guojia14@nudt.edu.cn (J. Guo), wanghaifeng20@nudt.edu.cn (H. Wang), hcpnudt@hotmail.com (C. Hou)
A Novel Adaptive Causal Sampling Method for Physics-Informed Neural Networks
Abstract
Physics-Informed Neural Networks (PINNs) have become a kind of attractive machine learning method for obtaining solutions of partial differential equations (PDEs). Training PINNs can be seen as a semi-supervised learning task, in which only exact values of initial and boundary points can be obtained in solving forward problems, and in the whole spatio-temporal domain collocation points are sampled without exact labels, which brings training difficulties. Thus the selection of collocation points and sampling methods are quite crucial in training PINNs. Existing sampling methods include fixed and dynamic types, and in the more popular latter one, sampling is usually controlled by PDE residual loss. We point out that it is not sufficient to only consider the residual loss in adaptive sampling and sampling should obey temporal causality. We further introduce temporal causality into adaptive sampling and propose a novel adaptive causal sampling method to improve the performance and efficiency of PINNs. Numerical experiments of several PDEs with high-order derivatives and strong nonlinearity, including Cahn Hilliard and KdV equations, show that the proposed sampling method can improve the performance of PINNs with few collocation points. We demonstrate that by utilizing such a relatively simple sampling method, prediction performance can be improved up to two orders of magnitude compared with state-of-the-art results with almost no extra computation cost, especially when points are limited.
keywords:
Partial differential equation, Physics-Informed Neural Networks, Residual-based adaptive sampling, Causal sampling.1 Introduction
Many natural phenomena and physics laws can be described by partial differential equations (PDEs), which are powerful modeling tools in quantum mechanics, fluid dynamics and phase field, etc. Traditional numerical methods play an important role in solving many kinds of PDEs in the science and engineering fields. However, complex nonlinear problems always require the delicate design of schemes, heavy preparation for mesh generation, and expensive computational costs. Due to the rapid development of machine learning, data-driven methods attract much attention not only in traditional areas of the computer field, such as computer vision (CV) and natural language processing (NLP) but also scientific computing field, which motivates a new field of scientific machine learning (SciML)[1][2][3][4][5]. Data-driven methods for solving PDEs utilize machine learning tools to learn the nonlinear mapping from inputs (spatio-temporal data) to outputs (solution of PDEs), which omits heavy preparation and improves computational efficiency. Physics-Informed Neural Networks (PINNs) [6] are a kind of representative work in this field. They have received extensive attention and much recent work[7] [8] [9] [10] [11] based on PINNs are put forward immediately after them.
PINNs are a class of machine learning algorithms where the loss function is specially designed based on the given PDEs with initial and boundary conditions. Automatic-differentiation technique [12] is utilized in PINNs to calculate the exact derivatives of the variables. By informing physics prior information into machine learning method, PINNs enhance interpretability and thus are not a class of pure black-box models. According to the classification of machine learning, PINNs can be seen as semi-supervised learning algorithms. PINNs are trained to not only minimize the mean squared error between the prediction of initial and boundary points and their given exact values but also satisfy PDEs in collocation points. The former is easy to be implemented, while the latter needs to be explored further. Therefore the selection and sampling of collocation points are vital for the prediction and efficiency of PINNs. The traditional sampling method of PINNs is to sample uniform or random collocation points before training, which is a kind of fixed sampling method. Then several adaptive sampling methods have been proposed, including RAR[13], adaptive sampling[14], bc-PINN method[15], importance sampling[16], RANG[17], RAD and RAR-D[18], Evo and Causal Evo[19].
Though the importance of sampling for PINNs has been enhanced to a certain extent in these works, temporal causality has not been emphasized in sampling, especially for solving time-dependent PDEs. Wang et al. [20] proposed the causal training algorithm for PINNs by informing designed residual-based temporal causal weights into the loss function. This algorithm can make sure that loss in the previous time should be minimized in advance, which respects temporal causality. However, in [20], the collocation points are sampled evenly and fixedly in each spatio-temporal sub-domain, which is not suitable in many situations. We indicate that collocation points should also be sampled under the foundation of respecting temporal causality. This argument stems from traditional numerical schemes. Specifically, the designed iterative schemes calculate the solution from the initial moment to the next moment according to the time step. Similar to this, the sampling method should also obey this temporal causality guideline.
Motivated by traditional numerical schemes and temporal causality, we propose a novel adaptive causal sampling method that collocation points are adaptively sampled according to both PDE residual loss and temporal causal weight. This idea is original from the adaptation mechanism of the finite element method (FEM), which can better improve computational efficiency, and from the temporal causality of traditional numerical schemes, which obeys the temporal order.
