suppSupplementary Material References
A Regression Framework for Studying Relationships among Attributes under Network Interference
Abstract
To understand how the interconnected and interdependent world of the twenty-first century operates and make model-based predictions, joint probability models for networks and interdependent outcomes are needed. We propose a comprehensive regression framework for networks and interdependent outcomes with multiple advantages, including interpretability, scalability, and provable theoretical guarantees. The regression framework can be used for studying relationships among attributes of connected units and captures complex dependencies among connections and attributes, while retaining the virtues of linear regression, logistic regression, and other regression models by being interpretable and widely applicable. On the computational side, we show that the regression framework is amenable to scalable statistical computing based on convex optimization of pseudo-likelihoods using minorization-maximization methods. On the theoretical side, we establish convergence rates for pseudo-likelihood estimators based on a single observation of dependent connections and attributes. We demonstrate the regression framework using simulations and an application to hate speech on the social media platform X.
Keywords: Dependent Data, Generalized Linear Models, Minorization-Maximization, Pseudo-Likelihood
1 Introduction
In the interconnected and interdependent world of the twenty-first century, individual and collective outcomes—such as personal and public health, economic welfare, or war and peace—are affected by relationships among individual, corporate, state, and non-state actors. To understand how the world of the twenty-first century operates and make model-based predictions, it is vital to study networks of relationships and gain insight into how the structure of networks affects individual and collective outcomes.
While the structure of networks has been widely studied (see Kolaczyk, 2017, and references therein), the structure of networks is rarely of primary interest. Instead, we often wish to understand how networks affect individual or collective outcomes. For example, social, economic, and financial relationships among individual and corporate actors can affect the welfare of people, but the outcome of primary interest is the welfare of billions of people around the world. Relationships among state and non-state actors can affect war and peace, but the outcome of primary interest is the welfare of nations. Contact networks mediate the spread of infectious diseases, but the outcome of primary interest is public health. A final example is causal inference under network interference: If the outcomes of units are affected by the treatments or outcomes of other units, the spillover effect of treatments on outcomes can be represented by an intervention network, but the target of statistical inference is the direct and indirect causal effects of treatments on outcomes.
To learn how networks are wired and how the structure of networks affects outcomes of interest, data on outcomes and connections among units are needed along with predictors . Statistical work on joint probability models for dependent outcomes and connections is scarce. Snijders et al. (2007) and Niezink and Snijders (2017) develop models for behavioral outcomes and connections using continuous-time Markov processes, assuming that the behavioral outcomes and connections are observed at two or more time points. Wang et al. (2024) combine Ising models for binary outcomes with exponential family models for binary connections, with applications to causal inference (Clark and Handcock, 2024). In a Bayesian framework, Fosdick and Hoff (2015) unite models for continuous outcomes with latent variable models that capture dependencies among connections. A common feature of these approaches is that the models and methods in these works may be useful in small populations with, say, hundreds of members, but may be less useful in large populations with, say, thousands or millions of members. For example, many of these models make dependence assumptions that are reasonable in small populations but are less reasonable in large populations. In the special case of exponential-family models, it is known that models that make unreasonable dependence assumptions can give rise to undesirable probabilistic and statistical behavior in large populations, such as model near-degeneracy (Handcock, 2003; Schweinberger, 2011; Chatterjee and Diaconis, 2013). In addition, these works rely on Monte Carlo and Markov chain Monte Carlo methods for moment- and likelihood-based inference, which limits the scalability of the mentioned approaches. Last, but not least, the theoretical properties of statistical procedures based on dependent outcomes and connections , such as the convergence rates of estimators, are unknown.
While statistical work on joint probability models for is scarce, recent progress has been made on conditional models for outcomes and connections . For example, the literature on network-aware regression uses conditional models for outcomes : Lei et al. (2024) assume that the dependence among outcomes decays as a function of distance in the population network, while Li et al. (2019) and Le and Li (2022) encourage outcomes of connected units to be similar. A related branch of literature, concerned with causal inference under network interference, leverages conditional models for outcomes given treatment assignments and connections . Some of them consider fixed connections (e.g., Tchetgen Tchetgen et al., 2021; Ogburn et al., 2024), while others combine conditional models for with marginal models for , assuming that connections are independent (Li and Wager, 2022). Other works advance autoregressive network models for (Huang et al., 2019, 2020; Zhu et al., 2020). Conditional models for connections include stochastic block and exponential-family models with covariates (e.g., Handcock, 2003; Huang et al., 2024; Wang et al., 2024; Stein et al., 2025).
All of the cited work is limited to special cases, such as real-valued outcomes or binary connections, rather than presenting a comprehensive regression framework for studying relationships among attributes under network interference . To fill the void left by existing work, we propose a comprehensive regression framework for studying relationships among attributes under network interference based on joint probability models for . The proposed regression framework has important advantages over existing work, including interpretability, scalability, and provable theoretical guarantees:
-
1.
We show in Sections 2.1 and 2.2 that the proposed regression framework can be viewed as a generalization of linear regression, logistic regression, and other regression models for studying relationships among attributes under network interference, adding a simple and widely applicable set of tools to the toolbox of data scientists. We demonstrate the advantages of the regression framework with an application to hate speech on the social media platform X in Section 6.
-
2.
The proposed regression framework can be applied to small and large populations by leveraging additional structure to control the dependence among outcomes and connections, facilitating the construction of models with complex dependencies among outcomes and connections in small and large populations.
-
3.
We develop scalable methods using minorization-maximization algorithms for convex optimization of pseudo-likelihoods in Section 3. To disseminate the regression framework and its scalable methods, we provide an R package.
-
4.
We establish theoretical guarantees for pseudo-likelihood estimators in Section 4. To the best of our knowledge, these are the first theoretical guarantees for joint probability models of based on a single observation of . The simulation results in Section 5 demonstrate that pseudo-likelihood estimators perform well as the number of units and the number of parameters increases.
In addition, the regression framework has conceptual and statistical advantages:
-
5.
Compared with conditional models for outcomes and connections , the proposed regression framework for provides insight into outcome-connection dependencies, in addition to outcome-outcome and connection-connection dependencies.
-
6.
Compared with conditional models for outcomes , conclusions based on the proposed regression framework are not limited to a specific population network , but can be extended to the superpopulation of all possible population networks. In addition, the proposed regression framework provides insight into the probability law governing the superpopulation of all possible population networks.
-
7.
The proposed regression framework retains the advantages of two general approaches to building joint probability models for dependent data, elucidated in the celebrated paper by Besag (1974): Specifying a joint probability distribution directly guarantees desirable mathematical properties, while specifying it indirectly via conditional probability distributions helps build complex models from simple building blocks. We show how to directly specify a joint probability model from simple building blocks. The resulting regression framework possesses desirable mathematical properties and induces conditional distributions that can be represented by regression models, facilitating interpretation. We showcase these advantages in Sections 2.2 and 6.2.
We elaborate the proposed regression framework in the remainder of the article.
2 Regression under Network Interference
Consider a population of units , where each unit possesses
-
•
one or more binary, count-, or real-valued predictors , which may include covariates and treatment assignments;
-
•
binary, count-, or real-valued outcomes or responses ;
-
•
binary, count-, or real-valued connections to other units , which represent indicators of connections or weights of connections (e.g., the number of interactions between and ).
We first consider undirected connections, for which equals , and describe extensions to directed connections in Section 6. We write , , , , , and , and refer to without and without as and , respectively. In line with Generalized Linear Models (GLMs), we introduce a known scale parameter and define and . Throughout, is an indicator function, which is if its argument is true and is otherwise. We write and to indicate that remains bounded and , respectively.
Following the bulk of the literature on regression models, we condition on predictors . To construct joint probability models for dependent responses and connections , we introduce a family of probability measures dominated by a -finite measure , with densities of the form
| (1) |
-
•
and are known functions of responses of units and connections of pairs of units ;
-
•
are known functions describing the relationship of predictors and responses of units , which can depend on ;
-
•
are known functions specifying how the responses and connections of pairs of units depend on the predictors, responses, and connections to other units, which can depend on ;
-
•
is a parameter vector of dimension , where and ensures that , with the dependence of on suppressed;
-
•
is a -finite product measure of the form
where and are -finite measures that depend on the support sets of responses and connections (e.g., Lebesgue or counting measure).
Remark: Importance of Additional Structure. To respect real-world constraints and facilitate theoretical guarantees, joint probability models for dependent responses and connections should leverage additional structure, e.g., local dependence structure. For one thing, units in large populations may not be aware of most other units in the population, so it is not credible that the responses and connections of units depend on the responses and connections of all other units in the population. In addition, models permitting strong dependence among the responses and connections of all units in the population may suffer from model near-degeneracy (Handcock, 2003; Schweinberger, 2011; Chatterjee and Diaconis, 2013). By contrast, Stewart and Schweinberger (2025) demonstrate that leveraging additional structure to control dependence can lead to theoretical guarantees. Motivated by these considerations, we assume that each unit has a known set of neighbors , which includes and is independent of connections , and that the dependence among responses and connections is local in the sense that it is limited to overlapping neighborhoods. We provide examples of joint probability models for with local dependence in Sections 2.2 and 6.1.
