A global structure-preserving kernel method for the learning of Poisson systems
Abstract
A structure-preserving kernel ridge regression method is presented that allows the recovery of globally defined, potentially high-dimensional, and nonlinear Hamiltonian functions on Poisson manifolds out of datasets made of noisy observations of Hamiltonian vector fields. The proposed method is based on finding the solution of a non-standard kernel ridge regression where the observed data is generated as the noisy image by a vector bundle map of the differential of the function that one is trying to estimate. Additionally, it is shown how a suitable regularization solves the intrinsic non-identifiability of the learning problem due to the degeneracy of the Poisson tensor and the presence of Casimir functions. A full error analysis is conducted that provides convergence rates using fixed and adaptive regularization parameters. The good performance of the proposed estimator is illustrated with several numerical experiments.
1 Introduction
The study of Poisson systems plays a crucial role in understanding a wide range of physical phenomena, from classical mechanics to fluid dynamics [Mars 99, Orte 04, Holm 09, Holm 11a, Holm 11b]. These systems, characterized by their inherent geometric structures and conservation laws, present unique challenges in modeling and simulation. Traditional methods for learning and approximating Poisson systems often require extensive domain knowledge and computational resources. In recent years, several machine learning techniques have emerged as powerful tools for addressing complex scientific problems that could offer new avenues for efficiently learning the structures underlying Poisson systems.
Recent literature has extensively explored the learning and prediction of some Poisson systems. These studies incorporate varying degrees of domain-specific knowledge into learning algorithms, enhancing their ability to accurately model and predict such systems’ behavior. An initial approach involved directly learning the Hamiltonian [Grey 19, Davi 23, Hu 24] or Lagrangian [Cran 20, Chen 22] functions using neural networks or other machine learning models, such as Gaussian processes [Offe 24, Pfö 24, Beck 22]. It is worth pointing out that proper variational integrators [Mars 01, Leok 12] should be adopted to match the predicted vector field with observed time series data [Zhu 20]. Researchers have also proposed learning the generating function that produces the flow map [Chen 21, Rath 21]. Alternative approaches aim to parameterize a (possibly universal) family of symplectic or Poisson maps to fit the flow map directly [Chen 19, Jin 20, Baja 23, Jin 22, Eldr 24b], with SympNet being a prominent example [Jin 20]. Using SympNet, symplectic autoencoders have been developed to achieve a structure-preserving model reduction of Hamiltonian systems [Bran 23], effectively mapping high-dimensional systems to low-dimensional representations. Additionally, physics-informed neural networks have become popular for solving known physical partial differential equations with high precision [Rais 19] and convergence analysis in certain scenarios [Doum 23, Shin 20], though they enforce the PDEs as loss functions and thus do not preserve the exact structure. In general, to characterize and replicate the flow of (port-)Hamiltonian systems with exact structure preservation remains challenging, with a notable exception in the literature for linear port-Hamiltonian systems [Orte 24].
This paper proposes a non-standard kernel ridge regression method that allows the recovery of globally defined and potentially high-dimensional and nonlinear Hamiltonian functions on Poisson manifolds out of datasets made of noisy observations of Hamiltonian vector fields. We now spell out three key features of the approach proposed in this paper.
First, much of the existing research in this field operates under the assumption that the underlying dynamical system is Hamiltonian or that the flow map is symplectic [Chen 19, Jin 20], allowing for the use of generating function models or universal parameterizations of symplectic maps to directly model the flow. However, this assumption does not extend to general Poisson systems on manifolds for which the Hamiltonian function cannot be globally expressed in canonical coordinates, and the flow map is generally not symplectic. Moreover, due to the potential degeneracy of the Poisson tensor, Poisson manifolds typically possess a family of functions known as Casimirs, which do not influence the Hamiltonian vector fields. Preserving these Casimirs is an intrinsic requirement for any machine learning algorithm applied to such systems. Inspired by the Darboux-Weinstein theorem [Wein 83, Libe 12, Vais 12], recent approaches have proposed learning coordinate transformations to convert coordinates into canonical ones, followed by inverse transformations to retrieve the dynamics [Jin 22, Baja 23]. While the local existence of these transformations is guaranteed, their global behavior remains unclear, particularly in cases where coordinate patches overlap, and numerical errors on the preservation of Casimir values accumulate. The Lie-Poisson Network [Eldr 24b, Eldr 24a] attempts to approximate flows of the special case of Lie-Poisson systems using compositions of flow maps of linear systems, preserving Casimirs exactly through projection but not addressing the expressiveness of the constructed flows. Rather than learning the flow map, we propose to discover an underlying Hamiltonian function of the Poisson system from Hamiltonian vector fields in a structure-preserving manner. The presence of Casimir functions renders the identification of the Hamiltonian function from the observed vector field infeasible, which is a challenge that lies beyond the scope of the work already presented by the authors in [Hu 24] and necessitates the development of new algorithms to address this issue.
Second, while significant research has focused on the forward problem of learning the flow map of dynamical systems using approaches like Physics-Informed neural networks (PINNs), symbolic regression [Brun 16], Gaussian processes, or kernel methods, the inverse problem of uncovering unknown Hamiltonian functions from data remains relatively underexplored. Unlike neural networks or likelihood-based methods that rely on iterative or stochastic gradient descent to optimize objective functions, kernel methods offer a more straightforward, easy-to-train, and data-efficient alternative. By transforming the optimization problem into a convex one, kernel methods enable the derivation of a closed-form solution for the Hamiltonian function estimation problem in a single step, even on manifolds. Another advantage of kernel methods is that by selecting a kernel with inherent symmetry, the learning scheme can be designed to automatically preserve it, which is particularly important when learning mechanical systems. We recall that due to the celebrated Noether’s Theorem, symmetries usually carry in their wake additional conserved quantities when dealing with mechanical systems. The Reproducing Kernel Hilbert Space (RKHS) framework also facilitates rigorous estimation and approximation error bounds, offering both theoretical insights and interpretability. Additionally, it is well-suited for the design of online learning paradigms.
Finally, while the literature on learning physical dynamical systems is extensive and the idea of structure-preserving kernel regression has already been proposed to recover either interacting potentials of particle systems [Feng 23] or Hamiltonian functions on Euclidean spaces [Hu 24], the majority of studies have been confined to the context of Euclidean spaces, with a lack of attention to scenarios where the underlying configuration space is a more general manifold, which is typically the case in many applications like rigid body mechanics, robotics, fluids, or elasticity. This generalization introduces a two-fold challenge in model construction or for the learning of either the flows of dynamical systems or their corresponding Hamiltonian functions, namely, preserving simlutaneously the manifold and the variational structures. When a model is designed to predict Hamiltonian vector fields on a manifold, ensuring that the predicted flow remains on the manifold and preserves symplectic or Poisson structures necessitates structure-preserving integrators. However, even in Euclidean spaces, the design of variational integrators is complex and often requires implicit methods, indicating a heightened difficulty in the manifold setting. Additionally, standard methods such as Galerkin projections are typically approximately but not exactly manifold-preserving [Boro 20] and typically fail to preserve the variational structure. In [Magg 21], an algorithm is proposed to identify interacting potentials on a Riemannian manifold, though the estimated potential remains dependent only on the Euclidean scalar distance. This approach requires a prior selection of a finite set of basis functions and coordinate charts or embeddings. In contrast, our work introduces a kernel method that globally estimates a Hamiltonian function for Poisson systems on the phase-space manifold and yields a globally well-defined and chart-independent solution. This sets it apart from existing approaches in the literature [Feng 23, Magg 21, Lu 19].
Main Results.
This paper proposes a method to learn a Hamiltonian function of a globally defined Hamiltonian system on a -dimensional Poisson manifold from noisy realizations of the corresponding Hamiltonian vector field , that is:
where are IID random variables with values on the Poisson manifold and with the same distribution , and are independent random variables on the tangent spaces ( is a particular realization of with mean zero and variance . In this setup, we consider the inverse problem consisting in recovering the Hamiltonian function , or a dynamically equivalent version of it, by solving the following optimization problem,
| (1.1) |
where is the Hamiltonian vector field corresponding to the function , is the reproducing kernel Hilbert space (RKHS) associated to a kernel function that will be introduced later on, is a Riemannian metric on , and is a Tikhonov regularization parameter. The solution in the RKHS is sought to minimize the natural regularized empirical risk defined in this setup. We shall call the solution of the optimization problem (1.1) the structure-preserving kernel estimator of the Hamiltonian function.
We now summarize the outline and the main contributions of the paper.
-
1.
In Section 2, we review basic concepts in Riemannian geometry, including differentials on Riemannian manifolds and the definitions of random variables and integration in this context. Additionally, we provide the necessary background on Poisson mechanics, covering topics such as Hamiltonian vector fields, Casimir functions, compatible structures, and Lie-Poisson systems, illustrated with two real-world examples: rigid-body dynamics and underwater vehicle dynamics.
-
2.
In Section 3, we extend the differentiable reproducing property, previously established for the compact [Zhou 08] and Euclidean cases [Hu 24] to Riemannian manifolds. Specifically, we show that the differential of a function in the reproducing kernel Hilbert space (RKHS) associated to a kernel function , when paired with a vector , can be represented as the RKHS inner product of with the differential of the kernel section of evaluated along . This property is pivotal throughout our analysis. Following this, we derive the solution of the optimization problem (1.1) using operator representations and ultimately express it as a closed-form formula made of a linear combination of kernel sections, similar to the standard Representer theorem. Importantly, this formula provides a globally defined expression on the Poisson manifold , independent of the choice of local coordinates, though we also present the formula in local charts. In Subsection 3.5, we study the case in which the Hamiltonian that needs to be learned is known to be a priori invariant with respect to the canonical action of a given Lie group and show that if the kernel is chosen to be invariant under that group action, then the flow of the estimated Hamiltonian inherently conserves momentum maps, as a direct consequence of Noether’s theorem.
-
3.
In Section 4, we utilize the operator representation of the estimator to derive bounds for estimation and approximation errors. These bounds demonstrate that, as the number of random samples increases, the estimator converges to a true Hamiltonian function with high probability.
-
4.
In Section 5, we implement the structure-preserving kernel ridge regression in Python and conduct extensive numerical experiments. These experiments focus on two primary scenarios: Hamiltonian systems on symplectic manifolds (Subsection 5.2) and Lie-Poisson systems (Subsection 5.1). In subsection 5.2, we aim to recover the Hamiltonian function for the classical two-vortex system on products of -spheres, which exhibits singularities, as well as another well-behaved Hamiltonian function represented as a 3-norm defined on the same manifold. In Subsection 5.1, we address symmetric Poisson systems on cotangent bundles of Lie groups. Through Lie-Poisson reduction, these systems can be modeled as Lie-Poisson systems on the dual of a Lie algebra. Numerical simulations validate the effectiveness, ease of training, and data efficiency of our proposed kernel-based approach.
We emphasize that, although this paper focuses on recovering Hamiltonian functions from observed Hamiltonian vector fields, the proposed framework is more broadly applicable. Specifically, it can be extended to any scenario where the observed quantity (in this paper ) is the image by a vector bundle map of the differential of a function (in this paper ) on the manifold. This makes the framework versatile for various systems beyond Hamiltonian dynamics; for example, in gradient systems with an underlying control-dependent potential function, the same algorithm can be applied to learn an optimal control force based on sensor-measured external forces.
2 Preliminaries on Poisson mechanics
2.1 Hamiltonian systems on Poisson manifolds
The aim of this paper is to learn Hamiltonian systems on Poisson manifolds. In this subsection, we will provide a brief introduction to Poisson mechanics relevant to the learning problems; for more details, see [Mars 99, Orte 04, Libe 12, Vais 12]. Let be a manifold and denote by the space of all smooth functions defined on it.
Definition 2.1.
A Poisson bracket (or a Poisson structure) on a manifold is a bilinear map such that:
- (i)
-
is a Lie algebra.
- (ii)
-
is a derivation in each factor, that is,
for all , and .
A manifold endowed with a Poisson bracket on is called a Poisson manifold.
Example 2.2 (Symplectic bracket).
Any symplectic manifold is a Poisson manifold with the Poisson bracket defined by the symplectic form as follows:
| (2.1) |
where are the Hamiltonian vector fields of , respectively, uniquely determined by the equalities and ( denotes the interior product and the exterior derivative).
Example 2.3 (Lie-Poisson bracket).
If is a Lie algebra, then its dual algebra is a Poisson manifold with respect to the Lie-Poisson brackets and defined by
| (2.2) |
where is the Lie bracket on , denotes the pairing between and , and is the functional derivative of at defined as the unique element that satisfies
| (2.3) |
By the derivation property of the Poisson bracket, the value of the bracket at (and thus as well) depends on only through the differential . Thus, a Poisson tensor associated with the Poisson bracket can be defined as follows.
Definition 2.4.
Let be a Poisson manifold. The Poisson tensor of this Poisson bracket is the contravariant anti-symmetric two-tensor
defined by
| (2.4) |
and where are any two functions such that and .
