A Numerical Verification Framework for Differential Privacy in Estimation
Abstract
This work proposes an algorithmic method to verify differential privacy for estimation mechanisms with performance guarantees. Differential privacy makes it hard to distinguish outputs of a mechanism produced by adjacent inputs. While obtaining theoretical conditions that guarantee differential privacy may be possible, evaluating these conditions in practice can be hard. This is especially true for estimation mechanisms that take values in continuous spaces, as this requires checking for an infinite set of inequalities. Instead, our verification approach consists of testing the differential privacy condition for a suitably chosen finite collection of events at the expense of some information loss. More precisely, our data-driven, test framework for continuous range mechanisms first finds a highly-likely, compact event set, as well as a partition of this event, and then evaluates differential privacy wrt this partition. This results into a type of differential privacy with high confidence, which we are able to quantify precisely. This approach is then used to evaluate the differential-privacy properties of the recently proposed Moving Horizon Estimator. We confirm its properties, while comparing its performance with alternative approaches in simulation.
I INTRODUCTION
A growing number of emerging, on-demand applications, require data from users or sensors in order to make predictions and/or recommendations. Examples include smart grids, traffic networks, or home assistive technology. While more accurate information can benefit the quality of service, an important concern is that sharing personalized data may compromise the privacy of its users. This has been demonstrated over Netflix datasets [1], as well as on traffic monitoring systems [2].
Initially proposed from the database literature, Differential Privacy [3] addresses this issue, and has become a standard in privacy specification of commercial products. More recently, differential privacy has attracted the attention of the Systems and Control literature [4] and been applied on control systems [5], optimization [6], and estimation and filtering [7]. In particular, the work [8] develops the concept of differential privacy for Kalman filter design. The work [9] proposes a more general moving-horizon estimator via a perturbed objective function to enable privacy. To the best of our knowledge, all of these works only propose sufficient and theoretical conditions for differential privacy.
However, the design of such algorithms can be subtle and error-prone. It has been proved that a number of algorithms in the database literature are incorrect [10] [11], and their claimed level of privacy can not be achieved. Motivated by this, the work [12] introduces an approach to detect the violation of differential privacy for discrete mechanisms. Yet, this method is only applicable for mechanisms that result in a small and finite number of events. Further, a precise characterization of its performance guarantees is not provided.
This motivates our work with contributions in two directions. First, we build a tractable, data-driven, framework to detect violations of differential privacy in system estimation. To handle the infinite collection of events of continuous spaces, the evaluation is conditioned over a highly-likely, compact set. This results into a type of approximate differential privacy with high confidence. We then approximate this set in a data-driven fashion. Further, tests are performed wrt a collectively-exhaustive and mutually exclusive partition of the approximated highly-likely set. By assuming the probability of these events is upper bounded by a small constant, and implementing an exact hypothesis test procedure, we are able to quantify the approximate differential privacy of the estimation wrt two adjacent inputs with high-likelihood. Second, we employ this procedure to evaluate the differential privacy of a previously proposed, -MHE estimator. Our experiments show some interesting results including: i) the theoretical conditions for the -MHE seem to hold but may be rather conservative, ii) there is an indication that perturbing the output estimation mapping results in a better performance than perturbing the input sensor data, iii) differential privacy does depend on sensor locations, and iv) the -MHE performs better than a differentially-private EKF.
II Problem Formulation
Consider a sensor network performing a distributed estimation task. Sensors may have different owners, who wish to maintain their locations private. Even if communication among sensors is secure, an adversary may have access to the estimation on the target, and other network side information111This can be any information including, but not limited to, the target’s true location, and all other sensor positions. to gain critical knowledge about any individual sensor; see Figure 1.
