A New Crossover Algorithm for LP Inspired by the Spiral Dynamic of PDHG
Abstract
Motivated by large-scale applications, there is a recent trend of research on using first-order methods for solving LP. Among them, PDLP, which is based on a primal-dual hybrid gradient (PDHG) algorithm, may be the most promising one. In this paper, we present a geometric viewpoint on the behavior of PDHG for LP. We demonstrate that PDHG iterates exhibit a spiral pattern with a closed-form solution when the variable basis remains unchanged. This spiral pattern consists of two orthogonal components: rotation and forward movement, where rotation improves primal and dual feasibility, while forward movement advances the duality gap. We also characterize the different situations in which basis change events occur. Inspired by the spiral behavior of PDHG, we design a new crossover algorithm to obtain a vertex solution from any optimal LP solution. This approach differs from traditional simplex-based crossover methods. Our numerical experiments demonstrate the effectiveness of the proposed algorithm, showcasing its potential as an alternative option for crossover.
1 Introduction
Linear programming (LP), which refers to optimizing a linear function over a polyhedron, is one of the most fundamental classes of optimization problems. It has been extensively studied in both academia and industry and has been applied to solve real-world applications in transportation, scheduling, economy, resource allocation, etc.
Two classic methods for solving LP are simplex methods and interior point methods (IPMs). The simplex methods, proposed by Dantzig in the late 1940s (Dantzig, 1951), start from a vertex and pivot between vertices to monotonically improve the objective (Dantzig, 1963). IPMs (Karmarkar, 1984), on the other hand, utilize a self-concordant barrier function to ensure that solutions remain inside the polyhedron, approaching an optimal solution by following a central path (Renegar, 1988).
Motivated by applications of large-scale LP, there has been a recent trend towards developing first-order methods (FOMs) for LP, such as PDLP (Applegate et al., 2021; Lu and Yang, 2023a; Lu et al., 2023), SCS (O’Donoghue et al., 2016; O’Donoghue, 2021), and ABIP (Lin et al., 2021; Deng et al., 2024). The key advantage of FOMs is their low iteration cost, primarily involving matrix-vector multiplications, which avoids the need for solving linear equations as required in the simplex methods and IPMs. This advantage makes them particularly well-suited for GPU implementation. Among these, PDLP stands out as the most promising, with its GPU implementation demonstrating numerical performance on par with state-of-the-art LP solvers on standard benchmark sets and demonstrating superior performance on large-scale instances (Lu and Yang, 2023a; Lu et al., 2023). PDLP is based on the primal-dual hybrid gradient (PDHG) method, enhanced by various numerical improvements (Applegate et al., 2021). Variants of PDLP have been implemented in both commercial and open-source optimization solvers, such as COPT (Ge et al., 2024), Xpress (Xpress, 2014), Google OR-Tools (Perron and Furnon, 2024), HiGHS (Huangfu and Hall, 2018), and Nvidia cuOpt (Fender, 2024).
While the behaviors of simplex methods and IPMs are well-studied—simplex methods move over vertices, and IPMs follow the central path—the convergence behaviors of PDLP and other FOMs toward an optimal solution are less well-understood. For example, we plot the 2-dimensional primal trajectories 111For the LP , we reformulate it as and plot the trajectories of from different methods solving the reformulated problem. of different LP methods in Figure 1. PDHG seems to progress in a more chaotic and winding manner compared to other classic methods.
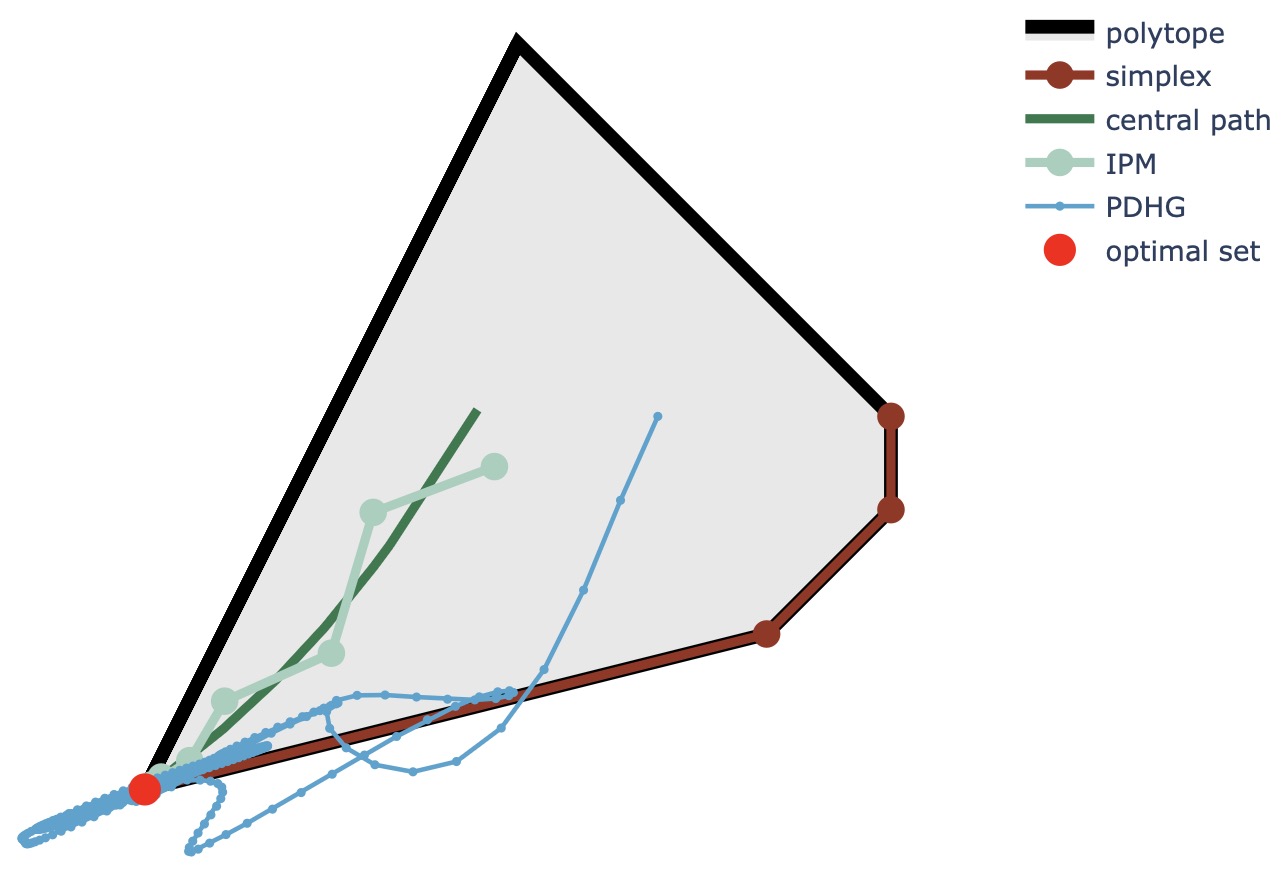
The first contribution of this paper is to present a geometric viewpoint on the convergence behavior of the PDHG algorithm when applied to LP problems (Section 2). Similar to simplex methods, we can define basic and non-basic variables for PDHG iterates. We define a phase as a series of consecutive PDHG iterates that share the same set of basic variables. Within each phase, we demonstrate that PDHG behaves like a spiral, consisting of two orthogonal components: rotation and forward movement. The rotation improves primal and dual feasibility, while the forward movement advances the duality gap. We also characterize the different situations in which basis change events occur.
