A Construction for Balancing Non-Binary Sequences Based on Gray Code Prefixes
Abstract
We introduce a new construction for the balancing of non-binary sequences that make use of Gray codes for prefix coding. Our construction provides full encoding and decoding of sequences, including the prefix. This construction is based on a generalization of Knuth’s parallel balancing approach, which can handle very long information sequences. However, the overall sequence—composed of the information sequence, together with the prefix—must be balanced. This is reminiscent of Knuth’s serial algorithm. The encoding of our construction does not make use of lookup tables, while the decoding process is simple and can be done in parallel.
Index Terms:
Balanced sequence, DC-free codes, Gray code prefix.I Introduction
The use of balanced codes is crucial for some information transmission systems. Errors can occur in the process of storing data onto optical devices due to the low frequency of operation between structures of the servo and the data written on the disc. This can be avoided by using encoded balanced codes, as no low frequencies are observed. In such systems, balanced codes are also useful for tracking the data on the disc. Balanced codes are also used for countering cut-off at low frequencies in digital transmission through capacitive coupling or transformers. This cut-off is caused by multiple same-charge bits, and results in a DC level that charges the capacitor in the AC coupler [1]. In general, the suppression of low-frequency spectrum can be done with balanced codes.
A large body of work on balanced codes is derived from the simple algorithm for balancing sequences proposed by Knuth [2]. According to Knuth’s parallel algorithm, a binary sequence, , of even length , can always be balanced by complementing its first or last bits, where . The index is then encoded as a balanced prefix that is appended to the data. The decoder can easily recover from the prefix, and then again complementing the first or last bits to obtain the original information. For Knuth’s serial (or sequential) algorithm, the prefix is used to provide information regarding the information sequence’s initial weight. Bits are sequentially complemented from one side of the overall sequence, until the information sequence and prefix together are balanced. Since the original weight is indicated by the prefix, the decoder simply has to sequentially complement the bits until this weight is attained.
Al-Bassam [3] presented a generalization of Knuth’s algorithm for binary codes, non-binary codes and semi-balanced codes (the latter occur where the number of 0’s and 1’s differs by at most a certain value in each sequence of the code). The balancing of binary codes with low DC level is based on DC-free coset codes. For the design of non-binary balanced codes, symbols in the information sequence are -ary complemented from one side, but because this process does not guarantee balancing, an extra redundant symbol is added to enforce the balancing (similar to our approach later on). Information regarding how many symbols to complement is sent by using a balanced prefix.
Capocelli et al. [4] proposed using two functions that must satisfy certain properties to encode any -ary sequence into balanced sequences. The first function is similar to Knuth’s serial scheme: it outputs a prefix sequence depending on the original sequence’s weight. Additionally, all the -ary sequences are partitioned into disjointed chains, where each chain’s sequences have unique weights. The second function is then used to select an alternate sequence in the chain containing the original information sequence, such that the chosen prefix and the alternate sequence together are balanced.
Tallini and Vaccaro [8] presented another construction for balanced -ary sequences that makes use of balancing and compression. Sequences that are close to being balanced are encoded with a generalization of Knuth’s serial scheme. Based on the weight of the information sequence, a prefix is chosen. Symbols are then “complemented in stages”, one at a time, until the weight that balances the sequence and prefix together is attained. Other sequences are compressed with a uniquely decodable variable length code and balanced using the saved space.
Swart and Weber [5] extended Knuth’s parallel balancing scheme to -ary sequences with parallel decoding. However, this technique does not provide a prefix code implementation, with the assumption that small lookup tables can be used for this. Our approach aims to implement these prefixes via Gray codes. Swart and Weber’s scheme will be expanded on in Section II-A, as it also forms the basis of our proposed algorithm.
Swart and Immink [6] described a prefixless algorithm for balancing of -ary sequences. By using the scheme from [5] and applying precoding to a very specific error correction code, it was shown that balancing can be achieved without the need for a prefix.
Pelusi et al. [7] presented a refined implementation of Knuth’s algorithm for parallel decoding of -ary balanced codes, similar to [5]. This method significantly improved [4] and [8] in terms of complexity.
The rest of this paper is structured as follows. In Section II, we present the background for our work, which includes Swart and Weber’s balancing scheme for -ary sequences [5] and non-binary Gray code theory [10]. In Section III, a construction is presented for sequences where . Section IV extends on our proposed construction to sequences with . Finally, Section V deals with the redundancy and complexity of our construction compared to prior art constructions, our conclusions are presented in Section VI.
