A Graph-guided Multi-round Retrieval Method for Conversational Open-domain Question Answering
Abstract.
In recent years, conversational agents have provided a natural and convenient access to useful information in people’s daily life, along with a broad and new research topic, conversational question answering (QA). Among the popular conversational QA tasks, conversational open-domain QA, which requires to retrieve relevant passages from the Web to extract exact answers, is more practical but less studied. The main challenge is how to well capture and fully explore the historical context in conversation to facilitate effective large-scale retrieval. The current work mainly utilizes history questions to refine the current question or to enhance its representation, yet the relations between history answers and the current answer in a conversation, which is also critical to the task, are totally neglected. To address this problem, we propose a novel graph-guided retrieval method to model the relations among answers across conversation turns. In particular, it utilizes a passage graph derived from the hyperlink-connected passages that contains history answers and potential current answers, to retrieve more relevant passages for subsequent answer extraction. Moreover, in order to collect more complementary information in the historical context, we also propose to incorporate the multi-round relevance feedback technique to explore the impact of the retrieval context on current question understanding. Experimental results on the public dataset verify the effectiveness of our proposed method. Notably, the F1 score is improved by 5% and 11% with predicted history answers and true history answers, respectively.
1. Introduction
In recent years, the rise of machine learning techniques has accelerated the development of conversational agents, such as Alexa111https://www.alexa.com/., Siri222https://www.apple.com/siri/., and Xiaodu333https://dueros.baidu.com/.. These conversational agents provide a natural and convenient way for people to chit-chat, complete well-specified tasks, and seek information in their daily life. People often prefer to ask conversational questions when they have complex information needs or are of interest to certain broad topics. It is therefore essential to endow conversational agents with the capability to answer conversational questions, which introduces a broad and new research area, namely conversational question answering (QA). Nowadays, conversational QA has attracted more and more researchers who have developed various tasks with different emphases, including but not limited to conversational knowledge-based QA (Christmann et al., 2019; Zhang et al., 2020), conversational machine reading comprehension (Reddy et al., 2019), conversational search (Hashemi et al., 2020), and conversational open-domain QA (Qu et al., 2020). Among them, conversational open-domain QA is more practical yet more challenging. Apart from highly historical context-dependent, elliptical, and even unanswerable questions, it requires to retrieve the relevant passages from the Web and to extract the text spans from the retrieved passages as the exact answers to the given questions.
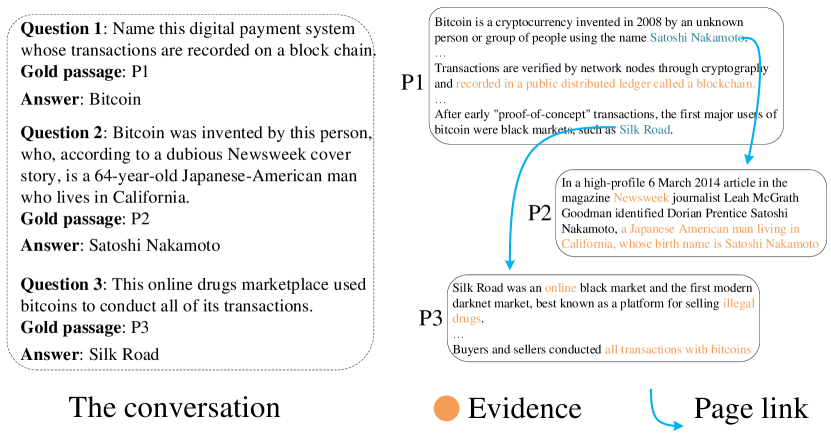
A typical solution to the problem of conversational open-domain QA is decoupled into historical context modeling, followed by a traditional 3-R open-domain QA pipeline: Retriever, Ranker, and Reader. Historical context modeling plays an important role in understanding the current question with reference to its historical context. With it in place, this problem is then transformed to single-turn QA and handled by the traditional QA techniques (Wang et al., 2019; Lu et al., 2019; Zheng et al., 2019). On historical context modeling, existing conversational open-domain QA models simply pre-append history questions (and sometimes answers too) to the current question (Elgohary et al., 2018; Qu et al., 2020). They, however, somehow overlook the relations between history answers and the current answer. As shown in Figure 1, the gold passages containing answers in a conversation are often highly related and connected via hyperlinks. We also observe that in the QBLink dataset (Elgohary et al., 2018) about 60% answers can be found in the two-hop connected passages containing history answers. To address this problem, we introduce a new component called Explorer into the existing 3-R pipeline. Underlying the Explorer is a novel graph-guided retrieval method. Following Retriever, it aims to boost retrieval coverage by capturing the relations among answers across conversation turns via a passage graph. In particular, Explorer first constructs an initial passage graph with the passages containing history answers and the passages retrieved by Retriever. It then expands the initial graph by walking hops via hyperlinks to include more potentially relevant passages. Afterward, a new list of passages is retrieved by applying a Graph Attention Network (GAT) model on the passage graph and the list is passed to the following Ranker and Reader to extract the most probable answer.
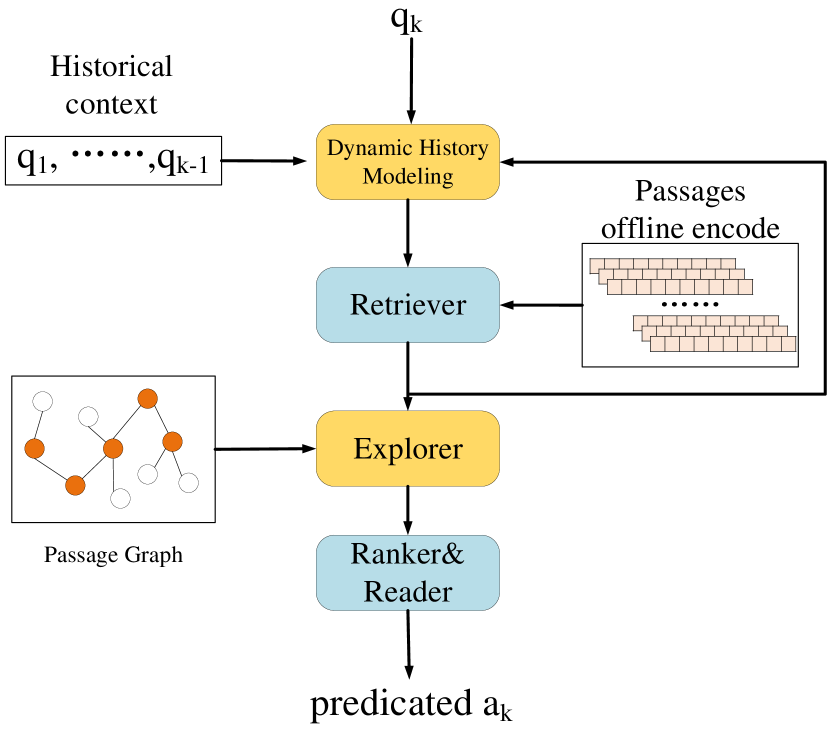
As aforementioned, the conversational open-domain QA involves multiple components. Therefore, how to design an effective pipeline, where the components can work collaboratively and interact closely deserves careful consideration. A few existing methods have applied multi-round retrieval methods to open-domain QA, which allow the retriever to receive feedback signals from either the retriever (Feldman and El-Yaniv, 2019) or the reader(Das et al., 2018), and generate new queries to update retrieval results. This mechanism can be regarded as relevance feedback (Harman, 1992), which has been well explored in traditional information retrieval. However, the impact of relevance feedback on historical context modeling in conversational QA is not yet studied. Inspired by this idea, we propose dynamic history modeling (DHM) to incorporate relevance feedback to enhance the typical historical context modeling component. In particular, DHM considers not only the historical context and the current question but also the candidate passages returned by the retriever, which can be deemed as the retrieval context. The attention mechanism is then adopted to screen out more relevant information in the historical context according to the retrieval context to enhance contextual question understanding. With multi-rounds of retrieval and feedback loops, question embeddings are dynamically refined and improved retrieval performance can be expected.