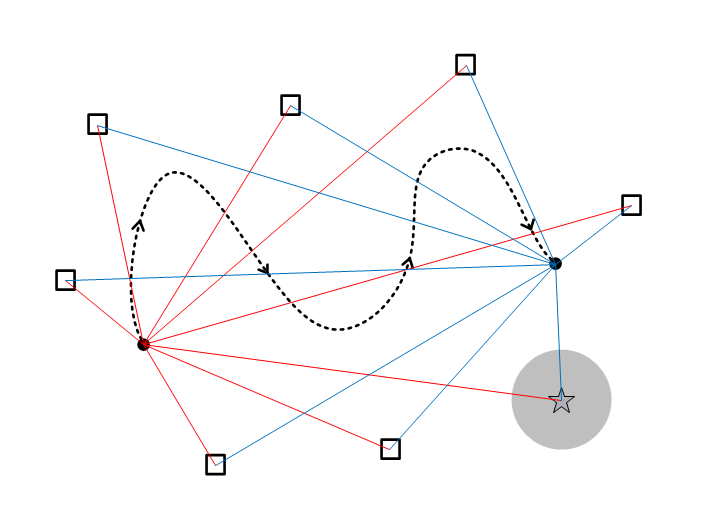
We now start by defining the concept of differential privacy in estimation, and state our problem objectives.
Let a system and observation models be of the form :
| (1) |
where , and . Here, and represent the iid process and measurement noises at time step , respectively.
Let be a time horizon, and the sensor data up to time be denoted by . An estimator or mechanism of (1) is a stochastic mapping: , for some , which assigns sensor data to a random state trajectory estimate. We will assume that the distribution of , , is independent of the distribution of . In Section V, we test a -MHE filter that takes this form and assimilates sensor data online. Roughly speaking, the -MHE employs a moving window and sensor data to estimate the state at time ; see [9] for more information.
Definition 1
((,-adjacent), -approximate, Differential Privacy) Let be a state estimator of System 1 and a distance metric on . Given , is (, -adjacent), -approximate, differentially private if for any , with we have
| (2) |
for and for all . In what follows, we use the notation -adj- (resp. -adj, for ).
This notion of privacy matches the standard definition of [4][8], for a -adjacency relation given by a distance . We are mostly interested in the case of and the standard -adj differential privacy [9]. However, later we discuss how to choose a to approximate it via -adj- differential privacy. Ideally, is to be chosen as small as possible. Here, is induced by the 2-norm. However, the results do not depend on the choice of metric.
Finding theoretical conditions that guarantee ,-adj differential privacy can be difficult, conservative, and hard to verify. Thus, in this work we aim to:
-
1.
Obtain a tractable, numerical test procedure to evaluate the differential privacy of an estimator; while providing quantifiable performance guarantees of its correctness.
-
2.
Verify numerically the differential-privacy guarantees of the -MHE filter of [9]; and compare its performance with that of an extended Kalman filter.
-
3.
Evaluate the differences in privacy/estimation when the perturbations are directly applied to the sensor data before the filtering process is done.
Our approach employs a statistical, data-driven method. Although a main motivation for this work is the evaluation of the -MHE filter, the method can be used to verify the privacy of any mappings with a continuous space range.
III Approximate ,-adj Differential Privacy
In this section, we start by introducing a notion of high-likelihood ,-adj differential privacy. This is a first step to simplify the evaluation of differential privacy via the proposed numerical framework. A second step lies on the identification of a suitable space partition.
Definition 2
(High-likelihood ,-adj Differential Privacy). Suppose that is a state estimator of System 1. Given , we say that is ,-adj differentially private with high likelihood if there exists an event with such that, for any two , , with , we have:
for and all events .
Lemma 1
Suppose that is a high-likelihood ,-adj differentially private estimator, with likelihood . Then, is ,-adj- differentially private with .
Proof:
Let be the high-likely event wrt which is high-likely differentially private. Let be its complement and . We have
similarly, the roles of and can be exchanged. ∎
Definition 2 still requires checking conditions involving an infinite number of event sets. Our test framework limits evaluations to a finite collection as follows.
Definition 3 (Differential privacy wrt a space partition)
Let be an estimator of System 1 and be a space partition222By partition we mean a collection of mutually exclusive and collectively exhaustive set of events wrt . of . We say that is ,-adj differentially private wrt if the definition of ,-adj differential privacy holds for each .
The following helps explain the relationship between ,-adj differential privacy wrt a partition and the original ,-adj differential privacy.
Lemma 2
Let be a state estimator of System 1, and consider a partition of , , which is finer than another partition (). That is, each can be represented by the disjoint union . Then, if is ,-adj differentally private wrt , then it is also differentially private wrt .
