A Review of Star Schema Benchmark
Abstract
This paper examines the Star Schema Benchmark, an alternative to the flawed TPC-H decision support system and presents reasons why this benchmark should be adopted over the industry standard for decision support systems.
Keywords:
TPC-H; databases; star schema benchmark; DBMS; profiling;I INTRODUCTION
The TPC organization is responsible for defining benchmarking standards. One such standard is TPC-H, an ad hoc decision support benchmark [1]. TPC-H has been criticized for not adhering to a Ralph Kimball model of data marts, not adhering to Edgar F. Codd’s definition of a 3NF data schema, as well as not allowing freedom in indexing and partitioning [2, 3, 4]. The Star Schema Benchmark (SSB) was designed to test star schema optimization to address the issues outlined in TPC-H with the goal of measuring performance of database products and to test a new materialization strategy. The SSB is a simple benchmark that consists of four query flights, four dimensions, and a simple roll-up hierarchy [5]. The SSB is significantly based on the TPC-H benchmark with improvements that implements a traditional pure star-schema and allows column and table compression.
The SSB is designed to measure performance of database products against a traditional data warehouse scheme. It implements the same logical data in a traditional star schema whereas TPC-H models the data in pseudo 3NF schema [6].
II Compression
Typically higher degrees of correlation can be found between columns of transactional data. Highly correlated columns are often able optimized using compression routines and column stores. However due to the data distribution, it is impractical and unrealistic to attempt to use compression on the TPC-H schema as can be seen in Section VI. SSB allows the columns in tables to be compressed by whatever means available in the database system used, as long as reported data retrieved by queries has the values specified in the schema definition [5]. It has been shown that compressing data using column-oriented compression algorithms as well as keeping the data in a compressed format may improve performance significantly by as much as an order of magnitude [7]. Data stored in columns is more compressible than data stored in rows. This is due to the fact that compression algorithms perform better on data with low information entropy. Entropy in data compression refers to the randomness of the data being passed into the compression algorithm. The higher the entropy, the lower the compression ratio. In other words, the more random the data is the harder it becomes to compress it [8].
This observation only immediately affects compression ratio, less time is spent in input/output activities as data is read from disk into memory if the data is compressed [9]. Some heavier compression algorithms that optimize for compression ratio may not be as suited in comparison to lighter schemes that forfeit compression ratio for decompression performance. If a query executor can operate directly on compressed data, then decompression can be avoided completely, furthermore, decompression can be avoided then performance can be further improved. One example would be the query executor having the ability to perform the same operation on multiple column values at once [9].
It has been shown that the most significant compression differences between row and column stores are the cases where a column has been sorted and contains consecutive repeating of some value in that column [9]. It is extremely easy to summarize these value repeats in a column-store. It is even easy to operate directly on this summary. In contrast, in a row-store, surrounding data from other attributes significantly complicates the process. For this reason, compression will typically have a more significant impact on query performance when the percentage of columns accessed have some order [9].
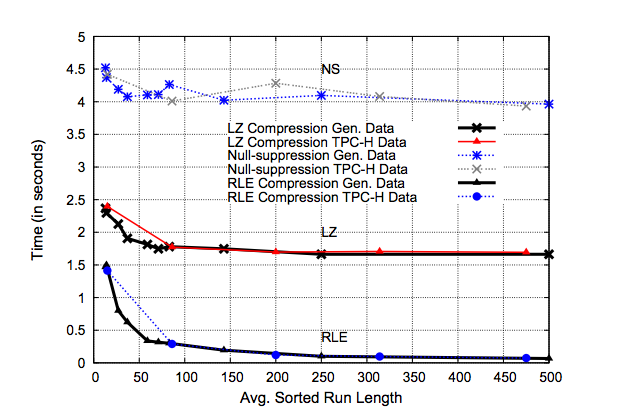
Figure 1 shows the comparison of query performance on TPC-H and generated data using RLE, LZ, and null-suppression compression schemes.