To summarize, in this paper we propose a novel graph-guided and multi-round retrieval method to enhance the existing conversational open-domain QA pipeline. Specifically, we incorporate a graph-based explorer and a feedback-based DHM component into the pipeline, as illustrated in Figure 2. The key contributions of this work are three-fold:
-
•
We propose a novel graph based Explorer, which models relations among answers across conversation turns via the passage graph. By expanding history answers and passages retrieved by the retriever via the hyperlink structure, more relevant passages can be discovered for subsequent answer extraction.
-
•
We incorporate the relevance feedback technique in historical context modeling to iteratively refine current question understanding with reference to the retrieval context. Multi-round retrieval allows us to acquire more relevant passages based on dynamic question embeddings.
-
•
Extensive experiments on the public dataset show significant performance improvement over baselines by 5% and 11% under two different settings, i.e., with predicted history answers and true history answers, respectively. We will release the data and codes of this work to facilitate other researchers.
2. Related work
Our work is closely related to conversational question answering and open-domain question answering.
2.1. Conversational QA
Conversational question answering (QA) is an emerging topic in QA. It has been formulated as the tasks of conversational knowledge-based QA (KBQA) (Saha et al., 2018; Christmann et al., 2019; Shen et al., 2019), conversational search (Dalton et al., 2020; Ren et al., 2020), conversational machine reading comprehension (MCR) (Choi et al., 2018; Reddy et al., 2019), and conversational open-domain QA (Elgohary et al., 2018; Qu et al., 2020). It is worth emphasizing that the first one relies on knowledge graphs, and the rest three tasks reply questions based upon documents. Conversational search allows users to interact with the search engine to find the documents that contain potential answers to their questions. Different from conversational search, the gold passage that contains true answers is given in conversational MCR, and it further extracts a text span as the exact answer from the given passage. Comparatively, conversational open-domain QA is more challenging in a sense that it not only retrieves the relevant passages from the Web but also extracts the text answer spans.
The common problem that all above-mentioned conversational QA tasks have to address is how to understand the historical context in the conversation. For example, there are often questions with ellipsis and/or coreference resolution problems. The common solution in the existing methods is to utilize the historical context to reformulate the current question or refine its representation. A simple strategy is to pre-append all the historical context (Elgohary et al., 2018) or heuristically select some words or sentences from the context (Choi et al., 2018) to expand the current question. Elgohary et al. (Elgohary et al., 2019) constructed the CANARD dataset, which is able to transform a context-dependent question into a self-contained question. Based on this dataset, a series of question rewriting methods have been proposed. Specifically, some regard question rewriting as a sequence-to-sequence task to incorporate the context into a standalone question. For example, Vakulenko et al. (Vakulenko et al., 2020) used both retrieval and extractive QA tasks to examine the effect of sequence-to-sequence question rewriting on the end-to-end conversational QA performance. Differently, Voskarides et. al. (Voskarides et al., 2020) modeled query resolution as a binary term classification problem. For each term appearing in the previous turns of conversation, it decides whether or not to add this term to the question in the current turn. Given the gold passage in conversational MCR, the authors in (Qu et al., 2019) designed a history attention mechanism to implement “soft selection” from conversation histories. The current conversational QA methods have presented various ways to modeling the historical context, and utilizing the historical context to enhance the current question representation. However, they ignore relations among answers (or answer passages) across the conversation turns. Some efforts (Huang et al., 2018; Chen et al., 2020) in conversational MCR captures the conversational flow by incorporating intermediate representations generated during the process of answering previous questions. Differently, we attempted to model relations more directly and explicitly by exploring the passage graph.
2.2. Open-domain QA
Open-domain question answering (QA) (Chen et al., 2017; Wang et al., 2018a, b), which aims to answer questions from the Web, has attracted wide attention from the academic field in recent years. In 2017, Chen et al. (Chen et al., 2017) first introduced neural methods to open-domain QA using a textual source. They proposed DrQA, a pipeline model with a TF-IDF based retriever and a neural network based reader that was trained to find an answer span given a question and a retrieved paragraph. Later, Wang et al. (Wang et al., 2018a) added a ranker between the retriever and reader to rank the retrieved passages more precisely in 2018. Our proposed method also follows the retriever, ranker and reader pipeline. In addition to TF-IDF based retrievers, dense based retrievers have also been well developed recently (Lee et al., 2019; Karpukhin et al., 2020; Chang et al., 2019), where all passages are offline encoded in advance to allow efficient large-scale retrieval. In (Karpukhin et al., 2020), the authors show that the retriever can be practically implemented using dense representations in open-domain QA, where embeddings are learned from a small number of questions and passages. Our method applies both dense based and TF-IDF based retrievers. The selected top-ranked passages are further extended and explored based on the structure of our constructed passage graph by our proposed explorer.
There are also researchers exploiting the graph-based retriever for open-domain QA. Min et al. (Min et al., 2019) utilized the available knowledge base to build a passage graph and proposed a graph retriever to encode passages. In (Asai et al., 2020), authors introduced a graph based recurrent retrieval approach that is learned to retrieve reasoning paths over the Wikipedia graph to answer multi-hop open-domain questions. Distinctly, we aimed to capture the conversation flow with the help of the passage graph. Recently, multi-round retrieval methods have been proposed (Feldman and El-Yaniv, 2019; Das et al., 2018; Xiong et al., 2020). The authors in (Feldman and El-Yaniv, 2019) proposed the multi-hop retrieval method, which iteratively retrieved supporting paragraphs by forming a joint vector representation of both question and returned paragraph. Das et al. (Das et al., 2018) proposed a gated recurrent unit to update the question at each round conditioned on the state of the reader, where the retriever and the reader iteratively interact with each other. Our proposed method also includes a multi-round retrieval mechanism. Beyond existing methods, our focus is to explore relevance feedback, particularly the returned passages, to screen out the most useful information in the historical context to better formulate the current question.
