A Generative Adversarial Framework for Optimizing Image Matting and Harmonization Simultaneously
Abstract
Image matting and image harmonization are two important tasks in image composition. Image matting, aiming to achieve foreground boundary details, and image harmonization, aiming to make the background compatible with the foreground, are both promising yet challenging tasks. Previous works consider optimizing these two tasks separately, which may lead to a sub-optimal solution. We propose to optimize matting and harmonization simultaneously to get better performance on both the two tasks and achieve more natural results. We propose a new Generative Adversarial (GAN) framework which optimizing the matting network and the harmonization network based on a self-attention discriminator. The discriminator is required to distinguish the natural images from different types of fake synthesis images. Extensive experiments on our constructed dataset demonstrate the effectiveness of our proposed method. Our dataset and dataset generating pipeline can be found in https://git.io/HaMaGAN.
Index Terms— image matting, image harmonization, generative adversarial, optimize simultaneously.
1 Introduction
Image composition, especially portrait composition, is a practical technique that can be applied to image editing, digital entertainment, advertisement, and so on. It requires a foreground matting based on the input portrait image, and then the foreground portrait is pasted another background image. However, since these two pictures are not taken simultaneously, the composite image will be unnatural. Therefore, image harmonization, which seeks to adjust the background to fit the foreground to make the whole picture look harmonious, is also important in the composition process.
Previous work has paid much attention to the image matting methods. [1, 2, 3, 4, 5, 6] focus on extracting foreground alpha mattes automatically. These methods use Adobe image dataset [7] and have excellent results, but they often optimize the image matting problem on the alpha matte level and suppose that the new background image is unknown.
Image harmonization methods such as [8, 9, 10] use the CNN model to transfer the background to be compatible with the foreground. Deep learning methods do better in results, but they often require a large number of paired images. However, there is usually no suitable composite and ground-truth pair of images for the image harmonization task. Cong. [10] released a large-scale image harmonization dataset, which was generated by changing the foreground color segementated by coarse mask. They employ a network to adjust the foreground to harmonized with background used the coarse mask. It is not suitable for portrait editing, because it cannot separate the details, like the hair and fingers, which will bring difficulties to the harmonization.
Different from previous work, we consider to optimize the image matting and image harmonization simultaneously in one framework. Therefore the image matting may be more accurate and suitable for the new background, and the harmonization will also benefit from the more accurate input alpha matte. To achieve this goal, we conduct a new dataset for training these two tasks simultaneously. Inspired by [10], we can treat a real image as a harmonized one and segment the background region by alpha matte, rather than a rough mask. We adjust the background region to be inconsistent with the foreground, thus we can get a synthetic discordant composite image. The new dataset contains the portraits images from Matting Human Datasets [11]. We name our new dataset as Human Matting and Harmonization dataset (HMH dataset). Besides, a new generative adversarial framework (GAN) is proposed for combining these two tasks together. The framework has two generators; one is an image matting network, which is used to generate alpha mattes for the harmonization task, the other is an image harmonization network, which is used to process our composite image to make them harmonious. For quick implementation, we employ two off-the-shelf networks: the IndexNet [6] for automatically generating the alpha matte and an attention U-Net [10] for adjusting the color and details of the composite image. And we also use a self-attention discriminator [12] to capture the non-local feature of the separated spatial region to help to optimize the IndexNet and the attention U-Net.
To verify our new GAN framework’s performance, we conducted several experiments on our constructed dataset. This work’s main contributions are two-fold:
-
•
We propose a new GAN framework to optimize the image matting problem and image harmonization problem simultaneously. The proposed algorithm can improve the accuracy of the alpha mattes and optimize the details of the composite image.
-
•
We release the first large-scale dataset, HMH dataset, for handling image harmonization and image matting for portraits together.