III Detail
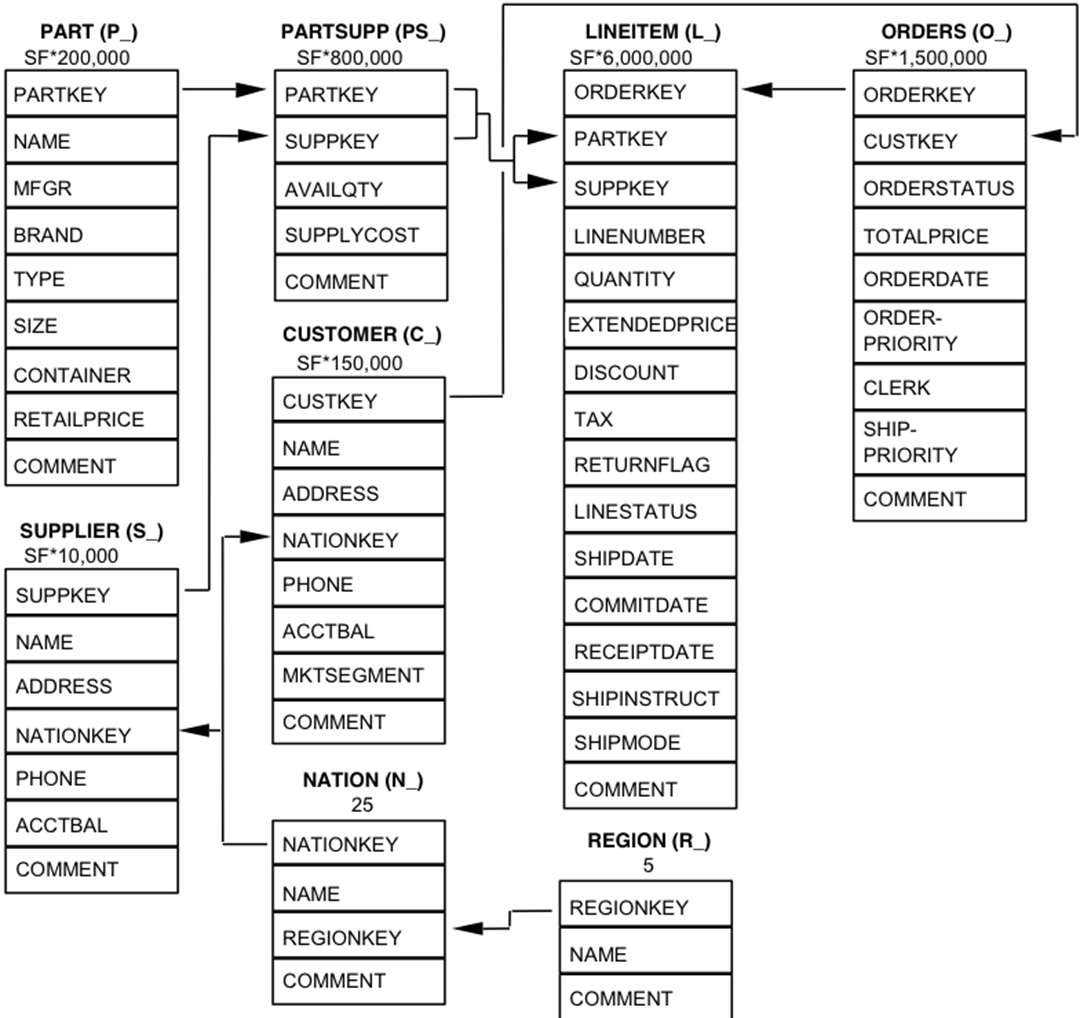
Schema modifications were made to the TPC-H schema transform it into the more efficient star schema form. The TPC-H tables LINEITEM and ORDERS are combined into one sales fact tale named LINEORDER. LINEORDER is consistent with a denormalized warehouse per the Kimball model [10]. Kimball claims that a star schema helps to reduce the number of complex and often unnecessary joins [10].
