A non-monotone smoothing Newton algorithm for solving the system of generalized absolute value equations
Abstract: The system of generalized absolute value equations (GAVE) has attracted more and more attention in the optimization community. In this paper, by introducing a smoothing function, we develop a smoothing Newton algorithm with non-monotone line search to solve the GAVE. We show that the non-monotone algorithm is globally and locally quadratically convergent under a weaker assumption than those given in most existing algorithms for solving the GAVE. Numerical results are given to demonstrate the viability and efficiency of the approach.
2000 Mathematics Subject Classification. 65F10, 65H10, 90C30
Keywords. Generalized absolute value equations; Smoothing function; Smoothing Newton algorithm; Non-monotone line search; Global and local quadratic convergence.
1 Introduction
The system of generalized absolute value equations (GAVE) is to find a vector such that
| (1.1) |
where and are two known matrices, is a known vector, and denotes the componentwise absolute value of . To the best of our knowledge, GAVE (1.1) was first introduced by Rohn in [34] and further investigated in [30, 20, 12, 26, 15, 28] and references therein. Obviously, when with being the identity matrix, GAVE (1.1) becomes the system of absolute value equations (AVE)
| (1.2) |
which is the subject of numerous research works; see, e.g., [24, 48, 49, 3, 21, 11] and references therein.
GAVE (1.1) and AVE (1.2) have attracted considerable attention in the field of optimization for almost twenty years, and the primary reason is that they are closely related to the linear complementarity problem (LCP) [24, 30] and the horizontal LCP (HLCP) [26], which encompass many mathematical programming problems and have many practical applications [6, 27]. In addition, GAVE (1.1) and AVE (1.2) are also bound up with the system of linear interval equations [33].
Due to the combinatorial character introduced by the absolute value operator, solving GAVE (1.1) is generally NP-hard [20, Proposition 2]. Moreover, if GAVE (1.1) is solvable, checking whether it has a unique solution or multiple solutions is NP-complete [30, Proposition 2.1]. Recently, GAVE (1.1) and AVE (1.2) have been extensively investigated in the literature, and the main research effort can be summarized to the following two aspects.
On the theoretical side, one of the main branches is to investigate conditions for existence, non-existence and uniqueness of solutions of GAVE (1.1) or AVE (1.2); see, e.g., [34, 26, 44, 24, 13, 30, 12, 45, 43] and references therein. Specially, the following necessary and sufficient conditions that ensure the existence and uniqueness of solution of GAVE (1.1) can be found in [26, 45] (see section 2 for the definition of the column -property).
Theorem 1.1.
Theorem 1.2.
It is easy to conclude that Theorem 1.1 and Theorem 1.2 imply that has the column -property if and only if matrix is nonsingular for any diagonal matrix with (see Lemma 2.3 for more details).
On the numerical side, there are various algorithms for solving AVE (1.2) or GAVE (1.1). For example, Mangasarian proposed concave minimization method [21], generalized Newton method [22], and successive linear programming method [23], for solving AVE (1.2). Zamani and Hladík proposed a new concave minimization algorithm for AVE (1.2) [48], which solves a deficiency of the method proposed in [21]. Zainali and Lotfi modified the generalized Newton method and developed a stable and quadratic convergent method for AVE (1.2) [47]. Cruz et al. proposed an inexact semi-smooth Newton method for AVE (1.2) [7]. Shahsavari and