A flexible family of distributions on the cylinder
Abstract
We propose a flexible family of distributions, generalized -distributions, on the cylinder which is obtained as a conditional distribution of a trivariate distribution. The new distribution has unimodality or bimodality, symmetry or asymmetry, depending on the values of parameters and flexibly fits the cylindrical data. The circular marginal of this distribution is distributed as a generalized -distribution on the circle. Some other properties are also investigated. The proposed distribution is applied to the real cylindrical data.
Key words and phrases: circular-linear correlation, circular-linear regression, generalized von Mises distribution, Johnson–Wehrly model, Mardia–Sutton model
1 Introduction
Directional or circular data often appear in a variety of scientific fields and various stochastic models have been proposed for analyzing such data. For univariate circular data, there have been many distributions investigated in terms of both tractability and applicability, see Jones and Pewsey (2005), Kato and Jones (2010) and Kato and Jones (2015). However, we sometimes encounter situations which involve both circular and linear variables, namely cylindrical data such as the pair of wind direction and temperature (Mardia and Sutton, 1978) or directions and distances of animal movements (Fisher, 1993). For such data, the distribution on the cylinder is needed, but there are not so many distributions compared to univariate circular distributions. We give a brief review below for several cylindrical distributions known in the literature. Johnson and Wehrly (1978) gave a distribution based on the principle of maximum entropy subject to constraints on certain moments, and Mardia and Sutton (1978) provided another distribution as a conditional distribution of a trivariate normal distribution or a maximum entropy distribution. An extension of the distribution by Mardia and Sutton (1978) was studied by Kato and Shimizu (2008), which can also be derived as a maximum entropy distribution or a conditional of a trivariate normal.
In this paper, we propose the generalized -distribution on the cylinder, which is a natural extension of the member of the exponential family given by Kato and Shimizu (2008). The proposed distribution is also regarded as a cylindrical extension of the generalized -distribution on the circle proposed by Siew et al. (2008). In fact, the circular marginal distribution is the generalized -distribution on the circle. The proposed distribution can be obtained as a conditional distribution of a trivariate distribution and characterized as the maximum -entropy distribution. This is a quite flexible distribution which allows for both asymmetry and variations in tail weight in terms of parameter values. We investigate some properties such as marginal and conditional distributions, modality, moments, circular-linear correlation and skewness. We briefly discuss a circular-linear regression model derived from the conditional distribution. For practical use, we provide an iterative algorithm for parameter estimation.
Subsequent sections are organized as follows. Section 2 provides a derivation of the distribution. In Section 3 some properties of the new distribution are studied. We apply the proposed distribution to the data set of the wind direction and ozone level given in Johnson and Wehrly (1977) in Section 4.
2 Derivation
Suppose that a trivariate random vector is distributed as a trivariate distribution with degrees of freedom , mean vector and variance-covariance matrix , where
for (), and From Kotz and Nadarajah (2004), the distribution of has density
We use a cylindrical coordinate , where and with and , and consider the conditional distribution of given , which provides a distribution on the cylinder. Define new parameters as
with , , and , where
Then we have
where . The conditional probability density function of is represented as
| (1) |
where and the normalizing constant is
| (2) | |||||
Here denotes Appell’s double hypergeometric function (Gradshteyn and Ryzhik, 2007, 9.180.4) defined by
with Pochhammer’s symbol
and the beta function. The distribution with density function (2) has nine parameters , , , and with restriction . The resulting distribution should be called the generalized -distribution on the cylinder. Relationships between the new and original parameters are:
-
(a)
.
-
(b)
.
-
(c)
.
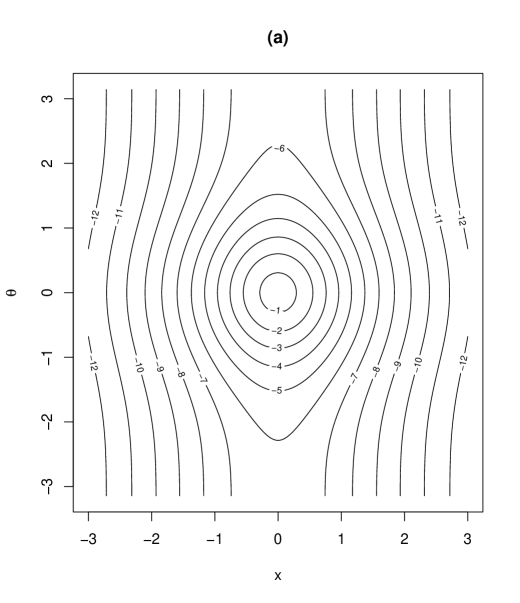
As being introduced in (2), the parameter was assumed positive. However, the density is still valid when the parameter space of is extended to . Note that corresponds to the degrees of freedom in the generalized -distribution on the cylinder (2) and the parameter determines the degree of concentration around the mode. The proposed distribution with density (2) has 9 parameters. The roles of the parameters are as follows: and are location parameters of and , respectively, and is the scale parameter of . and in determines the degree of correlation between and , and controls the skewness of . and determine the morality of the distribution, discussed in Section 3.3. controls the tail weight of the distribution. To see the role of and , we provide contour plots of the proposed density (2) in Figure 1 for some combinations of and . Other parameters are specified as . The column (I) in Figure 1 illustrates the interpretation of : as increases, the tail weight of the density increases. The role of as controlling the skewness of the distribution can be seen from the column (II) in Figure 1. The interpretation of are discussed in Section 3.3.
