A Deep Reinforcement Learning-based Sliding Mode Control Design for Partially-known Nonlinear Systems*
Abstract
Presence of model uncertainties creates challenges for model-based control design, and complexity of the control design is further exacerbated when coping with nonlinear systems. This paper presents a sliding mode control (SMC) design approach for nonlinear systems with partially known dynamics by blending data-driven and model-based approaches. First, an SMC is designed for the available (nominal) model of the nonlinear system. The closed-loop state trajectory of the available model is used to build the desired trajectory for the partially known nonlinear system states. Next, a deep policy gradient method is used to cope with unknown parts of the system dynamics and adjust the sliding mode control output to achieve a desired state trajectory. The performance (and viability) of the proposed design approach is finally examined through numerical examples.
I Introduction
Controller design for nonlinear dynamical systems has been an area of research interest for decades. Various methods for controller design for nonlinear systems have been proposed including feedback linearization [1], backstepping control [2], and sliding mode control (SMC) [3]. Generally, there are plant-model mismatches that arise from parameter uncertainty [4], measurement noise and external disturbances. SMC is a control design technique that offers robustness to these uncertainties in nonlinear systems with stability guarantees [5, 3]. However, SMC requires bounds on uncertainties and adds a discontinuity to the system through the function, which results in chattering and deteriorates the performance of the SMC. Furthermore, the uncertain knowledge of the system equations would result in a conservative SMC design. Data-driven approaches to control, such as model-free reinforcement learning (RL), require no information about the system and can learn control laws from the data through interactions with system without models [6]. However, RL cannot provide stability guarantees and suffers from high sample complexity. In this paper, a reinforcement learning-based SMC design approach is proposed to cope with uncertainties without known bounds by combining the advantages of both RL and SMC.
RL consists of an agent that interacts with the environment and improves its control actions to maximize the discounted future rewards received from the environment based on the action provided [7]. The distinguishing feature of RL is “learning by interaction with the environment” independent of the complexity of the system, thereby enabling RL to be used for complicated control tasks.
There have been recent advancements in the field of artificial intelligence by fusing RL and deep learning techniques. Deep reinforcement learning (DRL) algorithms are resulted from employing deep neural networks to approximate components of reinforcement learning (value function, policy, and model) [8]. Deep Q network (DQN) is a combination of deep neural networks and an RL algorithm called Q-learning which contributed to a significant progress in the fields of games, robotics, and so on [9]. However, DQN is only capable of solving discrete problems with low-dimensional action spaces. Therefore, In particular, continuous policy gradient methods were proposed to cope with continuous action spaces. Deterministic policy gradient methods [10] can particularly be useful for controller design applications.
A deterministic policy gradient algorithm based on deep learning and actor-critic is presented in [11]. This method, called deep deterministic policy gradient (DDPG), can handle continuous and high-dimensional action spaces and is used in this paper to design a sliding mode controller. DDPG is an actor-critic, model-free, off-policy algorithm, in which critic learns the Q-function using off-policy data, and actor learns the policy using the sampled policy gradient [11].
A number of previous studies employed RL for designing SMC. Authors in [12] estimated the uncertainties and disturbance terms respectively by an NN approximator and a disturbance observer for the SMC integrated with RL. Moreover, [13] proposed optimal guaranteed cost SMC integrated with the approximate dynamic programming (ADP) algorithm based on a single critic neural network (NN) for constrained-input nonlinear systems with disturbances. Different from the existing works, in our work, we assume the system is partially known and the goal is to achieve a desired performance for the original system using the knowledge of a simplified model of the system. In particular, we present an RL-based SMC design approach which preserves the structure of the SMC law by combining the SMC designed for the nominal model and the RL for coping with uncertainties. Instead of using fixed bounds for SMC, the proposed approach can cope with time-varying (and even state- and input-dependent) uncertainties by virtue of the model-free off-policy policy gradient RL algorithm.
