A Principled Approach to Data Valuation for Federated Learning
Abstract
Federated learning (FL) is a popular technique to train machine learning (ML) models on decentralized data sources. In order to sustain long-term participation of data owners, it is important to fairly appraise each data source and compensate data owners for their contribution to the training process. The Shapley value (SV) defines a unique payoff scheme that satisfies many desiderata for a data value notion. It has been increasingly used for valuing training data in centralized learning. However, computing the SV requires exhaustively evaluating the model performance on every subset of data sources, which incurs prohibitive communication cost in the federated setting. Besides, the canonical SV ignores the order of data sources during training, which conflicts with the sequential nature of FL. This paper proposes a variant of the SV amenable to FL, which we call the federated Shapley value. The federated SV preserves the desirable properties of the canonical SV while it can be calculated without incurring extra communication cost and is also able to capture the effect of participation order on data value. We conduct a thorough empirical study of the federated SV on a range of tasks, including noisy label detection, adversarial participant detection, and data summarization on different benchmark datasets, and demonstrate that it can reflect the real utility of data sources for FL and has the potential to enhance system robustness, security, and efficiency. We also report and analyze “failure cases” and hope to stimulate future research.
Keywords:
Data valuationFederated learningShapley value.1 Introduction
Building high-quality ML models often involves gathering data from different sources. In practice, data often live in silos and agglomerating them may be intractable due to legal constraints or privacy concerns. FL is a promising paradigm which can obviate the need for centralized data. It directly learns from sequestered data sources by training local models on each data source and distilling them into a global federated model. FL has been used in applications such as keystroke prediction [8], hotword detection [22], and medical research [3].
A fundamental question in FL is how to value each data source. FL makes use of data from different entities. In order to incentivize their participation, it is crucial to fairly appraise the data from different entities according to their contribution to the learning process. For example, FL has been applied to financial risk prediction for reinsurance [1], where a number of insurance companies who may also be business competitors would train a model based on all of their data and and the resulting model will create certain profit. In order to prompt such collaboration, the companies need to concur with a scheme that can fairly divide the earnings generated by the federated model among them.
The SV has been proposed to value data in recent works [11, 10, 6]. The SV is a classic way in coopereative game theory to distribute total gains generated by the coalition of a set of players. One can formulate ML as a cooperative game between different data sources and then use the SV to value data. An important reason for employing the SV is that it uniquely possesses a set of appealing properties desired by a data value notion: it ensures that (1) all the gains of the model are distributed among data sources; (2) the values assigned to data owners accord with their actual contributions to the learning process; and (3) the value of data accumulates when used multiple times.
Despite the appealing properties of the SV, it cannot be directly applied to FL. By definition, the SV calculates the average contribution of a data source to every possible subset of other data sources. Thus, evaluating the SV incurs prohibitive communication cost when the data is decentralized. Moreover, the SV neglects the order of data sources, yet in FL the importance of a data source could depend on when it is used for training. For instance, in order to ensure convergence, the model updates are enforced to diminish over time (e.g., by using a decaying learning rate); therefore, intuitively, the data sources used toward the end of learning process could be less influential than those used earlier. Hence, a new, principled approach to valuing data for FL is needed.
In this paper, we propose the federated SV, a variant of the SV designed to appraise decentralized, sequential data for FL. The federated SV can be determined from local model updates in each training iteration and therefore does not incur extra communication cost. It can also capture the effect of participation order on data value as it examines the performance improvement caused by each subset of players following the actual participation order in the learning process. Particularly, the federated SV preserves the desirable properties of the canonical SV. We present an efficient Monte Carlo method to compute the federated SV. Furthermore, we conduct a thorough empirical study on a range of tasks, including noisy label detection, adversarial participant detection, and data summarization on different benchmark datasets, and demonstrate that the federated SV can reflect the actual usefulness of data sources in FL. We also report and analyze cases in which the proposed federated SV can be further improved and hope to stimulate future research on this emerging topic.
2 Related Work
Various data valuation schemes have been studied in the literature, and from a practitioner’s point of view they can be classified into query-based pricing that attaches prices to user-initiated queries [18, 28]; data attribute-based pricing that builds a price model depending on parameters such as data age and credibility using public price registries [9]; and auction-based pricing that sets the price dynamically based on auctions [21, 25]. However, one common drawback of the existing strategies is that they cannot accommodate the unique properties of data as a commodity; for instance, the value of a data source depends on the downstream learning task and the other data sources used for solving the task.