Under the assumption , if we use reparametrization , then the density (2) has a similar expression to the family of distributions introduced by Jones and Pewsey (2005):
The restriction in (2) is changed into .
(I)
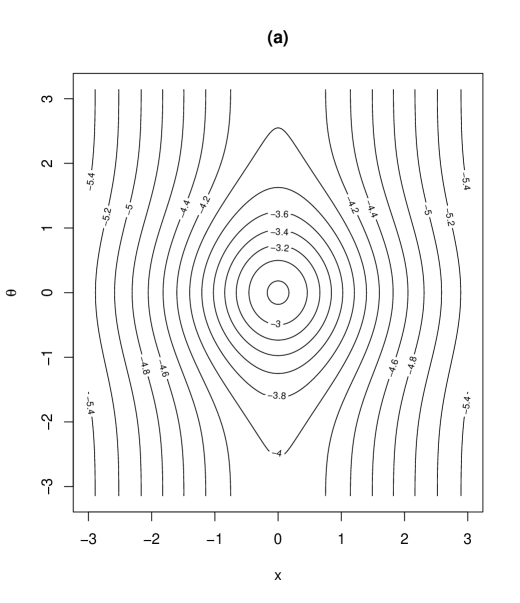
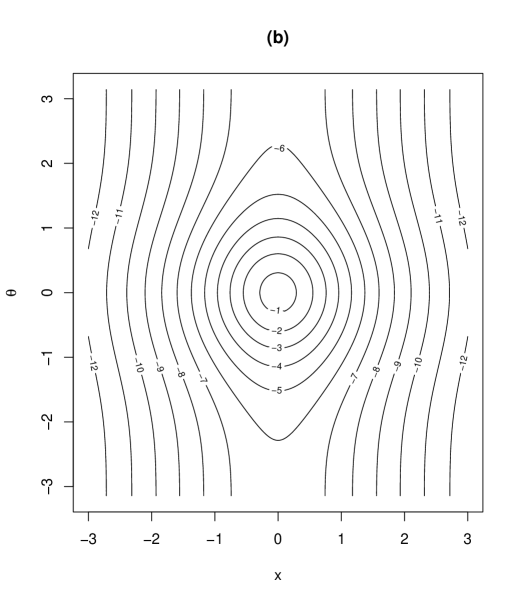
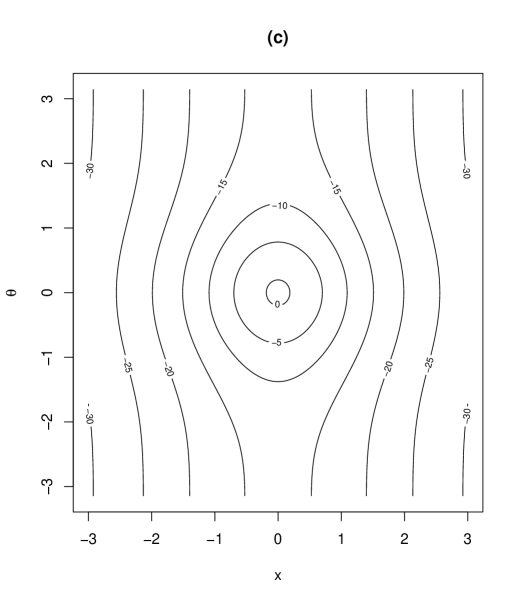
(II)
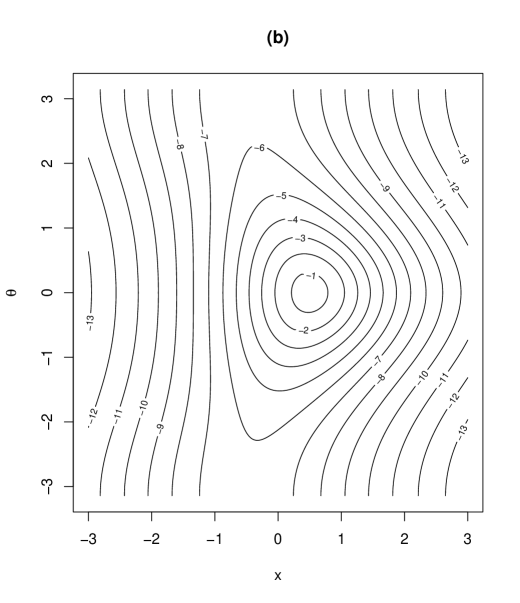
3 Properties
3.1 Special cases
1. Under the assumption in (2), letting , we have an extension of the distribution by Mardia and Sutton (1978). Its joint probability density function (Kato and Shimizu, 2008) is
| (3) |
with the normalizing constant
| (4) |
Here denotes the modified Bessel function of the first kind and order given by
2. When , (2) reduces to
| (5) |
The normalizing constant is represented as
using the Gauss hypergeometric function . If we replace and let , we have the distribution proposed by Mardia and Sutton (1978) and the constant tends to . This agrees with the fact that when in (4).
