A New Simple Stochastic Gradient Descent Type Algorithm With Lower Computational Complexity for Bilevel Optimization
Abstract
Bilevel optimization has been widely used in many machine learning applications such as hyperparameter optimization and meta learning. Recently, many simple stochastic gradient descent(SGD) type algorithms(without using momentum and variance techniques) have been proposed to solve the bilevel optimization problems. However, all the existing simple SGD type algorithms estimate the hypergradient via stochastic estimation of Neumann series. In the paper, we propose to estimate the hypergradient via SGD-based Estimation(i.e., solving the linear system with SGD). By using warm start initialization strategy, a new simple SGD type algorithm SSGD based on SGD-based Estimation is proposed. We provide the convergence rate guarantee for SSGD and show that SSGD outperforms the best known computational complexity achieved by the existing simple SGD type algorithms. Our experiments validate our theoretical results and demonstrate the efficiency of our proposed algorithm SSGD in hyperparameter optimization applications.
Index Terms:
Bilevel optimization, stochastic gradient descent(SGD)-based Estimation, simple SGD type algorithms, warm start.I Introduction
Bilevel optimization has become a powerful tool for many machine learning applications such as meta learning[1, 2, 3, 4], hyperparameter optimization[5], and reinforcement learning[6, 7]. It has a nested structure which contains two levels of optimization tasks, and the feasible region of the upper level(UL) function is restricted by the optimal solutions of the lower level(LL) problem. Generally, bilevel optimization can be expressed as follows:
| (1) | ||||
where is the UL function, is the LL function, and is the solution set of the LL problem.
Many deterministic algorithms have been proposed to solve the bilevel problem (1). In early works, the bilevel problem is reformulated into single level problem using the first order optimality conditions of the LL problem[8, 9, 10, 11]. However, such type of methods often involve a large number of constraints, and are not applicable in complex machine learning problems. To address the problem, gradient based algorithms have been revisited to solve problem (1). Depending on the way to approximate the hypergradient , these algorithms can be generally categorized into the iterative differentiation(ITD) based approach[1, 5, 12, 13, 14] and the approximate implicit differentiation(AID) based approach[12, 15, 16, 17].
ITD based approach treats the iterative optimization algorithm for the LL problem as a dynamical system, and approximates the hypergradient by back-propagation(BP) along the dynamical system [12, 18], this kind of hypergradient approximation method termed as BP in the paper. Since computing the gradient along the entire dynamical system is computationally challenging for high-dimensional problems, [5] proposed to truncate the path to compute the gradient. On the other hand, the convergence of ITD based approach for solving problem has also been studied. [1] assumed that the LL function is strongly convex, and provided the asymptotic convergence analysis. To address the case that the LL function is convex, [19] proposed BDA and the asymptotic convergence analysis is provided. For the nonasymptotic convergence analysis of ITD based approach, see [14].
AID based approach applies implicit function theorem to the first order optimality conditions of the LL problem, and approximates the hypergradient by solving a linear system[15, 16]. There are mainly two methods to solve the linear system: conjugate gradient descent(CG)[12] and approximating the Hessian inverse with Neumann series[17], these two hypergradient approximation methods termed as CG and Neumann series(NS) in the paper. For the nonasymptotic convergence analysis of the AID based approach, see [14, 17].
In fact, in many machine learning applications, the bilevel optimization takes the following form:
| (2) | ||||
where UL function and LL function take the expected values with respect to(w.r.t.) random variables and , respectively; is strongly convex w.r.t. and is nonconvex w.r.t. . Notice that if and are discrete random variables, the values of and are chosen from the given data sets and , respectively, and the probability to sample data from and is equal, respectively, then the objective functions in problem (2) can be written as and .
In order to achieve better efficiency than deterministic algorithms for solving problem (2), many stochastic algorithms have been proposed. Without considering the loop to estimate the Hessian inverse, these existing stochastic algorithms for problem (2) can be categorized into single loop algorithms and double loop algorithms according to the number of loops.
For single loop algorithms, the upper variable and the LL variable are updated simultaneously. As far as we know, the first single loop algorithm proposed for solving problem (2) is the two-timescale stochastic approximation(TTSA) algorithm[7], which is a simple SGD type algorithm. To ensure convergence, a larger step size for the LL problem and a smaller step size for the UL problem are required. Moreover, to reach an -stationary point, the computational complexity is in terms of the target accuracy . Recently, based on momentum and variance techniques, some single loop algorithms with improved computational complexity have been proposed, see e.g., [20, 21].
