[2]\fnmChi-Hao \surWu
1]\orgdivDepartment of Mathematics & Statistics, \orgnameThe State University of New York at Albany, \orgaddress\cityAlbany, \postcode12222, \stateNY, \countryUSA
[2]\orgdivDepartment of Mathematics, \orgnameUniversity of California Los Angeles, \orgaddress\cityLos Angeles, \postcode90095, \stateCA, \countryUSA
A federated Kaczmarz algorithm
Abstract
In this paper, we propose a federated algorithm for solving large linear systems that is inspired by the classic randomized Kaczmarz algorithm. We provide convergence guarantees of the proposed method, and as a corollary of our analysis, we provide a new proof for the convergence of the classic randomized Kaczmarz method. We demonstrate experimentally the behavior of our method when applied to related problems. For underdetermined systems, we demonstrate that our algorithm can be used for sparse approximation. For inconsistent systems, we demonstrate that our algorithm converges to a horizon of the least squares solution. Finally, we apply our algorithm to real data and show that it is consistent with the selection of Lasso, while still offering the computational advantages of the Kaczmarz framework and thresholding-based algorithms in the federated setting.
keywords:
federated learning, Kaczmarz method, sparse approximation, feature selectionpacs:
[MSC Classification]65F10, 65F20
1 Introduction
In this paper, we propose a federated algorithm for solving large linear systems. Federated learning was originally proposed by [1] to train neural networks in a decentralized setting. The global model is trained across multiple clients (e.g., mobile devices, sensors, or edge nodes) without transferring local data to a central server. This method improves privacy, reduces communication overhead, and enables learning from heterogeneous, distributed datasets; for instance, see [2] for more details. On the other hand, the Kaczmarz algorithm [3] is an iterative method for solving overdetermined linear systems, and the randomized Kaczmarz algorithm (RK) [4] is a version with a particular sampling scheme. Given a matrix , we denote by the -th row of , and we denote the Frobenius norm,
To solve a linear system for , , RK considers the iteration,
where ’s are independent identically distributed (i.i.d.) random variables with distribution for . For consistent overdetermined linear systems, it was shown in [4] that RK converges linearly to the solution in expectation. In a broader framework, it is also known that RK can be viewed as a stochastic gradient descent method with carefully chosen step sizes [5].
We consider the federated setting where there are local clients, and each client owns a subset of equations. In particular, let be the overdetermined, consistent linear system we aim to solve, where and . The system is partitioned into parts,
and the -th client sees the system for ; note that locally the system may be underdetermined for . We briefly describe the framework of federated algorithms using federated averaging (FedAvg) [1] as an example. At each federated round, a subset of local clients is selected, and the global server broadcasts the current global parameters (position) to the selected local clients. Each of the selected clients performs local updates using the global position as the initial and returns the updated local position after some iterations. The global server averages the local updates returned by the local clients and uses the averaged position as the updated global position. The process is iterated until it converges. Following the notation used in the federated optimization community [2], we denote by the solution at the global server after federated rounds, and the solution at the -th client after local iterations during the -th federated round. We propose Algorithm 1 for solving large linear systems in a federated setting.
We briefly comment on the ideas behind Algorithm 1 and the difficulties for the convergence analysis. In our setting, we allow the linear systems at the local clients , to be underdetermined for , and it is known that RK converges to the orthogonal projection of the initial position onto the affine subsets
| (1) |
for underdetermined linear systems; in particular, if the initial position is orthogonal to the null space of , RK converges to the least norm solution of ; see [6]. Based on this observation, we see that defined in Algorithm 1 is approximating a normal vector to a hyperplane containing (up to a normalizing constant), and projecting onto ’s is approximately the same as projecting onto
Therefore, instead of treating the local model changes ’s as simply displacements, we transform them into approximate hyperplanes ’s, which we then use at the server to run RK. In some sense, Algorithm 1 is a stochastic process where at each time , we choose a collection of affine subsets, dependent on , onto which to project. Given that it is difficult to study the convergence with a purely algebraic approach, we take a more geometric approach; see Section 2 for details.
For the convergence analysis, we consider two scenarios. First, we study the scenario where the local clients run finitely many iterations and the server runs one iteration ( in Algorithm 1). Second, we study the scenario where the local clients run infinitely many iterations ( in Algorithm 1), and the server runs some finite number of iterations. We state the assumptions that we make in our main theorems, except for Corollary 1, where the system is allowed to be underdetermined.
Assumption 1.
The linear system is overdetermined.
By an appropriate translation, one can assume that the true solution , and thus it is natural to also include the second assumption:
Assumption 2.
The solution to the linear system is .
The proof for the first scenario () utilizes that of RK applied to a suitable linear system. Specifically, we show the following:
Theorem 1.
Following the notation in Algorithm 1, assume , and . Let be the global update after iterations. Then there exists such that
For the second scenario, let us first assume the server performs one RK iteration ( in Algorithm 1). Since we assume that the solution , the ’s defined in (1) are linear subspaces for . Denote by the orthogonal projection operator onto for . We see that (following the notation in Algorithm 1),
| (2) |
defines the sequence produced by our federated Kaczmarz algorithm. We first prove a technical theorem that characterizes the decay of Algorithm 1 when the current position is one unit distance away from the true solution, which involves studying a function related to (2); see Theorem 4. Then we use the technical theorem to prove the following:
Theorem 2.