The PARTSUPP table is dropped since it would belong to a different data mart than the ORDERS and LINEITEM data, furthermore, it contains temporal data that varies. The comment attributes for LINEITEMS, ORDERS, and shipping instructions are also dropped as a data warehouse does not store such information in a fact table, they can’t be aggregated and take significant storage space.
A dimension table called DATE is added to the schema as is in line with a typical data warehouse. However, as this is a commonly reserved word in many DBMS systems, a more relevant name can be used to avoid SQL errors or having to wrap the table name in back-tick identifiers. These table simplifications result in a proper star schema data mart. LINEORDER serves as a central fact table. Dimension tables are created for CUSTOMER, PART, SUPPLIER, and DATE. A series of tables for SHIPDATE, RECEIPTDATE, and RETURNFLAG, should also be constructed, but would result in a too complicated a schema for our simple star schema benchmark. SSBM concentrates on queries that select from the LINEORDER table exactly once. It prohibits the use of self-joins or sub-queries as well as or table queries also involving LINEORDER. The classic warehouse query selects from the table with restrictions on the dimension table attributes. SSBM supports queries that appear in TPC-H. SSB consists of one large fact table (LINEORDER) and four dimensions tables (CUSTOMER, SUPPLIER, PART, Date). It is common practice to combine LINEITEM and ORDER in TPC-H to get LINEORDER in SSB. LINEORDER represents one row for each one in LINEITEM.
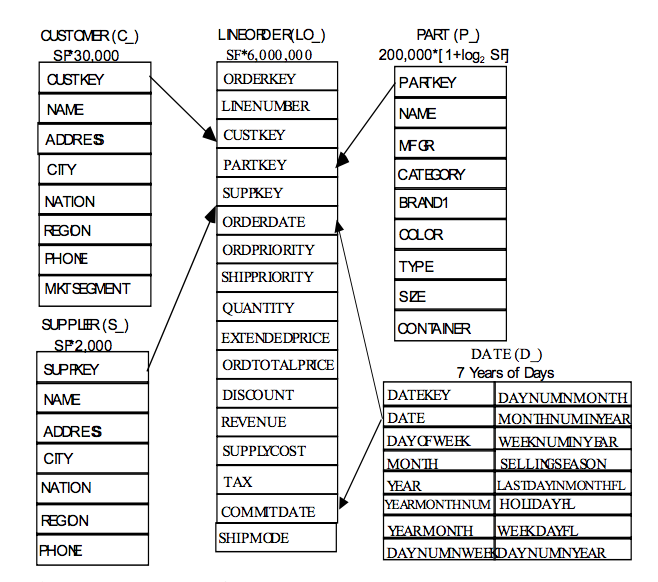
III-1 PARTSUPP
As seen in fig. 3 the PARTSUPP table was removed to keep in line with the data warehousing principles of Kimball. The problem with this methodology is that the LINEITEM and ORDERS tables have fine temporal grain. The PARTSUPP table has a Periodic Snapshot grain. Periodic snapshot grains are fact tables that summarize many measurement events occurring over a some period of time, such as a day, a week, or a month. Subsequently, transactions that add new rows over time to LINEORDER do not modify rows in PARTSUPP. One solution would be to treat PARTSUPP and LINEORDER as separate fact tables, isolating queries separately and not joined together. This is done in all but one of the queries where PARTSUPP is in the WHERE clause (Q1, Q11, Q16, Q20) but not in Q9, where PARTSUPP, ORDERS, and LINEITEM all appear [11]. Q9 is intended to find, for each nation and year, the profits for certain parts ordered that year [11]. The problem is that it is beyond the bounds of reason that the PS_AVAILQTY would have remained constant during all these past years. This difference in grain between PARTSUPP and LINEORDER is what causes the problem. One reason for having the PARTSUPP is to break up what might be a star schema and so that query plans do not appear to be too simple.
