A Monte Carlo EM Algorithm for the Parameter Estimation of Aggregated Hawkes Processes
Abstract
A key difficulty that arises from real event data is imprecision in the recording of event time-stamps. In many cases, retaining event times with a high precision is expensive due to the sheer volume of activity. Combined with practical limits on the accuracy of measurements, aggregated data is common. In order to use point processes to model such event data, tools for handling parameter estimation are essential. Here we consider parameter estimation of the Hawkes process, a type of self-exciting point process that has found application in the modeling of financial stock markets, earthquakes and social media cascades. We develop a novel optimization approach to parameter estimation of aggregated Hawkes processes using a Monte Carlo Expectation-Maximization (MC-EM) algorithm. Through a detailed simulation study, we demonstrate that existing methods are capable of producing severely biased and highly variable parameter estimates and that our novel MC-EM method significantly outperforms them in all studied circumstances. These results highlight the importance of correct handling of aggregated data.
Keywords Hawkes processes self-exciting processes aggregated data binned data MC-EM algorithm
1 Introduction
Point processes are extensively used to model event data and have found wide applications in many fields including seismology [23] and cyber-security [24]. One representation of a point process is via the counting process , where denotes the number of events up to time , and . Due to limited recording capabilities and storage capacities, retaining event times with a high precision is expensive and often infeasible. Therefore, in much real-world data, it is common to instead observe a times series of the aggregated process,
for some , which we refer to as the bin width. This aggregated process may arise from a predetermined binning of the data into counts, or equivalently from the rounding of event times. In the context of network traffic data, for example, the resolution of the recorded times can be anywhere from milliseconds to seconds (as is the case with the Los Alamos National Laboratory (LANL) NetFlow data [26]), or even coarser. In this setting the value of this aggregated process at each time point is the number of events with that rounded time-stamp.
Intuitively, when aggregating data we lose information and essentially ‘blur’ our view of the continuous time point process, making it potentially problematic to apply methods which assume a continuous time framework. Thus, the problem we consider here is to infer upon the underlying continuous process from the observed aggregated data.
The Hawkes process is a type of ‘self-exciting’ process which provides us with a model for contagious event data. Their flexibility and real-world relevancy has resulted in a host of applications. In the case of financial data for example, this allows propagation of stock crashes and surges to be modeled [1, 3, 8, 9, 7]. Propagation of social media events has also been modeled using Hawkes processes, in particular ‘twitter cascades’ are considered in [25, 15]. Further applications include the modeling of civilian deaths due to insurgent activity in Iraq [18], and predicting origin times and magnitudes of earthquakes [22].
Formally, the Hawkes process is a class of stochastic process with the defining property that
where . It is characterized via its conditional intensity function (CIF) , defined as
where is called the background intensity and is the excitation kernel. This means the intensity at an arbitrary time-point is dependent on the history of the process, producing self-exciting behavior. Depending on the kernel , the excitation may be quite local, or have longer term effects [10].
We can also consider a Hawkes process as a branching process of time-stamped events. From this viewpoint, formalised in [11], events can be seen to arrive either via immigration or birth. That is, an event can be triggered by the background intensity rate , in which case the event is seen as an immigrant. Alternatively, an event which is cause by self-excitation can be considered a descendant, referred to as being generated ‘endogenously’. Unlike a homogeneous Poisson point process, where events happen independently and at a constant rate, self-exciting processes are such that there is a higher likelihood of events happening in the near future of an arbitrary event and this is due to endogenous triggering [25]. In this way we can consider the branching ratio of a Hawkes process, defined as
| (1) |
The inequality above ensures that the process does not ‘explode’, a case in which we have infinite events occurring in some finite time interval [16].
As introduced in Hawkes’ original paper, exponential decay is a common choice for the excitation kernel due to the simplifications it provides for the theoretical derivations [10, 16]. In this case we can write the excitation kernel as a sum of exponential decays,
| (2) |
Here, and as is most common, we let when considering the exponential kernel. In this case, the branching ratio defined in (1) becomes
Given this model, we wish to estimate the parameter set . Other kernels can be used, including a power-law function of form , in which case . In the continuous time setting, parameter estimation for any of these kernels is straightforward.
