A Deep Decomposition Network
for Image Processing:
A Case Study of Visible and Infrared Image Fusion
Abstract
Image decomposition into constituent components has many applications in the field of image processing. It aims to extract salient features from the source image for subsequent pattern recognition. In this paper, we propose a new image decomposition method based on a convolutional neural network. It is applied to the task of image fusion. In particular, a pair of infrared and visible light images are decomposed into three high-frequency feature images and a low-frequency feature images respectively. The two sets of feature images are fused using a novel fusion strategy to obtain fused feature maps. The feature maps are subsequently reconstructed to obtain the fused image. Compared with the state-of-the-art fusion methods, the proposed approach achieves better performance in both subjective and objective evaluation.
Index Terms:
image fusion, image decomposition, deep learning, infrared image, visible image.I Introduction
Image fusion is an important task in image processing. It aims to extract important features from images of multi-modal sources and reconstruct the fused image using the complementary information conveyed by the multiple pictures by means of a fusion strategy. In general, there are several concrete image fusion tasks, involving the visible light and infrared image fusion, multi-exposure image fusion, medical image fusion and multi-focus Image Fusion. At present, diverse fusion methods are used in a range of applications, such as security surveillance, autonomous driving, medical diagnosis, camera photography, target recognition and other fields, for this purpose. The existing fusion methods can be divided into two categories: traditional methods and deep learning methods [1]. Most of the traditional approaches apply signal processing methods to decompose the multi-modal images into high-frequency and low-frequency signals and then merge them. With the development of deep learning, methods based on deep neural networks have also shown a great potential in image fusion.
Traditional methods can further be subdivided into two categories: i) multi-scale decomposition approaches, and ii) representation learning methods. In the multi-scale domain, the image is decomposed into multi-scale representation feature maps. The multi-scale feature representations are then fused by various specific fusion strategies. Finally, the corresponding inverse transform is used to obtain the fused image. There are many representative multi-scale decomposition methods, such as pyramid [2], curvelet [3], contourlet [4],discrete wavelet transform [5], etc.
In the representation learning domain. Most methods are based on sparse representation such as sparse representation (SR) with gradient histogram (HOG) [6], joint sparse representation (JSR) [7], approximate sparse representation with multi-selection strategy [8]. In the low-rank domain, Li and Wu et al. proposed a low-rank representation (LRR) based fusion method [9]. In addition, recent advanced approaches, such as MDLatLRR [10] are based on image decomposition with Latent LRR. This method can extract source image features in the low-rank domains.
Although the methods based on multi-scale decomposition and representation learning have achieved promising performance, they still have some problems. These methods are very complicated, and the dictionary learning stage is a time-consuming operation especially for online training. Besides, if the source image is complex, these methods will not be able to extract the features well. In order to solve this problem, in recent years, many methods based on deep learning have been proposed [1] to take advantage of the powerful feature extraction capabilities of neural networks.
In 2017, Liu et al. proposed a method based on convolutional neural network for multi-focus image fusion [11]. In ICCV2017, Prabhakar et al. proposed DeepFuse [12] to solve the problem of multi-exposure image fusion. In 2018, Li and Wu et al. proposed a new paradigm for infrared and visible light image fusion, based on denseblock and autoencoder structure [13]. In the subsequent two years, with the rapid development of deep learning, a large number of excellent methods emerged. They include IFCNN [14] proposed by Zhang et al., the fusion network based on GANs (PerceptionGAN) [15] proposed by Fu et al., the multi-scale fusion network framework (NestFuse) [16] proposed by Li et al. (2020), the Transformer-based fusion network(PPTFusion) [17] and DualFusion [18] based on Dual-branch autoencoder. Most of these methods use the powerful feature extraction function of neural networks, and perform fusion at the feature level. The fused image is then obtained by some specific decoding strategies.
However, the methods based on deep networks also have some shortcomings: 1) As a feature extraction tool, neural network cannot explain the meaning of the extracted features. 2) The network is complex and takes a long time to train. 3) The available size of multimodal paired datasets is small, and many methods resort to using other data sets for training. This is not ideal for extracting multimodal images.
To solve these problems, we draw on both, the traditional and deep learning methods, and propose a novel network that can be used to decompose images. Taking infrared and visible light image fusion as an example, the proposed network decomposes infrared and visible light images into high and low frequency signals. Novel fusion rules are then used to combine the decomposed images, and the fused low and high frequency signals recombined to reconstruct the output fused image. The key innovation of the proposed method is that it makes use of deep neural network for both, image decomposition, as well as feature extraction. Compared with the state-of-the-art methods, our fusion framework achieves better performance in both subjective and objective evaluation.
This paper is structured as follows. In Section II, we introduce the closest related work. In Section III, we described our proposed fusion method in detail. In Section IV, we introduce the experiments carried on to validate our method and discuss the experimental settings. The experimental results are analyzed and compared to baseline methods in the same section. Finally, in the last section V, we draw the paper to conclusion.
II RELATED WORKS
There are many effective methods, whether based on traditional image signal processing or deep learning. Both frameworks inspired the work presented in this paper.
II-A Wavelet Decomposition and Laplacian Filter
The wavelet transform has been successfully applied to many image processing tasks. The most common wavelet transform technique for image fusion is the Discrete Wavelet Transform (DWT) [19, 20]. DWT is a signal processing tool that decomposes signals into high and low frequency signals. Generally speaking, low-frequency information contains the main characteristics of the signal, whereas high-frequency information conveys the details. In the field of image processing, 2-D DWT is usually used to decompose images. The wavelet decomposition of the image is given as follows:
| (1) |
where is a low-pass filter, and is a high-pass filter. The input signal is an image combining the signals of all bands. Along the and directions, high-pass and low-pass filtering are performed respectively. As shown in Fig.1, the low-frequency image is a coarse approximation of the content of the three high-frequency images which contain the vertical detail, diagonal detail, and horizontal detail, respectively.

In addition, the Laplacian operator is a simple differential operator having the rotation invariance properties. The Laplacian transform of a two-dimensional image function is the isotropic second derivative, defined as:
| (2) |
For digital image processing the equation is approximated by its discrete form as:
| (3) | ||||
The Laplacian operator can also be expressed in the form of a convolution template, using it as a filtering kernel:
| (4) |
where and are the template and the extended template of the discrete Laplacian operator. The second differential characteristic of this template is used to determine the position of the edge. The filters are often used in image edge detection and image sharpening, as shown in Fig.2.
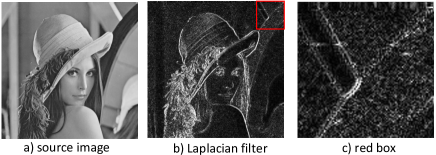
It should be noted that the traditional edge filtering operator is just a high-frequency filter. While highlighting the edges, the filters also amplify the noise.
II-B Decomposition-based Fusion Methods
Li and Wu et al. proposed a method [10] to decompose images using low-rank representation [21] (LatLRR). In essence, their method can be described by the following optimization problem:
| (5) |
where is a hyper-parameter, is the nuclear norm, and is the norm. is observed data matrix. is the low-rank coefficients matrix. is a projection matrix. is a sparse noisy matrix. The authors use this method to decompose the image into detail image and base image . We can see from Fig .3 that is a high-frequency image, and is a low-frequency image.
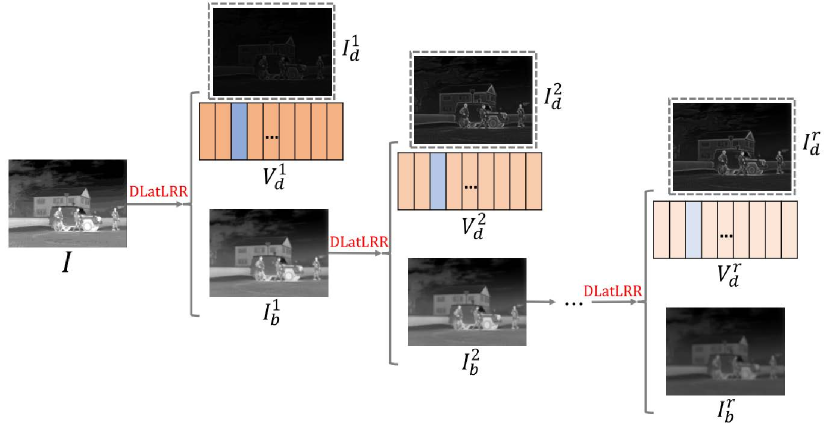
As shown in Fig .3, the low-frequency image is further decomposed to obtain a cascade of high-frequency images , and .
Similarly, this method decomposes the infrared image and the visible light image to obtain high-frequency images and low-frequency images. After fusing the information in the decomposed frequency, the fused image is obtained by means of reconstruction.
II-C Deep Learning-based Fusion Methods
In 2017, Liu et al. proposed a neural network-based method [11]. The authors divide the image into many small patches. Then CNN is used to determine whether each small patch is blurry or clear. The network builds a decision activation map to indicate which pixels of the original image are clear and which are focused. The authors showed that a well-trained network can accomplish multi-focus fusion tasks very well, but their method is not suitable for other image fusion applications.
