A quantum extension of SVM-perf for training nonlinear SVMs in almost linear time
Abstract
We propose a quantum algorithm for training nonlinear support vector machines (SVM) for feature space learning where classical input data is encoded in the amplitudes of quantum states. Based on the classical SVM-perf algorithm of Joachims [1], our algorithm has a running time which scales linearly in the number of training examples (up to polylogarithmic factors) and applies to the standard soft-margin -SVM model. In contrast, while classical SVM-perf has demonstrated impressive performance on both linear and nonlinear SVMs, its efficiency is guaranteed only in certain cases: it achieves linear scaling only for linear SVMs, where classification is performed in the original input data space, or for the special cases of low-rank or shift-invariant kernels. Similarly, previously proposed quantum algorithms either have super-linear scaling in , or else apply to different SVM models such as the hard-margin or least squares -SVM which lack certain desirable properties of the soft-margin -SVM model. We classically simulate our algorithm and give evidence that it can perform well in practice, and not only for asymptotically large data sets.
1 Introduction
Support vector machines (SVMs) are powerful supervised learning models which perform classification by identifying a decision surface which separates data according to their labels [2, 3]. While classifiers based on deep neural networks have increased in popularity in recent years, SVM-based classifiers maintain a number of advantages which make them an appealing choice in certain situations. SVMs are simple models with a smaller number of trainable parameters than neural networks, and thus can be less prone to overfitting and easier to interpret. Furthermore, neural network training may often get stuck in local minima, whereas SVM training is guaranteed to find a global optimum [4]. For problems such as text classification which involve high dimensional but sparse data, linear SVMs — which seek a separating hyperplane in the same space as the input data — have been shown to perform extremely well, and training algorithms exist which scale efficiently, i.e. linearly in [5, 6, 7], or even independent of [8], the number of training examples .
In more complex cases, where a nonlinear decision surface is required to classify the data successfully, nonlinear SVMs can be used, which seek a separating hyperplane in a higher dimensional feature space. Such feature space learning typically makes use of the kernel trick [9], a method enabling inner product computations in high or even infinite dimensional spaces to be performed implicitly, without requiring the explicit and resource intensive computation of the feature vectors themselves.
While powerful, the kernel trick comes at a cost: many classical algorithms based on this method scale poorly with . Indeed, storing the full kernel matrix in memory itself requires resources, making subquadratic training times impossible by brute-force computation of . When admits a low-rank approximation though, sampling-based approaches such as the Nystrom method [10] or incomplete Cholesky factorization [11] can be used to obtain running times, although it may not be clear a priori whether such a low-rank approximation is possible. Another special case corresponds to so-called shift-invariant kernels [12], which include the popular Gaussian radial basis function (RBF) kernel, where classical sampling techniques can be used to map the high dimensional data into a random low dimensional feature space, which can then be trained by fast linear methods. This method has empirically competed favorably with more sophisticated kernel machines in terms of classification accuracy, at a fraction of the training time. While such a method seems to strike a balance between linear and nonlinear approaches, it cannot be applied to more general kernels. In practice, advanced solvers employ multiple heuristics to improve their performance, which makes rigorous analyses of their performance difficult. However, methods like SVM-Light [13], SMO [14], LIBSVM [15] and SVMTorch [16] still empirically scale approximately quadratically with for nonlinear SVMs.
The state-of-the-art in terms of provable computational complexity is the Pegasos algorithm [8]. Based on stochastic sub-gradient descent, Pegasos has constant running time for linear SVMs. For nonlinear SVMs, Pegasos has running time, and is not restricted to low-rank or shift-invariant kernels. However, while experiments show that Pegasos does indeed display outstanding performance for linear SVMs, for nonlinear SVMs it is outperformed by other benchmark methods on a number of datasets. On the other hand, the SVM-perf algorithm of Joachims [1] has been shown to outperform similar benchmarks [17], although it does have a number of theoretical drawbacks compared with Pegasos. SVM-perf has scaling for linear SVMs, but an efficiency for nonlinear SVMs which either depends on heuristics, or on the presence of a low-rank or shift-invariant kernel, where linear in scaling can also be achieved. However, given the strong empirical performance of SVM-perf, it serves as a strong starting point for further improvements, with the aim of overcoming the restrictions in its application to nonlinear SVMs.
Can quantum computers implement SVMs more effectively than classical computers? Rebentrost and Lloyd were the first to consider this question [18], and since then numerous other proposals have been put forward [19, 20, 21, 22, 23]. While the details vary, at a high level these quantum algorithms aim to bring benefits in two main areas: i) faster training and evaluation time of SVMs or ii) greater representational power by encoding the high dimensional feature vectors in the amplitudes of quantum states. Such quantum feature maps enable high dimensional inner products to be computed directly and, by sidestepping the kernel trick, allow classically intractable kernels to be computed. These proposals are certainly intriguing, and open up new possibilities for supervised learning. However, the proposals to date with improved running time dependence on for nonlinear SVMs do not apply to the standard soft-margin -SVM model, but rather to variations such as least squares -SVMs[18] or hard-margin SVMs [23]. While these other models are useful in certain scenarios, soft-margin -SVMs have two properties - sparsity of weights and robustness to noise - that make them preferable in many circumstances.