For a double loop algorithm, it contains two loops in which the inner loop is used to update the LL variable to obtain an approximation to the optimal solution of the LL problem, and the outer loop is used to update the UL variable . Following the direction, [17] proposed a bilevel stochastic approximation(BSA) algorithm and the computational complexity is in terms of the target accuracy . By introducing warm start initializaiton strategy, stocBiO[14] achieves the computational complexity of in terms of the target accuracy . In addition, in order to improve the computational complexity of the simple SGD type double loop algorithms, variance reduction is used for both UL variable and LL variable in [22], and the computational complexity is in terms of the target accuracy .
Although many stochastic algorithms have been proposed to solve problem (2), little attention is paid to the the hypergradient estimation process except a few attempts recently. [23] noticed that to estimate the hypergradient, the existing single loop algorithms and double loop algorithms require an additional loop to estimate Hessian inverse. By studying the well known hypergradient approximation methods such as BP[12], CG[12], and NS[17], they identified a general approximation formulation of hypergradient computation. Based on the formulation and the momentum based variance reduction technique used in [24], they proposed a fully single loop algorithm(FSLA) in which an additional loop to estimate the Hessian inverse is not required.
In the paper, our goal is to design a new simple stochastic gradient descent(SGD) type algorithm for problem (2), which can achieve lower computational complexity compared with the existing simple SGD type algorithms(simple SGD type algorithms refer to stochastic algorithms that do not use momentum and variance techniques). We notice that the existing simple SGD type algorithms(i.e., BSA, TTSA, and stocBiO) for solving problem (2) estimate the hypergradient via stochastic estimation of Neumann series, this kind of hypergradient estimation method termed as Stochastic NS in the paper. Inspired by the work in [23], we study some hypergradient estimation methods: Stochastic BP, Stochastic NS, and SGD-based Estimation, and find that the algorithm has the potential to converge faster by using SGD-based Estimation to estimate the hypergradient. Based on the finding, by using warm start initialization strategy, a new simple SGD type algorithm SSGD based on SGD-based Estimation is proposed. Through our theoretical analysis, SSGD can achieve lower complexity compared with the existing simple SGD type algorithms. The main contributions of this paper are:
-
1.
We propose to use SGD-based Estimation to estimate the hypergradient.
-
2.
We propose a new simple SGD type algorithm SSGD.
-
3.
We prove that SSGD can achieve lower computational complexity compared with the existing simple SGD type algorithms. As shown in Table I, the computational complexity of SSGD to reach an -stationary point outperforms that of BSA and stocBiO by an order of and , respectively. In addition, in terms of the target accuracy , the computational complexity of SSGD outperforms that of TTSA by an order of .
-
4.
We perform experiments to validate our theoretical results and demonstrate the application of our algorithm in hyperparameter optimization.
The rest of this paper is organized as follows. In Section II, we first make some settings for problem (2), and specify the problem to study in this paper. Then, for problem (2), we introduce some hypergradient estimation methods and analyze them. In Section III, we propose a new simple SGD type algorithm for problem (2). The convergence and complexity results of our proposed algorithm are provided in Section IV. Experimental results are provided in Section V. In Section VI, we conclude and summarize the paper.
Notations. We use to denote the norm for vectors and spectral norm for matrices. For a twice differentiable function , denotes the gradient of taken w.r.t. all the variables , (resp. ) denotes its partial derivate taken w.r.t. (resp. ), denotes the Jacobian of w.r.t. , denotes the Hessian matrix of w.r.t. . Furthermore, for a twice differentiable function , which takes expected value w.r.t. random variable , we define
where is a sample set with samples , sampled over the distribution of , and is the sample size of . Similarly, the definitions of , , and can be obtained.
| Algorithm | loop | batch size | computational complexity |
|---|---|---|---|
| BSA[17] | double | ||
| TTSA [7] | single | ||
| stocBiO [14] | double | ||
| SSGD(Ours) | double |
II Analysis
In this section, we first make some settings for problem (2), and then introduce some hypergradient estimation methods for problem (2). Finally, we analyze these hypergradient estimation methods.
II-A Preliminaries
In the following, we make some assumptions on the objective functions in problem (2).
Assumption 1.
The functions and are -strongly convex w.r.t. for any and , and is nonconvex w.r.t. .
Assumption 2.
The functions and satisfy
-
•
is -Lipschitz, i.e., for , , we have
-
•
and are -Lipschitz, i.e., for , , we have
-
•
and are - and -Lipschitz, i.e., for , , we have
Furthermore, the same assumption holds for and for any given and .
In fact, for problem , Assumptions 1 and 2 are widely adopted to establish the convergence of the stochastic algorithms such as BSA, TTSA, and stocBiO. Based on Assumptions 1 and 2, the differentiability of , and the Lipschitz continuity of and can be ensured, as shown below.
