NewReferences
A Graphical Point Process Framework for Understanding Removal Effects in Multi-Touch Attribution
Abstract
Marketers employ various online advertising channels to reach customers, and they are particularly interested in attribution – measuring the degree to which individual touchpoints contribute to an eventual conversion. The availability of individual customer-level path-to-purchase data and the increasing number of online marketing channels and types of touchpoints bring new challenges to this fundamental problem. We aim to tackle the attribution problem with finer granularity by conducting attribution at the path level. To this end, we develop a novel graphical point process framework to study the direct conversion effects and the full relational structure among numerous types of touchpoints simultaneously. Utilizing the temporal point process of conversion and the graphical structure, we further propose graphical attribution methods to allocate proper path-level conversion credit, called the attribution score, to individual touchpoints or corresponding channels for each customer’s path to purchase. Our proposed attribution methods consider the attribution score as the removal effect, and we use the rigorous probabilistic definition to derive two types of removal effects. We examine the performance of our proposed methods in extensive simulation studies and compare their performance with commonly used attribution models. We also demonstrate the performance of the proposed methods in a real-world attribution application.
Keywords: Granger Causality, Graphical Model, High Dimensional Statistics, Multi-Touch Attribution, Point Process.
1 Introduction
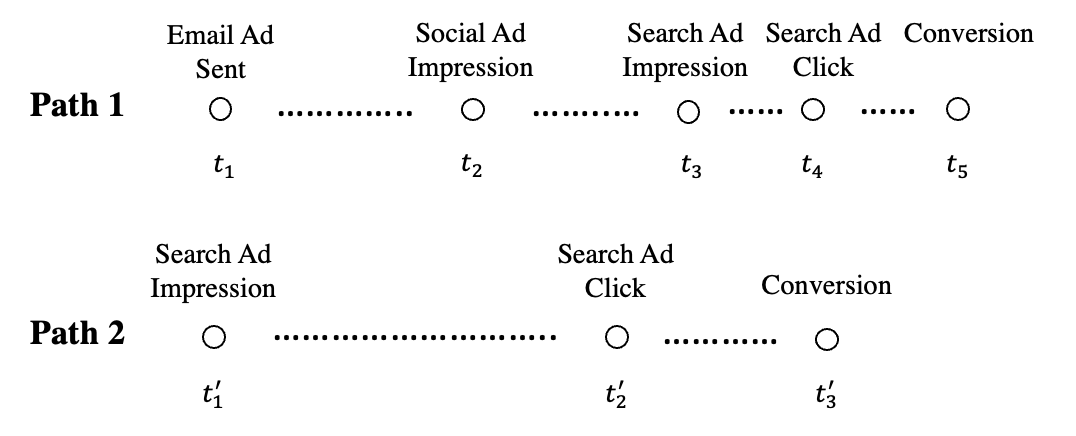
Attribution is a classic problem. The granularity of data plays an important role in studying this problem. Early work investigating synergies across channels employed aggregate data to extract insights for customer targeting and marketing budget allocation (e.g., Naik & Raman, 2003). With advances in online data collection, individual customer-level path-to-purchase data, describing when and how individual customers interact with various channels in their purchase funnels, becomes available. Such data availability led attribution modeling to a new phase. Paths to purchases differ among customers, and the temporal distances between touchpoints also differ. In Figure 1, we provide two illustrative examples of customer-level path-to-purchase data. As shown in Path 1, one customer received an email ad about the focal product at time , and then this customer saw an ad about the product on social media at time . Later, this customer searched for this product in a search engine, and its paid ad appeared at the top of the search result page at time . This customer clicked on this product ad at time to visit the product’s website and then purchased the product at time . As shown in Path 2, another customer saw a search engine ad about this product at time and then clicked on this ad at time to visit the product’s website and converted at time .
Researchers have started to utilize customer-level path-to-purchase data for attribution modeling (e.g., Xu et al., 2014; Li & Kannan, 2014; Anderl et al., 2016). In recent years, we have witnessed an increasing number of online marketing channels and types of touchpoints. The channels include various search engines (e.g., Google, Bing), social media platforms (e.g., LinkedIn, Twitter, Instagram, Tiktok, Snapchat, WhatsApp), display ads, emails, web banners, app banners, customer support, desktop notification, and many others. Meanwhile, there are a lot of different types of touches within each search engine/platform/media. For example, ad impressions and ad clicks are different touchpoints that may have different conversion effects. To enable granular marketing, marketers are interested in evaluating the marketing performance of each search engine/platform/media and even the performance of a particular type of touchpoints. But in most existing research about attribution modeling, touchpoints on the path are typically aggregated to the channel they belong to (e.g., search, display, email); different search engines/platforms/media within the same channels are not differentiated, and different types of touchpoints within the same search engine/platform/media are not differentiated either. For example, both search ad impression and click are considered customers’ interactions with the search channel and are not studied separately; touchpoints via Instagram, Twitter, and other social media platforms are not differentiated but studied as one social media channel as a whole. In addition, in most existing studies, only a few channels are studied simultaneously.
Similar to recent work in attribution modeling, we also focus on the path-to-purchase data. But we aim to achieve finer granularity by conducting attribution at the path level and providing touchpoint-wise scores. Namely, we aim to allocate appropriate credit for the conversion to each touchpoint or a subset of touchpoints for each customer’s path to purchase. By doing this, we can provide attribution scores for both individual touchpoints and channels, which can help marketers make better marketing decisions. Also, we would like to study the touchpoints from more channels simultaneously, which better suits firms’ current needs.
Attributing proper credit to each touchpoint is very challenging, as touchpoints interplay with each other both within-channel and across-channel. For instance, seeing email and social ads may increase a customer’s future probability of searching for the product in a search engine and then clicking the search ad to visit the firm’s website and make an online purchase. Also, a touchpoint (e.g., search ad impression) may trigger the occurrence of a future touchpoint within the same channel (e.g., search ad click), leading to a conversion. The phenomenon that the earlier touches may increase the probability of the occurrence of future touches and the possible conversions are well discussed in Li & Kannan (2014) as carryover effect (through the same channels) and spillover effects (through other channels).
To properly capture both direct and indirect conversion effects of various touchpoints, we must consider the following characteristics in attribution modeling. Firstly, different types of touchpoints may significantly vary in their probability of occurring, exciting other types of touchpoints and affecting purchase conversion. Modeling the multivariate nature of different types of touchpoints is necessary. Secondly, all marketing effects, including conversion effects and the interactive effects among touches, decay over time. It is essential to consider the time interval between two touches in attribution modeling. Solely utilizing the sequence information of the touches ignores such decaying effects, resulting in estimation biases. Thirdly, touchpoints and purchase conversions will likely gather together as clusters on the timeline. In other words, the path-to-purchase data are clumpy (Zhang et al., 2013). Fourthly, the attribution modeling and its estimation methods need to be scalable for analyzing a large number of marketing channels and types of touchpoints.
1.1 Related Literature
The attribution problem has been studied broadly by researchers from both academia and industry for over two decades. In this subsection, we provide a brief overview of existing approaches, and more details can be found in the survey papers (Kannan et al., 2016; Gaur & Bharti, 2020). Existing attribution models can be classified into two major categories: rule-based heuristics and data-driven approaches.
1.1.1 Rule-based Heuristics
Simple rule-based heuristics are widely used for multi-touch attribution in practice. For example, the last-touch attribution method assigns the credit solely to the touchpoint directly preceding the conversion; the first-touch attribution assigns the credit to the first touchpoint in the customer journey; the U-shaped method assigns an equal amount of credit to the first and the last touchpoints while evenly distributing the remaining credit amongst the other touchpoints. These rule-based heuristics can still be easily employed for the path-to-purchase data, but they either ignore the effects of other touchpoints or do not consider the interactive effects among touchpoints. They are also criticized for being biased and lacking rationale justifying their appropriateness as attribution measures (Singal et al., 2022).
1.1.2 Data-driven Approaches
The data-driven approaches mainly consist of incremental value (or removal effect) approaches and Shapley value approaches. The main novelty of previous work in this category comes from the following two perspectives. The majority of research focuses on proposing new models to describe user behavior (e.g., Shao & Li, 2011; Breuer et al., 2011; Danaher & van Heerde, 2018; Xu et al., 2014; Zhao et al., 2019), while the others focus on studying the attribution scoring methods such as the justification and fairness of Sharpley value (e.g., Dalessandro et al., 2012; Singal et al., 2022).
