A local direct method for module identification in dynamic networks with correlated noise
Abstract
The identification of local modules in dynamic networks with known topology has recently been addressed by formulating conditions for arriving at consistent estimates of the module dynamics, under the assumption of having disturbances that are uncorrelated over the different nodes. The conditions typically reflect the selection of a set of node signals that are taken as predictor inputs in a MISO identification setup. In this paper an extension is made to arrive at an identification setup for the situation that process noises on the different node signals can be correlated with each other. In this situation the local module may need to be embedded in a MIMO identification setup for arriving at a consistent estimate with maximum likelihood properties. This requires the proper treatment of confounding variables. The result is a set of algorithms that, based on the given network topology and disturbance correlation structure, selects an appropriate set of node signals as predictor inputs and outputs in a MISO or MIMO identification setup. Three algorithms are presented that differ in their approach of selecting measured node signals. Either a maximum or a minimum number of measured node signals can be considered, as well as a preselected set of measured nodes.
Index Terms:
Closed-loop identification, dynamic networks, correlated noise, system identification, predictor input and predicted output selection.I Introduction
In recent years increasing attention has been given to the development of new tools for the identification of large-scale interconnected systems, also known as dynamic networks. These networks are typically thought of as a set of measurable signals (the node signals) interconnected through linear dynamic systems (the modules), possibly driven by external excitations (the reference signals). Among the literature on this topic, we can distinguish three main categories of research. The first one focuses on identifying the topology of the dynamic network [1, 2, 3, 4, 5]. The second category concerns identification of the full network dynamics [6, 7, 8, 9, 10, 11], including aspects of identifiability, particularly addressed in [12, 13, 14], while the third one deals with identification of a specific component (module) of the network, assuming that the network topology is known (the so called local module identification), see [15, 16, 17, 18, 19, 20].
In this paper we will further expand the work on the local module identification problem. In [15], the classical direct-method [21] for closed-loop identification has been generalized to a dynamic network framework using a MISO identification setup. Consistent estimates of the target module can be obtained when the network topology is known and all the node signals in the MISO identification setup are measured. The work has been extended in [22, 23, 24] towards the situation where some node signals might be non-measurable, leading to an additional predictor input selection problem. A similar setup has also been studied in [18], where an approach has been presented based on empirical Bayesian methods to reduce the variance of the target module estimates. In [16] and [19], dynamic networks having node measurements corrupted by sensor noise have been studied, and informative experiments for consistent local module estimates have been addressed in [20].
A standing assumption in the aforementioned works [15], [18], [20], [23] is that the process noises entering the nodes of the dynamic network are uncorrelated with each other. This assumption facilitates the analysis and the development of methods for local module identification, reaching consistent module estimates using the direct method. However, when process noises are correlated over the nodes, the consistency results for the considered MISO direct method collapse. In this situation it is necessary to consider also the noise topology or disturbance correlation structure, when selecting an appropriate identification setup. Even though the indirect and two-stage methods in [16, 20] can handle the situation of correlated noise and deliver consistent estimates, the obtained estimates will not have minimum variance.
In this paper we particularly consider the situation of having dynamic networks with disturbance signals on different nodes that possibly are correlated, while our target moves from consistency only, to also minimum variance (or Maximum Likelihood (ML)) properties of the obtained local module estimates. We will assume that the topology of the network is known, as well as the (Boolean) correlation structure of the noise disturbances, i.e. the zero-elements in the spectral density matrix of the noise. While one could use techniques for full network identification (e.g., [8]), our aim is to develop a method that uses only local information. In this way, we avoid (i) the need to collect node measurements that are “far away” from the target module, and (ii) the need to identify unnecessary modules that would come with the price of higher variance in the estimates.
Using the reasoning first introduced in [25], we build a constructive procedure that, choosing a limited number of predictor inputs and predicted outputs, builds an identification setup that guarantees maximum likelihood (ML) properties (and thus asymptotic minimum variance) when applying a direct prediction error identification method. In this situation we have to deal with so-called confounding variables (see e.g. [25], [26]), that is, unmeasured variables that directly or indirectly influence both the predicted output and the predictor inputs, and lead to lack of consistency. The effect of confounding variables will be mitigated by extending the number of predictor inputs and/or predicted outputs in the identification setup, thus including more measured node signals in the identification. Preliminary results for the particular “full input” case have been presented in [27]. Here we generalize that reasoning to different node selection schemes, and provide a generally applicable theory that is independent of the particular node selection scheme selected.
This paper is organized as follows. In section II, the dynamic network setup is defined. Section III provides a summary of available results from the existing literature of local module identification related to the context of this paper. Next, important concepts and notations used in this paper are defined in Section IV while the MIMO identification setup and main results are presented in subsequent sections. Sections VII-IX provide algorithms and illustrative examples for three different ways of selecting input and output node signals: the full input case, the minimum input case, and the user selection case. This is followed by Conclusions. The technical proofs of all results are collected in the Appendix.
II Network and identification setup
Following the basic setup of [15], a dynamic network is built up out of scalar internal variables or nodes , , and external variables , . Each internal variable is described as:
| (1) |
where is the delay operator, i.e. ,
-
•
are proper rational transfer functions, referred to as modules;
-
•
There are no self-loops in the network, i.e. nodes are not directly connected to themselves ;
-
•
is generated by the external variables that can directly be manipulated by the user and is given by where are stable, proper rational transfer functions;
-
•
is process noise, where the vector process is modelled as a stationary stochastic process with rational spectral density , such that there exists a white noise process , with covariance matrix such that , where is square, stable, monic and minimum-phase. The situation of correlated noise, as considered in this paper, refers to the situation that and are non-diagonal, while we assume that we know a priori which entries of are nonzero.
We will assume that the standard regularity conditions on the data are satisfied that are required for convergence results of the prediction error identification method111See [21] page 249. This includes the property that has bounded moments of order higher than ..
When combining the node signals we arrive at the full network expression
which results in the matrix equation:
| (2) |
It is assumed that the dynamic network is stable, i.e. is stable, and well posed (see [28] for details). The representation (2) is an extension of the dynamic structure function representation [12]. The identification problem to be considered is the problem of identifying one particular module on the basis of a selection of measured variables , and possibly r.
Let us define as the set of node indices such that , i.e. the node signals in are the -in-neighbors of the node signal . Let denote the set of indices of the internal variables that are chosen as predictor inputs. It seems most obvious to have , but this is not necessary, as will be shown later in this paper. Let denote the set of node indices such that has a path to . Let denote the set of indices not in , i.e. , reflecting the node signals that are discarded in the prediction/identification. Let denote the vector , where . Let denote the vector , where . The vectors , , and are defined analogously. The ordering of the elements of , , and is not important, as long as it is the same for all vectors. The transfer function matrix between and is denoted . The other transfer function matrices are defined analogously.
| Network matrix with modules | |
| Network noise model | |
| Target module with input and output | |
| Node signal , output of the target module | |
| Node signal , input of the target module | |
| Set of indexes of nodes that appear in the vector of predicted | |
| outputs | |
| Set of indexes of nodes that appear in the vector of predictor | |
| inputs for predicted outputs | |
| Set of indexes of nodes that appear in the vector of predictor | |
| inputs for prediction of node | |
| Output node signal if it is not in set | |
| Set of indexes of nodes that appear both in the predicted output, | |
| and in the predictor input | |
| Set of indexes of nodes that only appear as predictor input: | |
| Set of indexes of nodes that only appear as predictor input, | |
| that do not have any confounding variable effect: | |
| Set of indexes of nodes that only appear as predictor input: | |
| Set of indexes of nodes that are removed (immersed) from the | |
| network when predicting | |
| Set of indexes of nodes that are removed (immersed) from the | |
| network when predicting | |
| Disturbance signal on node | |
| Index set of nodes that are -in-neighbors of | |
| (White noise) innovation of the noise process | |
| Index set of all node signals: | |
| Network matrix of the immersed and transformed network (8) | |
| (White noise) innovation of the noise process in the immersed | |
| and transformed network (8) |
To illustrate the notation, consider the network sketched in Figure 1, and let module be the target module for identification.
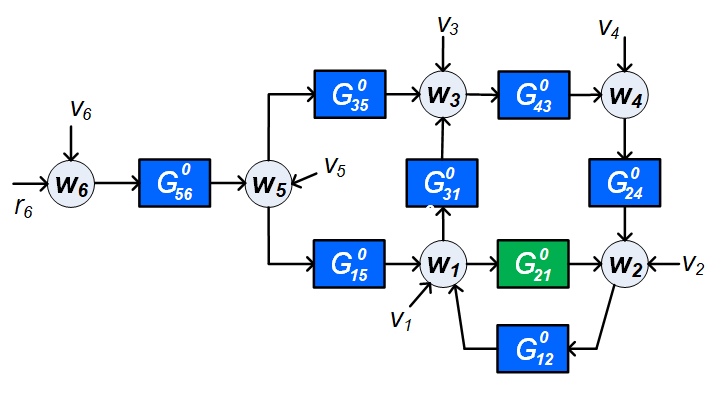
Then , ; . If we choose the set of predictor inputs as , then the set of remaining (nonmeasured) signals, becomes .
