A Polynomial Time Quantum Algorithm for Exponentially Large Scale Nonlinear Differential Equations via Hamiltonian Simulation
Abstract
Quantum computers have the potential to efficiently solve a system of nonlinear ordinary differential equations (ODEs), which play a crucial role in various industries and scientific fields. However, it remains unclear which system of nonlinear ODEs, and under what assumptions, can achieve exponential speedup using quantum computers. In this work, we introduce a class of systems of nonlinear ODEs that can be efficiently solved on quantum computers, where the efficiency is defined as solving the system with computational complexity of , where is the evolution time, is the allowed error, and is the number of variables in the system. Specifically, we employ the Koopman-von Neumann linearization to map the system of nonlinear ODEs to Hamiltonian dynamics and find conditions where the norm of the mapped Hamiltonian is preserved and the Hamiltonian is sparse. This allows us to use the optimal Hamiltonian simulation technique for solving the nonlinear ODEs with overhead. Furthermore, we show that the nonlinear ODEs include a wide range of systems of nonlinear ODEs, such as the nonlinear harmonic oscillators and the short-range Kuramoto model. This is the first concrete example of solving systems of nonlinear ODEs with exponential quantum speedup by the Koopman-von Neumann linearization, although it is noted that this assumes efficient preparation of the initial state and computation of the output. These findings contribute significantly to the application of quantum computers in solving nonlinear problems.
I Introduction
Nonlinear differential equations play a very important role in industry as well as in scientific fields such as physics and mathematics. If quantum computers can be used to analyze such nonlinear differential equations and accelerate the computation, the applications of quantum computers will expand greatly. Besides, the relationship between nonlinear differential equations and machine learning is also attracting attention recently [1]. This could be a new route for the application of quantum computers to the field of machine learning. However, since quantum systems are essentially linear, and hence nontrivial treatment is required to apply quantum computers for solving nonlinear differential equations.
Attempts to linearize nonlinear differential equations have long been studied. The well-known ones are the Carleman linearization [2] and the Koopman-von Neumann linearization [3]. These two linearizations are also closely related to quantum mechanics, and Ref. [4] discusses how to embed and linearize nonlinear differential equations into quantum mechanical systems in a unified framework. In this context, the Carleman linearization maps variables of the system including their higher order nonlinear terms directly to the complex probability amplitudes of a quantum system.
Quantum algorithms for solving nonlinear differential equations using this mapping have been proposed [5]. In Ref. [5], the authors develop the quantum Carleman linearization, a quantum algorithm for dissipative quadratic ordinary differential equations. That algorithm has complexity , where is the evolution time, is the allowed error, and measures decay of the solution. In the quantum Carleman linearization, two infinite dimensional linearizations, the Carleman linearization and the forward Euler method, are applied, and the linearized problem can be solved by the high-precision quantum linear system algorithm (QLSA) [6]. In applying QLSA, the sparsity and the condition number of the matrix are important parameters. The quantum Carleman linearization only inherits the number of terms in the equation as the sparsity. And, two cutoff parameters introduced for those linearizations as accuracy parameters give the bound of the condition number. Further, the complexity depends on the decay . This is inevitable because the linearized differential equations are not Hamiltonian dynamics by applying the Carleman linearization.
On the other hand, the Koopman-von Neumann linearization embeds classical variables via a position state in a continuous variable quantum system. For its discretization, we can employ a number state and its corresponding orthogonal polynomials. The advantage of the latter approach is that such an embedding maps the nonlinear differential equations to Hamiltonian dynamics. While an infinite-dimensional Hilbert space must be truncated by regulating the total particle number, Ref. [7] showed that the truncation error is , where is a dimensionless parameter characterizing the strength of the nonlinearity and is the total particle number. Furthermore, the Hamiltonian simulation [8] was shown to be applied by giving a block encoding, a technique of encoding a matrix as a block of a unitary [9], of the Hamiltonian into which the nonlinear system was embedded. Then, the time complexity was shown to be characterized by the max norm of the matrix embedded in the block encoding, which finally depends on the nonlinear equations.
However, the computational complexity is not fully understood as follows. One problem is that it has been unclear whether or not the mapped Hamiltonian is sparse and whether or not the norm of the Hamiltonian dynamics is conserved. Another and more serious problem is that the nonlinearity was assumed to be sufficiently small, which implicitly depends on the max norm of the mapped Hamiltonian 111Because of this, the previous version of this paper imposed a condition .. Therefore it is still unclear for what kind of nonlinear differential equations can be solved using a quantum computer with what computational complexity in terms of the problem parameters, system size , accuracy , and simulation time . This motivates to evaluate the computational complexity of solving nonlinear differential equation based on the Koopman-von Neumann linearization more in detail.
