A memory-based spatial evolutionary game with the dynamic interaction between learners and profiteers
Abstract
Spatial evolutionary games provide a valuable framework for elucidating the emergence and maintenance of cooperative behavior. However, most previous studies assume that individuals are profiteers and neglect to consider the effects of memory. To bridge this gap, in this paper, we propose a memory-based spatial evolutionary game with dynamic interaction between learners and profiteers. Specifically, there are two different categories of individuals in the network, including profiteers and learners with different strategy updating rules. Notably, there is a dynamic interaction between profiteers and learners, i.e., each individual has the transition probability between profiteers and learners, which is portrayed by a Markov process. Besides, the payoff of each individual is not only determined by a single round of the game but also depends on the memory mechanism of the individual. Extensive numerical simulations validate the theoretical analysis and uncover that dynamic interactions between profiteers and learners foster cooperation, memory mechanisms facilitate the emergence of cooperative behaviors among profiteers, and increasing the learning rate of learners promotes a rise in the number of cooperators. In addition, the robustness of the model is verified through simulations across various network sizes. Overall, this work contributes to a deeper understanding of the mechanisms driving the formation and evolution of cooperation.
With the burgeoning development of artificial intelligence, reinforcement learning methods have become increasingly prevalent in exploring structured population behavior in evolutionary games. In light of the ubiquitous profit-seeking behavior observed in society and the inherent memory mechanisms of individuals, we propose a novel model in this paper, i.e., the memory-based spatial evolutionary game model with the dynamic interaction between learners and profiteers, where the memory mechanism is described by the memory length and the memory decay factor, and the dynamic interactions between learners and profiteers are modeled by a two-state homogeneous Markov chain. In addition, we conduct numerous simulations and analyses to verify the correctness of the theoretical derivations, the memory mechanism, and the dynamic interaction between two different categories of individuals on the impact of the frequency of cooperators, respectively, and study the emergence and evolution of cooperative behavior from a micro perspective.
I Introduction
Cooperative behavior has been observed across various scales, ranging from microorganisms to complex animal societies, underscoring its ubiquity in the natural world. Scholars across disciplines, including sociologists simpson2015beyond , psychologists henrich2021origins , economists niyazbekova2023sustainable , physicists guo2023third , and mathematicians sun2023state , etc. feng2023evolutionary ; li2023open have shown interest in understanding the origins and sustainability of cooperation. The network evolutionary game, as a combination of complex networks and evolutionary game theory, provides a practical framework for studying the emergence of cooperative behaviors in structured groups, where each node in a complex network represents an individual and the edges indicate the interactions between the individuals. Typical game models include the prisoner’s dilemma game wang2022levy , snowdrift game pi2022evolutionary2 , stag hunt game wang2013evolving with two players, and the public goods game wang2022replicator with multiple players. Besides, evolutionary games based on various structured populations have been widely proposed and studied, spanning square lattice networks with periodic boundaries flores2022cooperation ; szabo2016evolutionary , small-world networks lin2020evolutionary ; chen2008promotion , scale-free networks shen2024extortion ; kleineberg2017metric , temporal networks li2020evolution ; sheng2023evolutionary , and higher-order networks alvarez2021evolutionary ; kumar2021evolution . In addition to these, evolutionary games have recently gained attention and success in other areas as well capraro2024outcome .
In recent years, researchers extensively explored the underlying drivers behind the spontaneous emergence and sustenance of cooperative behaviors within competitive environments, corroborating their findings through numerous simulation experiments. A seminal contribution is the five rules proposed by Nowak nowak2006five . These rules encompass kin selection, direct reciprocity, indirect reciprocity, network reciprocity, and group selection, which elucidates diverse pathways to cooperation. Moreover, the mechanisms favoring cooperation include reputation mechanism xia2023reputation , trust xie2024trust , reward and punishment wang2014rewarding , etc. wang2018exploiting ; arefin2021imitation ; zhang2023evolutionary , which have also received extensive attention and investigation by scholars. In addition to these, many recent studies employ reinforcement learning methods to study the behavior of individuals in network evolutionary games, and Q-learning has especially become a dominant approach in these studies. For example, Yang et al. integrated Q-learning agents into the evolutionary prisoner’s dilemma game on the square lattice with periodic boundary conditions and found that interaction state Q-learning promotes the emergence and evolution of cooperation yang2024interaction . Shi and Rong delved into the dynamics of Q-learning and frequency adjusted Q-learning algorithms in multi-agent systems and revealed the intrinsic mechanisms of these algorithms from the perspective of evolutionary dynamics shi2022analysis . Ding et al. explored the impact of Q-learning on cooperation by involving extortion and observed that Q-learning significantly boosts the cooperation level of the network ding2019q . Therefore, amidst the rapid advancement of artificial intelligence, it is important to consider the influence of intelligent individuals equipped with learning on evolutionary dynamics.
In real systems, the memory of intelligent individuals significantly affects decision-making processes, and their actions are not limited to the current situation, but they also take past experiences into consideration. Some researchers discovered this phenomenon and achieved fruitful results in network evolutionary games. For example, the classical game tactics like generous-tit-for-tat (GTFT) nowak1992tit and win-stay, lose-shift (WSLS) nowak1993strategy proposed by Nowak are demonstrated to yield promising results in repeated prisoner’s dilemma games. In addition, Pi et al. considered the memory mechanism and proposed two strategy-updating rules based on profiteers and conformists and found that the memory mechanism promotes cooperation over a large parameter area pi2022evolutionary . Ma et al. examined the effect of working memory capacity, a crucial neural function, on cooperation in repeated prisoner’s dilemma experiments and discovered that the level of cooperation was optimal when subjects remembered the first two rounds of information and that there was a sudden increase in the level of cooperation as memory capacity increased from none to minimal ma2021limited . Lu et al. proposed a prisoner’s dilemma game model with a memory effect on spatial lattices and observed that the memory effect could effectively change the cooperative behavior in the spatial prisoner’s dilemma game lu2018role . Therefore, the memory mechanism of the individual performs an indispensable role in the emergence of cooperative behaviors.