In this work we present a method to extend SVM-perf to train nonlinear soft-margin -SVMs with quantum feature maps in a time that scales linearly (up to polylogarithmic factors) in the number of training examples, and which is not restricted to low-rank or shift-invariant kernels. Provided that one has quantum access to the classical data, i.e. quantum random access memory (qRAM) [24, 25], quantum states corresponding to sums of feature vectors can be efficiently created, and then standard methods employed to approximate the inner products between such quantum states. As the output of the quantum procedure is only an approximation to a desired positive semi-definite (p.s.d.) matrix, it is not itself guaranteed to be p.s.d., and hence an additional classical projection step must be carried out to map on to the p.s.d. cone at each iteration.
Before stating our result in more detail, let us make one remark. It has recently been shown by Tang [26] that the data-structure required for efficient qRAM-based inner product estimation would also enable such inner products to be estimated classically, with only a polynomial slow-down relative to quantum, and her method has been employed to de-quantize a number of quantum machine learning algorithms [26, 27, 28] based on such data-structures. However, in practice, polynomial factors can make a difference, and an analysis of a number of such quantum-inspired classical algorithms [29] concludes that care is needed when assessing their performance relative to the quantum algorithms from which they were inspired. More importantly, in this current work, the quantum states produced using qRAM access are subsequently mapped onto a larger Hilbert space before their inner products are evaluated. This means that the procedure cannot be de-quantized in the same way.
2 Background and Results
Let be a data set with , and labels . Let be a feature map where is a real Hilbert space (of finite or infinite dimension) with inner product , and let be the associated kernel function defined by . Let denote the largest norm of the feature mapped vectors. In what follows, will always refer to the norm, and other norms will be explicitly differentiated.
2.1 Support Vector Machine Training
Training a soft-margin -SVM with parameter corresponds to solving the following optimization problem:
OP 1.
(SVM Primal)
Note that, following [1], we divide by to capture how scales with the training set size. The trivial case corresponds to a linear SVM, i.e. a separating hyperplane is sought in the original input space. When one considers feature maps in a high dimensional space, it is more practical to consider the dual optimization problem, which is expressed in terms of inner products, and hence the kernel trick can be employed.
OP 2.
(SVM Dual)
| s.t. |
This is a convex quadratic program with box constraints, for which many classical solvers are available, and which requires time polynomial in to solve. For instance, using the barrier method [30] a solution can be found to within in time . Indeed, even the computation of the kernel matrix takes time , so obtaining subquadratic training times via direct evaluation of is not possible.
2.2 Structural SVMs
Joachims [1] showed that an efficient approximation algorithm - with running time - for linear SVMs could be obtained by considering a slightly different but related model known as a structural SVM [31], which makes use of linear combinations of label-weighted feature vectors:
Definition 1.
For a given data set , feature map , and , define
With this notation, the structural SVM primal and dual optimization problems are:
OP 3.
(Structural SVM Primal)
| s.t. |
OP 4.
(Structural SVM Dual)
| s.t. |
where and denotes the -norm.
Whereas the original SVM problem OP 1 is defined by constraints and slack variables , the structural SVM OP 3 has only one slack variable but constraints, corresponding to each possible binary vector . In spite of these differences, the solutions to the two problems are equivalent in the following sense.
Theorem 1 (Joachims [1]).
While elegant, Joachims’ algorithm can achieve scaling only for linear SVMs — as it requires explicitly computing a set of vectors and their inner products — or to shift-invariant or low-rank kernels where sampling methods can be employed. For high dimensional feature maps not corresponding to shift invariant kernels, computing classically is inefficient. We propose instead to embed the feature mapped vectors and linear combinations in the amplitudes of quantum states, and compute the required inner products efficiently using a quantum computer.
2.3 Our Results
In Section 3 we will formally introduce the concept of a quantum feature map. For now it is sufficient to view this as a quantum circuit which, in time , realizes a feature map , with maximum norm , by mapping the classical data into the state of a multi-qubit system.
Our first main result is a quantum algorithm with running time linear in that generates an approximately optimal solution for the structural SVM problem. By Theorem 1, this is equivalent to solving the original soft-margin -SVM.
Quantum nonlinear SVM training: [See Theorems 6 and 7] There is a quantum algorithm that, with probability at least , outputs and such that if is the optimal solution of OP 3, then
where , and is feasible for OP 3. The running time is
where , is the time required to compute feature map on a quantum computer and is a term that depends on both the data as well as the choice of quantum feature map.
Here and in what follows, the tilde big-O notation hides polylogarithmic terms. In the Simulation section we show that, in practice, the running time of the algorithm can be significantly faster than the theoretical upper-bound. The solution is a -sparse vector of total dimension . Once it has been found, a new data point can be classified according to
where is the predicted label of . This is a sum of inner products in feature space, which classical methods require time to evaluate in general. Our second result is a quantum algorithm for carrying out this classification with running time independent of .
Quantum nonlinear SVM classification: [See Theorem 8] There is a quantum algorithm which, in time
outputs, with probability at least , an estimate to to within accuracy. The sign of the output is then taken as the predicted label.
3 Methods
Our results are based on three main components: Joachims’ linear time classical algorithm SVM-perf, quantum feature maps, and efficient quantum methods for estimating inner products of linear combinations of high dimensional vectors.
