2022
These authors contributed equally to this work.
These authors contributed equally to this work.
[1,7]\fnmJayashree \surKalpathy-Cramer
1]\orgdivMartinos Center for Biomedical Imaging, \orgaddress\cityBoston, \stateMA, \countryUSA
2]\orgdivMassachusetts Institute of Technology, \orgaddress\cityCambridge, \stateMA, \countryUSA
3]\orgdivNeuroPoly, \orgnamePolytechnique Montreal, \orgaddress\cityMontreal, \stateQC, \countryCanada
4]\orgnameOregon Health and Science University, \orgaddress\cityPortland, \stateOR, \countryUSA
5]\orgnameNational Eye Institute, \orgaddress\cityBethesda, \stateMD, \countryUSA
6]\orgdivMGH & BWH Center for Clinical Data Science, \orgaddress\cityBoston, \stateMA, \countryUSA
7]\orgnameUniversity of Colorado Anschutz Medical Campus, \orgaddress\cityAurora, \stateCO, \countryUSA
A generalized framework to predict continuous scores from medical ordinal labels
Abstract
Background: Many variables of interest in clinical medicine, like disease severity, are recorded using discrete ordinal categories such as normal/mild/moderate/severe. These labels are used to train and evaluate disease severity prediction models. However, ordinal categories represent a simplification of an underlying continuous severity spectrum. Using continuous scores instead of ordinal categories is more sensitive to detecting small changes in disease severity over time. Here, we present a generalized framework that accurately predicts continuously valued variables using only discrete ordinal labels during model development.
Methods: We study the framework using three datasets: disease severity prediction for retinopathy of prematurity and knee osteoarthritis and breast density prediction from mammograms. For each dataset deep learning models are trained using discrete labels, and the model outputs were converted into continuous scores. The quality of the continuously valued predictions was compared to expert severity scores that were more detailed than the discrete training labels. We study the performance of conventional and Monte Carlo dropout multi-class classification, ordinal classification, regression, and Siamese models.
Findings: We found that for all three clinical prediction tasks, models that take the ordinal relationship of the training labels into account outperformed conventional multi-class classification models. Particularly the continuous scores generated by ordinal classification and regression models showed a significantly higher correlation with expert rankings of disease severity and lower mean squared errors compared to the multi-class classification models. Furthermore, the use of MC dropout significantly improved the ability of all evaluated deep learning approaches to predict continuously valued scores that truthfully reflect the underlying continuous target variable.
Interpretation: We showed that accurate continuously valued predictions can be generated even if the model development only involves discrete ordinal labels. The novel framework has been validated on three different clinical prediction tasks and has proven to bridge the gap between discrete ordinal labels and the underlying continuously valued variables.
keywords:
Retinopathy of prematurity, knee osteoarthritis, breast density, deep learning, continuous score, weakly supervised learning1 Introduction
Many clinical variables, like disease severity, are communicated and recorded as discrete ordinal classes.
However, in reality they are distributed on a continuous spectrum. (Campbell2016PlusVariability, )
The discretization of continuously valued variables facilitates documentation and communication and standardizes treatment decisions at the cost of losing information.
As illustrated in Figure 1, two patients that fall into the same severity category will receive the same label.
Consequently, if their data is used to develop a prediction model, it will be treated exactly the same during training, regardless of their exact position along the continuous spectrum.
The ability of Deep Learning (DL) to learn and recognize subtle patterns from large amounts of data has led to tremendous successes in automated medical image analysis. (Anwar2018MedicalReview, )
DL models have achieved and, in some cases, even exceeded human performance in disease detection and automatic severity classification for numerous diseases such as diabetic retinopathy, retinopathy of prematurity, and osteoarthritis. (Gulshan2016DevelopmentPhotographs, ; Brown2018AutomatedNetworks, ; Tiulpin2018AutomaticApproach, )
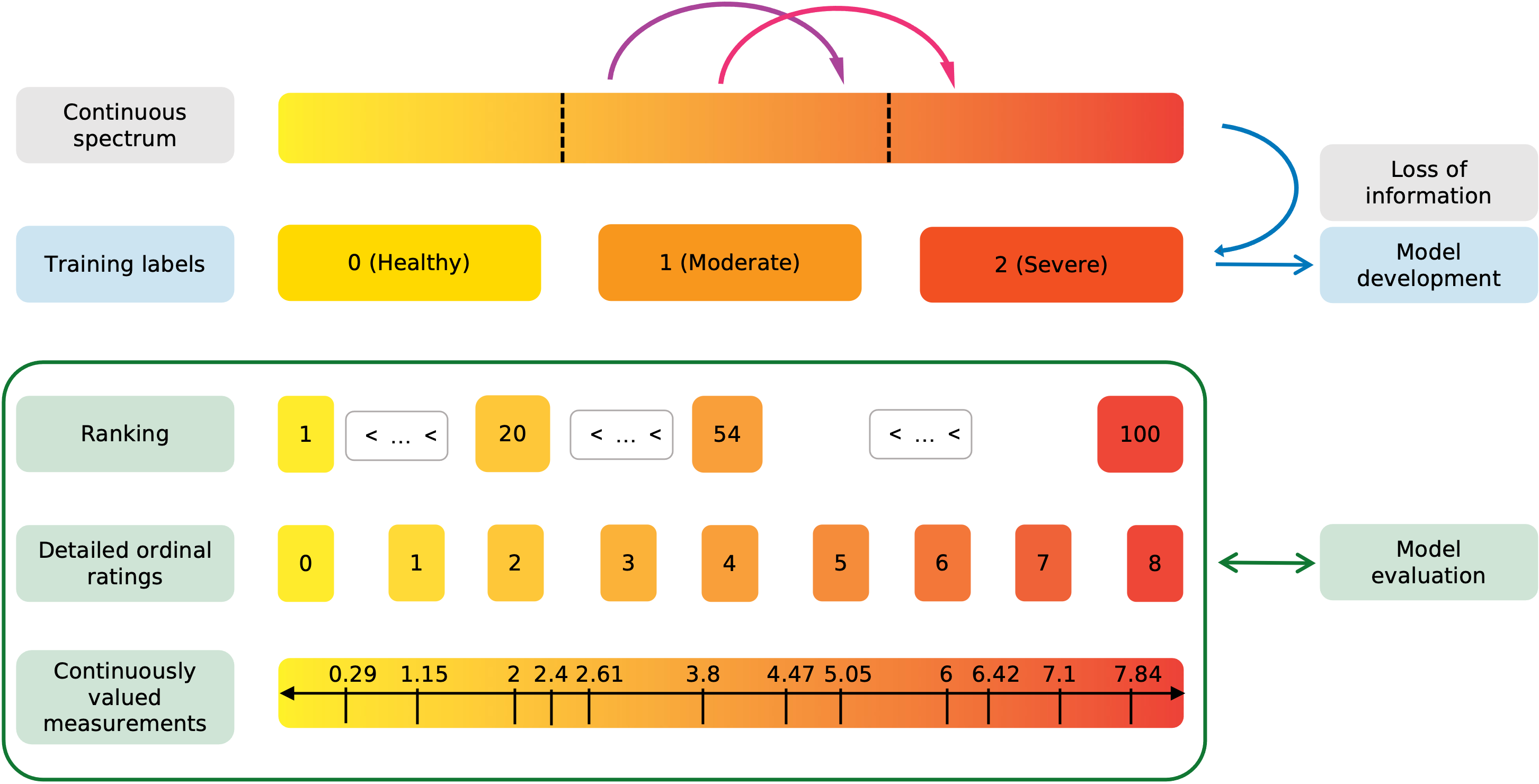
Yet, these successes have been build on the simplifying assumption that disease severity prediction can be formulated as a simple classification task.
Researchers mostly use DL architectures that are intended for the classification of nominal categories and ignore the inherent ordinal nature of the available training labels. More so, disease severity prediction tasks are often simplified even more by treating them as binary problems, e.g., the identification of severe disease (Stidham2019PerformanceColitis, ), cases for referral (DeFauw2018ClinicallyDisease, ; Leibig2017LeveragingDetection, ), or disease detection (Gulshan2016DevelopmentPhotographs, ).
Advantages of continuous scores
In addition to the class, the position of a case on the continuous spectrum contains valuable clinical information that is not captured by current approaches. Antony2016QuantifyingNetworks
Therefore, the use of continuous scores to describe clinical variables that are distributed on a continuous spectrum provides several advantages over discrete ordinal variables.
First, continuous metrics allow for the detection and quantification of changes within a class, i.e., an increase in disease severity that does not constitute a transition between class and . Li2020SiameseImaging ; Brown2018FullyLearning
In Figure 1 the purple and magenta arrows represent similar large increases in disease severity.
While the magenta transition would get detected by the traditional classification approach, the purple transition would not.
The only difference between the two transitions is that the magenta one crosses the class boundary from moderate to severe, while the purple arrow represents a within class change.
The detection of within-class changes allows to detect disease deterioration earlier and act upon it if required.
Second, the higher degree of information presented in continuous vs. ordinal scores can be useful for efficient patient stratification, particularly the identification of cases close to a decision boundary.
