A Safe Exploration Strategy for Model-free Task Adaptation in Safety-constrained Grid Environments
Abstract
Training a model-free reinforcement learning agent requires allowing the agent to sufficiently explore the environment to search for an optimal policy. In safety-constrained environments, utilizing unsupervised exploration or a non-optimal policy may lead the agent to undesirable states, resulting in outcomes that are potentially costly or hazardous for both the agent and the environment. In this paper, we introduce a new exploration framework for navigating the grid environments that enables model-free agents to interact with the environment while adhering to safety constraints. Our framework includes a pre-training phase, during which the agent learns to identify potentially unsafe states based on both observable features and specified safety constraints in the environment. Subsequently, a binary classification model is trained to predict those unsafe states in new environments that exhibit similar dynamics. This trained classifier empowers model-free agents to determine situations in which employing random exploration or a suboptimal policy may pose safety risks, in which case our framework prompts the agent to follow a predefined safe policy to mitigate the potential for hazardous consequences. We evaluated our framework on three randomly generated grid environments and demonstrated how model-free agents can safely adapt to new tasks and learn optimal policies for new environments. Our results indicate that by defining an appropriate safe policy and utilizing a well-trained model to detect unsafe states, our framework enables a model-free agent to adapt to new tasks and environments with significantly fewer safety violations.
1 Introduction
Learning through trial and error is a critical approach for humans to learn new concepts which has also been an inspiration for developing Reinforcement Learning (RL) methods [34]. In RL methods, the desired behavior is learned through interaction with the environment, where the agent receives feedback based on the decisions it makes. While RL methods have demonstrated remarkable performance across various domains, including video games [28, 21, 38], conventional recommender systems [44, 35, 19], and enhancing the responses of large language models [8, 26]. Their applications in many real-world situations such as autonomous driving [20, 3], medical usage [32, 31, 37] and recommendation systems in sensitive domains [31, 30] have been restricted due the potential to make dangerous and irreversible mistakes. This problem is more severe for model-free agents given that they don’t have any prior knowledge about the environment and they predominantly rely on a trial-and-error approach to learn the optimal policy.
In numerous real-world scenarios, the environment within which the agents interact demands careful consideration of safety. For instance, in the realm of autonomous cars, many safety features have been developed to identify possible collision situations and take preventive actions to avoid them. In the field of medical applications, providing suggestions for intricate and potentially dangerous situations often involves discussions led by professional experts, rather than relying solely on AI-based systems. Similarly, recommendation systems on movie platforms must consciously account for safety considerations, ensuring the appropriateness of suggestions for specific age ranges. In all the examples provided, diverse solutions for safety considerations have been implemented to identify hazardous states and prompt alternative responses beyond their initially planned actions. These responses may involve reducing the speed of the vehicle to avoid a collision, deferring diagnosis to experts instead of relying solely on AI, or executing predefined tasks such as excluding certain suggestions from the available options in a recommendation system.
Applying RL in real-world scenarios that demand safety considerations, similar to the examples mentioned earlier, introduces the risk of potentially dangerous mistakes due to the random exploration required during the training phase [31, 12, 17]. On the other hand, exploration is an indispensable component of RL, allowing the agent to learn the optimal policy, especially in model-free settings where no information about the task or environment is provided to the agent. The inherent risk associated with the use of RL in these scenarios, arising from the free exploration strategy, makes employing RL an inefficient approach.
In this work, we propose a framework for training model-free RL agents to navigate grid environments where exploration requires consideration of safety constraints. These environments encompass hazardous states, the exploration of which might be dangerous or costly for the agent or the environment. Consequently, employing RL in such contexts amplifies the potential of encountering undesirable states due to unsupervised exploration strategies.
Our method empowers the RL agent to identify risky states, where the agent may navigate towards undesirable states through inappropriate actions selected by random exploration or a suboptimal policy. Subsequently, our framework enables the agent to recognize situations where free exploration becomes unsafe, prompting the selection of actions based on a safe policy rather than relying on random or suboptimal policies. Defining the safe policy is highly dependent on the environment and can be a set of predefined actions for the agent, relinquishing control to a human or supervisor, or employing any other secure approach as a substitute for the suboptimal RL policy that utilizes a free exploration strategy. The primary contribution of this paper lies in the design of a framework that can efficiently detect situations when free interaction (random exploration or using suboptimal policy) is unsafe for the model-free RL agent. The proposed method determines when free interaction should be replaced with a more reliable and secure strategy for selecting actions to learn the optimal policy while reducing the risk of visiting undesirable states in the training phase.