3. Our Proposed Method
As illustrated in Figure 2, our proposed method comprises the following five components. DHM receives as input the current question , the historical context 444It is noticed that the history answers are also included in if the true history answers are allowed to use., and the passages returned from the retriever if any. It generates a query vector representation via an attention mechanism. The Retriever retrieves a list of passages that is determined relevant to the question representation vector from a large passage collection . The Explorer then utilizes the passages received from the Retriever and the passages containing history answers to construct an initial passage graph, and expands from the initial passage graph via hyperlink structure to cover more potentially relevant passages. The representations of passages in the passage graph are then updated with a graph neural network model. And a new list of passages is retrieved and passed to the subsequent Ranker and Reader to re-rank and read the passages to extract the text answer span. We elaborate each component in the following sections.
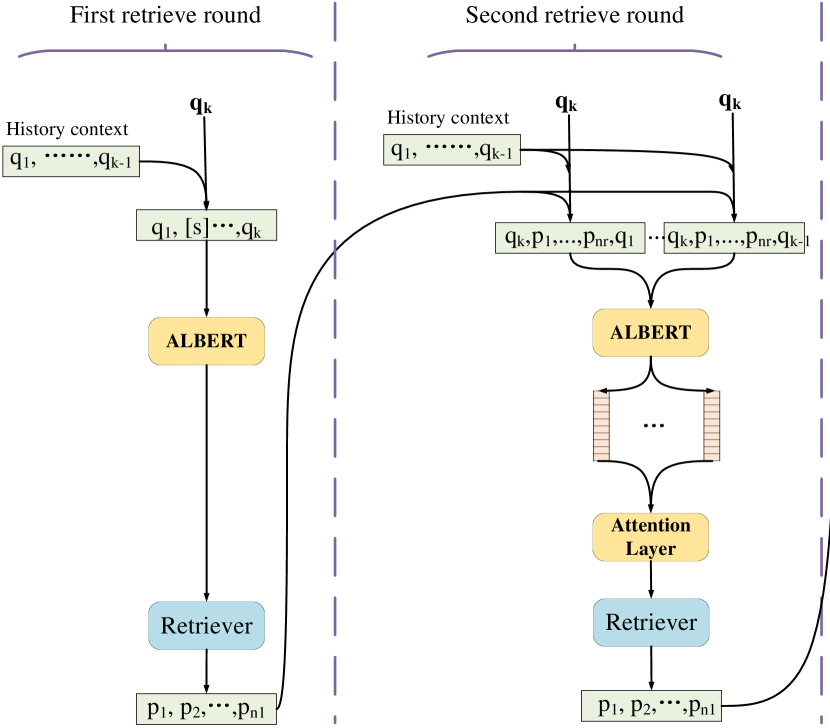
3.1. DHM and Retriever
Our proposed method contains multi-rounds of retrieval, as shown in Figure 3. In the first round, given the current question and historical context , DHM encodes the text as a representation vector and then feeds it to the retriever from which the feedback, i.e., retrieved passages is received. In the following rounds, DHM utilizes and current question to attend to history towards the representation vector refinement iteratively.
The First Round of Retrieval. We pre-append all history questions to the current question , denoted as . To accommodate the BERT (Devlin et al., 2019) based question encoder, we introduce two special tokens, [CLS] and [SEP]. is represented as a text sequence “[CLS] [SEP], , [SEP] [SEP]”. We use ALBERT (Lan et al., 2019) to obtain the first-round question representation vector , which is formulated as,
| (1) |
where is the ALBERT based question encoder, is the question projection matrix, and . Similarly, for each passage in we obtain its representation as follows,
| (2) |
where is the ALBERT based passage encoder, is the passage projection matrix, , and is equal to . It is critical that paragraph encodings are independent of questions in order to enable storing precomputed paragraph encodings and executing the efficient maximum inner product search (MIPS) algorithm (Lee et al., 2019; Karpukhin et al., 2020). Otherwise, any new question would require re-processing the entire passage collection (or at least a significant part of it). Benefiting from this, we can calculate the similarity score via the inner product of and each passage efficiently, and select the top- passages , , , , where is the number of the passages in .
The Following Rounds of Retrieval. The returned passages in are incorporated into the history questions and the current question in the form of triplet , where each triplet contains the current question , the top- passages in , and the -th history question. It is formulated as “[CLS] [SEP] , …, [SEP] [SEP] [SEP]”. As such, interactions among the history question, the current question and the retrieval feedback are encouraged. The representation of is calculated as follow,
| (3) |
A history attention network is then followed to aggregate the representation vectors into the refined question vector with learned attention weights. Formally, the attention layer is defined as follows,
| (4) |
where , denotes the attention weight of the -th triplet, and . The attention weights help to capture certain contexts that are more relevant to the current round of retrieval. With the new question representation , we re-calculate the similarity scores and select the new list of top- passages as before. The question representation vector is continuously updated when the returned passage changes in each round. After several rounds, the final rank list of passages is delivered to the following Explorer.
3.2. Explorer
Essentially, our proposed explorer is equipped with a graph-guided candidate answer passage expansion method. Based on the observation that answers are also highly related in conversation QA, we design Explorer to model relations of answers by constructing a passage graph. In general, the explorer goes through the following three steps: initialization, expansion, and graph modeling, as illustrated in Figure 4.