To address these difficulties, we present a class of systems of nonlinear ordinary differential equations (ODEs) that can be reducible to the efficient Hamiltonian simulation. (See Fig. 1.) Here, solving a system of ODEs means deriving a quantity described by a multivariate polynomial of finite degree of the variables in the system that have evolved for a finite time. The efficiency means that the time evolution of the system of ODEs can be simulated with a computational complexity of , where is the evolution time, is the allowed error, and is the number of variables in the proposed ODEs.
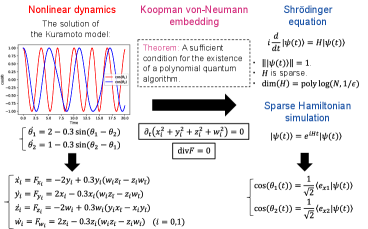
There are two major challenges to solving this problem: first, the norm is not conserved when mapped to Hamiltonian dynamics. The second and the most important one is that the mapped Hamiltonian is not sparse, making it impossible to efficiently apply the Hamiltonian simulation. We show that the proposed ODEs can resolve these two conditions, and they can be solved exponentially efficiently for the number of variables.
Furthermore, we rigorously evaluate the truncation error in a similar way to Ref. [11], which guarantees that the number of qubits required to achieve an accuracy scales . This compliments the argument given in Ref. [7] and allows us to argue the computational complexity more rigorously.
The proposed ODEs are embedded into Hamiltonian dynamics and applied to the Hamiltonian simulation [9], thus they depends on neither condition number nor the decay of the solution. While the reducible ODEs are a restricted class of systems of ODEs, we claim the broad applications by showing that the proposed ODEs include a wide range of systems of nonlinear ODEs, e.g., classical linear and nonlinear harmonic oscillators, and the short-range Kuramoto model [12]. The short-range Kuramoto model considers locally coupled oscillators, where coupling strength decays with distance, while the classical Kuramoto model describes phase synchronization in globally coupled ones.
blackWe identified the mathematical conditions that allow nonlinear ODEs to be tackled on a quantum computer via the Koopman-von Neumann linearization method, without relying on the Carleman linearization. Based on these conditions, we were able to find the two specific examples mentioned above, although they are toy models. It is expected that this method can be extended to a wider range of practical nonlinear differential equations in the future. Furthermore, while we focused on Hermite polynomials, note that the same approach applies to other orthogonal polynomials.
The rest of this paper is organized as follows. In Sec. II, we briefly review an existing linearization technique of nonlinear ODEs into a quantum system using the position operator embedding. In Sec. III, we introduce a class of nonlinear ODEs and show that the proposed ODEs are embedded into Hamiltonian dynamics. We evaluate the upper bounds of the max norm and the spectral norm of the Hamiltonian associated with the proposed ODEs. Then, we prove the approximation theorem of the cut-offed Hamiltonian dynamics. In Sec. IV, we introduce an approximate representation to reduce the spatial complexity. In Sec. V, we show the algorithm of simulating the proposed ODEs by assuming the sparse access model and the quantum singular value transformation [9]. In Sec. VI, as some applications, we show that the proposed ODEs include classical linear and nonlinear harmonic oscillators, and the short-range Kuramoto model [12]. Section VII is devoted to a conclusion.
II Preliminary: Reduction to the evolution equation in Hilbert space
In this section, we follow Ref. [4] and introduce a method for embedding a nonlinear system into an infinite dimensional linear system. For simplicity, let us consider one-dimensional case
| (1) |
where is an analytic function. To map Eq. (1) to a linear system, first, we introduce a hermitian operator with the complete set of eigenvectors such that
| (2) |
and
| (3) |
where is the basis set in the occupation number representation and is a normalized classical orthogonal polynomial defined by the trinomial recurrence formula
| (4) |
where . Using creation and annihilation operators and , i.e.,
| (5) |
we have the representation of as the operator function of and . Second, introducing a hermitian operator satisfying the commutation relation , where is determined by the choice of the classical orthogonal polynomials, the following vector
| (6) |
satisfies the Shrödinger equation
| (7) |
where the Hamiltonian is written as
| (8) |
Specifically, if we chose Hermitian polynomial, are the creation and annihilation operators of the harmonic oscillator, and is the momentum operator, which leads .
