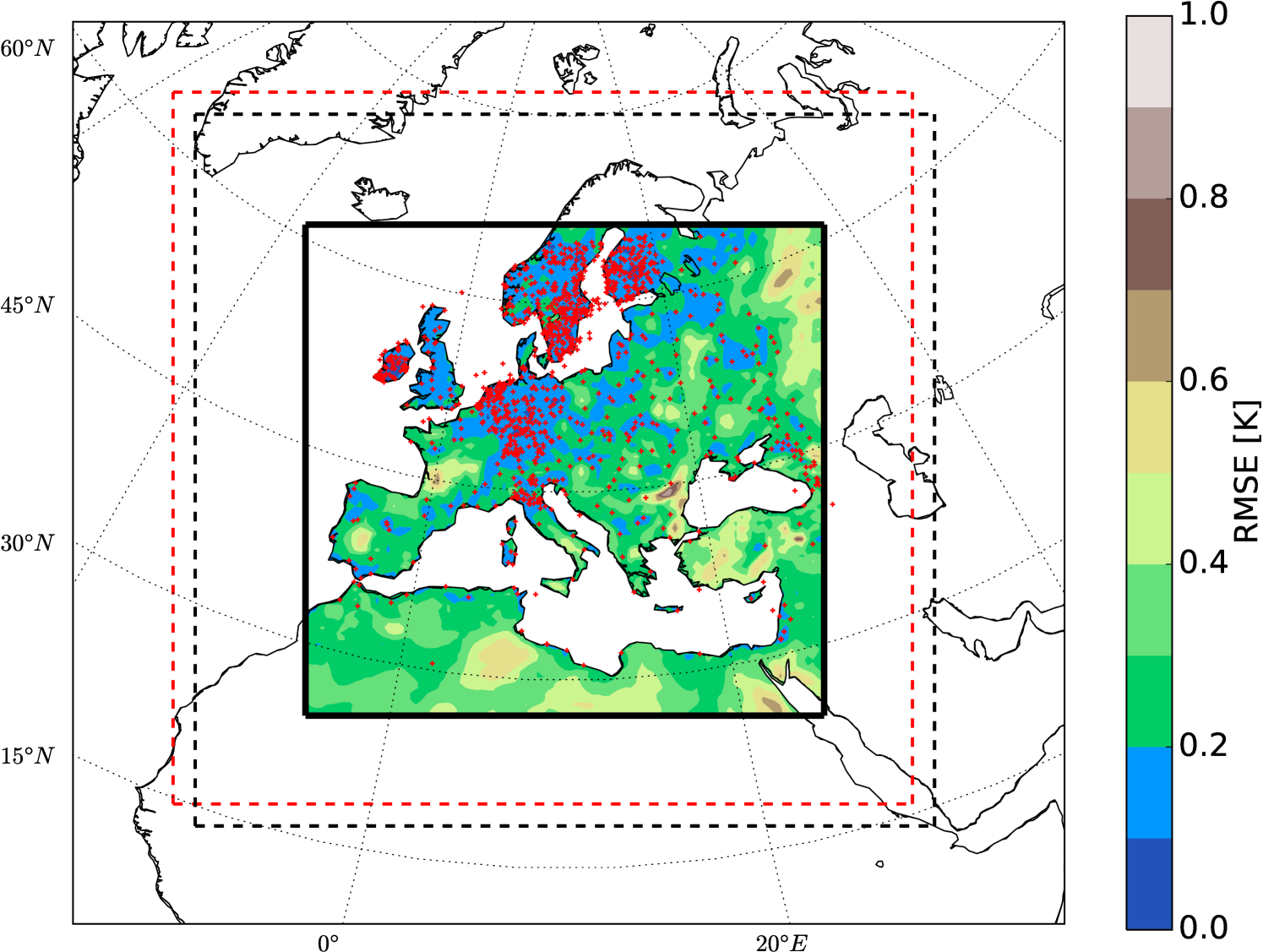
Figures 5 and 6 show the constrained simulations with 500 and 1100 pseudo-observations, respectively. The error reduction has maximum values around the observations’ locations. Comparing Figures 1 and 6, indicates that the OI method - despite its implementation easiness - can significantly reduce the systematic error of the model.
4 Conclusion
Using an OSEE, I conducted a simple numerical experiment to highlight the problematic features of RCMs in prediction of the near surface temperatures over Europe. By applying a fast and cheap DA method, I demonstrated that despite the easiness of OI, it can significantly reduce the bias of the regional model for monthly averaged values of near surface temperature. This method could potentially be applied for conducting long-term climate reanalysis data-sets with less complications than the classical DA methods. However, for a real application of this method, there exist several open questions: (i) is there enough proxy data available for the study region (for example less coverage over Central Asia)? (ii) how is the accuracy of the data in value and timing? (iii) with which data we shall drive the RCM (for initialization and boundary conditions)?