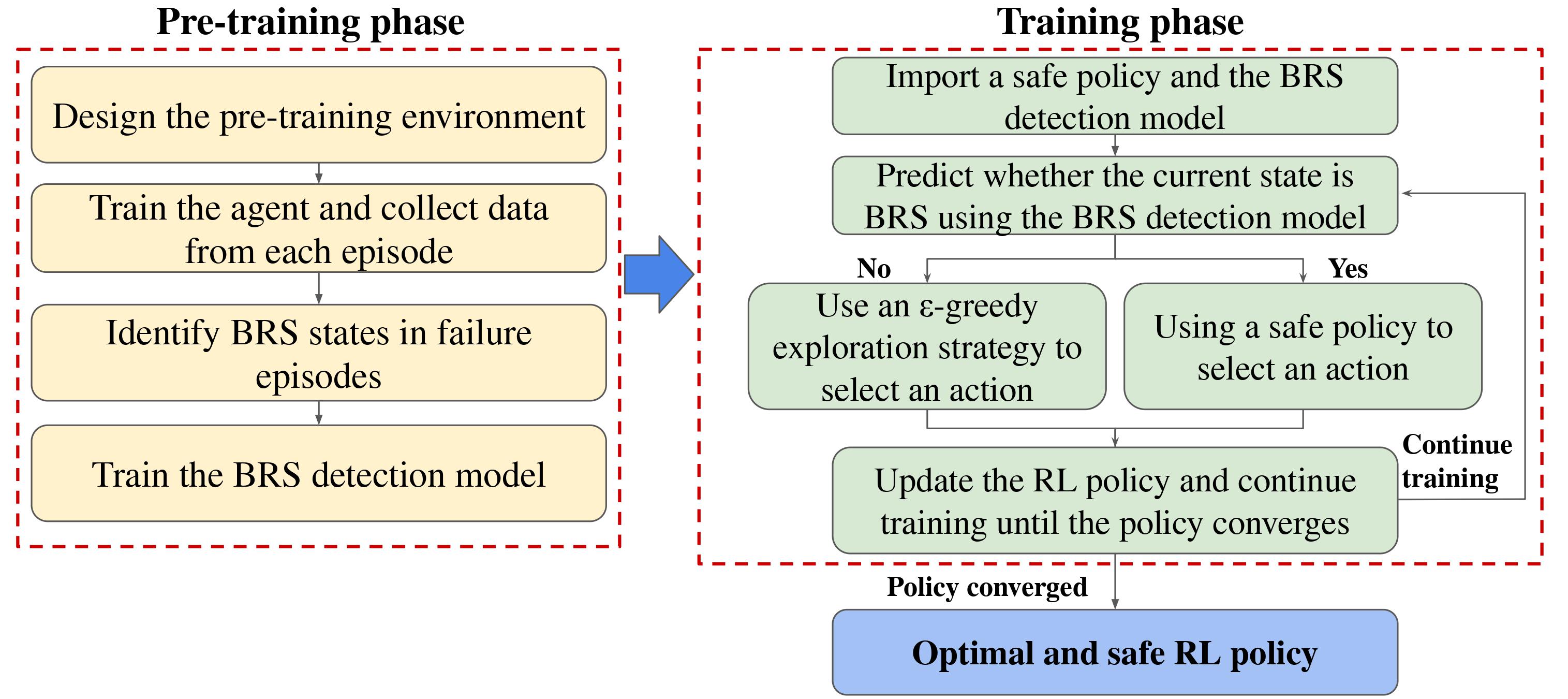
As shown in Figure 1 our proposed framework involves a pre-training phase conducted in a simulator or controlled segment of the environment, that has the same dynamics as the main environment but without hazardous consequences for entering undesirable states. During the pre-training phase, the agent interacts freely with the pre-training environment to train a model capable of identifying states that may not be initially undesirable but if the agent enters these states, inappropriate actions selected by random exploration or suboptimal policy may lead the agent into undesirable states. The model trained in the pre-training phase is then applied to the main environment, which the model-free agent has not encountered before. This enables the agent to recognize unsafe situations, where free interaction with the environment is risky. In such cases, future actions are selected using a safe policy which is defined particularly for each environment and task.
2 Related Work
Given the inherent risk and uncertainty associated with applying RL methods, safety considerations have been extensively investigated within the realm of RL methods [6, 13, 12, 11, 37, 39, 40].
One of the most important safety considerations in RL revolves around safe exploration [31, 12, 24, 16, 15, 27, 23] to avoid exposing the agent to dangerous states and consequently avoid harmful outcomes. Abeel et al. [1] proposed an apprenticeship framework to train an RL agent in safety-critical environments where the agent relies on a teacher that should act safely and near-optimally. Hans et al. [17] introduced a method to assess a state’s safety level, alongside a backup policy to navigate the system from critical to safe states. In [25] the need for a safe exploration strategy in Markov Decision Process (MDP) has been discussed, and a safe but potentially suboptimal exploration strategy for safety-constrained environments has been proposed. Turchetta et al. [39] proposed SAFEMDP algorithm which is more similar to our work and enables RL agents to explore the reachable portion of the MDP while adhering to safety constraints and gaining statistical confidence in unvisited state-action pairs using noisy observations.
Unlike many similar works on safe exploration techniques, our framework does not require prior knowledge about the distribution of unsafe states or initializing in a safe state. However, our framework needs pre-training in an environment with similar dynamics to the main environment in order to learn risky situations, given information provided in the state representation and/or agent observations.
Safe training for RL methods in safety-constrained environments has been extensively explored [41, 43, 36, 42, 2]. As a few examples, in [43] a model-free safe control strategy for deep reinforcement learning (DRL) agents has been suggested to prevent safety violation in the training phase. Thananjeyan et al. [36] proposed an algorithm called Recovery RL that leverages offline data in order to identify safety violation zones before policy learning and similar to our method, utilizes two different policies, one for learning the task and another for considering the safety constraints in the environment. Our framework proposes a more structured strategy to identify dangerous situations by computing reachable sets of undesirable states using high-level features that are observable for the agent. Another difference between our framework and methods similar to Recovery RL lies in defining the backup (safe) policy. Unlike these methods, our approach leverages a predefined safe policy instead of learning it from offline data. We propose defining a predefined safe policy and primarily focus on identifying dangerous situations in previously unseen environments with different state spaces and reward distributions, rather than learning the safe policy and applying it to a similar environment for a different task.
Another set of methods similar to ours addresses safety in reachability problems, aiming to enable RL agents to learn safe policies considering environmental safety constraints. Similar approaches [10, 9, 18, 22] have proposed enabling RL agents to attain a safe policy by computing reachable sets using Hamiltonian methods and defining a value function to assign negative values to reachable areas of undesirable states. Some key differences between these methods and our framework lie in applications, computational complexity, and the primary goal of the methods. Our method focuses on providing a safe learning framework, whereas other methods primarily analyze the safety levels of learned policies.
3 Problem Definition and Background
Similar to most RL problems, we formulate our problem of interest as a Markov Decision Process (MDP) which is defined as a tuple , where is the set of states; denotes the set of actions; is the transition function that represents the dynamics of the environment and returns the probability of transitioning to a specific state given the agent’s previous state and the action chosen at state state; is the reward function and is the discount factor.
We denote the set of failure states as which getting into them is dangerous or costly for the agent and/or the environment. The complementary set of is which contains all safe states that the agent can interact with to learn the optimal policy for the given task. Our objective is to equip the agent with the capability to identify states that upon transitioning to them, random exploration or utilizing a suboptimal policy may direct the agent into undesirable states within the next timesteps.
To determine these states, we utilize the computation of a set called Backward Reachable Set (BRS). BRS is widely used in various domains such as control and reachability problems [9, 5], robot navigation [4], and reinforcement learning [18, 10]. The BRS is the set of states in which the agent can end up within a set of states called target states within the next timesteps [5]. In this study, we compute the BRS for our failure states. Thus our set of target states is and in the following sections, denotes the backward reachable set of failure states .