To generalize the above result for a multidimensional case, we focus on an initial value problem described by the following -dimensional ODE
| (9) |
where is a multivariate analytic function and is a function of on the interval . And let us introduce hermitian operators with the complete set of eigenvectors . Then, for the nonlinear dynamical system, defining the Hamiltonian as
| (10) |
the Shrödinger equation (7) holds for the following tensor product of states
| (11) |
where .
blackThe state in Eq. (11) does not preserve the norm in general. Thus, to avoid the global decaying term, we assume that
| (12) |
Furthermore, expanding Eq. (11) in the occupation number representation, we have
| (13) |
The factor in Eq. (13) can complicate the representation of desired outputs. Actually, since the output quantity can be obtained as an inner product
| (14) |
where is an arbitrary state in the Hilbert space restricted to the subspace bounded by the total occupation number , we need to remove from the inner product. In general, the value after time evolution is unknown and its measurement cost is also non trivial. Thus, we assume that is known and we require that
| (15) |
From the above considerations, we present our problem setting for the system of nonlinear differential equations.
Problem 1.
We consider a system of -dimensional ODEs
| (16) |
where is a function of on the interval and is a multivariate analytic function. The system satisfies that and , where is the weight function of a classical orthogonal polynomial system. Then, for a given initial value , the problem is to approximate the output of a -degree multivariate polynomial within the accuracy .
blackOn a classical computer, solving Problem 1 requires overhead in space and time. Our goal here is to solve such a problem in qubits and computation time on a quantum computer.
We see that Problem 1 can be divided into three parts. The first part is the preparation of the initial state , which encodes the initial value . The second part is the efficient Hamiltonian simulation using the Hamiltonian given by Eq. (10). The third part is the evaluation of the output as the inner product in Eq. (14).
In this paper, we focus on the second problem and make the assumptions regarding the first and third ones. The assumption for the initial state preparation is given as
Assumption 1.
Given an initial value , we assume an oracle that prepares the initial state in Problem 1.
The reason for making Assumption 1 is that the distribution of initial values differs for each problem, and whether it is possible to efficiently encode these initial values into a quantum computer depends on whether the data structure of these initial values can be used.
On the other hand, the assumption for the evaluation of the output is given as
Assumption 2.
We assume an oracle that prepares the quantum state , such that the inner product represents the output multivariate polynomial in Problem 1.
To argue the efficient Hamiltonian simulation using the Hamiltonian in Eq. (10), we need to evaluate the Hamiltonian on the Hilbert space restricted to the subspace bounded by the total occupation number , which is also the accuracy parameter in the algorithmic view point. Therefore, we focus on deriving a sufficiently large scale of the total occupation number to achieve the required output accuracy through the analysis of the simulation error defined in the following.
Definition 1.
For a given Hamiltonian on a Hilbert space and an initial state , we denote and as the Hamiltonian on the subspace bounded by the total occupation number and the quantum state in , respectively. Then, for any quantum state , we define the simulation error by
| (17) |
In the next section, we introduce a restricted class of ODEs that can be solved using the Koopman-von Neumann embedding. By evaluating the error Eq. (17) defined in Eq. (17), we derive the total occupation number required to achieve the desired accuracy .
In the rest of the paper, for a given Hilbert space , a Hamiltonian and a quantum state , we denote , and as the Hilbert space restricted to the subspace bounded by the total occupation number , the truncated Hamiltonian on and the truncated quantum state in , respectively.
III Nonlinear ODEs reducible to Hamiltonian dynamics
We introduce one restricted ODE class solvable with the Koopman-von Neumann embedding, which means that the ODE class is reduced to the evolution equation through Hermite polynomial expansion and satisfies Eq. (12) and Eq. (15).
Definition 2.
A system of -dimensional ODEs in the interval solvable with the Koopman-von Neumann embedding is a system of nonlinear ODEs defined by a family of index sets each of which determines the variables engaged in an interaction, and coupling constants of the interactions:
| (18) |
where the index sets , and the coupling constants satisfy the followings:
-
1
For any , .
-
2
For any , there exists at least one and at most sets such as .
-
3
For any , real numbers are assigned such that .
Note that the other ODE class with terms in which the degree of each variable is two or higher can be reduced to Eq. (18) by introducing dummy variables [7] and considering multiple systems, each identical to the original, including in their initial conditions. In Sec. VI, we show the applicability of the proposed system of ODEs by reducing several systems to it.
The proposed system of ODEs satisfies Eq. (12) trivially, since the term of Eq. (18) does not contain . It also satisfies Eq. (15) as follows. Considering that the weight function of the Hermite polynomial system is , we can check Eq. (15) directly:
| (19) | |||||
| (20) |
where Eq. (20) is derived as follows. Focusing one in Eq. (19), we can see that the term
| (21) |
appears only once at each through the sum . Putting these terms together for each , we obtain Eq. (20).
