A graphical user interface software for lattice QCD based on Python acceleration technology
Abstract
A graphical user interface (GUI) software is provided for lattice QCD simulations, aimed at streamlining the process. The current version of the software employs the Metropolis algorithm with the Wilson gauge action. It is implemented in Python, utilizing Just-In-Time (JIT) compilation to enhance computational speed while preserving Python’s simplicity and extensibility. Additionally, the program supports parallel computations to evaluate physical quantities at different inverse coupling values, allowing users to specify the number of CPU cores. The software also enables the use of various initial conditions, as well as the specification of the save directory, file names, and background settings. Through this software, users can observe the configurations and behaviors of the plaquette under different values.
I Introduction
Currently, we recognize four fundamental interactions in nature: strong interaction, weak interaction, electromagnetic interaction, and gravitational interaction. Among these, gravitational and electromagnetic interactions are long-range interactions. Gravitational interaction plays a significant role in celestial dynamics, and the electromagnetic interaction can be observed in various forms at the macroscopic scale that our human eyes can directly see. In contrast, strong interaction is a short-range interaction, with effects typically observed at scales much smaller than those of electromagnetic interactions, usually at the femtometer level (). This scale makes the observation of strong interactions particularly challenging.
Moreover, strong interactions exhibit unique effects that are not directly applicable from studies of the macroscopic world, such as quarks carrying fractional electric charges, unlike macroscopic objects which can only possess integral charges. The mathematical framework describing strong interactions is also more complex than that for electromagnetic interactions; for example, electromagnetic interactions are described using abelian groups, while strong interactions require non-abelian groups.
These factors contribute to the relatively less comprehensive understanding of strong interactions compared to electromagnetic interactions, leaving many avenues for further research. Quantum Chromodynamics (QCD) is the theory dedicated to the study of strong interactions, quarks, gluons, and related phenomena. Perturbation theory is ineffective in the low-energy regime of QCD, necessitating the development of non-perturbative methods to address QCD problems. Lattice QCD represents one such non-perturbative approach that allows the study of QCD from first principles. In lattice QCD, we utilize formulations in Euclidean spacetime rather than Minkowski spacetime. Additionally, it is essential to discretize physical quantities defined in continuous spacetime, and the discrete gauge action used is the Wilson gauge action[1, 2]
| (1) |
where is the inverse coupling and is the plaquette
| (2) | ||||
is the link variable. A gauge invariant quantity about plaquette is as follows
| (3) |
In this article, the configuration of the Wilson gauge field and will be calculated.
The Metropolis algorithm is used to handle the simulation of lattice QCD. In pure SU(3) lattice gauge theory, the conditional transition probability of a Markov process is[2]
| (4) |
where the configuration changes from to . In many Monte Carlo algorithms, detailed balance condition is used
| (5) |
where satisfies . Thus
| (6) |
The conditional transition probability can be further written as the product of the priori selection probability and the acceptance probability . Therefore, when the priority selection probability has symmetry
| (7) |
we can obtain
| (8) |
In the Metropolis algorithm, the acceptance probability can be simplified to[3]
| (9) |
where .
II Improvement of Computational Speed
The enhancement of computational speed arises from both hardware and software improvements.
From a hardware perspective, a combination of CPUs and GPUs can be employed to accelerate computations. Intel’s Gordon Moore famously proposed Moore’s Law[4, 5], which states that the number of transistors (or MOSFETs) on a computer chip doubles approximately every two years (or 18 months in some versions), leading to a corresponding doubling of microprocessor performance every 18 months. This law dominated chip development for an extended period[6]; however, Intel’s production of 14-nanometer chips in 2014 was followed by a delay in the introduction of its 10-nanometer process until 2019. While some companies have claimed successful research into 7-nanometer or even smaller sizes, many current technology nodes have become equivalent dimensions rather than actual channel lengths of MOSFETs. From a physical standpoint, as MOSFET sizes continue to shrink, issues such as increased tunneling currents and decreased effective carrier mobility in the channel become more prevalent. Additionally, the radius of a silicon atom is approximately 111 picometers. These aspects indicate that the size of individual MOSFET is nearing a physical limit. Hardware structure also plays a significant role; for instance, when CPUs and GPUs are manufactured using the same semiconductor technology, GPUs generally outperform CPUs in matrix parallel computations due to their architectural advantages.