Ketabchi proposed two types of proximal algorithms to solve AVE (1.2) [36]. Haghani introduced generalized Traub’s method for AVE (1.2) [11]. Ke and Ma proposed an SOR-like iteration method for AVE (1.2) [18]. Caccetta et al. proposed a smoothing Newton method for AVE (1.2) [3]. Saheya et al. summarized several systematic ways of constructing smoothing functions and proposed a unified neural network model for solving AVE (1.2) [35]. Zhang and Wei proposed a generalized Newton method which combines the semismooth and the smoothing Newton steps for AVE (1.2) [49]. In [19], Lian et al. further considered the generalized Newton method for GAVE (1.1) and presented some weaker convergent conditions compared to the results in [22, 15]. Wang et al. proposed modified Newton-type iteration methods for GAVE (1.1) [42]. Zhou et al. established Newton-based matrix splitting methods for GAVE (1.1) [51]. Jiang and Zhang proposed a smoothing-type algorithm for GAVE (1.1) [29]. Tang and Zhou proposed a quadratically convergent descent method for GAVE (1.1) [40]. Hu et al. proposed a generalized Newton method for absolute value equations associated with second order cones (SOCAVE), which is an extension of GAVE (1.1) [15]. For more numerical algorithms, one can refer to [1, 4, 10, 8, 46, 17, 25] and references therein.
By looking into the mathematical format of GAVE (1.1), non-differentiability is caused by the absolute value operator. Smoothing algorithms have been successfully applied to solve GAVE (1.1) [29, 40]. However, monotone line search techniques were used in the methods proposed in [29, 40]. Recently, great attention has been paid to smoothing algorithms with non-monotone line search; see, e.g., [39, 38, 16, 52] and references therein. Non-monotone line search schemes can improve the likelihood of finding a global optimum and improve convergence speed in cases where a monotone line search scheme is forced to creep along the bottom of a narrow curved valley [50]. It is therefore interesting to develop non-monotone smoothing algorithms for solving GAVE (1.1). This motivates us to develop a non-monotone smoothing Newton algorithm for solving GAVE (1.1). Our work here is inspired by recent studies on weighted complementarity problem [39, 41].
The rest of this paper is organized as follows. In section 2, we provide some concepts and results used throughout the paper. In section 3, we develop a non-monotone smoothing Newton algorithm for solving GAVE (1.1), while section 4 is devoted to discussing the convergence. Numerical experiments are given in section 5. Finally, section 6 concludes this paper.
Notation. is the set of all real matrices, , and . and denote the nonnegative and positive real number, respectively. (or simply if its dimension is clear from the context) is the identity matrix. The superscript “” takes transpose. For , refers to its th entry, is in with its th entry . Inequality means for all , and similarly for . We use to denote the case that a positive scalar tends to . We use to mean is bounded uniformly as . For any , we define We denote the diagonal matrix whose th diagonal element is by and define . The symbol stands for the -norm. For a matrix , we use and to denote the smallest singular value and the largest singular value, respectively. For a differentiable mapping , we denote by the Jacobian of at and denotes the gradient of at . For , we also denote by .
2 Preliminaries
In this section, we collect some basic notions as well as corresponding assertions, which are useful in this paper.
Definition 2.1.
([37]) Let be a set of matrices , a matrix is called a column representative of if