By this notation, the network equation (2) is rewritten as:
| (3) |
where and have zeros on the diagonal.
For identification of module we select such that , and subsequently estimate a multiple-input single-output model for the transfer functions in , by considering the one-step-ahead predictor222 refers to , and and refer to signal samples and , , respectively, for all . ([21]) and the resulting prediction error , leading to:
| (4) |
where arguments and have been dropped for notational clarity. The parameterized transfer functions , and are estimated by minimizing the sum of squared (prediction) errors: where is the length of the data set. We refer to this identification method as the direct method, [15].
III Available results and problem specification
The following results are available from previous work:
-
•
When is chosen equal to and noise is uncorrelated to all , , then can be consistently estimated in a MISO setup, provided that there is enough excitation in the predictor input signals, see [15].
-
•
When is a subset of , and disturbance are uncorrelated, confounding variables333A confounding variable is an unmeasured variable that has paths to both the input and output of an estimation problem [29]. can occur in the estimation problem, and these have to be taken into account in the choice of in order to arrive at consistent estimates of , see [23].
-
•
In [26] relaxed conditions for the selection of have been formulated, while still staying in the context of MISO identification with noise spectrum of () being diagonal. This is particularly done by choosing additional predictor input signals that are not in ,.i.e. that are no in-neighbors of the output of the target module.
- •
- •
In this paper, we go beyond consistency properties, and address the following problem: How to identify a single module in a dynamic network for the situation that the disturbance signals can be correlated, i.e. not necessarily being diagonal, such that the estimate is consistent and asymptotically has Maximum Likelihood, and thus also minimum variance, properties.
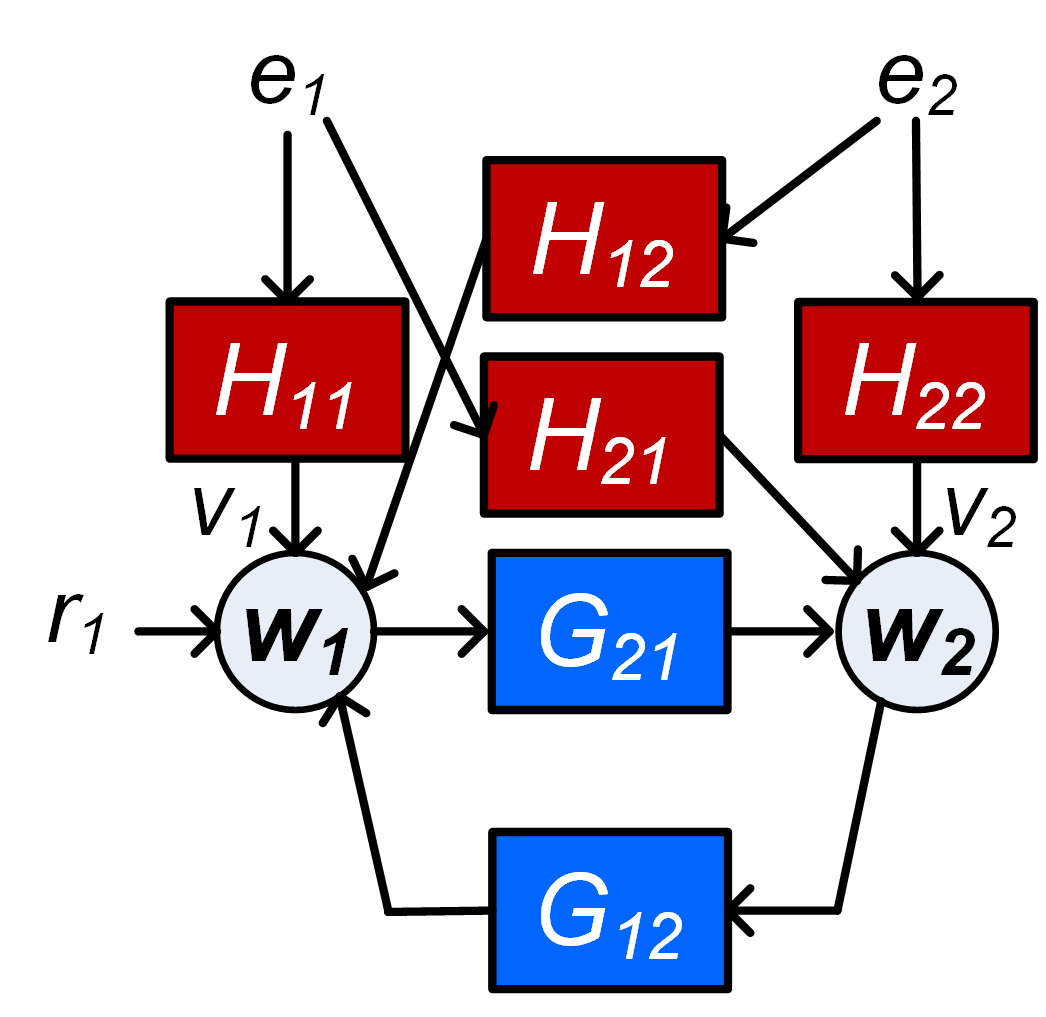
Addressing this problem requires a more careful treatment and modelling of the noise that is acting on the different node signals. This can be illustrated through a simple Example that is presented in [25], where a two-node network is considered as given in Figure 2, with and being dynamically correlated. In this case, a SISO identification using the direct method with input and output will lead to a biased estimate of because of the unmodelled correlation of the disturbance signals on and 444In this particular example the bias is caused by the presence of .. For an analysis of this, see [25]. If both node signals and are predicted as outputs, then the correlation between the disturbance signals can be incorporated in a non-diagonal noise model, thus leading to an unbiased estimate of . In this way bias due to correlation in the noise signals can be avoided by predicting additional outputs other than the output of the target module. This leads to the following two suggestions:
-
•
confounding variables can be dealt with by modelling correlated disturbances on the node signals, and
-
•
this can be done by moving from a MISO identification setup to a MIMO setup.
These suggestions are being explored in the current paper. Next we will present an example to further illustrate the problem.
Example 1
Consider the network sketched in Figure 1, and let module be the target module for identification. If the node signals , and can be measured, then a two-input one-output model with inputs and output can be considered. This can lead to a consistent estimate of and , provided that the disturbance signal is uncorrelated to all other disturbance signals. However if e.g. and are dynamically correlated, implying that a noise model of the two-dimensional noise process is non-diagonal, then a biased estimate will result for this approach. A solution is then to include in the set of predicted outputs, and by adding node signal as predictor input for . We then combine predicting on the basis of with predicting on the basis of . The correlation between and is then covered by modelling a non-diagonal noise model of the joint process .
In the next sections we will formalize the procedure as sketched in Example 1 for general networks.
IV Concepts and notation
In line with [29] we define the notion of confounding variable.
Definition 1 (confounding variable)
Consider a dynamic network defined by
| (5) |
with a white noise process, and consider the graph related to this network, with node signals and . Let and be two subsets of measured node signals in , and let be the set of unmeasured node signals in . Then a noise component in is a confounding variable for the estimation problem , if in the graph there exist simultaneous paths555A simultaneous path from to node signal and implies that there exist a path from to as well as from to . from to node signals and , while these paths are either direct666A direct path from to node signal implies that there exist a path from to which does not pass through nodes in . or only run through nodes that are in .
We will denote as the node signals in that serve as predicted outputs, and as the node signals in that serve as predictor inputs. Next we decompose and into disjoint sets according to: where are the node signals that are common in and ; is the output of the target module; if then is void; are the node signals that are only in . In this situation the measured nodes will be and the unmeasured nodes will be determined by the set , where .
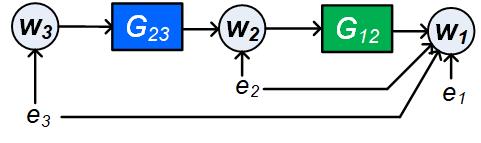
There can exist two types of confounding variable namely direct and indirect confounding variables. For direct confounding variables the simultaneous paths mentioned in the definition are both direct paths, while in all other cases we refer to the confounding variables as indirect confounding variables. For example, in the network as shown in Figure 3 with , and , for the estimation problem , is a direct confounding variable since it has a simultaneous path to and where both the paths are direct paths. Meanwhile is an indirect confounding variable since it has a simultaneous path to and where one of the path is an unmeasured path777An unmeasured path is a path that runs through nodes in only. Analogously, we can define unmeasured loops through a node ..