On the software side, while programs can be written more concisely, this may lead to decreased performance efficiency. Therefore, it is essential to find ways to enhance the calculation speed of software. One study demonstrated that researchers were able to multiply two matrices by parallelizing the code to run across all 18 processing cores, optimizing the memory hierarchy of the processor, and utilizing Intel’s Advanced Vector Extensions (AVX) instructions. The optimized code completed the computation in just 0.41 seconds, whereas Python 2 required 7 hours and Python 3 required 9 hours[6]. This underscores the importance of software-hardware synergy in improving computational speed.
Python allows for concise and highly extensible programming. However, Python code typically exhibits slower execution speeds, necessitating acceleration techniques to enhance computational efficiency. Just-In-Time (JIT) Compilation is a method that improves program execution efficiency by dynamically compiling bytecode or other intermediate code into machine code during program execution[7]. This allows the program to run directly on machine code, thereby reducing the overhead associated with interpretation.
III Main Features of the Software
III.1 Graphical User Interface (GUI)
The GUI of the program is developed using Tkinter, providing an intuitive interface for parameter setup and simulation execution. The layout is modernized with custom fonts and colors, enhancing the user experience. Users can set lattice size, , iterations, CPU core numbers, and initial scheme.
III.2 Custom Background Images
The GUI allows for custom background images to enhance visual appeal. Users can personalize the background by replacing the background.jpg file used in the GUI.
III.3 Initialization Schemes and Boundary Conditions
The program supports two types of initial lattice schemes (hot start or cold start), enabling users to explore various initial conditions. Additionally, periodic boundary conditions are employed.
III.4 Parallel Processing
Users can process simulations for multiple values in parallel, specifying the number of CPU cores to optimize the utilization of multi-core systems. The program leverages Python’s multiprocessing module to efficiently handle simulations across different values, executing each simulation in independent processes that update results separately.
Currently, the version of the program does not implement Numba parallelization for matrix multiplication within one configuration. This decision is based on the observation that such parallelization involves frequent thread activation and deactivation, which can be time-consuming and less efficient compared to parallel simulations across different values. However, if computations are limited to a single or if an exceptionally high number of CPU cores are available, internal parallel computations may still be considered.
III.5 Visualization and Data Saving
Upon completion of the simulation, the program saves the final lattice configuration and data in .npy format, automatically storing them in the specified directory. The .npy format is a file format used by NumPy [8]. Graphs illustrating the variation of with iteration counts are generated for each , assisting users in understanding the temporal evolution of the system. The visualization utilizes Matplotlib for saving images[9].
IV User Instructions
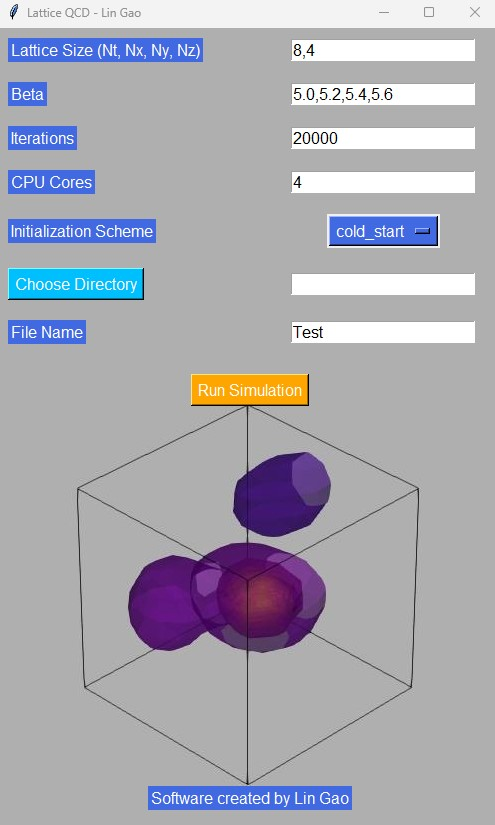
Refer to Fig. 1 for an example of input parameters. In the GUI, set the required parameters (lattice size, , iteration counts, CPU core numbers, and initialization scheme).
1. Lattice Size: The lattice size supports two input methods. When , only and need to be specified. The program will automatically interpret these as , , , and . In this example, the input “8,4” indicates and . If , , and are not equal, all four parameters must be provided, separated by commas.