Proposition 1.
The proof of Proposition 1 is in the supplementary material. From Assumption 1 and Proposition 1, we know that is nonconvex and differentiable. Therefore, we want the algorithms to find an -stationary point defined as follows.
Definition 1.
For problem (2), we call an -stationary point of if .
To facilitate our analysis of the complexity of the algorithm when it reaches the stationary point, we borrow the metrics of complexity as defined in Definition 2 of [14].
Definition 2.
For a stochastic function with , , and being a random variable, and a vector , let Gc be the number of partial derivatives or , and let Jv and Hv be the number of Jacobian vector products and Hessian vector products , respectively.
To prove the convergence of the stochastic algorithms, as adopted in [7, 14, 17], we make the following assumptions on the stochastic derivatives.
Assumption 3.
For problem (2), the stochastic derivatives , , , and are unbiased estimates of , , , and , respectively. Furthermore, their variances satisfy
where , , , and are positive constants.
II-B Introduction of Some Hypergradient Estimation Methods
In the paper, we study the hypergradient estimation methods: Stochastic BP, Stochastic NS, and SGD-based Estimation, where Stochastic NS is adopted to estimate the hypergradient for all the existing simple SGD type algorithms for solving problem (2), and Stochastic BP and SGD-based Estimation are developed in this paper for problem (2). Notice that Stochastic NS is actually a stochastic version of NS. In the similar way, we obtain Stochastic BP by introducing stochastic estimation into BP, and based on AID, we obtain SGD-based Estimation by solving linear system with SGD.
In the following, we introduce how each of these hypergradient estimation methods estimates the hypergradient in a general simple SGD type algorithm shown in Algorithm 1, with problem (2) satisfying Assumptions 1, 2, and 3.
As shown in Algorithm 1, given , first, an approximation to the optimal solution of the LL problem is obtained through the SGD updates in line 5 of Algorithm 1. Based on the output , these hypergradient estimation methods estimate the hypergradient as follows.
Stochastic BP. Notice that , and that
| (4) | ||||
For in the form of (4), Stochastic BP estimates the hypergradient by automatic differentiation. Specifically, since has a dependence on through the SGD updates in line 5 of Algorithm 1, Stochastic BP computes by automatic differentiation along these SGD updates, and can be obtained as follows:
| (5) |
where with being the identity matrix, and (for the derivation, see Appendix D.2 in [14]). Then,
| (6) | ||||
is used to estimate the hypergradient in (4), where is a sample set sampled from the distribution of and is given in (5).
In fact, Stochastic BP is a variant of BP, and in (6) can be directly obtained by introducing stochastic estimation into the hypergradient approximation formula of BP in Proposition 2 in [14].
Stochastic NS. From Proposition 1, we have
| (7) | ||||
with . For in the form of (7), Stochastic NS estimates the hypergradient by solving the following linear system:
| (8) |
By approximating Hessian inverse with the first terms of the following Neumann series:
| (9) |
and computing over a sample set sampled from the distribution of , an approximate solution of (8) is obtained, and takes the form of
| (10) |
where , , and sample sets are sampled from the distribution of . Then,
| (11) |
is used to estimate the hypergradient in (7), where is the aforementioned sample set, is a sample set sampled from the distribution of , and is given in (10). Note that sample sets are mutually independent.
In fact, in (11) can be directly obtained by introducing stochastic estimation into the hypergradient approximation formula of NS in eq.(3) in [22], which is the reason we call this hypergradient estimation method Stochastic NS. Furthermore, for more details about Stochastic NS, see subsection 2.2 in [14].
SGD-based Estimation. SGD-based Estimation estimates the hypergradient in the way similar to Stochastic NS except that the approximate solution to (8) is obtained by using SGD. Notice that the solution to (8) is equivalent to the optimal solution of the following optimization problem:
| (12) |
SGD-based Estimation obtains an approximate solution to (12) by solving (12) with steps of SGD as follows:
| (13) | ||||
where is the step size, and for each , and are the sample sets sampled from the distributions of and , respectively. Then,
| (14) |
is used to estimate the hypergradient, where and are the sample sets sampled from the distributions of and , respectively.
II-C Analysis of Hypergradient Estimation Methods
Define , , where denotes the -algebra generated by random variables.
Then, similar to the discussion in the proof of Lemma 3 in the supplementary material, from the iteration in line 16 of Algorithm 1, we can obtain formula (19) in the supplementary material in which for Stochastic BP and Stochastic NS, and for SGD-based Estimation. By shifting the terms, we have
The upper bound of involves the term . In the following, the upper bound of is provided. For the proof, see Lemma 10 in the supplementary material.