II Preliminaries
Let be a -ary information sequence of length , where is from a non-binary alphabet. A prefix of length is appended to . The prefix and information together are denoted by of length , where . Let refer to the weight of , that is the algebraic sum of symbols in . The sequence is said to be balanced if
Let represent this value obtained at the balancing state. For the rest of the paper, the parameters , , and are chosen in such a way that the balancing value, , leads to a positive integer.
II-A Balancing of -ary Sequences
Any information sequence, of length and alphabet size , can always be balanced by adding (modulo ) to that sequence one sequence from a set of balancing sequences [5]. The balancing sequence, is derived as
where and are positive integers with and . Let be the iterator through all possible balancing sequences, such that and . Let refer to the resulting sequence when adding (modulo ) the balancing sequence to the information sequence, , where denotes modulo addition. The cardinality of balancing sequences equals and amongst them, at least one leads to a balanced output .
Since and can easily be determined for the -th balancing sequence using , we will use the simplified notation to denote .
Example 1
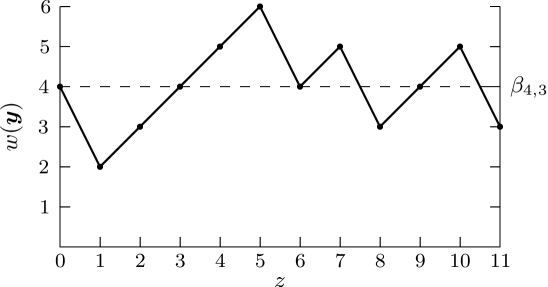
Let us consider the balancing of the 3-ary sequence 2101, of length 4. The encoding process is illustrated below, with weights in bold indicating that the sequences are balanced.
For this example, there are four occurrences of balanced sequences.
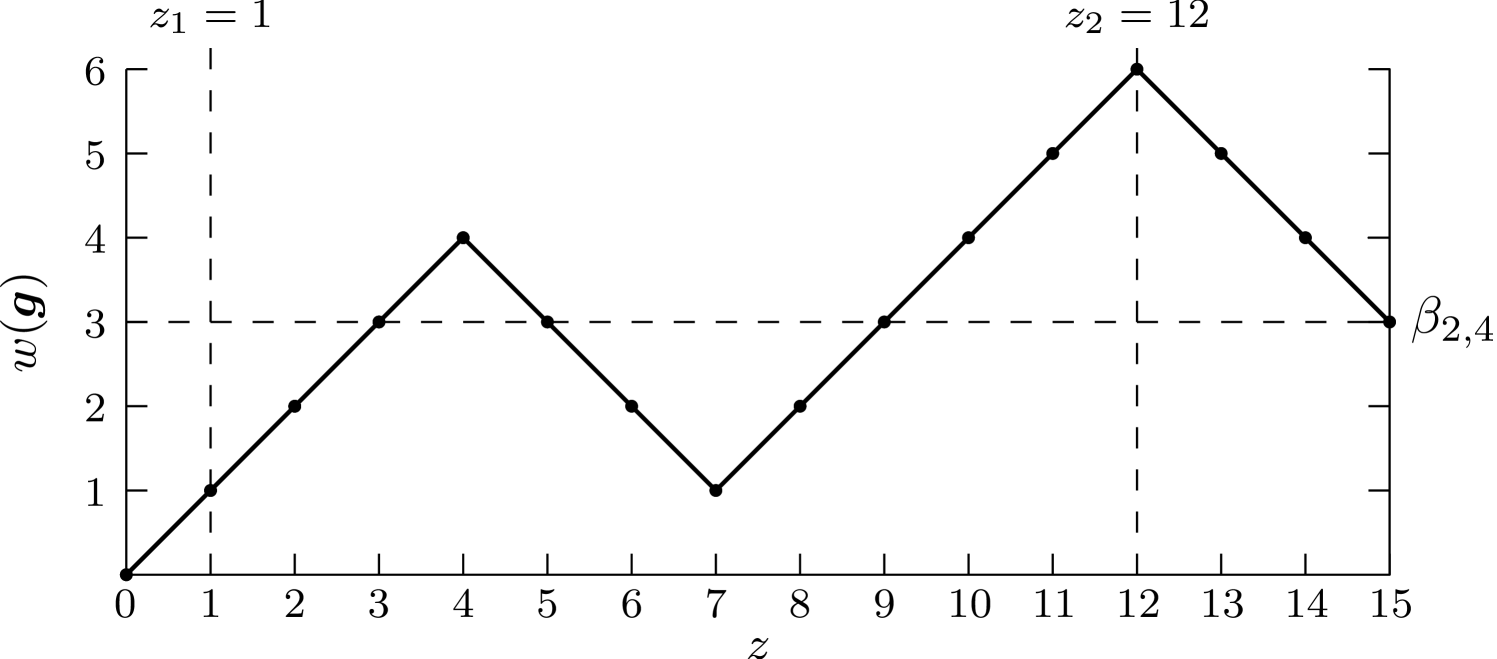
A -random walk refers to a path with random increases of and decreases of . In our case, a random walk graph is the plot of the function of versus . In general, the random walk graph of always forms a -random walk [5]. Fig. 1 presents the -random walk for Example 1. The dashed line indicates the balancing value .