In order to enable the network to fuse visible light images and infrared images, Li and Wu proposed a deep neural network (DenseFuse) [13] based on an auto-encoder. First they train a powerful encoder and decoder to extract the features of the original image, and then reconstruct it without losing information. The infrared image and the visible light image are encoded. The two sets of coding features are then fused. Finally, the fused features are input into the decoder to obtain the fused image. These methods use the encoder to decompose the image into several latent features. Then these features are fused and reconstructed to obtain the fused image.
In the past few years, Generative Adversarial Networks (GANs) have also been applied to image fusion. The pioneering work based on this approach is FusionGan [22]. The generator inputs infrared and visible light images and outputs a fused image. In order to improve the quality of the generated image, the authors designed an application-specific loss function.
These deep learning-based methods have the ability to map images into a high-dimensional feature space to process and fuse features. CNN can effectively extract the different dimensions images features. However, the CNN-based image fusion methods needs to a well-designed network structure, and can only be applied to specific image fusion tasks. In view of the evident effectiveness of image decomposition and neural network based feature extraction, we propose a novel method which combines multi-layer image decomposition and feature extraction using a unified neural network framework for infrared and visible light image fusion.
III PROPOSED FUSION METHOD
In this section, the proposed multi-scale decomposition-based fusion network is introduced in detail. Firstly, the fusion framework is presented in section III-C. Then, the details of the training phase are described in Section III-A. Next, in Section III-B we design the loss function for the network training. Finally, we present different fusion strategies in Section 14.
III-A Network Structure
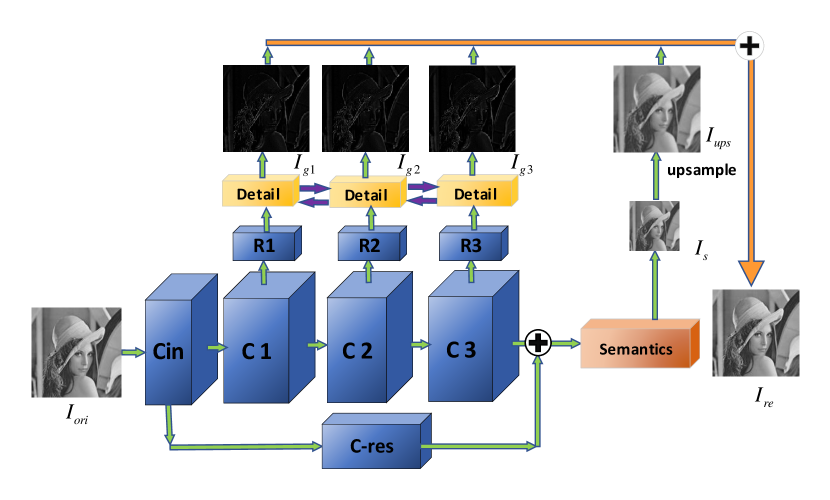
Our goal is to construct and train a deep neural network so that it decomposes the source image into several high-frequency signals and one low-frequency signal for subsequent fusion operations. The structure of the network is shown in Fig. 4, and the network settings are detailed in Table I.
| Block | Layer | Channel | Channel | Size | Size | Size | Activation |
| (input) | (output) | (kernel) | (input) | (output) | |||
| Cin | Conv(Cin-1) | 1 | 16 | 3 | 256 | 256 | LeakyReLU |
| Conv(Cin-2) | 16 | 32 | 3 | 256 | 256 | LeakyReLU | |
| Conv(Cin-3) | 32 | 64 | 3 | 256 | 256 | LeakyReLU | |
| C1 | Conv(C1) | 64 | 64 | 3 | 256 | 256 | LeakyReLU |
| C2 | Conv(C2) | 64 | 64 | 3 | 256 | 256 | LeakyReLU |
| C3 | Conv(C3) | 64 | 64 | 3 | 256 | 256 | LeakyReLU |
| R1 | Conv(R1) | 64 | 64 | 1 | 256 | 256 | - |
| R2 | Conv(R2) | 64 | 64 | 1 | 256 | 256 | - |
| R3 | Conv(R3) | 64 | 64 | 1 | 256 | 256 | - |
| Detail | Conv(D0) | 64 | 32 | 3 | 256 | 256 | LeakyReLU |
| Conv(D1) | 32 | 16 | 3 | 256 | 256 | LeakyReLU | |
| Conv(D2) | 16 | 1 | 3 | 256 | 256 | Tanh | |
| C-res | Conv(C-res1) | 64 | 64 | 3 | 256 | 256 | ReLU |
| Conv(C-res2) | 64 | 64 | 3 | 256 | 256 | ReLU | |
| Conv(C-res3) | 64 | 64 | 3 | 256 | 256 | ReLU | |
| Semantic | Conv(S0) | 64 | 32 | 3 | 256 | 128 | ReLU |
| Conv(S1) | 32 | 16 | 3 | 128 | 64 | ReLU | |
| Conv(S2) | 16 | 1 | 3 | 64 | 64 | Tanh | |
| Upsample | Upsample | 1 | 1 | - | 64 | 256 | - |
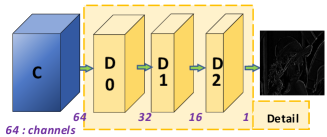
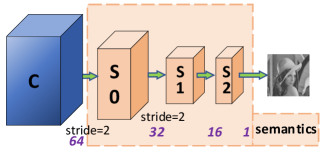
In Fig. 4 and Table I, is the original input image, and is the reconstructed image. The backbone of the network is constituted by four feature extraction convolutional blocks (). The low-frequency feature extraction part is the block in the figure. The block shown in Fig. 6 includes two down-sampling convolutional layers () with a stride of 2 and a common convolutional layer () which generates a low-resolution semantic image . Then is up-sampled to the same size as to obtain the low-frequency image .
We copy the features of different depth () and and then reshuffle their channels with convolutional layers (). Subsequently, we input them into the branch of the shared weights to obtain three high-frequency images , and . The detail branch here is shown in Fig. 5 and Table I, which includes three convolutions (D0, D1, D2). The number of channels is reduced to 1 to obtain a high-frequency image. The reason for adding reshuffle layers () here is that the detail block is weight-sharing. The feature maps that extract high-frequency information should follow the same channel distribution. So we add a convolutional layer that does not share weights, and reshuffle and sort the feature channels so that the features can adapt to the weight-shared details block.
Finally, the three high-frequency images (, , ) and one low-frequency image () are added pixel by pixel to obtain the final reconstructed image . Note that the high-frequency image and the low-frequency image are complementary. In fact, when the network learns to generate images, the high-frequency image can be viewed as the residual data of the low-frequency image. Bearing this in mind, we reflect this reality in terms of a residual branch ( block). We skip-connect the result of directly to the front of the block, adding it to the result of , and input it to the following layers. In this way, and process the residual data between the source image and the semantic image intuitively. In order to make the skip-connected data more closely match the deep features of , we performed three convolutions in block to enhance the semantics of the skip-connected features.
As shown in the activation function in Table I, to consider the properties of low-frequency and high-frequency images jointly, we choose LeakyRelu [23] as the activation function of the convolution layers in the backbone network and the high frequency components (), and the Relu function is used as the activation function of the convolution layers of the residual branch () and the block (). The output of Relu has a certain degree of sparseness, which allows our low-frequency features to filter out irrelevant information and retain more blurred but semantic information. As a final consideration, in order to constrain the pixel value of the resulting image to a controllable range, we use the activation function at the last layer of the and blocks.
In general, the convolution block performs a convolution operation () to obtain a set of feature maps containing various features. After the three identical convolution operations(), three sets of shallow features are extracted. Applying two downsampling () operations, a deep feature is obtained. We argue that shallow features contain more low-level information such as texture and detailed features. We reshuffle the channels and feed these three sets of shallow features into the high-frequency branch ) to obtain three high-frequency images. As deep features, in contrast, contain more semantic and global information, we convolve and upsample them to obtain our low-frequency images. We use the residual branch () to explicitly combine the high-frequency low-frequency features. Lastly, we add these feature images pixel by pixel to get a reconstructed image.
III-B Loss Function
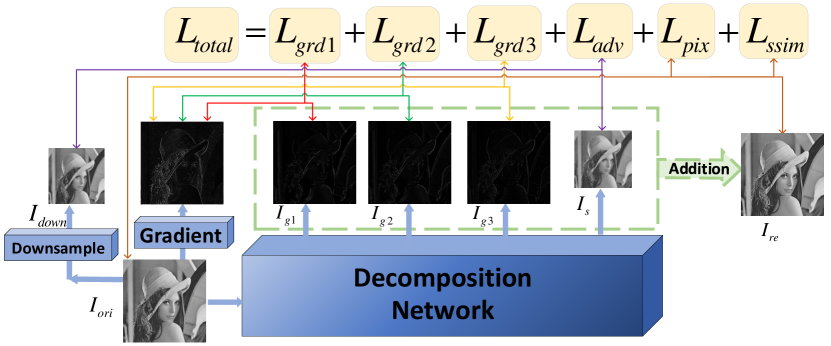
In the training phase, the loss function () of our network consists of three components. They are the gradient loss () of the high-frequency image, the distribution loss () of the low-frequency image, and the content reconstruction loss () of the reconstructed image. The formula of the loss function is defined as follows:
| (6) |
and are hyper-parameters balancing the three losses.