1.1 Continuous Time Framework
Typically, maximum likelihood estimation (MLE) is used to estimate parameters of a point process from a set of exact event times . The CIF, or hazard function, of a point process is formally defined as
| (3) |
where and are the conditional PDF and CDF, respectively, of the next arrival time, given the history of the process. From (3) we have that
| (4) |
where denotes the last observed time prior to . From (1.1), the joint likelihood of the univariate observations over the window is
Thus, from Proposition 7.2.III of [5], the log-likelihood is given by
| (5) |
If specifically considering a Hawkes process with exponential excitation kernel of form this log-likelihood can be simplified and expressed recursively as shown in [16]. In this paper we consider methods that are required when we instead observe a binned sequence of event counts. An alternative but equivalent representation of this is a discretization or rounding of the latent time-stamps, but here we will consider the observed data as the aggregation of to bins.
1.2 Aggregated Data
In the literature, the issue of aggregated data is handled in many ways, from uniformly redistributing events across the bin [3], to only retaining unique time-stamps and discarding the rest [19]. Here, we propose a novel Monte Carlo-Expectation Maximization (MC-EM) method and compare it to two existing approaches, evaluating the performance of parameter estimation for each. The methods compared are:
There are other methods which have been covered in the literature, but are not considered here due to lack of applicability to this problem. As an example, a significant amount of the literature which aims to work with aggregated data considers binning the time-points such that the process contains at most one event per bin as in [21]. This is inappropriate here as we do not have access to the latent event times and so cannot select an appropriate discretization level, . Likewise, some literature considers modeling binned behavior as a Bernoulli process [4]. Again, this is invalid here as it fails to account for the number of events in a bin and thus will heavily bias results. There exist methods that handle missing data when we observe continuous time-points with gaps in the recording windows [17]. That is, when the data considered contains precise but intermittent recordings. This is a closely related issue, however differs in the fact that when handling aggregated data, we do not have any precise times to work with.
We now outline the two methods against which we will compare our novel MC-EM approach.
1.3 Hawkes INAR() Approximation
It is shown in [12, 13] that the distribution of the bin-count sequence of Hawkes processes can be represented by an integer-valued autoregressive model, known as the INAR() model, further details of which can be found in [12]. By representing the binned Hawkes counting process as an INAR() process, a non-parametric estimator for kernel is then formulated in terms of conditional least squares (CLS).
Let be the bin width, the univariate Hawkes process bin-count sequence is denoted , for and denotes the counts in the bin. Then, defining some support , the CLS-operator is used on the bin counts , with maximal lag . Thus,
where the design matrix is given as
and is the lagged bin-count sequence, being . Then the entries of ,
are estimates for the excitation kernel at the corresponding time-points. Kernel parameters and are then estimated by fitting an exponential function to these points.
Simulation studies examining the effect of bin width and parameter are presented in [12, 14], where they determine to have the greatest bearing on the quality of the estimates. There are however two points to note with this method. Firstly, CLS requires the inversion of . In this case, this matrix contains the event counts per bin, and so it is possible to have cases where this matrix is singular, in particular when the counting process is very sparse. Secondly, as it is currently presented, this method does not constrain the parameter estimates to be those of a stationary Hawkes process. Therefore it is possible to yield infeasible estimates.
1.4 Binned Likelihood
An alternative method, briefly mentioned in [20] and developed here, considers sampling at each discrete time-point ( with ), thus representing as a piecewise constant function within each bin. Letting be the number of events occurring in the sampling interval and using (5) we have that the log-likelihood of the underlying Hawkes process is
| (6) |
where and denotes the history of the process until time .
The assumption of a piecewise constant CIF is equivalent to assuming Poisson. However, it is important to note that this assumption is not correct as it ignores the excitation within each bin and therefore will be biased, especially in cases where the intensity is high relative to the bin width, . Nevertheless it provides us with a simple approximation. To estimate the process parameters we maximize (6) with constraints ensuring stationarity, as expressed by (1). In the case of an exponential excitation kernel, explicitly this implies and .
We will now propose an alternative method of parameter estimation which iteratively uses ‘legal’ sets of continuous candidate time-points and therefore does not assume a piecewise constant CIF.
2 Monte Carlo EM Algorithm for Aggregated Data
The EM algorithm [6] is an iterative method for the computation of the maximizer of a likelihood. The idea of this algorithm is to augment the observed data by a latent quantity [27]. In the case considered here, the observed data are the event counts per unit time. We denote this by , where denotes the counts in the bin (). The latent data, denoted are the unobserved, true event times which are rounded on recording and the set of parameters to be estimated is denoted . The algorithm proceeds as follows:
-
1.
