Harbin Institute of Technology, ShenZhen \cityShenzhen \countryChina \affiliation \institutionHarbin Institute of Technology, ShenZhen \cityShenzhen \countryChina \affiliation \institutionHarbin Institute of Technology, ShenZhen \cityShenzhen \countryChina \affiliation \institutionHarbin Institute of Technology, ShenZhen \cityShenzhen \countryUnited Kingdom \affiliation \institutionHarbin Institute of Technology, ShenZhen \cityShenzhen \countryChina \affiliation \institutionHarbin Institute of Technology, ShenZhen \cityShenzhen \countryChina
A Generic Multi-Player Transformation Algorithm for Solving Large-Scale Zero-Sum Extensive-Form Adversarial Team Games
Abstract.
Many recent practical and theoretical breakthroughs focus on adversarial team multi-player games (ATMGs) in ex ante correlation scenarios. In this setting, team members are allowed to coordinate their strategies only before the game starts. Although there existing algorithms for solving extensive-form ATMGs, the size of the game tree generated by the previous algorithms grows exponentially with the number of players. Therefore, how to deal with large-scale zero-sum extensive-form ATMGs problems close to the real world is still a significant challenge. In this paper, we propose a generic multi-player transformation algorithm, which can transform any multi-player game tree satisfying the definition of AMTGs into a 2-player game tree, such that finding a team-maxmin equilibrium with correlation (TMECor) in large-scale ATMGs can be transformed into solving NE in 2-player games. To achieve this goal, we first introduce a new structure named private information pre-branch, which consists of a temporary chance node and coordinator nodes and aims to make decisions for all potential private information on behalf of the team members. We also show theoretically that NE in the transformed 2-player game is equivalent TMECor in the original multi-player game. This work significantly reduces the growth of action space and nodes from exponential to constant level. This enables our work to outperform all the previous state-of-the-art algorithms in finding a TMECor, with , , , and significant improvements in the different Kuhn Poker and Leduc Poker cases (21K3, 21K4, 21K6 and 21L33). In addition, this work first practically solves the ATMGs in a 5-player case which cannot be conducted by existing algorithms.
Key words and phrases:
Team-maxmin Equilibrium with Correlation, Adversarial Team Games, Multi-Player Games, Nash Equilibrium, Game Theory1. Introduction
Games have been critical testbeds for exploring how effectively machines can make sophisticated decisions since the early days of computing Bard et al. (2020). Finding a equilibrium in games has become a significant criterion for evaluating artificial intelligence levels. In recent years, many great results have been obtained from the field of 2-player zero-sum (2p0s) games based on Nash Equilibrium (NE) Nash (1951) in non-complete information environments Zinkevich et al. (2007); Brown et al. (2019); Zhou et al. (2020). However, solving equilibrium in multi-player zero-sum games with three or more players remains a tricky challenge. There are three main reasons for this: Firstly, the CFR-like algorithms for finding NE are widely used in 2p0s games, but no theoretical guarantees are provided in the literature whether they can be directly used in multi-player games Brown (2020); Secondly, NEs are not unique in multi-player games, and the independent strategies of each player cannot easily form a unique NE Brown and Sandholm (2019b); Thirdly, computing NEs is PPAD-complete for multi-player zero-sum games Chen and Deng (2005).
The Team-maxmin Equilibrium (TME) von Stengel and Koller (1997); Basilico et al. (2017b) is a solution concept that can handle multi-player games. In this paper, we are concerned with adversarial team multi-player games. It models a situation in which a team of players shares the same utility function against an adversary. Based on the various forms of correlation between team members, this concept is extended to extensive-games Celli and Gatti (2018). Notably, we focus on the ex ante coordination scenario of team members. More specifically, team members are allowed to coordinate and agree on a common strategy before the game starts, but they cannot communicate during the game. The variant of TME in this scenario is called Team-maxmin Equilibrium with Correlation (TMECor), and its computation is shown to be FNP-hard Hansen et al. (2008a). To the best of our knowledge, Celli and Gatti Celli and Gatti (2018) first proposed a linear programming algorithm capable of solving TMECor in 2018. The essence of this algorithm is hybrid column generation, where the team members and adversary use different forms of strategy representation. The Associated Recursive Asynchronous Multiparametric Disaggregation Technique (ARAMDT) proposed by Zhang and An (2020a) also uses mixed-integer linear program (MILP) to find the TMECor. Since the feasible solutions of MILP are too large for large-scale games, this significantly limits their ability to efficiently handle large-scale games.
The TMECor can be considered as an NE between the team and the adversary that maximizes the utility of the team. In adversarial team multi-player games, the advantage of TMECor over NE is unique, considerably reducing the difficulty of finding optimal strategies. Nonetheless, there are fewer algorithms for TMECor. Therefore, it is an interesting and worthwhile research topic to utilize the algorithms (e.g., CFR, CFR+, etc.) of solving Nash equilibrium in two-player zero-sum extensive-form games for finding a TMECor. Inspired by Carminati et al. (2022), we attempt to make a connection between large-scale adversarial team multi-player games and 2-player zero-sum games, achieving better performance and faster convergence than the state-of-the-art algorithms.