-
•
The incremental value (or removal effect) approaches compute the change in the conversion probability when one touchpoint or a set of touchpoints are removed from a customer’s path. As a result, the change in the conversion probability is also known as the removal effect. In the past decade, researchers have developed a variety of models to describe consumer behavior, such as regression models (e.g., Shao & Li, 2011; Breuer et al., 2011; Danaher & van Heerde, 2018; Zhao et al., 2019), Markov models (Yang & Ghose, 2010; Anderl et al., 2016; Berman, 2018; Kakalejčík et al., 2018), Bayesian models (e.g., Li & Kannan, 2014), time series models (Kireyev et al., 2016; De Haan et al., 2016), survival theory-based models (Zhang et al., 2014; Ji et al., 2016), deep learning models (Li et al., 2018; Kumar et al., 2020), and so on. The main novelty of previous work in this line comes from modeling user behavior. Most of them consider the touchpoints as deterministic rather than stochastic events and ignore the dynamic interactions among these marketing communications and interventions (Xu et al., 2014). However, it is important to account for the exciting effects of these touchpoints. Also, as pointed out by Singal et al. (2022), there exists little (if any) theoretical justification for the attribution based on the incremental value.
-
•
The Shapley value approaches apply the game theory-based concept of Shapley value (Shapley, 1953) for allocating credit to individual players in a cooperative game. Due to the nature of the Shapley value, it typically provides channel-level but not path-level attribution or touchpoint-wise attribution scores. In addition, existing methods based on Shapley value did not take into account the temporal distance between touchpoints in the path-to-purchase data, including (Dalessandro et al., 2012; De Haan et al., 2016; Kireyev et al., 2016; Berman, 2018; Singal et al., 2022). For example, the most recent work by Singal et al. (2022) used a discrete Markov chain model to describe the transitions in a customer’s state along the customer journey through the conversion funnel, which does not incorporate the temporal distance when the customer moves from a state to another state in one transition.
-
•
Attribution has also been investigated from other angles. For example, Xu et al. (2014) proposed a Bayesian method using a multivariate point process and calculated the attribution scores using simulations. However, this simulation-based attribution method is computationally expensive and unable to provide a path-level score for each observed path with a conversion.
1.2 Our Approach
To the best of our knowledge, none of the existing models can study the full relational structure of numerous types of touches across multi-channels, which is essential to understanding both the direct and indirect conversion effects of each type of touch and the corresponding channels. Given the potentially large number of various types of touchpoints under study, a model that can simultaneously study the interactive and conversion effects of these many types of touchpoints is in need. To fill these research gaps, we make the following efforts in this work:
Firstly, we develop a novel graphical point process model for attribution to describe customer behavior in the multi-channel setting using customer-level path-to-purchase data. The graphical model not only learns the direct conversion effects of numerous types of touchpoints but also estimates exciting effects among different types of touches simultaneously.
Secondly, we propose graphical attribution methods to allocate proper conversion credit, called the attribution score, to individual touchpoints and the corresponding channels for each customer’s path to purchase. Our proposed methods consider the attribution score as the removal effect. We derive two versions of the removal effect using the temporal point process of conversion and the graphical structure.
Thirdly, we propose a regularization method for simultaneous edge selection and parameter estimation. We design a customized alternating direction method of multipliers (ADMM) to solve this optimization problem in an efficient and scalable way. In addition, we provide a theoretical guarantee by establishing the asymptotic theory for parameter estimates.
In what follows, we briefly introduce the idea of our proposed graphical point process model. As the first step, we model path-to-purchase data as multivariate temporal point processes. More specifically, the proposed method considers individual paths of touchpoints as independent event streams. Each stream consists of various types of touchpoints (events) occurring irregularly and asynchronously on a common timeline. To capture the dynamic inter-dependencies (e.g., exciting patterns) among touches from a large number of independent event streams, the proposed method models event streams as multivariate temporal point processes. The multivariate temporal point processes are commonly characterized using conditional intensity functions (Gunawardana et al., 2011), which describe the instantaneous rates of occurrences of future touchpoints given the history of prior touchpoints. The proposed model can consider the temporal distances and the clumpy nature of touches. Xu et al. (2014) is the first paper to tackle attribution modeling using multivariate temporal point processes. They consider advertisement clicks and purchases as dependent random events in continuous time and cast the model in the Bayesian hierarchical framework.
The proposed model further introduces a Granger causality graph that is a directed graph to represent the dependencies among various event types. The nodes in the graph represent event types, and directed edges depict the historical influence of one type of event on the others, which are called the Granger causality relations (Granger, 1969). The proposed graphical model allows for a large number of online marketing channels and types of touchpoints. By fully capturing the Granger causality relations among various event types, the proposed model simultaneously measures how the numerous types of touches affect conversion, as well as the exciting effects of different types of touches within and across channels.
Based on the learned graph, we propose graphical attribution methods to assign proper credit for conversions to each type of touchpoint or a corresponding channel. The conversion credit, also called attribution scores, are calculated at the path level from a granular point of view. They can be aggregated to the channel level when necessary. The first attribution method measures the direct effect of the event(s) of interest on the conversion. This is the relative change in conversion intensity when we remove only the event(s) of interest from the path and assume other touchpoints on the path remain unaffected. The second attribution method fully uses the graphical causality structure and measures the total removal effect of the event(s) of interest. The corresponding attribution score is the marginal lift of the expected intensity of conversion by considering not only the removal of the events of interest but also the potential loss of subsequent customer-initiated events.
We examine the performance of our proposed methods in simulation studies and compare their performance with commonly used attribution models using two sets of simulated data. One data set is simulated from the multivariate Hawkes process (Hawkes, 1971). The other data set is simulated from a modified version of the Digital Advertising System Simulation (DASS) developed by Google Inc. The simulated data includes online customer browsing behavior and injected advertising events that impact customer behavior. Our proposed methods outperform the benchmark models in measuring channels’ contribution to conversions. Moreover, we demonstrate the performance of the proposed methods in a real-world attribution application.
1.3 Our Contributions
We provide practitioners with a new attribution modeling tool to understand how different marketing efforts contribute to conversions at a finer granularity in online multi-channel settings, where there exist a potentially large number of different types of touchpoints nowadays. Our tool distributes proper credit to individual touchpoints and the corresponding channels by conducting attribution modeling at the individual customer path level. Our tool helps firms’ granular marketing operations, budget allocation, profit maximization, etc.
In addition to the substantive contribution, we have the following methodological contributions to the literature.
Firstly, we contribute to the attribution modeling literature by proposing a graphical point process model to describe customer behavior using individual customer-level path-to-purchase data. We rigorously model the exciting effects of numerous types of touches in this framework and develop an efficient penalized algorithm for model estimation. We apply Granger causality in a marketing context to study the temporal relations among marketing activities. We also establish the asymptotic theory for parameter estimates.
Secondly, our proposed graphical attribution methods contribute to the literature on the incremental value (or removal effect) approaches. We provide a rigorous probabilistic definition of attribution scores and derive two types of removal effects, namely, the direct and total removal effects. We develop a new efficient thinning-based simulation method and a backpropagation algorithm for the calculation of two types of removal effects, respectively.
We organize the rest of the paper as follows. We introduce the proposed graphical point process model in Section 2 and the proposed graphical attribution methods in Section 3. We present the model estimation, computational details, and asymptotic properties in Section 4. We then demonstrate the performance of the proposed method and algorithm with the simulated data in Section 5 and provide an empirical application in Section 6. We conclude this work in Section 7.
2 Graphical Point Process Model
To tackle the attribution problem, we first propose a graphical point process model. This model utilizes customer-level path-to-purchase data to learn the full relational structure among different types of touchpoints. This section introduces the proposed graphical point process model.
Our graphical point process model considers the observed individual paths to purchases as independent event streams, where each stream consists of various types of events (i.e., touchpoints and conversions) occurring irregularly and asynchronously on a common timeline. Suppose there are unique types of events, which can be labeled as . A customer’s path is represented by with , where is the total count of occurred events and is the length of observation. For the -th event , is its timestamp, and is its event label which specifies the type of touchpoint (e.g., social ad impression, social ad click, email sent, email ad click, search ad impression, search ad click, display ad impression, display ad click) or conversion. Without loss of generality, let denote the label of conversion. Given the path , if there exists such that , which means there is a conversion event, then such a path is called a positive path. Otherwise, is called a negative path. Suppose we observe paths, , where is the -th path with length .
To capture the dynamic inter-dependencies among touches from a large number of independent event streams, the proposed framework models event streams as multivariate temporal point processes. It introduces a directed Granger causality graph to represent the dependencies among various types of touchpoints in the event streams. In this section, we first provide a brief overview of the temporal point process and the Granger causality graph. Then we will introduce our proposed model in detail.
2.1 Temporal Point Process
For an event type labeled as , we can describe its occurrence on the timeline as a temporal point process . The function is the number of type- events that happened until time , which is a right-continuous and non-decreasing piece-wise function :
We assume has almost surely step size and does not jump simultaneously. If , then is the number of type- events that occurred during the interval , which can also be denoted by . Putting event types together, we let denote the vector of counting functions . The coordinate , , is characterized by its conditional intensity
which describes the instantaneous rates of occurrence of future type- events. The filtration is the -algebra of all events up to but excluding , referring to the historical information before time .