Hamiltonian vector fields and Hamilton’s equations. Given a Poisson manifold and , there is a unique vector field such that
| (2.5) |
The unique vector field is called the Hamiltonian vector field associated with the Hamiltonian function . Let be the flow of the Hamiltonian vector field ; then, for any ,
| (2.6) |
We call (2.6) the Hamilton equations associated with the Hamiltonian function . Let be the vector bundle map associated to the Poisson tensor defined in (2.4), that is,
| (2.7) |
Then the Hamiltonian vector field defined in (2.5) can be expressed as . Furthermore, the Poisson bracket is given by
Poisson geometry is closely related to symplectic geometry: for instance, every Poisson bracket determines a (generalized) foliation of a Poisson manifold into symplectic (immersed) submanifolds such that the leaf that passes through a given point has the dimension of the rank of the Poisson tensor at that point. We recall that the non-degeneracy hypothesis on symplectic forms implies that the Poisson tensor, in that case, has constant maximal rank. The following paragraph describes a distinctive feature of Poisson manifolds with respect to the symplectic case.
Casimir functions. As we just explained, an important difference between the symplectic and Poisson cases is that the Poisson tensor could be degenerate, which leads to the emergence of Casimir functions. A function is called a Casimir function if for all , that is, is constant along the flow of all Hamiltonian vector fields, or, equivalently, , that is, generates trivial dynamics. Casimir functions are conserved quantities along the equations of motion associated with any Hamiltonian function. The Casimirs of a Poisson manifold are the center of the Poisson algebra which is defined by
If the Poisson tensor is non-degenerate (symplectic case), then consists only of all constant functions on . The following Lie-Poisson systems are two examples that admit non-constant Casimirs.
Example 2.5 (Rigid body Casimirs [Mars 99]).
The motion of a rigid body follows a Lie-Poisson equation on the dual of the Lie algebra of the special orthogonal group determined by the Hamiltonian function
where is a diagonal matrix. The Poisson bracket on is given by
| (2.8) |
Hence, it can be easily checked that is a Casimir function of Poisson structure (2.8). Furthermore, for any analytic function , the function is also a Casimir.
Example 2.6 (Underwater vehicle Casimirs [Leon 97]).
The underwater vehicle dynamics can be described using the Lie-Poisson structure on and the Hamiltonian function
where are matrices coming from first principles and physical laws, is the mass of the body, is the gravity constant, and is the vector that links the center of buoyancy to the center of gravity. For the underwater vehicle, and correspond, respectively, to angular and linear components of the impulse of the system (roughly, the momentum of the system less a term at infinity). The vector describes the direction of gravity in body-fixed coordinates. The Poisson bracket on is
where and are smooth functions on and the Poisson tensor is given by
In this equation, the operation is the standard isomorphism of with the Lie algebra of the rotation group and is defined by for . There are six Casimir functions for the underwater vehicle dynamics
It can be easily checked that for any analytic function , the function is also a Casimir.
The momentum map and conservation laws. Symmetries are particularly important in mechanics since they are, on many occasions, associated with the appearance of conservation laws. This fact is the celebrated Noether’s Theorem [Noet 18]. A modern and elegant way to encode this fact uses the momentum map, an object introduced in [Lie 93, Sour 65, Sour 69, Kost 09, Sour 66]. The definition of the momentum map requires a canonical Lie group action, that is, an action that respects the Poisson bracket. Its existence is guaranteed when the infinitesimal generators of this action are Hamiltonian vector fields. In other words, if the Lie algebra of the group that acts canonically on the Poisson manifold then, for each with associated infinitesimal generator vector field , we require the existence of a globally defined function , such that
Definition 2.7.
Let be the Lie algebra of a Lie group acting canonically on the Poisson manifold . Suppose that for any , the vector field is globally Hamiltonian, with Hamiltonian function . The map defined by the relation
for all and , is called a momentum map of the –action.
Notice that momentum maps are not uniquely determined; indeed, and are momentum maps for the same canonical action if and only if for any , . Obviously, if is symplectic and connected, then is determined up to a constant in .
Noether’s theorem is formulated in terms of the momentum map by saying that the fibers of the momentum map are preserved by the flow of the Hamiltonian vector field associated with any -invariant Hamiltonian function.
Example 2.8 (The linear momentum).
Take the phase space of the –particle system, that is, . The additive group acts on it by spatial translation on each factor: , with . This action is canonical and has an associated momentum map that coincides with the classical linear momentum
Example 2.9 (The angular momentum).
Let act on and then, by lift, on , that is, . This action is canonical and has an associated momentum map
which is the classical angular momentum.
Example 2.10 (Lifted actions on cotangent bundles).
The previous two examples are particular cases of the following situation. Let be a Lie group acting on the manifold and then by lift on its cotangent bundle . Any such lifted action is canonical with respect to the canonical symplectic form on and has an associated momentum map given by
| (2.9) |
for any and any .
2.2 High-order differentials and random variables on Riemannian manifolds
We start by reviewing higher-order differentials and the spaces of bounded differentiable functions on general manifolds, which will allow us to examine the regularity of functions in a reproducing kernel Hilbert space (RKHS) later on in Section 3.1. Finally, we introduce some basic facts about statistics on Riemannian manifolds that will be needed later on. For further details, see [Penn 19, Hsu 02, Emer 12] and references therein.
Let be a smooth manifold with an atlas , where is an index set. A function is said to be in the class if for any chart , the function is a function and the -order derivative of is continuous.
Definition 2.11 (Differentials).
If is in the class, we define its differential of as
where is a differentiable curve with and .
In the sequel, we shall also denote as the differential of . The differential can be identified with a function on . Then, if is regular enough, we can continue taking the differential of on . In this way, we can define high-order differentials as follows.
Definition 2.12 (High-order differentials).
If is in class, we define the -order differential of denoted as inductively to be the differential of .
Remark 2.13.
For a differentiable function , we denote as the -order differential with respect to the first variable and -order differential with respect to the second variable.
Remark 2.14 (Functions with bounded differentials).
Having defined high-order differentials, we can now define the spaces of functions with bounded differentials for all positive integers . We assume first that is a second-countable manifold, and we hence can construct a complete Riemannian metric on it [Nomi 61]. A general result [Tu 08, Proposition 12.3] guarantees that the higher order tangent bundles are also second countable and can hence also be endowed with complete metrics Let now be the subset of given by
where and
Here, stands for the norm of in the tangent space that is defined using the complete Riemannian metric on .
The metric is also used to define the gradient of a function which is the vector field defined by its differential as
For a differentiable function , a Fundamental Theorem of Calculus can be formulated as
| (2.10) |
where is a differentiable curve with and . Taking absolute values and using the Cauchy-Schwarz inequality, we obtain
for each . Note that, if we choose to be the geodesic connecting and , then is the geodesic distance of and .
Random variables on Riemannian manifolds. Let be a smooth, connected, and complete -dimensional Riemannian manifold with Riemannian metric . Existence and uniqueness theorems from the theory of ordinary differential equations guarantee that there exists a unique geodesic integral curve going through the point at time with tangent vector . The Riemannian exponential map at denoted by maps each vector to the point of the manifold reached in a unit time, that is,
where is the geodesic starting at along the vector . Let be the first time when the geodesic stops to be length-minimizing. The point is called a cut point and the corresponding tangent vector is called a tangent cut point. The set of all cut points of all geodesics starting from is the cut locus and the set of corresponding vectors the tangential cut locus . Thus, we have . Define the maximal definition domain for the exponential chart as
where is the unit sphere in the tangent space with respect to the metric . Then the exponential map is a diffeomorphism from on its image . Denote by the inverse of the exponential map. The Riemannian distance . Recall that for connected complete Riemannian manifolds we have that
It is easy to check that is an open star-shaped subset of , so is a smooth chart and one has that for any Borel measurable function on
where is the Riemannian measure on the manifold is the pullback of by , and denotes the -dimensional Lebesgue measure on .
Definition 2.15 (Random variables on Riemannian manifold).
Let be a probability space and be a Riemannian manifold. A random variable on the Riemannian manifold is a Borel measurable function from to .
Let be the Borel -algebra of . The random variable on the Riemannian manifold has a probability density function (real, positive and integrable function) if for all ,
The definitions of the mean and variance of a random variable on a Riemannian manifold can be found in the literature [Penn 06].
Remark 2.16 (Random variables on tangent spaces).
Since the tangent space of a manifold at any given point is a vector space, the definition of a random variable on them is the same as for vector spaces. Let be a random variable on the tangent space with density , that is, is a Borel measurable function from to .
(i) (Mean and variance). The mean and variance of a random variable on are defined as
where is the -dimensional Lebesgue measure.
(ii) (Independence). Let and are two random variables on the tangent spaces and , respectively. Let and be the Borel -algebras of and , respectively. Then we say and are independent if for all and , we have that
2.3 Compatible structures and local coordinate representations
This subsection introduces the concept of compatible structure, a vector bundle map from the tangent space of the Poisson manifold to itself that enables us to express Hamiltonian vector fields as images of gradients by a vector bundle map. Using this tool, we can formulate adapted differential reproducing properties in RKHS setups and establish an operator framework later in Section 3 for them. Finally, we shall apply the Poisson-Darboux-Lie-Weinstein theorem to provide local coordinate representations of the compatible structure.
We first endow the Poisson manifold with a Riemannian metric and define the vector bundle map by
| (2.11) |
where is the vector bundle map defined in (2.7) and is the vector bundle isomorphism determined by the Riemannian metric . Notice that the vector bundle map may not be an isomorphism due to the possible degeneracy of the Poisson tensor , but nevertheless, the map is always well-defined since we do not need to use the inverse of at any moment. Note that the Poisson tensor and the Riemannian metric are linked by the following relation:
| (2.12) |
We call the compatible structure associated with the Poisson tensor and the Riemannian metric . Using the compatible structure , the Hamiltonian vector field associated with a Hamiltonian function can be expressed as
| (2.13) |
Remark 2.17.
If the Poisson manifold is symplectic with a symplectic form , then , and the relationship (2.12) reduces to
where is, in this case, an isomorphism from to . When the compatible structure defined in (2.12) satisfies , it is called a complex structure, and the corresponding manifold is said to be a Kähler manifold. Even-dimensional Euclidean vector spaces are special cases of Kähler manifolds by choosing as the canonical (Darboux) symplectic matrix , whose Hamiltonian vector field associated with a Hamiltonian function is expressed as .
Using the compatible structure , we obtain a useful property of Casimir functions which will be needed later on in Section 3 to prove the uniqueness of the solution to the learning problem.
Proposition 2.18.
Let be a Poisson manifold equipped with a Riemannian manifold . Then for any vector field and any :
| (2.14) |
Furthermore, Casimir functions are constant along the flow of the vector field , that is, for any vector field and any .
Proof.
By the definition of the compatible structure and the vector bundle map , we have that
where the second and fifth equalities are due to the equation (2.12) and the symmetry of the Riemannian metric , and the third equality holds thanks to the anti-symmetry of the Poisson tensor . Furthermore, let . Then equation (2.14) implies that for all ,
∎
Local coordinate representations. We start by recalling the local Lie-Darboux-Weinstein coordinates of Poisson manifolds (see the original paper [Wein 83] or [Libe 12, Vais 12] for details).
Theorem 2.19 (Lie-Darboux-Weinstein coordinates).
Let be a –dimensional Poisson manifold and a point where the rank of the Poisson structure equals , . There exists a chart of whose domain contains the point and such that the associated local coordinates, denoted by , satisfy
for all , , . For all , , the Poisson bracket is a function of the local coordinates exclusively, and vanishes at . Hence, the restriction of the bracket to the coordinates induces a Poisson structure that is usually referred to as the transverse Poisson structure of at . This structure is unique up to isomorphisms.
If the rank of is constant and equal to on a neighborhood of then, by choosing the domain of the chart contained in , the coordinates satisfy
for all , .
This theorem proves that if the rank of the Poisson structure around a given point is locally constant, then there exist local coordinates in which the Poisson tensor can be represented by a constant matrix as . Hence, the Poisson bracket can be locally expressed as (using the Einstein convention in the summation of the indices)
Furthermore, for any one-form , the vector bundle map can be locally expressed as
| (2.15) |
Note that is the bundle isomorphism with respect to the Riemannian metric . Thus, for any , the bundle isomorphism can be expressed as
| (2.16) |
Therefore, combining equations (2.15) and (2.16), the compatible structure defined in (2.11) has the local representation
which proves that the matrix representation of the bundle map is given by , that is,
| (2.17) |
3 Structure-preserving kernel regressions on Poisson manifolds
This section proposes a structure-preserving kernel regression method to recover Hamiltonian functions on Poisson manifolds, which is a significant generalization of the same learning problem on even-dimensional symplectic vector spaces [Hu 24]. First, in Section 3.1, we establish a differential reproducing property, which not only ensures the existence and boundedness of function gradients in the RKHS but also provides an operator framework to represent the minimizers of our structure-preserving kernel regression problems. In Section 3.3, we present an operator framework to represent the estimator for the structure-preserving regression problem. In Section 3.4, we develop a differential kernel representation of the estimator, providing a closed-form solution that is computationally feasible in applications. The error analysis of this structure-preserving estimator is conducted later in Section 4, where we establish convergence rates with both fixed and adaptive regularization parameters.
