A majorized PAM method with subspace correction for low-rank composite factorization model
Ting Tao111(taoting@fosu.edu.cn) School of Mathematics, Foshan University, Foshan
Yitian Qian222(yitian.qian@polyu.edu.hk) Department of Applied Mathematics, The Hong Kong Polytechnic University, Hong Kong and Shaohua Pan333(shhpan@scut.edu.cn) School of Mathematics, South China University of Technology, Guangzhou
Abstract
This paper concerns a class of low-rank composite factorization models arising from matrix completion. For this nonconvex and nonsmooth optimization problem, we propose a proximal alternating minimization algorithm (PAMA) with subspace correction, in which a subspace correction step is imposed on every proximal subproblem so as to guarantee that the corrected proximal subproblem has a closed-form solution. For this subspace correction PAMA, we prove the subsequence convergence of the iterate sequence, and establish the convergence of the whole iterate sequence and the column subspace sequences of factor pairs under the KL property of objective function and a restrictive condition that holds automatically for the column -norm function. Numerical comparison with the proximal alternating linearized minimization method on one-bit matrix completion problems indicates that PAMA has an advantage in seeking lower relative error within less time.
Let be the space of all real matrices, equipped with the trace inner product and its induced Frobenius norm . Fix any and write . We are interested in the low-rank composite factorization model
(1)
where is a lower bounded -smooth (i.e., is continuously differentiable and its gradient is Lipschitz continuous with modulus ) function, and denote the Euclidean norm of the th column of and , is a regularization parameter, is a small constant, and is a proper lower semicontinuous (lsc) function to promote sparsity and satisfy the following two conditions:
(C.1)
, for , and for ;
(C.2)
is differentiable on , and its proximal mapping has a closed-form.
Model (1) has a wide application in matrix completion and sensing (see, e.g., [3, 6, 14, 8]). Among others, the term plays a twofold role: one is to ensure that (1) has a nonempty set of optimal solutions and then a nonempty set of stationary points, and the other is to guarantee that (1) has a balanced set of stationary points (see Proposition 1). The regularization term aims at promoting low-rank solutions via column sparsity of factors and . Table 1 below provides some examples of to satisfy conditions (C.1)-(C.2), where and satisfy (C.2) by [9, 26]. When , model (1) is the column -norm regularization problem studied in [24], and when , it becomes the factorized form of the nuclear-norm regularization problem [15, 18]. In the sequel, we write
(2)
Table 1: Some common functions satisfying conditions (C.1)-(C.2)
1.1 Related work
Problem (1) is a special case of the optimization models considered in [1, 2, 10, 16, 17, 25], for which the nonsmooth regularization term has a separable structure and the nonsmooth function associated with each block has a closed-form proximal mapping. Hence, the proximal alternating linearized minimization (PALM) methods and their inertial versions developed in [1, 2, 17, 25] are suitable for dealing with (1), whose basic idea is to minimize alternately a proximal version of the linearization of at the current iterate, the sum of the linearization of at this iterate and . The iteration of these PALM methods depends on the global Lipschitz moduli and of the partial gradients and for any fixed and . These constants are available whenever that of is known, but they are usually much larger than that of , which brings a challenge to the solution of subproblems with a first-order method. Although the descent lemma can be employed to search a tighter one in computation, it is consuming due to solution of additional subproblems. Since the Lipschitz constant of is available or easier to estimate, it is natural to ask whether an efficient alternating minimization (AM) method can be designed by using the Lipschitz continuity of only. The block coordinate variable metric algorithms in [10, 16] are also applicable to (1), but their efficiency is dependent on an appropriate choice of variable metric linear operators, and their convergence analysis requires the exact solutions of variable metric subproblems. Now it is unclear which kind of variable metric linear operators is suitable for (1), and whether the variable metric subproblems involving nonsmooth have a closed-form solution.
Recently, the authors tried an AM method for problem (1) with by leveraging the Lipschitz continuity of only (see [24, Algorithm 2]), tested its efficiency on matrix completion problems with for , but did not achieve any convergence results on the generated iterate sequence [24]. This work is a deep dive of [24] and aims to provide a convergence certificate for the iterate sequence of this AM method.
1.2 Main contribution
We achieve a majorization of at each iterate by using the Lipschitz continuity of , and propose a proximal AM method by minimizing this majorization alternately, which is an extension of the proximal AM algorithm of [24] to the general model (1). The main contributions of this work involve the following three aspects.