In the E (Expectation) step, we evaluate
(7) where denotes the sample space for . That is, we compute the expectation of the log-posterior with respect to the conditional predictive distribution , where is the current, approximation.
-
2.
In the M (Maximization) step, we update the value of the conditional expectation with its maximizer .
When (7) is analytically intractable we require Monte Carlo methods for numerical computation. This is known as MC-EM [27]. If we are able to sample directly from , then we can approximate the integral in (7) with
where is the Monte Carlo sample of . However, no such sampling regime is possible in the Hawkes process setting. We therefore use importance sampling to simulate a legal proposal for (that is, a set of event times that match the binned counts) from an alternative distribution which is simple to sample from (see Section 2.1 for details). Each of these proposals is then weighted depending on the probability it came from the desired distribution. That is, given a set of samples , we assign weights
| (8) |
and approximate (7) with
| (9) |
We note that the numerator of (8) can be expressed as
where is the number of event times in lying in bin , and is 1 if is in the set and 0 otherwise. Therefore, if only proposing legal event times, we have that
where, is given by (5).
However, the question remains of how to best sample the latent times. Here, the density we would ideally like to sample from is that of the missing event times given the bin counts and the model parameters . Therefore for this method to be most efficient and to ensure meaningful weights, the alternative distribution should be as close as possible to the true distribution of the time-stamps.
2.1 Sampling Method
It is possible to uniformly redistribute the events across a bin in order to generate a legal set of event times. However, especially for Hawkes processes with high activity, this is not optimal as it leads to weights that are too small to compute (9). Therefore, we propose an alternative method which samples from a distribution that more closely matches . Here, this is developed for the exponential kernel but it is easily extendible to other kernels (see Appendices A and B for details regarding power-law and rectangular kernels, respectively).
Without loss of generality, consider having already simulated until time-point . Then, suppose we know that there are time-points in the next non-empty bin, being . The joint probability of these events can be expressed using factorization. That is
For brevity, we refer to as . Note that for the simplest case of an exponential kernel, we can express this as
where
As we wish to simulate possible realizations of the events given observed counts, we should account for the the fact that each time-point is known to have occurred within a given interval. That is, we account for the observed interval range for events in a given bin by considering the truncated joint density. We require that . Therefore, we can express the conditional CDF over this region as
Even in the simplest case of an exponential decay kernel, this appears intractable due to the form of the conditional intensity function for a Hawkes process. Therefore we truncate the PDF by considering the joint CDF. As with the joint PDF, we can use factorization to express the joint CDF as
where we can use the form given in (1.1) for the CDF of each successive time-point given the history of the process. That is, the joint CDF of time-points is given by
In the case of an exponential decay kernel, this is
Thus the joint truncated PDF of time-points given the history, can be expressed as
| (10) |
where
The set of proposed time-stamps for the given bin are those that maximize (10).
In this way we can sequentially simulate a continuous version of the observed aggregate Hawkes process by progressively handling each bin such that we jointly maximize this likelihood.