An example is the multivariate Hawkes process (Hawkes, 1971) with the conditional intensity function
Here is the baseline intensity serving as a background rate of occurrence regardless of historical impact, and is called an impact function. Intuitively, each of the past -events with has a positive contribution to the occurrence of the current type- event by increasing the conditional intensity of event type , and this influence may decrease through time. Such positive influence is called an exciting effect from event type to event type .
2.2 Granger Causality Graph
Let be the set of various types of labeled events (i.e., touchpoints and conversions), whose historical influences on each other are of great interest. We use the Granger causality relations (Granger, 1969) to describe the temporal dependencies among the studied types of touchpoints. If the history of event type helps to predict event type above and beyond the history of event type alone, event type is said to “Granger-cause” event type . The Granger causality was introduced and discussed in the original paper Granger (1969) and follow-up papers (Granger, 1980, 1988), while Sims (1972) gave an alternative definition of Granger causality.
For any event label subset , let be the subprocess . For example, means the subprocess of all the event types other than and . For a temporal point process, the Granger causality is defined below.
Definition 1.
(Local independence (Didelez, 2008)) The temporal point process is locally independent on given , denoted by , if the conditional intensity is measurable with respect to for all . Otherwise, is said to be locally dependent on given with respect to , or .
The above definition was introduced by Didelez (2008) for marked point processes in an interval . Eichler (2012) studied the stationary multivariate point processes like multivariate Hawkes processes in and used the notion “Granger non-causality”. The above definition is equivalent to saying the temporal point process does not Granger-cause with respect to historical information . Otherwise, Granger-causes with respect to . For ease of interpretation, we also say that event type Granger-causes event type in an unambiguous manner.
We use a directed graph like Figure 2 to represent the temporal dependencies among various types of touchpoints in the conversion paths. The node set of the graph represents the set of event types . The edge set represents the Granger causality relations between the various event types. If Granger-causes with respect to , then the directed edge from node to node , denoted by , is said to belong to . Such a graph is called a Granger causality graph. For a multivariate temporal point process, the Granger causality graph is defined below.
Definition 2.
2.3 The Proposed Graphical Point Process Model
We treat each path to purchase as a -dimensional point process . In the attribution problem, there are two categories of event types, firm-initiated event types and customer-initiated event types. The firm-initiated event types (Wiesel et al., 2011) are initiated by firms such as email sent, social ad impression, and display impression. The customer-initiated event types (Bowman & Narayandas, 2001; Wiesel et al., 2011) are initiated by customers or prospective customers, including conversion, search ad impression and click, email click, and so forth. Let and denote the set of firm-initiated event types and the set of customer-initiated event types and thus and . Suppose there are customer-initiated event types for some . Without loss of generality, let with conversion labeled as and . We assume that the point process of the firm-initiated event types is controlled by the firms or ad advertisers strategically. In other words, only serves as an observed input whose conditional intensity function does not require learning. For the point process of customer-initiated event types , we model it through the following conditional intensity:
| (1) |
-
•
is the baseline intensity, which corresponds to the sources of the occurrence of type- events other than the occurrence history of itself and other types of touchpoints, namely the intrinsic tendency of the occurrence.
-
•
, is a bounded, left-continuous kernel function, when and The kernel function describes the shapes of the touchpoints’ impact. For example, accounts for a constant impact of a previous type- event within of its occurrence; works for an exponential decaying impact; can be used when the decaying impact is even faster.
-
•
, is the Granger causality coefficient. The value of describes the scale of the temporal dependence.
To interpret the coefficient , we introduce the following theorem.
Theorem 1.
Assume a point process with conditional intensity functions defined in (1) follows the Granger causality graph . For any event labels and , if the condition holds, then
This result is an adaptation from the case of the multivariate Hawkes process (Eichler, 2012; Xu et al., 2016). Analogous to the multivariate Hawkes process, the meaning of can be described in two cases: implies an exciting effect from event type to event type by increasing its conditional intensity ; the case implies no Granger causality from event type to event type since is not affected by the occurrence of any type- event. By such construction, we can use the matrix to stand for the graphical Granger causality structure for customer-initiated event types.
As the firm-initiated event types are fully controlled by marketers or ad advertisers, in our proposed model, we assume that they are not dependent on other types of events. That is to say, the ground truth of for is known with for any .
3 Graphical Attribution Method
The goal of attribution is to assign proper credit for conversions to each type of touchpoint or a corresponding channel. We adopt the path-level scoring approach to obtain a granular view. This approach does not rely on the distribution of the firm-initiated event types . So it can work for cases where customers are treated with different advertising strategies.
The path-level credit, called the attribution score, represents the potential fractional loss of a conversion on a path given the absence of certain event(s). We will refer to this value by the removal effect of the event(s). In this section, we first derive a version of the removal effect using the temporal point process of conversion – direct removal effect by analyzing the incremental contribution of each touchpoint. Then we fully use the graphical structure and propose another version of the removal effect – total removal effect – which explains the marginal increase in the chance of conversion.
3.1 Direct Removal Effect
In this subsection, we calculate attribution scores using the direct removal effect from the point of view of the graphical point process. We define the direct removal effects (DRE) as the relative change in conversion intensity when we remove only the event(s) of interest from the path and assume other touchpoints on the path remain unaffected. That is, the direct removal effect considers merely the influence of the studied event(s) on an occurrence of conversion and ignores their influence on other events. Graphically speaking, the direct removal effect focuses on the direct Granger causality parent nodes of conversion and does not depend on the hierarchy beyond them.
For a positive path , suppose there is a conversion at for some , that is, . Let be the set of occurred events before whose event labels belong to , where is an arbitrary event label subset. Especially, let stand for , which is the truncated path before . We are interested in the influence of a subset of touchpoints on this conversion and call a removal set. Let denote the point process with respect to path with for . Let be the corresponding filtration . We can calculate the attribution score as the direct removal effect of with respect to path :
| (2) |
The above definition is a general statement that does not depend on any assumptions of point process modeling.
Suppose that the conversion event satisfies model (1), which means the conditional intensity function of this conversion takes the form
| (3) |
We can derive more specific attribution scores based on Equation (2) and (3). For example, the direct removal effect of touchpoint can be calculated by
This expression shows the relationship between the Granger causality graph and the attribution score. A touchpoint can be attributed with a score only if its touchpoint type is a parent node of the conversion node on the graph or . Generally, for a subset of , its direct removal effect is
| (4) |
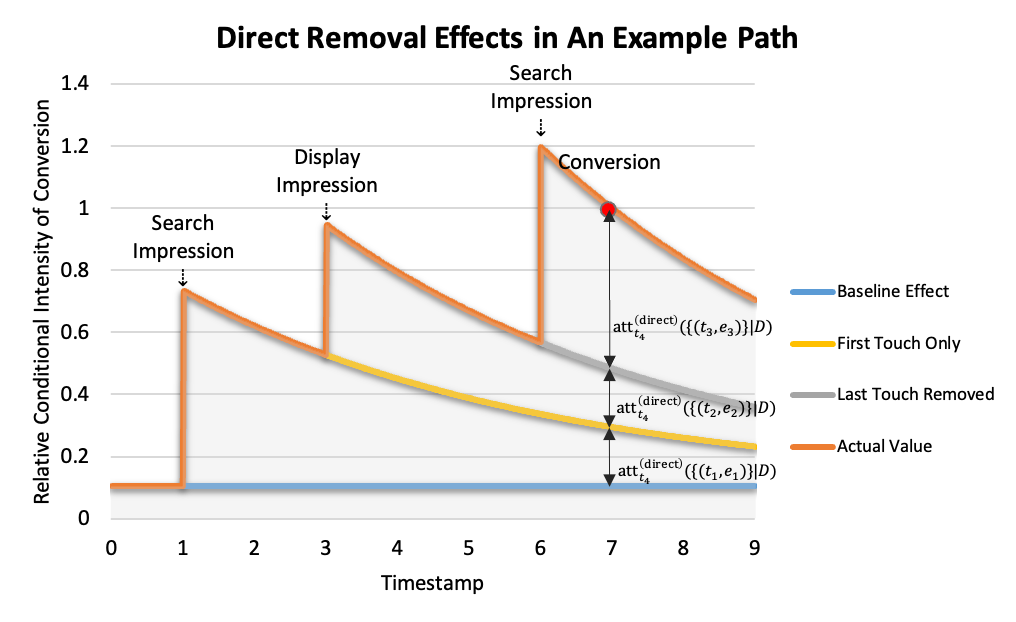
Besides, under model (1), the baseline effect can be defined to be . For example, Figure 3 shows the direct removal effects of touchpoints with respect to a path consisting of three touchpoints and a conversion.
