A declarative approach to data narration
Abstract.
This vision paper lays the preliminary foundations for Data Narrative Management Systems (DNMS), systems that enable the storage, sharing, and manipulation of data narratives. We motivate the need for such formal foundations and introduce a simple logical framework inspired by the relational model. The core of this framework is a Data Narrative Manipulation Language inspired by the extended relational algebra. We illustrate its use via examples and discuss the main challenges for the implementation of this vision.
1. Introduction
A data narrative (DN) is a structured composition of messages that (a) convey findings over the data, and, (b) are typically delivered via visual means in order to facilitate their reception by an intended audience (Outa et al., 2020). Data narration (Segel and Heer, 2010; Carpendale et al., 2016) refers to the notoriously tedious process of crafting a DN by extracting insights from data and telling stories with the goal of "exposing the unanticipated" (Tukey, 1977) and facilitating the understanding of insights. Data narration is practiced in many domains and by various domain experts, ranging from data journalists to public authorities.
Consider the two infograhpics of Figure 1111American Heart Association: ”Women and Risk of Stroke Infographic”, https://www.goredforwomen.org/en/know-your-risk/risk-factors/risk-of-stroke-in-women-infographic,222Good: ”Infographic: Stroke, a Silent Killer of Women, Facts About Women and Strokes”, https://www.good.is/infographics/facts-about-women-and-strokes. These two infographics can be seen as "physical" representations of the DNs. In (Outa et al., 2020), a conceptual model for DNs was proposed. The goal of the present paper is to propose a logical representation of DNs, to bridge the gap between the physical and conceptual representations.


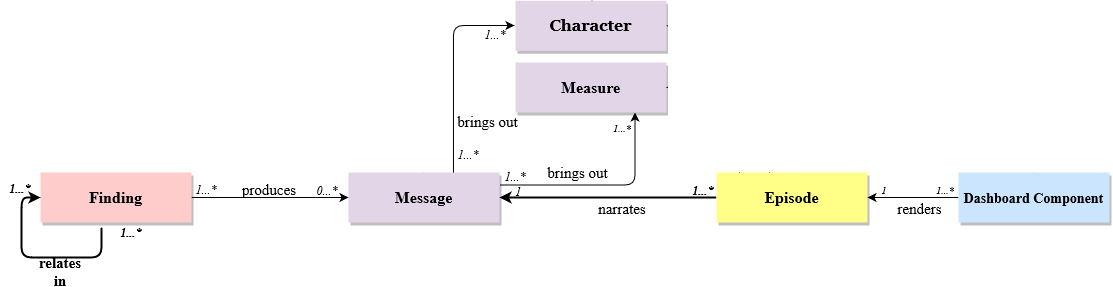
Let us first briefly review the proposed conceptual model for DNs (Outa et al., 2020). This model is based on 4 layers following Chatman’s organisation (Chatman, 1980), who defined narrative as a pair of (a) story (content of the narrative), and, (b) discourse (expression of it). In the conceptual model, the factual layer handles the exploration of facts (i.e., the underlying data) for fetching findings while the intentional layer models the subjective substance of the story, identifying the messages, characters and measures the narrator intends to communicate. As to the discourse, the structural layer models the structure of the DN, its plot being organized in terms of episodes, while the presentational layer deals with its rendering, that is communicated to the audience through visual artifacts named dashboard components). The interested reader is redirected to (Outa et al., 2020) for a deeper presentation of the model.
For instance, in the DN of Figure 1 bottom, an episode of the DN is rendered in the upper right dashboard component, with the message indicating that measure ‘stroke deaths’ is 57/100000 for character ‘black women’.
Figure 2 is an excerpt of this conceptual model considered in the present paper. Indeed, in this vision paper, our goal is to show the benefit of manipulating data narratives declaratively, i.e., with a formal logical data model and a manipulation language. We voluntarily keep this model and language simple, mostly inspired by the relational data model and extended relational algebra (Garcia-Molina et al., 2009). As will be discussed in Section 7, taking into account all the concepts of the domain will need to revisit the model and language, while keeping the flavor of the manipulation described here. These manipulations rely on the concept of message which is the conceptual model’s corner stone. A message is rooted in the facts analyzed, conveying essential findings that can be related to one another. The message allows introducing episodes, the building blocks of the discourse. Each episode of the discourse is specifically tied to a message which it aims to convey, with dashboard components being their presentational counterparts.