We consider a trajectory of states , to be safe, when it starts from and follows a policy for a maximum of timesteps if and only if for . comprises of all states leading to failure states within timesteps, i.e., s.t. . with respect to over a time horizon of maximum timesteps is defined as follows:
| (1) |
4 Method
Our proposed framework includes two phases, namely pre-training and safe training. In the pre-training phase, a binary classification model is trained to detect dangerous states. In the safe training phase, this model is applied to identify dangerous states in a new environment. Upon detection, the agent switches from its current action selection strategy, which may involve random exploration or a suboptimal policy, to a more reliable policy known as the safe policy to prevent the agent from entering undesirable states.
4.1 Pre-training Phase
The pre-training phase takes place in an environment that has similar dynamics as the main environment. It could be either a controlled portion of the main environment or a simulated environment where getting into failure states does not have catastrophic consequences.
The primary goal during the pre-training phase is to train a model capable of predicting the states that lie in BRS given observable features for the agent in the environment. In our specific domain, the safety constraint entails avoiding collisions with a moving obstacle.
We allow the agent to interact with the pre-training environment using an -greedy exploration strategy to find the optimal policy for a given task, while simultaneously computing the BRS from the episodes where the agent encountered failure states . To that end, we define a signed function which is a signed distance between the current state and the target state which in our work is an undesirable state. Since is a signed distance function, by using the function , it becomes possible to identify whether the agent reaches failure states . Using the defined distance function , we consider a conservative perspective to formulate a value function for states in the trajectory as follows:
| (2) |
The proposed value function is designed to capture the minimum distance with the obstacle that is achieved by a trajectory starting from state by following policy over a time horizon of [0, t]. In other words, this value function represents the minimum value attained by all states in a trajectory starting from and following policy over a time horizon with the duration of timesteps. This minimum value is then assigned as the value for all states in the trajectory . Given the defined value function, if one state in the trajectory is an undesirable state (), a negative value is assigned not only to that state but also to all other states present in the same trajectory. By computing the proposed value function within a finite time horizon [0, t], we are now able to redefine the BRS as follows:
| (3) |
By utilizing the proposed value function, we can identify BRS states and utilize them to train a binary classification model. This model is then employed in new environments to detect whether the agent is in a BRS state.
4.2 Safe Training Phase
When the agent encounters a new environment wherein it has to learn a policy to solve the given task, it often searches for optimal policy by utilizing some form of exploration that can potentially be random, which may lead to a suboptimal policy during the transient search phase for the optimal policy. By leveraging the BRS detection model, we can enable the agent to identify states within the BRS of undesirable states. This model determines whether the agent is currently within the BRS of undesirable states given the agent’s observations. Upon detection of such states, the agent can replace an exploratory or suboptimal policy, which it had been using to explore the environment, with a predefined safe policy. Switching between a suboptimal/random policy and a safe policy when the agent enters allows the agent to explore the environment while avoiding entering undesirable states . The definition of the safe policy is highly dependent on the environment and the task and will be further explained in Section 6.
5 Experimental Results
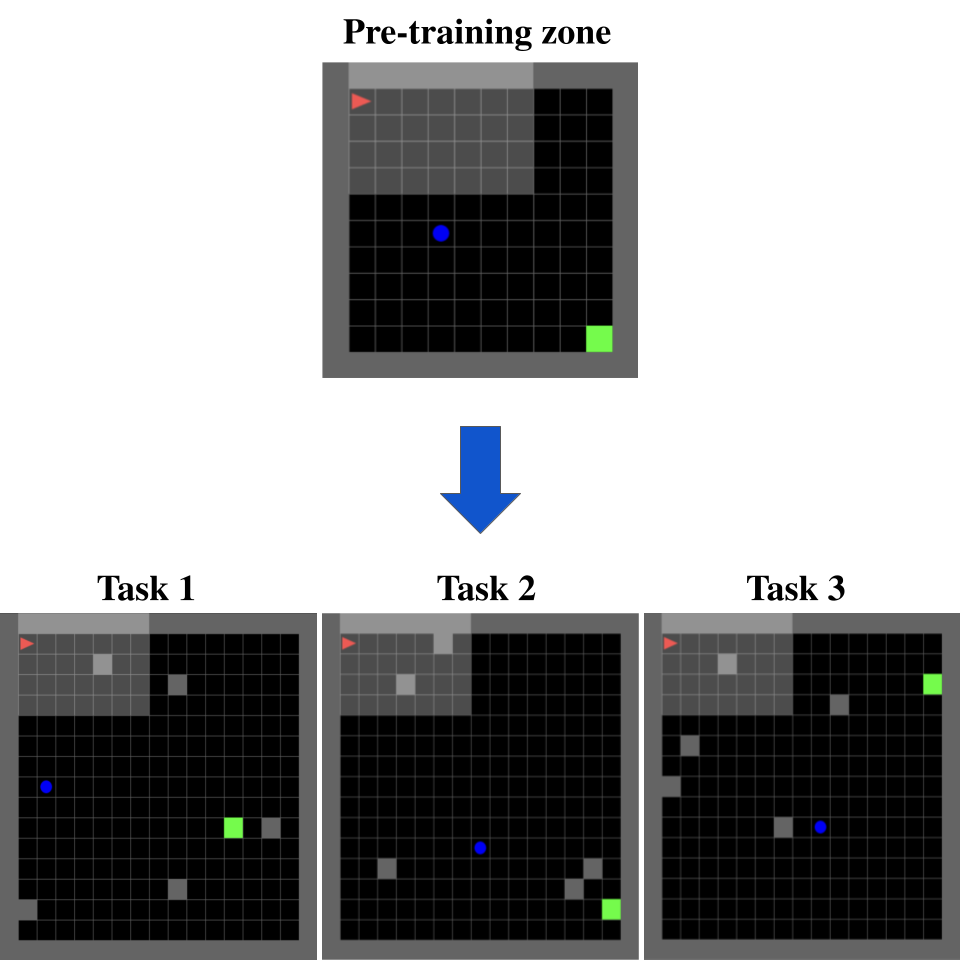
We evaluated our framework through an autonomous navigation task designed with MiniGrid [7] platform. As shown in Figure 2 our designed environments contain a moving obstacle that the agent must navigate around and reach the goal state. The obstacles move vertically in all environments and change direction upon reaching the upper or lower boundary of the environments. Reaching the goal state or interacting with the environment for a duration exceeding a maximum threshold of timesteps terminates the episode with a reward of +1 and 0, respectively. Collision with the moving obstacles constitutes a safety constraint violation in this setting which terminates the episode with a reward of -1. The environment encompasses four actions: ”turn right”, ”turn left”, ”move forward”, and ”do nothing”, that turning actions alter the agent’s direction, while the ”move forward” action moves the agent by one state in its current direction. The ”do nothing” action is exclusively designated for our safe policy, as outlined later, and is only accessible when the agent employs the safe policy. The objective of each task in this setup is for the agent to learn a policy to reach the goal state without colliding with the moving obstacle. The state representation in this scenario includes the agent’s vertical and horizontal positions, as well as the vertical position of the obstacle, (given its exclusive vertical movement) and its direction. QLearning and SARSA, two instances of model-free RL algorithms with distinct characteristics, were examined to assess our framework. However, given that our framework primarily concerns exploration strategy rather than specific learning algorithm properties, any alternative model-free algorithm can be utilized in place of them.