(i) The proposed PAMA only involves the Lipschitz constant of , which is usually known or easier to estimate before starting algorithm. Then, compared with the existing PALM methods and their inertial versions in [1, 2, 17, 25], this PAMA has a potential advantage in running time due to avoiding the estimation of and in each iteration.
(ii) As will be shown in Section 3, our PAMA is actually a variable metric proximal AM method. Different from the variable metric methods in [10, 16], our variable metric linear operators are natural products of majorizing by the Lipschitz continuity of . In particular, by introducing a subspace correction step to per subproblem, we overcome the difficulty that the variable metric proximal subproblems involving have no closed-form solutions.
(iii) Our majorized PAMA with subspace correction has a theoretical certificate. Specifically, we prove the subsequence convergence of the iterate sequence for all in Table 1, and establish the convergence of the whole iterate sequence and the column subspace sequences of factor pairs under the KL property of and the restrictive conditions (29a)-(29b) that can be satisfied by , or by - if there is a stationary point with distinct nonzero singular values. To the best of our knowledge, this appears to be the first subspace correction AM method with convergence certificate for low-rank composite factorization models. Hastie et al. [13] proposed a PAMA with subspace correction (named softImpute-ALS) for the factorization form of the nuclear-norm regularized least squares model, but did not provide the convergence analysis of the iterate sequence even the objective value sequence.
1.3 Notation
Throughout this paper, means a identity matrix, denotes the set of all matrices with orthonormal columns, and means . For a matrix , and denote the spectral norm, nuclear norm, and column -norm of , respectively, with , , and . For an integer , . For a matrix , means the th column of , denotes its index set of nonzero columns, and denote the subspace spanned by all columns and rows of . For an index set , we write , and define
(3)
2 Preliminaries
Recall that for a proper lsc function , its proximal mapping associated with parameter is defined as
for . The mapping is generally multi-valued unless the function is convex. The following lemma states that the proximal mapping of the function in (2) can be obtained with that of . Since its proof is immediate by condition (C.1), we do not include it.
Before introducing the concept of stationary points for problem (1), we first recall from [19] the notion of subdifferentials.
Definition 2.1
Consider a function
and a point with finite.
The regular subdifferential of at , denoted by
, is defined as
and the basic (known as limiting or Morduhovich) subdifferential of at is defined as
The following lemma characterizes the subdifferential of the function in (2). Since the proof is immediate by [19, Theorem 10.49 & Proposition 10.5], we omit it.
Lemma 2.2
At a given , and with
Motivated by Lemma 2.2, we introduce the following concept of stationary points.
Definition 2.2
A factor pair is called a stationary point of problem (1) if
where, for each , the sets and take the same form as in Lemma 2.2.
2.2 Relation between column -norm and Schatten -norm
Fix any . Recall that the column -norm of a matrix is defined as , while its Schatten -norm is defined as .
The following lemma states that is not greater than -norm .
Lemma 2.3
Fix any of rank .
For any with , it holds that and consequently .
Proof:
For each , , which implies that
For each , let . As , we have for each . Note that the function is concave because . Moreover, if , . For each with , from Jensen’s inequality,
which by and implies that
.
Together with for each , it follows that
(4)
The first part then follows. For the second part, let have the thin SVD as with and . By the definition, it holds that
where the inequality is implied by the above (2.2). The proof is completed.
By invoking Lemma 2.3, we obtain the factorization form of the Schatten -norm.
Proposition 2.1
For any matrix with rank , it holds that
Proof:
From [20, Theorem 2], it follows that the following relation holds
which together with Lemma 2.3 immediately implies that
By taking and where
with
and is the thin SVD of , we get . The result holds.
2.3 Kurdyka-Lojasiewicz property
We recall from [1] the concept of the KL property of an extended real-valued function.
Definition 2.3
Let be a proper lower semicontinuous (lsc) function.
The function is said to have the Kurdyka-Lojasiewicz (KL) property
at if there exist ,
a continuous concave function satisfying
(i)
and is continuously differentiable on ,
(ii)
for all , ;
and a neighborhood of such that for all
If satisfies the KL property at each point of ,
then it is called a KL function.
Remark 2.1
By Definition 2.3 and [1, Lemma 2.1], a proper lsc function has the KL property at every point of . Thus, to show that a proper lsc is a KL function, it suffices to check that has the KL property at any critical point.