The SV uniquely satisfies the properties desired by a data value notion. The use of the SV for pricing personal data can be traced back to [16, 4] in the context of marketing survey, collaborative filtering, recommendation systems, and networks. Despite the desirable properties of the SV, computing the SV is known to be expensive. In its most general form, the SV can be -complete to compute [5]. The computational issue becomes even more serious when the SV is used to value training data for ML, because calculating it requires re-training models for many times. Most of the recent work on the SV-based data valuation has been focused on the centralized learning setting and improving its computational efficiency [11, 10, 13, 6]. Two important assumptions of the canonical SV are that the training performance on every combination of data points is measurable and that the performance does not depend on the order of training data. These two assumptions are plausible for centralized learning because the entire data is accessible to the coordinator and the data is often shuffled before being used for training. However, they are no longer valid for the federated setting.
Existing work on pricing data in FL can be roughly categorized into two threads. One thread of work [14, 15] studies the mechanism design to incentivize participation given the disparity of data quality, communication bandwidth, and computational capability among different participants. In these works, the authors assume that the task publisher (i.e., the coordinator) has some prior knowledge about the data quality of a participant and design an optimal contract to maximize the utility of the coordinator subject to rationality constraints of individual participants. However, it remains a question how to precisely characterize data quality in FL. Another thread of work investigates the way to measure data quality and share the profit generated by the federated model according to the data quality measurement. Wang et al. [29] and Song et al. [27] apply the canonical SV to value each data source; however, as discussed earlier, the direct application of the SV is intractable in practice due to the decentralized data and conceptually flawed due to the sequential participation of participants. Recently, Yu et al. [30] has studied at the intersection of two threads by proposing a fair profit sharing scheme while considering individual costs incurred by joining FL as well as the mismatch between contribution and payback time. Our work can be potentially integrated with their work to better characterize the data contribution.
3 Data Valuation based on SV
Cooperative game theory studies the behaviors of coalitions formed by game players. Formally, a cooperative game is defined by a pair , where denotes the set of all players and is the utility function, which maps each possible coalition to a real number that describes the utility of a coalition, i.e., how much collective payoff a set of players can gain by forming the coalition. One of the fundamental questions in cooperative game theory is to characterize the importance of each player to the overall cooperation. The SV [26] is a classic method to distribute the total gains generated by the coalition of all players. The SV of player with respect to the utility function is defined as the average marginal contribution of to coalition over all :
| (1) |
We suppress the dependency on when the utility used is clear and use to represent the value allocated to player .
The formula in (1) can also be stated in the equivalent form:
| (2) |
where is a permutation of players and is the set of players which precede player in . Intuitively, imagine all players join a coalition in a random order, and that every player who has joined receives the marginal contribution that his participation would bring to those already in the coalition. To calculate , we average these contributions over all the possible orders.
Applying these game theory concepts to data valuation, one can think of the players as data contributors and the utility function as a performance measure of the model trained on the set of training data . The SV of each data contributor thus measures its importance to learning an ML model. The following desirable properties that the SV uniquely possesses motivate many prior works [16, 4, 12, 10, 13, 6] to adopt it for data valuation.
-
1.
Group Rationality: The value of the model is completely distributed among all data contributors, i.e., .
-
2.
Fairness: (1) Two data contributors who are identical with respect to what they contribute to a dataset’s utility should have the same value. That is, if data contributor and are equivalent in the sense that , then . (2) Data contributor with zero marginal contributions to all subsets of the dataset receive zero payoff, i.e., if , , then .
-
3.
Additivity: The values under multiple utilities sum up to the value under a utility that is the sum of all these utilities: for .
The group rationality property states that any rational group of data contributors would expect to distribute the full yield of their coalition. The fairness property requires that the names of the data contributors play no role in determining the value, which should be sensitive only to how the utility function responds to the presence of a seller. The additivity property facilitates efficient value calculation when data are used for multiple applications, each of which is associated with a specific utility function. With additivity, one can compute value shares separately for each application and sum them up.
There are two assumptions underlying the definition of the SV:
-
1.
Combinatorially Evaluable Utility: The utility function can be evaluated for every combination of players;
-
2.
Symmetric Utility: The utility function does not depend on the order of the players.
Both of the assumptions are plausible for centralized learning. Since the entire data is accessible to the coordinator, it is empowered to evaluate the model performance on the data from an arbitrary subset of contributors. Furthermore, in centralized learning, the data is often shuffled before being used for training. Hence, it is reasonable to consider the model performance to be independent the order of data points in the training set. In the next section, we will argue that these two assumption are no longer valid for FL and propose a variant of the SV amenable to the federated setting.