Remark 1
Confounding variables are defined in accordance with their use in [26], on the basis of a network description as in (5). In this definition absence of confounding variables still allows that there are unmeasured signals that create correlation between the inputs and outputs of an estimation problem, in particular if the white noise signals in are statically correlated, i.e being non-diagonal. It will appear that this type of correlations will not hinder our identification results, as analysed in Section VI-C.
V Main results - Line of reasoning
On the basis of the decomposition of node signals as defined in the previous section we are going to represent the system’s equations (5) in the following structured form:
| (6) | |||||
where we make the notation agreement that the matrix is not necessarily monic, and the scaling of the white noise process is such that . Without loss of generality, we can assume for the sake of brevity.
Our objective is to end up with an an identification problem in which we identify the dynamics from inputs to outputs , while our target module is present as one of the scalar transfers (modules) in this identified (MIMO) model. This can be realized by the following steps:
-
1.
Firstly, we write the system’s equations for the measured variables as
(7) with a white noise process, while is monic, stable and stably invertible and the components in are zero if it concerns a mapping between identical signals. This step is made by removing the non-measured signals from the network, while maintaining the second order properties of the remaining signals. This step is referred to as immersion of the nodes in [23].
-
2.
As an immediate result of the previous step we can write an expression for the output variables , by considering the upper part of the equation (7), as
(8) with .
-
3.
Thirdly, we will provide conditions to guarantee that , i.e the target module appearing in equation (8) is the target module of the original network (invariance of target module). This will require conditions on the selection of node signals in .
-
4.
Finally, it will be shown that, on the basis of (8), under fairly general conditions, the transfer functions and can be estimated consistently, and with maximum likelihood properties. A pictorial representation of the identification setup with the classification of different sets of signals in (8) is provided in Figure 4. The figure also contains set which will be introduced in the sequel.
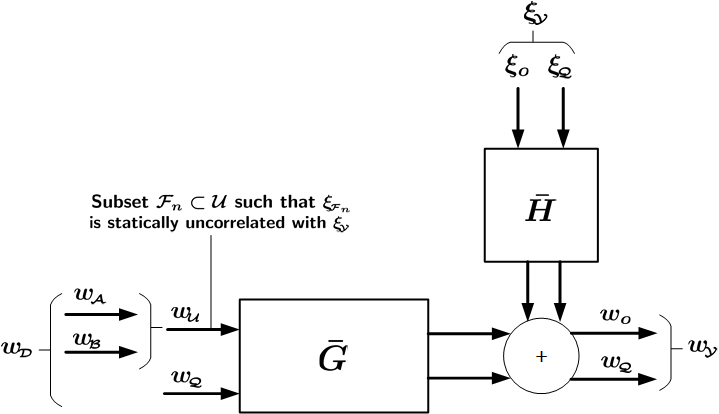
The combination of steps 3 and 4 will lead to a consistent and maximum likelihood estimation of the target module . It has to be noted that an identification setup results, in which signals can simultaneously act as input and as output (the set ). Because is restricted to be hollow, this does not lead to trivial transfers between signals that are the same. A related situation appears when identifying a full network, while using all node signals as both inputs and outputs, as in [8].
The steps 1)-4) above will require conditions on the selection of node signals, based on the known topology of the network and an allowed correlation structure of the disturbances in the network. Specifying these conditions on the selection of sets , will be an important objective of the next section.
VI Main Results - Derivations
VI-A System representation after immersion (Steps 1-2)
First we will show that a network in which signals in are removed (immersed) can indeed be represented by (7).
Proposition 1
Consider a dynamic network given by (6), where the set of all nodes is decomposed in disjunct sets , , and as defined in Section IV. Then, for the situation ,
-
1.
there exists a representation (7) of the measured node signals , with monic, stable and stably invertible, and a white noise process, and
-
2.
for this representation there are no confounding variables for the estimation problem .
Proof: See appendix.
(a) (b) (c)
The consequence of Proposition 1 is that the output node signals in can be explicitly written in the form of (8), in terms of input node signals and disturbances, without relying on (unmeasured) node signals in . The particular structure of network representation (7) implies that there are no confounding variables for the estimation problem . This will be an important phenomenon for our identification setup. Based on (8), a typical prediction error identification method can provide estimates of and from measured signals and with . In this estimation problem, confounding variables for the estimation problem are treated by correlated noise modelling in , while confounding variables for the estimation problem are not present, due to the structure of (7).
In the following example, the step towards (7) will be illustrated, as well as its effect on the dynamics in .
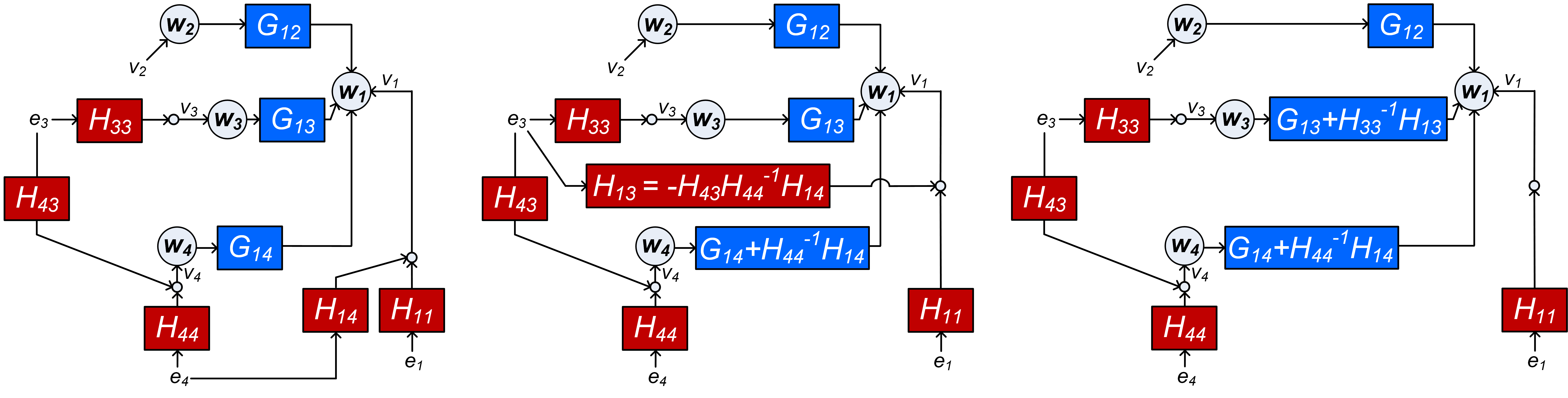
Example 2
Consider the 4-node network depicted in Figure 5(a), where all nodes are considered to be measured, and where we select , , and . In this network, there is a confounding variable for the problem (i.e ), meaning that for the situation the noise model in (7) will not be block diagonal. Therefore the network does not comply with the representation in (7) and (8). We can remove the confounding variable, by shifting the effect of into a transformed version of , which now becomes , as depicted in Figure 5(b). However, since this shift also affects the transfer from to , the change of needs to be mitigated by a new term , in order to keep the network signals invariant. In the resulting network the confounding variable for is removed, but a new confounding variable ( for has been created. In the second step, shown in Figure 5(c), the term is removed by incorporating its effect in the module which now becomes . In the resulting network there are no confounding variables for . This representation complies with the structure in (7). Note that in the transformed network, the dynamics of is left invariant, while the dynamics of and have been changed. The intermediately occurring confounding variables relate to a sequence of linked confounders, as discussed in [26].
In the next subsection it will be investigated under which conditions our target module will remain invariant under the above transformation to a representation (7) without confounding variables.
VI-B Module invariance result (Step 3)
The transformation of a network into the form (7), leading to the resulting identification setup of (8), involves two basic steps, each of which can lead to a change of dynamic modules in . These two steps are
-
(a)
Removing of non-measured signals in (immersion), and
-
(b)
Transforming the system’s equations to a form where there are no confounding variables for .
Module invariance in step (a) is covered by the following Condition:
Condition 1 (parallel path and loop condition[23])
Let be the target network module to be identified. In the original network (6):
-
•
Every path from to , excluding the path through , passes through a node , and
-
•
Every loop through passes through a node in .
This condition has been introduced in [23] for a MISO identification setup, to guarantee that when immersing (removing) nonmeasured node signals from the network, the target module will remain invariant. As an alternative, more generalized notions of network abstractions have been developed for this purpose in [30]. Condition 1 will be used to guarantee module invariance under step (a).
Step (b) above is a new step, and requires studying module invariance in the step transforming a network from an original format where all nodes are measured, into a structure that complies with (7), i.e. with absence of confounding variables for .
We are going to tackle this problem, by decomposing the set into two disjunct sets aiming at the situation that in the transformed network, the modules stay invariant, while for the modules we accept that the transformation can lead to module changes. We construct by choosing signals such that in the original network there are no confounding variables for the estimation problem . For the selection of , we do allow confounding variables for the estimation problem . By requiring a particular “disconnection” between the sets and , we can then still guarantee that the modules stay invariant.
The following condition will address the major requirement for addressing our step (b).