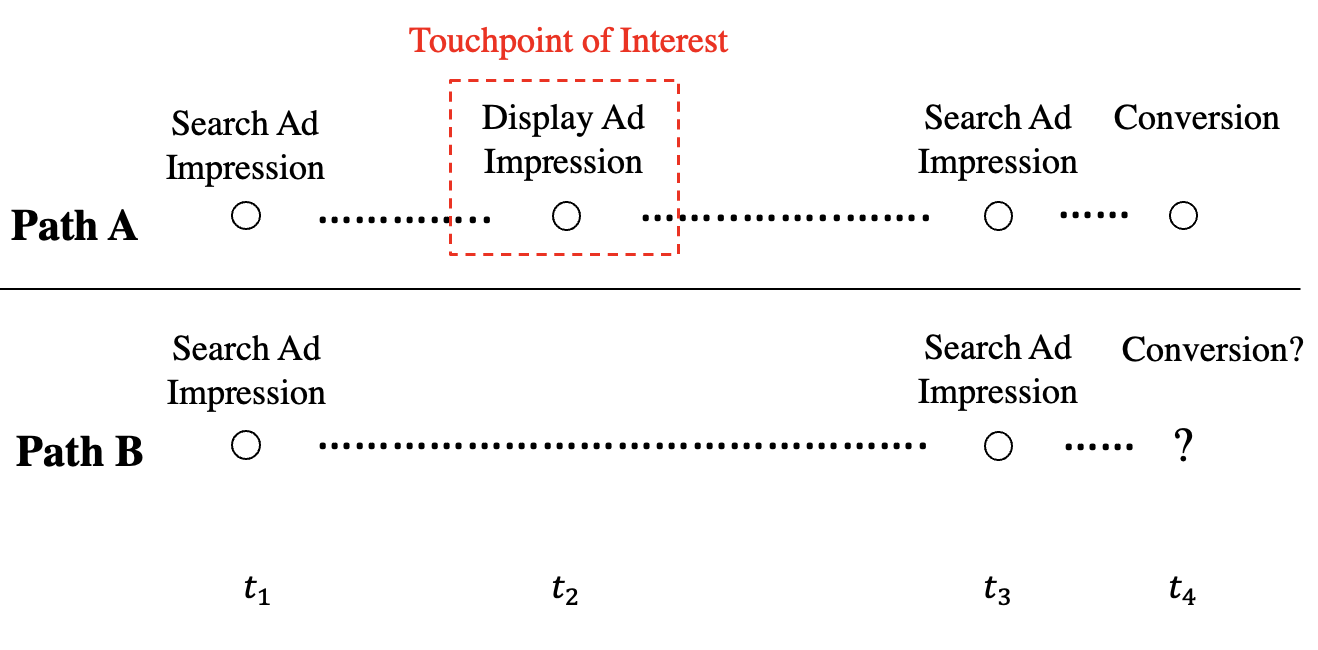
In the following context, we will explain the attribution score’s general form (2) in probability language. Consider an ideal experiment of two customers, A and B, with a toy example shown in Figure 4. Suppose A and B react to touchpoints in the same way. Their conditional intensity functions for customer-initiated event types follow the same model. We observe , the path of A, with a conversion at . Let denote the path of B. Suppose , the touchpoints on are a subset of those on . Assume that there is no information about . Namely, we do not observe whether B converts or not. We can sample the process to obtain a complete path . We exploit the thinning operation for a temporal point process, which uses some definite rule to delete points of a basic point process, yielding a new point process.
Theorem 2.
(Lewis & Shedler, 1979; Ogata, 1981) Assume a univariate temporal point process in with intensity function . Let be the timestamps of . There exists a function satisfying a.s.
For , delete the point at with probability . Then the remaining points form a point process in the interval with intensity function .
We refer to the point process as a background process for the desired point process . In general, Ogata (1981) suggested using a Poisson process as the background process for point process simulation. To sample the , we can look for a constant satisfying for and use the Poisson process with rate as the background process.
With a closer look at the problem, we can find that sampling a Poisson process as the background process is not necessary. The point process of conversion for A, , can also serve as a background process. Based on (3), we have before any occurrence of conversion for B. Theorem 2 tells us that if we delete the conversion at in with probability , then we obtain a process following the distribution described in (3) for B. Compared with (2), this probability is nothing but the direct removal effect of with respect to path .
3.2 Total Removal Effect
The direct removal effect of a given subset of events describes the expected loss of conversion by comparing the path without it to the original path. In this subsection, we study another attribution score that measures the overall influence resulting from removing the subset of events along the path. The corresponding attribution score is the marginal lift of the expected intensity of conversion by considering not only the removal of the events of interest but also the potential loss of other related customer-initiated events.
For example, the direct removal effect of the first touchpoint can be studied through . But removing such a touchpoint in the early stage of the path will result in more than the removal of itself. Some later touchpoints may get affected and tend not to occur. So may not well represent a possible remaining path described by model (1) because is not guaranteed to follow the same model as . In other words, the direct removal effect may not well reflect the overall influence of the removal of the touchpoint.
By model (1), for any (including conversion),
The removal of from may result in the missing of certain subsequent touchpoints as well as paid conversion. The actual remaining path may contain even fewer event occurrences, which yields a subset of . This inspires us to perform the thinning operation to according to Theorem 2 instead of thinning the univariate process only.
Let be the event index of the first event in . Recall the ideal experiment of two customers, A and B. Now we assume that for A and the process of the customer-initiated event types is unknown for B. Let first. By Theorem 2, if we delete the touchpoint in from with probability sequentially for , then the obtained process follows model (1). Suppose is the thinned version of with being the actual removal set. Figure 5 shows a toy example of this idea. As a result, given a subset of a path , its total removal effect (TRE) is defined by
where the conditional expectation is with respect to the actual removal set from the random thinning operation. The algorithm with the thinning operation is summarized in Algorithm 1.

The largest value of is , denoted by for ease of notation. Using the thinning algorithm, we can derive an explicit form of the total removal effect:
During the thinning operation, the value of depends on sampling a sequence of Bernoulli random variables. Let be the Bernoulli random variable for thinning event . Then the conditional probability mass function of is
The above probability mass function could be difficult to implement in practice due to the combinatorial subset calculation. Under model (1), we can change the order of summation to derive the total removal effect according to the linear decomposition of the direct removal effect in (4).
This result implies another iterative algorithm, which is simulation-free and more efficient. The basic idea is to redistribute the obtained scores from the direct removal effect. It adopts an intuitive backpropagation way of scoring as summarized in Algorithm 2, and the backpropagation, introduced by Rumelhart et al. (1986), has been gaining popularity in artificial neural networks.
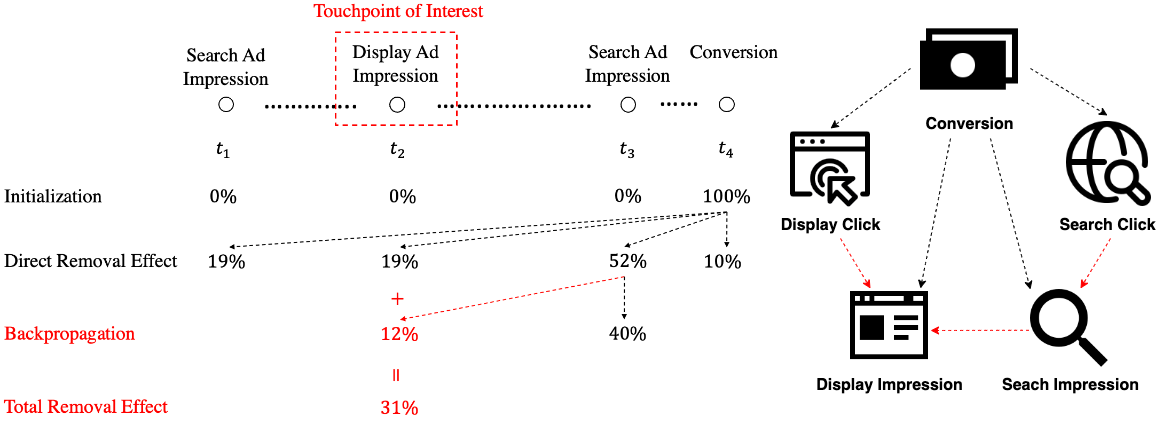
As shown by the example path in Figure 6, instead of going forward along the path, the score flows backward from the last touchpoint to the previous touchpoints. This flow follows the reverse graph of the Granger causality graph, whose arrows point from an event type to its Granger causality parents.
3.3 Remark on the Two Scoring Methods
In this subsection, we discuss the difference between the proposed two attribution scoring methods and their implementation in an extreme case.