3 Simulation Studies
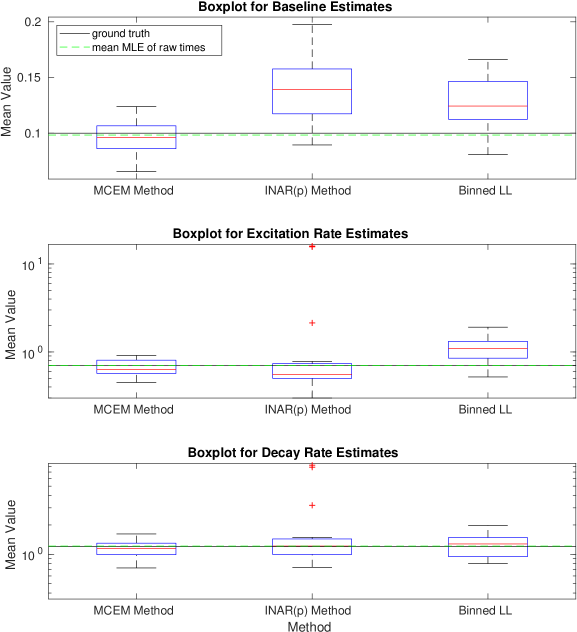
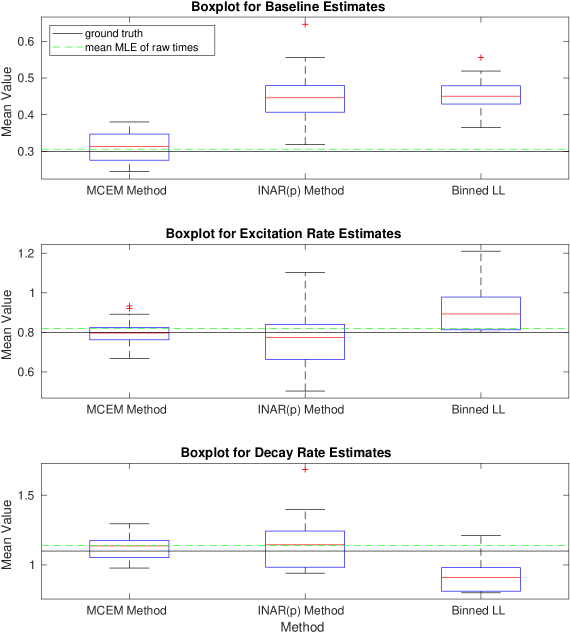
Given parameters and some maximum simulation time , we can simulate realizations of a Hawkes process. The generated events are those which form the latent space , and aggregating these to different allows us to simulate the count data . We can then apply each of the three methods detailed: the binned log-likelihood, INAR() approximation, and the MC-EM method. Figures 1-6 show boxplots for the estimates of each of and for 20 realizations of a Hawkes process with the ground truth parameters specified. The mean value of each parameter estimate is presented on the vertical axis. We clearly see that the INAR() approximation method can yield highly variable results. In Figure 1, the boxplots for both the excitation rate, , and the decay rate have been presented on a log-scale in order to show the results on one axis. Clearly, the INAR() method has resulted in outliers that are factors of 10 away from the ground truth. The remaining figures all likewise show the MC-EM method to perform better than either of the two alternative approaches considered for a range of different parameter sets. In particular, again in Figure 5 we note that the excitation rate estimates have been presented on a log-scale due to the extreme outliers in the INAR() method. The binned log-likelihood method, whilst suffering less from extreme outliers, performs less well than the MC-EM method in all cases.
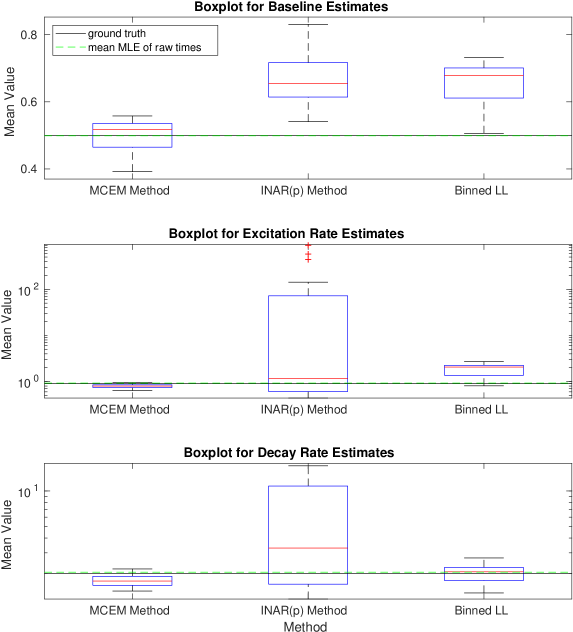
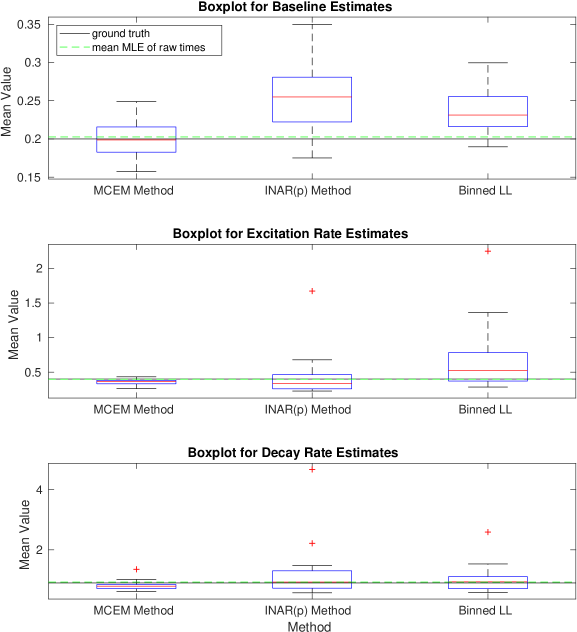
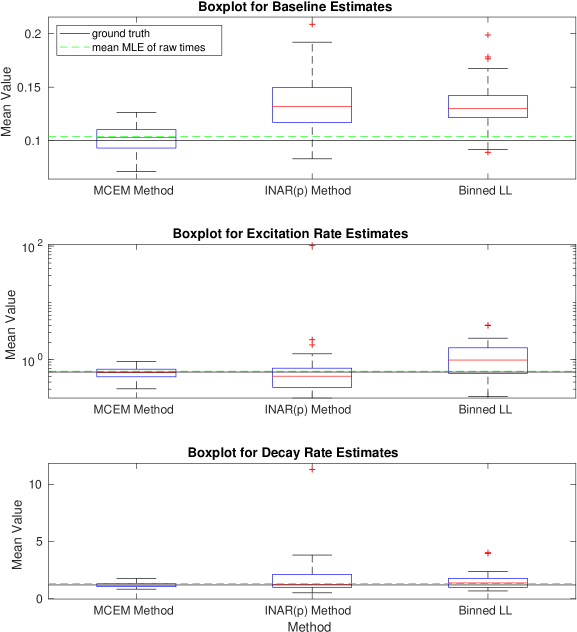
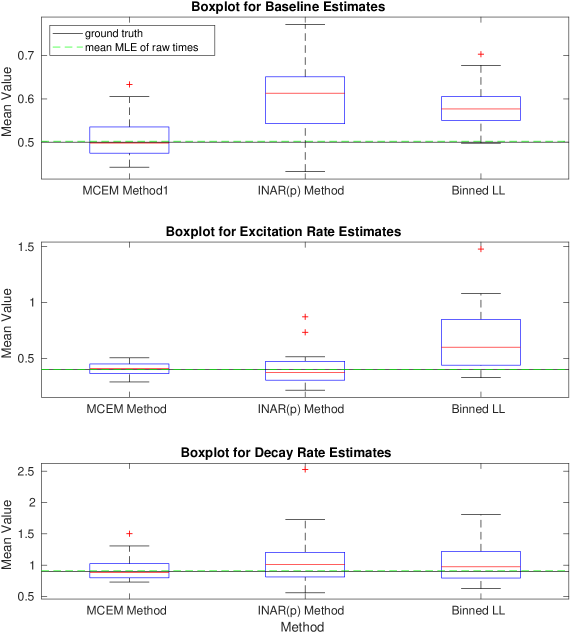
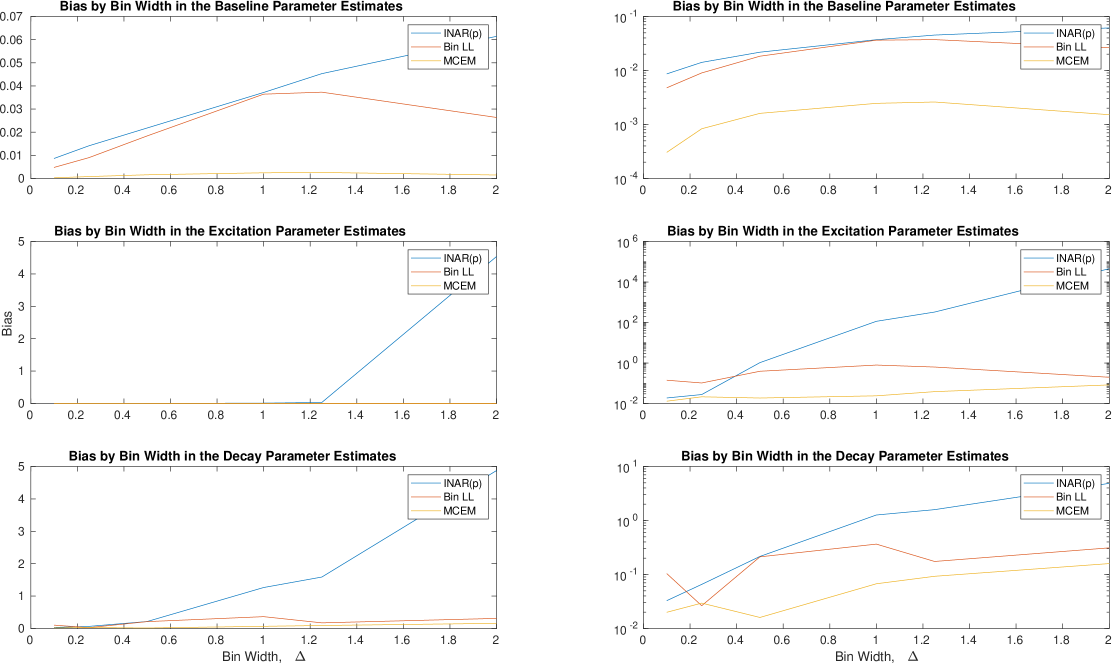