Third, expert perception of class boundaries can be subject to changes over time. (Moleta2017Plus2007, )
Therefore, models ignoring the continuous nature of disease severity could become less valuable over time as, e.g., the perception of what constitutes mild versus moderate disease severity shifts.
Lastly, an algorithm that predicts a continuous score is more likely to fulfill notions of individual fairness as similar individuals that are close to the label decision boundaries will be more likely to receive similar scores compared to using a simple classification algorithm. Dwork2012FairnessAwareness
Related work
Previous attempts to predict continuous disease severity scores have made use of either conventional classification networks or Siamese networks.
Redd et al. proposed to aggregate the softmax outputs from a conventional 3-class convolutional network into one continuously valued vascular severity score for disease severity classification in retinopathy of prematurity (ROP). Redd2019EvaluationPrematurity
This score strongly correlates with experts’ ranking of overall disease severity.
Furthermore, changes in this score over time accurately reflect disease progression. Brown2018FullyLearning
However, the training objective of multi-class classification models is to separate the latent space representation of classes as much as possible. This could therefore lead to unstable predictions and confusion at the class boundaries.
Using Siamese networks, Li et al. showed that the continuously valued difference relative to a reference pool of images correlates with expert’s rankings of disease severity and reflects temporal changes in severity in knee osteoarthritis and ROP. Li2020SiameseImaging
Similarly, in a study on an x-ray based severity score for COVID-19, a score generated by a Siamese network highly correlated with radiologist-determined severity scores.
However, the performance of Siamese networks for the predictions of continuous scores has not been compared to other methods and their calibration has not been studied yet.
Study aim
Here, we aim to identify model development strategies that lead to the prediction of accurate continuous scores. Most importantly, while we utilize widely available discrete ordinal labels for training, the models’ performance to predict accurate continuous scores is evaluated using labels on a finer scale than the training ground truth (illustrated in the green box in Figure 1) on three datasets: disease severity prediction for ROP and knee osteoarthritis and breast density estimation from mammograms. Following this process, we aim to show that it is possible to develop models that are capable to recover the information lost through the discretization of the continuous target variable.
2 Methods
2.1 Datasets
All images were de-identified prior to data access; ethical approval for this study was therefore not required. Dataset splits were performed on a patient level. The size of all dasets is listed in Table 1 and class distributions for each dataset are listed in Appendix A.
2.1.1 ROP
ROP is an eye disorder mainly developed by prematurely born babies and is among the leading causes of preventable childhood blindness. shah2016retinopathy
It is characterized by a continuous spectrum of abnormal growth of retinal blood vessels which is typically categorized into three discrete severity classes: normal, pre-plus, or plus. (Quinn2005ThePrematurity, ; Campbell2016PlusVariability, )
We use the same dataset, labels, and preprocessing as described by Brown et al.(Brown2018AutomatedNetworks, )
In addition to the standard diagnostic labels, the test set was labeled by five raters on a scale from 1 to 9 and five experts ranked an additional 100 ROP photographs based on severity.(Taylor2019MonitoringLearning, ; Brown2018AutomatedNetworks, )
2.1.2 Knee osteoarthritis
The global prevalence of knee osteoarthritis is 22.9% for individuals over 40, causing chronic pain and functional disability. cui2020global
Knee osteoarthritis can be diagnosed with radiographic images and disease severity is typically evaluated using the Kellgren-Lawrence (KL) scale consisting of the following severity categories: none, doubtful, mild, moderate, and severe. (kellgren1957radiological, )
We use the the Multicenter Osteoarthritis Study (MOST) dataset. 100 images from the test were ranked by their severity by three experts. (Li2020SiameseImaging, )
All images were center cropped to 224x224 pixels and intensity scaled between 0 and 1 as preprocessing.
2.1.3 Breast density
Breast density is typically categorized as fatty, scattered, heterogeneous, or dense, depending on the amount of fibroglandular tissue present.(Liberman2002BreastBI-RADS, )
Women with high breast density are at a higher risk of developing breast cancer and require additional MRI screening. (Boyd1995QuantitativeStudy, ; Bakker2019SupplementalTissue, )
We use a subset of the Digital Mammographic Imaging Screening Trial (DMIST) dataset. (Pisano2005DiagnosticScreening, )
Furthermore, for 1892 mammographs from the test dataset, an automatic assessment of the volumetric breast density was obtained using the commercially available Volpara Density software which has demonstrated a good agreement with expert ratings of breast density (see Figure 5). (highnam2010robust, ; wanders2017volumetric, )
Preprocessed mammograms were of size 224x224 pixels.
| Dataset | Size | Training | Validation | Test |
| ROP | 5611 | 4322 | 722 | 467 (9-point scale) |
| 100 (ranked) | ||||
| Knee OA | 14273 | 12268 | 1905 | 100 (ranked) |
| Breast Density | 83034 | 70293 | 10849 | 1892 (Volpara Density) |
2.2 Model training
2.3 Model types
Four model types were trained: multi-class and ordinal classification, regression, and Siamese. The model output was converted to a continuous score value for each model to represent the underlying severity spectrum of the medical tasks studies.
Classification
All classification models for this study were trained with cross-entropy loss. The continuous severity score is computed as the of the softmax outputs weighted by their class (Equation 1), leading to scores from 0 to k-1.
| (1) |
with being the number of classes and the softmax probability of class .
Ordinal classification
In ordinal classification, the task is broken up into a binary classification tasks, leading to one output unit less than the number of classes. (Li2006OrdinalClassification, ) During training, the ordinal loss function penalizes larger misclassification errors more than smaller errors (e.g., predicting class 2 when the ground truth label is 0 is penalized more than if the models predicts class 1). We use the CORAL loss as described by Cao et al. for model optimization.Cao2020RankEstimation
A continuous score is generated by summing over the output probabilities (Equation 2), resulting in values ranging from 0 to k-1.
| (2) |
Regression
Similar to ordinal models, regression models require the ordinality of the target output. However, unlike ordinal models, the output of regression models is a continuous value rather than a discrete class. The regression models were trained using the mean squared error loss function with the class number as the target value. The raw model output yields a continuous value; hence, no conversion is required to receive a continuous score.
Siamese
Siamese models compare pairs of images to evaluate their similarity. They are composed of two branches consisting of identical sub-networks with shared weights where each of the two images is processed in one of the branches. The lower the Euclidean distance between the outputs of each branch the higher the similarity between the inputs. Following a procedure described by Li et al., at test time, the target images are compared to ten anchor images associated with class 0. Li2020SiameseImaging Here, the continuous score is the median of the Euclidean distances between the target and the ten anchor images.
2.4 Monte Carlo dropout
By utilizing dropout not just during training but also at test time, yields slightly different Monte Carlo (MC) predictions.(gal2016dropout, ) The MC predictions can subsequently be averaged, to obtain the final output prediction. All models referred to as MC models were trained with spatial dropout after each residual block of the ResNets models, and MC iterations at test time. The dropout rates are , , and for ROP, knee osteoarthritis, and breast density, respectively, and were selected empirically and based on current literature.
2.5 Model training
Model parameters were selected based on initial data exploration and empirical results. All ROP models were using a ResNet18 and all knee osteorarthritis and breast density models a ResNet50. A detailed description of the training parameters can be found in Appendix B.
2.6 Evaluation
2.6.1 Metrics
Ranked datasets
The model performance was evaluated based on the ranked test data using the following three metrics. First, we computed Spearman’s rank coefficient between the rank and the predicted score. A monotonic increase between both metrics is expected; hence, a Spearman coefficient of 1 corresponds to a perfect correlation. Second, we computed agreement between the ground truth rank and the rank based on the continuous score using mean squared error (MSE) to quantify the correspondence between the predictions and ground truth. Here, the ranks were normalized to the maximum rank. Finally, the classification performance was assessed using clinically relevant AUCs. We defined the clinically relevant classification and normal/pre-plus vs. plus for ROP, none/doubtful vs. mild/moderate/severe for knee osteoarthritis, and fatty/scattered vs. heterogeneous/dense for breast density.
ROP
A subset of the ROP test set had expert ratings from 1 to 9 based on the quantitative scale previously published by Taylor et al. (Taylor2019MonitoringLearning, ) The correspondence between the expert rating and the continuous predicted scores were measured using the MSE.
2.6.2 Statistical analysis
Metrics were bootstrapped (500 iterations) and 95% confidence intervals were evaluated for statistical analysis. Bootstrapped metrics yielding two-sided -test with a p-value inferior to 5% were considered statistically different.
3 Results
3.1 Predicted score compared with severity rankings
Agreement between predicted score and severity rankings
We first assessed how well the predicted continuous scores reflect a ranking of the images in each dataset.
Retinal photographs and knee radiographs were ranked by domain experts with increasing disease severity.
The mammograms were ranked with increasing density based on the quantitative continuously valued Volpara breast density score.