3 A majorized PAMA with subspace correction
Fix any . Recall that is Lipschitz continuous with modulus . Then, for any , it holds that
(5)
which together with the expression of immediately implies that
(6)
Note that , so is a majorization of at .
Let be the current iterate. It is natural to develop an algorithm for problem (1) by minimizing the function alternately or by the following iteration:
Compared with the PALM method, such a majorized AM method is actually a variable metric proximal AM method. Unfortunately, due to the nonsmooth regularizer , these two variable metric subproblems have no closed-form solutions, which brings a great challenge for convergence analysis of the generated iterate sequence. Inspired by the fact that variable metric proximal methods are more effective especially for ill-conditioned problems, we introduce a subspace correction step to per proximal subproblem so as to guarantee that the variable metric proximal subproblem at the corrected factor has a closed-form solution, and propose the following majorized PAMA with subspace correction.
Algorithm 1(A majorized PAMA with subspace correction)
Initialization: Input parameters and .
Choose , and let
.
Fordo
1.
Compute
2.
Perform a thin SVD for such that with and , and set
3.
Compute
4.
Find a thin SVD for such that with and , and set
5.
Set and .
end (For)
Remark 3.1
(a) Steps 2 and 4 are the subspace correction steps. Step 2 is constructing a new factor pair by performing an SVD for , whose column space can be regarded as a correction one for that of . This step guarantees that the proximal minimization of the majorization with respect to has a closed-form solution. Similarly, step 4 is constructing a new factor pair by performing an SVD for , whose column space can be viewed as a correction one for that of . This step ensures that the proximal minimization of the majorization with respect to has a closed-form solution. By Theorem 4.1, the objective value at is strictly less than the one at , while the objective value at is strictly less the one at .
From this point of view, the subspace correction steps contribute to reducing the objective values. To the best of our knowledge, such a subspace correction technique first appeared in the alternating least squares method for the nuclear-norm regularized least squares factorized model [13], and here it is employed to treat the nonconvex and nonsmooth problem (1). From steps 2 and 4, for each ,
(8a)
(8b)
(b) In steps 1 and 3, we introduce a proximal term with a uniformly positive proximal parameter to guarantee the sufficient decrease of the objective value sequence. As will be shown in Section 5, its uniformly lower bound or is easily chosen. By the optimality of and in steps 1 and 3 and [19, Exercise 8.8], for each , it holds that
(c) By step 1, equations (8a)-(8b) and the expression of , we have
where
with and for each . By invoking Lemma 2.1, for each ,
(9)
While by step 3, equations (8a)-(8b) and the expression of ,
Recall that is assumed to have a closed-form proximal mapping, so the main cost of Algorithm 1 in each step is to perform an SVD for and , which is not expensive because is usually chosen to be far less than .
From Remark 3.1, Algorithm 1 is well defined. For its iterate sequences
, and
, the following two propositions establish the relation among their column spaces and nonzero column indices. Since the proof of Proposition 3.2 is similar to that of [24, Proposition 4.2 (iii)], we here do not include it.
Proposition 3.1
Let
be the sequence generated by Algorithm 1. Then, for every , the following inclusions hold
Proof:
From equation (8a), and . While from step 2 of Algorithm 1, , by which it is easy to check that and . Then,
(11)
Similarly, from equation (8b), and . From step 4 of Algorithm 1, . Then, it holds that
(12)
From the above equations (11)-(12), we immediately obtain the desired result.
Proposition 3.2
Let
be the sequence generated by Algorithm 1. Then, there exists such that for all ,
This section will establish the convergence of the objective value sequence and the iterate sequence generated by Algorithm 1 under additional conditions for the function .
4.1 Convergence of objective value sequence
To achieve the convergence of sequences and , we require the following assumption on or .
Assumption 1
For any given of and , the factor pair satisfies
where and are the submatrix consisting of the first columns of and .
Assumption 1 is rather mild, and it can be satisfied by the function associated with some common to promote sparsity. For example, when and , Assumption 1 holds by [5], when , it holds due to [21, Lemma 1], and when , it holds by Proposition 2.1.
Under Assumption 1, by following the similar proof to that of [24, Proposition 4.2 (i)], we can establish the convergence of the objective value sequences, which is stated as follows.
Theorem 4.1
Let be the sequence generated by Algorithm 1, and write . Then, under Assumption 1, for each ,
(15)
(16)
so and converge to the same point, say, .
As a direct consequence of Theorem 4.1,
we have the following conclusion.