In this paper, we mainly focus on the sampling methods for PINNs. Our specific contributions are as follows:
-
•
We analyze the failure of adaptive sampling and figure out that sampling should obey temporal causality, otherwise leading to sampling confusion and trivial solution of PINNs.
-
•
We introduce temporal causality into sampling and propose a novel adaptive causal sampling method.
-
•
We investigate our proposed method in several numerical experiments and gain better results than state-of-the-art sampling methods with almost no extra computational cost and with few points, which shows the high efficiency of our proposed method and potential in computationally complex problems, such as large-scale problems and high-dimensional problems.
The structure of this paper is organized as follows. Section 2 briefly introduces the main procedure of PINNs and analyzes the necessity of introducing temporal causality in sampling. Section 3 proposes a novel adaptive causal sampling method. In Section 4, we investigates several numerical experiments to demonstrate the performance of proposed method. The final section concludes the whole paper.
2 Background
In this section, we first provide a brief overview of PINNs. Then, by investigating an illustrative example, we analyze the necessity of temporal causality in sampling.
2.1 Physics-Informed Neural Networks
PINNs are a class of machine learning algorithms where the prior physics information including initial and boundary conditions, and corresponding PDEs form are informed into the loss function. Here we consider the general form of nonlinear PDEs with initial and boundary conditions
| (1) | ||||
where and are the space and time coordinates respectively, is the solution of PDEs system of Equation (1). is the computational domain and represents the boundary. is a nonlinear differential operator, is the initial function, and represents boundary operator, including periodic, Dirichlet, Neumann boundary conditions etc.
The universal approximation theory[21] can guarantee that, there exists a deep neural network with nonlinear activation function and tunable parameters namely weights and bias, such that the PDEs solution can be approximated by it. Then the prediction of the solution can be converted to the optimization problem of training a deep learning model. The aim of training PINNs is to minimize the loss function and find the optimal parameters . The usual form of loss function in PINNs is composited by three parts with tunable coefficients
| (2) |
where
| (3) | ||||
, and are initial data, boundary data and residual collocation points respectively, which are the inputs of PINNs. In the loss function, the calculation of derivatives, e.g. can be obtained via automatic differentiation[12]. Besides, the gradients with respect to network parameters are also computed via this technique. Moreover, the hyper-parameters are usually tuned by users or by automatic algorithms in order to balance training of different loss terms.
2.2 Analysis of sampling
2.2.1 Existing sampling methods
In original PINNs[6], collocation points are uniformly or randomly sampled before the whole training procedure, which can be seen as a fixed type of sampling. This type is quite useful for solving some PDEs, however, for more complicated PDEs, it has difficulties in both prediction accuracy and convergence efficiency. To improve the sampling performance for PINNs, the adaptive idea is utilized in PINNs, which forms the adaptive type of sampling. Residual-based adaptive refinement (RAR) in PINNs is first proposed by Lu[13] which adds new collocation points in areas with large PDE residuals. This kind of adaptive sampling methods pursue improved prediction accuracy by automatically sampling more collocation points.
Compared with these sampling methods with increasing number of sampled points, we aim to achieve better accuracy under the foundation of limited and few points, which can save computing resources. Thus in this paper we focus on automatically adaptive sampling methods with limited sampled points. First we analyze the failure of existing adaptive sampling methods, then propose our novel sampling method to overcome the failure.
2.2.2 An illustrative example
To motivate our method in Section 3, here we provide an illustrative example with the adaptive sampling method. We consider the one-dimensional Cahn Hilliard equation with initial and boundary conditions
| (4) | ||||
where represents the whole computational space and describes the boundary.
This initial boundary value problem (IBVP) is quite difficult to be solved with the original PINNs[6]. Mattey has investigated this example by original PINNs and proposed backward compatible sequential PINN method (bc-PINN)[15] to improve the performance. In [15], collocation points are sampled in both original PINNs and bc-PINN which is a quite numerous number. The relative error obtained by bc-PINN solution is 0.0186 whereas for the original PINNs solution the error is 0.8594.
We utilize causal PINN[20], a mature PINNs training method, with the neural network of 4 hidden layers with 128 neurons in each layer. We divide the whole computational domain into spatio-temporal sub-domains. The division is even in time with expression as and we record -th time interval as . Suppose that in -th sub-domain, collocation points are sampled. Then we remark temporal PDE residual loss of -th sub-domain as and the calculation is as follows
| (5) |
In order to investigate the adaptive method with limited points, we consider another residual-based adaptive sampling[16] that collocation points are resampled according to the distribution proportional to the PDE residual loss. Specifically, collocation points in each spatio-temporal sub-domain are sampled according to the distribution proportional
| (6) |
which is related to the residual loss in each spatio-temporal sub-domain. The total number of automatic sampled collocation points stays unchanged 1000 in this example. Here we use Latin Hypercube Sampling strategy (LHS) [22] to generate 1000 collocation points before the causal training procedure. Then we recalculate the distribution proportional ratio and resample points every 1000 iterations of gradient descent algorithm, which can be seen as a dynamic type of sampling. We train the causal PINN model via Adam optimizer for iterations.