Clearly, the Hamiltonian corresponding to the proposed ODEs is written by
| (22) | |||||
| (23) |
where and . \colorblack
Then, as stated in Def. 1, we analyze the error given by Eq. (17) that occurs when the initial state is time evolved in the Hilbert space restricted to the subspace bounded by the total occupation number . First, we prove the following technical lemma.
Lemma 1.
For the Hamiltonian given by Eq. (22), which corresponds to a system of -dimensional ODEs defined by Eq. (18), we consider the Hamiltonian on the Hilbert space restricted to the subspace bounded by the total occupation number . Then, the Hamiltonian is -sparse, the max norm of is , and the spectral norm of is .
Proof.
See Appendix A for all the lemmas. ∎
The reason of exponential dependence of the norm on is as follows. When the system of ODEs is embedded in the sum of local Hamiltonians, the variables are replaced by creation and annihilation operators. Consequently, corresponds to the maximum degree of creation and annihilation operators in the local Hamiltonian. As a result, the norm is .
The spectral norm of the Hamiltonian is crucial for analyzing the error in the time evolution of the state. This is because if the norm is too large, the simulation becomes infeasible, as the approximation error can no longer be guaranteed to converge asymptotically.
Additionally, we introduce a rescaled Hamiltonian
| (24) |
that incorporates a scaling parameter . The rescaling is defined by the transformation . The rationale behind this rescaling is technical: it is intended to suppress the divergence of inequalities used in error evaluation. Here, we present our main result in the following.
Theorem 1.
Proof.
blackThe proof is outlined as follows. To evaluate the simulation error, we need to observe how behaves for sufficiently large . This requires to evaluate the transition amplitude in Fock space, which can be analyzed using the same technique as the Lieb-Robinson bound in the Floquet-Hilbert space proposed in Ref. [11]. In this evaluation, we also use the result of Lemma 1. Next, following the proof technique in Ref. [7], we demonstrate our claim by expanding and as power series in the nonlinear parameter and comparing their expansions. See Appendix B in detail. ∎
blackWhether the approximation holds depends on the behavior of the higher-order terms when the time evolution operator, defined by the Hamiltonian , is expanded as a series of Hermite polynomials. The total occupation number ensures a sufficiently large dimension, preventing the loss of information in the output caused by the truncation of the Hilbert space. Theorem 1 demonstrates that these guarantees can be achieved for and , with scalings of and , respectively.
As shown later, since we apply the block encoding of to the optimal block-Hamiltonian simulation [9], the effective time required to simulate time is from Lemma 1. More importantly, Theorem 1 shows that if is sufficiently larger than , an approximated position state in the finite occupation number representation is sufficient to obtain a degree polynomial output, which motivates the truncation of the Hilbert space.
IV Truncation of the space and initial states preparation
The Hamiltonian in the previous section is not efficient in terms of spatial complexity because the input size is proportional to the number of variables . Thus, let us consider truncating the space of the occupation basis such that the total number is limited by some integer determined by some required precision.
We introduce the following encoding [7]. For any given state such that ,
| (26) |
where , i.e., is all the combinations that take integers, allowing for duplicates from integers , in ascending order. Then, the -truncated subspace is defined to be the Hilbert space spanned by the support . The occupation number representation of an initial state
| (27) |
is encoded into the -truncated subspace such as
| (28) |
where is the normalization constant.
blackFurthermore, in an initial value problem, the occupation number representation of an initial position state is encoded into the -truncated subspace such as
| (29) | |||||
| (30) | |||||
| (31) |
where is the -truncated basis in Eq. (26), is the normalized constant 222 is a constant thanks to the preservation of , i.e., Eq. (15)., and
| (32) |
Here, is the normalized -th order Hermite polynomial. Clearly, the needed qubit size for these initial states is .
Whether the initial state such as and can be efficiently prepared depends on the access models. Thus, instead of Assumption 1, we assume the following initial state preparation.
Assumption 1’.
For a given classical description of an initial state , there exists an oracle that prepares the -truncated initial state in the basis given by Eq. (26).
We briefly discuss the computational complexity of initial state preparation. In general, whether a superposition state with arbitrary coefficients can be efficiently prepared depends on the structure of the coefficients themselves, as it is constrained by the known trade-off between time and space complexities [14, 15].
Therefore, it is generally unreasonable to assume that the initial state can be prepared in logarithmic time. For example, if all the initial values are independent, the state cannot be prepared in time. However, we expect this assumption to hold for problems of practical importance in applications.