4 Valuing Data for FL
4.1 Federated Shapley Value
A typical FL process executes the following steps repeatedly until some stopping criterion is met: (1) The coordinator samples a subset of participants; (2) The selected participants download the current global model parameters from the coordinator; (3) Each selected participant locally computes an update to the model by training on the local data; (4) The coordinator collects an aggregate of the participant updates; (5) The coordinator locally updates the global model based on the aggregated update computed from the participants that participate in the current round.
Let be the set of participants that participate in at least one round of the FL process. Our goal is to assign a real value to each participant in to measure its contribution to learning the model. Suppose the learning process lasts for rounds. Let the participants selected in round be and we have .
In FL, different participants contribute to the learning process at different time and the performance of the federated model depends on the participation order of participants. Clearly, the symmetric utility assumption of the SV does not hold. Moreover, FL is designed to maintain the confidentiality of participants’ data and in each round, only a subset of participants are selected and upload their model updates. Hence, the coordinator can only know the model performance change caused by adding a participant’s data into the subset of participants’ data selected earlier. However, computing the SV requires the ability to evaluate the model performance change for every possible subset of participants. Unless the participants are able to bear considerable extra communication cost, the combinatorially evaluable utility assumption is invalid for FL. Hence, the SV cannot be used to value the data of different participants in the federated setting.
We propose a variant of the SV amenable to the federated setting. The key idea is to characterize the aggregate value of the set of participants in the same round via the model performance change caused by the addition of their data and then use the SV to distribute the value of the set to each participant. We will call this variant the federated SV and its formal definition is given below. We use to denote the utility function which maps any participants’ data to a performance measure of the model trained on the data. Note that unlike in the canonical SV definition where takes a set as an input, the argument of is an ordered sequence. For instance, means the utility of the model that is trained on A’s data first, then B’s data. Furthermore, let be a shorthand for for and for .
Definition 1 (The Federated Shapley Value).
Let denote the set of participants selected by the coordinator during a -round FL process. Let be the set of participants selected in round and . Then, the federated SV of participant at round is defined as
| (3) |
and otherwise. The federated SV takes the sum of the values of all rounds:
| (4) |
We will suppress the dependency of the federated SV on whenever the underlying utility function is self-evident.
Due to the close relation between the canonical SV and the federated SV, one can expect that the federated variant will inherit the desirable properties of the canonical SV. Indeed, Theorem 1 shows that the federated SV preserves the group rationality, fairness, as well as additivity.
Theorem 1.
The federated SV defined in (4) uniquely possesses the following properties:
-
1.
Instantaneous group rationality: .
-
2.
Fairness: (1) if , for some round , then . (2) , for some round , then .
-
3.
Additivity: for all .
The proof of the theorem follows from the fact that the federated Shapley value calculates the Shapley value for the players selected in each round which distributes the performance difference from the previous round.
By aggregating the instantaneous group rationality equation over time, we see that the federated SV also satisfies the long-term group rationality:
| (5) |
The long-term group rationality states that the set of players participates in a -round FL process will divide up the final yield of their coalition.
4.2 Estimating the Federated SV
Similar to the canonical SV, computing the federated SV is expensive. Evaluating the exact federated SV involves computing the marginal utility of every participant to every subset of other participants selected in each round (see Eqn. 3). To evaluate , we need to update the global model trained on with the aggregate of the model updates from and calculate the updated model performance. The total complexity is , where is the maximum number of participants selected per round. In this section, we present efficient algorithms to approximate the federated SV. We say that is a -approximation to the true SV if . These algorithms utilize the existing approximation methods developed for the canonical SV [23, 12] to improve the efficiency of per-round federated SV calculation.
The idea of the first approximation algorithm is to treat the Shapley value of a participant as its expected contribution to the participants before it in a random permutation using Eqn. 2 and use the sample average to approximate the expectation. We will call this algorithm permutation sampling-based approximation hereinafter and the pseudocode is provided in Algorithm 2. An application of Hoeffding bound indicates that to achieve -approximation in each round of updating, the number of utility evaluations required for rounds is .
