Wei Tian et al
*Rongliang Chen, Shenzhen Institutes of Advanced Technology, Chinese Academy of Sciences, Shenzhen, P.R. China.
A Parallel Scalable Domain Decomposition Preconditioner for Elastic Crack Simulation Using XFEM
Abstract
[Abstract]In this paper, a parallel overlapping domain decomposition preconditioner is proposed to solve the linear system of equations arising from the extended finite element discretization of elastic crack problems. The algorithm partitions the computational mesh into two types of subdomains: the regular subdomains and the crack tip subdomains based on the observation that the crack tips have a significant impact on the convergence of the iterative method while the impact of the crack lines is not that different from those of regular mesh points. The tip subdomains consist of mesh points at crack tips and all neighboring points where the branch enrichment functions are applied. The regular subdomains consist of all other mesh points, including those on the crack lines. To overcome the mismatch between the number of subdomains and the number of processor cores, the proposed method is divided into two steps: solve the crack tip problem and then the regular subdomain problem during each iteration. The proposed method was used to develop a parallel XFEM package which is able to test different types of iterative methods. To achieve good parallel efficiency, additional methods were introduced to reduce communication and to maintain the load balance between processors. Numerical experiments indicate that the proposed method significantly reduces the number of iterations and the total computation time compared to the classical methods. In addition, the method scales up to 8192 processor cores with over 70% parallel efficiency to solve problems with more than degrees of freedom.
\jnlcitation\cname, , ,and (\cyear2021), \ctitleA Parallel Domain Decomposition Preconditioner for Elastic Crack Simulation Using XFEM, \cjournalInternational Journal for Numerical Methods in Engineering, \cvol2021;00:1–6.
keywords:
elastic crack, XFEM, preconditioner, domain decomposition method, parallel computing1 Introduction
Crack simulation in elastic materials is one of the most challenging problems in engineering applications. The extended finite element method (XFEM), which is widely appied to such problems, extends the polynomial approximation spaces to include additional enriched degrees of freedom (DOFs) to capture the discontinuities and singularities1, 2. XFEM has been successfully used for many problems, such as the simulation of fatigue crack growth in materials with inclusions and voids 3, 4, the simulation of multi-material fracture propagation 5, 6, and the computation of immiscible multi-phase flows 7, 8.
As a result of the strong singularity at the crack tip, the system of linear equations arising from the XFEM discretization for crack problems is highly ill-conditioned 9, 10. The condition number of the matrix from the standard finite element method (FEM) grows in the order ), while it is ) or worse for XFEM 11, where denotes the mesh size. The discretized system is difficult to solve using standard iterative methods because of the ill-conditioned matrix, especially when the size of the problem is large. There are many techniques to reduce the singularities of crack problems. For example, Lang, Sharma, and coworkers suggested the use of the Heaviside enrichment function to capture the discontinuities12, 13, while Menouillard, Elguedj, and coworkers used part of the branch enrichment functions to represent the crack tip physics 14, 15. These methods make the resulting system easier to solve, but the accuracy and order of convergence are reduced. Another approach is to replace some of the polynomial approximation spaces by special shape functions without any extra DOFs, called the intrinsic XFEM 16, 17, 18 like the iXFEM 19, 20. Although these methods require more complex shape functions and result in a larger stiffness matrix bandwidth, the size of the algebraic system is smaller than that of the standard XFEM. The other class of strategies is to preserve the discretization scheme but seek efficient preconditioning techniques to reduce the condition number of the discretized system. There are several methods, including the additive Schwarz preconditioner 21, 22 and the multigrid preconditioner 23, 24. These methods treat the entire crack area as a special domain and do not distinguish the crack line and crack tip area where the singularities mainly come from. These methods have been shown to work well for a variety of problems, however their parallel performance still needs to be explored when the scale of the problem and the number of processor cores are large.
In this paper, we refer to the approach of Chen and Cai 25 to study the parallel scalability of an efficient domain decomposition preconditioner for the elastic crack problem. The main innovation of the algorithm is based on the observation that the singularities of the algebraic system mainly originate from the crack tip area. The normal part from standard FEM and the enriched part from Heaviside enrichment do not result in a large condition number. Therefore, a straightforward idea is to separate the crack tip subdomain and handle it individually. In Chen’s paper, the algorithm is verified using a simple crack model with a small mesh in the MATLAB platform. There are still remaining issues that need to be investigated, such as whether the method works for complex crack models with a large number of processors. Based on Chen and Cai’s work, a parallel version of their method is proposed and developed into a parallel package. In parallel computing, the load balance should be maintained and communications between processors should be decreased. The enrichment operations around cracks result in a non-uniform distribution of DOFs between processors, and the crack tip subdomains in the algorithm make the number of subdomains larger than the number of processors. These problems in parallel computing have to be addressed to increase scalability and parallel efficiency. In addition, to ensure the convenience of implementation, the submatrix for each crack tip is aggregated into one processor and solved locally because the crack may propagate anywhere in the computational domain. Based on our numerical analysis, this approach is rational because the communication between processors for the aggregation operation can be ignored as the main time-consuming part is to solve the regular subdomain problem.
The remainder of this paper is organized as follows. The governing equations and domain decomposition preconditioner are presented in Section 2. A benchmark case is used to verify the parallel XFEM code in Section 3. The numerical results are presented and discussed in Section 4. Finally, concluding remarks are presented in Section 5.
2 Methodology
2.1 The governing equations and discretization
In this study, we consider an elastostatic crack problem. As illustrated in Figure 1, the domain contains an edge crack , where the internal pressure along the crack surface is . A prescribed displacement is imposed on part of the boundary , and the rest of the boundary is subject to a surface force g. The unit normal to the boundaries is denoted as n. The crack surface is distinguished by and , such that and with the unit normal to and by and , respectively. We define , and , where , . The equilibrium equations and boundary conditions are given by 26
| (1) |

where f is a given body force, is the stress tensor corresponding to the displacement field u, and is the gradient operator . For the linear elasticity problem, the relationship between the stress and strain is
| (2) |
where "trace" is the trace of a tensor, and I is the identity matrix. The material Lamé constants and are functions of the Young’s modulus E and Poisson’s ratio v,
| (3) |
The solution of (1) lies in the space of admissible displacement field
| (4) |
where is the usual Sobolev space related to the regularity of the solution. A detailed description of the problem in a nonsmooth domain can be found in the work of Grisvard 27. Similarly, the test function space can be defined as
| (5) |
The variational formulation of (1) is to find such that
| (6) |
where the bilinear form a(,) and linear form l() are defined as
| (7) |
To discretize (6), we apply the corrected XFEM28, which uses a level set function to track the position of cracks, the branch enrichment functions to describe the asymptotic field around the crack tips, and the ramp function to handle the blending area. In this study, the computational domain was discretized by a structured Cartesian mesh with quadrilateral elements. As illustrated in Figure 2, the computational domain is initially divided into the crack tip enriched domain , the blending area , the Heaviside enriched domain , and the unenriched domain . The Heaviside enriched domain is the area where all elements are cut by the crack line, excluding the elements that contain the crack tip. The crack tip enriched domain is the area within a radius of the crack tip, where all the nodes for each element are enriched by the branch enrichment functions. The blending domain is the area around , where only a part of the nodes for each element are enriched by the branch enrichment functions. The unenriched domain is the area without any enriched nodes, such that . Note that the Heaviside enriched domain may overlap with and , and the nodes in the overlap area are enriched by multiple enrichment functions.
For elements in , the displacement field is continuous, so the piecewise linear continuous function from the standard FEM can be adopted as the basis function. In the area around cracks, additional basis functions should be adopted to represent the physics of the problem, except for the standard basis function. For the elements in , the variables cross cracks are discontinuous, and the additional basis function is the Heaviside function, which represents the discontinuity
| (8) |
where is the unit normal to the negative side of the crack surface, and is a point on the crack surface that has the shortest distance to x. For the elements in , the analytical displacement fields for the combined mode I and II loading can be found in 29. The analytical solutions are not only discontinuous but also includes singularities. The branch enrichment functions can be selected from the basic terms of the analytical solutions.
| (9) |
where is the local polar coordinate corresponding to the crack tip. The approximation of the displacement field for the corrected XFEM can be formulated as follows 28, 30
| (10) |
where , , and represent the set of all mesh nodes, the nodal subset for elements cut by cracks, and the nodal subset for elements around the crack tips within an enrichment radius , respectively; , , and are the standard FEM shape functions; is the unknown associated with the node set ; and are the unknowns for the enriched nodal subset and ; represents a ramp function that is employed to overcome the problem of blending elements in 31. Based on the approximation in (10), the discrete system for (6) has the following formulation:
| (11) |
where F is the force vector, is the unknown, and , known as the stiffness matrix, is an symmetrical sparse matrix, whose structure is as follows:
| (12) |
where is the stiffness matrix related to the standard FEM basis, which has the same nonzero structure as the standard FEM; and are the stiffness matrices related to the enriched DOFs, which are denser than ; and the other parts are the coupling matrices for regular DOFs and enriched DOFs.
In addition, the linear dependency for the local enrichment in each crack tip should be carefully considered, as described in the work of Fries15. The detailed numerical method for eliminating the linear dependency can be found in Appendix A. Unlike the standard FEM, the matrix K from the corrected XFEM is highly ill-conditioned, and the linear system is difficult to solve 32. An efficient method for solving the ill-conditioned system is to use the preconditioned Krylov subspace with a well-designed preconditioner. The main focus of this study is to design an efficient and scalable preconditioner to solve the large-scale linear system (11).
2.2 The additive Schwarz method and algorithmic framework
Because of the singularities of the asymptotic field around the crack tip, the linear system (11) is difficult to solve using classical iterative methods, such as GMRES and CG, especially for large-scale problems in parallel computing. To accelerate the iterative method, preconditioning techniques are required. One of the most popular preconditioning methods in parallel computing is the additive Schwarz method 33. Solving the linear system by combining the left preconditioned Krylov subspace method with the additive Schwarz method (11) is equivalent to solving the following preconditioned system:
| (13) |
where is the additive Schwarz preconditioner.
The additive Schwarz method is a type of overlapping domain decomposition method. This can be defined in two ways. The first is the algebraic method, which obtains the subdomain matrices and overlaps algebraically based on the matrix K 34. The second method is the geometrical method, which begins by partitioning the physical domain into nonoverlapping subdomains (i=1, 2, …, N) and then extending each subdomain into an overlapping subdomain by adding layers of elements from the neighboring subdomains. For each subdomain, the submatrix is obtained as follows:
| (14) |
where N is the number of subdomains, is a restriction operator from the global domain to the overlapping subdomain , which is an rectangular matrix, where is the global matrix size and is the local matrix size. Only one component in each row of is set to one, which is related to the DOF belonging to , and the other components are set to zero. is the extension operator from local to global, which is usually the transpose of the restriction operator. Depending on the method of treating the overlap, there are three types of additive Schwarz preconditioners: classical additive Schwarz preconditioner, restricted additive Schwarz preconditioner, and harmonic additive Schwarz preconditioner. In this study, we adopt the classical additive Schwarz preconditioner (ASM), which is defined as
| (15) |
where is the approximation of the inverse matrix of , which is usually computed by the incomplete Cholesky factorization (ICC).
The numerical results in Section 4.2 indicate that the algebraic additive Schwarz preconditioner and the standard geometrical additive Schwarz preconditioner do not work well for the crack problems considered in this study. The differences in the properties of the subdomains with and without cracks, which can be quite extensive, must be considered when constructing the additive Schwarz preconditioner. In this paper, a geometrical additive Schwarz preconditioner is considered after carefully examining the properties of the crack tip subdomains.
As illustrated in Figure 3, all subdomains are classified into two types: regular subdomains and crack tip subdomains . The regular subdomains are partitioned based on the geometry of the computational domain , regardless of the crack position. The number of regular subdomains is equal to the number of processors . The number of crack tip subdomains is equal to the number of crack tips. Thus, and . For parallel computing, the submatrices from regular subdomains are allocated to each processor locally, whereas the submatrices from the crack tip subdomains may be distributed over arbitrary processors. For convenience of calculation, the submatrices from the crack tip subdomains are aggregated and stored on specific processors to compute the inverse matrix of each subdomain according to (15). To decrease the communication between processors, the processors should include the enrichment area around the crack tips as much as possible.
During each iteration of the preconditioned Krylov subspace iterative method, we need to compute , where x is the residual vector or the vector of unknowns defined on the domain . The ASM preconditioner can be expressed as:
| (16) |
This was computed in parallel. That is, on the th processor core, we compute
| (17) |
then obtain the global vector by adding them together
| (18) |
where includes two parts in the processors, which include a regular subdomain and an enriched crack tip subdomain. The subvector in each processor core with overlap is defined as
| (19) |
Let and , then, . is solved by solving the linear system of the equations locally. For the specific processors, we solve and , and then . Here, we distinguish the restriction and extension operators by subscripts and in the processors. This means that and are extension operators for regular subdomains and tip subdomains in the processors. A subscript is not needed for the other processors because only one subdomain problem needs to be solved by each processor. Note that the restriction and extension operators with subscript deal with all types of DOFs, whereas operators with subscript or without any subscript only deal with regular DOFs and Heaviside DOFs. The above algorithm is summarized Algorithm 1.
-
Step 1:
Obtain the submatrices for tip subdomains and distribute them to the specific processors.
-
Step 2:
Obtain with overlaps in all processors.
-
Step 3:
Each processor gets the subvector from global vector x.
For the specific processors, and .
For the other processors, . -
Step 4:
In the specific processors, solve the linear equations
,
the other processors do nothing and wait for these processors. -
Step 5:
In all processors, solve the linear equations
-
Step 6:
For the specific processors, .
For the other processors, let . -
Step 7:
Assemble the vector y by
The main idea of the algorithm is to handle the crack tip subdomain separately. The difference between this method and the standard domain decomposition method (sDDM) is depicted in Figure 4. In sDDM, all the subdomain problems are solved in parallel on each processor, and the communication between the processors is only from the overlaps. In our method, the crack tip submatrix is obtained and stored on specific processors. To reduce communication, a flag in each processor indicates whether the processor has crack tips inside, and the data transfer mainly occurs among processors that include crack tips. If more than two processors share a crack tip area, the one that holds most of the crack tip occupies the subdomain and the problem is solved locally. During each iteration of the preconditioned Krylov subspace method, these processors need to perform more work than sDDM because the linear system from the crack tip area needs to be solved while the other processors are idle and wait for the processors to finish the operation. This affects the synchronization between processors and hence the parallel efficiency. The numerical results in Section 4.7 demonstrate that this effect is very small, as the most time-consuming step is to solve the linear equations from the regular subdomains. It takes very little time to solve the crack tip problem because the size of the crack tip submatrix is usually much smaller than that of the regular subdomain.
Remark 1: In XFEM, the unknowns can be classified into three types: the normal DOFs from standard FEM, the Heaviside DOFs from elements cut by cracks, and the crack tip DOFs from the crack tip area. Accordingly, there are different strategies for choosing subdomain DOFs and overlapping DOFs in (14). Here, three subdomain strategies are introduced referred to as the algebraic subdomain strategy S0, the regular geometrical subdomain strategy S1, and the advanced subdomain strategy S2. A comparison of their performances is discussed in Section 4.2.
-
S0:
The subdomain DOFs and overlapping DOFs are determined based on the stiffness matrix K and totally ignore the geometry information.
-
S1:
The computational domain is divided into subdomains without consideration of the crack lines. Each subdomain include all types of DOFs. The overlap part for each subdomain has the same type of DOF as the inner part.
-
S2:
The computational domain is divided into regular subdomains and crack tip subdomains. The regular subdomain includes normal DOFs and Heaviside DOFs, and the crack tip subdomain includes all types of DOFs. There are no interactions between the two types of subdomains. If a node is located in a crack tip subdomain, the corresponding DOFs no longer belong to a regular subdomain. The overlap for each subdomain has the same type of DOF as the corresponding subdomain.
Remark 2: In practice, the inverse matrix , which is usually dense and memory consuming, is not implemented. In the preconditioned Krylov subspace iterative method, the explicit formulation of the entire preconditioner matrix is not required because the matrix-vector multiplications are only performed during each iteration. According to (15), the preconditioner is a block diagonal matrix. When performing the matrix-vector multiplications, the multiplication of submatrices and subvectors is computed locally on each processor and then assembled into the global vector. For subdomain strategy S2, the number of subdomains is larger than the number of processors, and the crack tip subdomains have to be specially considered.
3 Benchmark case
In this study, a parallel XFEM package on top of the open-source package PETSc 35 was developed to study the above algorithm. To verify the accuracy and robustness of the code, a benchmark problem was employed to investigate the convergence rate, accuracy, and condition number of the coefficient matrix.
The benchmark problem is a two-dimensional edge-crack model, as shown in Figure 5. The domain is a square of , and an edge crack is located in the left half of the domain. The problem type is plain stress. Young’s modulus MPa, and Poisson’s ratio . The mesh was refined from to , and the corresponding mesh size changed from 0.222 to 0.005. The boundaries are subject to analytical displacement in the literature 29. For comparison, an FEM model without cracks was employed with the same material constants and mesh size. There are two strategies for the crack tip enrichment: topological enrichment (top-XFEM) and geometrical enrichment (geo-XFEM) 36. The top-XFEM method enriches the crack tip with fixed layers of elements, and the enrichment area varies with mesh refinement. The geo-XFEM method provides a fixed enrichment radius, regardless of the mesh refinement.