In Figure 7 we also consider the bias across different levels of aggregation. That is, for each of the realizations of a self-exciting process for a given parameter set, we can aggregate the data to different levels and compare the bias in the parameter estimates. The right hand plot in Figure 7 presents the bias on a log-scale. It is evident that the INAR() method is more biased for larger bin widths. The binned log-likelihood performs better, however, still not as well as the MC-EM method which most consistently exhibits a low bias.
4 Conclusion
Here we presented a new technique for handling aggregated data using an MC-EM algorithm. By sampling from a distribution close to that of the latent event times given the observed times and current parameter estimate, we have proposed a surrogate legal set of candidate time-points. This allows estimation of parameters using methods for continuous time-points. We further compared this to the INAR() approximation proposed in [12] and a binned log-likelihood method which assumes a piecewise constant CIF within each interval. For the parameter sets considered, the MC-EM method has appeared to out-perform both alternatives. The MC-EM approach also provides us with additional flexibility in that the level of aggregation does not need to be consistent across the dataset. That is, provided the interval bounds are known, can vary. The issues arising from aggregated data could also be handled via a MCMC (MCMH) algorithm and exploring this is the subject of future work.
Appendix A Power-Law Kernel
The proposed MC-EM method can still be applied if intending to consider a regularized power-law kernel of the form
for . In this case, to ensure a stationary Hawkes process, we have that
Therefore the stationarity condition is met for [2].
