A Note on Parameter Estimation for Misspecified Regression Models with Heteroskedastic Errors
Abstract
Misspecified models often provide useful information about the true data generating distribution. For example, if is a non–linear function of the least squares estimator is an estimate of , the slope of the best linear approximation to the non–linear function. Motivated by problems in astronomy, we study how to incorporate observation measurement error variances into fitting parameters of misspecified models. Our asymptotic theory focuses on the particular case of linear regression where often weighted least squares procedures are used to account for heteroskedasticity. We find that when the response is a non–linear function of the independent variable, the standard procedure of weighting by the inverse of the observation variances can be counter–productive. In particular, ordinary least squares may have lower asymptotic variance. We construct an adaptive estimator which has lower asymptotic variance than either OLS or standard WLS. We demonstrate our theory in a small simulation and apply these ideas to the problem of estimating the period of a periodic function using a sinusoidal model.
keywords:
[class=MSC]keywords:
T1The author thanks the Editor and two reviewers for their constructive comments.
t1Long’s work was supported by a faculty startup grant from Texas A&M University.
1 Introduction
Misspecified models are common. In prediction problems, simple, misspecified models may be used instead of complex models with many parameters in order to avoid overfitting. In big data problems, true models may be computationally intractable, leading to model simplifications which induce some level of misspecification. In many scientific domains there exist sets of well established models with fast computer implementations. A practitioner with a particular data set may have to choose between using one of these models (even when none are exactly appropriate) and devising, testing and implementing a new model. Pressed for time, the practitioner may use an existing misspecified model. In this work we study how to fit a misspecified linear regression model with heteroskedastic measurement error. Problems involving heteroskedastic measurement error and misspecified models are common in astronomy. We discuss an example in Section 2.
Suppose independent across and independent across for . Suppose
where with and , independent across and independent of and . Define
The parameter is the slope of the best fitting least squares line. The parameter may be of interest in several situations. For example, minimizes mean squared error in predicting from among all linear functions, ie . Define . The function is the non–linear component of .
When the model is correctly specified (ie ), weighted least squares (WLS) using the inverse of the observation variances as weights is asymptotically normal and has minimum asymptotic variance among all WLS estimators. In the case with model misspecification and , independent, we show that WLS estimators remain asymptotically normal. However weighting by the inverse of the observation variances can result in a larger asymptotic variance than other weightings, including ordinary least squares. Using the asymptotic variance formula we determine an optimal weighting which has lower asymptotic variance than standard WLS (using the inverse of the observation variances as weights) and OLS. The optimal weighting function has the form where is a function of the degree of model misspecification and the design. We find adaptive estimators for in the cases where the error variances are assumed known and where the error variances belong to one of groups with group membership known. We also briefly consider the case where and are dependent. In this setting the OLS estimator is consistent but weighted estimators are generally not consistent.
This work is organized as follows. In Section 2 we introduce a motivating problem from astronomy and offer some heuristic thinking about misspecified models and heteroskedasticity. For those readers primarily interested in the statistical theory, Section 2 can be skipped. In Section 3 we review some relevant literature and develop asymptotic results for the linear model. We present results for simulated data and the astronomy application in Section 4. We conclude in Section 5.
2 Misspecified Models and Heteroskedastic Error in Astronomy
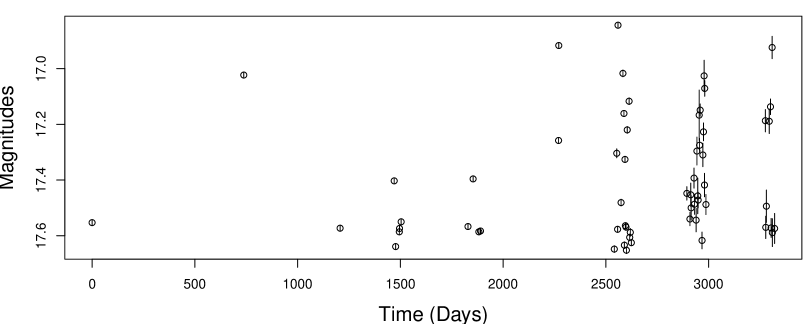
Periodic variables are stars that vary in brightness periodically over time. Figure 1a shows the brightness of a single periodic variable star over time. This is known as the light curve of the star. Two sigma uncertainties are plotted as vertical bars around each point. Magnitude is inversely proportional to brightness, so lower magnitudes are plotted higher on the y–axis. This is a periodic variable so the changes in brightness over time are periodic. Using this data one may estimate a period for the star. When we plot the brightness measurements as time modulo period (Figure 1b), the pattern in brightness variation becomes clear. Periodic variables play an important role in several areas of astronomy including extra–galactic distance determination and estimation of the Hubble constant [26, 21]. Modern surveys, such as OGLE-III, have collected hundreds of thousands of periodic variable star light curves [28].