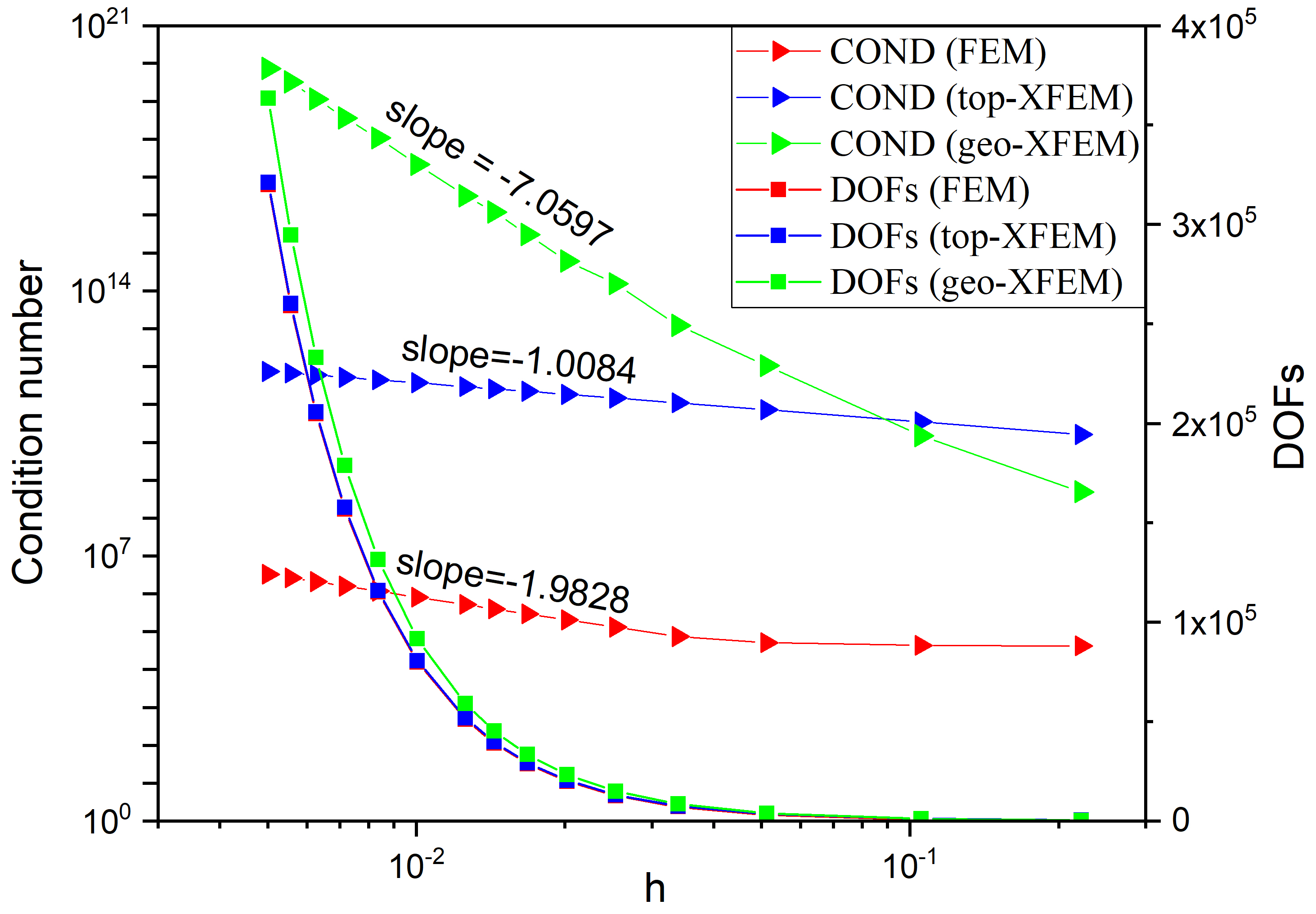
The relationship between the number of DOFs and the condition number (COND) of the stiffness matrix is plotted in Figure 6, demonstrating that the top-XFEM and geo-XFEM introduce some extra enriched DOFs, and the condition number is much larger than that of FEM. The number of DOFs for geo-XFEM is generally larger than that for top-XFEM because the fixed enrichment radius enriches more layers of elements when the mesh is deeply refined. If the mesh size is coarse, the top-XFEM may generate more enriched DOFs than geo-XFEM because the actual radius of the fixed layers of elements is larger than . From the curve of the condition number, it is observed that the condition number of geo-XFEM is smaller than that of top-XFEM when the mesh is coarse, but the condition number increases rapidly and becomes much larger when the mesh is refined. According to the curve slope, the growth of the condition number with mesh refinement is for the standard FEM, for the top-XFEM, and for the geo-XFEM. The results agree well with FEM theory and the numerical results of Tian et al.11.
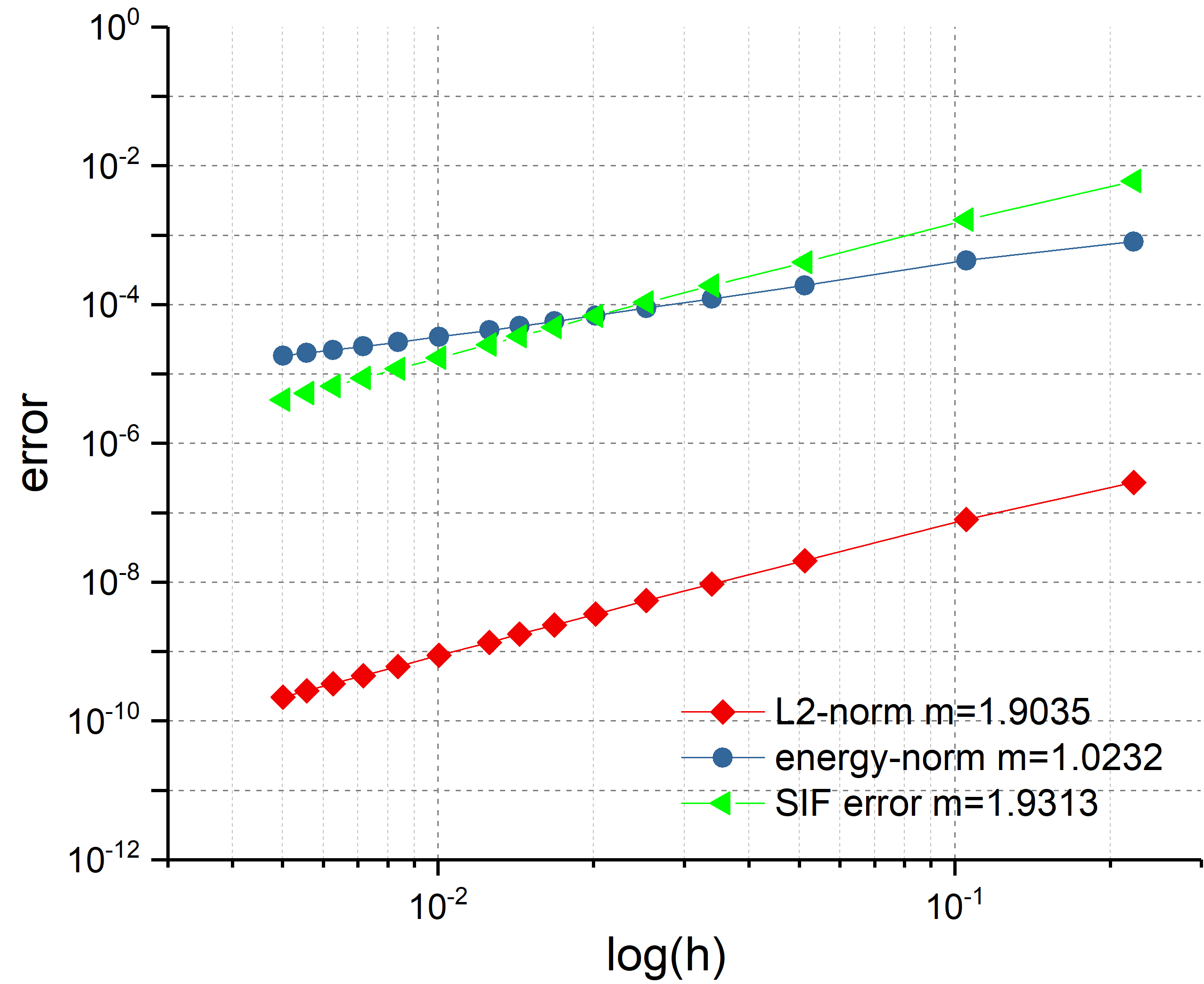
To discuss the code accuracy and convergence rate, three mesh-dependent parameters are introduced to represent the error of the numerical results, the L-2 norm, energy-norm, and SIF error. The definitions are formulated as follows.
| L2-norm | (20) | |||
| Energy-norm | (21) | |||
| SIF-error | (22) |
where , and are the numerical displacement, strain, and stress, respectively. The superscript denotes the numerical solutions, and is the number of mesh points as introduced in equation (10). Here, the analytical mode I stress intensity factor (SIF) is .
Figure 7 displays the convergence results using a log-log plot for the L2-norm, energy-norm, and SIF error. It is observed that the convergence order is 1.9035 for the L2-norm, 1.0232 for the energy-norm and 1.9313 for the SIF error, which is in good agreement with the work of Fris28.
4 Numerical results and discussion
4.1 Crack tip enrichment
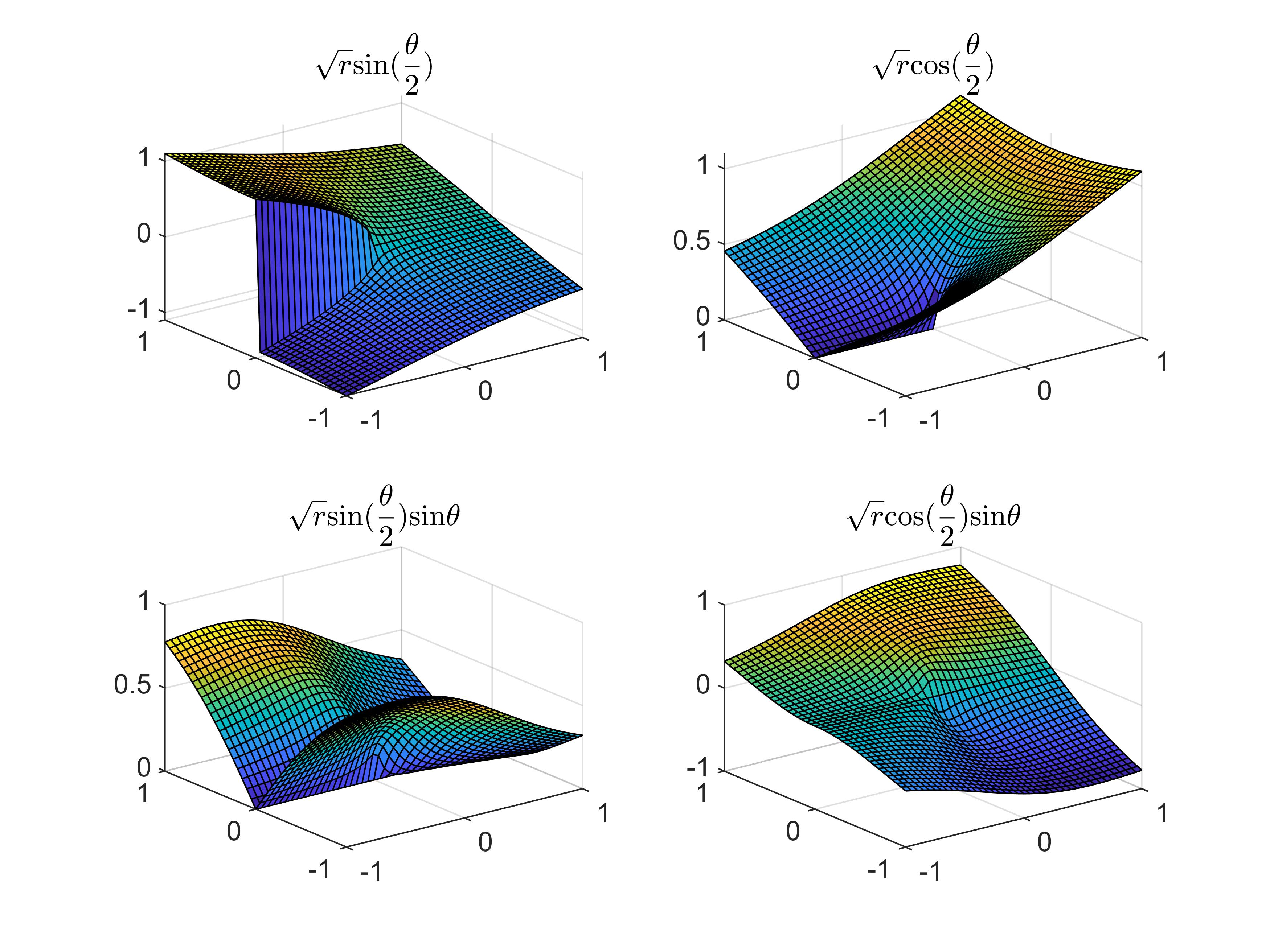
In this section, the focus is on the crack-tip area where the difficulty arises. There are two important roles for the branch enrichment functions (9): localization of where the crack is and providing the crack tip area with more information on the analytical solutions15. The graphical representation of these functions is provided in Figure 8. It is observed that only the first term includes a strong discontinuity, which localizes the position of the crack inside the element. The other three terms, which employ more physics in the solution, are continuous. As discussed in Section 3, the condition number of the stiffness matrix from the XFEM is much larger than that of the standard FEM, which presents significant challenges in problem solving. In applications, only the first few terms 37 are adopted for simplicity, to decrease the number of DOFs and the condition number of the discrete system. The effect of adopting different terms of enrichment functions on the solver and the accuracy of the numerical results is also investigated. The crack model is the same as that described in Section 3.
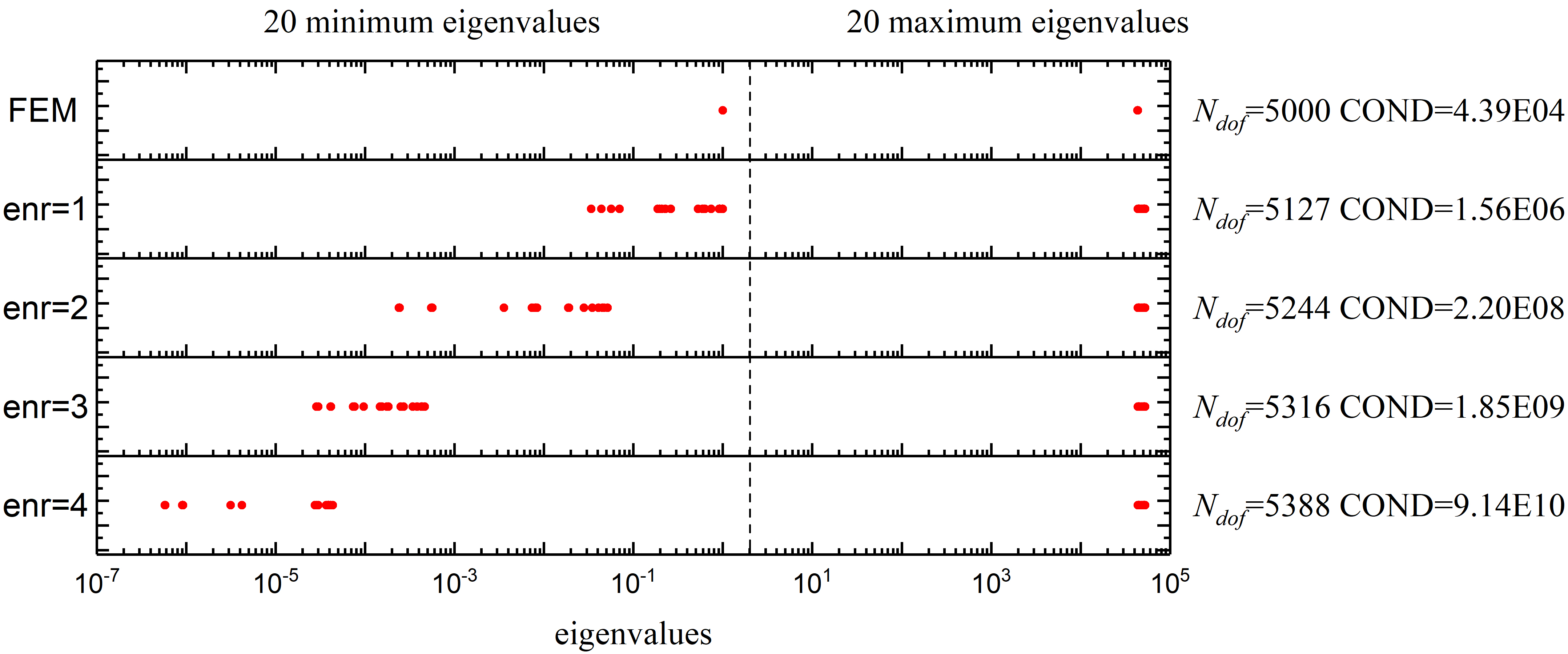
In Figure 9, the distribution of eigenvalues for different XFEMs is displayed. The number of DOFs () and the condition number of the linear system are also compared. Here, “enr=1” indicates that the crack tip elements are enriched only by the first term of equation (9); “enr=2” indicates that the first two terms are used for enrichment, and so on. It is observed that the maximum eigenvalues remain almost constant, while the minimum eigenvalues decrease quickly with increasing terms (9). The condition number of a linear system is closely related to the distribution of the eigenvalues. A small minimum eigenvalue results in a large condition number. This observation suggests that the main problem arises from the branch enrichment in the crack tip area.
In Figure 10, the L2-norm and SIF errors for the four XFEMs are explored with respect to mesh refinement, whereby with the same mesh size, the full enrichment functions (enr=4) provided the most accurate results. The more the number of enrichment terms used, the better the results obtained. That is, with more enrichment terms, the basis functions in (9) include more information about the analytical solution around the crack tip, and the numerical results are more credible. Table 1 shows the convergence order for the L2-norm, energy-norm, and SIF errors. The results demonstrate that more enrichment terms yield a better convergence order. The XFEM with four enrichment functions can achieve the optimal convergence rate like the standard FEM.