The direct removal effect regards the contributions from each touchpoint as individual components. While the total removal effect of a specified subset of touchpoints is the cumulative influence resulting from its removal along the path. The direct removal effect regards the conversion event as the only response, while the whole vector/subprocess of customer-initiated event types is the response for the total removal effect. Intuitively, on the score-flow graph in Figure 6, the direct removal effect lets the score directly come out from the conversion node, and the total removal effect is based on the continual flow of the score until it reaches a specified node or a node with no parents.
These two scores differ in the context of additivity. Suppose and are two mutually exclusive subsets of the truncated path . The direct removal effect under model (1) has the additive property implied by the definition that
However, for the total removal effect, we let the score flow between the two sets during backpropagation wherever there is Granger causality between their event types. Hence the total removal effect is subadditive and thus not incremental
As a result, to obtain the total removal effect of a channel, we should select the removal set as the set of all the corresponding individual touchpoints rather than take the sum of touchpoint-wise scores.

We consider an extreme case illustrated by the Granger causality graph in Figure 7. In practice, we believe that touchpoints in each channel Granger-cause conversion separately, and hence the conversion node has multiple parents on the Granger causality graph like Figure 2. But here we use this example to justify the proposed two attributions scores. On the graph, conversion is the event type labeled as , and all the other event types are touchpoints, where the touchpoint type labeled as is the only firm-initiated event type. Suppose there is no baseline intensity for any customer-initiated event type, namely for . Then a type- event will be the only reason for the occurrence of a type- event. Suppose we observe a path with the same pattern as Figure 7. That is,
If we look at the direct removal effect of each touchpoint, we get
where for . The direct removal effect ignores the importance of touchpoints in the early stage since they cannot instantly trigger a conversion. On the other hand, the total removal effect gives
It seems that the total removal effect can over-allocate since there is only conversion on path . This issue was also pointed out by Singal et al. (2022) as a drawback of attribution methods based on the removal effect. However, it does not mean the scores are wrong. This extreme over-allocation problem implies that it might be inappropriate to calculate such an attribution score for each touchpoint. In Figure 7, it is likely that event types to all belong to the same channel. A detailed example can be the case where email sent, email open, and email click are the touchpoints, and conversion can be only triggered by email click (invite-only purchase through email link). In this case, we can regard event types to as an entirety using the removal set . Then we have
If event types to are actually from different channels, it means the graph is not likely true, or there is no need to distinguish these channels from each other since they are highly dependent.
To summarize, the direct removal effect serves as an explanatory score by allocating the credit of a conversion event to each touchpoint according to its incremental influence. Both proposed methods can give channel-level scores, but the total removal effect provides a marginal point of view for conversion. In other words, it better applies to cases where the leave-one-channel-out loss of conversion is the desired quantity.
4 Estimation
In this section, we develop a regularized estimator for our proposed model. We design an computationally efficient alternating direction method of multipliers (ADMM) algorithm to solve the corresponding optimization problem. We also derive the graphical model selection consistency and the rates of convergence rate of model estimates and attribution scores in the asymptotic regime.
We introduce some necessary notations to facilitate the presentation. For any -dimensional vector , where is an arbitrary integer, let , , and denote its -norm, -norm, and -norm respectively. Let denote the non-negative part of that is defined by . For a matrix , the matrix -norm is defined as .
4.1 Model Learning
Suppose there are paths in total, , where is the -th path on time interval . Suppose the kernel functions are known. Let be the vector of baseline intensities of and be the -th column of for . Learning the model turns into an optimization problem:
where is the loss function given the -th path . Consider a least-squares functional:
Compared with the negative log-likelihood, the least-squares functional enjoys better computational efficiency. Its equivalent form was proposed for estimating the additive risk model by Lin & Ying (1994). It was also adopted by Hansen et al. (2015) and Bacry et al. (2020) for point process models.
Assume that the edge set is sparse, we add the sparsity constraints on the coefficients as follows:
| (5) |
where are the regularization parameters to control the individual sparsity of coefficient vectors . It is worth pointing out that are separable in the objective function (5). Thus, the optimization problem can be decomposed into node-wise model learning. For each node , learning its parent nodes yields
| (6) |
where
In the following context, we write . Let with
Now the conditional intensity can be written as . Let and , where for ,
Then the regularized solution satisfies
| (7) |
The above problem is equivalent to a linearly constrained one
Apply the alternating direction method of multipliers (ADMM), where the corresponding augmented Lagrangian function is
The learning algorithm is shown in Algorithm 3.
4.2 Asymptotic Properties
In this subsection, we derive the rate of convergence of the proposed estimator. The customer-initiated part of our model (1) is similar to Hawkes process (Hawkes, 1971). But unlike the typical multivariate Hawkes process, model (1) is not guaranteed a stationary point process. As a result, the asymptotic results are derived under the assumption that the sample size , instead of the length of observation (Guo et al., 2018; Yu et al., 2020). In survival analysis, Lin & Ying (1994) studied the additive risk model, and Lin & Lv (2013) established the consistency of the corresponding -regularized estimator. Combining these works, we will show that under certain conditions, including irrepresentability, our proposed estimator is consistent in both the classical fixed setting and the sparse high-dimensional setting, where is comparable to the sample size .
Assumption 1.
(I.I.D.) The process of the customer-initiated event types , are independent and follow model (1).
The convergence properties of the estimator rely on the identical distribution of the observations. We do not need to assume the external (firm-initiated) events are I.I.D. across paths. They may vary from one path to another, but model (1) should be true for each individual.
Assumption 2.
(Bounded input) There exist constants and such that and a.s. for .
Define the active set and its complement . We use to denote the cardinality of the active set . Let be the population version of . Assume the sub-matrix is non-singular and define .
Assumption 3.
(Irrepresentability) There exists a constant such that
This condition is adapted from Condition 3 in Lin & Lv (2013), which is a generalization of Condition (15) in Wainwright (2009) for linear regression with LASSO.
Now we establish the rate of convergence and the model selection consistency of the regularized estimator. By abuse of notation, let denote the true value. We consider two scenarios, where the number of event types is fixed or diverges while the active set is sparse in the sense that is bounded from .
Theorem 3.
Under Assumptions 1-3, there exist and such that the regularized estimator in (7) satisfies the following properties:
-
(i)
If is fixed, then for any constant , when is chosen properly, and is sufficiently large, with probability at least ,
-
•
(Edge selection)
-
•
(-error) ;
-
•
-
(ii)
If diverges, then for any constant , when is chosen properly, and is sufficiently large, with probability at least ,
-
•
(Edge selection)
-
•
(-error) .
-
•
In the above Theorem, we do not specify the choices of and for ease of presentation. The choices in detail can be found in the supplementary materials.
Then we move on to the rate of convergence of attribution scores. For a positive path with a conversion at , we would like to analyze the direct removal effect of a subset . In practice, for Equation (2), we can only obtain the estimate of the conditional intensities. As a result, for model (1), we use the estimated direct removal effect given by
Let denote the cardinality of the removal set . For the kernel functions, suppose there exists such that .
Theorem 4.
Given a path with a conversion at , under the above assumptions for , there exists dependent on and such that the estimated direct removal effect of the removal set satisfies either of the following condition:
-
(i)
If is fixed and is sufficiently large, then for any constant , with probability at least ,
-
(ii)
If diverges and is sufficiently large, then for any constant , with probability at least ,
The constants , , , and come from Theorem 3 corresponding to . Based on the analysis of the estimated direct removal effect, we then provide an error bound of the total removal effect in estimation. We refer to the estimated total removal effect as
where is the actual removal set obtained by the thinning operation in Algorithm 1 using estimated thinning probabilities. Besides , for each , suppose there exists such that .
Theorem 5.
Given a path with a conversion at and a removal set , under the above assumptions for , there exists dependent on , , and such that the estimated total removal effect of satisfies either of the following condition:
-
(i)
If is fixed and is sufficiently large, then for any constant , with probability at least ,
-
(ii)
If diverges and is sufficiently large, then for any constant , with probability at least ,
5 Simulation Study
In this section, we carry out two simulation experiments to examine the performance of our graphical attribution methods. In the first part, we validate the proposed graphical attribution methods using data simulated from the multivariate Hawkes process. In the second part, we compare the proposed methods with the commonly used attribution models using data simulated from a modified version of the Digital Advertising System Simulation (DASS) developed by Google Inc. The simulated data includes online customer browsing behavior and injected advertising events that impact this customer behavior.