2. : Multiple values for can be input simultaneously to facilitate parallel computations. Different values should be separated by commas.
3. Iteration Counts: One complete update of all lattice points is called one sweep. Furthermore, it is computationally economic to repeat the updating step 10 times for the visited variable, since the computation of the sum of staples is costly[2]. In this context, one iteration corresponds to 10 sweeps.
4. Initialization Scheme: The default option is a cold start; however, users can also select a hot start.
5. File Saving Options: Users can specify the save directory and file name. In this example, if the file name is designated as “Test”, all file names of generated configurations and plaquette-related files will begin with “Test”.
After completing these parameter settings, press the “Run Simulation” button to initiate the simulation.
V Results and Discussion
This paper presents a lattice QCD simulation program based on the Metropolis algorithm, utilizing a GUI to facilitate intuitive user input, thereby visualizing and simplifying the simulation process. This implementation demonstrates the program’s advantages in user-friendliness. In this section, a discussion will focus on the computational speed of the JIT-optimized Python 3. Additionally, further testing will be conducted on the data generated by this GUI software.
V.1 computational speed
Both C++ and JIT-optimized Python 3 programs were developed for multiplying two matrices, measuring the computation time. The relevant codes are provided in Appendix A and Appendix B. As shown in Fig. 2, the computation time for matrix multiplication increases as the matrix size () grows from 200 to 2000 for both methods.
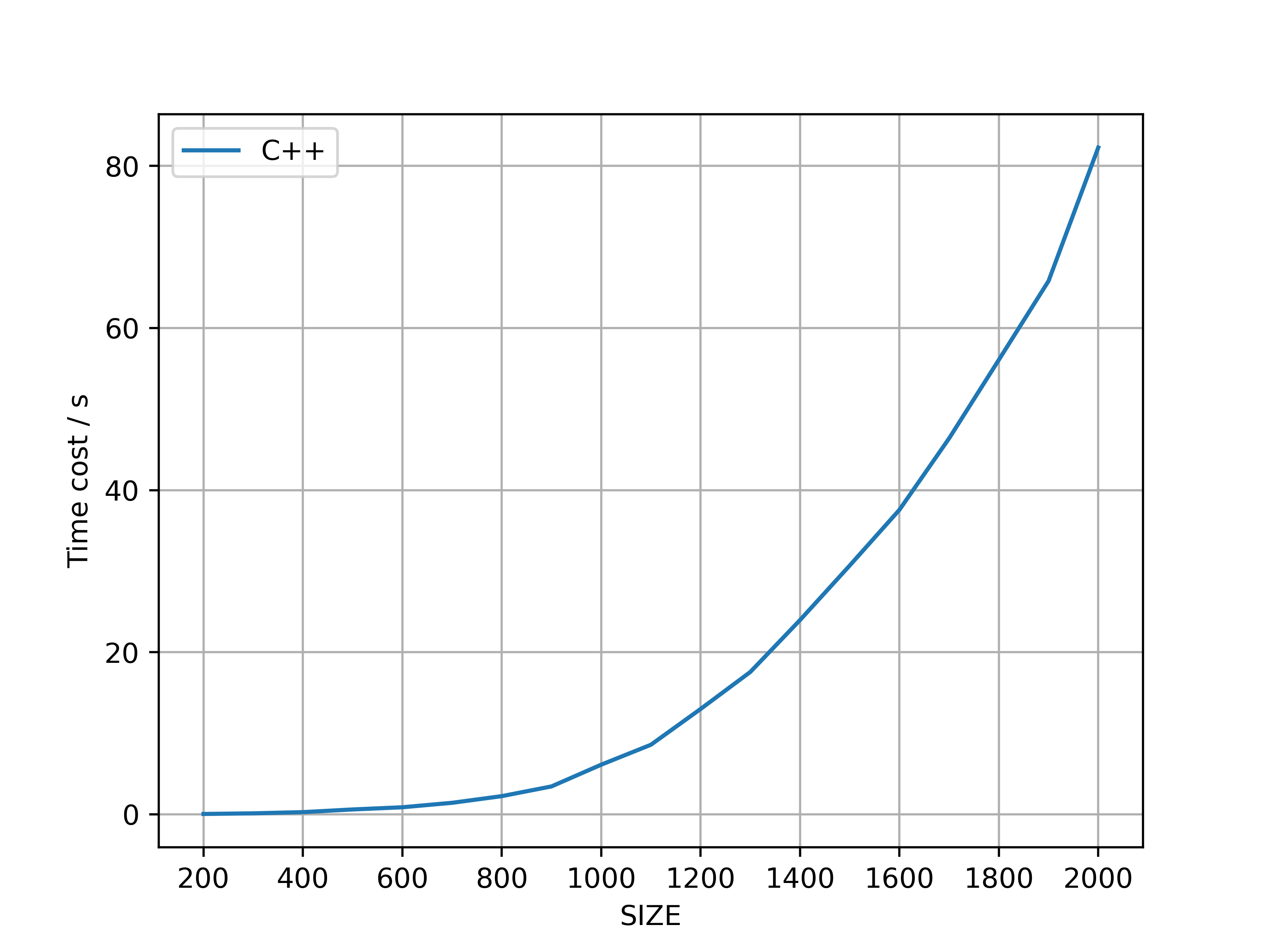
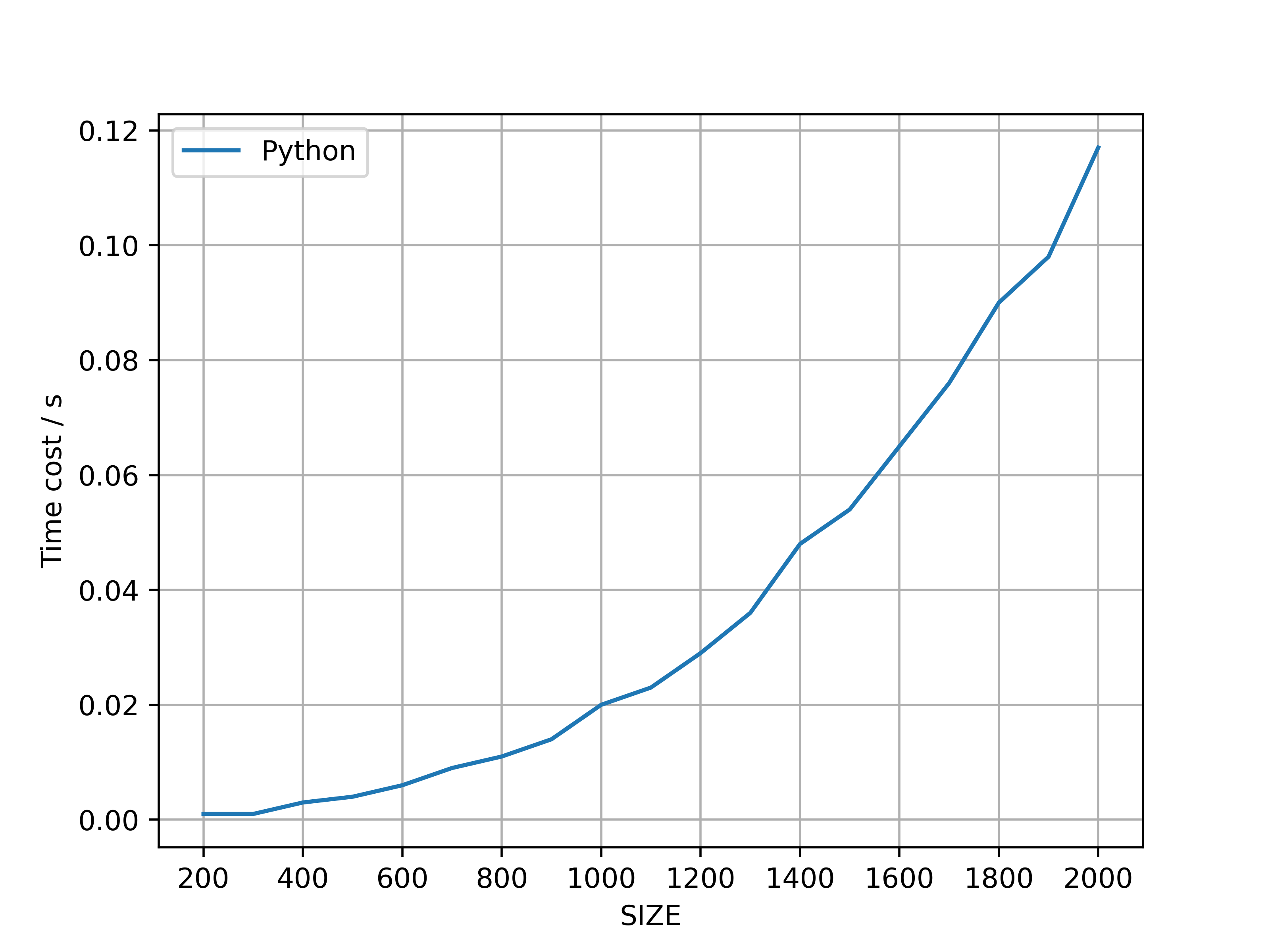
The time complexity of matrix multiplication is typically . Therefore, for two matrices, the time required for multiplication is approximately proportional to . Consequently, when the matrix size doubles (i.e., becomes ), the computation time increases by a factor of eight. In this test, using C++ as an example, the following time costs were observed for smaller matrix sizes: resulted in , in , and in , which aligns with the expected eightfold growth. However, for larger matrices, such as , the time cost escalated to , leading to the observation that .