Creating a Snapshot on the PARTSUPP table seems to be overly complicated as to create a non-trivial join that was designed to complicate the query path and add more load to the system artificially. In the TPC-H benchmark PS_AVAILQTY is never updated, not even during the refresh that inserts new rows into the ORDERS table. In SSB data warehouse, it is more reasonable to leave out the PARTSUPP tale and instead create a new column SUPPLYCOST for each LINEORDER Fact row. A data warehouse contains derived data only, so there is no reason to normalize in order to guarantee one fact in one place.
It is possible, and perhaps likely that subsequent orders for the same part and supplier might repeat this SUPPLYCOST. If the last part of some kind were to be deleted its reasonable to believe that it might result in the loss of the price charged. Since SSB is attempting to simplify queries this might be an acceptable solution. In fact, SSB adds the LO_PROFIT column to the LINEORDER table which aids in making these calculations simpler and execution time quicker.
III-2 LINEORDERS
The LINEITEM and ORDERS table are combined into one sales fact table that is named LINEORDER. This is a standard denormalization aligned with the data warehousing per Kimball [10]. This combination of tables into one sales fact table reduces the need for many complex joins spread across the most common queries. All columns in the ORDERS and LINEITEMS tables that make us wait to insert a Fact row after an order is placed on ORDERDATE is dropped. An example is not wanting to wait until we know when the order is shipped, when it is received, and whether it is returned before we can query the existence of an order.
III-A NATION and REGION
The NATION and REGION tables are denormalized into the CUSTOMER and SUPPLIER tables and a CITY column is added. This simplifies the schema considerably, both for writing queries and computing queries as the two largest tables of TPC-H are pre-joined. Queries do not have to perform the join and users writing queries against the schema do not have to express the join in their queries. NATION and REGION might be appropriate in an OLTP system to enforce integrity, but not in a data warehouse system where the data is cleaned before being loaded and dimension tables are not so limited in space use as the fact table. NATION and REGION are added to the ADRESSS columns.
IV Queries
The reasons for the departure from the TPC-H query format are multiple. The most common reason is an attempt to provide the Functional Coverage and Selectivity Coverage features explained in Set Query Benchmark [12, 5]. The benchmark queries are chosen as much as possible to span the tasks performed by an important set of Star Schema queries, so that prospective users can derive a performance rating from the weighted subset they expect to use in practice. It is difficult to provide true functional coverage with a small number of queries, but SSB at least tries to provide queries that have up to four dimensional restrictions. Selectivity coverage is the idea that the total number of fact table rows retrieved will be determined by the selectivity of restrictions on the dimensions. SSB introduces variety into the selectivity by varying the queries results sets. The goal of SSB is to provide functional coverage as well as selectivity coverage. Some model queries are based on the TPC-H query set, but need to be modified so vary the selectivity. These are the only queries that will not have an equal counterpart in TPC-H.
IV-1 Query Flights
Compared to the TPC-H’s 22 queries, SSB contains four query flights that each consist of three to four queries with varying selectivity. Each flight consists of a sequence of queries that someone working with data warehouse systems would ask such as a dill down [5].
IV-2 Caching
One other issue arises in running the Star Schema Benchmark queries, and that is the caching effect that reduces the number of disk accesses necessary when query Q2 follows query Q1, because of overlap of data accessed between Q1 and Q2. SSB attempts to minimize overlap, however in situations where this cannot be done, SSB will take whatever steps are needed to reduce caching effects of one query on another [5].
V Data Distribution
Similar to TPC-H all of the data in SSB is uniformly distributed. Selectivity hierarchies are introduced in all dimension tables similar to the manufacturer/brand hierarchy in TPC-H [5]. This uniform data distribution is aided by a tool called SSB-DBGEN. SSB-DBGEN is tool similar to TPC-H DBGEN that makes populating the database for benchmark runs simple and allow for quick transitions between transaction tests. However, SSB-DBGEN is not easy to adapt to different data distributions as its metadata and actual data generation implementations are not separated [13].