3.1 RKHS on Riemannian manifolds
The structure-preserving learning of Hamiltonian systems on symplectic vector spaces has been tackled by proving a differential reproducing property in [Hu 24]. We shall show in this section that this differential reproducing property still holds on a generic Riemannian manifold, and we will give a global version of it, where the term global means that the result that we provide is not formulated in terms of locally defined partial derivatives but of globally defined differentials as in (2.11) that do not depend on specific choices of local coordinates.
We first quickly recall Mercer kernels and the associated reproducing kernel Hilbert spaces (RKHS). A Mercer kernel on a non-empty set is a positive semidefinite symmetric function , where positive semidefinite means that it satisfies
| (3.1) |
for any , , and any . Property (3.1) is equivalent to requiring that the Gram matrices are positive semidefinite for any and any given . We emphasize that the positive semidefiniteness of kernels in non-Euclidean spaces requires care in the sense that the natural non-Euclidean generalization of positive definite kernels in Euclidean spaces (like the Gaussian kernel) may not be positive definite [Fera 15, Da C 23a, Da C 23b, Li 23]. However, as the next proposition shows, it is easy to construct Mercer kernels in any non-Euclidean space.
Proposition 3.1.
[Van 12, page 69] For any real-valued function on an non-empty set , the function is a Mercer kernel on . Moreover, if are Mercer kernels on , so is .
A Mercer kernel is the key element to define a reproducing kernel Hilbert space (RKHS) as follows.
Definition 3.2 (RKHS).
Let be a Mercer kernel on a nonempty set . A Hilbert space of real-valued functions on endowed with the pointwise sum and pointwise scalar multiplication, and with inner product is called a reproducing kernel Hilbert space (RKHS) associated to if the following properties hold:
- (i)
-
For all , we have that the function .
- (ii)
-
For all and for all , the following reproducing property holds
The Moore-Aronszajn Theorem [Aron 50] establishes that given a Mercer kernel on a set , there is a unique Hilbert space of real-valued functions on for which is a reproducing kernel, which allows us to talk about the RKHS associated to . Conversely, an RKHS naturally induces a kernel function that is a Mercer kernel. Therefore, there is a bijection between RKHSs and Mercer kernels.
We now state a differential reproducing property on Riemannian manifolds whose proof can be found in Appendix A.1. The following theorem is a generalization of similar results proved for compact [Nova 18, Zhou 08], bounded [Ferr 12], and unbounded [Hu 24] subsets of Euclidean spaces.
Theorem 3.3 (Differential reproducing property on Riemannian manifolds).
Let be a complete Riemannian manifold. Let be a Mercer kernel such that , for some (see Remark 2.14 for the definition of this space). Then the following statements hold:
- (i)
-
For all , we have that the function for all and .
- (ii)
-
A differential reproducing property holds true for all :
(3.2) - (iii)
-
Denote . The inclusion is well-defined and bounded:
(3.3)
For convenience, we use the following notation in what follows: given , we denote by the function on given by and we call it the kernel section of at . Therefore, can be regarded as a function on such that . For any function , we denote by the function in given by (by the reproducing property). Furthermore, for a Poisson manifold equipped with a Riemannian metric , we shall also denote by the family of Hamiltonian vector fields parametrized by the elements in , that is, given any , is the Hamiltonian vector field of the function . In particular, for any and any vector , is a function on the manifold .
Remark 3.4.
Corollary 3.5.
Let be a Riemannian manifold. Denote by the RKHS associated with the kernel . Then for each vector field and each , we have that
Proof.
By the reproducing property, we have that for each , , for all . Let be the flow of the vector field . Then,
∎
3.2 The structure-preserving learning problem
As we already explained in the introduction, the data that we are given for the learning problem are noisy realizations of the Hamiltonian vector field whose Hamiltonian function we are trying to estimate, that is,
where are IID random variables with values in the Poisson manifold with the same distribution and are independent random variables on the tangent spaces with mean zero and variance (see Remark 2.16). We notice that unlike the Euclidean case studied in [Hu 24] where it was supposed that have the same distribution in , in the present situation, the tangent spaces are different vector spaces even though they are isomorphic and hence, we can not assume that the random variables in different spaces have the same distribution. However, the independence hypothesis and the assumptions on the moments are sufficient for our structure-preserving kernel regression.
Notation. We shall write the random samples as:
where the symbol ‘’ stands for the vectorization of the corresponding matrices. We shall denote by and the realizations of the random variables and , respectively. The collection of realizations is denoted by
In the sequel, if is a function, we then shall denote the value by .
Structure-preserving kernel ridge regression. The strategy behind structure-preservation in the context of kernel regression is that we search the vector field that minimizes a risk functional among those that have the form , where belongs to the RKHS associated with a kernel defined on the Poisson manifold . This approach obviously guarantees that the learned vector field is Hamiltonian. To make the method explicit, we shall be solving the following optimization problem
| (3.4) | ||||
| (3.5) |
where is the Hamiltonian vector field of and is the Tikhonov regularization parameter. We shall refer to the minimizer as the structure-preserving kernel estimator of the Hamiltonian function . The functional is called the regularized empirical risk.
Remark 3.6.
(i) If then the differential reproducing property in Theorem 3.3 implies that the functions in are all differentiable because and hence they always have a Hamiltonian vector field associated. This implies that the regularized empirical risk defined in (3.5) and the associated optimization problem (3.4) is always well-defined in that situation.
(ii) The minimization problem (3.4) might be ill-posed since for any Casimir function and , the function shares the same Hamiltonian vector field as . This could result in the lack of unique solutions for the minimization problem. Later on in Remark 3.14, we show how ridge regularization solves this problem.
Given the probability measure and the Riemannian metric on the manifold , a vector field is said -integrable if the following norm of is finite, that is,
| (3.6) |
Denote by the space consisting of all -integrable vector fields. The measure-theoretic analogue of (3.5) is referred to as regularized statistical risk and is defined by
| (3.7) |
where the norm is defined in (3.6) and are the Hamiltonian vector fields of and , respectively. We denote by the best-in-class functional with the minimal regularized statistical risk, that is,
| (3.8) |
We note that by the strong law of large numbers, the regularized empirical and statistical risks are consistent within the RKHS, that is, for every , we have that
where means taking the conditional expectation for all random variables given all .
3.3 Operator representations of the kernel estimator
In order to find and study the solutions of the inverse learning problems (3.4)-(3.5) and (3.7)-(3.8), we introduce the operators and as
| (3.9) |
where and is the compatible structure defined in (2.11). By Theorem 3.3, if the Mercer kernel , then the functions in are differentiable, and hence the operators and are well-defined. We aim to show that the image of the operator belongs to the space . To achieve this, we must make the following boundedness assumption on the compatible structure .
Assumption 3.7.
The compatible structure defined in (2.11) satisfies
| (3.10) |
where is a positive function on the Poisson manifold bounded above by some constant ().
Using this boundedness condition on the compatible structure , we can obtain the boundedness of the operators and defined in (3.9) as maps from to and from to , respectively. A detailed proof of the following proposition can be found in the Appendix A.2
Proposition 3.8.
Let be a Poisson manifold and let be a Mercer kernel. Suppose that Assumption 3.7 holds. Then, the operator defined in (3.9) is a bounded linear operator that maps into with an operator norm that satisfies , where . The adjoint operator of is given by
As a consequence, the bounded linear operator , defined by
| (3.11) |
is a positive trace class operator that satisfies .
Remark 3.9.
(i) The proof of Proposition 3.8 shows that the boundedness condition of the compatible structure in Assumption 3.7 can be weakened by requiring that the function is positive -integrable with respect to the probability measure . This condition obviously holds if is compactly supported or it is a Gaussian probability measure, which shows this boundedness condition holds for a large class of compatible structures.
(ii) When the Poisson manifold is symplectic and the compatible structure satisfies then it is a complex structure and becomes a Kähler manifold. Even-dimensional vector spaces are special cases of Kähler manifolds by picking as the complex structure the one naturally associated to the canonical (Darboux) symplectic form. In these cases, the boundedness condition (3.10) naturally holds by choosing . This is why this condition never appears in [Hu 24].
We now deal with the empirical version of the operator defined in (3.9). For convenience, we define the inner product on the product space as follows:
| (3.12) |
where for . Furthermore, we denote by the corresponding norm.
Proposition 3.10.
Proof.
3.4 The global solution of the learning problem
We now derive a kernel representation for the solution of the learning problem (3.4)-(3.5). More precisely, we derive a closed-form expression for the estimator of a Hamiltonian function of the data-generating process by defining a generalized differential Gram matrix on manifolds. We shall see that the symmetric and positive semidefinite properties of this generalized differential Gram matrix guarantee the uniqueness of the estimator. The main expression that will be obtained is stated below in Theorem 3.13 and amounts to a differential version of the Representer Theorem for Poisson manifolds and that is how we shall refer to it. In order to derive it, we first define a generalized differential Gram matrix as
| (3.15) |
As it was studied in [Hu 24], in symplectic vector spaces endowed with the canonical symplectic form , the generalized differential Gram matrix defined in (3.15) reduces to the usual differential Gram matrix , where represents the matrix of partial derivatives of with respect to the first and second arguments.
The general differential Gram matrix defined in (3.15) corresponds, roughly speaking, to the operator defined in (3.13) (see also [Hu 24]). In the following proposition that is proved in the appendix, we see that the generalized differential Gram matrix is symmetric and positive semidefinite.
Proposition 3.12.
Theorem 3.13 (Differential Representer Theorem on Poisson manifolds).
Proof.
Denote the space by
By part (i) of Theorem 3.3, is a subspace of . Then by the representation of the operator in the equation (3.13), we know that , that is, is an invariant space for the operator . This implies that, for any , . By Proposition 3.12, the operator is positive semi-definite, we can conclude that the restriction is invertible and since the space is finite-dimensional then it is also an invariant subspace of , that is
Then, there exists a vector such that
| (3.17) |
Then, applying on the left of both sides on the estimator in (3.14) and plugging (3.17) into the identity, we obtain that
| (3.18) |
Therefore, we obtain that
Since the matrix is invertible due to the positive semi-definiteness of that we proved in Proposition 3.12, we can write that
| (3.19) |
This shows that the function in (3.17) with determined by (3.19) coincides with minimizer (3.14) of the regularized empirical risk functional in (3.5). Since by Proposition 3.11, this minimizer is unique, the result follows. ∎
Remark 3.14 (On the uniqueness of the estimated Hamiltonian).
Define the kernel of the operator as follows:
It can be checked that is a closed vector subspace of . Indeed, let be a convergent sequence in such that as , for some . Then, by (A.4) in the proof of Proposition 3.8 and Assumption 3.7, it holds that
which implies that and hence is a closed subspace of . Therefore, can be decomposed as
where denotes the orthogonal complement of with respect to the RKHS inner product . Using this decomposition and the expression of the kernel estimator (3.16), we conclude that
| (3.20) |
which is due to the fact that for any ,
where the second and fourth equalities follow by Proposition 2.18, and the third equality is due to the differential reproducing property (3.2) in Theorem 3.3.
In general, the space could contain Casimir functions in and this could, in principle, cause ill-posedness of the learning problem since adding Casimir functions in to would not change the corresponding Hamiltonian vector field. Therefore, one may wonder why, according to Theorem 3.13, the estimator is unique but not up to Casimir functions. The explanation is in the regularization term. Indeed, let be the minimizer in (3.16) and let . Even though and have the same Hamiltonian vector field associated, it is easy to show that is a minimizer of (3.4) if and only if . This is because of (3.20) and
Local coordinate representation of the kernel estimator. In applications, it is important to have local coordinate expressions for the kernel estimator . Recall that by Theorem 3.13, the kernel estimator is given by
where is given by
Since can be locally represented as (2.17), it suffices to write down the Gram matrix locally. Let be the available data points and let , , be local coordinates on open sets containing the points , for all . Let be the matrix associated to the Riemannian metric in the local coordinates . We first compute the following function for each ,
By the definition of the Gram matrix in (3.15) and combining it with the local representation of in (2.17), we obtain that
which shows that the -component matrix of the general Gram matrix is given by
| (3.21) |
3.5 Symmetries and momentum conservation by kernel estimated Hamiltonians
Studies have been carried out to bridge invariant feature learning with kernel methods [Mrou 15]. In this subsection, we will see that if the unknown Hamiltonian function is invariant under a canonical group action, then the structure-preserving kernel estimator can also be made invariant under the same action by imposing certain symmetry constraints on the kernel . As a result, the fibers of any momentum map associated with that group action that are preserved by the flow of the ground-truth Hamiltonian will also be preserved by the flow of the estimator .
Definition 3.15.
Left be a group acting on the manifold . A function on the Poisson manifold is called -invariant if
A kernel is called argumentwise invariant by the group action if
Argumentwise invariant kernels can be constructed by double averaging (using the Haar measure if the group is compact) or, alternatively, if is an arbitrary Mercer kernel and is a -invariant function. Then the function defined as is an argumentwise invariant kernel.
Proposition 3.16 (Noether’s Theorem for the structure-preserving kernel estimator).