Accurate period estimation algorithms are necessary for creating the folded light curve (Figure 1b). A common procedure for determining the period is to perform maximum likelihood estimation using some parametric model for light curve variation. One popular model choice is a sinusoid with harmonics. Let the data for a single periodic variable be where is the brightness at time , measured with known uncertainty . Magnitude variation is modeled as
| (2.1) |
where independent across . Here is the frequency, is the amplitude of the harmonic, and is the phase of the harmonic. Let and . Let be a grid of possible frequencies. The maximum likelihood estimate for frequency is
| (2.2) |
Generalized Lomb–Scargle (GLS) is equivalent to this estimator with [32]. The analysis of variance periodogram in [23] uses this model with a fast algorithm for computing .
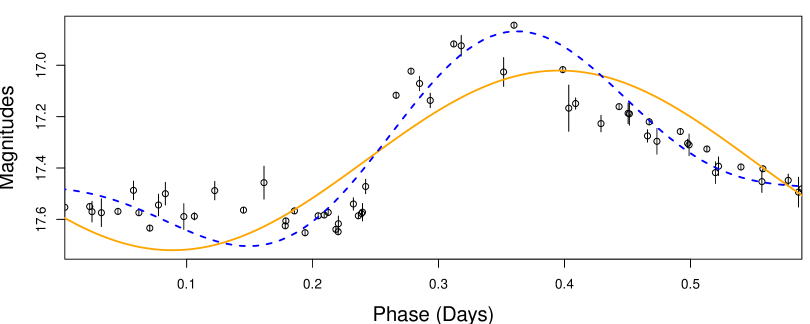
We used estimator (2.2) with to determine the period of the light curve in Figure 1a. The estimates for period were essentially the same for both and so in Figure 1b we folded the light curve using the estimate. The solid orange line is the maximum likelihood fit for the model (notice the sinusoidal shape). The blue dashed line is for the model.
While the period estimates are accurate, both models are misspecified. In particular, note that the vertical lines around the brightness measurements are four standard deviations () in width. If the model is correct, we would expect about 95% of these intervals to contain the maximum likelihood fitted curves. For the model, 10% of the intervals contain the fitted curve. For , 37% of observations contain the ML fitted curve. The source of model misspecification is the light curve shape which cannot be perfectly represented by a sinusoid with harmonics. The light curve has a long, slow decline and a sudden, sharp increase in brightness.
The parameter fits of misspecified models are estimates of an approximation. In the case, the parameter fits are the orange line in Figure 1b and the approximation is the sinusoid which is closest to the true light curve shape. In many cases this approximation may be useful. For example the period of the approximation may match the period of the light curve.
When fitting a misspecified model with heteroskedastic measurement error, one should choose a weighting which ensures the estimator has small variance and thus is likely close to the approximation. The use of the inverse of the observation variances as weights (in Equation (2.3)) is motivated by maximum likelihood theory under the assumption that the model is correct. However as we show in Section 3 for the linear model, these weights are generally not optimal when there is model misspecification.
As a thought experiment, consider the case where one observation has extremely small variance and other observations have much larger variance. The maximum likelihood fitted curve for this data will be very close to the observation with small variance. However the best sinusoidal approximation to the true function at this point may not be particularly close to the true function. Thus using the inverse of observation variances as weights may overweight observations with small variance in the case of model misspecification. We make these ideas precise in Section 3.3.
The choice of weights is not critical for the light curve in Figure 1a because it is well sampled (), so the period is easy to determine. However in many other cases light curves are more poorly sampled (), in which case weighting may affect period estimation accuracy.
2.1 Sinusoidal Fit and Linear Models
Finding the best fitting sinusoid is closely related to fitting a linear model. Using the sine angle addition formula we can rewrite the maximum likelihood estimator from Equation (2.2) as
The sum over can be simplified by noting the linearity of the model and reparameterizing. Let . Let and . Define . Let be a diagonal matrix where . Define
We rewrite the ML estimator as
Every frequency in the grid of frequencies determines a design matrix . At a particular , the which minimizes the objective function is the weighted least squares estimator
| (2.3) |
The frequency estimate may then be written as
| (2.4) |
Thus estimating frequency involves performing a weighted least squares regression (Equation (2.3)) at every frequency in the grid . The motivation for the procedure is maximum likelihood. As discussed earlier, in cases where the model is misspecified, there is no theoretical support for using as the weight matrix in either Equation (2.3) or (2.4).
3 Asymptotic Theory
3.1 Problem Setup and Related Literature
Let be the matrix with row equal to . Let . Let be the diagonal matrix of observation variances such that . Let be a diagonal positive definite matrix. The weighted least squares estimator is
In this work we seek which minimize error in estimating .