Proof:
By assumption, it holds that . Take , then, from the properties of partition, we obtain:
Similarly, the roles of and can be exchanged.∎
Thus, it follows intuitively that is ,-adj differentially private if it is ,-adj differentially private wrt infinitesimally small partitions. Now, by considering partitions of a given resolution, we can also guarantee a type of approximate ,-adj privacy:
Lemma 3
Consider a partition such that for all . Then, if ,-adj differential privacy holds wrt the partition , then is ,-adj- differentially private with .
Proof:
For any , we have By hypothesis,
for , and where is the complement of . Thus,
Now, if , we have
Similarly, the roles of can be exchanged. ∎
Our approach is based on checking differential privacy wrt a partition given by , where is the complement of a highly likely event, and is a partition of .
IV Differential Privacy Test Framework
In this section, we present the components of our test framework (Section IV-A) and its theoretical guarantees (Section IV-B).
IV-A Overview of the differential-privacy test framework
Privacy is evaluated wrt two -close , as follows:
-
1.
Instead of verifying ,-adj privacy for an infinite number of events, an EventListGenerator module extracts a finite collection EventList. This is done by partitioning an approximated high-likely event set.
-
2.
Next, a WorstEventSelector module identifies the worst-case event in EventList that violates ,-adj differential privacy with the highest probability.
-
3.
Finally, a HypothesisTest module evaluates ,-adj ifferential privacy wrt the worst-case event.
The overall description is summarized in Algorithm 1.
We now describe each module in detail.
IV-A1 EventListGenerator module.
Consider System 1, with initial condition . The estimated state under for a given , belongs to a set of all possible estimates given and . Denote this set as .
In [9], this set is bounded as all disturbances and initial distribution are assumed to have a compact support. However, can be unbounded for other estimators. To reduce the set of events to be checked for ,-adj differential privacy: a) we approximate the set by a compact, high-likely set in a data-driven fashion, and b) we finitely partition this set by a mutually exclusive collection of events; see Algorithm 2.
Inspired by [13] focusing on reachability, we employ the Scenario Optimation approach to approximate a high-likely set via a product of ellipsoids; see Algorithm 3. Here, defines the number of estimate samples (filter runs) required to guarantee that the output set contains of the probability mass of with high confidence . Then, a convex optimization problem is solved to find the output set as a hyper-ellipsoid with parameters and .
The data-driven approximation of the high-likely set can now be partitioned using e.g. a grid per time step. This is what we do in simulation later. For the -MHE, the last (window size) steps would not be evaluated for differential privacy. Thus, the high-likely set is the product of ellipsoids. Alternatively, an outline on how to re-use the sample runs of Algorithm 3 to find a finite partition of the approximated set with a common upper-bounded probability is provided as follows.
Observe that is a function of , and denote the output of Algorithm 3 by . For , we can choose a number of samples and solve a similar convex problem as in step [13:]. The resulting hyper-ellipsoid, , satisfies as they contain common sample runs, and with confidence . Similarly, the complement of , , is such that and . This process can be repeated by choosing different subsets of sample runs to find a finite collection of sets such that and . Wlog, it can be assumed that the sets are mutually exclusive by re-assigning sets overlaps to one of the sets. This approach can be extended to achieve any desired upper bound for a desired . To do this, first run Algorithm 3 with respect to so that . This results into a set with probability at least and high confidence . By selecting a subset of sample runs and solving the associated optimization problem, one can obtain with the desired probability lower-bound . Now, following the previous strategy for , we can obtain a partition of and with probability upper bounded by and high confidence .
We also note that a finite partition of a compact set is always guaranteed to exist under certain conditions, in particular, as the following:
Lemma 4
Let be a compact set in d. If is an absolutely continuous measure wrt the Lebesgue measure in d, and if the Randon-Nikodym derivative of is a continuous function, then there is a finite partition of of a given resolution .
Proof:
First of all, from absolutely continuity, , where is the Lebesgue measure, and the Randon-Nikodym derivative. Second, observe that we can take arbitrarily small-volume neighborhoods , of points of , to make as small as we like. This follows from , where is the standard volume of the set wrt the Lebesgue measure, and by compactness of and continuity of . Using these neighborhoods, we can construct an open cover of , i.e. . By compactness of , there must exist a finite subcover , i.e. . From this cover, we can obtain , with probabilities , for each . Now the sets can then be used to construct a finite partition of , with probabilities that will be less or equal than . ∎
IV-A2 WorstEventSelector module.