Condition 2
Condition 2 is not a restriction on , as such a decomposition can always be made, e.g. by taking and . The flexibility in choosing this decomposition will be instrumental in the sequel of this paper.
Example 3 (Example 2 continued)
In the example network depicted in Figure 5, we observe that in the original network there is a confounding variable for . However in the step towards creating a network without confounding variables for an intermediate step occurs, where there is also a confounding variable for , as depicted in Figure 5(b). For the choice , , is not valid since there exists a confounding variable () for which violates the second condition that there should be no confounding variables for . Therefore the appropriate choice satisfying Condition 2 is and . Note that this matches with the situation that in the transformed network (Figure 5(c)), the module remains invariant, and the modules get changed.
We can now formulate the module invariance result.
Theorem 1 (Module invariance result)
Let be the target network module. In the transformed system’s equation (8), it holds that under the following conditions:
Proof: See appendix.
VI-C Identification results (Step 4)
If the conditions of Theorem 1 are satisfied, then the target module can be identified on the basis of the system’s equation (8). For this system’s equation we can set up a predictor model with input and outputs , for the estimation of and . This will be based on a parameterized model set determined by
while the actual data generating system is represented by . The corresponding identification problem is defined by considering the one-step-ahead prediction of in the parametrized model, according to where denotes the past of , i.e. . The resulting prediction error becomes: , leading to
| (9) |
and the weighted least squares identification criterion
| (10) |
with any positive definite weighting matrix. This parameter estimate then leads to an estimated subnetwork and noise model , for which consistency and minimum variance results will be formulated next.
Theorem 2 (Consistency)
Consider a dynamic network represented by (7), and a related (MIMO) network identification setup with predictor inputs and predicted outputs , according to (8). Let be the set of node signals for which is statically uncorrelated with 888This implies that . and let . Then a direct prediction error identification method according to (9)-(10), applied to a parametrized model set will provide consistent estimates of and if:
-
a.
is chosen to satisfy ;
-
b.
for a sufficiently high number of frequencies, where ;
(data-informativity condition). - c.
Proof: See appendix.
The consistency theorem has a structure that corresponds to the classical result of the direct prediction error identification method applied to a closed-loop experimental setup, [21]. A system in the model set condition (a), an informativity condition on the measured data (b), and a loop delay condition (c). Note however that conditions (b) and (c) are generalized versions of the typical closed-loop case [21, 15], and are dedicated for the considered network setup.
It is important to note that Theorem 2 is formulated in terms of conditions on the network in (7), which we refer to as the transformed network. However, it is quintessential to formulate the conditions in terms of properties of signals in the original network, represented by (6).
Proposition 2
Proof: See appendix.
Condition (b) of Theorem 2 requires that there should be enough excitation present in the node signals, which actually reflects a type of identifiability property [13]. Note that this excitation condition may require that there are external excitation signals present at some locations, see also [15, 31, 32, 33, 14, 34], and [35], where it is shown that , with the cardinality of . Since we are using a direct method for identification, excitation signals are not directly used in the predictor model, although they serve the purpose of providing excitation in the network. A first result of a generalized method where, besides node signals , also signals are included in the predictor inputs, is presented in [36].
Since in the result of Theorem 2 we arrive at white innovation signals, the result can be extended to formulate Maximum Likelihood properties of the estimate.
Theorem 3
Consider the situation of Theorem 2, and let the conditions for consistency be satisfied. Let be normally distributed, and let be parametrized independently from and . Then, under zero initial conditions, the Maximum Likelihood estimate of is
| (11) | |||||
| (12) |
Proof: Can be shown by following a similar reasoning as in Theorem 1 of [8].
So far, we have analysed the situation for given sets of node signals , , , and . The presented results are very general and allow for different algorithms to select the appropriate signals and specify the particular signal sets, that will guarantee target module invariance and consistent and minimum variance module estimates with the presented local direct method. In the next sections we will focus on formulating guidelines for the selection of these sets, such that the target module invariance property holds, as formulated in Theorem 1. For formulating these conditions, we will consider three different situations with respect to the availability of measured node signals.
-
(a)
In the Full input case, we will assume that all in-neighbors of the predicted output signals are measured and used as predictor input;
-
(b)
In the Minimum input case, we will include the smallest possible number of node signals to be measured for arriving at our objective;
-
(c)
In the User selection case, we will formulate our results for a prior given set of measured node signals;
VII Algorithm for signal selection: full input case
The first algorithm to be presented is based on the strategy that for any node signal that is selected as output, we have access to all of its -in-neighbors, that are to be included as predictor inputs. This strategy will lead to an identification setup with a maximum use of measured node signals that contain information that is relevant for modeling our target module . The following strategy will be followed:
-
•
We start by selecting and ;
-
•
Then we extend in such a way that all -in-neighbors of are included in .
-
•
All node signals in that have noise terms , that are correlated with any , (direct confounding variables for ), are included in too. They become elements of .
-
•
With it follows that by construction there are no direct confounding variables for the estimation problem .
-
•
Then we choose as a subset of nodes that are not in nor in . This set needs to be introduced to block the indirect confounding variables for the estimation problem , and will be chosen to satisfy Condition 2a and 2c of Theorem 1.
-
•
Every node signal , for which there are only indirect confounding variables and cannot be blocked by a node in , is
-
–
moved to if Conditions 2a and 2c of Theorem 1 are satisfied and ; (else)
-
–
included in and moved to ;
-
–
-
•
Finally, we define the identification setup as the estimation problem , with and .
Note that because all -in-neighbors of are included in , we automatically satisfy the parallel path and loop condition 1. In order for the selection of node signals to satisfy the conditions of Theorem 1, we will specify the following Property 1.
Property 1
Let the node signals be chosen to satisfy the following properties:
-
1.
If, in the original network, there are no confounding variables for the estimation problem , then is void implying that is not present;
-
2.
If, in the original network, there are confounding variables for the estimation problem , then all of the following conditions need to be satisfied:
-
a.
For any confounding variable for the estimation problem , the unmeasured paths from the confounding variable to node signals pass through a node in .
-
b.
There are no confounding variables for the estimation problem .
-
c.
Every path from to passes through a measured node in .
-
a.
Property 2a) ensures that, after including in the set of measured signals, there are no indirect confounding variables for the estimation problem , and Property 2b) guarantees that there are no confounding variables for the estimation problem . Together we satisfy Condition 2a) of Theorem 1. Also, Property 2c) guarantees condition 2c) of Theorem 1 to be satisfied. Finally, as per the algorithm, can be either in or . Therefore at the end of the algorithm, we will obtain sets of signals that satisfy the conditions in Theorem 1 for target module invariance.
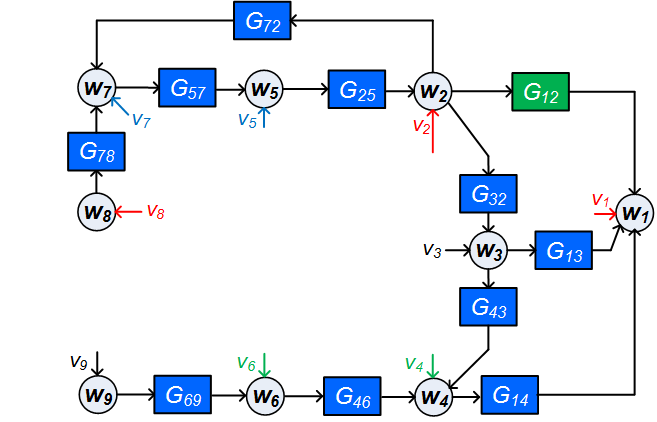
Example 4
Consider the network in Figure 6. is the target module that we want to identify. We now select the signals according to the algorithm presented in this section. First we include the input of the target module in and the output of the target module in . Next we include all -in-neighbors of (i.e. and ) in . All node signals in that have noise terms , that are correlated with any need to be included in too. This concerns , since is correlated with . Now has changed and we need to include the -in-neighbors of , which is , in , leading to . After a check we can conclude that all node signals in that have noise terms , that are correlated with any are included in too. The result now becomes
| ; | (13) | ||||
| ; | (14) |
Since is dynamically correlated with , in the resulting situation we will have a confounding variable for the estimation problem (i.e. ). As per condition 2a of Property 1, the path of the confounding variable to should be blocked by a node signal in , which can be either or . cannot be chosen in since this would create a confounding variable for (i.e. ). Moreover, would also create an unmeasured path with , thereby violating Condition 2c of Property 1. When is chosen in , the conditions in Property 1 are satisfied and hence we choose . The resulting estimation problem is , and will according to Theorem 2 provide a consistent and maximum likehood estimate of .
VIII Algorithm for signal selection: minimum input case
Rather than measuring all node signals that are -in-neighbors of the output of our target module , we now focus on an identification setup that uses a minimum number of measured node signals, according to the following strategy:
-
•
We start by selecting and ;
-
•
Then we extend with a minimum number of node signals that satisfies the parallel path and loop Condition 1.