The second approximation algorithm makes use of the group testing technique [11] to estimate the per-round federated SV and we will call this algorithm group testing-based approximation. In our scenario, each ”test” corresponds to evaluating the utility of a subset of participant updates. The key idea of the algorithm is to intelligently design the sampling distribution of participants’ updates so that we can calculate Shapely differences between the selected participants from the test results with high-probability bound on the error. Based on the result in [11], the number of tests required to estimate the Shapley differences up to is , where and other variables are defined in Algorithm 3. We can then take any participant and estimate the corresponding SV using the permutation sampling-based approximation, denote it as . Then, the SV of all other users can be estimated using the estimated difference of the SV with participant (we choose the th participant as the pivot participant in the pseudo-code in Algorithm 4). The number of utility evaluation required for estimating up to is . are chosen so that are minimized. Algorithm 1, 2, 3, and 4 present the pseudo-code for both permutation sampling and group testing.
If we treat as constant, while permutation sampling-based approximation is . Therefore, when the number of selected participants in each round is large, group testing-based approximation is significantly faster than permutation sampling-based one. One the other hand, when the number of selected participants is small, permutation sampling-based approximation is more preferable since its utility evaluation complexity tends to have a smaller constant.
5 Empirical Study
In this section, we conduct the first empirical evaluation on a range of real-world FL tasks with different datasets to study whether the proposed data value notion can reflect the real utility of data. The tasks include noisy data detection, adversarial participant removal and data summarization. We would expect that a good data value notion will assign low value to participants with noisy, adversarial, and low-quality data, which will in turn help us remove those participants.
5.1 Baseline Approaches
We will compare the federated SV with the following two baselines.
Federated Leave-One-Out One natural way to assign the contribution to a participant update at round is by calculating the model performance change when the participant is removed from the set of participants selected at round , i.e., , and if participant is not selected in round . The Leave-One-Out (LOO) value for FL takes the sum of the LOO values of all rounds: .
Random The random baseline does not differentiate between different participants’ contribution and just randomly selects participants to perform a given task.
In the figures, we will use Fed. LOO and Fed. SV to denote federated leave-one-out and federated Shapley Value approach, respectively.
5.2 Experiment Setting
For each task, we perform experiments on the MNIST [20] as well as the CIFAR10 dataset [19]. Following [24], we study two ways of partitioning the MNIST data over participants: IID, where the data is shuffled, and then partitioned into 100 participants each receiving 600 examples, and Non-IID, where we first sort the data by digit label, divide it into 200 shards of size 300, and assign each of 100 participants 2 shards. For MNIST, we train a simple multilayer-perceptron (MLP) with 2-hidden layers with 200 neurons in each layer and ReLu activations as well as a simple CNN. For all experiments on CIFAR10, we train a CNN with two 5x5 convolution layers (the first with 32 channels, the second with 64, each followed by 2x2 max pooling), a fully connected layer with 512 neurons with ReLu activation, and a final softmax output layer. In each round of training, we randomly select 10 participants out of 100, unless otherwise specified. We run 25 rounds for training on MNIST, achieving up to 97% and 92% global model accuracy for the IID and the non-IID setting, respectively. For CIFAR10, we run up to 50 to 200 rounds of training. We achieve up 77% and 70% test accuracy in IID and non-IID setting, respectively, for 200 rounds of training. As a side note, the state-of-the-art models in [17] can achieve test accuracy of 99.4% for CIFAR10; nevertheless, our goal is to evaluate the proposed data value notion rather than achieving the best possible accuracy. We use the permutation sampling approach in Algorithm 2 to estimate the Shapley value in all experiments since the number of participants is small.
5.3 Noisy Label Detection
Labels in the real world are often noisy due to annotators’ varying skill-levels, biases or malicious tampering. We show that the proposed data value notion can help removing the noisy participants. The key idea is to rank the participants according to their data value, and drop the participants with the lowest values.