Proposition 2.
Apply Algorithm 1 to solve problem (2). Suppose Assumptions 1, 2, and 3 hold. let , , and define , , where is the initial value to solve problem (12)(see line 13 in Algorithm 1), and is the optimal solution to the LL problem of problem (2) with . For , in Assumptions 1, 2 and , , , in Algorithm 1, let , , , be any positive integers, and . Then,
-
•
For Stochastic BP, for with in (6), we have
-
•
For Stochastic NS, for with in (11), we have
-
•
For SGD-based Estimation, for with in (14), we have
is in (3) with , , , , , are given in Assumptions 1, 2.
From Proposition 2, it is easy to find that there are some differences for Stochastic BP, Stochastic NS, and SGD-based Estimation regarding the upper bound of . For Stochastic BP and Stochastic NS, the upper bound for involves and , respectively. While for SGD-based Estimation, the term is involved in the upper bound of .
Thus, to ensure that is a sufficiently small number, a sufficiently large for Stochastic BP and a sufficiently large for Stochastic NS may be required. In contrast, for SGD-based Estimation, we notice that in the term is the initial value to solve problem (12). Apply warm start initialization strategy to (i.e., , where is the output of the -th iteration to solve problem (12) given ) can allow us to track the errors, such as , …, , in the preceeding loops. Thus, a smaller number may be able to ensure to be a sufficiently small number, and there is no restriction on . Notice that warm start initialization strategy is used in stocBiO[14] to initialize the initial values for solving the LL problem, and the improved computational complexity is obtained.
The above discussion inspires us to think that SGD-based Estimation may be able to allow to be sufficiently small under weaker restrictions on than Stochastic BP and than Stochastic NS. Thus, SGD-based Estimation may be able to make Algorithm 1 converge faster than Stochastic BP and Stochastic NS.
Next, we perform experiments on a synthetic bilevel optimization problem, a special case of problem (2), to evaluate the performance of Algorithm 1 under different hypergradient estimation methods.
Synthetic Bilevel Optimization Problem. We consider the following synthetic bilevel optimization problem:
| (15) |
with
where , and and are the data sets constructed as follows: given , first randomly sample data points , from normal distribution with a mean of 0 and a variance of 0.01; then, for each , we set , and construct by , where is the Gaussian noise with mean 0 and variance 1; finally, dividing the dataset equally into two parts, we obtain training set and validation set , with the training set size and validation set size being 10000, respectively.
It is easy to verify that is strongly convex w.r.t. . Moreover, for each , the minimum solution of the LL problem is
and the hypergradient is
where
and , can be obtained by replacing and in and with and .
In the following, we use Algorithm 1 to solve problem (15), and compare the performance of Algorithm 1 under different hypergradient estimation methods. To be specific, the hypergradient estimation methods that we consider are Stochastic BP, Stochastic NS, and SGD-based Estimation, where for SGD-based Estimation, we use two initialization strategies to initialize in line 13 of Algorithm 1, i.e., non-warm start initialization strategy and warm start initialization strategy. For non-warm start initialization strategy, we set , to be zero vectors. For warm-start initialization strategy, we set , , where for each , is obtained by the iteration steps starting from in (13). The experimental details are in the supplementary material.
To simplify the narrative, we refer to Algorithm 1 as Stochastic BP(resp. Stochastic NS) if Algorithm 1 estimates the hypergradient via Stochastic BP(resp. Stochastic NS). Similarly, if Algorithm 1 estimates the hypergradient via SGD-based Estimation and using the non-warm start initialization strategy(resp. warm start initialization strategy) to initialize , we refer to Algorithm 1 as SGD_W_Start_False(resp. SGD_W_Start_True). Furthermore, we use P__(P__) to denote that the iteration step () is set to be for P.
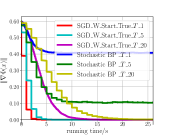
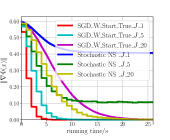
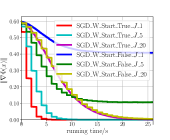
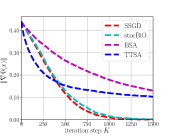
In the experiments, data sets and are constructed by setting . From Fig. 1LABEL:sub@fig_first_case, we observe that to converge to a stationary point with , is sufficient for SGD_W_Start_True, and a larger () is required for Stochastic BP. Furthermore, SGD_W_Start_True always converges faster than Stochastic BP for . From Fig. 1LABEL:sub@fig_second_case, we observe that to converge to a stationary point with , is sufficient for SGD_W_Start_True, and a larger () is required for Stochastic NS. Furthermore, SGD_W_Start_True with has a faster convergence speed than Stochastic NS with . From Fig. 1LABEL:sub@fig_third_case, we observe that to converge to a stationary point with , is sufficient for SGD_W_Start_True, and a larger () is required for SGD_W_Start_False. Furthermore, SGD_W_Start_True with has a faster convergence speed than SGD_W_Start_False with .