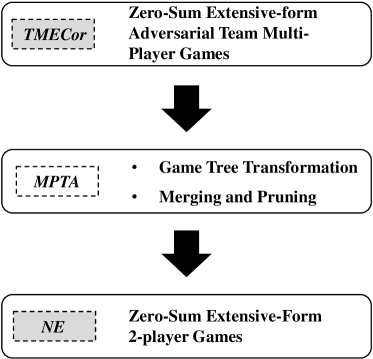
Main Contributions. The most outstanding outcome of our work is a generic multi-player transformation algorithm (MPTA) that can convert a tree of adversarial team multi-player games (ATMGs) into a tree of 2-player zero-sum games with theoretical guarantees. Thus, the classical and efficient algorithms in 2-player zero-sum games can be used to solve TMECor in large-scale ATMGs (e.g., CFR Zinkevich et al. (2007), CFR+ Tammelin et al. (2015), DCFR Brown and Sandholm (2019a), MCCFR Lanctot et al. (2009), etc.). One of the reasons why large-scale ATMGs are difficult to solve is that the action space grows exponentially with the increase in players. To design this algorithm, we propose a new structure, calling it private information pre-branch, which can reduce the growth of action space from exponential to a constant level. Theoretically, the more players, the more obvious the effect of reducing the action space. Therefore, the transformed game tree of our method is smaller in size compared to similar algorithms, such that it can speed up the computation of TMECor and make it possible to use it in larger scale team games, which are closer to real-world problems. Furthermore, to provide a primary theoretical guarantee for our work, we prove the equilibrium equivalence of the game before and after the transformation. Finally, the performance of our method has been proven to be excellent through multiple sets of experiments. The experimental results show that the team-maxmin strategy profile obtained by our algorithm is closer to TMECor than the baseline algorithm at the same time and significantly reduces the running time in the same iteration rounds.
2. Related Work
Many studies have focused on adversarial team multi-player games (ATMGs) in an attempt to find a solution since the concept of Team-maxmin Equilibrium (TME) was introduced in 1997. Kannan et al. Kannan et al. (2002) adapt the idea of a team game and develop an algorithm for finding optimal paths based on information networks. Hansen et al. Hansen et al. (2008b) prove that the task of obtaining a TME is FNP-hard and calculate the theoretical time complexity for the first time. According to the communication capabilities of the team members, Celli and Gatti Celli and Gatti (2018) define three different scenarios and corresponding equilibriums for the first time in the extensive-form ATMGs. In particular, it is the first time that computing the TMECor of ATMGs (i.e., the equilibrium in the scenario where team members are allowed to communicate before the game starts) using a column generation algorithm combined with hybrid representation.
Thereafter, Zhang and An (2020a, b); Zhang et al. (2021) propose a series of improvements to the Hybrid Column Generation (HCG) algorithm. The main disadvantage of this method is that the feasible solution space of integer or mixed-integer linear program is too large, which severely limits the size and speed of games it can solve. Basilico et al. Basilico et al. (2017a) propose a modified version of the quasi-polynomial time algorithm and an algorithm named IteratedLP which is a novel anytime approximation algorithm. IteratedLP’s working principle is to maintain the current solution, which provides a policy that can be returned at any time for each team member. Farina et al. Farina et al. (2018a) adopt a new realization form representation for mapping the problem of finding an optimal ex-ante-coordinated policy for the team to the problem of finding NE. Zhang and Sandholm Zhang and Sandholm (2022) devise a tree decomposition algorithm for solving team games. To reduce the number of constraints required, the authors use a tree decomposition for constraints and represent the team’s strategy space by the correlated strategies of a polytope. Since the team need to sample a strategy policy for each player from a joint probability distribution, Farina et al. Farina et al. (2021) propose a modeling on computing the optimal distribution outcome and allowing the team to obtain the highest payoff by increasing the upper limit on the number of strategy files. Cacciamani et al. Cacciamani et al. (2021) and celli et al. Celli et al. (2019) use multi-agent reinforcement learning approaches. The former adds a game-theoretic centralized training regimen and serves as a buffer of past experiences. Unfortunately, these reinforcement learning methods can only be applied in particular circumstances. The idea of a team being represented by a single coordinator as used by Carminati et al. Carminati et al. (2022) is closely related to ours. However, the size of game tree generated by the algorithm used by the authors grows exponentially as the action space increases. This situation makes it difficult to use this algorithm for large-scale team games.
In our work, we propose an innovative approach for transforming a team multi-player game tree into a 2-player game tree, where the 2-player game tree is constructed in a form that is distinct from the method by Carminati et al. (2022). In the converted game tree, the coordinator represents the strategy in the same way as the team members. At the same time, the number of new nodes is greatly reduced, allowing the game tree to avoid exponential increases in size.
3. Preliminaries
This section briefly introduces some of the basic concepts and definitions used in this paper. To learn more details, see also Celli and Gatti (2018); Zinkevich et al. (2007). For clarity and intuition, detailed descriptions of some variables are shown in Table 1.
| Variable | Detailed description |
| The information set of player at decision node . | |
| The set of the player ’s normal-form plans where can reach the terminal node . | |
| The strategy of player at decision node . | |
| The probability that player will follow the actions specified by the normal-form plan . | |
| The shared utility of the team with reaching terminal node . | |
| The formulaic definition of normal-form strategies, i.e., the probability distribution of the normal-form plans of player . |
3.1. Extensive-Form Games and Nash Equilibrium
An extensive-form game is the tree-form model of imperfect-information games with sequential interactions Kuhn (1950a); Brown and Sandholm (2017).