Remark: Fixed versus Random Design. In line with the bulk of the literature on regression models, we consider a fixed design: We view predictors and neighborhoods as exogenous and known, and we do not make assumptions about the mechanism generating them. Thus, Equation (1) specifies the joint probability density function of responses and connections conditional on predictors and neighborhoods . If and were random, the conditional model for could be combined with marginal models for and . In the social media application in Section 6, the neighborhoods are fixed and known: The neighborhoods of users are the sets of followees, because users choose whom to follow and hence who can influence them, and these choices are observed. If the neighborhoods were unobserved, one could view them as unobserved constants (if neighborhoods were fixed) or unobserved variables (if neighborhoods were random) and learn them from attributes or connections . The problem of how to learn neighborhoods is an open problem and constitutes a promising avenue for future research.
2.1 GLM Representations
The proposed joint probability models of can be viewed as generalizations of Generalized Linear Models (GLMs) (Efron, 2022). GLMs form a well-known, interpretable, and widely applicable statistical framework for univariate responses given predictors (), including logistic regression (), Poisson regression (), and linear regression (). GLMs are characterized by two properties:
-
1.
Conditional mean: The conditional mean of response , conditional on predictors with weights , is a (possibly nonlinear) function of a linear predictor .
-
2.
Conditional distribution: The conditional distribution of response is an exponential family distribution with a known scale parameter , which admits a density with respect to a -finite measure of the form
with cumulant-generating function
The conditional mean can be obtained by differentiating : (Corollary 2.3, Brown, 1986, pp. 35–36).
The relationship to GLMs facilitates the interpretation and dissemination of results. The following proposition clarifies the relationship to GLMs.
Proposition 1: GLM Representation of Conditionals. Consider any pair of units () and assume that and are affine functions of for any given , in the sense that there exist known functions , , , and such that
Then the conditional distribution of response by unit can be represented by a GLM with linear predictor
and cumulant-generating function
To ease the notation, we henceforth write instead of .
Proposition 2.1 supplies a recipe for representing the conditional distribution of responses by a GLM:
-
1.
Conditional distribution: The conditional distribution of response is an exponential family distribution, which can be represented by a GLM with conditional mean , linear predictor , and scale parameter .
-
2.
Conditional mean: The conditional mean can be obtained by differentiating : . Since the map is one-to-one and invertible (Theorem 3.6, Brown, 1986, p. 74), can be obtained by inverting .
Thus, the proposed regression framework for dependent responses and connections inherits the GLM advantages of being interpretable and widely applicable, without assuming that responses or connections are independent. As a result, the proposed regression framework can be viewed as a generalization of GLMs.
2.2 Example: Model Specification
We showcase how a joint probability model for dependent responses and connections with local dependence can be constructed, leveraging additional structure in the form of overlapping neighborhoods to control the dependence among responses and connections in small and large populations.
We focus on units with binary, count-, or real-valued predictors and responses and binary connections . Starting with , we capture the main effect of and the interaction effect of and by specifying as follows:
| (2) |
Turning to , we define neighborhood-related terms
| (3) |
To capture unobserved heterogeneity in the propensities of units to form connections, we introduce the -vector . In addition, we penalize connections among units and with non-overlapping neighborhoods and capture transitive closure along with treatment and outcome spillover by specifying as follows:
| (4) |
where denotes the -vector whose whose th and th coordinates are and whose other coordinates are all . The parameters can be interpreted as the propensities of units to form connections; discourages connections among units with non-overlapping neighborhoods; quantifies the tendency towards transitive closure among connections; and and capture treatment and outcome spillover, respectively. Sections 2.2.1 and 2.2.2 demonstrate that the interpretation of these effects is facilitated by the fact that the conditional distributions of and can be represented by GLMs.
2.2.1 GLM Representation of Responses
To interpret the model specified by Equations (2) and (4), we take advantage of the fact that the conditional distribution of response by unit can be represented by a GLM with linear predictor
| (5) |
Figure 1 depicts the predictors, responses, and connections that affect the conditional distribution of response . We provide three specific examples, depending on the support set of response .

Example 1: Real-valued Responses . Let and
-
1.
Conditional distribution: The conditional distribution of response is .
-
2.
Conditional mean: The conditional mean can be obtained by differentiating with respect to , giving :
Under certain restrictions on , the conditional distribution of is -variate Gaussian. The restrictions on depend on the neighborhoods and and connections of pairs of units ; see Proposition A in Section A of the Supplementary Materials.
Example 2: Count-valued Responses . Let and
-
1.
Conditional distribution: The conditional distribution of response is .
-
2.
Conditional mean: The conditional mean can be obtained by differentiating with respect to , giving .
Example 3: Binary Responses . Let and .
-
1.
Conditional distribution: The conditional distribution of response is .
-
2.
Conditional mean: The conditional mean can be obtained by differentiating with respect to , giving .
Interpretation of Examples. According to Equations (2) and (4), regardless of the conditional distribution of response , can be viewed as an intercept, while captures the relationship between predictor and response . The parameters and capture two distinct spillover effects:
-
•
Treatment spillover: allows the outcome of unit to be affected by the treatments of its neighbors and non-neighbors , provided and and are connected (see Figure 1).
-
•
Outcome spillover: allows the outcome of unit to be affected by the outcomes of its neighbors and non-neighbors , provided and and are connected (see Figure 1).
The proposed regression framework can be used for causal inference under network interference, which studies treatment spillover. That said, the framework is considerably broader, because it permits outcome spillover, and spillover need not be studied in a causal setting.
2.2.2 GLM Representation of Connections
The conditional mean of connection depends on the linear predictor
where is the change in due to transforming from to . The logistic regression representation of facilitates interpretation: e.g., captures heterogeneity among units in forming connections. If , the sparsity-inducing term penalizes connections between pairs of units with non-overlapping neighborhoods, where the -term can be motivated in the special case of Bernoulli random graphs (Krivitsky et al., 2023): If and the expected degrees are bounded, then and . In addition, the model captures three forms of dependencies. First, the model encourages and to be connected when and are both connected to some , provided and . Second, the model encourages and to be connected when or , provided and . Third, the model encourages and to be connected when , provided and .
3 Scalable Statistical Computing
To learn the regression framework from a single observation of dependent responses and connections , we develop scalable methods based on convex optimization of pseudo-likelihoods using minorization-maximization methods.
3.1 Pseudo-Loglikelihood
Let
| (6) |
where the dependence on predictors is suppressed and and are defined by
The pseudo-loglikelihood is based on full conditional densities of responses and connections and is hence tractable. In addition, is a sum of exponential family loglikelihood functions and , each of which is concave and twice differentiable on the convex set (Brown, 1986, Theorem 1.13, p. 19 and Lemma 5.3, p. 146), proving Lemma 3.1:
Lemma 1: Convexity and Smoothness. The set is convex and the pseudo-loglikelihood function , considered as a function of for fixed , is twice differentiable with a negative semidefinite Hessian matrix on .
In light of the tractability and concavity of , it makes sense to base statistical learning on pseudo-likelihood estimators of the form
| (7) |
where denotes the gradient with respect to while denotes the -norm of vectors . The quantity can be viewed as a convergence criterion of a root-finding algorithm and can depend on . The set consists of maximizers of when , and maximizers and near-maximizers when .
3.2 Minorization-Maximization (MM)
While pseudo-likelihood estimators can be obtained by standard root-finding algorithms, inverting the negative Hessian of at each iteration is time-consuming, because inversions require operations and can increase with . We thus divide the task of estimating parameters into two subtasks using MM methods (Hunter and Lange, 2004). In the example model specified by Equations (2) and (4) for binary, count-, or real-valued predictors and responses and binary connections , we partition into nuisance parameters, , and parameters of primary interest, . We then partition the negative Hessian of accordingly:
| (8) |
where , , and . We suppress the dependence of , , and on and henceforth write instead of .
Iteration then consists of two steps:
-
Step 1: Find satisfying .
-
Step 2: Find satisfying .
In Step 1, it is inconvenient to invert the high-dimensional matrix
| (9) |
where . We thus increase by maximizing a minorizer of , replacing by a constant matrix that only needs to be inverted once.