A fundamental distinction among different LP methods is that simplex methods identify an optimal vertex (i.e., an optimal basis), whereas IPMs and FOMs may find an interior point within the optimal solution set. Specifically, IPMs converge to the analytic center of the optimal solution set, while FOMs can reach any optimal solution depending on the initial solution. On the other hand, vertex solutions obtained via simplex methods are generally more precise, sparse, and informative. For example, vertex solutions are particularly useful for LP subroutines in branch-and-bound MIP solvers, as they enhance integrality and also benefit warm starts. Consequently, the process of “crossover,” which involves deriving an optimal vertex from any arbitrary optimal solution, has been extensively studied for IPMs. Most modern LP solvers include a crossover step following IPM solving. The algorithmic framework for contemporary crossover was introduced by Megiddo (1991) and has been further refined by Bixby and Saltzman (1994) and Andersen and Ye (1996). These approaches, which rely on simplex methods to adjust variables to their bounds, are referred to as simplex-based crossover.
Inspired by the spiral behavior of PDHG, our second contribution is the design of a new crossover method to generate a vertex solution from a PDLP solution. This crossover leverages PDLP itself and its spiral axes (referred to as spiral rays in this paper), eliminating the need for any simplex steps. We present a numerical study that demonstrates the effectiveness of our proposed crossover algorithm, which may provide a practical alternative to simplex-based crossover methods.
Organization of the paper.
The paper is organized as follows. Section 1.1 reviews related studies in PDHG and crossover approaches. Section 2 presents the spiral behavior of PDHG for LP. Section 3 proposes a new crossover algorithm inspired by the spiral structure of PDHG without the need for simplex methods. Section 4 presents a numerical study of our crossover approach.
Notations.
We use bold letters for vectors and matrices. Let be the -th component of vector , and be the vector formed by components for . Let be the -th column of matrix , and be the submatrix formed by columns for . Let be the entry in the -th row and -th column of matrix , and be the submatrix formed by entries for . We use to express the element-wise inequality for all . Let and be a vector or matrix of zeros and ones, respectively. Let be the identity matrix. The dimension of a vector or a matrix will be unspecified whenever it is clear from the context. Let denote the -dimensional Euclidean space and . The vector norm is -norm. The -norm where is a positive definite matrix. The matrix norm is the spectral norm. means the -th point , while without the parenthesis means to the power of . is the Moore–Penrose inverse of . The operator projects onto the set using 2-norm. The range of an operator is denoted as while the closure of a set is denoted as .
1.1 Related Work
PDLP and related.
PDHG was studied in Chambolle and Pock (2011) for image processing applications. Applegate et al. (2021) developed a restarted PDHG algorithm for solving linear programs (LPs), which, together with a few practical enhancements, leads to the PDLP solver. Compared with other popular FOM solvers such as SCS and ABIP, there is no linear system to solve in PDLP, making it a more suitable choice for large-scale LPs. cuPDLP, the GPU implementation of PDLP, demonstrated strong numerical performance on par with commercial LP solvers, and has attracted attention from both the academic and solver industry (Lu and Yang, 2023a; Lu et al., 2023). Recently, additional numerical enhancements have been proposed to speed up the algorithm further. Xiong and Freund (2024) pointed out that the central-path-based scaling can markedly improve the convergence rate of PDHG. Lu and Yang (2024a) embedded Halpern iteration (Halpern, 1967) in PDLP, achieving accelerated theoretical guarantees and improved computational results.
The practical success of PDLP motivates a stream of theoretical analysis. Lu and Yang (2022) showed PDHG has a linear convergence rate when solving LP. Applegate et al. (2023) revealed that an accelerated linear convergence rate can be achieved with restarts, and such an accelerated linear rate matches the lower bound. Applegate et al. (2024) illustrated that for infeasible/unbounded LP, PDHG iterates diverge towards the direction of infeasibility/unboundedness certificate; thus, one can detect the infeasibility/unboundedness of LP using PDHG without additional effort. Lu and Yang (2024b) discovered that PDHG has a two-stage behavior when solving LP. In the first stage, PDHG uses finite iterations to verify the optimal active variables; in the second stage, PDHG solves a homogeneous linear inequality system with a significantly improved linear rate. This explains the slow behaviors of PDHG when the LP is near-degeneracy. Xiong and Freund (2024) introduced level-set geometry that characterizes the difficulty of PDHG for LP, which shows that PDHG converges faster for LP with a regular non-flat level-set around the optimal solution set.
For more general fixed point problems, trajectories of various FOMs were studied in Poon and Liang (2019, 2020), which showed that eventually (after a finite number of iterations), these algorithms follow a straight line or a spiral structure if the problem is non-degenerate. Unfortunately, this non-degeneracy assumption is generally never satisfied for real-world LP instances.
Crossover.
Crossover, or purification, refers to the process that moves a feasible or optimal solution to a vertex solution, also known as the extreme point, basic feasible solution, or corner solution. Purification methods (Charnes and Kortanek, 1963; Charnes et al., 1965) were proposed even earlier than those non-vertex LP methods, including the ellipsoid methods (Khachiyan, 1979) and IPMs (Karmarkar, 1984).
Given a basis and a feasible solution , the purification algorithm (Charnes and Kortanek, 1963; Charnes et al., 1965) generates a null space vector step same as the direction in simplex methods and then tries to move along it without worsening the objective or update for feasible directions, which will finally return a feasible vertex with the objective value no worse in finite steps. Given a basis and a strictly interior feasible point, Kortanek and Jishan (1988) improved Charnes’s method by drawing the vertex back to the interior if it is not optimal. An optimal extreme point will be reached in a finite number of steps. If the feasible point is not entirely in the interior, Kortanek and Jishan (1988) also provided another purification method that considers dual feasibility. Combining Kortanek’s second method with a proper cleanup will return an optimal basis. Given a dual optimal solution , Amor et al. (2006) constructed an auxiliary dual LP by adding box constraints around to the original dual problem. Dualizing back to obtain an auxiliary primal LP, Amor claimed that the auxiliary primal LP can be efficiently solved by simplex methods, and then an optimal vertex can be easily recovered.
Starting from an optimal primal-dual solution pair, Megiddo (1991) designed a strongly polynomial crossover approach to an optimal vertex. Megiddo also pointed out that given only the optimal primal or dual solution, solving a general LP is theoretically as hard as solving it from scratch. Megiddo’s crossover method lays down the algorithmic and theoretical foundation for modern crossover algorithms in modern LP solvers. Our randomized crossover modifies Megiddo’s crossover framework, which will be introduced in Section 3.
With the boom of various IPMs and MIP applications, crossover gradually plays a significant role in the LP solvers. The key task becomes refining IPM solutions to optimal vertices. Mehrotra (1991) added a controlled random cost perturbation to eliminate dual degeneracy at the sacrifice of losing only a little optimality. Especially for nondegenerate LPs, an indicator (Tapia and Zhang, 1991) can be calculated from the interior solution to identify the basis. Bixby and Saltzman (1994) implemented a modified simplex method, which accepts an interior feasible point as a super-basic solution. Then similar to a normal simplex method, Bixby’s algorithm uses the primal (or dual) ratio test to push primal (or dual) variables to bound if possible or pivots it into (or out of) the bound. Andersen and Ye (1996) used the strictly complementary property of IPM solutions to define a perturbed LP problem. Andersen’s method obtains a basis and then recovers feasibility by pivoting and taking a weighted average with the given IPM solution. Ge et al. (2021) also proposed a perturbation crossover method that combines variable fixing and random cost perturbation. They proved that as long as the perturbation is sufficiently small, their crossover approach will not bring objective loss.
Our crossover modifies Megiddo’s framework and adopts random perturbation, together with PDLP and ordinary least squares (OLS) solver as subroutines. More details will be discussed in Section 3.
2 Spiral Behavior of PDHG for LP
In this section, we present a geometric viewpoint on the spiral behavior of PDHG on LPs. For ease of presentation, we consider PDHG based on the standard form of LP, while most of the results can be naturally extended to other formulations. More formally, we consider
| (1) | ||||
where . The dual problem associated with (1) is
| (2) | ||||
2.1 Preliminaries
2.1.1 PDHG for LP
PDHG solves the following saddle-point formulation of (1) and (2)
and the detail is presented in Algorithm 1. Without loss of generality, we assume the primal and the dual step sizes are the same throughout the paper (otherwise, we can rescale the primal or dual variables correspondingly, see Applegate et al. (2023)).