Definition 0 (Extensive-form Games).
A finite extensive-form game is a tuple :
-
(1)
A set of players, ;
-
(2)
A set of all the possible actions, , where denotes a set of available actions of player ;
-
(3)
A set is the set of nodes in the game tree, . can also be represented action histories (sequence of actions from root node to current node );
-
(4)
A set contains all the leaf nodes of game tree, ;
-
(5)
For each decision node , the result returned by function is all available actions at node ;
-
(6)
Given a node , the function is player who takes an action after node ;
-
(7)
For each player , the utility function is the payoff mapped from the terminal node to the reals ;
-
(8)
A set belonging to player , all nodes are indistinguishable to in .
The Nash equilibrium is a common solution concept in zero-sum extensive-form games and is a strategy profile for player denoted as . Given the strategy profile for players, , an NE can be formally represented as
| (1) |
3.2. Adversarial Team Multi-Player Games and Team-Maxmin Equilibrium with Correlation
In this paper, we concentrate on extensive-form adversarial team multi-player games. Formally, an adversarial team multi-player game (ATMG) has players, in which a team consisting of team members against independently an adversary . We refer to and as the chance player and team (coordinator) respectively. We set up the scenario restricted to a zero-sum extensive-form ATMG, where . Regardless of whether the team wins or loses, team members share benefits equally with the same utility function in ATMG. That is, . Moreover, this work will focus on games with perfect recall, where all players are able to recall their previous actions and the corresponding information sets.
Definition 0 (Behavioral Strategy).
A behavioral strategy of player is a function that assigns a distribution over all the available actions to each .
A behavioral strategy profile is composed of each player’s behavioral strategy, where . The extensive-form ATMGs also provide additional strategy representation:
Definition 0 (Normal-Form Plan).
A normal-form plan of player is a tuple specifying one action for each information set of player .
Furthermore, the normal-form strategy of player is denoted as , which is the probability distribution over the normal-form plans. Similarly, a normal-form strategy profile is . Given a normal-form strategy of player , refers to all normal-form strategies in except . A TMECor is proven to be a Nash equilibrium (NE) which maximizes the team’s utility Zhang et al. (2022); von Stengel and Koller (1997). Concerning ATMG settings, TMECor differs from NE in that it always exists and is unique. The team members use behavioral strategies during the TME calculating procedure. This is due to the lack of necessity for coordination among team members. However, our work focus on the scenario of ex ante correlation. If the behavioral strategy is still adopted, the correlation between the normal-form strategies of team members cannot be accurately obtained because of a lack of coordination Farina et al. (2018b). Therefore, in order to compute TMECor, it is necessary for team members to adopt normal-form strategies.
A TMECor is able to find through a linear programming formulated over the normal-form strategy profile of all players:
| (2) |
4. Method
4.1. Overview
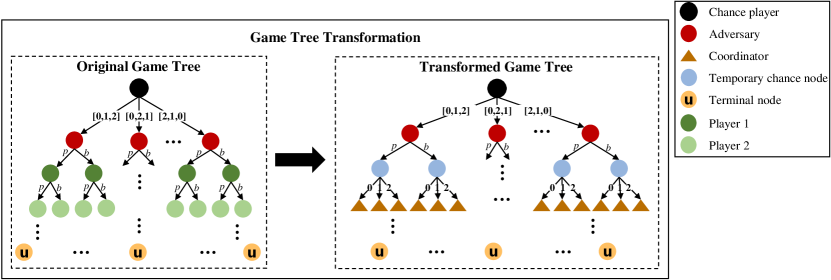
To solve the adversarial team multi-player games, the core of our work is to transform an ATMGs-based multi-player game into a 2-player game, then use the well-established algorithms in 2-player games to find a NE equivalent to the TMECor, as shown in Figure 2. For achieving this purpose, we first construct a new structure representation for the team member nodes in the original multi-player game tree. Secondly, we utilize this structure to design an algorithm named MPTA, which is used to transform a original multi-player game tree into a 2-player game tree. The MPTA consists of two phases: 1) traversing over the whole original game tree and transforming all nodes to obtain a 2-player game tree; 2) merging information sets with temporary private information and pruning for 2-player game tree.
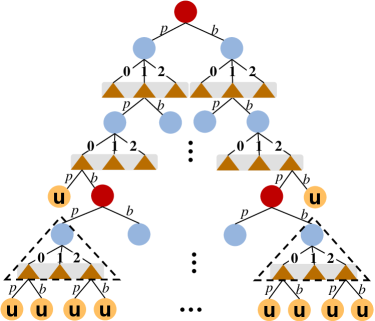
4.2. The Structure of Private Information Pre-Branch
We add coordinator players and temporary opportunity nodes to the MPTA process, and they form a new structure, which we call the private information pre-branch (PIPB), as shown in the virtual triangle box in Figure 3. The coordinator player only makes decisions for one team member at a time, so we give him all possible information of hand cards in advance. The extensive-form game has property with sequence decision, and we assume that the adversary takes action first in the game process. The parent of each coordinator player node must be a temporary chance node according to this structure. In other words, the coordinator makes decisions based on the structure of PIPB.
Proposition 1 (growth of action space).
Given a transformed game , each occurrence of a coordinator player node in the game tree increases the action space by , where indicate the number of cards.