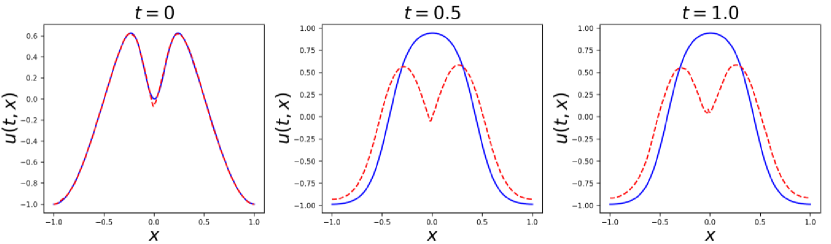
After such sufficient training, the whole loss is reduced to magnitude, which means PINNs converge. However, the prediction results in Figure LABEL:fig:ch2_adap and 2 show that such adaptive sampling method leads to convergence to wrong solution.
2.2.3 Analyze the failure via the sampling perspective
In Section 2.2.2, the adaptive sampling suffers in converging to correct solution. In this section, we analyze this failure in the sampling perspective, and we first briefly introduce the specially designed residual loss in causal PINN:
| (7) |
which consists of temporal PDE residual loss in each sub-domain in Equation (5) and the corresponding temporal weight
| (8) |
Here is a tunable hyper-parameter that determines the ”slope” of temporal weights. In this paper, we choose its value from . The intuitive explanation of temporal weight in Equation (8) is the temporal priority of training, which represents temporal training order. Suppose that in -th sub-domain, the value of temporal weight is large, which represents that the residual loss should be minimized in advance. When the value is zero, it means that the corresponding residual loss has not been minimized yet.
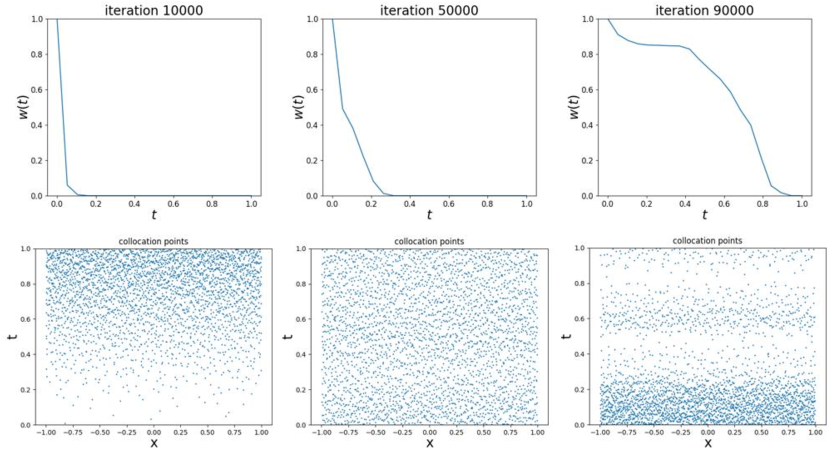
Figure 3 shows the values of temporal weights in the whole temporal domain and the distribution of sampled collocation points at different training iterations. The top results show the temporal weights in different training iterations, which illustrates the training process. For clearer illustration, we take the left figure in the first row as an example. At training iteration, the model in sub-domain is trained, however in the remaining sub-domains where temporal weights are zero, it has not been trained yet.
In the bottom figures, we can see that at the beginning of training, collocation points gather at the area near , namely most sampled points are far away from the initial time, where temporal weights are large. Then as training iteration increases, points tend to gather at the area near , which is very unreasonable and breaks the rule of temporal causality order. Thus we point out that the adaptive sampling in which collocation points are sampled only based on the residual loss is not reliable.
2.2.4 Sampling should obey temporal causality
In order to explore the reason for above failure and propose a reliable sampling method, we analyze the residual loss and the temporal causality mechanics in causal PINN. According to Equation (3) and (5), we have
| (9) |
Then we utilize the forward Euler scheme
| (10) |
with as the time step to discrete the partial derivative , then Equation (9) can be transformed to
| (11) | ||||
We can see that the foundation of minimization of temporal residual loss is the accurate prediction of both and , which requires sufficient training in with enough collocation points. Thus in the scenario of limited points, collocation points need to be sampled where training priority needs most, in order to guarantee the minimization is carried out correctly and reliably.
Then according to the temporal causality mechanics in Equation (7) and (8), when is minimized, then temporal residual loss can begin to be minimized, which constitutes the training order of PINN. Analogy to traditional iterative schemes[23], the calculation is done from the initial time to later one according to the time step, respecting the temporal causality. Only when the solution in front time is calculated well the solution in later time can be predicted accurately. Based on the above analysis, we point out that sampling should also respect this principle to ensure that loss is minimized on the premise that the solution converges to the right one.