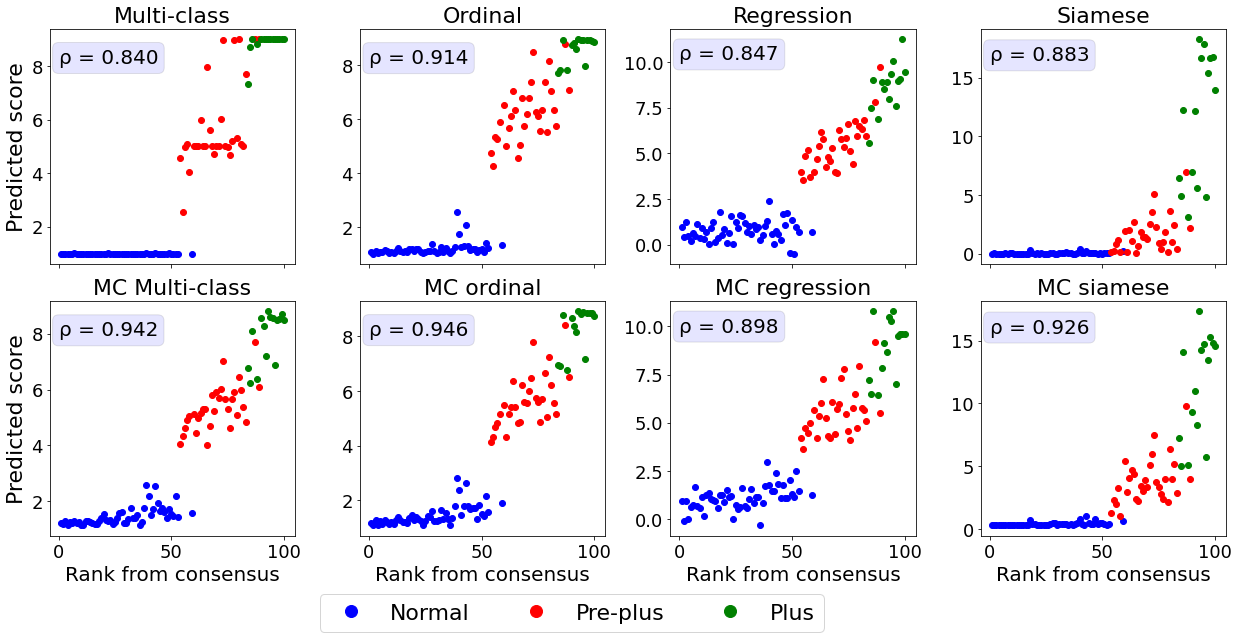
The relationship between the ground truth rankings and the predicted continuous scores are presented in Figure 2.
For all datasets, the multi-class models without MC dropout display horizontal plateaus around the class boundaries where the predicted score is more or less constant with increasing rank.
Similar patterns can be observed for the Siamese and MC Siamese models, especially for normal ROP and knee osteoarthritis cases.
| Model | MSE | Spearman | clinically relevant AUC |
|---|---|---|---|
| ROP | |||
| Multi-class | |||
| MC multi-class | |||
| Ordinal | |||
| MC ordinal | |||
| Regression | |||
| MC regression | |||
| Siamese | |||
| MC Siamese | |||
| Knee osteoarthritis | |||
| Multi-class | |||
| MC multi-class | |||
| Ordinal | |||
| MC ordinal | |||
| Regression | |||
| MC regression | |||
| Siamese | |||
| MC Siamese | |||
| Breast density | |||
| Multi-class | |||
| MC multi-class | |||
| Ordinal | |||
| MC ordinal | |||
| Regression | |||
| MC regression | |||
| Siamese | |||
| MC Siamese | |||
Agreement between predicted and ground truth rankings
A linear correlation between the predicted continuous score and the consensus rank cannot be assumed as the predicted score will increment variably depending on the severity increase from a patient of rank and .
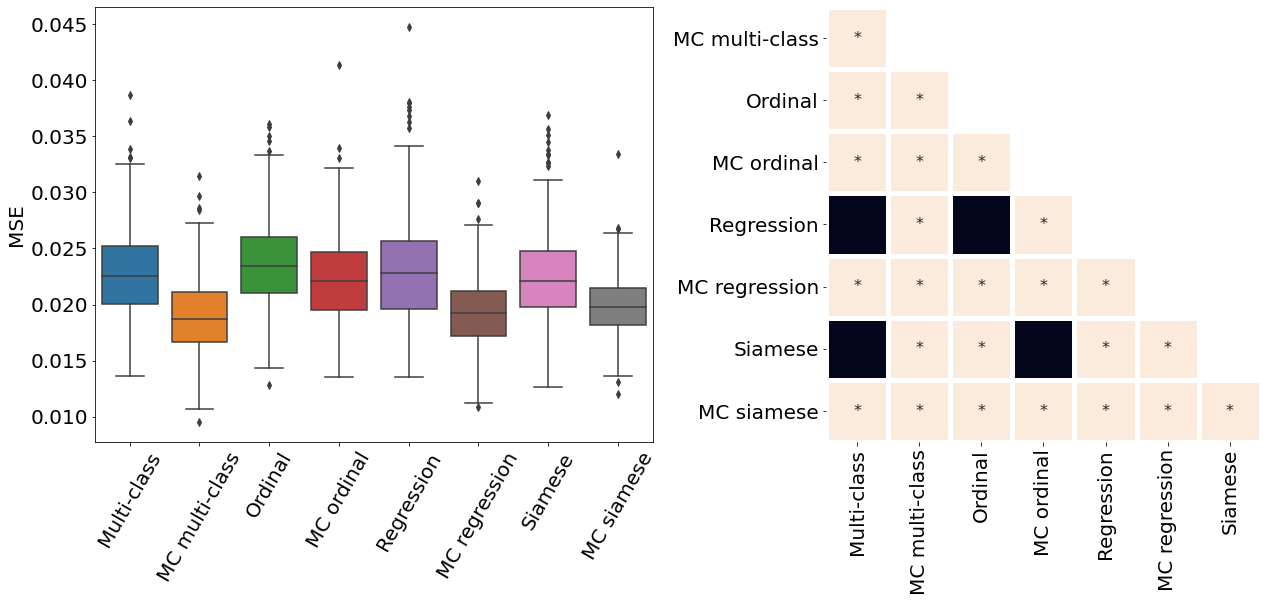
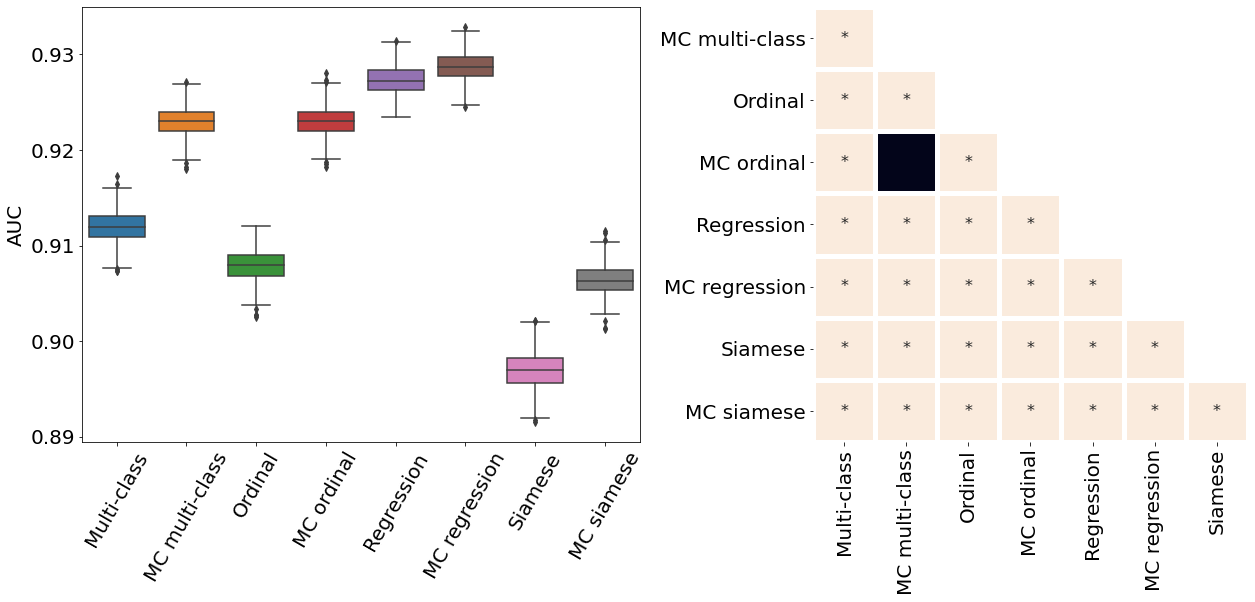
Therefore, we used the Spearman correlation coefficient and MSE to quantify the agreement between the ground truth ranking and the ranking based on the predictions (see Table 2 and Appendix C).
All MC dropout models were associated with a statistically significant higher Spearman correlation coefficient and lower MSE compared to their non-MC counterparts (p-value , see Appendix D for pair-wise statistical comparisons between the models).
The higher Spearman correlation coefficients and lower MSE indicate that the addition of MC dropout during training and inference improves the ability of DL models to correctly rank the images based on the continuous predicitions.
The models with the best correspondence between actual and predicted rank were MC multi-class and MC ordinal models for ROP, MC multi-class and MC regression for knee osteoarthritis, and MC regression and MC Siamese networks for breast density.