4.3. Phase 1: Game Tree Transformation
The primary distinction between the MPTA and previous approaches is that the coordinator player in the transformed game tree represents a team member who is playing rather than the entire team. Team members have both private information, e.g., the hand cards, and public information that can be observed by other players, including adversary, e.g., the game history. Note that the coordinator player only knows the private information of a team member currently represented and public information of the current situation, but not the other players’ private information. The pseudo-code of the transformation process is depicted in Algorithm 1.
Since our algorithm is built on a game tree, we first construct a complete game tree based on an improved generic game scenario (e.g., Kuhn Poker Kuhn (1950b)), as illustrated in the dashed box on the left of Figure 1. The chance player who deals the cards is the root node in the original game tree, and its branches represent different dealing situations. As the number of cards rises, the number of chance player’s child nodes often increases as well. The nodes below the root node are the players’ decision nodes, where the players choose their actions in turn according to the principles of a sequential game. The payoff for a round will be calculated once all players have finished their actions and reached the terminal nodes. In particular, team members share the benefits whether they win or lose because they use the same utility function in ATMG.
Then, an original game tree will be passed as a parameter to the MPTA. We add each of its branches to the transformed game tree for the root node. Player decision nodes in can be divided into two categories: decision nodes of team members and an adversary. The adversary decision nodes are unmodified. That is, the same branches are built in for adversary nodes. We introduce a coordinator player to replace the team member who is taking action. More specifically, we transform the team member decision nodes into the coordinator player, who provides the current player’s strategies. However, the coordinator player is not aware of the team member’s hand cards when first choosing an action on behalf of the team member. Thus, we construct temporary chance nodes to represent all potential situations for a team member’s hand cards, as shown in Figure 3. We design the information pool for storing information of team members, which will contribute to optimizing our approach in Subsection 4.4.
4.4. Phase 2: Merging and Pruning
Merging information sets with temporary private information.
The information set, which includes both the public action histories and the private information of players, is an indispensable property of imperfect information games. Each branch of the root node represents a different distribution of cards. In the original game tree, there are no multiple nodes belonging to the same information set within the same branch. On the contrary, the condition is quite dissimilar after transformation. We begin at the root node and select two branches of the transformed game tree where one player has the same hand cards, except for temporary chance nodes. The nodes of players are traversed in turn. The player’s nodes on the same layer belong to a single information set in the case of same game histories, even though they have different virtual private information. In our work, nodes are given the same number to mark the same information set.
Pruning for transformed tree.
Under the same branch of root node, the coordinator does not know private information if and only if he makes the first decisions for each team member in turn. Their private information is stored in the information pool when all team members have been replaced by the coordinator. Then, the coordinator will be allowed to extract the current team member’s hand cards from information pool to make the next decisions. During the transformation process, the coordinator is only authorized to extract the private information of one player at a time, which means that the private information of team members is independent of each other. In this way, we can prune the transformed game tree to make its scale smaller, as shown in Algorithm 2.
5. Equilibrium Equivalence Proof
As a primary guarantee for this work, we prove theoretically that game trees before and after the transformation are essentially equivalent. It is further reasoned that TMECor in the adversarial team multi-player games is equivalently related to NE in 2-player zero-sum extensive-form games. For simplicity, we denote the original game tree by and the transformed game tree is represented as the return value of in Algorithm 1. is used to represent the TMECor in . Given a player , denotes the strategy in and denotes the normal-form strategy in . Let be the set of decision nodes reached according to player ’s strategy and is the coordinator player in . Note that temporary chance node is not the players’ decision node. The equilibrium equivalence will be proved according to the following lemmas and theorems.
Lemma 0.
Given a multi-player game tree that satisfies the definition of ATMGs, and the transformed game tree , for any player , any decision node in can be mapped to the decision node in . Formally, in , and , .
Proof.
We can prove that Lemma 4 holds according to the process of transformation in Algorithm 1, using the characteristics of the game tree structure. To avoid notational confusion, let and represent the set of leaf nodes in and , respectively.
-
•
For leaf node: because the leaf nodes correspond to the players’ payoff, they are added directly to the game tree without any changes. Formally, .
-
•
For adversary node: in is mapped to in by our method, which provides a guarantee for the equality of and .
-
•
For chance node: the root node of the game tree is not changed during the transformation. So in and in are same.
-
•
For team member node: For any decision node of team member , there is always a corresponding decision node of coordinator player with the same game histories in the transformed game tree.
Since the coordinator player does not know the private information of all players, temporary chance node of the PIPB structure in will provide the coordinator player with all potential situations of hand cards.
This is the end of the proof. ∎
Lemma 0.
Given a multi-player game tree that satisfies the definition of ATMGs, and the transformed game tree , for any player , any decision node in can maintain the correspondence with the decision node in . Formally, in , and , .
Proof.
The proof process is similar to that of Lemma 4, and the above process is not repeated in this proof. Furthermore, the coordinator nodes added by in belongs to the same information set. Therefore, their correspondence with decision nodes in still holds.
This is the end of the proof. ∎
Corollary 0.
Given a multi-player game tree that satisfies the definition of ATMGs, and the transformed game tree , for any player in the original game, his strategies must be mapped in the transformed game. Formally,
Proof.
Theorem 7.
Given a multi-player game tree that satisfies the definition of ATMGs, and the transformed game tree , for any team member and opponent player , we have:
where the strategy is a mapping of strategy from to .
Proof.