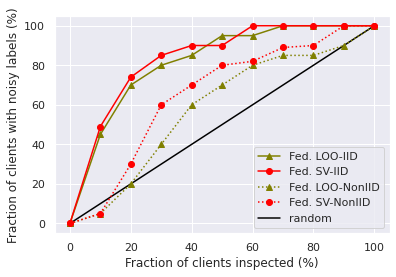
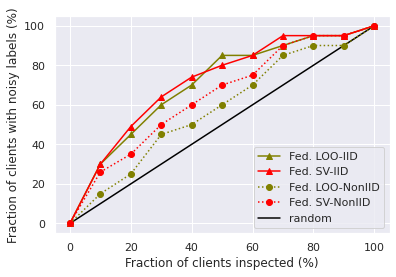
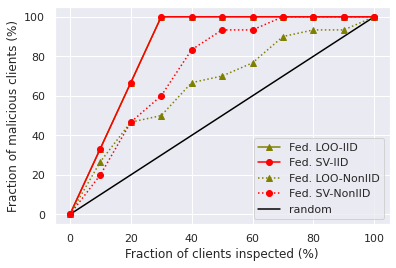
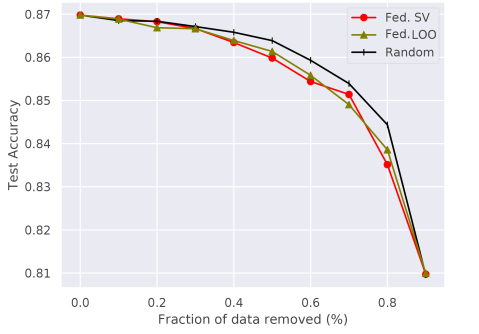
We set 20 participants’ local data to be noisy where noise flipping ratio is 10% for MNIST, and 3% for CIFAR10. The performances of different data value measures are illustrated in Figure 1a and 1b. We inspect the label of participant’s local training instances that have the lowest scores, and plot the change of the fraction of detected noisy participants with the fraction of the inspected participants. We can see that when the training data is partitioned in IID setting, federated LOO and federated SV perform similarly. However, in the Non-IID setting, the federated SV outperforms federated LOO. We conjecture that this is because for Non-IID participants, the trained local models tend to overfit, diverge from the global model, and exhibit low accuracy. In comparison with the federated SV, federated LOO only computes the marginal contribution of a participant to the largest subset of other selected participants and therefore the noisy participants are harder to be identified by federated LOO.
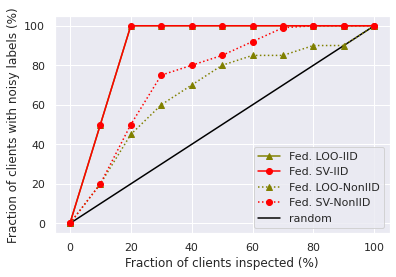
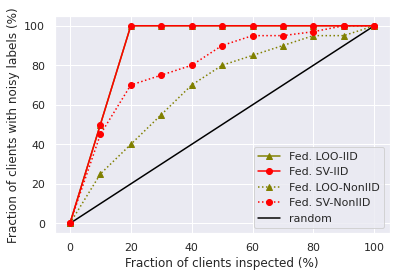
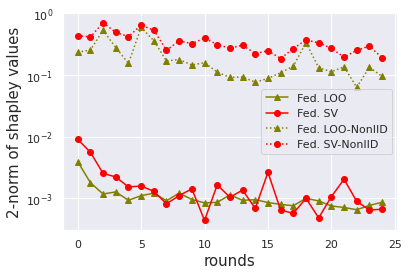
We also find that, with the number of training rounds increases, the total contribution of participants in each round will decrease, as shown in Figure 2a. This makes sense since the federated SV satisfies instantaneous group rationality in Theorem 1, and the improvement of global model’s utility will slowdown when it is close to convergence. That is, it is relatively easy to improve the global model’s utility in earlier rounds, while harder to further improve the utility in later rounds. Hence, the contribution of participants selected in early rounds is inflated. This inspires us to consider a variant of data value measures, which normalize the per-round data values by their norms and then aggregate them across all rounds. The performance of noisy label detection with the normalized versions of federated SV and federated LOO is shown in Figure 1c and 1d. As we can see, it is much easier to separate noisy participants from benign participants with the normalized version of data value notions. However, the normalized federated SV no longer preserves the group rationality and additivity property. We leave developing more detailed analysis of different variants of data value as future work.
5.4 Backdoor Attack Detection
Motivated by privacy concerns, in FL, the coordinator is designed to have no visibility into a participant’s local data and training process. This lack of transparency in the agent updates can be exploited so that an adversary controlling a small number of malicious participants can perform a backdoor attack. The adversary’s objective is to cause the jointly trained global model to misclassify a set of chosen inputs, i.e. it seeks to poison the global model in a targeted manner, while also ensures that the global model has a good performance on the clean test data. We focus on backdoor attacks based on the model replacement paradigm proposed by [2].
For CIFAR10, following the settings in [2], we choose the feature of vertically stripped walls in the background (12 images) as the backdoor. For MNIST, we implement pixel-pattern backdoor attack in [7]. We set the ratio of the participants controlled by the adversary to be 30%. We mix backdoor images with benign images in every training batch (20 backdoor images per batch of size 64) for compromised participants, following the settings in [2].