Profiteers commonly adhere to the Fermi rule, a strategy updating rule where individuals are more inclined to adopt the strategy of another individual with a higher payoff perc2010coevolutionary ; yao2023inhibition ; jusup2022social . On the other hand, learners frequently employ Q-learning, a prevalent strategy updating rule where decisions are informed by previous learning experiences wang2024enhancing ; zhu2023co ; mcglohon2005learning . However, most of the previous studies simplified the scenario by considering either profiteers or learners independently, while in practice, these two categories interact continuously, i.e., the neighbor of an individual consists of both profiteers and learners, and an individual is not maintaining a category all the time. Therefore, to bridge this gap, we consider the dynamic interaction between profiteers and learners in this paper, where each individual changes from a learner (profiteer) to a profiteer (learner) with a certain probability over time, which can be described as a two-state homogeneous discrete Markov chain. The different categories of individuals are mainly reflected in the different strategy updating rules they adopt. Concretely, the profiteer uses the classical Fermi rule, preferring to imitate the strategy of individuals with higher payoffs, whereas the learner employs Q-learning in reinforcement learning and decides which strategy to utilize by continuously learning from the past. Furthermore, as we mentioned before, memory acts as a crucial role in individuals’ decision-making processes. Therefore, we introduce the memory mechanism into the evolution of the game. Specifically, the payoff of an individual is not solely dependent on a single game round but is a cumulative payoff, which is related to the memory length and the memory decay factor of the individual. This reflects the fact that an individual’s memory is not infinite and a longer event has a smaller effect on the individual. Through our investigation of the memory-based snowdrift game with the dynamic interaction between profiteers and learners on regular square lattices with periodic boundary conditions and Watts-Strogatz small-world networks watts1998collective , we find that the memory mechanism of individuals promotes the emergence and maintenance of cooperation among profiteers and the dynamic interaction between learners and profiteers enhances the cooperative behavior of the structured populations.
In the remainder of this paper, we first present the memory-based game model with the dynamic interaction between learners and profiteers in detail in Sec. II. Following that, in Sec. III, we show the simulation results and conduct thorough analyses. In the last section, we summarize the work and offer outlooks of this paper.
II Model
In this section, we introduce the memory-based spatial evolutionary game with the dynamic interaction between learners and profiteers, which is described in terms of four aspects: (i) the game model, (ii) the memory mechanism, (iii) the dynamic interactions between learners and profiteers, and (iv) the stationary distribution of the number of learners and profiteers.
II.1 Game model
In this study, we adopt the classical snowdrift game (SDG) for its generality, where the reward (R) for the interaction of two cooperative strategies is fixed to 1, the punishment (P) for the interaction of two defective strategies is set to 0, and for the interaction of cooperative and defective strategies, the cooperator receives a sucker’s payoff (S) of while the defector yields a temptation to defect (T) of . Hence, the payoff matrix of SDG is represented as follows:
| (1) |
where indicates the cost-to-benefit when both individuals are cooperators, and it takes a value ranging from 0 to 1, which is a flexible parameter.
II.2 Memory mechanism
Next, we provide a detailed explanation of the memory mechanism proposed in this paper. Each individual in the system possesses a memory, i.e. they are capable of knowing their payoffs from the previous rounds of interactions with their neighbors. Hereby, denotes the length of the individual’s memory, and the payoff in the past rounds has an impact on the individual’s current payoff. However, it is acknowledged that the impact of past interactions diminishes over time. To account for this, we introduce a memory decay factor , which characterizes the decreasing influence of past events on an individual’s current payoff. Therefore, the payoff of individual at time based on the memory mechanism can be expressed as
| (2) |
where represents the actual payoff of individual obtained from playing the snowdrift game with all neighbors in round , and it can be calculated as
| (3) |
where means the set consisting of all neighbors of individual . We emphasize that when the evolutionary time is smaller than the memory length, i.e., , then the individual’s memory length is considered as . Besides, is the strategy of individual , where a unit vector indicates a defective strategy and denotes cooperation.
II.3 Dynamic interactions between learners and profiteers
In reality, individuals exhibit diverse behaviors, with some driven primarily by profit-seeking motives (referred to as profiteers), while others rely on self-learning strategies (referred to as learners). Therefore, our proposed model incorporates the interaction between these two categories of individuals mentioned above. Furthermore, individuals are not fixed in their roles throughout the evolutionary game process, i.e., individuals cannot always be profiteers or learners, and they undergo mutual transitions between the two states. For this reason, we introduce a Markov process to capture this dynamic. Specifically, a profiteer (resp. learner) changes to be a learner (resp. profiteer) with the probability (resp. ) at every moment, and the state transition matrix representing these probabilities is given by
| (4) |
where denotes the probability of an individual transitioning from a learner to a profiteer and represents the probability of remaining a learner. Analogously, indicates the probability of an individual switching from a profiteer to a learner, while denotes the probability of staying a profiteer. We highlight that there is no relationship between the transition probabilities and . The only requirement is that they must satisfy the definition of probability, meaning both and must fall between 0 and 1.