PDHG can be viewed as conducting projected primal gradient descent and projected dual gradient ascent with extrapolation in turn, and for primal-dual feasible LPs, it is guaranteed to converge to an optimal solution (see, for example, Lu and Yang (2022, 2023b) for intuitions of this extrapolation step). Overall, updates in PDHG are simple, with only matrix-vector multiplication as the bottleneck, while converging to an optimal primal-dual pair at a linear rate.
PDHG, together with other FOMs, has been observed to spiral in practice. For example, Applegate et al. (2023) plotted a spiral trajectory of PDHG for a 2-dimensional bilinear saddle-point problem. Deng et al. (2024) visualized the first 3 dimensions of ABIP iterations when solving an LP from NETLIB (Gay, 1985), which also forms an oscillation. These observations encourage FOMs to restart from the average among previous steps, fast approaching the spiral center. From the theoretical aspect, restart accelerates PDHG to converge at a faster linear rate (Applegate et al., 2023).
2.1.2 Infimal Displacement Vector
For infeasible LPs, PDHG iterates do not converge but rather diverge along a vector called the infimal displacement vector (IDV) of the PDHG operator (Applegate et al., 2024). Formally, we denote as the PDHG operator, i.e.,
If , is firmly non-expansive with respect to the norm where the positive definite matrix . Its IDV is defined as the minimum perturbation we should subtract from to ensure it has a fixed point:
Definition 1 (Infimal displacement vector (Pazy, 1971)).
The unique infimal displacement vector for PDHG with the step size is defined as
where is the operator corresponding to PDHG.
Proposition 2 ((Pazy, 1971; Baillon, 1978)).
Let be a non-expansive operator and is the initial point. Then the infimal displacement vector of the operator satisfies
If further is firmly non-expansive, then
Proposition 2 implies that PDHG will diverge along if the LP is primal or dual infeasible, and will converge () if the LP is primal-dual feasible.
2.2 PDHG Spiral Behavior
In this part, we formally present the PDHG spiral behavior when solving LPs. At a high level, PDHG identifies different bases from phase to phase. During each phase, the iterates follow a spiral ray, where the ray direction and the spiral center are derived later.
First, we define the basis of PDHG iterates, which characterizes the active primal variables. This definition is very similar to the basis defined for the simplex method. The fundamental difference is that the corresponding columns of the basis in the constraint matrix may not form a nonsingular square matrix.
Definition 3 (PDHG basis).
For a PDHG iterate , the basis and the non-basis form a partition of the primal variables, defined as
We further call a basic variable if and a non-basic variable if .
Then according to changes in the PDHG basis, we can divide the PDHG solving process into multiple phases.
Definition 4 (Phase and basis change event).
We call a sequence of consecutive PDHG iterations form a phase if they share the same PDHG basis. A basis change event occurs when two sequential PDHG iterations have different PDHG bases.
Within one phase, the spiral ray—including the spiral center and the ray direction, which are key to describing the PDHG spiral behavior—is defined as follows.
Definition 5 (Spiral ray).
A spiral behavior along the spiral ray is a trajectory in the form of
where the eigenvalues of the diagonalizable consist of contingent one and non-real complex eigenvalues with the modulus strictly less than one, is orthogonal to all eigenvectors associated with the eigenvalue of one, and for all . We refer to the vector as the ray direction, the vector as the spiral center, and together as the spiral ray.
The captures the rotation with the radius decreasing linearly along the direction corresponding to the complex eigenvalues, while the captures the forward movement. The orthogonality between rotation and forward movement allows us to analyze their effects independently.
To gain intuition about the above definition of PDHG basis, phase, basis change event, and spiral ray, we illustrate them with the following example:
Example 6 (PDHG spiral and basis change events).
We apply PDHG to solve a toy LP with two primal variables and one constraint.
| (3) | ||||
PDHG uses the step size and relative tolerance , and starts from . It takes 3235 steps to the unique optimal solution .
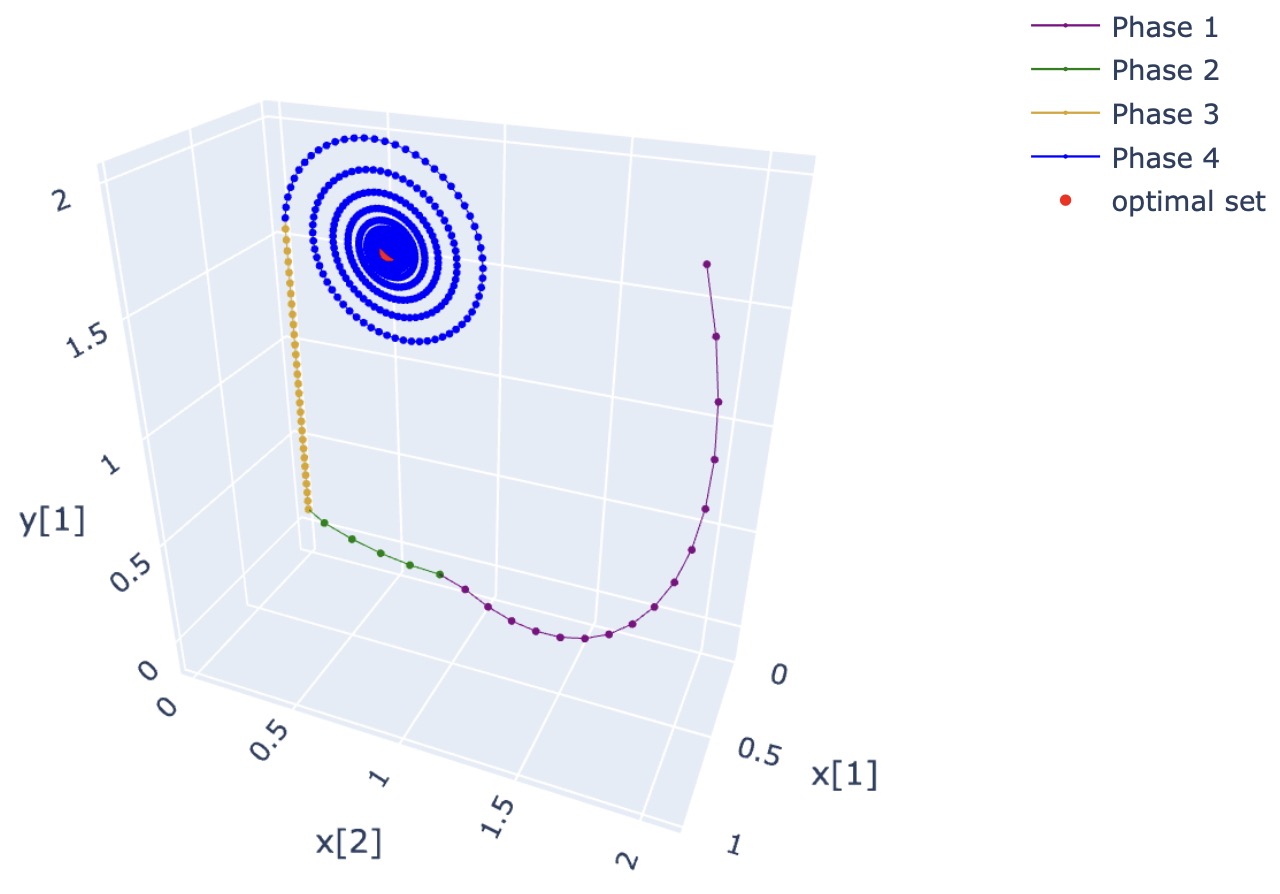
The whole trajectory of the primal-dual solution is shown in Figure 2(a), which can be divided into four phases.