There is a long history of studying estimators for misspecified models, often in the context of sandwich estimators for asymptotic variances. In [10], it was shown that when the true data generating distribution is not in the model, the MLE converges to the distribution in the model which minimizes Kullback–Liebler divergence, ie
The asymptotic variance has a “sandwich” form which is not the inverse of the information matrix. [30] and [31] studied this behavior in the context of the linear regression model and the OLS estimator, proposing consistent estimators of the asymptotic variance. See [18] and [15] for sandwich estimators with improved finite sample performance and [27] for recent work on sandwich estimators in a Bayesian context. [2] provides a summary of sandwich estimators and proposes a bootstrap estimator for the asymptotic variance. By specializing our asymptotic theory from the weighted to the unweighted case, we rederive some of these results. However our focus is different in that we find weightings for least squares which minimize asymptotic variance, rather than estimating the asymptotic variance of unweighted procedures.
Other work has focused on correcting model misspecification, often by modeling deviations from a parametric regression function with some non–parametric model. [1] studied model misspecification when response variances are known up to a constant due to repeated measurements, ie where is known. A Gaussian prior was placed on and the non–linear component was modeled as being drawn from a Gaussian process. See [13] for an example with homoskedastic errors in the context of computer simulations. See [6] for an example in astronomy with known heteroskedastic errors. Our focus here is different in that instead of correcting model misspecification we consider how weighting observations affects estimation of the linear component of .
Heteroskedasticity in the partial linear model
is studied in [17] and [16]. Here for some function . The parameter is some unknown function. The response depends on the covariates linearly and the covariates nonlinearly. When is estimated poorly, weighting by the inverse of the observation variances causes parameter estimates of to be inconsistent. In contrast, ignoring observation variances leads to consistent estimates of . Qualitatively these conclusion are similar to our own in that they caution against using weights in the standard way.
3.2 Asymptotic Results
Our asymptotic theory makes assumptions on the form of the weight matrix.
Assumptions 1 (Weight Matrix).
Suppose is a positive definite diagonal matrix with elements
where , , is a bounded function, is a discrete random variable independent of and , is for all and , and is uniformly in bounded above by an random variable (ie where is ).
These assumptions include both the ordinary least squares (OLS) estimator where and the standard weighted least squares estimator where (assuming ). In both these cases and for all . These additional terms are used in Sections 3.5 and 3.6 to construct adaptive estimators for the known and unknown variance cases.
Assumptions 2 (Moment Conditions).
Suppose and are independent, the design is full rank, and for all . Assume , , , and the variances are bounded below by a positive constant .
The major assumption here is independence between and . We address dependence in Section 3.7.
See Section A.1 for a proof. If the response is linear () then the variance is
Setting we have . This is the standard weighted least squares estimator. This can be shown to minimize the variance using the Cauchy Schwartz inequality. With , the asymptotic variance can be rewritten
| (3.2) |
This is the sandwich form of the covariance for OLS derived in [30] and [31] (see [2], specifically Equations 1-3), valid even when and are not independent.
3.3 OLS and Standard WLS
For notational simplicity define
The asymptotic variances for OLS () and standard WLS () are
Each of these asymptotic variances is composed of the same two terms. The term is caused by model misspecification while the term is the standard asymptotic variance in the case of no model misspecification. The coefficient on is larger for because by Jensen’s Inequality. The coefficient on is larger for because . The relative merits of OLS and standard WLS depend on the size of the coefficients and the precise values of and . However, qualitatively, OLS and standard WLS suffer from high asymptotic variance in opposite situations which depend on the distribution of the errors. To make matters concrete, consider error distributions of the form
where are small non–negative numbers and is large. Note that and do not depend on .
-
•
: In this situation the error standard deviation is usually and occasionally some large value . The result is large asymptotic variance for OLS. Since ,
For large this will be large. In contrast the coefficients on and for standard WLS can be bounded. For the coefficient on we have . The coefficient on with is
Therefore
In summary, standard WLS performs better than OLS when there are a small number of observations with large variance.
-
•
: In this situation the error standard deviation is usually and occasionally some small value . For standard WLS with large and small, the coefficient for is
Thus the asymptotic variance induced by model misspecification will be large for standard WLS. In contrast, we can bound the asymptotic variance above for OLS, independently of and . Since , and
The case where both and are non–zero presents problems for both OLS and standard WLS. For example if , both OLS and standard WLS can be made to have large asymptotic variance by setting small and large. In the following section we construct an adaptive weighting which improves upon both OLS and standard WLS.
3.4 Improving on OLS and Standard WLS
Let be a linear function from the set of matrices to such that whenever is positive definite. We seek some weighting for which (recall that is the asymptotic variance) is lower than OLS and standard WLS. Natural choices for include the trace (minimize the sum of variances of the parameter estimates) and the (minimize the variance of one of the parameter estimates).
Theorem 3.2.