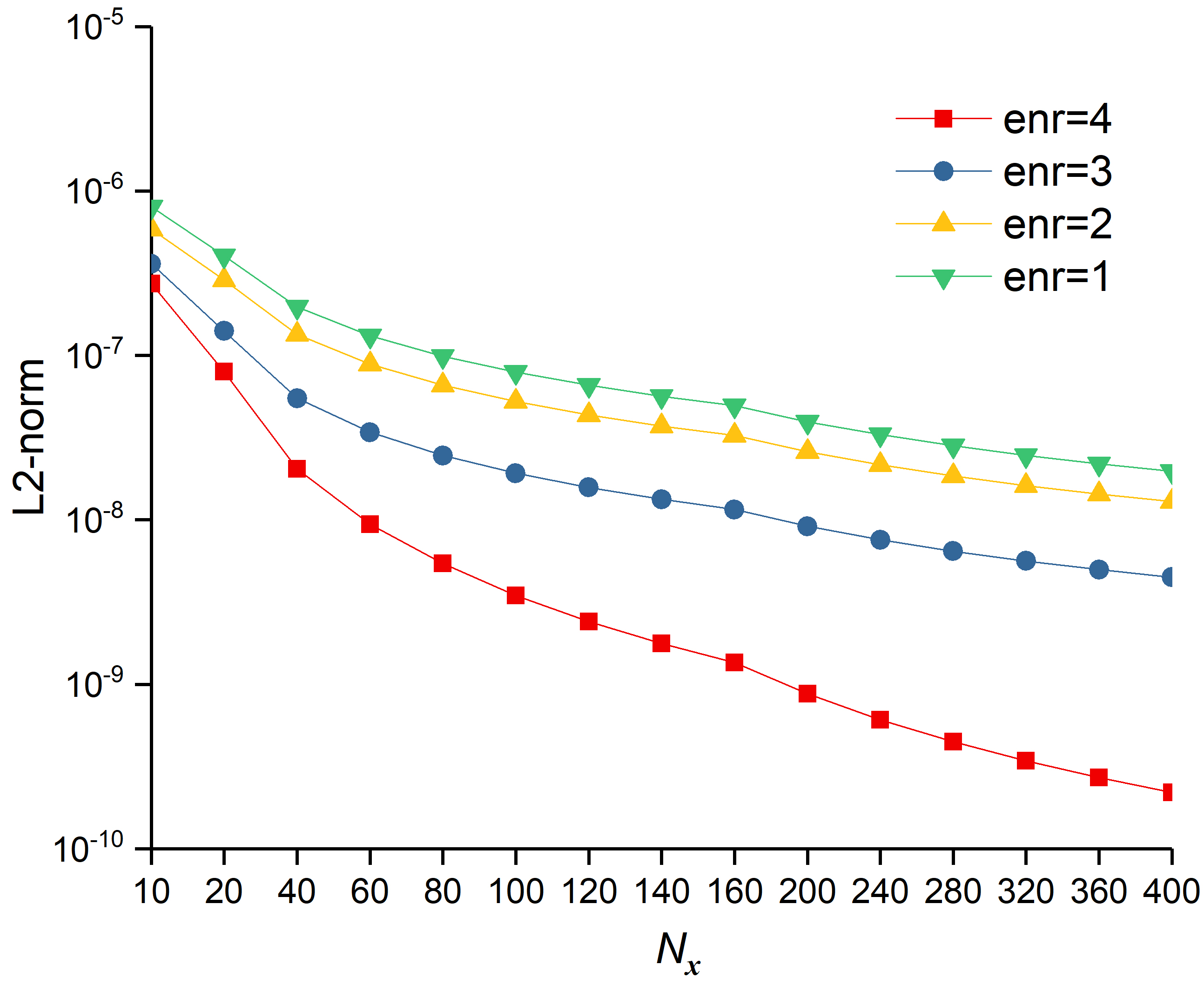
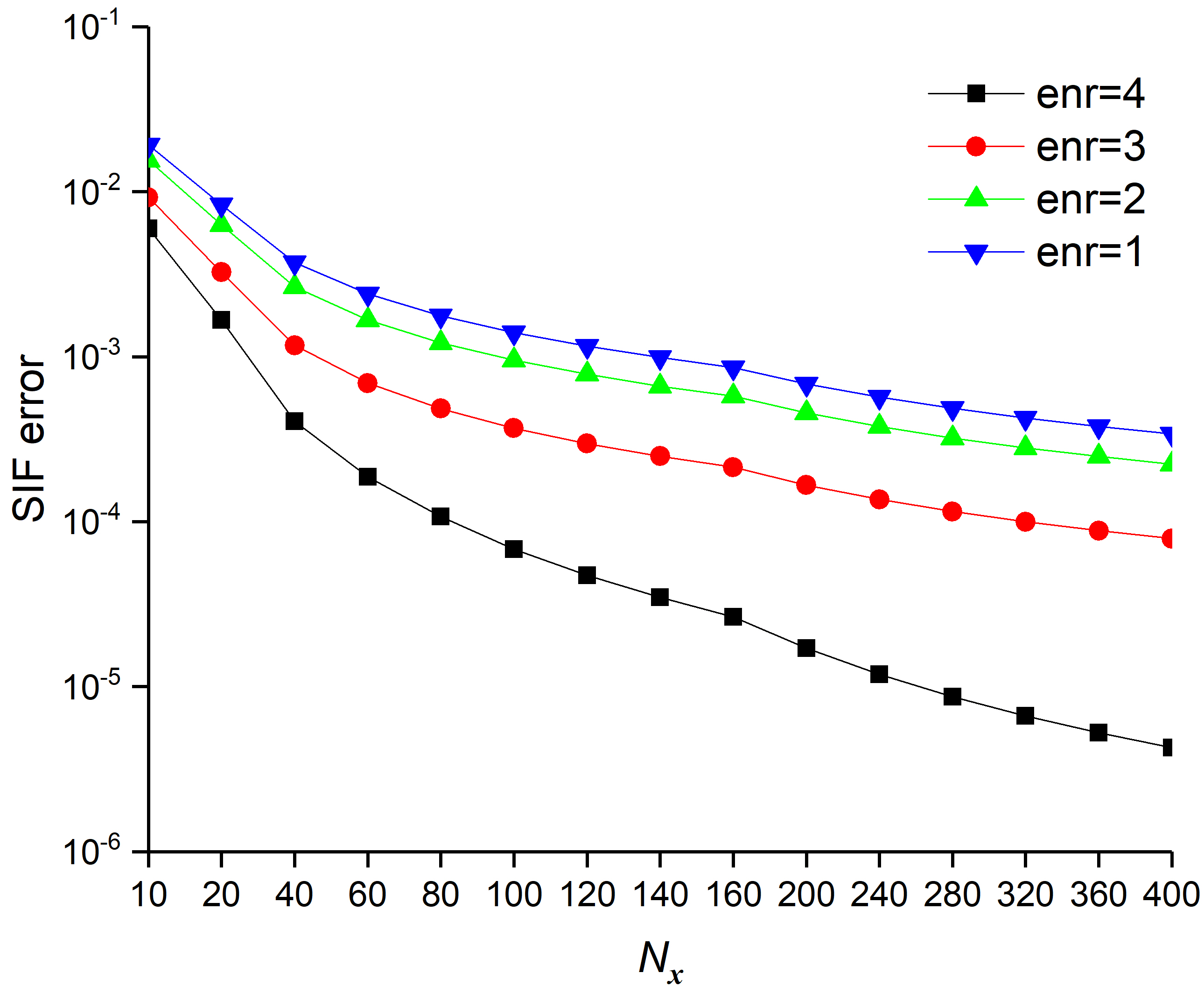
| enr=4 | enr=3 | enr=2 | enr=1 | |
| L2-norm | 1.9035 | 1.1434 | 1.0098 | 0.9812 |
| energy-norm | 1.0232 | 0.3973 | 0.3993 | 0.3951 |
| SIF error | 1.9313 | 1.2402 | 1.1081 | 1.0578 |
The above discussion indicates that the full enrichment function (enr=4), apart from increasing the condition number of the linear system, also increases the accuracy of the results significantly, and provides the best convergence order. For a linear system that uses part of the branch enrichment functions for the crack problem, conventional iterative solvers can provide good performance. However, the numerical tests demonstrate that these solvers do not converge well for enr=4, unless a good preconditioner is applied to decrease the condition number.
Note that the stiffness matrix resulting from the XFEM discretization of linear elastic problem is symmetric. After applying the boundary conditions and eliminating the linear dependency, the coefficient matrix for the linear system is symmetric positive definite (SPD) 38. For this type of system, the conjugate gradient (CG) algorithm is a good choice for SPD matrices 39. For each subdomain problem, the submatrix is also symmetric, and the complete Cholesky factorization (CC) or incomplete Cholesky factorization (ICC) is adopted as the subdomain solver. Therefore, all cases in this study are solved by CG with an ASM preconditioner for the enr=4 problem, and the subsolver for each subdomain is CC or ICC with levels of fill-ins, abbreviated as ICC().
4.2 Comparison of subdomain strategies
In this section, the performances of the different subdomain strategies introduced in Section 2.2 are compared. The branch crack model shown in Figure 13a is employed for the discussion. Young’s modulus MPa, and Poisson’s ratio . Initially, the condition number of the stiffness matrix is studied before and after preconditioning with a small mesh, as it is difficult to compute the condition number for large size matrices. The mesh size of 2626 is partitioned into 55 subdomains. The overlapping size is 2. There are 1352 regular DOFs, 1088 enriched DOFs, and the assembled stiffness matrix size is 24402440. According to the results in Table 2, it is observed that the condition number of the stiffness matrix is very large without the preconditioner. For the preconditioner with strategy S0, improvements do not impact the magnitude of the condition number. Comparing the results of S1 and S2, the minimum singular value and condition number with strategy S2 are noticeably smaller than those of S1. As the magnitude of the condition number decreases from to , the domain decomposition method S2 significantly decreases the condition number.
| K | ||||
| S0 | S1 | S2 | ||
| 8.10e+04 | 3.34e+02 | 2.72e+03 | 8.00e+02 | |
| 9.58e-08 | 1.53e-09 | 5.68e-07 | 4.47e-03 | |
| 8.46e+11 | 2.19e+11 | 4.80e+09 | 1.79e+05 | |
To compare the performance of the three subdomain strategies in parallel computing, two different meshes with mesh sizes of and are adopted for this discussion. The corresponding number of nodes is 1 million and 25 million, respectively. The number of processors used to solve the two problems is 24 and 1024, respectively. The overlapping size is 4 for S0, and 2 for S1 and S2. The subdomain solver of each processor for S0 and S1 is ICC(9). For S2, the subdomain solver is the complete Cholesky factorization (CC) for the tip subdomains and ICC(9) for regular subdomains. As displayed in Table 3, for the linear elastic crack problem, strategy S0 with the preconditioned CG method converges very slowly. When the mesh is refined to 25 million nodes, more than 4500 iterations are required for convergence. The geometrical additive Schwarz preconditioner with strategies S1 and S2 can reduce the number of iterations significantly. Compared with S1, S2 requires fewer iterations and elapsed time as it handles the crack tip subdomain separately, where the difficulties originate. Therefore, the domain decomposition preconditioner from S2 has better performance than the algebraic domain decomposition method S0 and the traditional geometrical domain decomposition method S1.
| subdomain strategy | 1 million nodes (24 CPUs) | 25 million nodes (1024 CPUs) | ||
| ITER | (s) | ITER | (s) | |
| S0 | 2083 | 87.01 | 4631 | 137.97 |
| S1 | 628 | 16.12 | 2983 | 50.59 |
| S2 | 263 | 12.39 | 1249 | 39.85 |
4.3 Mesh-independent convergence