We also need to consider the proposed univariate sampling method and thus the complete log-likelihood of sampled time-points. Both of these points fundamentally rely on expressing the conditional PDF and CDF. Firstly, for the sampling method introduced in Section 2.1, we now have that
Similarly, the joint conditional CDF is given by
In the case of regularized power-law kernel, this is
Then, (10) gives the form for the truncated PDF, as previously. All that remains is to adjust the log-likelihood for the CIF with regularized power-law function when implementing the MC-EM algorithm. Using (5) that is,
Appendix B Rectangular Kernel
We can also consider a rectangular kernel of the form
for . In this case, stationarity holds if
Note that here represents a small shift of the excitation effect. Therefore, if , there is an increase in the process intensity immediately after an arbitrary event. In the case of a rectangular kernel,
The remaining equations follow as previously by substituting the above CIF.
Appendix C The MC-EM algorithm
Acknowledgment
Leigh Shlomovich is funded by an Industrial Strategy Engineering and Physical Sciences Research Council Scholarship and Lekha Patel is funded by an Imperial College President’s Scholarship.
References
- [1] E. Bacry, K. Dayri, and J. F. Muzy. Non-parametric kernel estimation for symmetric Hawkes processes. Application to high frequency financial data. The European Physical Journal B, 85(5):157, May 2012.
- [2] E. Bacry, I. Mastromatteo, and J.-F. Muzy. Hawkes Processes in Finance. Market Microstructure and Liquidity, 1(1), June 2015.
- [3] C. G. Bowsher. Modelling security market events in continuous time: Intensity based, multivariate point process models. Journal of Econometrics, 141(2):876–912, Dec. 2007.
- [4] D. R. Brillinger. Maximum likelihood analysis of spike trains of interacting nerve cells. Biological Cybernetics, 59(3):189–200, Aug. 1988.