Lemma 2: Minorizer. Define
where is the identity matrix and is the -vector of ones. Then the function
is a minorizer of at for fixed , in the sense that
Lemma 3.2 is proved in Section B of the Supplementary Materials. Step 1 may be implemented by an MM algorithm, as the closed-form maximizer of the minorizer is
| (10) |
We accelerate the MM step in Equation (10) with quasi-Newton methods. Details can be found in Section E of the Supplementary Materials. Compared to a Newton-Raphson algorithm, the accelerated MM-step reduces the per-iteration computational complexity from to . Step 2 updates the low-dimensional parameter vector of interest given the high-dimensional nuisance parameter vector by a Newton-Raphson step. The concavity of , established in Lemma 3.1, guarantees that
3.3 Quantifying Uncertainty
The uncertainty about the maximum pseudo-likelihood estimator of the data-generating parameter vector can be quantified based on the covariance matrix of the sampling distribution of , which we derive as follows: The mean-value theorem for vector-valued functions (Ortega and Rheinboldt, 2000, Equations (2) and (3), pp. 68–69) implies that there exist real numbers such that
| (11) |
where
Here, is the th coordinate of and is the row vector of partial derivatives of with respect to (). Leveraging Equation (11) along with gives the exact covariance matrix :
If is large, can be replaced by , because is small with high probability according to Theorem 4 in Section 4. The resulting approximation of is
| (12) |
which can be estimated by simulating responses and connections from using Markov chain Monte Carlo methods.
Remark: Asymptotic Distribution. Establishing asymptotic normality for pseudo-likelihood estimators based on a single observation of dependent responses and connections in scenarios with parameters is an open problem. Asymptotic normality results in the most closely related literature—the literature in applied probability concerned with Ising models, Gibbs measures, and Markov random fields in single-observation scenarios (e.g., Jensen and Künsch, 1994; Comets and Janzura, 1998)—assume the presence of lattice structure and a fixed number of parameters , in addition to other assumptions motivated by applications in physics. In the current setting, none of these assumptions holds, although simulation results in Section 5 suggest that the sampling distribution of is approximately normal and that normal-based confidence intervals based on Equation (12) achieve close-to-nominal coverage probabilities.
4 Theoretical Guarantees
We establish convergence rates for pseudo-likelihood estimators based on a single observation of dependent responses and connections . To cover a wide range of models for binary, count-, and real-valued responses and connections, we introduce a general theoretical framework and showcase convergence rates in a specific example.
We denote by the data-generating parameter vector and by a hypercube with center and width . Let
and, for some and , let
where is the -induced matrix norm. The set can be a proper subset of , provided is a high probability subset of . The definition of is motivated by the fact that characterizing the set of all for which the Hessian is invertible can be challenging, but finding a sufficient condition for invertibility is often possible.
Theorem 1: Convergence Rate. Consider a single observation of generated by model (1) with parameter vector , where is a finite, countably infinite, or uncountable set. Assume that there exists a sequence satisfying so that the events and occur with probability , where . Then there exists a positive integer such that, for all , the random set is non-empty and, with probability , satisfies
Theorem 4 is proved in Section C of the Supplementary Materials. The requirement implies , so the convergence rate depends on
-
•
the strength of concentration of the gradient around its expectation via ;
-
•
the inverse negative Hessian in a neighborhood of and a high probability subset of via .
The strength of concentration of can be quantified by concentration inequalities for dependent random variables. In general, the strength of concentration depends on the sample space and the tails of the distribution, the smoothness of the functions and , and the dependence induced by model (1). To control the dependence among responses and connections , one can take advantage of additional structure (e.g., one or more neighborhood structures, non-overlapping or overlapping subpopulations, or a metric space in which units are embedded). For example, each unit can have one or more neighborhoods (e.g., geographical neighbors and colleagues in the workplace), and the responses and connections of the unit can be affected by any geographical neighbor and any colleague. Theoretical guarantees can be obtained as long as the neighborhoods are not too large and do not overlap too much.
Specific convergence rates depend on the model. To demonstrate, consider predictors , responses , and connections generated by a model capturing heterogeneity in the propensities of units to form connections, transitive closure among connections with weight , and treatment spillover with weight ; compare Equations (2) and (4) in Section 2.2. Since and , it is reasonable to specify and . Convergence rates can be obtained under the following conditions.
Condition 1: Predictors. There exist finite constants such that, for each , and there exists such that and .
Condition 2: Parameters. The parameter space is and there exists a constant , not depending on , such that .
Condition 3: Dependence. The population consists of overlapping subpopulations , which can be represented as vertices of a subpopulation graph with an edge connecting and if (). For each , the number of subpopulations at geodesic distance in is . For each , the neighborhood is
There exists a constant such that .
Condition 4 imposes restrictions on . Condition 4 requires that the data-generating parameter vector be contained in a compact subset of . The set of estimators is not restricted by Condition 4 and consists of all such that . Condition 4 can be weakened in special cases, allowing ; see Section D.3 of the Supplementary Materials. Condition 4 controls the dependence among responses and connections and can be weakened to , as demonstrated by Stewart and Schweinberger (2025) in the special case of connections (without predictors and responses ).
Corollary 1: Example of Convergence Rate. Consider a single observation of dependent responses and connections generated by the model with parameter vector . If Conditions 4–4 hold, there exist constants and along with an integer such that, for all , the quantity satisfies
and the random set is non-empty and satisfies
with probability at least .
Corollary 4 is proved in Section D of the Supplementary Materials. The same method of proof can be used to establish convergence rates for pseudo-likelihood estimators based on other models for dependent responses and connections , provided there is additional structure to control the dependence among responses and connections.
5 Simulation Results
To evaluate the performance of pseudo-likelihood estimators and the accompanying uncertainty quantification, we simulate data from the example model specified by Equations (2) and (4). The coordinates of the nuisance parameter vector, , , , are independent Gaussian draws with mean and standard deviation . The parameter vector of primary interest, , , , , , , is specified as . The sparsity parameter ensures that each unit has on average approximately 30 connections, regardless of the value of . The neighborhood structure is based on intersecting subpopulations , where consists of the 50 units (). For each , we define the neighborhood to be the 50- or 75-unit union of all subpopulations containing .
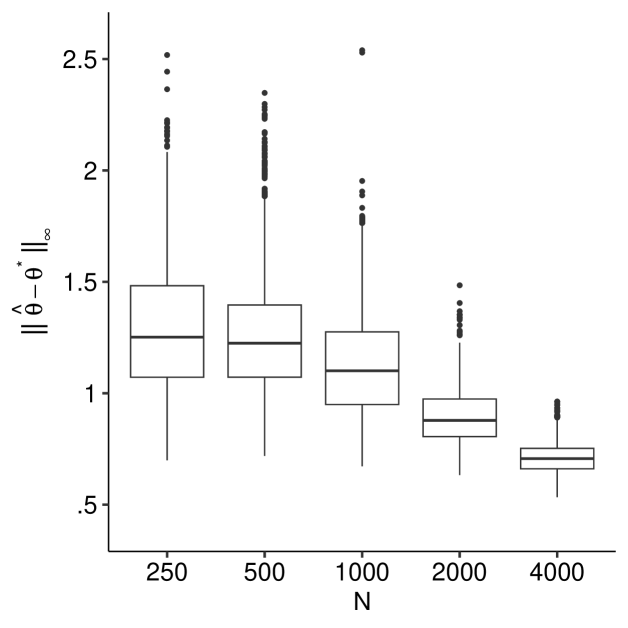
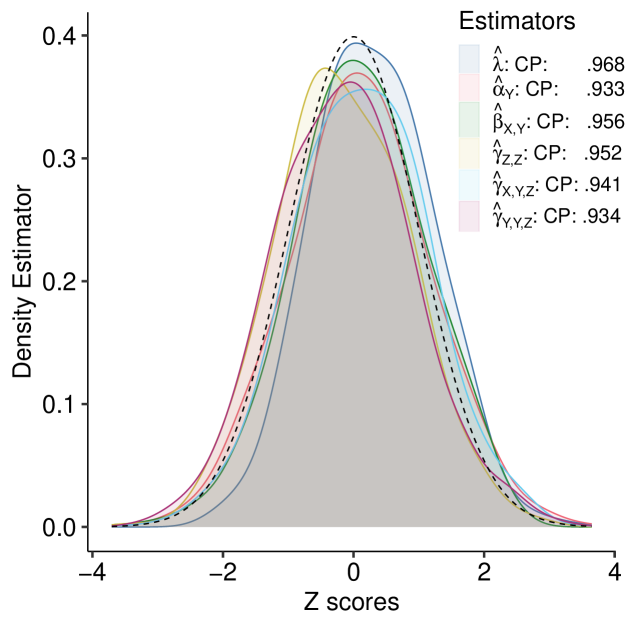
In Figure 2, the left panel shows that decreases as increases. The right panel depicts the empirical distributions of the standardized univariate estimators and the empirical coverage probabilities, demonstrating that the covariance estimator in Equation (12) appears accurate and normal-based inference seems reasonable. As discussed in Section 1, comparisons to other estimation approaches are infeasible due to their lack of scalability.
6 Hate Speech on X
We analyze posts of U.S. state legislators on the social media platform X in the six months preceding the insurrection at the U.S. Capitol on January 6, 2021 (Kim et al., 2022), with a view to studying how hate speech depends on the attributes of legislators and connections among them. Using Large Language Models (LLMs), we classify the contents of 109,974 posts by 2,191 legislators as “non-hate speech” or “hate speech,” as explained in Section G of the Supplementary Materials. The response of legislator indicates whether released at least one post classified as hate speech. We use four covariates: indicates that legislator ’s party affiliation is Republican, indicates that legislator is female, indicates that legislator is white, and is the state legislature that legislator is a member of (e.g., New York). The directed connections are based on the mentions and reposts exchanged between January 6, 2020 and January 6, 2021: if legislator mentioned or reposted posts by legislator in a post. To construct the neighborhoods of legislators , we exploit the fact that users of X choose whom to follow and that these choices are known, so is defined as the union of and the set of users followed by .