As shown in Fig. 7, calculates the mean square error loss between the high-frequency feature map (, , ) and the gradient the input image and accumulates them. The loss, , is formally defined as
| (7) | ||||
where is the input source image and is the high-frequency image. The is the mean square error between and . The gradient image of the original image is obtained by using the Laplacian gradient operator . The Laplacian operator performs a mathematical convolution operation according to Equ.4.
In Equ.6, is a data distribution loss. It combines the loss of the high-frequency image, and the loss of the reconstructed image. We define reconstruction loss and detail loss as strong loss and semantic loss as weak loss. The reconstruction loss constrains the final generated image, and the detail loss constrains the high frequency features of the image. In addition, the final feature results consists of high-frequency features and low-frequency features. The mean square error loss of the reconstruct loss and detail loss is a strong constraint loss at the pixel level. If the low-frequency semantic loss is also a strong loss, then it is the sum of three strong losses. Each loss has a pixel-level strong constraint on the image data, which will lead to conflicts and contradictions. Therefore, we use the mean square error function to constrain the loss of high frequency information and reconstruction. Then, the downsampled image is used as the beacon of low frequency image data distribution, and its data distribution is guided by the adversarial loss function .
| (8) |
where is the low-frequency semantic image generated by the network, is the low-frequency blurred image obtained by downsampling the source image twice, and is the adversarial loss.
| (9) | |||
where , and represents the number of images. Here we use the loss function defined in LSGAN [24].
In Equ. 6, is the image content reconstruction loss of the reconstructed image. It consists of two elements. One is the pixel-level reconstruction loss , and the other is the structural similarity loss as follows:
| (10) |
where is a hyper-parameter that balances the two losses. and are calculated as follows:
| (11) | ||||
As shown in the Fig. 7, the total loss function is given as follows:
| (12) | |||
are the hyper-parameters used for balancing the three losses.
III-C Image Fusion
Once the system is trained, each test image is first decomposed, as shown in Fig. 9. The fusion strategy (”FS” in Fig.9) fuses the corresponding feature images. These are then reconstructed to obtain the final fused image.

In particular, in Fig.9, and represent infrared and visible light image respectively. The two images are fed into the decomposition network to obtain two sets of feature images. One group of feature images comes from the visible light images, including three visible light high-frequency images (, , ) and one visible light low-frequency image (). Another group of feature images comes from infrared images, comprising three infrared high-frequency images (, , ) and one infrared low frequency image (). For the corresponding four groups of feature images, our fusion strategy offers a variety of options to obtain the final fused image as discussed in the following subsection.
III-D Fusion strategy
We design a fusion strategy to get a fused image. As shown in the Fig.8, we first use the decomposition network to decompose the visible light image and the infrared image to obtain two sets of high and low frequency feature images. The corresponding high-frequency and low-frequency feature images (such as and ) are fused using different specific fusion strategies to obtain fused high-frequency feature images and low-frequency feature images (, , , ). Finally, the fusion feature image is added pixel by pixel to obtain the fused image , which is the same as reconstructing an image in the training phase.
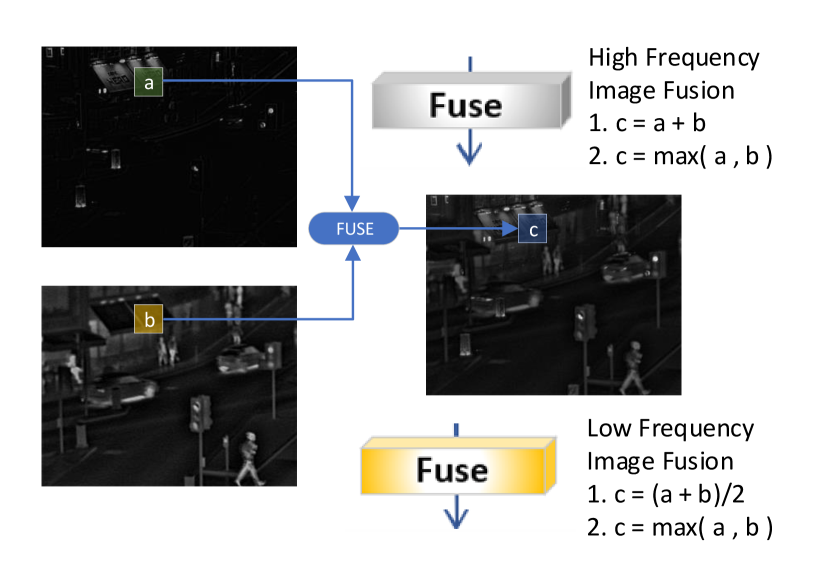
We used two fusion strategies for both high-frequency image fusion, and low-frequency image fusion, namely, pixel-wise averaging (avg) and pixel wise max pooling (max) as shown in Fig.10.

The formulas for high frequency feature fusion and low frequency feature fusion are given as follows:
| (13) | |||||
where represents the high-frequency image index, and denotes the number of pixels in the image. and represent a pixel in the corresponding three groups of high-frequency images, and and are the pixels in the low-frequency image. We calculate and fuse the corresponding pixels to produce the fused high frequency image and low frequency image . Finally, the three fusion features are added to obtain the final fused image as follows:
| (14) |
IV EXPERIMENTS AND ANALYSIS
IV-A Training and Testing Details
The choice of hyper-parameters is guided by the requirement to maintain the contributions to the final loss values of the same order of magnitude. Accordingly, in formula 12, we set = 0.1, = 100, = 10 by cross validation.
Our goal is to train a powerful decomposition network that can decompose images into high-frequency and low-frequency components. In this sense, our input images in the training phase are not limited to multi-modal image data. We can also use MS-COCO[25] and Imagenet[26] or other images to achieve this goal. In our experiment, we use MS-COCO as the training set to design our decomposition network. We select about 80,000 images as input images. These images are converted to gray scale images which are then resized to 256256.
For the infrared image and visible light image fusion task, we use the TNO dataset [27] and the RoadScene dataset [28]. For the RoadScene dataset, we convert the images to gray scale to keep the the visible light image channels consistent with infrared image. For the multi-focus image fusion task, we use the Lytro dataset [29]. The Lytro image are split according to the RGB channels to obtain three pairs of images. The fusion result is merged according to the RGB to obtain a fused image. For the medical image fusion task, we use the Harvard dataset[30]. For the multi-focus image fusion task, we use the dataset in [31].
We input batchsize of 64 images to the network every iteration. And, we select Adam[32] optimiser with an adaptive learning rate decay method[33] as the learning rate scheduler. We set the initial learning rate to 1e-3, the attenuation factor to 0.5, the stopping criterion to 5 iterations, and the minimum learning rate threshold to 1e-8. We set the maximum number of epoches to 1000.
In the test phase, because our network is fully convolutional, we input infrared images and visible light images without preprocessing operations.
The experiment is conducted on the two NVIDIA TITAN Xp GPUs and 128GB of CPU memory. We decompose 1000 images with 256256 resolution one by one and calculate the average calculation time. It takes about 2ms to decompose each image.
IV-B The role of the adversarial loss
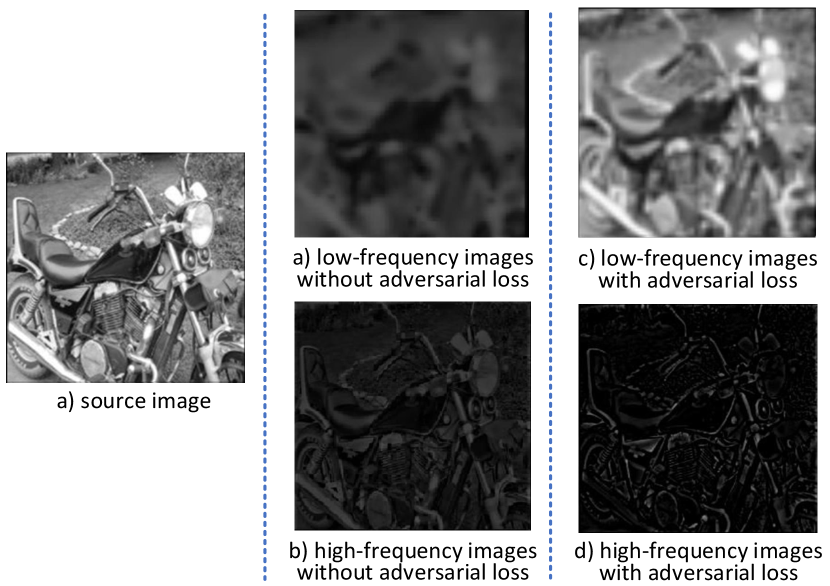
As shown in Fig 11(a), it is difficult for the network to learn to extract the semantic low-frequency content, if we do not impose constraints on the low-frequency image . More crucially, low-frequency images tend to lose important semantic information.