3.1 SVM-perf: a linear time algorithm for linear SVMs
On the surface, the structural SVM problems OP 3 and OP 4 look more complicated to solve than the original SVM problems OP 1 and OP 2. However, it turns out that the solution to OP 4 is highly sparse and, consequently, the structural SVM admits an efficient algorithm. Joachims’ original procedure is presented in Algorithm 1.
The main idea behind Algorithm 1 is to iteratively solve successively more constrained versions of problem OP 3. That is, a working set of indices is maintained such that, at each iteration, the solution is only required to satisfy the constraints for . The inner for loop then finds a new index which corresponds to the maximally violated constraint in OP 3, and this index is added to the working set. The algorithm proceeds until no constraint is violated by more than . It can be shown that each iteration must improve the value of the dual objective by a constant amount, from which it follows that the algorithm terminates in a number of rounds independent of .
Theorem 2 (Joachims [1]).
In terms of time cost, each iteration of the algorithm involves solving the restricted optimization problem
| s.t. |
which is done in practice by solving the corresponding dual problem, i.e. the same as OP 4 but with summations over instead of over all . This involves computing
-
•
matrix elements
-
•
inner products
where is the solution to the dual of the optimization problem in the body of Algorithm 1. In the case of linear SVMs, and can each be explicitly computed in time . The cost of computing matrix is , and subsequently solving the dual takes time polynomial in . As Joachims showed that , and since can be computed in time , the entire algorithm therefore has running time linear in . Note that Joachims considered the special case of -sparse data vectors, for which can be computed in time rather than . In what follows we will not consider any sparsity restrictions.
For nonlinear SVMs, the feature maps may be of very large dimension, which precludes explicitly computing and directly evaluating as is done in SVM-perf. Instead, one must compute as a sum of inner products , which are then each evaluated using the kernel trick. This rules out the possibility of an algorithm, at least using methods that rely on the kernel trick to evaluate each . Noting that , the inner products are similarly expensive to compute directly classically if the dimension of the feature map is large.
3.2 Quantum feature maps
We now show how quantum computing can be used to efficiently approximate the inner products and , where high dimensional can be implemented by a quantum circuit using only a number of qubits logarithmic in the dimension. We first assume that the data vectors are encoded in the state of an -qubit register via some suitable encoding scheme, e.g. given an integer , could be encoded in qubits by approximating each of the values of by a length bit string which is then encoded in a computational basis state of qubits. Once encoded, a quantum feature map encodes this information in larger space in the following way:
Definition 2 (Quantum feature map).
Let be -qubit input and -qubit output registers respectively . A quantum feature map is a unitary mapping satisfying
for each of the basis states , where , with real amplitudes . Denote the running time of by .
Note that the states are not necessarily orthogonal. Implementing such a quantum feature map could be done, for instance, through a controlled parameterized quantum circuit.
We also define the quantum state analogy of from Definition 1:
Definition 3.
Given a quantum feature map , define as
where
3.3 Quantum inner product estimation
Let real vectors have corresponding normalized quantum states and . The following result shows how the inner product can be estimated efficiently on a quantum computer.
Theorem 3 (Robust Inner Product Estimation [32], restated).
Let and be quantum states with real amplitudes and with bounded norms . If and can each be generated by a quantum circuit in time , and if estimates of the norms are known to within additive error, then one can perform the mapping where, with probability at least , . The time required to perform this mapping is .
Thus, if one can efficiently create quantum states and estimate the norms , then the corresponding can be approximated efficiently. In this section we show that this is possible with a quantum random access memory (qRAM), which is a device that allows classical data to be queried efficiently in superposition. That is, if is stored in qRAM, then a query to the qRAM implements the unitary . If the elements of arrive as a stream of entries in some arbitrary order, then can be stored in a particular data structure [33] in time and, once stored, can be created in time polylogarithmic in . Note that when we refer to real-valued data being stored in qRAM, it is implied that the information is stored as a binary representation of the data, so that it may be loaded into a qubit register.
Theorem 4.
Let . If, for all , are stored in qRAM, and if and are known then, with probability at least , an estimate satisfying
can be computed in time
| (1) |
where .
A similar result applies to estimating inner products of the form .
Theorem 5.
Let and . If are known for all and if and are stored in qRAM for all then, with probability at least , can be estimated to within error in time
4 Linear Time Algorithm for Nonlinear SVMs
The results of the previous section can be used to generalize Joachims’ algorithm to quantum feature-mapped data. Let denote the cone of positive semi-definite matrices. Given , let , i.e. the projection of onto , where is the Frobenius norm. Denote the -th row of by .
Define to be a quantum subroutine which, with probability at least , returns an estimate of the inner product of two vectors satisfying . As we have seen, with appropriate data stored in qRAM, this subroutine can be implemented efficiently on a quantum computer.
Our quantum algorithm for nonlinear structural SVMs is presented in Algorithm 2. At first sight, it appears significantly more complicated than Algorithm 1, but this is due in part to more detailed notation used to aid the analysis later. The key differences are (i) the matrix elements are only estimated to precision by the quantum subroutine; (ii) as the corresponding matrix is not guaranteed to be positive semi-definite, an additional classical projection step must therefore be carried out to map the estimated matrix on to the p.s.d. cone at each iteration; (iii) In the classical algorithm, the values of are deduced by whereas here we can only estimate the inner products to precision , and is known only implicitly according to . Note that apart from the quantum inner product estimation subroutines, all other computations are performed classically.