6.1 Model Specification
To accommodate binary responses and connections that are directed, i.e., may not be equal to , we consider a model of the form
| (13) |
where because when ; see Example 3 in Section 2.2.1. Since , we henceforth write instead of .
Using the definitions of and in Equation (3), we specify and as follows:
| (14) |
| (15) |
where the th coordinate of -vector is and all other coordinates are . Here, quantifies the activity of legislators , i.e., their tendency to mention or repost posts of other legislators; quantifies the attractiveness of legislators , i.e., the tendency for other legislators to mention or repost posts by them; discourages connections between legislators with non-overlapping neighborhoods; capture the effects of covariates on connections ; is the weight of the interaction of and ; quantifies the tendency to reciprocate connections; quantifies the tendency to form transitive connections; and captures spillover from covariate on response through connection ; note that the spillover effect should not be interpreted as a causal effect, because the party affiliations of legislators are not under the control of investigators (Kim et al., 2022). Since with probability , we set to address the identifiability problem that would result if all and were allowed to vary freely. These model terms were chosen based on domain knowledge, because model selection is an open problem: For instance, the statistic with weight is included to assess whether the party affiliation of state legislators affects posts of state legislators who are connected () and whose neighborhoods overlap (). In practice, data scientists can consult domain experts to make informed choices regarding model specifications.
6.2 Results
| Weight | Estimate | Standard Error | Weight | Estimate | Standard Error |
|---|---|---|---|---|---|
| .134 | .033 | ||||
| .105 | .037 | ||||
| .094 | .07 | ||||
| .127 | .016 | ||||
| .005 | .025 | ||||
| .013 | .049 | ||||
| .006 |
To interpret the results, we exploit the fact that the conditional distributions of responses and connections can be represented by logistic regression models, with log odds
and
For instance, the positive sign of suggests that the more Republicans interact with legislator , the higher is the conditional probability that legislator uses offensive text in a post, holding everything else constant. Alternatively, one can interpret in terms of the conditional probability of observing a connection: The positive sign of indicates that Republican legislators are more likely to interact with legislators who post harmful language. Other estimates align with expectations. For example, serving for the same state is the strongest predictor for reposting and mentioning activities (), while matching gender () and race () likewise increase the conditional probability to interact. At the same time, connections affect other connections: For example, forming a connection that leads to a transitive connection is observed more often than expected under the model with , holding everything else constant.
6.3 Model Assessment
| Without network interference | (.103) | (.097) | (.093) | (.113) |
|---|---|---|---|---|
| With network interference | (.134) | (.105) | (.094) | (.127) |
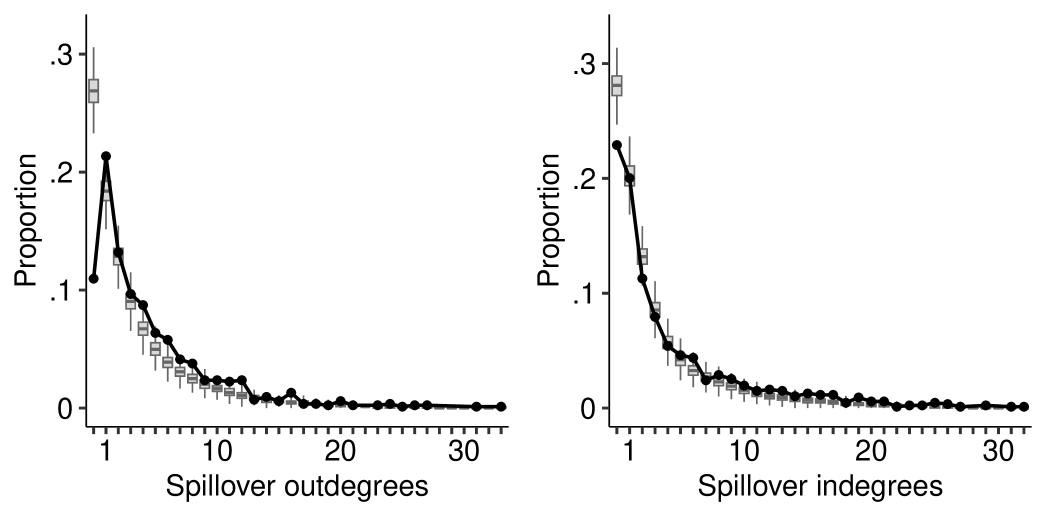
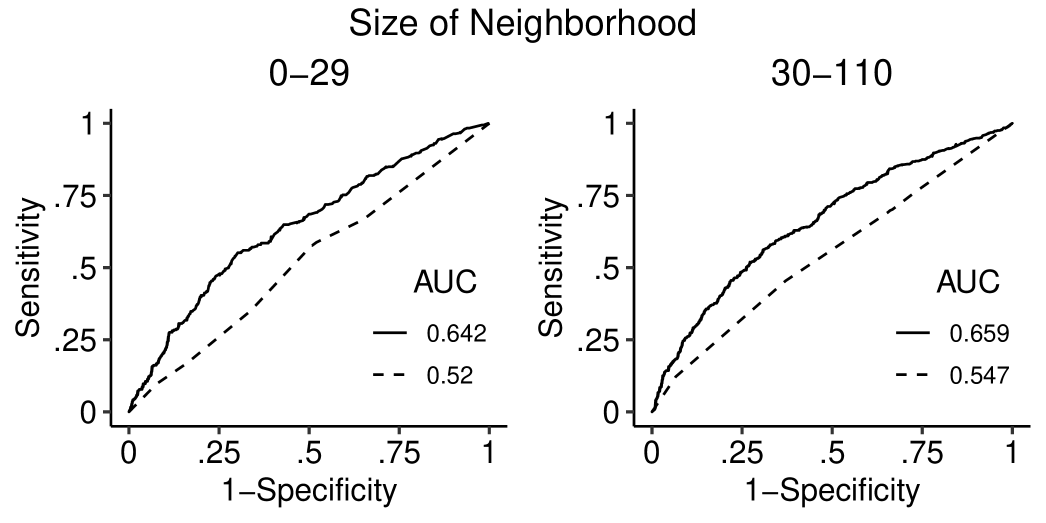
We assess the model using model-based predictions of . First, we focus on the subnetwork of all pairs of legislators with and , with a view to assessing how well the interplay of , , and can be represented by the model. Figure 3 shows that the model captures the effect of on among pairs of legislators with . Second, we compare predictions of responses based on models with and without network interference. Predictions without network interference are based on the logistic regression model for with weights , , , and , which assumes that the posts of legislators are independent and do not depend on the connections among the legislators. By contrast, predictions with network interference are based on the joint probability model for specified by Equation (13), which allows the posts of state legislators to be affected by the posts of connected legislators whose sets of followees overlap. Figure 4 demonstrates that predictions based on models with network interference outperform those without network interference, suggesting that posts of connected state legislators with overlapping sets of followees are interdependent. Table 2 compares estimates of , , , and based on models with and without network interference. While both models agree on the signs of parameter estimates, the estimates of and differ by a factor of 2 and 5, respectively, suggesting that network interference affects parameter estimates. Third, we demonstrate in Section G.2 of the Supplementary Materials that the model preserves salient features of connections .
7 Discussion
The proposed regression framework is flexible, allowing data scientists to specify a wide range of models for dependent responses and connections .
The large set of possible models raises the question of how data scientists can select a model from a set of candidate models. While model selection for independent responses is well-established and model selection for independent connections is an active area of research (e.g., Wang and Bickel, 2017; Wang et al., 2024; Stein et al., 2025), model selection for dependent responses and connections with parameters is an open problem. Two model selection ideas that hold promise are those of Ravikumar et al. (2010) for high-dimensional graphical models for dependent responses and those of Chen and Chen (2012) for high-dimensional generalized linear models for independent responses based on the extended BIC.
Likewise, open questions remain in the realm of uncertainty quantification, as discussed in Section 3.3. For example, a proof of asymptotic normality based on dependent data remains elusive. A related avenue for future research is Godambe information: If were constant, it could be pulled out of the approximate covariance matrix in Equation (12), giving rise to Godambe information. Simulations suggest that uncertainty quantification based on Godambe information achieves comparable accuracy to the method reported here, while avoiding multiple matrix inversions.
The question of neighborhood recovery is another important direction for future research, as discussed in Section 2.
Supplementary Materials
The supplementary materials contain proofs of all theoretical results.
Acknowledgements
The authors are indebted to the constructive comments and suggestions of an anonymous associate editor and two referees, which have led to numerous improvements.
Disclosure Statement
The authors report there are no competing interests to declare.