3.2 Marginal and conditional distributions
The marginal distribution of is
| (6) |
where
| (7) |
The distribution with density (6) is a member of the generalized -distributions on the circle proposed by Siew et al. (2008), and is possibly bimodal and asymmetric. Cosine and sine moments of the generalized -distributions are given in their paper. The generalized t-distributions include the generalized von Mises distribution (cf. Yfantis and Borgman, 1982) as a special case. As another special case when in (2), the marginal distribution of belongs to the family of symmetric distributions by Jones and Pewsey (2005). Note that the marginal density (6) is independent of and which are the parameters of the proposed density (2). On the other hand, the marginal distribution of does not have a closed form in general. When , we can obtain the marginal distribution of in a closed form given by
where is defined by (2) and is obtained by replacing and with and , respectively, in defined in (3.2). Note that this density is symmetric about .
In (2), the conditional distribution of given has the generalized -density function provided by
| (8) |
with the normalizing constant
The conditional distribution of given is a member of the generalized -distributions on the circle given by
where . As shown in Siew et al. (2008), the mean direction of with density (6) depends on . Thus the conditional mean direction depends on through . The result that the conditional distributions of and are the generalized -distribution comes from the fact that the conditional distribution of a multivariate distribution is again a multivariate distribution (Joe, 2015).
3.3 Modality
We consider the modality of the distribution with density (2). The mode of (2), whenever the value of is specified, is . Similar to Siew et al. (2008), we discuss maximization of the function with respect to . The solution of an equation