-
•
Phase 1 (in purple)
-
–
The first 16 steps form a huge arc while moving forward. Then PDHG hits the plane and a basis change event happens.
-
–
During Phase 1, we have and .
-
–
-
•
Phase 2 (in green)
-
–
During iterations from steps 17 to 21, PDHG arcs around within the plane until it reaches another plane.
-
–
During Phase 2, we have and .
-
–
-
•
Phase 3 (in khaki)
-
–
Marching against and , the trajectory degenerates to a ray along axis.
-
–
During Phase 3, we have and .
-
–
-
•
Phase 4 (in blue)
-
–
Finally, leaves its bound and the optimal PDHG basis is identified. There is no more basis change event and PDHG spirals towards the optimal solution.
-
–
During Phase 4, we have and .
-
–
Notice that PDHG has already found the optimal PDHG basis in Phase 2, but changes the basis two more times due to the obstruction from the lower bound of . Actually, Phase 2 and Phase 4 share the same spiral center, and the directions of their spiral rays are both zero vectors.
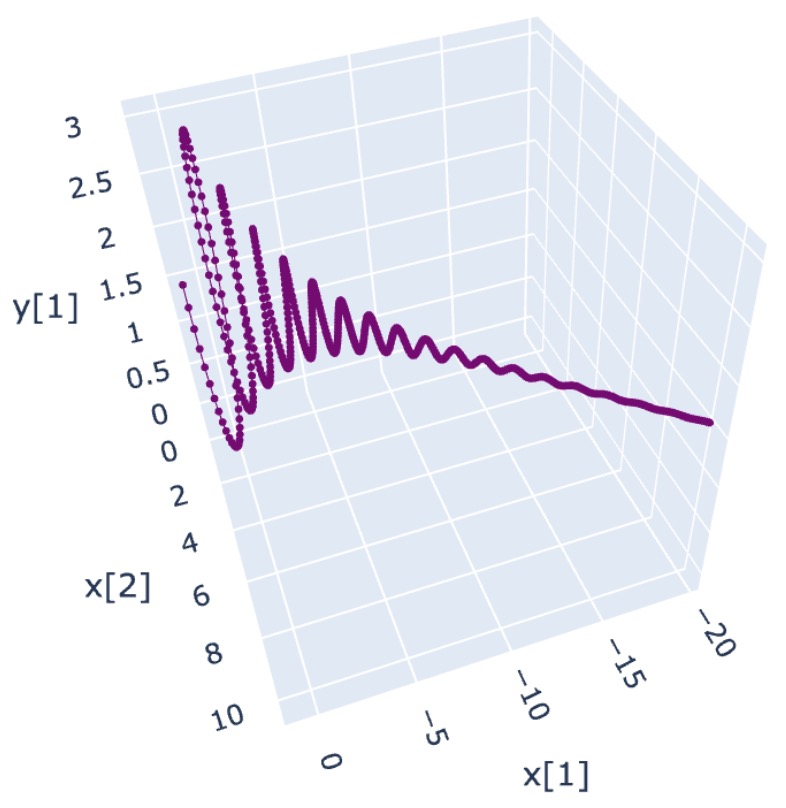
Another interesting fact is that no basis change event will happen if we remove the bounds . Phase 1 will continue and be fully observed as a combination of rotation and forward movement, as displayed in Figure 2(b). Moreover, the rotation converges rapidly; thus, PDHG may diverge almost straightly along the IDV, which is an instance of the spiral ray.
Note that the basis change events split the PDHG trajectory into multiple similar spiral phases. Our next goal is to analyze the spiral behavior within each phase, when the PDHG basis remains unchanged.
2.2.1 PDHG Spiral Behavior within One Phase
Within one phase, the basis of the PDHG iterates does not change, and it turns out the PDHG iterates follow a spiral ray, as observed in the example stated in the previous section. This can be formalized in the next theorem:
Theorem 7 (The spiral behavior of PDHG).
Within one phase given the PDHG basis , PDHG iterates as
| (4) |
where is the initial point of the phase, the matrix
| (5) |
the spiral center is given by
| (6) | ||||
and the ray direction is given by
| (7) | ||||
Moreover, the rotation part converges to , i.e.,
| (8) |
and the forward movement is orthogonal to the rotation, i.e.,
| (9) |
where .
The proof is given in Appendix A.
Equation (4) presents a closed-form solution of the iterates within one phase. Intuitively, PDHG spirals by rotating around and moving forward along . The rotation and forward movement are orthogonal to each other. No matter how PDHG rotates in the hyperplane , it will firmly step one unit of along the spiral ray at each iteration. The ray direction is unique for one phase regardless of the initial solution , but the spiral centers may depend on the initial solution (i.e., the projection term in (6)).
Furthermore, in terms of the influence of the step size , in general, a larger step size will not only help the rotation converge faster by reducing the moduli of the eigenvalues of but also accelerate the forward movement along the ray direction.
2.2.2 Understanding How the Spiral Behavior Helps the Convergence
Theorem 7 presents orthogonally decomposed spiral behavior of PDHG into forward movement along the ray direction and rotation within the hyperplane . These evidences almost form a satisfying description of what PDHG is doing in one phase. Here we would like to further discuss how the trajectory of a spiral can lead PDHG to the optimum.
The optimality of an LP contains primal feasibility, dual feasibility, and duality gap. Considering how the PDHG spiral affects all three aspects, we have the following proposition:
Proposition 8.
Within one phase given the PDHG basis , the rotation improves the primal and dual feasibility by approaching the spiral center with the least squares primal error and dual error . The forward movement improves the duality gap at the spiral center in the sense that the duality gap along the spiral ray monotonically decays, i.e., . Furthermore, if the forward movement is nonzero (i.e., ), we have a strict decay of the duality gap when moving along the direction of , i.e., .
The proof is provided in Appendix B.
The primal feasibility is naturally improved via rotating to minimize the difference between and . In contrast, when optimizing the dual feasibility, PDHG not only aims to satisfy , but also prefers to activate . This can be explained from the perspective of complementary slackness. In a primal-dual optimal solution to (1), the complementary slackness condition requires . Therefore, for those primal variables in , it is better to activate the corresponding dual constraints for optimality.
As for the effect of rotation in the duality gap, damped oscillation occurs around the primal and dual objectives at the spiral center, resulting in the total duality gap exhibiting an oscillating improvement.
2.2.3 Basis Change Event
Basis change events happen between two adjacent periods when the spiral hits new bounds or escapes from current bounds, i.e., for the phase with PDHG basis , the next step satisfies
| (10) |
or
| (11) |
We call the condition (10) the “leaving basis” condition, since the basic coordinate satisfying (10) leaves the basis in the next iteration. Similarly, we call condition (11) the “entering basis” condition, since the non-basic coordinate satisfying (11) enters the basis in the next iteration.
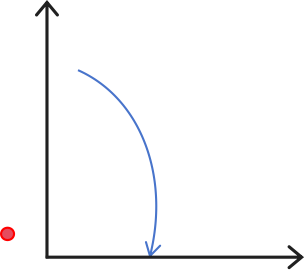
To be more specific, the basis change event corresponds to the activation of and the satisfaction of . From the perspective of the spiral, as shown in Figure 3, three typical reasons will cause a basic variable to leave the basis:
-
•
First, the spiral center is located outside the bounds (and forward movement is ignored for simplicity). Since rotation converges to the center, PDHG will meet bounds before converging, yielding a basis change event.
-
•
Second, although the spiral center is located inside the bounds (and forward movement is ignored for simplicity), the spiral radius, i.e., the distance between the current point and the spiral center, is too large.
-
•
Third, the spiral ray has a strictly negative component in its direction, which will eventually hit the bound.
For the entering basis event, when violates the dual constraints , the corresponding components of have a tendency to increase, making the projection operator redundant in the next step.