Funding
The authors acknowledge support by DFG award FR 4768/1-1 (CF) and ARO award W911NF-21-1-0335 (CF, MS, SB).
References
- Besag (1974) Besag, J. (1974). Spatial interaction and the statistical analysis of lattice systems. Journal of the Royal Statistical Society: Series B 36, 192–225.
- Brown (1986) Brown, L. (1986). Fundamentals of Statistical Exponential Families: With Applications in Statistical Decision Theory. Hayworth, CA, USA: Institute of Mathematical Statistics.
- Chatterjee and Diaconis (2013) Chatterjee, S. and P. Diaconis (2013). Estimating and understanding exponential random graph models. The Annals of Statistics 41, 2428–2461.
- Chen and Chen (2012) Chen, J. and Z. Chen (2012). Extended BIC for small--large- sparse GLM. Statistica Sinica 22, 555–574.
- Clark and Handcock (2024) Clark, D. A. and M. S. Handcock (2024). Causal inference over stochastic networks. Journal of the Royal Statistical Society Series A: Statistics in Society 187, 772–795.
- Comets and Janzura (1998) Comets, F. and M. Janzura (1998). A central limit theorem for conditionally centred random fields with an application to Markov fields. Journal of Applied Probability 35, 608–621.
- Efron (2022) Efron, B. (2022). Exponential families in theory and practice. Cambridge, MA: Cambridge University Press.
- Fosdick and Hoff (2015) Fosdick, B. K. and P. D. Hoff (2015). Testing and modeling dependencies between a network and nodal attributes. Journal of the American Statistical Association 110, 1047–1056.
- Handcock (2003) Handcock, M. S. (2003). Statistical models for social networks: Inference and degeneracy. In R. Breiger, K. Carley, and P. Pattison (Eds.), Dynamic Social Network Modeling and Analysis, pp. 1–12. Washington, D.C.: National Academies Press.
- Huang et al. (2019) Huang, D., W. Lan, H. H. Zhang, and H. Wang (2019). Least squares estimation of spatial autoregressive models for large-scale social networks. Electronic Journal of Statistics 13, 1135–1165.
- Huang et al. (2020) Huang, D., F. Wang, X. Zhu, and H. Wang (2020). Two-mode network autoregressive model for large-scale networks. Journal of Econometrics 216, 203–219.
- Huang et al. (2024) Huang, S., J. Sun, and Y. Feng (2024). PCABM: Pairwise covariates-adjusted block model for community detection. Journal of the American Statistical Association 119, 2092–2104.
- Hunter and Lange (2004) Hunter, D. R. and K. Lange (2004). A tutorial on MM algorithms. The American Statistician 58, 30–37.
- Jensen and Künsch (1994) Jensen, J. L. and H. R. Künsch (1994). On asymptotic normality of pseudo likelihood estimates for pairwise interaction processes. Annals of the Institute of Mathematical Statistics 46, 475–486.
- Kim et al. (2022) Kim, T., N. Nakka, I. Gopal, B. A. Desmarais, A. Mancinelli, J. J. Harden, H. Ko, and F. J. Boehmke (2022). Attention to the COVID‐19 pandemic on Twitter: Partisan differences among U.S. state legislators. Legislative Studies Quarterly 47, 1023–1041.
- Kolaczyk (2017) Kolaczyk, E. D. (2017). Topics at the Frontier of Statistics and Network Analysis: (Re)Visiting the Foundations. Cambridge University Press.
- Krivitsky et al. (2023) Krivitsky, P. N., P. Coletti, and N. Hens (2023). A tale of two datasets: Representativeness and generalisability of inference for samples of networks. Journal of the American Statistical Association 118, 2213–2224.
- Le and Li (2022) Le, C. M. and T. Li (2022). Linear regression and its inference on noisy network-linked data. Journal of the Royal Statistical Society Series B: Statistical Methodology 84, 1851–1885.
- Lei et al. (2024) Lei, J., K. Chen, and H. Moon (2024). Least squares inference for data with network dependency. Available at arXiv:2404.01977.
- Li and Wager (2022) Li, S. and S. Wager (2022). Random graph asymptotics for treatment effect estimation under network interference. The Annals of Statistics 50, 2334 – 2358.
- Li et al. (2019) Li, T., E. Levina, and J. Zhu (2019). Prediction models for network-linked data. The Annals of Applied Statistics 13(1), 132–164.
- Niezink and Snijders (2017) Niezink, N. M. D. and T. A. B. Snijders (2017). Co-evolution of social networks and continuous actor attributes. The Annals of Applied Statistics 11, 1948–1973.
- Ogburn et al. (2024) Ogburn, E. L., O. Sofrygin, I. Diaz, and M. J. Van der Laan (2024). Causal inference for social network data. Journal of the American Statistical Association 119, 597–611.
- Ortega and Rheinboldt (2000) Ortega, J. M. and W. C. Rheinboldt (2000). Iterative solution of nonlinear equations in several variables. Society for Industrial and Applied Mathematics.
- Ravikumar et al. (2010) Ravikumar, P., M. J. Wainwright, and J. Lafferty (2010). High-dimensional Ising model selection using -regularized logistic regression. The Annals of Statistics 38, 1287–1319.
- Schweinberger (2011) Schweinberger, M. (2011). Instability, sensitivity, and degeneracy of discrete exponential families. Journal of the American Statistical Association 106, 1361–1370.
- Snijders et al. (2007) Snijders, T. A. B., C. E. G. Steglich, and M. Schweinberger (2007). Modeling the co-evolution of networks and behavior. In K. van Montfort, H. Oud, and A. Satorra (Eds.), Longitudinal models in the behavioral and related sciences, pp. 41–71. Lawrence Erlbaum.
- Stein et al. (2025) Stein, S., R. Feng, and C. Leng (2025). A sparse beta regression model for network analysis. Journal of the American Statistical Association. To appear.
- Stewart and Schweinberger (2025) Stewart, J. R. and M. Schweinberger (2025). Pseudo-likelihood-based -estimators for random graphs with dependent edges and parameter vectors of increasing dimension. The Annals of Statistics. To appear.
- Tchetgen Tchetgen et al. (2021) Tchetgen Tchetgen, E. J., I. R. Fulcher, and I. Shpitser (2021). Auto-G-computation of causal effects on a network. Journal of the American Statistical Association 116, 833–844.
- Wang et al. (2024) Wang, J., X. Cai, X. Niu, and R. Li (2024). Variable selection for high-dimensional nodal attributes in social networks with degree heterogeneity. Journal of the American Statistical Association 119, 1322–1335.
- Wang and Bickel (2017) Wang, Y. X. and P. J. Bickel (2017). Likelihood-based model selection for stochastic block models. The Annals of Statistics 45, 500–528.
- Wang et al. (2024) Wang, Z., I. E. Fellows, and M. S. Handcock (2024). Understanding networks with exponential-family random network models. Social Networks 78, 81–91.
- Zhu et al. (2020) Zhu, X., D. Huang, R. Pan, and H. Wang (2020). Multivariate spatial autoregressive model for large scale social networks. Journal of Econometrics 215, 591–606.
Supplementary Materials:
A Regression Framework for Studying Relationships among Attributes under Network Interference
1
Appendix A Proofs of Propositions 2.1 and A
Proof of Proposition 2.1. The joint probability density function of stated in Equation (1) in Section 2 implies that the conditional probability density function of can be written as
where , , and , while
Proposition 2. Consider Example 1 in Section 2.2.1. Let be the matrix with elements
| (A.1) |
and let be the -vector with coordinates
| (A.2) |
Denote by the identity matrix and define . If is positive definite, the conditional distribution of is -variate Gaussian with mean vector and covariance matrix .
Remark. The requirement that be positive definite imposes restrictions on . The restrictions on depend on the neighborhoods of units and connections among pairs of units .
Proof of Proposition A. Example 1 in Section 2.2.1 demonstrates that the conditional distribution of is Gaussian with conditional mean
| (A.3) |
where
and
The conditional variance of is
| (A.4) |
Let be the conditional mean of . Upon taking expectation on both sides of (A) conditional on , we obtain
| (A.5) |
which implies that
and hence
| (A.6) |
where
By comparing Equations (A.4) and (A) to Equations (2.17) and (2.18) of \citetsupprue2005gaussian and invoking Theorem 2.6 of \citetsupprue2005gaussian, we conclude that the conditional distribution of is -variate Gaussian with mean vector and precision matrix with elements
provided for all and is positive definite; note that is satisfied in undirected networks with .
To state these results in matrix form, note that (A.5) can be expressed as
implying
while can be expressed as
implying
To conclude, the conditional distribution of is -variate Gaussian with mean vector and covariance matrix , provided is positive definite.
Appendix B Proofs of Lemmas 3.1 and 3.2
Proof of Lemma 3.1. Lemma 3.1 is proved in the sentence preceeding the statement of Lemma 3.1 in Section 3.1.