| (9) |
is a value which maximizes if the sign of is positive, where
Equation (9) can be solved numerically for any combinations of and . Without loss of generality, we let . Then (9) has closed form solutions when and . The results are given in Table 1, where , and . See Yfantis and Borgman (1982) for more discussion as to the solutions of (9).
| Condition | Modes | |
|---|---|---|
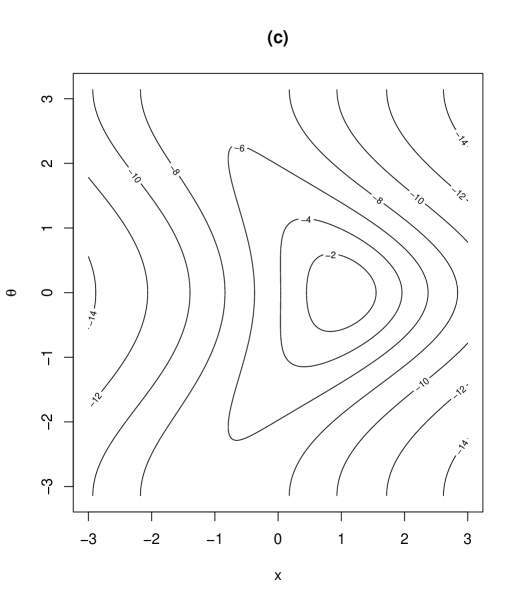
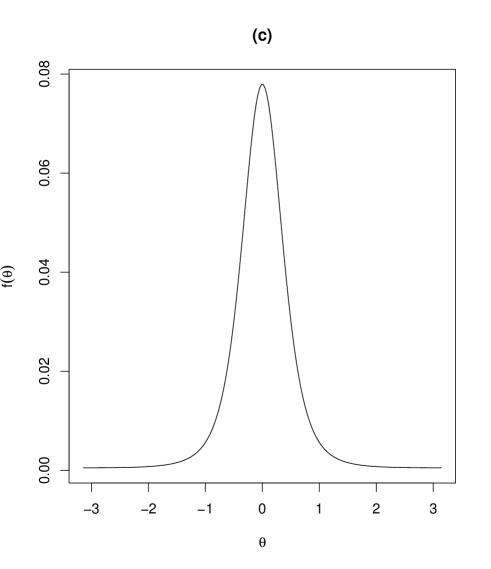
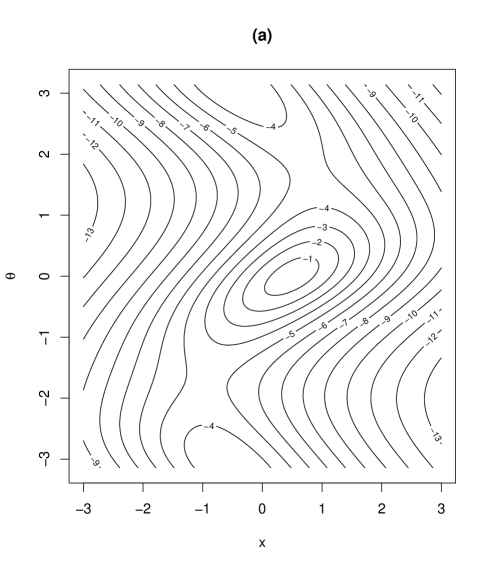
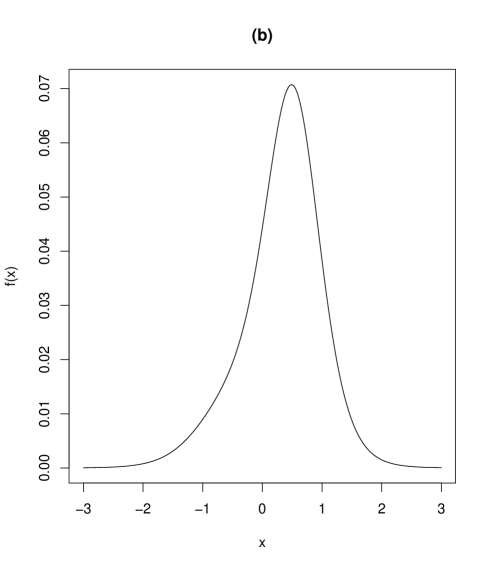
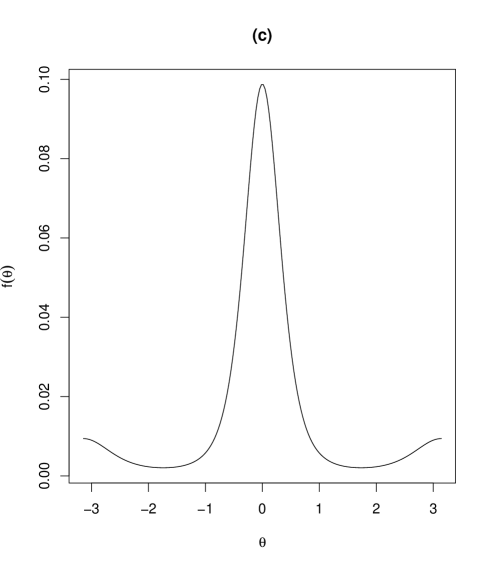
Contour plots and marginal density plots of the proposed distribution are given in Figure 2. Figure 2 shows the case when , , , and (II) , , , while the other parameters are set as , , , , . In the case of (I) in Figure 2, the joint density is unimodal and the marginal densities of and are symmetric. On the other hand, in the case of (II) in Figure 3, the joint density is bimodal and the marginal density of is asymmetric. In fact, the marginal density of is possibly skew depending on the values of the parameters, as will be seen in Section 3.5. The marginal density of in Figure 3 is bimodal as given in Table 1.
In the case where a unimodal distribution is desired, we put, for example, with restriction to get a unimodal density function from (2). This submodel can be useful for modeling multimodality when a finite mixture model is easier to interpret than a bimodal distribution.
(I)
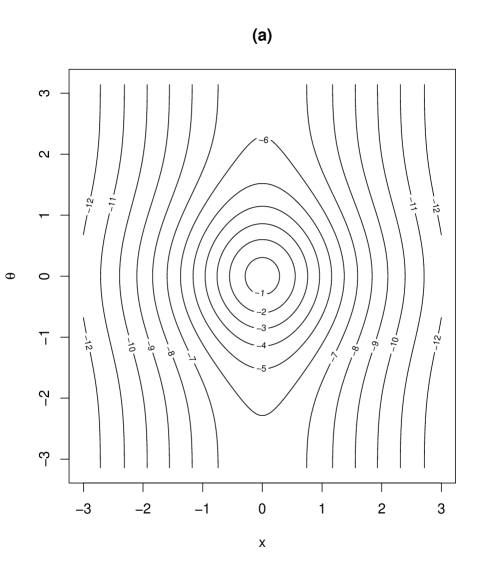
(II)
3.4 Moments and circular-linear correlation
We consider moments of the proposed distribution. Let and be the trigonometric moments of (6) under replacement with , which are obtainable using the results by Siew et al. (2008). Moments of a random vector having (2) are given by
| (10) |
and
| (11) |
where is obtained by replacing with in in (3.2).