where and denote the th column of and , respectively. is said to have the column -property if the determinants of all column representative matrices of are all positive or all negative.
Definition 2.2.
([33]) An interval matrix is defined by . A square interval matrix is called regular if each is nonsingular.
Definition 2.3.
(See, e.g., [9]) The classic (one-sided) directional derivative of a function at in the direction is defined by
provided that the limit exists. Accordingly, denotes the directional derivative for the vector-valued function .
Definition 2.4.
([9]) A vector-valued function is said to be Lipschitz continuous on a set if there is a constant such that
Moreover, is called locally Lipschitz continuous on if it is Lipschitz continuous on all compact subsets .
If is locally Lipschitz continuous, by Rademacher’s Theorem, is differentiable almost everywhere [31]. Let be the set where is differentiable, then the generalized Jacobian of at in the sense of Clarke [5] is
where “” denotes the convex hull.
Definition 2.5.
([32]) A locally Lipschitz continuous vector-valued function is called semismooth at if
exists for any .
Lemma 2.1.
([32]) Let , then the directional derivative exists for any if is semismooth at .
Lemma 2.2.
Throughout the rest of this paper, we always assume that the following assumption holds.
Assumption 2.1.
Let matrices and satisfy has the column -property.
It is known that, if Assumption 2.1 holds, GAVE (1.1) has a unique solution for any [26]. In addition, we have the following lemma, which is needed in the subsequent discussion.
Lemma 2.3.
Assumption 2.1 holds if and only if matrix is nonsingular for any diagonal matrix with .
Proof.
The result can be straightly derived from Theorem 1.1 and Theorem 1.2. Indeed, it follows from Theorem 1.1 that Assumption 2.1 holds if and only if
for any nonnegative diagonal matrices with , that is,
| for any nonnegative diagonal matrices with . | (2.1) |
Let
Then, on one hand, for any , we have . Thus, . On the other hand, for any , can be expressed by with
Hence, . It follows from the above discussion that . Then (2.1) is equivalent to
for any with . This completes the proof. ∎
Remark 2.1.
For symmetric matrices and , under the assumption that , the authors in [2, Lemma 1] proved the nonsingularity of for any diagonal matrix whose elements are equal to or . We should mentioned that the symmetries of the matrices and can be relaxed there and our result here is more general than theirs.
Remark 2.2.
In [29], the authors used the assumption that , while in [40], the authors used the assumption that the interval matrix is regular. The interval matrix is regular is weaker than that and examples can be found in [49, Examples 2.1 and 2.3]. In addition, it is easy to prove that is regular implies that Assumption 2.1 holds, but the reverse is not true. For instance, let
then has the column -property [26] while is not regular. Indeed, there exists a singular matrix In conclusion, our Assumption 2.1 here is more general than those used in [29, 40].
3 The algorithm
In this section, we develop a non-monotone smoothing Newton algorithm for solving GAVE (1.1). To this end, we first consider an equivalent reformulation of GAVE (1.1) by introducing a smoothing function for the absolute value operator.
3.1 A smoothing function for with
In this subsection, we consider a smoothing function for with and discuss some of its properties, which lay the foundation of the next subsection.
Since is not differentiable at , in order to overcome the hurdle in analysis and application, researchers construct numerous smoothing functions for it [35]. In this paper, we adopt the following smoothing function , defined by