Classification performance
All MC dropout models showed a slightly higher or comparable classification performance, as assessed by AUC, to their non-MC equivalent (see Table 2).
The only exceptions were the Siamese models for ROP and knee osteoarthritis and the regression knee osteoarthritis model.
In these three cases, though statistically significant, the AUC of the MC models was only (or less) lower the one of their non-MC equivalents.
The model associated with the best classification did not necessarily correspond to the best continuous severity scores.
The following models have the overall best performance for each dataset: MC multi-class (knee osteoarthritis), MC ordinal (ROP), and MC regression (breast density).
3.2 Comparison of predicted ROP scores with disease severity ratings
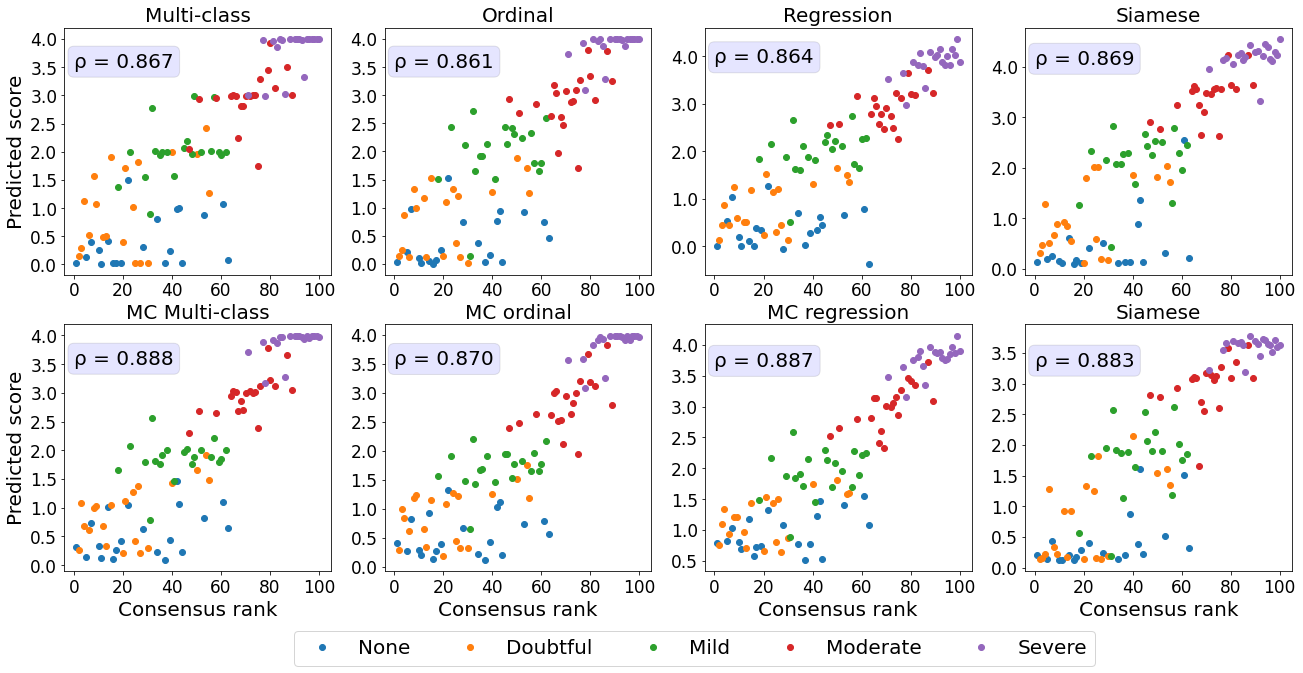
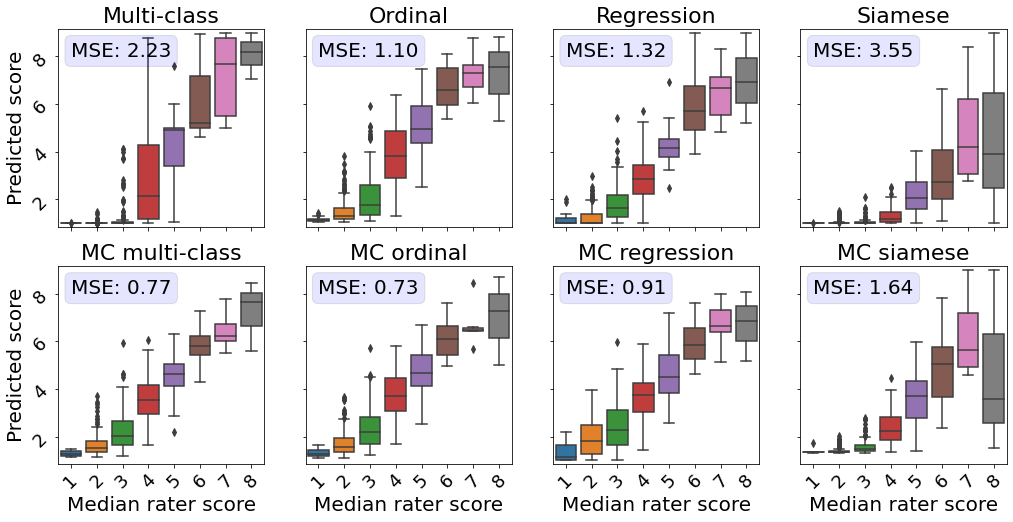
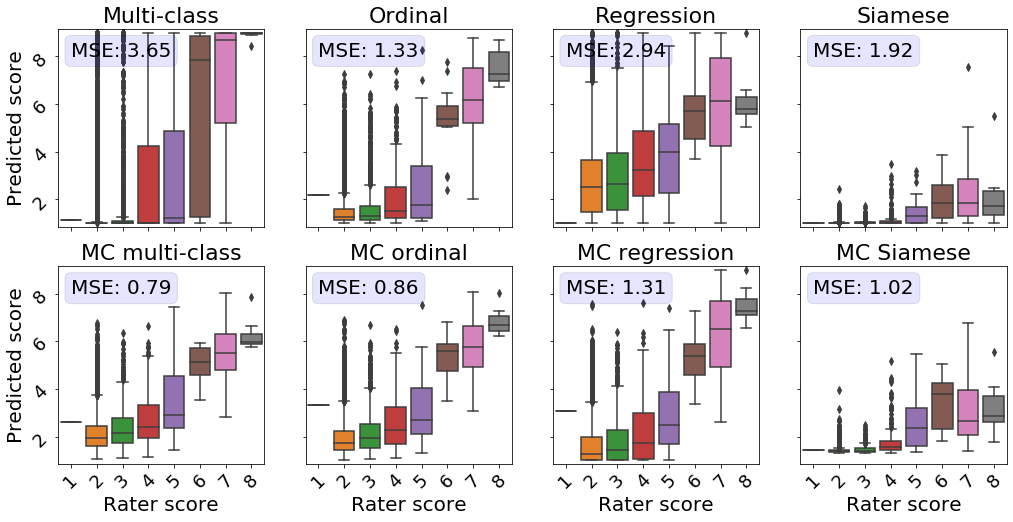
Next, we evaluated the correspondence between the predicted scores and more detailed severity ratings generated by domain experts.
An subset of the test dataset was rated by five experts on a scale from 1 to 9 instead of the standard scale from 1 to 3. Taylor2019MonitoringLearning
This dataset allowed us to evaluate the quality of the continuous model outputs on a more granular scale than the 3-class labels the models were trained on.
Perfect continuous predictions would result in increasing disease severity scores with increasing ground severity ratings.
All MC models showed a higher correspondence between the true severity ratings and predicted scores, as reflected by a lower MSE in comparison with their conventional counterparts (see Figure 3).
The models predicting the experts’ ratings the most accurately are the MC multi-class and MC ordinal models.
While Siamese networks showed decent correspondence between the predicted score and the ranked severity , a direct comparison with the severity ratings reveals that the predictions from these models are not well calibrated.
The multi-class model without MC showed the second worst performance in this analysis.
Images rated from 1 to 3 by experts mainly obtained scores near 0, which does not highlight the severity differences as perceived by human experts.
Furthermore, for retinal photographs associated with a score of 4, the model predicted values on the entire spectrum, i.e., from 1 to 9, which is undesirable.