Moreover, we derive another type of moments of a random vector having (5) given by putting in (2). After some calculations, the moments for nonnegative integers and turn out to be
| (12) |
where denotes the associated Legendre function (Gradshteyn and Ryzhik, 2007, 8.711.2) defined by
Next, we study the circular-linear correlation between and (cf. Mardia and Jupp, 1999, p. 245) which is defined as
where and are Pearson’s correlation coefficients. We only consider the case when has density (5) for simplicity because the circular-linear correlation of with density (2) is not feasible to compute analytically. Note that the in case of (2) can be obtained by numerical calculation. A straightforward calculation shows that
| (13) |
where
and and denote and , calculable from (12). Note that since and . We can observe that is an increasing function of , and if and only if . Furthermore, letting , it is seen that (13) reduces to the circular-linear correlation of the distribution proposed by Mardia and Sutton (1978) because (5) goes to the Mardia–Sutton model. This is confirmed from the fact that and as .
3.5 Skewness of marginal distribution on the real line
For the proposed density (2), we derive the skewness of the marginal density of defined as
Straightforward calculation shows that
| (14) |
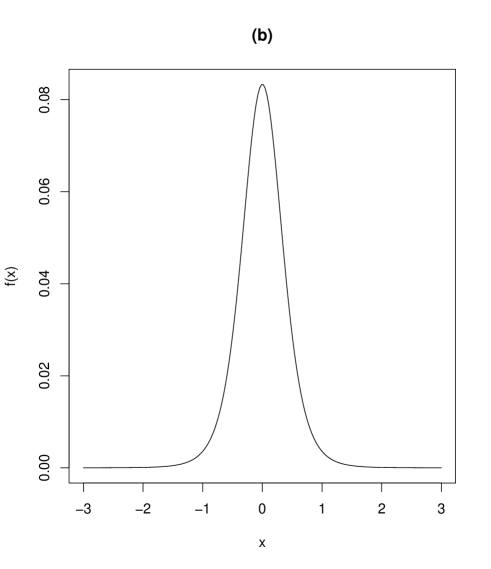
where and , which are calculable from (10) and (11). We can easily obtain from (14) that as and when . Figure 4 shows that a graph of skewness as a function of . We see from Figure 4 that the marginal distribution of X of the proposed model can be left and right skewed according to the values of the parameters.
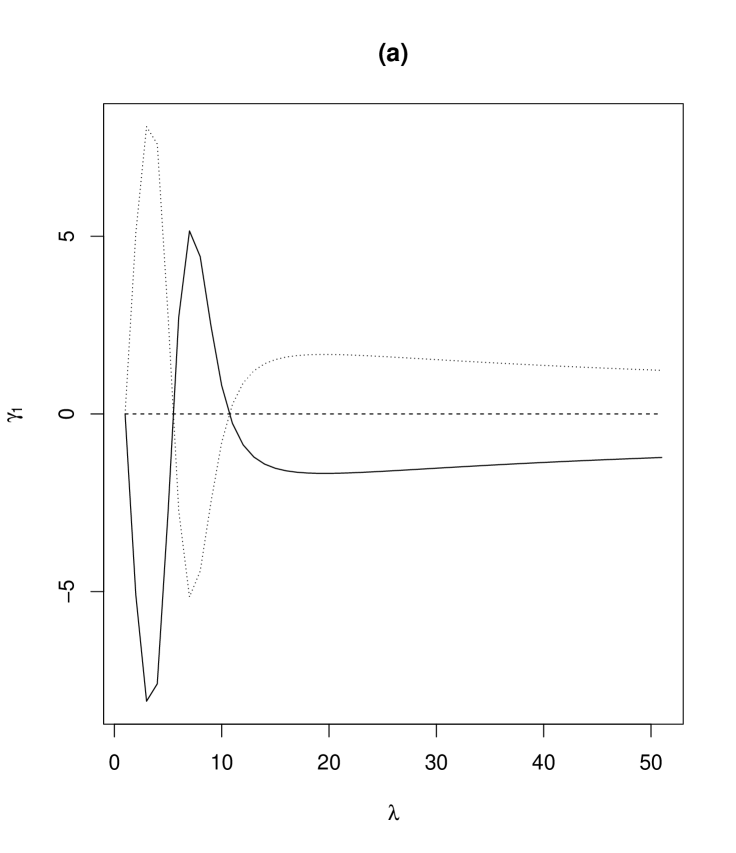
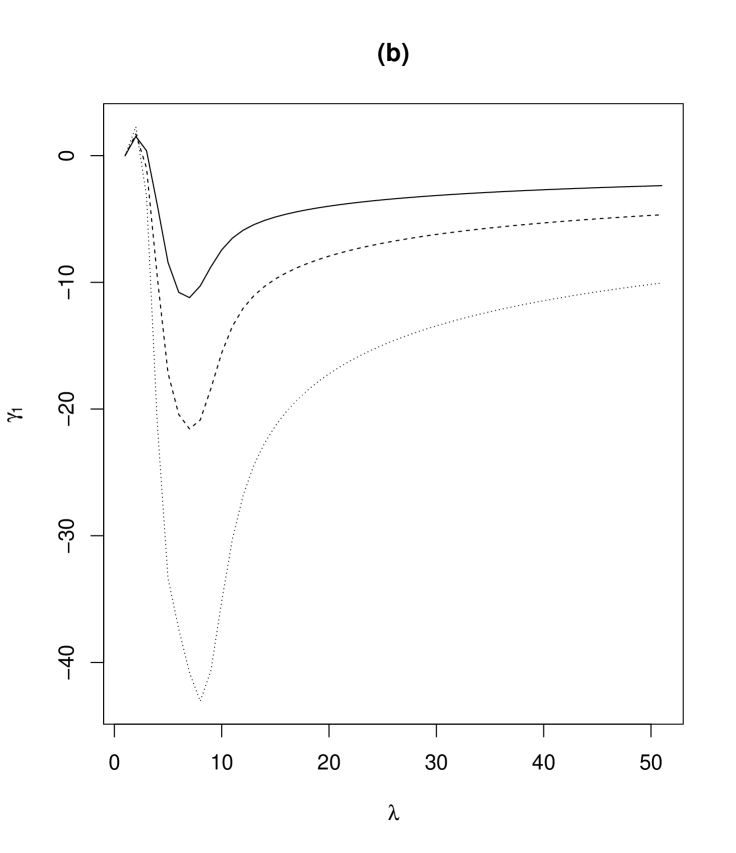
3.6 Regression
We can derive a circular-linear regression model from the conditional distribution with density (8). In fact, the conditional mean of given is
and the conditional variance of given is
Note that the conditional variance is dependent on , i.e. the regression model is possibly heterogeneous. As a reduced model, if we let , we have , which is independent of . Moreover if and in (8), we have and, in this case, we obtain a regression model
with random errors which are independent and identically distributed according to the generalized -distribution.
3.7 Maximizing -entropy
The related distribution proposed by Mardia and Sutton (1978) and Kato and Shimizu (2008) can be characterized as the maximum entropy distribution under certain moment conditions. Also a maximum entropy distribution under certain moment conditions relates to the proposed distribution with density (2). We consider the -entropy (see Eguchi, 2009, Section 13.2.4) defined as
Then the maximum entropy distribution subject to constraints on the moments
is the distribution with density
| (15) |
3.8 Parameter estimation