Following the notation in Algorithm 1, assume , and . Let be the global update after iterations. Then there exists such that
Perhaps interestingly, Theorem 4 also gives an alternative proof for the convergence of classical RK; see Corollary 2. Finally, in the second scenario, we also deduce that Algorithm 1 converges linearly to the orthogonal projection from the initial global position onto when the whole system is underdetermined. Specifically, if is a single point, Algorithm 1 converges to the true solution as before.
Corollary 1.
We demonstrate experimentally the behavior of FedRK when applied to related problems. For sparse approximation problems, the system is modeled as where is a wide matrix (), is a true sparse signal, and is noise. Given a sparsity level , the hard thresholding operator is defined as the orthogonal projection onto the entries with the largest magnitudes. By combining with a hard thresholding operator, the Kaczmarz algorithm has been proposed as a method to solve such problems; see for instance [7, 8]. In the federated setting, we show that our algorithm can be combined with the hard thresholding operator to solve the sparse approximation problem; see Algorithm 2. For the least squares problem, where is a tall matrix () and the goal is to minimize , it is known that the randomized Kaczmarz algorithm does not converge to the least squares solution in general, but its iterates reach within a horizon of the solution; see [9]. In the federated setting, we show that our algorithm has the same behavior. Moreover, we show that by adding a suitable amount of noisy columns to , one can shrink the horizon. Finally, we apply Algorithm 2 to the prostate cancer data considered in [10], and we demonstrate that the selection of Algorithm 2 is consistent with Lasso.
1.1 Contribution
We summarize our contributions. First, we propose the federated Kaczmarz algorithm (FedRK) for solving large linear systems in the federated setting, and we prove the linear convergence of our algorithm. As a corollary of our analysis, we give an alternative proof for the linear convergence of the classic randomized Kaczmarz algorithm (RK). Second, we demonstrate experimentally that our algorithm can be combined with hard thresholding to solve sparse approximation problems. We also demonstrate experimentally that it converges to a horizon of the least squares solution as the RK when applied to inconsistent systems. Finally, we apply our algorithm to real data and show the possible use for feature selection in the federated setting.
1.2 Organization
The rest of the paper is organized as follows. In Section 2, we present our main results. We first present Theorem 4, which characterizes the convergence behavior when a collection of local clients is selected and the current position is one unit distance away from the true solution; the proof of Theorem 4 can be interesting in its own right. In particular, a corollary of Theorem 4 is an alternative proof for the linear convergence of the classic RK; see Corollary 2. We then prove the convergence theorems of our algorithm. The proofs of Theorem 1 and Theorem 2 are based on slightly different strategies, and we provide roadmaps of the proofs as guides. In Section 3, we present the experiments. We demonstrate experimentally the linear convergence of Algorithm 1. Perhaps interestingly, our experiment shows that running more local iterations helps the algorithm converge faster, which is usually not seen in other federated algorithms. We then apply Algorithm 2 to sparse approximation problems and Algorithm 1 to least squares problems for inconsistent systems; our results show that our algorithm behaves similarly to the classical RK, which hints that our algorithm can be efficiently combined with other Kaczmarz variants to extend other variants to the federated setting. Finally, we apply Algorithm 2 to real data and show that our algorithm can potentially be used for feature selection in the federated setting. In Section 4, we present some discussion and future directions.
2 Main Results
2.1 Notation
In this section, we define the notation used throughout. Denote by . We partition the system into parts,
and the -th client sees the system for . Let be defined as in (1) for . Under Assumption 2, we have are linear subspaces for . We denote by the orthogonal projection onto a linear subspace .
Let be the set of probability measures on . Given and , we denote by the set of probability measures such that
| (3) |
for instance, the uniform distribution over is in . An object that forms the core of our analysis is the following function,
| (4) |
for , , and . For , this function measures the average decrease of the norm of , when randomly projecting onto the hyperplanes formed by the normal vectors . In fact, we will study the function on a refined domain; see Section 2.2 for more details.
For the readers’ convenience, we review some notions in geometry and topology; one can find detailed descriptions in [11] and [12], for instance. A topological space is a pairing , where is the whole space and is the topology, i.e. a collection of open subsets satisfying
-
•
-
•
implies
-
•
implies , where is an arbitrary index set (possibly uncountable)
A set is compact if any open covering of admits a finite sub-covering. A map between two topological spaces is continuous if is open for all open sets . If between two topological spaces is continuous, then is compact implies is compact. Another ingredient in our proof is the implicit function theorem, which we recall the statement:
Theorem 3 (Implicit function theorem).
Let be an open subset, and be smooth. Given such that and is invertible, then, in a open neighborhood of , the level set
is smoothly parameterized by ; i.e. in a neighborhood of there exists a smooth function such that
2.2 A technical theorem
In this section, we prove our main technical theorem, and deduce the convergence of the classical randomized Kaczmarz as a corollary. To motivate the setting, we start with a discussion of how one can reduce the analysis to a function on the product of two spheres.
Given , one has by linearity
and
This shows that the normal vector obtained after normalizing is independent of the length of . Similarly, for , one has
This suggests that it is natural to study our problem on the unit sphere . Given , denote
| (5) |
and . We will consider as a function on for technical reasons that will become clear later; see Figure 1 for an illustration. It is clear that is smooth for each . We have the following:
Theorem 4.