As shown in Fig 11(b), without the adversarial loss, the high-frequency images will contain some information that should not appear, such as the brightness, contrast, colors distribution and other semantic information, which are not high-frequency information.
In order to allow the block to learn the useful low-frequency information, we guide it using weak supervision loss. As in Equ. 9, we regard the down-sampled image as an approximate solution of the low-frequency image, so that the low-frequency image generated by the network follows the distribution of low-frequency images.
As shown in 11(c and d), the high-frequency images do not learn wrong low-frequency information, and the low-frequency images contain almost all low-frequency semantic information.
IV-C The details of the decomposed images

Although the loss function of our high-frequency image is calculated with reference to a gradient map produced by the Laplacian operator, there is some discrepancy between them. In Fig 12, we present the high-frequency images decomposed by the proposed decomposition network and the Laplacian operator. It can be seen that the Laplacian gradient images only extract part of the high-frequency information content, and the image has a lot of noise.
The high-frequency image decomposed by our decomposition network not only retains almost all high-frequency information content, but also extracts the object contour and other detailed information. Thus our high-frequency images contain a certain degree of semantic information for recognition.
IV-D Comparison with State of The Art Methods
We select ten classic and state of the art fusion methods to compare with our proposed method, including Curvelet Transform (CVT)[34], dualtree complex wavelet transform (DTCWT)[35], Laplacian Pyramid (LP)[36], Ratio of Low-pass Pyramid (RP)[37], DenseFuse[13], the GAN-based fusion network (FusionGAN)[22], a general end-to-end fusion network(IFCNN)[14], ResNetFusion [38], NestFuse[16], HybridMSD [39], PMGI [40], FusionDN[28], U2Fusion[41], MDLatLRR[10], Guided Filtering Fusion(GFF)[42], MEF-GAN[43], Guided Filter focus region detection(GFDF)[44], Convolutional Sparse Representation(CSR)[45], Cross Bilateral Filter fusion method(CBF)[46], Discrete Cosine Harmonic Wavelet Transform(DCHWT)[47] and Multi-resolution Singular Value Decomposition (MSVD)[48]. We use the publicly available codes of these methods and the parameters recommended by their inventors to obtain the fused images.
As there are currently no generally agreed evaluation indicators to measure the quality of the fused image, we will use several objective measures for a comprehensive comparison, as well as a subjective evaluation.
IV-D1 Subjective and objective evaluation
In different fields, for different tasks, everyone has his/her own criteria for judging. We focus on the subjective impression of each picture, such as lightness, fidelity, noise, and clarity etc. We report the results of all approaches and highlight some specific local areas.
Subjective feelings are good indicators of the fusion performance. However, they cannot be a basis of objective evaluation. We select fifteen objective evaluation indicators from the popular objective indicators in the literature for a comprehensive evaluation. They are: Edge Intensity(EI)[49], Cross Entropy(CE)[47], SF[50], Structural SIMilarity (SSIM) [51], modified structural similarity (MS-SSIM)[52], Entropy (EN)[53], Sum of Correlation Coefficients (SCD)[54], Fast Mutual Information ( and )[55], Mutual Information ()[56], Standard Deviation of Image (SD)[57],, Definition (DF)[58], Average gradient (AG)[59] [47], Revised Mutual Information ()[60], [61], Nonlinear Correlation Information Entropy ()[62], correlation coefficient (CC)[63], Phase Congruency Measurement ()[64] [65], [66], [66],[67] and [49] respectively.
The objective evaluation indicators are cluster into two categories. One group evaluates the fused image by calculating measures such as edge(EI), the number of mutations in the image(SF), average gradient(AG), entropy (EN), clarity(DF), Cross Entropy(CE), and contrast of the image(SD), . The other group evaluates the fused image by comparison with the source image. Examples include the mutual information (MI, and ),Structural SIMilarity (SSIM, MS-SSIM) and a more complex evaluation method (, , , , and ).
SCD and CC calculates the correlation coefficients between images. SSIM and calculate the similarity between images. calculate the mutual information between features. represents the ratio of noise added to the final image. EN measure the amount of information. VIFF is used to measure the loss of image information to the distortion process. CrossEntropy and MI measure the degree of information correlation between images.
Among them, the lower the value of the and the CE and the higher other values, the better the fusion quality of the approach.
We compare the proposed method with other benchmarking methods. The results of the average values computed over all fused images are shown in Tables. The best value in the quality table is made bold in red and bold, and the second best value is given in bold and italic.
IV-D2 Visible and Infrared Image Fusion
As shown in Fig. 14(r) and Fig. 14(q and r), it can be observed that our method has more texture features and is easier to identify small objects. In TNO dataset, our results can distinguish infrared and visible objects, and reflect more details, such as texture of branches in the sky. And in the RoadScene dataset, the distant people in our results have a clearer outline.
As shown in Table II, it can be seen that our results rank in top 2 in multiple indicators. Other indicators are also better than most methods. It can be demonstrated that our method maintains a effective structural similarity with the source images, preserving a large information correlation with the source images, without introducing noise, artifacts, etc.
Comprehensive analysis from subjective and objective evaluation shows that the strategy can achieve better results for infrared and visible light image fusion tasks.
IV-D3 Multi-exposure Image Fusion
As shown in Fig. 15(m and k), it can be observed from the green salient box that our results can well fuse the details of small objects in different exposure environments. Most methods have completely lost the detail information. At the same time, our results look clearer for the exposure and contrast fusion of the whole environment. As shown in the Table IV, our method can achieve the best results in some indicators, and other indicators are more than half of the methods.
Considering comprehensively, for multi-exposure image fusion task, our method with ”add+avg” strategy can get better results .
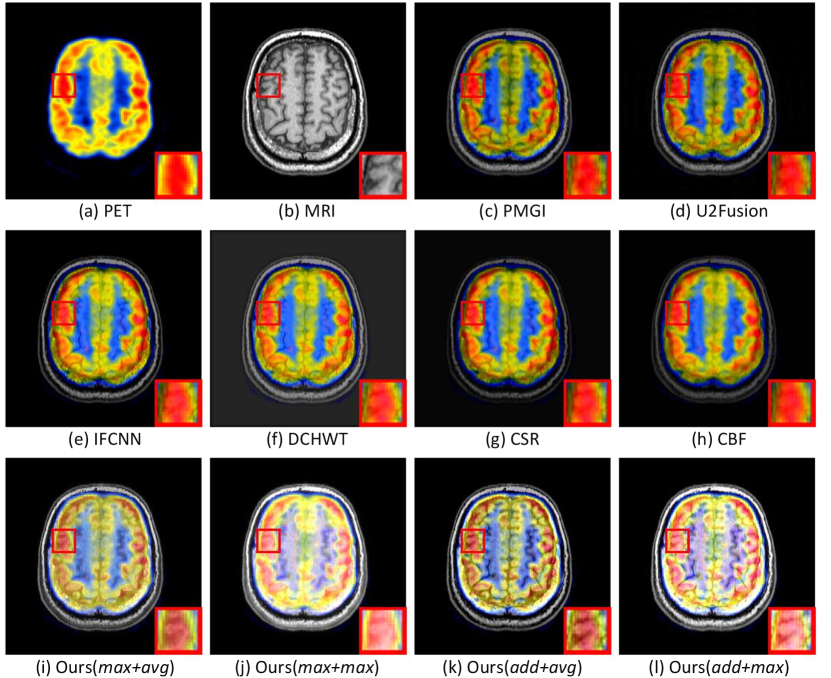
IV-D4 Medical Image Fusion
As shown in Fig. 15(k and i), the texture information of brain folds in MRI images is preserved in our medical image results, while other methods lose a lot of texture information. Although the distribution of PET very important, the MRI texture information is more important. The (k)(add+avg) result perfectly fuses the information of both, but the PET information of the (i)(add+max) result is a little distorted.
It can be seen from Table V that the ”add+avg” and ”add+max” strategies have obtained the top two of most indicators. But considering the influence of subjective evaluation, on the whole, using ”add+avg” strategy can better accomplish the medical image fusion task.
IV-D5 Multi-focus Image Fusion
As shown in Fig. 17(k), using add+avg strategy, our result image can capture images with different focal lengths very clearly. As shown in Table VI, it can be seen that our results rank in top 2 in multiple indicators. Other indicators are also better than most methods.
Especially, the result with ”add+avg” strategy is the best in several indicators. Obviously, for the multi-focus image fusion task, our method using ”add+avg” strategy can get better results compared with other methods.
IV-D6 Image Fusion
We do experiments on four different image fusion tasks on five datasets. It is concluded that our method with ”add+avg” and ”add+max” strategy can accomplish most of the fusion tasks and get better results. This is also a matter of course, because the high frequency information of different source images should be different. For example, details of infrared images and visible images describe different texture features of different objects. More notably, when applied to multi-focus image tasks, the details are not distributed in same place. Therefore, it is feasible and effective to use addition operation for high frequency information.