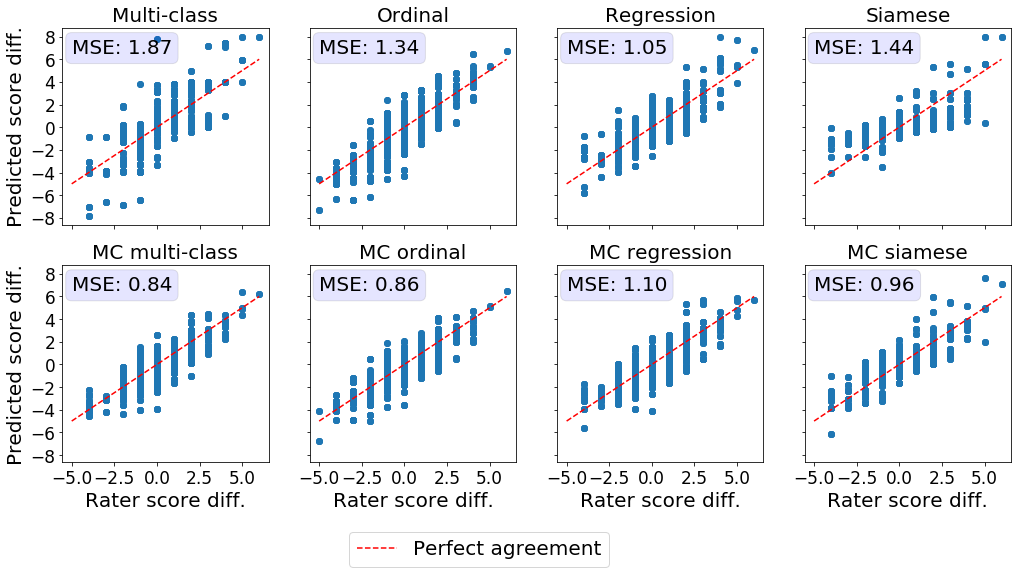
Detection of temporal changes in disease severity
Another important characteristic of a reliable severity score is its ability to reflect slight changes in disease severity over time. The disease evolution was quantified as the difference in the ground truth severity ratings or predicted severity scores between photographs of the same patient taken at different time points. We then compared the difference in experts’ ratings to the difference in the predicted scores using MSE (see Figure 4). Ideally, the difference in the expert’s scores should be equal to the difference in the models’ predictions. MC dropout improved the correspondence between the disease evolution as perceived by experts and predicted by the DL models for multi-class, ordinal, and Siamese models. Prediction differences from MC multi-class and MC ordinal models matched the severity shifts in the experts’ ratings most closely. The conventional multi-class model presents multiple outliers and is associated with the highest MSE.
3.3 Comparing predicted breast density scores with continuously valued ground truth breast density measurements
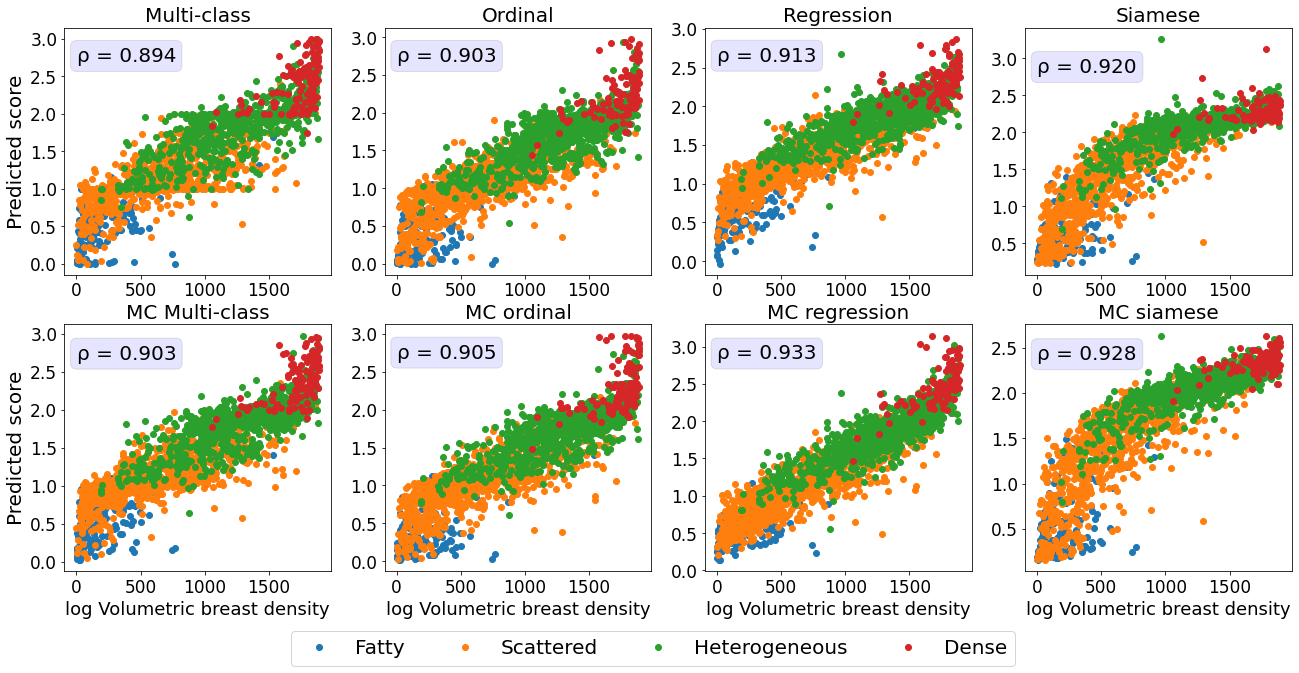
Lastly, we evaluated the ability of the breast density prediction models trained to accurately reflect the continuously valued Volpara Density measurements.
The subset of mammograms with the Volpara Densitymeasurements provided us with the unique opportunity to evaluate algorithms trained using ordinal labels on a continuously valued ground truth.
Therefore, unlike with the ranked score analysis presented in Section 3.1, here we directly compared the Volpara Density scores with the continuously valued model predictions.
Ideal continuously valued predictions would correlate linearly with the Volpara Density scores.
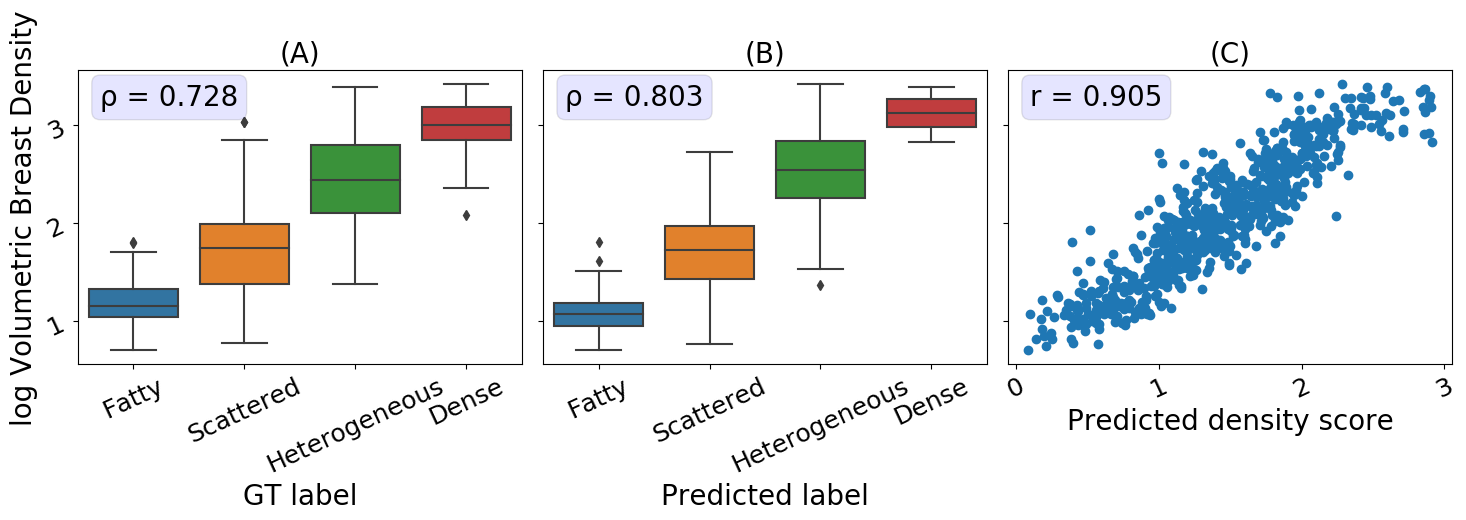
We first assessed the relationship between the Volpara Density scores and the discrete ground truth labels generated by domain experts used for training.
As illustrated in the boxplot in Figure 5A, and by the Spearman correlation coefficient of 0.73, there is a high agreement between the ground truth labels and the Volpara Density scores.
The MC multiclass model’s predictions, both class and continuous score, are a close proxy to the volumetric breast density measurements, as seen in Figure 5B and 5C with a Spearman correlation coefficient of 0.803 (classification) and Pearson correlation coefficient of 0.91 (continuous scores).
The high correlation between the continuous breast density predictions and Volpara Density measurements indicates that our model is able to generate an accurate continuous prediction while being trained on only a finite number of classes.
4 Discussion
The underlying continuous nature of many prediction targets for DL image analysis tasks, such as breast density and disease severity, has to be taken into account in the process of model design. Here, we studied the capability of DL models to intrinsically learn a continuous score while being trained using discrete ordinal labels. Our results show that training a conventional multi-class classification model without MC dropout does not lead to predictions that reflect the underlying continuous nature of the target variable. Approaches that model the relationship between the ordinal labels, such as ordinal classification, regression, and Siamese networks, provide continuous predictions that closely capture the continuity of the target variable even without the use of MC dropout. Finally, using MC dropout during training and inference increased the ability of the DL models to predict meaningful continuous scores. MC dropout multi-class classification ranked among the best performing models in this study.
Multi-class classification models
Ignoring the ordinal relationship between the training label classes causes conventional multi-class prediction models to return predictions that are clustered around the values of the training labels.