We now discuss how to select an , a most-likely event that leads to a violation of ,-adj differential privacy; see Algorithm 4.
The returned WorstEvent () is then used in Hypothesis Test function in Algorithm 1. First, WorstEventSelector receives an EventList from EventListGenerator. The algorithm runs the estimator times with each sensor data, and counts the number of estimates that fall in each event of the list, respectively. Then, a PVALUE function is run to get ; see Algorithm 5 (top). The -values quantify the probability of the Type I error of the test (refer to the next subsection).
IV-A3 HypothesisTest module.
The hypothesis test module aims to verify ,-adj privacy in a data-driven fashion for a fixed . Given a sequence of statistically-independent trials, the ocurrence or non-occurrence of is a Bernouilli sequence and the number of occurrences in trials is distributed as a Binomial.
Thus, the verification reduces to evaluating how the parameters of two Binomial distributions differ. More precisely, define , . By running times the estimator, we count the number of as , . Thus, each can be seen as a sample of the binomial distribution B, for . However, instead of evaluating , we are interested in testing the null hypothesis , with an additional . This can be addressed by considering samples of B() distribution. It is easy to see the following:
Lemma 5 ([12].)
Let B(), and be sampled from B(), then, is distributed as B().
Hence, the problem can be reduced to the problem of testing the null hypothesis on the basis of the samples , . Checking whether or not , are generated from the same binomial distribution can be done via a Fisher’s exact test [14] wth -value being equal to 1 - Hypergeometric.cdf() (cumulative hypergeometric distribution) . As an exact test, provides firm evidence against the null hypothesis with a given confidence.
The -value is the Type I error of the test, or the probability of incorrectly rejecting when it is indeed true. The null hypothesis is rejected based on a significance level (typically , or ). If is such that , then the probability that a mistake is made by rejecting is very small (smaller or equal than ). Since Condition 2 involves two inequalities and , we need to evaluate two null hypotheses. This results into and values that should be larger than if we want to accept ; see Algorithm 5. In simulation, we choose in both WorstEventSelector and HypothesisTest for the purpose of i) increasing the accuracy of the test for the worst event, ii) some additional practical considerations as follows.
In the WorstEventSelector, the -values for all the events are computed using the same , for example, . And then the worse event which gives the minimum -value is selected. Later, in HypothesisTest, are counted with respect to the worse event and then we keep increasing and running PVALUE with the same until the -value is larger than . The critical values are reported in Section . The reasons why we select the same in WorstEventSelector are:
-
•
The p-value evolves consistently with respect to the test . For example, the event with is the most possible event that shows the violatation of differential privacy. From Figure 2, we can see that no matter what value is chosen, the -values for that event are the smallest, which means in WorstEventSelector, it will always be returned as the worst event . This happens similarly for the event selected from , the -values are always the largest. In that case, it is safe to select one specific in WorstEventSelector to decide which event is the worst.
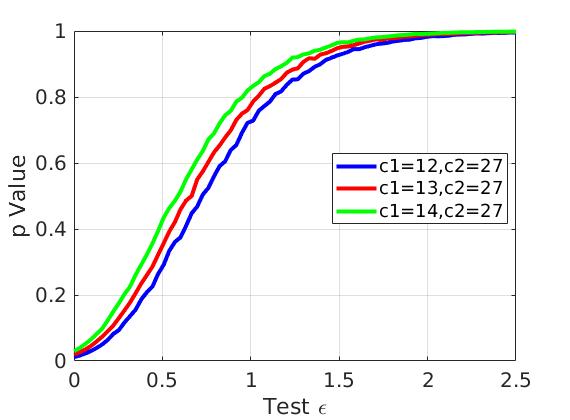
Figure 2: -values evolution with respect to different choices of event. It is clear that no matter what value is chosen, -values for the worst event are the smallest. -
•
On the other hand, the variations may come from the scenarios that constant, but share different values, such as (10,20), (15,30), (20, 40). From Figure 3, for different , the -values are almost similar. Hence, in this case, in WorstEventSelector, the returned worst event is still the one of the events, if any, that are most likely to show the violations of differential privacy.