For learners and profiteers, the key difference between them lies in their strategy updating rules. Profiteers tend to imitate the strategy of the neighbor with the highest payoff, employing the Fermi rule for strategy updating, i.e., at each round of evolution, a profiteer randomly selects an individual from its neighbors and adopts neighbor’s strategy according to the following probability:
| (5) |
where and signify the strategy expressed as unit vectors and payoff based on the memory mechanism of individual , respectively. The parameter means the noise factor, which is utilized to describe the irrational choices of individuals in the game.
On the other hand, learners use a reinforcement learning algorithm known as Q-learning for strategy updates. Specifically, the Q-learning algorithm can be regarded as a Markov decision process, where the decision of an individual is only relevant to the current situation and is not influenced by past events, which can be represented by a tuple . Hereby, (the number of cooperators among neighbors) and denote the state space and action space of individual . is the state transition probability after adopting action in state , and represents the reward of individual for performing action in state , which can be obtained by Eq. 2. Each learner owns a Q-table, which will be updated after each round of the game with all neighbors according to the following equation:
| (6) |
where and denote the learning rate and discount factor, respectively. A smaller causes the individual to focus more on the immediate payoff, otherwise, the individual focuses more on past experiences. represents the utility obtained by the individual in state when taking action at time . indicates the immediate payoff gained by the individual in state at time when performing action at time , which is determined by Eq. 2. The term signifies the maximum Q-value received by the individual in the future state . Therefore, the learner learns to update the Q-table by constantly playing games with its neighbors during the evolutionary process to guide the updating of its strategy. In particular, to portray the random choice of individuals in real situations, which is a compromise between exploration and exploitation, we introduce the -greedy algorithm. Specifically, at each decision point, exploration occurs with probability , i.e., a strategy is randomly selected from the action set with a uniform probability distribution, and exploitation is performed with probability , i.e., the strategy with the highest Q-value in the current state is taken, and if there is more than one, then one is chosen randomly.
II.4 Stationary distribution of the number of learners and profiteers
As we mentioned before, individuals are allowed to switch between profiteers and learners, with the corresponding transition matrix shown in Eq. 4. The transition probability is independent of the initial moment, which can be viewed as a two-state homogeneous Markov chain with state space , where denotes the category of each individual at time . Moreover, for any , there always exists a positive integer such that , indicating the ergodicity of the Markov chain. By the ergodic theorem, we have:
| (7) |
where indicates the stationary distribution of the Markov chain . Substituting Eq. 4 into Eq. 7, we obtain the solution and , which implies that as evolutionary time extends indefinitely, the probability of an individual being a learner is , while the probability of being a profiteer is .
Furthermore, based on the fact that whether each individual is a profiteer or a learner is independent of the other individuals, i.e., the categories of individuals are independent of each other, we can yield the expected number of profiteers and learners in the network when the evolution stabilizes, as expressed in the following equation:
| (8) |
where represents the size of the network.
To provide a clearer understanding of our model, we present an illustrative example of the model in Fig. 1. Each individual possesses a probability of transitioning between being a profiteer and a learner, showcasing dynamic interactions between the two categories in the network. Profiteers and learners utilize Fermi rules and Q-learning to update their strategies, respectively. Notably, each learner maintains a Q-table. Taking individual highlighted within the red square as an example, it is surrounded by two cooperators and two defectors among its neighbors. According to the Q-table, we can get that the Q-value of adopting a cooperative strategy in the current state is 17.72, surpassing the Q-value (13.92) for choosing a defective strategy. Consequently, individual will opt for the cooperative strategy during exploitation at the next moment.
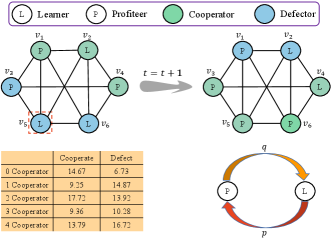
III Simulation results and analysis
In this section, we aim to validate the impact of the proposed model on the evolution of cooperative behavior through numerical simulations and provide an analysis of the results. We conduct simulations on two categories of networks: (i) regular square lattice (SL) with periodic boundary conditions and von Neumann neighborhood with the network size of ; (ii) Watts-Strogatz small-world network (WS) with , where each individual is initially connected to its 2 nearest neighbors on the left and right, and with a reconnection probability of 0.2. Initially, each individual is assigned to defect or cooperate with all its neighbors with a coin toss. Subsequently, individuals update their strategies using the reinforcement learning method called -greedy Q-learning or the Fermi rule based on their categories, and the probability that a learner takes an exploration when updating the strategy is set to . We primarily focus on the evolution between profiteers and learners, the emergence of cooperative behaviors, and a microscopic view of the distribution of cooperators and defectors. In addition, we validate the robustness of the model by performing simulations on networks with different sizes. According to our simulations, the evolution of the cooperation frequency is stable after 1000 steps of iterations. Therefore, in all simulations, we average the last 500 of the entire 5000 time steps to obtain the result of one simulation. Additionally, to mitigate interference from other factors, we perform 20 independent simulations and take the average value of them to get the final outcome.