| Methods | EI | CE | SF | SCD | SSIM | SD | DF | AG | |||||||
| CVT | 42.9631 | 1.5894 | 11.1129 | 1.5812 | 0.3945 | 0.7025 | 0.8963 | 0.0275 | 27.4613 | 5.4530 | 0.2267 | 0.8033 | 4.2802 | 1.4707 | |
| DTCWT | 42.4889 | 1.6235 | 11.1296 | 1.5829 | 0.3936 | 0.7057 | 0.9053 | 0.0232 | 27.3099 | 5.4229 | 0.2385 | 0.8034 | 4.2370 | 1.5428 | |
| LP | 44.7055 | 1.4291 | 11.5391 | 1.5920 | 0.3558 | 0.7037 | 0.9404 | 0.0237 | 30.5623 | 5.7422 | 0.2420 | 0.8035 | 4.4690 | 1.5845 | |
| RP | 44.9054 | 1.3420 | 12.7249 | 1.5769 | 0.2631 | 0.6705 | 0.8404 | 0.0583 | 28.8385 | 6.1799 | 0.2227 | 0.8032 | 4.6013 | 1.4390 | |
| DenseFuse | 36.4838 | 1.4015 | 9.3238 | 1.5329 | 0.3897 | 0.7108 | 0.8692 | 0.0352 | 38.0412 | 4.6176 | 0.4487 | 0.8077 | 3.6299 | 3.0035 | |
| FusionGan | 32.5997 | 1.9353 | 8.0476 | 0.6876 | 0.4142 | 0.6235 | 0.6135 | 0.0352 | 29.1495 | 4.2727 | 0.2766 | 0.8039 | 3.2803 | 1.7975 | |
| IFCNN | 44.9725 | 1.4413 | 11.8590 | 1.6126 | 0.3739 | 0.7168 | 0.9129 | 0.0346 | 33.0086 | 5.9808 | 0.3419 | 0.8051 | 4.5521 | 2.2513 | |
| ResNetFusion | 26.2360 | 1.6188 | 5.9182 | 0.1937 | 0.1003 | 0.4560 | 0.3030 | 0.0550 | 46.9280 | 2.5853 | 0.1211 | 0.8027 | 2.4010 | 0.8014 | |
| NestFuse | 37.5627 | 1.4463 | 9.5383 | 1.5742 | 0.3702 | 0.7057 | 0.8816 | 0.0428 | 37.3780 | 4.7890 | 0.4672 | 0.8077 | 3.7475 | 3.1049 | |
| HybridMSD | 46.3200 | 1.3157 | 12.3459 | 1.5773 | 0.3207 | 0.7094 | 0.9276 | 0.0435 | 31.2742 | 6.0954 | 0.2567 | 0.8039 | 4.6878 | 1.6987 | |
| PMGI | 37.2133 | 1.5656 | 8.7194 | 1.5738 | 0.3949 | 0.6976 | 0.8684 | 0.0340 | 33.0167 | 4.4328 | 0.3021 | 0.8046 | 3.6223 | 2.0237 | |
| U2Fusion | 48.4915 | 1.3255 | 11.0368 | 1.5946 | 0.3381 | 0.6758 | 0.9147 | 0.0800 | 31.3794 | 5.8343 | 0.2490 | 0.8035 | 4.7392 | 1.6460 | |
| max+avg | 29.8401 | 1.7925 | 7.9033 | 1.5954 | 0.2618 | 0.7253 | 0.8554 | 0.0083 | 25.3466 | 3.9337 | 0.2661 | 0.8037 | 3.0034 | 1.7100 | |
| max+max | 33.3120 | 1.3613 | 8.3395 | 1.6093 | 0.2576 | 0.6911 | 0.8347 | 0.0183 | 38.5507 | 4.1666 | 0.4812 | 0.8079 | 3.2861 | 3.1549 | |
| add+avg | 46.0796 | 1.4945 | 12.0109 | 1.6364 | 0.4171 | 0.7193 | 0.9196 | 0.0457 | 27.5005 | 6.1199 | 0.2396 | 0.8034 | 4.6589 | 1.5612 | |
| Ours | add+max | 48.6587 | 1.2340 | 12.3736 | 1.6547 | 0.4075 | 0.6962 | 0.8978 | 0.0565 | 39.9552 | 6.2775 | 0.3618 | 0.8057 | 4.8675 | 2.4344 |
| Methods | EI | CE | SF | SCD | SSIM | SD | DF | AG | |||||||
| CVT | 59.7642 | 1.1498 | 14.7379 | 1.3418 | 0.3631 | 0.6641 | 0.8721 | 0.0318 | 36.0884 | 6.9618 | 0.2994 | 0.8056 | 5.7442 | 2.1473 | |
| DTCWT | 57.3431 | 1.2475 | 14.7318 | 1.3329 | 0.2383 | 0.6567 | 0.8725 | 0.0412 | 34.7264 | 6.7810 | 0.3280 | 0.8060 | 5.5228 | 2.3358 | |
| LP | 59.5437 | 1.1479 | 15.3634 | 1.3617 | 0.3092 | 0.6875 | 0.9110 | 0.0250 | 37.3478 | 7.1062 | 0.3432 | 0.8064 | 5.7627 | 2.4641 | |
| RP | 50.8057 | 1.1250 | 19.1529 | 1.2829 | 0.2624 | 0.6341 | 0.8297 | 0.0773 | 38.4519 | 8.8084 | 0.3024 | 0.8057 | 6.1410 | 2.1717 | |
| DenseFuse | 34.0135 | 1.0665 | 8.5541 | 1.3491 | 0.3801 | 0.6928 | 0.8529 | 0.0125 | 44.0963 | 5.6010 | 0.4309 | 0.8079 | 3.2740 | 3.0226 | |
| FusionGan | 35.4048 | 1.8991 | 8.6400 | 0.8671 | 0.3609 | 0.6142 | 0.7352 | 0.0168 | 42.3040 | 3.9243 | 0.4067 | 0.8077 | 3.3469 | 2.9564 | |
| IFCNN | 57.6653 | 1.1486 | 15.0677 | 1.3801 | 0.3456 | 0.6746 | 0.8798 | 0.0315 | 35.8183 | 7.0401 | 0.4212 | 0.8076 | 5.6242 | 2.9980 | |
| ResNetFusion | 39.4317 | 1.1539 | 8.4967 | 0.2179 | 0.1034 | 0.3599 | 0.2363 | 0.0550 | 66.8924 | 3.8041 | 0.2316 | 0.8046 | 3.6011 | 1.6695 | |
| NestFuse | 53.9286 | 1.3026 | 14.2820 | 1.2597 | 0.3484 | 0.6679 | 0.8272 | 0.0432 | 48.9920 | 6.2840 | 0.5141 | 0.8098 | 5.1834 | 3.7602 | |
| HybridMSD | 62.2138 | 1.1032 | 16.4475 | 1.2642 | 0.2887 | 0.6961 | 0.9127 | 0.0460 | 37.1333 | 7.5600 | 0.3429 | 0.8061 | 6.0725 | 2.4377 | |
| PMGI | 47.2067 | 1.6395 | 10.9368 | 1.0989 | 0.3644 | 0.6640 | 0.8926 | 0.0146 | 49.3262 | 5.1288 | 0.4657 | 0.8100 | 4.4426 | 3.4343 | |
| U2Fusion | 66.2529 | 1.4806 | 15.8242 | 1.3551 | 0.3199 | 0.6813 | 0.9150 | 0.0671 | 42.9368 | 7.5930 | 0.3929 | 0.8075 | 6.3133 | 2.8624 | |
| max+avg | 39.5260 | 1.2660 | 10.7887 | 1.3488 | 0.2312 | 0.6938 | 0.8236 | 0.0095 | 31.8339 | 4.8193 | 0.3675 | 0.8065 | 3.8632 | 2.5851 | |
| max+max | 39.6608 | 1.0061 | 10.6186 | 1.3311 | 0.2217 | 0.6741 | 0.7550 | 0.0123 | 39.6899 | 4.7187 | 0.5343 | 0.8098 | 3.8444 | 3.7182 | |
| add+avg | 64.6144 | 1.3276 | 16.5089 | 1.4158 | 0.3879 | 0.6892 | 0.9166 | 0.0605 | 35.9280 | 7.7619 | 0.3453 | 0.8063 | 6.2778 | 2.4657 | |
| Ours | add+max | 64.1570 | 1.0596 | 16.2412 | 1.4129 | 0.3676 | 0.6700 | 0.8446 | 0.0653 | 42.3352 | 7.6144 | 0.3994 | 0.8070 | 6.2102 | 2.8425 |
| Methods | EI | CE | SF | SSIM | DF | AG | CC | ||||||
| U2Fusion | 76.2068 | 3.6551 | 23.1641 | 0.4123 | 0.4475 | 0.5474 | 0.9393 | 0.1107 | 9.4715 | 0.5648 | 7.4982 | 1.0131 | |
| GFF | 72.9816 | 2.4105 | 23.2912 | 0.4752 | 0.5094 | 0.5614 | 0.7765 | 0.0444 | 9.7177 | 0.7704 | 7.3722 | 0.6247 | |
| PMGI | 69.9908 | 3.4868 | 23.7738 | 0.4883 | 0.5370 | 0.5547 | 0.9361 | 0.1076 | 9.7482 | 0.5954 | 7.2044 | 1.0125 | |
| IFCNN | 68.9809 | 3.9597 | 25.6184 | 0.4794 | 0.5202 | 0.6024 | 0.9532 | 0.0585 | 10.6159 | 0.7092 | 7.3755 | 0.9683 | |
| MEF-GAN | 58.1997 | 2.6383 | 15.9812 | 0.2598 | 0.2559 | 0.5059 | 0.8269 | 0.0847 | 6.4662 | 0.4287 | 5.5098 | 0.9670 | |
| GFDF | 73.5531 | 1.8508 | 24.2111 | 0.4774 | 0.4575 | 0.5750 | 0.8502 | 0.0476 | 9.7459 | 0.8349 | 7.4140 | 0.6347 | |