Several factors contribute to this phenomenon. Matrix multiplication involves extensive data reading and writing. When the matrix size exceeds the CPU’s cache capacity, memory access becomes more frequent, leading to increased computation time. Furthermore, matrix multiplication requires significant data transfer, particularly for large matrices, which can create a memory bandwidth bottleneck. Additionally, matrix rows and columns are stored linearly in memory; accessing matrices—especially in a column-major order—can result in poor cache utilization, negatively impacting performance. Moreover, the standard triple-loop algorithm is inefficient for large-scale matrices. Although more efficient algorithms exist, their complexities may not be straightforward, and their implementation can be complex. Consequently, due to the aforementioned factors, computation time often increases significantly in practical applications.
The results indicate that the JIT-optimized Python3 program for multiplying two double-precision matrices took , while the C++ implementation took . It is evident that, thanks to the optimizations in matrix multiplication provided by NumPy and Numba, the JIT-optimized Python3 implementation is faster than the C++ triple-loop algorithm. Moreover, the program is significantly more concise, which is advantageous when writing larger programs.
V.2 Configuration Testing
The software was tested with the parameters Lattice Size (Nt, Nx, Ny, Nz) set to (8, 4, 4, 4), , iteration = 2000, and the number of CPU cores set to 4. The key results and discussions are presented below.
The generated configurations consist of some SU(3) matrices, specifically with dimensions of , where the last indicates the size of the SU(3) matrices. This dimension is derived under the consideration of complex values. If only real values are considered, the overall size becomes .
A thorough examination of all the complex matrices in the configuration revealed that they are indeed SU(3) matrices.
V.3 Plaquette Testing
As illustrated in Fig. 3, after 1000 iterations, the curves for the same starting from different initial conditions converge. This convergence is observed for all tested values, indicating that the system reaches equilibrium after 1000 iterations.