Theorem 8.
Given a multi-player game tree that satisfies the definition of ATMGs, and the transformed game tree , a Nash equilibrium in has equilibrium equivalence with TMECor in . Formally, .
Proof.
Assuming that is a TMECor, then according to Equation 2, we can get:
According to Corollary 6, the above formula can be converted into
and denote the inner minimization problem in the definition of TMECor and NE respectively. We assume that existing a that is larger than the value of , i.e., . By Theorem 7, it can be converted that: . This is unreasonable since by hypothesis is a maximum. Hence, we get that:
This is the end of the proof.
∎
6. experimental evaluation
In this section, we describe the setup of experimental scenarios and comparison methods. The performance of our method is verified by comparing with the state-of-the-art algorithm in different scenarios.
6.1. Experimental Setting
We conduct our experiments with standard testbed in the adversarial team multi-player games (ATMGs). More exactly, we use modified versions of Kuhn Poker Kuhn (1950b) and Leduc Poker Southey et al. (2005). By taking the number of players and cards as parameters and modifying the team’s utility function, they are possible to satisfy the definition of ATMGs. We set up scenarios in which a group of players forms a team against a single player and unify the team’s utility function to meet the definition of ATMGs. Furthermore, we can achieve the purpose of generating multiple experimental platforms with different complexity by taking the number of players, suits, and cards as parameters. We adopt a total of 12 scenarios of varying difficulty, 6 each for Kuhn Poker and Leduc Poker, where the default maximum number of bets allowed per betting round is 1. In Kuhn Poker, the experiment is set up with players from 3 to 5, and cards are set to 3, 4, 6, and 8. In Leduc Poker, players are set from 3 to 5, cards are set by 3, 4, and 6, suits are set 3. It is worth noting that the more complex 5-player scenario has not been attempted before. All experiments are run on a machine with 18-core 2.7GHz CPU and 250GB memory.
We use the Counterfactual Regret Minimization plus (CFR+) to interface with the MPTA and the baseline algorithm, which is an excellent approach for finding Nash equilibrium in 2-player zero-sum extensive-form games. Nevertheless, our method can still use other CFR-like algorithms. In this paper, the baseline algorithm is Team-Public-Information Conversion Algorithm (TPICA), which is the previous best method similar to our work. It gives the coordinator information that is common to the whole team and provides all team members with the corresponding actions for each possible private state.
6.2. Experimental Results
Total runtime for finding a TMECor.
In Table 2, we describe in detail the size of the game trees in different scenarios, both the original game tree and the transformed tree through our method. Furthermore, they are compared with the basic method (TPICA) proposed by Carminati et al. Carminati et al. (2022). TPICA and our work share the same goal of finding a TMECor in ATMGs using the effective tools of 2p0s games. The data in Table 2 shows that our method significantly reduces the size of the game trees generation after the transformation compared to TPICA. In Kuhn Poker, the sizes of 21K3, 21K4, and 21K6 are reduced by , , and , respectively. The blank cells in Table 2 indicate that TPICA fail to convert due to out-of-memory and thus cannot obtain a valid game tree. In the four cases of 21K4, 21K4, 21K6, and 21L33 where both MPTA and TPICA can work, the total time required by our approach to compute a TMECor is 0.76s, 9.26s, 144s, and 240s respectively, which is , , , and faster than TPICA. This shows that our method is effective in reducing the action space, as it improves the solving speed by several orders of magnitude. It is worth noting that MPTA is still available in other large-scale scenarios where TPICA cannot transform original game trees. In particular, 41K6 and 41L33 are 5-player cases that have never been used as experiments by previous algorithms due to their sheer size. In addition, we also observe that the reason for the speed-up is mainly due to the special structure, which greatly reduces the number of adversary nodes and temporary chance nodes.
| Game instances | Total nodes | Team nodes | Adversary nodes | Runtime | Improvements | |||||
| Original | TPICA | MPTA | TPICA | MPTA | TPICA | MPTA | TPICA | MPTA | ||
| 21K3 | 151 | 5,395 | 583 | 300 | 144 | 294 | 72 | 139s | 0.76s | 182.89 |
| 21K4 | 601 | 1,337,051 | 3,097 | 3,888 | 768 | 4,632 | 384 | 1560s | 9.26s | 168.47 |
| 21K6 | 3,001 | 34,191,721 | 23,161 | 261,360 | 5,760 | 368,760 | 2,880 | ¿27h | 144s | 694.44 |
| 31K6 | 23,401 | 271,441 | 75,240 | 22,680 | 825s | |||||
| 31K8 | 109,201 | 1,713,601 | 475,440 | 142,800 | 5,093s | |||||
| 41K6 | 115,921 | 1,796,401 | 528,480 | 105,120 | 3,051s | |||||
| 21L33 | 13,183 | 10,777,963 | 57,799 | 614,172 | 14,664 | 475,566 | 6,864 | 56,156s | 240s | 233.98 |
| 21L43 | 42,589 | 251,749 | 64,008 | 29,736 | 3,006s | |||||
| 21L63 | 218,011 | 1,954,351 | 497,940 | 229,620 | 9,024s | |||||
| 31L33 | 161,491 | 948,151 | 262,500 | 80,220 | 4,014s | |||||
| 31L43 | 738,241 | 5,994,241 | 1,661,760 | 504,000 | 137,817s | |||||
| 41L33 | 1,673,311 | 12,226,231 | 3,535,320 | 809,880 | 143,475s | |||||
Solving efficiency.