A desirable property of an algorithm is to maintain a similar convergence rate under different mesh resolutions 40, 41 referred to as mesh-independent convergence. In this section, the mesh-independent convergence of the additive Schwarz preconditioner is discussed by comparing the number of iterations and the norm of errors, including SIF-error, L2-norm, and energy-norm, as introduced in Section 3. The crack model remains the same as that of Section 4.2. The mesh is refined from 512512 to 40964096, such that the mesh resolution changes from to , where is the element size for the coarsest mesh. The number of processor cores for parallel computing is 192, and the overlapping size ranges from 1 to 8 to maintain the thickness of the overlap region between processors constant. Here, the overlapping size for the regular subdomain and crack tip subdomain is the same and the subsolver was the complete Cholesky factorization for both. To compute the norm of errors, the results of the finer mesh size were adopted as reference. The in equations (20,21, and 22) without superscript are the results of the finer mesh.
The convergence performance is presented in Table 4. Clearly, the number of iterations changes slightly with mesh refinement. The SIF error, L2-norm, and energy norm become increasingly smaller. This demonstrates that the performance of the domain decomposition method in this study is independent of mesh resolution. It should be noted that the subsolver in Table 4 is the complete Cholesky factorization instead of the incomplete Cholesky factorization, as our numerical experiments indicate that the subsolver ICC() cannot achieve mesh-independent convergence. Although the convergence of complete Cholesky factorization is mesh-independent, it is too time-consuming and unsuitable for large-scale parallel computing. The subsolver for the regular subdomains in the following discussions is also ICC().
| OLP | ITER | SIF-error | L2-norm | Energy-norm | |
| 512 | 1 | 229 | 3.92e-04 | 8.77e-11 | 1.49e-06 |
| 1024 | 2 | 248 | 1.18e-04 | 2.46e-11 | 6.48e-07 |
| 2048 | 4 | 238 | 3.13e-05 | 6.28e-12 | 3.27e-07 |
| 4096 | 8 | 238 | 7.06e-06 | 1.71e-12 | 1.82e-07 |
4.4 The impact of submatrix reordering
In standard FEM, the DOFs are usually ordered field by field (FbF), which orders one field DOFs and then another. For the corrected XFEM, the regular DOFs are ordered first and then the crack-tip enriched DOFs and Heaviside DOFs. Figure 11a displays the structure of the stiffness matrix. In parallel computing, DOFs are usually ordered block by block (BbB), such that each processor orders local DOFs sequentially, and the starting index of processor is numbered after processor regardless of the type of DOFs. Figure 11b displays the structure of the stiffness matrix. It is observed that the bandwidths from the two orders are still too large for subdomain solvers such as ICC factorization 42. Additional reordering techniques are required to decrease the bandwidth and improve the performance of the subsolver. The matrix reordering methods include ND, 1WD, RCM, and QMD 43, 44. The structure of the stiffness matrix with these four reordering methods is displayed in Figure 11c11f. It is observed that RCM can considerably decrease the bandwidth. The performance of the reordering techniques in parallel computing is investigated next. The crack model remains the same as in Section 4.2 and the preconditioner is the left ASM.
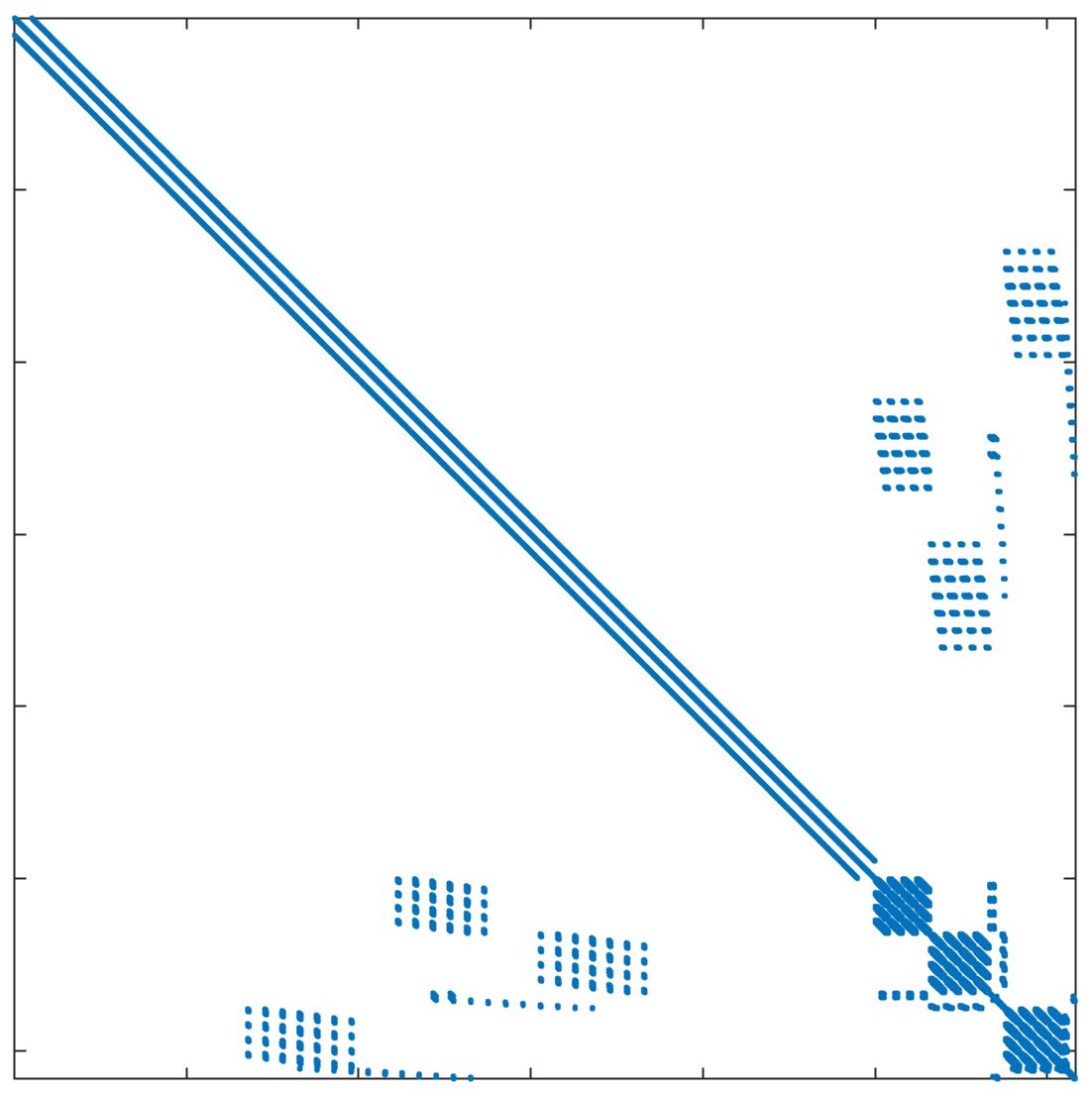
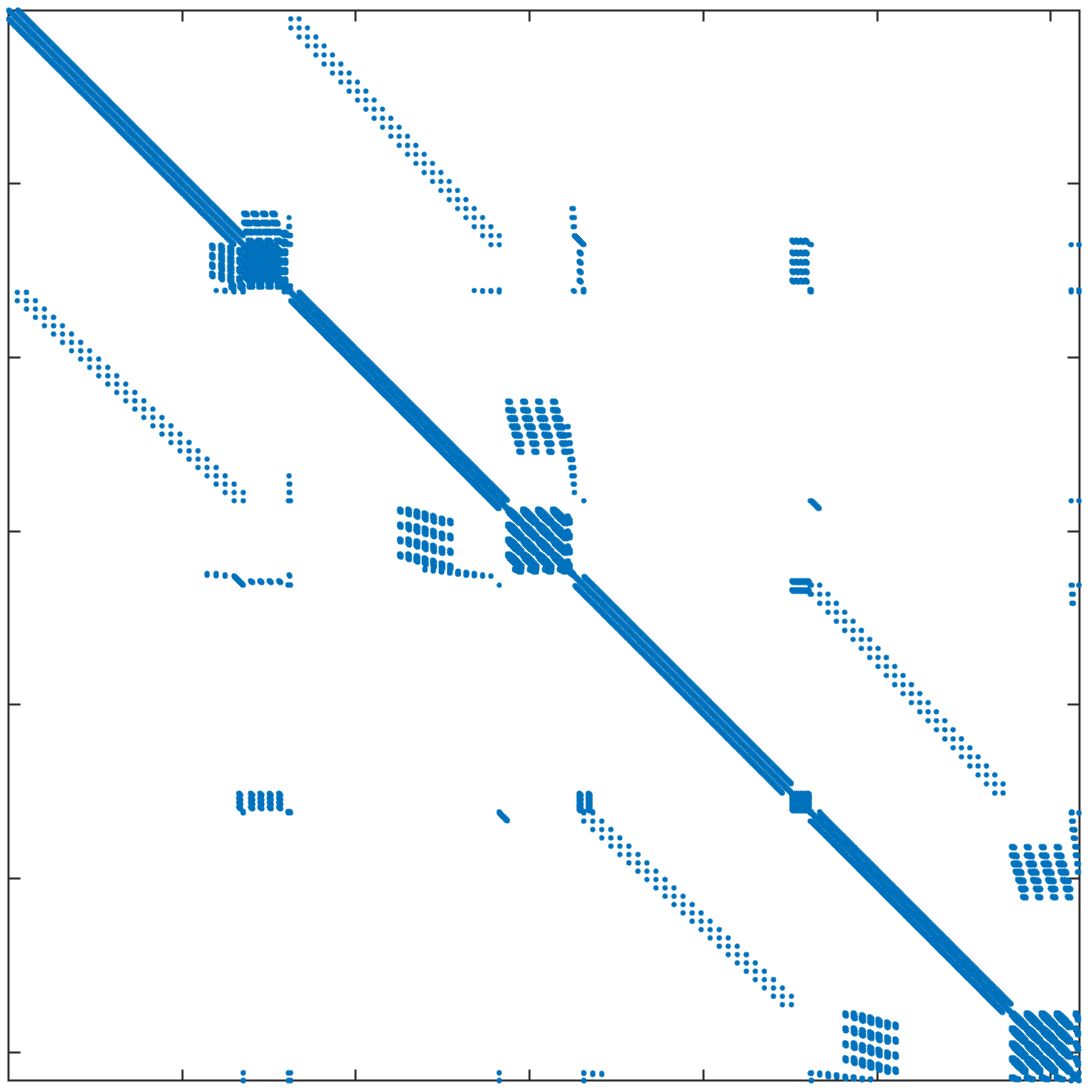
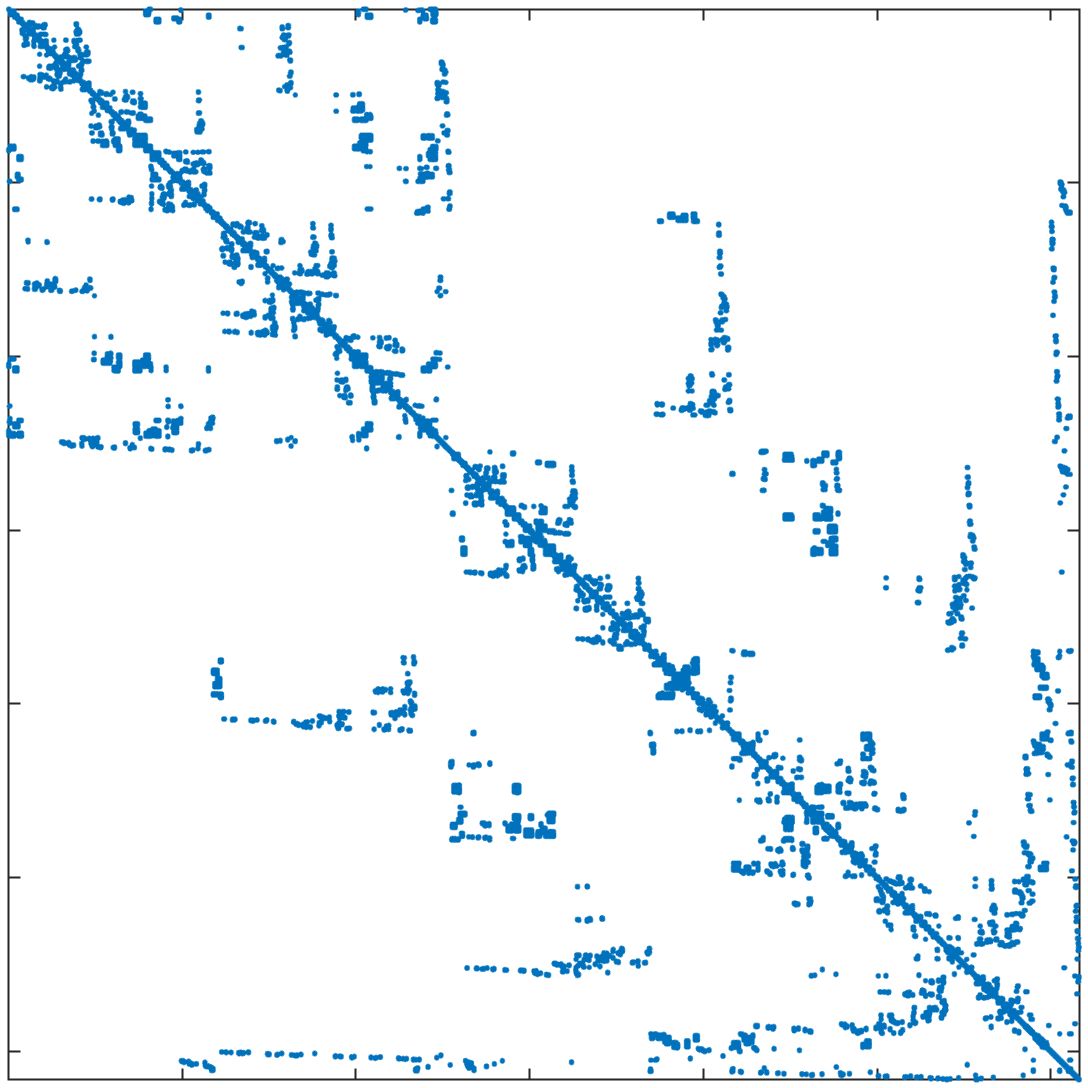
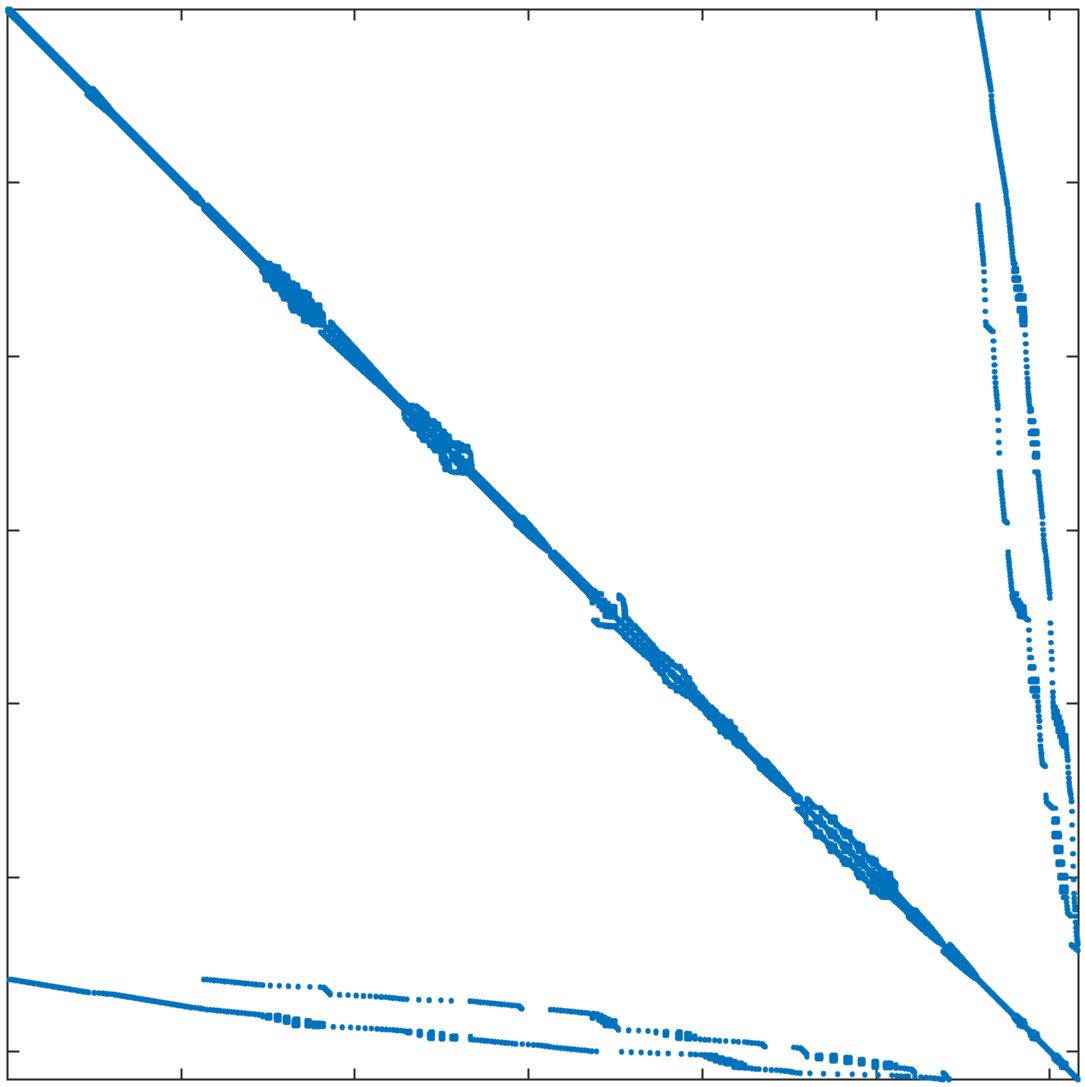
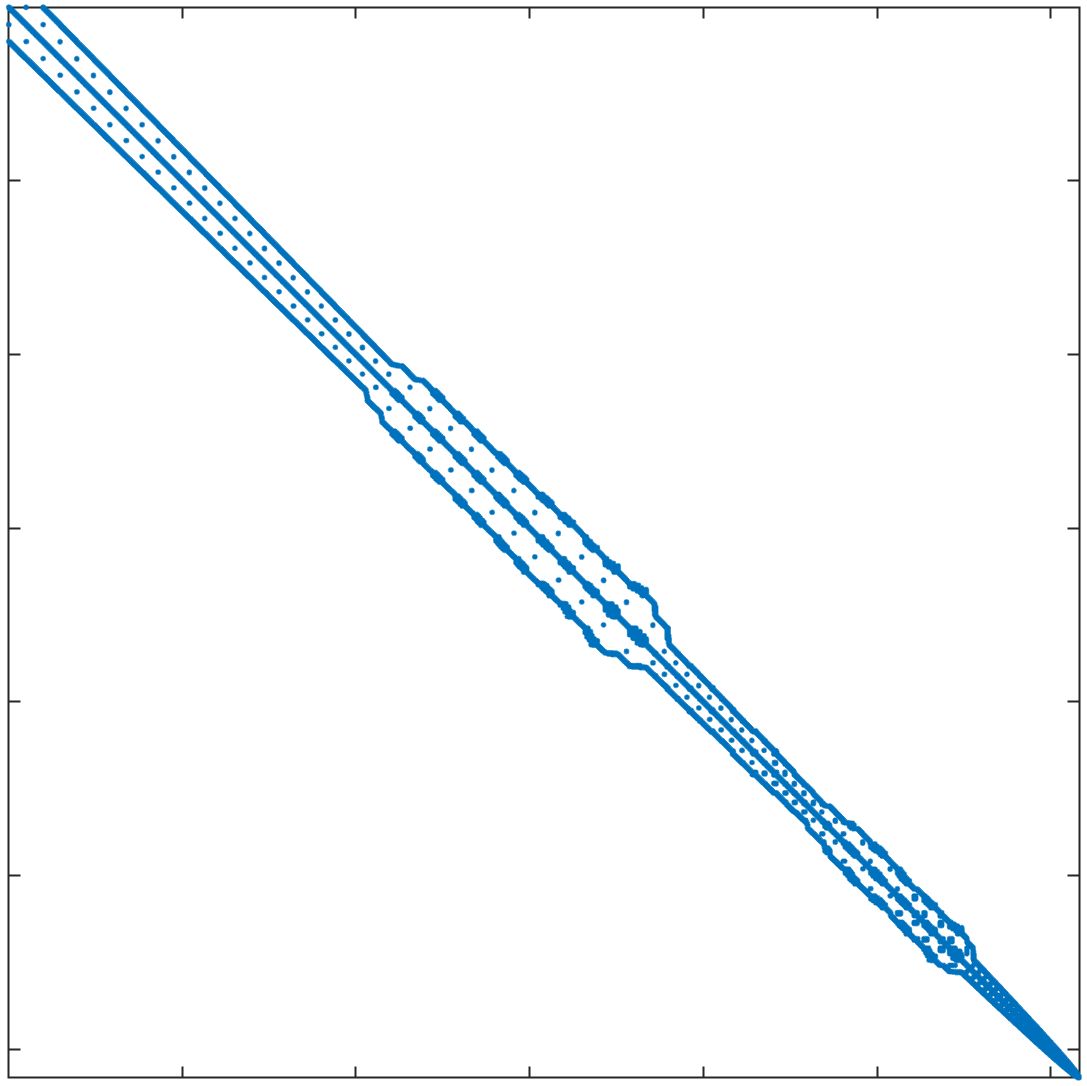
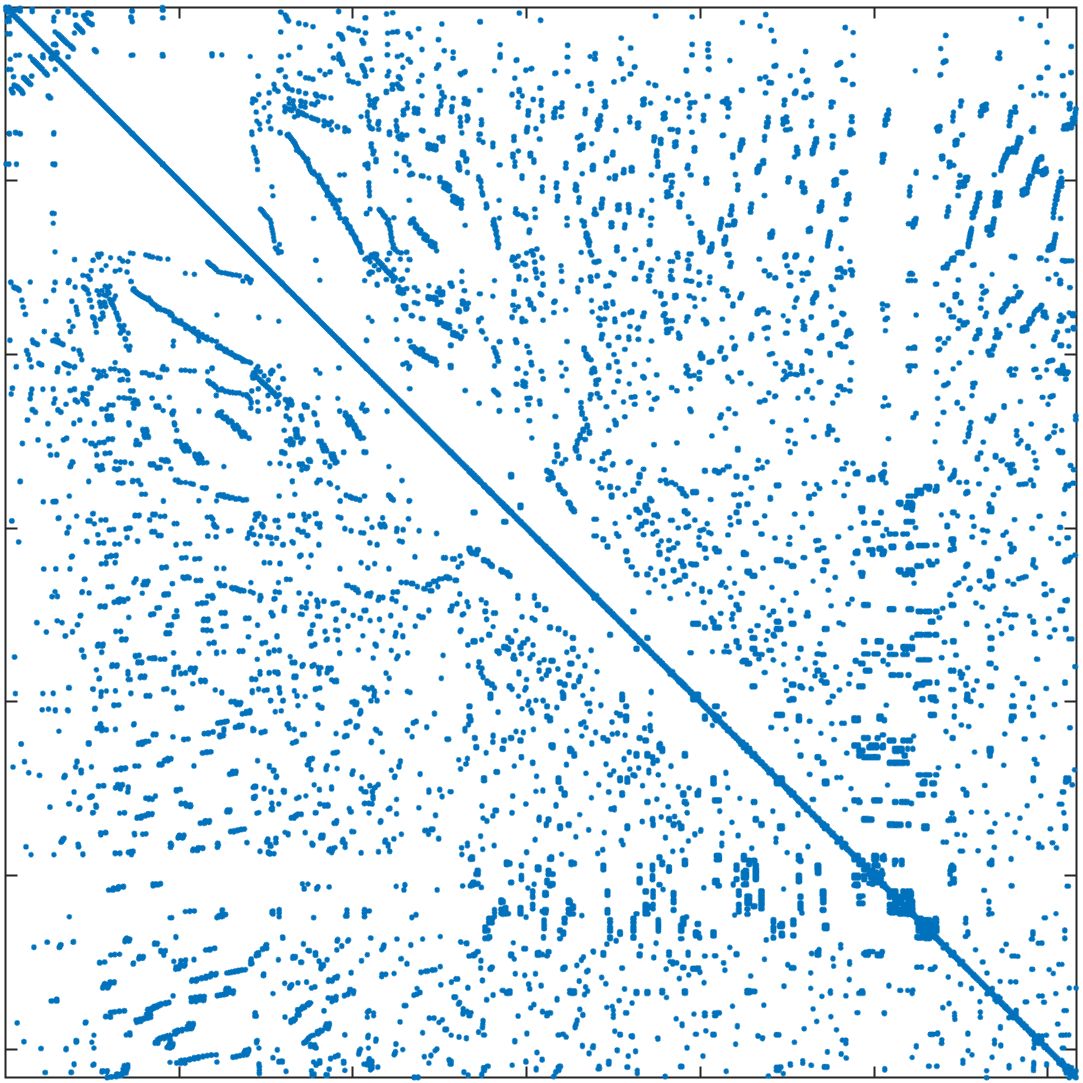
In Table 5, the number of iterations and elapsed time of the solver are listed for the mesh with 1 million nodes and 25 million nodes. The DOFs in each processor are ordered using the BbB method by default. If the reordering method is "Natural", this means that there is no additional reordering method. The results show that compared with the natural order, ND has less elapsed time for both cases, while 1WD has no improvement and requires more iterations and elapsed time. RCM requires the least number of iterations and elapsed time among these reordering methods. QMD offers some but not tangible improvements. As RCM performs the best, it will be used as the default matrix reordering technique in the following discussions.
| reordering method | 1 million nodes | 25 million nodes | ||
| ITER | (s) | ITER | (s) | |
| Natural | 302 | 15.1 | 1476 | 52.31 |
| ND | 295 | 14.3 | 1496 | 49.02 |
| 1WD | 312 | 17.25 | 1510 | 56.77 |
| RCM | 263 | 12.39 | 1249 | 39.85 |
| QMD | 297 | 15.33 | 1475 | 46.96 |
4.5 The level of fill-ins for ICC
Generally, for large-scale parallel computing, complete Cholesky factorization for a symmetric sparse matrix is very time- and memory-consuming as the complexity is for an matrix 45. An incomplete Cholesky factorization with levels of fill-ins, abbreviated as ICC(), is an optional method for obtaining the subdomain preconditioner in (15) because the complexity is . The effect of the ICC fill-ins level on the linear solver is investigated next by comparing the number of iterations and elapsed time. The branch crack model is employed in this section; the mesh is 50005000; and the number of unknowns is 50,015,964. The problem is computed by 1024 processors with a left ASM preconditioner; the overlapping sizes for the regular subdomains and crack tip subdomains are 2 and 6, respectively.