It is worth highlighting that differing from the optimality improvement in one phase, the basis change event is usually triggered by the combined action of rotation and forward movement, instead of by one side alone. For example, though the spiral center may lie outside the bounds as shown in Figure 3(a), the spiral ray is likely to intersect the bounds, leading to a basis change event similar to the second case in Figure 3(b).
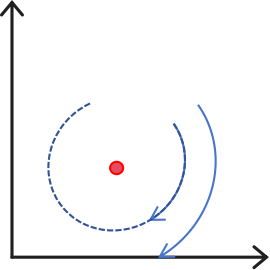
3 Crossover inspired by PDHG
Without loss of generality, we assume is full row rank in this section. For a primal-dual feasible LP, PDLP returns only a primal-dual optimal solution pair with PDHG basis satisfying (12)
| (12) | ||||
rather than the optimal vertex with basis satisfying (13)
| (13) | ||||
Compared with (12), here a vertex must be determined by linearly independent columns of , and there may also be zero components in . Crossover for PDLP refers to obtaining a solution that satisfies (13) from a solution satisfying (12).
One important observation is that if we properly fix variables on bounds, then a feasible solution to LP is also an optimal solution to the LP, which is formally stated below in Proposition 9.
Proposition 9.
Given the primal-dual optimal solution to (1), denote , , , and . Any feasible solution satisfying
| (14) | ||||
also form a primal-dual optimal solution to the original LP.
Proof.
Therefore, we can iteratively push and in (14) to their bounds and fix those on bounds until a vertex is found, which is precisely the idea of Megiddo (1991).
Another important phenomenon, which is the key to our crossover method, is that when PDHG starts from a primal (or dual) feasible solution within one phase, it also becomes the start of the primal (or dual) PDHG spiral ray:
Proposition 10.
Within one phase with PDHG basis and the initial solution , if , then we have . Similarly, if , then we have .
Proof.
To prove , we have and
The second equation utilizes the property of Moore–Penrose inverse that . Analogously, we also have . ∎
3.1 Crossover Framework
Many crossover frameworks have been designed (Megiddo, 1991; Bixby and Saltzman, 1994; Andersen and Ye, 1996), most combining simplex methods and IPMs. Following Megiddo’s idea, our crossover mainly includes three parts.
-
1.
Primal push moves towards their bounds while maintaining the primal feasibility. After this process, the primal part of an optimal vertex solution is found, although degeneracy may exist.
-
2.
Dual push moves to activate as many dual constraints as possible while maintaining the dual feasibility. After this process, the dual part of an optimal vertex solution is obtained.
-
3.
Linear independence check will no more change solution values but select basic columns to construct the nonsingular square matrix .
The fundamental difference between our crossover algorithm and Megiddo’s scheme is that we use directions and inspired by PDHG rather than the pivot direction in simplex methods to move the variables. Another difference from Meggido’s framework is that we check the linear independence after the dual push is completed to separate the two processes more independently, while Meggido checks the linear independence immediately once the dual push identifies newly activated dual constraints. In terms of theoretical guarantees, following the same analysis of Megiddo (1991), we can show that this PDHG-inspired crossover will succeed with probability (w.p.) 1.
We formally present the crossover scheme in Algorithm 2, which includes three major components:
Primal push.
Our primal push blends two approaches: solving one auxiliary LP and a few sequential OLS problems that identify the ray of PDHG iterates.
After recognizing the basic set , we build an auxiliary LP with random cost perturbation ,
| (16) | ||||
and solve (16) with PDLP. This auxiliary LP has multiple optimal solutions w.p. 0 (see Lemma 1 in Ge et al. (2021)), so with proper perturbation to avoid the unbounded case, we have the unique optimal solution to (16). Then can be the primal part of an optimal vertex of (1).
Unfortunately, due to the numerical residuals in practice, we may not correctly fix all the variables on bounds at once. To reduce the negative impact of the issue, the first thing to consider is to control the amplitude of disturbance, see Mehrotra (1991); Ge et al. (2021) for more specific discussions. Besides, a verification scheme needs to be designed.
Therefore, after solving (16), we solve a series of OLS problems (17) with various randomly generated costs to calculate the PDHG primal ray directions (7).
| (17) |
From Proposition 10, since the current primal solution is still feasible for (16) with cost perturbation, it is located at the primal spiral center of the rotation in the current phase of PDHG. We can then start from and move along until reaching new boundaries, mirroring how the PDHG solves the auxiliary LPs. At the end of the primal push, no more primal variable can be pushed to its bound when columns of are linearly independent. OLS can be solved by the direct QR factorization, LSMR (Fong and Saunders, 2011), or the conjugate gradient (CG) method.
The reason why we only solve one auxiliary LP is that the auxiliary LP (16) is in most cases enough to obtain a primal solution close to a vertex and that the OLS has lower complexity to reduce the support and verify the termination of primal push. Directly following the primal spiral ray avoids unnecessary oscillation. However, when the original LP is too large, or the resulting OLS is too hard to solve, using multiple auxiliary LPs can be beneficial for the primal push.
Dual push.
In the dual push, we still combine the auxiliary LP and sequential OLS.
For the auxiliary LP, we sum up the non-negative dual slacks as a penalty to activate more dual constraints.
| (18) | ||||
Then similarly, we compute a series of OLS (19) with perturbed right-hand side to calculate the dual ray directions of PDHG (7).
| (19) |
More constraints are fixed to be active step by step until rows of are linearly independent when will be uniquely determined by .
Linear independence check.
After the primal and dual push, should reach some vertex. All we need is to identify columns from to form an optimal basis with . Here we apply LU factorization twice. We first decompose as
where divides the rows according to the decomposition. The basic candidates become
Then, we only need to select linearly independent columns from , where the second LU decomposition is involved.
3.2 Practical Consideration
We discuss several practical considerations when implementing our proposed crossover scheme.
LP formulation.
So far, we have built our theory and algorithm design on the standard LP (1). In practice, the general LP formulation (20) is more convenient and thus widely used.
| (20) | ||||
To extend the concept of the basis on the general form, we reformulate it as (21) via introducing the artificial variable .
| (21) | ||||
where aims to avoid the right-hand-side term becoming , as the presence of may render the LP highly sensitive to perturbations, causing the optimal solution to change drastically. This reformulation guarantees the constraint matrix to be full row rank, where we can easily apply the definition of the basic solution.
Non-basis identification.
At the beginning of primal and dual push, we need to determine and to construct the auxiliary LP and OLS. For an IPM solution, which tends to stay away from bounds, the central path and strict complementarity are crucial for identifying non-basic variables. Identification is typically done by comparing the orders of magnitude of and . In contrast, PDHG can benefit from the sparsity of its solution, induced by the projection, to more aggressively fix variables to their bounds.
We take
and after is updated in primal push
with and . This criterion works well in our experiments for purifying the PDLP solutions.
Perturbation.
The cost and right-hand-side perturbations guide the direction of crossover. They are perturbed as
where are independently and uniformly distributed over the interval . The first normalized terms function as a center to stabilize the disturbance, preventing the unfixed non-basic variables from occasionally escaping boundaries.
Efficiency of OLS.
Currently, all the OLS problems are solved independently from scratch. Note that the coefficient matrices of two adjacent OLS problems differ in only a few columns or rows; thus, further development on reusing the factorization (probably via low-rank updates) may largely enhance the efficiency of our crossover to the level of the classic simplex-based crossover.
Understanding solution structures between PDLP and IPMs.
This crossover scheme can be applied to solutions obtained by IPMs or PDLP. However, their structures differ as discussed below.
IPMs find the analytical center of the optimal solution face, and the obtained solutions tend to be denser, while PDLP solutions are usually much sparser because of the projection operator.
IPMs and PDHG both have a strong ability to distinguish non-basic variables. IPMs can identify the strictly complementary solution pair with a sufficiently small duality gap (Andersen and Ye, 1996). PDHG can correctly classify variables as basic and non-basic in the scope of PDHG basis within finite iterations (Lu and Yang, 2024b).