The simulations in this study are driven with ERAInterim which is produced by sophisticated methodologies combining available observations and models for the recent time (last 40 years). For the past climate simulations which go beyond the time-span of observations (i.e., for time spans greater than several centuries), the uncertainties in the model initialization and forcing (i.e., radiation, anthropogenic, volcanic) will increase significantly. Therefore, for such studies usage of ensemble simulation approach (different models, different initializations, different forcing) is of important interest and should be considered. However, by applying an ensemble of simulations the complexity and implementation of data analysis will increase exponentially. Such a cheap and fast method presented here, may pave the wave for handling these big data-sets in a way that the models’ bias are corrected by available observations.
SUPPLEMENTARY MATERIAL
- Title:
-
Open Access codes for analysis and plotting
- Open Source Codes:
-
All the applied codes in this research and the CCLM model set-up files are uploaded and hosted at https://github.com/bijanfallah/historical_runs along with a README file. The scientific codes are written in Python, BASH and GNU Octave under GNU GENERAL PUBLIC LICENSE. For any question or feedback please do not hesitate to contact me by email: info@bijan-fallah.com .
- Optimal Interpolation Code:
-
The optimal interpolation Fortran module with Octave interface of GeoHydrodynamics and Environment Research (GHER) is used. The code and the documentation can be obtained at their website:
(http://modb.oce.ulg.ac.be/mediawiki/index.php/Optimal_interpolation_Fortran_module_with_Octave_interface).
References
- (1)
- Acevedo (2015) Acevedo, W. (2015), Towards Paleoclimate Reanalysis via Ensemble Kalman Filtering, Proxy Forward Modeling and Fuzzy Logic, PhD thesis, Freie Universität Berlin.
-
Acevedo et al. (2016)
Acevedo, W., Fallah, B., Reich, S. & Cubasch, U. (2016), ‘Assimilation of pseudo-tree-ring-width observations
into an atmospheric general circulation model’, Clim. Past Discuss.
2016, 1–26.
http://www.clim-past-discuss.net/cp-2016-92/ -
Asharaf et al. (2012)
Asharaf, S., Dobler, A. & Ahrens, B. (2012), ‘Soil moisture-precipitation feedback processes in
the indian summer monsoon season’, J. Hydrometeor. 13(5), 1461–1474.
http://dx.doi.org/10.1175/JHM-D-12-06.1 - Barth et al. (2008) Barth, A., Azcárate, A. A., Joassin, P., Beckers, J.-M. & Troupin, C. (2008), Introduction to optimal interpolation and variational analysis, Technical report, GeoHydrodynamics and Environment Research.
-
Bhend et al. (2012)
Bhend, J., Franke, J., Folini, D., Wild, M. & Brönnimann, S.
(2012), ‘An ensemble-based approach to
climate reconstructions’, Clim. Past 8(3), 963–976.
http://www.clim-past.net/8/963/2012/ - Brönnimann (2011) Brönnimann, S. (2011), ‘Towards a paleoreanalysis?’, ProClim-Flash 1(51), 16.
-
Chen et al. (2015)
Chen, X., Xing, P., Luo, Y., Nie, S., Zhao, Z., Huang, J., Wang, S.
& Tian, Q. (2015), ‘Surface
temperature dataset for north america obtained by application of optimal
interpolation algorithm merging tree-ring chronologies and climate model
output’, Theoretical and Applied Climatology pp. 1–17–.
http://dx.doi.org/10.1007/s00704-015-1634-4 -
Dee et al. (2011)
Dee, D. P., Uppala, S. M., Simmons, A. J., Berrisford, P., Poli, P., Kobayashi,
S., Andrae, U., Balmaseda, M. A., Balsamo, G., Bauer, P., Bechtold, P.,
Beljaars, A. C. M., van de Berg, L., Bidlot, J., Bormann, N., Delsol, C.,
Dragani, R., Fuentes, M., Geer, A. J., Haimberger, L., Healy, S. B.,
Hersbach, H., Hólm, E. V., Isaksen, L., Kållberg, P., Köhler, M.,
Matricardi, M., McNally, A. P., Monge-Sanz, B. M., Morcrette, J.-J., Park,
B.-K., Peubey, C., de Rosnay, P., Tavolato, C., Thépaut, J.-N. & Vitart, F. (2011), ‘The era-interim
reanalysis: configuration and performance of the data assimilation system’,
Q.J.R. Meteorol. Soc. 137(656), 553–597.
http://dx.doi.org/10.1002/qj.828 -
Evans et al. (2013)
Evans, M., Tolwinski-Ward, S., Thompson, D. & Anchukaitis, K.