Section A.2 contains a proof. The proportionality is due to the fact that the estimator is invariant to multiplicative scaling of the weights.
Corollary 3.1.
Under Assumptions 2,
with strict inequality if is positive definite and the distribution of is not a point mass.
A proof is contained in Section A.3. Thus if we can construct a weight matrix which satisfies Assumptions 1 with , then by the preceding theorem the associated weighted estimator will have lower asymptotic variance then either OLS or standard WLS. We now construct such a weighting in the case of known and unknown error variances.
3.5 Known Error Variances
With the known we only need to estimate and in in Equation (3.3). Let . Let
Let be a root consistent estimator of (eg is root consistent by Theorem 3.1) and let
Let
Then we have
| (3.4) |
The estimated optimal weighting matrix is the diagonal matrix with diagonal elements
| (3.5) |
A few notes on this estimator:
-
•
The term is an estimate of . These estimates are weighted by . The term normalizes the weights. This weighting is motivated by the fact that
Analysis of the first order term shows
and
Thus by weighting the estimates by , we can somewhat account for the different variances. Unfortunately since the variance depends on , , and which are unknown, it is not possible to weight by exactly the inverse of the variances. Other weightings are possible and in general adaptivity will hold.
-
•
Since and are positive semi–definite, . Thus for estimating , we use the maximum of a plug–in estimator and (Equation (3.4)).
See Section A.4 for a proof. Theorem 3.3 shows it is possible to construct better estimators than both OLS and standard WLS. In practice, it may be best to iteratively update estimates of starting with a known root consistent estimator such as . We take this approach in our numerical simulations in Section 4.1.
For the purposes of making confidence regions we need estimators of the asymptotic variance. Above we developed consistent estimators for and . We take a plug–in approach to estimating the asymptotic variance for a particular weighting . Specifically
| (3.6) |
We also define the oracle which is the same as but uses and rather than and . While cannot be used in practice, it is useful for evaluating the performance of in simulations.
Finally suppose the error variance is known up to a constant, i.e. where is known but and are unknown. In the case without model misspecification, one can simply use weights since the weighted estimator is invariant up to rescaling of the weights. The situation is more complicated when model misspecification is present. Simulations and informal mathematical derivations (not included in this work) suggest that replacing the with in Equation (3.5) results in weights that are suboptimal. In particular, when (underestimated errors), the resulting weights are closer to OLS than optimal while if (overestimated errors), the resulting weights are closer to standard WLS than optimal.
3.6 Unknown Error Variances
Suppose for observation we observe , the group membership of observation . Observations in group have the same (unknown) variance . See [8], [5], and [9] for work on grouped error models in the case where the response is linear.
The are assumed independent of and , with probability mass function (supported on ). While the for are fixed unknown parameters, the probability mass function induces the probability distribution function on . So we can define
for any function .
Theorem 3.1 shows that even if the were known, standard weighted least squares is not generally optimal for estimating in this model. It is not possible to estimate as proposed in Section 3.5 because that method requires knowledge of . However we can re–express the optimal weight function as
where the last equality defines . Note that is a fixed unknown parameter, not a random variable. One can estimate with and with
where is a root consistent estimator of (for example suffices by Theorem 3.1). The estimated weight matrix is diagonal with
| (3.7) |
See Section A.5 for a proof. Thus in the case of unknown errors it is possible to construct an estimator which outperforms standard WLS and OLS. As is the case with known errors, one can iteratively update , starting with some (possibly inefficient) root consistent estimate of .
For estimating the asymptotic variance we cannot use Equation (3.6) because that method required an estimate of , a quantity for which we do not have an estimate in the unknown error variance setting. Instead note that the asymptotic variance of Equation (3.1) may be rewritten
Thus a natural estimator for the asymptotic variance is
| (3.8) |
3.7 Dependent Errors
Suppose one drops the independence assumption between and . This will be the case whenever the error variance is a function of , a common assumption in the heteroskedasticity literature [3, 4, 12]. We require the weight matrix to be diagonal positive definite with diagonal elements , some function of the error variance. The estimator for is
Recalling we write for , we have the following result.
Theorem 3.5.
Assuming , , and exist and is positive definite,
| (3.9) |
See Section A.6 for a proof. If and are independent then the r.h.s is and the estimator is consistent (as demonstrated by Theorem 3.1). Interestingly the estimator is also consistent if one lets (OLS), regardless of the dependence structure between and . However weighted estimators will not generally be consistent (including standard WLS). This observation suggests the OLS estimator may be preferred in the case of dependent errors. We show an example of this situation in the simulations of Section 4.1.