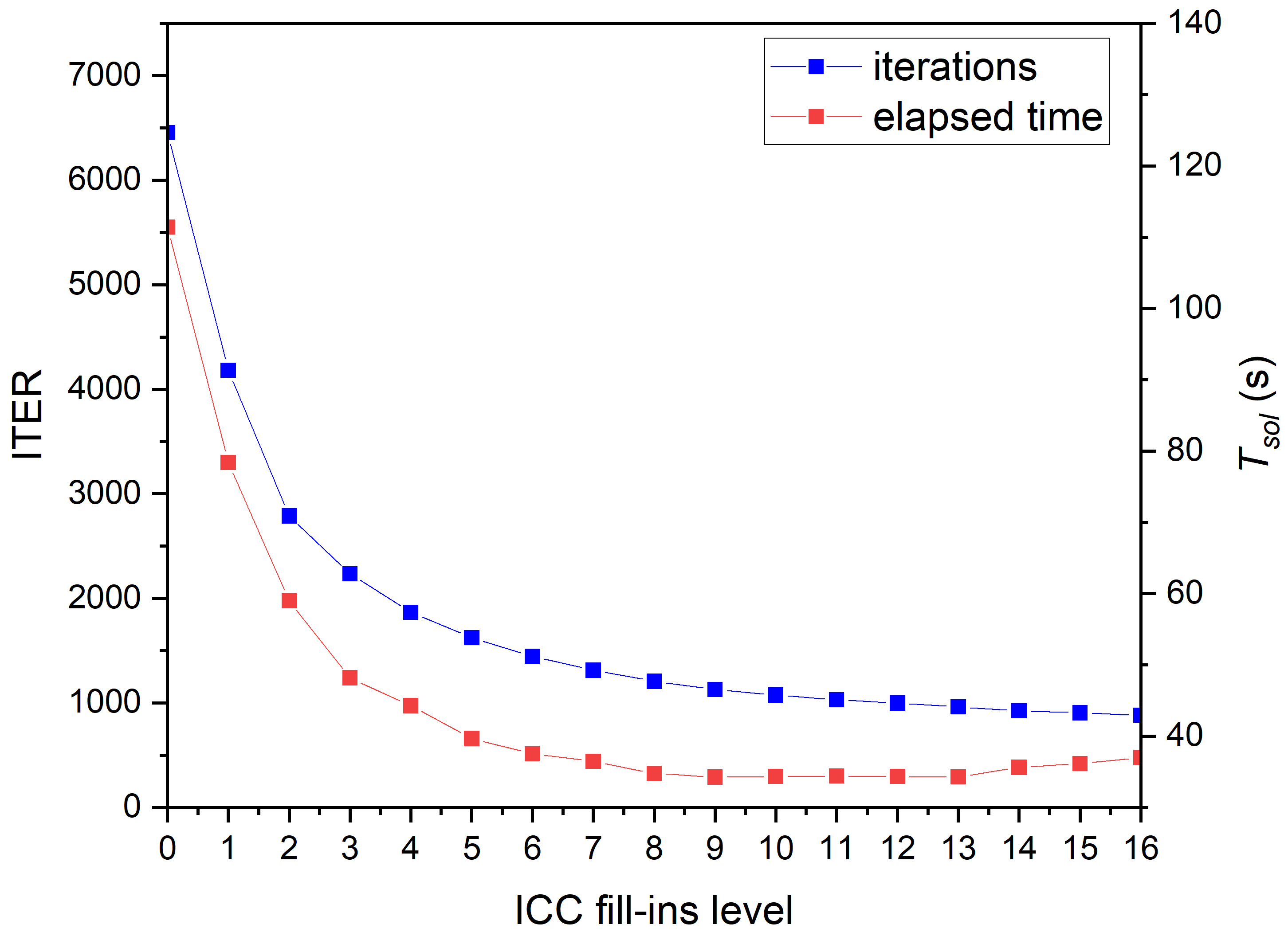
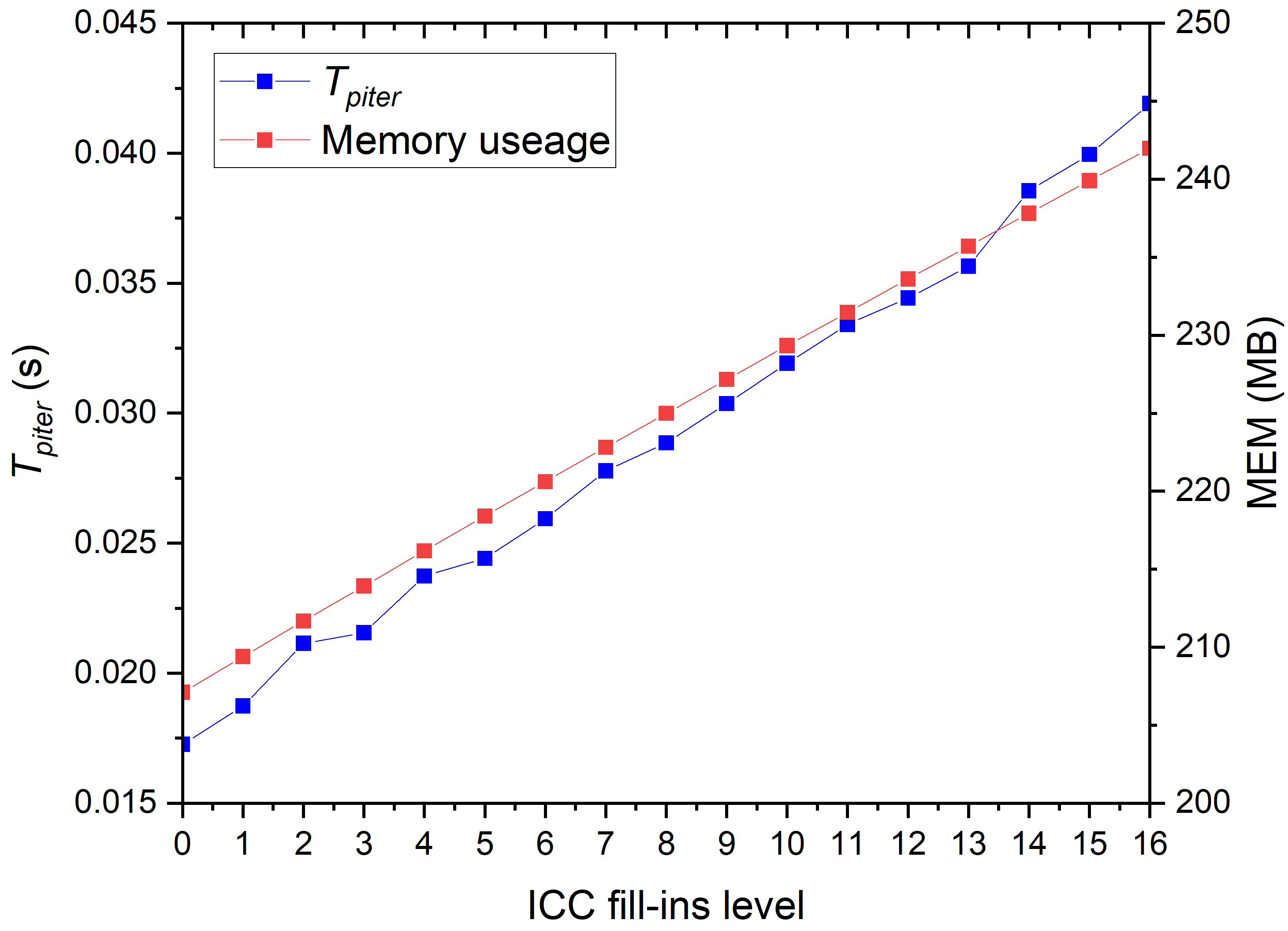
The effects of ICC fill-ins level for tip subdomains and regular subdomains are discussed separately. When considering regular subdomains, the subsolver for the crack tip subdomain is fixed as complete Cholesky factorization. When considering crack tip subdomains, the subsolver for the regular subdomain is fixed as ICC(9). The results are summarized in Table 6 and Figure 12. On the left of Table 6, the ICC fill-ins level for the regular subdomain changes from 0 to 16 indicating that the number of iterations continues to decrease. The elapsed time of the solver decreases at first, and finally, there are some increases. Memory usage increases continuously with the increase of the ICC fill-ins level, increasing to a maximum when the subsolver is the complete Cholesky factorization. In Figure 12a, the number of iterations and the elapsed time drop quickly at first and then gradually when the fill-ins level is smaller than 5. When the fill-ins level is larger than 9, the elapsed time begins to increase as the elapsed time per iteration increases continuously, as shown in Figure 12b. This is the reason why increases for large fill-ins level. Compared with the results of complete Cholesky factorization in the last row of Table 6, although the ICC() requires more iterations to converge, the cost for each step is much less, which results in less total time used. On the right part of Table 6, the situation is different. When the ICC fill-ins level for the crack tip subdomain is less than 7, the solver does not converge. With the increase of the ICC fill-ins level, the solver converges and quickly attains the results of CC. This indicates that the crack tip subdomain solver is much more sensitive to the accuracy of matrix factorization because the crack tip submatrix is singular. The iterations, elapsed time, and memory usage are remarkably close to those of complete Cholesky factorization in the last row. As the crack tip submatrix is denser, there is no significant difference between complete Cholesky factorization and incomplete Cholesky factorization with large fill-ins level in terms of time consumption and memory usage. For these reasons, the subsolver for the tip subdomain is set as CC, and that for the regular subdomain is ICC(9), which achieves the best performance.
|
|
|||||||||||
| ITER | (s) | (s) | MEM (MB) | ITER | (s) | (s) | MEM (MB) | |||||
| 0 | 6454 | 111.43 | 0.069 | 207.11 | - | - | - | - | ||||
| 1 | 4182 | 78.39 | 0.092 | 209.40 | - | - | - | - | ||||
| 2 | 2789 | 58.99 | 0.112 | 211.67 | - | - | - | - | ||||
| 3 | 2235 | 48.18 | 0.141 | 213.93 | - | - | - | - | ||||
| 4 | 1865 | 44.27 | 0.167 | 216.17 | - | - | - | - | ||||
| 5 | 1625 | 39.67 | 0.201 | 218.40 | - | - | - | - | ||||
| 6 | 1447 | 37.54 | 0.244 | 220.61 | - | - | - | - | ||||
| 7 | 1313 | 36.48 | 0.295 | 222.81 | - | - | - | - | ||||
| 8 | 1206 | 34.80 | 0.348 | 225.00 | 1400 | 43.03 | 0.028 | 226.99 | ||||
| 9 | 1128 | 34.26 | 0.386 | 227.17 | 1381 | 41.86 | 0.031 | 227.02 | ||||
| 10 | 1076 | 34.35 | 0.445 | 229.33 | 1235 | 37.55 | 0.032 | 227.04 | ||||
| 11 | 1030 | 34.42 | 0.511 | 231.47 | 1142 | 35.33 | 0.033 | 227.06 | ||||
| 12 | 998 | 34.36 | 0.563 | 233.60 | 1139 | 34.53 | 0.038 | 227.08 | ||||
| 13 | 962 | 34.30 | 0.625 | 235.71 | 1136 | 34.40 | 0.041 | 227.08 | ||||
| 14 | 924 | 35.62 | 0.689 | 237.82 | 1128 | 33.92 | 0.042 | 227.10 | ||||
| 15 | 905 | 36.16 | 0.765 | 239.90 | 1123 | 33.87 | 0.045 | 227.11 | ||||
| 16 | 883 | 37.01 | 0.854 | 241.98 | 1128 | 34.53 | 0.046 | 227.12 | ||||
| CC | 739 | 128.24 | 25.036 | 449.57 | 1128 | 34.10 | 0.054 | 227.17 | ||||
Abbreviation: is the ICC fill-ins level; ITER is the number of iterations; is the elapsed time for solver; is the elapsed time for submatrix factorization; MEM is the memory usage per processor core in megabytes; CC means complete Cholesky factorization.
4.6 The overlapping size
In this section, the impact of overlapping size, which plays a critical role in the additive Schwarz method is studied. Overlap in the additive Schwarz method represents the communication between processor cores. Generally, a larger overlapping size can decrease the number of iterations because the local processor can obtain more information from neighboring processors. Meanwhile, a larger overlapping size increases the cost of the subsolver for local problems. Therefore, an appropriate overlapping size should be used to achieve the best performance. The crack model is a branch crack; the mesh size is 50005000; and the problem is solved using 1024 processors. The subsolver for regular subdomains is ICC(9), and the crack tip subdomain is CC.
Table 7 shows the effect of overlapping size in terms of iterations and elapsed time. Here, the overlapping size for regular subdomains and tip subdomains is discussed separately. On the left part of Table 7, the overlapping size for tip subdomains is fixed as 6, and that for regular subdomains varies from 1 to 7. The number of iterations keeps decreasing continuously, while the elapsed time drops at first and then begins to increase when the overlapping size is larger than 2, as the elapsed time per iteration is always increasing. It is known that each layer of overlapping elements in the geometrical domain decomposition method includes many DOFs, increasing the communication between processors. Therefore, the overlapping size for the regular subdomain can be set to OLP(2). On the right part of Table 7, the overlapping size for regular subdomains is fixed as 2, and that for crack tip subdomains varies from 1 to 7. With the increasing overlapping size, the iterations always decrease and the elapsed time keeps decreasing as well when the overlapping size is smaller than 6. When the overlapping size is 7, there is little increase in elapsed time. The elapsed time per iteration exhibits little change when the overlapping size increases, which can be explained by the crack tip subdomain being usually much smaller than the regular subdomain, leading to much less DOFs from crack tip overlap. The main communication during iterations mainly comes from regular subdomains. The overlapping size for crack tip subdomain has an effect on the number of iterations but not much on the elapsed time per iteration. As summarized, the overlapping size for regular subdomain is chosen as OLP(2) and for the crack tip subdomain, it is OLP(6).
| OLP(tip)=6, OLP(reg) varies | OLP(reg)=2, OLP(tip) varies | |||||
| OLP | ITER | ITER | ||||
| 1 | 1232 | 35.99 | 0.029 | 1304 | 39.17 | 0.030 |
| 2 | 1126 | 33.60 | 0.030 | 1250 | 37.24 | 0.030 |
| 3 | 1098 | 34.52 | 0.031 | 1185 | 35.31 | 0.030 |
| 4 | 1080 | 34.26 | 0.032 | 1150 | 35.12 | 0.031 |
| 5 | 1070 | 34.62 | 0.032 | 1138 | 34.50 | 0.030 |
| 6 | 1058 | 34.59 | 0.033 | 1128 | 33.65 | 0.030 |
| 7 | 1041 | 36.40 | 0.035 | 1130 | 34.02 | 0.030 |
Abbreviation: OLP is overlapping size; ITER is the number of iterations; is the total elapsed time of solver; is elapsed time per iteration.
