Gennaro Notomista
University of Waterloo
Waterloo, ON, Canada
11email: gennaro.notomista@uwaterloo.ca
A Constrained-Optimization Approach to the
Execution of Prioritized Stacks of
Learned Multi-Robot Tasks
Abstract
This paper presents a constrained-optimization formulation for the prioritized execution of learned robot tasks. The framework lends itself to the execution of tasks encoded by value functions, such as tasks learned using the reinforcement learning paradigm. The tasks are encoded as constraints of a convex optimization program by using control Lyapunov functions. Moreover, an additional constraint is enforced in order to specify relative priorities between the tasks. The proposed approach is showcased in simulation using a team of mobile robots executing coordinated multi-robot tasks.
keywords:
Multi-robot motion coordination, Distributed control and planning, Learning and adaptation in teams of robots1 Introduction
Learning complex robotic tasks can be challenging for several reasons. The nature of compound tasks, made up of several simpler subtasks, renders it difficult to simultaneously capture and combine all features of the subtasks to be learned. Another limiting factor of the learning process of compound tasks is the computational complexity of machine learning algorithms employed in the learning phase. This can make the training phase prohibitive, especially when the representation of the tasks comprises of a large number of parameters, as it is generally the case when dealing with complex tasks made up of several subtasks, or in the case of high-dimensional state space representations.
For these reasons, when there is an effective way of combining the execution of multiple subtasks, it is useful to break down complex tasks into building blocks that can be independently learned in a more efficient fashion. Besides the reduced computational complexity stemming from the simpler nature of the subtasks to be learned, this approach has the benefit of increasing the modularity of the task execution framework, by allowing for a reuse of the subtasks as building blocks for the execution of different complex tasks. Discussions and analyses of such advantages can be found, for instance, in [26, 9, 32, 16].
Along these lines, in [13], compositionality and incrementality are recognized to be two fundamental features of robot learning algorithms. Compositionality, in the context of learning to execute multiple tasks, is intended as the property of learning strategies to be in a form that allows them to be combined with previous knowledge. Incrementality, guarantees the possibility of adding new knowledge and abilities over time, by, for instance, incorporating new tasks. Several approaches have been proposed, which exhibit these two properties. Nevertheless, challenges still remain regarding tasks prioritization and stability guarantees [21, 25, 28, 34, 6]. The possibility of prioritizing tasks together with the stability guarantees allows us to characterize the behavior resulting from the composition of multiple tasks.
In fact, when dealing with redundant robotic systems—i.e. systems which possess more degrees of freedom compared to the minimum number required to execute a given task, as, for example, multi-robot systems—it is often useful to allow for the execution of multiple subtasks in a prioritized stack. Task priorities may allow robots to adapt to the different scenarios in which they are employed by exhibiting structurally different behaviors. Therefore, it is desirable that a multi-task execution framework allows for the prioritized execution of multiple tasks.
In this paper, we present a constrained-optimization robot-control framework suitable for the stable execution of multiple tasks in a prioritized fashion. This approach leverages the reinforcement learning (RL) paradigm in order to get an approximation of the value functions which will be used to encode the tasks as constraints of a convex quadratic program (QP). Owing to its convexity, the latter can be solved in polynomial time [3], and it is therefore suitable to be employed in a large variety of robotic applications, in online settings, even under real-time constraints. The proposed framework shares the optimization-based nature with the one proposed in [18] for redundant robotic manipulators, where, however, it is assumed that a representation for all tasks to be executed is known a priori. As will be discussed later in the paper, this framework indeed combines compositionality and incrementality—i.e. the abilities of combining and adding sub-tasks to build up compound tasks, respectively—with stable and prioritized task execution in a computationally efficient optimization-based algorithm.
Figure 1 pictorially shows the strategy adopted in this paper to allow robots to execute multiple prioritized tasks learned using the RL paradigm. Once a value function is learned using the RL paradigm (using, e.g., the value iteration algorithm [2]), this learned value function is used to construct a control Lyapunov function [30] in such a way that a controller synthesized using a min-norm optimization program is equivalent to the optimal policy corresponding to the value function [20]. Then, multiple tasks encoded by constraints in a min-norm controller are combined in a prioritized stack as in [17].
To summarize, the contributions of this paper are the following: (i) We present a compositional and incremental framework for the execution of multiple tasks encoded by value functions; (ii) We show how priorities among tasks can be enforced in a constrained-optimization-based formulation; (iii) We frame the prioritized multi-task execution as a convex QP which can be efficiently solved in online settings; (iv) We demonstrate how the proposed framework can be employed to control robot teams to execute coordinated tasks.
2 Background and Related Work
2.1 Multi-Task Learning, Composition, and Execution
The prioritized execution framework for learned tasks proposed in this paper can be related to approaches devised for multi-task learning—a machine learning paradigm which aims at leveraging useful information contained in multiple related tasks to help improve the generalization performance of all the tasks [35]. The learning of multiple tasks can happen in parallel (independently) or in sequence for naturally sequential tasks [10, 29], and a number of computational frameworks have been proposed to learn multiple tasks (see, e.g., [35, 14, 24], and references therein). It is worth noticing how, owing to its constrained-optimization nature, the approach proposed in this paper is dual to multi-objective optimization frameworks, such as [27, 5] or compared to the Riemannian motion policies [23, 15, 22].
Several works have focused on the composition and hierarchy of deep reinforcement learning policies. The seminal work [33] shows compositionality for a specific class of value functions. More general value functions are considered in [12], where, however, there are no guarantees on the policy resulting from the multi-task learning process. Boolean and weighted composition of reward, (Q-)value functions, or policies are considered in [11, 19, 34]. While these works have shown their effectiveness on complex systems and tasks, our proposed approach differs from them in two main aspects: (i) It separates the task learning from the task composition; (ii) It allows for (possibly time-varying and state-dependent) task prioritization, with task stacks that are enforced at runtime.
2.2 Constraint-Based Task Execution
In this paper, we adopt a constrained-optimization approach to the prioritized execution of multiple tasks learned using the RL paradigm. In [17], a constraint-based task execution framework is presented for a robotic system with control affine dynamics
| (1) |
where and denote state and control input, respectively. The tasks to be executed are encoded by continuously differentiable, positive definite cost functions . With the notation which will be adopted in this paper, the constraint-based task execution framework in [17] can be expressed as follows:
| (2) | ||||
where and are the Lie derivatives of along the vector fields and , respectively. The components of are used as slack variables employed to prioritize the different tasks; is a Lipschitz continuous extended class function—i.e. a continuous, monotonically increasing function, with — is an optimization parameter, and is the prioritization matrix, known a priori, which enforces relative constraints between components of of the following type: , for , which encodes the fact that task is executed at higher priority than task .
2.3 From Dynamic Programming to Constraint-Driven Control
To illustrate how controllers obtained using dynamic programming can be synthesized as the solution of an optimization program, consider a system with the following discrete-time dynamics:
| (3) |
These dynamics can be obtained, for instance, by (1), through a discretization process. In (3), denotes the state, the input, and the input set may depend in general on the time and the state . The value iteration algorithm to solve a deterministic dynamic programming problem with no terminal cost can be stated as follows [2]:
| (4) |
with , where is the initial state, and is the cost incurred at time . The total cost accumulated along the system trajectory is given by
| (5) |
In this paper, we will consider and we will assume there exists a cost-free termination state.111Problems of this class are referred to as shortest path problems in [2].
Adopting an approximation scheme in value space, can be replaced by its approximation by solving the following approximate dynamic programming algorithm:
In these settings, deep RL algorithms can be leveraged to find parametric approximations, , of the value function using neural networks. This will be the paradigm considered in this paper in order to approximate value functions encoding the tasks to be executed in a prioritized fashion.
The bridge between dynamic programming and constraint-driven control is optimal control. In fact, the cost in (5) is typically considered in optimal control problems, recalled, in the following, for the continuous time control affine system (1):
| (7) | ||||
Comparing (7) with (5), we recognize that the instantaneous cost in (5) in the context of the optimal control problem (7) corresponds to , where is a continuously differentiable and positive definite function.
A dynamic programming argument on (7) leads to the following Hamilton-Jacobi-Bellman equation:
where is the value function—similar to (6) for continuous-time problems—representing the minimum cost-to-go from state , defined as
| (8) |
The optimal policy corresponding to the optimal value function (8) can be evaluated as follows [4]:
| (9) |
In order to show how the optimal policy in (9) can be obtained using an optimization-based formulation, we now recall the concept of control Lyapunov functions.
Definition 2.1 (Control Lyapunov function [30]).
A continuously differentiable, positive definite function is a control Lyapunov function (CLF) for the system (1) if, for all
| (10) |
To select a control input which satisfies the inequality (10), a universal expression—known as the Sontag’s formula [31]—can be employed. With the aim of encoding the optimal control input by means of a CLF, we will consider the following modified Sontag’s formula originally proposed in [7]:
| (11) |
where .