Given and , let
Denote
Given defined in (3), consider defined as
Then, for . Moreover, for all , there exists such that
Proof.
To make our presentation clear, we can assume that the index set, . Our first objective is to show that is open.
Given such that and , one can find such that
is a basis. One can consider defined as
Denote by the Jacobian matrix of , and denote by , the submatrices when the partial derivatives are only taken with respect to , , respectively. A direct calculation shows
and it is clear from our choice that is of full rank. If one considers the level set
then there exists an open ball such that is a function of and by the implicit function theorem.
Given , there exists such that
since is compact and is closed. By the argument above, there exists , and a diffeomorphism such that and
i.e., is a function of in a neighborhood of . By continuity of , there exists such that
Define , and let . We claim that , and so is an interior point. For ,
Finally, one has
since , and this shows that is an interior point.
One has is compact, since is open. One also has that for all , and therefore there exists such that
Finally, by pigeonhole principle, there exists such that
for fixed . This concludes our proof. ∎
As a corollary, we demonstrate how Theorem 4 implies the convergence of the classical randomized Kaczmarz algorithm. Indeed, the classical setting can be viewed as the scenario where one has local clients, and each local client has one equation of the linear system ; see [13]. This corresponds to and are -dimensional linear subspaces (hyperplanes) in Theorem 4.
Recall that we defined in (3). Given a sampling scheme , if we denote by the normal vector (unique up to sign) of for , the randomized Kaczmarz algorithm is defined by
| (6) |
We have the following:
Proof.
First, we describe what in Theorem 4 is in this scenario. By picking small enough, one has that . Let be the normal vectors of the hyperplanes . One has
and
this implies that , and therefore .
Now, we study the convergence of the randomized Kaczmarz algorithm. By (6),
Pick some . We recognize the summation above is equal to . By Theorem 4, the function, , satisfies
(Note: the function is independent of here). Therefore,
by which one can iterate to conclude .
Finally, a closer look shows that
which gives the variational formula for the constant . This concludes our proof. ∎
In Corollary 2, we showed the convergence of the randomized Kaczmarz algorithm for all sampling schemes in . This includes the sampling scheme in [4]. Indeed, if we denote the sampling scheme in [4],
which clearly implies that . This concludes our discussion here.
As a second corollary, we demonstrate how one can produce different variations of Theorem 4; the following form will be used in the study of Algorithm 1.
Corollary 3.
Proof.
To make our presentation clear, we assume without loss of generality. Given and , by Theorem 4 there exists such that the function defined as
satisfies the bound . In particular, we have
which implies
This concludes the proof of the first statement. For the second statement, we see that is properly defined on , and
| (7) |
Note that
and by the first statement
which can then be combined with (7) to conclude the proof. ∎
2.3 Proof of Theorem 1, Theorem 2 and Corollary 1
Roadmap of the proof for Theorem 1: When the local clients run only finitely many iterations, the local updates are not exactly orthogonal projections onto a linear subspace; therefore, the idea of the proof is different from the proof of Theroem 2. For Theorem 1, the key observation is that when running only one global iteration (), the global update is essentially randomly selecting one of the local updates. From this perspective, one can compare the scheme with the classic RK algorithm applying to a suitable overdetermined linear system to deduce the convergence.
Proof of Theorem 1.
Denote the expected global position conditioning on the subset of local clients that is selected. One can observe that
| (8) |
where is the position of client after local iterations. The idea of the proof is to compare the dynamics with a suitable choice of RK algorithm.
Fix . Denote the rows at client . Then
| (9) |
Using (9), we have
One can see that the right hand side is the expected decrease when using RK to solve , where consists of copies of . One can then deduce the convergence using the convergence analysis of classic RK. ∎
Given , we consider defined as
and the uniform distribution over . Then we consider the following function
| (10) |
One can see that characterizes the convergence rate when ; for instance, see the proof of Corollary 2. We prove two lemmas, and then prove Theorem 2 as a consequence of these lemmas. Let us briefly describe the proof strategy.
Roadmap of the proof for Theroem 2: Fix a collection of linear subspaces at the local clients . First, we demonstrate that for an overdetermined system, one can find a small enough such that the -neighborhood of these linear subspaces has empty intersection on the unit sphere; this is done in Lemma 1. Using Corollary 3, we know that if the initial position at a given federated round is away from some linear subspace , then we are guaranteed to shrink the distance between our current position and the solution by a constant factor via projection onto . By Lemma 1, we know that an arbitrary point on the unit sphere is at least away from some linear subspace. At each federated round, there is always some chance to select a client with being -away from the normalized global position, and we are guaranteed to shrink the current position by a uniform factor if we orthogonally project onto . Using this fact, we show that on average we can shrink our current position by a constant factor regardless of our initial position at a given federated round; this is done in Lemma 2. Finally, everything is put together with the scaling argument in Corollary 2 to obtain Theorem 2. To deduce Corollary 1 for the underdetermined system, the key observation is to decompose the initial position as , where and . One can see that is a fixed point for the orthogonal projections onto ’s, and that the orthogonal projections onto ’s restricted to reduce to a determined system; these observations allow us to deduce Corollary 1 from Theorem 2.