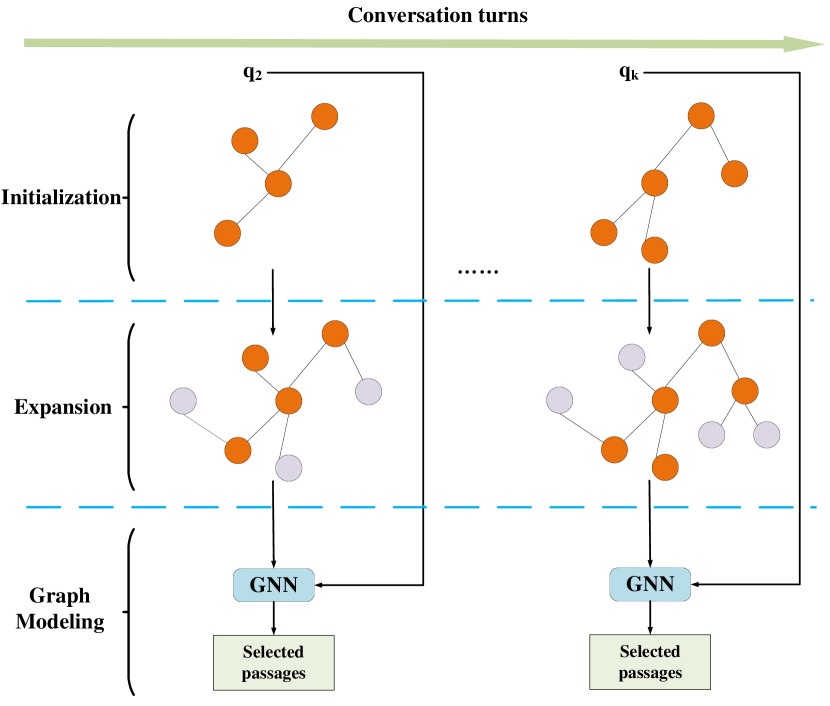
We first construct an initial passage graph , where are some selected passages and are hyperlinks among them. includes the passages containing gold/predicted answers in previous turns of the conversation and the passages retrieved by the dense retriever described in the previous section. To increase the pool of relevant passages, we also run a simple TF-IDF based retrieval model. Altogether we have
| (5) |
where , , and denote the set of passages that contain previous gold/predicted answers, the passages returned by the dense retriever, and the passage returned by the TF-IDF retriever, respectively. Starting from the initial passage nodes , we expand the passage set to by adding the hyperlink-connected passages via,
| (6) |
where denotes the passages linked to the passages in via the Web hyperlinks. Through expansion, a larger set of passages is obtained, where refers to the number of passages in . Meanwhile, we obtain the corresponding expanded passage graph , whose nodes are passages in and edges are hyperlinks among them.
To take advantage of the structure information, we apply a Graph Attention network (Veličković et al., 2018) to update the embeddings of the passages in . For each passage in , we input it to an ALBERT encoder to obtain its embedding by Eqn.(2) and then update the node embedding as follows,
| (7) |
Based on the updated embeddings, we re-calculate the similarity between the question and the passages in . Specifically, we obtain the question embedding by Eqn.(1) and calculate the similarity of passage to as follows,
| (8) |
Finally, the top- passages are selected according to their ranks based on similarity calculation, where denotes the number of passages in . is then passed to the following Ranker and Reader for further processing.
3.3. Ranker and Reader
Given the list of passages , Ranker re-ranks the passages more precisely and Reader predicts a text span as an answer. We first construct the reformatted text sequence by concatenating the question text and the passage text. is “[CLS] [SEP] [SEP]”. For each token in , a BERT encoder generates its representation , and for the whole text sequence, BERT encoder generates its representation .
Ranker conducts a listwise reranking of the top- passages received from Explorer and calculates the reranking score for each passage in as,
| (9) |
where . Reader then predicts an answer span by computing two scores for each token in passages in as the start token and the end token, respectively, formulated as,
| (10) |
where is the number of tokens, and both and . Finally, the text span with the highest score is extracted as the answer. We will detail the inference process in the following section.
3.4. Training and Inference
Training. Recall that we encode the large collection of passages offline for efficient retrieval. Specifically, we follow the previous work (Lee et al., 2019; Qu et al., 2020) to pretrain a passage encoder so that it can provide reasonably good retrieval results to the subsequent components for further processing. After offline encoding, a set of passage vectors are obtained. Note that while the parameters of the passage encoder are fixed after pretraining, the parameters of the question encoder are updated along with those of the explorer, the ranker and the reader.
After passage offline encoding, we then train the retriever, the explorer, the ranker, and the reader. For each passage in , we calculate the retrieval score as follows,
| (11) |
To train the retriever, we set the retriever loss as follows,
| (12) |
where indicates whether the passage is a gold passage. If the gold passage is not presented in , we manually include it in the retrieval results. Similar to the retriever loss, we respectively define the explorer loss and the ranker loss as follows,
| (13) |
where and are the explorer score and ranker score of the passage in , respectively. The reader loss is formulated as,
| (14) | |||
where and indicate whether the token is the start token and the end token, respectively. Considering the limitation of GPU memory, we first train the retriever, the ranker, and the reader jointly via the sum of their losses, and then train DHM and the explorer separately.
Inference. For each passage in , we obtain the explorer score and the ranker score by Eqn.(8) and Eqn.(9), respectively. For each token, the reader then assigns it the probabilities of being the start token and the end token . Following the convention (Devlin et al., 2019; Qu et al., 2020), we consider the top 20 text spans only to ensure tractability. Invalid predictions, including the cases where the start token comes after the end token, or the predicted span overlaps with a question in the conversation context, are all discarded. The predicted score of a potential answer is then calculated as,
| (15) |
The model finally outputs the answer span with the maximum overall score to respond to the current question.
| items | Train | Dev | Test | |
| QA pairs | # Dialogs | 4,383 | 490 | 771 |
| # Questions | 31,526 | 3,430 | 5,571 | |
| # Avg.Questions per Dialog | 7.2 | 7.0 | 7.2 | |
| Collection | # passages | 11 million | ||
| Passage Graph | # nodes | 11 million | ||
| # edges | 105 million | |||
| # Avg. edges per node | 17 | |||
4. Experiments
4.1. Dataset
To conduct experiments, we used the public available dataset OR-QuAC (Qu et al., 2020), which expands the QuAC dataset (Choi et al., 2018) to the open-domain QA setting. Each conversation in this dataset contains a series of questions and answers, and is supplemented with a collection of passages. There are totally 5,644 conversations covering 40,527 questions. The passage collection is from the English Wikipedia dump file of 10/20/2019, and it contains about 11 million passages. We further crawled the internal page links in the Wikipedia via Wikiextractor555https://github.com/attardi/wikiextractor. to facilitate passage graph construction. The statistics of the above dataset are summarized in Table 1.
4.2. Experimental Settings
Evaluation Protocols. Following the previous work (Choi et al., 2018; Qu et al., 2020), we employed the word-level F1 and the human equivalence score (HEQ), which are two metrics provided by the QuAC challenge (Choi et al., 2018) to evaluate the Conversational QA systems. HEQ computes the percentage of examples for which system F1 exceeds or matches human F1. It measures whether a system can give answers as good as an average human. This metric is computed on a question level (HEQ-Q) and a dialog level (HEQ-D). Besides, to evaluate the retrieval performance of the retrieval passage list, we also applied the Mean Reciprocal Rank (MRR) and Recall to evaluate the Retriever component of the baselines, our Explorer component, and the Ranker component.
Implementation Details. We utilized the pretrained passages embedding vectors released in (Qu et al., 2020) to make a fair comparison. The , are both set to 128, and is set to 5, the same as (Qu et al., 2020). The number of retrieved passages from the retriever is 3. Limited by our GPU memory, both and is set to 1, and the retrieve rounds are 2. There are two GAT layers, where the numbers of heads are 128 and 64, respectively. The passage embeddings are stored in a 2080Ti card and the model is in another 2080Ti card.