4 Numerical Experiments
4.1 Simulation




| WLS | OLS | |||
|---|---|---|---|---|
| 0.536 | 0.945 | 0.807 | —– | |
| 0.393 | 0.96 | 0.843 | 0.759 | |
| 0.925 | 0.945 | 0.956 | —– |
We conduct a small simulation study to demonstrate some of the ideas presented in the last section.111Code to reproduce the work in this section can be accessed at http://stat.tamu.edu/~jlong/hetero.zip or by contacting the author. Consider modeling the function using linear regression with an intercept term. Let . The best linear approximation to is where and . We first suppose is drawn independently from from a discrete probability distribution such that and . Since has support on a finite set of values, we can consider the cases where is known (Section 3.5) and where only the group of observation is known (Section 3.6). We let be the trace of the matrix.
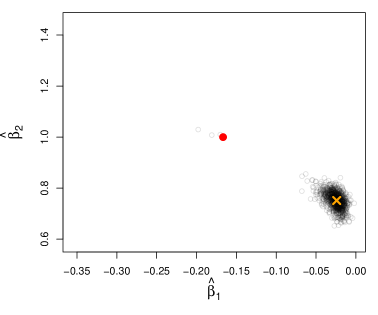
We generate samples of size , times and make scatterplots of the parameter estimates using weights (standard WLS), (OLS), , and . The OLS estimator does not require any knowledge about the . The fourth estimator uses only the group of observation . For the two adaptive estimators, we use as an initial root consistent estimator of and iterate twice to obtain the weights.
Results are shown in Figure 2. The red ellipses are the asymptotic variances. The results show that OLS outperforms standard WLS. Estimating the optimal weighting with or without knowledge of the variances outperforms both OLS and standard WLS. Exact knowledge of the weights (c) somewhat outperforms only knowing the group membership of the variances (d).
We construct 95% confidence regions using estimates of the asymptotic variance and determine the fraction of times (out of the simulations) that the true parameters are in the confidence regions. Recall that in Section 3.5 we proposed (Equation (3.6)) as well as the oracle for estimating the asymptotic variance when the error variances are known. In Section 3.6 we proposed (Equation (3.8)) when the error variances are unknown. The estimator can also be used when the error variances are known. We use all three of these methods for constructing confidence regions for standard WLS, OLS, and . For we use only because requires knowledge of . Table 1 contains the results. While for OLS the nominal coverage probability is approximately attained, the other methods are anti–conservative for and . Estimates for WLS are especially poor. The performance of the oracle is rather good, suggesting that the problem lies in estimating and .

To illustrate the importance of the , independence assumption, we now consider the case where is a function of . Specifically,
All other parameters in the simulation are the same as before. Note that the marginal distribution of is the same as the first simulation. We know from Section 3.7 that weighted estimators may no longer be consistent. In Figure 3 we show a scatter plot of parameter estimates using standard WLS and OLS. We see that the WLS estimator has low variance but is highly biased. The OLS estimator is strongly preferred.
4.2 Analysis of Astronomy Data
[25] identified 483 RR Lyrae periodic variable stars in Stripe 82 of the Sloan Digital Sky Survey III. We obtained 450 of these light curves from a publicly available data base [11].222We use only the g–band data for determining periods. Figure 1a shows one of these light curves. These light curves are well observed (), so it is fairly easy to estimate periods. For example, [25] used a method based on the Supersmoother algorithm of [7]. However there is interest in astronomy in developing period estimation algorithms that work well on poorly sampled light curves [29, 19, 14, 24]. Well sampled light curves offer an opportunity to test period estimation algorithms because ground truth is known and they can be artificially downsampled to create realistic simulations of poorly sampled light curves.
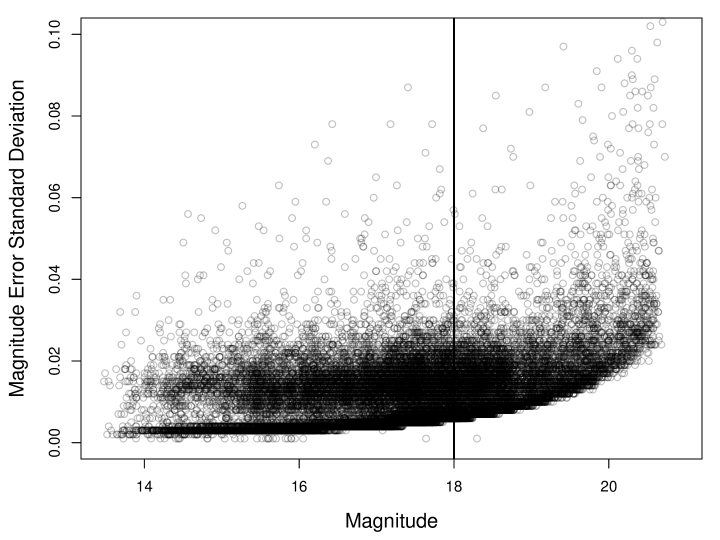
As discussed in Section 2, each light curve can be represented as where is the time of the brightness measurement made with uncertainty . In Figure 4 we plot magnitude error () against magnitude () for all observations of all 450 light curves. For higher magnitudes (less bright observations), the observation uncertainty is larger. In an attempt to ensure independence between and assumed by our asymptotic theory, we use only the bright stars in which all magnitudes are below 18 (left of the vertical black line in Figure 4). In this region, magnitude and magnitude error are approximately independent. This reduces the sample to 238 stars. We also ran our methods on the larger set of stars. Qualitatively, the results which follow are similar.