Above adaptive sampling method obviously disobey this principle. Specifically, at the beginning of training, very less collocation points near initial time are sampled, due to the high residual loss concentrating on latter area, which cannot ensure adequate training in front area. Thus prediction solution of causal PINN tends to converge to trivial one. After training for several iterations, residual loss in front area is quite high where more points are sampled, however this sampling behavior breaks the temporal causality principle. In this section, we analyze the failure of adaptive sampling and propose our argument: sampling method should obey temporal causality. And in Section 3 and 4, we will further verify this by proposing new sampling method and exploring in numerical experiments.
3 Adaptive Causal Sampling method
Based on the above illustrative example and simple analysis, we consider introducing temporal causality into the sampling method. First, we divide the whole computational domain into spatio-temporal sub-domains along the direction of time. We fix the total amount of sampled collocation points as unchanged during the whole training procedure. The amount of collocation points sampled in each spatio-temporal sub-domain is calculated by the distribution ratio, which is adaptively related to both PDE residual loss and temporal weight in each sub-domains. Here, we propose the novel temporal causal sampling distribution ratio:
In Equation (6), the existing residual-based adaptive sampling only focus on PDE residual loss. The intuition is that where PDE residual loss is larger, more collocation points should be sampled in order to minimize the loss faster. However, in Section 2.2.3 we point out that this existing adaptive sampling is not reliable. Then we introduce temporal weight into the distribution ratio in Equation (12), thus sampling can be controlled by both PDE residual loss and temporal causality.
Due to the total number of points is limited, points should be sampled where needed most. According to the temporal causal sampling distribution ratio, when both temporal weight value and PDE residual loss are large, loss in corresponding sub-domains needs to be minimized in advance, where more points should be sampled to accelerate the minimization procedure, thus the value of ratio should be large. And when in some sub-domains the value of temporal weight is very small or nearly zero, which means the temporal order of training is relatively low, even though PDE residual loss is quite large, the ratio in these areas should be small. Besides, the value of temporal weight dynamically changes according to the residual loss of previous sub-domains, thus the sampled points dynamically and adaptively change from front spatio-temporal sub-domains to latter ones, which obeys the temporal causality.
The specific procedure is as follows. We utilize the temporal causal sampling distribution ratio as sampling distribution probability. Thus the number of sampled collocation points in -th sub-domain is . Then LHS is used to generate the corresponding number of random points. Based on Equation (12), when the temporal weight in -th sub-domain is zero, none of the points are sampled in this sub-domain, which obeys temporal causality. For more general cases, for example, the temporal weight of -th sub-domain is nonzero, then the number distribution of collocation points is based on the product of PDE residual loss and temporal weight.
The pseudo-codes of our proposed resampling procedure and adaptive causal sampling method(ACSM) are given in Algorithm 1 and 2 respectively. Here, we provide several remarks on these two algorithms. is a user-defined hyper-parameter that needs to be fixed before the training procedure. This hyper-parameter is problem-dependent and can be different in solving various PDEs. In this paper, we mainly discuss situations with few collocation points, which is a vital and efficient case. Besides, the extra resampling procedure will not increase computational complexity. In practice, we do the resampling procedure every 1000 iterations in the following numerical experiments.
4 Numerical Experiments
In this section, we first illustrate the computational devices, reference solution and, error index, and then demonstrate some numerical experiments.
We finish all the numerical experiments on a Nvidia GeForce RTX 3070 card. Besides, the reference solution are generated on a laptop with Intel(R) Core(TM) i7-10875H (2.30 GHz) and 16GB RAM. The software package used for all the computations is Pytorch 1.10. All the variables defined for computations in Pytorch are of float32 data type.
The reference solutions are all generated by the chebfun package [25]. The accuracy of prediction is calculated with the reference solution. Here we utilize the relative norm to evaluate the trained model performance:
| (13) |
where is the predicted solution and is the reference solution on a set of testing points .
We aim to demonstrate the effectiveness and efficiency of our proposed method in the following numerical experiments, where adaptive sampling suffers difficulties in converging to the accurate solution. Thus we can show that adaptive sampling should obey temporal causality and our proposed ACSM is a workable and efficient way. Due to the purpose of chasing the adaptive sampling method with limited points, the following numerical experiments are all set under the foundation that the total number of sampled points is unchanged and limited.