| DeepFuse | 58.4911 | 3.4316 | 19.7907 | 0.4901 | 0.5433 | 0.5814 | 0.9570 | 0.0371 | 7.9679 | 0.6248 | 5.9601 | 1.0244 | |
| FusionDN | 68.8311 | 3.2806 | 22.0760 | 0.5558 | 0.5340 | 0.5781 | 0.7903 | 0.0190 | 9.2019 | 0.8081 | 6.9623 | 0.6147 | |
| max+avg | 43.1195 | 2.2750 | 14.8597 | 0.4296 | 0.4361 | 0.6037 | 0.9108 | 0.0023 | 5.7758 | 0.6302 | 4.3684 | 0.9703 | |
| max+max | 35.5574 | 1.2851 | 12.1623 | 0.4387 | 0.4060 | 0.5900 | 0.8328 | 0.0039 | 4.5982 | 0.8444 | 3.5538 | 1.0246 | |
| add+avg | 79.2416 | 3.6129 | 27.2045 | 0.5275 | 0.5442 | 0.5796 | 0.9502 | 0.0932 | 11.1081 | 0.6924 | 8.1807 | 0.9782 | |
| Ours | add+max | 69.2224 | 2.7025 | 24.1946 | 0.4942 | 0.5006 | 0.5940 | 0.9000 | 0.0671 | 9.6762 | 0.7376 | 7.1423 | 0.9382 |
| Methods | EI | SF | SSIM | VIF | SD | DF | |||||||
| PMGI | 62.0459 | 18.4579 | 0.1927 | 0.1778 | 0.1468 | 0.1396 | 0.5801 | 0.7838 | 0.0249 | 0.2634 | 52.7224 | 7.2918 | |
| U2Fusion | 46.2968 | 14.3793 | 0.1546 | 0.2154 | 0.1712 | 0.2005 | 0.5696 | 0.7981 | 0.0191 | 0.3018 | 57.6757 | 5.2656 | |
| IFCNN | 61.5885 | 20.2496 | 0.2006 | 0.2149 | 0.1424 | 0.5780 | 0.6090 | 0.7881 | 0.0309 | 0.3351 | 64.2122 | 7.2945 | |
| DCHWT | 57.5602 | 18.3965 | 0.1891 | 0.1607 | 0.1486 | 0.5531 | 0.6085 | 0.7898 | 0.0222 | 0.2919 | 56.6969 | 6.8922 | |
| CSR | 61.5017 | 19.1411 | 0.1908 | 0.2071 | 0.1386 | 0.5629 | 0.5902 | 0.7826 | 0.0299 | 0.2871 | 55.2012 | 7.1761 | |
| CBF | 61.4869 | 19.1834 | 0.1962 | 0.2157 | 0.1472 | 0.5695 | 0.6012 | 0.7909 | 0.0291 | 0.2983 | 56.2595 | 7.0992 | |
| max+avg | 71.8719 | 24.7649 | 0.5056 | 0.4066 | 0.2948 | 0.7254 | 0.9108 | 0.8382 | 0.0044 | 0.5158 | 77.8777 | 8.7039 | |
| max+max | 74.5375 | 25.2957 | 0.5022 | 0.3818 | 0.2888 | 0.7086 | 0.8570 | 0.8396 | 0.0058 | 0.5881 | 95.7545 | 8.8149 | |
| add+avg | 95.9522 | 31.1427 | 0.5906 | 0.4866 | 0.4086 | 0.7423 | 0.9298 | 0.8433 | 0.0279 | 0.6635 | 77.0983 | 11.7871 | |
| Ours | add+max | 98.6637 | 32.1464 | 0.6054 | 0.4833 | 0.4147 | 0.7408 | 0.8932 | 0.8505 | 0.0240 | 0.7373 | 93.8827 | 12.0055 |
| Methods | AG | MI | QG | CC | VIFF | ||||||||
| PMGI | 0.4978 | 0.1678 | 0.8048 | 6.0292 | 2.2892 | 0.4282 | 0.8613 | 0.1660 | 0.0574 | 0.2029 | 0.0130 | 0.2800 | |
| U2Fusion | 0.5786 | 0.2102 | 0.8052 | 4.3710 | 2.4827 | 0.4892 | 0.8718 | 0.1840 | 0.0646 | 0.1611 | 0.0045 | 0.2937 | |
| IFCNN | 0.5735 | 0.5399 | 0.8051 | 5.9112 | 2.4056 | 0.5445 | 0.8625 | 0.2029 | 0.0602 | 0.1919 | 0.0138 | 0.5737 | |
| DCHWT | 0.4911 | 0.5243 | 0.8046 | 5.5238 | 2.2234 | 0.3233 | 0.8634 | 0.1878 | 0.0624 | 0.2025 | 0.0147 | 0.4463 | |
| CSR | 0.5144 | 0.5309 | 0.8046 | 5.8969 | 2.2151 | 0.4894 | 0.8529 | 0.1731 | 0.0489 | 0.1957 | 0.0153 | 0.5661 | |
| CBF | 0.5471 | 0.5374 | 0.8048 | 5.8732 | 2.2932 | 0.5429 | 0.8574 | 0.1836 | 0.0536 | 0.2032 | 0.0163 | 0.5740 | |
| max+avg | 0.5879 | 0.8270 | 0.8056 | 6.9650 | 2.6338 | 0.6631 | 0.9125 | 0.4378 | 0.3115 | 0.7888 | 0.5188 | 0.5909 | |
| max+max | 0.6177 | 0.7958 | 0.8061 | 7.1472 | 2.8014 | 0.6417 | 0.9025 | 0.4319 | 0.2910 | 0.7865 | 0.5394 | 0.5537 | |
| add+avg | 0.5766 | 0.8624 | 0.8052 | 9.3113 | 2.4738 | 0.7313 | 0.9090 | 0.4509 | 0.3367 | 0.8246 | 0.7171 | 0.6485 | |
| Ours | add+max | 0.6210 | 0.8604 | 0.8060 | 9.5239 | 2.7425 | 0.7311 | 0.9095 | 0.4566 | 0.3642 | 0.8674 | 0.7579 | 0.6308 |
| Methods | EI | CE | SF | EN | SSIM | VIF | EN | DF | AG | VIFF | ||||
| CNN | 74.8426 | 0.2176 | 20.5655 | 7.5498 | 0.4410 | 0.3845 | 0.8303 | 0.0561 | 1.2668 | 7.5498 | 8.6838 | 7.2248 | 1.0196 | |
| DCHWT | 68.8342 | 0.2129 | 19.1235 | 7.5385 | 0.4225 | 0.3959 | 0.8438 | 0.0152 | 1.1401 | 7.5385 | 8.0241 | 6.6455 | 0.9646 | |
| PMGI | 54.3821 | 0.3815 | 13.6508 | 7.5314 | 0.3751 | 0.3430 | 0.8196 | 0.0122 | 1.1511 | 7.5314 | 5.8043 | 5.0955 | 0.9634 | |
| U2Fusion | 75.6982 | 0.3294 | 19.1046 | 7.5275 | 0.3632 | 0.3104 | 0.7795 | 0.0519 | 1.4957 | 7.5275 | 8.1977 | 7.1401 | 1.1211 | |
| IFCNN | 73.2405 | 0.2225 | 20.3514 | 7.5432 | 0.4148 | 0.3716 | 0.8367 | 0.0429 | 1.1924 | 7.5432 | 8.5298 | 7.0835 | 0.9852 | |
| CSR | 68.1733 | 0.2762 | 18.6452 | 7.5221 | 0.4153 | 0.3446 | 0.7984 | 0.0346 | 1.2672 | 7.5329 | 8.1495 | 6.4281 | 0.9875 | |
| max+avg | 50.0733 | 0.0403 | 13.1598 | 7.4942 | 0.3513 | 0.2487 | 0.8535 | 0.0046 | 0.8481 | 7.4942 | 5.5959 | 4.7698 | 0.7489 | |
| max+max | 49.5689 | 0.0765 | 12.8854 | 7.4911 | 0.3451 | 0.2466 | 0.8404 | 0.0059 | 0.7974 | 7.4911 | 5.5495 | 4.7246 | 0.7112 | |
| add+avg | 79.8711 | 0.0893 | 20.9724 | 7.5851 | 0.4637 | 0.4032 | 0.8146 | 0.0622 | 1.4421 | 7.5851 | 9.0202 | 7.6387 | 1.0453 | |
| Ours | add+max | 79.1167 | 0.0967 | 20.6914 | 7.5819 | 0.4593 | 0.3968 | 0.8117 | 0.0590 | 1.3709 | 7.5819 | 8.9609 | 7.5732 | 1.0063 |
V CONCLUSIONS
We developed a decomposition network fusion framework for fusing infrared and visible light images. It includes a novel multi-network for image decomposition. With the help of the decomposition network, the infrared image and the visible light image are decomposed into multiple high-frequency feature images and a low-frequency feature image, respectively. The corresponding feature maps are fused using a specific fusion strategy to obtain the fused feature maps. Finally, the fused band pass images reconstructed from the fused feature maps are added pixel by pixel to obtain the final fused image. The proposed image decomposition network is universal, and can be extended for use with any number of images. In any case, the decomposition neural networks can use GPUs for matrix calculation acceleration.