VI Scaling
Both TPC-H and SSB generate data at different scales using the scaling factor. The scale factor determines the amount of information initially loaded into the benchmark tables. Scale factor increases the size of the database during the testing process. As the scale factor increases, the number of rows added to the tables increase. Data is generated proportionally to scale factor. The scale factor impacts the number of generated lines. Only for the PARTS, data is not scaled linearly but logarithmically [5].
VII Experiments
VII-A Out of the Box Configuration
Utilizing an Amazon Web Services (AWS) Elastic Compute Cloud (EC2) m1.small instance running CentOS 6.5, we installed MySQL 5.6.12, PostgreSQL 9.4, and SQLite 3.9.2. We created two databases on each DBMS, one for testing the TPC-H schema and one for the SSB schema. We then used the DBGEN and SSB-DBGEN tools respectively to populate the newly created databases with data using a scale factor of 1. TPC-H and SSB both use a base scale factor which can be used to scale the size of the benchmark. The sizes of each of the tables are defined relative to this scale factor. Using QGEN and SSB-QGEN, we generated randomized TPC-H and SSB queries. Next we mapped 10 TPC-H queries to the closest matching SSB query flight and query. Some TPC-H have direct mapping such as TPCHQ3 and TPCH6. The remaining queries that did not have direct TPC-H equivalents were matched based on the business logic of the query, as well as the complexity of the query. No indices were added to the schemes except those created by the DBMS for primary keys. Our query pair mapping of TPC-H to SSB can be seen in fig. 4.