Let be a Lie group acting canonically on the Poisson manifold . If the Mercer kernel is argumentwise invariant under the group then the kernel estimator in Theorem 3.13 is -invariant. If additionally, the group action has a momentum map associated, then its fibers are preserved by the flow of the corresponding Hamiltonian vector field , that is,
Proof.
By [Gins 12, Property 3.13], if the kernel is argumentwise invariant under -action, then the corresponding RKHS consists exclusively of -invariant functions. This implies that the kernel estimator is -invariant since . The statement on the momentum conservation is a straightforward consequence of Noether’s Theorem (see, for instance, [Mars 99, Theorem 11.4.1]). ∎
4 Estimation and approximation error analysis
We now analyze the extent to which the structure-preserving kernel estimator can recover the unknown Hamiltonian on a Poisson manifold . A standard approach is to decompose the reconstruction error into the sum of what we shall call estimation and approximation errors, and further decompose the estimation error into what we shall call sampling error and noisy sampling error. More specifically,
| (4.1) | ||||
where is the best-in-class function introduced in (3.8) that minimizes the regularized statistical risk (3.7) and is the noise-free part of the estimator . Indeed, the noisy sampling error can be computed as
where the noise vector is
which, by hypothesis, follows a multivariate distribution with zero mean and variance .
Following the approach introduced in [Feng 23, Hu 24], we shall separately analyze these three errors. The estimation of the total error relies on both the operator representations in Section 3.3 and the differential kernel representations in Section 3.4 of the estimator. Since the operator representations of the estimator are similar to those in the Euclidean case, the approximation error and sampling error can be analyzed following an approach very close to the one in [Hu 24]. Therefore, to obtain the total error in (4.1), it is sufficient to analyze the noisy sampling error. As in the previous sections, we assume that is a Mercer kernel. The proofs of the following results can be found in the appendix.
Lemma 4.1.
Let be a Mercer kernel. For any function and , with probability at least , there holds
Lemma 4.2 (Error bounds of noisy sampling error).
Assumption 4.3 (Source condition).
Assume that the unknown Hamiltonian function in the Poisson system (2.6) lies in so-called source space, that is,
| (4.2) |
for some and .
Proposition 4.4.
If a Hamiltonian function satisfies the source condition (4.2), then . In other words, .
Proof.
Recall first that by Proposition 3.8, the operator is a positive compact operator. Let (possibly ) be the spectral decomposition of with and be an orthonormal basis of . Hence for any , we have , which implies that is adjoint. Notice that by the representation of the operator given in (3.11), for an arbitrary Casimir function (if it is not an empty set), we have that , which implies that for all . Hence for any , we have for all . Then we obtain that . Finally for arbitrary , we compute the inner product , which yields that for any . Therefore, we conclude that . ∎
Proposition 4.5.
Let (possibly ) be a spectral decomposition of , with an orthonormal basis with for all . Then, has the following characterization
Proof.
First, we show that . For an arbitrary , we can define a function such that for all . One computes
Furthermore, since , we have that
which yields that . Now, we show that . For an arbitrary , there exists a function with norm , such that . Let be the projection of onto , then . Hence, we obtain that
which implies that for all since . Therefore,
Combing Proposition 4.4, we have that . Therefore, we can conclude that . ∎
In Section 3.4, we showed that the kernel estimator . In this section, we will prove that for an arbitrary Hamiltonian function in the source space , the kernel estimator converges to the Hamiltonian as tends to infinity.
Notice that the results in Lemma 4.2 are very similar to the error bounds of the noisy sampling error in [Hu 24]. Hence, combining the approximation error and the noisy sampling error bounds obtained in [Hu 24], we immediately formulate probably approximately correct (PAC) bounds for the reconstruction error in which the regularization constant remains fixed and the size of the estimation sample is allowed to vary independently from it.
Theorem 4.6 (PAC bounds of the total reconstruction error).
Notice that by Theorem 4.6, we can make the total reconstruction error arbitrarily small with the probability close to one with a fixed regularization parameter. However, this theorem provides no convergence rates. Similar to the approach followed in [Hu 24], we now consider an adaptive regularization parameter to obtain convergence rates. To this end, we shall assume that
| (4.3) |
where the symbol means that has the order as . Then, combining Lemma 4.2 with [Hu 24, Theorem 4.7], we obtain convergence rates for the total reconstruction error when . If we further suppose that the coercivity condition in the following definition holds, we can then improve the convergence integral to .
Definition 4.7 (Coercivity condition).
Theorem 4.8 (Convergence upper rates for the total reconstruction error).
Let be the unique minimizer of the optimization problem (3.4). Suppose that satisfies (4.3) and that satisfies the source condition (4.2), that is, . Then for all , and for any , with probability as least , it holds that
where
Moreover, if the coercivity condition (4.4) holds, then for all , and for any , and with probability as least , it holds that
where
Theorem 4.8 guarantees that the structure-preserving kernel estimator provides a function that is close to the data-generating Hamiltonian function with respect to the RKHS norm. As a consequence, we now prove that the flow of the learned Hamiltonian system will uniformly approximate that of the data-generating one.
In the following lemma and proposition, we take the Sasaki metric on the tangent buddle induced by the Riemannian metric on the Poisson manifold . To define Sasaki metric on , let and be tangent vectors to at . Choose curves in
with , and , . Then the Sasaki metric is defined as
| (4.5) |
where is the canonical projection, stands for the covariant derivative. As stated in Remark 2.14, we shall assume that this Sasaki metric (4.5) is complete. Then we obtain the following lemma.
Lemma 4.9.
Let . Then for any and , we have
where is the geodesic distance on the Riemannian manifold .
Proof.
Since , we have that . Then by the Fundamental Theorem of Calculus (2.10), we obtain that
where is a differentiable curve connecting and in the Riemannian manifold with Sasaki metric induced by the Riemannian metric on . Denote with and for all . For each , let be a smooth curve such that and . Denote with and for all . Notice that
Then, by the definition of the Sasaki metric in (4.5), we obtain
Let and for . Choose the be the geodesic curve in . Let be a curve which is parallel along the curve , i.e., for all . Then we obtain that . Therefore,
where is the geodesic distance on the Riemannian manifold . The result follows. ∎
Proposition 4.10 (From discrete data to continuous-time flows).
Let be the structure-preserving kernel estimator of using a kernel . Let and be the flows over the time interval of the Hamilton equations associated to the Hamiltonian functions and , respectively. Suppose that the geodesic distance of the Poisson manifold is in for each and that the norm of the family is uniformly bounded, that is, . Then, for any initial condition , we have that
with the constant , where is the constant introduced in Assumption 3.7.
Proof.
Let . For each and , we have
By the equation (A.4), we have that for any ,
Since , Theorem 3.3 implies that . Then by Lemma 4.9, for any ,
Furthermore, for each , we can choose such that the point is in the geodesic curve connecting and . Now, by hypothesis, . Therefore, we obtain that
Then by the integral form of Grönwall’s inequality, for , we obtain
Therefore, we obtain
where . The result follows. ∎
5 Test examples and numerical experiments
This section spells out the global structure-preserving kernel estimator and illustrates its performance on two important instances of Poisson systems, namely, Hamiltonian systems on non-Euclidean symplectic manifolds and Lie-Poisson systems on the dual of a Lie algebra. More precisely, we shall derive explicit expressions for the global estimator in (3.16) in these two scenarios.
5.1 Learning of Lie-Poisson systems
The Lie-Poisson systems introduced in Example 2.3 are very important examples of Poisson systems. In this subsection, we shall make explicit the estimator in this case. Let be a Lie algebra and be its dual equipped with the Lie-Poisson bracket defined in (2.2). A straightforward computation shows that the Lie-Poisson dynamical system associated with a Hamiltonian function is
| (5.1) |
where is the functional derivative introduced in (2.3). Since and are vector spaces, natural Riemannian metrics can be obtained out of a non-degenerate inner product on . The non-degeneracy of allows us to define musical isomorphisms and by , , and , as well as a natural non-degenerate inner product on given by , . Notice that
| (5.2) |
Using these relations and (2.3), we note that
| (5.3) |
Consequently,
| (5.4) |
We now compute the compatible structure defined in (2.12) associated with the Lie-Poisson systems (5.1). Note first that, for any and , by (5.1) and (5.4), we have that
As this can be done for any Hamiltonian function and their gradients span , this yields
| (5.5) |
To compute the estimator to one first evaluates explicitly using (5.5), we then set
and substitute it into (3.16). More explicitly, note that the generalized differential Gram matrix defined in (3.15) reduces in this case to
for all . Therefore, the estimator in Theorem 3.13 turns to
| (5.6) |
In what follows, we demonstrate the effectiveness of this learning scheme using two examples. The first one is the three-dimensional classical rigid body, which models the motion of solid bodies without deformation. The second example is the dynamics of the underwater vehicle, which has a nine-dimensional underlying phase space. We emphasize that the state spaces of Lie-Poisson systems are duals of Lie algebras and, hence, are isomorphic to Euclidean spaces; in such a framework, the Gaussian kernel is a natural choice of universal kernels. As such, even when does not belong to , we can hope for learning a proxy function in that is close to a ground-truth Hamiltonian .
We will see in these two examples that can only recover the ground-truth Hamiltonian function up to a Casimir function. We emphasize that the estimator is always unique, and the possible difference by a Casimir function is present because , while the ground-truth may not belong to , and hence the difference between and could converge not to zero, but to a Casimir function. An analytic reason for this is that the Hamiltonian functions that we shall be using for data generation are quadratic and violate the source condition (4.2) (see Example 2.9 in [Hu 24] for a characterization of the RKHS of the Gaussian kernel). To better illustrate this point, we provide a third example in which the Hamiltonian satisfies the source condition (4.2) for sufficiently large ( is the constant introduced in (4.2); see also Proposition 4.5). In that case, according to Theorem 4.8, converges to in the norm, and the difference converges to as . We will see that, numerically, accurately recovers the ground-truth Hamiltonian.
5.1.1 The rigid body
Rigid body motion has been introduced in Example 2.5. Using (5.5), the compatible structure associated with the Euclidean metric in can be written in this case as
Numerical results We pick and consider the standard Gaussian kernel with parameter on . In order to generate the data, we set and sample states from the uniform distribution on the cube . We then obtain the Hamiltonian vector fields at these states that, this time, we do not perturb with noise (). In view of (4.3), we set the regularization parameter with . We then perform a grid search for the parameters and using -fold cross-validation, which results in the optimal parameters and . Given that is -dimensional, we fix the third dimension, that is, , and visualize both the ground-truth Hamiltonian functions and the reconstructed Hamiltonian functions in the dimensions , see Figure 5.1 (a) and (b). The ground-truth Hamiltonian is quadratic and violates the source condition (4.2), so and could differ by a Casimir function.
From Example 2.5, all possible Casimir functions are of the form for some function . We try to compensate for the difference via a simple Casimir of the form , for some constant . After trial and error, we select and visualize the “Casimir-corrected” estimator, that is , see Figure 5.1 (c). We also visualize the mean-square error of the predicted Hamiltonian vector fields in a heatmap, see Figure 5.1 (d).
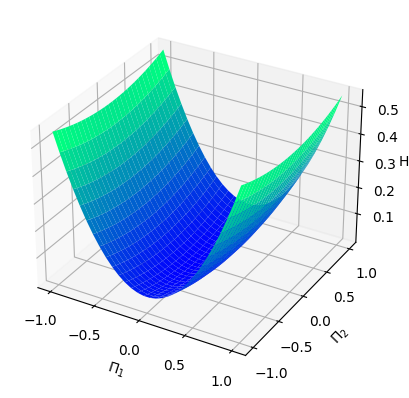
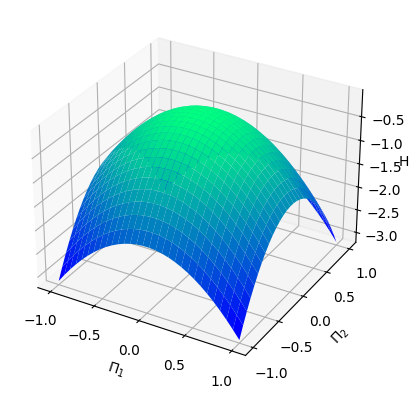
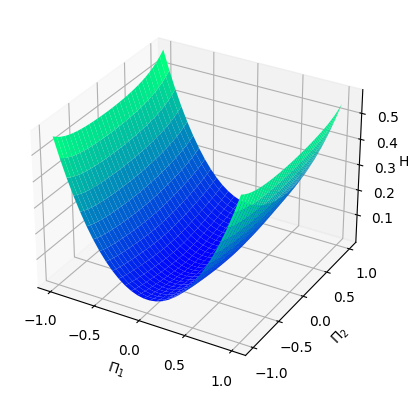
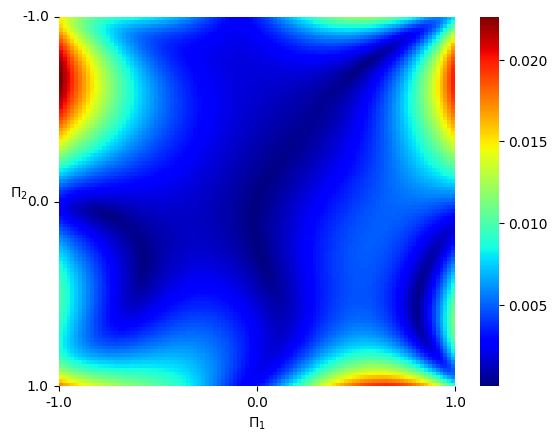
Analysis In this setting, the Hamiltonian function is a quadratic function, which, according to Example 2.9 in [Hu 24], does not belong to . In particular, the source condition (4.2) cannot be satisfied. Therefore, even though the Gaussian kernel is universal, the proxy function in , which approximates the ground-truth Hamiltonian , can only be learned at best up to a Casimir function. That is why we choose to manually correct the estimator by adding a Casimir function. From the numerical results, we see that without the “Casimir correction”, and can be very different, despite the fact that the Hamiltonian vector fields are very well replicated.