We performed subjective and objective evaluation of the proposed method. The experimental results show that the advocated method achieves the state of the art performance. The advantage of the proposed approach is the simplicity of the network structure. The subjective evaluation suggests that our CNN extracts the semantics of the image and filters out the noise, while preserving the edges, and other high-frequency information. We intend to study image decomposition based on deep learning, to simplify the complex image decomposition calculations such as wavelet transformation, low-rank decomposition, etc. We will also explore other network structures and address different applications. The network we proposed can be used for different image processing tasks, including multi-focus fusion, medical image fusion, multi-exposure fusion, and some basic computer vision tasks such as detection, recognition, and classification.
References
- [1] Y. Liu, X. Chen, Z. Wang, Z. J. Wang, R. K. Ward, and X. Wang, “Deep learning for pixel-level image fusion: Recent advances and future prospects,” Information Fusion, vol. 42, pp. 158–173, 2018.
- [2] T. Mertens, J. Kautz, and F. Van Reeth, “Exposure fusion: A simple and practical alternative to high dynamic range photography,” Computer Graphics Forum, vol. 28, no. 1, pp. 161–171, 2009.
- [3] Z. Zhang and R. S. Blum, “A categorization of multiscale-decomposition-based image fusion schemes with a performance study for a digital camera application,” Proceedings of the IEEE, vol. 87, no. 8, pp. 1315–1326, 1999.
- [4] K. P. Upla, M. V. Joshi, and P. P. Gajjar, “An edge preserving multiresolution fusion: Use of contourlet transform and mrf prior,” IEEE Transactions on Geoscience and Remote Sensing, vol. 53, no. 6, pp. 3210–3220, 2014.
- [5] A. B. Hamza, Y. He, H. Krim, and A. S. Willsky, “A multiscale approach to pixel-level image fusion,” Computer-Aided Engineering, vol. 12, no. 2, pp. 135–146, 2005.
- [6] J.-j. Zong and T.-s. Qiu, “Medical image fusion based on sparse representation of classified image patches,” Biomedical Signal Processing and Control, vol. 34, pp. 195–205, 2017.
- [7] Q. Zhang, Y. Fu, H. Li, and J. Zou, “Dictionary learning method for joint sparse representation-based image fusion,” Optical Engineering, vol. 52, no. 5, p. 057006, 2013.
- [8] Y. Bin, Y. Chao, and H. Guoyu, “Efficient image fusion with approximate sparse representation,” International Journal of Wavelets, Multiresolution and Information Processing, vol. 14, no. 04, p. 1650024, 2016.
- [9] H. Li and X.-J. Wu, “Multi-focus image fusion using dictionary learning and low-rank representation,” in International Conference on Image and Graphics. Springer, 2017, pp. 675–686.
- [10] H. Li, X.-J. Wu, and J. Kittler, “Mdlatlrr: A novel decomposition method for infrared and visible image fusion,” IEEE Transactions on Image Processing, 2020.
- [11] Y. Liu, X. Chen, H. Peng, and Z. Wang, “Multi-focus image fusion with a deep convolutional neural network,” Information Fusion, vol. 36, pp. 191–207, 2017.
- [12] K. R. Prabhakar, V. S. Srikar, and R. V. Babu, “Deepfuse: A deep unsupervised approach for exposure fusion with extreme exposure image pairs.” in ICCV, 2017, pp. 4724–4732.
- [13] H. Li and X.-J. Wu, “Densefuse: A fusion approach to infrared and visible images,” IEEE Transactions on Image Processing, vol. 28, no. 5, pp. 2614–2623, 2018.
- [14] Y. Zhang, Y. Liu, P. Sun, H. Yan, X. Zhao, and L. Zhang, “Ifcnn: A general image fusion framework based on convolutional neural network,” Information Fusion, vol. 54, pp. 99–118, 2020.
- [15] Y. Fu, X.-J. Wu, and T. Durrani, “Image fusion based on generative adversarial network consistent with perception,” Information Fusion, 2021.
- [16] H. Li, X.-J. Wu, and T. Durrani, “Nestfuse: An infrared and visible image fusion architecture based on nest connection and spatial/channel attention models,” IEEE Transactions on Instrumentation and Measurement, 2020.
- [17] Y. Fu, T. Xu, X. Wu, and J. Kittler, “Ppt fusion: Pyramid patch transformerfor a case study in image fusion,” arXiv preprint arXiv:2107.13967, 2021.
- [18] Y. Fu and X.-J. Wu, “A dual-branch network for infrared and visible image fusion,” in 2020 25th International Conference on Pattern Recognition (ICPR). IEEE, 2021, pp. 10 675–10 680.
- [19] H. Li, B. S. Manjunath, and S. K. Mitra, “Multisensor image fusion using the wavelet transform,” Graphical Models and Image Processing, vol. 57, no. 3, pp. 235–245, 1995.
- [20] L. J. Chipman, T. M. Orr, and L. N. Graham, “Wavelets and image fusion,” in Proceedings., International Conference on Image Processing, vol. 3. IEEE, 1995, pp. 248–251.
- [21] G. Liu and S. Yan, “Latent low-rank representation for subspace segmentation and feature extraction,” in 2011 international conference on computer vision. IEEE, 2011, pp. 1615–1622.
- [22] J. Ma, W. Yu, P. Liang, C. Li, and J. Jiang, “Fusiongan: A generative adversarial network for infrared and visible image fusion,” Information Fusion, vol. 48, pp. 11–26, 2019.
- [23] A. L. Maas, A. Y. Hannun, and A. Y. Ng, “Rectifier nonlinearities improve neural network acoustic models,” in Proc. icml, vol. 30, no. 1, 2013, p. 3.
- [24] X. Mao, Q. Li, H. Xie, R. Y. Lau, Z. Wang, and S. Paul Smolley, “Least squares generative adversarial networks,” in Proceedings of the IEEE international conference on computer vision, 2017, pp. 2794–2802.
- [25] T.-Y. Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Dollár, and C. L. Zitnick, “Microsoft coco: Common objects in context,” in European conference on computer vision. Springer, 2014, pp. 740–755.
- [26] J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, “Imagenet: A large-scale hierarchical image database,” in 2009 IEEE conference on computer vision and pattern recognition. Ieee, 2009, pp. 248–255.
- [27] A. Toet et al., “Tno image fusion dataset,” Figshare. data, 2014.
- [28] H. Xu, J. Ma, Z. Le, J. Jiang, and X. Guo, “Fusiondn: A unified densely connected network for image fusion.” in AAAI, 2020, pp. 12 484–12 491.
- [29] M. Nejati, S. Samavi, and S. Shirani, “Multi-focus image fusion using dictionary-based sparse representation,” Information Fusion, vol. 25, pp. 72–84, 2015.
- [30] Harvard, “[online],” http://www.med.harvard.edu/Aanlib/.
- [31] J. Cai, S. Gu, and L. Zhang, “Learning a deep single image contrast enhancer from multi-exposure images,” IEEE Transactions on Image Processing, vol. 27, no. 4, pp. 2049–2062, 2018.
- [32] D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” arXiv: Learning, 2014.
- [33] M. D. Zeiler, “Adadelta: An adaptive learning rate method,” arXiv: Learning, 2012.
- [34] F. Nencini, A. Garzelli, S. Baronti, and L. Alparone, “Remote sensing image fusion using the curvelet transform,” Information fusion, vol. 8, no. 2, pp. 143–156, 2007.
- [35] J. J. Lewis, R. J. Callaghan, S. G. Nikolov, D. R. Bull, and N. Canagarajah, “Pixel-and region-based image fusion with complex wavelets,” Information fusion, vol. 8, no. 2, pp. 119–130, 2007.