| (3.1) |
which can be derived from the perspective of the convex conjugate [35].
In the following, we give some properties related to the smoothing function (3.1).
Proposition 3.1.
Let be defined by (3.1), then we have
-
(i)
-
(ii)
is continuously differentiable on , and when , we have
-
(iii)
is a convex function on , i.e., for all and
-
(iv)
is Lipschitz continuous on
-
(v)
is strongly semismooth on .
Proof.
The proofs of (i) and (ii) are trivial.
Now we turn to the result (iii). For any and , we have
| (3.2) |
On one hand,
| (3.3) |
On the other hand,
| (3.4) |
Consider the result (iv). For any , we have
Hence, is Lipschitz continuous with Lipschitz constant .
Finally, we prove the result (v). It follows from the result (iii) that is semismooth on [32]. Note that is arbitrarily many times differentiable for all with and hence strongly semismooth at these points. Therefore, it is sufficient to show that it is strongly semismooth at . For any , is differentiable at , and hence, . In addition, by Lemma 2.1, the classic directional derivative of at exists and
from which we have
Then the result follows from Lemma 2.2. ∎
3.2 The reformulation of GAVE (1.1)
In this subsection, based on the earlier subsection, we will give a reformulation of GAVE (1.1) and explore some of its properties.
Let , we first define the function as
| (3.5) |
where is defined by
with being the smoothing function given in (3.1). According to Proposition 3.1 (i), it holds that
| (3.6) |
Then it follows from (3.6) that solving GAVE (1.1) is equivalent to solving the system of nonlinear equations . Before giving the algorithm for solving , we will give some properties of the function .
Proposition 3.2.
Let be defined by (3.5), then we have
-
(i)
is continuously differentiable on , and when and (for all ) or , the Jacobian matrix of is given by
(3.7) with
(3.8) -
(ii)
is strongly semismooth on
Proof.
The result (i) holds from Proposition 3.1 (ii).
Now we turn to prove the result (ii). Since is strongly semismooth on if and only if its component function , , are [32], and the composition of strongly semismooth functions is a strongly semismooth function [9, Theorem 19], the result (ii) follows from Proposition 3.1 (v) and the fact that a continuously differentiable function with a Lipschitz continuous gradient is strongly semismooth [14]. ∎
3.3 The non-monotone smoothing Newton algorithm for GAVE (1.1)
Now we are in position to develop a non-monotone smoothing Newton algorithm to solve the system of nonlinear equations , and so is GAVE (1.1).
Let be given in (3.5) and define the merit function by
Clearly, solving the system of nonlinear equations is equivalent to solving the following unconstrained optimization problem
with the vanished objective function value. We now propose a non-monotone smoothing Newton algorithm to solve by minimizing the merit function , which is described in Algorithm 1.
| (3.9) |
| (3.10) |
| (3.11) |
| (3.12) |
Remark 3.1.
Before ending this section, we will show that Algorithm 1 is well-defined. To this end, we need the following lemma.
Proof.
Then we have the following theorem.
Theorem 3.1.
Proof.
We will prove it by mathematical induction. Suppose that , and for some . Since , it follows from Lemma 3.1 that is nonsingular. Hence, can be uniquely determined by (3.9). If , then Algorithm 1 terminates. Otherwise, implies that , from which and the second equation in (3.12) we have . In the following, we divide our proof in three parts.
Firstly, we will show that . On one hand, if is generated by step , it follows from (3.9) that . On the other hand, if is generated by step , we first show that there exists at least a nonnegative integer satisfying (3.11). On the contrary, for any nonnegative integer , we have