-
•
Every node signal in for which there is a direct or indirect confounding variable for the estimation problem is included in and .
-
•
With and it follows that by construction there are no confounding variables for the estimation problem .
-
•
Finally, we define the identification setup as the estimation problem , with .
As we can observe, the algorithm does not require selection of set . This is attributed to the way we handle the indirect confounding variables for the estimation problem . Instead of tackling these confounding variables by adding blocking node signals (as in full input case) to be added as predictor inputs, we deal with them by moving the concerned to and thus to the set of predicted outputs. We choose this approach in order to minimize the required number of measured node signals. In this way, by construction, there will be no direct or indirect confounding variables for the estimation problem . From this result, we can guarantee that the conditions in Theorem 1 will be satisfied since . Thus at the end of the algorithm we obtain a set of signals that provides target module invariance.
Example 5
Consider the same network as in example 4 represented by Figure 6. Applying the algorithm of this section, we first include the input of the target module in and the output of the target module in . There exist two parallel paths from to , namely and and no loops through . In order to satisfy Condition 1 we can include either in such that or both in such that . We choose the former to have minimum number of node signals. Because of the correlation between and there is a confounding variable for the estimation problem . According to step 3 of the algorithm, is then moved to and , leading to . Because of this change of we have to recheck for presence of confounding variables. However this change does not introduce any additional confounding variables. The resulting estimation problem is with , , and .
In comparison with the full input case, the algorithm in this section will typically have a higher number of predicted output nodes and a smaller number of predictor inputs. This implies that there is a stronger emphasis on estimating a (multivariate) noise model . Given the choice of the direct identification method, and the choice of signals to satisfy the parallel path and loop condition, this algorithm indeed adds the smallest number of additional signals to be measured, as the removal of any of the additional signals will lead to conflicts with the required conditions.
IX Algorithm for signal selection: User selection case
Next we focus on the situation that we have a prior given set of nodes that we have access to i.e. a set of nodes that can (possibly) be measured. We refer to these nodes as accessible nodes while the remaining nodes are called inaccessible. This strategy is different from the full input case since we do not assume that we have access to all in-neighbours of .
This will lead to an identification setup with use of accessible node signals that contain information which is relevant for modeling our target module .
We consider the situation that nodes and are accessible nodes and there are accessible nodes that satisfy the parallel path and loop Condition 1.
The following strategy will be followed:
-
1.
We start by selecting and ;
-
2.
Then we extend to satisfy the parallel path and loop Condition 1;
-
3.
We include in all accessible -in-neighbors of ;
-
4.
We extend in such a way that for every non-accessible -in-neighbor of we include all accessible nodes that have path to that runs through non-accessible nodes only.
-
5.
If there is a direct confounding variable for , or an indirect one that has a path to that does not pass through any accessible nodes, then is included in and ;
-
6.
A node signal , is included in if there are either no confounding variables for or only indirect confounding variables that have paths to that pass through accessible nodes.
-
7.
Every node signal that has a direct confounding variable for , or an indirect confounding variable with a path to that does not pass through any accessible nodes is:
-
•
included in if condition 2a and 2c of Theorem 1 are satisfied on including it in (else)
-
•
included in and ; return to step 3.
-
•
-
8.
Every node signal , for which there are only indirect confounding variables as meant in Step 6, is
-
9.
By construction there are no confounding variables for .
In the algorithm above, the prime reasoning is to deal with confounding variables for . Direct confounding variables lead to including the respective node in the outputs or shifting the respective input node to , while indirect confounding variables are treated by either shifting the input node to or, if its effect can be blocked, by adding an accessible node to the inputs in , or, if the blocking conditions can not be satisfied, by including the node in the output . Note that the algorithm always provides a solution if Condition 1 of Theorem 1 (parallel path and loop condition) can be satisfied.
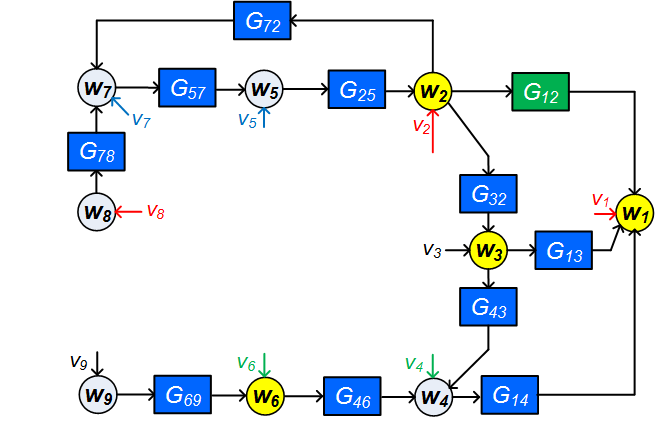
Example 6
Consider the same network as in example 4 represented by Figure 7. However, we are given that only the nodes and are accessible. We now select the signals according to the algorithm presented in this section. First we include in and in . Then we extend such that the parallel path and loop Condition 1 is satisfied. This is done by selecting . According to step 4, we extend by node as it serves as nearest accessible in-neighbor of , being an inaccessible in-neighbor of . As per Step 5, since and are correlated, is moved to and . As per Step 6, there are no confounding variables for the estimation problem and hence is included in . Since and are correlated, it implies that there is an indirect confounding variable for the estimation problem , which however does not pass through an accessible node. Step 7 does not apply since has no confounding variables. Step 8 requires to deal with the indirect confounding variable for . Checking Conditions 2a and 2c of Theorem 1 for and , it appears that every path from or from to passes through a measured node and there are no confounding variable for the estimation problem . Hence we include in . As a result, the estimation problem is .
Remark 2
Rather than starting the signal selection problem from a fixed set of accessible notes, the provided theory allows for an iterative and interactive algorithm for selecting accessible nodes in sensor allocation problems in a flexible way.
X Discussion
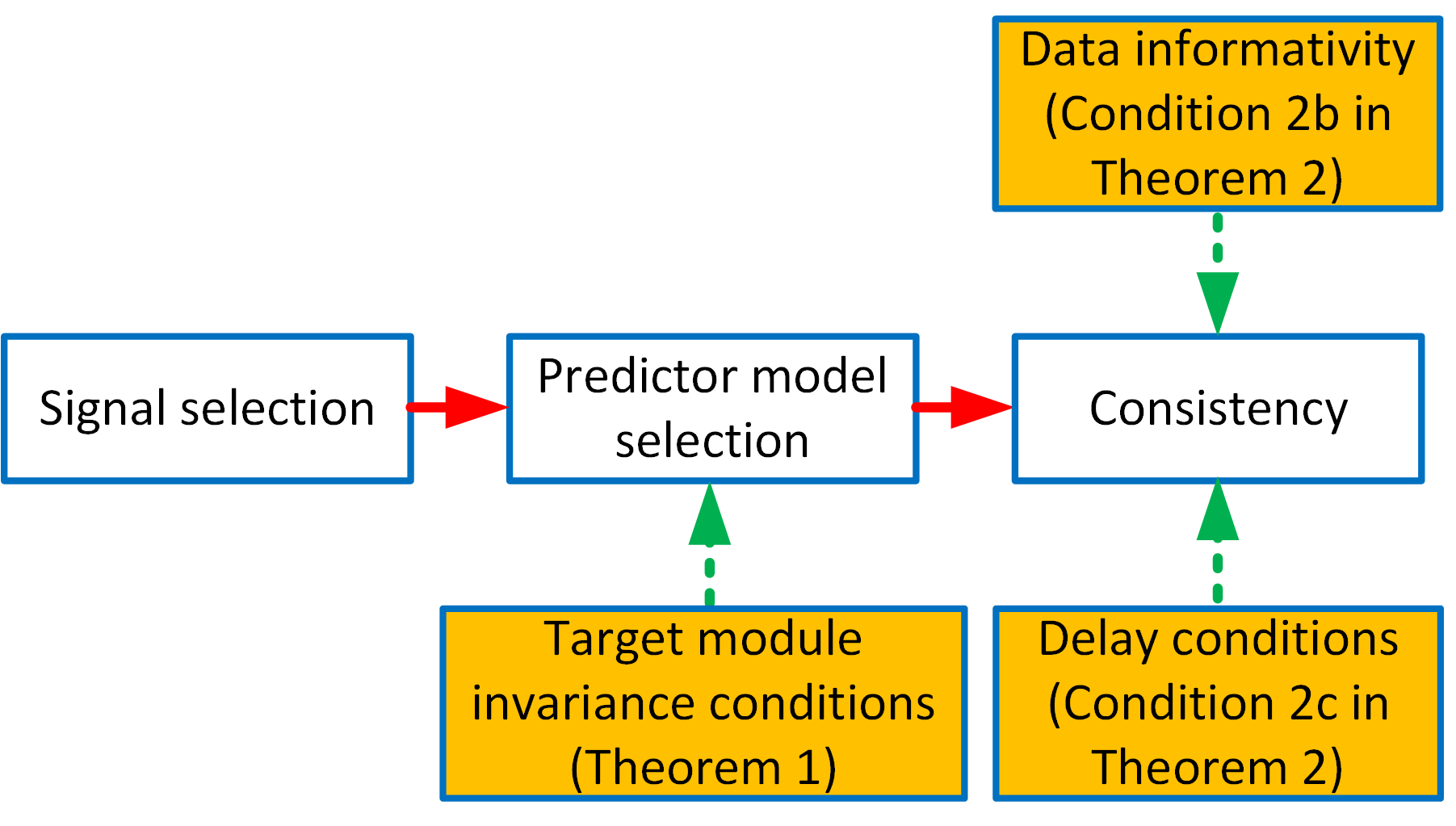
All three presented algorithms lead to a set of selected node signals that satisfy the conditions for target module invariance, and thus provide a predictor model in which no confounding variables can deteriorate the estimation of the target module. Only in the “User selection case” this is conditioned on the fact that appropriate node signals should be available to satisfy the parallel path and loop condition. Under these circumstances the presented algorithms are sound and complete [37]. This attractive feasibility result is mainly attributed to the addition of predicted outputs, that adds flexibility to solve the problem of confounding variables.