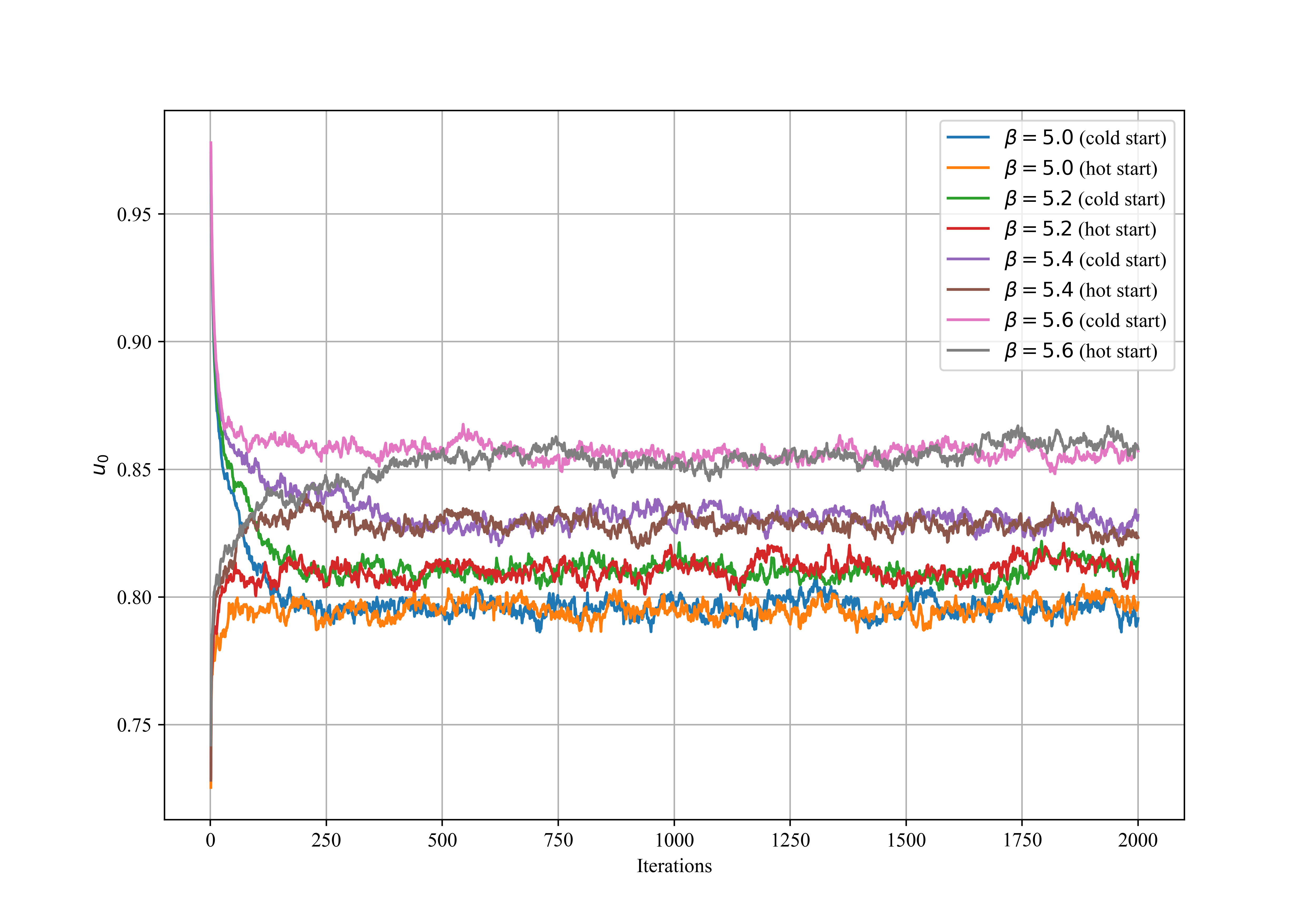
The software allows for intuitive input of parameters such as lattice size and iterations, executing the Metropolis algorithm’s update process in parallel and achieving system equilibrium. This demonstrates the software’s effectiveness in lattice QCD simulations. The actual results show that with adjustments to and iteration counts, the physical quantity exhibits reasonable variations that align with physical expectations.
VI conclusion
This paper presents a graphical user interface (GUI) software for lattice QCD based on Python acceleration techniques, achieving a complete workflow from input parameters to result output. This approach offers a new perspective for studying numerical simulations of lattice QCD, facilitating wider user adoption and understanding through an intuitive GUI design. The simulation software provides an easy-to-use platform that combines parallel computing and interactive visualization, assisting users in performing lattice QCD calculations. The main conclusions are as follows:
User Friendliness and Experience. The GUI facilitates parameter input and result saving, allowing users to conduct physical simulation experiments without writing code. This interface design is particularly appealing to students, users outside computational physics, and researchers in experimental physics who may not be adept at programming. Additionally, the software incorporates customizable background images, enabling users to modify the background according to their preferences. The background images enhance the visual feedback, making the simulation experience more vivid and intuitive, thereby highlighting the importance of visual elements in improving interface friendliness. Furthermore, the software design emphasizes flexibility, permitting users to freely adjust simulation parameters according to specific research needs. Users can input lattice size, set different ranges for , and choose initial conditions, accommodating a variety of experimental contexts.
Python Acceleration Techniques. Python offers simplicity and high scalability in programming. However, traditional Python programs are significantly slower than C/C++ for numerical calculations. This study utilizes Just-In-Time (JIT) compilation techniques to accelerate Python computations, preserving Python’s simplicity while enhancing its computational speed. In the example in this article, the JIT-optimized Python program for matrix multiplication even outperforms the traditional C++ triple-loop algorithm.