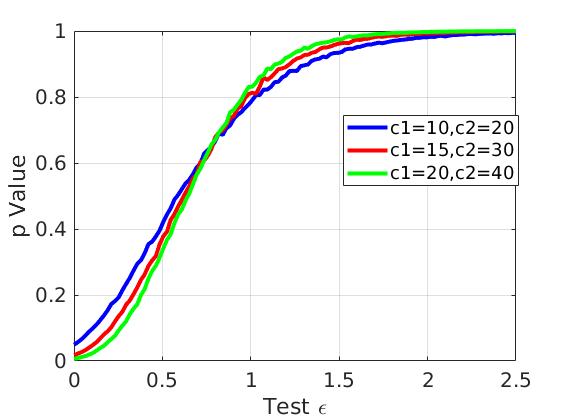
Figure 3: -values evolution with respect to different choices of event. For different choices of event, the variations are not significant.
IV-B Theoretical Guarantee
Here, we specify the guarantees of the numerical test.
Theorem 1
Let be a state estimator of System 1, and let and . We denote two -adjacent sensor data as , and a partition of the high-likely () set from Algorithm 3 with high confidence as such that for all . Then, if is selected accordingly, and the estimator passes the test in Algorithm 1, then is approximately ,-adj differentially private wrt , , and , with confidence .
Proof:
First, from Scenario Optimization is a highly likely event () with high confidence (), and approximate differential privacy with is a consequence of the previous lemmas in Section III. Second, as Fisher’s test is exact, the chosen significance level characterizes exactly the Type I error of the test for any number of samples. If Fisher’s test is applied to the worst-case event in the partition, we can guarantee approximate differential privacy with confidence does not hold with probability . ∎
To extend the result over any two -adjacent sensor data, one would have to sample over the measurement space and evaluate the ratio of passing the tests.
V EXPERIMENTS
In this section, we evaluate our test on a toy dynamical system. All simulations are performed in MATLAB (R2020a).
System Example.
Consider a non-isotropic oscillator in 2 with potential function Thus, the corresponding oscillator particle with position moves from initial conditions under the force . The discrete update equations of our (noiseless) dynamic system take the form , where, is a constant matrix. At each time step , the system state is perturbed by a uniform distribution over . The distribution of initial conditions is given by a truncated Gaussian mixture with mean vector uch that in Theorem 4 of [9] is 0.1.
The target is tracked by a sensor network of 10 nodes located on a circle with center and radius . The sensor model is homogeneous and given by:
where is the position of sensor on the circle, and is the position of the target at time . Here, the hyperbolic tangent function is applied in an element-wise way. The vector represents the observation noise of each sensor, which is generated from the same truncated Gaussian mixture distribution at each time step in simulation, indicating that the volume of random noise has a limit. All these observations are stacked together as sensor data in -MHE.
In order to implement the -MHE filter, we consider a time horizon and a moving horizon .
With these simulation settings, in Theorem 4 of [9] can be computed as: , .
-adjacent sensor data.
Let us use and to
represent the angle of a single sensor that is moved to check for
differential privacy. Denote (distance on the unit circle).
By exploiting the Lipschitz’s properties of the function , it can
be verified that the corresponding measurements satisfy:
Thus,
in order to generate -adjacent sensor data, we take
In the sequel, we take .
Numerical Verification Results of -MHE. Here, evaluate the differential privacy of -MHE with parameters and . An entropy factor determines the distribution of the filter, from — a deterministic to — a uniformly distributed random variable.
Fixing , we run the -MHE filter for a number of () runs to obtain a high-likely set characterized by . This allows us to produce an ellipsoid that contains at least 0.95 of the high-likely set with probability . At each time step , we consider a grid partition of the high-likely set consisting of 4 regions (). The EventList is obtained by storing all of the possible combinations of these sets, which results in a total of for . Followed by this, we re-run -MHE enough times using both sets of sensor data, respectively. As shown in Algorithm 4, we obtain for each event and, finally the event with minimum -value is returned as the WorstEvent. After this, we record with respect to this event from another set of runs. Then, -values are computed for different values of . We then use these with the significance parameter (0.05 in this work) to accept or reject the null hypothesis and decide whether ,-adj differential privacy is satisfied.