4.7 Parallel scalability analysis
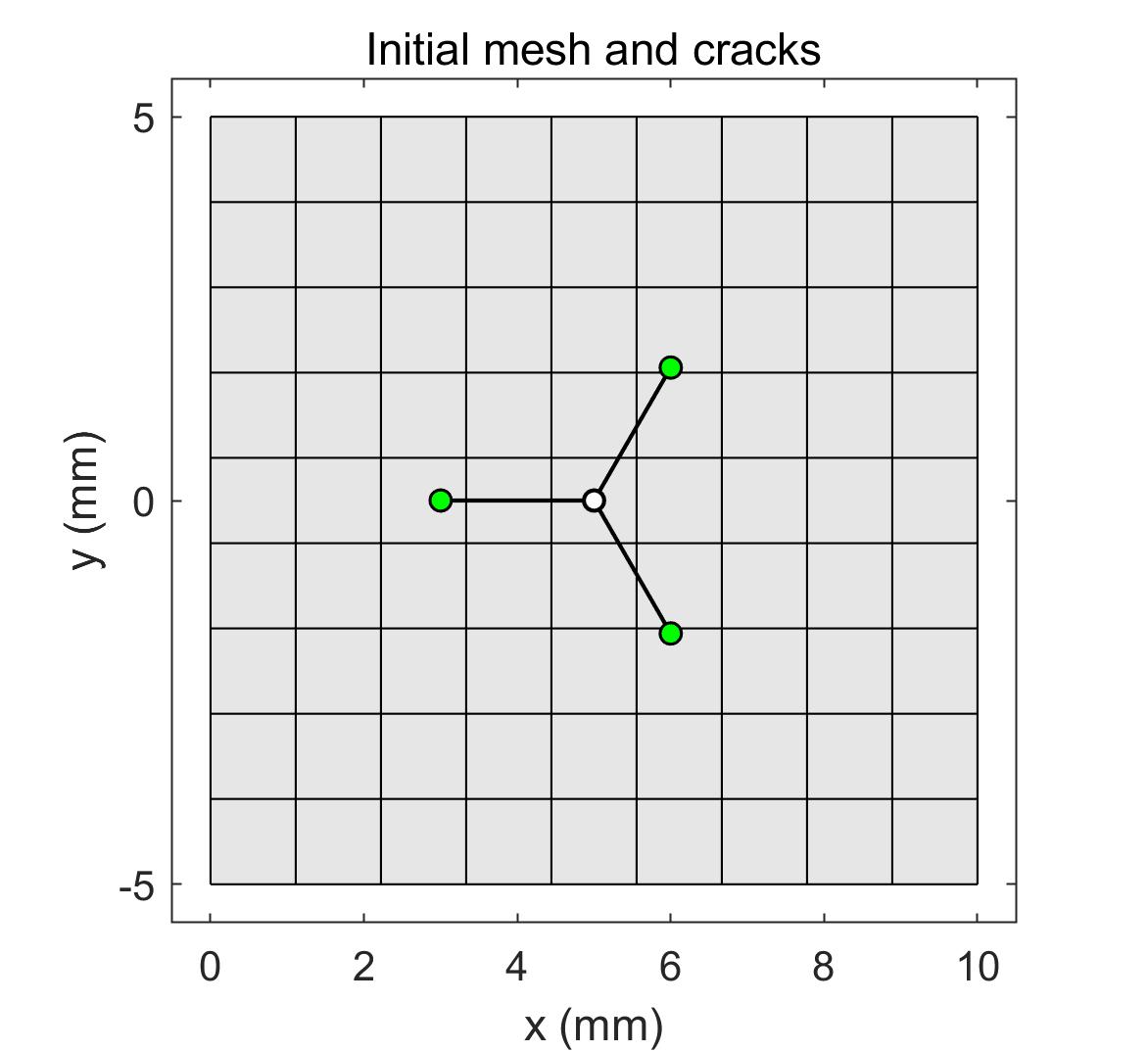
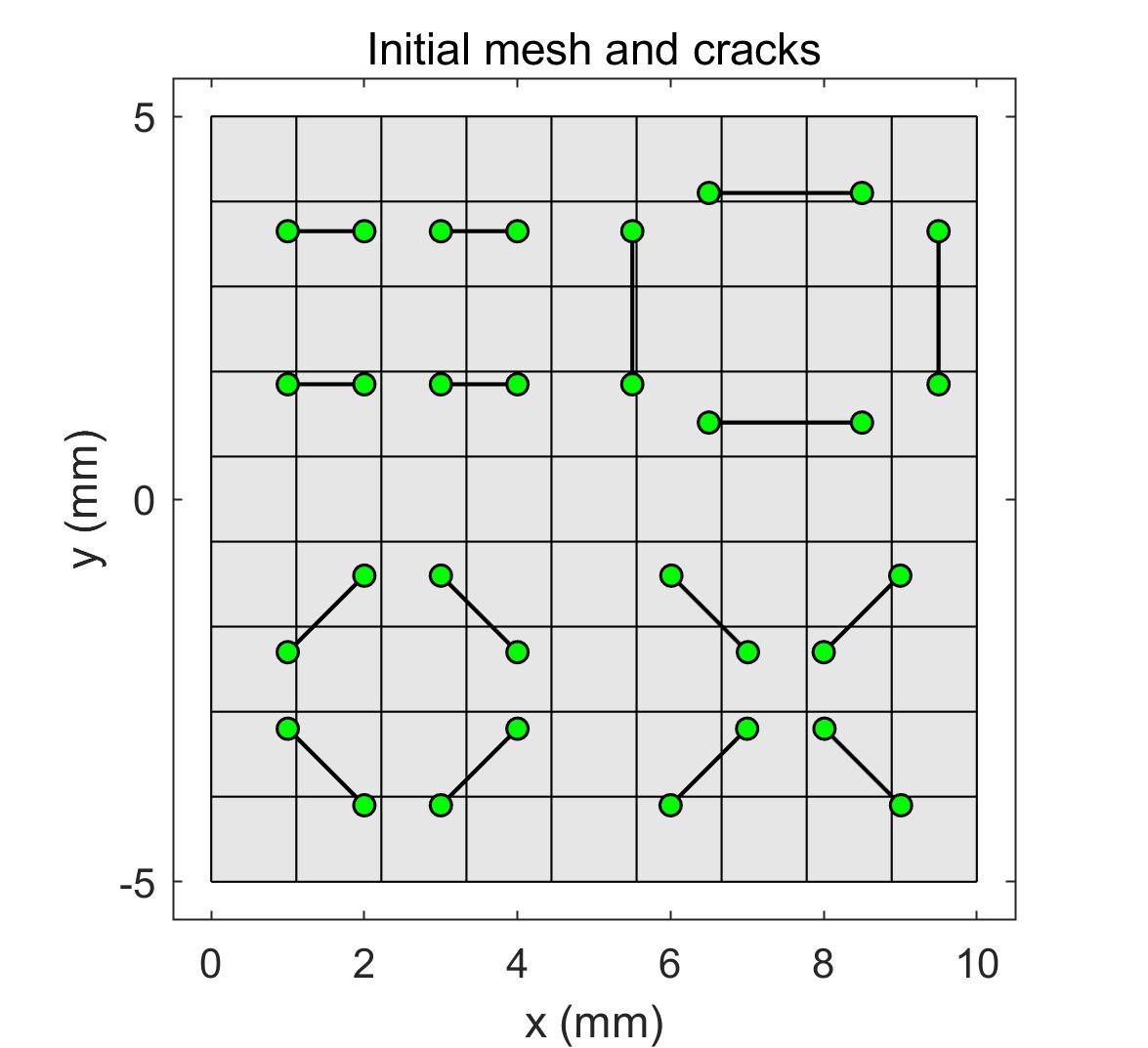
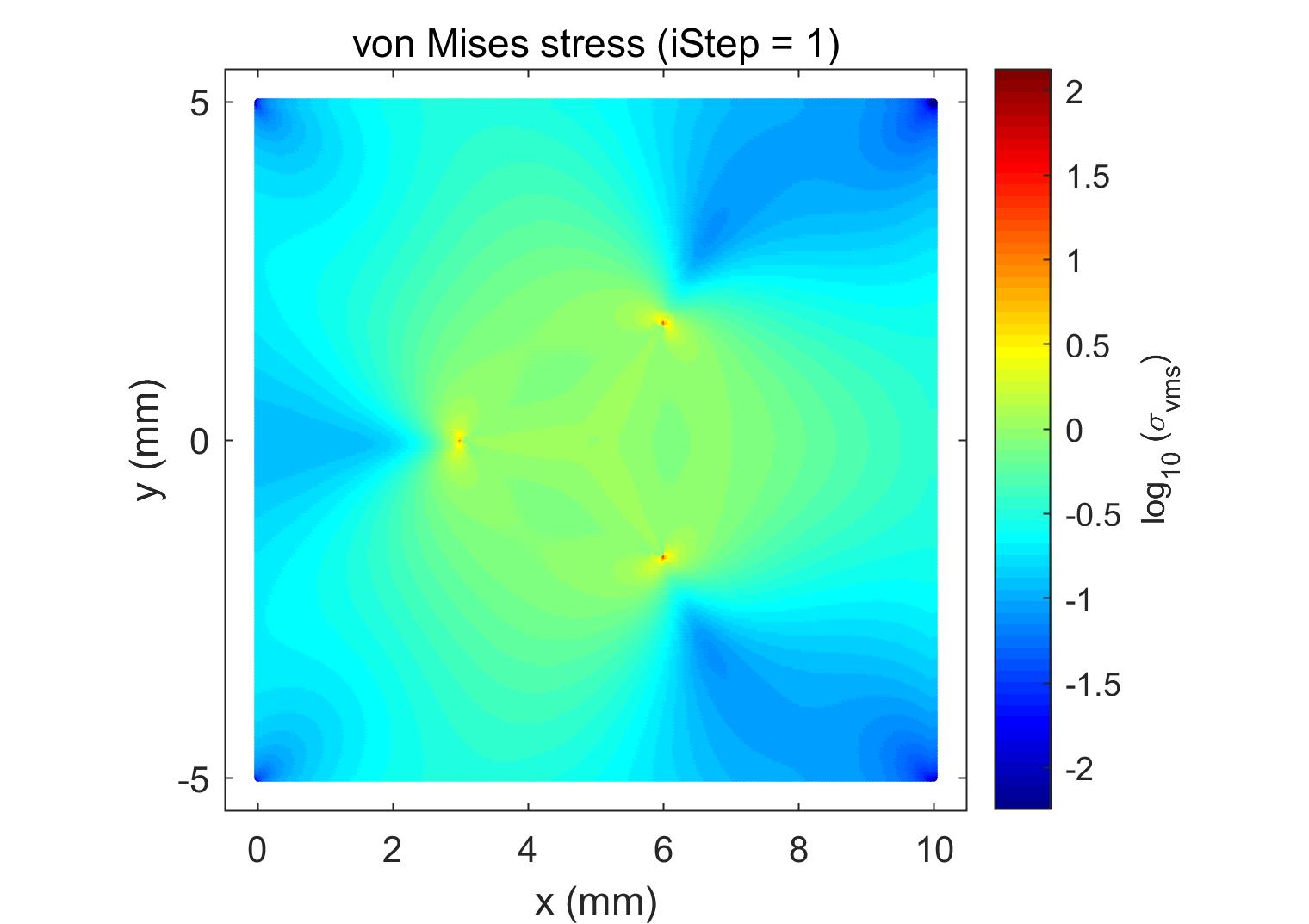
In this section, the parallel scalability of the proposed algorithm is discussed. As shown in Figure 13, a square domain of size 10 m10 m with cracks inside is considered. The first crack model is a branch crack with three crack tips. The second crack model has 16 cracks in the domain and 32 crack tips. The problem type is plain stress. Young’s modulus MPa, and Poisson’s ratio . The boundaries of the domain are fixed with zero displacement. The crack surface is compressed with 1.0 MPa inner water pressure. The relative convergence tolerance was . The submatrix in each processor for all cases was reordered by RCM. The numerical results for the two crack models are illustrated in Figure 14, which plots the Von-Misses stress contour. It is observed that the high stress is concentrated in the crack tip area. The results agree with the theoretical analysis that singularities near crack tips generate a large stress around. In the following, parallel scalability is investigated by changing the subdomain solver and the number of processors. Based on the discussions above, the subsolvers ICC(8), ICC(9), and CC are considered for the two cases. The overlapping size for regular subdomains is 2, and crack tip subdomains is 6.
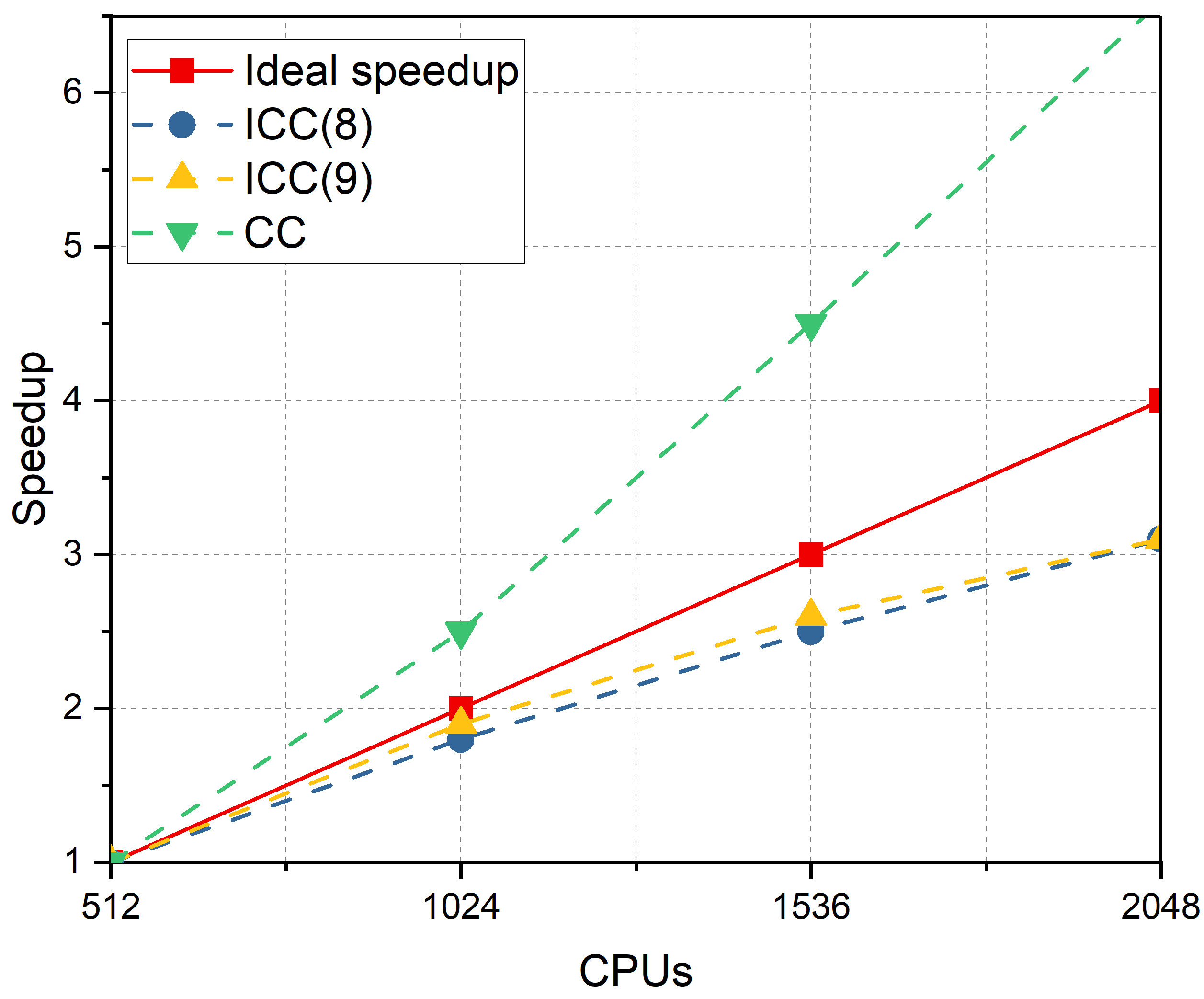
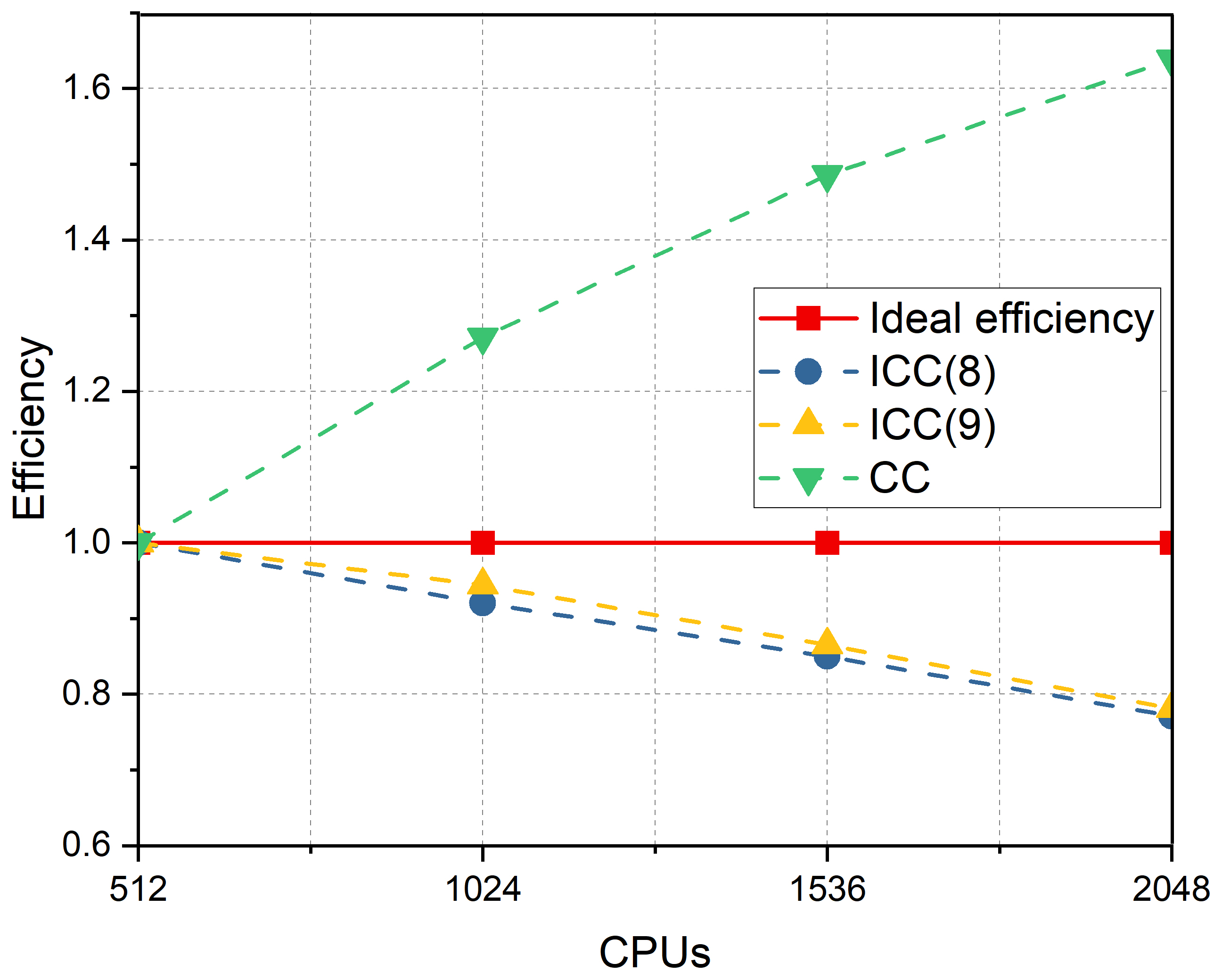
For the branch crack model, the mesh size is . After XFEM discretization, there were regular DOFs and 15964 enriched DOFs. The number of processor cores varied from 512, 1024, 1536, to 2048. The numerical results are summarized in Table 8. The number of iterations and elapsed time decrease with an increase of the ICC fill-ins level. When the subdomain solver is set to CC, the iterations decrease to a minimum, whereas the solver time becomes much longer than that of ICC(). As for scalability with respect to the number of processors, the iterations increase continuously, and the elapsed time decreases significantly. In the last column for , the subsolver time for crack tip subdomains occupies a relatively small percentage, and has a small impact on the scalability. The speedup and parallel efficiencies are displayed in Figure 15. The speedup with the subdomain solver ICC() keeps increasing but is smaller than the ideal speedup, and the efficiency keeps decreasing with the increase of processors. The situation is different for the subdomain solver CC. The speedup and efficiency both exceed the ideal speedup and ideal efficiency while the rate of increase continues to decrease. This is because the complexity of ICC(l) has a linear dependence on the number of processors, whereas for subsolver CC, the dependence is super-linear.