Proof of Lemma 3.2. Letting denote the parameter space of , suppose that is any twice differentiable function and that is non-negative definite for all for some constant matrix (). Then the function given by
satisfies for all , because Taylor’s theorem (Theorem 6.11, \citealpsupp[p. 124]magnus_matrix_2019) gives
where (). The inequality implies that
is non-negative definite. Lemma 3.1 proves that is concave and that the restriction of to has the properties of stated above, proving Lemma 3.2.
Appendix C Proof of Theorem 4
Theorem 4 is a generalization of Theorem 2 of \citetsupp[][abbreviated as S25]StSc20 from exponential family models for binary connections to exponential family models for binary, count-, and real-valued responses and connections . We henceforth suppress predictors .
Proof of Theorem 4. Let and consider events
Define
It follows from results of S25 that , considered as a function of for fixed , is a homeomorphism and is continuously differentiable.
In the event , the set is non-empty. By construction of the sets and , the set is non-empty for all , because contains the data-generating parameter vector provided :
In the event , the set satisfies provided . By assumption, there exists a sequence such that . Therefore, there exists an integer such that for all . Consider any and any . Since is continuous on , there exists, for each , a real number (which depends on ) such that
| (C.1) |
As is a homeomorphism and continuously differentiable, we can invoke Lemma 1 of S25 to conclude that is related to by the following inequality:
| (C.2) |
To take advantage of (C.2), observe that, for all and all ,
| (C.3) |
because for all , for all , and . Using (C.3) along with the definition of , we obtain
| (C.4) |
and, using (C.2),
| (C.5) |
In light of the fact that
the set is non-empty and satisfies
| (C.6) |
in the event , provided .
The event occurs with probability . The probability of event is bounded below by
The above inequality stems from a union bound, while the identity follows from the assumption that the probabilities of the events and satisfy
where the first result leverages the fact that by Lemma 7 of S25.
Appendix D Corollaries 4 and D.3
To state and prove Corollaries 4 and D.3, we first introduce notation along with background on conditional independence graphs \citepsuppgraphical.models and couplings \citepsuppLi02.
D.1 Notation and Background
We consider the model of Corollary 4, with joint probability mass function
| (D.1) |
The parameter vector is and the vector of sufficient statistics is , with coordinates
-
•
(),
-
•
,
-
•
,
where the terms and are defined as follows:
| (D.2) |
In light of , we do not distinguish between and or and . To ease the presentation, we write rather than , and rather than . Expectations, variances, and covariances with respect to the conditional distributions of and are denoted by , , and , , , respectively.
Conditional independence graph. Let be the total number of responses and connections and
| (D.3) |
be the vector consisting of responses and connections. The conditional independence structure of the model can be represented by a conditional independence graph with a set of vertices and a set of undirected edges . We refer to elements of and as vertices and edges of . There are two distinct subsets of vertices in :
-
•
the subset corresponding to responses ;
-
•
the subset corresponding to connections .
An undirected edge between two vertices in represents dependence of the two corresponding random variables conditional on all other random variables. The vertices in are connected to the following subsets of vertices (neighborhoods):
-
•
The neighborhood of in consists of all and all such that and .
-
•
The neighborhood of in consists of
-
1.
and ;
-
2.
all and such that and ;
-
3.
all and such that and provided that either holds or holds.
-
1.
Let be the length of the shortest path from vertex to vertex in and let be the set of vertices with distance to the th vertex in :
We define the maximum degree of vertices relating to connections in as follows:
| (D.4) |
Coupling matrix. Let be the subvector consisting of responses and connections with indices . The set of random variables excluding the random variable with is denoted by . Consider any and define
We use the total variation distance between the conditional distributions and for quantifying the amount of dependence induced by the model, where is the data-generating parameter vector. The total variation distance between and can be bounded from above by using coupling methods \citepsuppLi02. A coupling of and is a joint probability distribution for a pair of random vectors with marginals and . For convenience, we define , where the first elements are given by and , respectively. The basic coupling inequality \citepsupp[][Theorem 5.2, p. 19]Li02 shows that any coupling satisfies
| (D.5) |
where denotes the total variance distance between probability measures. If the two sides in Equation (D.5) are equal, the coupling is called optimal. An optimal coupling is guaranteed to exist, but may not be unique \citepsupp[][pp. 99–107]Li02. To prove Corollary 4, we need an upper bound on the spectral norm of the coupling matrix , so we construct a coupling that is convenient but may not be optimal.
A coupling of and can be constructed as follows:
-
Step 1: Set and .
-
Step 2: Set .
-
(a)
If , pick the smallest element and let be distributed according to an optimal coupling of and .
-
(b)
If , pick the smallest element and let be distributed according to an optimal coupling of and.
-
(a)
-
Step 3: Replace by and repeat Step 2 until .
Based on , we construct a coupling matrix with elements
Overlapping subpopulations. To obtain convergence rates based on a single observation of dependent random variables , we need to control the dependence of in the form of . In line with the simulation setting in Section 5, we therefore assume that overlapping subpopulations characterize the neighborhoods. The neighborhood of unit is then defined as
| (D.6) |
Let be a subpopulation graph with a set of vertices and a set of edges connecting distinct subpopulations and with . Define
| (D.7) |
Using the background introduced above, we restate Condition 4 more formally.
Condition 4: Dependence. The population consists of intersecting subpopulations , whose intersections are represented by subpopulation graph . Let be defined by (D.4) and be defined by (D.7), and assume that
where and with . The constant is identical to the constant in Condition 4. In addition, for each unit , the neighborhood is defined by (D.6), and there exists a constant such that .
The assumption implies that is bounded above by a constant .
D.2 Proof of Corollary 4
To prove Corollary 4, define
| (D.8) |
and
| (D.9) |
where the constants and are identical to the corresponding constants defined in Condition 4 and Equation (D.4), respectively.
Proof of Corollary 4. We prove Corollary 4 using Theorem 4 in five steps:
-
Step 1: We bound
and choose so that .
-
Step 2: We show that is invertible for all and all .
-
Step 3: We prove that the event occurs with probability at least.
-
Step 4: We bound .
-
Step 5: We bound .
The proof of Corollary 4 leverages auxiliary results supplied by Lemmas D.4, D.5, and D.6, which show that there exists an integer such that, for all ,
where , , and are constants.
Step 1: Since , Lemma 6 of S25 establishes
where
with defined in (D.4). Choosing
| (D.10) |
implies that the event
occurs with probability at least
Step 3: Lemma D.7 shows that there exists an integer such that, for all , the event occurs with probability at least
Step 4: The quantity
is bounded below by
and is bounded above by
using , , , and . Since , , and defined in (D.4) are constants, there exist constants such that
Step 5: Substituting the bounds on , , and supplied by Lemmas D.4, D.5, and D.6 into (D.10) reveals that
| (D.11) |
using and (). To bound , we invoke Condition 4:
Define
Since , , , , , , and are independent of , so is . We conclude that
Conclusion. Theorem 4 implies that, for all , the random set is non-empty and satisfies
with probability at least
using .
D.3 Statement and Proof of Corollary D.3
If subpopulations do not overlap, can grow as a function . Condition D.3 details how fast can grow.
Condition 5. The parameter space is and the data-generating parameter vector satisfies
where and are constants, is identical to the constant in Condition 4, is identical to the constant in (D.4), and is identical to the constant in the definition of in Section 4.
Corollary D.3 replaces Condition 4 by Condition D.3. Resulting from this, the constant coming up in Condition D.1 is redefined as .
Corollary 2. Consider a single observation of dependent responses and connections generated by the model with parameter vector . If Conditions 4, D.1, and D.3 are satisfied with , there exist constants and along with an integer such that, for all , the quantity satisfies
and the random set is non-empty and satisfies
with probability at least .
Proof of Corollary D.3. The proof of Corollary D.3 resembles the proof of Corollary 4, with Condition 4 replaced by Condition D.3. The proof of Corollary 4 shows that
where the constants , , , and are defined in Lemmas D.4, D.5, and D.6, and Equation (D.4), respectively. Condition D.3 implies that
which in turn implies that
where . The remainder of the proof of Corollary D.3 resembles the proof of Corollary 4. We conclude that there exists an integer such that, for all , the random set is non-empty and satisfies
with probability at least .
D.4 Bounding
Lemma 3. Consider the model of Corollary 4. If Conditions 4 and D.1 are satisfied along with either Condition 4 or Condition D.3 with , there exists a constant along with an integer such that, for all ,
-
•
is invertible for all and all ,
-
•
the event occurs with probability at least ,
-
•
,
Proof of Lemma D.4. We first partition in accordance with , given by and :
| (D.12) |
where the matrices and define the covariance matrices of the sufficient statistics corresponding to the parameters and , respectively. Define , where and are the covariances of the degree terms with the transitive connection term with weight and spillover term with weight , respectively.
We wish to bound the infinity norm of , given by
where and () are diagonal matrices, and
is the Schur complement of with respect to the block .
The -induced norm is submultiplicative, so
| (D.13) |
We bound the terms , , and one by one.