V Computational complexity of Hamiltonian simulation
In this section, we argue the Hamiltonian simulation of the mapped Hamiltonian of a system of -dimensional ODEs in Def. 2. We assume that we can access the mapped Hamiltonian matrix through the sparse-access oracles [9].
Definition 3.
Let be a hermitian matrix that is -sparse, and each element of has absolute value at most . Suppose that we have access to the following sparse-access oracles acting on two -qubit registers
| (33) | |||||
| (34) |
where is the index for the -th non-zero entry of the -th row of , or if there are less than non-zero entries, then it is , and similarly is the index for the -th non-zero entry of the -th column of , or if there are less than non-zero entries, then it is . Additionally assume that we have access to an oracle that returns the entries of in a binary description
| (35) |
where is a -bit binary description of the -matrix element of .
V.1 Hamiltonian simulation of ODEs solvable with the Koopman-von Neumann embedding
Following Refs. [9, 8], we show the optimal block-Hamiltonian simulation of a system of -dimensional ODEs in Def. 2.
Theorem 2.
Let us consider a system of -dimensional ODEs in Def. 2 and the rescaled mapped Hamiltonian
| (36) |
where and are given as defined in Theorem 1. Denote that
| (37) |
Under the assumption of the sparse-access oracles, we can implement a -block encoding of with a single use of , two uses of and additionally using one and two qubit gates while using auxilliary qubits, where is the number of bits to represent a binary description of .
Proof.
Then, we apply the above block encoding to the optimal block-Hamiltonian simulation [9].
Theorem 3.
For a given -block encoding of in Theorem 2, we can implement -block encoding , with uses of or its inverse, uses of controlled- or its inverse and with two-qubit gates and using auxilliary qubits, where
| (38) | |||||
| (39) |
Proof.
From Theorem 1, 2, and 3, we can estimate the leading gate complexity of Hamiltonian simulation in the following. First, the total occupation number is from Theorem 1. Second, the gate complexity of the block-encoding of the Hamiltonian is from Theorem 2. Third, the gate complexity of the block-encoding of is from Eq. (38) and Eq. (39) of Theorem 3. Therefore, the total gate complexity is roughly estimated to be .
blackIn Ref. [5], the quantum approach based on the Carleman linearization has a complexity of , where is the decay of the solution. In contrast, our method offers three advantages: it scales linearly in (instead of quadratically), depends only on (rather than ), and does not rely on the decay factor .
On the other hand, the classical approach based on the -th order Runge-Kutta method, when the dependencies among ODE variables are local, the computational complexity scales as . Our method scales only logarithmically with , thereby significantly reducing the computational overhead for large systems. This improved complexity is made possible by leveraging the structural properties of the system, such as locality in variable dependencies and the source-free condition. However, when comparing classical and quantum methods, note that quantum methods assume that the initial state can be efficiently prepared and the output can be efficiently computed.
VI Application
In this section, we show three examples of ODEs can be reduced to the proposed ODEs in Def. 2. The first two examples are the classical harmonic oscillators, and the undamped and unforced Duffing equations. Recently, a quantum algorithm has been proposed for solving coupled harmonic oscillators, a classical mechanical system, with exponential quantum speedup [16]. While their study can only handle essentially linear systems, we show that our research is capable of addressing nonlinear systems, enabling exponential quantum speedup with respect to the number of variables in the system.
The other is the Kuramoto model, a simplification of a model introduced by Kuramoto [17] to study huge populations of coupled limit cycle oscillators. We show that the short-range Kuramoto model can be reduced to a system of ODEs in Def. 2, which is one of the promising application candidates for quantum computers, since the treatment of short-range couplings (oscillators embedded in a lattice with nearest-neighbor interactions) presents formidable difficulties both at the analytical and numerical level [12].
VI.1 Classical harmonic oscillator
Let us given the following classical harmonic oscillators; for ,
| (40) |
where and . Introducing the following variable transformations,
| (41) | |||||
| (42) | |||||
| (43) |
we can derive the following equations,
| (44) | |||||
| (45) | |||||
| (46) |
which trivially satisfy Eq. (12). It is shown that this linear system satisfies Eq. (15) as follows. Checking that
| (47) | |||||
| (48) |
then we can derive that
| (49) |
which corresponds to the energy conservation.
VI.2 Undamped and unforced Duffing equations
Let us given the following nonlinear classical harmonic oscillators: for ,
| (50) | |||||
where , , and . Introducing the following variable transformations,
| (51) | |||||
| (52) | |||||
| (53) | |||||
| (54) | |||||
| (55) |
we can derive the following equations,
| (56) | |||||
| (57) | |||||
| (58) | |||||
| (59) | |||||
| (60) |
from which it is trivial that
| (61) |
Furthermore, checking that
| (62) | |||||
| (63) | |||||
| (64) | |||||
| (65) | |||||
| (66) |
we can derive that the sum of those is zero.