| Subsolver | ITER | Ideal | Speedup | Efficiency | |||
| 512 | ICC(8) | 1149 | 64.09 | 1 | 1.0 | 100.0% | 1.81% |
| ICC(9) | 1083 | 62.97 | 1 | 1.0 | 100.0% | 1.44% | |
| CC | 704 | 324.91 | 1 | 1.0 | 100.0% | 0.22% | |
| 1024 | ICC(8) | 1206 | 34.82 | 2 | 1.8 | 92.0% | 3.25% |
| ICC(9) | 1128 | 33.34 | 2 | 1.9 | 94.4% | 2.98% | |
| CC | 739 | 127.76 | 2 | 2.5 | 127.2% | 0.47% | |
| 1536 | ICC(8) | 1266 | 25.14 | 3 | 2.5 | 85.0% | 4.25% |
| ICC(9) | 1183 | 24.26 | 3 | 2.6 | 86.5% | 4.08% | |
| CC | 785 | 72.89 | 3 | 4.5 | 148.6% | 0.92% | |
| 2048 | ICC(8) | 1299 | 20.77 | 4 | 3.1 | 77.1% | 5.90% |
| ICC(9) | 1233 | 20.16 | 4 | 3.1 | 78.1% | 5.61% | |
| CC | 804 | 49.57 | 4 | 6.6 | 163.9% | 1.73% |
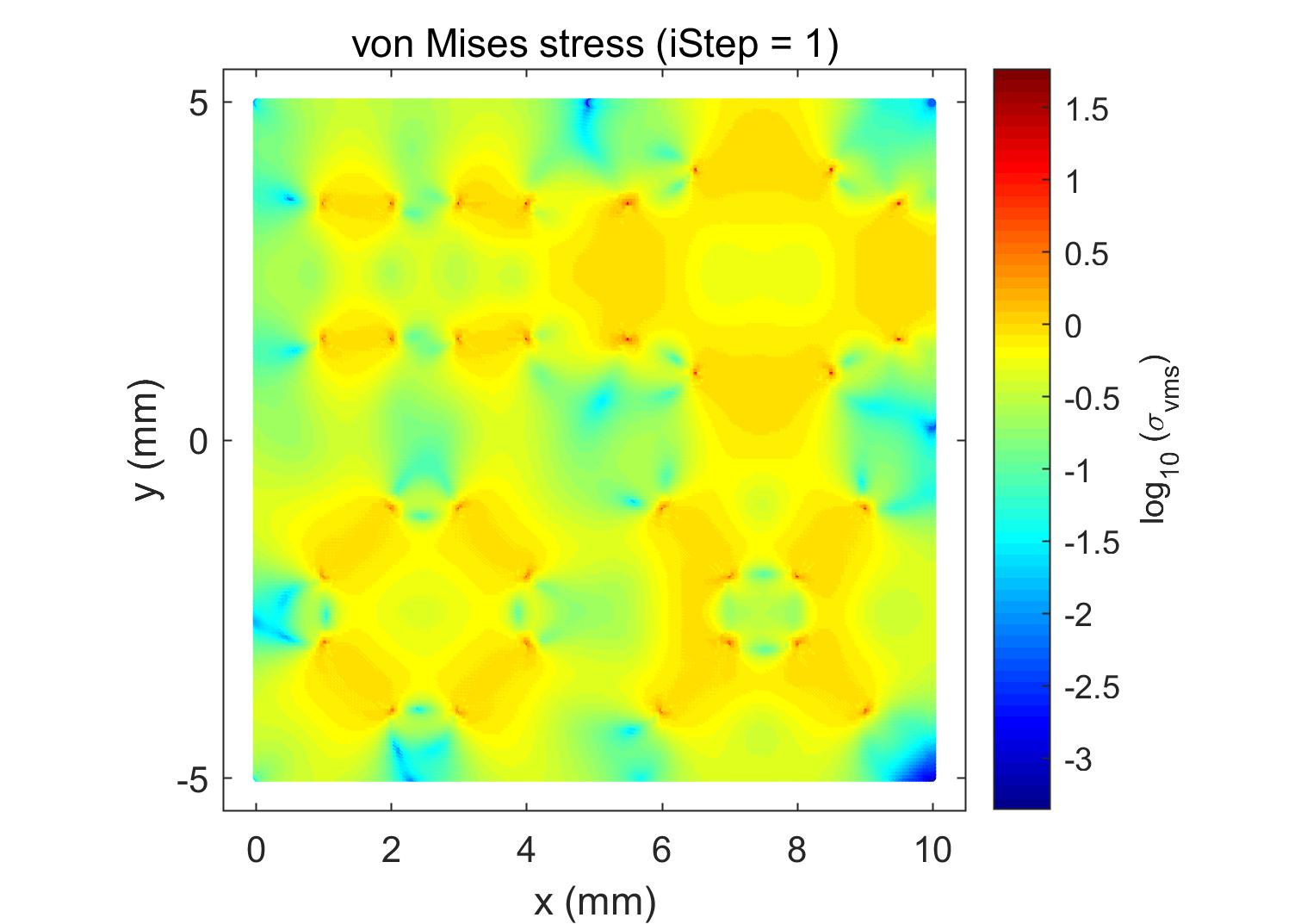
A more complex model is considered in Figure 13b to test the strong scalability of the proposed algorithm. The mesh is refined to , which has regular DOFs and 123216 enriched DOFs after XFEM discretization. Based on the discussion so far, this large-scale problem is exceedingly difficult to solve because the condition number of the linear system is large (larger than ). Generally, the difficulty in solving a crack problem increases with mesh refinement and the number of cracks. If the domain has more cracks, the linear system includes more singularities, which makes the stiffness matrix more ill-conditioned. In this case, the subdomain solvers were ICC(8), ICC(9), and CC with different numbers of processors: 2048, 4096, 6144, and 8192. The numerical results are presented in Table 9. The results indicate that the basic principle of the subdomain solver and the scalability are the same as that of the branch crack model mentioned above. The difference is that the 16-cracks model requires more iterations and elapsed time to achieve convergence. In the last column for , the subsolver time for the crack tip subproblem is considerable when the number of processors is 8192, as a result of the reduced parallel efficiency. The speedup and efficiency are displayed in Figure 16. Comparing Figure 15 and Figure 16, the speedup and efficiency for the 16-cracks model are lower than those of the branch crack model with the same number of processors and ICC fill-ins level.
| Subsolver | ITER | Ideal | Speedup | Efficiency | |||
| 2048 | ICC(8) | 1381 | 77.34 | 1 | 1.0 | 100.0% | 2.67% |
| ICC(9) | 1342 | 77.83 | 1 | 1.0 | 100.0% | 2.59% | |
| CC | 732 | 340.73 | 1 | 1.0 | 100.0% | 0.45% | |
| 4096 | ICC(8) | 1438 | 44.39 | 2 | 1.7 | 87.1% | 4.88% |
| ICC(9) | 1372 | 43.35 | 2 | 1.8 | 89.8% | 4.49% | |
| CC | 781 | 136.58 | 2 | 2.5 | 124.7% | 0.87% | |
| 6144 | ICC(8) | 1496 | 31.28 | 3 | 2.5 | 82.4% | 7.09% |
| ICC(9) | 1415 | 31.09 | 3 | 2.5 | 83.4% | 6.58% | |
| CC | 821 | 79.60 | 3 | 4.3 | 142.7% | 1.49% | |
| 8192 | ICC(8) | 1529 | 27.44 | 4 | 2.8 | 70.5% | 9.33% |
| ICC(9) | 1481 | 27.16 | 4 | 2.9 | 71.6% | 9.22% | |
| CC | 863 | 55.56 | 4 | 6.1 | 153.3% | 2.75% |
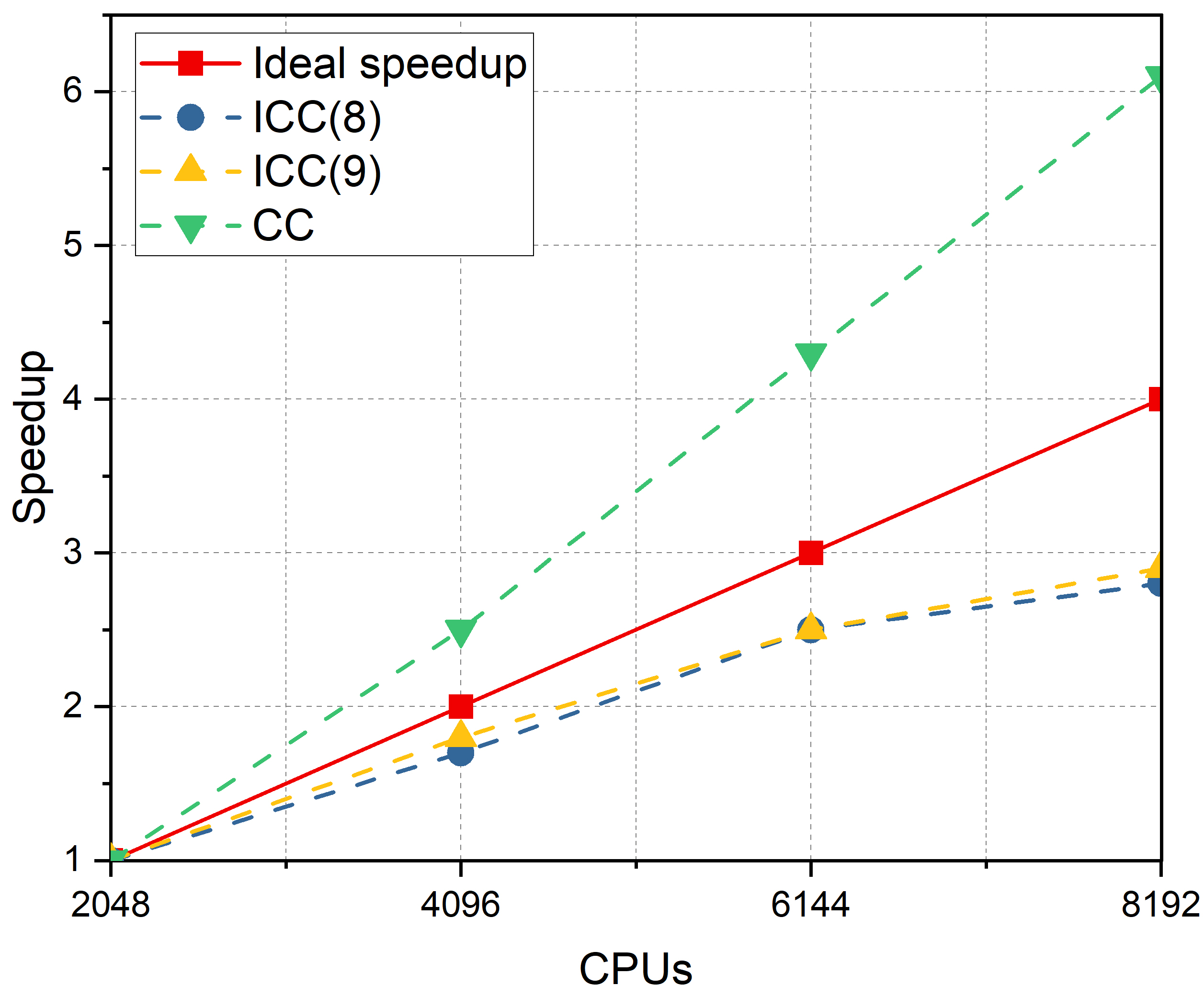
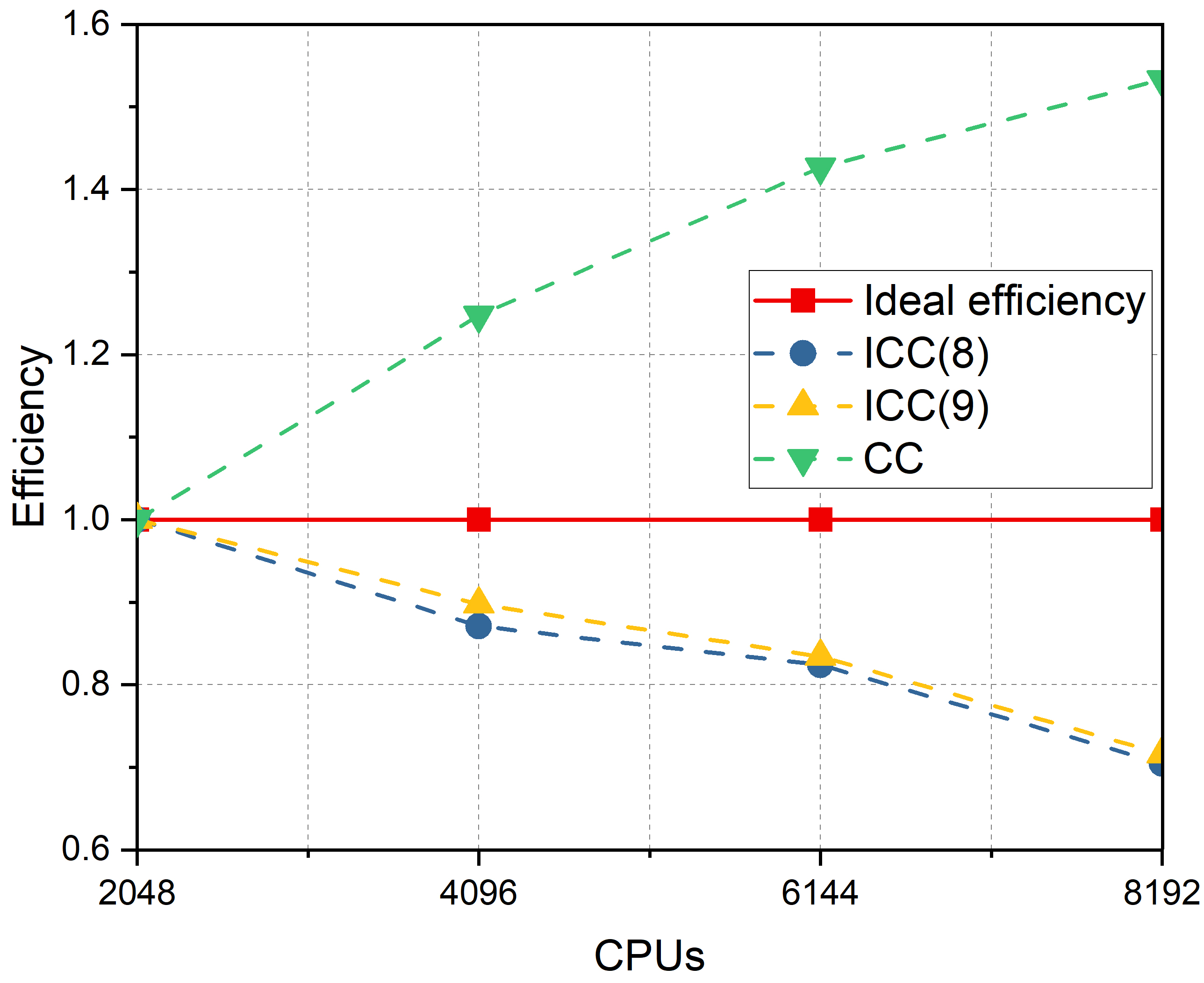
The parallel analysis for the two crack models demonstrates that the proposed parallel domain decomposition preconditioner is scalable in terms of the number of processors. For a model with more cracks and refined mesh, the algorithm retains scalability. Despite the increase in the number of iterations and elapsed time to converge, the parallel efficiency remains at more than 70%. Currently, the crack tip subproblem is solved on the part of processor cores, which decreases the parallel efficiency when the number of processors is large although the crack tip solver time is only a small percentage of that of regular subdomains. Such a restriction will be removed in future studies by solving the crack tip subproblem, employing all processors in parallel.
5 Conclusions
In this study, a parallel domain decomposition preconditioner was introduced to solve the elastic crack problem using corrected XFEM discretization. Ascribing the difficulty of the problem to the crack tip area, a special domain decomposition method was adopted, in which the regular subdomains include normal DOFs from standard FEM and Heaviside DOFs across cracks, and the crack tip subdomains include all types of DOFs within a radius of the crack tips. An innovative algorithm based on the additive Schwarz method was proposed to speedup the iterations for solving the system of linear equations. In parallel computing, the algorithm solves the crack tip sub-problems first, then solves the regular sub-problems on all processors, and finally combines the two parts for the matrix-vector multiplication by the iterative solver. The effect of subdomain strategies, ICC fill-ins level, matrix reordering techniques, and overlapping size on the solver was further studied. The scalability and parallel efficiency of the algorithm were discussed using a branch crack model and 16-cracks model in a large number of processor cores. The numerical results demonstrate the effectiveness of the algorithm in terms of scalability and computation time. The parallel efficiency remained above 70% with more than DOFs.
Acknowledgments
This work was supported by the Special Project on High-performance Computing under the National Key R&D Program (No. 2016YFB0200601) and Youth Program of National Natural Science Foundation of China (Project No. 11801543).
Conflict of interest
The authors declare no potential conflict of interests.
Appendix A eliminating linear dependency
For the corrected XFEM, the branch enrichment functions are linearly dependent for a bilinear element. A description of a single crack tip was performed and presented in the work of T.P. Fries28, which introduced a pair of parameters to remove the linear dependency. However, there are still issues to address, such as whether the choice of element and DOFs for the elimination are unique and which choice generates the minimum condition number for the linear system. In this section, we numerically discuss which equations to eliminate and how to eliminate them. The formulation of the branch enrichment functions in a quadrilateral element is
| (23) |
There are 16 local enrichment functions in the element. For a two-dimensional problem, the number of corresponding DOFs is 32. In practice, there are many enrichment elements and enriched DOFs for each crack tip. These DOFs are distinguishable from other crack tips as a group. Of these 2 enrichment functions (4 enriched DOFs) have to be eliminated.