| -greedy Exploration | Safe Exploration | ||||||
|---|---|---|---|---|---|---|---|
| Algorithm | Task | Average Collision Rate | Average Success Rate | Sum of Reward | Average Collision Rate | Average Success Rate | Sum of Reward |
| QLearning | Task 1 | 0.287 | 0.679 | 405.259 | 0.062 | 0.860 | 1090.833 |
| Task 2 | 0.148 | 0.849 | 1082.735 | 0.032 | 0.965 | 1486.630 | |
| Task 3 | 0.129 | 0.870 | 1313.034 | 0.048 | 0.950 | 1600.665 | |
| SARSA | Task 1 | 0.170 | 0.772 | 732.294 | 0.011 | 0.892 | 1217.235 |
| Task 2 | 0.101 | 0.895 | 1232.721 | 0.009 | 0.987 | 1559.047 | |
| Task 3 | 0.092 | 0.906 | 1425.101 | 0.027 | 0.972 | 1670.998 | |
5.1 Pre-training
We initially define a simpler environment in a 10x10 grid that contains a moving obstacle and a goal state. We train the agent for 4000 episodes in the pre-training environment with a high exploration rate (0.6) and collect data from all training episodes. To identify the BRS for the moving obstacle in the pre-training environment, the signed distance function () is defined as the Euclidean distance between the obstacle and the agent. We compute the BRS of the moving obstacle for timesteps utilizing the value function described in equation 3. By computing BRS during the pre-training phase, we identified states where if the agent enters them, random exploration or actions chosen by a suboptimal policy can potentially lead the agent to collide with the obstacle within the next 2 timesteps. After identifying the BRS states, we train a binary classification model to detect BRS and non-BRS states given state features including the direction of the agent, the direction of the moving obstacle, and the signed distance.
In this work, we proceeded to train several classification models, including KNN, SVM, random forest, decision tree, and a simple CNN, to perform a binary classification task for detecting BRS and non-BRS states. Given the properties of the features present in the state representation and agent observation, the SVM classification model exhibited superior performance compared to other tested methods (when we utilized Q-Learning as our pre-training algorithm, SVM achieved an accuracy of 0.92 and an F1 score of 0.83, whereas it attained an accuracy of 0.92 and an F1 score of 0.77 when the SARSA algorithm was employed). Therefore, the SVM classification model has been chosen as the primary BRS detection model in our experiments.
5.2 Task Adoption Using BRS Detection Model and a Safe Policy
In the next step, we randomly generate three 15x15 grid environments, each containing a goal state, 5 blocked states that are inaccessible to the agent, and a vertically moving obstacle. To ensure the agent navigates past the moving obstacle, we randomly place the goal state in the right one-third of the environment, while placing the obstacle randomly outside that area.
We call each environment a task and train model-free agents using our framework and -greedy exploration strategy as a baseline with the same exploration rate (0.2) for 2000 episodes and 20 runs for each task. We then evaluate how safely each agent adapts to a new task in an environment that has been slightly changed.
In the proposed framework, when the agent interacts with the environment, it uses the BRS detection model to determine if the current state is safe for random exploration or using a suboptimal policy. When a state is identified as BRS, the agent follows a predefined policy focused on collision prevention rather than reaching the goal state or finding the optimal policy. Our safe policy keeps the agent in its current state if the moving obstacle is approaching by choosing ”do nothing” action. If the agent is in the path of the obstacle, it considers the shortest trajectory of actions to move away from the obstacle’s path, then maintains the agent’s position outside the obstacle’s path by selecting ”do nothing” action as long as the state remains identified as BRS by the BRS detection model.