Theorem 6.
Proof.
See Appendix B. ∎
Theorem 7.
Algorithm 2 has a time complexity of
| (2) |
where , and is the iteration at which the algorithm terminates.
The total number of outer-loop iterations (indexed by ) of Algorithm 2 is upper-bounded by the choice of . One may wonder why we do not simply set as this would ensure that, with high probability, the algorithm outputs a nearly optimal solution. The reason is that also affects the the quantities , and . These in turn impact the running time of the two quantum inner product estimation subroutines that take place in each iteration, e.g. the first quantum inner product estimation subroutine has running time that scales like . While the upper-bound on of is independent of , it can be large for reasonable values of the other algorithm parameters , , and . For instance, the choice of which, as we show in the Simulation section, lead to good classification performance on the datasets we consider, corresponds to , and . In practice, we find that this upper-bound on is very loose, and the situation is far better in practice: the algorithm can terminate successfully in very few iterations with much smaller values of . In the examples we consider, the algorithm terminates successfully before reaches , corresponding to .
The running time of Algorithm 2 also depends on the quantity which is a function of both the dataset as well as the quantum feature map chosen. While this can make hard to predict, we will again see in the Simulation section that in practice the situation is optimistic: we empirically find that is neither too small, nor does it scale noticeably with or the dimension of the quantum feature map.
4.1 Classification of new test points
As is standard in SVM theory, the solution from Algorithm 2 can be used to classify a new data point according to
where is the predicted label of . From Theorem 5, and noting that , we obtain the following result:
Theorem 8.
Let be the output of Algorithm 2, and let be stored in qRAM. There is a quantum algorithm that, with probability at least , estimates the inner product to within error in time
Taking the sign of the output then completes the classification.
5 Simulation
While the true performance of our algorithms for large and high dimensional quantum feature maps necessitate a fault-tolerant quantum computer to evaluate, we can gain some insight into how it behaves by performing smaller scale numerical experiments on a classical computer. In this section we empirically find that the algorithm can have good performance in practice, both in terms of classification accuracy as well as in terms of the parameters which impact running time.
5.1 Data set
To test our algorithm we need to choose both a data set as well as a quantum feature map. The general question of what constitutes a good quantum feature map, especially for classifying classical data sets, is an open problem and beyond the scope of this investigation. However, if the data is generated from a quantum problem, then physical intuition may guide our choice of feature map. We therefore consider the following toy example which is nonetheless instructive. Let be the Hamiltonian of a generalized Ising Hamiltonian on spins
| (3) |
where are vectors of real parameters to be chosen, and are Pauli and operators acting on the -th qubit in the chain, respectively. We generate a data set by randomly selecting points and labelling them according to whether the expectation value of the operator with respect to the ground state of satisfies
| (4) |
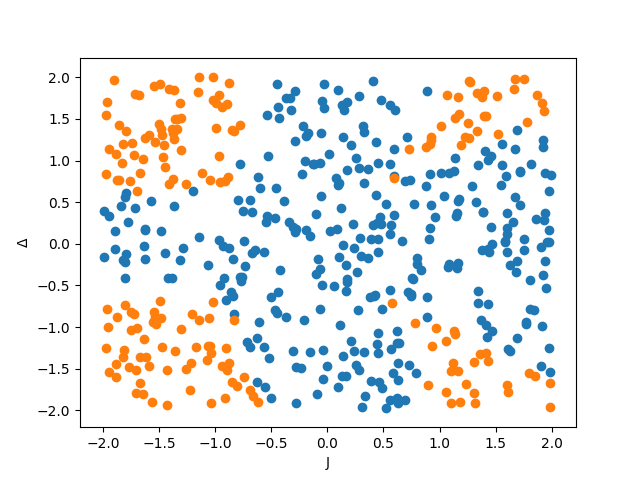
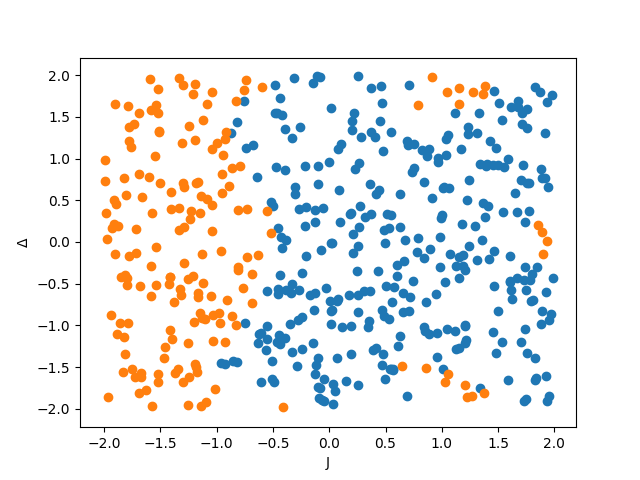
for some cut-off value , i.e. the points are labelled depending on whether the average total magnetism squared is above or below . In our simulations we consider a special case of (3) where , and , where are real. Examples of data sets corresponding to such a Hamiltonian, whose parameters we notate by
can be found in Fig 1.