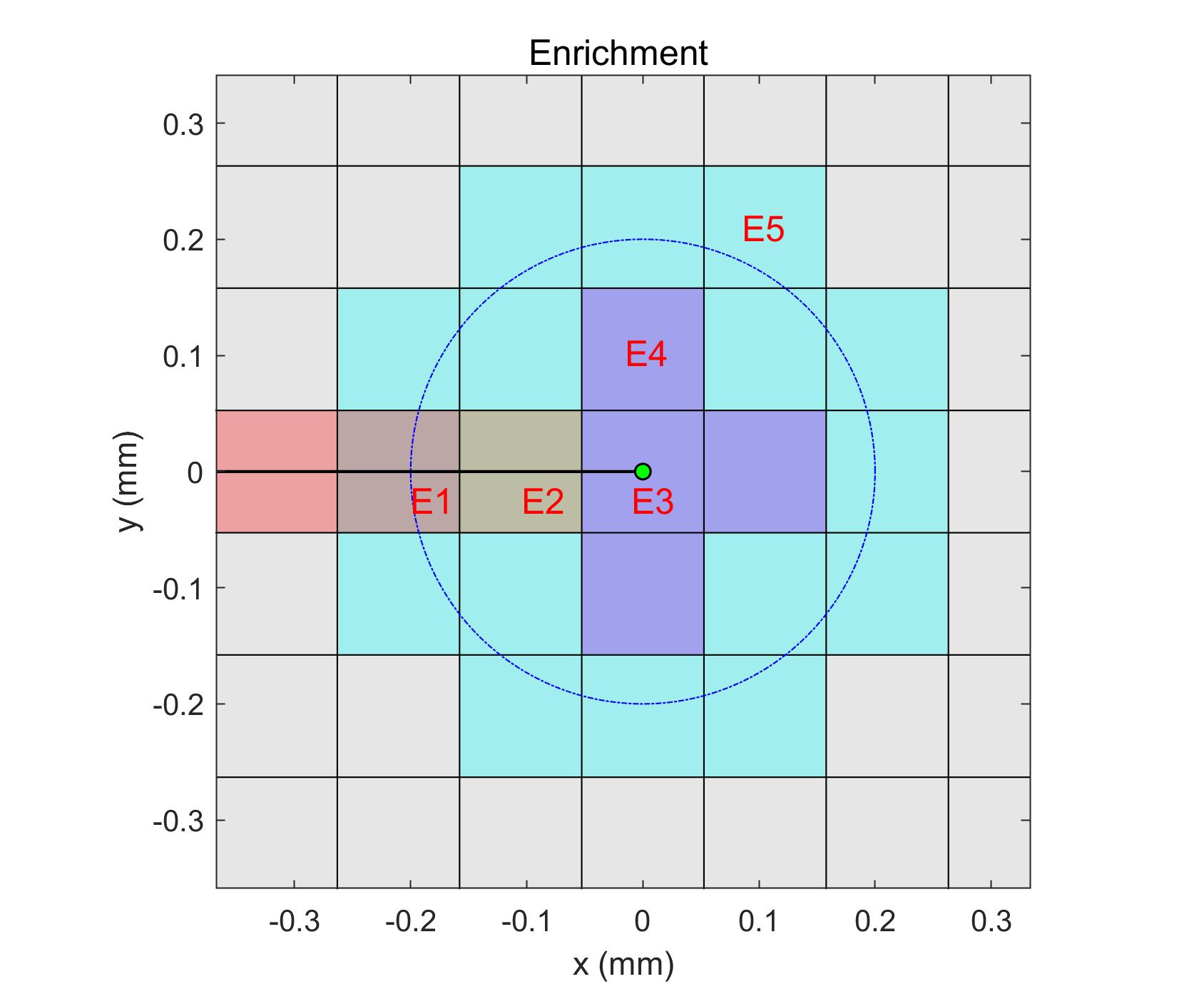



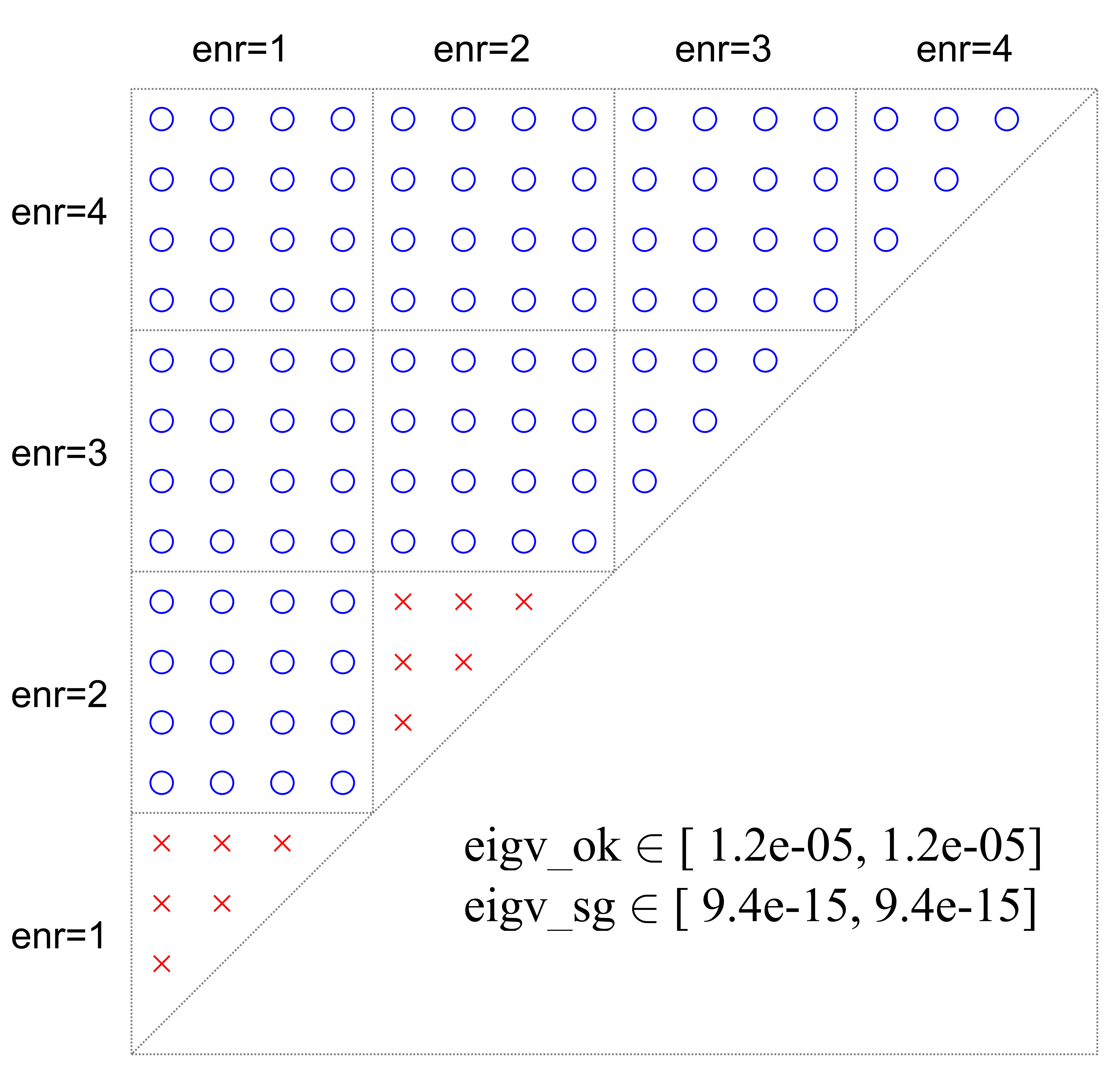
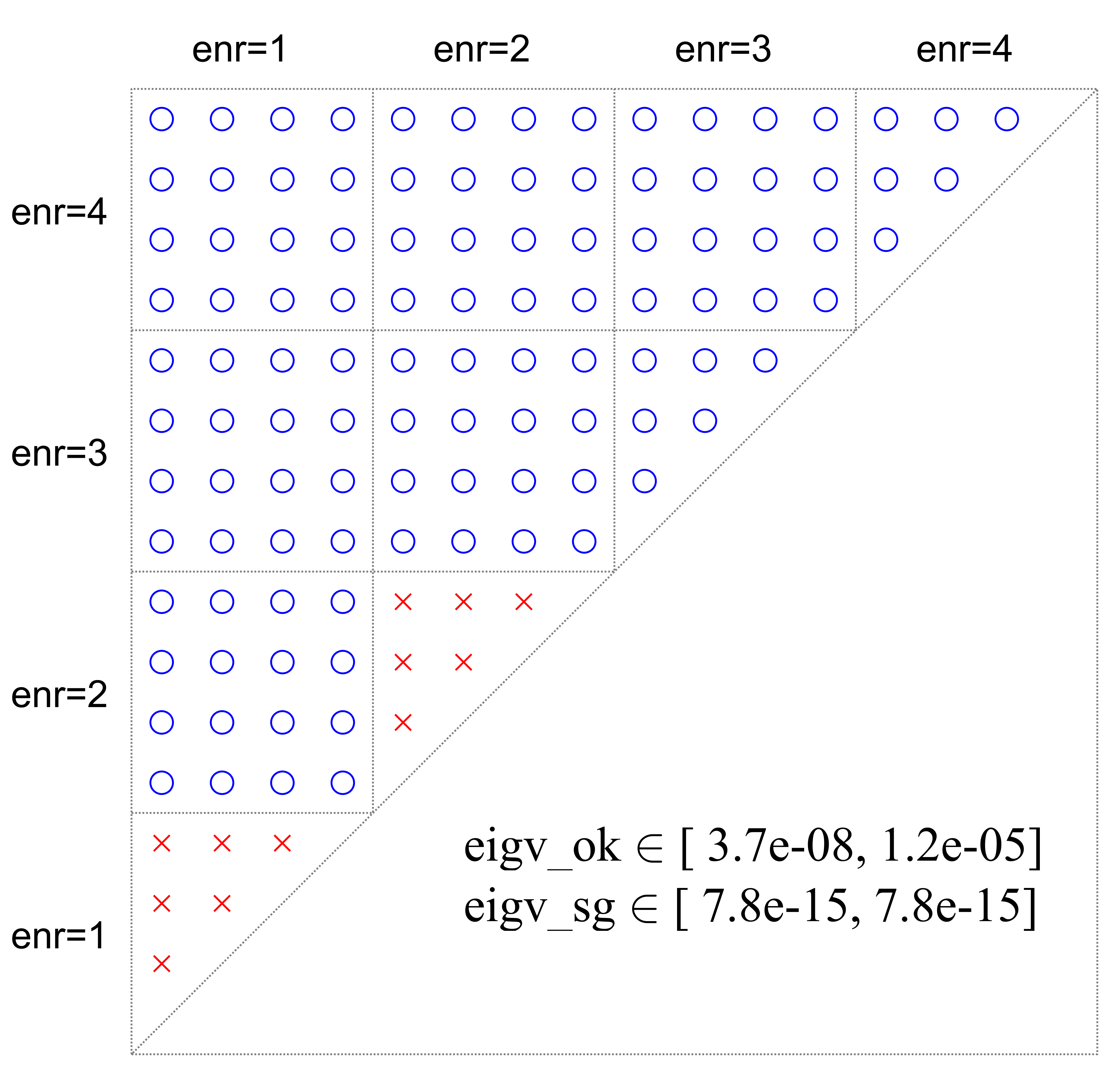
In Figure 17, a simple case was employed to demonstrate the enrichment procedure for a crack tip. The element size is 0.1, and the enrichment radius , which results in only one layer of elements being completely in . Around the crack tip, 21 elements were enriched by the branch enrichment functions, and the number of enriched nodes was 32. There are five types of enrichment elements: E1 represents the blending element cut by a crack; E2 represents an element cut by a crack, and all nodes are within ; E3 is the crack tip element; E4 is the enriched element without cracks inside; and E5 is the blending element without cracks inside. Two local enrichment functions need to be eliminated from these five types of elements, and we study whether the local enrichment functions are still linearly dependent after elimination by comparing the minimum eigenvalues. The threshold value is , and if the minimum eigenvalue is larger than this value, the elimination to remove the linear dependency has been successful (called good elimination); otherwise, the linear dependency is preserved (called bad elimination). In Figure 18, all possible combinations, , are displayed. eigv_ok denotes the range of minimum eigenvalues for good elimination, and eigv_sg denotes the minimum eigenvalue range for bad elimination, which preserves linear dependency. It is observed that the two enrichment functions based on the first or the second term in equation 9, completely preserve the linear dependency for E1, E2, E4, and E5. For the crack tip element E3, two additional combinations also maintain a linear dependency. Considering the range of minimum eigenvalues, the magnitude of the minimum eigenvalue for all bad eliminations is . For good elimination in E3 and E4, the magnitude of the minimum eigenvalue is . While for E1, E2, and E5, the magnitude of the minimum eigenvalues is , , and , respectively, but all are larger than . Therefore, eliminating two local equations in E3 or E4 is a good choice as the linear system after this elimination has the largest minimum eigenvalue.
For a multi-crack model, two enrichment terms (four enriched DOFs) were eliminated for each crack tip in the linear system, as discussed above. In our code, we eliminated the 12th and 16th functions for the E4 element, which means that the last two terms in (9) of the 4th node for an E4 element will be eliminated. All the results in this study were obtained after this elimination.
References
- 1 Moës N, Dolbow J, Belytschko T. A finite element method for crack growth without remeshing. International Journal for Numerical Methods in Engineering 1999; 46(1): 131–150.
- 2 Belytschko T, Black T. Elastic crack growth in finite elements with minimal remeshing. International Journal for Numerical Methods in Engineering 1999; 45(5): 601–620.
- 3 Jiang S, Du C, Gu C, Chen X. XFEM analysis of the effects of voids, inclusions and other cracks on the dynamic stress intensity factor of a major crack. Fatigue & Fracture of Engineering Materials & Structures 2014; 37(8): 866–882.
- 4 Wang Z, Yu T, Bui TQ, et al. Numerical modeling of 3-D inclusions and voids by a novel adaptive XFEM. Advances in Engineering Software 2016; 102: 105–122.
- 5 Stein N, Dölling S, Chalkiadaki K, Becker W, Weißgraeber P. Enhanced XFEM for crack deflection in multi-material joints. International Journal of Fracture 2017; 207(2): 193–210.
- 6 Liu P, Luo Y, Kang Z. Multi-material topology optimization considering interface behavior via XFEM and level set method. Computer Methods in Applied Mechanics and Engineering 2016; 308: 113–133.
- 7 Fahsi A, Soulaïmani A. Numerical investigations of the XFEM for solving two-phase incompressible flows. International Journal of Computational Fluid Dynamics 2017; 31(3): 135–155.
- 8 Sauerland H, Fries TP. The stable XFEM for two-phase flows. Computers & Fluids 2013; 87: 41–49.
- 9 Chahine E, Laborde P, Renard Y. Crack tip enrichment in the XFEM using a cutoff function. International Journal for Numerical Methods in Engineering 2008; 75(6): 629–646.
- 10 Malekan M, Barros FB. Well-conditioning global–local analysis using stable generalized/extended finite element method for linear elastic fracture mechanics. Computational Mechanics 2016; 58(5): 819–831.
- 11 Wen L, Tian R. An extra dof-free and well-conditioned XFEM. Proceedings of the 5th International Conference on Computational Methods 2014; 437.
- 12 Lang C, Makhija D, Doostan A, Maute K. A simple and efficient preconditioning scheme for heaviside enriched XFEM. Computational Mechanics 2014; 54(5): 1357–1374.
- 13 Sharma A, Villanueva H, Maute K. On shape sensitivities with heaviside-enriched XFEM. Structural and Multidisciplinary Optimization 2017; 55(2): 385–408.
- 14 Menouillard T, Song JH, Duan Q, Belytschko T. Time dependent crack tip enrichment for dynamic crack propagation. International Journal of Fracture 2010; 162(1-2): 33–49.
- 15 Elguedj T, Gravouil A, Maigre H. An explicit dynamics extended finite element method. Part 1: mass lumping for arbitrary enrichment functions. Computer Methods in Applied Mechanics and Engineering 2009; 198(30-32): 2297–2317.
- 16 Fries TP, Belytschko T. The intrinsic XFEM: a method for arbitrary discontinuities without additional unknowns. International Journal for Numerical Methods in Engineering 2006; 68(13): 1358–1385.
- 17 Zhao J, Hou Y, Song L. Modified intrinsic extended finite element method for elliptic equation with interfaces. Journal of Engineering Mathematics 2016; 97(1): 147–159.
- 18 Wu JY, Qiu JF, Nguyen VP, Mandal TK, Zhuang LJ. Computational modeling of localized failure in solids: XFEM vs PF-CZM. Computer Methods in Applied Mechanics and Engineering 2019; 345: 618–643.
- 19 Tian R, Wen L, Wang L. Three-dimensional improved XFEM (IXFEM) for static crack problems. Computer Methods in Applied Mechanics and Engineering 2019; 343: 339–367.
- 20 Tian R, Wen L. Improved XFEM an extra-dof free, well-conditioning, and interpolating XFEM. Computer Methods in Applied Mechanics and Engineering 2015; 285: 639–658.
- 21 Tran T, Stephan EP. An overlapping additive Schwarz preconditioner for boundary element approximations to the Laplace screen and Lamé crack problems. Journal of Numerical Mathematics 2004; 12(4): 311–330.
- 22 Svolos L, Berger-Vergiat L, Waisman H. Updating strategy of a domain decomposition preconditioner for parallel solution of dynamic fracture problems. Journal of Computational Physics 2020; 422: 109746.
- 23 Berger-Vergiat L, Waisman H, Hiriyur B, Tuminaro R, Keyes D. Inexact Schwarz-algebraic multigrid preconditioners for crack problems modeled by extended finite element methods. International Journal for Numerical Methods in Engineering 2012; 90(3): 311–328.
- 24 Waisman H, Berger-Vergiat L. An adaptive domain decomposition preconditioner for crack propagation problems modeled by XFEM. International Journal for Multiscale Computational Engineering 2013; 11(6).
- 25 Chen X, Cai XC. Effective two-level domain decomposition preconditioners for elastic crack problems modeled by extended finite element method. Communications in Computational Physics 2020; 28(4): 1561–1584.
- 26 Howell P, Kozyreff G, Ockendon J. Applied Solid Mechanics. Cambridge University Press . 2009.
- 27 Grisvard PG. Elliptic Problems in Non Smooth Domains. SIAM . 1985.
- 28 Fries TP. A corrected XFEM approximation without problems in blending elements. International Journal for Numerical Methods in Engineering 2008; 75(5): 503–532.
- 29 Sih GC. Mechanics of Fracture Initiation and Propagation: Surface and volume energy density applied as failure criterion. Springer Science & Business Media . 2012.
- 30 Sutula D, Kerfriden P, Dam vT, Bordas SP. Minimum energy multiple crack propagation. Part-II: discrete solution with XFEM. Engineering Fracture Mechanics 2018; 191: 225–256.
- 31 Fries TP. Overview and comparison of different variants of the XFEM. Proceedings in Mathmatics and Mechanics 2014; 14(1): 27–30.
- 32 Fries TP, Belytschko T. The extended/generalized finite element method: an overview of the method and its applications. International Journal for Numerical Methods in Engineering 2010; 84(3): 253–304.
- 33 Cai XC, Sarkis M. A restricted additive Schwarz preconditioner for general sparse linear systems. SIAM Journal on Scientific Computing 1999; 21(2): 792–797.
- 34 Toselli A, Widlund O. Domain Decomposition Methods-Algorithms and Theory. Springer Science & Business Media . 2006.
- 35 Balay , Brown , Buschelman , Eijkhout , Gropp . PETSc Users Manual Revision 3.3. Sports Medicine 2013; 23(46): 21-30.
- 36 Tarancón J, Vercher A, Giner E, Fuenmayor F. Enhanced blending elements for XFEM applied to linear elastic fracture mechanics. International Journal for Numerical Methods in Engineering 2009; 77(1): 126–148.
- 37 Menouillard T, Song JH, Duan Q, Belytschko T. Time dependent crack tip enrichment for dynamic crack propagation. International Journal of Fracture 2010; 162(1-2): 33–49.
- 38 Menk A, Bordas SPA. A robust preconditioning technique for the extended finite element method. International Journal for Numerical Methods in Engineering 2011; 85(13).
- 39 Saad Y. Iterative Methods for Sparse Linear Systems. SIAM . 2003.
- 40 Hiptmair R, Jerez-Hanckes C, Urzúa-Torres C. Mesh-independent operator preconditioning for boundary elements on open curves. SIAM Journal on Numerical Analysis 2014; 52(5): 2295–2314.
- 41 Brown PN, Vassilevski PS, Woodward CS. On mesh-independent convergence of an inexact Newton–multigrid algorithm. SIAM Journal on Scientific Computing 2003; 25(2): 570–590.
- 42 Oliveira SLGd, Carvalho C, Osthoff C. The effect of symmetric permutations on the convergence of a restarted gmres solver with ILU-type preconditioners. 2019 Winter Simulation Conference (WSC) 2019: 3219–3230.
- 43 Behrisch M, Bach B, Henry Riche N, Schreck T, Fekete JD. Matrix reordering methods for table and network visualization. Computer Graphics Forum 2016; 35(3): 693–716.
- 44 Liiv I. Seriation and matrix reordering methods: An historical overview. Statistical Analysis and Data Mining: The ASA Data Science Journal 2010; 3(2): 70–91.
- 45 Napov A. Conditioning analysis of incomplete Cholesky factorizations with orthogonal dropping. SIAM Journal on Matrix Analysis and Applications 2013; 34(3): 1148–1173.