The novelty of our work reported in this paper lies in fusing model-based and data-driven approaches for the design of an SMC for a class of nonlinear systems. The model-based part of the controller is obtained through available knowledge about the nonlinear system dynamics. The data-driven part of the controller is then calculated using DDPG algorithm to cope with the discrepancy between the original system and the available model of the system. Moreover, no information about the unknown parts of the system dynamics is needed, and the desired performance is reached. Furthermore, the control input, as well as the system states are penalized when defining the reward function for the RL agent to limit chattering. It is noted that since the plant-model mismatch is used by DDPG to update the SMC output, the proposed design approach interacts with the actual system online and hence leads to less conservative results compared to the traditional robust SMC design methods in the literature.
The remainder of this paper is organized as follows. Preliminaries and problem statement are provided in Section \@slowromancapii@. Section \@slowromancapiii@ describes the SMC design process. Section \@slowromancapiv@ discusses the DDPG algorithm for SMC design purposes. Simulation results are presented in Section \@slowromancapv@ to validate the performance of the proposed design approach, and concluding remarks are provided in Section \@slowromancapvi@.
II Problem Statement and Preliminaries
This section first presents the model of the system under study and then provides a brief description of the policy gradient method in reinforcement learning.
II-A System Model
Consider a class of nonlinear systems with measurable states described in the normal form as
| (1) |
where is the vector of all system states, is the control input, , and . Assume that and are unknown. A simplified model of the original system in (1) can be represented as follows
| (2) |
where is the vector of all simplified system states. The goal is to design an RL-based sliding mode controller (SMC) with partial knowledge of the system dynamics (here, the partial knowledge is the simplified system model). It is noted that the simplified system can be even considered to be a linear approximation of the original system.
Remark 1
The original system model can be described in the strict feedback form
| (3) |
where the uncertainties are assumed to only exist in the expression of . The simplified model of the system described by (3) will also be in the strict feedback form. However, the strict feedback form can be transformed into the normal form using a state transformation
| (4) |
where requires no information about , and the simplified model can be transformed similarly. Therefore, the RL-based SMC design approach proposed in this paper can be extended to treat systems in the form of (3).
II-B Policy Gradient in Reinforcement Learning
A reinforcement learning (RL) agent aims at learning a policy that maximizes the discounted future rewards (expected return). The return at time step is the total discounted reward from as , where is the reward received by taking action in state , and is the discount rate. For non-episodic tasks, is . The value function evaluates the expected return beginning from state under policy , and represented as . The expected return beginning from state and taking action is defined as Q-value following policy . The RL agent aims at maximizing its expected return beginning from the initial state; thus, the agent’s goal is to maximize .
In policy gradient algorithms, which are suitable for RL problems with continuous action space [10], the policy is parametrized by additional sets of parameters , which can be the weights of a neural network (). In this case, the objective function for RL agent turns into . In policy gradient algorithms, the goal is to update policy parameters to maximize ; hence, the parameters are updated in the direction of . In [7], it is shown that for stochastic policies
| (5) |
where is the state distribution following policy .
Actor-critic algorithms, which use policy gradient theorem, consist of an actor which adjusts policy parameters , and a critic which estimates by with parameters [14]. The critic tries to adjust parameters in order to minimize the following mean squared error (MSE)
| (6) |
For designing controllers using policy gradient in this paper, continuous deterministic policy is used, and the gradient of policy should be adapted to improve the deterministic policy. According to [10], in policy improvement methods, a common approach to update policy is to find a greedy policy such that
The notation is used to show the deterministic policy. Since the greedy policy improvement is computationally expensive for continuous action spaces, the alternative method for improving the parametrized policy is to move in the direction of . Hence, the updating formula for improving policy is represented as [10]
| (7) |
where is the learning rate. It is shown in [10] that
| (8) |
which implies that the update formula (7) moves policy parameters in the direction that maximizes . The update formula is used later in the paper to find a suitable control action for the original system (1).
III Design of an SMC for the Original System
Since and as well as their bounds are unknown, designing a controller for the original system is not straightforward. First, an SMC for the simplified system is designed to use the existing knowledge. Then, RL is used to cope with the uncertainties in the original system while preserving the structure of the sliding mode controller.