This behavior is reflected in the plateaus visible in Figure 2, and the medians in Figures 3, and 10, a lower Spearman correlation coefficient and higher MSE.
Due to the definition of the training objective, multi-class classification models are optimized to precisely predict a specific class and discouraged from predicting scores at the class boundaries.
This behavior is desirable for nominal classification, where the classes should be separated as clearly as possible with minimal overlap in the feature latent space to avoid ambiguous predictions.
However, the approach is not appropriate for problems with a target variable with an underlying continuous nature and explains the limited performance of the multi-class classification models to predict meaningful continuous scores.
Siamese networks
Siamese networks showed decent correspondence between the ranked severity and the predicted score (Figure 2.
However, a direct comparison between the predicted score and the severity determined by domain experts (Figure 3, reveals that the predictions are not well calibrated.
The predictions do not accurately reflect disease severity on a more granular scale than the labels used for model training.
Siamese networks are not trained to predict a specific value, unlike the other models, but rather to detect whether two images stem from the same or different classes. Koch2015SiameseRecognition
Therefore, they can pick up subtle differences in disease severity. Li2020SiameseImaging
Here, we obtained predictions comparing the input image of interest to a pool of anchor images that are typical representations of the class corresponding to the lowest label score.
While the predicted difference between the anchor images and the target images resulted in accurate ordinal predictions (Figure 2, it was not well calibrated to the underlying continuous variable, particularly at the extremes.
MC dropout improves prediction of continuous variables
Through the use of MC dropout, all four model types evaluated showed an improvement in the quality of the continuous scores as reflected in significantly higher Spearman correlation coefficients and lower MSE (see Table 2).
MC multi-class classification networks were consistently among the highest performing models for all tasks and datasets evaluated, making them the top-performing models in our study.
MC dropout presents a simple way to obtain meaningful continuous predictions from models trained using ordinal labels without sacrificing and, in some cases, even significantly improving predictive performance (see Table 2).
However, MC dropout comes at a higher computational cost as inference requires multiple passes of the same input image to obtain the final prediction.
If the additional computational burden is a concern, ordinal classification or regression are alternatives to conventional multi-class classification models that are easy to train and provide decent continuous predictions without the use of MC dropout.
Limitations
There are some limitations to this study. First, we treated the available ordinal labels as ground truth. For all three image analysis tasks analyzed here, high inter-rater variability, particularly around the decision boundaries between severity classes, have been reported. Campbell2016PlusVariability ; Kalpathy-Cramer2016PlusAnalysis ; Reijman2004ValidityApproach ; RedondoInter-andMammograms It would be desirable for future work to explore the influence of noisy and biased ordinal ratings for the task of learning and predicting a continuous variable. Second, due to the latent nature of the variable of interest, for most of our analysis, we had to rely on proxy variables such as rankings and more granular expert disease severity ratings. Lastly, MC dropout predictions were based on 50 samples, an empirically chosen value based on common practices and our own experience.
5 Conclusion
In this work, we present a generalizable framework to predict meaningful continuous scores while only using discrete ordinal labels for model development. Our findings are particularly relevant to disease severity prediction tasks as the available labels are usually coarse and ordinal, but continuous disease severity predictions could provide crucial information that allows for earlier detection of deterioration and more personalized treatment planning.
Acknowledgments
The authors would like to thank Laura Coombs from the American College of Radiology for providing the DMIST dataset and the Volpara Density scores.
Declarations
5.1 Funding
J.P.C and S.O. are funded by the National Institutes of Health (Bethesda, MD) [R01 HD107493], an investigator-initiated grant from Genentech (San Francisco, CA) [R21 EY031883], and by unrestricted departmental funding and a Career Development Award (J.P.C.) from Research to Prevent Blindness (New York, NY) [P30 EY10572]. M.F.C. previously received grant funding from the National Institutes of Health (Bethesda, MD), and National Science Foundation (Arlington, VA). J.P.C, S.O., M.F.C., J.K-C., and K.H. are supported by research funding from Genentech (San Francisco, CA)[R21 EY031883]. J.K-C. and K.V.H. are supported by funding from the National Institutes of Health (Bethesda, MD) [R01 HD107493] and National Cancer Institute (Bethesda, MD) [U01CA242879]. A.L. has a scholarship from Mitacs [IT24359], NSERC, and “Fondation et Alumni de Polytechnique Montréal”.
5.2 Conflict of interest
M.F.C. is an unpaid member of the scientific advisory board for Clarity Medical Systems (Pleasanton, CA), was previously a Consultant for Novartis (Basel, Switzerland) and was previously an equity owner at InTeleretina, LLC (Honolulu, HI).
Dr. Campbell was a consultant to Boston AI Lab (Boston, MA), and is an equity owner of Siloam Vision.J.K-C. is a consultant/advisory board member for Infotech, Soft.
The other authors declare no competing financial or non-financial interests.
5.3 Code availability
The code used to train the models can be found at https://github.com/andreanne-lemay/gray_zone_assessment.
5.4 Data availability
Access to the MOST dataset for knee osteoarthritis can be requested through the NIA Aging Research Biobank https://agingresearchbiobank.nia.nih.gov/. The breast density, and ROP datasets are not publicly accessible due to patient privacy restrictions.
5.5 Author’s contributions
Study concept and design: K.H., A.L., J.K.-C., J.P.C. Data collection: J.P.C., S.O., and J.K.-C. Data analysis and interpretation: all authors. Drafting of the manuscript: A.L., K.H. Critical revision of the manuscript for important intellectual content and final approval: all authors. Supervision: J.K.-C., J.P.C.
Appendix A Dataset label distributions
List of label distributions for each dataset.
Retinopathy of prematurity
Dataset size: 5511 images
-
•
Normal: 4535 images ()
-
•
Pre-plus disease: 804 images ()
-
•
Plus disease: 172 images ()
Knee osteoarthritis (OA)
Dataset size: 14173 images
-
•
No OA (KL 0): 5793 images ()
-
•
Doubtful OA (KL 1): 2156 images ()
-
•
Mild OA (KL 2): 2355 images ()
-
•
Moderate OA (KL 3): 2604 images ()
-
•
Severe OA (KL 4): 1265 images ()
Breast density
Dataset size: 108230 images
-
•
Fatty: 12428 images ()
-
•
Scattered: 47909 images ()
-
•
Heterogeneously dense: 41325 images (
-
•
Dense: 6568 images ()
Appendix B Model training parameters
ROP
ROP models had a ResNet18 architecture and were trained with a batch size of 24, a learning rate of 1e-4 for 25 epochs, and the best model was selected using the highest accuracy on the validation set. Balanced class sampling mitigated the class imbalance during training. Data augmentation consisted of random rotation of 15 degrees with a probability of 0.5, random flips with a probability of 0.5, and random zooms of 0.9 to 1.1 with a probability of 0.5.
Knee osteoarthritis
ResNet50 architecture was selected for the knee osteoarthritis model and was trained with the following parameters: batch size of 16, learning rate of 5e-6, 75 epochs. The final model was chosen based on the best loss value on the validation set. The data sampler used balanced weights during training to help with data imbalance. Images were randomly rotated of 15 degrees with a probability of 0.5 and randomly flipped with a probability of 0.5 as data augmentation.
Breast density
Breast density models were trained with a ResNet50 architecture for 75 epochs by batches of 8 with a learning rate of 5e-5. The best model was selected using the best loss score on the validation set. The same data augmentation as the knee osteoarthritis model was applied for breast density.
Appendix C Predicted rank vs. ground truth rank
Figure 6 contains the same data from Figure 2 presented in Section 3.1. The predicted scores were ordered to determine a rank and were plotted against the expert’s ranks. The MSE displayed in Table 2 was computed on these two variables. Since a linear correlation is expected on the rank-to-rank analysis, the Pearson coefficient was used.
Appendix D Pair-wise statistical comparisons
Only the metrics showing no statistical differences between two metrics were included (only some metrics from Table 2). If no figure for a specific metric and dataset is present, it means all the pair-wise comparisons showed a statistical difference. All metrics presented in Table 2, Figure 3, Figure 4, and Figure 10 were analysed.