While the Web abounds with DNs, manipulating them in a declarative way using the concepts of this model has not yet been proposed, to our knowledge. This paper aims at filling this gap, by envisioning a DN Management System (DNMS), the foundations of which should include a logical layer enabling the declarative manipulation of DNs.
The outline of the paper is the following. Section 2 motivates the need for a logical layer. Section 3 introduce the logical model for DNs and Section 4 the algebra for manipulating DNs. Section 5 illustrates the languages while Section 6 presents related work and Section 7 concludes this vision paper by discussing the main challenges for the implementation of DNMS.
2. Motivation
As indicated above, the corner stone of a DN is a message, that associates characters with measures. Intuitively, a DN is an ordered set of messages and will be manipulated based on the characters and measures they deal with.
We list below simple queries that should be expressed over DNs. Each one corresponds to an operation of the algebraic language introduced in Section 4.
-
•
Find DNs concerning some characters or measures, e.g., DNs about stroke deaths. This selection operation allows to find DNs that satisfy a given condition.
-
•
Retain from DNs only the messages about some characters or measures, e.g., messages concerning Hispanic and Native American women. This projection-like operation produces new DNs keeping only a subset of messages.
-
•
Concatenate messages of several DNs. For example, produce a DN with all messages of the DNs of Figure 1. This concatenation operation allows gathering messages.
-
•
Remove duplicate messages in DNs. This duplicate elimina-tion operation only keeps one occurrence of each message in a DN.
-
•
Synthesize groups of messages in DNs. For instance, produce DNs aggregating messages about stroke cases and stroke deaths. This group-aggregate-like operation groups messages in each DN using grouping conditions and merges them using built-in merging functions.
-
•
Manipulate sets of DNs using the classical set operations (cross-product, intersection, union and difference).
-
•
Change the plot of DNs, for example, arranging messages according to some measures. This order by-like operation allows to modify the order of messages in the DNs.
Composing these operations enables to devise complex query expressions as will be seen in more details in Section 5. We simply mention here a few complex operations that we postulate will be very useful in practice:
-
•
Connect the dots between DNs, i.e., merge DNs that have characters, or characters and measures in common. This join-like operation can be expressed with a combination of cross product, group-aggregate and selection.
-
•
Summarize a narrative for a particular character (e.g., from women stroke to stroke, France to Europe, etc.). This roll-up-like operation supposes to find in the DNDB narratives with messages having characters that generalize the particular character. It can be expressed using selection, cross product, projection, and group-aggregate.
-
•
Detail DNs for a particular character. This drill-down-like operation can be seen as the inverse of the previous one and can be expressed with the same combination of selection, cross product, projection, and group-aggregate.
3. Logical data model
This section presents the data model of the logical framework. Again, in this vision paper, the goal is not to define a thorough logical layer for DNs, but instead to give the flavor of what this logical layer should be for an end-to-end DNMS.
3.1. Data narrative components
Atomic concepts and relations
The atomic components of the model are characters and measures. For instance, the DN of Figure 1 (bottom) includes character ‘black women’ and measure ‘stroke death’. To keep things simple in this preliminary version of the model, measure values and units (e.g., 57/100000) are not part of the present preliminary model. The semantics of the message is given by a predicate connecting characters and measures, in the spirit of semantic triples.
We also assume binary relations between characters as the bases for the relations between messages. Relations between characters are at the core of relations between findings (see Figure 2). In data narration, it is common to use these relations as transitions between episodes of the narrative’s plot, and it has been seen that most transitions are of the following nature: specialisation, temporal or spatial (cf. e.g., (Hullman et al., 2017)). More precisely,
-
•
a specialization relation, noted , allows to classify characters in a hierarchy, for instance to indicate that black women is more specific than women,
-
•
a spatial relation, noted to indicate that is in a spatial relation with . For instance Greece France.