III.1 Evolution and statistics of the number of profiteers and learners
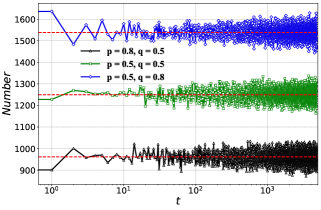
In order to verify the theory of dynamic interaction between learners and profiteers proposed in this paper, we first plot the evolutionary curves of the number of learners over time under different transition probabilities of and , and the result is shown in Fig. 2(a), where the red straight line indicates the theoretical value, which is calculated according to Eq. 8. We do not plot the evolution of profiteers since it can be obtained by subtracting the number of learners from the size of the network. From Fig. 2(a), we can see that the number of learners in all three cases evolves over time and stabilizes around , subsequently fluctuating around a certain value, which closely aligns with the one marked by the red theoretical straight line. Additionally, we present the theoretical and simulated values of the number of learners and profiteers, along with the relative error between them in Tab. 1 in the form of data for the three different scenarios. This provides a more intuitive insight into the gap between theory and simulation. The theoretical value is calculated using Eq. 8, while the simulated value is obtained by averaging the last 1000 steps of the evolution curve in Fig. 2(a). The relative error is determined by , where and denote the theoretical and simulated values, respectively. We find that the theoretical and simulated results for all three situations are very close to each other, and the maximum relative error is only 0.096%, which confirms the correctness of our theoretical derivation. Furthermore, by comparing the number of learners and profiteers at the stable time under the three cases, we observe that increasing leads to an increase in the number of profiteers, while a larger results in more learners in the network, which is consistent with the results demonstrated in Fig. 2(a).
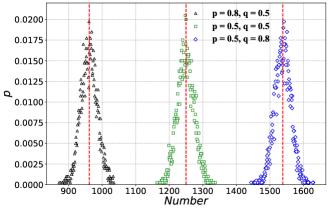
Subsequently, we record the number of learners in the last 4000 steps in each scenario and plot the probability distribution of the number of learners under three sets of transition probabilities according to the law of large numbers by considering the frequency as probability. The result is shown in Fig. 2(b), where the red straight line represents the theoretical values. Similarly, we present some numerical characteristics for each of the three distributions in Tab. 2, including standard deviation, skewness, and kurtosis, where the standard deviation is calculated using the method in the library in Python, while the skewness and kurtosis are obtained employing the and methods in the library, respectively. We observe that all three distributions approximately follow a normal distribution and that the span of each distribution is relatively small, explaining the small standard deviation of each distribution, which is consistent with the result in Tab. 2. Moreover, it can be clearly seen that the red theoretical straight line exactly passes through the tip of each distribution, which also verifies the correctness of our theory in another way. The skewness of all three statistical distributions of the number of learners exhibited in Tab. 2 is less than 0. It indicates that all three distributions have negative skewness, i.e., the left skewness, where there are fewer data located on the left side of the mean than on the right side of the mean, whereas profiteers are the reverse. The kurtosis of learners under both and is less than 0, which means that the overall data distribution is relatively flat compared to the normal distribution and is platykurtic, while the kurtosis under is greater than 0, which implies that the overall data distribution is relatively steep compared to the normal distribution and is leptokurtic. It is worth noting that the standard deviation and kurtosis are the same for both profiteers and learners, while the skewness is just the opposite. This discrepancy arises because the network contains only two categories of individuals, profiteers and learners, and the standard deviation and kurtosis are essentially even-ordered central moments, whereas the skewness is an odd-ordered central moment.
| Results | ||||||
|---|---|---|---|---|---|---|
| Learner | Profiteer | Learner | Profiteer | Learner | Profiteer | |
| Theoretical values | 961.538 | 1538.462 | 1250 | 1250 | 1538.462 | 961.538 |
| Simulated values | 961.379 | 1538.621 | 1248.799 | 1251.201 | 1538.403 | 961.597 |
| Relative error | 0.017% | 0.010% | 0.096% | 0.096% | 0.004% | 0.006% |
| Results | ||||||
|---|---|---|---|---|---|---|
| Learner | Profiteer | Learner | Profiteer | Learner | Profiteer | |
| Standard deviation | 24.148 | 24.148 | 25.905 | 25.905 | 24.999 | 24.999 |
| Skewness | -0.038 | 0.038 | -0.021 | 0.021 | -0.081 | 0.081 |
| Kurtosis | -0.144 | -0.144 | -0.223 | -0.223 | 0.451 | 0.451 |
III.2 Emergence and evolution of cooperative behavior
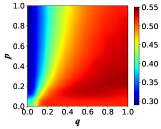
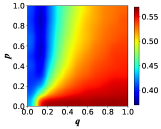
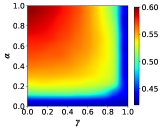
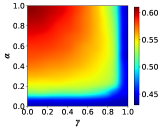
In this section, we investigate the effect of some model parameters on the emergence and evolution of cooperative behaviors. Primarily, we present the heat map of the cooperation ratio with respect to the transition probabilities and between profiteers and learners, as shown in Fig. 3. The -axis is set as with the range [0, 1], which denotes the transition probability from profiteers to learners, and the -axis is set as with the same range, which means the transition probability from learners to profiteers. Both networks exhibit that when is fixed, increasing the transition probability leads to a rise in the proportion of cooperators, i.e., the incorporation of learners promotes the emergence of cooperative behavior compared to a population of pure profiteers. This insight offers a fresh perspective to explain the widespread cooperative behavior in real-world scenarios. Although many individuals strive to behave as profiteers by imitating the strategies of individuals with high payoffs, there are still learners who are self-learning based on their past experiences, and the existence of learners is exactly the reason that further enhances the proportion of cooperators in the population.