5.2 Quantum feature map
For quantum feature map we choose
| (5) |
where is the ground state of (3) and, as it is a normalized state, has corresponding value of . We compute such feature maps classically by explicitly diagonalizing . In a real implementation of our algorithm on a quantum computer, such a feature map would be implemented by a controlled unitary for generating the (approximate) ground state of , which could be done by a variety of methods e.g. by digitized adiabatic evolution or methods based on imaginary time evolution [34, 35], with running time dependent on the degree of accuracy required. The choice of (5) is motivated by noting that condition (4) is equivalent to determining the sign of , where is a vector which depends only on , and not on the choice of parameters in (see Appendix E). By construction, defines a separating hyperplane for the data, so the chosen quantum feature map separate the data in feature space. As the Hamiltonian is real, it has a set of real eigenvectors and hence can be defined to have real amplitudes, as required.
5.3 Numerical results
We first evaluate the performance of our algorithm on data sets for and increasing orders of from to .
-
•
For each value of , a data set was generated for points sampled uniformly at random in the range .
-
•
The values of were fixed and chosen to give roughly balanced data, i.e. the ratio of to labels is no more than 70:30 in favor of either label.
-
•
Each set of data points was divided into training and test sets in the ratio 70:30, and training was performed according to Algorithm 2 with parameters .
-
•
These values of and were selected to give classification accuracy competitive with classical SVM algorithms utilizing standard Gaussian radial basis function (RBF) kernels, with hyperparameters trained using a subset of the training set of size used for hold-out validation. Note that the quantum feature maps do not have any similar tunable parameters, and a modification of (5), for instance to include a tunable weighting between the two parts of the superposition, could be introduced to further improve performance.
-
•
The quantum inner product estimations in the algorithm were approximated by adding Gaussian random noise to the true inner product, such that the resulting inner product was within of the true value with probability at least . Classically simulating quantum inner product estimation with inner products distributed according to the actual quantum procedures underlying Theorems 4 and 5 was too computationally intensive in general to perform. However, these were tested on small data sets and quantum feature vectors, and found to behave very similarly to adding Gaussian random noise. This is consistent with the results of the numerical simulations in [32].
Note that the values of chosen correspond to . This is an upper-bound on the number of iterations needed for the algorithm to converge to a good solution. However, we find empirically that is sufficient for the algorithm to terminate with a good solution across the range of we consider.
The results are shown in Table 1. We find that (i) with these choices of our algorithm has high classification accuracy, competitive with standard classical SVM algorithms utilizing RBF kernels with optimized hyperparameters. (ii) is of the order in these cases, and does scale noticeably over the range of from to . If were to decrease polynomially (or worse, exponentially) in then this would be a severe limitation of our algorithm. Fortunately this does not appear to be the case.
| 0.010 | 0.018 | 0.016 | 0.011 | |
| iterations | 36 | 38 | 39 | 38 |
| accuracy | 93.3 | 99.3 | 99.0 | 98.9 |
| RBF accuracy | 86.7 | 96.0 | 99.0 | 99.7 |
We further investigate the behaviour of by generating data sets for fixed and ranging from to . For each , we generate random data sets , where each data set consists of points sampled uniformly at random in the range , and random values of chosen to give roughly balanced data sets as before. Unlike before, we do not divide the data into training and test sets. Instead, we perform training on the entire data set, and record the value of in each instance. The results are given in Table 2 and show that across this range of (i) the average value is of order (ii) the spread around this average is fairly tight, and the minimum value of in any single instance is of order . These support the results of the first experiment, and indicate that the value of may not adversely affect the running time of the algorithm in practice.
| 5 | 7 | ||||
|---|---|---|---|---|---|
| 1.28 | 1.34 | 1.32 | 1.44 | 1.16 | |
| 3.41 | 2.33 | 3.16 | 3.82 | 3.96 | |
| s.d. () | 8.6 | 20.4 | 16.2 | 19.6 | 6.4 |
6 Conclusions
We have proposed a quantum extension of SVM-perf for training nonlinear soft-margin -SVMs in time linear in the number of training examples , up to polylogarithmic factors, and given numerical evidence that the algorithm can perform well in practice as well as in theory. This goes beyond classical SVM-perf, which achieves linear scaling only for linear SVMs or for feature maps corresponding to low-rank or shift-invariant kernels, and brings the theoretical running time and applicability of SVM-perf in line with the classical Pegasos algorithm which — in spite of having best-in-class asymptotic guarantees — has empirically been outperformed by other methods on certain datasets. Our algorithm also goes beyond previous quantum algorithms which achieve linear or better scaling in for other variants of SVMs, which lack some of the desirable properties of the soft-margin -SVM model. Following this work, it is straightforward to propose a quantum extension of Pegasos. An interesting question to consider is how such an algorithm would perform against the quantum SVM-perf algorithm we have presented here.
Another important direction for future research is to investigate methods for selecting good quantum feature maps and associated values of for a given problem. While work has been done on learning quantum feature maps by training parameterizable quantum circuits [36, 37, 19, 38], a deeper understanding of quantum feature map construction and optimization is needed. In particular, the question of when an explicit quantum feature map can be advantageous compared to the classical kernel trick – as implemented in Pegasos or other state-of-the-art algorithms – needs further investigation. Furthermore, in classical SVM training, typically one of a number of flexible, general purpose kernels such as the Gaussian RBF kernel can be employed in a wide variety of settings. Whether similar, general purpose quantum feature maps can be useful in practice is an open problem, and one that could potentially greatly affect the adoption of quantum algorithms as a useful tool for machine learning.