Parallel Computing. The software’s parallel computing capability significantly improves simulation efficiency. By fully leveraging the computational power of multi-core processors, users can obtain simulation results under different values in a shorter time. This efficiency not only conserves computational resources but also enables researchers to conduct larger-scale experiments, exploring a broader parameter space and thereby advancing physical research.
Diverse Data Output and Research Applicability. The program outputs include the final lattice configurations and the data as a function of iteration, saved in format. Additionally, graphs depicting the variation of with iteration will be generated for each . These outputs provide researchers with diverse options for post-processing and data analysis. The output images illustrate the evolution of under different values and initialization schemes, visually reflecting the impact of model parameters on the system state. The data files facilitate loading into other computational environments for further analysis and data mining, thereby providing researchers with convenient data management and analysis options.
Future Work. Overall, the functionality of this program effectively implements stable simulations using the Metropolis algorithm and demonstrates excellence in numerical simulation and user interface friendliness. The analysis and discussion of the results indicate that this method lays a solid foundation for further model expansion and performance optimization. Due to Python’s high scalability, this software is easily extendable to incorporate more functionalities in future versions, including additional physical quantities and alternative actions. Currently, the software only supports simple periodic boundary conditions, and future versions may consider other boundary conditions. Furthermore, machine learning techniques are increasingly influencing lattice QCD research, and integration of machine learning content will be considered in subsequent versions[10]. Lastly, further optimization of the parallelization aspect will include the potential addition of GPU acceleration.
VII Software Acquisition
The link to this GUI software is as follows: https://drive.google.com/file/d/1f0XgoQmge_hFssSsSxWd5C0s2aYYc_qF/view?usp=sharing.
You may need the following.
-
•
Python 3.x
-
•
Some packages: numpy, numba, matplotlib
Acknowledgments
Appendix A Python program for matrix multiplication
Appendix B C++ program for matrix multiplication
References
- Wilson [1974] K. G. Wilson, Phys. Rev. D 10, 2445 (1974).
- Gattringer and Lang [2010] C. Gattringer and C. B. Lang, Quantum chromodynamics on the lattice, Vol. 788 (Springer, Berlin, 2010).
- Metropolis et al. [1953] N. Metropolis, A. W. Rosenbluth, M. N. Rosenbluth, A. H. Teller, and E. Teller, The journal of chemical physics 21, 1087 (1953).
- Moore [1965] G. E. Moore, Sidsel Lond Grosen, Agnete Meldgaard Hansen & Jo Krøjer (1965).
- Moore [2006] G. E. Moore, IEEE Solid-State Circuits Society Newsletter 11, 36 (2006).
- Leiserson et al. [2020] C. E. Leiserson, N. C. Thompson, J. S. Emer, B. C. Kuszmaul, B. W. Lampson, D. Sanchez, and T. B. Schardl, Science 368, eaam9744 (2020), https://www.science.org/doi/pdf/10.1126/science.aam9744 .
- Lam et al. [2015] S. K. Lam, A. Pitrou, and S. Seibert, in Proceedings of the Second Workshop on the LLVM Compiler Infrastructure in HPC (2015) pp. 1–6.
- Harris et al. [2020] C. R. Harris, K. J. Millman, S. J. Van Der Walt, R. Gommers, P. Virtanen, D. Cournapeau, E. Wieser, J. Taylor, S. Berg, N. J. Smith, et al., Nature 585, 357 (2020).
- Hunter [2007] J. D. Hunter, Computing in science & engineering 9, 90 (2007).
- Gao et al. [2024] L. Gao, H. Ying, and J. Zhang, Physical Review D 109, 074509 (2024).
- OpenAI [2023] OpenAI, arXiv preprint arXiv:2303.08774 (2023), arXiv:2303.08774 [cs.CL] .
- Lightman et al. [2023] H. Lightman, V. Kosaraju, Y. Burda, H. Edwards, B. Baker, T. Lee, J. Leike, J. Schulman, I. Sutskever, and K. Cobbe, arXiv preprint arXiv:2305.20050 (2023), arXiv:2305.20050 [cs.LG] .