As shown in [20], the modified Sontag’s formula (11) is equivalent to the solution of the optimal control problem (7) if the following relation between the CLF and the value function holds:
| (12) |
where . The relation in (12) corresponds to the fact that the level sets of the CLF and those of the value function are parallel.
The last step towards the constrained-optimization-based approach to generate optimal control policies is to recognize the fact that, owing to its inverse optimality property [7], the modified Sontag’s formula (11) can be obtained using the following constrained-optimization formulation, also known as the pointwise min-norm controller:
| (13) | ||||
where . This formulation shares the same optimization structure with the one introduced in (2) in Section 2, and in the next section we will provide a formulation which strengthens the connection with approximate dynamic programming.
In Appendix A, additional results are reported, which further illustrate the theoretical equivalence discussed in this section, by comparing the optimal controller, the optimization-based controller, and a policy learned using the RL framework for a simple dynamical system.
3 Prioritized Multi-Task Execution
When , the min-norm controller solution of (13) is the optimal policy which would be learned using a deep RL algorithm. This is what allows us to bridge the gap between constraint-driven control and RL and it is the key to execute tasks learned using the RL paradigm in a compositional, incremental, prioritized, and computationally-efficient fashion.
Following the formulation given in (2), the multi-task prioritized execution of tasks learned using RL can be implemented executing the control input solution of the following optimization program:
| (14) | ||||