VI.3 Kuramoto model
The short-range Kuramoto model [12] is given in the following.
Definition 4.
The short-range Kuramoto model has the following governing equations: for ,
| (67) |
where the system is composed of limit-cycle oscillators, with phases and coupling constant .
We can reduce the short-range Kuramoto model to a system of ODEs in Def. 2 as follows. For given variables , let us consider the following initial value problem,
| (68) | |||||
| (69) | |||||
| (70) | |||||
| (71) | |||||
where the initial conditions are and . From the above definition, for any , it clearly follows that
| (72) | |||
| (73) |
Furthermore, noting that under the initial condition , we can derive that
| (74) |
From Eq. (73) and Eq. (74), the initial conditions are maintained throughout the dynamics.
Let us consider the following variable transformations,
| (75) | |||||
| (76) | |||||
| (77) | |||||
| (78) |
which satisfy that for any ,
| (79) | |||
| (80) |
Substituting the variable transformations into Eq. (68), Eq. (69), Eq. (70), and Eq. (71), we obtain the following two equations,
| (82) | |||||
Noting that
| (83) | |||||
| (84) |
we see that variables follow the Kuramoto model.
VII Conclusion
In this study, we present a class of nonlinear ordinary differential equations (ODEs) solvable with the Koopman-von Neumann embedding in the form of mapping to Hamiltonian dynamics. And we showed that the proposed ODEs can be efficiently solvable with a computational complexity of , where is the evolution time, is the allowed error, and is the number of variables in the proposed ODEs.
The major challenges were that the mapped Hamiltonian is not sparse in general and the max norm and spectral norm of the mapped quantum state are not always conserved. Furthermore, the nonlinearity of the proposed ODEs we can handle was forced to be assumed to be sufficiently small, since which implicitly depends on the max norm of the mapped Hamiltonian.
To overcome the problem, we found a concrete form of nonlinear ODEs for which the mapped Hamiltonian is sparse and the norm of the quantum state is preserved. And as the result, we proved that if is sufficiently larger than , an approximated position state in the finite occupation number representation is sufficient to obtain a degree polynomial output. Furthermore, we expanded the Hamiltonian dynamical system in an orthogonal polynomial basis and approximated it in a truncated subspace to save the quantum memory cost. Compared to the quantum Carleman linearization [5], the proposed ODEs are embedded into Hamiltonian dynamics and applied to the Hamiltonian simulation [9], thus they depends on neither condition number nor the decay of the solution.
As an application, we showed that the proposed ODEs include classical harmonic oscillators, undamped and unforced Duffing equations, and the short-range Kuramoto model. Recently, a quantum algorithm has been proposed for solving coupled harmonic oscillators, a classical mechanical system, with exponential quantum speedup [16]. While their study can only handle essentially linear systems, our research is capable of addressing nonlinear systems, enabling exponential quantum speedup with respect to the number of variables in the system. Furthermore, the previous study assumes an oracle for parameters such as spring constants for Hamiltonian simulation, while our research successfully presents conditions for mapping to sparse Hamiltonian dynamics from specific partial differential equation constraints. Actually, the coupled harmonic oscillators can be reduced into the proposed ODEs, due to the linearity of the system there is no error from the truncation.
Although our method has been developed with applications to nonlinear dynamics in mind, its potential use for solving large linear systems represents an intriguing avenue for future research. Our result finding conditions under which large scale nonlinear differential equations can be solved efficiently using a quantum computer makes an important contribution to the application of quantum computers to nonlinear problems.
Acknowledgements.
We would like to thank Kaoru Mizuta for his valuable comment on evaluating the truncation error. K.F. is supported by MEXT Quantum Leap Flagship Program (MEXT Q-LEAP) Grant No. JPMXS0118067394 and JPMXS0120319794, JST COI-NEXT Grant No. JPMJPF2014.Appendix A Proof of Lemma 1
For convenience, denote the local operator given by Eq. (23) as
| (85) |
and as the Hilbert space restricted to the subspace bounded by the total occupation number .
First, we prove the sparsity of the Hamiltonian . Note that, from and the definition of , it satisfies that
| (86) |
Considering the Hilbert space restricted to the subspace bounded by the total occupation number , the number of non zero number states is at most . From Eq. (86), we do not need to consider the local Hamiltonian
| (87) |
acting on the local vacuum states. From the definition of , since the number of having the index is at most and the size of is at most and and are -sparse, then the operator given by
| (88) |
acts on at most number states. Therefore, since the number of having the indices of not vacuum states is upper bounded by , the Hamiltonian is -sparse.