Therefore, even though the PDLP solution may be less accurate than the IPM solution, it can still be refined to the vertex successfully in practice.
4 Experiments
In this section, we present experimental results to demonstrate the competence of our crossover algorithm. Our experiment does not plan to surpass the state-of-the-art crossover code implemented in commercial solvers but rather to verify the effectiveness of our proposed crossover algorithm. Further practical improvements are necessary to explore performance enhancement, which is beyond the scope of this paper.
Benchmark dataset.
We conduct our crossover experiment on the NETLIB collection (Gay, 1985). Considering the efficiency of the experiment, we select 100 instances from NETLIB according to two rules:
Software and hardware.
Tests are run on a MacBook Pro with an 8-core Apple M2 CPU and 24GB unified memory. Algorithm 2 is implemented in Julia and can be accessed at https://github.com/MIT-Lu-Lab/crossover.
Initialization and time limit.
We first solve the NETLIB LPs using cuPDLP-C inside COPT 7.1 (Ge et al., 2024) without GPU acceleration to the relative tolerance of . Then the optimal primal-dual solution is passed to the Julia implementation of our crossover algorithm. A crossover time limit of 300 seconds is set and the random seed is set to 0 for reproducibility.
OLS solving.
OLS solving to identify the spiral ray direction is a critical step in our crossover algorithm. For most instances, aside from six rare exceptions, the OLS is solved via an automatic selection between direct solver and LSMR based on the dimensions. Specifically, if the matrix or in the OLS has fewer than 1000 rows or columns, we solve the OLS by direct factorization. Otherwise, we use the iterative solver LSMR with a relative tolerance of . The auxiliary LPs are again solved by cuPDLP-C.
For the six exceptions marked in blue, custom methods for OLS or auxiliary LPs are chosen. Due to occasional numerical issues, we always use direct solver or LSMR, which are labeled “d” and “*” respectively. The label “i” indicates the auxiliary LPs are solved by the IPM in COPT to avoid the timeout of cuPDLP-C.
Results.
The numerical results are shown in Table LABEL:tbl:netlib, where “# supp. PDLP” is the number of support (i.e., components not on their bounds) of the initial solution, “# supp. COPT” and “# supp. cross” are the numbers of support of vertices from the crossover algorithm in COPT commercial solver and our crossover approaches. We also report the running time of our algorithm in the “time (sec)” column.
Our crossover overall succeeds in 93 out of 100 instances. The instance “cycle” only recovers a primal optimal vertex, but this vertex solution appears much sparser than the optimal vertex from COPT crossover. Here we still count it as a success, included in the 93 successful instances.
Significant enhancement of the solution sparsity is observed in both COPT and our crossover methods, with comparable levels of improvement. In several instances, our crossover performs differently from the classic simplex-based crossover in COPT, implying that our approach has the potential to serve as a viable alternative to the traditional method.
Due to the instability of FOMs, the auxiliary LPs take a long time to solve for certain instances, sometimes even causing a timeout. The numerical difficulty with LPs and OLS is another factor contributing to the failure. However, despite failing to recover the optimal basis for these problems, the number of support of most primal solutions is still successfully reduced.
| prob | nRows | nCols | # supp. PDLP | # supp. COPT | # supp. cross | time (sec) |
|---|---|---|---|---|---|---|
| 25fv47 | 821 | 1571 | 600 | 583 | 584 | 11.63 |
| 80bau3b | 2262 | 9799 | 1851 | 1758 | 1753 | 1.30 |
| adlittle | 56 | 97 | 61 | 45 | 44 | 0.01 |
| afiro | 27 | 32 | 14 | 13 | 14 | 0.01 |
| agg | 488 | 163 | 62 | 57 | 57 | 0.39 |
| agg2 | 516 | 302 | 141 | 120 | 121 | 5.32 |
| agg3 | 516 | 302 | 144 | 124 | 125 | 5.71 |
| bandm | 305 | 472 | 306 | 294 | 294 | 0.54 |
| beaconfd | 173 | 262 | 89 | 89 | 89 | 0.04 |
| blend | 74 | 83 | 56 | 54 | 54 | 0.01 |
| bnl1 | 643 | 1175 | 689 | 451 | 448 | 11.33 |
| bnl2 | 2324 | 3489 | 1519 | 1171 | 1168 | 40.05 |
| boeing1 | 351 | 384 | 207 | 196 | 195 | 0.78 |
| boeing2 | 166 | 143 | 69 | 55 | 55 | 0.04 |
| bore3d | 233 | 315 | 126 | 126 | 126 | 0.06 |
| brandy | 220 | 249 | 135 | 134 | 134 | 0.12 |
| capri | 271 | 353 | 246 | 220 | 225 | 0.26 |
| cre-a | 3516 | 4067 | 579 | 492 | 484 | 23.35d |
| cre-c | 3068 | 3678 | 590 | 508 | 503 | 43.49d |
| cycle | 1903 | 2857 | 994 | 224 | 105 | 36.27a |
| czprob | 929 | 3523 | 924 | 866 | 866 | 27.00 |
| d2q06c | 2171 | 5167 | 1612 | 1543 | 1541 | t |
| d6cube | 415 | 6184 | 136 | 115 | 101 | 13.85 |
| degen2 | 444 | 534 | 207 | 207 | 207 | 0.84 |
| degen3 | 1503 | 1818 | 640 | 637 | 637 | 153.40 |
| e226 | 223 | 282 | 127 | 127 | 127 | 0.17 |
| etamacro | 400 | 688 | 292 | 271 | 272 | 0.59 |
| fffff800 | 524 | 854 | 357 | 312 | 315 | 2.59 |
| finnis | 497 | 614 | 259 | 227 | 229 | 1.61 |
| fit1d | 24 | 1026 | 12 | 12 | 12 | 0.01 |
| fit1p | 627 | 1677 | 634 | 627 | 627 | 7.79 |
| fit2d | 25 | 10500 | 22 | 20 | 20 | 0.01 |
| fit2p | 3000 | 13525 | 3004 | 2997 | 2997 | 5.47 |
| forplan | 161 | 421 | 83 | 83 | 83 | 1.69 |
| ganges | 1309 | 1681 | 1278 | 1175 | 1176 | 2.89i |
| gfrd-pnc | 616 | 1092 | 349 | 336 | 336 | 1.32 |
| greenbeb | 2392 | 5405 | 1048 | 937 | 942 | 135.27 |
| grow15 | 300 | 645 | 533 | 299 | 300 | 0.31 |
| grow22 | 440 | 946 | 849 | 440 | 440 | 0.76 |
| grow7 | 140 | 301 | 237 | 140 | 140 | 0.04 |
| israel | 174 | 142 | 80 | 70 | 69 | 0.63 |
| kb2 | 43 | 41 | 27 | 27 | 27 | 0.01 |
| ken-07 | 2426 | 3602 | 2236 | 2234 | 2234 | 1.44 |
| lotfi | 153 | 308 | 126 | 99 | 98 | 0.02 |
| maros-r7 | 3136 | 9408 | 3136 | 3136 | 3136 | 0.39 |
| maros | 846 | 1443 | 345 | 340 | 270 | 5.58 |
| modszk1 | 687 | 1620 | 666 | 666 | 666 | 10.68 |
| nesm | 662 | 2923 | 726 | 550 | 545 | 46.11i* |
| osa-07 | 1118 | 23949 | 357 | 355 | 355 | 0.20 |
| osa-14 | 2337 | 52460 | 873 | 781 | 781 | f |
| osa-30 | 4350 | 100024 | 1733 | 1536 | 1536 | f |
| pds-02 | 2953 | 7535 | 1379 | 332 | 313 | 15.32 |
| perold | 625 | 1376 | 580 | 546 | 544 | 61.55 |
| pilot.ja | 940 | 1988 | 789 | 681 | 682 | t |
| pilot | 1441 | 3652 | 1299 | 1287 | 1298 | t |