Corollary 4.1
Let be the sequence given by Algorithm 1. Then, under Assumption 1, the following assertions are true.
(i)
and ;
(ii)
the sequence is bounded;
(iii)
by letting , for each ,
(iv)
and .
Proof:(i)-(ii) Part (i) is obvious by Theorem 4.1, so it suffices to prove part (ii). By Theorem 4.1, for each . Recall that is lower bounded, so the function is coercive. Thus, the sequence is bounded. Along with part (i), the sequence is bounded. The boundedness of
implies that of because and for each by equations (8a)-(8b).
(iii) Fix any . From equations (8a)-(8b), it holds that
Combining these two inequalities with the definition of and Theorem 4.1 leads to
Along with , we get the result.
(iv) The result follows by part (iii) and the convergence of .
Remark 4.1
By Corollary 4.1 (ii) and Remark 3.1 (c), there exists a constant such that for all and , and , where and are the diagonal matrices appearing in Remark 3.1 (c).
4.2 Subsequence convergence of iterate sequence
For convenience, for each , write . The following theorem shows that every accumulation point of is a stationary point of problem (1).
Theorem 4.2
Under Assumption 1, the following assertions hold true.
(i)
The accumulation point set of is nonempty and compact.
(ii)
For each , it holds that with ,
for some and such that ,
and
for some with .
(iii)
For each , the factor pairs and are the stationary points of (1) and .
Proof:
Part (i) is immediate by Corollary 4.1 (ii). We next take a closer look at part (ii).
Pick any . Then, there exists an index set such that . From steps 2 and 4 of Algorithm 1, it follows that
(17)
(18)
with and for each . Note that and . By the compactness of , there exists an index set such that the sequences and are convergent, i.e., there are and such that
and .
Together with and the above equation (17), we obtain
(19)
Along with , we have .
By using (18) and the similar arguments, there are and such that and . Along with , .
By Corollary 4.1 (iv), .
(iii) Pick any . There exists an index set such that . We first claim that the following two limits hold:
(20)
Indeed, for each , by the definition of in step 1 and the expression of ,
From Corollary 4.1 (i) and , we have . Now passing the limit to the above inequality and using , Corollary 4.1 (i) and the continuity of results in .
Along with the lower semicontinuity of , we get . Similarly,
for each , by the definition in step 3 and the expression of ,
Following the same arguments as above leads to the second limit in (20).
Now passing the limit to the inclusions in Remark 3.1 (b) and using (20) and Corollary 4.1 (i) and (iv) results in the following inclusions
Let and . By part (ii), and . By Lemma 2.2 and the above inclusions, and for each ,
By part (ii), for each , which implies that
with .
Write . Then, the above two equalities for all can be compactly written as
(22a)
(22b)
By part (ii), and . Recall that and . There exist and such that ,
and
Let be the distinct singular values of . For each , write . From the above equality and [11, Proposition 5], there is a block diagonal orthogonal with such that
Let , and let and be the matrices consisting of the first columns of and . Then, and . Also, . Along with and by part (ii), we have and . Substituting into (22a)-(22b) yields
By the expressions of and , we have and .
Then and . Along with the above two equalities, and , we obtain
(24a)
(24b)
Combining (24a), (22b) and and invoking Definition 2.2, we conclude that is a stationary point of (1), and combining (24b), (22a) and and invoking Definition 2.2, we have that is a stationary point of (1).
By part (ii) and the expression of , we have , so the rest only argues that . Using the convergence of and , equation (20) and the continuity of yields that and . The result holds by the arbitrariness of .
Remark 4.2
Theorems 4.1 and 4.2 provide the theoretical guarantee for Algorithm 1 to solve problem (1) with associated with - in Table 1. These results also provide the theoretical certificate for softImpute-ALS (see [13, Algorithm 3.1]).
4.3 Convergence of iterate sequence
Assumption 2
Fix any with same as in Remark 4.1. There exists such that for any , either or .
It is easy to check that Assumption 2 holds for and -. Under Assumptions 1-2, we prove that the sequences and converge to the same limit.
Lemma 4.1
Under Assumptions 1-2, for each , when ,
and for . There exist and such that for .
Proof: By Proposition 3.2, for all , , so that . By combining Remark 4.1 with equation (9) and using Assumption 2,
which means that . In addition, the lower semicontinuity of implies that . Then, . Together with Proposition 3.2, we obtain the first part of conclusions. Suppose on the contrary that the second part does not hold. There will exist an index set such that . By the continuity of , the sequence must have a cluster point, say , satisfying , a contradiction to the first part.