-
•
a temporal relation, noted to indicate that is in temporal relation with . For instance, in Europe, Spring 2nd quarter.
-
•
we also assume a general similarity relation noted to indicate that character is similar to character , for instance birth control pills is similar to abortion pills.
Complex concepts
A message is a tuple associating characters with measures. Formally, a message is a tuple where is a set of characters, is a set of measures and is a predicate333For the sake of consistency, is a singleton.. The simplest message is the empty message, .
Running example
Consider the messages of Figure 3. Messages to and to are inspired from those of the DNs of Figure 1, restricting to a subset of messages and simplifying many characters. Message is inspired from a DN about covid.

Since findings can be related to one another (e.g. findings about black women are more specific than those concerning all women), we consider that relations over characters also applies to messages. For example, among messages of Figure 3, is more general than regarding characters ‘black women’ and ‘women’. Given two messages we consider the transition relation between them which can be one of: spatial, temporal, generalization, similarity.
Formally, for and it is if and is one of .
3.2. Data model
To be consistent with the conceptual description of DNs of Figure 2, we define a DN as a sequence of episodes. Each episode narrating a message, i.e., a tuple, a DN is formally defined as a tuple of tuples. We distinguish its schema, which consists in the number of messages (remember that each message has the same structure), from its instance.
Unless otherwise specified, all sets are infinite and countable. Let be a set of characters, a set of measures, a set of predicates and the set of messages . Let be a set of DN names.
Data narrative
The schema of a DN of length (i.e., with messages) is a couple where is the DN name. A DN instance is a tuple of messages.
For the sake of readability, in what follows we will consider a DN of length as an injective function from to . For instance, the DN can be seen as the function where and . We abuse notations and note if a message appears in the DN , and the set of messages of DN .
Data Narrative Database (DNDB)
A DNDB schema is a set of DN schemas and a DNDB instance is a set of DN instances.
Example
Continuing the running example, , is a DNDB instance that organizes the messages of Figure 3:
; ; .
4. Data Narrative Manipulation Language (DNML)
This section presents an algebra for manipulating DNs. The focus is the description of the operators in their general form; more user-friendly constructors, specially for expressing conditions, will be discussed in Section 7. All operators have the same signature in the sense that they are applied over a DNDB instance and output a DNDB instance. Finally, note that DNs can be manipulated using their schemas, i.e., their names and lengths. However, it is preferable to also manipulate DNs with conditions over their messages and this is why most operators rely on logical formulas for expressing these conditions. In what follows, let be a DNDB and , and be instances of .
4.1. Constants
The first operation is the constant DN. Given a message , it is simply:
4.2. Unary operators
Selection
Selects the DNs in instance that satisfy a given condition.
where is a logical formula to express selection conditions, for instance:
-
•
(has character )
-
•
(has measure )
-
•
(has predicate )
-
•
(has character in relation with , being one of the relations over characters)
-
•
(has messages that are in relation where is one of the relations over messages)
-
•
(has only empty messages)
Example
The operation
looks for DNs about stroke deaths in instance of the running example. Its output is .
Projection
For each DN in I, keeps only the messages satisfying a condition.
where is a logical formula, similar to those used for the selection and is the restriction of DN to the set of messages satisfying .
Example
The operation produce DNs and , projecting a subset of messages of DNs in instance , i.e., those containing Black women as characters.
; ; .
Duplicate-elimination
For each DN in , keeps only one occurrence of each message.
Group-aggregate
For each DN in , groups the messages using a grouping condition and aggregates each group using a specific aggregation function.
where the are grouping conditions on the set of messages of the DN. It is not requested that the grouping conditions partition the set of messages, which allows one message to appear in several groups. The are aggregation functions for merging a set of messages into one message.
Example
The operation
,
where and are conditions about characters ‘Black women’ and ‘White women’ and is an aggregation function computing the union of characters and measures in the input messages. The output DNs contain two messages, the former concerning Black women and the latter White women:
;
;
.
Full group-aggregate
Another group-aggregate operation allows to merge messages across DNs into one DN.
Example
The operation , with , and as in previous example, outputs
Order by
Allows to change the order of messages in the DNs.
where the are selection conditions over messages (like the ones used e.g., for the selection operation) and the are sorting functions, mapping a set of messages to a tuple of messages.