In conclusion, the above experimental results show that compared with Stochastic BP and Stochastic NS, Algorithm 1 can obtain a faster convergence speed by using SGD-based Estimation to estimate the hypergradient and using warm start initialization strategy for SGD-based Estimation.
III Algorithm
In Section II, we find that compared with Stochastic BP and Stochastic NS, SGD-based Estimation can make Algorithm 1 achieve a faster convergence speed. Notice that all the existing simple SGD type algorithms for solving problem (2) use Stochastic NS to estimate the hypergradient. It is natural to think that using SGD-based Estimation to estimate the hypergradient may allow us to obtain an algorithm with lower computational complexity for problem (2).
As shown in Algorithm 2, by using warm start initialization strategy, a new simple SGD type algorithm SSGD based on SGD-based Estimation is proposed, in which warm start is not only used for SGD-based Estimation, but also for solving LL problem.
In Algorithm 2, given , SSGD runs steps of SGD to obtain an approximation to the optimal solution of the LL problem(see line 6 in Algorithm 2). Note that the initial value is initialized by using warm start and is set to be , where is equal to , which is the output of the -th iteration starting from in line 6 of Algorithm 2.
After setting , the hypergradient is estimated via SGD-based Estimation. Specifically, SSGD first obtains an approximation to the optimal solution of the following optimization problem
using steps of SGD starting from (see line 11 in Algorithm 2), where we also adopt a warm start with . Then, by setting ,
| (16) | ||||
is constructed as an estimate to . Note that sample sets are mutually independent in the hypergradient estimation process.
For the sample sets in Algorithm (2), we suppose the sample sets for all , for all , and have the sizes of , , and , respectively. Furthermore, we suppose sample set and the sample sets for all have the same sample size .
Remark 1.
From Algorithm 2, it is easy to observe that there are three loops. However, since in the classification of the existing stochastic algorithms for solving problem (2), the loop to estimate the hypergradient, i.e., approximate the Hessian inverse, is typically not counted. To be consistent with the existing literature, when performing classification, the loop to solve linear system in lines 9-12 of Algorithm 2 is not counted. Then, it is obvious that SSGD can be either a single loop algorithm(i.e., ) or a double loop algorithm(i.e., ). Although in the analysis that follows, it can be concluded that the convergence of SSGD is guaranteed for any . To obtain a lower computational complexity than the existing simple SGD type algorithms, is required for SSGD, where is the condition number. Therefore, we call SSGD a double loop algorithm, as shown in Table I.
IV Theoretical Results
In this section, we provide the convergence and complexity results of SSGD. Detailed theoretical analysis can be found in the supplementary material.
We first show that the convergence of SSGD can be guaranteed for any and . Furthermore, the complexity result is provided.
Theorem 1.
Apply SSGD to solve problem (2). Suppose Assumptions 1, 2, and 3 hold. Define , , , , and
where is the condition number, , is defined in Proposition 1, , , and are defined in Lemma 7 in the supplementary material, and , are the stepsizes. Let , and choose stepsizes , , and
where is defined in Lemma 4 in the supplementary material. Then, for any and , we have
Furthermore, to achieve an -accurate stationary point, the computational complexity is .
Theorem 1 shows that SSGD converges sublinearly w.r.t. the number of iterations, the batch sizes , for gradient estimation, for Jacobian estimation, and for Hessian matrix estimation. In addition, from Theorem 1, we know that when and , SSGD can achieve the lowest computational complexity . Compared with the existing simple SGD type algorithms listed in Table I, this computational complexity of SSGD outperforms that of BSA, TTSA, and stocBiO by an order of , , and in terms of the target accuracy , respectively. While, in terms of the condition number , it has a higher complexity compared with the algorithms listed in Table I.
Notice that the convergence result and the complexity result of Theorem 1 are established under the assumption that and . In the following, we show that by imposing some restrictions on and , SSGD can obtain a lower computational complexity.
Theorem 2.
Apply SSGD to solve problem (2). Suppose Assumptions 1, 2, and 3 hold. Define , , , , and
where , is defined in Proposition 1, , , and . Let , and select , ,
where , and . Then, we have
Furthermore, a computational complexity of the order of is sufficient for SSGD to reach an -accurate stationary point.