Before discussing the numerical results, we first introduce the comparison methods in the following numerical experiments: std-PINNs (original PINNs with fixed sampling [6]), bc-PINN (backward compatible sequential PINN [15]), CausalPINN-fixed (causal PINN [20] with fixed sampling), CausalPINN-dynamic (causal PINN with dynamic sampling) and CausalPINN-adaptive (causal PINN with adaptive sampling). Besides, we select the well-performed and easy-implemented LHS[22] as the basic sampling method. In this paper, all the fixed and dynamic sampling are based on LHS. The difference between fixed and dynamic is whether collocation points are resampled according to the number of training iterations. More specifically, for fixed sampling, we utilize LHS only once at the beginning of training and fixed sampled collocation points during the whole training procedure. For dynamic sampling, we utilize LHS every 1000 training iterations to resample collocation points. For adaptive sampling, we utilize the adaptive sampling method with distribution ratio (6).
In the following numerical experiments, we mainly consider periodic boundary conditions, and hard constraint is utilized to strictly satisfy them. We embed the input coordinates into Fourier expansion by using
| (14) |
with and m = 10. Here is the number of layers of the neural network. It can be proved that any exactly satisfies a periodic constraint[26]. Then the loss function can be reduced to two parts
| (15) |
4.1 Cahn Hilliard Equation
We first consider the one-dimensional Cahn Hilliard equation, which is mentioned in Section 2.2.2,
| (16) |
with the same initial and boundary conditions as Equation (4).
Cahn Hilliard equation plays an important role in studying diffusion separation and multi-phase flows. It has strong non-linearity and fourth-order derivative, which results in numerical challenges. Parameters in Equation (16) control the system evolution process. Specifically, the parameter represents the mobility parameter, and parameter is related to the surface tension at the interface. Different parameters lead to different physics evolution phenomena.
To simplify the derivative calculation, we utilize the phase space representation which represents a high-order PDE into coupled with multiple lower-order PDEs. We introduce an intermediate function :
| (17) |
Then Equation (16) can be transformed to a system of equations
| (18) | ||||
As for the network architecture design, the two outputs of neural network are and . Thus, the PDE residual loss can be divided into two parts, and , namely
| (19a) | ||||
| (19b) | ||||
Then the composite residual loss is
| (20) |
We also impose periodic boundary conditions as hard-constraints, thus the total training loss can be expressed as
| (21) |
We choose and to enforce the initial condition. Besides, to balance the magnitude of residual loss between Equation (19a)) and (19b), we choose and .
4.1.1 Case 1
We consider a numerical experiment in paper [15]. Let parameter and . The entire computational field is . We divide the whole spatio-temporal domain into sub-domains evenly in time direction. Total 1000 collocation points
are sampled in this case and the loss function is minimized by using ADAM iterations. The network architecture used has 4 hidden layers with 128 neurons in each layer and the output layer has two neurons, namely and . A Runge-Kutta time integrator with time step is used in chebfun.
| Method | collocation points | Relative error |
|---|---|---|
| std-PINNs | 8.594[15] | |
| bc-PINN | 1.86[15] | |
| CausalPINN-fixed | 1000 | 4.796 |
| CausalPINN-dynamic | 1000 | 4.632 |
| CausalPINN-adaptive | 1000 | 4.684 |
| ACSM | 1000 | 7.046 |
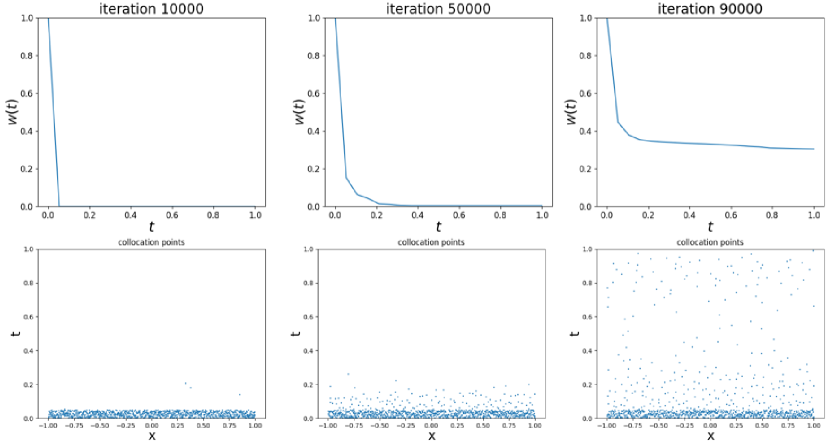
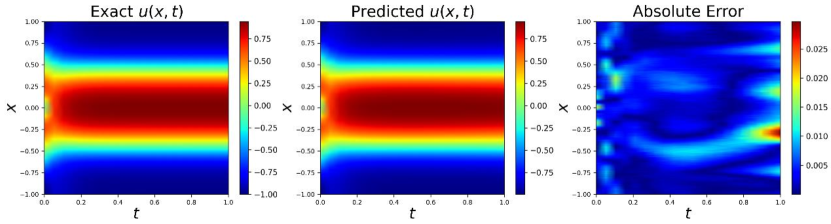
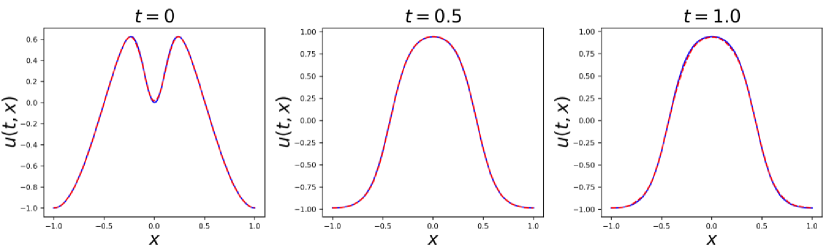
The result of temporal causal weight and sampled points is in Fig 4. We can see that as the iteration increases, collocation points are gradually sampled from the initial time to the later one, which respects the temporal causality. The predict results with our proposed method are shown in Fig 5 and 6. Compared with adaptive sampling in the illustrative example of Section 2.2.2, our method obeys temporal causality and converges to the accurate solution, which proves the effectiveness of ACSM. As for the relative error, ours is in this case which is two magnitudes less than that without causal sampling . More comparison details of different sampling methods are shown in Table 1. ACSM achieves the best performance among these sampling methods.