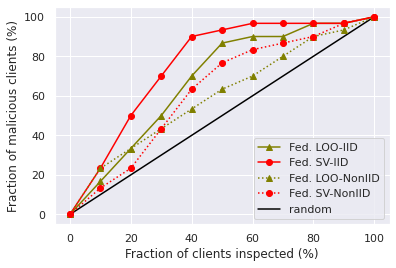
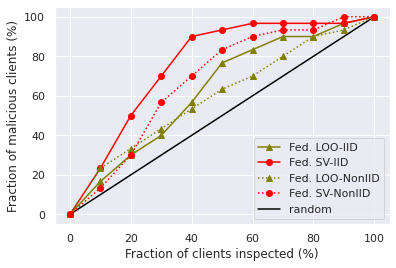
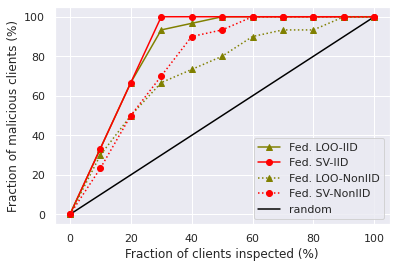
In Figure 3a and 3b, we show the success rate of backdoor detection with respect to the fraction of checked participants. Both of the figures indicate that federated SV is a more effective than federated LOO for detecting compromised participants. In the Non-IID setting, both compromised participants and some benign participants tend to have low contribution on the main task performance, which makes the compromised participants more difficult to be identified by the low data values. Hence, we also test the performance of normalized version of federated SV/LOO for this task and Figure 3c and 3d show that the performance improves a lot compared with the original definitions.

5.5 Data Summarization
In our data summarization experiments, we investigate whether the federated SV can facilitate federated training by identifying the most valuable participants. Per communication round, a percentage of the selected participants is ignored for the update of the global model. We use data value measures to dismiss participants that are expected to contribute the least to the model accuracy. The data values are calculated on a separate validation set, which contains 1000 and 800 random samples for MNIST and CIFAR10, respectively. During each communication round of FL, we compute the data value summands. After training has finished, we compute the total data value.
We then repeat training, while maintaining an identical selection of participants per round. During each round, we dismiss a certain fraction of the selected participants. We compute and average the results for the random baseline three times per run.
We train a small CNN model on the MNIST dataset. The CNN consists of two 5x5 convolution layers, each followed with 2x2 max pooling and ReLu activations. Two fully connected layers (input, hidden and output dimensions of 320, 50, 10, respectively) with intermediate ReLu activation follow the second convolution layer. We apply dropout on the second convolution and first fully connected layer. For CIFAR10, we operate on 1000-dimensional feature vectors extracted with an imagenet-pretrained MobileNet v2 mode.111We use preprocessing and the pretrained model as provided by PyTorch Hub We train a MLP with 2-hidden layers with 1000 neurons in each layer and ReLu activations.
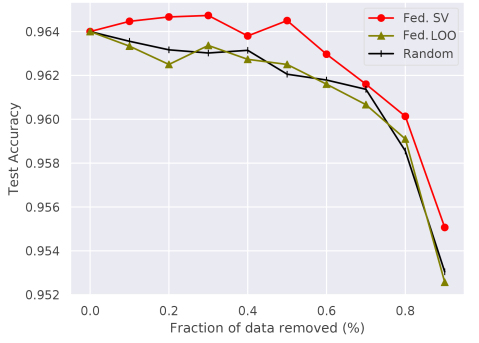
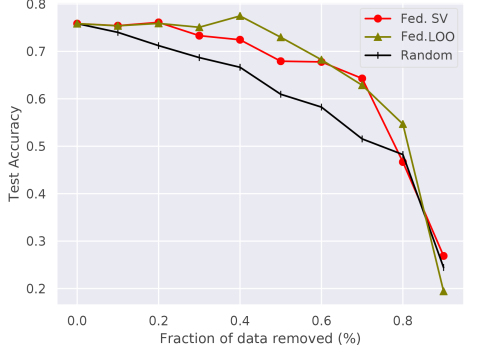
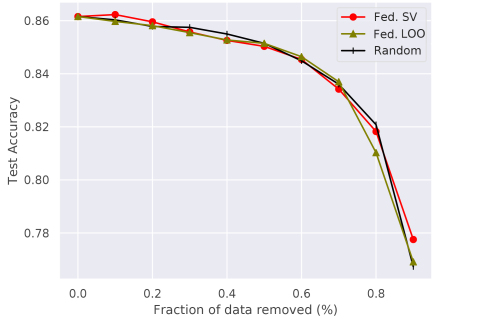
We evaluate our algorithm for FL of 10 rounds on MNIST and 100 rounds on CIFAR10. The results of our experiments are shown in Figure 4. For the MNIST IID case, the federated SV approach outperforms both baselines. While it also consistently outperforms the random baseline in the non-IID setting, federated LOO achieves higher test accuracies for lower fractions of dismissed samples. Here, analysis of the federated SV per participant shows that it tends to be higher for participants that are selected throughout the FL. Furthermore, we observe that participants that were sampled few times also are more likely to have a negative federated SV, compared to the IID setting. We hypothesize that this bias negatively affects the performance of the federated SV-based summarization in the non-IID setting.