We first explain some channel-level metrics for attribution methods. In general, suppose there are channels, labeled as . Inspired by the previous literature Anderl et al. (2016); Li & Kannan (2014), we calculate the proportion of channel-level conversion count (proportion of CCC) for each channel , which is
where is a path following the same distribution as other than having no touchpoints of channel . is interpreted as the number of conversions resulting from channel . The first term of is the number of conversions out of paths, and the second term is the number of conversions out of paths when channel is turned off. To obtain this quantity for synthetic data, we can disable all the related touchpoint types and run the simulator again with the same seed. Then the decrease in total conversions is the desired value.
Let denote the set of touchpoint types belonging to channel , for . Then the corresponding removal set with respect to the conversion at in the path is . We use the proportion of channel-level aggregated score (proportion of CAS) to estimate the proportion of CCC for channel , which is
Recall that the attribution score is an incremental component or marginal loss with respect to conversion. Its aggregated version, CAS, is the overall decrease in conversion counts for each channel compared with the total number of conversions and thus can be used to estimate CCC. Let denote the vector of proportions of CCC and denote the vector of the proportions of CAS. We adopt the KL divergence and the Hellinger distance to measure the estimation accuracy, where
5.1 Simulation Based on Hawkes Process
In this subsection, we verify our attribution methods using a dataset simulated from the multivariate Hawkes process (Hawkes, 1971).
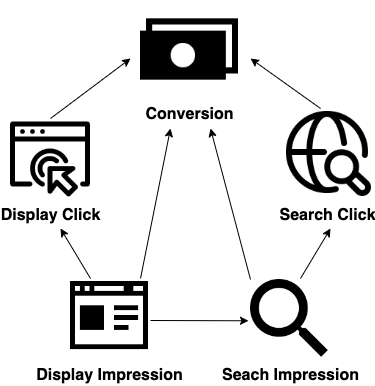
Referring to Equation (1), our model reduces to a multivariate Hawkes process if is a Poisson process for each . In other words, the multivariate Hawkes process is nested in our model. Therefore, we simulate a data set using a multivariate Hawkes process according to Figure 2, which involves channels, display and search, and types of touchpoints: display impression, display click, search impression, and search click. Display impression is regarded as a firm-initiated event type, following a Poisson process distribution with a rate of . A total of paths are simulated with days for . We take for each possible pair of connected nodes. The baseline intensities of search impression and conversion are set as and , and the two click touchpoint types have zero baselines.
| Display click | Search impression | Search click | Conversion | |
|---|---|---|---|---|
| Display impression | 0.08 | 0.08 | 0 | 0.01 |
| Display click | 0 | 0 | 0 | 0.08 |
| Search impression | 0 | 0 | 0.08 | 0.02 |
| Search click | 0 | 0 | 0 | 0.1 |
| Conversion | 0 | 0 | 0 | 0 |
| Channel: | TRE | DRE |
|---|---|---|
| Display: | ||
| Search: | ||
| KL divergence | ||
| Hellinger distance |
The Granger causality coefficients are given in Table 1. The simulation results are summarized in Table 2, which are calculated over independent runs. As shown in Table 2, our graphical TRE attribution method, which takes into account the Granger causality among different types of touchpoints is accurate in estimating the true removal effects of both search and display channels. The proportions of CAS for both channels calculated by TRE are very close to the ground truth. Also, the KL divergence and the Hellinger distance of TRE are very small. This is not surprising since Theorem 2 guarantees that and are identically distributed. In contrast, the graphical DRE method tends to underestimate the contribution of the display channel because it ignores the exciting effect of the display impression on the search impression.
5.2 Simulation Based on DASS
Next, we compare our graphical attribution methods with existing methods, including DNAMTA (Li et al., 2018), logistic regression, Markov model (Anderl et al., 2016), as well as the rule-based methods including last-touch, first-touch, linear, time-decay, and U-shaped. Table 3 lists the description of the models under comparison. Among them, the Markov model provides channel-level scores directly and the others provide path-level scores that can be aggregated to the channel level.
| Method | Type | Scoring Description |
|---|---|---|
| TRE | Data-driven | Total removal effect of the graphical point process model. |
| DRE | Data-driven | Direct removal effect of the graphical point process model. |
| DNAMTA | Data-driven | An incremental score derived from the conversion probability of Deep Neural Net With Attention multi-touch attribution model developed in Li et al. (2018). |
| Logistic | Data-driven | An incremental score derived from the conversion probability of logistic regression. |
| Markov | Data-driven | Removal effect of Markov model developed in Anderl et al. (2016). |
| Last | Rule-based | Last-touch attribution, assigning all credit to the touchpoint closest to the conversion. |
| First | Rule-based | First-touch attribution, assigning all credit to the initial touchpoint on a path. |
| Linear | Rule-based | Linear attribution, assigning equal credit to each touchpoint before the conversion. |
| Decay | Rule-based | Time-decay attribution, where touchpoints closer to the conversion receive more credit than touchpoints that are farther away in time from the conversion. |
| U-shaped | Rule-based | U-shaped attribution, assigning of the credit to both the first touchpoint and the last touchpoint, with the other touchpoints splitting the remaining equally. |
For model comparison, we simulate data from a modified version of the Digital Advertising System Simulation (DASS). DASS (Sapp et al., 2016), developed by Google Inc., is a popular attribution simulator in the industry and its effectiveness is well accepted by practitioners. “It generates the data to which observational models can be applied, as well as the ability to run virtual experiments with simulated customers to measure the actual incremental value of marketing for direct comparison” (Sapp et al., 2016). We modified DASS to work with two desired features and call it DASS+. DASS simulates transitions between the browsing states of each customer without any clear regard for timestamps while DASS+ uses a transition matrix reflecting these browsing states in each minute. On the other hand, DASS has no explicit restriction on the number of advertisements that can be served. With DASS+, the number of ads is capped to a fixed amount, and the ads can be served in a pre-determined distribution across the simulation timeframe.
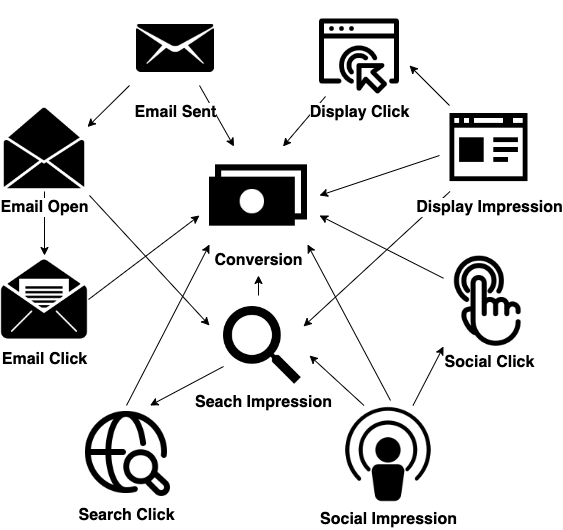
This synthetic data involves channels, email, display, search, and social including types of touchpoints: email sent, email open, email click, display impression, display click, search impression, search click, social impression, and social click. With all channels turned on, we obtain valid paths out of customers. Among them, there are positive paths and negative paths. The simulation period is days for each path. For model learning, we use the timestamp of the very first event as the starting time () and use the timestamp of the final event on the path as the terminal time.
Figure 8 shows the Granger causality graph learned by our proposed model for simulated data. Most types of touchpoints have exciting effects on conversion. Similar to the first simulation study, we confirm the intra-channel carry-over effects for every channel, even with more channels present. Also, we confirm the inter-channel spill-over effects from other channels to search impression.
| Channel: | TRE | DRE | DNAMTA | Logistic | Markov | Last | First | Linear | Decay | U-shaped |
|---|---|---|---|---|---|---|---|---|---|---|
| Display: | ||||||||||
| Email: | ||||||||||
| Search: | ||||||||||
| Social: | ||||||||||
| KL divergence | ||||||||||
| Hellinger distance | ||||||||||
Table 4 summarizes the proportions of CAS, as well as the KL divergence and the Hellinger distance for different methods, which are calculated over independent runs. Our two graphical attribution methods, achieve the most accurate results. The rule-based methods (i.e., last-touch, first-touch, linear, time-decay, and U-shaped method) underestimate the contribution of the search channel and overestimate those of other channels, particularly the display channel. They are unable to take the baseline effect into consideration and thus are outperformed by other methods. Among all the methods, our graphical attribution methods have the smallest estimation errors, which demonstrates the advantage of our proposed graphical attribution methods in measuring channels’ contribution to conversions.
6 Real Application
In this section, we apply the proposed methods to a real-world use case. The data are about paid conversions of an online subscription product of a Fortune 500 company within consecutive months. There are paths and conversions in total.
The touchpoints belong to channels with more specific details. For the search channel, a branded search is a specific company or product being advertised while a non-branded search is a generic search result, not for a specific company or product. For the social channel, an owned social click is within the company’s control and not paid for (e.g. a corporate LinkedIn post) and an earned social click is outside the company’s control but not paid for either (e.g. a third party sharing a corporate LinkedIn post). For the email channel, awareness means the ad is just trying to make a customer aware of products. A promotion email means that there is a discount-priced product being offered. Call to action means the customer is already familiar with the product, and the ad contains a specific call to action (e.g. buy now).