5.1.2 Underwater vehicle dynamics
The Lie-Poisson underwater vehicle dynamics has been introduced in Example 2.6. Using also a Euclidean metric, (5.5), the compatible structure is
Numerical results We pick , , , and . We consider the standard Gaussian kernel with parameter on . We set and sample states from the uniform distribution on the cube , and then obtain the Hamiltonian vector fields at these states. We set the regularization parameter with . We then perform a grid search of the parameters and using -fold cross-validation, which results in the optimal parameter and . Given that is -dimensional, we fix the 3rd to 9th dimensions, that is, , , and visualize both the ground-truth Hamiltonian functions and the reconstructed Hamiltonian functions in the dimensions , see Figure 5.2 (a) and (b). The ground-truth Hamiltonian does not satisfy the source condition (4.2), so and generically differ by a Casimir function. We also visualize the mean-square error of the predicted Hamiltonian vector fields with a heatmap, see Figure 5.2 (c).
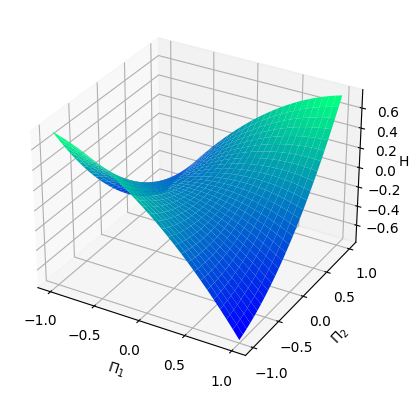
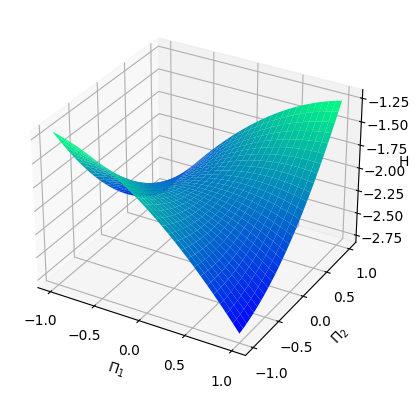
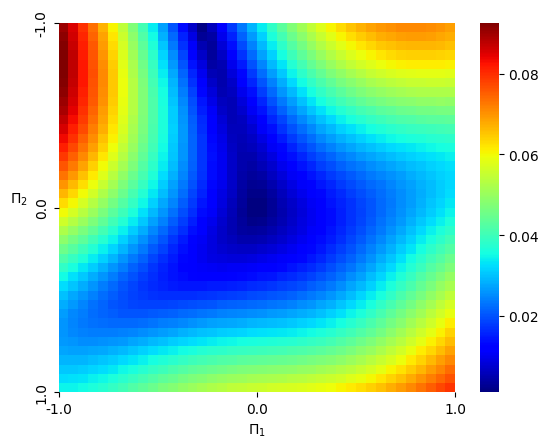
Analysis In this setting, the Hamiltonian function is a quadratic function, which, according to Example 2.9 in [Hu 24], does not belong to . In particular, the source condition (4.2) cannot be satisfied. Therefore, even though the Gaussian kernel is universal, the proxy function in , which approximates the ground-truth Hamiltonian , can only be learned at best up to a Casimir function. From Example 2.6, all possible Casimir functions are of the form for some function . To determine such a function , one might consider running a polynomial regression to approximate . From the -axis, we see that, although the shapes of the Hamiltonian look alike, the exact Hamiltonian value still differs significantly by a constant, which is a trivial Casimir function. On the other hand, we notice that the Hamiltonian vector fields are very well replicated.
5.1.3 Exact recovery of Hamiltonians in the RKHS
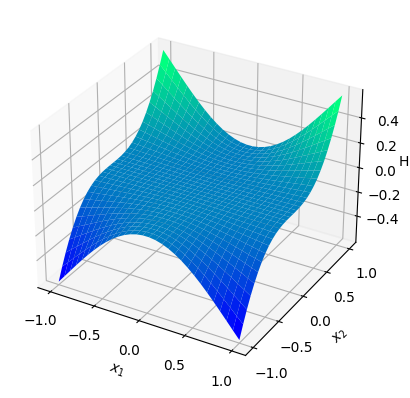
In the rigid body and the underwater vehicle examples, we saw that even though the Hamiltonian vector field can be learned very well, the data-generating Hamiltonian function can only be estimated up to a Casimir function due to the violation of the source condition. We now aim to manually pick a ground-truth Hamiltonian that satisfies the source condition and reconstruct the Hamiltonian function accurately from the data. To find such a Hamiltonian, we use [Minh 10], which provides an orthonormal basis of the RKHS of the Gaussian kernel. It turns out that exactly one of the basis functions is a Casimir and any other basis function belongs to according to Example 2.5. Moreover, by Proposition 4.5, the basis functions, except the Casimir basis element, satisfies the source condition for sufficiently large . In view of the above, we consider the standard Gaussian kernel on with fixed parameter and choose the Hamiltonian function as
| (5.7) |
The Lie-Poisson structure is the same as the one we used for the rigid body, with the only difference in the experiment being the Hamiltonian function.
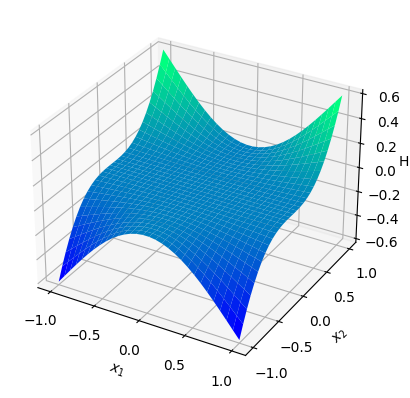
Numerical results To guarantee the matching of the RKHS, we consider the standard Gaussian kernel with the fixed parameter (the same as the ground-truth) on . We set and sample states from the uniform distribution on the cube , and then obtain the Hamiltonian vector fields at these states. In view of (4.3), we set the regularization parameter with . We then perform a grid search of the parameter using -fold cross-validation, which results in the optimal parameter . Given that is -dimensional, we fix the third dimension, that is, , and visualize both the ground-truth Hamiltonian functions and the reconstructed Hamiltonian functions in the dimensions , see Figure 5.3 (a) and (b).
Analysis In this setting, the Hamiltonian function is chosen to satisfy the source condition (4.2). In this case, both the ground-truth Hamiltonian and the estimator belong to . The possibility of the presence of Casimir functions is eliminated, and hence by Theorem 4.8, converges to in the RKHS norm. As shown in Figure 5.3 (c), the Hamiltonian function can replicated even without “Casimir correction”, in contrast with the rigid body example.
5.2 Learning on non-Euclidean symplectic manifolds
As mentioned in Example 2.2, any symplectic manifold is a Poisson manifold. Let be a symplectic manifold with a symplectic form . Then the Hamiltonian vector field associated with Hamiltonian function defined in (2.5) is
where is the bundle isomorphism induced by the symplectic form and given by
| (5.8) |
with the bundle isomorphism induced by the Riemannian metric . Unlike in the more general Poisson setting, is a bundle isomorphism in the symplectic setup. We aim to learn the Hamiltonian function out of the equation
| (5.9) |
Following Theorem 3.13, the kernel estimator in (3.16) is
where is given by
In applications, it is important to compute the kernel estimator in pre-determined local patches that cover the manifold . By the local representations (2.17) and (3.21), the compatible structure and the generalized Gram matrix of the Hamiltonian system (5.9) are
In what follows, we demonstrate the effectiveness of this learning scheme on two examples that share the same symplectic manifold with the same symplectic form and the same Riemannian metric , while governed by two different Hamiltonian functions . The first Hamiltonian function is the restricted Euclidean 3-norm to the manifold , and the second one describes the two-vortex dynamics. We will see that the first Hamiltonian is “well-behaved” and the second Hamiltonian exhibits singularities.
We emphasize that, technically, there are three challenges in relation to learning these systems. First, it is difficult to verify that a given Hamiltonian function belongs to the RKHS of a pre-determined kernel on the manifold due to the lack of results in the literature on the characterization of functions in this type of RKHS on manifolds. Second, in case the Hamiltonian function does not lie in the RKHS of the selected kernel , it is important to investigate the universality properties of kernels on manifolds to hope for at least a good approximation. Third, the Hamiltonian function of the two-vortex system exhibits singularities, which pose even more difficulties to recover from , since the vector field diverges at singularities. We will see that even in this example, still recovers the qualitative behaviors of the Hamiltonian function.
5.2.1 Metric, symplectic, and compatible structures in
Let , the product of copies of unit -spheres in . The phase space for the -vortex problem is , where is the diagonal, that is,
The symplectic structure on is given by
| (5.10) |
where is the Cartesian projection on to the -th factor, the natural symplectic form on , and the vorticity of the th vortex. The Poisson structure is given by
where is the triple product of for .
Local coordinates. We first consider the local structure of the unit sphere as a Riemannian manifold. We parametrize the unit sphere in terms of two angles, that is, (the colatitude) and (the longitude), and use two patches and to cover the whole sphere . The first patch is given by
which implies that the semicircle from the north pole to the south pole lying in the -plane is not covered by this chart. In order to cover the whole sphere, we need another chart obtained by deleting the semicircle in the -plane from to and with . In view that the patch is already topologically dense in , we omit the explicit parameterization of for convenience and focus on the first patch.
The unit sphere admits a natural symplectic form given by its area form that is locally expressed by and a Riemannian metric inherited from the ambient Euclidean metric in . The corresponding matrix forms in the coordinate patch can be expressed by
These structures induce local symplectic and Riemannian metrics on the patch (that is, two copies of ) of the product manifold given by
where . The matrix form of the product metric is
hence, the compatible structure of -vortex system is
5.2.2 A universal kernel and data sampling on
Universal kernel. Consider the RKHS defined on a Hausdorff topological space . Let be an arbitrary but fixed compact subset of and denote by the completion in the RKHS norm of the span of kernel sections determined by the elements of . We write this as:
| (5.11) |
Denote now by the uniform closure of . A kernel is called universal if for any compact subset , we have that , with the set of real-valued continuous functions on . Equivalently, this implies that for any , and any function , there exists a function , such that . Many kernels that are used in practice are indeed universal [Micc 06, Stei 01], e.g., the Gaussian kernel on Euclidean space. For non-Euclidean spaces there is still a lack of literature in this field. The universality of kernels is a crucial feature in recovering unknown functions using the corresponding RKHS. In our learning approach, we shall consider the kernel on defined by
| (5.12) |
where is a constant and is the injection map. We emphasize that since is continuous and injective, by [Chri 10, Theorem 2.2], the kernel in (5.12) is universal for all on .
Sampling method. Note that the total surface of the unit sphere is
The cumulative distribution function can be computed as such that
which factorizes into the product of the margins
One can hence obtain a uniform distribution on by sampling uniformly on the interval , and compute
This extends to a uniform distribution on the product space , which we adopt to generate training data.
5.2.3 Exact recovery of Hamiltonians using a universal kernel
In our first example, we consider as Hamiltonian function on the Euclidean 3-norm on .
Formulation We choose the globally defined Hamiltonian function
where is the usual 3-norm on defined as . In local coordinates, we focus on the patch and so that the Hamiltonian become
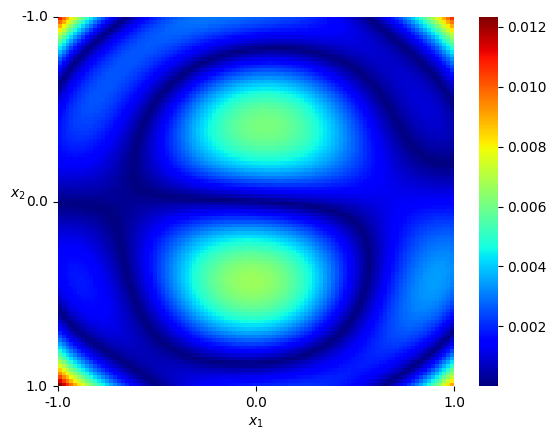
We shall call any Hamiltonian function constructed in this way a spherical 3-norm because the domain is on the products of spheres. The restricted Gaussian kernel as in (5.12) will be adopted for learning, also focused on the patch on .