| (3.13) |
which together with gives
Since is differentiable at and , by letting in the above inequality, we have
| (3.14) |
In addition, from (3.9) we have
| (3.15) |
Since and , (3.15) implies that , which contradicts to (3.14). Therefore, there exists such that in step . In this case, it follows from (3.9) that .
Secondly, we will show that . Indeed, if is generated by step , then it follows from and (3.10) that . Otherwise, by step , we can also obtain . In fact, implies that . Thereby, (3.11) implies that . Consequently, and the first equation in (3.12) imply
Finally, we will show that . As mentioned earlier, we have by step and by step , respectively. For the latter, since and , . In a word, . In addition, it follows from and the first equation in (3.12) that
from which and we obtain .
The proof is completed by letting , and . ∎
4 Convergence analysis
In this section, we will analyze the convergence of Algorithm 1. In what follows, we assume that for all . To establish the global convergence of Algorithm 1, we need the following lemmas.
Lemma 4.1.
Proof.
Proof.
We first prove that the level set
is bounded for any . On the contrary, there exists a sequence such that and , where is some constant. Since
| (4.1) |
we can conclude that is bounded. It follows from this and the unboundedness of that . Since the sequence is bounded, it has at least one accumulation point . Then, there exists a subsequence such that with . It follows from the continuity of the -norm that . In the following, we remain . From (4.1), we have
| (4.2) |
Since
from the boundedness of , we have
Hence, by letting in (4.2), we have , i.e., . Since , it follows from Lemma 4.3 that is nonsingular. Thus, we have , which contradicts to the fact that .
If is generated by Algorithm 1, then for all . Hence, is bounded based on the aforementioned disscussion. ∎
Remark 4.1.
The proof of Lemma 4.2 is inspired by that of [40, Theorem 2.3], which was considered in the case that the interval matrix is regular. In addition, similar to the proof of [29, Lemma 4.1], the boundedness of can be derived under the assumption that . Our result here seems more general than those in [29, Lemma 4.1].
Now we show the global convergence of Algorithm 1.
Theorem 4.1.
Proof.
Lemma 4.2 implies the existence of the accumulation point of generated by Algorithm 1. Let be any accumulation point of , then there exists a subsequence of converging to . For convenience, we still denote the subsequence by .
By Lemma 4.1, is convergent because it is monotonically decreasing. Thus, there exists a constant such that . As for all , provided that . Then, from the continuity of we have . In the following, we assume that and derive a contradiction.
According to the first equation in (3.12), we have
| (4.3) |
By the fact that , we have . Based on Theorem 3.1 and Lemma 4.1, we have . Since , is nonsingular and is continuously differentiable at .
Let . We claim that must be a finite set. In fact, if is an infinite set, then , i.e., holds for infinitely many . By letting with , we have . This leads to a contradiction due to and . Hence, we can suppose that there exists an index such that for all . Then, for all , (generated by step ) satisfies , i.e.,
from which and (4.3) we have .
On one hand, if for all with being a fixed constant, then , which implies that
| (4.4) |
Here and in the sequel, is the unique solution of .
On the other hand, has a subsequence converging to . Without loss of generality, we may assume that . Let , then . Moreover, for all , it follows from the definition of and Theorem 3.1 that