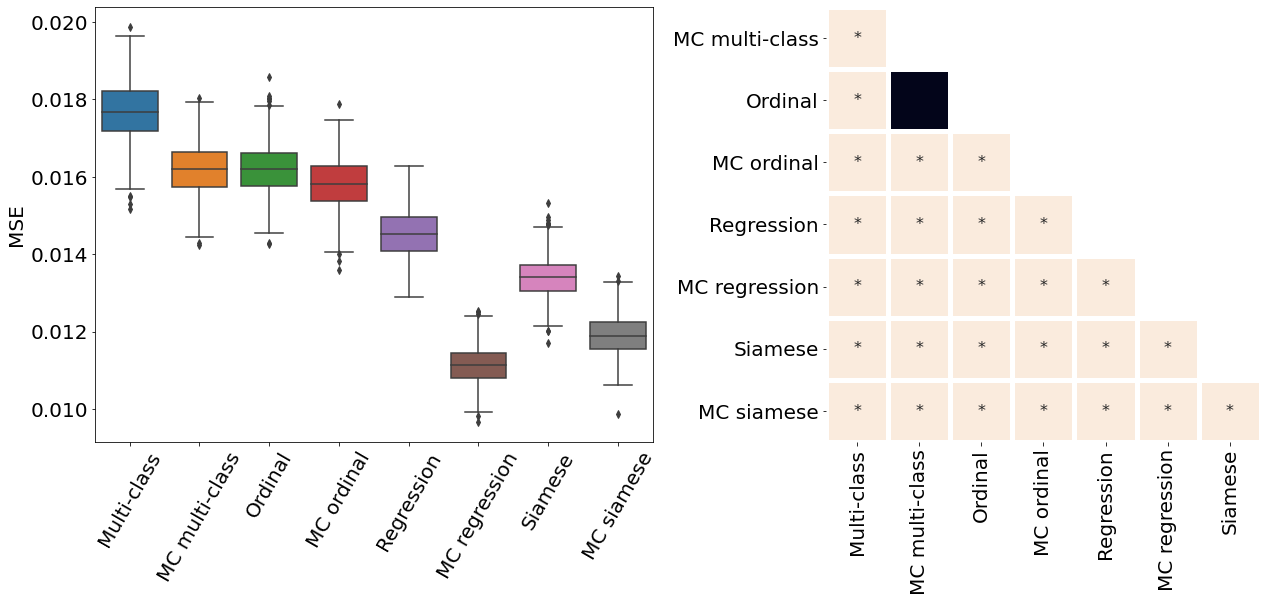
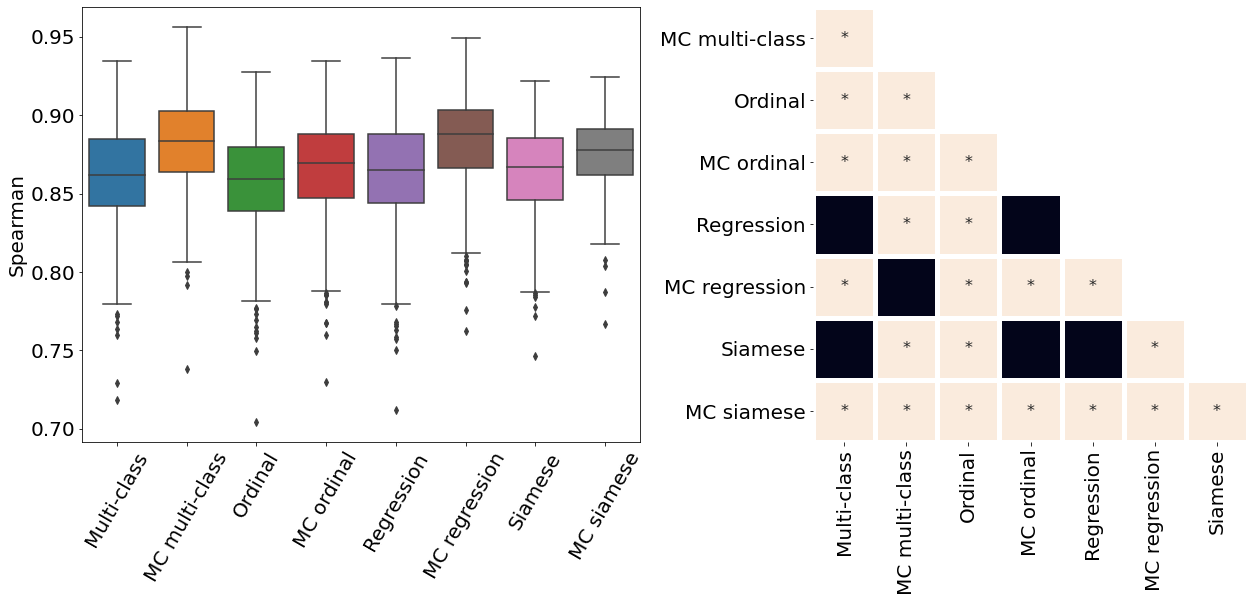
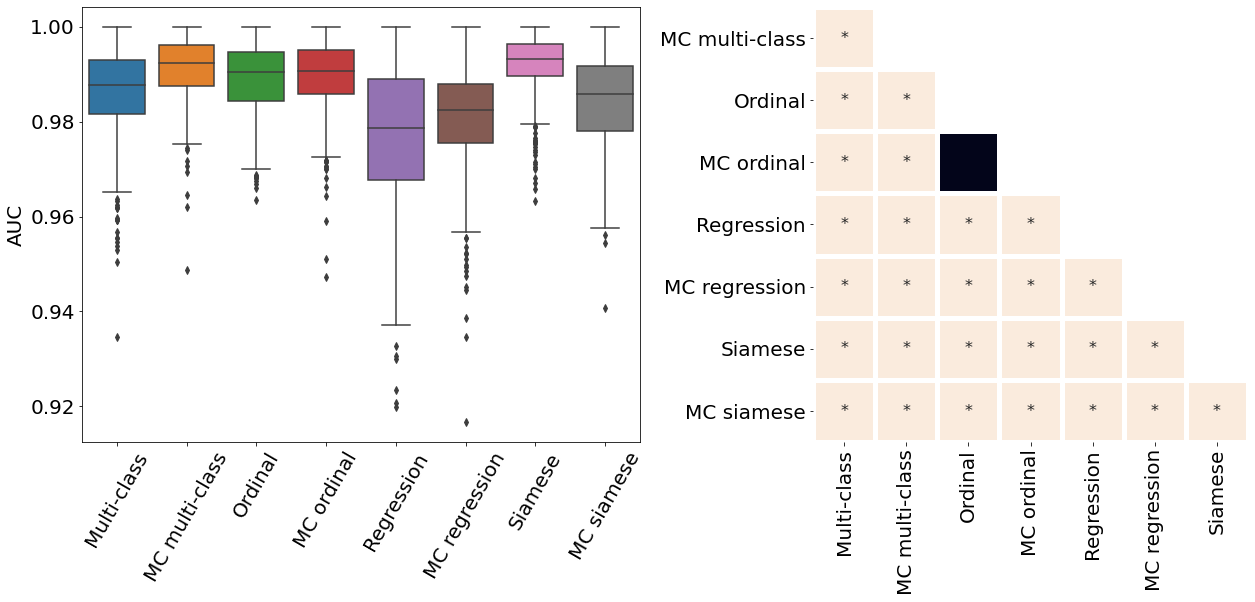
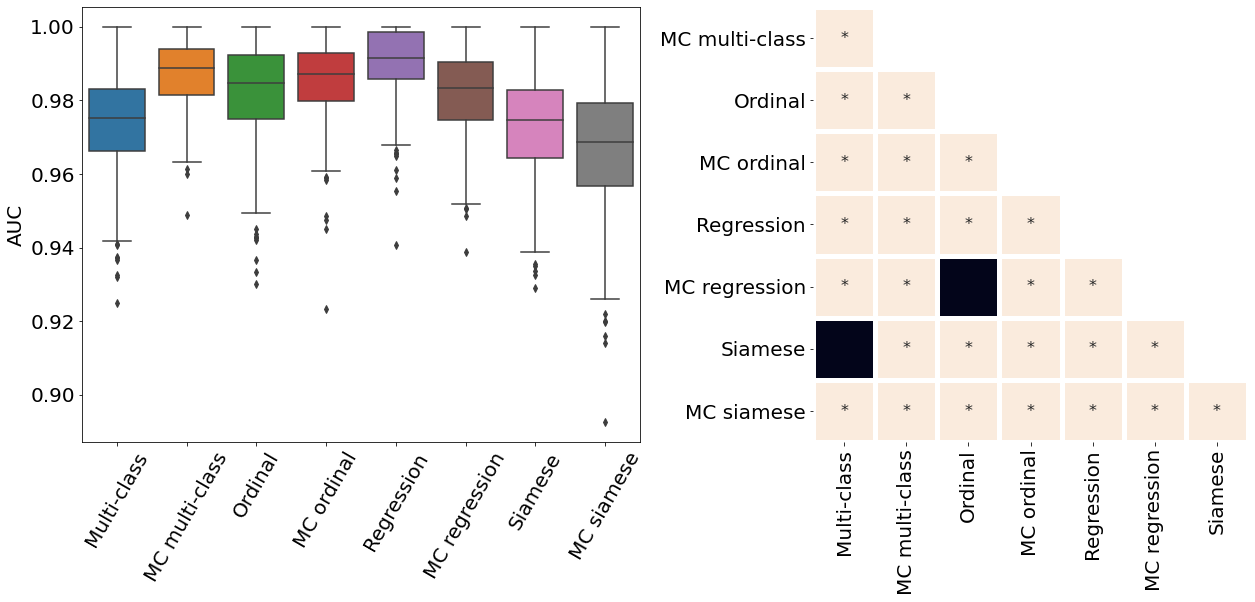
Appendix E ROP - Score on out-of-distribution dataset
The ROP models were further tested on a dataset from a different population and acquired at different centers from the training dataset. Figure 10 illustrates the correspondence between the predicted and rater scores for this out-of-distribution dataset. Similar to the in-distribution test set (see Figure 3), all the MC models had a better MSE compared with the non-MC corresponding models and MC multi-class and MC ordinal are the best performing models. The multi-class and regression models for most severity scores predicted a wide range of values, often from 1 to 9 which could lead to medical errors. The miscalibration of Siamese models is especially noticeable in Figure 10 as visually, the predicted and rater score do not match for high severity values. This out-of-distribution dataset contains only a few plus and pre-plus images, i.e., only 328 plus and pre-plus cases compared to 7565 normal cases. Driven by a large number of outliers particularly within images with the lower disease severity ratings (normal cases), the MSE is particularly high for the conventional multi-class, ordinal classification, and regression models. The low number of images with higher disease severity scores also explains why the MSE is not extremely high even though the Siamese networks are visually miscalibrated.