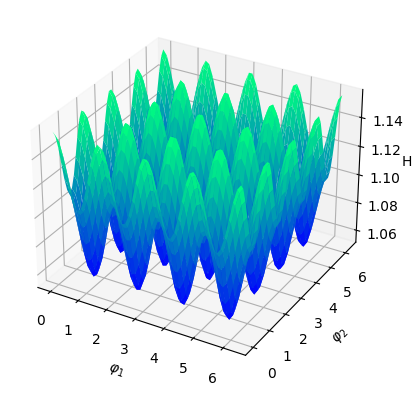
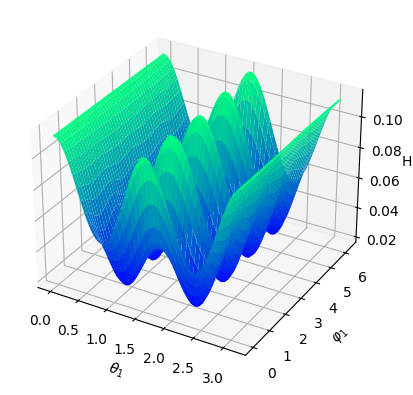
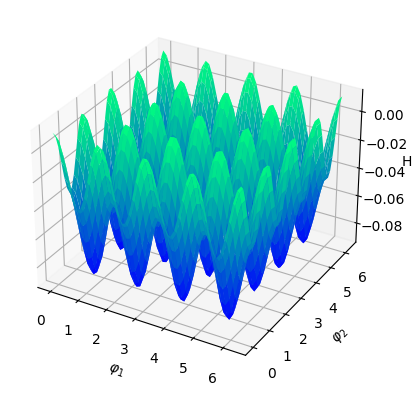
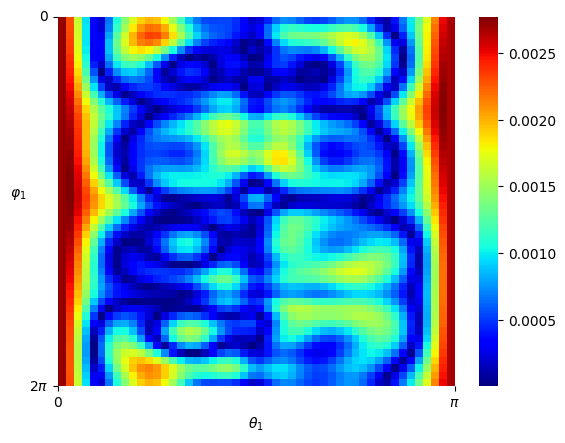
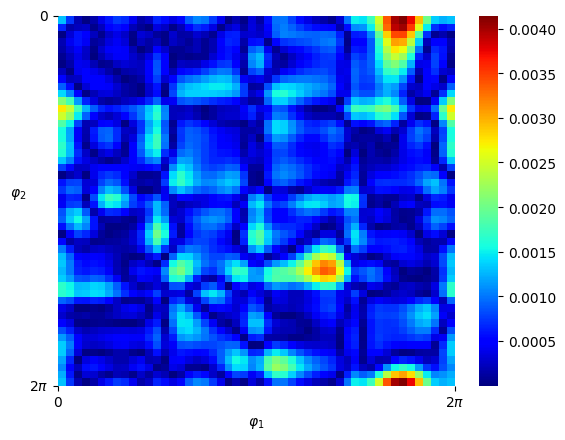
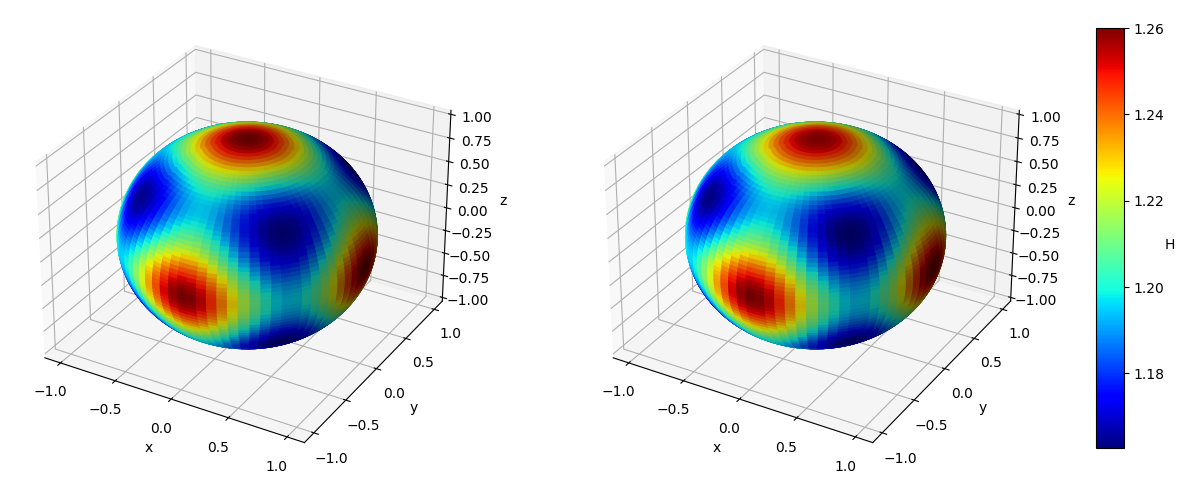
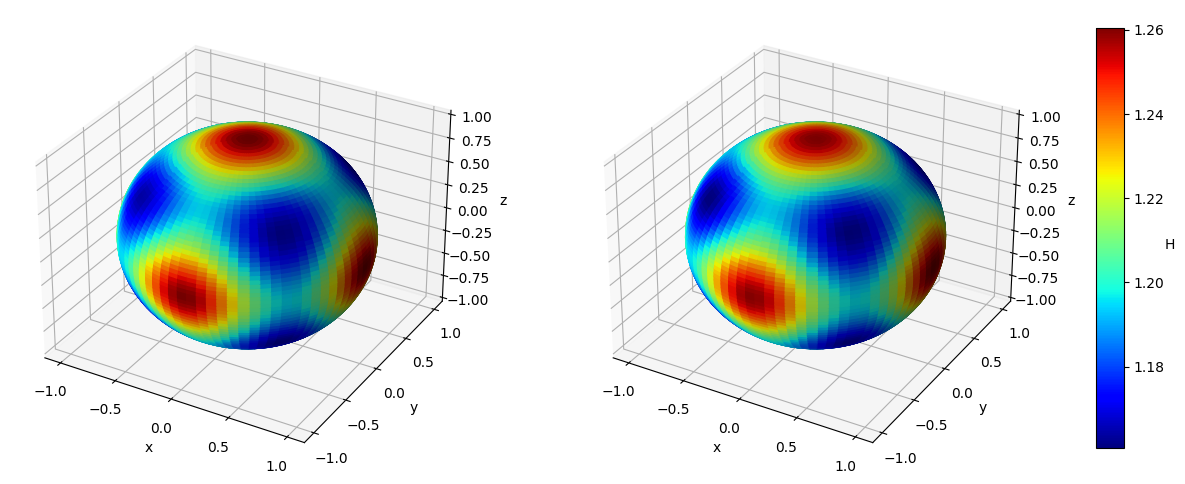
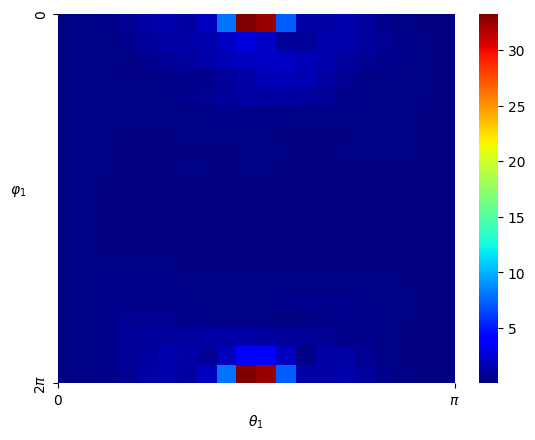
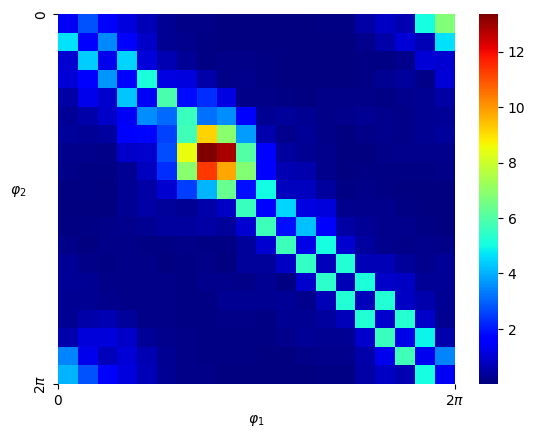
Numerical results We set and sample states from the uniform distribution on , and then obtain the Hamiltonian vector fields at these states. In view of (4.3), we set the regularization parameter with . We perform hyperparameter tunning and selected parameter and . Given that is -dimensional, we fix two of the dimensions, that is, , , and visualize both the ground-truth Hamiltonian functions and the reconstructed Hamiltonian functions in the remaining dimensions, see Figure 5.4 (a)(b) and (c)(d). We also visualize the absolute error of the predicted Hamiltonian function in a heatmap, after a vertical shift to offset any potential constant, see Figure 5.4 (e)(f). We also picture the Hamiltonian function globally on the first sphere and the second sphere respectively as heatmaps, while fixing and respectively on the other sphere, see Figure 5.5. Lastly, we picture the absolute error of the learned Hamiltonian in the setting of only one sphere and increased to 2000, see Figure 5.6, which demonstrates the enhanced quantitative performance of the algorithm as the number of data becomes large.
5.2.4 Recovery of two-vortex dynamics
The Hamiltonian function of the two-vortex dynamics is
| (5.13) |
for , and the Hamiltonian vector field is given by
Moreover, in local coordinate, the Hamiltonian can be written as
and, as we have seen in (2.13), the Hamiltonian vector field can be locally written as
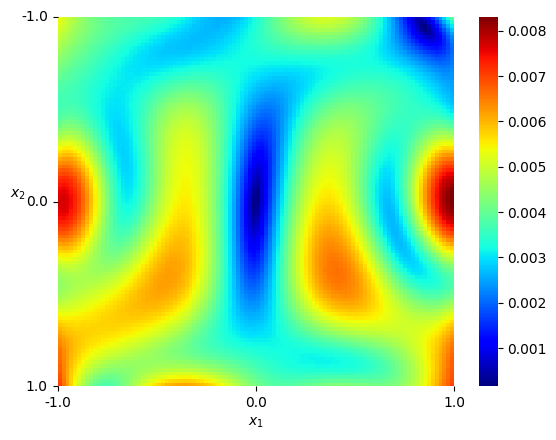
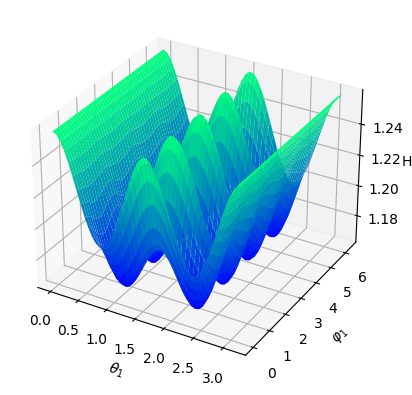
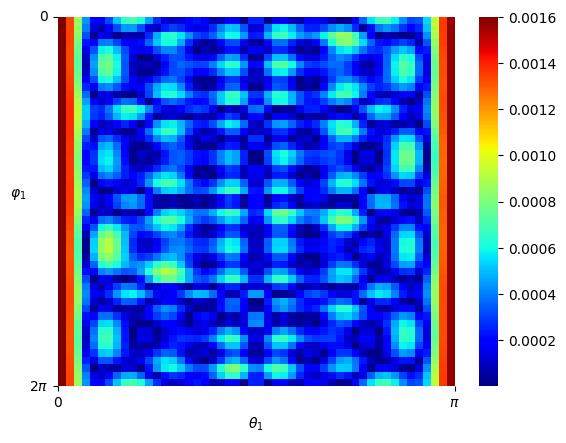
Numerical results For the numerical experiment, since the patch is topologically dense in the space , we shall assume that all the training data will fall into this patch for computational convenience. We consider the standard Gaussian kernel with parameter on but restricted to . Since the Gaussian kernel is positive-definite on the entire , it is also positive-definite when restricted to the manifold , and hence constitutes a valid choice of a kernel on . We set and sample states from the uniform distribution on as elaborated above, and then obtain the Hamiltonian vector fields at these states. In view of (4.3), we set the regularization parameter with . We performed hyperparameter tunning and set and . Given that is -dimensional, we shall respectively fix two of the dimensions, that is, , and , and respectively visualize the mean-square error of the predicted Hamiltonian vector fields in a heatmap, see Figure 5.7 (a)(b)(c). In the end, we picture the Hamiltonian function globally on the first sphere as a heatmap, while fixing on the second sphere, see Figure 5.8.