In order to simulate challenging period recovery settings, we downsample each of these light curves to have . We estimate periods using sinusoidal models with harmonics. For each model we consider three methods for incorporating the error variances. In the first two methods, we weight by the the inverse of the observations variances () as suggested by maximum likelihood for correctly specified models and the identity matrix (). Since this is not a linear model, it is not possible to directly use the weighting idea proposed in Section 3.5. We propose a modification for the light curve scenario. We first fit the model using identity weights and determine a best fit period. We then determine the optimal weighting at this period following the procedure of Section 3.5. Recall from Section 2 that at a fixed period, the sinusoidal models are linear. Using the new weights, we then refit the model and estimate the period. A period estimate is considered correct if it is within 1% of the true value.
| 10 | 0.09 | 0.16 | 0.15 | 0.13 | 0.11 | 0.11 | 0.03 | 0.03 | 0.03 |
|---|---|---|---|---|---|---|---|---|---|
| 20 | 0.46 | 0.58 | 0.59 | 0.63 | 0.68 | 0.69 | 0.69 | 0.77 | 0.77 |
| 30 | 0.64 | 0.78 | 0.79 | 0.71 | 0.82 | 0.83 | 0.82 | 0.86 | 0.85 |
| 40 | 0.75 | 0.79 | 0.79 | 0.80 | 0.85 | 0.85 | 0.87 | 0.92 | 0.92 |
The fraction of periods estimated correctly are contained in Table 2. In nearly all cases ignoring observation uncertainties () outperforms using the inverse of the observation variances as weights (). The improvement is greatest for the model and least for the model, possibly due to the decreasing model misspecification as the number of harmonics increases. The very poor performance of the models with 10 magnitude measurements is due to overfitting. With , there are 8 parameters which is too complex a model for 10 observations. Optimizing the observation weights does not appear to improve performance over not using weights. This is potentially due to the fact that the model is highly misspecified (see Figure 1b).
5 Discussion
5.1 Other Problems in Astronomy
Heteroskedastic measurement error is ubiquitous in astronomy problems. In many cases some degree of model misspecification is present. In this work, we focused on the problem of estimating periods of light curves. Other problems include:
-
•
[22] observe the brightness of galaxies through several photometric filters. Variances on the brightness measurements are heteroskedastic. The brightness measurements for each galaxy are matched to a set of templates. Assuming a normal measurement error model, maximum likelihood would suggest weighting the difference between observed brightness and template brightness by the inverse of the observation variance. In personal communication, [22] stated that galaxy templates contained some level of misspecification. [22] addressed this issue by inflating observation variances, using weights of instead of . The choice of was based on qualitative analysis of model fits. Section 3.3 provides a theoretical justification for this practice.
-
•
[20] models spectra of galaxies as linear combinations of simple stellar populations (SSP) and non–linear distortions. While parameters which define an SSP are continuous, a discrete set of SSPs are selected as prototypes and the galaxies are modeled as linear combinations of the prototypes. This is done for computational efficiency and to avoid overfitting. However prototype selection introduces some degree of model misspecification as the prototypes may not be able to perfectly reconstruct all galaxy spectra. Galaxy spectra are observed with heteroskedastic measurement error and the inverse of the observation variances are used as weights when fitting the model (see Equation 2.2 in [20]).
5.2 Conclusions
We have shown that WLS estimators can perform poorly when the response is not a linear function of the predictors because observations with small variance have too much influence on the fit. In the misspecified model setting, OLS suffers from the usual problem that observations with large variance induce large asymptotic variance in the parameter estimates. For cases in which some observations have very small variance and other observations have very large variance, procedures which optimize the weights may achieve significant performance improvements as shown in the simulation in Section 4.1.
This work primarily focused on the case where and are independent. However results from Section 3.7 showed that when independence fails, weighted estimators will typically be biased. This additional complication makes OLS more attractive relative to weighted procedures.
For practitioners we recommend caution in using the inverse of the observation variances as weights when model misspecification is present. As a check, practitioners could fit models twice, with and without weights, and compare performance based on some metric. More sophisticated methods, such as specifically tuning weights for optimal performance may be attempted. Our asymptotic theory provides guidance on how to do this in the case of the linear model.
Appendix A Technical Notes
A.1 Proof of Theorem 3.1
Let be the function applied to the rows of . We sometimes write for . We have
In part 1 we show that
In part 2 we show that
Thus by Slutsky’s Theorem
-
1.