References
- \bibcommenthead
- (1) Campbell JP, Kalpathy-Cramer J, Erdogmus D, Tian P, Kedarisetti D, Moleta C, et al. Plus Disease in Retinopathy of Prematurity: A Continuous Spectrum of Vascular Abnormality as a Basis of Diagnostic Variability. Ophthalmology. 2016 11;123(11):2338–2344. 10.1016/j.ophtha.2016.07.026.
- (2) Anwar SM, Majid M, Qayyum A, Awais M, Alnowami M, Muhammad , et al. Medical Image Analysis using Convolutional Neural Networks: A Review. J Med Syst. 2018;42:226. 10.1007/s10916-018-1088-1.
- (3) Gulshan V, Peng L, Coram M, Stumpe MC, Wu D, Narayanaswamy A, et al. Development and Validation of a Deep Learning Algorithm for Detection of Diabetic Retinopathy in Retinal Fundus Photographs. JAMA. 2016 12;316(22):2402. 10.1001/jama.2016.17216.
- (4) Brown JM, Campbell JP, Beers A, Chang K, Ostmo S, Chan RVP, et al. Automated diagnosis of plus disease in retinopathy of prematurity using deep convolutional neural networks. JAMA Ophthalmology. 2018;136(7):803–810. 10.1001/jamaophthalmol.2018.1934.
- (5) Tiulpin A, Thevenot J, Rahtu E, Lehenkari P, Saarakkala S. Automatic knee osteoarthritis diagnosis from plain radiographs: A deep learning-based approach. Scientific Reports. 2018 12;8(1):1727. 10.1038/s41598-018-20132-7.
- (6) Stidham RW, Liu W, Bishu S, Rice MD, Higgins PDR, Zhu J, et al. Performance of a deep learning model vs human reviewers in grading endoscopic disease severity of patients with ulcerative colitis. JAMA Network Open. 2019 5;2(5):e193963. 10.1001/jamanetworkopen.2019.3963.
- (7) De Fauw J, Ledsam JR, Romera-Paredes B, Nikolov S, Tomasev N, Blackwell S, et al. Clinically applicable deep learning for diagnosis and referral in retinal disease. Nature Medicine. 2018 9;24(9):1342–1350. 10.1038/s41591-018-0107-6.
- (8) Leibig C, Allken V, Ayhan MS, Berens P, Wahl S. Leveraging uncertainty information from deep neural networks for disease detection. Scientific Reports. 2017 12;7(1):17816. 10.1038/s41598-017-17876-z.
- (9) Antony J, McGuinness K, O’Connor NE, Moran K. Quantifying radiographic knee osteoarthritis severity using deep convolutional neural networks. In: Proceedings - International Conference on Pattern Recognition; 2016. p. 1195–1200. Available from: http://www.adamondemand.com/clinical-management-of-osteoarthritis/.
- (10) Li MD, Chang K, Bearce B, Chang CY, Huang AJ, Campbell JP, et al. Siamese neural networks for continuous disease severity evaluation and change detection in medical imaging. npj Digital Medicine. 2020 12;3(1):48. 10.1038/s41746-020-0255-1.
- (11) Brown JM, Kalpathy-Cramer J, Campbell JP, Beers A, Chang K, Ostmo S, et al. Fully automated disease severity assessment and treatment monitoring in retinopathy of prematurity using deep learning. Proceedings of SPIE–the International Society for Optical Engineering. 2018;(March 2018):22. 10.1117/12.2295942.
- (12) Moleta C, Campbell JP, Kalpathy-Cramer J, Chan RVP, Ostmo S, Jonas K, et al. Plus Disease in Retinopathy of Prematurity: Diagnostic Trends in 2016 Versus 2007. American Journal of Ophthalmology. 2017 4;176:70–76. 10.1016/j.ajo.2016.12.025.
- (13) Dwork C, Hardt M, Pitassi T, Reingold O, Zemel R. Fairness through awareness. ITCS 2012 - Innovations in Theoretical Computer Science Conference. 2012;p. 214–226. 10.1145/2090236.2090255.
- (14) Redd TK, Campbell JP, Brown JM, Kim SJ, Ostmo S, Chan RVP, et al. Evaluation of a deep learning image assessment system for detecting severe retinopathy of prematurity. British Journal of Ophthalmology. 2019 11;103(5):580–584. 10.1136/bjophthalmol-2018-313156.
- (15) Shah PK, Prabhu V, Karandikar SS, Ranjan R, Narendran V, Kalpana N. Retinopathy of prematurity: Past, present and future. World journal of clinical pediatrics. 2016;5(1):35.
- (16) Quinn GE. The international classification of retinopathy of prematurity revisited: An international committee for the classification of retinopathy of prematurity. Archives of Ophthalmology. 2005;123(7):991–999. 10.1001/archopht.123.7.991.
- (17) Taylor S, Brown JM, Gupta K, Campbell JP, Ostmo S, Chan RVP, et al. Monitoring Disease Progression with a Quantitative Severity Scale for Retinopathy of Prematurity Using Deep Learning. JAMA Ophthalmology. 2019;137(9):1022–1028. 10.1001/jamaophthalmol.2019.2433.
- (18) Cui A, Li H, Wang D, Zhong J, Chen Y, Lu H. Global, regional prevalence, incidence and risk factors of knee osteoarthritis in population-based studies. EClinicalMedicine. 2020;29:100587.
- (19) Kellgren JH, Lawrence J. Radiological assessment of osteo-arthrosis. Annals of the rheumatic diseases. 1957;16(4):494.
- (20) Liberman L, Menell JH.: Breast imaging reporting and data system (BI-RADS). Radiol Clin North Am. Available from: https://pubmed.ncbi.nlm.nih.gov/12117184/.
- (21) Boyd NF, Byng JW, Jong RA, Fishell EK, Little LE, Miller AB, et al. Quantitative classification of mammographic densities and breast cancer risk: Results from the canadian national breast screening study. Journal of the National Cancer Institute. 1995;87(9):670–675. 10.1093/jnci/87.9.670.
- (22) Bakker MF, de Lange SV, Pijnappel RM, Mann RM, Peeters PHM, Monninkhof EM, et al. Supplemental MRI Screening for Women with Extremely Dense Breast Tissue. New England Journal of Medicine. 2019;381(22):2091–2102. 10.1056/nejmoa1903986.
- (23) Pisano ED, Gatsonis C, Hendrick E, Yaffe M, Baum JK, Acharyya S, et al. Diagnostic Performance of Digital versus Film Mammography for Breast-Cancer Screening. New England Journal of Medicine. 2005 10;353(17):1773–1783. 10.1056/NEJMoa052911.
- (24) Highnam R, Brady M, Yaffe MJ, Karssemeijer N, Harvey J. Robust breast composition measurement-Volpara TM. In: International workshop on digital mammography. Springer; 2010. p. 342–349.
- (25) Wanders JO, Holland K, Veldhuis WB, Mann RM, Pijnappel RM, Peeters PH, et al. Volumetric breast density affects performance of digital screening mammography. Breast cancer research and treatment. 2017;162(1):95–103.
- (26) Li L, Lin Ht. Ordinal Regression by Extended Binary Classification. In: Advances in Neural Information Processing Systems. vol. 19; 2006. .
- (27) Cao W, Mirjalili V, Raschka S. Rank consistent ordinal regression for neural networks with application to age estimation. Pattern Recognition Letters. 2020;p. 325–331. 10.1016/j.patrec.2020.11.008.
- (28) Gal Y, Ghahramani Z. Dropout as a bayesian approximation: Representing model uncertainty in deep learning. In: international conference on machine learning. PMLR; 2016. p. 1050–1059.
- (29) Koch G, Zemel R, Salakhutdinov R. Siamese Neural Networks for One-shot Image Recognition. International Conference on Machine Learning. 2015;37(5108). 10.1136/bmj.2.5108.1355-c.
- (30) Kalpathy-Cramer J, Campbell JP, Erdogmus D, Tian P, Kedarisetti D, Moleta C, et al. Plus Disease in Retinopathy of Prematurity: Improving Diagnosis by Ranking Disease Severity and Using Quantitative Image Analysis. Ophthalmology. 2016;123(11):2345–2351. 10.1016/j.ophtha.2016.07.020.
- (31) Reijman M, Hazes JMW, Pols HAP, Bernsen D. Validity and reliability of three definitions of hip osteoarthritis: cross sectional and longitudinal approach. Ann Rheum Dis. 2004;63:1427–1433. 10.1136/ard.2003.016477.