7 Acknowledgements
We are grateful to Shengyu Zhang for many helpful discussions and feedback on the manuscript.
References
- Joachims [2006] Thorsten Joachims. Training linear SVMs in linear time. In Proceedings of the 12th ACM SIGKDD international conference on Knowledge discovery and data mining, pages 217–226. ACM, 2006. doi: 10.1145/1150402.1150429.
- Boser et al. [1992] Bernhard E Boser, Isabelle M Guyon, and Vladimir N Vapnik. A training algorithm for optimal margin classifiers. In Proceedings of the fifth annual workshop on Computational learning theory, pages 144–152. ACM, 1992. doi: 10.1145/130385.130401.
- Cortes and Vapnik [1995] Corinna Cortes and Vladimir Vapnik. Support-vector networks. Machine Learning, 20(3):273–297, 1995. doi: 10.1023/A:1022627411411.
- Burges [1998] Christopher JC Burges. A tutorial on support vector machines for pattern recognition. Data mining and knowledge discovery, 2(2):121–167, 1998. doi: 10.1023/A:1009715923555.
- Ferris and Munson [2002] Michael C Ferris and Todd S Munson. Interior-point methods for massive support vector machines. SIAM Journal on Optimization, 13(3):783–804, 2002. doi: 10.1137/S1052623400374379.
- Mangasarian and Musicant [2001] Olvi L Mangasarian and David R Musicant. Lagrangian support vector machines. Journal of Machine Learning Research, 1(Mar):161–177, 2001. doi: 10.1162/15324430152748218.
- Keerthi and DeCoste [2005] S Sathiya Keerthi and Dennis DeCoste. A modified finite Newton method for fast solution of large scale linear SVMs. Journal of Machine Learning Research, 6(Mar):341–361, 2005.
- Shalev-Shwartz et al. [2011] Shai Shalev-Shwartz, Yoram Singer, Nathan Srebro, and Andrew Cotter. Pegasos: Primal Estimated sub-GrAdient SOlver for SVM. Mathematical programming, 127(1):3–30, 2011. doi: 10.1145/1273496.1273598.
- Scholkopf and Smola [2001] Bernhard Scholkopf and Alexander J Smola. Learning with kernels: support vector machines, regularization, optimization, and beyond. MIT press, 2001.
- Williams and Seeger [2001] Christopher KI Williams and Matthias Seeger. Using the Nyström method to speed up kernel machines. In Advances in Neural Information Processing Systems, pages 682–688, 2001.
- Fine and Scheinberg [2001] Shai Fine and Katya Scheinberg. Efficient SVM training using low-rank kernel representations. Journal of Machine Learning Research, 2(Dec):243–264, 2001.
- Rahimi and Recht [2008] Ali Rahimi and Benjamin Recht. Random features for large-scale kernel machines. In Advances in Neural Information Processing Systems, pages 1177–1184, 2008.
- Joachims [1999] Thorsten Joachims. Making large-scale SVM learning practical. In Advances in Kernel Methods-Support Vector Learning. MIT-press, 1999.
- Platt [1999] John C Platt. Fast training of support vector machines using sequential minimal optimization. MIT press, 1999.
- Chang and Lin [2011] Chih-Chung Chang and Chih-Jen Lin. LIBSVM: A library for support vector machines. ACM Transactions on Intelligent Systems and Technology, 2(3):27, 2011. doi: 10.1145/1961189.1961199.
- Collobert and Bengio [2001] Ronan Collobert and Samy Bengio. SVMTorch: Support vector machines for large-scale regression problems. Journal of Machine Learning Research, 1(Feb):143–160, 2001. doi: 10.1162/15324430152733142.
- Joachims and Yu [2009] Thorsten Joachims and Chun-Nam John Yu. Sparse kernel SVMs via cutting-plane training. Machine Learning, 76(2-3):179–193, 2009. doi: 10.1007/s10994-009-5126-6.
- Rebentrost et al. [2014] Patrick Rebentrost, Masoud Mohseni, and Seth Lloyd. Quantum support vector machine for big data classification. Physical Review Letters, 113(13):130503, 2014. doi: 10.1103/PhysRevLett.113.130503.
- Havlíček et al. [2019] Vojtěch Havlíček, Antonio D Córcoles, Kristan Temme, Aram W Harrow, Abhinav Kandala, Jerry M Chow, and Jay M Gambetta. Supervised learning with quantum-enhanced feature spaces. Nature, 567(7747):209–212, 2019. doi: 10.1038/s41586-019-0980-2.
- Schuld and Killoran [2019] Maria Schuld and Nathan Killoran. Quantum machine learning in feature hilbert spaces. Physical Review Letters, 122(4):040504, 2019. doi: 10.1103/PhysRevLett.122.040504.
- Kerenidis et al. [2019] Iordanis Kerenidis, Anupam Prakash, and Dániel Szilágyi. Quantum algorithms for second-order cone programming and support vector machines. arXiv preprint arXiv:1908.06720, 2019.
- Arodz and Saeedi [2019] Tomasz Arodz and Seyran Saeedi. Quantum sparse support vector machines. arXiv preprint arXiv:1902.01879, 2019.