Concatenation
Flattens all DNs in I into one DN, by concatenating all their messages.
4.3. Binary operators
The classical relational binary operations have their standard set theoretic meaning.
4.4. Properties
We give here a few insights on the properties of the algebra, a complete study thereof is part of our future work.
Closure
: By definition, each operator defines a set of DNs from a set of DNs.
Completeness
From a given set of messages, all narratives can be obtained using the constant and cross-product operators, which together form the core of the algebra.
Minimality
The minimal set of operators includes constant, cross product, both group-aggregates, order by, union and difference. All other operations can be expressed from this set. We can anticipate that some expressions will be popular and deserve to be promoted as operators, like the join in the relational algebra that is a shortcut from cross product followed by selection.
Some properties of the operators
Like in the case of the relational algebra, the cross product is non commutative, admits one absorbing element (the empty set) and one neutral element (the empty DN, i.e., ). Set operations keep their usual properties. Note that, because DNDB instances are sets of DNs of different length, intersection cannot be expressed by combining cross product, selection and projection, while it is the case for the relational algebra.
5. Example
In this section, we give some examples of useful and easy to express queries in DNML. They are based on the running example.
Comparing messages
We first illustrate how to "join" DNs having contradictory messages for characters women and stroke,
-
(1)
select DNs about women and stroke:
-
(2)
group by messages with women and stroke, aggregate by keeping messages that are contradictory:
, where
, is a function merging messages that are contradictory otherwise producing an empty message, and is a function producing an empty message. -
(3)
project out empty messages:
Roll-up and drill-down
Assume we want to see DNs about ’black women, stroke’ and then to "roll-up" from ’black women’.
-
(1)
select the DNs with characters ’black women’,’stroke’
-
(2)
select the DNs with characters more general than ’black women’
-
(3)
compute the cross product of found DNs:
-
(4)
group by messages with black women and one more general character, aggregate by merging messages:
, where
, is a function merging messages, and is a function producing an empty message. -
(5)
project out empty messages:
6. Related work
Data narrative modeling
Calegari et al. (Calegari, 2022) proposed a narrative metamodel based on the conceptual model of (Outa et al., 2020), to provide abstract models to data narratives. They explored the definition of model transformation for converting narrative models into HTML or a Jupyter computational notebook. Zhang et al.(Zhang et al., 2022) proposed a framework for creating data storytelling applications from three major perspectives: concept, component, and procedure with the absence of any logical means. Bach et al. (Bach et al., 2018) introduces narrative design patterns, defined as "a low-level narrative device that serves a specific intent". A pattern can be used individually or in combination with others to give form to a story. Five major patterns of group are identified: argumentation, flow, framing, emotion, engagement. For example, if the intent of the data narrator is to persuade and convince audience, he can use one of the following patterns: compare, concretize, and repetition. Importantly, these patterns are not specifically related to a visualization or interaction medium.
Many approaches exist for describing DN crafting, mostly describing an essentially manual process (Chen and et al., 2018; Lee et al., 2015; Duangphummet and Ruchikachorn, 2021), while others proposing approaches for automatically generating simple data narratives (Wang et al., 2020; Shi et al., 2021b, a). In all cases, no manipulation language was specifically proposed for manipulating DNs.
Languages for DN
A DNDB is a set of tuples of tuples of sets, i.e., a form of nested relation, albeit with tuples of different lengths. This means that the proposed language, DNML, is likely to be expressed in the nested relational algebra (NRA) (Abiteboul et al., 1995). However, due to the relatively simple structure of DNs, some of NRA’s operations are not needed (e.g., nesting/unnesting, powerset).
Many languages or primitives were proposed to express data exploration sessions (Vassiliadis et al., 2019; El et al., 2020; Youngmann et al., 2022). While relevant for understanding the logic under the discoveries of finding, these languages are not adapted the manipulation of messages and are not devised as an algebra. Some are not even meant to be used by humans, since, e.g., in (El et al., 2020), primitives are used to generate exploration sessions through reinformcement learning.