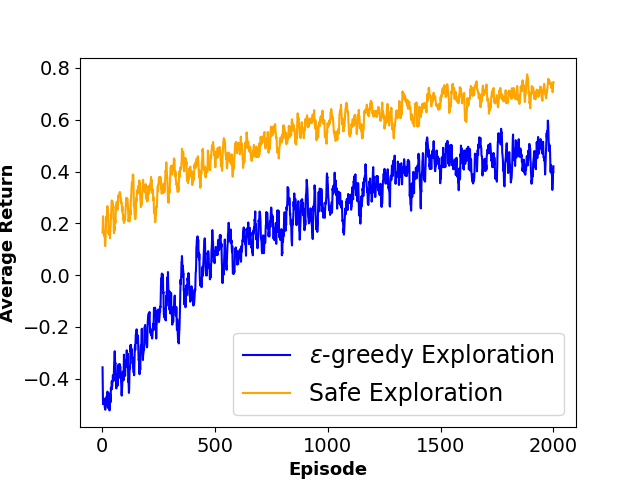
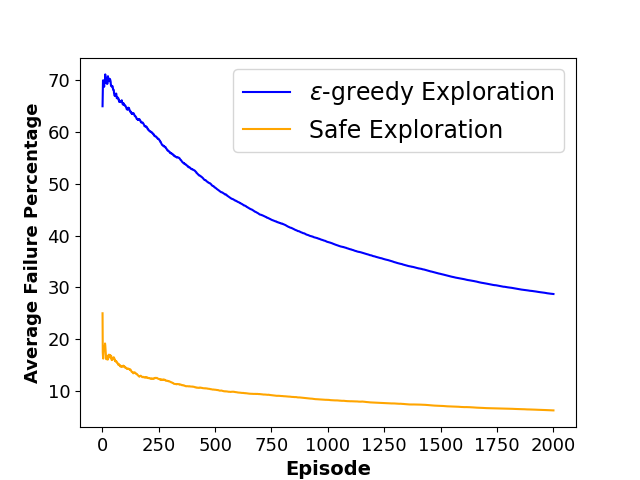
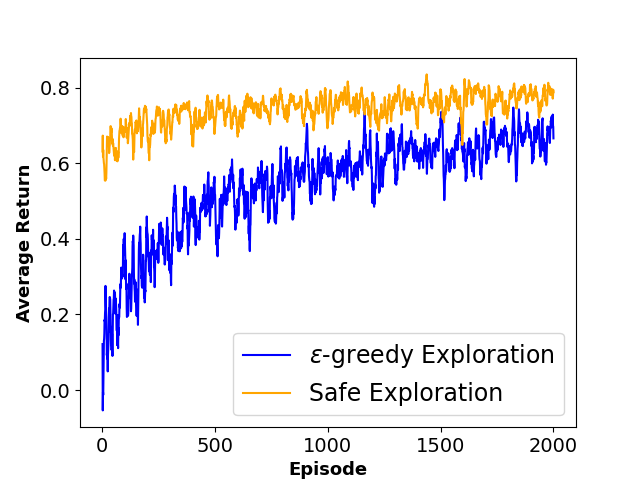
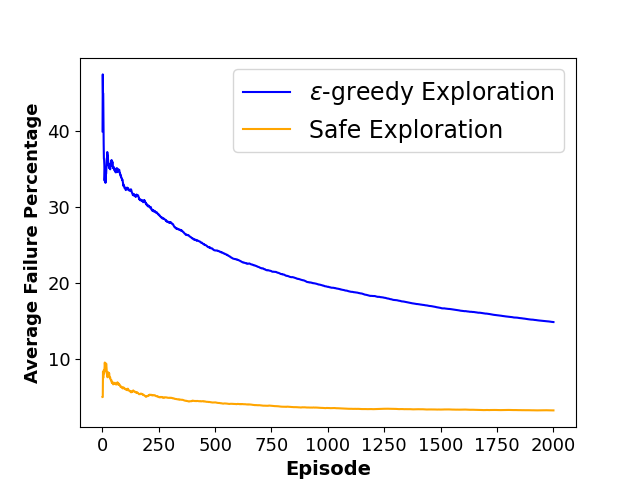
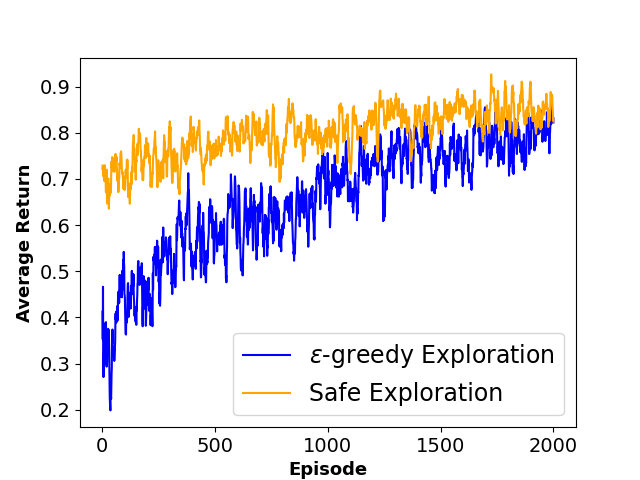
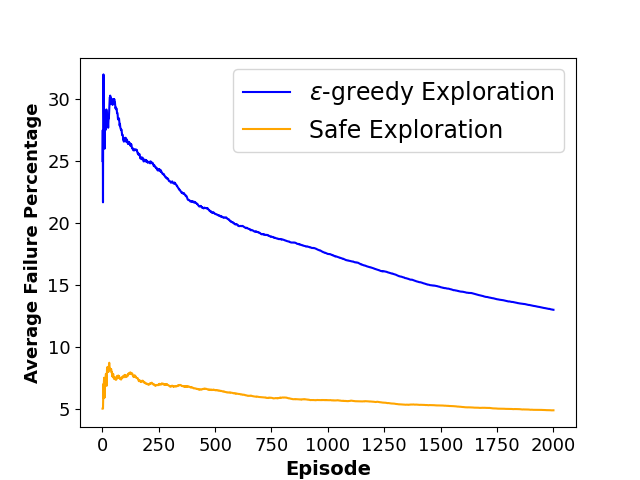
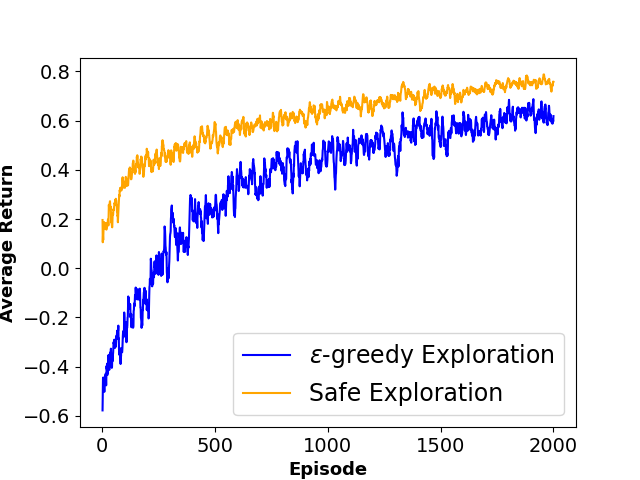
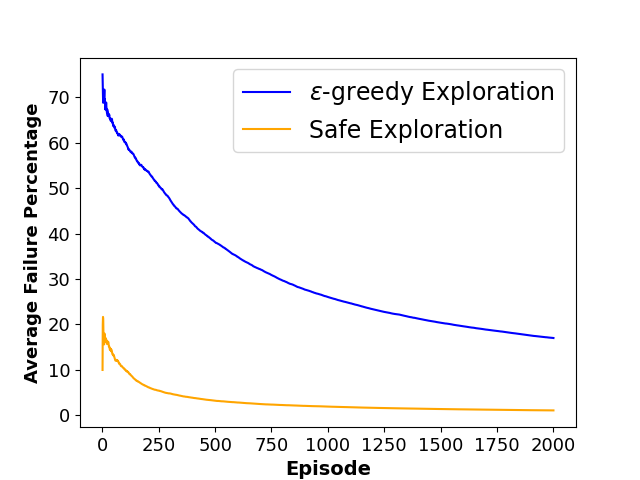
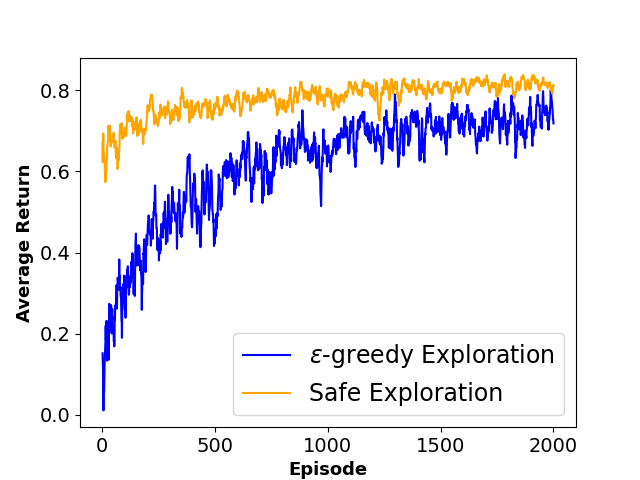
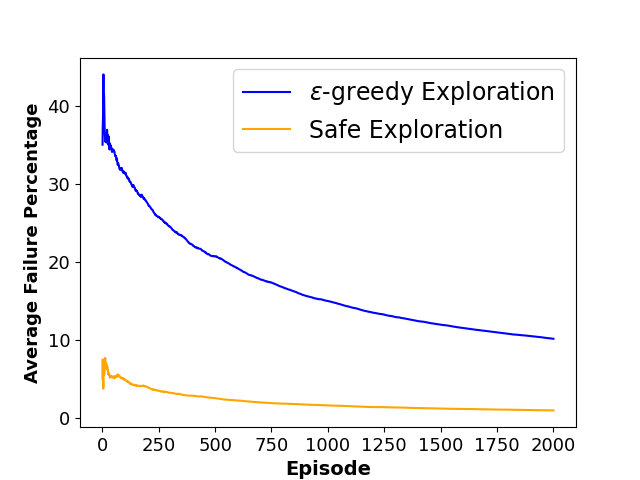
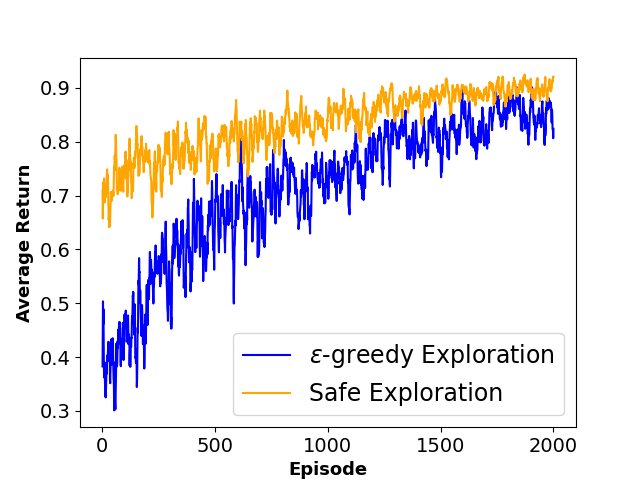
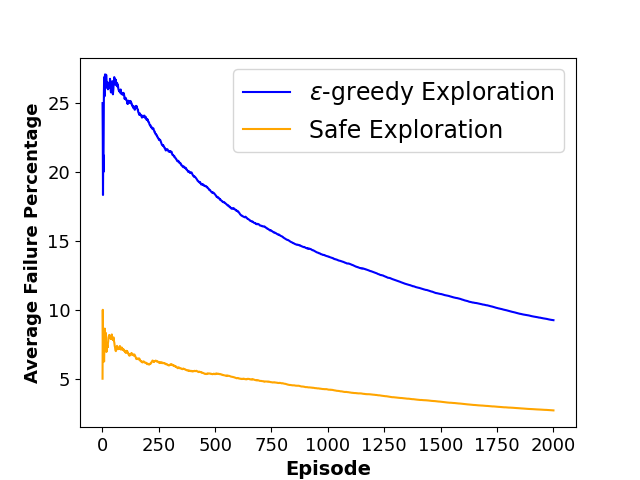
To evaluate the performance of each approach, we define three metrics namely ”Average Collision Rate”, representing the average percentage of episodes that concluded in a collision with a moving obstacle, ”Average Success Rate”, indicating the average percentage of episodes where the agent successfully reached the goal state within the defined limited time steps and ”Sum of Reward”, showing the sum of discounted rewards achieved by the agent throughout the training phase. The average results of agent behavior during the training process for both algorithms along with the utilized hyperparameters are also presented in Figures 3 and 4.
As shown in Table 1, results indicate that our framework significantly reduces the number of collisions and achieves a higher reward during the training phase, which shows the effectiveness of our method in creating a safer and more efficient training process for model-free RL agents.
6 Discussion and Future Works
We propose a framework to enhance the efficiency of model-free agents exploring new safety-constrained grid environments. In this section, we highlight a few limitations and considerations to be aware of when utilizing this framework for other domains.
Our framework offers insights into potentially unsafe states for the model-free agent. The primary contribution of our work lies in detecting instances where random exploration or suboptimal policies may pose risks in safety-constrained environments and should be substituted with more reliable approaches. However, defining a suitable safe policy depends on the specific environment and the task. In this work, to facilitate defining an appropriate safe policy, we narrowed the scope of the work to grid environments. While we demonstrate an instance of a safe policy as a set of predefined behaviors in our experiments, defining a reliable safe behavior can be challenging for certain environments, potentially diminishing the effectiveness of this framework.