Second, we show the max norm of the Hamiltonian . Let us consider and two number states and such that . Remembering that , and
| (89) | |||||
| (90) |
we derive that must be satisfied for . Thus, if for any , then we obtain that
| (91) |
Then, the max norm is upper bounded by
| (92) | |||||
| (93) | |||||
| (94) |
where and .
Third, we show the spectral norm of the Hamiltonian . Let us consider a fixed -cite-excited state and denote as the index subset of the cites. For the state such that and , we can derive that
| (95) | |||||
| (96) | |||||
| (97) | |||||
| (98) |
where .
From the above and Eq. (86), for the -cite-excited state , we derive that
| (99) | |||||
| (100) | |||||
| (103) | |||||
| (104) |
where we used Eq. (91) to derive Eq. (99) and we used that the number of index subsets containing an index is at most to derive Eq. (104). Therefore,
| (105) |
Since is a hermitian, is also upper bounded by Eq. (105). From the relation , the claim follows.
Appendix B Proof of Theorem 1
In preparation for proving Theorem 1, we prove the following two lemmas.
Lemma 2.
Let us consider a system of -dimensional ODEs in Def. 2 and the mapped Hamiltonian
| (107) | |||||
Then, for arbitrary quantum states and respectively,
where and .
Proof.
Note that conserves the total occupation number from the definition of the proposed ODE in Def. 2, which is checked by the fact that consists of the sum of the operators Furthermore, since consists of the sum of products of at most creation or annihilation operators, when .
Then, let us show the claim by induction. For , since , the claim clearly follows. Assume that the claim is satisfied for . Considering the following state
| (109) | |||||
| (110) |
is a quantum state in the Hilbert space restricted to the subspace of the total occupation numbers from to . Therefore, since , the claim follows.
∎
Lemma 3.
Let us consider a system of -dimensional ODEs in the interval in Def. 2 and define the rescaled mapped Hamiltonian
| (112) | |||||
where , , and . Then, for the Hamiltonian on , arbitrary states and respectively, for ,
| (113) |
where .
Proof.
We follow the proof technique in Ref. [11]. We first employ the interaction picture. Defining the unitary operator
| (114) |
the time evolution operator is represented as , where
| (115) | |||||
| (116) |
Then, using the Dyson series expansion, we derive that
| (117) | |||||
| (118) | |||||
| (119) | |||||
| (120) | |||||
| (121) | |||||
| (122) |
where . To derive Eq. (119) and Eq. (120), we used the result of Lemma 2. To derive Eq. (121), we used the result of Lemma 1. To derive the last inequality, we used the following inequality [11];
| (123) |
and the following relation
| (124) | |||||
| (125) | |||||
| (126) |
∎
Then, we prove Theorem 1. Basically, we follow the proof given in Ref. [7]. For the original system of ODEs in Def. 2, let us consider the rescaled system of ODEs and divide it into a linear part and a non-linear part as
| (127) |
where
| (128) | |||||
| (129) |
and define that
| (130) |
Similarly, we can derive the representation of the Hamiltonian and we denote that .
First, for a quantum state , from Lemma 3,
| (131) | |||||
| (132) |
where . Thus, the second term of Eq. (132) can be ignored if a sufficiently large is taken. For instance, we find a sufficiently large to satisfy the following inequality;
| (133) |
where remember that , , and . Using the Stirling’s formula, we derive that
| (134) | |||
Then, we can derive one sufficient condition to satisfy Eq. (133),
| (136) | |||||
Second, let us examine the exact output quantity. We can expand as a power series in :
| (137) | |||||
| (138) |
To show the convergence of Eq. (138), consider an initial value problem given by Eq. (127) and . Since Eq. (127) is infinitely differentiable in , the solution is , and we consider the finite simulation time, then from the regular perturbation theorem [18] the solution can be expanded in Taylor expansion,
| (139) |
and can be negligible if is sufficiently large. For instance, we find a sufficiently large to satisfy the following inequality;
| (140) | |||||
| (141) | |||||
| (142) | |||||
| (143) |
Noting that
| (144) | |||||
| (145) | |||||
| (146) |
we can derive one sufficient condition to satisfy Eq. (140),
| (147) | |||||
Remembering that is a specified polynomial of in the occupation number representation, we can apply Eq. (139) to this polynomial to obtain
| (148) |
Finally, we show that for if is derived from the ODEs consisting of degree polynomials and is satisfied. Since it takes applications of to couple from to any component with , all terms in
| (149) |
that are affected by the truncation have at least factors of , which implies the result.