For a fixed sensor setup , we now report on the numerical results. We first show the simulation results when no entropy term exists ( in Theorem 4 of [9]. We use to denote below). In Figure 4, from the left figure, the -value is always equal to 0, which means that the null hypothesis should always be rejected for all test . Thus, the two sets of sensor data are distinguishable when . On the other hand, the estimate RMSE error using the correct sensor data generated from () is almost zero and much smaller than . This error () employs sensor data that are in fact generated from adjacent sensor positions to .
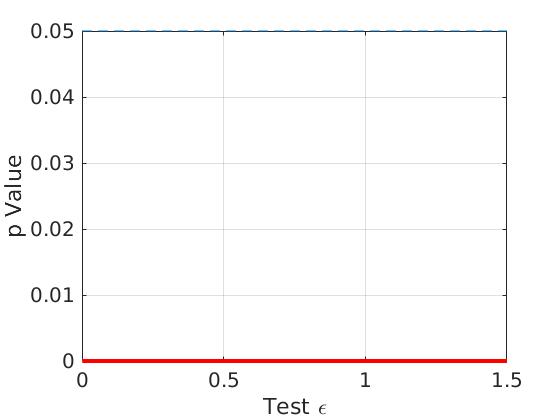
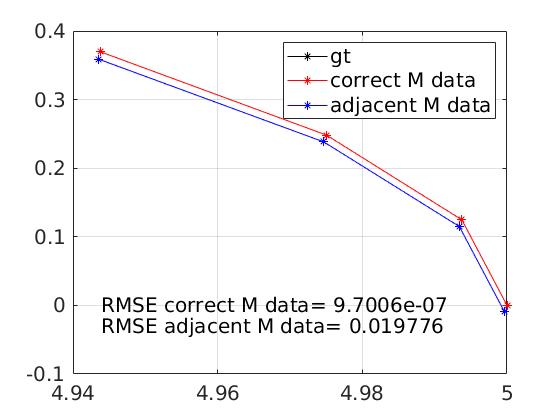
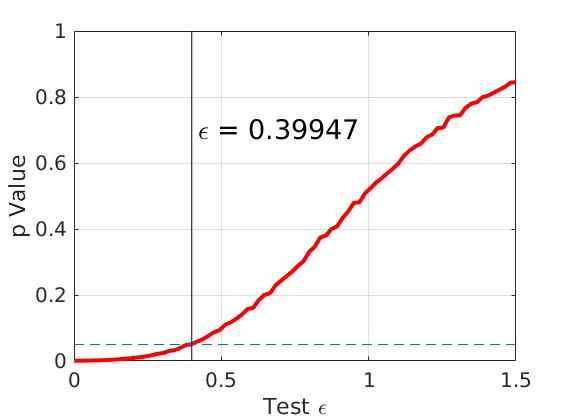
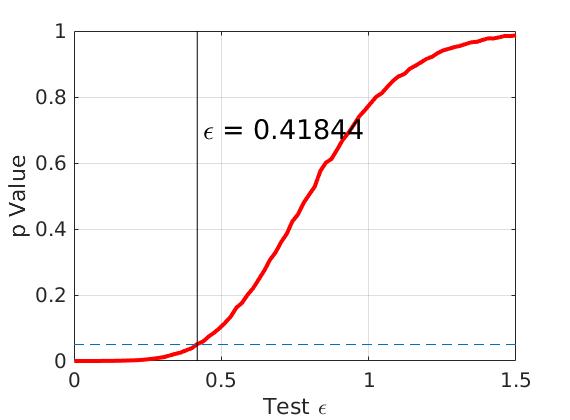
Then, we set and the simulation results are shown in Figure 5 (left figure). We obtain the critical value , where the -value is larger than 0.05. This means that the null hypothesis is not rejected and we accept that differential privacy holds for , and and these two sensor data sets. The corresponding estimate errors are found to be and for the estimates using the sensor data generated from and adjacent sensor positions, respectively. Recall that implies a relatively low noise injection level.