Note that the presented algorithms do not guarantee the consistency of the estimated target module. For this to hold the additional conditions for consistency, among which data-informativity and the delay in path/loop condition, need to be satisfied too, as illustrated in Figure 8. A specification of path-based conditions for data-informativity is beyond the scope of this paper, but first results on this problem are presented in [35]. Including these path-based conditions in the signal selection algorithms would be a next natural step to take. This also holds for the development of data-driven techniques to estimate the correlation structure of the disturbances.
It can be observed that the three algorithms presented in the previous sections rely only on the graphical conditions of the network. This paves way to automate the signal selection procedure using graph based algorithms that are scalable to large dimensions, with input being topology of the network and disturbance correlation structure represented as adjacency matrices. Also,
it can be observed that the three considered cases in the previous sections, most likely will lead to three different experimental setups for estimating the single target module. For all three cases we can arrive at consistent and maximum likehood estimates of the target module. However, because of the fact that the experimental setups are different in the three cases, the data-informativity conditions and the statistical properties of the target module estimates will be different. The minimum variance expressions, in the form of the related Cramér-Rao lower bounds, will typically be different for the different experimental setups. Comparing these bounds for different experimental setups is beyond the scope of the current paper and considered as topic for future research.
We have formulated identification criteria in the realm of classical prediction error methods. This will typically lead to complex non-convex optimization problems that will scale poorly with the dimensions (number of parameters) of the problems. However alternative optimization approaches are becoming available that scale well and that rely on regularized kernel-based methods, thus exploiting new developments that originate from machine learning, see e.g. [18], and relaxations that rely on sequential convex optimization, see e.g. [38, 39].
XI CONCLUSIONS
A new local module identification approach has been presented to identify local modules in a dynamic network with given topology and process noise that is correlated over the different nodes. For this case, it is shown that the problem can be solved by moving from a MISO to a MIMO identification setup. In this setup the target module is embedded in a MIMO problem with appropriately chosen inputs and outputs, that warrant the consistent estimation of the target module with maximum likelihood properties. The key part of the procedure is the handling of direct and indirect confounding variables that are induced by correlated disturbances and/or non-measured node signals, and thus essentially dependent on the (Boolean) topology of the network and the (Boolean) correlation structure of the disturbances. A general theory has been developed that allows for specification of different types of algorithms, of which the “full input case”, the “minimum input case” and the “user selection case” have been illustrated through examples. The presented theory is suitable for generalization to the estimation of sets of target modules.
Appendix A Proof of Proposition 1
Starting with the network representation (6), we can eliminate the non-measured node variables from the equations, by writing the last (block) row of (6) into an explicit expression for :
and by substituting this into the expressions for the remaining -variables. As a result
| (15) |
with , and where
| (16) |
with , and
| (17) |
with .
On the basis of (A), the spectral density of is given by . Applying a spectral factorization [40] to will deliver with a monic, stable and minimum phase rational matrix, and a positive definite (constant) matrix. Then there exists a white noise process defined by such that , with cov() = , while is of the form
| (18) |
and where the block dimensions are conformable to the dimensions of , and respectively. As a result, (A) can be rewritten as
| (19) |
By denoting
| (20) |
and premultiplying (19) with
| (21) |
while only keeping the identity terms on the left hand side, we obtain an equivalent network equation:
| (22) |
with
| (23) | |||||
| (24) | |||||
| (25) | |||||
| (26) | |||||
| (27) | |||||
| (28) |
where and .
The next step is now to show that that the block elements and in can be made . This can be done by variable substitution as follows:
The second row in (22) is replaced by an explicit expression for according to
Additionally, this expression for is substituted into the first block row of (22), to remove the -dependent term on the right hand side, leading to
| (29) |
with
| (30) | |||||
| (31) | |||||
| (32) | |||||
| (33) |
Since because of these operations, the matrix might not be hollow, we move any diagonal terms of this matrix to the left hand side of the equation, and premultiply the first (block) equation by the diagonal matrix , to obtain the expression
| (34) |
with
| (35) | |||||
| (36) | |||||
| (37) |
As final step, we need the matrix to be monic, stable and minimum phase to obtain the representation as in (7). To that end, we consider the stochastic process with . The spectral density of is then given by with the covariance matrix of , that can be decomposed as . From spectral factorization [40] it follows that the spectral factor of satisfies
| (38) |
with a stable and minimum phase rational matrix, and an “all pass” stable rational matrix satisfying .
The signal can then be written as
By defining , this can be rewritten as
As a result, is a monic stable and stably invertible rational matrix, and is a white noise process with spectral density given by . Therefore we can write (34) as,
| (39) |
where . Let . Pre-multiplying (39) with while only keeping the identity terms on the left hand side, we obtain an equivalent network equation:
| (40) |
where , and . In order to make hollow, we move any diagonal terms of this matrix to the left hand side of the equation, and pre-multiply the third (block) equation by the diagonal matrix . This will modify (3,3) (block) element of the matrix to , which we need to be monic, stable and stably invertible. Applying spectral factorization as before [40], we can write the term as where is monic, stable and stably invertible and is a white noise process with covariance . This completes the proof for obtaining (7).
The absence of confounding variables for the estimation problem can be proved as follows. Since all non-measured nodes are removed in the network represented by (7), the only non-measured signals in the network are the noise signals in and they do not have any unmeasured paths to any nodes in the network (i.e. to ). Due to the block-diagonal structure of in (7), the only non-measured signals that have direct paths to originate from , while the only non-measured signals that have direct paths to originate from . Therefore there does not exist an element of that has simultaneous unmeasured paths or direct paths to both and .
Appendix B Proof of Theorem 1
In order to prove Theorem 1, we first present three preparatory Lemmas.
Lemma 1
Consider a dynamic network as defined in (6), a vector of white noise sources with , and two subsets of nodes and , . If in there is no confounding variable for the estimation problem , then
where , are the noise model transfer functions in the immersed network (A) related to the appropriate variables.
Proof:
If in there is no confounding variable for the formulated estimation problem, then for all , there do not exist simultaneous paths from to and , that are direct or pass through nodes in only.
For the network where signals are immersed, it follows from (17), that where and . The first term in the sum (i.e. ) is the noise model transfer in the direct path from to and the second part of the sum is the transfer function in the unmeasured paths (i.e. paths through only) from to . If all paths from a node signal to pass through a node in , then there are no direct or unmeasured paths from to nodes in . This implies that for all (i.e ). A dual reasoning applies to paths from to .
Consider .
Then we have . If the condition in the lemma is satisfied, implying that there do not exist simultaneous paths, then in each of the product terms we either have or where . This proves the result of lemma 1.
Lemma 2
Consider a dynamic network as defined in (A) with target module , where the non-measured node signals are immersed, while the node sets are chosen according to the specifications in Section IV.
Then is given by the following expressions:
| (41) |
| (42) |
where is the row vector corresponding to the row of node signal in (if ) or in (if ), and is the element corresponding to the column of node signal in .
Proof: For the target module we have the following cases that can occur:
- 1.
- 2.
- 3.
- 4.
Lemma 3
Consider a dynamic network as defined in (A) where the non-measured node signals are immersed, and let be decomposed in sets and satisfying Condition 2. Then the spectral density has the unique spectral factorization with constant and monic, stable, minimum phase, and of the form
| (43) |
where the block dimensions are conformable to the dimensions of , , and respectively.