Bounding . The proof of Lemma 9 in S25 shows that
| (D.14) |
for all , where is an upper bound on the inverse standard deviation of connections of pairs of units with conditional on . Under the model considered here, the conditional distribution of is Bernoulli, as shown in Section 2.2.2. Therefore, is given by
Applying the bounds on supplied by Lemma D.7 gives
| (D.15) |
provided , where corresponds to the constant defined in (D.4) and corresponds to the constant in Condition 4. For the second inequality of (D.15), we use the fact that for all . With
we therefore deduce that is an bound on the inverse standard deviation of connections :
Bounding .
Define ,
where
and are the covariance terms of the degree terms with the sufficient statistics pertaining to the transitive connection term weighted by and the spillover term weighted by , respectively.
Then
We bound the terms and one by one.
By Lemma 13 of S25, . The term refers to the covariances between the degrees of units and . An upper bound on -th element of can be obtained by
| (D.16) |
where corresponds to the constant from Condition 4 and is defined in (D.4). On the third line, note that only depends on connection if . Therefore, the covariance of with respect to any other connection is 0. The first inequality follows from the observation that and , which follows from by Condition 4 and . The second inequality follows from Lemma 15 in S25 bounding the pairs of units and such that from above by . Since the bound from (D.16) holds for all , we obtain . Taken together,
| (D.17) |
Bounding . Write
The elements of are then given by
The inverse of is
implying that
| (D.18) |
Invoking the inequalities from (D.14) and (D.17), we obtain for
| (D.19) |
where corresponds to the constant defined in (D.4) and corresponds to the constant from Condition 4.
By applying Lemma D.7 along with (LABEL:eq:boundcac), we get for
Thus, the numerator of (D.18) is bounded above by
| (D.20) |
The denominator of (D.18), which is the determinant of , is
Applying the property of positive semidefinite matrices that is true for all vectors and (), we obtain
where
| (D.21) |
The final inequality follows from invoking (LABEL:eq:boundcac) along with Lemma D.7.
For (D.21), we obtain
Next, we show that the third term
is smaller than the second term
Define
Then the second term can be restated as follows:
while the third term is
where the Cauchy-Schwarz inequality is invoked on the third and last line. This translates to the following lower bound on :
where is defined in (D.8) and the function is defined in (D.2). For the second inequality, we use the result from the proof of Lemma 13 in S25, which implies that
| (D.22) |
where the function is defined in (D.2). By Lemma D.7, we get
where is defined in (D.9). When combined with (D.22), this results in
where the second inequality is again from the proof of Lemma 13 in S25.
By applying Lemma D.7 and expanding the quadratic term, we obtain
where is defined in (D.8) and corresponds to the constant from Condition 4. The second inequality follows from the assumption by Condition 4 along with and . Lemma D.7 shows that
where is defined in (D.8). For all , we obtain by definition
which results in the following bound for the denominator of (D.18):
using the fact that , , and , which implies that
Under Conditions 4 and D.3 with , we have, for all ,
Thus, there exists a real number along with an integer such that
for all , which implies that
| (D.23) |
Observe that (LABEL:eq:denom) provides a positive lower bound on the determinant of for , demonstrating that
| (D.24) |
Combining (LABEL:eq:boundw), (LABEL:eq:denom), and (D.24) shows that, for all ,
| (D.25) |
where is a constant.
Conclusion. We show in two steps that is invertible for all and all . First, by Lemma 9 in S25, the matrix is invertible for all and all . Second, (D.24) demonstrates that the determinant of is bounded away from for all and all . Thus, is nonsingular for all and all , and so is by Theorem 8.5.11 of \citetsupp[][p. 99]harville_matrix_1997. Combining (LABEL:hessian_break), (D.14), (D.17), and (D.25) shows that, for all and all ,
Conditions 4 and D.3 with imply that
Thus, there exists an integer such that the two maxima in the upper bound on are equal to for all , so that
| (D.26) |
where and are constants. Substituting (LABEL:last.inequality) into the definition of concludes the proof of Lemma D.4:
D.5 Bounding
Lemma 4. Consider the model of Corollary 4. Then , where is a constant.
Proof of Lemma D.5. The term is defined in
where
The sensitivity of the sufficient statistic vector with respect to changes of responses is quantified by the vector :
where
The sensitivity of the sufficient statistic vector with respect to changes of connections is quantified by the vector :
where
Define
| (D.27) |
-
•
For , the statistic refers to the degree effects of unit :
The term is if and is otherwise. Since the statistic is unaffected by the response, for all . For the sum in (D.27) over all , where holds times, yielding for all .
- •
-
•
The statistic refers to the spillover effect given by
where the function is defined in (D.2). For , the terms are if and otherwise. For all ,
because according to Lemma 15 in S25 there are at most units such that and for according to Condition 4. Combining and gives
where corresponds to the constant in Condition 4.
Combining the results for for gives
where is a constant.
D.6 Bounding
Lemma 5. Consider the model of Corollary 4. If Conditions 4, 4, and D.1 are satisfied with , there exists a constant such that for all . If the population consists of non-overlapping subpopulations with dependence restricted to subpopulations, the same result holds when Condition 4 is replaced by Condition D.3.
Proof of Lemma D.6. To bound from above, we use the Hölder’s inequality
| (D.28) |
where
We can therefore bound by bounding the elements of the upper triangular coupling matrix which are
Next, we define a symmetrized version of the coupling matrix denoted by with elements
The symmetry of yields the following upper bound for (D.28):
| (D.29) |
where the constant 1 in the second line stems from the diagonal elements of .
Consider any such that and define the event as the event that there exists a path of disagreement between vertices and in . A path of disagreement between vertices and in is a path from to in such that the coupling with joint probability mass function disagrees at each vertex on the path, in the sense that holds for all vertices on the path. Theorem 1 of \citetsupp[p. 753]BeMa94 shows that
| (D.30) |
where is a Bernoulli product measure based on independent Bernoulli experiments with success probabilities . With , the success probabilities are
where
| (D.31) |
Lemma D.7 provides the following upper bound:
| (D.32) |
where corresponds to the positive constant from Condition 4 and is defined in (D.4). Combining (D.32) with Condition D.3 shows that
| (D.33) |
The constant coincides with the constant considered in Condition D.1.
Next, we construct the set
and two additional graphs with the same set of vertices as :
-
1.
:
-
•
Vertex relating to connection has edges to vertices that relate to all connections and responses with .
-
•
Vertex relating to attribute has edges to vertices that relate to all connections and responses with for a fictional unit with .
-
•
-
2.
: The set includes edges of all vertices with to vertices in .
The graph is a covering of , so
| (D.35) |
Combining the previous results gives
| (D.36) |
using (D.29), (D.30), (D.34), (D.35). Sorting the vertices without by the geodesic distance to (i.e., by the length of the shortest path to ), we obtain
| (D.37) |
For the event in with and to occur, there must exist at least one vertex in each set at which the coupling disagrees. Therefore, we next derive bounds on to obtain an upper bound on . Following Lemma D.7, Condition D.1 implies that for and
| (D.38) |
and , with constants , and being functions of the constants and defined in Condition D.1 and the constant defined in (D.4). The probability of event in can then be bounded as follows:
The first inequality follows from
because and . Defining , we obtain for
| (D.39) |
with the inequality for all .
Plugging (D.38) and (D.39) in (D.37), we obtain:
| (D.40) |
resulting in two series that we bound one by one. With being the function giving the upper ceiling of a positive real number and , the first series can be bounded as follows:
The above bound is based on a Taylor expansion of , which establishes the inequality implying for any and any . This, in turn, implies the inequality for any and any . With , we apply the same inequality to the second series:
Plugging these results into (D.40) gives
| (D.41) |
D.7 Auxiliary Results
Lemma 6. Consider the model of Corollary 4. Condition D.1 implies that there exist constants , , such that, for all and all ,
Proof of Lemma D.7. With the set
we constructed from two additional graphs and as follows:
-
1.
:
-
•
Vertex relating to connection has edges to vertices that relate to all connections and responses with .
-
•
Vertex relating to attribute has edges to vertices that relate to all connections and responses with for a fictional unit with .
-
•
-
2.
: The set includes edges of all vertices with to vertices in .
The graph is equivalent to the graph cover defined in Lemma 16 of S25. Therefore, we are able to use results from the proof of Lemma 16 in S25 demonstrating that Condition D.1 implies the following bound for :
where corresponds to the constant defined in (D.4) and the constants and with correspond to the constant from Condition D.1. Defining and , this bound is:
The bound for differs to the result from S25 since for our definition of there are additional responses in .
Adding edges , defined as the edges from vertices to other vertices with a geodesic distance of two in , to reduces the geodesic distance between all vertices from in to in . Therefore, holds for and . This allows us to relate the bounds for to bounds for with and :
and
with and . This proves the statement with and .