where are the approximated value functions encoding the tasks learned using the RL paradigm (e.g. value iteration). In summary, with the RL paradigm, one can get the approximate value functions ; the robotic system is then controlled using the control input solution of (14) in order to execute these tasks in a prioritized fashion.
Remark 3.1.
The Lie derivatives contain the gradients . When are approximated using neural networks, these gradients can be efficiently computed using back propagation.
We conclude this section with the following Proposition 3.2, which ensures the stability of the prioritized execution of multiple tasks encoded through the value functions by a robotic system modeled by the dynamics (1) and controlled with control input solution of (14).
Proposition 3.2 (Stability of multiple prioritized learned tasks).
Consider executing a set of prioritized tasks encoded by approximate value functions , by solving the optimization problem in (14). Assume the following:
-
1.
All constraints in (14) are active
-
2.
The robotic system can be modeled by driftless control affine dynamical system, i.e.
-
3.
The instantaneous cost function used to learn the tasks is positive for all and .
Then,
as , where denotes the null space of the prioritization matrix . That is, the tasks will be executed according to the priorities specified by the prioritization matrix in (2).
Proof 3.3.
The Lagrangian associated with the optimization problem (14) is given by , where and defined as follows: the -th component of is equal to , while the -th row of is equal to . and are the Lagrange multipliers corresponding to the task and prioritization constraints, respectively.
From the KKT conditions, we obtain:
| (15) |
where . By resorting to the Lagrange dual problem, and by using assumption 1, we get the following expression for :
| (16) |