II-B Non-binary Gray Codes
Binary Gray codes were first proposed by Gray [9] for solving problems in pulse code communication, and have been extended to various other applications. The assumption throughout this paper is that a Gray code is mapped from a set of possible sequences appearing in the normal lexicographical order. This ordering results in the main property of binary Gray codes: two adjacent codewords differ in only one bit.
The -Gray code is a set of -ary sequences of length such that any two adjacent codewords differ in only one symbol position. This set is not unique, as any permutation of a symbol column within the code could also generate a new -Gray code. In this work, a unique set of -Gray codes is considered, as presented by Guan [10]. This set possesses an additional property: the difference between any two consecutive sequences’ weights is . This same set of Gray codes was already determined in [11] through a recursive method.
Let be any sequence within the set of all -ary sequences of length , listed in the normal lexicographic order. These sequences are mapped to -Gray code sequences, , such that any two consecutive sequences are different in only one symbol position.
Table I shows a -Gray code, where is the 3-ary representation of the index and is the corresponding Gray code sequence. We see that for , the adjacent sequences’ weights differ by or .
| 0 | 9 | 18 | ||||||
|---|---|---|---|---|---|---|---|---|
| 1 | 10 | 19 | ||||||
| 2 | 11 | 20 | ||||||
| 3 | 12 | 21 | ||||||
| 4 | 13 | 22 | ||||||
| 5 | 14 | 23 | ||||||
| 6 | 15 | 24 | ||||||
| 7 | 16 | 25 | ||||||
| 8 | 17 | 26 |
We will make use of the following encoding and decoding algorithms from [10].
II-B1 Encoding algorithm for -Gray code
Let and denote respectively a -ary sequence of length and its corresponding Gray code sequence.
Let be the sum of the first symbols of , with and . Then
The parity of determines ’s symbols from . If is even then the symbol stays the same, otherwise the -ary complement of the symbol is taken.
II-B2 Decoding algorithm for -Gray code
Let , and be defined as before, with and . Then
III Construction for
For the sake of simplicity, we will briefly explain the construction for information lengths limited to , with being a positive integer. More details can be found in our conference paper [13]. In the next section we will show how this restriction can be avoided.
The main component of this technique is to encode the balancing indices, , into Gray code prefixes that can easily be encoded and decoded. The prefix together with the information sequence must be balanced.
The condition, , is enforced so that the cardinality of the -Gray code is equal to that of the balancing sequences, making .
III-1 Encoding
Let be the concatenation of the Gray code prefix with , with representing the concatenation. As stated earlier, for the sequences we obtain a -random walk, and for the Gray codes we have a -random walk. Therefore, when we concatenate the two sequences together, the random walk graph of forms a -random walk, i.e. increases of 0 or 2 and decreases of or .
This concatenation of a Gray code prefix, , with an output sequence, , does not guarantee the balancing of the overall sequence, since the increases of 2 in the random walk graph do not guarantee that it will pass through a specific point. An extra symbol is added to ensure overall balancing, with if , otherwise , thus forcing the random graph to a specific point. The overall sequence is the concatenation of , and , i.e. . The length of is .
In summary, the balancing of any -ary sequence of length , where , can be achieved by adding (modulo ) an appropriate balancing sequence, , and prefixing a redundant symbol with a Gray code sequence, . The construction relies on finding a Gray code prefix to describe , and at the same time be balanced together with .
Example 2
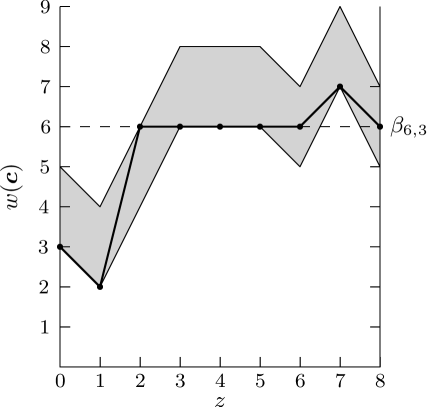
Let us consider the encoding of the ternary sequence, 201 of length 3. Since , the length of Gray code prefixes will be . The overall length is and the balancing value is . The encoding process below is followed.