In Theorem 2, the convergence of SSGD is established under the assumption that and . Furthermore, a computational complexity by an order of is obtained in Theorem 2, which is lower than the lowest computational complexity obtained in Theorem 1. Compared with the algorithms listed in Table I, SSGD achieves the lowest computational complexity.
V Experimental Results
In this section, we first validate our theoretical results on synthetic bilevel optimization problems. Then, we apply our proposed algorithm on a hyperparameter optimization problem.
V-A Synthetic Bilevel Optimization Problems
In the following, we perform experiments on the bilevel problem in (15). The experimental details are in the supplementary material.
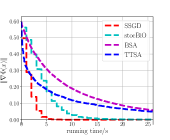
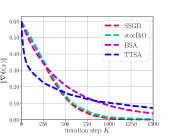
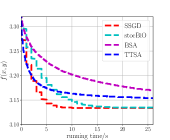
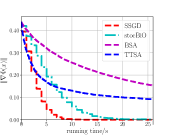
Firstly, we compare our proposed algorithm SSGD with the existing simple SGD type algorithms BSA, TTSA, and stocBiO. In the experiments, we consider two datasets, i.e., datasets constructed by setting and datasets constructed by setting .
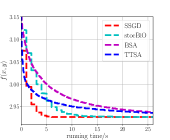
From Fig. 2LABEL:sub@fig_third_case and Fig. 3LABEL:sub@fig_third_case, we observe that SSGD and stocBiO run almost the same number of iteration steps to converge to the stationary point with , less than that of BSA and TTSA. However, compared with SSGD, a larger to estimate the hypergradient is required for stocBiO to converge to the stationary point with . As a result, Fig. 2LABEL:sub@fig_second_case and Fig. 3LABEL:sub@fig_second_case show that SSGD converges fastest among all the compared methods. Furthermore, from Fig. 2LABEL:sub@fig_first_case and Fig. 3LABEL:sub@fig_first_case, we observe that SSGD converges to the point with the smallest upper objective function value for both cases.
Then, we study the influence of iteration step , iteration step , batch size, and stepsize on the convergence behavior of SSGD in Algorithm 2. In the experiments, the datasets are constructed by setting .
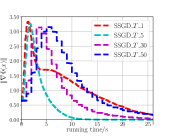
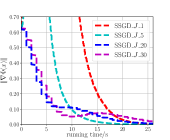
Fig. 4LABEL:sub@fig_first_case shows the convergence behavior of SSGD under different choices of , where SSGD__ indicates that is set to be . It shows that beginning from 1, increasing can speed up the convergence of SSGD, but when reaches , increasing can slow down the convergence speed of SSGD. Fig. 4LABEL:sub@fig_second_case shows the convergence behavior of SSGD under different choices of , where SSGD__ indicates that is set to be . We observe that SSGD converges fastest when is chosen to be 5.
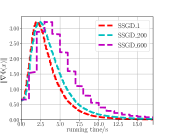
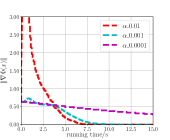
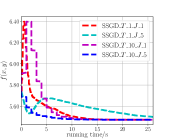
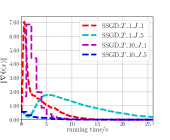
Fig. 5LABEL:sub@fig_first_case shows the convergence behavior of SSGD under different batch sizes with SSGD_ indicating that the batch size is set to be . It shows that SSGD converges fastest when batch size is set to be 1, and increasing batch size can slow down the convergence speed of SSGD. Fig. 5LABEL:sub@fig_second_case shows the convergence behavior of SSGD under different stepsizes . It shows that choosing a larger stepsize allows SSGD to converge faster.
Fig. 6 shows the convergence behavior of SSGD under different choices of and , where SSGD____ indicates that is set to be and is set to be . It shows that SSGD converges faster in the double loop case(i.e., ) than in the single loop case(i.e., ).
V-B Hyper-parameter Optimization
In this section, we use a hyperparameter optimization problem, i.e., data hyper-cleaning[5], to evaluate the performance of our algorithm. Data hyper-cleaning is to train a classifier under the case that some data in the training set is corrupted. Following [5], when we train a linear classifier, data hyper-cleaning task can be expressed as a bilvel optimization problem whose UL function is given by
and whose LL function is given by
where denotes the cross-entropy loss, is the sigmoid function, is the coefficient of the regular term and is set to be , and and denote the validation set and training set, respectively.
| Method | MNIST | FashionMNIST | CIFAR10 | |||
|---|---|---|---|---|---|---|
| Acc. | F1 score | Acc. | F1 score | Acc. | F1 score | |
| stocBiO | 89.90 | 63.92 | 82.18 | 65.17 | 38.36 | 64.07 |
| BSA | 80.67 | 14.20 | 72.57 | 16.51 | 22.72 | 21.09 |
| TTSA | 88.88 | 33.94 | 80.62 | 32.54 | 35.69 | 40.03 |
| SSGD | 90.32 | 83.81 | 82.32 | 80.45 | 38.35 | 66.16 |
In the following experiments, we compare our proposed algorithm SSGD with BSA, TTSA, stocBiO on three datasets: MNIST [26], FashionMNIST [27] and CIFAR10. Each sample in the training set is corrupted with probability . More results and details are in the supplementary material.