4.3. Baselines
To the best of our knowledge, only one published work (Qu et al., 2020), ORConvQA, aims to solve the conversational open-domain QA problem. We compared our proposed method with ORConvQA and the baselines in (Qu et al., 2020) as follows:
-
•
DrQA (Chen et al., 2017): This model uses a TF-IDF retriever and a RNN based reader. The original distantly supervised setting is not applied, since the full supervision is allowed in the dataset and adopted for all the methods.
-
•
BERTserini (Yang et al., 2019): This model uses a BM25 retriever implemented in Anserini 666http://anserini.io/. and a BERT reader. Their BERT reader is similar to ours, except that it does not support reranking and thus cannot benefit from joint learning.
-
•
ORConvQA (Qu et al., 2020): It is an open-retrieval conversational question answering method. It uses a dense retriever, ranker, and reader pipeline, which is similar to ours. ORConvQA utilizes a sliding window to append previous questions.
-
•
ORConvQA without history (ORConvQA w/o hist.): This is ORConvQA with the history window size . However, the first question is always included in the reformulated current question.
Following the previous work (Qu et al., 2020), we evaluated all methods under the setting of no true history answers. The results of these baselines are public in (Qu et al., 2020). We also evaluated ORConvQA and ours with true history answers, denoted as ORConvQA-ta and “Ours-ta”, respectively.
| Methods | Dev | Test | ||||||||||
| Rt-R | Rt-M | Rr-M | H-Q | H-D | F1 | Rt-R | Rt-M | Rr-M | H-Q | H-D | F1 | |
| DrQA | 0.2000 | 0.1151 | N/A | 0.0 | 0.0 | 4.5 | 0.2253 | 0.1574 | N/A | 0.1 | 0.0 | 6.3 |
| BERTserini | 0.2656 | 0.1767 | N/A | 14.1 | 0.2 | 19.3 | 0.2507 | 0.1784 | N/A | 20.4 | 0.1 | 26.0 |
| ORConvQA w/o hist | 0.5271 | 0.4012 | 0.4472 | 15.2 | 0.2 | 24.0 | 0.2859 | 0.1979 | 0.2702 | 20.7 | 0.4 | 26.3 |
| ORConvQA | 0.5714 | 0.4286 | 0.5209 | 17.5 | 0.2 | 26.9 | 0.3141 | 0.2246 | 0.3127 | 24.1 | 0.6 | 29.4 |
| ORConvQA-ta | 0.6833 | 0.5414 | 0.6392 | 19.6 | 0.2 | 31.4 | 0.4721 | 0.3810 | 0.4765 | 29.6 | 1.2 | 34.6 |
| Ours | 0.6338 | 0.4112 | 0.5410 | 17.6 | 0.2 | 28.1 | 0.3674 | 0.2043 | 0.3508 | 30.3 | 1.0 | 33.4 |
| Ours-ta | 1.2 | |||||||||||
4.4. Overall Comparison
The results of all methods are summarized in Table 2, from which we have the following findings.
(1) As expected, traditional single-turn open-domain QA methods, i.e. DrQA and BERTserini, perform worse than the conversational QA methods, since they consider no historical context. And thus they fail to solve the elliptical and coherence problems in conversations. Moever, the methods based on a BERT reader, i.e. BERTserini, ORConvQA, and “Ours”, have a significant improvement over DrQA, a RNN based reader. This indicates pretrained BERT is more powerful than RNN in producing semantic representations.
(2) The dense retriever based methods, including ORConvQA and “Ours”, surpass the BM25 retriever based methods. This is also verified in the single-turn QA (Lee et al., 2019; Karpukhin et al., 2020). On the one hand, the semantic similarities can be learned and reflected via the distances in the embedding space. On the other hand, the dense retrievers allow joint learning of different components in the conversational open-domain QA pipeline.
(3) Our method achieves the best performance, substantially surpassing all baselines. In specific, our method has a dense retriever and a BERT reader, outperforming DrQA and BERTserini consistently. Although our method has the same ranker and reader as ORConvQA, our method still considerably surpasses it. This verifies that our proposed graph-guided and multi-round dynamic retrieval method is able to provide a better list of passages containing more relevant passages to the following ranker and reader.
(4) Both ORConvQA and “Ours” with true history answers surpass with predicted history answers. This demonstrates that the history answers indeed provide useful and necessary information for the current question understanding, which is consistent with the observation on the QuAC dataset (Choi et al., 2018). “Ours-ta” significantly outperforms ORConvQA-ta, and it improves the recall to 0.84. That is because that our proposed Explorer fully takes advantages of the history answers by activates them in the passage graph. Therefore, when true history answers available, gold passages can be easily found via the graph structure.
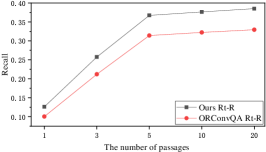
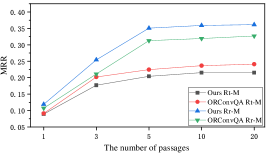
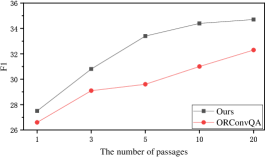
To justify the performance of the retrieval passage list, we compared the performance of our model and the best baseline ORConvQA by varying the number of retrieved passages . From Figure 5, our observations are as follows,
(1) Looking at both Figure 5(a) and 5(b), we can see that when the number of returned passages increases, both Recall and MRR rise. This is because more and more gold passages are retrieved with the increased number of returned passages. We can also find that the F1 score increases fast at the beginning and then gradually degrades. This shows that although increasing the number of returned passages benefits Recall and MRR, it also becomes a heavy burden to the reader as more noisy passages are also delivered to it.
(2) In terms of Rt-R, “Ours” outperforms ORConvQA significantly. The retrieved passages of ours contain more gold passages, because our proposed explorer find more relevant passages via the graph structure. But in terms of Rt-M, ORConvQA exceeds “Ours”. It may be because of the GAT layer, which allows the embeddings become more similar to the surroundings. Thus, it is easier for our explorer to retrieve more gold passages and their neighbors but cannot precisely distinguish them. However, compared to MRR, improving recall is more important for the retriever in the pipeline, because the following ranker can further re-rank the passages in the list. As shown in Table 2, the Rr-M of ours outperforms that of ORConvQA, demonstrating that our ranker works well and provides a complementation to our explorer.
4.5. Component-wise Evaluation
We further tested the variants of our model to further verify the effectiveness of the components in the pipeline.
-
•
Ours w/o Ranker: The ranker is excluded from the pipeline. And the ranker’s score is removed from the final predicted score in Eqn.(15).
-
•
Ours w/o DHM: DHM is excluded from the pipeline. That is, the question representation vector is generated as described in the first round of retrieval. Since there is no dynamic history modeling, there is no multi-round retrieval process and no relevance feedback from the retriever.