The underlined symbols represent the appended prefix, the bold underlined symbol is , which is chosen such that is obtained whenever possible, and the bold weights indicate that balancing was achieved. Fig. 2 presents the random walk graph for the weight of the overall sequence, , with the shaded area indicating the possible weights as a result of the flexibility in choosing .
III-2 Decoding
The decoding consists of recovering the index from the Gray code prefix, , and finding and to reconstruct . The original sequence is then obtained as , where represents modulo subtraction.
As an example, Table II shows the decoding of every Gray code sequence into balancing sequences using the -Gray code set.
| Gray code () | Sequence () | |||
|---|---|---|---|---|
| 0 | ||||
| 1 | ||||
| 2 | ||||
| 3 | ||||
| 4 | ||||
| 5 | ||||
| 6 | ||||
| 7 | ||||
| 8 |
Example 3
Consider the received ternary sequence of length (one of the balanced sequences from Example 2). The -Gray code prefixes were used in encoding the original sequence.
IV Construction for
We will now generalize the technique described in the previous section to sequences of any length, i.e. .
The idea is to use a subset of the -Gray code with an appropriate length to encode the indices that represent the balancing sequences. Therefore, the cardinality of -Gray code prefixes must be greater than that of the balancing sequences, i.e. or .
However, the challenge is to find the appropriate subset of -Gray code prefixes that can uniquely match the balancing sequences, and still guarantee balancing when combined with and .
IV-A -Gray code prefixes for odd
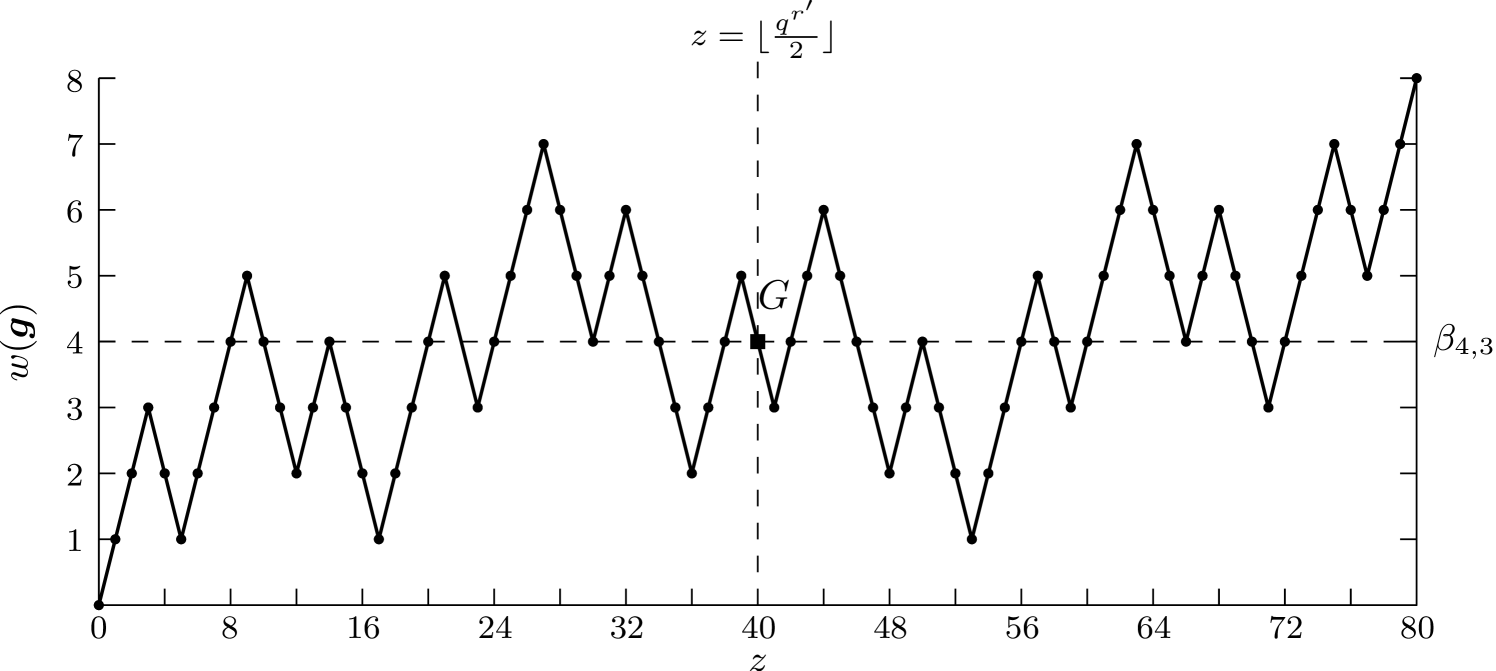
When examining the random walk graph for Gray codes with odd, one notices that the random walk forms an odd function around a specific point. Fig. 3 presents the -Gray code random walk graph, with being the intersection point between the horizontal line, , and the vertical line, . The graph forms an odd function around this point . In general, for -Gray codes where is odd, the random walk of the Gray codes gives an odd function centered around and , where represents the floor function.