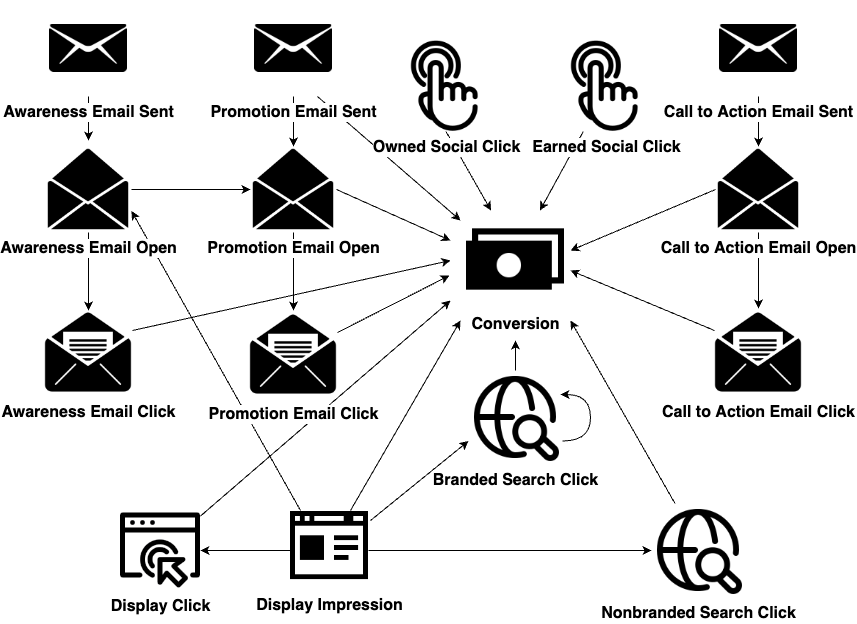
The learned Granger causality graph is shown in Figure 9. Besides the excitation from touchpoints to a potential conversion, the graphical point process model finds the interactions between touchpoints within and across channels. For example, an awareness email open touchpoint may increase the chance of opening a promotion email. A display impression can trigger search clicks and awareness emails open. There is also a self-loop for the branded search click, meaning that clicks of this type tend to appear in clusters. Figure 10 visualizes the proportions of CAS among different methods. The two graphical attribution methods and DNAMTA have similar results by giving the search channel the highest proportion of credit (). As far as the display channel is concerned, compared with the direct removal effect (), the total removal effect assigns more credit () since a display impression may trigger a search click. Logistic regression emphasizes the importance of the display channel more than other algorithmic methods by assigning scores to the display channel () close to the search channel (). The rule-based methods, together with the Markov model, tend to give the highest scores to the email channel ().
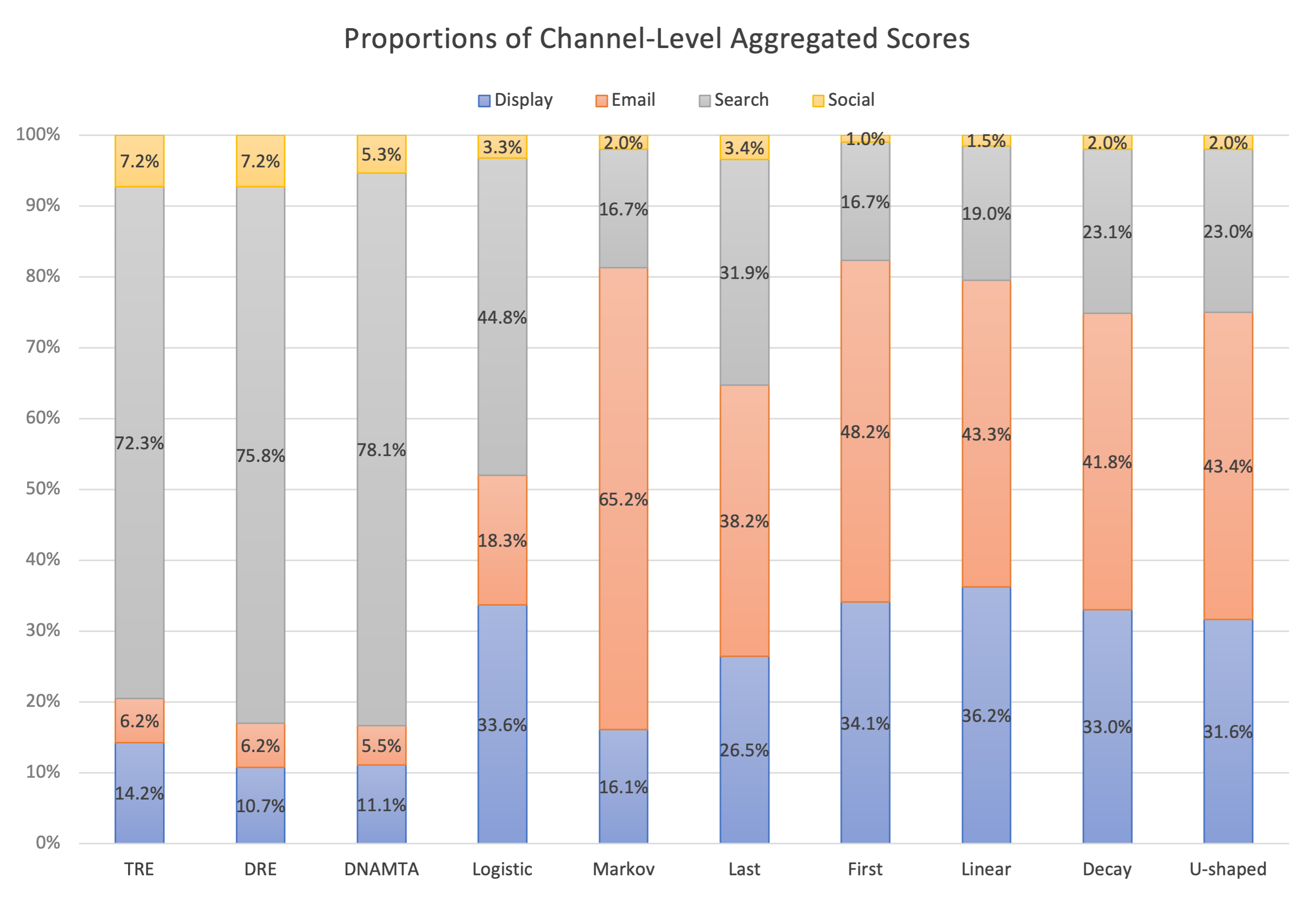
Based on the Granger causality graph, there indeed exists a hierarchical structure for the event types, and thus it is necessary to build a model with the response being more than just conversion. The channel-level aggregated scores obtained from our graphical methods reflect that the search channel is the most effective channel. The total removal effect emphasizes the importance of the display channel, which may play a key role in the early stage of a positive path.
7 Conclusion
In this paper, we propose a novel graphical point process framework for multi-touch attribution. First, we develop a graphical point process model to analyze customer-level path-to-purchase data. The graphical model utilizes the Granger causality to reveal the exciting effects among touches as well as the direct conversion effects of numerous types of touchpoints. Then, in the framework of the point process, we further propose graphical attribution methods to allocate proper conversion credit to individual touchpoints and the corresponding channels for each customer’s path to purchase. Our proposed attribution methods consider the attribution score as the removal effect, and we study two types of removal effects. We provide the probabilistic definition and the mathematical form of the removal effects. We develop a new efficient thinning-based simulation method and a backpropagation algorithm for the calculation. We employ a regularization method to select edges and estimate parameters simultaneously. We develop an ADMM to solve this optimization problem with desired computational efficiency and scalability. In addition, we provide a theoretical guarantee by establishing the asymptotic theory for parameter estimates.
References
- (1)
- Anderl et al. (2016) Anderl, E., Becker, I., Von Wangenheim, F. & Schumann, J. H. (2016), ‘Mapping the customer journey: Lessons learned from graph-based online attribution modeling’, International Journal of Research in Marketing 33(3), 457–474.
- Bacry et al. (2020) Bacry, E., Bompaire, M., Gaïffas, S. & Muzy, J.-F. (2020), ‘Sparse and low-rank multivariate hawkes processes’, Journal of Machine Learning Research 21(50), 1–32.
- Berman (2018) Berman, R. (2018), ‘Beyond the last touch: Attribution in online advertising’, Marketing Science 37(5), 771–792.