To design SMC for the simplified system, by defining a stable sliding surface as
| (9) |
the controller is
| (10) |
where
| (11) |
The error is defined as
| (12) |
Therefore, the error system is a nonlinear system in the normal form as
| (13) |
Now, a new stable sliding surface is defined for the error system as . The first-order derivative of is
| (14) |
With the control law (10) for the simplified model, we consider the controller for the original system in the form of
| (15) |
where is used to compensate for the plant-model mismatch and will be learned by RL. By substituting and in (14) with (10) and (15), turns into
| (16) |
To design an SMC for the error system, is chosen as
| (17) |
where and need to be designed. Ideally, consider a Lyapunov function candidate ,
| (18) |
such that , which guarantees in finite time. Also, (18) shows the deficiency of the nominal controller (10).
If the original system does not have any unknown parts ( and ), and , then and nothing is left to be designed. However, the original system model is not completely available. The desired case is when the simplified system is close to the original system, but it might not be always the case. When and are large, is significant and alone will not achieve the control objective with stability guarantees. To learn in the form of (17) without the knowledge of and , DDPG is used, which is elaborated in the next section.
Remark 2
For a tracking controller design problem using sliding mode for the original system represented in (1), where the desired output for the first state is , first a new system based on the simplified system (equation (2)) and the desired output is defined by assuming . Hence, this system dynamics turn into
| (19) |
Then, the procedure described above for designing SMC for the original system can be employed by replacing with in equations (9)-(16).
IV Deep Reinforcement Learning Controller Design for the Error System
Deep deterministic policy gradient (DDPG) algorithm was introduced in [11]. In this method, actor learns a deterministic policy while critic learns the Q-value function. Since the Q-value update may cause divergence [11], a copy of the actor network and a copy of the critic network are considered as target networks. DDPG uses soft target updates instead of directly copying weights from the original network. Hence, target network weights are updated slowly based on the learned network. Although soft target update may slow down the learning process, its stability improvement outweighs the low learning speed. A major challenge in deterministic policy gradient methods is exploration; adding noise to the deterministic policy can improve the exploration and avoid sub-optimal solutions [11]. The added noise can be an Ornstein-Uhlenbeck process [15]. Based on [11], in DDPG algorithm, the critic updates Q network weights to minimize the following loss
| (20) |
where represents Q network parameters, while and are target Q network and target actor network parameters, respectively. Sample-based loss can be simply calculated by
| (21) |
where is a mini-batch of the sampled data and is the number of samples in the mini-batch.
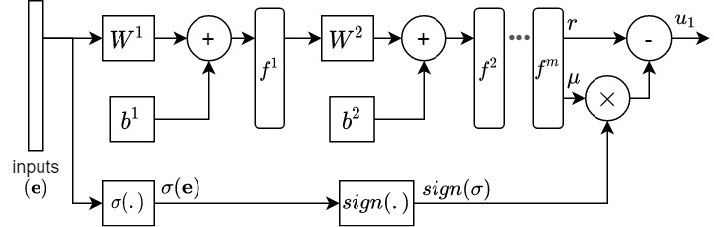
For designing SMC, the structure considered for the actor network is shown in Fig. 2. The output layer is customized to achieve the desired form of control signal given in (17). Based on Fig. 2, the activation functions of the last layer (before the custom layer) generate two outputs; the one that generates is linear, while for generating , tangent hyperbolic (tanh) activation function is used. Rectified linear activation function is used for the rest of the layers. It is assumed that no information is available about the sign of , and might be positive or negative; since the output of tanh function is between -1 and 1, is bounded between -1 and 1. Bounds on result in limited chattering of the control signal (in case larger bounds on are needed, can be multiplied by a fixed number). If the sign of does not change in a vicinity of the origin, then tanh activation function can be replaced by sigmoid function.