2 METHODS
2.1 Overview
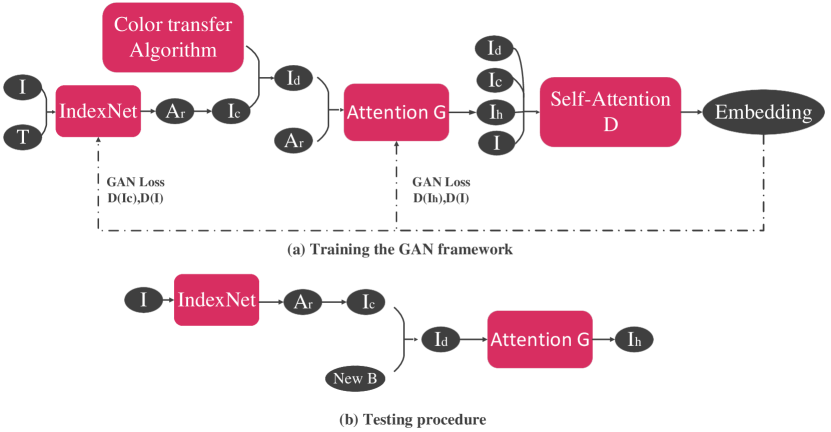
Our framework is based on generative adversarial networks (GANs), which can generate result alpha matte and harmonious image simultaneously. Figure 1 shows the structure of the proposed framework, which has three sub-networks. IndexNet [6] is employed for the image matting task. An attention generator is used to perform the image harmonization task, and a self-attention discriminator is employed to optimize the two generators.
The input of the IndexNet is a real image and its corresponding trimap , and the output of the IndexNet is the image matting result alpha . We train the IndexNet model to expect the result alpha matte to be as close to ground truth alpha matte as possible.
The harmonization network is added at the end of the image matting network. We composite a disharmonious image with the predicted , a synthetic background with color adjustment, and the original image as the foreground,
| (1) |
The harmonization network takes and as inputs and produces the harmonious image . A reconstructive loss between and is employed for the baseline.
To make the generated image looks more natural, we further employ a discriminator to optimize these two tasks simultaneously. The discriminator is a self-attention [12] model. We conduct several types of fake samples compare with the real sample to form the adversarial loss, as shown in Section 2.3. During the test phase, we choose to select a new background from the background dataset randomly and combine the new background with the predicted foreground split by from the original image as the input of the harmonization network and then get the final composite image.
2.2 Dataset Construction
Prepare Human Portrait Matting datasets: The original dataset we use is Matting Human Datasets [11] from Kaggle. The dataset has the real image and its corresponding alpha matte . To make this dataset available to our framework, we use to segment out the foreground of and calculate the background through the inpaint function in OpenCv. Finally, we have four sub-sets: , , , .
Background Adjustment: In the background adjustment procedure, we randomly choose a transfer function to transfer the color, change the illumination degree, or enhance the color of the background image. In the procedure of the background adjustment, the color transfer method we use is Reinhard color transfer method [13] . The color transfer function inputs are the background and a target image randomly selected from our training dataset, which is a different image that its background are different from the original background. The program extracts the target color from and transfers and generates . This process is shown below:
| (2) |
Then will be recombined with the new foreground as the disharmonious image as shown in equation 1. The process of the background adjustment are shown in Figure 3 in the supplementary materials.
Finally, we get the training triplet for each image: an alpha matte, an RGB image, and a disharmonious image, which form our new Human Matting and Harmonization dataset (HMH dataset).
2.3 Framework
IndexNet Generator. We employ IndexNet as the image matting network. The IndexNet can dynamically predict indices for individual local regions, conditional on the input local feature map itself. More details can be referred in [6]. We use alpha matte to generate trimap and mask, then we concatenate the real image and trimap and put them into the whole model. During training, we use the alpha prediction loss. Only loss from the unknown region of the trimap can be calculated. The output should be multiplied with mask , and the trimap should be multiplied with . Then they added to generate result alpha . We want the to be close to real alpha image through .
Attention Enhanced Generator. We employ a U-Net with attention blocks following [10] as our harmonization network. Different from [10], we enforce the generated image to be close to real image by .
Self-attention Discriminator To generate a more natural composite image and optimize these two tasks together, we propose to use a self-attention discriminator [12] to evaluate the difference between synthesis images and real images. And the generators are required to produce more natural results to mimic the distribution of real images.
The discriminator is trained to distinguish the real images from several fake composite images:
-
•
. We use the predicted alpha matte to segment the foreground and composite it with the corresponding real background in the dataset.
-
•
. We use the predicted alpha matte to segment the foreground and composite it with the disharmonious background.
-
•
. We use the prediction alpha matte to segment the foreground and composite it with the disharmonious background, and then the whole image is adjusted by the harmonization network to get a harmonious composite image.
Thus, the adversarial loss we used is,
| (3) |
When training, we need to minimize , that is we want to produce large scores for real images and minimize the score of the generated image. The adversarial losses for the two generators are given by
| (4) |
That is we want the generated images to fool the discriminator and obtain large scores. The total loss function for training the matting model and the harmonization model is:
| (5) |
and are used to control the GAN loss weight, and we minimize , to minimize the difference between the synthesis images and real images.