Lemma 1
The random walk graph of -Gray codes where is odd forms an odd function around the point .
It was proved in [11] that any -Gray code, where is odd, is reflected. That is, the random walk graph of the -Gray code forms an odd function centered around the point .
This implies that any subset of an -Gray code around the center of its random walk graph, where the information sequence is such that is odd (i.e. is odd), always has an average weight equal to . As we need a unique subset of Gray code sequences for any case, we choose elements from the “middle” values of and call it the -centered subset. The index for this subset is denoted by , with . When is even (i.e. is even), it is not guaranteed that the subset of -Gray codes’ average weight around the center equals exactly . However, it will be very close to it, with a rounded value that is equal to . We formalize these observations in the subsequent lemma.
Let denote the subset of Gray code sequences that are used to encode the index , let denote the average weight of a set of sequences and let denote rounding to the nearest integer.
Lemma 2
For an -Gray code subset, , where is odd and the -th codewords are chosen with , the following holds:
-
•
if is odd with and , then ,
-
•
if is even with and , then .
Proof:
To simplify notation in this proof, we simply use to represent throughout.
If is odd, it follows directly from Lemma 1 that choosing sequences (where is odd) from to , centered around , will result in , since the random walk forms an odd function around this point.
In cases where is even, if was chosen as , we would have exactly (using the same reasoning as for the case where is odd), as we use elements to the left of and elements to the right of it. However, this would mean that elements are being used. Thus, must be used. Let be the weight of the -th Gray code, then
The lowest possible value of is , and its highest possible value is . Thus,
and with some manipulations it can be shown that
Finally, where is odd, we have , and rounding to the nearest integer results in . ∎
IV-B -Gray code prefixes for even
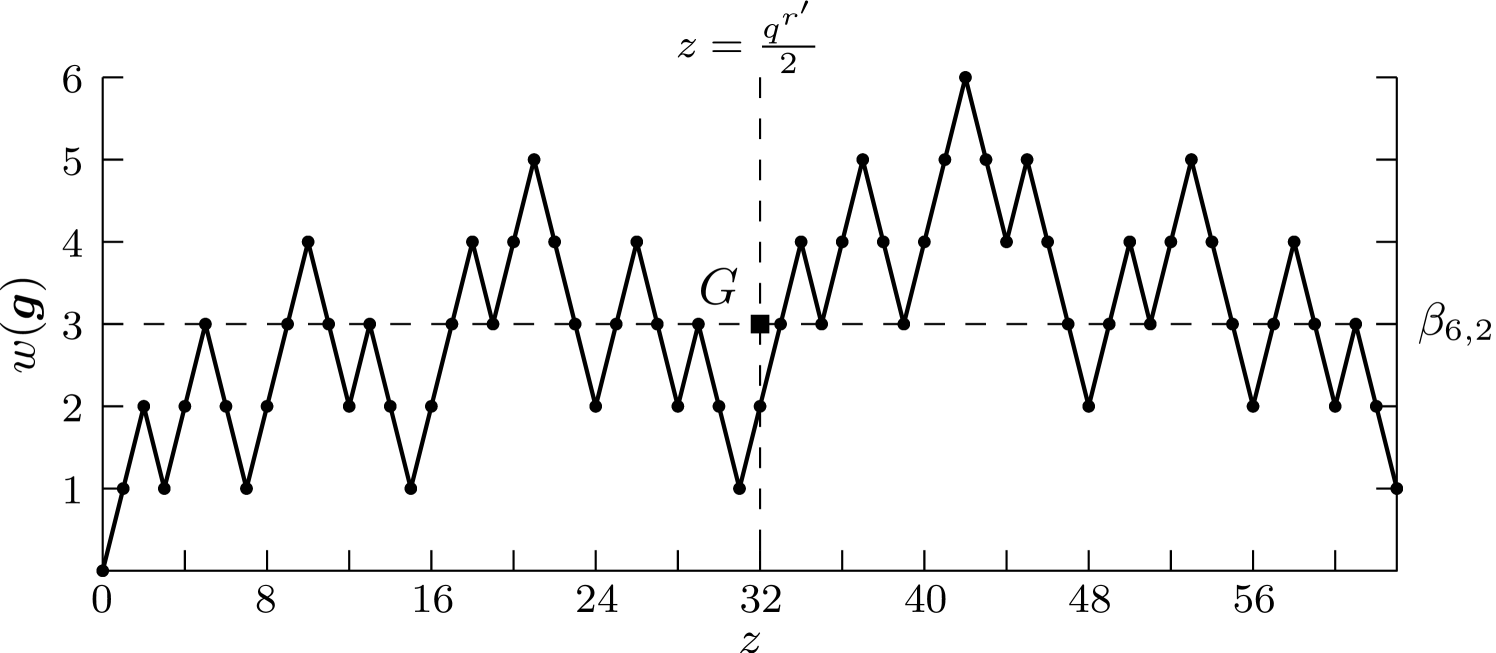
For the encoding of sequences that make use of -Gray code prefixes where is even, a different approach is followed. The subset of Gray code prefixes is obtained by placing a sliding window of length over the random walk graph of the -Gray code sequences, and shifting it until we obtain a subset with an average weight value of . Fig. 4 shows the -Gray code random walk graph.