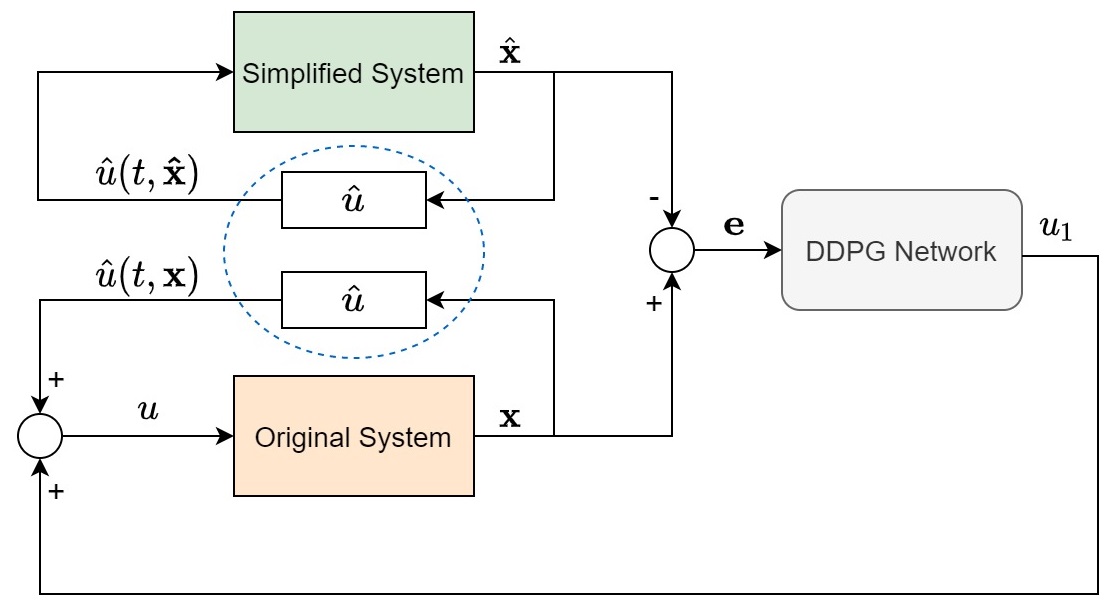
The structure of the closed-loop system controlled by DDPG controller is shown in Fig. 2. The DDPG network uses as input and generates as its output. For DDPG to learn the optimal control signal, the performance index needs to be defined. By sampling every seconds from the original and the simplified system states, the objective would be for the DDPG algorithm to maximize the following cost function
| (22) |
where , is a weight indicating the importance of the error system state in the optimization problem, penalizes (i.e., large control efforts and hence high amplitude chattering), and denotes the episode length. Based on the defined objective function, the reward at step of each episode is simply considered as . It is noted that when , the summation over in (22) turns into an integral, and the optimal solution results from solving the HJB equations [16].
The SMC design procedure for the nonlinear error system (13) is summarized as follows.
Remark 3
It is noted that the data-driven component of the proposed SMC action does not need information about bounds on the uncertain parts of the system model. Instead, it learns to utilize the discrepancy between the simplified model and the original system through interaction with the closed-loop system. Therefore, the performance of the proposed SMC is less conservative compared to traditional robust SMC design approaches in the literature that only use bounds on the model uncertainties.
V Simulation Results and Discussion
To evaluate the performance of the proposed RL-based sliding mode controller design approach, a nonlinear spring-mass-damper system is used.
V-1 Case description
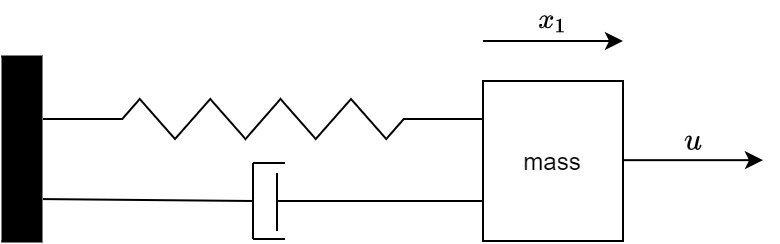
The state-space representation of the nonlinear mass-spring-damper shown in Fig. 3 (the original system) is as follows
| (23) |
where is the mass, is the damping coefficient for the nonlinear damper, and and represent the nonlinear spring parameters. The available model of the system is, however, a linear system (i.e., the simplified system) derived based on the available knowledge of the physical system with the following differential equation:
| (24) |
The constant values in equations (23) and (24) are given in Table I. Our goal is to solve a tracking control problem using the proposed RL-based sliding mode control design method. According to Remark 2 and the design process explained in the previous sections, the control law for tracking of the simplified system turns into
| (25) |
when the following sliding surface is used:
Then, the controller for the original system turns into
where , and DDPG will be employed to learn and .