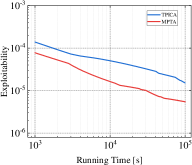
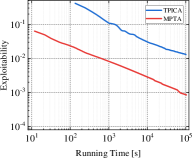
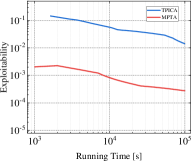
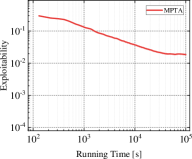
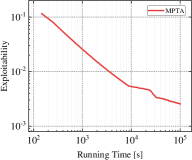
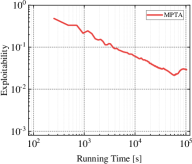
Exploitability is widely used as a significant evaluation criterion for a strategy profile. Informally, it represents the gap between the current policy and the optimal policy. Thus, a smaller exploitability indicates that the current strategy is closer to the TMECor in the original multi-player games. In addition to the comparison of the total solution time, we also need insight into the relationship between the solving efficiency of the transformed game trees and algorithms in the running process. For this purpose, we select three cases each in Kuhn Poker and Leduc Poker to test MPTA and baseline method’s variation of exploitability over time within a limited running time of 100,000 seconds, as shown in Figure 4. In the three comparable cases: 21K3, 21K6, and 21L33, we observe that the curve representing MPTA is always below the TPICA, and the distance between the two curves increases with the increase of the size gap of game trees. This suggests that the CFR+ is more efficient in solving the transformed game tree for MPTA. In the remaining scenarios, we can find that the convergence rate to equilibrium is faster in 41K6 than in 31L43 and 41L33 and the curve representing the MPTA fluctuates more sharply in 41L33. This indicates that the process of computing equilibrium is more difficult when the game scale increases.
Execution efficiency.
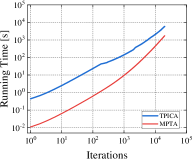
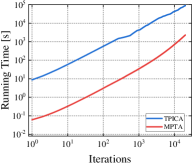
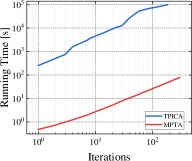
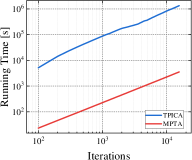
Finding a TMECor is an iterative process, and we show a comparison of the time taken by the algorithms within the same number of iteration rounds in Figure 5. As can be seen from Figure 5, in all comparing circumstances, the game trees transformed by MPTA take considerably less time to complete the computation of a normal-form strategy profile than by TPICA in any number of iteration rounds. 21K6 and 21L33 are an order of magnitude larger than 21K3 and 21K4. However, the results in Figure 5(c) and Figure 5(d) show that the advantages of our approach are more evident in these two large-scale games.
7. conclusions and future work
In this paper, we present a generic multi-player transformation algorithm (MPTA) which can transform a multi-player game tree satisfying the definition of ATMGs into a 2-player game tree, thereby establishing a bridge between 2p0s games and multi-player games. In addition, we analyze theoretically that the proposed new structure limits the growth of the transformed game’s action space from exponential to a constant level. At the same time, we also prove the equilibrium equivalence between the original game tree and the transformed game tree, which provides a theoretical guarantee for our work. We experiment with several scenarios of varying complexity and show that finding a TMECor is several orders of magnitude faster than the state-of-the-art baseline. As far as we know, this work is the first one to solve a ATMG with 5 or even more players.
In the future, we will be devoted to testing our algorithm in more challenging and complex scenarios in real world. We also plan to get the aid of deep neural networks’ powerful data processing and generalization capabilities to provide real-time strategies for agents.
References
- (1)
- Bard et al. (2020) Nolan Bard, Jakob N Foerster, Sarath Chandar, Neil Burch, Marc Lanctot, H Francis Song, Emilio Parisotto, Vincent Dumoulin, Subhodeep Moitra, Edward Hughes, et al. 2020. The hanabi challenge: A new frontier for ai research. Artificial Intelligence 280 (2020), 103216.
- Basilico et al. (2017a) Nicola Basilico, Andrea Celli, Giuseppe De Nittis, and Nicola Gatti. 2017a. Computing the Team-maxmin Equilibrium in Single-Team Single-Adversary Team Games. Intelligenza Artificiale 11, 1 (2017), 67–79. https://doi.org/10.3233/IA-170107
- Basilico et al. (2017b) Nicola Basilico, Andrea Celli, Giuseppe De Nittis, and Nicola Gatti. 2017b. Team-Maxmin Equilibrium: Efficiency Bounds and Algorithms. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, February 4-9, 2017, San Francisco, California, USA, Satinder Singh and Shaul Markovitch (Eds.). AAAI Press, 356–362. http://aaai.org/ocs/index.php/AAAI/AAAI17/paper/view/14264
- Brown (2020) Noam Brown. 2020. Equilibrium finding for large adversarial imperfect-information games. PhD thesis (2020).
- Brown et al. (2019) Noam Brown, Adam Lerer, Sam Gross, and Tuomas Sandholm. 2019. Deep Counterfactual Regret Minimization. In Proceedings of the 36th International Conference on Machine Learning, ICML 2019, 9-15 June 2019, Long Beach, California, USA (Proceedings of Machine Learning Research, Vol. 97), Kamalika Chaudhuri and Ruslan Salakhutdinov (Eds.). PMLR, 793–802.