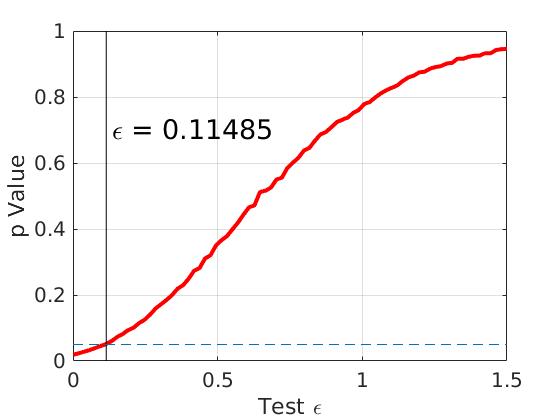
Decreasing to 0.7, leads to a larger entropy term in the -MHE: as shown in Figure 5 (right figure), the critical becomes smaller (), confirming that a higher level of ,-adj differential privacy is achieved. There is also a decrease in accuracy, which can be seen from .
Therefore, the tests reflect the expected trade-off between differential privacy and accuracy. In order to choose between two given estimation methods, a designer can either (i) first set a bound on what is the tolerable estimation error, then compare two methods based on the differential privacy level they guarantee based on the given test, or (ii) given a desired level of differential privacy, choose the estimation method that results into the smallest estimation error.
Regarding the approximation term , we can compute their values as discussed in Section IV-B. For each event , can be approximated as , so is obtained via ; is fixed and values are known from tests. Therefore, when , we get and ; , we get and .
Input Perturbation.
The work [8] proposes two approaches to obtain differentially-private estimators. The first one randomizes the output of regular estimator (-MHE belongs to this class). The second one perturbs the sensor data, which is then filtered through the original estimator. An advantage of this approach is that users do not need to rely on a trusted server to maintain their privacy since they can themselves release noisy signals. The question is which of the two approaches can lead to a better estimation result for the same level of differential privacy.
We can now compare these approaches numerically for the -MHE estimator method. By selecting and adding a Gaussian noise directly to both sets of adjacent sensor data, we re-run our test to find the trade-off between accuracy and privacy. The Gaussian noise has zero mean and the covariance matrix , where, is the identity matrix and is a matrix of random numbers inl . A value quantifies how much the sensor data is perturbed. In simulation, we change the value of and compare the results.
We first set in , see Figure 6 (left figure). The and estimate error are found to be and . Then, we decrease , see Figure 6 (right figure). We obtain , and . They also show that the higher level of differential privacy is achieved at the loss of accuracy. For the four cases, values are not significant, indicating the approximation method is meaningful.
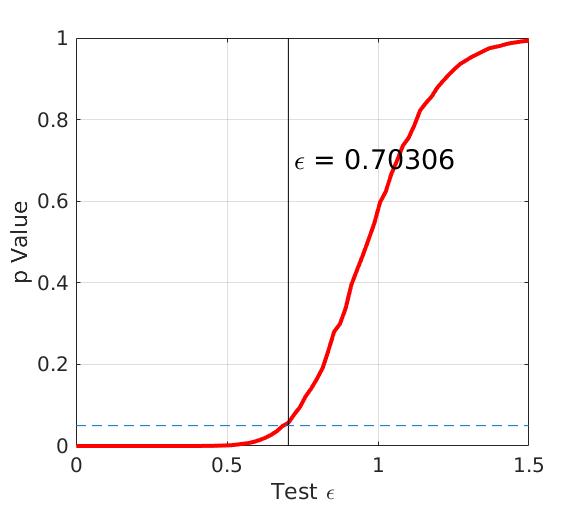
From (, , ) and (, , ), we find that although the level of differential privacy is close to each other, the estimate error of is only of that of . Thus, the second mechanism (adding noise directly at the mechanism input) seems to indicate that it can lead to better accuracy while maintaining the same ,-adj differential privacy guarantee for this set of sensors.
We further compare the performances of the two mechanisms on other sensor setups (e.g. uniformly located on the circle), see Table I.
| Sensor Setup | MHE | Input Perturbation | Better choice |
|---|---|---|---|
| -MHE | |||
| =0.2106 | |||
| -MHE | |||
From the table, we see that performance depend on the specific sensor setups. In 2 out of 3 sensor setups, perturbing the filter output seems the better option. However, more simulation results are needed to reach a reliable conclusion. Besides, we see that the approximation method works only when differential privacy holds ( is relatively small).
Differentially private EKF [8].
The framework can also be applied to other differentially private estimators. For comparison, we evaluate the performance of an extended Kalman filter applied to the same examples. Compared EKF, random noise ( is uniformly distributed over ) is added to the filter output at the update step, which makes the estimator differentially private. The initial guess is the same for the EKF and for the -MHE.