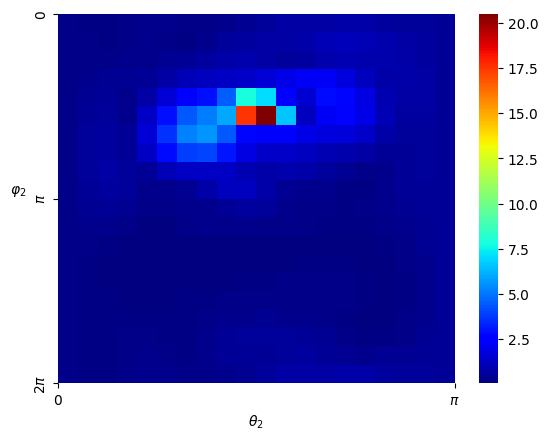
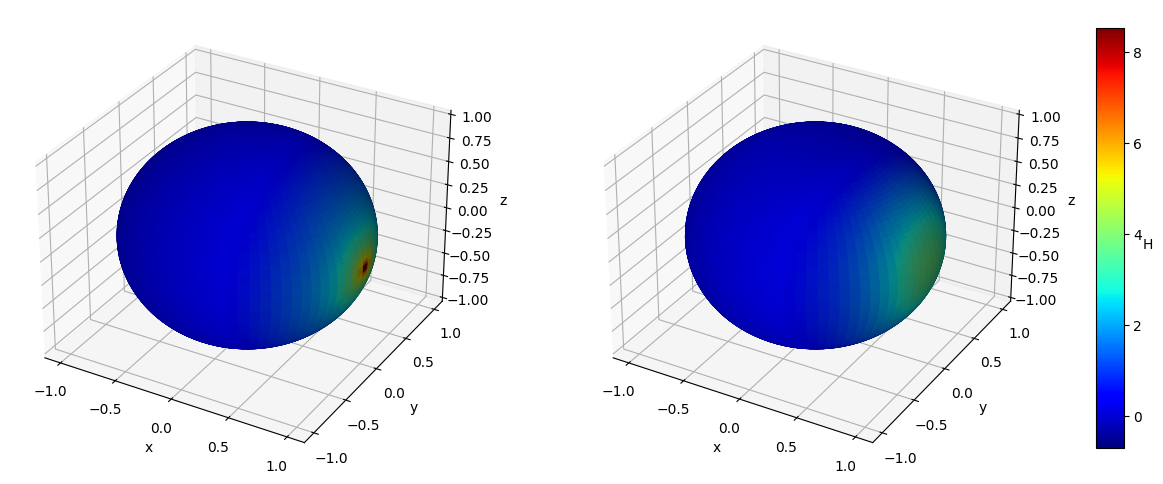
Analysis It can be seen that the estimator fully captures the qualitative behavior of the ground-truth Hamiltonian . Since exhibits singularities, by Theorem 3.2 (iii), cannot be in . In this scenario, even though the restricted Gaussian kernel to the manifold is universal, it only guarantees good approximation properties within the category of continuous functions, and not for functions with singularities.
6 Conclusion
This paper proposes a novel kernel-based machine learning method that offers a closed-form solution to the inverse problem of recovering a globally defined and potentially high-dimensional and nonlinear Hamiltonian function on Poisson manifolds. The method uses noisy observations of Hamiltonian vector fields on the phase space as data input. The approach is formulated as a kernel ridge regression problem, where the optimal candidate is sought within a reproducing kernel Hilbert space (RKHS) on the manifold, minimizing the discrepancy between the observed and candidate Hamiltonian vector fields (measured with respect to a chosen Riemannian metric) and an RKHS-based regularization term. Despite the complexities associated with optimization on a manifold, the problem remains convex, leading to an explicit solution derived by leveraging a “differential” version of the reproducing property on the manifold and considering the variations of the loss function.
The kernel method exhibits various key advantages. First, as we demonstrated in Section 3.1, the differential reproducing property allows the kernel ridge regression framework to naturally incorporate the differential equation constraints necessary for structure preservation, even on manifolds. Second, the method provides a closed-form solution, eliminating the computational burdens typically associated with iterative, gradient-based optimization. Additionally, the strict convexity of the Tikhonov-regularized kernel regression ensures a unique solution, addressing the ill-posedness that is inherent in recovering the Hamiltonian function in the presence of Poisson degeneracy due to the potential presence of Casimir functions. Finally, we introduced an operator-theoretic framework and a kernel estimator representation that enables a rigorous analysis of estimation and approximation errors. Additionally, when the target function exhibits a symmetry that is a priori known, as it is common in mechanical systems, an appropriate kernel can be selected to satisfy the symmetry constraints, further enhancing the method’s versatility, applicability, and structure-preservation features.
This paper tackles just one aspect of the broader class of structure-preserving inverse problems, focusing on extending prior approaches from Euclidean spaces to non-Euclidean manifolds. A significant challenge still lies in addressing systems defined in infinite-dimensional spaces, such as the space of measures. A notable example is the Schrödinger equation, which can be interpreted as a transport equation for measures under the Hamiltonian flow. Interestingly, this transport equation can also be viewed as a Hamiltonian flow within the Wasserstein space, referred to as the Wasserstein Hamiltonian flow. Extending the kernel-based framework to identify the potential function in the Schrödinger equation, thereby accommodating infinite-dimensional underlying spaces, is the focus of the authors’ research agenda.
The methodology in this paper assumes that Hamiltonian vector field data is directly available, which is a reasonable assumption when the observed data has a measurable physical interpretation, such as acceleration or force. However, in more realistic scenarios, the collected data might consist of discrete-time trajectories rather than continuous vector field observations. In this context, using variational integrators and other manifold-preserving techniques becomes crucial, yet these methods have not been fully explored in the existing literature in connection with this problem. Addressing this gap could open new avenues for applying structure-preserving kernel methods to a broader range of real-world problems.
As a final remark, a great wealth of knowledge has been accumulated on the qualitative behavior of Hamiltonian dynamical systems based on their geometry [Abra 78], symmetries [Mars 74, Orte 04], stability properties [Orte 05], or persistence [Mont 97b, Mont 97a, Orte 97] and bifurcation phenomena [Chos 02, Chos 03]. All these concepts surely have an interplay in relation to learnability that needs to be explored.
Symplectic vector space Symplectic manifold Poisson manifold Space Hamiltonian vector field Compatible structure Differential Gram matrix Estimator
Appendix A Appendices
A.1 The proof of Theorem 3.3
We prove (i) and (ii) simultaneously by induction on . The case is trivial since that means for any , satisfies the standard reproducing property in . Let now . Suppose that and (3.2) holds for any and . Then (3.2) implies that for any , , , , and ,
| (A.1) |
Denote and with with and .
Now, we turn to the case . In the following proof, let be a differentiable curve with and . Since with Riemannian metric is complete (see Remark 2.14), by Hopf-Rinow theorem, we can always choose to be geodesics with constant speed 1. We prove that (i) and (ii) hold for in three steps.
Step 1: Proving for all and . Equations (2.10) and (A.1) imply that the set of functions in satisfies
where is induced by the Riemannian metric on and we have used the assumption that . This means that lies in a closed ball of the Hilbert space with a finite radius. Since this ball is sequentially weakly compact (see [Conw 07, Theorem 4.2]), there is a sequence with and such that converges weakly to an element of as . The weak convergence tells us that
| (A.2) |
In particular, by taking with , it holds that
This is true for an arbitrary point . Hence as functions on . Since , we know .
Step 2: Proving the convergence
| (A.3) |
Using the notation introduced above, . Then equation (A.2) yields
By equation (2.10), we obtain that
where is chosen as a geodesic with constant speed 1, together with and , the second and fourth qualities are due to the formula (2.10), and the last two inequalities thank to and . As , (A.3) follows.
Step 3: Proving (3.2). Let . By (A.3) we have
That is, exists and equals . This verifies (3.2) for . Hence, the parts (i) and (ii) follow.
We conclude by proving part (iii) using (3.2) and (A.1). For , and , the Cauchy-Schwarz inequality implies that,
and for all , and ,
Therefore, and . Denote . It follows that
A.2 The proof of Proposition 3.8
Since , Theorem 3.3 yields that for any and ,
which implies that . Then by Assumption 3.7 and equation (2.13), we have that
| (A.4) |
Thus, the operator is bounded linear from to since
Furthermore, for any vector field , Corollary 3.5 and Proposition 2.18 imply that
where is the flow of the vector field and Remark 3.4(i) shows that . This leads to
Note that hence, for each ,
We now show that is a trace class operator; that is, we show that , where . The form of the operator automatically guarantees that it is positive semidefinite, and hence we have that . Therefore, it is equivalent to show that . To do that, we choose a countable spanning orthonormal set for whose existence is guaranteed by the continuity of the canonical feature map associated to that we established in [Hu 24, Lemma A.3] and [Owha 17, Theorem 2.4]. Then,
where the sixth inequality is derived by choosing an arbitrary orthonormal basis of the vector space as follows.
A.3 The proof of Proposition 3.12
Firstly, we prove the symmetry of . It is sufficient to show that for arbitrary. Denote . Then by Remark 3.4(i), we obtain that for any ,
Therefore, again by Remark 3.4(i), we have that
Since is a symmetric function, is also symmetric by definition. This proves that is symmetric.
We now show the positive semi-definiteness of . Let . Since is real symmetric, there exists an orthonormal matrix that diagonalizes , that is
where and are the real eigenvalues and the corresponding eigenvectors of , respectively. We now define . By Remark 3.4(i), we obtain that and that
Hence, for all and we can conclude that is positive semi-definite.
A.4 The proof of Lemma 4.1
A.5 The proof of Lemma 4.2
Proof.
We first notice that, by the symmetry of , for any , it holds that
| (A.5) |
Following an approach similar to the one in Theorem 3.13, we obtain that
where is defined in (3.15) and is a matrix in defined by
Indeed, in light of (A.5), the above definition can be verified since
Choose a basis of the vector space consisting of orthonormal eigenvectors of . Note that are also eigenvectors of . Then,
with as introduced in the statement of Proposition 3.3. The rest of the proof follows from the same argument as in [Hu 24, Appendix C]. ∎
Acknowledgments
The authors thank Lyudmila Grigoryeva for helpful discussions and remarks and acknowledge partial financial support from the School of Physical and Mathematical Sciences of the Nanyang Technological University. DY is funded by a Nanyang President’s Graduate Scholarship of Nanyang Technological University.
References
- [Abra 78] R. Abraham and J. E. Marsden. Foundations of Mechanics. Addison-Wesley, Reading, MA, 2nd Ed., 1978.
- [Aron 50] N. Aronszajn. “Theory of reproducing kernels”. Transactions of the American mathematical society, Vol. 68, No. 3, pp. 337–404, 1950.
- [Baja 23] J. Bajārs. “Locally-symplectic neural networks for learning volume-preserving dynamics”. Journal of Computational Physics, Vol. 476, p. 111911, 2023.
- [Beck 22] T. Beckers, J. Seidman, P. Perdikaris, and G. J. Pappas. “Gaussian Process Port-Hamiltonian Systems: Bayesian Learning with Physics Prior”. In: 2022 IEEE 61st Conference on Decision and Control (CDC), pp. 1447–1453, 2022.
- [Boro 20] V. Borovitskiy, A. Terenin, P. Mostowsky, and M. P. Deisenroth. “Matérn Gaussian processes on riemannian manifolds”. In: Proceedings of the 34th International Conference on Neural Information Processing Systems, Curran Associates Inc., Red Hook, NY, USA, 2020.
- [Bran 23] B. Brantner and M. Kraus. “Symplectic Autoencoders for Model Reduction of Hamiltonian Systems”. 2023.
- [Brun 16] S. L. Brunton, J. L. Proctor, and J. N. Kutz. “Discovering governing equations from data by sparse identification of nonlinear dynamical systems”. Proceedings of the National Academy of Sciences, Vol. 113, No. 15, pp. 3932–3937, 2016.
- [Chen 19] Z. Chen, J. Zhang, M. Arjovsky, and L. Bottou. “Symplectic recurrent neural networks”. arXiv preprint arXiv:1909.13334, 2019.
- [Chen 21] R. Chen and M. Tao. “Data-driven Prediction of General Hamiltonian Dynamics via Learning Exactly-Symplectic Maps”. In: M. Meila and T. Zhang, Eds., Proceedings of the 38th International Conference on Machine Learning, pp. 1717–1727, PMLR, 18–24 Jul 2021.
- [Chen 22] X. Chen, J. Duan, J. Hu, and D. Li. “Data-driven method to learn the most probable transition pathway and stochastic differential equation”. Physica D: Nonlinear Phenomena, 2022.
- [Chos 02] P. Chossat, J.-P. Ortega, and T. S. Ratiu. “Hamiltonian Hopf bifurcation with symmetry”. Archive for Rational Mechanics and Analysis, Vol. 163, pp. 1–33, 2002.
- [Chos 03] P. Chossat, D. Lewis, J.-P. Ortega, and T. S. Ratiu. “Bifurcation of relative equilibria in mechanical systems with symmetry”. Advances in Applied Mathematics, Vol. 31, pp. 10–45, 2003.