4.1.2 Case 2
Then we change the value of parameters, and set and , which weakening the mobility effect. Computational field is . In this case, we divide the whole spatio-temporal domain into sub-domains evenly in time direction. Total 3000 collocation points in this experiment and the loss function is minimized by using ADAM iterations. The network architecture is the same as that in case 1.
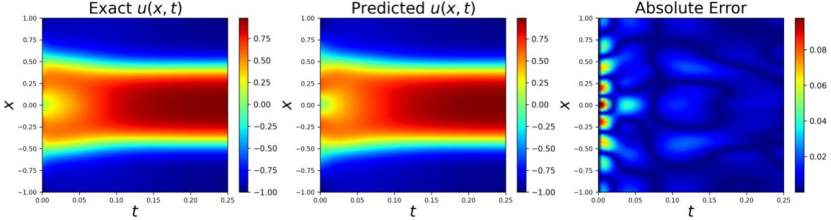
In this case, the solution changes more violently at the beginning of physics evolution than the latter one, which brings more challenges in numerical modeling. Fig 7 and 8 show the prediction results. We gain the relative error in this case. Fig 4 shows that the proposed sampling method obeys temporal causality and collocation points are gradually sampled in latter sub-domains as training iteration increases.
| Method | collocation points | Relative error |
|---|---|---|
| std-PINNs | 3000 | 2.213 |
| CausalPINN-fixed | 3000 | 4.452 |
| CausalPINN-dynamic | 3000 | 5.815 |
| CausalPINN-adaptive | 3000 | 4.076 |
| ACSM | 3000 | 1.633 |
4.2 Korteweg-de Vries (KdV) Equation
We consider the Korteweg–de Vries (KdV) equation, which describes the shallow water surfaces that interact weakly and nonlinearly, and long inner waves in densely layered oceans. The one-dimensional KdV equation takes the form
| (22) | ||||
with parameters . Here, we choose parameters as from [6]. KdV equation also contains high-order derivatives.
The initial condition is and boundary conditions are periodic. To gain the training and test data, we use Chebfun package to simulate the KdV equation up to a final time with time-step . The entire computational domain is . The PDE residual loss is defined as:
| (23) |
We also impose periodic boundary conditions as hard-constraints, thus the aggregate training loss can be expressed as
| (24) |
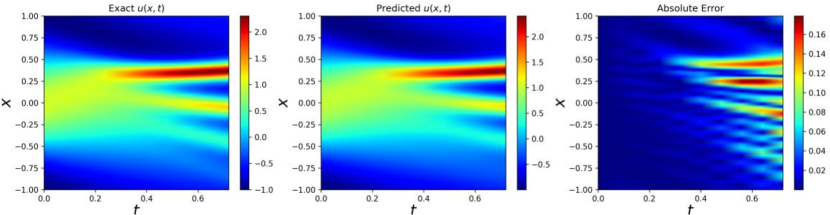
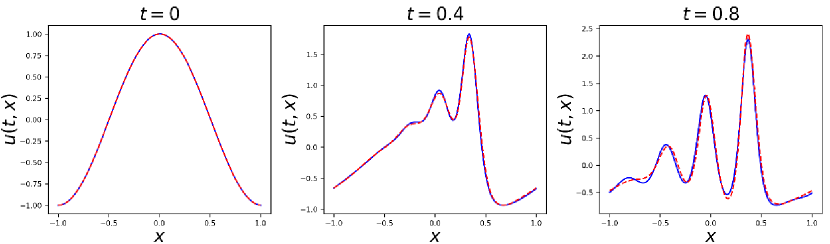
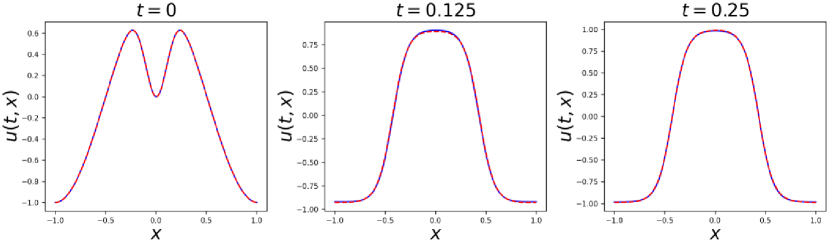
We choose and to enforce the initial condition. Besides, We divide the whole spatio-temporal domain into sub-domains evenly in time direction. We use total 300 collocation points in this experiment and the loss function is minimized by using ADAM iterations. The network architecture used has 4 hidden layers with 128 neurons in each layer and the output layer has one neuron .