However, this process does not always guarantee a subset of Gray code prefixes with an average weight value of exactly . Since we have flexibility in choosing , we can choose the average weight for the subset to be close to , and adjust as necessary to obtain exact balancing.
Lemma 3
An -Gray code subset, , where is even, can be chosen such that .
Proof:
A similar reasoning as in the proof of Lemma 2, where a symbol with weight is repeatedly removed from the set, can be used to find . ∎
IV-C Encoding
Having presented all the required components, we now propose our encoding algorithm. The length of the required Gray code prefix is
| (1) |
where represents the ceiling function.
The cardinality of -Gray codes equals . This implies that . The encoding will make use of a subset of Gray code sequences from the available ones.
Theorem 1
Any -ary sequence can be balanced by adding (modulo ) an appropriate balancing sequence, , and prefixing a redundant symbol, , with a Gray code sequence, , taken from the subset of -Gray code prefixes.
Proof:
Let denote the set of possible symbols for , i.e. , let denote the subset of Gray code sequences, and let denote the set of output sequences after the balancing sequences are added to the information sequence.
It is easy to see that
From Lemmas 2 and 3, the subset of -Gray code prefixes that corresponds to the balancing sequences is chosen such that
It was proved in [5] that the average weight of the sequences, , is such that
By considering , with length , as the overall sequence to be transmitted, it follows that:
This implies that there is at least one for which and at least one other for which . Taking the random walk’s increases into account, as well as the flexibility in choosing , we can conclude that there is at least one such that . ∎
The encoding algorithm consists of the following steps:
- 1.
-
2.
Incrementing through , determine the balancing sequences, , and add them to the information sequence to obtain outputs .
-
3.
For each increment of , append every with the corresponding Gray code prefix following the lexicographic order, with obtained from the -ary representations of the indices.
-
4.
Finally, set if , otherwise set .
We illustrate the encoding algorithm with the following two examples, one for an odd value of and the other for an even value of .
Example 4
Consider encoding the ternary sequence, , of length 5. Since , we require -Gray code prefixes to encode the indices. The overall sequence length is , and the balancing value is . The cardinality of the -Gray code is 27 and the required -centered subset of prefixes containing elements is such that .
The following process shows the possible sequences obtained. Again the underlined symbols represent the appended prefix, the bold underlined symbol is , and the bold weights indicate balancing.
Example 5
Consider encoding the 4-ary sequence, (312), of length 3. As before, , requiring -Gray code prefixes to be used. The overall sequence length is , and the balancing value is . The cardinality of the -Gray code equals 16. The -subset is found by employing a sliding window of length over the random walk graph of the -Gray code prefixes, shown in Fig. 5. A suitable subset is found where and , with an average weight value of 3, which equals .
The encoding process for the 4-ary sequence is shown next.
IV-D Decoding
Fig. 6 presents the decoding process of our proposed scheme, for any -ary information sequence. The decoding algorithm consists of the following steps:
-
1.
The redundant symbol is dropped, then the following symbols are extracted as the Gray code prefix, , converted to and used to find .
-
2.
From , the corresponding index is computed as .
-
3.
is used to find the parameters and , then is derived.
-
4.
Finally, the original sequence is recovered through .