We also observe that both federated SV and LOO perform worse on the CIFAR10 dataset summarization. We hypothesize that selection of good participant subsets is more effective on the MNIST dataset, as it contains a larger portion of redundant samples. Consequently, valuable information is less likely to be lost by dismissal of a fraction of participants.
6 Conclusion
This paper proposes the federated SV, a principled notion to value data for the process of FL. The federated SV uniquely possesses the properties desired by a data value notion, including group rationality, fairness, and additivity, while enjoying communication-efficient calculation and being able to capture the effect of participant participation order on the data value. We present algorithms to approximate the federated SV and these algorithms are significantly more efficient than the exact algorithm when the number of participants is large. Finally, we demonstrate that the federated SV can reflect the actual utility of data sources through a range of tasks, including noisy label detection, adversarial participant detection, and data summarization.
References
- rei [2019] Webank and swiss re signed cooperation mou, 2019. URL https://markets.businessinsider.com/news/stocks/webank-and-swiss-re-signed-cooperation-mou-1028228738#.
- Bagdasaryan et al. [2020] E. Bagdasaryan, A. Veit, Y. Hua, D. Estrin, and V. Shmatikov. How to backdoor federated learning. In International Conference on Artificial Intelligence and Statistics, pages 2938–2948, 2020.
- Brouwer [2019] W. D. Brouwer. The federated future is ready for shipping, 2019. URL https://medium.com/@_doc_ai/the-federated-future-is-ready-for-shipping-d17ff40f43e3.
- Chessa and Loiseau [2017] M. Chessa and P. Loiseau. A cooperative game-theoretic approach to quantify the value of personal data in networks. In Proceedings of the 12th workshop on the Economics of Networks, Systems and Computation, page 9. ACM, 2017.
- Deng and Papadimitriou [1994] X. Deng and C. H. Papadimitriou. On the complexity of cooperative solution concepts. Mathematics of Operations Research, 19(2):257–266, 1994.
- Ghorbani and Zou [2019] A. Ghorbani and J. Zou. Data shapley: Equitable valuation of data for machine learning. arXiv preprint arXiv:1904.02868, 2019.
- Gu et al. [2019] T. Gu, K. Liu, B. Dolan-Gavitt, and S. Garg. Badnets: Evaluating backdooring attacks on deep neural networks. IEEE Access, 7:47230–47244, 2019.
- Hard et al. [2018] A. Hard, K. Rao, R. Mathews, S. Ramaswamy, F. Beaufays, S. Augenstein, H. Eichner, C. Kiddon, and D. Ramage. Federated learning for mobile keyboard prediction. arXiv preprint arXiv:1811.03604, 2018.
- Heckman et al. [2015] J. R. Heckman, E. L. Boehmer, E. H. Peters, M. Davaloo, and N. G. Kurup. A pricing model for data markets. iConference 2015 Proceedings, 2015.
- Jia et al. [2019a] R. Jia, D. Dao, B. Wang, F. A. Hubis, N. M. Gurel, B. Li, C. Zhang, C. Spanos, and D. Song. Efficient task-specific data valuation for nearest neighbor algorithms. Proceedings of the VLDB Endowment, 12(11):1610–1623, 2019a.
- Jia et al. [2019b] R. Jia, D. Dao, B. Wang, F. A. Hubis, N. Hynes, N. M. Gurel, B. Li, C. Zhang, D. Song, and C. Spanos. Towards efficient data valuation based on the shapley value. arXiv preprint arXiv:1902.10275, 2019b.