Show : Recall that by Assumptions 1
where is a bounded function, are , and the is uniformly (in ) bounded by an random variable.
We show that . Noting that because is bounded and the have second moments we have
Using the fact that where is we have
Thus
where the last equality follows from the facts that and are independent. The desired result follows from the continuous mapping theorem.
-
2.
Show :
because and is independent of all other terms and mean . We have
So . The desired result now follows from the CLT and showing that . Note that
Thus
because the terms inside the summand are i.i.d. with expectation . Finally recalling that the is bounded above by which is uniform , we have
A.2 Proof of Theorem 3.2
Since , by Cauchy Schwartz
with equality iff
with probability 1.
A.3 Proof of Corollary 3.1
We must show
with strict inequality if is positive definite and the distribution of is not a point mass. The inequality follows from Theorem 3.2. By Theorem 3.2, the inequality is strict whenever the functions and are not proportional to with probability . Since and , . So if is not constant with probability , for any . Therefore is not proportional to with probability . Similarly, for to be proportional to , there must exist a such that
However since the constant and is not a point mass, such a does not exist.
A.4 Proof of Theorem 3.3
Let . In part 1 we show that
where is . In part 2 we show that
where is , is bounded uniformly by an random variable, and is a bounded function. Thus the weight matrix with diagonal elements satisfies Assumptions 1 with .
-
1.
Recall . Let be which changes definition at each appearance. Define . By the delta method we have
(A.1) and
(A.2) By assumption , thus
Note that . Further note that are i.i.d. with expectation . Thus by the CLT and Slutsky’s Theorem
(A.3) Since , by Equations (A.1) and (A.3) we have
which implies
Combining this result with Equation (A.2) we have
Since and are p.s.d., . Therefore
Thus
-
2.
From part 1, using the fact that , we have
The function is bounded because the are bounded below by a positive constant and . Note that since we have
where the right hand side is .
A.5 Proof of Theorem 3.4
A.6 Proof of Theorem 3.5
By the SLLN and the continuous mapping theorem
Note that
The summands in second term on the r.h.s. are i.i.d. with expectation . Therefore
References
- Blight and Ott [1975] B. Blight and L. Ott. A bayesian approach to model inadequacy for polynomial regression. Biometrika, 62(1):79–88, 1975.
- Buja et al. [2014] A. Buja, R. Berk, L. Brown, E. George, E. Pitkin, M. Traskin, K. Zhan, and L. Zhao. Models as approximations: How random predictors and model violations invalidate classical inference in regression. arXiv preprint arXiv:1404.1578, 2014.
- Carroll [1982] R. J. Carroll. Adapting for heteroscedasticity in linear models. The Annals of Statistics, pages 1224–1233, 1982.
- Carroll and Ruppert [1982] R. J. Carroll and D. Ruppert. Robust estimation in heteroscedastic linear models. The Annals of Statistics, pages 429–441, 1982.
- Chen and Shao [1993] J. Chen and J. Shao. Iterative weighted least squares estimators. The Annals of Statistics, pages 1071–1092, 1993.
- Czekala et al. [2015] I. Czekala, S. M. Andrews, K. S. Mandel, D. W. Hogg, and G. M. Green. Constructing a flexible likelihood function for spectroscopic inference. The Astrophysical Journal, 812(2):128, 2015.
- Friedman [1984] J. H. Friedman. A variable span smoother. Technical report, DTIC Document, 1984.
- Fuller and Rao [1978] W. A. Fuller and J. Rao. Estimation for a linear regression model with unknown diagonal covariance matrix. The Annals of Statistics, pages 1149–1158, 1978.
- Hooper [1993] P. M. Hooper. Iterative weighted least squares estimation in heteroscedastic linear models. Journal of the American Statistical Association, 88(421):179–184, 1993.
- Huber [1967] P. J. Huber. The behavior of maximum likelihood estimates under nonstandard conditions. In Proceedings of the fifth Berkeley symposium on mathematical statistics and probability, volume 1, pages 221–233, 1967.
- Ivezić et al. [2007] Ž. Ivezić, J. A. Smith, G. Miknaitis, H. Lin, D. Tucker, R. H. Lupton, J. E. Gunn, G. R. Knapp, M. A. Strauss, B. Sesar, et al. Sloan digital sky survey standard star catalog for stripe 82: The dawn of industrial 1% optical photometry. The Astronomical Journal, 134(3):973, 2007.
- Jobson and Fuller [1980] J. Jobson and W. Fuller. Least squares estimation when the covariance matrix and parameter vector are functionally related. Journal of the American Statistical Association, 75(369):176–181, 1980.
- Kennedy and O’Hagan [2001] M. C. Kennedy and A. O’Hagan. Bayesian calibration of computer models. Journal of the Royal Statistical Society. Series B, Statistical Methodology, pages 425–464, 2001.