Next we apply the theorem (see [12]) to establish a crucial property of the sequence , which will be used later to control the distance .
Lemma 4.2
For each , let and . Then, under Assumptions 1-2, for each , there exist such that for the matrices and ,
where is the same as in Lemma 4.1 and is the same as in Corollary 4.1 (iii).
Proof:
From steps 2 and 4 of Algorithm 1,
with and with .
By Lemma 4.1, for each , and . Let and . Then, for all , with , and
For each , by using [12, Theorem 2.1] with and , respectively, there exist and such that
(25)
(26)
Let and for each . By the expressions of in steps 2 and 4 of Algorithm 1, for each ,
(27)
where the last inequality is using (25), and the following relation
By the expressions of and in steps 2 and 4 of Algorithm 1,
(28)
Inequalities (4.3)-(4.3) imply that the first inequality holds.
Using inequality (26) and following the same argument as those for (4.3)-(4.3) leads to the second one.
Proposition 4.1
Let and . Let and be defined by (3) with such and . Suppose that Assumptions 1-2 hold, and that for each ,
(29a)
(29b)
with and . Then, there exists such that
Proof:
From the inclusions in Remark 3.1 (b) and Lemma 2.2, for each ,
By Lemma 4.1, for each , and .
Together with the above two inclusions, we have
and the equalities
Multiplying the first equality by and the second one by , we immediately have
By comparing the expressions of and with (4.3)-(4.3), for each ,
Recall that and for each . Together with and , it follows that for each ,
(33)
(34)
where we use for each , implied by the expressions of and . Recall that is Lipschitz continuous with modulus . For each ,
with , where the second inequality is using Lemma 4.2. For the term in inequality (4.3), it holds that
Combining the above two inequalities with (4.3) and the given (29a), we get
(35)
Using inequality (4.3) and following the same argument as those for (4.3) leads to
The desired result follows by combining the above two inequalities with (32).
Remark 4.3
When , by noting that
and , inequalities (29a)-(29b) automatically hold for all . If there exists such that the nonzero singular values of are distinct each other, then as will be shown in Proposition 2, inequalities (29a)-(29b) still hold for all .
Now we are ready to establish the convergence of the iterate sequence and the column subspace sequences and of factor pairs.
Theorem 4.3
Suppose that is a KL function, that Assumptions 1-2 hold, and inequalities (29a)-(29b) hold for all . Then, and converge to the same point ,
is a stationary point of (1) where and are the matrix consisting of the first columns of and with , and
(36a)
(36b)
where the set convergence is in the sense of Painlev-Kuratowski convergence.
Proof:
Using Theorems 4.1 and 4.2 and Proposition 4.1 and following the same arguments as those for [2, Theorem 1] yields the first two parts. For the last part, by Proposition 3.2,
we only need to prove , which by [19, Exercise 4.2] is equivalent to
(37)
To this end, we first argue that . By Lemma 4.1, and for all . Then, for each , for . By step 2 of Algorithm 1, for each , with and . This means that for all . Let be the thin SVD of with and .
Clearly, .
For each , let be such that . By invoking [7, Lemma 3], there exists such that for all sufficiently large ,
which by the convergence of means that . Let . Then, for any accumulation point of , we have
, and hence . Now pick any . Then,
From the boundedness of , there exists an accumulation point such that
, i.e., . This shows that . For the converse inclusion, from
, it is not hard to deduce that
which implies that . Now pick any . We have . Then, . This shows that , and the converse inclusion follows.
5 Numerical experiments
To validate the efficiency of Algorithm 1, we apply it to compute one-bit matrix completions with noise, and compare its performance with that of a line-search PALM described in Appendix B. All numerical tests are performed in MATLAB 2024a on a laptop computer running on 64-bit Windows Operating System with an Intel(R) Core(TM) i9-13905H CPU 2.60GHz and 32 GB RAM.
5.1 One-bit matrix completions with noise
We consider one-bit matrix completion under a uniform sampling scheme, in which the unknown true is assumed to be low rank. Instead of observing noisy entries of directly, where is a noise matrix with i.i.d. entries, we now observe with error the sign of a random subset of the entries of . More specifically, assume that a random sample of the index set is drawn i.i.d. with replacement according to a uniform sampling distribution for all and , and the entries of a sign matrix with are observed. Let be a cumulative distribution function of . Then, the above observation model can be recast as
(38)
and we observe noisy entries indexed by . More details can be found in [8]. Two common choices for the function or the distribution of are given as follows:
(I)
(Logistic regression/noise): The logistic regression model is described by (38) with and i.i.d. obeying the standard logistic distribution.