- Jia et al. [2019c] R. Jia, D. Dao, B. Wang, F. A. Hubis, N. Hynes, B. Li, C. Zhang, D. Song, and C. Spanos. Towards efficient data valuation based on the shapley value. AISTATS, 2019c.
- Jia et al. [2019d] R. Jia, X. Sun∗, J. Xu∗, C. Zhang, B. Li, and D. Song. An empirical and comparative analysis of data valuation with scalable algorithms. arXiv preprint arXiv:1911.07128, 2019d.
- Kang et al. [2019a] J. Kang, Z. Xiong, D. Niyato, S. Xie, and J. Zhang. Incentive mechanism for reliable federated learning: A joint optimization approach to combining reputation and contract theory. IEEE Internet of Things Journal, 6(6):10700–10714, 2019a.
- Kang et al. [2019b] J. Kang, Z. Xiong, D. Niyato, H. Yu, Y.-C. Liang, and D. I. Kim. Incentive design for efficient federated learning in mobile networks: A contract theory approach. In 2019 IEEE VTS Asia Pacific Wireless Communications Symposium (APWCS), pages 1–5. IEEE, 2019b.
- Kleinberg et al. [2001] J. Kleinberg, C. H. Papadimitriou, and P. Raghavan. On the value of private information. In Proceedings of the 8th conference on Theoretical aspects of rationality and knowledge, pages 249–257. Morgan Kaufmann Publishers Inc., 2001.
- Kolesnikov et al. [2019] A. Kolesnikov, L. Beyer, X. Zhai, J. Puigcerver, J. Yung, S. Gelly, and N. Houlsby. Big transfer (bit): General visual representation learning. arXiv preprint arXiv:1912.11370, 2019.
- Koutris et al. [2015] P. Koutris, P. Upadhyaya, M. Balazinska, B. Howe, and D. Suciu. Query-based data pricing. Journal of the ACM (JACM), 62(5):43, 2015.
- Krizhevsky et al. [2009] A. Krizhevsky, G. Hinton, et al. Learning multiple layers of features from tiny images. 2009.
- LeCun and Cortes [2010] Y. LeCun and C. Cortes. MNIST handwritten digit database. 2010. URL http://yann.lecun.com/exdb/mnist/.
- Lee and Hoh [2010] J.-S. Lee and B. Hoh. Sell your experiences: a market mechanism based incentive for participatory sensing. In Pervasive Computing and Communications (PerCom), 2010 IEEE International Conference on, pages 60–68. IEEE, 2010.
- Leroy et al. [2019] D. Leroy, A. Coucke, T. Lavril, T. Gisselbrecht, and J. Dureau. Federated learning for keyword spotting. In ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 6341–6345. IEEE, 2019.
- Maleki [2015] S. Maleki. Addressing the computational issues of the Shapley value with applications in the smart grid. PhD thesis, University of Southampton, 2015.
- McMahan et al. [2017] B. McMahan, E. Moore, D. Ramage, S. Hampson, and B. A. y Arcas. Communication-efficient learning of deep networks from decentralized data. In Artificial Intelligence and Statistics, pages 1273–1282, 2017.
- Mihailescu and Teo [2010] M. Mihailescu and Y. M. Teo. Dynamic resource pricing on federated clouds. In Cluster, Cloud and Grid Computing (CCGrid), 2010 10th IEEE/ACM International Conference on, pages 513–517. IEEE, 2010.
- Shapley [1953] L. S. Shapley. A value for n-person games. Contributions to the Theory of Games, 2(28):307–317, 1953.
- Song et al. [2019] T. Song, Y. Tong, and S. Wei. Profit allocation for federated learning. In 2019 IEEE International Conference on Big Data (Big Data), pages 2577–2586. IEEE, 2019.
- Upadhyaya et al. [2016] P. Upadhyaya, M. Balazinska, and D. Suciu. Price-optimal querying with data apis. PVLDB, 9(14):1695–1706, 2016.
- Wang et al. [2019] G. Wang, C. X. Dang, and Z. Zhou. Measure contribution of participants in federated learning. In 2019 IEEE International Conference on Big Data (Big Data), pages 2597–2604. IEEE, 2019.
- Yu et al. [2020] H. Yu, Z. Liu, Y. Liu, T. Chen, M. Cong, X. Weng, D. Niyato, and Q. Yang. A fairness-aware incentive scheme for federated learning. In Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society, pages 393–399, 2020.