One factor that may affect the efficacy of our method is the feasibility of designing an appropriate pre-training environment for the agent. In our problem of interest, navigating the grid environments, our pre-training environment comprised the similar dynamics of the main environments. However, in many real-world scenarios, designing an ideal pre-training environment may not be feasible due to the complexity and uncertainty of these environments. Therefore, it is crucial to consider this factor before deploying the proposed framework for a task.
Another limitation of our framework arises from the nature of training a machine learning model to detect unsafe situations and the inherent risk of false detections. Therefore, this framework does not guarantee error-free recognition. Consequently, in highly sensitive domains such as medical applications, relying solely on this framework may not be advisable.
Taking into account the mentioned limitations, our framework is most effective for tasks where we can design a pre-training zone with properties similar to the real environment and define a reliable safe policy. As a few examples of potential real-world applications of our framework, we can mention the task of indoor and outdoor autonomous navigation using RL [33, 29] and teaching new skills to humanoid robots [14].
In future works, we aim to explore alternative approaches for defining reliable safe policies in order to enable model-free agents to devise a set of actions for each unique situation, rather than solely relying on predefined behaviors. Additionally, we aim to work on more complex environments and evaluate the effectiveness of our framework in environments with high dimensions and complex dynamics.
7 Conclusion
In this study, we introduce an exploration framework to enable model-free RL agents to explore new environments and adapt to new tasks more safely compared to the traditional -greedy strategy. The core component of our framework is the pre-training phase that enables the agent to detect BRS states given high-level features extracted from the agent’s observation by training a binary classification model. Then, this model is used in a new environment to detect whether employing random exploration or a suboptimal policy is safe. Our experimental results demonstrate that by defining an effective safe policy and pre-training the agent in an appropriate pre-training environment, the agent can learn the optimal policy in new environments with significantly fewer violations of safety constraints and higher cumulative discounted reward.
References
- [1] P. Abbeel and A. Y. Ng. Exploration and apprenticeship learning in reinforcement learning. In Proceedings of the 22nd international conference on Machine learning, pages 1–8, 2005.
- [2] M. Alshiekh, R. Bloem, R. Ehlers, B. Könighofer, S. Niekum, and U. Topcu. Safe reinforcement learning via shielding. In Proceedings of the AAAI conference on artificial intelligence, volume 32, 2018.
- [3] A. Baheri, S. Nageshrao, H. E. Tseng, I. Kolmanovsky, A. Girard, and D. Filev. Deep reinforcement learning with enhanced safety for autonomous highway driving. In 2020 IEEE Intelligent Vehicles Symposium (IV), pages 1550–1555. IEEE, 2020.
- [4] A. Bajcsy, S. Bansal, E. Bronstein, V. Tolani, and C. J. Tomlin. An efficient reachability-based framework for provably safe autonomous navigation in unknown environments. In 2019 IEEE 58th Conference on Decision and Control (CDC), pages 1758–1765. IEEE, 2019.
- [5] S. Bansal, M. Chen, S. Herbert, and C. J. Tomlin. Hamilton-jacobi reachability: A brief overview and recent advances. In 2017 IEEE 56th Annual Conference on Decision and Control (CDC), pages 2242–2253. IEEE, 2017.
- [6] L. Brunke, M. Greeff, A. W. Hall, Z. Yuan, S. Zhou, J. Panerati, and A. P. Schoellig. Safe learning in robotics: From learning-based control to safe reinforcement learning. Annual Review of Control, Robotics, and Autonomous Systems, 5:411–444, 2022.
- [7] M. Chevalier-Boisvert, B. Dai, M. Towers, R. de Lazcano, L. Willems, S. Lahlou, S. Pal, P. S. Castro, and J. Terry. Minigrid & miniworld: Modular & customizable reinforcement learning environments for goal-oriented tasks. arXiv preprint arXiv:2306.13831, 2023.
- [8] J. Dai, X. Pan, R. Sun, J. Ji, X. Xu, M. Liu, Y. Wang, and Y. Yang. Safe rlhf: Safe reinforcement learning from human feedback. arXiv preprint arXiv:2310.12773, 2023.
- [9] J. F. Fisac, A. K. Akametalu, M. N. Zeilinger, S. Kaynama, J. Gillula, and C. J. Tomlin. A general safety framework for learning-based control in uncertain robotic systems. IEEE Transactions on Automatic Control, 64(7):2737–2752, 2018.
- [10] J. F. Fisac, N. F. Lugovoy, V. Rubies-Royo, S. Ghosh, and C. J. Tomlin. Bridging hamilton-jacobi safety analysis and reinforcement learning. In 2019 International Conference on Robotics and Automation (ICRA), pages 8550–8556. IEEE, 2019.
- [11] N. Fulton and A. Platzer. Safe reinforcement learning via formal methods: Toward safe control through proof and learning. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 32, 2018.
- [12] J. Garcia and F. Fernández. Safe exploration of state and action spaces in reinforcement learning. Journal of Artificial Intelligence Research, 45:515–564, 2012.
- [13] J. Garcıa and F. Fernández. A comprehensive survey on safe reinforcement learning. Journal of Machine Learning Research, 16(1):1437–1480, 2015.
- [14] J. García and D. Shafie. Teaching a humanoid robot to walk faster through safe reinforcement learning. Engineering Applications of Artificial Intelligence, 88:103360, 2020.
- [15] P. Geibel. Reinforcement learning with bounded risk. In Proceedings of the Eighteenth International Conference on Machine Learning, pages 162–169, 2001.
- [16] J. H. Gillulay and C. J. Tomlin. Guaranteed safe online learning of a bounded system. In 2011 IEEE/RSJ International Conference on Intelligent Robots and Systems, pages 2979–2984. IEEE, 2011.
- [17] A. Hans, D. Schneegaß, A. M. Schäfer, and S. Udluft. Safe exploration for reinforcement learning. In ESANN, pages 143–148, 2008.