(II)
(Laplacian noise): In this case, i.i.d. obey a Laplacian distribution Laplace with the scale parameter , and the function has the following form
Given a collection of observations from the observation model (38), the negative log-likelihood function can be written as
Under case (I),
for each , for , so is Lipschitz continuous with ; while under case (II), for any and each , if , otherwise . Clearly, for case (II), is Lipschitz continuous with .
First we take a look at the choice of parameters in Algorithm 1. From formulas (9)-(10) in Remark 3.1 (c), for fixed and , a smaller (respectively, ) will lead to a smooth change of the iterate (respectively, ), but the associated subproblems will require a little more running time. As a trade-off, we choose and for the subsequent numerical tests. The parameters and are chosen to be . The initial is generated by Matlab command with specified in the subsequent experiments. We terminate Algorithm 1 at the iterate when
or or .
The parameters of Algorithm 2 are chosen as and . For fair comparison, Algorithm 2 uses the same starting point as for Algorithm 1, and the similar stopping condition to that of Algorithm 1, i.e., terminate the iterate when or
or .
5.3 Numerical results for simulated data
We test the two solvers on simulated data for one-bit matrix completion problems. The true matrix of rank is generated by with and , where the entries of and are drawn i.i.d. from a uniform distribution on . We obtain one-bit observations by adding noise and recording the signs of the resulting values. Among others, the noise obeys the standard logistic distribution for case (I) and the Laplacian distribution for case (II) with . The noisy observation entries with are achieved by (38), where the index set is given by uniform sampling. We use the relative error to evaluate the recovery performance, where denotes the output of a solver.
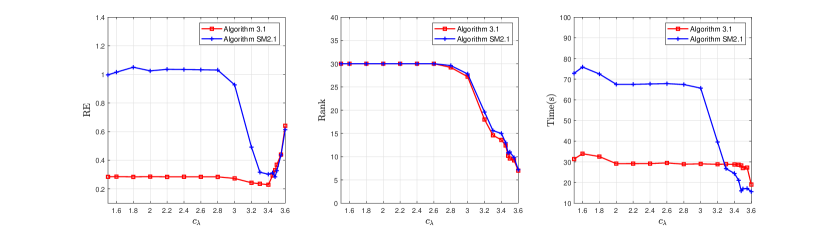
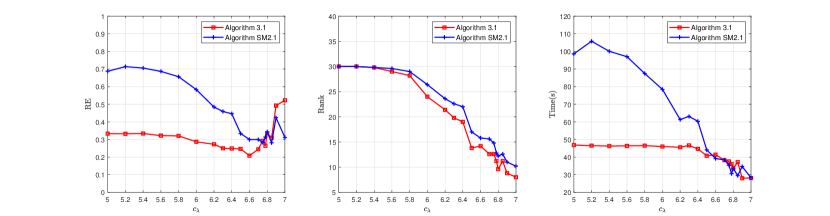
We take with and sample rate to test how the relative error (RE) and rank vary with parameter . The parameter in model (1) is always chosen to be .
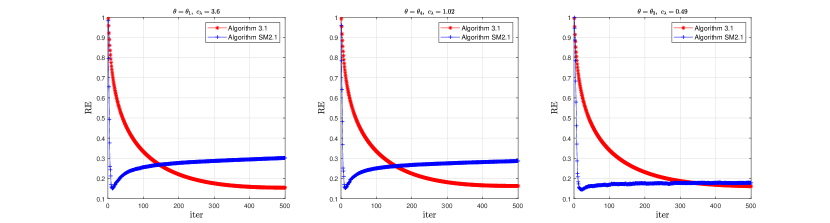
Figures 1-2 plot the average RE, rank and time (in seconds) curves by running five different instances with Algorithm 1 for and Algorithm 2 for , respectively. We see that when solving model (1) with smaller (say, for Figure 1 and for Figure 2), Algorithm 1 returns lower RE within less time; and when solving model (1) with larger (say, for Figure 1 and for Figure 2), the two solvers yield the comparable RE and require comparable running time. Note that model (1) with a small is more difficult than the one with a large . This shows that Algorithm 1 is superior to Algorithm 2 in terms of RE and running time for those difficult test instances. In addition, during the tests, we find that the relative errors yielded by the two solvers will have a rebound as the number of iterations increases, especially under the scenario where the sample ratio is low, but the RE yielded by Algorithm 2 rebounds earlier than the RE of Algorithm 1; see Figure 3 below.