- Li et al. [2019] Tongyang Li, Shouvanik Chakrabarti, and Xiaodi Wu. Sublinear quantum algorithms for training linear and kernel-based classifiers. In Proceedings of the 36th International Conference on Machine Learning. PMLR, 2019.
- Giovannetti et al. [2008] Vittorio Giovannetti, Seth Lloyd, and Lorenzo Maccone. Quantum random access memory. Physical Review Letters, 100(16):160501, 2008. doi: 10.1103/PhysRevLett.100.160501.
- Prakash [2014] Anupam Prakash. Quantum algorithms for linear algebra and machine learning. PhD thesis, UC Berkeley, 2014.
- Tang [2019] Ewin Tang. A quantum-inspired classical algorithm for recommendation systems. In Proceedings of the 51st Annual ACM SIGACT Symposium on Theory of Computing, pages 217–228, 2019. doi: 10.1145/3313276.3316310.
- Tang [2018] Ewin Tang. Quantum-inspired classical algorithms for principal component analysis and supervised clustering. arXiv preprint arXiv:1811.00414, 2018.
- Gilyén et al. [2018] András Gilyén, Seth Lloyd, and Ewin Tang. Quantum-inspired low-rank stochastic regression with logarithmic dependence on the dimension. arXiv preprint arXiv:1811.04909, 2018.
- Arrazola et al. [2020] Juan Miguel Arrazola, Alain Delgado, Bhaskar Roy Bardhan, and Seth Lloyd. Quantum-inspired algorithms in practice. Quantum, 4:307, 2020. doi: 10.22331/q-2020-08-13-307.
- Boyd and Vandenberghe [2004] Stephen Boyd and Lieven Vandenberghe. Convex optimization. Cambridge university press, 2004. doi: 10.1017/CBO9780511804441.
- Tsochantaridis et al. [2005] Ioannis Tsochantaridis, Thorsten Joachims, Thomas Hofmann, and Yasemin Altun. Large margin methods for structured and interdependent output variables. Journal of Machine Learning Research, 6(Sep):1453–1484, 2005.
- Allcock et al. [2020] Jonathan Allcock, Chang-Yu Hsieh, Iordanis Kerenidis, and Shengyu Zhang. Quantum algorithms for feedforward neural networks. ACM Transactions on Quantum Computing, 1(1), 2020. doi: 10.1145/3411466.
- Kerenidis and Prakash [2017] Iordanis Kerenidis and Anupam Prakash. Quantum recommendation systems. In 8th Innovations in Theoretical Computer Science Conference (ITCS 2017). Schloss Dagstuhl-Leibniz-Zentrum fuer Informatik, 2017. doi: 10.4230/LIPIcs.ITCS.2017.49.
- Motta et al. [2020] Mario Motta, Chong Sun, Adrian TK Tan, Matthew J O’Rourke, Erika Ye, Austin J Minnich, Fernando GSL Brandão, and Garnet Kin-Lic Chan. Determining eigenstates and thermal states on a quantum computer using quantum imaginary time evolution. Nature Physics, 16(2):205–210, 2020. doi: 10.1038/s41567-019-0704-4.
- Hsieh et al. [2019] Chang-Yu Hsieh, Qiming Sun, Shengyu Zhang, and Chee Kong Lee. Unitary-coupled restricted boltzmann machine ansatz for quantum simulations. arxiv prepring quant-ph/1912.02988, 2019.
- Romero et al. [2017] Jonathan Romero, Jonathan P Olson, and Alan Aspuru-Guzik. Quantum autoencoders for efficient compression of quantum data. Quantum Science and Technology, 2(4):045001, 2017. doi: 10.1088/2058-9565/aa8072.
- Farhi and Neven [2018] Edward Farhi and Hartmut Neven. Classification with quantum neural networks on near term processors. arXiv preprint arXiv:1802.06002, 2018.
- Lloyd et al. [2020] Seth Lloyd, Maria Schuld, Aroosa Ijaz, Josh Isaac, and Nathan Killoran. Quantum embeddings for machine learning. arXiv preprint arXiv:2001.03622, 2020.
- Brassard et al. [2002] Gilles Brassard, Peter Hoyer, Michele Mosca, and Alain Tapp. Quantum amplitude amplification and estimation. Contemporary Mathematics, 305:53–74, 2002.
Appendix A Proofs of Theorem 4 and Theorem 5
Lemma 1.
If and for are stored in qRAM, and if is known, then can be created in time , and estimated to additive error in time
Proof.
With the above values in qRAM, unitary operators and can be implemented in times and , which effect the transformations
can then be created by the following procedure:
Discarding the register, and applying the Hadamard transformation to the first register then gives
| (6) |
where is an unnormalized quantum state where the first qubit is orthogonal to . The state can therefore be created in time .
By quantum amplitude amplification and amplitude estimation [39], given access to a unitary operator acting on qubits such that (where is arbitrary), can be estimated to additive error in time and can be generated in expected time ,where is the time required to implement . Amplitude amplification applied to the unitary creating the state in (6) allows one to create in expected time , since . Similarly, amplitude estimation can be used to obtain a value satisfying in time . Outputting then satisfies .
∎
See 4
Proof.
See 5
Proof.