We provide a method for calculating the maximum likelihood estimates of the parameters in the generalized -distribution with density (2). When we observe , the log-likelihood function is given by
where . For obtaining the maximizer of , we propose the conditional maximization algorithm. We first divide the parameter into , where and . Given the value of and , maximizing is equivalent to maximizing
with respect to , where . Let , for , and for
Using the theory of weighted regression (see Andrews, 1974), the maximizer of given and can be obtained as
| (16) |
which deduces the maximizer . Since depends on , we calculate based on the current values in each iteration.
Given and , maximizing with respect to is equivalent to solving the following equation:
| (17) |
which deduces the maximizer .
Finally for maximizing under given and , we maximize
| (18) |
with respect to , where . This maximization problem is quite similar to obtaining the maximum likelihood estimates of the generalized -distribution on the circle (Siew et al., 2008), so that we can obtain the maximizer given and . Note that we carried out the maximization of (18) with use of numerical integration for getting the value of .
Therefore, the proposed estimation method is described in the following.
4 Empirical application
For an illustrative example, we consider a cylindrical dataset given in Johnson and Wehrly (1977) on the wind direction and ozone level taken at 6:00 pm at four-day intervals between April 18th and June 29th, 1975 at a weather station in Milwaukee with samples. We fitted the proposed generalized -distribution and its submodels. For submodels of (2), we consider two cases, namely, (GT-sub1) given in (5) and with (GT-sub2) discussed in the end of Section 3.3. When we carry on the estimation algorithm given in Section 3.8, we repeat the algorithm until the difference between update and current values are smaller than . For comparison, we also fitted the member of the exponential family given by Kato and Shimizu (2008) with density
which is reparametrized form of (3) with , and . Table 2 provides the maximum likelihood estimates of the parameters, AIC values, and the multivariate Kolmogorov-Smirnov statistics of goodness of fit testing given by Justel et al. (1997). In Table 1 of Justel et al. (1997), the bivariate Kolmogorov-Smirnov statistics distributions are reported. From the table, the upper , and percentiles are , and , respectively, for sample cases. Thus the percentiles in 19 sample cases are smaller than these values, so that the fitted four models are not rejected with significance level. Judging from AIC, we see that the two submodels of the proposed distribution, GT-sub1 and GT-sub2, gives better fits than the Kato and Shimizu distribution. Figure 4 shows scatter plots of the data and contour plots of the fitted densities of two submodels.