Table II shows the experimental results on three datasets over 270s. We observe that SSGD achieves the highest test accuracy on MNIST and FashionMNIST datasets, and achieves the highest F1 score on all the datasets. It shows that SSGD can obtain competetive results on data hyper-cleaning problem.
VI Conclusion
In the paper, we propose to use SGD-based Estimation to estimate the hypergradient for the nonconvex-strongly-convex bilevel optimization problems, and propose a novel simple SGD type algorithm. We provide the convergence guarantee for our algorithm, and prove that our proposed algorithm can achieve lower computational complexity compared with all the existing simple SGD type algorithms for bilevel optimization. Moreover, the experiments validate our theoretical results.
Acknowledgments
The work is partially supported by National Key R&D Program of China(2020YFB1313503 and 2018AAA0100300), National Natural Science Foundation of China(Nos. 61922019, 61733002, 61672125, and 61976041), and LiaoNing Revitalization Talents Program(XLYC1807088).
References
- [1] L. Franceschi, P. Frasconi, S. Salzo, R. Grazzi, and M. Pontil, “Bilevel programming for hyperparameter optimization and meta-learning,” in Proc. 35th Int. Conf. Mach. Learn. (ICML), Jul. 2018, pp. 1568–1577.
- [2] L. Bertinetto, J. F. Henriques, P. Torr, and A. Vedaldi, “Meta-learning with differentiable closed-form solvers,” in Proc. Int. Conf. Learn. Represent. (ICLR), 2019.
- [3] A. Rajeswaran, C. Finn, S. Kakade, and S. Levine, “Meta-learning with implicit gradients,” in Advances in Neural Information Processing Systems, 2019.
- [4] K. Ji, J. D. Lee, Y. Liang, and H. V. Poor, “Convergence of meta-learning with task-specific adaptation over partial parameters,” in Proc. 34th Conf. Neural Inf. Process. Syst. (NeurIPS), 2020.
- [5] A. Shaban, C. A. Cheng, N. Hatch, and B. Boots, “Truncated back-propagation for bilevel optimization,” in Proc. 22th Int. Conf. Artif. Intell. Statist., vol. 89, 2019, pp. 1723–1732.
- [6] V. Konda and J. Tsitsiklis, “Actor-critic algorithms,” in Advances in Neural Information Processing Systems, vol. 12, 1999.
- [7] M. Hong, H. T. Wai, Z. Wang, and Z. Yang, “A two-timescale framework for bilevel optimization: Complexity analysis and application to actor-critic,” 2020, arXiv: 2007.05170. [Online]. Available: https://arxiv.org/abs/2007.05170
- [8] P. Hansen, B. Jaumard, and G. Savard, “New branch-and-bound rules for linear bilevel programming,” SIAM J. Sci. Stat. Comput., vol. 13, no. 5, pp. 1194–1217, 1992.
- [9] C. Shi, J. Lu, and G. Zhang, “An extended kuhn–tucker approach for linear bilevel programming,” Appl. Math. Comput., vol. 162, no. 1, pp. 51–63, 2005.
- [10] Y. Lv, T. Hu, G. Wang, and Z. Wan, “A penalty function method based on kuhn–tucker condition for solving linear bilevel programming,” Appl. Math. Comput., vol. 188, no. 1, pp. 808–813, 2007.
- [11] S. Qin, X. Le, and J. Wang, “A neurodynamic optimization approach to bilevel quadratic programming,” IEEE Trans. Neural Netw. Learn. Syst., vol. 28, no. 11, pp. 2580–2591, 2017.
- [12] J. Domke, “Generic methods for optimization-based modeling,” in Proc. 15th Int. Conf. Artif. Intell. Statist., Apr. 2012, pp. 318–326.
- [13] L. Franceschi, M. Donini, P. Frasconi, and M. Pontil, “Forward and reverse gradient-based hyperparameter optimization,” in Proc. 34th Int. Conf. Mach. Learn. (ICML), vol. 70, Aug. 2017, pp. 1165–1173.