- Bowman & Narayandas (2001) Bowman, D. & Narayandas, D. (2001), ‘Managing customer-initiated contacts with manufacturers: The impact on share of category requirements and word-of-mouth behavior’, Journal of Marketing Research 38(3), 281–297.
- Breuer et al. (2011) Breuer, R., Brettel, M. & Engelen, A. (2011), ‘Incorporating long-term effects in determining the effectiveness of different types of online advertising’, Marketing Letters 22(4), 327–340.
- Dalessandro et al. (2012) Dalessandro, B., Perlich, C., Stitelman, O. & Provost, F. (2012), Causally motivated attribution for online advertising, in ‘Proceedings of the sixth International Workshop on Data Mining for Online Advertising and Internet Economy’, pp. 1–9.
- Danaher & van Heerde (2018) Danaher, P. J. & van Heerde, H. J. (2018), ‘Delusion in attribution: Caveats in using attribution for multimedia budget allocation’, Journal of Marketing Research 55(5), 667–685.
- De Haan et al. (2016) De Haan, E., Wiesel, T. & Pauwels, K. (2016), ‘The effectiveness of different forms of online advertising for purchase conversion in a multiple-channel attribution framework’, International Journal of Research in Marketing 33(3), 491–507.
- Didelez (2008) Didelez, V. (2008), ‘Graphical models for marked point processes based on local independence’, Journal of the Royal Statistical Society: Series B 70(1), 245–264.
- Eichler (2012) Eichler, M. (2012), ‘Graphical modelling of multivariate time series’, Probability Theory and Related Fields 153(1), 233–268.
- Gaur & Bharti (2020) Gaur, J. & Bharti, K. (2020), ‘Attribution modelling in marketing: Literature review and research agenda’, Academy of Marketing Studies Journal 24(4), 1–21.
- Granger (1969) Granger, C. W. (1969), ‘Investigating causal relations by econometric models and cross-spectral methods’, Econometrica 37(3), 424–438.
- Granger (1980) Granger, C. W. (1980), ‘Testing for causality: a personal viewpoint’, Journal of Economic Dynamics and Control 2, 329–352.
- Granger (1988) Granger, C. W. (1988), ‘Some recent development in a concept of causality’, Journal of Econometrics 39(1-2), 199–211.
- Gunawardana et al. (2011) Gunawardana, A., Meek, C. & Xu, P. (2011), ‘A model for temporal dependencies in event streams’, Advances in Neural Information Processing Systems 24, 1962–1970.
- Guo et al. (2018) Guo, X., Hu, A., Xu, R. & Zhang, J. (2018), ‘Consistency and computation of regularized mles for multivariate hawkes processes’, arXiv preprint arXiv:1810.02955 .
- Hansen et al. (2015) Hansen, N. R., Reynaud-Bouret, P. & Rivoirard, V. (2015), ‘Lasso and probabilistic inequalities for multivariate point processes’, Bernoulli 21(1), 83–143.
- Hawkes (1971) Hawkes, A. G. (1971), ‘Spectra of some self-exciting and mutually exciting point processes’, Biometrika 58(1), 83–90.
- Ji et al. (2016) Ji, W., Wang, X. & Zhang, D. (2016), A probabilistic multi-touch attribution model for online advertising, in ‘Proceedings of the 25th ACM International on Conference on Information and Knowledge Management’, pp. 1373–1382.
- Kakalejčík et al. (2018) Kakalejčík, L., Bucko, J., Resende, P. A. & Ferencova, M. (2018), ‘Multichannel marketing attribution using markov chains’, Journal of Applied Management and Investments 7(1), 49–60.
- Kannan et al. (2016) Kannan, P., Reinartz, W. & Verhoef, P. C. (2016), ‘The path to purchase and attribution modeling: Introduction to special section’, International Journal of Research in Marketing 33(3), 449–456.
- Kireyev et al. (2016) Kireyev, P., Pauwels, K. & Gupta, S. (2016), ‘Do display ads influence search? attribution and dynamics in online advertising’, International Journal of Research in Marketing 33(3), 475–490.
- Kumar et al. (2020) Kumar, S., Gupta, G., Prasad, R., Chatterjee, A., Vig, L. & Shroff, G. (2020), Camta: Causal attention model for multi-touch attribution, in ‘2020 International Conference on Data Mining Workshops (ICDMW)’, IEEE, pp. 79–86.
- Lewis & Shedler (1979) Lewis, P. W. & Shedler, G. S. (1979), ‘Simulation of nonhomogeneous poisson processes by thinning’, Naval Research Logistics Quarterly 26(3), 403–413.
- Li & Kannan (2014) Li, H. & Kannan, P. (2014), ‘Attributing conversions in a multichannel online marketing environment: An empirical model and a field experiment’, Journal of Marketing Research 51(1), 40–56.
- Li et al. (2018) Li, N., Arava, S. K., Dong, C., Yan, Z. & Pani, A. (2018), ‘Deep neural net with attention for multi-channel multitouch attribution’, arXiv preprint arXiv:1809.02230 .
- Lin & Ying (1994) Lin, D. Y. & Ying, Z. (1994), ‘Semiparametric analysis of the additive risk model’, Biometrika 81(1), 61–71.
- Lin & Lv (2013) Lin, W. & Lv, J. (2013), ‘High-dimensional sparse additive hazards regression’, Journal of the American Statistical Association 108(501), 247–264.
- Naik & Raman (2003) Naik, P. A. & Raman, K. (2003), ‘Understanding the impact of synergy in multimedia communications’, Journal of Marketing Research 40(4), 375–388.
- Ogata (1981) Ogata, Y. (1981), ‘On lewis’ simulation method for point processes’, IEEE Transactions on Information Theory 27(1), 23–31.
- Rumelhart et al. (1986) Rumelhart, D. E., Hinton, G. E. & Williams, R. J. (1986), ‘Learning representations by back-propagating errors’, Nature 323(6088), 533–536.
- Sapp et al. (2016) Sapp, S., Vaver, J., Shi, M. & Bathia, N. (2016), Dass: Digital advertising system simulation, Technical report, Google Inc.
- Shao & Li (2011) Shao, X. & Li, L. (2011), Data-driven multi-touch attribution models, in ‘Proceedings of the 17th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining’, pp. 258–264.
- Shapley (1953) Shapley, L. S. (1953), A value for n-person games, in H. W. Kuhn & A. W. Tucker, eds, ‘Contributions to the Theory of Games II’, Princeton University Press, pp. 307–317.
- Sims (1972) Sims, C. A. (1972), ‘Money, income, and causality’, American Economic Review 62(4), 540–552.
- Singal et al. (2022) Singal, R., Besbes, O., Desir, A., Goyal, V. & Iyengar, G. (2022), ‘Shapley meets uniform: An axiomatic framework for attribution in online advertising’, Management Science 68(10), 7457–7479.
- Wainwright (2009) Wainwright, M. J. (2009), ‘Sharp thresholds for high-dimensional and noisy sparsity recovery using -constrained quadratic programming (lasso)’, IEEE Transactions on Information Theory 55(5), 2183–2202.
- Wiesel et al. (2011) Wiesel, T., Pauwels, K. & Arts, J. (2011), ‘Practice prize paper—marketing’s profit impact: Quantifying online and off-line funnel progression’, Marketing Science 30(4), 604–611.
- Xu et al. (2016) Xu, H., Farajtabar, M. & Zha, H. (2016), Learning granger causality for hawkes processes, in ‘International Conference on Machine Learning’, PMLR, pp. 1717–1726.
- Xu et al. (2014) Xu, L., Duan, J. A. & Whinston, A. (2014), ‘Path to purchase: A mutually exciting point process model for online advertising and conversion’, Management Science 60(6), 1392–1412.
- Yang & Ghose (2010) Yang, S. & Ghose, A. (2010), ‘Analyzing the relationship between organic and sponsored search advertising: Positive, negative, or zero interdependence?’, Marketing Science 29(4), 602–623.
- Yu et al. (2020) Yu, X., Shanmugam, K., Bhattacharjya, D., Gao, T., Subramanian, D. & Xue, L. (2020), Hawkesian graphical event models, in ‘International Conference on Probabilistic Graphical Models’, PMLR, pp. 569–580.
- Zhang et al. (2013) Zhang, Y., Bradlow, E. T. & Small, D. S. (2013), ‘New measures of clumpiness for incidence data’, Journal of Applied Statistics 40(11), 2533–2548.
- Zhang et al. (2014) Zhang, Y., Wei, Y. & Ren, J. (2014), Multi-touch attribution in online advertising with survival theory, in ‘2014 IEEE International Conference on Data Mining’, IEEE, pp. 687–696.
- Zhao et al. (2019) Zhao, K., Mahboobi, S. H. & Bagheri, S. R. (2019), ‘Revenue-based attribution modeling for online advertising’, International Journal of Market Research 61(2), 195–209.