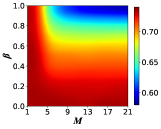
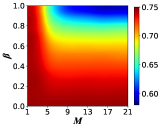
Subsequently, we delve into the impact of the memory mechanisms proposed in this paper on the evolution of cooperative behavior. We set the transition probability between profiteers and learners as , thus we can get that the profiteers and learners in the network are uniformly mixed according to Eq. 8. In this case, we plot the heat map of the cooperation ratio concerning the memory length and the memory decay factor, and the results of SL and WS networks are respectively shown in Figs. 4(a) and 4(b), from which we can obtain that increasing both the memory length and the memory decay factor causes a decrease in the number of cooperators for both SL and WS networks.
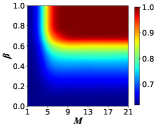
In addition, we demonstrate the changes in the proportion of cooperators concerning the memory mechanism for the pure profiteer scenario in Fig. 5, where the probability of converting from learner to profiteer is set to . In contrast, the probability of changing from profiteer to learner is . All other parameters are the same as in the numerical simulation in Fig. 4. It is obvious that the memory mechanism greatly facilitates the emergence of cooperative behavior in the case of pure profiteers. Notably, pure cooperators even appear on both networks when the memory length and memory decay factor are relatively large. Furthermore, upon comparing Figs. 5(a) and 5(b), we can observe that the area of the pure cooperators’ region of WS shown in Fig. 5(b) is significantly larger than that of SL presented in Fig. 5(a), which suggests that the WS network is more favorable to the survival of cooperators than the SL network. Therefore, we can conclude that while the memory mechanism facilitates the emergence of cooperative behavior in profiteers, it inhibits the evolution of cooperation in learners.
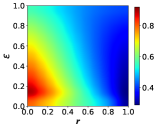
It is also crucial to study the effect of learners’ learning rate and discount factor in Eq. 6 on cooperative behavior. Thus, we exhibit the heat map depicting the percentage of cooperators on the SL and WS networks concerning and in Figs. 6(a) and 6(b), respectively. We set the payoff parameter, the transition probabilities between profiteers and learners, the memory decay factor, and the memory length to and . From Figs. 6(a) and 6(b), we can obtain that both SL and WS networks demonstrate a higher learning rate leads to a larger percentage of cooperators. On the contrary, increasing the discount factor results in a decrease in the cooperation frequency. This indicates that a larger learning rate and a greater tendency of learners toward immediate benefits promote the emergence and maintenance of cooperative behaviors in the network.
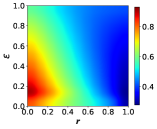
Next, we explore the influence of exploration rate and payoff parameter on the cooperative behavior, and the results are depicted in Fig. 7. With transition probabilities between profiteers and learners set to , and memory mechanism parameters held constant at and , both WS and SL networks reveal interesting insights. For relatively small values of the payoff parameter (), an appropriate increase in the exploration rate fosters cooperation, but excessive exploration hampers cooperative behavior. However, when is relatively large (), elevating the exploration rate consistently diminishes the prevalence of cooperators. Furthermore, we observe that an increase in the payoff parameter always reduces the fraction of cooperators, as higher values lead to greater payoffs for defectors based on Eq. 1, thereby incentivizing more individuals to adopt the defective strategy.
III.3 Snapshots of the evolution of cooperators on SL networks
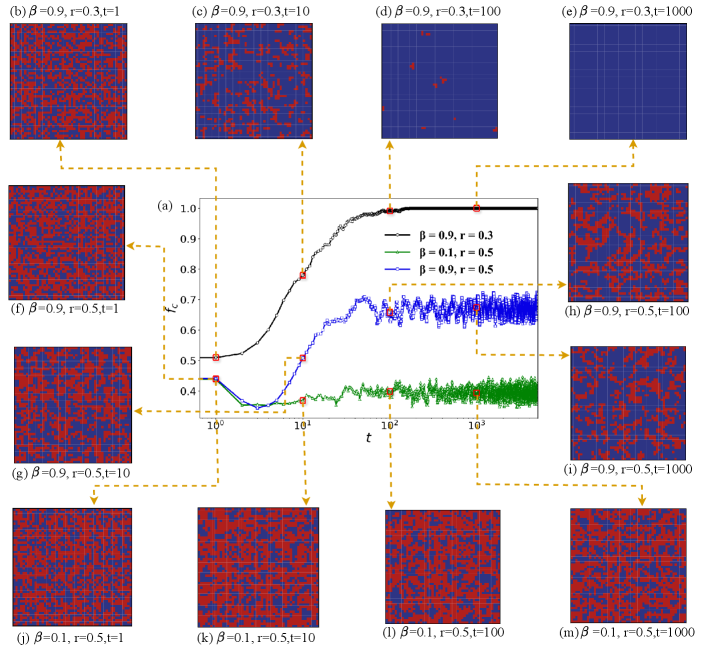
Then, we display the evolutionary curves of the cooperation ratio under three different parameter pairs (, ) and illustrate the distribution of cooperators and defectors on the SL networks at different instants from a micro perspective in Fig. 8. From Fig. 8(a), it is evident that the frequency of cooperators stabilizes around in all three situations, and then stabilizes with slight fluctuations around a certain value. In addition, we observe that the cooperation ratio of marked by blue squares is higher than that of labeled by green triangles, and lower than that of marked by black circles, which can be visually confirmed from the snapshots depicted in Figs. 8(b)-(m), where red represents the defector and blue indicates the cooperator.