Lemma 1.
Let be a collection of linear subspaces such that . Then there exits such that
Proof.
Define as
one can see that is continuous. Since , one has
This further implies that there exists such that for all by compactness of . This concludes our proof. ∎
Lemma 2.
Given , denote for all . Then defined in (10) satisfies
Proof.
Given , one has
which further implies
By Corollary 3, one has
which can be combined with the fact that there are subsets of containing to get
One can then take to conclude the proof. ∎
Proof of Theorem 2.
First, we assume that the server runs one global iteration (). Let be small enough so that Lemma 1 holds. For defined in Lemma 2, one has
by Lemma 1; this shows that covers , and therefore
By Lemma 2, one sees that
One can then iterate as in the proof Corollary 2 to conclude the proof. For general , we observe that the operator norm of an orthogonal projection is less than or equal to , and therefore the convergence result for general follows from .
∎
Finally, we demonstrate how one can deduce the convergence behavior for underdetermined systems.
Proof of Corollary 1.
Given an initial , we consider the orthogonal decomposition , where is defined as in the statement of Corollary 1. Then one has
| (11) | ||||
| (12) |
since for all and is a fixed point for projections onto ’s. On the other hand, if we focus on the linear subspace , , and it is reduced to a determined system, and we can apply Theorem 2 to deduce
for some . ∎
3 Experiments
In the following, we demonstrate experimentally the convergence of FedRK, and we demonstrate its behavior when applied to sparse approximation problems and least squares problems. Finally, we apply Algorithm 2 to real data and compare the result with Lasso.
3.1 FedRK
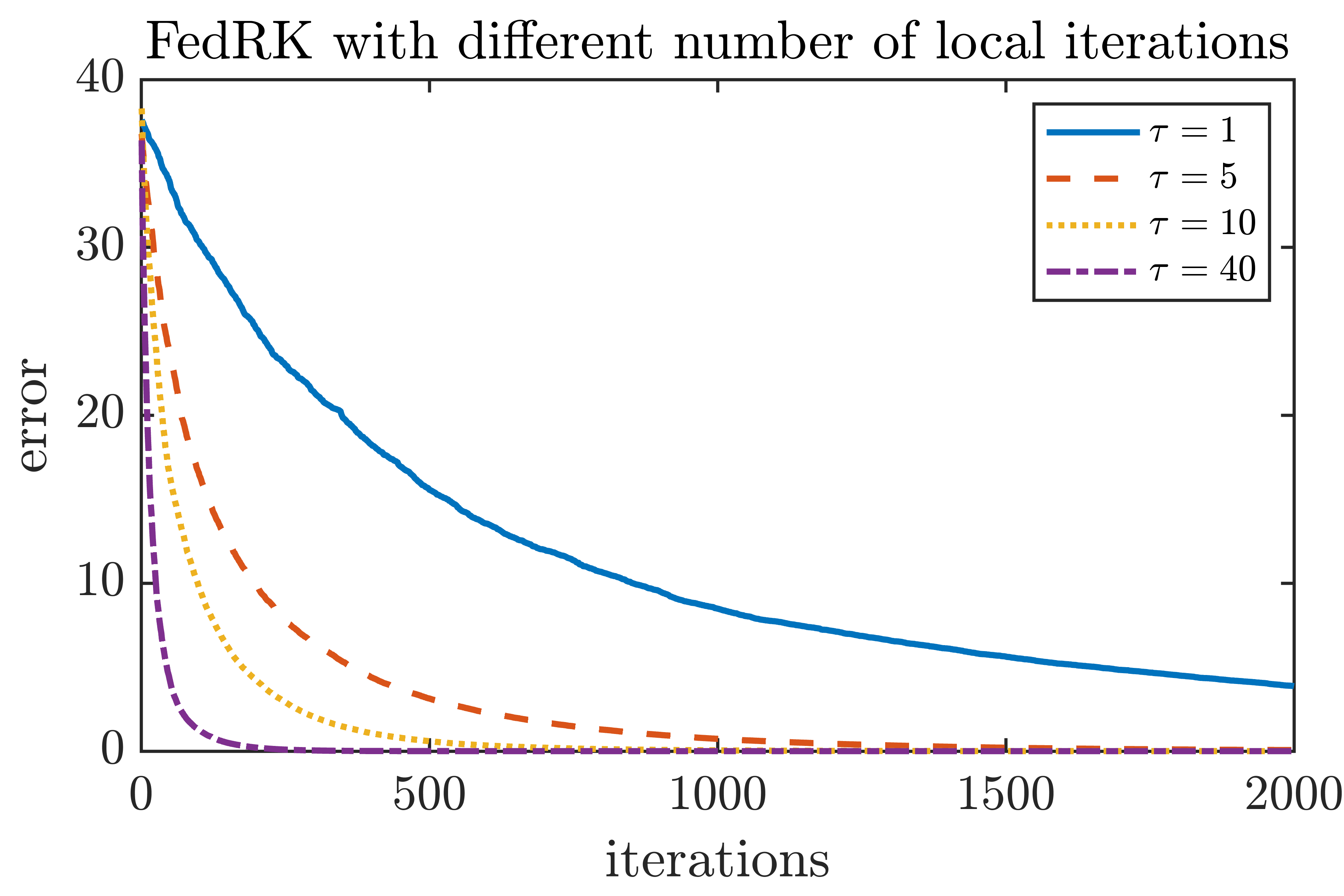
In this section, we consider solving an overdetermined consistent system. We consider , and , where the entries of and are generated as i.i.d. standard Gaussian. The data is distributed evenly to clients. At each federated round, five local clients are selected to participate in the update, and each of them run local iterations. The server runs 20 global iterations after receiving the local updates. This demonstrates the convergence behavior of Algorithm 1, and the results suggest that running more local iterations may improve the convergence rate. The results are in Figure 2.