-
•
Ours w/o Explorer: The Explorer is excluded from the pipeline. That is, the passage list rather than the list is delivered to the ranker and the reader.
| Methods | Dev | Test | ||||||||||
| Rt-R | Rt-M | Rr-M | H-Q | H-D | F1 | Rt-R | Rt-M | Rr-M | H-Q | H-D | F1 | |
| Ours w/o DHM | 0.5997 | 0.3988 | 0.5025 | 17.6 | 0.2 | 27.5 | 0.3350 | 0.1661 | 0.3157 | 30.3 | 1.0 | 32.6 |
| Ours w/o Explorer | 0.5846 | 0.3900 | 0.4981 | 17.5 | 0.0 | 27.3 | 0.2494 | 0.1351 | 0.2295 | 27.5 | 0.9 | 29.7 |
| Ours w/o Ranker | 0.6220 | 0.4057 | N/A | 17.6 | 0.2 | 27.9 | 0.3423 | 0.1892 | N/A | 20.4 | 1.0 | 33.1 |
| Ours | 0.6338 | 0.4112 | 0.5410 | 17.6 | 0.2 | 28.1 | 0.3674 | 0.2043 | 0.3508 | 30.3 | 1.0 | 33.4 |
We compared these three variants, and summarized the results in Table 3. By jointly analyzing Table 3, we gained the following insights.
(1) Removing the ranker component degrades the QA performance. To be more specific, “Ours w/o Ranker” drops by 0.3 in terms of F1. This statistic reveals the effectiveness of the ranker component. Although the ranker loss does not influence the retriever, the retriever performance also decreases. This is because that the joint training mechanism can improve all different components.
(2) “Ours” surpasses “Ours w/o Explorer”, which indicates that incorporating the passage graph is indeed beneficialin boosting the performance. Moreover, compared with “Ours w/o Ranker”, the performance of “Ours” drops more, which again reflects the effectiveness of our graph-guided retrieval component.
(3) “Ours” shows the consistent improvements over “Ours w/o DHM”. The improvement in terms of F1 is 0.8. Such phenomenon clearly reflects the great advantage of our novel multi-round dynamic retrieval method.
(4) By comparing three variants, it is clear that when the Explorer is excluded, the system performance drops the most. We believed that the improvement of our method comes from the graph guided retrieval. Meanwhile, when the Ranker is excluded, it only causes less impact on the overall performance.
| Current question | History questions | Attention | 1-round | 2-round | Explorer | Ranker |
| Weights | Retrieval | Retrieval | ||||
| Did he play any live shows? | What led Hank Snow to Nashville? | 0.3781 | [1 0 0 0 0] | [1 0 0 0 0] | [0 0 1 0 0] | [1 0 0 0 0] |
| Where did he get his start in Nasville? | 0.2049 | |||||
| What was his most popular song? | 0.2313 | |||||
| Did he win any awards | 0.1858 | |||||
| Why did he burn it? | Did Varg Vikernes commit any arson? | 0.5521 | [0 0 0 0 0] | [0 0 0 0 0] | [0 0 0 0 1] | [1 0 0 0 0] |
| When was the first case? | 0.4479 | |||||
| Did he accept and appear | What was Sakis Rouvas’ first | 1 | [0 0 0 0 0] | [0 0 0 1 0] | [0 0 0 0 1] | [0 0 1 0 0] |
| on the show? | tv appearance? |
4.6. Additional Analyses
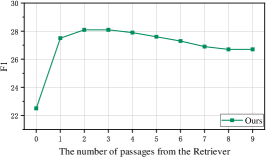
Impact of the number of passages in . As mentioned in Section 3.2, the Retriever component retrieves passages and then Explorer utilizes these passages to activate the corresponding nodes in the passage graph. Therefore, is an import hyper-parameter that needs to be explored. To this end, we carried out experiments on the development set to verify the impact of the number of passages in . The choices of are from to , and the comparison results are illustrated in Figure 6. It demonstrates that if the passages from the Retriever are not included to activate the nodes, the performance drops a lot. This is because that the retrieval result help locate an appropriate area in the big passage graph, and thus it contributes to the retrieval of the gold passage. Besides, as the number of passages from the Retriever increases, the F1 score rises and then gradually degrades. This experimental result tells us that more seed nodes do not represent better performance, because it also make it more difficult to retrieve the gold one when the number of nodes in the sub-graph gets larger.
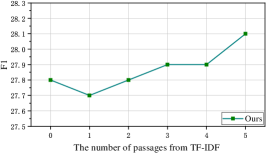
Impact of the number of passages from TF-IDF. Similarly, the Explorer utilizes the passages from TF-IDF to activate the nodes in the passage graph. Therefore, we conducted experiments to explore the number of passages from TF-IDF, and the number is set from to . The results are summarized in Figure 6. We can observe that selecting a certain amount of passages from TF-IDF as seed nodes benefiting the QA system. However, the performance drops when the number of passages is increased from to . This may be due to the fact that the quality of the passage list from TF-IDF is not as good as that from the dense retriever, thus the position of the gold passage is not at the front. And as the number of passages increases, the F1 score gradually rises because more and more relevant passages are added.
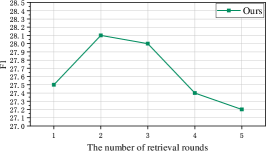
Impact of the number of retrieve rounds. As claimed before, our proposed DHM makes the multi-round retrieval possible, thus it is worth to exploit the number of retrieval rounds. However, due to the limitation of the GPU memory, we only tuned this value on the dev set when evaluating the system. The results are shown in Figure 6. We found that increasing the retrieval rounds does not improve the performance continuously. On the one hand, we did not tune the number of retrieval rounds in the training process. On the other hand, multi-round retrieval may bring more noise and probably suffer from the error propagation problem.
4.7. Case study
To gain deeper insights into the performance of our proposed method in conversational open-domain QA, we listed examples in Table 4. Each example includes the current question, history questions, and attention weights. To illustrate our proposed graph-guided and multi-round retrieval method, we also listed the labels of the retrieved passages from the 1-round retrieval, 2-round retrieval, the Explorer, and the Ranker. From examples in Table 4, we had the following observations.
Current questions. (1) Analyzing the current questions, we found that the coreference problem is common. For example, the pronoun “he” in question “Did he play any live shows?” refers to the name “Hank Snow” in the first history question. (2) It is also observed that there may be two coreferences in one question. For example, for the question “Did he accept and appear on the show”, “he” and “the show” refer to “Sakis Rouvas” and “the first tv appearance” in the history question, respectively. (3) Moreover, the current question may depend on the history answers. For the second question “Why did he burn it?”, we cannot clarify what the word “it” means only based on the history questions, and which turns out to be “the Fantoft Stave Church” in the previous answer “On 6 June 1992, the Fantoft Stave Church, dating from the 12th century and considered architecturally significant, was burned.”. This observation is consistent with our experiment results that “Ours-ta” and ORConvQA-ta largely surpass the ones than that without the previous true answers.