| parameter | value | parameter | value |
|---|---|---|---|
V-2 Implementation of DDPG
For implementing DDPG, Keras package [17] is used. For implementing the proposed control law, two networks with the same structure are used as the actor and its target. These networks consist of 6 layers. The output layer structure is customized to build the desired form of control signal as in (17) (shown in Fig. 2). Each of the first three layers includes 512 units with rectified linear activation function, while the fourth layer includes 64 units with linear function. The fifth layer includes 2 units and the last layer (output layer) is customized as shown in Fig. 2. The inputs to the networks are the error system states. The critic network and its target network are identical and divided into two parts; the first part with error system states as inputs consists of three 512-unit hidden layers. The second part also includes three 512-unit hidden layers but the input of this part is the output of the actor network. Then, the last layer of these two parts are concatenated and the concatenated output is connected to two 512-unit hidden layers. Finally, the output layer builds a single output. Ornstein–Uhlenbeck process with standard deviation of is added to the output of the actor network during the learning for exploration.
V-3 Experimental setting
The hyperparameters used in the simulation are listed in Table II. The reward for each step of an episode is considered as . To penalize the reward at each step equally, is considered in the simulation studies. This is a reasonable assumption since the controller design procedure is considered as an episodic task (for non-episodic tasks should be chosen to avoid unlimited return). The goal of using the DDPG network is for the states of the error system to reach zero in the desired time horizon (here, the horizon is considered to be ). By assuming , the prediction horizon (episode length) is . Besides, if the reward at each time step exceeds , the corresponding episode during the learning phase will be terminated. Each episode begins from the initial states .
| parameter | value | parameter | value |
|---|---|---|---|
V-4 Results and discussion
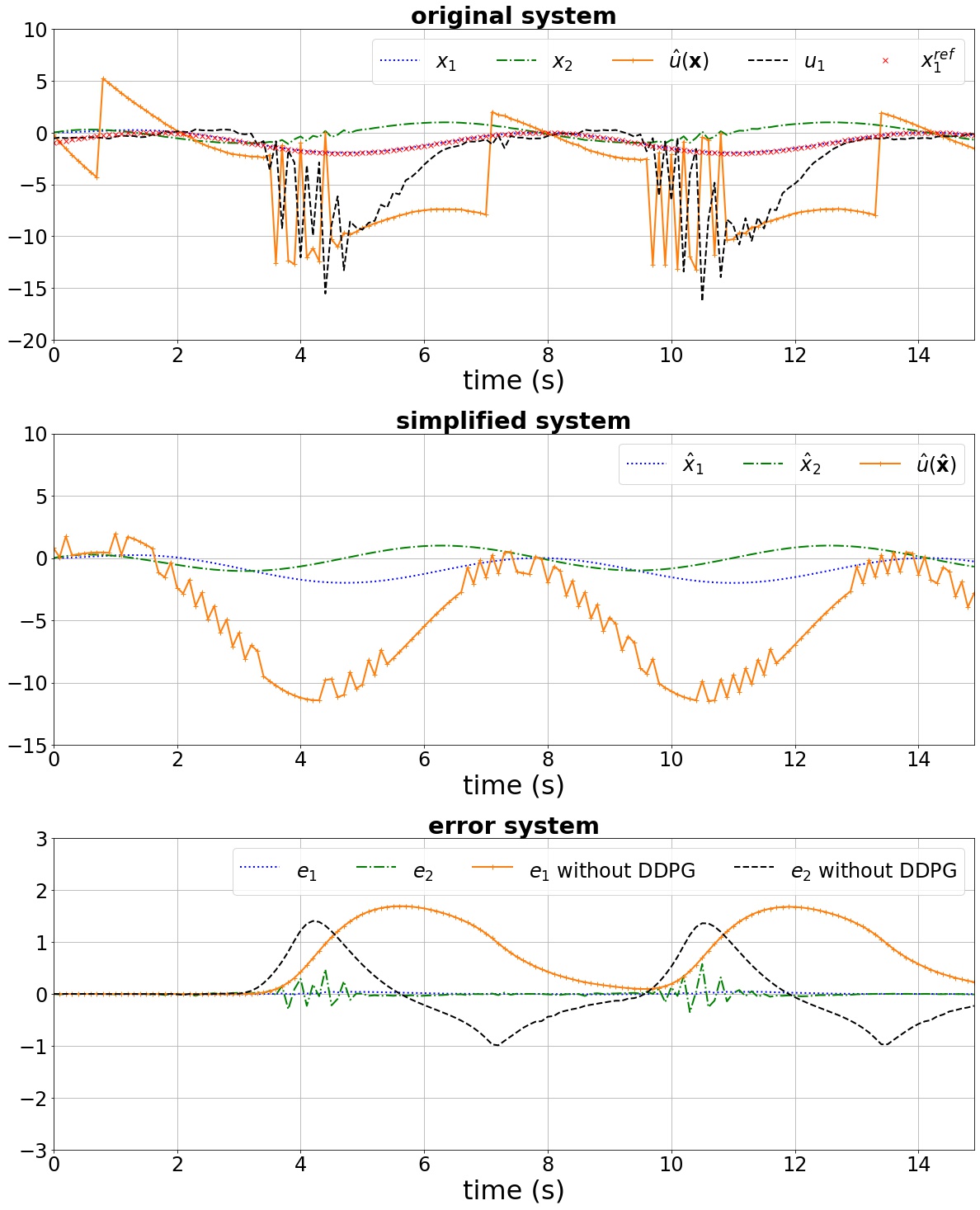
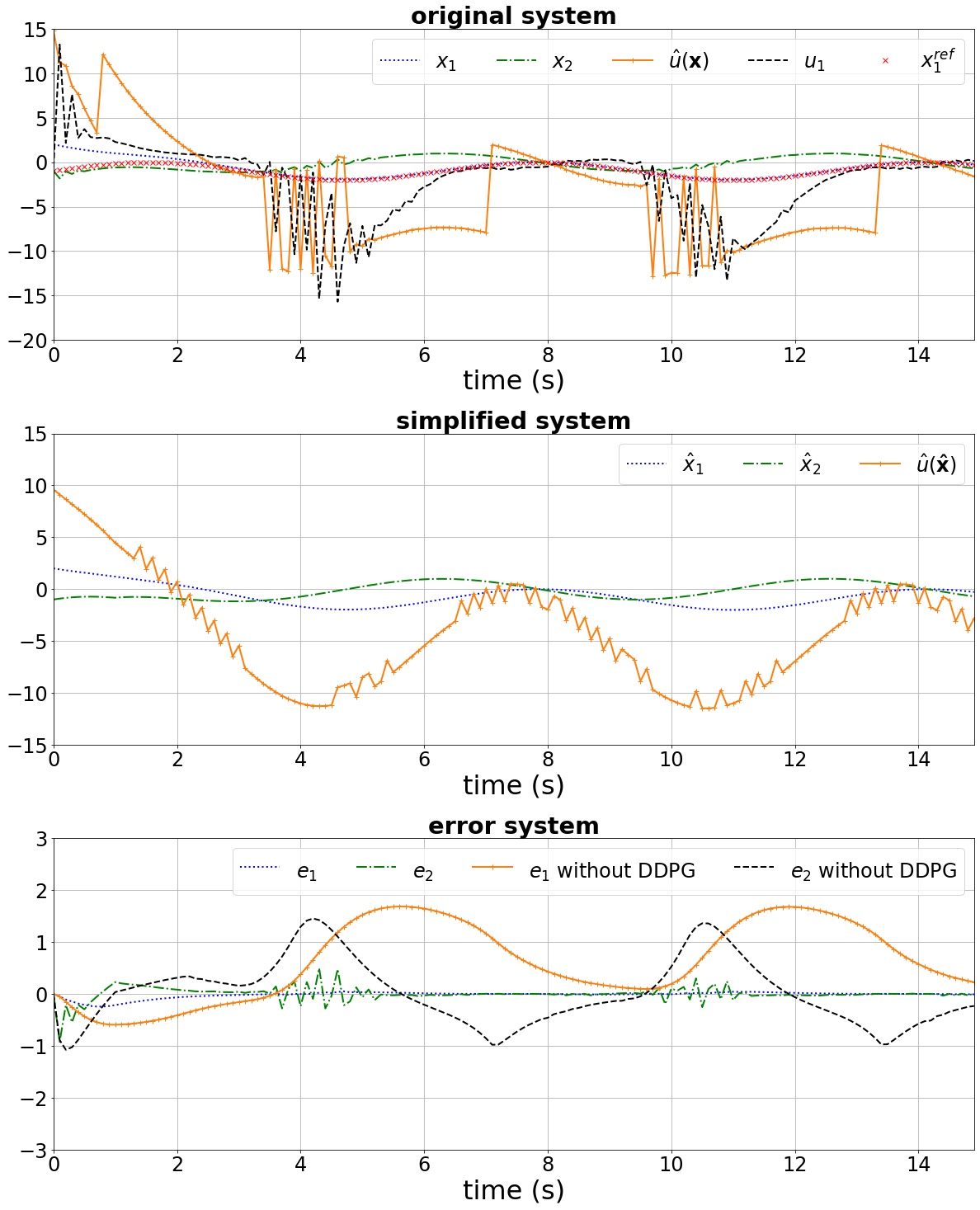
The performance of the proposed controller after convergence is shown in Fig. 4. The first subplot shows the original system states, the tracking signal , the control law calculated using the available simplified model (model-based controller ), and the output of the DDPG network (). The second subplot shows the performance of the simplified system using the SMC controller . The last subplot depicts the error system dynamics for two cases: 1) network is employed to compensate for the unknown parts