3.2 Sparse approximation problems
In this section, we consider the sparse signal recovery problem. For certain types of signals, one can find a good basis so that these signals can be approximated by sparse representations, and an important question is how one can reconstruct the sparse approximations [14]. One type of algorithm for this problem is the iterative hard thresholding algorithm [15]. Given a sparsity level , the objective is to solve
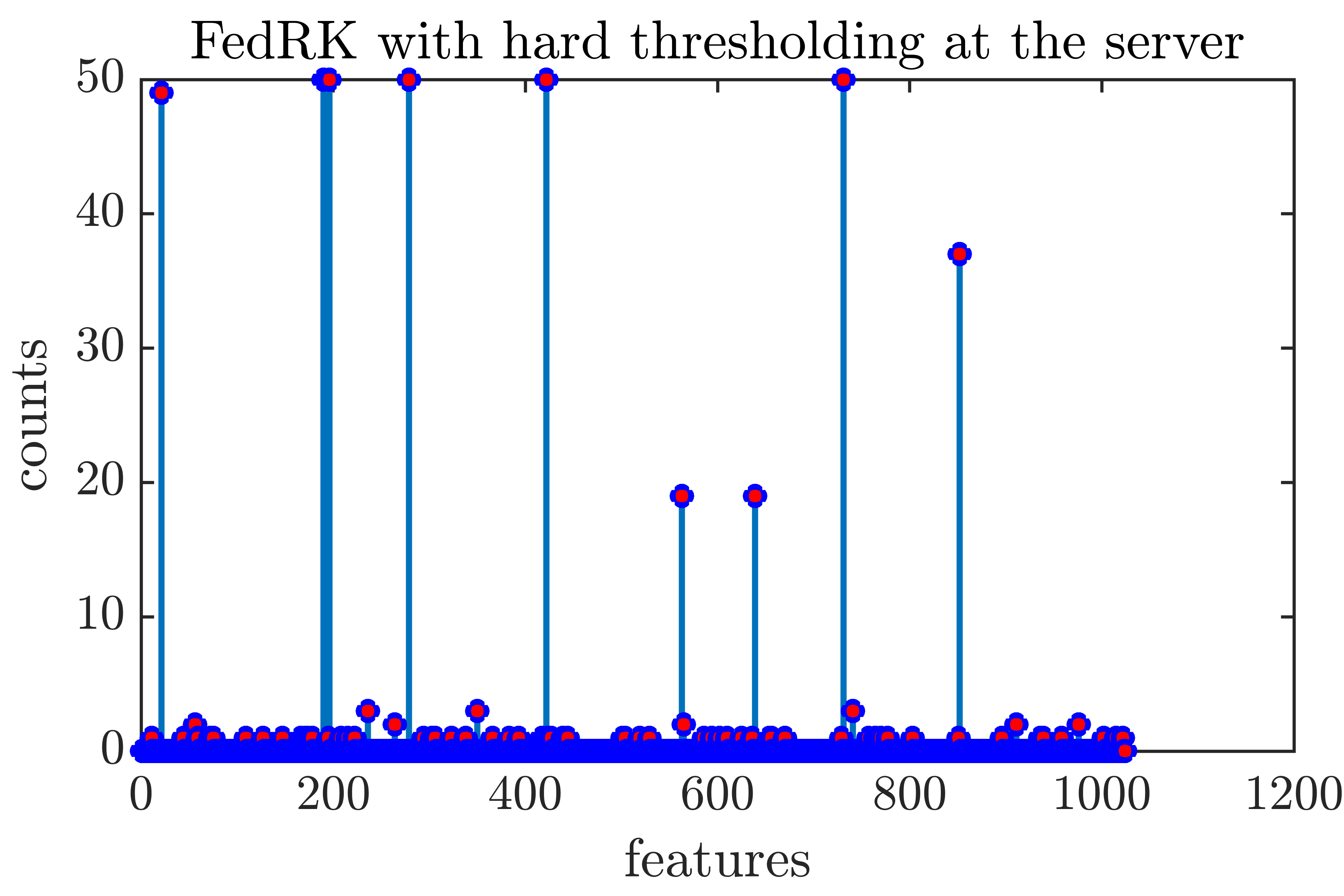
where counts the number of non-zero entries, and the iterative hard thresholding algorithm performs gradient descent followed by hard thresholding (projection onto the largest entries) in each iteration. Recently, it has been proposed to replace the gradient descent step with a RK projection [7, 8]. Our experiment demonstrates such a strategy can be extended to the federated setting. We consider the measurement matrix , the target sparse solution, the measurement noise, and the perturbed observation; the entries in and , and the non-zero entries of are all generated from the standard Gaussian. Data is distributed evenly to clients, and at each federated round, local clients participate. Each of the local clients runs local RK iterations, and the global server runs global iterations after receiving the local updates. The sparsity level in this experiment is , and we demonstrate that Algorithm 2 can recover the true signal. The experiment is performed 50 times with different initializations and sampling schemes, and we record the number of times each feature is selected in Figure 3.