Specifically, Figs. 8(b), (f), and (j) all demonstrate that the network is almost evenly mixed with cooperators and defectors at , while the blue region for (Figs. 8(b)-(e)) grows large as time progresses and eventually occupies the entire network, indicating that all the individuals become cooperators, and there are no defectors exist. For (Figs. 8(f)-(i)), the blue region gradually increases and eventually stabilizes, signifying that cooperators play a dominant role in it. In contrast, the blue region gradually diminishes over time and eventually stabilizes for (Figs. 8(j)-(m)), meaning that the defector holds a dominant role in it. Additionally, we can observe that the cooperators resist the invasion of the defectors mainly by forming clusters. These observations can be attributed to the fact that the transition probabilities between profiteers and learners are set to and , i.e., the network is ultimately all occupied by profiteers. Moreover, we can get that increasing the memory decay factor promotes cooperative behaviors as indicated in Fig. 5. Besides, according to Eq. 1, when a cooperator meets a defector, the defector’s payoff increases but the cooperator’s payoff decreases as the payoff parameter grows, which promotes the emergence and maintenance of defectors in the network.
III.4 Validation of the robustness of the model
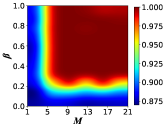
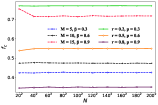
Note that in all of our previous simulations, the sizes of the SL and WS networks are fixed to . In this subsection, we aim to examine the evolution of cooperative behaviors on SL and WS networks with different sizes to verify the robustness of the model. We depict the variation of the cooperation frequency on SL and WS networks as a function of network size for three different sets of parameters (, ) and three distinct groups of parameters (, ) in Figs. 9(a) and 9(b), respectively.
From Fig. 9, we obtain that both SL and WS networks exhibit almost no influence of network size on cooperative behavior under the same set of parameters, which is further demonstrated by the range and standard deviation of each curve, and the results are shown in Tabs. 3 and 4. The reason we choose the range and standard deviation as our statistical metrics is that range indicates the extent of fluctuation in the proportion of cooperators and standard deviation quantifies the magnitude of fluctuation in the frequency of cooperators. A small range and standard deviation signify that network size has a negligible impact on the frequency of cooperators, validating the robustness of our findings across different network sizes. It can be seen that the maximum range and standard deviation of SL do not exceed 0.0402 and 0.0113, respectively, and the maximum range and standard deviation of WS are within 0.0324 and 0.0089, respectively, which signifies that the fluctuation ranges and magnitudes of on both networks are minimal. Notably, the fluctuation ranges and magnitudes on the WS network are even smaller than those on the SL network, consistent with the trends presented in Fig. 9. Furthermore, by comparing Figs. 9(a) and 9(b), we notice that the WS network exhibits a higher percentage of cooperators for the parameter set (, ) (denoted as dashed lines) compared to the SL network, while both networks show similar cooperation ratio for the parameter set (, ) (denoted as solid lines). Therefore, through this simulation, we can conclude that the results are consistent across different network sizes for SL and WS networks, confirming the robustness of the proposed model.

| Results | ||||||
|---|---|---|---|---|---|---|
| Range | 0.0036 | 0.0037 | 0.0402 | 0.0017 | 0.0107 | 0.0054 |
| Standard deviation | 0.0010 | 0.0011 | 0.0113 | 0.0004 | 0.0031 | 0.0016 |
| Results | ||||||
|---|---|---|---|---|---|---|
| Range | 0.0222 | 0.0324 | 0.0020 | 0.0049 | 0.0053 | 0.0050 |
| Standard deviation | 0.0062 | 0.0089 | 0.0006 | 0.0013 | 0.0014 | 0.0014 |
IV Conclusion and outlook
In this study, we investigate the evolution of cooperation on SL and WS networks with dynamic interactions between learners and profiteers, considering the category of individuals as a homogeneous discrete-time Markov chain with two states. Different categories of individuals update their strategies according to different rules, where learners adopt Q-learning while profiteers follow the Fermi rule. Additionally, we introduce the memory decay factor and memory length to enable individuals to compute payoffs based on a broader historical context rather than solely relying on the current round of the game. In the simulation, we begin with plotting the evolutionary curve and statistical distribution of learners and verify the theoretical analyses through various numerical features. Subsequently, we perform numerous simulations about the effect of the proposed model on cooperative behavior on the SL and WS networks. We find that dynamic interactions between profiteers and learners promote cooperation, increasing learning rate and decreasing discount factor in Q-learning increase the proportion of network cooperators, and memory mechanisms enhance the emergence of cooperation in pure profiteer groups. Then, we perform snapshots of the evolution of cooperators on SL networks and focus on the formation and evolution of the cooperation clusters from a micro perspective. We discover that cooperators resist the invasion of defectors mainly by forming cluster structures, with smaller payoff parameters and larger memory decay coefficients leading to larger clusters. Furthermore, our simulations on networks of varying sizes demonstrate the robustness of the model, revealing that network size has a negligible impact on the cooperation ratio on both SL and WS networks.
Based on our work, there are some extensions to further exploration in spatial evolutionary games. For example, we mainly focus on the dynamic interactions between profiteers and learners on static networks, while there actually exist structured networks that undergo dynamic changes over time holme2012temporal ; li2020evolution . These networks feature evolving interactions among individuals, presenting an intriguing opportunity to extend our model to investigate temporal networks. In addition to examining complete interactions, more and more scholars have recently turned their attention to stochastic and incomplete games li2021evolution ; li2022impact ; wang2021evolution , which is also worth considering in our future research endeavors. Moreover, some previous studies have pointed out that real-world scenarios often involve conformist behaviors pi2022evolutionary ; szolnoki2015conformity . Therefore, future research could explore the introduction of conformists and assess the impact of the three categories of individual dynamic interactions on the maintenance and evolution of cooperative behavior.