Lemma 7. Consider the model of Corollary 4. Then, for any pair of units such that ,
Proof of Lemma D.7. For all such that , the conditional probability of given is
with
Note that
where is the domain of excluding , corresponds to the constant from Condition 4, and matches the constant defined in (D.4). . The bounds for follow from the observation, that the degree statistic of unit can, first, only affected by connections with and, second, be at most 1 if this is the case. For , the bound follows from Lemma 18 of S25. For , the sufficient statistic counts the number of connections with overlapping neighborhoods and either or . For , the maximal change in the statistic is since and for , otherwise the maximal change is 0.
Upon applying the triangle inequality,
we obtain for
Upon collecting terms, we obtain the final result:
where and are constants.
Lemma 8. Consider the model of Corollary 4. Then, for any
Proof of Lemma D.7. The conditional probability of given is
where
Note that
where is the domain of without , corresponds to the constant from Condition 4, and matches the constant defined in (D.4). The bounds for are 0 as the corresponding statistics are not affected by changes in . For , the maximal change is bounded by the number of units such that , which is , times the maximal value of the predictors. The remainder of the proof of Lemma D.7 resembles the proof of Lemma D.7.
Lemma 9. Consider the model of Corollary 4. If Conditions 4, D.1, and D.3 are satisfied with , we obtain the following bounds for all elements of , being the covariance matrix of the sufficient statistics and defined in Section D.1, for all and all :
Proof of Lemma D.7. We first bound from above as follows:
| (D.42) |
where matches the constant defined in (D.4) and the function is defined in (D.2). On the second line of (D.42), we use that the fact that implies that and does not depend on for any . For the inequality in the last line of (D.42), we use the fact that the number of pairs for which is a function of is bounded above by (see proof of Lemma 19 in S25). Invoking Lemma 15 of S25 together with applying
gives:
We proceed with bounding :
because according to Condition 4. For the first inequality, we also use that
by Lemma 15 in S25. We obtain
which provides an upper bound on by the Cauchy-Schwarz inequality:
Lemma 10. Consider the model of Corollary 4. Define
Let be the maximum degree of vertices in . Then
Proof of Lemma D.7. The proof of Lemma D.7 resembles the proof of Lemma 21 in S25, adapted to the bounds on the conditional probabilities derived in Lemmas D.7 and D.7. We distinguish four cases, where with relates to:
-
1.
Connection of a pair of nodes with .
-
2.
Attribute with and .
-
3.
Connection of a pair of nodes with .
-
4.
Attribute with and .
In cases 1 and 2, is independent of , so that ; note that case 2 cannot occur, because Condition 4 ensures that there are no units with . In cases 3 and 4, depends on a non-empty subset of other vertices in . Consider any such that for some and define
Lemma 21 in S25 shows that
Plugging in the bounds on the conditional probabilities in Lemmas D.7 and D.7, we obtain
and
Since , we obtain
Lemma 11. Consider the model of Corollary 4. If Conditions 4 and D.1 are satisfied along with either Condition 4 or Condition D.3 with , there exists an integer such that, for all ,
where is defined in (D.8).
Proof of Lemma D.7. We prove Lemma D.7 by showing that
| (D.43) |
To prove the first line of (D.43), we first bound from below. We then use Theorem 1 of \citetsupp[][p. 207]Chetal07 to concentrate . Last, but not least, we show that there exists an integer such that the obtained lower bound for is, with high probability, greater than the deviation of from its mean. The first line of (D.43) follows from combining these steps. The second line of (D.43) can be established along the same lines. A union bound then establishes the desired result:
Step 1: Condition 4 implies that, for each unit , there exists a unit such that and . Thus, by Lemma D.7, Lemma 17 of S25, and Conditions 4 and 4, we obtain
Theorem 1 of \citetsupp[][p. 207]Chetal07 implies
Choosing
gives
Next, we demonstrate that there exists an integer such that, for all ,
To do so, we bound the three terms one by one. Using , the first term, , is bounded above by provided . The second term is bounded above by as shown in the proof of Lemma 14 in S25. The third term is bounded above by by Lemma D.6, where is a constant.
Combining these results gives
Similar to the proof of Lemma 14 in S25, this implies
Step 2: Conditions 4 and 4 along with Lemma D.7 establish
Once more, we invoke Theorem 1 of \citetsupp[][p. 207]Chetal07 to obtain
We proceed by showing that there exists an integer such that, for all ,
| (D.44) |
We bound the three terms on the left-hand side of (D.44) one by one. The bounds on the first term, , and third term, , are the same as in the first step. With regard to the second term, we obtain by the proof of Lemma D.5 with .
Appendix E Quasi-Newton Acceleration
The two-step algorithm described in Section 3.2 iterates two steps:
-
Step 1: Update given using a MM algorithm with a linear convergence rate (\citealpsuppbohning_monotonicity_1988, Theorem 4.1).
-
Step 2: Update given using a Newton-Raphson update with a quadratic convergence rate.
To accelerate Step 1, we use quasi-Newton methods (\citealpsupplange_optimization_2000): We approximate the difference between and , defined in Lemma 3.2 and Equation (9), respectively, by rank-one updates.
A first-order Taylor approximation of around shows that
| (E.1) |
where
| (E.2) |
Since a standard Newton-Raphson algorithm corresponds to (E.1) with , the change in consecutive estimates carries information on , which we want to approximate. More specifically, we approximate the difference between and . Thus we write and set , so that (E.1) becomes
| (E.3) |
which is called the inverse secant condition for updating . Given that (E.3) relates to the score functions through the definition of in (E.2) and estimates and , the updates of will be based on (E.3). We employ the parsimonious symmetric, rank-one update of \citetsuppdavidon_variable_1991 to satisfy (E.3) by updating as follows:
| (E.4) |
with and . We seed the algorithm with the MM update described in Section 3.2 by setting , the null matrix.
In summary, the quasi-Newton acceleration of the MM algorithm updates given as follows:
Unlike the unaccelerated MM algorithm, the described quasi-Newton algorithm does not guarantee that . Therefore, is updated by either the quasi-Newton update (E.5) or the MM update (10), whichever gives rise to the higher pseudo-likelihood. The resulting updates slightly increase the computing time per iteration while potentially dramatically decreasing the total number of iterations.
Appendix F MM Algorithm: Directed Connections
If connections are directed, may differ from . In such cases, the pseudo-loglikelihood can be written as
where and are defined by
We partition the parameter vector into
-
•
the nuisance parameter vector: , , , , ;
-
•
the parameter vector of primary interest: , , , , , , , .
As explained in Section 6.1, is set to in order to address identifiability issues. The negative Hessian is partitioned in accordance:
where , , and . Writing in place of , we compute at iteration :
-
Step 1: Given , find satisfying .
-
Step 2: Given , find satisfying .
In Step 1, it is inconvenient to invert the high-dimensional matrix
Note that the definition of vector differs from the undirected case described in Section 3.2. For , let be the -vector whose th and th coordinates are and whose other coordinates are . For , let be the -vector whose th coordinate is and whose other coordinates are . Along the lines of the MM algorithm for undirected connections described in Section 3.2, we increase by maximizing a minorizing function of , replacing by a constant matrix that is more convenient to invert. The constant matrix is defined as
where
-
•
and are diagonal matrices with elements on the main diagonal;
-
•
is a matrix with vanishing elements on its main diagonal and off-diagonal elements .
Applying Theorem 8.5.11 in \citetsuppharville_matrix_1997 to and shows that matrix can be inverted in operations. With the above change in the constant matrix , we estimate along the lines of Section 3.2.
Appendix G Hate Speech on X: Additional Information
G.1 Data
For the application, we use posts of 2,191 U.S. state legislators on the social media platform X collected by \citetsuppkim_attention_2022 in the six months leading up to and including the insurrection at the United States Capitol on January 6, 2021. We restrict attention to active legislators, that is, legislators who posted during the aforementioned period and mentioned or reposted content from other active legislators. Since reposts do not necessarily reflect politicians’ opinions, we exclude all reposts and non-unique posts that are direct copies of other users’ messages to gather information on responses. Employing large language models of \citetsuppcamacho-collados_tweetnlp_2022 pre-trained on these posts enables categorizing the 109,974 posts into those containing hate speech statements versus those that do not. Accordingly, the binary attribute equals 1 if the corresponding legislator sent at least one post classified as hate speech and 0 otherwise. The algorithm of \citetsuppcamacho-collados_tweetnlp_2022 provides for each Tweet a continuous value between 0 and 1. We classify the respective Tweet as using hate speech if its value is larger than 0.5. The attribute is 1 if legislator is a Republican and 0 otherwise. In addition, we incorporate information on each legislator’s gender ( if legislator is female and otherwise), race ( if legislator is white and otherwise), and state (). On the social media platform X, users have the ability to either mention or repost other users’ posts. The resulting network, denoted as , is based on the mentions and reposts exchanged between January 6, 2020 and January 6, 2021: if legislator mentioned or reposted legislator in a post.
G.2 Plots
In addition to the goodness-of-fit checks reported in Section 6, we assess whether the model preserves salient characteristics of connections . Figure 5 suggests that the proposed model captures the shared partner distribution, i.e., the numbers of connected pairs of legislators with , , shared partners.
chicago \bibliographysuppbase