Figure 1: Curves of relative error, rank and time for the two solvers under Case IFigure 2: Curves of relative error, rank and time for the two solvers under Case IIFigure 3: Curves of relative error for the two solvers under Case I with different
6 Conclusion
For the low-rank composite factorization model (1), we proposed a majorized PAMA with subspace correction by minimizing alternately the majorization of at each iterate and imposing a subspace correction step on per subproblem to ensure that it has a closed-norm solution. We established the convergence of subsequences for the generated iterate sequence, and achieved the convergence of the whole iterate sequence and the column subspace sequence of factor pairs under the KL property of and a restrictive condition that can be satisfied by the column -norm function. To the best of our knowledge, this is the first subspace correction AM method with convergence certificate for low-rank factorization models. The obtained convergence results also provide the convergence guarantee for softImpute-ALS proposed in [13]. Numerical comparison with a line-search PALM method on one-bit matrix completions validates the efficiency of the subspace correction PAMA.
References
[1]H. Attouch, J. Bolte, P. Redont and A. Soubeyran,
Proximal alternating minimization and projection methods for nonconvex problems: an approach
based on the Kerdyka-Łojasiewicz inequality,
Mathematics of Operations Research, 35(2010): 438-457.
[2]J. Bolte, S. Sabach, and M. Teboulle,
Proximal alternating
linearized minimization for nonconvex and nonsmooth problems, Mathematical
Programming, 146 (2014), pp. 459–494.
[3]S. Bhojanapalli, B. Neyshabur, and N. Srebro,
Global Optimality of Local Search for Low Rank Matrix Recovery, Advances in Neural Information Processing Systems, (2016), pp. 3873–3881.
[4]J. Barzilai and J. M. BorweinTwo-point step size gradient methods, IMA Journal of Numerical Analysis, 8(1988), pp. 141–148.
[5]S. J. Bi, T. Ta and S. H. Pan,
KL property of exponent of -norm and DC regularized factorizations for low-rank matrix recovery,
Pacific Journal of Optimization, 18(2022): 1–26.
[6]E. J. Candès and B. Recht,
Exact matrix completion via convex optimization
Foundations of Computational Mathematics, 9(2009): 717–772.
[7]X. Chen and P. Tseng,
Non-Interior continuation methods for solving semidefinite complementarity problems,
Mathematical Programming, 95(2003): 431–474.
[8]T. Cai and W. X. Zhou,
A max-norm constrained minimization approach to 1-bit matrix completion
Journal of Machine Learning Research, 9(2013): 3619–3647.
[9]W. Cao, J. Sun and Z. Xu,
Fast image deconvolution using closed-form thresholding formulas of regularization
Journal of Visual Communication and Image representation, 24(2013): 31–41.
[10]E. Chouzenoux, J. C. Pesque and A. Repetti,
A block coordinate variable metric forward-backward algorithm,
Journal of Global Optimization, 66(2016): 457–485.
[11]C. Ding, D. F. Sun and K. C. Toh,
An introduction to a class of matrix cone programming,
Mathematical Programming, 144(2014): 141–179.
[12]F. M. Dopico,
A note on sin theorems for singular subspace variations, BIT Numerical Mathematics, 40(2): 395–403.
[13]T. Hastie, R. Mazumder, J. D. Lee and R. Zadeh,
Matrix Completion and Low-Rank SVD via Fast Alternating Least Squares
Journal of Machine Learning Research, 16(2015): 3367-3402.
[14]P. Jain, P. Netrapalli and S. Sanghavi,
Low-rank matrix completion using alternating minimization
In Proceedings of the 45th annual ACM Symposium on Theory of Computing (STOC), (2013): 665–674.
[15]S. Negahban and M. Wainwright,
Estimation of (near) low-rank matrices with noise and high-dimensional scaling,
The Annals of Statistics, 39(2011): 1069–1097.
[16]P. Ochs,
Unifying abstract inexact convergence theorems and block coordinate variable metric iPiano,
SIAM Journal on Optimization, 29(2019): 541–570.
[17]T. Pock and S. Sabach,
Inertial proximal alternating linearized minimization (iPALM) for nonconvex and nonsmooth problems,
SIAM review, 9(2016): 1756–1787.