| Query | TPC-H | SSB |
|---|---|---|
| 1 | Q6 | Q1.1 |
| 2 | Q6 | Q1.2 |
| 3 | Q6 | Q1.3 |
| 4 | Q3 | Q5.1 |
| 5 | Q3 | Q5.2 |
| 6 | Q3 | Q5.3 |
| 7 | Q2 | Q12.1 |
| 8 | Q2 | Q12.2 |
| 9 | Q5 | Q13.1 |
| 10 | Q5 | Q13.2 |
Figure 5 shows the average execution time of each of the first ten queries of TPC-H executed on each DBMS. Figure 6 shows the average execution time of each of the first ten queries of SSB executed on each DBMS. It is clear from this graph that there is a significant decrease in average execution time across the board from TPC-H. In fact, there is an increase in execution time in all queries across all DBMS.
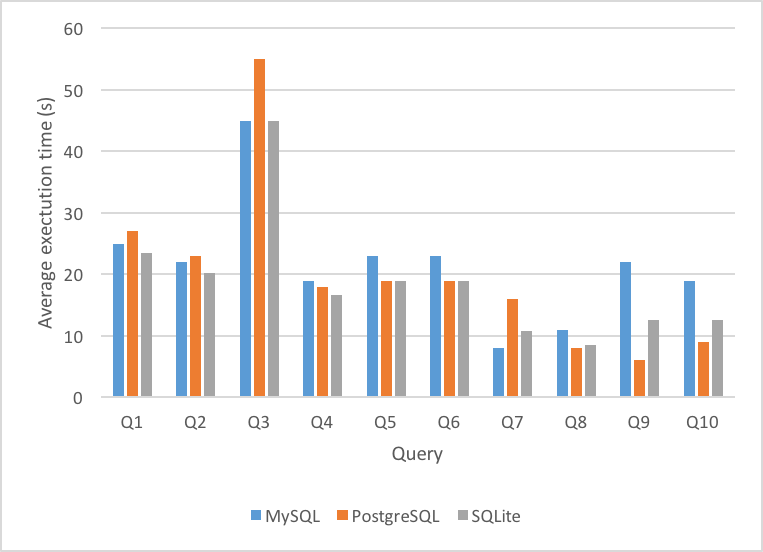
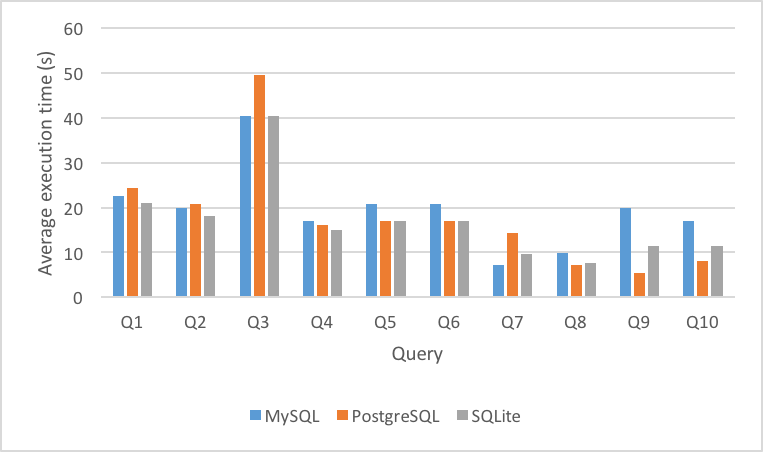
As can be seen from the data, even though the average execution time decreased significantly across the board from TPC-H to SSB, the ratio between each DBMS maintained.
VII-B Indexing
Next we analyzed the WHERE clauses and EXPLAIN output from each of the 10 queries in both TPC-H and SSB and created indices on those columns that would benefit from an index (all clauses specified in the WHERE clause as well as some composite keys).
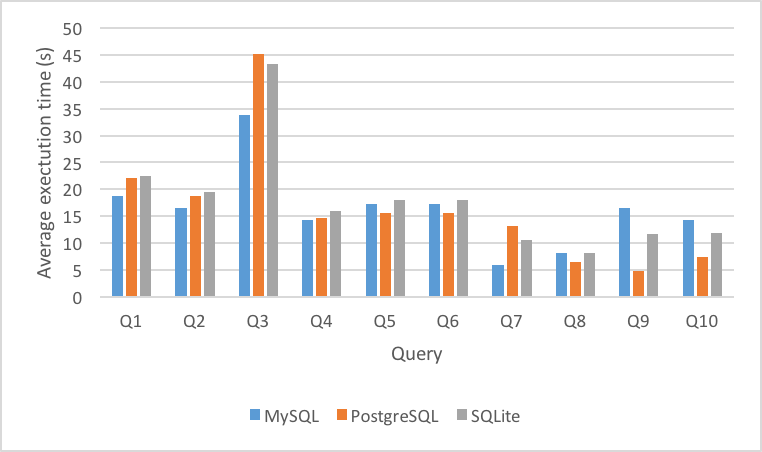
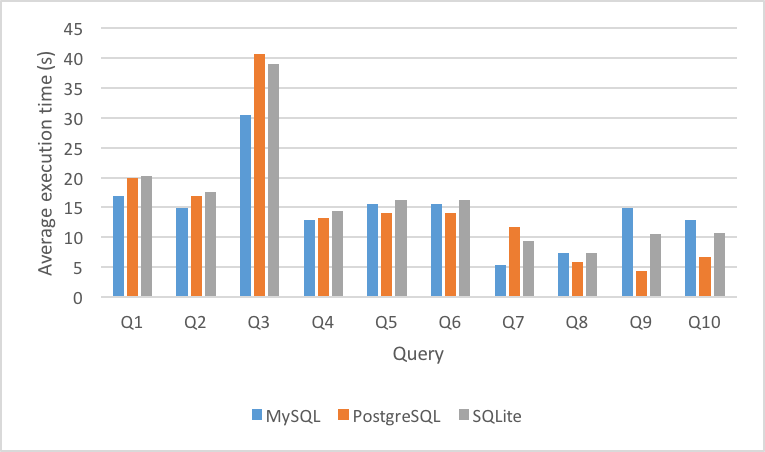
Figure 7 and Figure 8 show the average execution time per DBMS across the systems with indices added for queries Q1-Q10 in TPC-H and SSB. As can be seen in this data, adding indices changed the average execution time significantly, but also changed the results of the DBMS performance now. MySQL is the clear winner for speed alone after utilizing indices, whereas SQLite appeared to be the faster solution without index optimization.