Attention weights. (1) By jointly analyzing the history questions and attention weights, we found that the attention weights approximately reflect the importance of history questions. For example, in the first and second example, the first history question obtains the largest attention score. This adheres to our intuition because the first history question usually mentions the topic of the conversation. (2) It surprises us that the second history question of the second example also achieves a comparative attention score. As claimed before, in the second example, the gold passage and answer of the second history question provide important information to help understand the current question. Therefore, a comparative attention score becomes reasonable because it makes it easier to retrieve the corresponding evidence to clarify the current question. (3) The attention weights are not significantly discriminative. For example, in the first example, the attention weight of the fourth history question is 0.1858 although it may only provide little of useful information. This is partly due to the fact the questions in a conversation are always related more or less, since they usually have a same or similar topic.
Retrieval result. (1) From the result of the 1-round of retrieval, we found that it is easier for the dense retriever to handle the simple question, like the first example that contains one pronoun. However, for some more complex questions, it seems that it works not so well. (2) Analyzing the result of 2-round of retrieval, we found that it can make a supplement for the 1-round of retrieval in some cases. For example, in the third example, 1-round of retrieval does not retrieve the gold passage but 2-round of retrieval does. This may illustrate our dynamically multi-round retrieval method works partly due to its ability of handling the complex questions. And this observation is consistent with some recent studies (Xiong et al., 2020; Das et al., 2018) that focus on applying the multi-round retrieval method to answer the complex questions in open-domain QA. (3) It also can be observed that the Explorer obtains the best retrieval result, which is consistent with the experiment results in Section 4.4. For example, in the second example in Table 4, the Explorer retrieves the gold passage while both the 1-round and 2-round of retrieval do not. This is because our proposed Explorer models the relation among answers in the conversation. However, the position of the gold passage in the result of the Explorer is not as front as in the result of the Retriever. This is may be because of the graph neural network, but it is acceptable because the main target of retrieval is to improve the recall as much as possible. And fortunately, the following Ranker component refines the rank list.
5. Conclusion and Future Work
In this work, we present a novel conversational open-domain QA method, including DHM, Retriever, Explorer, Ranker, and Reader. Different from the previous work, our method focuses on exploiting the relations among answers across the conversation rather than only utilizing the historical context to enhance the current question. Specifically, we design the Explorer, which explores the neighbors of the passages from the Retriever, TF-IDF, and history answers via the passage graph. Moreover, we utilize the relevance feedback to dynamically attend the useful information of the historical context. Based on the dynamic question embeddings, we develop the multi-round retrieval method to retrieve more evidence for the subsequent answer extraction. To justify our method, we perform extensive experiments on the public dataset, and the experimental results demonstrate the effectiveness of our model.
In future, we plan to deepen and widen our work from the following aspects: (1) In this work, we utilized the hyperlinks in Wikipedia to construct the passage graph. Due to the practical concern that not all passages comes from Wikipedia, we will extend our method to the situation that the hyperlinks are hard to obtain by introducing the knowledge graphs. (2) the OR-QuAC dataset is from the conversational MCR area. There are still some differences between conversational open-domain QA and conversational MCR. Thus, it is necessary to conduct a dataset more suitable for the real conversational open-domain QA, where people ask questions for the purpose of their real information need. And (3), as shown in the Case Study, there are still complex questions in conversational QA. We will focus on these complex questions in our future work.
References
- (1)
- Asai et al. (2020) Akari Asai, Kazuma Hashimoto, Hannaneh Hajishirzi, Richard Socher, and Caiming Xiong. 2020. Learning to Retrieve Reasoning Paths over Wikipedia Graph for Question Answering. In International Conference on Learning Representations.
- Chang et al. (2019) Wei-Cheng Chang, X Yu Felix, Yin-Wen Chang, Yiming Yang, and Sanjiv Kumar. 2019. Pre-training Tasks for Embedding-based Large-scale Retrieval. In International Conference on Learning Representations.
- Chen et al. (2017) Danqi Chen, Adam Fisch, Jason Weston, and Antoine Bordes. 2017. Reading Wikipedia to Answer Open-Domain Questions. In Proceedings of the Annual Meeting of the Association for Computational Linguistics. ACL, 1870–1879.
- Chen et al. (2020) Yu Chen, Lingfei Wu, and Mohammed J. Zaki. 2020. GraphFlow: Exploiting Conversation Flow with Graph Neural Networks for Conversational Machine Comprehension. In Proceedings of the International Joint Conference on Artificial Intelligence. AAAI, 1230–1236.
- Choi et al. (2018) Eunsol Choi, He He, Mohit Iyyer, Mark Yatskar, Wen-tau Yih, Yejin Choi, Percy Liang, and Luke Zettlemoyer. 2018. QuAC: Question Answering in Context. In Proceedings of the International Conference on Empirical Methods in Natural Language Processing. ACL, 2174–2184.
- Christmann et al. (2019) Philipp Christmann, Rishiraj Saha Roy, Abdalghani Abujabal, Jyotsna Singh, and Gerhard Weikum. 2019. Look before you hop: Conversational question answering over knowledge graphs using judicious context expansion. In Proceedings of the International Conference on Information and Knowledge Management. ACM, 729–738.
- Dalton et al. (2020) Jeffrey Dalton, Chenyan Xiong, Vaibhav Kumar, and Jamie Callan. 2020. Cast-19: A dataset for conversational information seeking. In Proceedings of the International Conference on Research and Development in Information Retrieval. ACM, 1985–1988.
- Das et al. (2018) Rajarshi Das, Shehzaad Dhuliawala, Manzil Zaheer, and Andrew McCallum. 2018. Multi-step Retriever-Reader Interaction for Scalable Open-domain Question Answering. In International Conference on Learning Representations.
- Devlin et al. (2019) Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the International Conference of the North American Chapter of the Association for Computational Linguistics. ACL, 4171–4186.
- Elgohary et al. (2019) Ahmed Elgohary, Denis Peskov, and Jordan Boyd-Graber. 2019. Can You Unpack That? Learning to Rewrite Questions-in-Context. In Proceedings of the International Conference on Empirical Methods in Natural Language Processing. ACL, 5920–5926.
- Elgohary et al. (2018) Ahmed Elgohary, Chen Zhao, and Jordan Boyd-Graber. 2018. A dataset and baselines for sequential open-domain question answering. In Proceedings of the International Conference on Empirical Methods in Natural Language Processing. 1077–1083.
- Feldman and El-Yaniv (2019) Yair Feldman and Ran El-Yaniv. 2019. Multi-Hop Paragraph Retrieval for Open-Domain Question Answering. In Proceedings of the Annual Meeting of the Association for Computational Linguistics. ACL, 2296–2309.
- Harman (1992) Donna Harman. 1992. Relevance feedback revisited. In Proceedings of the International Conference on Research and Development in Information Retrieval. ACM, 1–10.