3 Experiments
3.1 Implemention details
Dataset and Evaluation Metric. We perform our experiments on the conducted HMH dataset, which is build on Matting Human Datasets [11]. It is currently the largest portrait matting dataset, containing 34,427 images and corresponding alpha mattes. We split it into a training dataset with 30982 images and a testing dataset with 3444 images. During the test phase, the background dataset we use is the Scene UNderstanding (SUN) dataset [14], which contains 130,519 images. All the image for training and testing are resized into .
For a fair comparison, we evaluate the image matting task using Mean Squared Error (MSE), Sum of Absolute Differences (SAD), perceptually motivated Gradient (Grad), and Connectivity (Conn) errors following [6]. And we use Mean opinion score (MOS) [15] to evaluate the harmonized image results following [10].
Implemention Details. For the matting network, we follow the training configurations used in [6] and pretrianed the matting network on Adobe Image Dataset. For the harmonization network, we also use the configuration and structure in [10] and pretrained the harmonization network on iHarmony4 dataset. Then we train IndexNet [6] on the conducted HMH dataset with the learning rate of for dconv, index and pred layers, and for other layers in fine-tuning stage. Finally, we jointly train the whole framework with the learning rate of 0.0002 for attention U-Net and self-attention discriminator, with the same learning rate in fine-tuning for IndexNet.
3.2 Results
Compared with Single Methods. Previous models often work independently on image matting and image harmonization, leading to a sub-optimal. In Table 1, we show how the two tasks benefit from training in a GAN network. After IndexNet fine-tuned [6] on our dataset, the MSE error has reduced , which indicate there exits a domain gap between Adobe Image Dataset and our human matting dataset. We trained our GAN framework on our dataset with the parameters of . Compare with the baseline IndexNet, jointly training can improve the results of matting with 11.69% in MSE, 9.65% in SAD, and 10.1% in Conn. We also offer the three image matting qualitative results in Figure 2. We can see that the place circled by blue circles have holes on the matting result.
To illustrate our method’s effectiveness in the harmonization task, we also conducted a user study to quantify the harmonize images. Specifically, we asked 30 raters to assign an integral score from 1 (bad quality) to 5 (excellent quality) to the harmonized images presented randomly. Our scoring standard is that the background and foreground of pictures are coordinated and conform to the actual situation. The results have shown in Table 1. From the results, we can see that our method has a score of 3.582 in terms of MOS. We also show our qualitative harmonization results in Figure 2. It can be seen that there are obvious white edges in the two images in the middle of the last row, which indicates that a rough segmentation boundary will make the foreground and background of the harmonization image seem not integrated. Our method makes a good transition between the portrait and the background.
| Task | Matting | Harmonization | ||||
| Index | MSE | SAD | Grad | Conn | MOS | Std |
| DM [1]‡ | 0.65 | 70.93 | 29.81 | 16.26 | - | |
| IN [6] | 0.11 | 16.43 | 15.05 | 16.78 | - | |
| IN [6]‡ | 0.02 | 4.39 | 8.65 | 4.28 | - | |
| Xue [16] | - | 2.32 | 0.40 | |||
| DIH [9] | - | 2.72 | 0.47 | |||
| U-Net [8] | - | 3.30 | 0.54 | |||
| DN [10] | - | 3.15 | 0.58 | |||
| Our | 0.02 | 3.96 | 8.68 | 3.84 | 3.58 | 0.55 |

Compared with Existing Image Harmonization Methods. We also compare our model with exsiting image harmonization methods [16, 9, 10] qualitatively, and show the results in Figure 4 in supplemental material. From Figure 4, we can see that our method can produce more natural composite images compared with other methods.
Image Matting Result with Different . This section tests our image matting effect with different parameters and with the same parameter . Then we compared our results alpha mattes with the ground truth alpha mattes pixel by pixel and shown the MSE results in Table 2. We can see that increasing the value can improve the matting precision in a specific range. When , it has the minimum amount of MSE at present.
| Method | MSE | SAD | Grad | Conn |
| 0.022 | 4.104 | 9.170 | 3.996 | |
| 0.020 | 3.962 | 8.681 | 3.843 | |
| 0.022 | 4.086 | 9.206 | 3.987 | |
| 0.022 | 4.289 | 9.077 | 4.166 |
Image Harmonization Result with Different . We also test image harmonious effect with different , and with the same parameter . the qualitative image can be seen in Figure 5 in supplemental material. We can see as the parameter increases, the background tends to change to a color closer to the foreground color and tends to become darker.