- Brown and Sandholm (2017) Noam Brown and Tuomas Sandholm. 2017. Safe and nested subgame solving for imperfect-information games. Advances in neural information processing systems 30 (2017).
- Brown and Sandholm (2019a) Noam Brown and Tuomas Sandholm. 2019a. Solving Imperfect-Information Games via Discounted Regret Minimization. In The Thirty-Third AAAI Conference on Artificial Intelligence, AAAI 2019, The Thirty-First Innovative Applications of Artificial Intelligence Conference, IAAI 2019, The Ninth AAAI Symposium on Educational Advances in Artificial Intelligence, EAAI 2019, Honolulu, Hawaii, USA, January 27 - February 1, 2019. AAAI Press, 1829–1836. https://doi.org/10.1609/aaai.v33i01.33011829
- Brown and Sandholm (2019b) Noam Brown and Tuomas Sandholm. 2019b. Superhuman AI for multiplayer poker. Science 365, 6456 (2019), 885–890.
- Cacciamani et al. (2021) Federico Cacciamani, Andrea Celli, Marco Ciccone, and Nicola Gatti. 2021. Multi-Agent Coordination in Adversarial Environments through Signal Mediated Strategies. In AAMAS ’21: 20th International Conference on Autonomous Agents and Multiagent Systems, Virtual Event, United Kingdom, May 3-7, 2021. ACM, 269–278. https://doi.org/10.5555/3463952.3463989
- Carminati et al. (2022) Luca Carminati, Federico Cacciamani, Marco Ciccone, and Nicola Gatti. 2022. A Marriage between Adversarial Team Games and 2-player Games: Enabling Abstractions, No-regret Learning, and Subgame Solving. In International Conference on Machine Learning, ICML 2022, 17-23 July 2022, Baltimore, Maryland, USA (Proceedings of Machine Learning Research, Vol. 162), Kamalika Chaudhuri, Stefanie Jegelka, Le Song, Csaba Szepesvári, Gang Niu, and Sivan Sabato (Eds.). PMLR, 2638–2657.
- Celli et al. (2019) Andrea Celli, Marco Ciccone, Raffaele Bongo, and Nicola Gatti. 2019. Coordination in adversarial sequential team games via multi-agent deep reinforcement learning. arXiv preprint arXiv:1912.07712 (2019).
- Celli and Gatti (2018) Andrea Celli and Nicola Gatti. 2018. Computational Results for Extensive-Form Adversarial Team Games. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, (AAAI-18), the 30th innovative Applications of Artificial Intelligence (IAAI-18), and the 8th AAAI Symposium on Educational Advances in Artificial Intelligence (EAAI-18), New Orleans, Louisiana, USA, February 2-7, 2018, Sheila A. McIlraith and Kilian Q. Weinberger (Eds.). AAAI Press, 965–972.
- Chen and Deng (2005) Xi Chen and Xiaotie Deng. 2005. 3-Nash is PPAD-complete. In Electronic Colloquium on Computational Complexity, Vol. 134. Citeseer, 2–29.
- Farina et al. (2018a) Gabriele Farina, Andrea Celli, Nicola Gatti, and Tuomas Sandholm. 2018a. Ex ante coordination and collusion in zero-sum multi-player extensive-form games. Advances in Neural Information Processing Systems 31 (2018).
- Farina et al. (2018b) Gabriele Farina, Andrea Celli, Nicola Gatti, and Tuomas Sandholm. 2018b. Ex ante coordination and collusion in zero-sum multi-player extensive-form games. In Advances in Neural Information Processing Systems 31: Annual Conference on Neural Information Processing Systems 2018, NeurIPS 2018, December 3-8, 2018, Montréal, Canada. 9661–9671. https://proceedings.neurips.cc/paper/2018/hash/c17028c9b6e0c5deaad29665d582284a-Abstract.html
- Farina et al. (2021) Gabriele Farina, Andrea Celli, Nicola Gatti, and Tuomas Sandholm. 2021. Connecting Optimal Ex-Ante Collusion in Teams to Extensive-Form Correlation: Faster Algorithms and Positive Complexity Results. In Proceedings of the 38th International Conference on Machine Learning, ICML 2021, 18-24 July 2021, Virtual Event (Proceedings of Machine Learning Research, Vol. 139), Marina Meila and Tong Zhang (Eds.). PMLR, 3164–3173. http://proceedings.mlr.press/v139/farina21a.html
- Hansen et al. (2008a) Kristoffer Arnsfelt Hansen, Thomas Dueholm Hansen, Peter Bro Miltersen, and Troels Bjerre Sørensen. 2008a. Approximability and parameterized complexity of minmax values. In Internet and Network Economics: 4th International Workshop, WINE 2008, Shanghai, China, December 17-20, 2008. Proceedings 4. Springer, 684–695.
- Hansen et al. (2008b) Kristoffer Arnsfelt Hansen, Thomas Dueholm Hansen, Peter Bro Miltersen, and Troels Bjerre Sørensen. 2008b. Approximability and Parameterized Complexity of Minmax Values. In Internet and Network Economics, 4th International Workshop, WINE 2008, Shanghai, China, December 17-20, 2008. Proceedings (Lecture Notes in Computer Science, Vol. 5385), Christos H. Papadimitriou and Shuzhong Zhang (Eds.). Springer, 684–695. https://doi.org/10.1007/978-3-540-92185-1_74
- Kannan et al. (2002) Rajgopal Kannan, Sudipta Sarangi, and Sundaraja Sitharama Iyengar. 2002. Strategic path reliability in information networks. Technical Report. DIW Discussion Papers.