where denotes an identity matrix of appropriate size. Substituting (16) in (15), we get and .
To show the claimed stability property, we will proceed by a Lyapunov argument. Let us consider the Lyapunov function candidate , where . The time derivative of evaluates to:
where, notice that and . By assumption 2, for all , and therefore , i.e. is positive semidefinite. Then, , where
| (17) |
as in Proposition 3 in [17], and we used assumption 2 to simplify the expression of .
By assumption 3, it follows that the value functions are positive definite. Therefore, from the definition of , in a neighborhood of , we can bound —defined by the gradients of —by the value of as , where is a class function.
Then, proceeding similarly to Proposition 3 in [17], we can bound as follows: , where . Hence, as , and as .
Remark 3.4.
The proof of Proposition 3.2 can be carried out even in case of time-varying and state-dependent prioritization matrix . Under the assumption that is bounded and continuously differentiable for all and uniformly in time, the norm and the gradient of can be bounded in order to obtain an upper bound for .
Remark 3.5.
Even when the prioritization stack specified through the matrix in (14) is not physically realizable—due to the fact that, for instance, the functions encoding the tasks cannot achieve the relative values prescribed by the prioritization matrix—the optimization program will still be feasible. Nevertheless, the tasks will not be executed with the desired priorities and even the execution of high-priority tasks might be degraded.
4 Experimental Results
In this section, the proposed framework for the execution of prioritized stacks of tasks is showcased in simulation using a team of mobile robots. Owing to the multitude of robotic units of which they are comprised, multi-robot systems are often highly redundant with respect to the tasks they have to execute. Therefore, they perfectly lend themselves to the concurrent execution of multiple prioritized tasks.