Thus,
By letting in the above inequality, we have
| (4.5) |
Under Assumption 2.1, GAVE (1.1) has a unique solution and thus Lemma 4.2 and Theorem 4.1 imply that the sequence generated by Algorithm 1 has a unique accumulation and . In the following, we will discuss the local quadratic convergence of Algorithm 1.
Lemma 4.3.
Proof.
5 Numerical results
In this section, we will present two numerical examples to illustrate the performance of Algorithm 1. Three algorithms will be tested, i.e., Algorithm 1 (denoted by “NSNA”), the monotone smoothing Newton algorithm proposed by Jiang and Zhang [29] (denoted by “JZ-MSNA”) and the monotone smoothing Newton algorithm proposed by Tang and Zhou [40] (denoted by “TZ-MSNA”). All experiments are implemented in MATLAB R2018b with a machine precision on a PC Windows 10 operating system with an Intel i7-9700 CPU and 8GB RAM.
We will apply the aforementioned algorithms to solve GAVE (1.1) arising from HLCP. Given and , HLCP is to find a pair such that
| (5.1) |
The equivalent relationship between GAVE (1.1) and HLCP (5.1) can be found in [26, Proposition 1].
Obviously, when , matrices and in Example 5.1 are symmetric positive definite while the corresponding matrices in Example 5.2 are nonsymmetric positive definite. Moreover, it is easy to verify that has the column -property [27], and thus HLCP (5.1) has a unique solution for any [37, Theorem 2]. Correspondingly, GAVE (1.1) with and satisfies Assumption 2.1 and has a unique solution for any .
In both examples, we define with
In addition, three sets of values of and are used, i.e., , and .
For NSNA, we set and choose such that , and . For JZ-MSNA, we set and choose to satisfy the conditions needed for this algorithm [29] (we refer to [29] for the definition of ). For TZ-MSNA, as in [40], we set and . For all methods, and methods are stopped if or the maximum number of iteration step is exceeded.
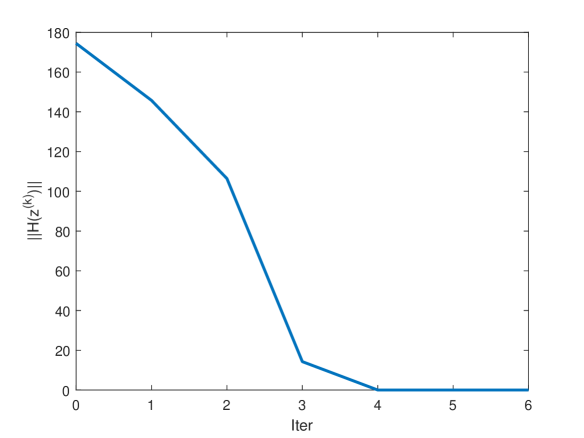
For Example 5.1, numerical results are shown in Tables 1-3, from which we can find that NSNA is better than JZ-MSNA and TZ-MSNA in terms of (the number of iterations) and (the elapsed CPU time in seconds). Figure 1 plots the convergence curves of the tested methods, from which the monotone convergence properties of all methods are shown222For JZ-MSNA and TZ-MSNA, is defined as in (3.5) with .. For Example 5.2, numerical results are shown in Tables 4-6, from which we can also find that NSNA is superior to JZ-MSNA and TZ-MSNA in terms of and . Figure 2 plots the convergence curves of the tested methods, from which the monotone convergence properties of JZ-MSNA and TZ-MSNA are shown and the nonmonotone convergence property of NSNA occurs. In conclusion, under our setting, NSNA is a competitive method for solving GAVE (1.1).
| Method | |||||
|---|---|---|---|---|---|
| NSNA | 5 | 5 | 6 | 6 | |
| 0.0044 | 0.0619 | 0.3364 | 0.9985 | ||
| JZ-MSNA | |||||
| TZ-MSNA | |||||
| Method | |||||
|---|---|---|---|---|---|
| NSNA | 5 | 6 | 7 | 7 | |
| 0.0035 | 0.0745 | 0.3975 | 1.3254 | ||
| JZ-MSNA | |||||
| TZ-MSNA | |||||
| Method | |||||
|---|---|---|---|---|---|
| NSNA | 3 | 3 | 3 | 3 | |
| 0.0021 | 0.0361 | 0.1536 | 0.5444 | ||
| JZ-MSNA | |||||
| TZ-MSNA | |||||
| Method | |||||
|---|---|---|---|---|---|
| NSNA | 4 | 5 | 6 | 6 | |
| 0.0031 | 0.0642 | 0.3332 | 1.0440 | ||
| JZ-MSNA | |||||
| TZ-MSNA | |||||
| Method | |||||
|---|---|---|---|---|---|
| NSNA | 6 | 7 | 7 | 8 | |
| 0.0047 | 0.0869 | 0.4074 | 1.4394 | ||
| JZ-MSNA | |||||
| TZ-MSNA | |||||
| Method | |||||
|---|---|---|---|---|---|
| NSNA | 3 | 3 | 3 | 3 | |
| 0.0024 | 0.0388 | 0.1623 | 0.5437 | ||
| JZ-MSNA | |||||
| TZ-MSNA | |||||