- Long et al. [2014] J. P. Long, E. C. Chi, and R. G. Baraniuk. Estimating a common period for a set of irregularly sampled functions with applications to periodic variable star data. arXiv preprint arXiv:1412.6520, 2014.
- Long and Ervin [2000] J. S. Long and L. H. Ervin. Using heteroscedasticity consistent standard errors in the linear regression model. The American Statistician, 54(3):217–224, 2000.
- Ma and Zhu [2013] Y. Ma and L. Zhu. Doubly robust and efficient estimators for heteroscedastic partially linear single-index models allowing high dimensional covariates. Journal of the Royal Statistical Society: Series B (Statistical Methodology), 75(2):305–322, 2013.
- Ma et al. [2006] Y. Ma, J.-M. Chiou, and N. Wang. Efficient semiparametric estimator for heteroscedastic partially linear models. Biometrika, 93(1):75–84, 2006.
- MacKinnon and White [1985] J. G. MacKinnon and H. White. Some heteroskedasticity-consistent covariance matrix estimators with improved finite sample properties. Journal of econometrics, 29(3):305–325, 1985.
- Mondrik et al. [2015] N. Mondrik, J. P. Long, and J. L. Marshall. A multiband generalization of the analysis of variance period estimation algorithm and the effect of inter-band observing cadence on period recovery rate. arXiv preprint arXiv:1508.04772, 2015.
- Richards et al. [2012] J. W. Richards, A. B. Lee, C. M. Schafer, P. E. Freeman, et al. Prototype selection for parameter estimation in complex models. The Annals of Applied Statistics, 6(1):383–408, 2012.
- Riess et al. [2011] A. G. Riess, L. Macri, S. Casertano, H. Lampeitl, H. C. Ferguson, A. V. Filippenko, S. W. Jha, W. Li, and R. Chornock. A 3% solution: determination of the hubble constant with the hubble space telescope and wide field camera 3. The Astrophysical Journal, 730(2):119, 2011.
- Salmon et al. [2015] B. Salmon, C. Papovich, S. L. Finkelstein, V. Tilvi, K. Finlator, P. Behroozi, T. Dahlen, R. Davé, A. Dekel, M. Dickinson, et al. The relation between star formation rate and stellar mass for galaxies at 3.5≤ z≤ 6.5 in candels. The Astrophysical Journal, 799(2):183, 2015.
- Schwarzenberg-Czerny [1996] A. Schwarzenberg-Czerny. Fast and statistically optimal period search in uneven sampled observations. The Astrophysical Journal Letters, 460(2):L107, 1996.
- Sesar et al. [2007] B. Sesar, Ž. Ivezić, R. H. Lupton, M. Jurić, J. E. Gunn, G. R. Knapp, N. De Lee, J. A. Smith, G. Miknaitis, H. Lin, et al. Exploring the variable sky with the sloan digital sky survey. The Astronomical Journal, 134(6):2236, 2007.
- Sesar et al. [2010] B. Sesar, Ž. Ivezić, S. H. Grammer, D. P. Morgan, A. C. Becker, M. Jurić, N. De Lee, J. Annis, T. C. Beers, X. Fan, et al. Light curve templates and galactic distribution of rr lyrae stars from sloan digital sky survey stripe 82. The Astrophysical Journal, 708(1):717, 2010.
- Shappee and Stanek [2011] B. J. Shappee and K. Stanek. A new cepheid distance to the giant spiral m101 based on image subtraction of hubble space telescope/advanced camera for surveys observations. The Astrophysical Journal, 733(2):124, 2011.
- Szpiro et al. [2010] A. A. Szpiro, K. M. Rice, and T. Lumley. Model-robust regression and a bayesian” sandwich” estimator. The Annals of Applied Statistics, pages 2099–2113, 2010.
- Udalski et al. [2008] A. Udalski, M. Szymanski, I. Soszynski, and R. Poleski. The optical gravitational lensing experiment. final reductions of the ogle-iii data. Acta Astronomica, 58:69–87, 2008.
- VanderPlas and Ivezic [2015] J. T. VanderPlas and Z. Ivezic. Periodograms for multiband astronomical time series. arXiv preprint arXiv:1502.01344, 2015.
- White [1980a] H. White. A heteroskedasticity-consistent covariance matrix estimator and a direct test for heteroskedasticity. Econometrica: Journal of the Econometric Society, pages 817–838, 1980a.
- White [1980b] H. White. Using least squares to approximate unknown regression functions. International Economic Review, pages 149–170, 1980b.
- Zechmeister and Kürster [2009] M. Zechmeister and M. Kürster. The generalised lomb-scargle periodogram. a new formalism for the floating-mean and keplerian periodograms. Astronomy and Astrophysics, 496(2):577–584, 2009.