Proof: On the basis of (A) we write and
| (44) |
with and the components of as specified in (17). Starting from the expression (44), the spectral density can be written as while it is denoted as
| (45) |
In this structure we are particularly going to analyse the elements
|
|
(46) |
If and satisfy Condition 2, then none of the white noise terms , will be a confounding variable for the estimation problems , or . Then it follows from Lemma 1 that all of the terms in (46) are zero. As a result we can write the spectrum in equation (45) as,
| (47) |
Then the spectral density has the unique spectral factorization [40]
| (48) |
where is of the form in (43), and monic, stable and minimum phase.
Next we proceed with the proof of Theorem 1.
With Lemma 2 it follows that is given by either (41) or (42). For analysing these two expressions, we first are going to specify and . From (16), we have
| (49) | |||||
| (50) |
where the first terms on the right hand sides reflect the direct connections from to (respectively from to ) and the second terms reflect the connections that pass only through nodes in . By definition, since the matrix in the network in (6) is hollow. Under the parallel path and loop condition 1, the second terms on the right hand sides of (49), (50) are zero, so that and .
What remains to be shown is that in (41) and (42), it holds that
| (51) |
while additionally for , it should hold that
| (52) |
With definition (20) for and the special structure of and in (18) that is implied by the result (43) of Lemma 3, we can write
| (53) |
implying that columns in this matrix related to inputs are zero.
In order to satisfy (52) we need the condition that: if then . This is equivalently formulated as (conditon 2b).
In order to satisfy (51) we note that is a row vector, of which the second part (the columns related to signals in ) is equal to , according to (53). Consequently, (51) is satisfied if for every it holds that . On the basis of (16), this condition is satisfied if for every there do not exist direct or unmeasured paths from to and from to (condition 2c).
Appendix C Proof of Theorem 2
Expression (8) can be written as
Substituting this into the expression for the prediction error (9), leads to
| (54) |
where and . The proof of consistency involves two steps.
-
1.
To show that achieves its minimum for and ,
-
2.
To show the conditions under which the minimum is unique.
Step 1: With Proposition 1 it follows that our data generating system can always be written in the form (7), such that . We denote as the matrix composed of the first and third (block) row of , such that . Substituting this into (54) gives
where is (block) structured as .
In order to prove that the minimum of is attained for and , it is sufficient to show that
| (55) |
is uncorrelated to . In order to show this, let , with as defined in the Theorem, while we decompose according to . Using a similar block-structure notation for , and , (55) can then be written as
|
|
(56) |
Since, by definition, is statically uncorrelated to , the -dependent term in (56) cannot create any static correlation with . Then it needs to be shown that the - and -dependent terms in (56) all reflect strictly proper filters. i.e. that they all contain at least a delay.
is strictly proper since both and are monic. Therefore, will have at least a delay in each of its transfers.
If all paths from to in the transformed network and in its parameterized model have at least a delay (as per Condition c in the theorem), then all terms and will have a delay.
We then need to consider the two remaining terms, and . From the definition of , each of the two terms can be represented as the sum of two terms. and represent paths from to and from to respectively in the transformed network. Whereas, and is partly induced by the parameterized model and partly by the paths from to and from to respectively in the transformed network.
According to condition c of the theorem (delay conditions), these transfer functions are strictly proper. This implies that (56) is statically uncorrelated to . Therefore we have, where . As a result, the minimum of , which is , is achieved for and .
Step 2: When the minimum is achieved, we have to be zero. From (54), we have Using the expression of from (8) and substituting it in the expression of we get, where,
Writing using Parseval’s theorem in the frequency domain, we have
| (57) |
The standard reasoning for showing uniqueness of the identification result is to show that if equals (i.e. when the minimum power is achieved), this should imply that and . Since is full rank and positive definite, the above mentioned implication will be fulfilled only if for a sufficiently high number of frequencies. On condition 2 of Theorem 2 being satisfied along with the other conditions in Theorem 1, it ensures that the minimum value is achieved only for and .
Appendix D Proof of Proposition 2
The disturbances in the original network are characterized by (A). From the results of Lemma 3, we can infer that the spectral density has the unique spectral factorization where is monic, stable, minimum phase, and of the form given in (43). Together with the form of in (43) it follows that is uncorrelated with . As a result, the set satisfies the properties of , so that in Condition c we can replace by . What remains to be shown is that the delay in path/loop conditions in the transformed network (8) can be reformulated into the same conditions on the original network (6). To this end we will need two Lemma’s.
Lemma 4
Consider a dynamic network as dealt with in Theorem 2, with reference to eq. (8), where a selection of node signals is decomposed into sets , , and which is obtained after immersion of nodes in . Let be any element , and let be any element .
If in the original network the direct path, as well as all paths that pass through non-measured nodes only, from to have a delay, then
is strictly proper.
Proof:
We will show that is strictly proper if all paths from to have a delay. For any , , is given by either (41) or (42) with .
The situation that is not covered by (41), (42) is the case where , but from (34) it follows that , for . So for this situation strictly properness is guaranteed.
We will now use (41) and (42) for given by any .
In (41) and (42), it will hold that is given by the appropriate component of (20), which, by the fact that (18) is monic, will imply that is strictly proper. By the same reasoning this also holds for .
From (41) and (42) it then follows that strictly properness of follows from strictly properness of if the inverse expression is proper. This latter condition is guaranteed by the fact that is strictly proper and and are proper as they reflect a module and network transfer function in the immersed network [41, 30].
Finally, strictly properness of follows from strictly properness of and the presence of a delay in all paths from to that pass through unmeasured nodes.
Lemma 5
Consider the transformed network and let be any elements . If in the original network all paths from to have a delay, then all paths from to in the transformed network have a delay.
Proof: This is proved using the Lemma 3 in [15] and Lemma 4. Let denote . From Lemma 4 we know is strictly proper if all paths from to in the original network have a delay. Therefore,
| (58) |
where the 0 represents . Using inverse rule of block matrices we have,
| (59) |
Considering (7) we can write where . So have where represents the transfer from to . Having 0 in (59) represents that the transfer function from to has a delay. Since has path only to with unit transfer function, to has a delay.
We now look into the proof of Proposition 2. For this we need to generalize the result we have achieved in Lemma 5 in terms of scalar node signals to set of node signals. If all existing paths/loops from to in the original network have at least a delay, then all existing paths/loops from to in the original network have at least a delay. If all existing paths/loops from to in the original network have at least a delay, then as a result of Lemma 5, all existing paths/loops from to in the transformed network have at least a delay. This implies that all existing paths/loops from to in the transformed network have at least a delay. Following the above reasoning, we can also show that if all existing paths from to in the original network have at least a delay, all existing paths from to in the transformed network have at least a delay.
Acknowledgment
The authors gratefully acknowledge discussions with and contributions from Arne Dankers, Giulio Bottegal and Harm Weerts on the initial research that led to the presented results.
References
- [1] D. Materassi and M. Salapaka, “On the problem of reconstructing an unknown topology via locality properties of the Wiener filter,” IEEE Trans. Automatic Control, vol. 57, no. 7, pp. 1765–1777, 2012.
- [2] B. Sanandaji, T. Vincent, and M. Wakin, “Exact topology identification of large-scale interconnected dynamical systems from compressive observations,” in Proc. American Control Conference (ACC), San Francisco, CA, USA, 2011, pp. 649–656.
- [3] D. Materassi and G. Innocenti, “Topological identification in networks of dynamical systems,” IEEE Trans. Automatic Control, vol. 55, no. 8, pp. 1860–1871, 2010.
- [4] A. Chiuso and G. Pillonetto, “A Bayesian approach to sparse dynamic network identification,” Automatica, vol. 48, no. 8, pp. 1553––1565, 2012.
- [5] S. Shi, G. Bottegal, and P. M. J. Van den Hof, “Bayesian topology identification of linear dynamic networks,” in Proc. 2019 European Control Conference, Napels, Italy, 2019, pp. 2814–2819.
- [6] A. Haber and M. Verhaegen, “Subspace identication of large-scale interconnected systems,” IEEE Transactions on Automatic Control, vol. 59, no. 10, pp. 2754–2759, 2014.
- [7] P. Torres, J. W. van Wingerden, and M. Verhaegen, “Hierarchical PO-MOESP subspace identification for directed acyclic graphs,” Intern. J. Control, vol. 88, no. 1, pp. 123–137, 2015.
- [8] H. H. M. Weerts, P. M. J. Van den Hof, and A. G. Dankers, “Prediction error identification of linear dynamic networks with rank-reduced noise,” Automatica, vol. 98, pp. 256–268, December 2018.
- [9] ——, “Identification of dynamic networks operating in the presence of algebraic loops,” in Proc. 55nd IEEE Conf. on Decision and Control (CDC). IEEE, 2016, pp. 4606–4611.
- [10] M. Zorzi and A. Chiuso, “Sparse plus low rank network identification: a nonparametric approach,” Automatica, vol. 76, pp. 355–366, 2017.
- [11] A. S. Bazanella, M. Gevers, J. M. Hendrickx, and A. Parraga, “Identifiability of dynamical networks: which nodes need to be measured?” in Proc. 56th IEEE Conference on Decision and Control (CDC), 2017, pp. 5870–5875.