| pilot4 | 410 | 1000 | 374 | 364 | 362 | 104.69 |
| pilot87 | 2030 | 4883 | 1856 | 1840 | 1839 | t |
| pilotnov | 975 | 2172 | 1809 | 708 | 680 | f |
| qap12 | 3192 | 8856 | 2940 | 2462 | 2446 | 93.34 |
| qap8 | 912 | 1632 | 656 | 466 | 418 | 9.54 |
| recipe | 91 | 180 | 24 | 24 | 24 | 0.01 |
| sc105 | 105 | 103 | 85 | 85 | 85 | 0.02 |
| sc205 | 205 | 203 | 184 | 184 | 184 | 0.09 |
| sc50a | 50 | 48 | 42 | 42 | 42 | 0.01 |
| sc50b | 50 | 48 | 48 | 48 | 48 | 0.07 |
| scagr25 | 471 | 500 | 317 | 307 | 307 | 0.57 |
| scagr7 | 129 | 140 | 98 | 97 | 97 | 0.01 |
| scfxm1 | 330 | 457 | 248 | 231 | 231 | 0.15* |
| scfxm2 | 660 | 914 | 501 | 473 | 471 | 3.04 |
| scfxm3 | 990 | 1371 | 754 | 711 | 711 | 12.42 |
| scorpion | 388 | 358 | 245 | 245 | 245 | 0.17 |
| scrs8 | 490 | 1169 | 276 | 276 | 276 | 0.29 |
| scsd1 | 77 | 760 | 31 | 7 | 11 | 0.02 |
| scsd6 | 147 | 1350 | 182 | 63 | 56 | 0.03 |
| scsd8 | 397 | 2750 | 551 | 147 | 143 | 0.21 |
| sctap1 | 300 | 480 | 263 | 164 | 168 | 0.20* |
| sctap2 | 1090 | 1880 | 811 | 562 | 562 | 17.23 |
| sctap3 | 1480 | 2480 | 1038 | 731 | 731 | 50.74 |
| seba | 515 | 1028 | 438 | 438 | 438 | 2.32 |
| share1b | 117 | 225 | 95 | 94 | 94 | 0.03 |
| share2b | 96 | 79 | 52 | 48 | 48 | 0.05 |
| shell | 536 | 1775 | 391 | 383 | 383 | 0.57 |
| ship04l | 402 | 2118 | 261 | 260 | 260 | 0.24 |
| ship04s | 402 | 1458 | 281 | 280 | 280 | 0.27 |
| ship08l | 778 | 4283 | 422 | 422 | 422 | 1.42 |
| ship08s | 778 | 2387 | 447 | 447 | 447 | 1.69 |
| ship12l | 1151 | 5427 | 707 | 706 | 706 | 4.67 |
| ship12s | 1151 | 2763 | 728 | 728 | 728 | 4.82 |
| sierra | 1227 | 2036 | 373 | 361 | 361 | 6.61 |
| stair | 356 | 467 | 350 | 349 | 349 | 0.76 |
| standata | 359 | 1075 | 71 | 50 | 50 | 0.03 |
| standgub | 361 | 1184 | 71 | 50 | 50 | 0.03 |
| standmps | 467 | 1075 | 190 | 174 | 174 | 0.26 |
| stocfor1 | 117 | 111 | 69 | 69 | 69 | 0.01 |
| stocfor2 | 2157 | 2031 | 1267 | 1267 | 1267 | 15.84 |
| truss | 1000 | 8806 | 802 | 691 | 689 | 17.45 |
| tuff | 333 | 587 | 165 | 122 | 113 | 0.76 |
| vtp.base | 198 | 203 | 55 | 55 | 55 | 0.03 |
| wood1p | 244 | 2594 | 39 | 39 | 39 | 1.49 |
| woodw | 1098 | 8405 | 696 | 550 | 550 | 3.31 |
5 Conclusions and Discussions
In this paper, we formally derive the spiral behavior of PDHG for solving LP. The spiral behavior can be decomposed by a rotation and a forward movement that are orthogonal to each other. This explicit formula and geometric perspective provide insights into the recent findings of the algorithm, including the infeasibility detection, the two-stage behavior, the local linear rate, etc.
Inspired by the spiral of PDHG, we propose a new randomized crossover approach that is distinct from the traditional crossover approach based on the simplex algorithm. Our crossover moves along the PDHG spiral ray, which can be calculated via solving OLS. Our numerical experiments demonstrate the effectiveness of the proposed approach.
Looking ahead, several future directions are worth exploring to enhance this crossover scheme. Firstly, we can reuse the factorization in the OLS solving, potentially speeding up the algorithm significantly. One potential enhancement is implementing a warm start for PDHG, which could speed up auxiliary LPs, although a theoretical guarantee for this remains to be established. Another promising direction involves developing a GPU-friendly OLS solver, which would allow the crossover method to leverage GPU parallelization. Additionally, designing a strategic perturbation could direct the solution toward a desired vertex more efficiently. If this perturbation is well-calibrated to avoid making the LP unbounded or infeasible, it could enable a purely PDHG-based, matrix-free crossover, making it particularly suitable for handling large-scale LPs.
Acknowledgement
This work was mostly done when the first author visited the second author at the University of Chicago, Booth School of Business. The authors thank the Booth School of Business for funding this visit. The authors also would like to thank Qi Huangfu for helpful discussions on the crossover algorithms in commercial LP solvers. The first author is partially supported by NSFC [Grant NSFC-72225009, 72394360, 72394365]. The second author is partially supported by AFOSR FA9550-24-1-0051.
References
- Dantzig [1951] George B Dantzig. Maximization of a linear function of variables subject to linear inequalities. Activity analysis of production and allocation, 13:339–347, 1951.
- Dantzig [1963] George B Dantzig. Linear programming and extensions. Princeton university press, 1963.
- Karmarkar [1984] Narendra Karmarkar. A new polynomial-time algorithm for linear programming. In Proceedings of the sixteenth annual ACM symposium on Theory of computing, pages 302–311, 1984.
- Renegar [1988] James Renegar. A polynomial-time algorithm, based on Newton’s method, for linear programming. Mathematical programming, 40(1):59–93, 1988.
- Applegate et al. [2021] David Applegate, Mateo Díaz, Oliver Hinder, Haihao Lu, Miles Lubin, Brendan O’Donoghue, and Warren Schudy. Practical large-scale linear programming using primal-dual hybrid gradient. Advances in Neural Information Processing Systems, 34:20243–20257, 2021.
- Lu and Yang [2023a] Haihao Lu and Jinwen Yang. cuPDLP.jl: A GPU implementation of restarted primal-dual hybrid gradient for linear programming in Julia. arXiv preprint arXiv:2311.12180, 2023a.
- Lu et al. [2023] Haihao Lu, Jinwen Yang, Haodong Hu, Qi Huangfu, Jinsong Liu, Tianhao Liu, Yinyu Ye, Chuwen Zhang, and Dongdong Ge. cuPDLP-C: A strengthened implementation of cuPDLP for linear programming by C language. arXiv preprint arXiv:2312.14832, 2023.
- O’Donoghue et al. [2016] Brendan O’Donoghue, Eric Chu, Neal Parikh, and Stephen Boyd. Conic optimization via operator splitting and homogeneous self-dual embedding. Journal of Optimization Theory and Applications, 169(3):1042–1068, June 2016. URL http://stanford.edu/~boyd/papers/scs.html.
- O’Donoghue [2021] Brendan O’Donoghue. Operator splitting for a homogeneous embedding of the linear complementarity problem. SIAM Journal on Optimization, 31:1999–2023, August 2021.
- Lin et al. [2021] Tianyi Lin, Shiqian Ma, Yinyu Ye, and Shuzhong Zhang. An ADMM-based interior-point method for large-scale linear programming. Optimization Methods and Software, 36(2-3):389–424, 2021.