[18]B. Recht, M. Fazel, and P. A. Parrilo,
Guaranteed minimum-rank solutions of linear matrix equations via nuclear norm minimization,
SIAM review, 52(2010): 471-501.
[19]R. T. Rockafellar and R. J-B. Wets,
Variational analysis, Springer, 1998.
[20]F. H. Shang, Y. Y. Liu and F. J. Shang ,
A Unified Scalable Equivalent Formulation for
Schatten Quasi-Norms,
Mathematics. 8(2020):1-19.
[21]N. Srebro, J. D. M. Rennie and T. Jaakkola,
Maximum-margin matrix factorization,
Advances In Neural Information Processing Systems, 17, 2005.
[22]G. W. Stewart and J. G. Sun,
Maximum-margin matrix factorization,
Academic Press,
Boston, 1990.
[23]T. Tao, S. H. Pan and S. J. Bi,
Error bound of critical points and KL property of exponent
for squared F-norm regularized factorization,
Journal of Global Optimization, 81(2021): 991–1017.
[24]T. Tao, Y T. Qian and S. H. Pan,
Column -norm regularized factorization model of low-rank matrix recovery and its computation,
SIAM Journal on Optimization, 32(2022): 959–988.
[25]Y. Y. Xu and W. T. Yin,
A globally convergent algorithm for nonconvex optimization based on block coordinate update,
Journal of Scientific Computing, 72(2017): 700-734.
[26]Z. Xu, X. Chang, F. Xu and H. Zhang,
regularization: A thresholding representation
theory and a fast solver,
IEEE Transactions on Neural Networks and Learning Systems, 23(2012): 1013–1027.
Appendix A
The following proposition states that any stationary point of problem (1) satisfies the balance, i.e., .
Proposition 1
Denote by the set of stationary points of (1). If for , then , and hence every
satisfies and , where for .
Proof:
Pick any . From Definition 2.2, it follows that for any ,
(39)
For each , from the first inclusion in (39) and Lemma 2.2, we have
and hence . Recall that for . For each , it holds that
and hence . Consequently, . For each , from the second inclusion in (39) and Lemma 2.2,
which by using the same arguments as above implies that , and then . Thus, . Together with equation (39), it follows that
which implies that and
. Consequently, the desired inclusion follows. From [23, Lemma 2.2], every satisfies .
Proposition 2
Suppose that Assumptions 1-2 holds with being strictly continuous on , that there is with having distinct nonzero singular values, and has the KL property at . Let for .
(i)
Then, for any and and ,
(ii)
there exists such that for all , ,
Proof:(i)
As has distinct nonzero singular values with , from Wely’s Theorem [22, Corollary 4.9], for any , . Fix any and any and . By [12, Theorem 2.1], we get the result.
(ii) As is a cluster point of and by Theorem 4.2 and
by Corollary 4.1 (iv), there exists such that . From part (i) with and , (25)-(26) hold with
, so Lemma 4.2 holds with . By the local Lipschitz continuity of with , inequalities (29a)-(29b) hold with . From Proposition 4.1,
(40)
Since has the KL property at , there exist , a neighborhood of , and a continuous concave function satisfying Definition 2.3 (i)-(ii) such that for all ,
(41)
Let . If necessary by increasing , .
Then
Together with the concavity of , it is easy to obtain that
where . By Theorem 4.2 (iii), and for
all (if necessary by increasing ). Thus, we have and hence . By repeating the above arguments, we have
This implies that , so . By induction, we
can obtain the desired result.
Appendix B: A line-search PALM method for problem (1).
As mentioned in the introduction, the iterations of the PALM methods in [2, 17, 25] depend on the Lipschitz constants of and . An immediate upper estimation for them is , but it is too large and will make the performance of PALM methods worse. Here we present a PALM method by searching a favourable estimation for them. For any given and , let and be defined by
The iterations of the line-search PALM method are described as follows.
Algorithm 2(A line-search PALM method)
Initialization:
Choose and an initial point .
For
1.
Select and compute
2.
whiledo
(a)
;
(b)
Compute
end (while)
3.
Select . Compute
4.
whiledo
(a)
;
(b)
Compute .
end (while)
5.
Let , and go to step 1.
end
Remark 1
In the implementation of Algorithm 2, we use the Barzilai-Borwein (BB) rule [4] to capture the initial in steps 1 and 3. That is, in step 1 is given by