|

|

|

|

|

|

|

|

|

|
|

|

|

|

|

|

|

|
6 Conclusions
In this paper, a non-monotone smoothing Newton method is proposed to solve the system of generalized absolute value equations. Under a weaker assumption, we prove the global and the local quadratic convergence of our method. Numerical results demonstrate that our method can be superior to two existing methods in some situations.
References
- [1] M. Achache, N. Hazzam. Solving absolute value equation via complementarity and interior-point methods, J. Nonlinear Funct. Anal., 39, 2018.
- [2] N. Anane, M. Achache. Preconditioned conjugate gradient methods for absolute value equations, J. Numer. Anal. Approx. Theroy, 49: 3–14, 2020.
- [3] L. Caccetta, B. Qu, G.-L. Zhou. A globally and quadratically convergent method for absolute value equations, Comput. Optim. Appl., 48(1): 45–58, 2011.
- [4] C.-R. Chen, Y.-N. Yang, D.-M. Yu, D.-R. Han. An inverse-free dynamical system for solving the absolute value equations, Appl. Numer. Math., 168: 170–181, 2021.
- [5] F.H. Clarke. Optimization and Nonsmooth Analysis, Wiley, New York, 1983.
- [6] R.W. Cottle, J.-S. Pang, R.E. Stone. The Linear Complementarity. Classics in Applied Mathematics, SIAM, Philadelphia, 2009.
- [7] J.Y.B. Cruz, O.P. Ferreira, L.F. Prudente. On the global convergence of the inexact semi-smooth Newton method for absolute value equation, Comput. Optim. Appl., 65(1): 93–108, 2016.
- [8] V. Edalatpour, D. Hezari, D.K. Salkuyeh. A generalization of the Gauss-Seidel iteration method for solving absolute value equations, Appl. Math. Comput., 293: 156–167, 2017.
- [9] A. Fischer. Solution of monotone complementarity problems with locally Lipschitzian functions, Math. Program., 76: 513–532, 1997.
- [10] X.-M. Gu, T.-Z. Huang, H.-B. Li, S.-F. Wang, L. Li. Two CSCS-based iteration methods for solving absolute value equations, J. Appl. Anal. Comput., 7(4): 1336–1356, 2017.
- [11] F.K. Haghani. On generalized Traub’s method for absolute value equations, J. Optim. Theory Appl., 166: 619–625, 2015.
- [12] M. Hladík. Bounds for the solution of absolute value equations, Comput. Optim. Appl., 69: 243–266, 2018.
- [13] S.-L. Hu, Z.-H. Huang. A note on absolute value equations, Optim. Lett., 4: 417–424, 2010.
- [14] S.-L. Hu, Z.-H. Huang, J.-S. Chen. Properties of a family of generalized NCP-functions and a derivative free algorithm for complementarity problems, J. Comput. Appl. Math., 230: 69–82, 2009.
- [15] S.-L. Hu, Z.- H. Huang, Q. Zhang. A generalized Newton method for absolute value equations associated with second order cones, J. Comput. Appl. Math., 235: 1490–1501, 2011.
- [16] Z.-H. Huang, S.-L. Hu, J.-Y. Han. Convergence of a smoothing algorithm for sysmetric cone complementarity problems with a nonmonotone line search, Sci. China Ser. A: Math., 52: 833–848, 2009.
- [17] Y.-F. Ke. The new iteration algorithm for absolute value equation, Appl. Math. Lett., 99: 105990, 2020.
- [18] Y.-F. Ke, C.-F. Ma. SOR-like iteration method for solving absolute value equations, Appl. Math. Comput., 311: 195–202, 2017.
- [19] Y.-Y. Lian, C.-X. Li, S.-L. Wu. Weaker convergent results of the generalized Newton method for the generalized absolute value equations, J. Comput. Appl. Math., 338: 221–226, 2018.
- [20] O.L. Mangasarian. Absolute value programming, Comput. Optim. Appl., 36(1): 43–53, 2007.
- [21] O.L. Mangasarian. Absolute value equation solution via concave minimization, Optim. Lett., 1(1): 3–8, 2007.
- [22] O.L. Mangasarian. A generalized Newton method for absolute value equations, Optim. Lett., 3(1): 101–108, 2009.
- [23] O.L. Mangasarian. Knapsack feasibility as an absolute value equation solvable by successive linear programming, Optim. Lett., 3: 161–170, 2009.
- [24] O.L. Mangasarian, R.R. Meyer. Absolute value equations, Linear Algebra Appl., 419: 359–367, 2006.
- [25] A. Mansoori, M. Erfanian. A dynamic model to solve the absolute value equations, J. Comput. Appl. Math., 333: 28–35, 2018.
- [26] F. Mezzadri. On the solution of general absolute value equations, Appl. Math. Lett., 107: 106462, 2020.