- Hashemi et al. (2020) Helia Hashemi, Hamed Zamani, and W Bruce Croft. 2020. Guided Transformer: Leveraging Multiple External Sources for Representation Learning in Conversational Search. In Proceedings of the International Conference on Research and Development in Information Retrieval. ACM, 1131–1140.
- Huang et al. (2018) Hsin-Yuan Huang, Eunsol Choi, and Wen-tau Yih. 2018. FlowQA: Grasping Flow in History for Conversational Machine Comprehension. In International Conference on Learning Representations.
- Karpukhin et al. (2020) Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. 2020. Dense Passage Retrieval for Open-Domain Question Answering. In Proceedings of the International Conference on Empirical Methods in Natural Language Processing. ACL, 6769–6781.
- Lan et al. (2019) Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, and Radu Soricut. 2019. ALBERT: A Lite BERT for Self-supervised Learning of Language Representations. In International Conference on Learning Representations.
- Lee et al. (2019) Kenton Lee, Ming-Wei Chang, and Kristina Toutanova. 2019. Latent Retrieval for Weakly Supervised Open Domain Question Answering. In Proceedings of the Annual Meeting of the Association for Computational Linguistics. ACL, 6086–6096.
- Lu et al. (2019) Xiaolu Lu, Soumajit Pramanik, Rishiraj Saha Roy, Abdalghani Abujabal, Yafang Wang, and Gerhard Weikum. 2019. Answering complex questions by joining multi-document evidence with quasi knowledge graphs. In Proceedings of the International Conference on Research and Development in Information Retrieval. ACM, 105–114.
- Min et al. (2019) Sewon Min, Danqi Chen, Luke Zettlemoyer, and Hannaneh Hajishirzi. 2019. Knowledge Guided Text Retrieval and Reading for Open Domain Question Answering. CoRR abs/1911.03868 (2019).
- Qu et al. (2020) Chen Qu, Liu Yang, Cen Chen, Minghui Qiu, W. Bruce Croft, and Mohit Iyyer. 2020. Open-Retrieval Conversational Question Answering. In Proceedings of the International conference on research and development in Information Retrieval. ACM, 539–548.
- Qu et al. (2019) Chen Qu, Liu Yang, Minghui Qiu, Yongfeng Zhang, Cen Chen, W Bruce Croft, and Mohit Iyyer. 2019. Attentive history selection for conversational question answering. In Proceedings of the International Conference on Information and Knowledge Management. ACM, 1391–1400.
- Reddy et al. (2019) Siva Reddy, Danqi Chen, and Christopher D Manning. 2019. CoQA: A Conversational Question Answering Challenge. Transactions of the Association for Computational Linguistics 7, 0 (2019), 249–266.
- Ren et al. (2020) Pengjie Ren, Zhumin Chen, Zhaochun Ren, Evangelos Kanoulas, Christof Monz, and Maarten de Rijke. 2020. Conversations with Search Engines. arXiv preprint arXiv:2004.14162 (2020).
- Saha et al. (2018) Amrita Saha, Vardaan Pahuja, Mitesh Khapra, Karthik Sankaranarayanan, and Sarath Chandar. 2018. Complex sequential question answering: Towards learning to converse over linked question answer pairs with a knowledge graph. In Proceedings of the AAAI Conference on Artificial Intelligence. AAAI, 705–713.
- Shen et al. (2019) Tao Shen, Xiubo Geng, QIN Tao, Daya Guo, Duyu Tang, Nan Duan, Guodong Long, and Daxin Jiang. 2019. Multi-Task Learning for Conversational Question Answering over a Large-Scale Knowledge Base. In Proceedings of the International Conference on Empirical Methods in Natural Language Processing. ACL, 2442–2451.
- Vakulenko et al. (2020) Svitlana Vakulenko, Shayne Longpre, Zhucheng Tu, and Raviteja Anantha. 2020. Question Rewriting for Conversational Question Answering. arXiv preprint arXiv:2004.14652 (2020).
- Veličković et al. (2018) Petar Veličković, Guillem Cucurull, Arantxa Casanova, Adriana Romero, Pietro Liò, and Yoshua Bengio. 2018. Graph Attention Networks. In International Conference on Learning Representations.
- Voskarides et al. (2020) Nikos Voskarides, Dan Li, Pengjie Ren, Evangelos Kanoulas, and Maarten de Rijke. 2020. Query Resolution for Conversational Search with Limited Supervision. In Proceedings of the International Conference on Research and Development in Information Retrieval. ACM, 921–930.
- Wang et al. (2019) Bingning Wang, Ting Yao, Qi Zhang, Jingfang Xu, Zhixing Tian, Kang Liu, and Jun Zhao. 2019. Document Gated Reader for Open-Domain Question Answering. In Proceedings of the International Conference on Research and Development in Information Retrieval. ACM, 85–94.
- Wang et al. (2018a) Shuohang Wang, Mo Yu, Xiaoxiao Guo, Zhiguo Wang, Tim Klinger, Wei Zhang, Shiyu Chang, Gerry Tesauro, Bowen Zhou, and Jing Jiang. 2018a. R3: Reinforced Ranker-Reader for Open-Domain Question Answering. In AAAI Conference on Artificial Intelligence. AAAI.
- Wang et al. (2018b) Shuohang Wang, Mo Yu, Jing Jiang, Wei Zhang, Xiaoxiao Guo, Shiyu Chang, Zhiguo Wang, Tim Klinger, Gerald Tesauro, and Murray Campbell. 2018b. Evidence Aggregation for Answer Re-Ranking in Open-Domain Question Answering. In International Conference on Learning Representations.
- Xiong et al. (2020) Wenhan Xiong, Xiang Lorraine Li, Srini Iyer, Jingfei Du, Patrick Lewis, William Yang Wang, Yashar Mehdad, Wen-tau Yih, Sebastian Riedel, Douwe Kiela, et al. 2020. Answering Complex Open-Domain Questions with Multi-Hop Dense Retrieval. arXiv preprint arXiv:2009.12756 (2020).
- Yang et al. (2019) Wei Yang, Yuqing Xie, Aileen Lin, Xingyu Li, Luchen Tan, Kun Xiong, Ming Li, and Jimmy Lin. 2019. End-to-End Open-Domain Question Answering with BERTserini. In Proceedings of the International Conference of the North American Chapter of the Association for Computational Linguistics. ACL, 72–77.
- Zhang et al. (2020) Shuo Zhang, Zhuyun Dai, Krisztian Balog, and Jamie Callan. 2020. Summarizing and Exploring Tabular Data in Conversational Search. In Proceedings of the International Conference on Research and Development in Information Retrieval. ACM, 1537–1540.
- Zheng et al. (2019) Yukun Zheng, Jiaxin Mao, Yiqun Liu, Zixin Ye, Min Zhang, and Shaoping Ma. 2019. Human behavior inspired machine reading comprehension. In Proceedings of the International Conference on Research and Development in Information Retrieval. ACM, 425–434.