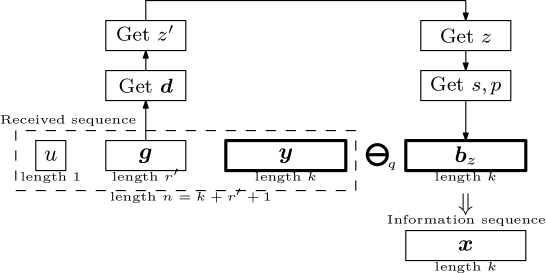
Example 6
Consider the decoding of the sequence, (the underlined symbols are the prefix and the bold underlined symbol is ), where and , that was encoded using -Gray code prefixes.
The first symbol is dropped, then the Gray code prefix is extracted as , which corresponds to , and the -subset of -Gray code prefixes is , thus . This can be seen from Table III, where the decoding of all -Gray codes is shown.
This implies that and , resulting in . Finally, the original information sequence is extracted as .
| Gray code () | Sequence () | ||||
|---|---|---|---|---|---|
| 0 | — | — | — | ||
| 1 | — | — | — | ||
| 2 | — | — | — | ||
| 3 | — | — | — | ||
| 4 | 0 | ||||
| 5 | 1 | ||||
| 6 | 2 | ||||
| 7 | 3 | ||||
| 8 | 4 | ||||
| 9 | 5 | ||||
| 10 | 6 | ||||
| 11 | 7 | ||||
| 12 | 8 | ||||
| 13 | 9 | ||||
| 14 | 10 | ||||
| 15 | 11 | ||||
| 16 | 12 | ||||
| 17 | 13 | ||||
| 18 | 14 | ||||
| 19 | 15 | ||||
| 20 | 16 | ||||
| 21 | 17 | ||||
| 22 | — | — | — | ||
| 23 | — | — | — | ||
| 24 | — | — | — | ||
| 25 | — | — | — | ||
| 26 | — | — | — |
V Redundancy and Complexity
In this section we compare the redundancy and complexity of our proposed scheme with some existing ones.
V-A Redundancy
Let denote the cardinality of the full set of balanced -ary sequences of length . According to [17],
The information sequence length, , in terms of the redundancy, , for the construction in [5] is
| (2) |
In [4], two schemes are presented for information symbols, where one satisfies the bound
| (3) |
and the other one satisfies
| (4) |
The construction in [8] presents the information sequence length in terms of the redundancy as
with , where and are scalars depending on and . If the compression aspect is ignored, the information sequence length is the same as in (4).
The prefixless scheme presented in [6] has information sequence length that satisfies
| (5) |
Two constructions with parallel decoding are presented in [7]. The first construction, where the prefixes are also balanced as in [5], has its information length as a function of as
| (6) |
The second construction, where the prefixes need not be balanced, is a refinement of the first and has an information length the same as (3).
As presented in Section IV, the redundancy of our new construction is given by . Therefore, the information sequence length in terms of redundancy is
| (7) |
Fig. 7 presents a comparison of the information length, , versus the redundancy, , for various constructions as discussed above. For all , our construction is only comparable to the information lengths from (2) and (6), although it does slightly improve on both.
However, the trade-off is that as the redundancy becomes greater, the complexity of our scheme tends to remain constant, as we see in the next section.

V-B Complexity
We estimate the complexity of our proposed scheme and compare it to that of existing algorithms.
The techniques in [4] and [8] both require digit operations for the encoding and decoding. The method from [5] takes digit operations for the encoding and digit operations for the decoding. A refined design of the parallel decoding method is presented in [7], where the complexity equals in the encoding case and digit operations in the decoding process.
The following pseudo code presents the steps of our encoding method:
Input: Information sequence, x of length k.
Output: Encoded sequence, y of length n=k+r.
for i=0:kq;
for j=z1:z2;
y(i) = [u | g(j) | x + b(s,p)(i)];
If (w(y(i))==beta)
// Testing for balanced sequence.
exit();
//Terminate the program.
end;
end;
In the above code, is the iterator through the output sequences and also through the balancing sequences, while is the iterator through the subset of Gray code sequences, ranging from to . The symbol ‘’ denotes the concatenation.
Our encoding scheme is based on the construction in [5] that has an encoding complexity of , and it takes to encode Gray code prefixes as presented in [10]. Therefore the encoding of our algorithm requires digit operations.
The decoding process consists of very simple steps: the recovery of the index from the Gray code requires digit operations [10]. After obtaining the index from the Gray code prefix, the balancing sequence is found and then the original information sequence is recovered through the operation, , which can be performed in parallel, resulting in a complexity of . Therefore the overall complexity for the decoding is digit operations.