Acknowledgment
This work was supported in part by the National Natural Science Foundation of China (NSFC) under Grant No. 62206230 and No. 12271083 and in part by the Natural Science Foundation of Sichuan Province under Grant No. 2022NSFSC0501.
References
References
- (1) Brent Simpson and Robb Willer. Beyond altruism: Sociological foundations of cooperation and prosocial behavior. Annual Review of Sociology, 41:43–63, 2015.
- (2) Joseph Henrich and Michael Muthukrishna. The origins and psychology of human cooperation. Annual Review of Psychology, 72:207–240, 2021.
- (3) Shakizada Niyazbekova, Angela Mottaeva, Madina Kharesova, and Liza Tsurova. Sustainable development of transport systems and development of economic cooperation between countries. In E3S Web of Conferences, volume 371, page 04039. EDP Sciences, 2023.
- (4) Hao Guo, Zhao Song, Matjaž Perc, Xuelong Li, and Zhen Wang. Third-party intervention of cooperation in multilayer networks. IEEE Transactions on Systems, Man, and Cybernetics: Systems, 2023.
- (5) Zaiben Sun, Xiaojie Chen, and Attila Szolnoki. State-dependent optimal incentive allocation protocols for cooperation in public goods games on regular networks. IEEE Transactions on Network Science and Engineering, 2023.
- (6) Minyu Feng, Bin Pi, Liang-Jian Deng, and Jürgen Kurths. An evolutionary game with the game transitions based on the markov process. IEEE Transactions on Systems, Man, and Cybernetics: Systems, 2023.
- (7) Qin Li, Bin Pi, Minyu Feng, and Jürgen Kurths. Open data in the digital economy: An evolutionary game theory perspective. IEEE Transactions on Computational Social Systems, 2023.
- (8) Lu Wang, Danyang Jia, Long Zhang, Peican Zhu, Matjaž Perc, Lei Shi, and Zhen Wang. Lévy noise promotes cooperation in the prisoner’s dilemma game with reinforcement learning. Nonlinear Dynamics, 108(2):1837–1845, 2022.
- (9) Bin Pi, Ziyan Zeng, Minyu Feng, and Jürgen Kurths. Evolutionary multigame with conformists and profiteers based on dynamic complex networks. Chaos: An Interdisciplinary Journal of Nonlinear Science, 32(2), 2022.
- (10) Lei Wang, Chengyi Xia, Li Wang, and Ying Zhang. An evolving stag-hunt game with elimination and reproduction on regular lattices. Chaos, Solitons & Fractals, 56:69–76, 2013.
- (11) Xiaofeng Wang and Matjaž Perc. Replicator dynamics of public goods games with global exclusion. Chaos: An Interdisciplinary Journal of Nonlinear Science, 32(7), 2022.
- (12) Lucas S Flores, Marco A Amaral, Mendeli H Vainstein, and Heitor CM Fernandes. Cooperation in regular lattices. Chaos, Solitons & Fractals, 164:112744, 2022.
- (13) György Szabó and István Borsos. Evolutionary potential games on lattices. Physics Reports, 624:1–60, 2016.
- (14) Zhiqi Lin, Hedong Xu, and Suohai Fan. Evolutionary accumulated temptation game on small world networks. Physica A: Statistical Mechanics and its Applications, 553:124665, 2020.
- (15) Xiaojie Chen and Long Wang. Promotion of cooperation induced by appropriate payoff aspirations in a small-world networked game. Physical Review E, 77(1):017103, 2008.
- (16) Aizhong Shen, Zili Gao, Dan Cui, and Chen Gu. Extortion evolutionary game on scale-free networks with tunable clustering. Physica A: Statistical Mechanics and its Applications, 637:129568, 2024.
- (17) Kaj-Kolja Kleineberg. Metric clusters in evolutionary games on scale-free networks. Nature Communications, 8(1):1888, 2017.
- (18) Aming Li, Lei Zhou, Qi Su, Sean P Cornelius, Yang-Yu Liu, Long Wang, and Simon A Levin. Evolution of cooperation on temporal networks. Nature Communications, 11(1):2259, 2020.
- (19) Anzhi Sheng, Aming Li, and Long Wang. Evolutionary dynamics on sequential temporal networks. PLoS Computational Biology, 19(8):e1011333, 2023.
- (20) Unai Alvarez-Rodriguez, Federico Battiston, Guilherme Ferraz de Arruda, Yamir Moreno, Matjaž Perc, and Vito Latora. Evolutionary dynamics of higher-order interactions in social networks. Nature Human Behaviour, 5(5):586–595, 2021.
- (21) Aanjaneya Kumar, Sandeep Chowdhary, Valerio Capraro, and Matjaž Perc. Evolution of honesty in higher-order social networks. Physical Review E, 104(5):054308, 2021.
- (22) Valerio Capraro, Joseph Y Halpern, and Matjaž Perc. From outcome-based to language-based preferences. Journal of Economic Literature, 62(1):115–154, 2024.
- (23) Martin A Nowak. Five rules for the evolution of cooperation. Science, 314(5805):1560–1563, 2006.
- (24) Chengyi Xia, Juan Wang, Matjaž Perc, and Zhen Wang. Reputation and reciprocity. Physics of Life Reviews, 2023.