- [18] K.-C. Hsu, V. Rubies-Royo, C. J. Tomlin, and J. F. Fisac. Safety and liveness guarantees through reach-avoid reinforcement learning. arXiv preprint arXiv:2112.12288, 2021.
- [19] L. Ji, Q. Qin, B. Han, and H. Yang. Reinforcement learning to optimize lifetime value in cold-start recommendation. In Proceedings of the 30th ACM International Conference on Information & Knowledge Management, pages 782–791, 2021.
- [20] B. R. Kiran, I. Sobh, V. Talpaert, P. Mannion, A. A. Al Sallab, S. Yogamani, and P. Pérez. Deep reinforcement learning for autonomous driving: A survey. IEEE Transactions on Intelligent Transportation Systems, 23(6):4909–4926, 2021.
- [21] D. Lee, H. Tang, J. Zhang, H. Xu, T. Darrell, and P. Abbeel. Modular architecture for starcraft ii with deep reinforcement learning. In Proceedings of the AAAI Conference on Artificial Intelligence and Interactive Digital Entertainment, volume 14, pages 187–193, 2018.
- [22] J. Li, D. Lee, S. Sojoudi, and C. J. Tomlin. Infinite-horizon reach-avoid zero-sum games via deep reinforcement learning. arXiv preprint arXiv:2203.10142, 2022.
- [23] P. Liu, K. Zhang, D. Tateo, S. Jauhri, Z. Hu, J. Peters, and G. Chalvatzaki. Safe reinforcement learning of dynamic high-dimensional robotic tasks: navigation, manipulation, interaction. In 2023 IEEE International Conference on Robotics and Automation (ICRA), pages 9449–9456. IEEE, 2023.
- [24] T. Mannucci, E.-J. van Kampen, C. De Visser, and Q. Chu. Safe exploration algorithms for reinforcement learning controllers. IEEE transactions on neural networks and learning systems, 29(4):1069–1081, 2017.
- [25] T. M. Moldovan and P. Abbeel. Safe exploration in markov decision processes. arXiv preprint arXiv:1205.4810, 2012.
- [26] L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. Wainwright, P. Mishkin, C. Zhang, S. Agarwal, K. Slama, A. Ray, et al. Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems, 35:27730–27744, 2022.
- [27] M. Pecka and T. Svoboda. Safe exploration techniques for reinforcement learning–an overview. In Modelling and Simulation for Autonomous Systems: First International Workshop, MESAS 2014, Rome, Italy, May 5-6, 2014, Revised Selected Papers 1, pages 357–375. Springer, 2014.
- [28] P. Peng, Y. Wen, Y. Yang, Q. Yuan, Z. Tang, H. Long, and J. Wang. Multiagent bidirectionally-coordinated nets: Emergence of human-level coordination in learning to play starcraft combat games. arXiv preprint arXiv:1703.10069, 2017.
- [29] J. Shabbir and T. Anwer. A survey of deep learning techniques for mobile robot applications. arXiv preprint arXiv:1803.07608, 2018.
- [30] A. Singh, Y. Halpern, N. Thain, K. Christakopoulou, E. Chi, J. Chen, and A. Beutel. Building healthy recommendation sequences for everyone: A safe reinforcement learning approach. In FAccTRec Workshop, 2020.
- [31] Y. Sui, A. Gotovos, J. Burdick, and A. Krause. Safe exploration for optimization with gaussian processes. In International conference on machine learning, pages 997–1005. PMLR, 2015.
- [32] Y. Sui, Y. Yue, and J. W. Burdick. Correlational dueling bandits with application to clinical treatment in large decision spaces. arXiv preprint arXiv:1707.02375, 2017.
- [33] H. Surmann, C. Jestel, R. Marchel, F. Musberg, H. Elhadj, and M. Ardani. Deep reinforcement learning for real autonomous mobile robot navigation in indoor environments. arXiv preprint arXiv:2005.13857, 2020.
- [34] R. S. Sutton and A. G. Barto. Reinforcement learning: An introduction. MIT press, 2018.
- [35] X. Tang, Y. Chen, X. Li, J. Liu, and Z. Ying. A reinforcement learning approach to personalized learning recommendation systems. British Journal of Mathematical and Statistical Psychology, 72(1):108–135, 2019.
- [36] B. Thananjeyan, A. Balakrishna, S. Nair, M. Luo, K. Srinivasan, M. Hwang, J. E. Gonzalez, J. Ibarz, C. Finn, and K. Goldberg. Recovery rl: Safe reinforcement learning with learned recovery zones. IEEE Robotics and Automation Letters, 6(3):4915–4922, 2021.
- [37] P. S. Thomas, B. Castro da Silva, A. G. Barto, S. Giguere, Y. Brun, and E. Brunskill. Preventing undesirable behavior of intelligent machines. Science, 366(6468):999–1004, 2019.
- [38] R. R. Torrado, P. Bontrager, J. Togelius, J. Liu, and D. Perez-Liebana. Deep reinforcement learning for general video game ai. In 2018 IEEE Conference on Computational Intelligence and Games (CIG), pages 1–8. IEEE, 2018.
- [39] M. Turchetta, F. Berkenkamp, and A. Krause. Safe exploration in finite markov decision processes with gaussian processes. Advances in neural information processing systems, 29, 2016.
- [40] J. Zhang, B. Cheung, C. Finn, S. Levine, and D. Jayaraman. Cautious adaptation for reinforcement learning in safety-critical settings. In International Conference on Machine Learning, pages 11055–11065. PMLR, 2020.
- [41] L. Zhang, Q. Zhang, L. Shen, B. Yuan, X. Wang, and D. Tao. Evaluating model-free reinforcement learning toward safety-critical tasks. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 37, pages 15313–15321, 2023.
- [42] W. Zhao, T. He, R. Chen, T. Wei, and C. Liu. State-wise safe reinforcement learning: A survey. arXiv preprint arXiv:2302.03122, 2023.
- [43] W. Zhao, T. He, and C. Liu. Model-free safe control for zero-violation reinforcement learning. In 5th Annual Conference on Robot Learning, 2021.
- [44] L. Zou, L. Xia, Z. Ding, J. Song, W. Liu, and D. Yin. Reinforcement learning to optimize long-term user engagement in recommender systems. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pages 2810–2818, 2019.