(2013), ‘Applications of proxy system
modeling in high resolution paleoclimatology’, Quaternary Science
Reviews 76(0), 16 – 28.
http://www.sciencedirect.com/science/article/pii/S0277379113002011 -
Evensen (2003)
Evensen, G. (2003), ‘The ensemble kalman
filter: theoretical formulation and practical implementation’, Ocean
Dynamics 53(4), 343–367.
http://dx.doi.org/10.1007/s10236-003-0036-9 - Fallah (2015) Fallah, B. (2015), Modelling the Asian Paleo-hydroclimatic Variability, PhD thesis, Freie Universität Berlin.
-
Fallah et al. (2016)
Fallah, B., Sodoudi, S. & Cubasch, U. (2016), ‘Westerly jet stream and past millennium climate
change in arid central asia simulated by cosmo-clm model’, Theoretical
and Applied Climatology 124(3), 1079–1088.
http://dx.doi.org/10.1007/s00704-015-1479-x - Gandin (1966) Gandin, L. (1966), ‘Objective analysis of meteorological fields’, Quarterly Journal of the Royal Meteorological Society 92(393).
- Hakim et al. (2013) Hakim, G., Annan, J., Broennimann, S., Crucifix, M., Edwards, T., Goosse, H., Paul, A., van der Schrier, G. & Widmann, M. (2013), ‘Overview of data assimilation methods’, PAGES 21(2).
-
Hakim et al. (2016)
Hakim, G. J., Emile-Geay, J., Steig, E. J., Noone, D., Anderson, D. M., Tardif,
R., Steiger, N. & Perkins, W. A. (2016), ‘The last millennium climate reanalysis project:
Framework and first results’, J. Geophys. Res. Atmos. 121(12), 6745–6764.
http://dx.doi.org/10.1002/2016JD024751 -
Haylock et al. (2008)
Haylock, M. R., Hofstra, N., Klein Tank, A. M. G., Klok, E. J., Jones, P. D.
& New, M. (2008), ‘A european
daily high-resolution gridded data set of surface temperature and
precipitation for 1950-2006’, J. Geophys. Res. 113(D20), n/a–n/a.
http://dx.doi.org/10.1029/2008JD010201 - Hughes et al. (2010) Hughes, M., Guiot, J. & Ammann, C. (2010), ‘An emerging paradigm: Process-based climate reconstructions’, PAGES news 18(2), 87–89.
-
Jones & Mann (2004)
Jones, P. D. & Mann, M. E. (2004),
‘Climate over past millennia’, Rev. Geophys. 42(2), RG2002.
http://dx.doi.org/10.1029/2003RG000143 -
Latif et al. (2016)
Latif, M., Claussen, M., Schulz, M. & Brücher, T., eds
(2016), Comprehensive Earth system
models of the last glacial cycle, Vol. 97, Eos.
https://eos.org/project-updates/comprehensive-earth-system-models-of-the-last-glacial-cycle -
Lovejoy et al. (2016)
Lovejoy, S., Crucifix, M. & Vernal, A. D., eds (2016), Characterizing Climate Fluctuations over
Wide-Scale Ranges, Vol. 97, Eos.
https://eos.org/meeting-reports/characterizing-climate-fluctuations-over-wide-scale-ranges -
Matsikaris et al. (2015)
Matsikaris, A., Widmann, M. & Jungclaus, J. (2015), ‘On-line and off-line data assimilation in
palaeoclimatology: a case study’, Clim. Past 11(1), 81–93.
http://www.clim-past.net/11/81/2015/ - Rockel et al. (2008) Rockel, B., Will, A. & Hense, A. (2008), ‘The regional climate model cosmo-clm(cclm)’, Meteorologische Zeitschrift 17(4), 347–348.
-
Steiger & Hakim (2015)
Steiger, N. & Hakim, G. (2015),
‘Multi-time scale data assimilation for atmosphere-ocean state estimates’,
Clim. Past Discuss. 11(4), 3729–3757.
http://www.clim-past-discuss.net/11/3729/2015/ -
Steiger et al. (2014)
Steiger, N., Hakim, G., Steig, E., Battisti, D. & Roe, G.
(2014), ‘Assimilation of time-averaged
pseudoproxies for climate reconstruction’, Journal of Climate 27(1), 426–441.
http://dx.doi.org/10.1175/2011JCLI4094.1