- [27] F. Mezzadri, E. Galligani. Modulus-based matrix splitting methods for horizontal linear complementarity problems, Numer. Algor., 83: 201–219, 2020.
- [28] X.-H. Miao, J.-T. Yang, B. Saheya, J.-S. Chen. A smoothing Newton method for absolute value equation associated with second-order cone, Appl. Numer. Math., 120: 82–96, 2017.
- [29] X.-Q. Jiang, Y. Zhang. A smoothging-type algorithm for absolute value equations, J. Ind. Manag. Optim., 9(4): 789–798, 2013.
- [30] O. Prokopyev. On equivalent reformulations for absolute value equations, Comput. Optim. Appl., 44(3): 363–372, 2009.
- [31] L.-Q. Qi. Convergence analysis of some algorithms for solving nonsmooth equations, Math. Oper. Res., 18: 227–244, 1993.
- [32] L.-Q. Qi, D.-F. Sun, G.-L. Zhou. A new look at smoothing Newton methods for nonlinear complementarity problems and box constrained variational inequalities, Math. Program., Ser. A, 87: 1–35, 2000.
- [33] J. Rohn. Systems of linear interval equations, Linear Algerbra Appl., 126: 39–78, 1989.
- [34] J. Rohn. A theorem of the alternatives for the equation , Linear Multilinear Algebra, 52(6): 421–426, 2004.
- [35] B. Seheya, C.T. Nguyen, J.-S. Chen. Neural network based on systematically generated smoothing functions for absolute value equation, J. Appl. Math. Comput., 61: 533–558, 2019.
- [36] S. Shahsavari, S. Ketabchi. The proximal mathods for solving absolute value equation, Numer. Algebra Control Optim., 11: 449–460, 2021.
- [37] R. Sznajder, M.S. Gowda. Generalizations of - and -properties; Extended vertical and horizontal linear complementarity problems, Linear Algebra Appl., 223/224: 695–715, 1995.
- [38] J.-Y. Tang. A variant nonmonotone smoothing algorithm with improved numerical results for large-scale LWCPs, Comp. Appl. Math., 37: 3927–3936, 2018.
- [39] J.-Y. Tang, H.-C. Zhang. A nonmonotone smoothing Newton algorithm for weighted complementarity problem, J. Optim. Theory Appl., 189: 679–715, 2021.
- [40] J.-Y. Tang, J.-C. Zhou. A quadratically convergent descent method for the absolute value equation , Oper. Res. Lett., 47: 229–234, 2019.
- [41] J.-Y. Tang, J.-C. Zhou. Quadratic convergence analysis of a nonmonotone Levenberg-Marquardt type method for the weighted nonlinear complementarity problem, Comput. Optim. Appl., 80: 213–244, 2021.
- [42] A. Wang, Y. Cao, J.-X. Chen. Modified Newton-type iteration methods for generalized absolute value equations, J. Optim. Theory Appl., 181: 216–230, 2019.
- [43] S.-L. Wu, C.-X. Li. The unique solution of the absolute value equations, Appl. Math. Lett., 76: 195–200, 2018.
- [44] S.-L. Wu, C.-X. Li. A note on unique solvability of the absolute value equation, Optim. Lett., 14: 1957–1960, 2020. https://doi.org/10.1007/s11590-019-01478-x.
- [45] S.-L. Wu, S.-Q. Shen. On the unique solution of the generalized absolute value equation, Optim. Lett., 15: 2017–2024, 2021.
- [46] D.-M. Yu, C.-R. Chen, D.-R. Han. A modified fixed point iteration method for solving the system of absolute value equations, Optimization, 2020. https://doi.org/10.1080/02331934.2020.1804568.
- [47] N. Zainali, T. Lotfi. On developing a stable and quadratic convergent method for solving absolute value equation, J. Coput. Appl. Math., 330: 742–747, 2018.
- [48] M. Zamani, M. Hladík. A new concave minimization algorithm for the absolute value equation solution, Optim. Lett., 2021. https://doi.org/10.1007/s11590-020-01691-z.
- [49] C. Zhang, Q.-J. Wei. Global and finite convergence of a generalized Newton method for absolute value equations, J. Optim. Theory Appl., 143: 391–403, 2009.
- [50] H.-C. Zhang, W.W. Hager. A nonmonotone line search technique and its application to unconstrained optimization, SIAM J. Optim., 14: 1043–1056, 2004.
- [51] H.-Y. Zhou, S.-L. Wu, C.-X. Li. Newton-based matrix splitting method for generalized absolute value equation, J. Comput. Appl. Math., 394: 113578, 2021.
- [52] J.-G. Zhu, H.-W. Liu, C.-H. Liu. A family of new smoothing functions and a nonmonotone smoothing Newton method for the nonlinear complementarity problems, J. Appl. Math. Comput., 37: 647–662, 2011.