Figure 9 and 10 show the prediction results of our proposed methods. Besides, the comparison results between different sampling methods are shown in Table 3, which illustrates that ACSM achieves best with very few collocation points.
| Method | collocation points | Relative error |
|---|---|---|
| std-PINNs | 300 | 5.348 |
| CausalPINN-fixed | 300 | 5.966 |
| CausalPINN-dynamic | 300 | 3.703 |
| CausalPINN-adaptive | 300 | 1.335 |
| ACSM | 300 | 5.662 |
4.3 Discussion of Sampling Efficiency
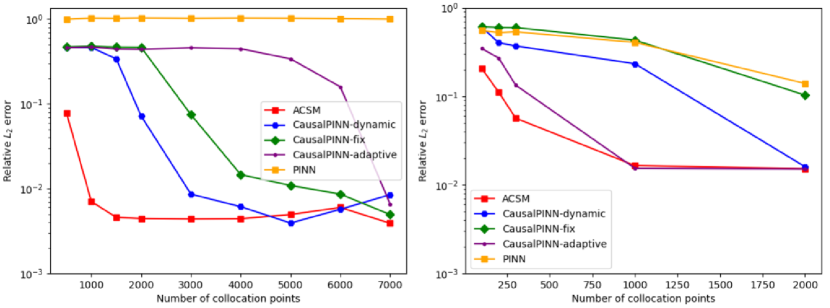
In subsection 4.1 and 4.2, we explore the prediction performance of our proposed method. In this subsection, we aim to discuss the sampling efficiency of different sampling methods. Here we show two efficiency experiments in Cahn Hilliard equation and KdV equation respectively. Figure 11 shows that when the number of collocation points is small, our proposed method performs better. Specifically, in the left sub-figure of Figure 11, ACSM can achieve magnitude of relative error in solving Cahn Hilliard equation (case 1), however other comparison methods only achieve or magnitude, which shows the superiority of ACSM in few points scenario. When the number is large, the relative error of ACSM is also comparable with other methods and stays the same error magnitude. In the right sub-figure, we can get a similar conclusion that ACSM performs better than others, especially in a few points scenario, and brings almost no extra computational cost, which demonstrates the sampling efficiency of ACSM. Due to such sampling efficiency in fewer data scenarios, our proposed method shows potential in solving high-dimensional and computationally complex PDEs, which always suffers from expensive computational cost and heavy time consumption.
5 Conclusion
In this paper, we focus on the performance of sampling methods for PINNs in solving PDEs. First, we analyze the failure of adaptive sampling method in few data scenario and bring out the argument that sampling should obey temporal causality. An adaptive causal sampling method for PINNs is proposed, which obeys the temporal causality. Numerical experiments are investigated on several nonlinear PDEs with high-order derivatives and strong nonlinearity, including Cahn Hilliard and KdV equations. However, the method in general can be applicable to other PDEs. By comparisons between different sampling methods, we conclude that our proposed adaptive causal sampling method improves the prediction performance up to two orders of magnitude and increases computational efficiency of PINNs with few collocation points, which shows potential in large-scale problems and high-dimensional problems.
6 Acknowledgments
The author thank Ph.D. candidate Ziyuan Liu and master candidate Kaijun Bao for their advice in revision of this paper. This work was partially supported by the Key NSF of China under Grant No. 62136005, the NSF of China under Grant No. 61922087, Grant No.61906201 and Grant No. 62006238.
References
- [1] G. E. Karniadakis, I. G. Kevrekidis, L. Lu, P. Perdikaris, S. Wang, L. Yang, Physics-informed machine learning, Nature Reviews Physics 3 422 – 440.
- [2] W. E, Machine learning and computational mathematics, Communications in Computational Physics 28 (5) (2020) 1639–1670.