4.1 Multi-Robot Tasks
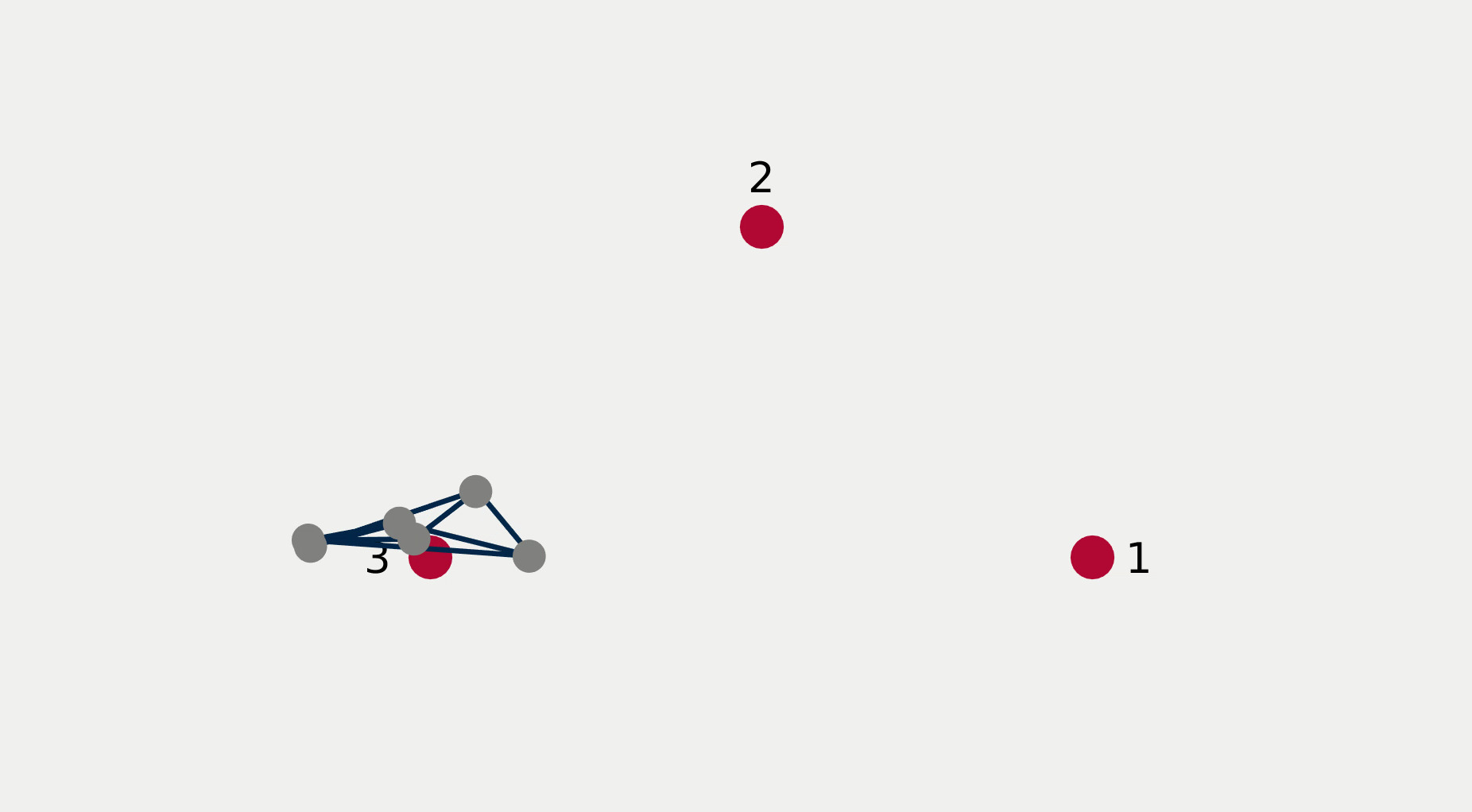
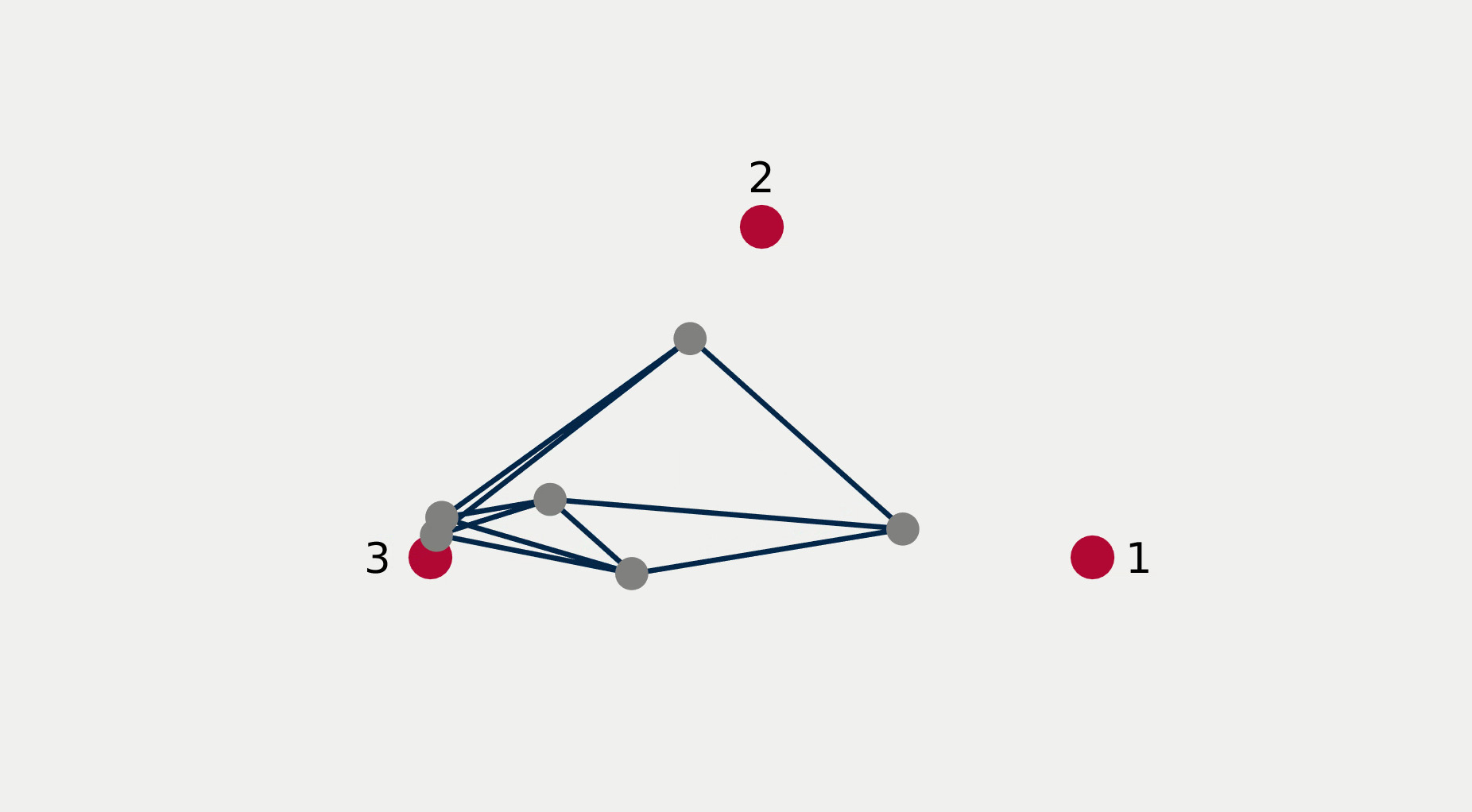
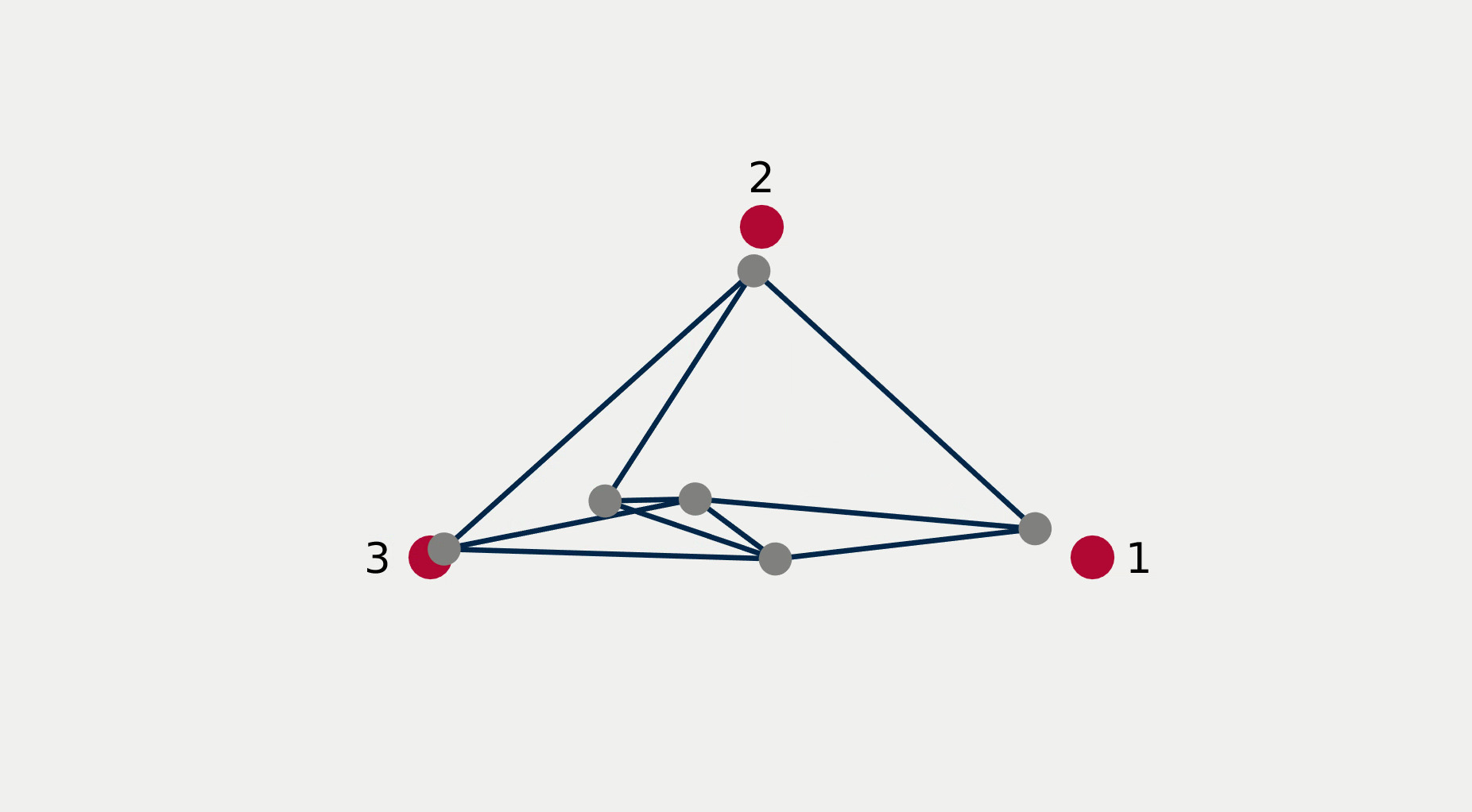
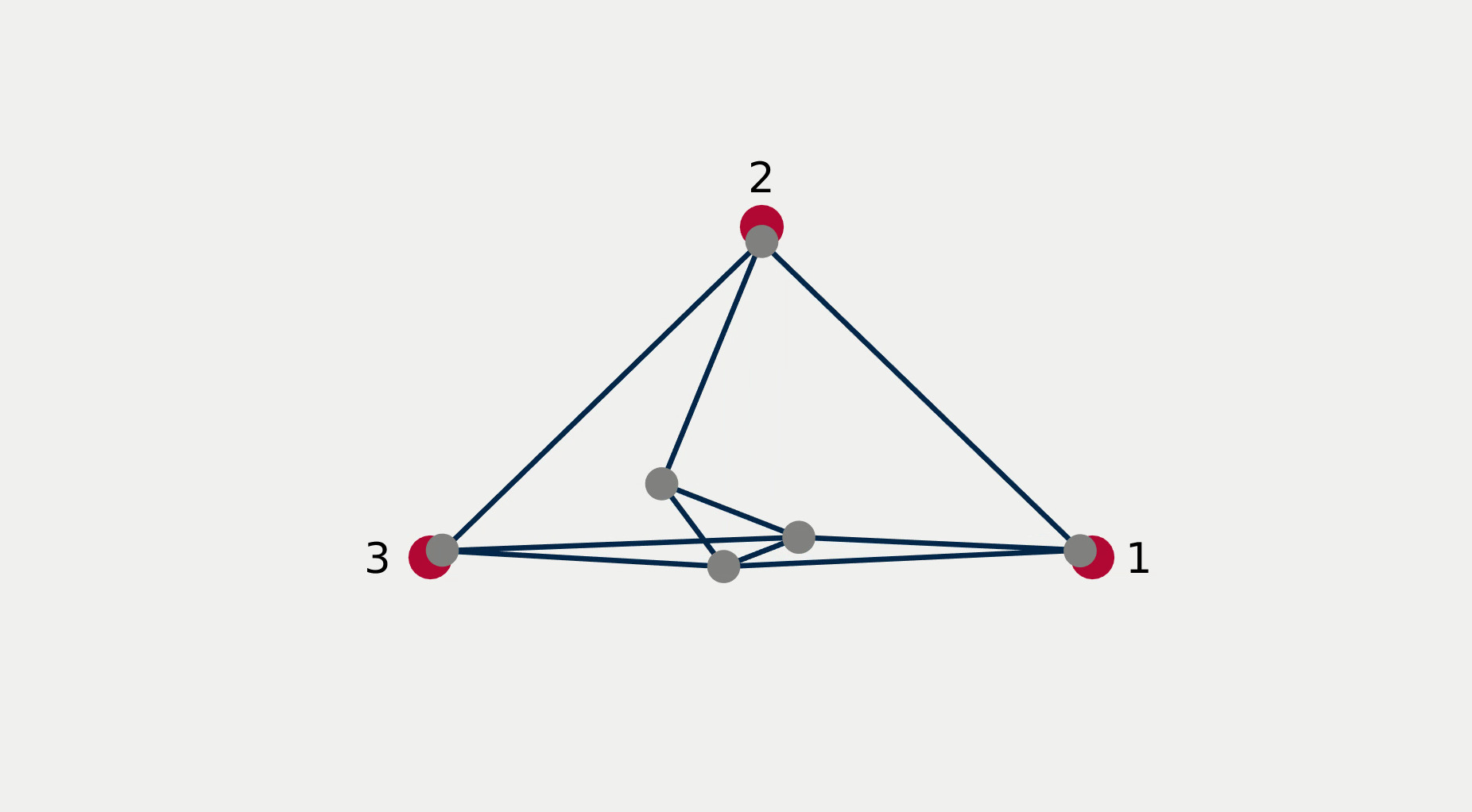
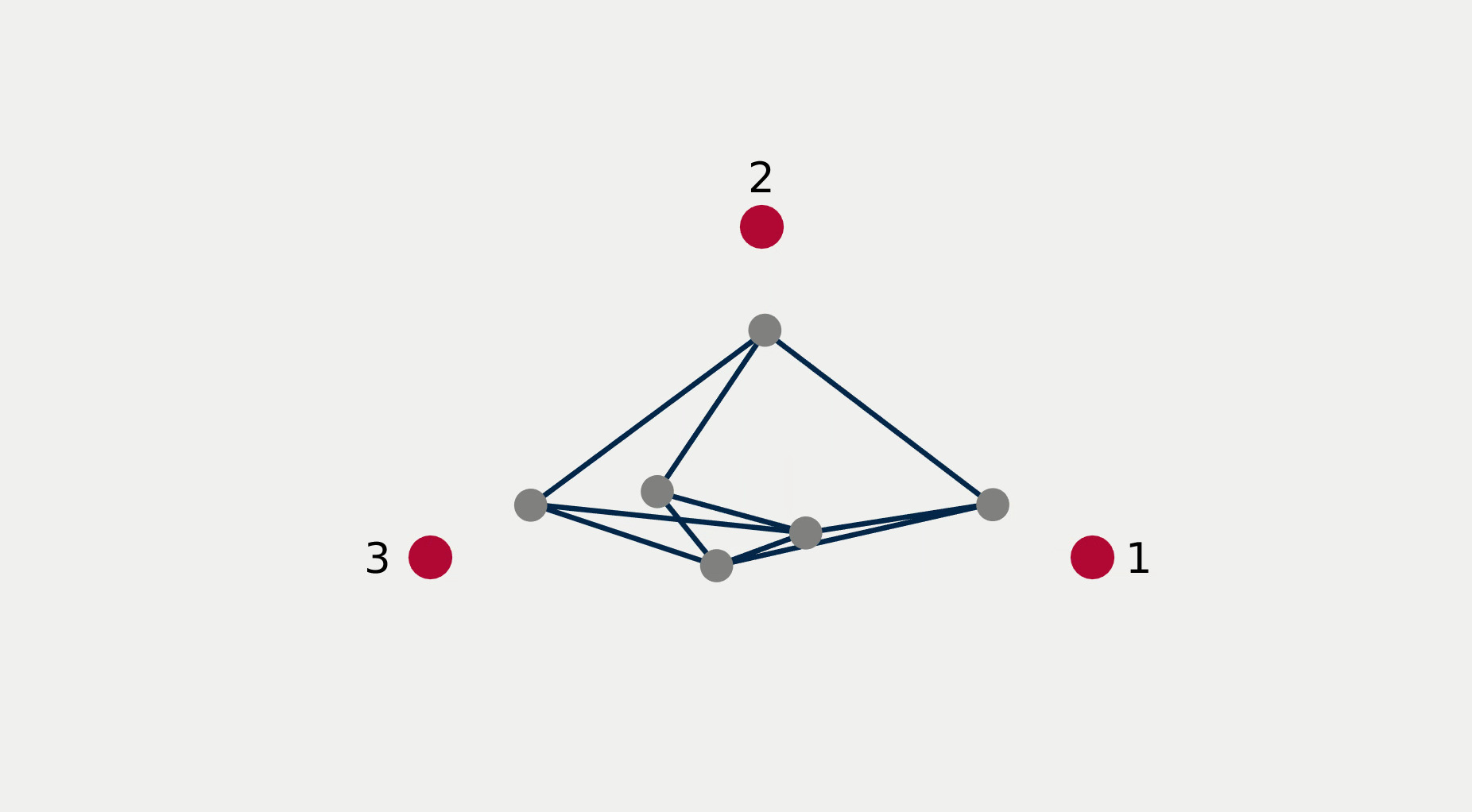
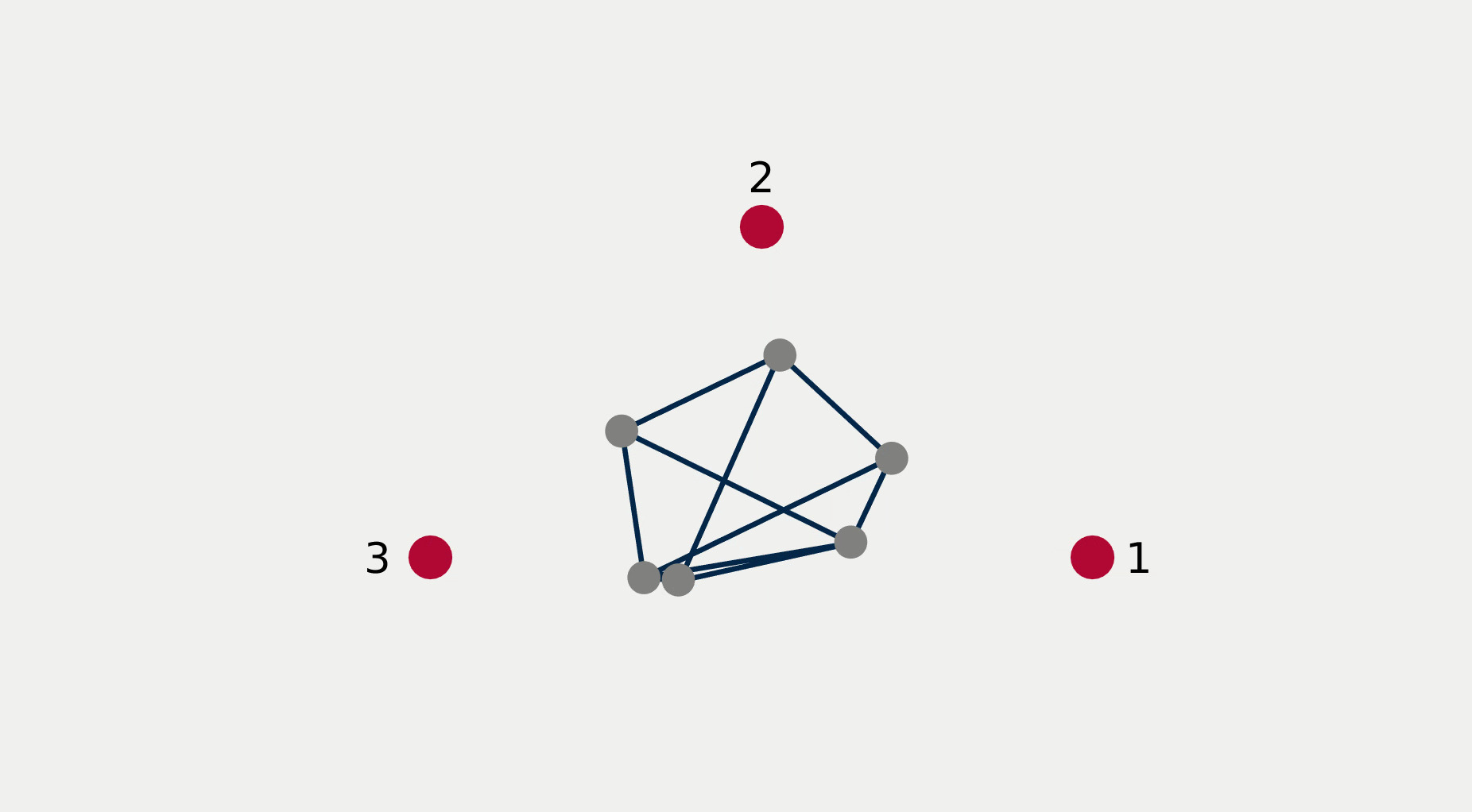
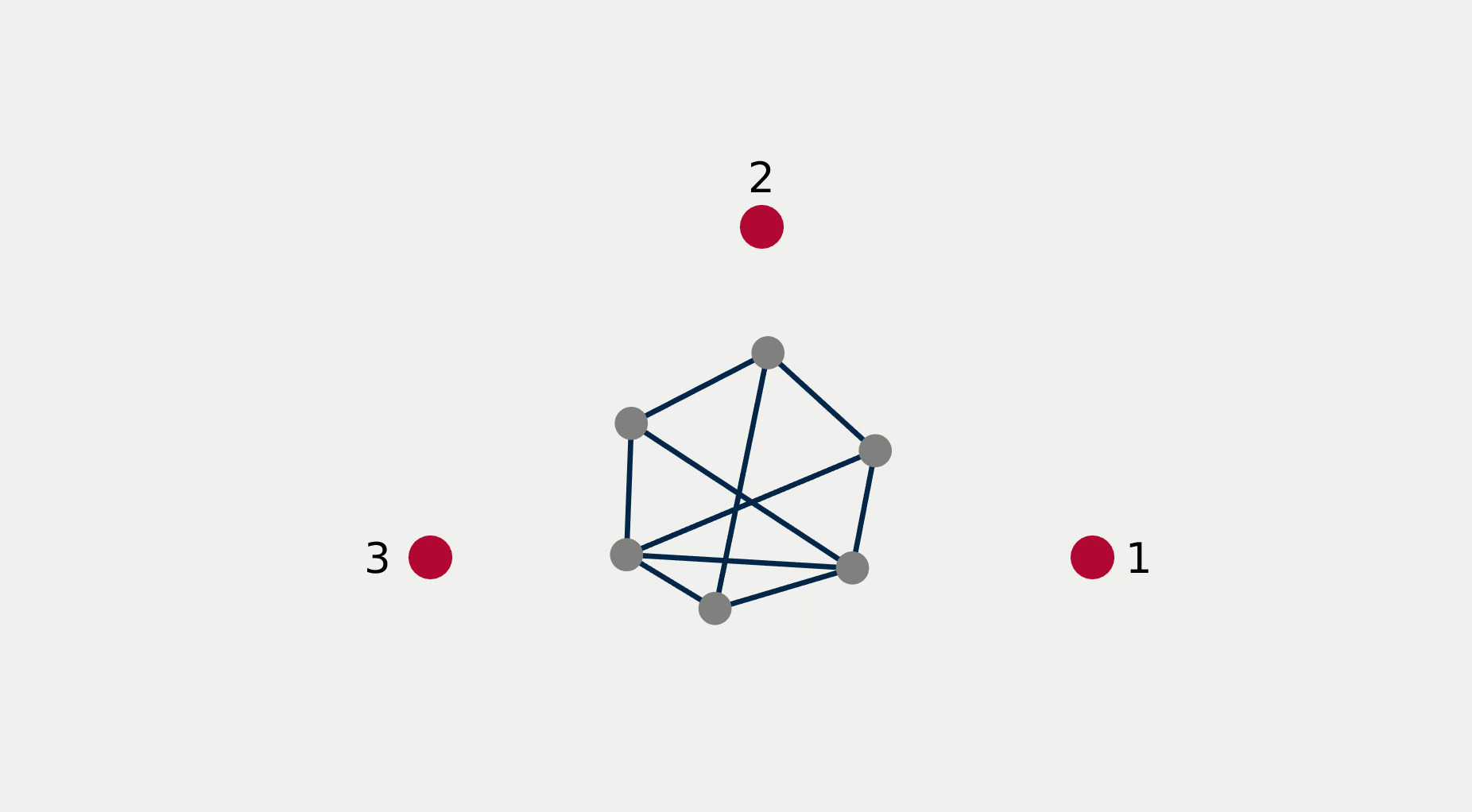
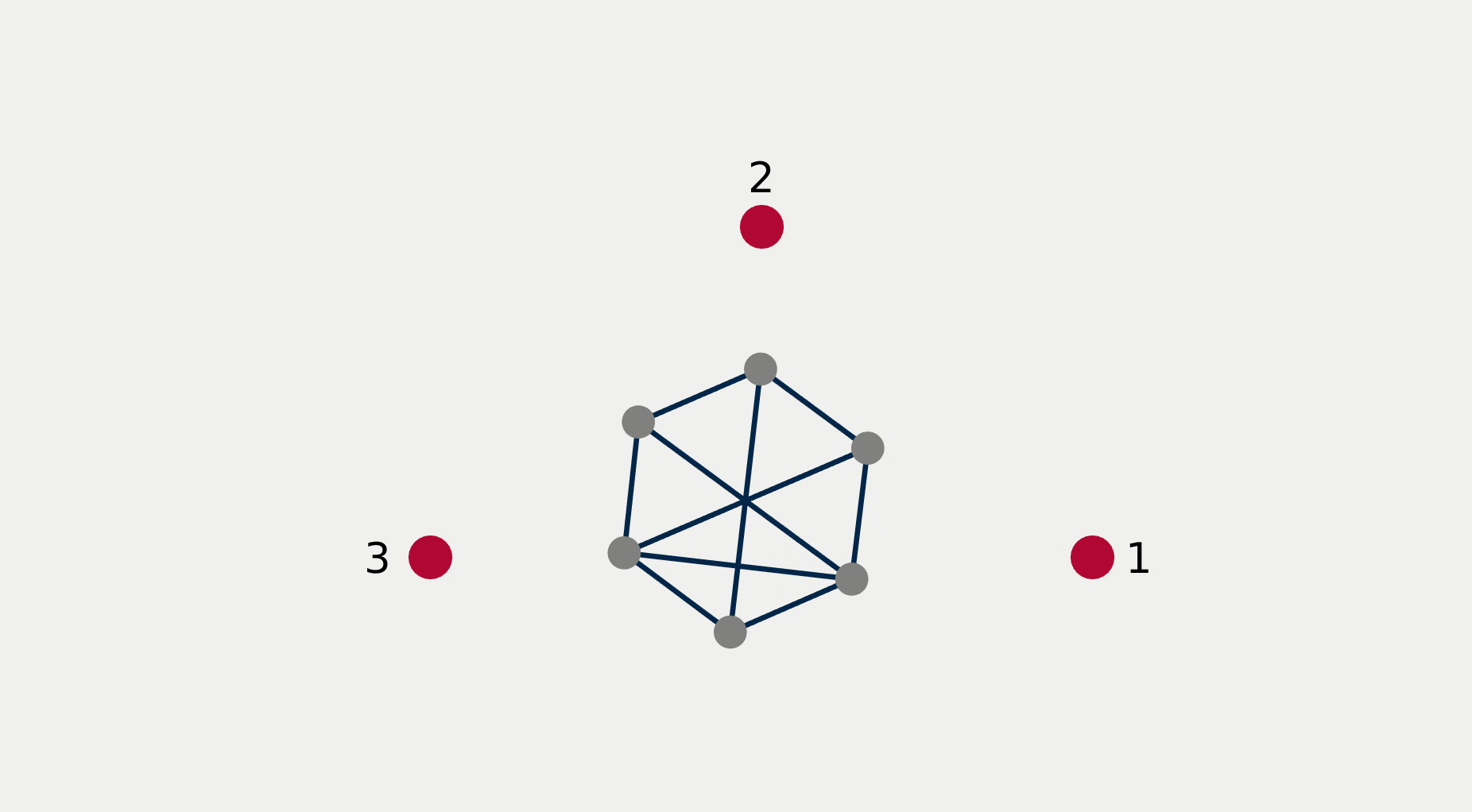
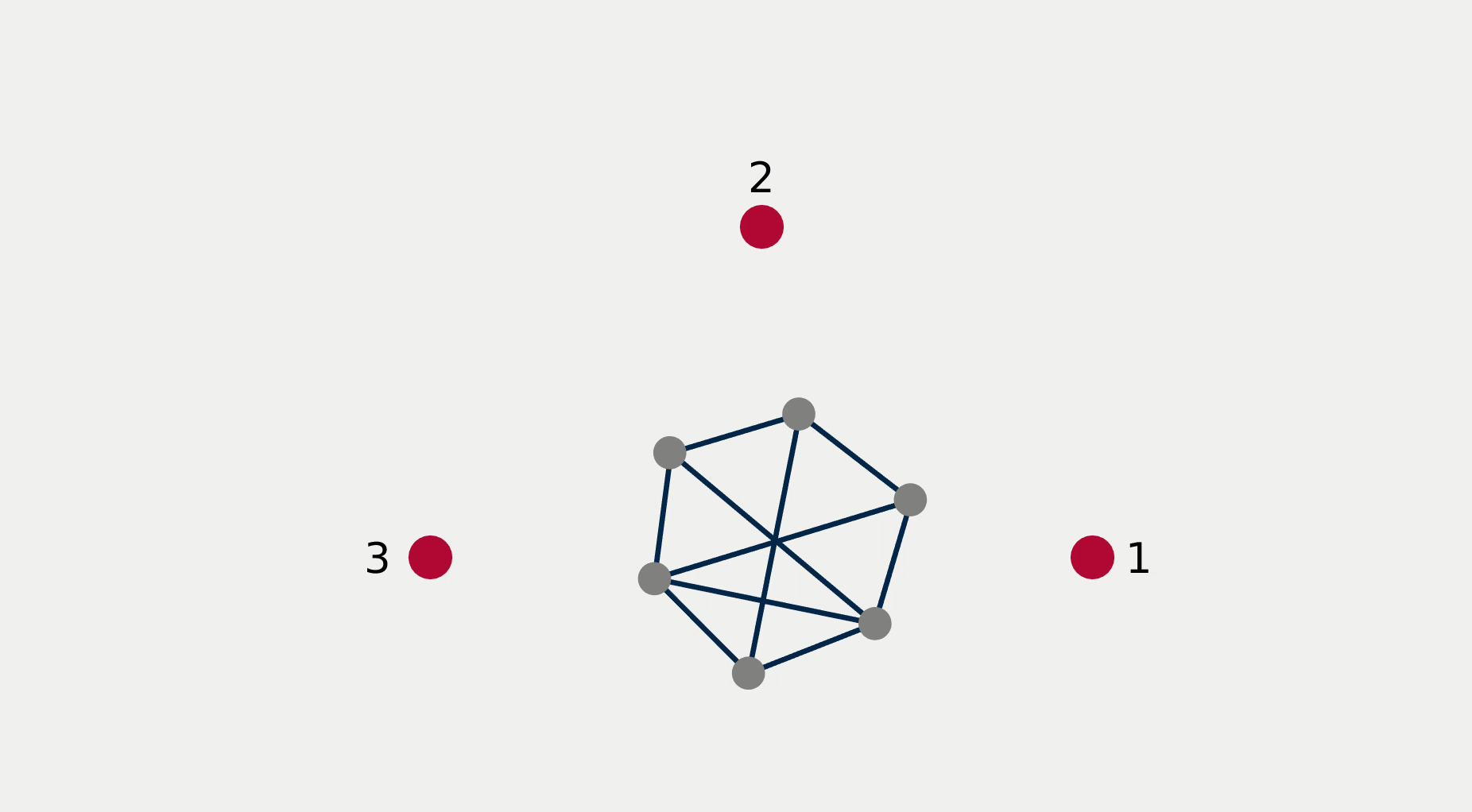
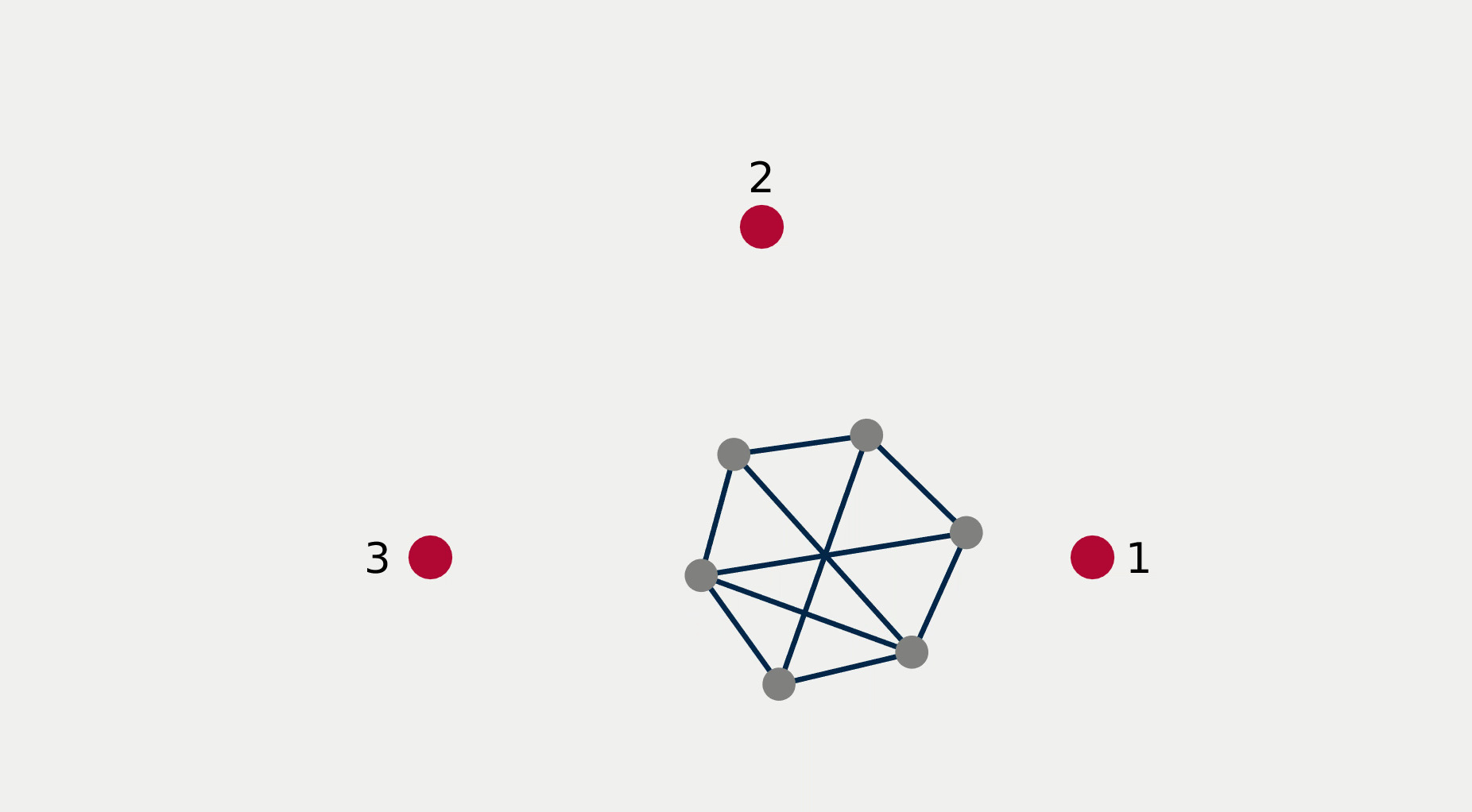
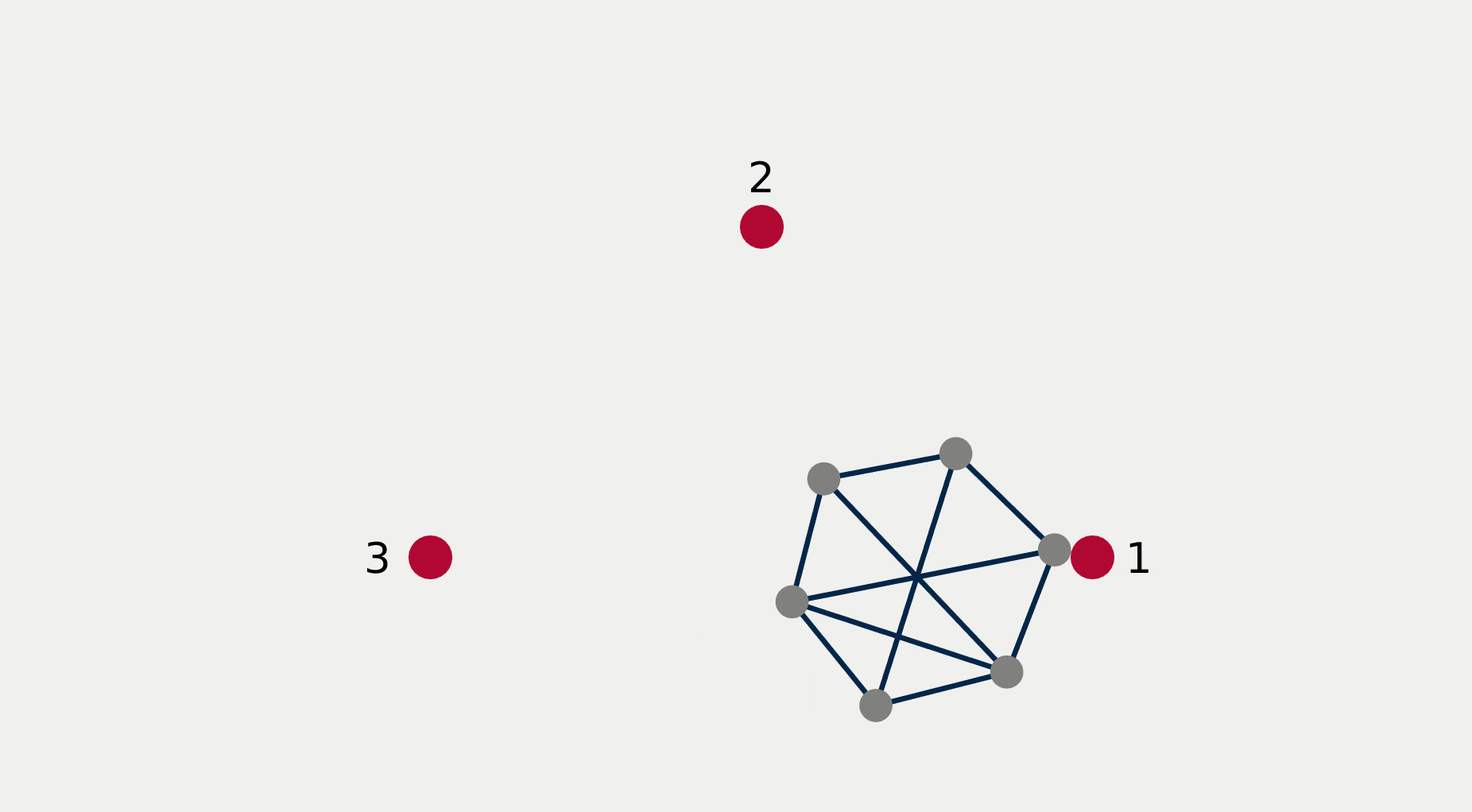
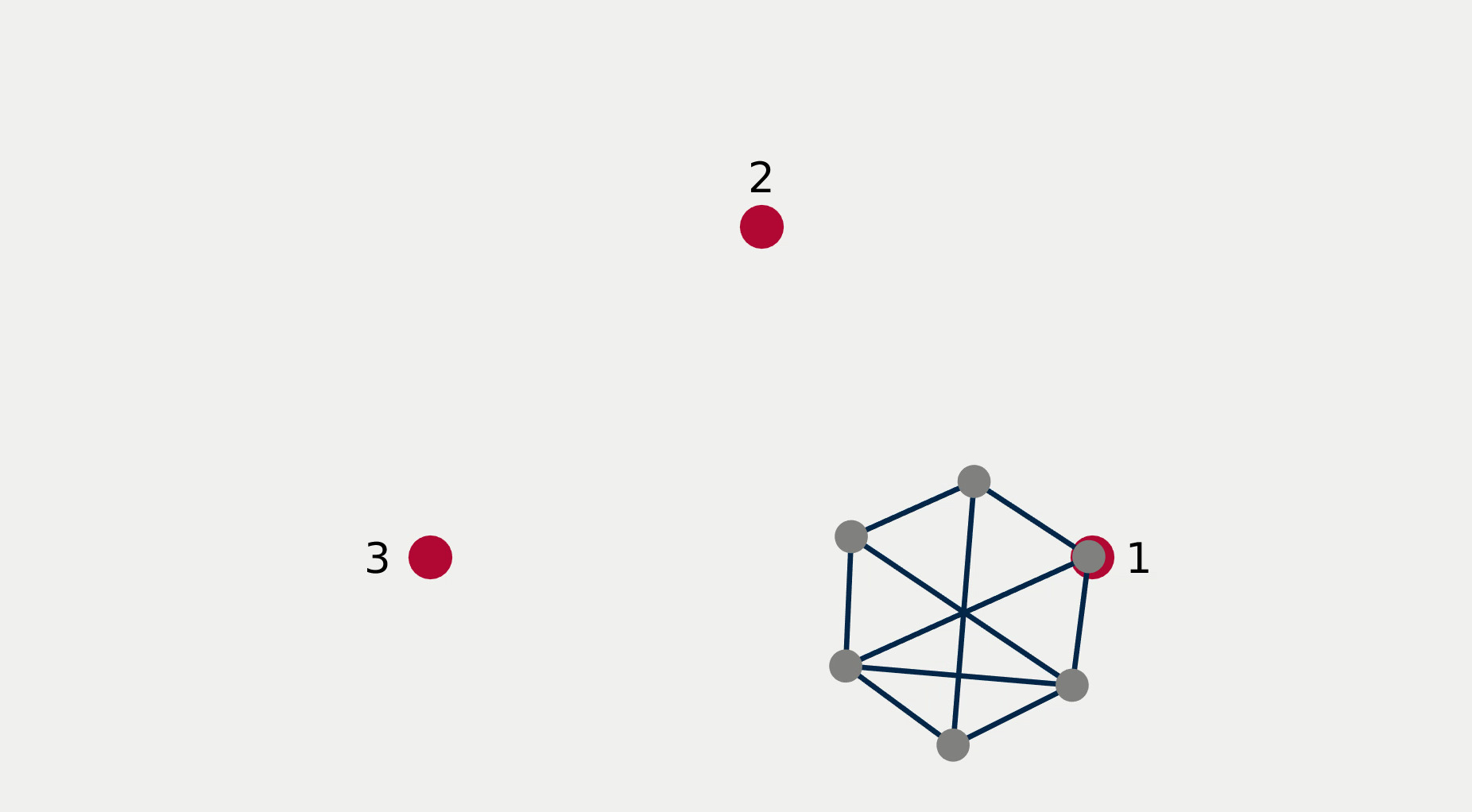
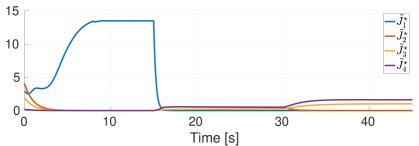
For multi-robot systems, the redundancy stems from the multiplicity of robotic units of which the system is comprised. In this section, we will showcase the execution of dependent tasks—two tasks are dependent if executing one prevents the execution of the other [1]—in different orders of priority. The multi-robot system is comprised of 6 planar robots modeled with single integrator dynamics and controlled to execute the following 4 tasks: All robots assemble an hexagonal formation (task ), robot 1 goes to goal point 1 (task ), robot 2 goes to goal point 2 (task ), robot 3 goes to goal point 3 (task ). While Task 1 is independent of each of the other tasks taken singularly, it is not independent of any pair of tasks 2, 3, and 4. This intuitively corresponds to the fact that it is possible to form a hexagonal formation in different points in space, but it might not be feasible to form a hexagonal formation while two robots are constrained to be in two pre-specified arbitrary locations.
Figure 2 reports a sequence of snapshots and the graph of the value functions encoding the four tasks recorded during the course of the experiment. Denoting by the condition under which task has priority higher than , the sequence of prioritized stacks tested in the experiment are the following:
| (18) |
The plot of the value functions in Fig. 2l shows how, for , since the hexagonal formation control algorithm has lower priority compared to the three go-to-goal tasks, its value function is allowed to grow while the other three value functions are driven to 0 by the velocity control input solution of (14) supplied to the robots. For , the situation is reversed: the hexagonal formation control is executed with highest priority while the value functions encoding the three go-to-goal tasks are allowed to grow—a condition which corresponds to the non-execution of the tasks. Finally, for , task , i.e. go-to-goal task for robot 1 to goal point 1 is added at higher priority with respect to tasks and . Since this is independent by task , it can be executed at the same time. As a result, as can be seen from the snapshots, the formation translates towards the red point marked with 1. Tasks and are successfully executed while tasks and are not executed since are not independent by the first two and they have lower priority.
Remark 4.1.
The optimization program responsible for the execution of multiple prioritized tasks encoded by value functions is solved at each iteration of the robot control loop. This illustrates how the convex optimization formulation of the developed framework is computationally efficient and therefore amenable to be employed in online settings. Alternative approaches for task prioritization and allocation in the context of multi-robot systems generally result in (mixed-)integer optimization programs, which are often characterized by a combinatorial nature and are not always suitable for an online implementation [8].
4.2 Discussion
The experiments of the previous section highlight several amenable properties of the framework developed in this paper for the prioritized execution of tasks encoded by a value function. First of all, its compositionality is given by the fact that tasks can easily be inserted and removed by adding and removing constraints from the optimization program (14). For the same reason the framework is incremental and modular as it allows for building a complex task using a number of subtasks which can be incrementally added to the constraints of an optimization-based controller. Moreover, it allows for seamless incorporation of priorities among tasks, and, as we showcased in Section 4.1, these priority can also be switched in an online fashion, in particular without the need of stopping and restarting the motion of the robots. Furthermore, Proposition 3.2 shows that the execution of multiple tasks using the constraint-driven control is stable and the robotic system will indeed execute the given tasks according to the specified priorities. Finally, as the developed optimization program is a convex QP, its low computational complexity allows for an efficient implementation in online settings even under real-time constraints on computationally limited robotic platforms.
5 Conclusion
In this paper, we presented an optimization-based framework for the prioritized execution of multiple tasks encoded by value functions. The approach combines control-theoretic and learning techniques in order to exhibit properties of compositionality, incrementality, stability, and low computational complexity. These properties render the proposed framework suitable for online and real-time robotic implementations. A multi-robot simulated scenario illustrated its effectiveness in the control of a redundant robotic system executing a prioritized stack of tasks.