- (25) Yunya Xie, Yu Bai, Yankun Zhang, and Zhengyin Peng. Trust-induced cooperation under the complex interaction of networks and emotions. Chaos, Solitons & Fractals, 182:114727, 2024.
- (26) Zhen Wang, Attila Szolnoki, and Matjaž Perc. Rewarding evolutionary fitness with links between populations promotes cooperation. Journal of Theoretical Biology, 349:50–56, 2014.
- (27) Zhen Wang, Marko Jusup, Lei Shi, Joung-Hun Lee, Yoh Iwasa, and Stefano Boccaletti. Exploiting a cognitive bias promotes cooperation in social dilemma experiments. Nature Communications, 9(1):2954, 2018.
- (28) Md Rajib Arefin and Jun Tanimoto. Imitation and aspiration dynamics bring different evolutionary outcomes in feedback-evolving games. Proceedings of the Royal Society A, 477(2251):20210240, 2021.
- (29) Yuji Zhang, Ziyan Zeng, Bin Pi, and Minyu Feng. An evolutionary game with revengers and sufferers on complex networks. Applied Mathematics and Computation, 457:128168, 2023.
- (30) Zhengzhi Yang, Lei Zheng, Matjaž Perc, and Yumeng Li. Interaction state q-learning promotes cooperation in the spatial prisoner’s dilemma game. Applied Mathematics and Computation, 463:128364, 2024.
- (31) Yiming Shi and Zhihai Rong. Analysis of q-learning like algorithms through evolutionary game dynamics. IEEE Transactions on Circuits and Systems II: Express Briefs, 69(5):2463–2467, 2022.
- (32) Hong Ding, Geng-shun Zhang, Shi-hao Wang, Juan Li, and Zhen Wang. Q-learning boosts the evolution of cooperation in structured population by involving extortion. Physica A: Statistical Mechanics and its Applications, 536:122551, 2019.
- (33) Martin A Nowak and Karl Sigmund. Tit for tat in heterogeneous populations. Nature, 355(6357):250–253, 1992.
- (34) Martin Nowak and Karl Sigmund. A strategy of win-stay, lose-shift that outperforms tit-for-tat in the prisoner’s dilemma game. Nature, 364(6432):56–58, 1993.
- (35) Bin Pi, Yuhan Li, and Minyu Feng. An evolutionary game with conformists and profiteers regarding the memory mechanism. Physica A: Statistical Mechanics and its Applications, 597:127297, 2022.
- (36) Shuangmei Ma, Boyu Zhang, Shinan Cao, Jun S Liu, and Wen-Xu Wang. Limited memory optimizes cooperation in social dilemma experiments. Royal Society Open Science, 8(8):210653, 2021.
- (37) Wenwen Lu, Juan Wang, and Chengyi Xia. Role of memory effect in the evolution of cooperation based on spatial prisoner’s dilemma game. Physics Letters A, 382(42-43):3058–3063, 2018.
- (38) Matjaž Perc and Attila Szolnoki. Coevolutionary games—a mini review. BioSystems, 99(2):109–125, 2010.
- (39) Yichao Yao, Ziyan Zeng, Bin Pi, and Minyu Feng. Inhibition and activation of interactions in networked weak prisoner’s dilemma. Chaos: An Interdisciplinary Journal of Nonlinear Science, 33(6), 2023.
- (40) Marko Jusup, Petter Holme, Kiyoshi Kanazawa, Misako Takayasu, Ivan Romić, Zhen Wang, Sunčana Geček, Tomislav Lipić, Boris Podobnik, Lin Wang, et al. Social physics. Physics Reports, 948:1–148, 2022.
- (41) Xianjia Wang, Zhipeng Yang, Guici Chen, and Yanli Liu. Enhancing cooperative evolution in spatial public goods game by particle swarm optimization based on exploration and q-learning. Applied Mathematics and Computation, 469:128534, 2024.
- (42) Peican Zhu, Zhaoheng Cao, Chen Liu, Chen Chu, and Zhen Wang. Co-evolution of synchronization and cooperation with multi-agent q-learning. Chaos: An Interdisciplinary Journal of Nonlinear Science, 33(3), 2023.
- (43) Mary McGlohon and Sandip Sen. Learning to cooperate in multi-agent systems by combining q-learning and evolutionary strategy. International Journal on Lateral Computing, 1(2):58–64, 2005.
- (44) Duncan J Watts and Steven H Strogatz. Collective dynamics of ‘small-world’networks. Nature, 393(6684):440–442, 1998.
- (45) Petter Holme and Jari Saramäki. Temporal networks. Physics Reports, 519(3):97–125, 2012.
- (46) Xiaopeng Li, Gang Hao, Zhipeng Zhang, and Chengyi Xia. Evolution of cooperation in heterogeneously stochastic interactions. Chaos, Solitons & Fractals, 150:111186, 2021.
- (47) Xiaopeng Li, Weiwei Han, Wenjun Yang, Juan Wang, Chengyi Xia, Hui-jia Li, and Yong Shi. Impact of resource-based conditional interaction on cooperation in spatial social dilemmas. Physica A: Statistical Mechanics and its Applications, 594:127055, 2022.
- (48) Guocheng Wang, Qi Su, and Long Wang. Evolution of state-dependent strategies in stochastic games. Journal of Theoretical Biology, 527:110818, 2021.
- (49) Attila Szolnoki and Matjaž Perc. Conformity enhances network reciprocity in evolutionary social dilemmas. Journal of The Royal Society Interface, 12(103):20141299, 2015.