3.3 Least squares
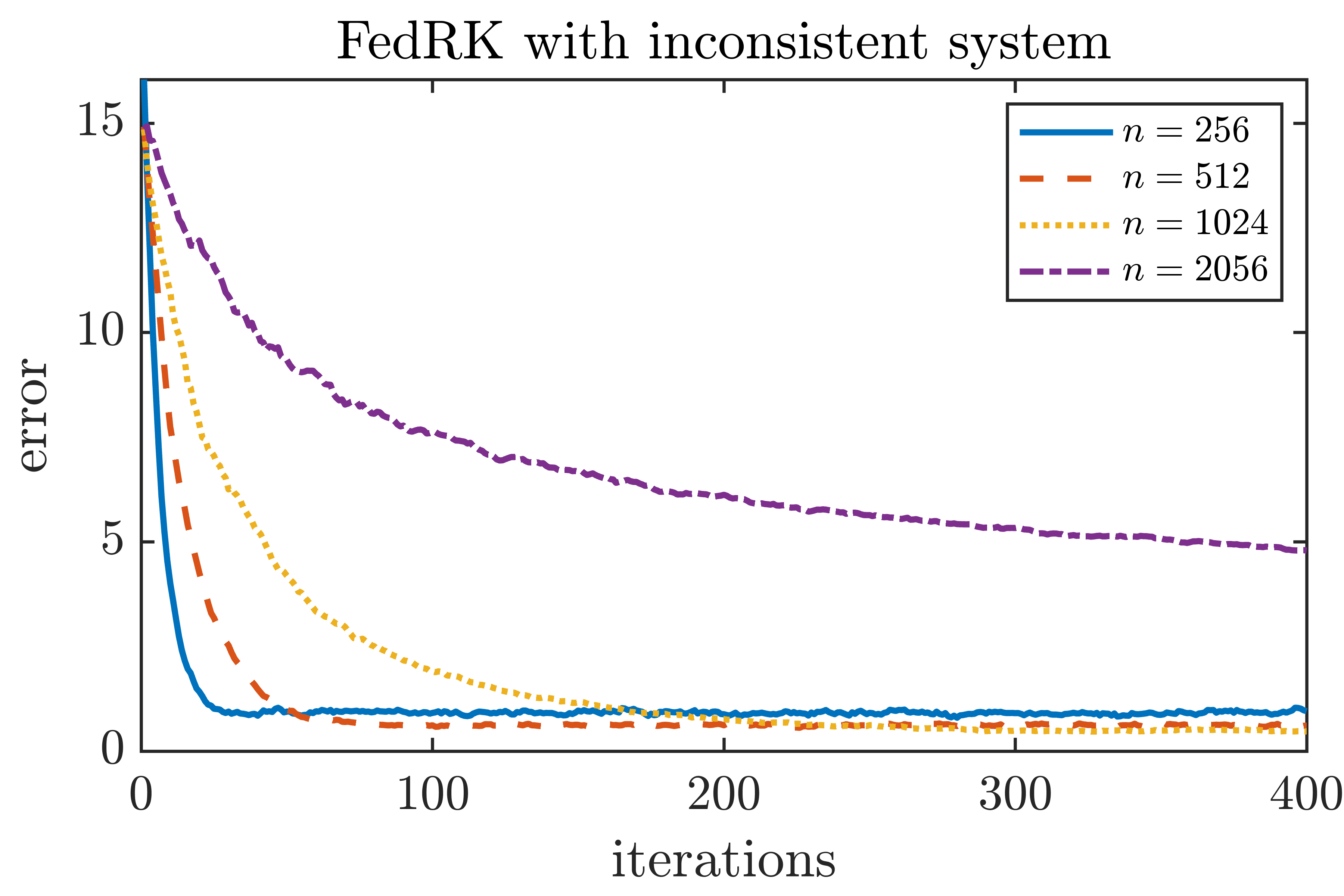
While the main objective of this paper is to solve consistent linear system, in many real‐world applications the right‐hand side is corrupted by noise or modeling error and one instead faces an inconsistent system. To assess the robustness of our method under these more realistic conditions, we consider general least squares problems. When the linear system is inconsistent, recall that classical RK does not converge to the least squares solution; however, its iterates do eventually remain within some horizon of the least squares solution [9]. We consider and , where the entries in and are generated from standard Gaussian. Our aim is to solve ; data are distributed evenly to clients. In each federated round, all local clients participate. We apply FedRK to the system, and the algorithm converges to a horizon of the least squares solution; moreover, by adding a suitable amount of noise one can shrink the convergence horizon. Specifically, we expand the matrix by adding gaussian noise columns,
where the entries in are generated as i.i.d. standard Gaussian, and we apply FedRK to solve the extended system ; note that the perturbation can be added at the clients level, and the strategy is suitable for the federated setting. To motivate our strategy, it is known that in high-dimensional space, two independent Gaussian vectors are almost orthogonal with high probability, and therefore the columns in are likely to be almost orthogonal to the column space of ; hence, the columns in capture the components of that is perpendicular to the column space of . This is inspired by the randomized extended Kaczmarz algorithm [16], where column operations are involved to solve the least squares problem; however, column operations are not suitable in the federated setting, and therefore, we create the extra matrix instead. This is motivated to the approach taken in [17], where the Monte Carlo method is combined with RK to solve the least squares problem. The strategy proposed in [17] does not involve column operations, and it would be interesting to see if it can be extended to the federated setting. The results are summarized in Figure 4.