- [12] J. Gonçalves and S. Warnick, “Necessary and sufficient conditions for dynamical structure reconstruction of LTI networks,” IEEE Trans. Automatic Control, vol. 53, no. 7, pp. 1670–1674, Aug. 2008.
- [13] H. H. M. Weerts, P. M. J. Van den Hof, and A. G. Dankers, “Identifiability of linear dynamic networks,” Automatica, vol. 89, pp. 247–258, March 2018.
- [14] J. Hendrickx, M. Gevers, and A. Bazanella, “Identifiability of dynamical networks with partial node measurements,” IEEE Trans. Autom. Control, vol. 64, no. 6, pp. 2240–2253, 2019.
- [15] P. M. J. Van den Hof, A. G. Dankers, P. S. C. Heuberger, and X. Bombois, “Identification of dynamic models in complex networks with prediction error methods - basic methods for consistent module estimates,” Automatica, vol. 49, no. 10, pp. 2994–3006, 2013.
- [16] A. G. Dankers, P. M. J. Van den Hof, X. Bombois, and P. S. C. Heuberger, “Errors-in-variables identification in dynamic networks – consistency results for an instrumental variable approach,” Automatica, vol. 62, pp. 39–50, 2015.
- [17] J. Linder and M. Enqvist, “Identification of systems with unknown inputs using indirect input measurements,” International Journal of Control, vol. 90, no. 4, pp. 729–745, 2017.
- [18] K. R. Ramaswamy, G. Bottegal, and P. M. J. Van den Hof, “Local module identification in dynamic networks using regularized kernel-based methods,” in Proc. 57th IEEE Conf. on Decision and Control (CDC), Miami Beach, FL, 2018, pp. 4713–4718.
- [19] N. Everitt, G. Bottegal, and H. Hjalmarsson, “An empirical bayes approach to identification of modules in dynamic networks,” Automatica, vol. 91, pp. 144–151, 5 2018.
- [20] M. Gevers, A. Bazanella, and G. Vian da Silva, “A practical method for the consistent identification of a module in a dynamical network,” IFAC-PapersOnLine, vol. 51-15, pp. 862–867, 2018.
- [21] L. Ljung, System Identification: Theory for the User. Englewood Cliffs, NJ: Prentice-Hall, 1999.
- [22] D. Materassi and M. Salapaka, “Identification of network components in presence of unobserved nodes,” in Proc. 2015 IEEE 54th Conf. Decision and Control, Osaka, Japan, 2015, pp. 1563–1568.
- [23] A. G. Dankers, P. M. J. Van den Hof, P. S. C. Heuberger, and X. Bombois, “Identification of dynamic models in complex networks with prediction error methods: Predictor input selection,” IEEE Trans. on Automatic Control, vol. 61, no. 4, pp. 937–952, 2016.
- [24] D. Materassi and M. V. Salapaka, “Signal selection for estimation and identification in networks of dynamic systems: a graphical model approach,” IEEE Trans. Automatic Control, vol. 65, no. 10, pp. 4138–4153, october 2020.
- [25] P. M. J. Van den Hof, A. G. Dankers, and H. H. M. Weerts, “From closed-loop identification to dynamic networks: generalization of the direct method,” in Proc. 56nd IEEE Conf. on Decision and Control (CDC). Melbourne, Australia: IEEE, 2017, pp. 5845–5850.
- [26] A. G. Dankers, P. M. J. Van den Hof, D. Materassi, and H. H. M. Weerts, “Conditions for handling confounding variables in dynamic networks,” IFAC-PapersOnLine, vol. 50, no. 1, pp. 3983–3988, 2017, proc. 20th IFAC World Congress.
- [27] P. M. J. Van den Hof, K. R. Ramaswamy, A. G. Dankers, and G. Bottegal, “Local module identification in dynamic networks with correlated noise: the full input case,” in Proc. 58th IEEE Conf. on Decision and Control (CDC), 2019, 5494-5499.
- [28] A. G. Dankers, “System identification in dynamic networks,” PhD dissertation, Delft University of Technology, 2014.
- [29] J. Pearl, Causality: Models, Reasoning, and Inference. New York: Cambridge University Press, 2000.
- [30] H. H. M. Weerts, J. Linder, M. Enqvist, and P. M. J. Van den Hof, “Abstractions of linear dynamic networks for input selection in local module identification,” Automatica, vol. 117, 2020.
- [31] M. Gevers and A. S. Bazanella, “Identification in dynamic networks: identifiability and experiment design issues,” in Proc. 54th IEEE Conference on Decision and Control (CDC). IEEE, 2015, pp. 4005–4010.
- [32] H. J. van Waarde, P. Tesi, and M. K. Camlibel, “Topological conditions for identifiabaility of dynamical networks with partial node measurements,” IFAC-PapersOnLine, vol. 51-23, pp. 319–324, 2018, proc. 7th IFAC Workshop on Distrib. Estim. and Control in Networked Systems.
- [33] H. H. M. Weerts, P. M. J. Van den Hof, and A. G. Dankers, “Single module identifiability in linear dynamic networks,” in Proc. 57th IEEE Conf. on Decision and Control (CDC). Miami Beach, FL: IEEE, 2018, pp. 4725–4730.
- [34] X. Cheng, S. Shi, and P. M. J. Van den Hof, “Allocation of excitation signals for generic identifiability of dynamic networks,” in Proc. 58th IEEE Conf. on Decision and Control (CDC), Nice, France, 2019, pp. 5507–5512.
- [35] P. M. J. Van den Hof and K. R. Ramaswamy, “Path-based data-informativity conditions for single module identification in dynamic networks,” in Proc. 59th IEEE Conf. Decision and Control, Jeju Island, Republic of Korea, 2020, to appear.
- [36] K. R. Ramaswamy, P. M. J. Van den Hof, and A. G. Dankers, “Generalized sensing and actuation schemes for local module identification in dynamic networks,” in Proc. 58th IEEE Conf. on Decision and Control (CDC), 2019, pp. 5519–5524.
- [37] D. Kroening and O. Strichmann, Decision Procedures - An algorithmic point of view, 2nd ed. Springer, 2016.
- [38] H. H. M. Weerts, M. Galrinho, G. Bottegal, H. Hjalmarsson, and P. M. J. Van den Hof, “A sequential least squares algorithm for ARMAX dynamic network identification,” IFAC-PapersOnLine, vol. 51-15, pp. 844–849, 2018, proc. 18th IFAC Symp. System Identification.
- [39] M. Galrinho, C. R. Rojas, and H. Hjalmarsson, “Parametric identification using weighted null-space fitting,” IEEE Trans. Automatic Control, vol. 64, no. 7, pp. 2798–2813, 2019.
- [40] D. Youla, “On the factorization of rational matrices,” IRE Trans. Information Theory, vol. 7, pp. 172–189, 1961.
- [41] N. Woodbury, A. Dankers, and S. Warnick, “Dynamic networks: representations, abstractions and well-posedness,” in Proc. 57th IEEE Conf. on Decision and Control, Miami Beach, FL, 2018, pp. 4719–4724.
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/a418a051-f674-4551-8d14-7de47f05b593/karthik_square.jpg) |
Karthik Raghavan Ramaswamy was born in 1989. He received his Bachelor’s in Electrical and Electronics Engineering (with Distinction) in 2011 from Anna University and Master’s in Systems and Control (with great appreciation) from TU Eindhoven in 2017. From 2011 to 2015 he was Control & Automation engineer at Larsen & Toubro. Currently, he is a PhD researcher with the Control Systems research group, Department of Electrical Engineering, TU Eindhoven, The Netherlands. His research interests are in the area of data driven modeling, dynamic network identification and machine learning. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/a418a051-f674-4551-8d14-7de47f05b593/Van_den_Hof.jpg) |
Paul Van den Hof received the M.Sc. and Ph.D. degrees in electrical engineering from Eindhoven University of Technology, Eindhoven, The Netherlands, in 1982 and 1989, respectively. In 1986 he moved to Delft University of Technology, where he was appointed as Full Professor in 1999. From 2003 to 2011, he was founding co-director of the Delft Center for Systems and Control (DCSC). As of 2011, he is a Full Professor in the Electrical Engineering Department, Eindhoven University of Technology. His research interests include data-driven modeling, identification for control, dynamic network identification, and model-based control and optimization, with applications in industrial process control systems and high-tech systems. He holds an ERC Advanced Research grant for a research project on identification in dynamic networks. Paul Van den Hof is an IFAC Fellow and IEEE Fellow, and Honorary Member of the Hungarian Academy of Sciences, and IFAC Advisor. He has been a member of the IFAC Council (1999–2005, 2017-2020), the Board of Governors of IEEE Control Systems Society (2003–2005), and an Associate Editor and Editor of Automatica (1992–2005). In the triennium 2017-2020 he was Vice-President of IFAC. |