- [14] Y. L. K. Ji, J. Yang, “Bilevel optimization: Convergence analysis and enhanced design,” in Proc. Int. Conf. Mach. Learn. (ICML), 2021.
- [15] F. Pedregosa, “Hyperparameter optimization with approximate gradient,” in Proc. Int. Conf. Mach. Learn. (ICML), 2016, p. 737–746.
- [16] J. Lorraine, P. Vicol, and D. Duvenaud, “Optimizing millions of hyperparameters by implicit differentiation,” in Proc. 23th Int. Conf. Artif. Intell. Statist., 2020, pp. 1540–1552.
- [17] S. Ghadimi and M. Wang, “Approximation methods for bilevel programming,” 2018, arXiv: 1802.02246. [Online]. Available: https://arxiv.org/abs/1802.02246
- [18] D. Maclaurin, D. Duvenaud, and R. P. Adams, “Gradient-based hyperparameter optimization through reversible learning,” in Proc. Int. Conf. Mach. Learn. (ICML), 2015.
- [19] R. Liu, P. Mu, X. Yuan, S. Zeng, and J. Zhang, “A generic first-order algorithmic framework for bi-level programming beyond lower-level singleton,” in Proc. Int. Conf. Mach. Learn. (ICML), 2020.
- [20] P. Khanduri, S. Zeng, M. Hong, H. T. Wai, Z. Wang, and Z. Yang, “A momentum-assisted single-timescale stochastic approximation algorithm for bilevel optimization,” 2021, arXiv: 2102.07367v1. [Online]. Available: https://arxiv.org/abs/2102.07367v1
- [21] Z. Guo, Y. Xu, W. Yin, R. Jin, and T. Yang, “On stochastic moving-average estimators for non-convex optimization,” 2021, arXiv: 2104.14840. [Online]. Available: https://arxiv.org/abs/2104.14840
- [22] J. Yang, K. Ji, and Y. Liang, “Provably faster algorithms for bilevel optimization,” in Advances in Neural Information Processing Systems, vol. 34, 2021, pp. 13 670–13 682.
- [23] H. H. J. Li, B. Gu, “A fully single loop algorithm for bilevel optimization without hessian inverse,” in Proc. AAAI Conf. Artif. Intell., vol. 36, 2022, pp. 7426–7434.
- [24] A. Cutkosky and F. Orabona, “Momentum-based variance reduction in non-convex sgd,” in Advances in Neural Information Processing Systems, vol. 32, 2019.
- [25] T. Chen, Y. Sun, and W. Yin, “Closing the gap: Tighter analysis of alternating stochastic gradient methods for bilevel problems,” in Advances in Neural Information Processing Systems, vol. 34, 2021, pp. 25 294–25 307.
- [26] Y. Lecun, L. Bottou, Y. Bengio, and P. Haffner, “Gradient-based learning applied to document recognition,” Proc. IEEE, vol. 86, pp. 2278–2324, 1998.
- [27] H. Xiao, K. Rasul, and R. Vollgraf, “Fashion-mnist: a novel image dataset for benchmarking machine learning algorithms,” 2017, arXiv: 1708.07747. [Online]. Available: https://arxiv.org/abs/1708.07747
| Haimei Huo received the B.S. degree in information and computing science from Changchun University of Science and Technology, China, in 2017. She is currently pursuing the PhD degree in computational mathematics from Dalian University of Technology, Dalian, China. Her research interests include machine learning and optimization. |
| Risheng Liu received his B.Sc. (2007) and Ph.D. (2012) from Dalian University of Technology, China. From 2010 to 2012, he was doing research as joint Ph.D. in robotics institute at Carnegie Mellon University. From 2016 to 2018, he was doing research as Hong Kong Scholar at the Hong Kong Polytechnic University. He is currently a full professor with the Digital Media Department at International School of Information Science & Engineering, Dalian University of Technology. He was awarded the ”Outstanding Youth Science Foundation” of the National Natural Science Foundation of China. His research interests include optimization, computer vision, and multimedia. |
| Zhixun Su received the B.S. degree in mathematics from Jilin University, Changchun, China in 1987, the M.S. degree in computer science from Nankai University, Tianjin, China in 1990, and the Ph.D. degree in computational mathematics from Dalian University of Technology, Dalian, China in 1993. He has been a Professor in the School of Mathematical Sciences, Dalian University of Technology, since 1999. He is currently the director of the Key Laboratory for Computational Mathematics and Data Intelligence of Liaoning Province and the vise director of Liaoning Center for Applied Mathematics. His current research interests include computer graphics, computer vision, computational geometry, and machine learning. |