- [36] P. J. Burt and E. H. Adelson, “The laplacian pyramid as a compact image code,” IEEE Transactions on Communications, vol. 31, no. 4, pp. 671–679, 1983.
- [37] A. Toet, “Image fusion by a ration of low-pass pyramid.” Pattern Recognition Letters, vol. 9, no. 4, pp. 245–253, 1989.
- [38] J. Ma, P. Liang, W. Yu, C. Chen, X. Guo, J. Wu, and J. Jiang, “Infrared and visible image fusion via detail preserving adversarial learning,” Information Fusion, vol. 54, pp. 85–98, 2020.
- [39] Z. Zhou, B. Wang, S. Li, and M. Dong, “Perceptual fusion of infrared and visible images through a hybrid multi-scale decomposition with gaussian and bilateral filters,” Information Fusion, vol. 30, pp. 15–26, 2016.
- [40] H. Zhang, H. Xu, Y. Xiao, X. Guo, and J. Ma, “Rethinking the image fusion: A fast unified image fusion network based on proportional maintenance of gradient and intensity.” in AAAI, 2020, pp. 12 797–12 804.
- [41] H. Xu, J. Ma, J. Jiang, X. Guo, and H. Ling, “U2fusion: A unified unsupervised image fusion network,” IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020.
- [42] S. Li, X. Kang, and J. Hu, “Image fusion with guided filtering,” IEEE Transactions on Image processing, vol. 22, no. 7, pp. 2864–2875, 2013.
- [43] H. Xu, J. Ma, and X.-P. Zhang, “Mef-gan: Multi-exposure image fusion via generative adversarial networks,” IEEE Transactions on Image Processing, 2020.
- [44] X. Qiu, M. Li, L. Zhang, and X. Yuan, “Guided filter-based multi-focus image fusion through focus region detection,” Signal Processing: Image Communication, 2019.
- [45] Y. Liu, X. Chen, R. K. Ward, and Z. J. Wang, “Image fusion with convolutional sparse representation,” IEEE signal processing letters, vol. 23, no. 12, pp. 1882–1886, 2016.
- [46] B. S. Kumar, “Image fusion based on pixel significance using cross bilateral filter,” Signal, image and video processing, vol. 9, no. 5, pp. 1193–1204, 2015.
- [47] ——, “Multifocus and multispectral image fusion based on pixel significance using discrete cosine harmonic wavelet transform,” Signal, Image and Video Processing, vol. 7, no. 6, pp. 1125–1143, 2013.
- [48] V. Naidu, “Image fusion technique using multi-resolution singular value decomposition,” Defence Science Journal, vol. 61, no. 5, p. 479, 2011.
- [49] C. S. Xydeas and V. S. Petrovic, “Objective pixel-level image fusion performance measure,” in Sensor Fusion: Architectures, Algorithms, and Applications IV, vol. 4051. International Society for Optics and Photonics, 2000, pp. 89–98.
- [50] A. M. Eskicioglu and P. S. Fisher, “Image quality measures and their performance,” IEEE Transactions on communications, vol. 43, no. 12, pp. 2959–2965, 1995.
- [51] Z. Wang, A. C. Bovik, H. R. Sheikh, and E. P. Simoncelli, “Image quality assessment: from error visibility to structural similarity,” IEEE transactions on image processing, vol. 13, no. 4, pp. 600–612, 2004.
- [52] K. Ma, K. Zeng, and Z. Wang, “Perceptual quality assessment for multi-exposure image fusion,” IEEE Transactions on Image Processing, vol. 24, no. 11, pp. 3345–3356, 2015.
- [53] J. W. Roberts, J. A. van Aardt, and F. B. Ahmed, “Assessment of image fusion procedures using entropy, image quality, and multispectral classification,” Journal of Applied Remote Sensing, vol. 2, no. 1, p. 023522, 2008.
- [54] V. Aslantas and E. Bendes, “A new image quality metric for image fusion: the sum of the correlations of differences,” Aeu-international Journal of electronics and communications, vol. 69, no. 12, pp. 1890–1896, 2015.
- [55] M. Haghighat and M. A. Razian, “Fast-fmi: non-reference image fusion metric,” in 2014 IEEE 8th International Conference on Application of Information and Communication Technologies (AICT). IEEE, 2014, pp. 1–3.
- [56] H. Peng, F. Long, and C. Ding, “Feature selection based on mutual information criteria of max-dependency, max-relevance, and min-redundancy,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 27, no. 8, pp. 1226–1238, 2005.
- [57] Y.-J. Rao, “In-fibre bragg grating sensors,” Measurement science and technology, vol. 8, no. 4, p. 355, 1997.
- [58] X. Desheng, “Research of measurement for digital image definition,” Journal of Image and Graphics, 2004.
- [59] G. Cui, H. Feng, Z. Xu, Q. Li, and Y. Chen, “Detail preserved fusion of visible and infrared images using regional saliency extraction and multi-scale image decomposition,” Optics Communications, vol. 341, pp. 199–209, 2015.
- [60] N. Cvejic, C. Canagarajah, and D. Bull, “Image fusion metric based on mutual information and tsallis entropy,” Electronics letters, vol. 42, no. 11, pp. 626–627, 2006.
- [61] Z. Liu, E. Blasch, Z. Xue, J. Zhao, R. Laganiere, and W. Wu, “Objective assessment of multiresolution image fusion algorithms for context enhancement in night vision: a comparative study,” IEEE transactions on pattern analysis and machine intelligence, vol. 34, no. 1, pp. 94–109, 2011.
- [62] Q. Wang, Y. Shen, and J. Jin, “Performance evaluation of image fusion techniques,” Image fusion: algorithms and applications, vol. 19, pp. 469–492, 2008.
- [63] S. Han, H. Li, H. Gu et al., “The study on image fusion for high spatial resolution remote sensing images,” Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. XXXVII. Part B, vol. 7, pp. 1159–1164, 2008.
- [64] J. Zhao, R. Laganiere, and L. Zheng, “Performance assessment of combinative pixel-level image fusion based on an absolute feature measurement,” International Journal of Innovative Computing Information & Control Ijicic, vol. 3, no. 6, 2006.
- [65] C. Yang, J.-Q. Zhang, X.-R. Wang, and X. Liu, “A novel similarity based quality metric for image fusion,” Information Fusion, vol. 9, no. 2, pp. 156–160, 2008.
- [66] G. Piella and H. Heijmans, “A new quality metric for image fusion,” in Proceedings 2003 international conference on image processing (Cat. No. 03CH37429), vol. 3. IEEE, 2003, pp. III–173.
- [67] Y. Chen and R. S. Blum, “A new automated quality assessment algorithm for image fusion,” Image and vision computing, vol. 27, no. 10, pp. 1421–1432, 2009.
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/754b34dc-b242-4425-b949-29266751db48/yu_fu.png) |
Yu Fu received the M.S. degree from Jiangnan University, China and A.B. degree from North China Institute Of Science And Technology, China. He is currently a Master student in the Jiangsu Provincial Engineerinig Laboratory of Pattern Recognition and Computational Intelligence, Jiangnan University. His research interests include image fusion, machine learning and deep learning. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/754b34dc-b242-4425-b949-29266751db48/Tianyang.jpg) |
Tianyang Xu received the B.Sc. degree in electronic science and engineering from Nanjing University, Nanjing, China, in 2011. He received the PhD degree at the School of Artificial Intelligence and Computer Science, Jiangnan University, Wuxi, China, in 2019. He was a research fellow at the Centre for Vision, Speech and Signal Processing (CVSSP), University of Surrey, Guildford, United Kingdom, from 2019 to 2021. He is currently an Associate Professor at the School of Artificial Intelligence and Computer Science, Jiangnan University, Wuxi, China. His research interests include visual tracking and deep learning. He has published several scientific papers, including IJCV, ICCV, TIP, TIFS, TKDE, TMM, TCSVT etc. He achieved top 1 tracking performance in several competitions, including the VOT2018 public dataset (ECCV18), VOT2020 RGBT challenge (ECCV20), and Anti-UAV challenge (CVPR20). |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/754b34dc-b242-4425-b949-29266751db48/WU.png) |
Xiao-Jun Wu received the B.Sc. degree in mathematics from Nanjing Normal University, Nanjing, China, in 1991, and the M.S. and Ph.D. degrees in pattern recognition and intelligent system from the Nanjing University of Science and Technology, Nanjing, in 1996 and 2002, respectively From 1996 to 2006, he taught at the School of Electronics and Information, Jiangsu University of Science and Technology, where he was promoted to a Professor. He was a Fellow of the International Institute for Software Technology, United Nations University, from 1999 to 2000. He was a Visiting Researcher with the Centre for Vision, Speech, and Signal Processing (CVSSP), University of Surrey, U.K., from 2003 to 2004. Since 2006, he has been with the School of Information Engineering, Jiangnan University, where he is currently a Professor of pattern recognition and computational intelligence. His current research interests include pattern recognition, computer vision, and computational intelligence. He has published over 300 articles in his fields of research. He was a recipient of the Most Outstanding Postgraduate Award from the Nanjing University of Science and Technology. |