| Model | AIC | g.o.f | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| GT | 41.38 | 31.14 | 1.25 | 68.90 | 0.11 | 6.28 | 0.03 | 1.35 | 23.84 | 417.79 | 0.180 |
| GT-sub1 | 41.37 | 31.17 | 1.24 | 74.81 | 0.08 | 0.30 | — | — | 28.28 | 240.20 | 0.314 |
| GT-sub2 | 41.01 | 32.70 | 1.41 | 6.08 | 0.49 | 0.19 | 0.15 | — | -1.00 | 203.34 | 0.359 |
| KS | 41.24 | 31.38 | 1.20 | 19.77 | 1.41 | 0.19 | 0.35 | 1.45 | — | 241.42 | 0.282 |
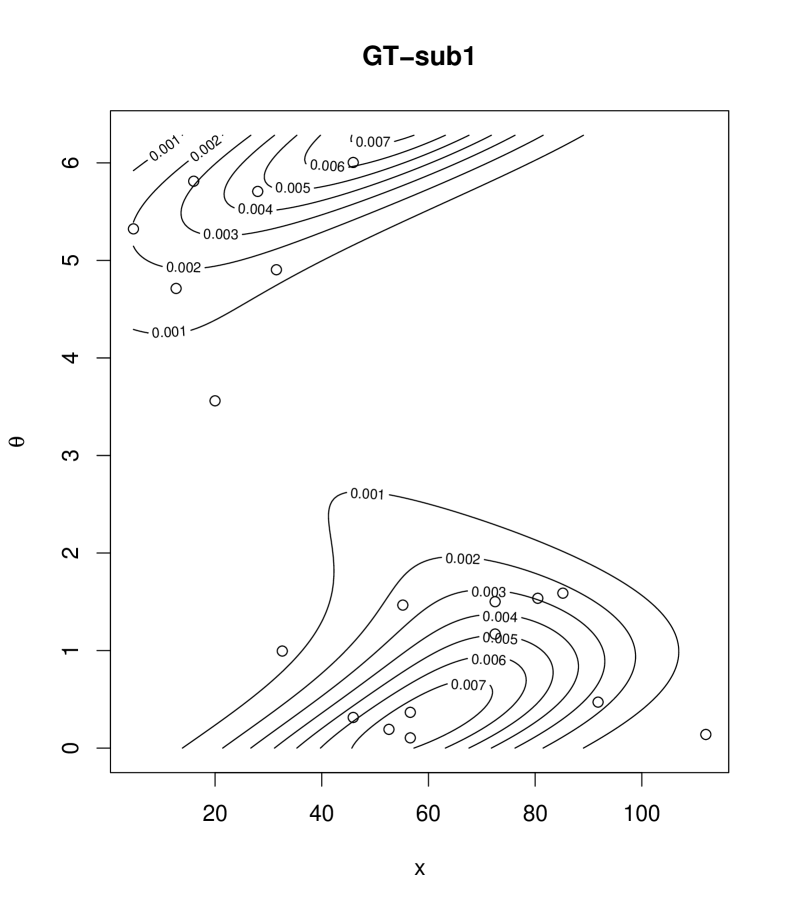
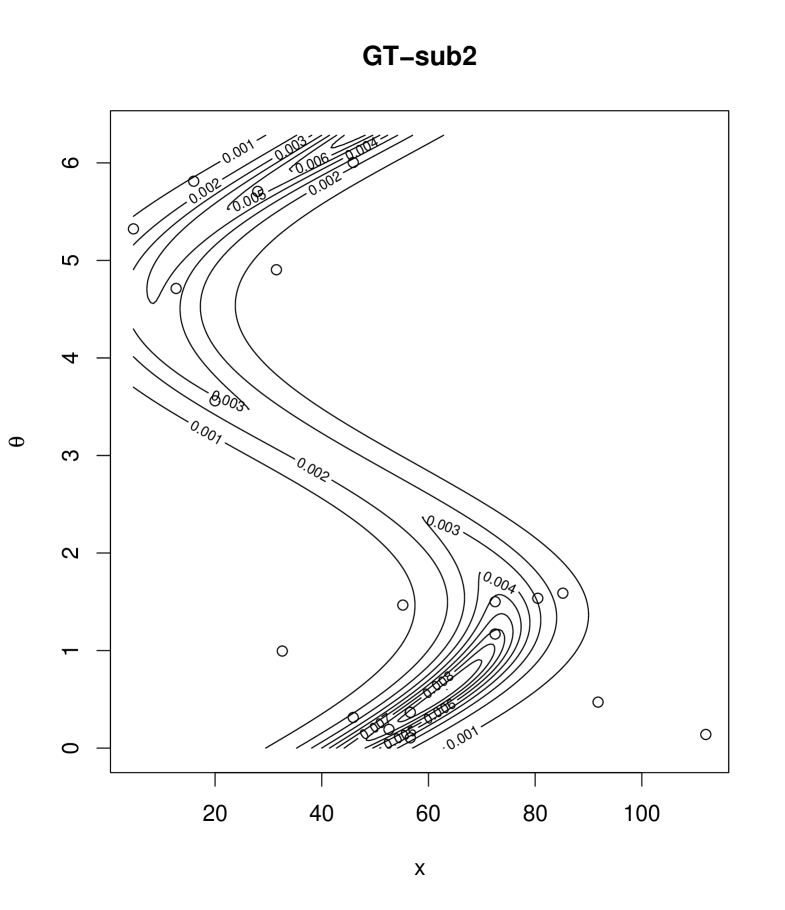
5 Conclusions
In this paper, we derived the distributions on the cylinder based on a trivariate -distribution. The derived distribution is considered as a cylindrical extension of the generalized -distribution on the circle proposed by Siew et al. (2008) and includes the exponential family given by Kato and Shimizu (2008). We investigated some properties of the proposed distribution including the marginal and conditional distributions, circular-linear correlation and the algorithm for parameter estimation. We applied our proposed distribution to the data set of the wind direction and ozone level given in Johnson and Wehrly (1977), and we confirmed that the proposed distribution gave a better fit than the distribution given by Kato and Shimizu (2008).
Acknowledgement
We would like to thank the two reviewers for many valuable comments and helpful suggestions which led to an improved version of this paper. The first author was supported in part by Grant-in-Aid for Scientific Research (10076) from Japan Society for the Promotion of Science (JSPS). The work of the third author was supported by JSPS KAKENHI Grant Number 25400218.
References
- [2] Andrews, D. F. (1974). A robust method for multiple linear regression, Technometrics, 16:523–532.
- [4] Eguchi, S. (2009). Information Divergence Geometry and the Application to Statistical Machine Learning. In Information Theory and Statistical Learning, Chapter 13, 309–332, Emmert-Streib, F. and Dehmer, M. Eds., New York, Springer.
- [6] Fisher, N. I. (1993). Statistical Analysis of Circular Data. Cambridge University Press, Cambridge.