- Kuhn (1950a) Harold W Kuhn. 1950a. Extensive games. Proceedings of the National Academy of Sciences 36, 10 (1950), 570–576.
- Kuhn (1950b) Harold W Kuhn. 1950b. A simplified two-person poker. Contributions to the Theory of Games 1 (1950), 97–103.
- Lanctot et al. (2009) Marc Lanctot, Kevin Waugh, Martin Zinkevich, and Michael Bowling. 2009. Monte Carlo sampling for regret minimization in extensive games. Advances in neural information processing systems 22 (2009).
- Nash (1951) John Nash. 1951. Non-cooperative games. Annals of mathematics (1951), 286–295.
- Southey et al. (2005) Finnegan Southey, Michael H. Bowling, Bryce Larson, Carmelo Piccione, Neil Burch, Darse Billings, and D. Chris Rayner. 2005. Bayes? Bluff: Opponent Modelling in Poker. In UAI ’05, Proceedings of the 21st Conference in Uncertainty in Artificial Intelligence, Edinburgh, Scotland, July 26-29, 2005. AUAI Press, 550–558.
- Tammelin et al. (2015) Oskari Tammelin, Neil Burch, Michael Johanson, and Michael Bowling. 2015. Solving Heads-Up Limit Texas Hold’em. In Proceedings of the Twenty-Fourth International Joint Conference on Artificial Intelligence, IJCAI 2015, Buenos Aires, Argentina, July 25-31, 2015, Qiang Yang and Michael J. Wooldridge (Eds.). AAAI Press, 645–652.
- von Stengel and Koller (1997) Bernhard von Stengel and Daphne Koller. 1997. Team-maxmin equilibria. Games and Economic Behavior 21, 1-2 (1997), 309–321.
- Zhang and Sandholm (2022) Brian Hu Zhang and Tuomas Sandholm. 2022. Team Correlated Equilibria in Zero-Sum Extensive-Form Games via Tree Decompositions. In Thirty-Sixth AAAI Conference on Artificial Intelligence, AAAI 2022, Thirty-Fourth Conference on Innovative Applications of Artificial Intelligence, IAAI 2022, The Twelveth Symposium on Educational Advances in Artificial Intelligence, EAAI 2022 Virtual Event, February 22 - March 1, 2022. AAAI Press, 5252–5259.
- Zhang and An (2020a) Youzhi Zhang and Bo An. 2020a. Computing Team-Maxmin Equilibria in Zero-Sum Multiplayer Extensive-Form Games. In The Thirty-Fourth AAAI Conference on Artificial Intelligence, AAAI 2020, The Thirty-Second Innovative Applications of Artificial Intelligence Conference, IAAI 2020, The Tenth AAAI Symposium on Educational Advances in Artificial Intelligence, EAAI 2020, New York, NY, USA, February 7-12, 2020. AAAI Press, 2318–2325. https://ojs.aaai.org/index.php/AAAI/article/view/5610
- Zhang and An (2020b) Youzhi Zhang and Bo An. 2020b. Converging to Team-Maxmin Equilibria in Zero-Sum Multiplayer Games. In Proceedings of the 37th International Conference on Machine Learning, ICML 2020, 13-18 July 2020, Virtual Event (Proceedings of Machine Learning Research, Vol. 119). PMLR, 11033–11043. http://proceedings.mlr.press/v119/zhang20c.html
- Zhang et al. (2021) Youzhi Zhang, Bo An, and Jakub Cerný. 2021. Computing Ex Ante Coordinated Team-Maxmin Equilibria in Zero-Sum Multiplayer Extensive-Form Games. In Thirty-Fifth AAAI Conference on Artificial Intelligence, AAAI 2021, Thirty-Third Conference on Innovative Applications of Artificial Intelligence, IAAI 2021, The Eleventh Symposium on Educational Advances in Artificial Intelligence, EAAI 2021, Virtual Event, February 2-9, 2021. AAAI Press, 5813–5821.
- Zhang et al. (2022) Youzhi Zhang, Bo An, and V. S. Subrahmanian. 2022. Correlation-Based Algorithm for Team-Maxmin Equilibrium in Multiplayer Extensive-Form Games. In Proceedings of the Thirty-First International Joint Conference on Artificial Intelligence, IJCAI 2022, Vienna, Austria, 23-29 July 2022, Luc De Raedt (Ed.). ijcai.org, 606–612. https://doi.org/10.24963/ijcai.2022/86
- Zhou et al. (2020) Yichi Zhou, Tongzheng Ren, Jialian Li, Dong Yan, and Jun Zhu. 2020. Lazy-CFR: fast and near-optimal regret minimization for extensive games with imperfect information. In 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, April 26-30, 2020. OpenReview.net. https://openreview.net/forum?id=rJx4p3NYDB
- Zinkevich et al. (2007) Martin Zinkevich, Michael Johanson, Michael Bowling, and Carmelo Piccione. 2007. Regret minimization in games with incomplete information. Advances in neural information processing systems 20 (2007).