in the original system dynamics; 2) when only the control law calculated based on the simplified system is used. Simulation results depict the efficacy of the proposed controller design in stabilizing the error system dynamics. It is noted that, in this example, the goal is to track a specific reference (), and the controller is successfully able to track the reference (in other words, converges to zero). The results reveal the capability of the proposed method to control a partially-known system, in which not only the dynamics are not completely available but also the available knowledge is not accurate (here the constants do not match their real values). Fig. 5 shows the return () at each episode during the learning process; as observed, after about 175 episodes, the proper action is found.
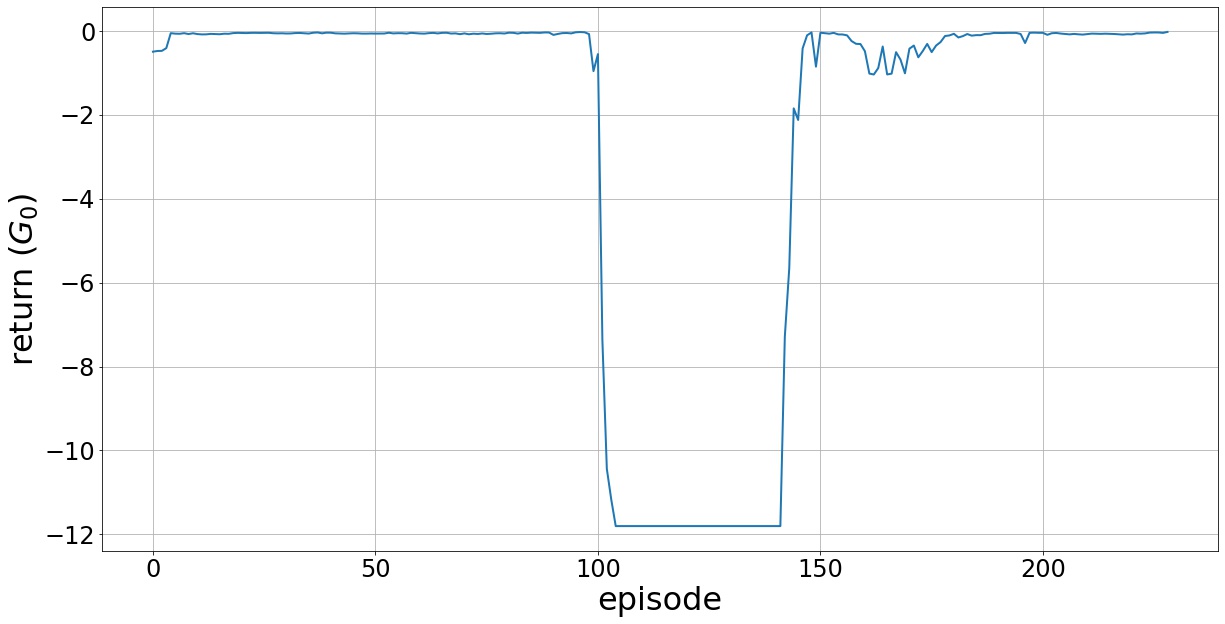
To demonstrate the generalization capability of the proposed controller, we use the learned controller to evaluate its performance when the initial condition for the system changes. The system is trained with as the initial state, while the performance is evaluated when the system initial condition is . From the results shown in Fig. 6, it is observed that with the proposed control design approach, successful tracking of the reference is achieved although the initial state for evaluation is different from the one used for learning the controller.