- [Chri 10] A. Christmann and I. Steinwart. “Universal Kernels on Non-Standard Input Spaces”. In: J. Lafferty, C. Williams, J. Shawe-Taylor, R. Zemel, and A. Culotta, Eds., Advances in Neural Information Processing Systems, p. , Curran Associates, Inc., 2010.
- [Conw 07] J. B. Conway. A Course in Functional Analysis. Springer Science & Business Media, second Ed., 2007.
- [Cran 20] M. Cranmer, S. Greydanus, S. Hoyer, P. Battaglia, D. Spergel, and S. Ho. “Lagrangian neural networks”. arXiv preprint arXiv:2003.04630, 2020.
- [Da C 23a] N. Da Costa, C. Mostajeran, and J.-P. Ortega. “The Gaussian kernel on the circle and spaces that admit isometric embeddings of the circle”. In: International Conference on Geometric Science of Information, pp. 426–435, Springer, 2023.
- [Da C 23b] N. Da Costa, C. Mostajeran, J.-P. Ortega, and S. Said. “Geometric Learning with Positively Decomposable Kernels”. arXiv preprint arXiv:2310.13821, 2023.
- [Davi 23] M. David and F. Méhats. “Symplectic learning for Hamiltonian neural networks”. Journal of Computational Physics, Vol. 494, p. 112495, 2023.
- [De V 05] E. De Vito, L. Rosasco, A. Caponnetto, U. De Giovannini, F. Odone, and P. Bartlett. “Learning from Examples as an Inverse Problem.”. Journal of Machine Learning Research, Vol. 6, No. 5, 2005.
- [Doum 23] N. Doumèche, G. Biau, and C. Boyer. “Convergence and error analysis of PINNs”. 2023.
- [Eldr 24a] C. Eldred, F. Gay-Balmaz, and V. Putkaradze. “CLPNets: Coupled Lie-Poisson Neural Networks for Multi-Part Hamiltonian Systems with Symmetries”. arXiv preprint arXiv:2408.16160, 2024.
- [Eldr 24b] C. Eldred, F. Gay-Balmaz, S. Huraka, and V. Putkaradze. “Lie–Poisson Neural Networks (LPNets): Data-based computing of Hamiltonian systems with symmetries”. Neural Networks, Vol. 173, p. 106162, 2024.
- [Emer 12] M. Émery. Stochastic calculus in manifolds. Springer Science & Business Media, 2012.
- [Feng 23] J. Feng, C. Kulick, Y. Ren, and S. Tang. “Learning particle swarming models from data with Gaussian processes”. Mathematics of Computation, 2023.
- [Fera 15] A. Feragen, F. Lauze, and S. Hauberg. “Geodesic exponential kernels: When curvature and linearity conflict”. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 3032–3042, 2015.
- [Ferr 12] J. C. Ferreira and V. A. Menegatto. “Reproducing properties of differentiable Mercer-like kernels”. Mathematische Nachrichten, Vol. 285, No. 8-9, pp. 959–973, 2012.
- [Gins 12] D. Ginsbourger, X. Bay, O. Roustant, and L. Carraro. “Argumentwise invariant kernels for the approximation of invariant functions”. In: Annales de la Faculté des sciences de Toulouse: Mathématiques, pp. 501–527, 2012.
- [Grey 19] S. Greydanus, M. Dzamba, and J. Yosinski. “Hamiltonian neural networks”. Advances in neural information processing systems, Vol. 32, 2019.
- [Holm 09] D. D. Holm, T. Schmah, and C. Stoica. Geometric mechanics and symmetry: from finite to infinite dimensions. Vol. 12, Oxford University Press, 2009.
- [Holm 11a] D. D. Holm. Geometric Mechanics. Part I: Dynamics and Symmetry. World Scientific Publishing Company, second Ed., 2011.
- [Holm 11b] D. D. Holm. Geometric Mechanics. Part II: Rotating, Translating and Rolling. World Scientific, second Ed., 2011.
- [Hsu 02] E. P. Hsu. Stochastic analysis on manifolds. American Mathematical Soc., 2002.
- [Hu 24] J. Hu, J.-P. Ortega, and D. Yin. “A Structure-Preserving Kernel Method for Learning Hamiltonian Systems”. arXiv preprint arXiv:2403.10070, 2024.
- [Jin 20] P. Jin, Z. Zhang, A. Zhu, Y. Tang, and G. E. Karniadakis. “SympNets: Intrinsic structure-preserving symplectic networks for identifying Hamiltonian systems”. Neural Networks, Vol. 132, pp. 166–179, 2020.
- [Jin 22] P. Jin, Z. Zhang, I. G. Kevrekidis, and G. E. Karniadakis. “Learning Poisson systems and trajectories of autonomous systems via Poisson neural networks”. IEEE Transactions on Neural Networks and Learning Systems, 2022.
- [Kost 09] B. Kostant. “Orbits, symplectic structures and representation theory”. Collected Papers, pp. 482–482, 2009.
- [Leok 12] M. Leok and T. Shingel. “General techniques for constructing variational integrators”. Frontiers of Mathematics in China, Vol. 7, pp. 273–303, 2012.
- [Leon 97] N. E. Leonard and J. E. Marsden. “Stability and drift of underwater vehicle dynamics: mechanical systems with rigid motion symmetry”. Physica D: Nonlinear Phenomena, Vol. 105, No. 1-3, pp. 130–162, 1997.
- [Li 23] S. Li. “Gaussian kernels on nonsimply connected closed Riemannian manifolds are never positive definite”. Bulletin of the London Mathematical Society, 2023.
- [Libe 12] P. Libermann and C.-M. Marle. Symplectic Geometry and Analytical Mechanics. Vol. 35, Springer Science & Business Media, 2012.
- [Lie 93] S. Lie and F. Engel. Theorie der Transformationsgruppen. Vol. 3, Teubner, 1893.
- [Lu 19] F. Lu, M. Zhong, S. Tang, and M. Maggioni. “Nonparametric inference of interaction laws in systems of agents from trajectory data”. Proceedings of the National Academy of Sciences, Vol. 116, No. 29, pp. 14424–14433, 2019.
- [Magg 21] M. Maggioni, J. Miller, H. Qiu, and M. Zhong. “Learning Interaction Kernels for Agent Systems on Riemannian Manifolds”. 2021.
- [Mars 01] J. E. Marsden and M. West. “Discrete mechanics and variational integrators”. Acta numerica, Vol. 10, pp. 357–514, 2001.
- [Mars 74] J. E. Marsden and A. Weinstein. “Reduction of symplectic manifolds with symmetry”. Reports on Mathematical Physics, Vol. 5, No. 1, pp. 121–130, 1974.
- [Mars 99] J. E. Marsden and T. S. Ratiu. Introduction to Mechanics and Symmetry. Springer-Verlag, New York, second Ed., 1999.
- [Micc 06] C. A. Micchelli, Y. Xu, and H. Zhang. “Universal Kernels.”. Journal of Machine Learning Research, Vol. 7, No. 12, 2006.
- [Minh 10] H. Q. Minh. “Some properties of Gaussian reproducing kernel Hilbert spaces and their implications for function approximation and learning theory”. Constructive Approximation, Vol. 32, pp. 307–338, 2010.
- [Mont 97a] J. A. Montaldi. “Persistance d’orbites périodiques relatives dans les systèmes hamiltoniens symétriques”. C. R. Acad. Sci. Paris Sér. I Math., Vol. 324, pp. 553–558, 1997.
- [Mont 97b] J. A. Montaldi. “Persistence and stability of relative equilibria”. Nonlinearity, Vol. 10, pp. 449–466, 1997.
- [Mrou 15] Y. Mroueh, S. Voinea, and T. A. Poggio. “Learning with Group Invariant Features: A Kernel Perspective.”. Advances in neural information processing systems, Vol. 28, 2015.
- [Noet 18] E. Noether. “Invariante Variationsprobleme”. Nachr. d. König. Gesellsch. d. Wiss. zu Göttingen Math. Physik, Vol. 2, pp. 235–257, 1918.
- [Nomi 61] K. Nomizu and H. Ozeki. “The existence of complete Riemannian metrics”. Proceedings of the American Mathematical Society, Vol. 12, No. 6, pp. 889–891, 1961.
- [Nova 18] E. Novak, M. Ullrich, H. Woźniakowski, and S. Zhang. “Reproducing kernels of Sobolev spaces on and applications to embedding constants and tractability”. Analysis and Applications, Vol. 16, No. 05, pp. 693–715, 2018.
- [Offe 24] C. Offen. “Machine learning of continuous and discrete variational ODEs with convergence guarantee and uncertainty quantification”. 2024.
- [Orte 04] J.-P. Ortega and T. S. Ratiu. Momentum Maps and Hamiltonian Reduction. Birkhauser Verlag, 2004.
- [Orte 05] J.-P. Ortega, V. Planas-Bielsa, and T. S. Ratiu. “Asymptotic and Lyapunov stability of constrained and Poisson equilibria”. Journal of Differential Equations, Vol. 214, No. 1, pp. 92–127, jul 2005.
- [Orte 24] J.-P. Ortega and D. Yin. “Learnability of Linear Port-Hamiltonian Systems”. Journal of Machine Learning Research, Vol. 25, No. 68, pp. 1–56, 2024.
- [Orte 97] J.-P. Ortega and T. S. Ratiu. “Persistence and smoothness of critical relative elements in Hamiltonian systems with symmetry”. Comptes Rendus de l’Académie des Sciences - Series I - Mathematics, Vol. 325, No. 10, pp. 1107–1111, nov 1997.
- [Owha 17] H. Owhadi and C. Scovel. “Separability of reproducing kernel spaces”. Proceedings of the American Mathematical Society, Vol. 145, No. 5, pp. 2131–2138, 2017.
- [Penn 06] X. Pennec. “Intrinsic statistics on Riemannian manifolds: Basic tools for geometric measurements”. Journal of Mathematical Imaging and Vision, Vol. 25, pp. 127–154, 2006.
- [Penn 19] X. Pennec, S. Sommer, and T. Fletcher. Riemannian Geometric Statistics in Medical Image Analysis. Academic Press, 2019.
- [Pfö 24] M. Pförtner, I. Steinwart, P. Hennig, and J. Wenger. “Physics-Informed Gaussian Process Regression Generalizes Linear PDE Solvers”. 2024.
- [Rais 19] M. Raissi, P. Perdikaris, and G. Karniadakis. “Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations”. Journal of Computational Physics, Vol. 378, pp. 686–707, 2019.
- [Rath 21] K. Rath, C. G. Albert, B. Bischl, and U. von Toussaint. “Symplectic Gaussian process regression of maps in Hamiltonian systems”. Chaos: An Interdisciplinary Journal of Nonlinear Science, Vol. 31, No. 5, p. 053121, 05 2021.
- [Rude 13] M. Rudelson, R. Vershynin, et al. “Hanson-wright inequality and sub-Gaussian concentration”. Electronic Communications in Probability, Vol. 18, 2013.
- [Shin 20] J. Shin, YeonjongDarbon and G. Em Karniadakis. “On the Convergence of Physics Informed Neural Networks for Linear Second-Order Elliptic and Parabolic Type PDEs”. Communications in Computational Physics, Vol. 28, No. 5, pp. 2042–2074, 2020.
- [Sour 65] J.-M. Souriau. Géométrie de l’espace de phases: calcul des variations et mécanique quantique. Faculté des sciences de Marseille, 1965.
- [Sour 66] J.-M. Souriau. “Quantification géométrique”. Comm. Math. Phys., Vol. 1, pp. 374–398, 1966.
- [Sour 69] J.-M. Souriau. Structure des Systèmes Dynamiques. Dunod, Paris, 1969.
- [Stei 01] I. Steinwart. “On the influence of the kernel on the consistency of support vector machines”. Journal of machine learning research, Vol. 2, No. Nov, pp. 67–93, 2001.
- [Tu 08] L. W. Tu. An Introduction to Manifolds. Springer, 2008.
- [Vais 12] I. Vaisman. Lectures on the Geometry of Poisson Manifolds. Vol. 118, Birkhäuser, 2012.
- [Van 12] C. Van Den Berg, J. P. R. Christensen, and P. Ressel. Harmonic Analysis on Semigroups: Theory of Positive Definite and Related Functions. Vol. 100, Springer Science & Business Media, 2012.
- [Wein 83] A. Weinstein. “The local structure of Poisson manifolds”. Journal of differential geometry, Vol. 18, No. 3, pp. 523–557, 1983.
- [Yuri 95] V. Yurinsky. Sums and Gaussian Vectors. Lecture Notes in Mathematics. Springer Berlin, Heidelberg, 1995.
- [Zhou 08] D.-X. Zhou. “Derivative reproducing properties for kernel methods in learning theory”. Journal of Computational and Applied Mathematics, Vol. 220, No. 1-2, pp. 456–463, 2008.
- [Zhu 20] A. Zhu, P. Jin, and Y. Tang. “Deep Hamiltonian networks based on symplectic integrators”. 2020.