Input Foreground Alpha or Background Alpha Matte. We also do some experiments to adjust the color of foreground to meet with the background using the same methods. Here Figure 6 in supplemental material shows our algorithm’s effect sample. In some pictures, the faces of the portrait are very red and do not match the background. Our algorithm can produce more natural results when changing the foreground.
4 Conclusions
In this work, we have proposed a new GAN framework to optimize the image matting model and image harmonization model simultaneously, and an original dataset composite method to generate a dataset that can be used both for two tasks. From experiments, we can confirm that joint training can generate better alpha matte as well as more a realistic harmonization effect. Our method shows the feasibility of simultaneously optimizing image matting and image harmonization tasks. In the future, we can use some training techniques and data enhancement methods further to improve the training accuracy and the effect of the framework.
References
- [1] Ning Xu, Brian Price, Scott Cohen, and Thomas Huang, “Deep image matting,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 2970–2979.
- [2] Guanying Chen, Kai Han, and Kwan-Yee K Wong, “Tom-net: Learning transparent object matting from a single image,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 9233–9241.
- [3] Quan Chen, Tiezheng Ge, Yanyu Xu, Zhiqiang Zhang, Xinxin Yang, and Kun Gai, “Semantic human matting,” in ACM Int. Conf. Multimedia, 2018, pp. 618–626.
- [4] Yu Wang, Yi Niu, Peiyong Duan, Jianwei Lin, and Yuanjie Zheng, “Deep propagation based image matting,” in IJCAI, 2018, vol. 3, pp. 999–1006.
- [5] Sebastian Lutz, Konstantinos Amplianitis, and Aljosa Smolic, “Alphagan: Generative adversarial networks for natural image matting,” arXiv preprint arXiv:1807.10088, 2018.
- [6] Hao Lu, Yutong Dai, Chunhua Shen, and Songcen Xu, “Indices matter: Learning to index for deep image matting,” in European Conference on Computer Vision, 2019, pp. 3266–3275.
- [7] Christoph Rhemann, Carsten Rother, Jue Wang, Margrit Gelautz, Pushmeet Kohli, and Pamela Rott, “A perceptually motivated online benchmark for image matting,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2009, pp. 1826–1833.
- [8] Jun-Yan Zhu, Philipp Krahenbuhl, Eli Shechtman, and Alexei A Efros, “Learning a discriminative model for the perception of realism in composite images,” in Proceedings of the IEEE International Conference on Computer Vision, 2015, pp. 3943–3951.
- [9] Yi-Hsuan Tsai, Xiaohui Shen, Zhe Lin, Kalyan Sunkavalli, Xin Lu, and Ming-Hsuan Yang, “Deep image harmonization,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 3789–3797.
- [10] Wenyan Cong, Jianfu Zhang, Li Niu, Liu Liu, Zhixin Ling, Weiyuan Li, and Liqing Zhang, “Dovenet: Deep image harmonization via domain verification,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2020, pp. 8394–8403.
- [11] Laurent H., “Matting human datasets,” [EB/OL], https://www.kaggle.com/laurentmih/aisegmentcom-matting-human-datasets.
- [12] Han Zhang, Ian Goodfellow, Dimitris Metaxas, and Augustus Odena, “Self-attention generative adversarial networks,” in International conference on machine learning, 2019, pp. 7354–7363.
- [13] Erik Reinhard, Michael Adhikhmin, Bruce Gooch, and Peter Shirley, “Color transfer between images,” IEEE Computer graphics and applications, vol. 21, no. 5, pp. 34–41, 2001.
- [14] Jianxiong Xiao, Krista A Ehinger, James Hays, Antonio Torralba, and Aude Oliva, “Sun database: Exploring a large collection of scene categories,” International Journal of Computer Vision, vol. 119, no. 1, pp. 3–22, 2016.
- [15] Christian Ledig, Lucas Theis, Ferenc Huszár, Jose Caballero, Andrew Cunningham, Alejandro Acosta, Andrew Aitken, Alykhan Tejani, Johannes Totz, Zehan Wang, et al., “Photo-realistic single image super-resolution using a generative adversarial network,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 4681–4690.
- [16] Su Xue, Aseem Agarwala, Julie Dorsey, and Holly Rushmeier, “Understanding and improving the realism of image composites,” ACM Transactions on graphics (TOG), vol. 31, no. 4, pp. 1–10, 2012.
5 Supplementary Material
In this section, we show our supplementary images.