Appendix C Initial state preparation from another access model
The initial state preparation from a more basic access model is an interesting problem. Here is a simple attempt. For , let us assume an oracle that prepares a superposition state
| (150) |
and consider the problem of converting the state into
| (151) |
where is the -th integers taken from integers , allowing for duplicates, and arranged in ascending order. Then, there exists an efficient algorithm to exchange the indices and the ascending ordered combinations .
Lemma 4.
Let be the total number of combinations that take integers, allowing for duplicates from integers , and the combination
| (152) |
of the integers be defined to be arranged in ascending order. For a given index , there exists an algorithm calculating the combination of integers corresponding to in time complexity. The inverse algorithm is in the same way.
Proof.
The total number of combinations that take integers, allowing for duplicates, from integers is . Suppose that the left-most integer is , then the number of combinations of the remaining integers is . Further, when the left-most integer is greater than or equal to , the number of combinations of the remaining integers is
| (153) |
Therefore, for a given index , the left-most integer can be determined by using binary search to find the such that , where denote that . The same method is then used for index to determine the left-second-most integer, which can be repeated to determine the other integers sequentially too.
Conversely, for a given combination of integers, first, if the left-most integer , then the index is at least larger than or equal to . Second, if the left-second-most integer , then the index is at least larger than , which can be repeated to determine the index . ∎
From Lemma 4, under the assumption of quantum arithmetic, there exist two oracles such that
| (154) | |||||
| (155) |
From the above consideration, let us show the existence of algorithm transforming to .
Lemma 5.
References
- Chen et al. [2018] R. T. Q. Chen, Y. Rubanova, J. Bettencourt, and D. K. Duvenaud, in Advances in Neural Information Processing Systems, Vol. 31, edited by S. Bengio, H. Wallach, H. Larochelle, K. Grauman, N. Cesa-Bianchi, and R. Garnett (Curran Associates, Inc., 2018).
- Carleman [1932] T. Carleman, Acta Mathematica 59, 63 (1932).
- Koopman [1931] B. O. Koopman, Proceedings of the National Academy of Sciences 17, 315 (1931).
- Kowalski [1997] K. Kowalski, J. Math. Phys. 38, 2483 (1997).
- Liu et al. [2021] J.-P. Liu, H. Ø. Kolden, H. K. Krovi, N. F. Loureiro, K. Trivisa, and A. M. Childs, Proceedings of the National Academy of Sciences 118, e2026805118 (2021).
- Harrow et al. [2009] A. W. Harrow, A. Hassidim, and S. Lloyd, Physical review letters 103, 150502 (2009).
- Engel et al. [2021] A. Engel, G. Smith, and S. E. Parker, Phys. Plasmas 28, 062305 (2021).
- Low and Chuang [2019] G. H. Low and I. L. Chuang, Quantum 3, 163 (2019).
- Gilyén et al. [2019] A. Gilyén, Y. Su, G. H. Low, and N. Wiebe, in Proceedings of the 51st Annual ACM SIGACT Symposium on Theory of Computing, STOC 2019 (Association for Computing Machinery, New York, NY, USA, 2019) p. 193–204.
- Note [1] Because of this, the previous version of this paper imposed a condition .
- Mizuta and Fujii [2023] K. Mizuta and K. Fujii, Quantum 7, 962 (2023).
- Acebrón et al. [2005] J. A. Acebrón, L. L. Bonilla, C. J. Pérez Vicente, F. Ritort, and R. Spigler, Rev. Mod. Phys. 77, 137 (2005).
- Note [2] is a constant thanks to the preservation of , i.e., Eq. (15).
- Zhang et al. [2022] X.-M. Zhang, T. Li, and X. Yuan, Phys. Rev. Lett. 129, 230504 (2022).
- Sun et al. [2023] X. Sun, G. Tian, S. Yang, P. Yuan, and S. Zhang, IEEE Trans. Comput. Aided Des. Integr. Circuits Syst. 42, 3301 (2023).
- Babbush et al. [2023] R. Babbush, D. W. Berry, R. Kothari, R. D. Somma, and N. Wiebe, Phys. Rev. X 13, 041041 (2023).
- Kuramoto [2012] Y. Kuramoto, Chemical Oscillations, Waves, and Turbulence, Springer Series in Synergetics (Springer Berlin Heidelberg, 2012).
- Hoppensteadt [2000] F. C. Hoppensteadt, Analysis and Simulation of Chaotic Systems, Second Edition (Springer New York, NY, 2000).