- [8] Gradshteyn, I. S. and Ryzhik, I. M. (2007). Table of Integrals, Series, and Products. Seventh Edition, Elsevier, Amsterdam.
-
[10]
Joe, H. (2015). Dependence Modeling with Copulas. Chapman
&Hal/CRC, Boca Raton. - [12] Jones, M. C. and Pewsey, A. (2005). A family of symmetric distributions on the circle. Journal of the American Statistical Association, 100:1422–1428.
- [14] Johnson, R. A. and Wehrly, T. (1977). Measures and models for angular correlation and angular-linear correlation. Journal of the Royal Statistical Society B, 39:222–229.
- [16] Johnson, R. A. and Wehrly, T. E. (1978). Some angular-linear distributions and related regression models. Journal of the American Statistical Association, 73:602–606.
- [18] Justel, A., Pea, D. and Zamar, R. (1997). A multivariate Kolmogorov-Smirnov test of goodness of fit. Statistics and Probability Letters, 35, 251–259.
- [20] Kato, S. and Jones, M. C. (2010). A family of distributions on the circle with links to, and applications arising from, Möbius transformation. Journal of the American Statistical Association, 105:249–262.
- [22] Kato, S. and Jones, M. C. (2015). A tractable and interpretable four-parameter family of unimodal distributions on the circle. Biometrika, 102, 181-190.
- [24] Kato, S. and Shimizu, K. (2008). Dependent models for observations which include angular ones. Journal of Statistical Planning and Inference, 138:3538-3549.
- [26] Kotz, S. and Nadarajah, S. (2004). Multivariate Distributions and Their Applications, Cambridge University Press, Cambridge.
- [28] Mardia, K. V. and Jupp, P. E. (1999). Directional Statistics. Wiley, Chichester.
- [30] Mardia, K. V. and Sutton, T. W. (1978). A model for cylindrical variables with applications. Journal of the Royal Statistical Society B, 40:229-233.
- [32] Siew, H-Y., Kato, S. and Shimizu, K. (2008). The generalized -distribution on the circle. Japanese Journal of Applied Statistics, 37:1-17.
- [34] Yfantis, E. A. and Borgman, L. E. (1982). An extension of the von Mises distribution. Communications in Statistics–Theory and Methods, 11:1695-1706.
- [35]