- [5] D. J. Daley and D. Vere-Jones. An introduction to the theory of point processes. Springer, New York, 2nd edition, 2003.
- [6] A. P. Dempster, N. M. Laird, and D. B. Rubin. Maximum likelihood from incomplete data via the EM algorithm. Journal of the Royal Statistical Society. Series B (Methodological), 39(1):1–38, 1977.
- [7] P. Embrechts, T. Liniger, and L. Lin. Multivariate Hawkes processes: an application to financial data. Journal of Applied Probability, 48(A):367–378, Aug. 2011.
- [8] V. Filimonov and D. Sornette. Quantifying reflexivity in financial markets: towards a prediction of flash crashes. Physical Review E, 85(5), May 2012.
- [9] J. D. Fonseca and R. Zaatour. Hawkes process: fast calibration, application to trade clustering, and diffusive limit. Journal of Futures Markets, 34(6):548–579, 2014.
- [10] A. G. Hawkes. Spectra of some self-exciting and mutually exciting point processes. Biometrika, 58(1):83–90, 1971.
- [11] A. G. Hawkes and D. Oakes. A cluster process representation of a self-exciting process. Journal of Applied Probability, 11(3):493–503, 1974.
- [12] M. Kirchner. Hawkes and INAR() processes. Stochastic Processes and their Applications, 126(8):2494–2525, Aug. 2016.
- [13] M. Kirchner. An estimation procedure for the Hawkes process. Quantitative Finance, 17(4):571–595, Apr. 2017.
- [14] M. Kirchner and A. Bercher. A nonparametric estimation procedure for the Hawkes process: comparison with maximum likelihood estimation. Journal of Statistical Computation and Simulation, 88(6):1106–1116, Apr. 2018.
- [15] R. Kobayashi and R. Lambiotte. TiDeH: Time-dependent Hawkes process for predicting retweet dynamics. In Tenth International AAAI Conference on Web and Social Media, Mar. 2016.
- [16] P. J. Laub, T. Taimre, and P. K. Pollett. Hawkes processes. arXiv:1507.02822 [math, q-fin, stat], July 2015.
- [17] T. M. Le. A multivariate hawkes process with gaps in observations. IEEE Transactions on Information Theory, 64(3):1800–1811, Mar. 2018.
- [18] E. Lewis and G. Mohler. A nonparametric EM algorithm for multiscale hawkes processes. Journal of Nonparametric Statistics, 1(1):20, May 2011.
- [19] F. Lorenzen. Analysis of Order Clustering Using High Frequency Data: A Point Process Approach. PhD thesis, Tilburg School of Economics and Management, Aug. 2012.
- [20] B. Mark, G. Raskutti, and R. Willett. Network Estimation From Point Process Data. IEEE Transactions on Information Theory, 65(5):2953–2975, May 2019.
- [21] K. Obral. Simulation, estimation and applications of hawkes processes. Master’s thesis, University OF Minnesota, June 2016.
- [22] Y. Ogata. Statistical models for earthquake occurrences and residual analysis for point processes. Journal of the American Statistical Association, 83(401):9–27, Mar. 1988.
- [23] Y. Ogata. Seismicity analysis through point-process modeling: A review. In M. Wyss, K. Shimazaki, and A. Ito, editors, Seismicity Patterns, their Statistical Significance and Physical Meaning, Pageoph Topical Volumes, pages 471–507. Birkhäuser Basel, Basel, 1999.
- [24] M. Price-Williams and N. A. Heard. Nonparametric self-exciting models for computer network traffic. Statistics and Computing, May 2019.
- [25] M.-A. Rizoiu, Y. Lee, S. Mishra, and L. Xie. A tutorial on Hawkes processes for events in social media. In S.-F. Chang, editor, Frontiers of Multimedia Research, pages 191–218. Association for Computing Machinery and Morgan & Claypool, New York, NY, USA, Dec. 2017.
- [26] M. J. M. Turcotte, A. D. Kent, and C. Hash. Unified host and network data set. In Data Science for Cyber-Security, Security Science and Technology, pages 1–22. World Scientific, Nov. 2018.
- [27] G. C. G. Wei and M. A. Tanner. A Monte Carlo implementation of the EM algorithm and the Poor Man’s Data Augmentation algorithms. Journal of the American Statistical Association, 85(411):699–704, 1990.