VI Conclusion
In this paper, model-based and data-driven control design approaches were fused to build a sliding mode controller for a class of partially-known nonlinear systems. A deterministic policy gradient approach (known as DDPG) was employed to cope with the mismatch between the available model of the system and the actual system dynamics online. A procedure for designing such controller was proposed and the performance of the design approach was evaluated through simulation studies.
References
- [1] J.-J. E. Slotine and J. Karl Hedrick, “Robust input-output feedback linearization,” International Journal of control, vol. 57, no. 5, pp. 1133–1139, 1993.
- [2] M. Krstic, P. V. Kokotovic, and I. Kanellakopoulos, Nonlinear and adaptive control design. John Wiley & Sons, Inc., 1995.
- [3] Y. Shtessel, C. Edwards, L. Fridman, and A. Levant, Sliding mode control and observation, vol. 10. Springer, 2014.
- [4] Y. Bao, J. M. Velni, and M. Shahbakhti, “Epistemic uncertainty quantification in state-space lpv model identification using bayesian neural networks,” IEEE Control Systems Letters, vol. 5, no. 2, pp. 719–724, 2021.
- [5] C. Edwards and S. Spurgeon, Sliding mode control: theory and applications. Crc Press, 1998.
- [6] Y. Bao and J. M. Velni, “Model-free control design using policy gradient reinforcement learning in lpv framework,” in 2021 European Control Conference (ECC), pp. 150–155, IEEE, 2021.
- [7] R. S. Sutton and A. G. Barto, Reinforcement learning: An introduction. MIT press, 2018.
- [8] Y. Ma, W. Zhu, M. G. Benton, and J. Romagnoli, “Continuous control of a polymerization system with deep reinforcement learning,” Journal of Process Control, vol. 75, pp. 40–47, 2019.
- [9] V. Mnih, K. Kavukcuoglu, D. Silver, A. A. Rusu, J. Veness, M. G. Bellemare, A. Graves, M. Riedmiller, A. K. Fidjeland, G. Ostrovski, et al., “Human-level control through deep reinforcement learning,” nature, vol. 518, no. 7540, pp. 529–533, 2015.
- [10] D. Silver, G. Lever, N. Heess, T. Degris, D. Wierstra, and M. Riedmiller, “Deterministic policy gradient algorithms,” in International conference on machine learning, pp. 387–395, PMLR, 2014.
- [11] T. P. Lillicrap, J. J. Hunt, A. Pritzel, N. Heess, T. Erez, Y. Tassa, D. Silver, and D. Wierstra, “Continuous control with deep reinforcement learning,” arXiv preprint arXiv:1509.02971, 2015.
- [12] Q.-Y. Fan and G.-H. Yang, “Adaptive actor–critic design-based integral sliding-mode control for partially unknown nonlinear systems with input disturbances,” IEEE transactions on neural networks and learning systems, vol. 27, no. 1, pp. 165–177, 2015.
- [13] H. Zhang, Q. Qu, G. Xiao, and Y. Cui, “Optimal guaranteed cost sliding mode control for constrained-input nonlinear systems with matched and unmatched disturbances,” IEEE transactions on neural networks and learning systems, vol. 29, no. 6, pp. 2112–2126, 2018.
- [14] I. Grondman, L. Busoniu, G. A. Lopes, and R. Babuska, “A survey of actor-critic reinforcement learning: Standard and natural policy gradients,” IEEE Transactions on Systems, Man, and Cybernetics, Part C (Applications and Reviews), vol. 42, no. 6, pp. 1291–1307, 2012.
- [15] G. E. Uhlenbeck and L. S. Ornstein, “On the theory of the brownian motion,” Physical review, vol. 36, no. 5, p. 823, 1930.
- [16] D. P. Bertsekas et al., Dynamic programming and optimal control: Vol. 1. 1995.
- [17] F. Chollet et al., “keras,” 2015.