- [3] G. Carleo, M. Troyer, Solving the quantum many-body problem with artificial neural networks, Science 355 (6325) (2017) 602–606.
- [4] S. R. Arridge, P. Maass, O. Öktem, C.-B. Schönlieb, Solving inverse problems using data-driven models, Acta Numerica 28 (2019) 1 – 174.
- [5] A. Karpatne, G. Atluri, J. H. Faghmous, M. S. Steinbach, A. Banerjee, A. R. Ganguly, S. Shekhar, N. F. Samatova, V. Kumar, Theory-guided data science: A new paradigm for scientific discovery from data, IEEE Transactions on Knowledge and Data Engineering 29 (2017) 2318–2331.
- [6] M. Raissi, P. Perdikaris, G. Karniadakis, Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations, Journal of Computational Physics 378 (2019) 686–707.
- [7] A. Jagtap, K. Kawaguchi, G. Karniadakis, Adaptive activation functions accelerate convergence in deep and physics-informed neural networks, Journal of Computational Physics 404 (2019) 109136.
- [8] K. Shukla, A. Jagtap, G. Karniadakis, Parallel physics-informed neural networks via domain decomposition, Journal of Computational Physics 447 (2021) 110683. doi:10.1016/j.jcp.2021.110683.
- [9] L. Yang, X. Meng, G. E. Karniadakis, B-PINNs: Bayesian physics-informed neural networks for forward and inverse PDE problems with noisy data, Journal of Computational Physics 425 (2021) 109913.
- [10] G. Pang, L. Lu, G. E. Karniadakis, fpinns: Fractional physics-informed neural networks, SIAM Journal on Scientific Computing 41 (4) (2019) A2603–A2626.
- [11] A. D. Jagtap, G. E. Karniadakis, Extended physics-informed neural networks (xpinns): A generalized space-time domain decomposition based deep learning framework for nonlinear partial differential equations, Communications in Computational Physics 28 (5) (2020) 2002–2041.
- [12] A. G. Baydin, B. A. Pearlmutter, A. A. Radul, J. M. Siskind, Automatic differentiation in machine learning: A survey, J. Mach. Learn. Res. 18 (1) (2017) 5595–5637.
- [13] L. Lu, X. Meng, Z. Mao, G. E. Karniadakis, Deepxde: A deep learning library for solving differential equations, SIAM Review 63 (1) (2021) 208–228.
- [14] C. L. Wight, J. Zhao, Solving allen-cahn and cahn-hilliard equations using the adaptive physics informed neural networks, Communications in Computational Physics 29 (3) (2021) 930–954.
- [15] R. Mattey, S. Ghosh, A novel sequential method to train physics informed neural networks for allen cahn and cahn hilliard equations, Computer Methods in Applied Mechanics and Engineering 390 (2022) 114474.
- [16] M. A. Nabian, R. J. Gladstone, H. Meidani, Efficient training of physics‐informed neural networks via importance sampling, Computer-Aided Civil and Infrastructure Engineering 36 (2021) 962 – 977.
- [17] W. Peng, W. Zhou, X. Zhang, W. Yao, Z. Liu, Rang: A residual-based adaptive node generation method for physics-informed neural networks, ArXiv abs/2205.01051.
- [18] C.-C. Wu, M. Zhu, Q. Tan, Y. Kartha, L. Lu, A comprehensive study of non-adaptive and residual-based adaptive sampling for physics-informed neural networks, ArXiv abs/2207.10289.
- [19] A. Daw, J. Bu, S. Wang, P. Perdikaris, A. Karpatne, Rethinking the importance of sampling in physics-informed neural networks, ArXiv abs/2207.02338.
- [20] S. Wang, S. Sankaran, P. Perdikaris, Respecting causality is all you need for training physics-informed neural networks, ArXiv abs/2203.07404.
- [21] T. Chen, H. Chen, Universal approximation to nonlinear operators by neural networks with arbitrary activation functions and its application to dynamical systems, IEEE transactions on neural networks 6 4 (1995) 911–7.
- [22] M. L. Stein, Large sample properties of simulations using latin hypercube sampling, Technometrics 29 (1987) 143–151.
- [23] J. Blazek, Computational Fluid Dynamics: Principles and Applications, 2015.
- [24] X. dong Liu, S. Osher, T. F. Chan, Weighted essentially non-oscillatory schemes, Journal of Computational Physics 115 (1994) 200–212.
-
[25]
T. A. Driscoll, N. Hale, L. N. Trefethen,
Chebfun Guide, Pafnuty
Publications, 2014.
URL http://www.chebfun.org/docs/guide/ - [26] S. Dong, N. Ni, A method for representing periodic functions and enforcing exactly periodic boundary conditions with deep neural networks, Journal of Computational Physics 435 (2021) 110242.