3.4 Prostate cancer data
In this section, we test our algorithm on the prostate cancer data [18], which was used in [10]. The features are 1. intercept (intcpt), 2. log(cancer volume) (lcavol), 3. log(prostate weight) (lweight), 4. age, 5. log(benign prostatic hyperplasia amount) (lbph), 6. seminal vesicle invasion (svi), 7. log(capsular penetration) (lcp), 8. Gleason score (gleason) and 9. percentage Gleason scores 4 or 5 (pgg45), and the target variable is log(prostate specific antigen) (lpsa). We adapt a more recent use of this data [19], where the Lasso is fit to the data. Let us briefly recall that given the data matrix and the target vector , Lasso solves
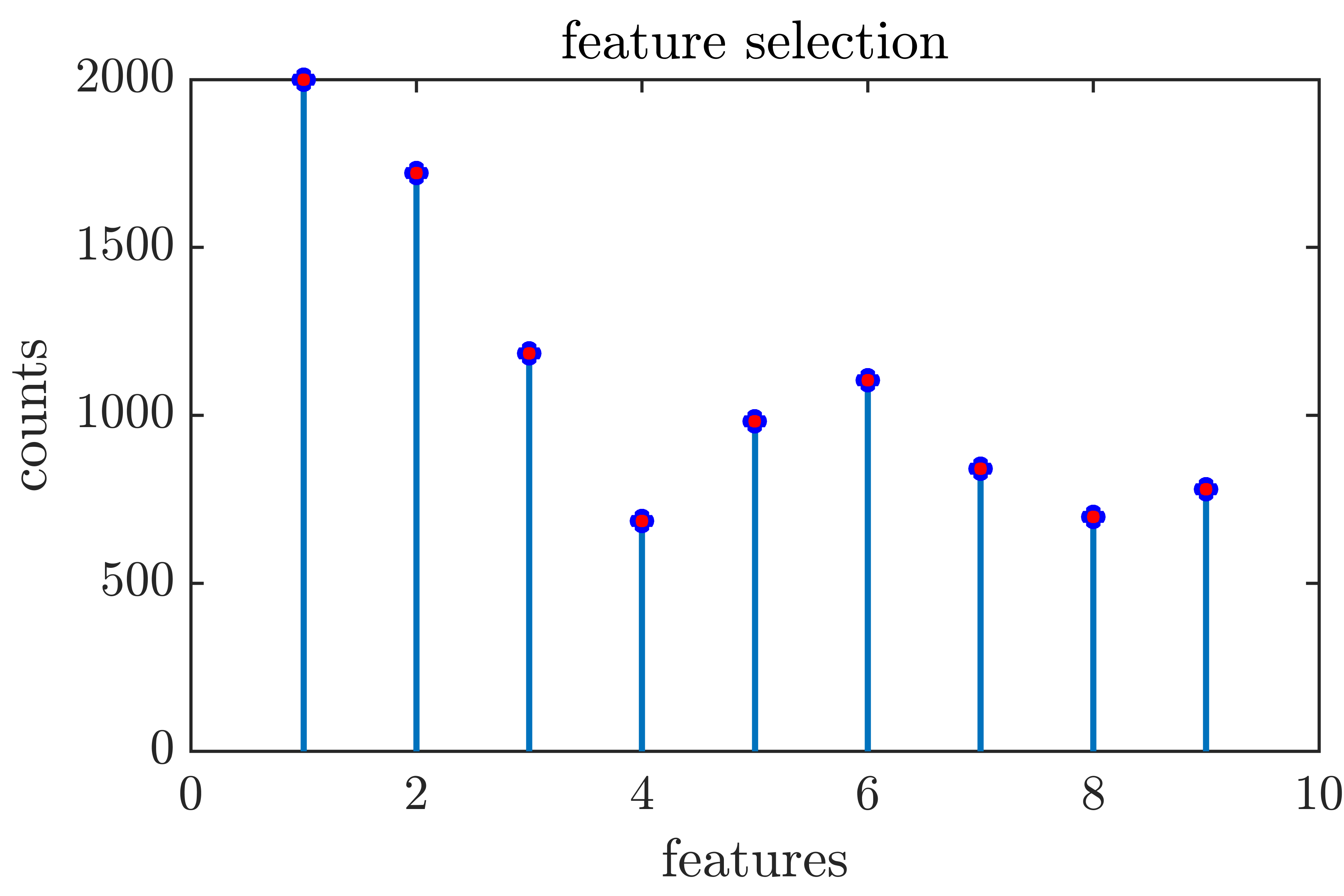
where is the regularizing parameter (here we assume that the intercept is included as the first column of ); it is known that when is large, tends to be sparse, and a feature is said to be selected if it has non-zero coefficients. In this case 4 features are selected: lcavol, lweight, lbph and svi for some chosen . Following [19], we first standardize the feature columns, then add an extra column of ones to represent the intercept; we distribute the data evenly to 7 local clients. To compare with the result in [19], we set the sparsity level to 5 (so that we include one for the intercept). At each federated round, 3 local clients participate and each of them runs 20 iterations using the local data; after receiving the local updates, the server runs 20 iterations of RK and then apply the hard thresholding operator . We performed 2000 federated rounds, and counted the number of times each feature has a non-zero coefficient after hard thresholding. The result is recorded in Figure 5, and the distribution is consistent with the analogous selection of Lasso if we look at the top 5 features.