VIII Conclusion
SSB is a variation of the TPC-H benchmark modified so that it represents a Kimball style database design. SSB is a popular benchmark for decision support systems and is a valid tool for evaluating the performance of DBMS executing star schema queries. Today’s systems rely heavily on sophisticated cost-based query optimizers to generate the most efficient query execution plans. SSB evaluates the optimizer’s capability to generate optimal execution plans under all circumstances.
The optimizer needs to be aware of the performance implications of operating directly on compressed data in its cost models. Further, cost models that only take into account I/O costs will likely perform poorly in the context of column-oriented systems since CPU cost is often the dominant factor.
Our experiment has successfully shown that SSB is a far better benchmark, it offers a much simpler schema and query execution set. SSB adheres to the Ralph Kimball definition of a data warehouse. TPC-H penalizes systems who are unable to optimize for correlated sub-queries, limited indexing, and partitioning. SSB helps to level the playing field so that IT decision makers and software architects can make informed choices when deciding which DBMS solution(s) to use.
References
- [1] R. Nambiar and M. Poess, Performance Evaluation and Benchmarking: Transaction Processing Performance Council Technology Conference, TPCTC 2009, Lyon, France, August 24-28, 2009, Revised Selected Papers. Springer Science & Business Media, 2009, vol. 5.
- [2] C. Coronel, S. Morris, and P. Rob, Database Systems: Design, Implementation, and Management. Cengage Learning, 2009.
- [3] C. Date, Relational Theory for Computer Professionals. ”O’Reilly Media, Inc.”, 2013.
- [4] R. O. Nambiar and M. Poess, “The making of tpc-ds,” pp. 1049–1058, 9 2006.
- [5] P. O’Neil, E. O’Neil, X. Chen, and S. Revilak, Performance Evaluation and Benchmarking, ser. Lecture Notes in Computer Science, R. Nambiar and M. Poess, Eds. Springer Berlin Heidelberg, 10 2009, vol. 5895.
- [6] A. M. C. S. R. L. P. Rocha, Alvaro; Correia, New Contributions in Information Systems and Technologies, Volume 1. Springer, 2015.
- [7] Big Data Benchmarks, Performance Optimization, and Emerging Hardware: 4th and 5th Workshops, BPOE 2014, Salt Lake City, USA, March 1, 2014 and Hangzhou, China, September 5, 2014, Revised Selected Papers. Springer, 2014, vol. 10.
- [8] S. Aghav, “Database compression techniques for performance optimization,” in ICCET 2010 - 2010 International Conference on Computer Engineering and Technology, Proceedings, vol. 6. IEEE, 2010, pp. 6–714.
- [9] D. Abadi, S. Madden, and M. Ferreira, “Integrating compression and execution in column-oriented database systems,” in Proceedings of the 2006 ACM SIGMOD international conference on Management of data - SIGMOD ’06. ACM Press, 6 2006, p. 671.
- [10] R. Kimball and M. Ross, “The data warehouse toolkit: The definitive guide to dimensional modeling,” 7 2013.
- [11] T. P. P. Council, “Tpc-h benchmark specification,” Published at http://www. tcp. org/hspec. html, pp. 1–134, 2011.
- [12] P. E. O’Neil, “The set query benchmark.” in The Benchmark Handbook, 1991, pp. 209–245.
- [13] T. Rabl, M. Poess, H.-A. Jacobsen, P. O’Neil, and E. O’Neil, “Variations of the star schema benchmark to test the effects of data skew on query performance,” in Proceedings of the ACM/SPEC international conference on International conference on performance engineering - ICPE ’13. ACM Press, 4 2013, p. 361.