Table II illustrates the EKF test results. Compared with those of -MHE, the performance of the EKF remains to be worse than that of -MHE with respect to both privacy level and RMSE (for all sensor setups). This is consistent with the fact that -MHE performs better than the EKF for multi-modal distributions.
| Sensor Setup | Better choice | ||
|---|---|---|---|
| -MHE | |||
| -MHE | |||
| -MHE |
Correctness of sufficient condition for -MHE.
Theorem 4 of [9] provides with a theoretical formula to calculate that guarantees ,-adj differential privacy. Since this condition is derived using several assumptions and upper bounds, the answer is in general expected to be conservative.
In order to make comparisons, we choose the sensor setup and take for simulation. The value of other parameters are: . Plug these values into the theorem, we can obtain . In simulation, the critical = 0.89281. Upon inspection, it is clear that the theoretical answer is much more conservative than the approximated one, which indicates that if , differential privacy is satisfied with high confidence wrt the given space partition. While this is a necessary condition for privacy, we run a few more simulations to test how this changes for finer space partitions.
-
1.
(9 regions per time step),
-
2.
(16 regions per time step),
-
3.
, much more computation are required (numebr of events increases exponentially)
As observed, a finer space partition leads an increase of . But the theoretical bound is still far from the observed values.
VI CONCLUSION
This work presents a numerical test framework to evaluate the differential privacy of continuous-range mechanisms such as state estimators. This includes a precise quantification of its performance guarantees. Then, we apply the numerical method on differentially-private versions of the -MHE filter, and compare it with other competing approaches. Future work will be devoted to obtain more efficient algorithms that; e.g., refine the considered partition adaptively.
References
- [1] A. Narayanan and V. Shmatikov, “How to break anonymity of the netflix prize dataset,” preprint arxiv:cs/0610105, 2006.
- [2] B. Hoh, T. Iwuchukwu, Q. Jacobson, D. Work, A. M. Bayen, R. Herring, J. Herrera, M. Gruteser, M. Annavaram, and J. Ban, “Enhancing privacy and accuracy in probe vehicle-based traffic monitoring via virtual trip lines,” IEEE Transactions on Mobile Computing, 2012.
- [3] C. Dwork, M. Frank, N. Kobbi, and S. Adam, “Calibrating noise to sensitivity in private data analysis,” in Theory of Cryptography, 2006.
- [4] J. Cortes, G. E. Dullerud, S. Han, J. L. Ny, S. Mitra, and G. J. Pappas, “Differential privacy in control and network systems,” in IEEE Int. Conf. on Decision and Control, 2016, pp. 4252–4272.
- [5] Y. Wang, Z. Huang, S. Mitra, and G. E. Dullerud, “Entropy-minimizing mechanism for differential privacy of discrete-time linear feedback systems,” in IEEE Int. Conf. on Decision and Control, 2014.
- [6] E. Nozari, P. Tallapragada, and J. Cortes, “Differentially private distributed convex optimization via functional perturbation,” IEEE Transactions on Control of Network Systems, 2019.
- [7] J. L. Ny, “Privacy-preserving filtering for event streams,” preprint arXiv: 1407.5553, 2014.
- [8] J. L. Ny and G. J. Pappas, “Differentially private filtering,” IEEE Transactions on Automatic Control, pp. 341–354, 2014.
- [9] V. Krishnan and S. Martínez, “A probabilistic framework for moving-horizon estimation: Stability and privacy guarantees,” IEEE Transactions on Automatic Control, pp. 1–1, 06 2020.
- [10] Y. Chen and A. Machanavajjhala, “On the privacy properties of variants on the sparse vector technique,” 2015.
- [11] M. Lyu, D. Su, and N. Li, “Understanding the sparse vector technique for differential privacy,” 2016.
- [12] Z. Y. Ding, Y. X. Wang, G. H. Wang, D. F. Zhang, and D. Kifer, “Detecting violations of differential privacy,” Proc.s of the 2018 ACM SIGSAC Conference on Computer and Communications Security.
- [13] A. Devonport and M. Arcak, “Estimating reachable sets with scenario optimization,” in Annual Learning for Dynamics & Control Conference, 2020.
- [14] R. A. Fisher, The design of experiments, 1935.