7. Discussion
We close this paper by discussing some of the main challenges raised by the development of end-to-end DNMS.
Modeling the complexity of data narration
The logical layer proposed in this paper only covers a small portion of data narration, i.e., the complex process that goes from data exploration to the visual presentation of messages. In particular, to account for the complexity of the process, all the concepts and relations present in the model of (Outa et al., 2020) should have a counterpart in the logical layer.
For instance, the provenance of messages (how findings in the dataset were discovered), and the meaning carried to the reader should be logically modeled. For provenance, messages should be linked to a collection of findings, independently of the form of findings, as well as to the queries the findings are results of. For the semantics, one can assume extending the message predicates with user-intuitive semantics, which requires including measure values, units, quantification, etc. A challenge will be to cover all the data narration process while keeping the model and language simple enough.
Data model
As noted above, the data model proposed above is very close to RA. In fact, if the order of messages is not included in the data model, DNs could simply be defined as sets of messages, i.e., relations of arity 2. However, this simplicity would oblige to code the complexity of DN, leading to unnatural queries. Besides, as explained in the previous paragraph, this model is meant to be extended to cover the complete conceptual model of (Outa et al., 2020).
More semantics should be added in the different layers of the conceptual model of (Outa et al., 2020). For instance, at the message level, this can be achieved by using predicates having semantics known to the reader, like in (Wang et al., 2020), or by modeling the relations between characters using e.g., property graphs. At the data exploration layer, modeling findings can be done by relating characters and measures in the spirit of (Anadiotis et al., 2022). Semantics can also be added by modeling the intentions of the narrator using abstract primitives like the ones of (Vassiliadis et al., 2019) or narrative patterns of Bach et al. (Bach et al., 2018).
Manipulation language
As mentioned above, extending DNML will be needed to account for the complexity of the data narration process. An eye should be kept on query languages for sequences (Mecca and Bonner, 2001) and query languages for the Semantic Web (Arenas et al., 2018). A challenge will be to keep the formalism simple enough for ensuring its adoption by the narrators, analysts or data enthusiasts.
This can be achieved by, e.g., (i) devising operations summarizing complex expressions that are useful in practice, in the spirit of join for RA, (ii) devising a SQL-like language for DNs, (iii) using built in predicates for the logical formulas used in the operations (e.g., selection, projection, group-aggregate). In this last case, for instance, predicate could be used to express that DN has character , i.e., logical formula .
RDBMS like stack
On the long term, the challenge will be to implement a DNMS on the model of the successful achievements of RDBMSs, notably, a clear distinction of conceptual, logical, physical layers with intuitive mappings between the objects of different layers, loading facilities for populating the DNDB from existing DNs, data organization at the physical layer, including specific index mechanisms (e.g., inspired by information retrieval techniques), optimizations at the logical and physical layer, etc.
References
- (1)
- Abiteboul et al. (1995) Serge Abiteboul, Richard Hull, and Victor Vianu. 1995. Foundations of Databases. Addison-Wesley.
- Anadiotis et al. (2022) Angelos-Christos G. Anadiotis, Oana Balalau, Catarina Conceição, Helena Galhardas, Mhd Yamen Haddad, Ioana Manolescu, Tayeb Merabti, and Jingmao You. 2022. Graph integration of structured, semistructured and unstructured data for data journalism. Inf. Syst. 104 (2022), 101846.
- Arenas et al. (2018) Marcelo Arenas, Georg Gottlob, and Andreas Pieris. 2018. Expressive Languages for Querying the Semantic Web. ACM Trans. Database Syst. 43, 3 (2018), 13:1–13:45.
- Bach et al. (2018) Benjamin Bach, Moritz Stefaner, Jeremy Boy, Steven Drucker, Lyn Bartram, Jo Wood, Paolo Ciuccarelli, Yuri Engelhardt, Ulrike Koppen, and Barbara Tversky. 2018. Narrative Design Patterns for Data-Driven Storytelling.
- Calegari (2022) Daniel Calegari. 2022. Computational narratives using Model-Driven Engineering. In XLVIII Latin American Computer Conference, CLEI 2022, Armenia, Colombia, October 17-21, 2022. IEEE, 1–9.