Table IV summarizes the complexities for various constructions, where the orders of digit operations it takes to complete the encoding/decoding are compared.
VI Conclusion
An efficient construction has been proposed for balancing non-binary information sequences. By making use of Gray codes for the prefix, no lookup tables are used, only linear operations are needed for the balancing and the Gray code implementation. The encoding scheme has a complexity of digit operations. For the decoding process, once the Gray code prefix is decoded using digit operations, the balancing sequence is determined and the rest of the decoding process is performed in parallel. This makes the decoding fast and efficient.
Possible future research directions include finding a mathematical procedure to determine the subset of Gray code sequences for even, given that it was found manually, by using a sliding window over the random walk graph. Practically, the redundant symbol only needs to take on values of zero (when the random walk falls on the balancing value) or one (when the random walk falls just below the balancing value). Thus, unnecessary redundancy is contained in , especially for large values of . However, the flexibility over increases the occurrences of balanced sequences. These additional balanced outputs could potentially be used to send auxiliary data that could reduce the redundancy. This property was proved for the binary case [12]. Additionally, given that the random walk graph passes through other weights in the region of the balancing value, the scheme can be extended to the construction of constant weight sequences with arbitrary weights.
References
- [1] K. A. S. Immink, Codes for Mass Data Storage Systems, 2nd ed., Shannon Foundation Publishers, Eindhoven, The Netherlands, 2004.
- [2] D. E. Knuth, “Efficient balanced codes,” IEEE Transactions on Information Theory, vol. 32, no. 1, pp. 51–53, Jan. 1986.
- [3] S. Al-Bassam, “Balanced codes,” Ph.D. dissertation, Oregon State University, USA, Jan. 1990.
- [4] R. M. Capocelli, L. Gargano and U. Vaccaro, “Efficient -ary immutable codes,” Discrete Applied Mathematics, vol. 33, no. 1–3, pp. 25–41, Nov. 1991.
- [5] T. G. Swart and J. H. Weber, “Efficient balancing of -ary sequences with parallel decoding,” in Proceedings of the IEEE International Symposium on Information Theory, Seoul, Korea, 28 Jun.–3 Jul. 2009, pp. 1564–1568.
- [6] T. G. Swart and K. A. S. Immink, “Prefixless -ary balanced codes with ECC,” in Proceedings of the IEEE Information Theory Workshop, Seville, Spain, Sep. 9–13, 2013.
- [7] D. Pelusi, S. Elmougy, L. G. Tallini and B. Bose, “-ary balanced codes with parallel decoding,” IEEE Transactions on Information Theory, vol. 61, no. 6, pp. 3251–3264, Jun. 2015.
- [8] L. G. Tallini and U. Vaccaro, “Efficient -ary immutable codes,” Discrete Applied Mathematics, vol. 92, no. 1, pp. 17–56, Mar. 1999.
- [9] F. Gray, “Pulse code communication,” U. S. Patent 2632058, Mar. 1953.
- [10] D.-J. Guan, “Generalized Gray codes with applications,” in Proceedings of National Science Council, Republic of China, Part A, vol. 22, no. 6, Apr. 1998, pp. 841–848.
- [11] M. C. Er, “On generating the N-ary reflected Gray codes,” IEEE Transactions on Computers, vol. 33, no. 8, pp. 739–741, Aug. 1984.
- [12] J. H. Weber and K. A. S. Immink, “Knuth’s balancing of codewords revisited,” IEEE Transactions on Information Theory, vol. 56, no. 4, pp. 1673–1679, Apr. 2010.
- [13] E. N. Mambou, and T. G. Swart, “Encoding and decoding of balanced -ary sequences using a Gray code prefix,” in Proceedings of the IEEE International Symposium on Information Theory, Barcelona, Spain, Jul. 10–15, 2016, pp. 380–384.
- [14] K. A. S. Immink and J. H. Weber, “Very efficient balanced codes,” IEEE Transactions on Information Theory, vol. 28, no. 2, pp. 188–192, Feb. 2010.
- [15] L. G. Tallini and B. Bose, “Balanced codes with parallel encoding and decoding,” IEEE Transactions on Computers, vol. 48, no. 8, pp. 794–814, Aug. 1999.
- [16] B. Bose, “On unordered codes,” Proceedings of the International Symposium on Fault-Tolerant Computing, Pittsburgh, PA, 1987, pp. 102–107.
- [17] Z. Star, “An asymptotic formula in the theory of compositions,” Aequationes Mathematicae, vol. 13, no. 1, pp. 279–284, Feb. 1975.