With the above data in qRAM, an almost identical analysis to that in Theorem 4 can be applied to deduce that, for any , with probability at least , an estimate satisfying
can be computed in time
and the total time required to estimate all terms (i.e. for all ) is thus . The probability that every term is obtained to accuracy is therefore . In this case, the weighted sum can be computed classically, and satisfies
and similarly . ∎
Appendix B Proof of Theorem 6
The analysis of Algorithm 2 is based on [13, 31], with additional steps and complexity required to bound the errors due to inner product estimation and projection onto the p.s.d. cone.
See 6
Lemma 2.
When Algorithm 2 terminates successfully after at most iterations, the probability that all inner products are estimated to within their required tolerances throughout the duration of the algorithm is at least .
Proof.
Each iteration of the Algorithm involves
-
•
inner product estimations , for all pairs . The probability of successfully computing all inner products to within error is at least .
-
•
inner product estimations , for . The probability of all estimates lying within error is at least .
Since the algorithm terminates successfully after at most iterations, the probability that all the inner products are estimated to within their required tolerances is
where the right hand side follows from Bernoulli’s inequality.
∎
By Lemma 2 we can analyze Algorithm 2, assuming that all the quantum inner product estimations succeed, i.e. each call to produces an estimate of within error . In what follows, let be the matrix with elements for , let .
Lemma 3.
, where is the spectral norm.
Proof.
The relation between the spectral and Frobenius norms is elementary. We thus prove the upper-bound on the Frobenius norm. By assumption, all matrix elements satisfy . Thus,
where the second equality follows from the definition of in Algorithm 2, the first inequality because projecting onto the p.s.d cone cannot increase its Frobenius norm distance to a p.s.d matrix , and the third inequality because the size of the index set increases by at most one per iteration. ∎
To proceed, let us introduce some additional notation. Given index set , define
and let and be the maximum values of and respectively, subject to the constraints . Since above is positive semi-definite, its matrix elements can expressed as
| (7) |
for some set of vectors .
The next lemma shows that the solution obtained at each step is only slightly suboptimal as a solution for the restricted problem .
Lemma 4.
.
Proof.
We now show that and can be used to define a feasible solution for OP3 where the constraints are restricted to only hold over the index set .
Lemma 5.
Define . It holds that for all .
Proof.
First note that
| (10) |
where the second inequality is due to , the third is because , the fourth follows from Lemma 3.
The next lemma shows that at each step which does not terminate the algorithm, the solution violates the constraint indexed by in OP 3 by at least .
Lemma 6.
where .
Proof.
Next we show that each iteration of the algorithm increases the working set such that the optimal solution of the restricted problem increases by a certain amount. Note that we do not explicitly compute , as it will be sufficient to know that its value increases each iteration.
Lemma 7.
While ,
Proof.
Given at iteration , define by
For any , the vector is entrywise non-negative by construction, and satisfies
is therefore a feasible solution of OP 4. Furthermore, by considering the Taylor expansion of the OP 4 objective function it is straightforward to show that
| (11) |
for any satisfying (See Appendix D). We now show that this condition holds for the defined above. The gradient of satisfies
and since it follows that
| (12) |
Also:
∎
Corollary 1.
If , Algorithm 2 terminates after at most iterations.
Proof.
Lemma 7 shows that the optimal dual objective value increases by at least each iteration. For , this increase is at least . is upperbounded by , the optimal value of OP 4 which, by Lagrange duality, is equal to the optimum value of the primal problem OP 3, which is itself upper bounded by (corresponding to feasible solution . Thus, the algorithm must terminate after at most iterations. ∎
Lemma 8.
Proof.
By construction . The termination condition implies that
therefore satisfy all the constraints of OP 3. ∎
We are now in a position to prove Theorem 6.
See 6
Proof.
The guarantee of termination with iterations for is given by Corollary 1, and the feasibility of is given by Lemma 8.
Let the algorithm terminate at iteration . Then, and, by strong duality, is optimal for the corresponding primal problem
OP 5.
| s.t. |
for defined by (7), i.e.
Separately, note that
| (14) |
Denote by the vector in given by
Then,
The first inequality follows from the fact that is feasible for OP 4. The second inequality is due to (14). The third comes from the definition and observing that , and the fourth inequality follows from Lemma 3.
∎
Appendix C Proof of Theorem 7
See 7
Proof.
The initial storing of data to qRAM take time . Thereafter, each iteration involves
-
•
inner product estimations , for all pairs . By Theorem 4, each requires time . By design and . The running time to compute all inner products is therefore .
-
•
The classical projection of a matrix onto the p.s.d cone, and a classical optimization subroutine to find . These take time and respectively, independent of .
-
•
Storing the for and the for in qRAM, and computing classically. These take time , and respectively.
-
•
inner product estimations , for . By Theorem 5, each of these can be estimated to accuracy with probability at least in time . As , it follows that all inner products can be estimated in time .
The total time per iteration is therefore
and since the algorithm terminates after at most steps, the result follows.
∎
Appendix D Proof of Equation 11
Let where is positive semi-definite. Here we show that
for any satisfying . The change in under a displacement for some satisfies
which is maximized when
If then . If then, as is concave, the best one can do is choose , which gives
where the last line follows from .
Appendix E Choice of quantum feature map
Let be the Pauli operator acting on qubit in an qubit system. Define and let be expressed in the computational basis. Define the vectorized form of to be . Define the states
where , is any qubit state, and is the all zero state on qubits. It holds that
Thus