- Carpendale et al. (2016) Sheelagh Carpendale, Nicholas Diakopoulos, Nathalie Henry Riche, and Christophe Hurter. 2016. Data-Driven Storytelling (Dagstuhl Seminar 16061). Dagstuhl Reports 6, 2 (2016), 1–27.
- Chatman (1980) S.B. Chatman. 1980. Story and Discourse: Narrative Structure in Fiction and Film.
- Chen and et al. (2018) S. Chen and et al. 2018. Supporting Story Synthesis: Bridging the Gap between Visual Analytics and Storytelling. TVCG (2018).
- Duangphummet and Ruchikachorn (2021) Apiwan Duangphummet and Puripant Ruchikachorn. 2021. Visual Data Story Protocol: Internal Communications from Domain Expertise to Narrative Visualization Implementation. In VISIGRAPP.
- El et al. (2020) Ori Bar El, Tova Milo, and Amit Somech. 2020. Automatically Generating Data Exploration Sessions Using Deep Reinforcement Learning. In SIGMOD.
- Garcia-Molina et al. (2009) Hector Garcia-Molina, Jeffrey D. Ullman, and Jennifer Widom. 2009. Database systems - the complete book (2. ed.). Pearson Education.
- Hullman et al. (2017) Jessica Hullman, Robert Kosara, and Heidi Lam. 2017. Finding a Clear Path: Structuring Strategies for Visualization Sequences. Comput. Graph. Forum 36, 3 (2017), 365–375.
- Lee et al. (2015) Bongshin Lee, Nathalie Henry Riche, Petra Isenberg, and Sheelagh Carpendale. 2015. More Than Telling a Story: Transforming Data into Visually Shared Stories. IEEE Comput Graph Appl 35, 5 (2015), 84–90.
- Mecca and Bonner (2001) Giansalvatore Mecca and Anthony J. Bonner. 2001. Query Languages for Sequence Databases: Termination and Complexity. IEEE TKDE 13, 3 (2001), 519–525.
- Outa et al. (2020) Faten El Outa, Matteo Francia, Patrick Marcel, Verónika Peralta, and Panos Vassiliadis. 2020. Towards a Conceptual Model for Data Narratives. In ER.
- Segel and Heer (2010) Edward Segel and Jeffrey Heer. 2010. Narrative Visualization: Telling Stories with Data. TVCG 16, 6 (2010), 1139–1148.
- Shi et al. (2021a) D. Shi, F. Sun, X. Xu, Xingyu Lan, David Gotz, and Nan Cao. 2021a. AutoClips: An Automatic Approach to Video Generation from Data Facts. Comput. Graph. Forum 40, 3 (2021), 495–505.
- Shi et al. (2021b) Danqing Shi, Xinyue Xu, Fuling Sun, Yang Shi, and Nan Cao. 2021b. Calliope: Automatic Visual Data Story Generation from a Spreadsheet. TVCG 27, 2 (2021), 453–463.
- Tukey (1977) John W. Tukey. 1977. Exploratory data analysis.
- Vassiliadis et al. (2019) Panos Vassiliadis, Patrick Marcel, and Stefano Rizzi. 2019. Beyond roll-up’s and drill-down’s: An intentional analytics model to reinvent OLAP. Inf Syst 85 (2019), 68–91.
- Wang et al. (2020) Yun Wang, Zhida Sun, Haidong Zhang, Weiwei Cui, Ke Xu, Xiaojuan Ma, and Dongmei Zhang. 2020. DataShot: Automatic Generation of Fact Sheets from Tabular Data. TVCG 26, 1 (2020), 895–905.
- Youngmann et al. (2022) Brit Youngmann, Sihem Amer-Yahia, and Aurélien Personnaz. 2022. Guided Exploration of Data Summaries. Proc. VLDB Endow. 15, 9 (2022), 1798–1807.
- Zhang et al. (2022) Yangjinbo Zhang, Mark Reynolds, Artur Lugmayr, Katarina Damjanov, and Ghulam Mubashar Hassan. 2022. A Visual Data Storytelling Framework. Informatics 9, 4 (2022). https://doi.org/10.3390/informatics9040073