Appendix A Comparison Between Optimal Control, Optimization-Based Control, and RL policy
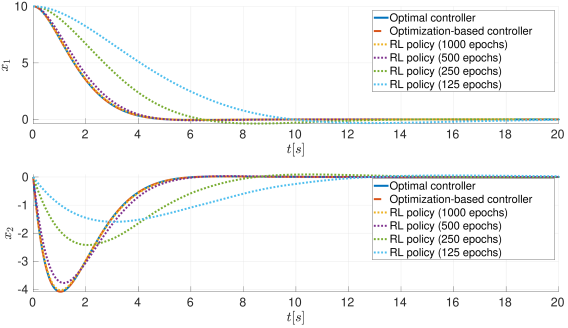
To compare optimal controller, optimization-based controller, and RL policy, in this section, we consider the stabilization of a double integrator system to the origin. The system dynamics are given by: , where and . The instantaneous cost considered in the optimal control problem (7) is given by where . The reward function of the value iteration algorithm employed to learn an approximate representation of the value function has been set to , and the resulting value function has been shifted so that .
The results of the comparison are reported in Fig. 3. Here, the optimization-based controller solution of (13) with is compared to the optimal controller given in (9), and the RL policy corresponding to the approximate value function . As can be seen, the optimization-based controller and the optimal controller coincide, while the RL policy becomes closer and closer as the number of training epochs increases.
Appendix B Implementation Details
The results reported in Section 4 have been obtained using a custom value function learning algorithm written in Python. The details of each multi-robot task are given in the following.
Each robot in the team of robots is modeled using single integrator dynamics , where are position and velocity input of robot . The ensemble state and input will be denoted by and , respectively. For the formation control task, the expression of the cost is given by , where the value of is the formation energy defined as , being the neighborhood of robot , i.e. the set of robots with which robot shares an edge, and
| (19) |
with . The entry of the matrix corresponds to the desired distance to be maintained between robots and .
The cost function for the go-to-goal tasks is given by , where is the desired goal point.
Remark B.1 (Combination of single-robot and multi-robot tasks).
Single-robot tasks (e.g. the go-to-goal tasks considered in this paper) are combined with multi-robot tasks (e.g. the formation control task) by defining the task gradient required to compute and in the optimization program (14) in the following way: , where the -th entry is the approximate value function for task and robot .
References
- [1] Antonelli, G.: Stability analysis for prioritized closed-loop inverse kinematic algorithms for redundant robotic systems. IEEE Transactions on Robotics 25(5), 985–994 (2009). 10.1109/TRO.2009.2017135
- [2] Bertsekas, D.P.: Reinforcement learning and optimal control. Athena Scientific Belmont, MA (2019)
- [3] Boyd, S., Vandenberghe, L.: Convex optimization. Cambridge University Press (2004)
- [4] Bryson, A.E., Ho, Y.C.: Applied optimal control: optimization, estimation, and control. Routledge (2018)
- [5] Bylard, A., Bonalli, R., Pavone, M.: Composable geometric motion policies using multi-task pullback bundle dynamical systems. arXiv preprint arXiv:2101.01297 (2021)
- [6] Dulac-Arnold, G., Mankowitz, D., Hester, T.: Challenges of real-world reinforcement learning. arXiv preprint arXiv:1904.12901 (2019)
- [7] Freeman, R.A., Primbs, J.A.: Control lyapunov functions: New ideas from an old source. In: Proceedings of 35th IEEE Conference on Decision and Control, vol. 4, pp. 3926–3931. IEEE (1996)
- [8] Gerkey, B.P., Matarić, M.J.: A formal analysis and taxonomy of task allocation in multi-robot systems. The International journal of robotics research 23(9), 939–954 (2004)
- [9] Ghosh, D., Singh, A., Rajeswaran, A., Kumar, V., Levine, S.: Divide-and-conquer reinforcement learning. arXiv preprint arXiv:1711.09874 (2017)
- [10] Gupta, A., Yu, J., Zhao, T.Z., Kumar, V., Rovinsky, A., Xu, K., Devlin, T., Levine, S.: Reset-free reinforcement learning via multi-task learning: Learning dexterous manipulation behaviors without human intervention. arXiv preprint arXiv:2104.11203 (2021)
- [11] Haarnoja, T., Pong, V., Zhou, A., Dalal, M., Abbeel, P., Levine, S.: Composable deep reinforcement learning for robotic manipulation. In: 2018 IEEE international conference on robotics and automation (ICRA), pp. 6244–6251. IEEE (2018)
- [12] Haarnoja, T., Tang, H., Abbeel, P., Levine, S.: Reinforcement learning with deep energy-based policies. In: International Conference on Machine Learning, pp. 1352–1361. PMLR (2017)
- [13] Kaelbling, L.P.: The foundation of efficient robot learning. Science 369(6506), 915–916 (2020)
- [14] Micchelli, C.A., Pontil, M.: Kernels for multi–task learning. In: NIPS, vol. 86, p. 89. Citeseer (2004)
- [15] Mukadam, M., Cheng, C.A., Fox, D., Boots, B., Ratliff, N.: Riemannian motion policy fusion through learnable lyapunov function reshaping. In: Conference on Robot Learning, pp. 204–219. PMLR (2020)
- [16] Nachum, O., Gu, S., Lee, H., Levine, S.: Data-efficient hierarchical reinforcement learning. arXiv preprint arXiv:1805.08296 (2018)
- [17] Notomista, G., Mayya, S., Hutchinson, S., Egerstedt, M.: An optimal task allocation strategy for heterogeneous multi-robot systems. In: 2019 18th European Control Conference (ECC), pp. 2071–2076. IEEE (2019)
- [18] Notomista, G., Mayya, S., Selvaggio, M., Santos, M., Secchi, C.: A set-theoretic approach to multi-task execution and prioritization. In: 2020 IEEE International Conference on Robotics and Automation (ICRA), pp. 9873–9879. IEEE (2020)
- [19] Peng, X.B., Chang, M., Zhang, G., Abbeel, P., Levine, S.: Mcp: Learning composable hierarchical control with multiplicative compositional policies. arXiv preprint arXiv:1905.09808 (2019)
- [20] Primbs, J.A., Nevistić, V., Doyle, J.C.: Nonlinear optimal control: A control lyapunov function and receding horizon perspective. Asian Journal of Control 1(1), 14–24 (1999)
- [21] Qureshi, A.H., Johnson, J.J., Qin, Y., Henderson, T., Boots, B., Yip, M.C.: Composing task-agnostic policies with deep reinforcement learning. arXiv preprint arXiv:1905.10681 (2019)
- [22] Rana, M.A., Li, A., Ravichandar, H., Mukadam, M., Chernova, S., Fox, D., Boots, B., Ratliff, N.: Learning reactive motion policies in multiple task spaces from human demonstrations. In: Conference on Robot Learning, pp. 1457–1468. PMLR (2020)
- [23] Ratliff, N.D., Issac, J., Kappler, D., Birchfield, S., Fox, D.: Riemannian motion policies. arXiv preprint arXiv:1801.02854 (2018)
- [24] Ruder, S.: An overview of multi-task learning in deep neural networks. arXiv preprint arXiv:1706.05098 (2017)
- [25] Sahni, H., Kumar, S., Tejani, F., Isbell, C.: Learning to compose skills. arXiv preprint arXiv:1711.11289 (2017)
- [26] Schwartz, A., Thrun, S.: Finding structure in reinforcement learning. Advances in neural information processing systems 7, 385–392 (1995)
- [27] Sener, O., Koltun, V.: Multi-task learning as multi-objective optimization. arXiv preprint arXiv:1810.04650 (2018)
- [28] Singh, S.P.: Transfer of learning by composing solutions of elemental sequential tasks. Machine Learning 8(3), 323–339 (1992)
- [29] Smith, V., Chiang, C.K., Sanjabi, M., Talwalkar, A.: Federated multi-task learning. arXiv preprint arXiv:1705.10467 (2017)
- [30] Sontag, E.D.: A lyapunov-like characterization of asymptotic controllability. SIAM journal on control and optimization 21(3), 462–471 (1983)
- [31] Sontag, E.D.: A ’universal’ construction of artstein’s theorem on nonlinear stabilization. Systems & control letters 13(2), 117–123 (1989)
- [32] Teh, Y.W., Bapst, V., Czarnecki, W.M., Quan, J., Kirkpatrick, J., Hadsell, R., Heess, N., Pascanu, R.: Distral: Robust multitask reinforcement learning. arXiv preprint arXiv:1707.04175 (2017)
- [33] Todorov, E.: Compositionality of optimal control laws. Advances in neural information processing systems 22, 1856–1864 (2009)
- [34] Van Niekerk, B., James, S., Earle, A., Rosman, B.: Composing value functions in reinforcement learning. In: International Conference on Machine Learning, pp. 6401–6409. PMLR (2019)
- [35] Zhang, Y., Yang, Q.: A survey on multi-task learning. IEEE Transactions on Knowledge and Data Engineering (2021)