- Deng et al. [2024] Qi Deng, Qing Feng, Wenzhi Gao, Dongdong Ge, Bo Jiang, Yuntian Jiang, Jingsong Liu, Tianhao Liu, Chenyu Xue, Yinyu Ye, et al. An enhanced alternating direction method of multipliers-based interior point method for linear and conic optimization. INFORMS Journal on Computing, 2024.
- Ge et al. [2024] Dongdong Ge, Qi Huangfu, Zizhuo Wang, Jian Wu, and Yinyu Ye. Cardinal Optimizer (COPT) user guide. https://guide.coap.online/copt/en-doc, 2024.
- Xpress [2014] FICO Xpress. FICO Xpress Optimization Suite. 2014.
- Perron and Furnon [2024] Laurent Perron and Vincent Furnon. OR-Tools, 2024. URL https://developers.google.com/optimization/.
- Huangfu and Hall [2018] Qi Huangfu and JA Julian Hall. Parallelizing the dual revised simplex method. Mathematical Programming Computation, 10(1):119–142, 2018.
- Fender [2024] Alex Fender. Advances in optimization AI. https://www.nvidia.com/en-us/on-demand/session/gtc24-s62495/, 2024.
- Megiddo [1991] Nimrod Megiddo. On finding primal- and dual-optimal bases. ORSA Journal on Computing, 3(1):63–65, 1991.
- Bixby and Saltzman [1994] Robert E Bixby and Matthew J Saltzman. Recovering an optimal LP basis from an interior point solution. Operations Research Letters, 15(4):169–178, 1994.
- Andersen and Ye [1996] Erling D Andersen and Yinyu Ye. Combining interior-point and pivoting algorithms for linear programming. Management Science, 42(12):1719–1731, 1996.
- Chambolle and Pock [2011] Antonin Chambolle and Thomas Pock. A first-order primal-dual algorithm for convex problems with applications to imaging. Journal of mathematical imaging and vision, 40:120–145, 2011.
- Xiong and Freund [2024] Zikai Xiong and Robert M Freund. The role of level-set geometry on the performance of PDHG for conic linear optimization. arXiv preprint arXiv:2406.01942, 2024.
- Lu and Yang [2024a] Haihao Lu and Jinwen Yang. Restarted Halpern PDHG for linear programming. arXiv preprint arXiv:2407.16144, 2024a.
- Halpern [1967] Benjamin Halpern. Fixed points of nonexpanding maps. 1967.
- Lu and Yang [2022] Haihao Lu and Jinwen Yang. On the infimal sub-differential size of primal-dual hybrid gradient method and beyond. arXiv preprint arXiv:2206.12061, 2022.
- Applegate et al. [2023] David Applegate, Oliver Hinder, Haihao Lu, and Miles Lubin. Faster first-order primal-dual methods for linear programming using restarts and sharpness. Mathematical Programming, 201(1):133–184, 2023.
- Applegate et al. [2024] David Applegate, Mateo Díaz, Haihao Lu, and Miles Lubin. Infeasibility detection with primal-dual hybrid gradient for large-scale linear programming. SIAM Journal on Optimization, 34(1):459–484, 2024.
- Lu and Yang [2024b] Haihao Lu and Jinwen Yang. On the geometry and refined rate of primal–dual hybrid gradient for linear programming. Mathematical Programming, pages 1–39, 2024b.
- Poon and Liang [2019] Clarice Poon and Jingwei Liang. Trajectory of alternating direction method of multipliers and adaptive acceleration. Advances in neural information processing systems, 32, 2019.
- Poon and Liang [2020] Clarice Poon and Jingwei Liang. Geometry of first-order methods and adaptive acceleration. arXiv preprint arXiv:2003.03910, 2020.
- Charnes and Kortanek [1963] A Charnes and KO Kortanek. An opposite sign algorithm for purification to an extreme point solution. Office of Naval Research, Memorandum, (129), 1963.
- Charnes et al. [1965] A Charnes, KO Kortanek, and W Raike. Extreme point solutions in mathematical programming: An opposite sign algorithm. Systems Research Memorandum, (129):97–98, 1965.
- Khachiyan [1979] Leonid Genrikhovich Khachiyan. A polynomial algorithm in linear programming. In Doklady Akademii Nauk, volume 244, pages 1093–1096. Russian Academy of Sciences, 1979.
- Kortanek and Jishan [1988] KO Kortanek and Zhu Jishan. New purification algorithms for linear programming. Naval Research Logistics (NRL), 35(4):571–583, 1988.
- Amor et al. [2006] Hatem Ben Amor, Jacques Desrosiers, and François Soumis. Recovering an optimal LP basis from an optimal dual solution. Operations research letters, 34(5):569–576, 2006.
- Mehrotra [1991] Sanjay Mehrotra. On finding a vertex solution using interior point methods. Linear Algebra and its Applications, 152:233–253, 1991.
- Tapia and Zhang [1991] RA Tapia and Yin Zhang. An optimal-basis identification technique for interior-point linear programming algorithms. Linear algebra and its applications, 152:343–363, 1991.
- Ge et al. [2021] Dongdong Ge, Chengwenjian Wang, Zikai Xiong, and Yinyu Ye. From an interior point to a corner point: smart crossover. arXiv preprint arXiv:2102.09420, 2021.
- Lu and Yang [2023b] Haihao Lu and Jinwen Yang. On a unified and simplified proof for the ergodic convergence rates of PPM, PDHG and ADMM. arXiv preprint arXiv:2305.02165, 2023b.
- Gay [1985] David M Gay. Electronic mail distribution of linear programming test problems. Mathematical Programming Society COAL Newsletter, 13:10–12, 1985.
- Pazy [1971] Amnon Pazy. Asymptotic behavior of contractions in Hilbert space. Israel Journal of Mathematics, 9:235–240, 1971.
- Baillon [1978] Jean-Bernard Baillon. On the asymptotic behavior of nonexpansive mappings and semigroups in Banach spaces. Houston J. Math., 4:1–9, 1978.
- Fong and Saunders [2011] David Chin-Lung Fong and Michael Saunders. LSMR: An iterative algorithm for sparse least-squares problems. SIAM Journal on Scientific Computing, 33(5):2950–2971, 2011.
Appendix A Proof of Theorem 7
Proof of Theorem 7.
For each phase given PDHG the basis , the PDHG operator can be rewritten as
Since the non-basic part is always , we focus on the basic part of PDHG iterates
where is defined in (5).
Suppose we have the SVD decomposition of
| (23) |
where has non-zero diagonal elements, and are two unitary matrices. The first columns of and the remaining respectively form the basis of the image of and the kernel of . Analogously, the first columns of and the remaining respectively form the basis of the image of and the kernel of .
| (24) |
We can reorder the middle matrix as
to obtain several blocks and contingent ones on the diagonal. Moreover, since is a submatrix of and , we still have
For one block with , it is easy to prove that by verifying that the modulus of its eigenvalues is strictly less than 1. Therefore, we have
| (25) |
For the vector , we have
and
Here we utilize the property of Moore–Penrose inverse that . Then we have
where the part can be verified in a similar way.
To prove (9), for all , we use (22) to obtain
where the last equation utilizes the property of Moore–Penrose inverse that .
∎
Appendix B Proof of Proposition 8
Proof of Proposition 8.
From (6), we have
| (27) | ||||
is the optimal solution to the OLS problem , while is the optimal solution to the OLS problem .
From (7), we have
| (28) | ||||
implying that the forward movement will not improve the primal or dual feasibility.
Suppose we have the SVD decomposition of (23) and let denote the nonzero-diagonal matrix in , then
and similarly
The last inequality of is activated if and only if , i.e., belongs to the image of . From (7), belongs to the image of if and only if belongs to the image of . Moreover, (28) tells us belongs to the kernel of , so belongs to the image of if and only if . Similarily, is activated if and only if , i.e., belongs to the image of , or if and only if . Combining the primal and dual parts completes the proof. ∎