4 Discussion
In this paper, we proposed a federated algorithm (Algorithm 1) for solving large linear systems and derived its convergence property. When applied to inconsistent systems, our experiments showed that it converges to a horizon of the least squares solution. We also proposed a modified version of our algorithm (Algorithm 2) for sparse approximation problems. We applied Algorithm 2 to real data and showed that it has potential use for feature selection in the federated setting. For future work, it would be interesting to extend the approach here to more general optimization problems.
Acknowledgements DN was partially supported by NSF DMS 2408912.
References
- \bibcommenthead
- McMahan et al. [2017] McMahan, B., Moore, E., Ramage, D., Hampson, S., Arcas, B.A.: Communication-efficient learning of deep networks from decentralized data. In: Artificial Intelligence and Statistics, pp. 1273–1282 (2017). PMLR
- Wang et al. [2021] Wang, J., Charles, Z., Xu, Z., Joshi, G., McMahan, H.B., Al-Shedivat, M., Andrew, G., Avestimehr, S., Daly, K., Data, D., et al.: A field guide to federated optimization. arXiv preprint arXiv:2107.06917 (2021)
- Karczmarz [1937] Karczmarz, S.: Angenaherte auflosung von systemen linearer glei-chungen. Bull. Int. Acad. Pol. Sic. Let., Cl. Sci. Math. Nat., 355–357 (1937)
- Strohmer and Vershynin [2009] Strohmer, T., Vershynin, R.: A randomized kaczmarz algorithm with exponential convergence. Journal of Fourier Analysis and Applications 15(2), 262–278 (2009)
- Needell et al. [2014] Needell, D., Ward, R., Srebro, N.: Stochastic gradient descent, weighted sampling, and the randomized kaczmarz algorithm. Advances in neural information processing systems 27 (2014)
- Ma et al. [2015] Ma, A., Needell, D., Ramdas, A.: Convergence properties of the randomized extended gauss–seidel and kaczmarz methods. SIAM Journal on Matrix Analysis and Applications 36(4), 1590–1604 (2015)
- Jeong and Needell [2023] Jeong, H., Needell, D.: Linear convergence of reshuffling kaczmarz methods with sparse constraints. arXiv preprint arXiv:2304.10123 (2023)
- Zhang et al. [2015] Zhang, Z., Yu, Y., Zhao, S.: Iterative hard thresholding based on randomized kaczmarz method. Circuits, Systems, and Signal Processing 34, 2065–2075 (2015)
- Needell [2010] Needell, D.: Randomized kaczmarz solver for noisy linear systems. BIT Numerical Mathematics 50, 395–403 (2010)
- Tibshirani [1996] Tibshirani, R.: Regression shrinkage and selection via the lasso. Journal of the Royal Statistical Society Series B: Statistical Methodology 58(1), 267–288 (1996)
- Munkres [2014] Munkres, J.: Topology (2nd Edition). Prentice-Hall, NJ (2014)
- Spivak [1999] Spivak, M.: A Comprehensive Introduction to Differential Geometry. Publish or Perish, Inc., TX (1999)
- Huang et al. [2024] Huang, L., Li, X., Needell, D.: Randomized kaczmarz in adversarial distributed setting. SIAM Journal on Scientific Computing 46(3), 354–376 (2024)
- Needell and Tropp [2009] Needell, D., Tropp, J.A.: Cosamp: Iterative signal recovery from incomplete and inaccurate samples. Applied and computational harmonic analysis 26(3), 301–321 (2009)
- Blumensath and Davies [2008] Blumensath, T., Davies, M.E.: Iterative thresholding for sparse approximations. Journal of Fourier analysis and Applications 14, 629–654 (2008)
- Zouzias and Freris [2013] Zouzias, A., Freris, N.M.: Randomized extended kaczmarz for solving least squares. SIAM Journal on Matrix Analysis and Applications 34(2), 773–793 (2013)
- Epperly et al. [2024] Epperly, E.N., Goldshlager, G., Webber, R.J.: Randomized kaczmarz with tail averaging. arXiv preprint arXiv:2411.19877 (2024)
- Stamey et al. [1989] Stamey, T.A., Kabalin, J.N., McNeal, J.E., Johnstone, I.M., Freiha, F., Redwine, E.A., Yang, N.: Prostate specific antigen in the diagnosis and treatment of adenocarcinoma of the prostate. ii. radical prostatectomy treated patients. The Journal of urology 141(5), 1076–1083 (1989)
- Hastie et al. [2009] Hastie, T., Tibshirani, R., Friedman, J.H., Friedman, J.H.: The Elements of Statistical Learning: Data Mining, Inference, and Prediction. Springer, NY (2009)