A Sampling Control Framework and Applications to Robust and Adaptive Control
Abstract
In this paper, we propose a novel sampling control framework based on the emulation technique where the sampling error is regarded as an auxiliary input to the emulated system. Utilizing the supremum norm of sampling error, the design of periodic sampling and event-triggered control law renders the error dynamics bounded-input-bounded-state (BIBS), and when coupled with system dynamics, achieves global or semi-global stabilization. The proposed framework is then extended to tackle the event-triggered and periodic sampling stabilization for a system where only partial state is available for feedback and the system is subject to parameter uncertainties. The proposed framework is further extended to solve two classes of event-triggered adaptive control problems where the emulated closed-loop system does not admit an input-to-state stability (ISS) Lyapunov function. For the first class of systems with linear parameterized uncertainties, even-triggered global adaptive stabilization is achieved without the global Lipschitz condition on nonlinearities as often required in the literature. For the second class of systems with uncertainties whose bound is unknown, the event-triggered adaptive (dynamic) gain controller is designed for the first time. Finally, theoretical results are verified by two numerical examples.
I Introduction
The majority of modern control relies on its digital implementation in microprocessors and/or is deployed in a networked environment. And the sampled-data control scheme [2, 3] thus arises from the demand of more efficient controller execution to reduce computation cost and save communication bandwidth in applications, such as multi-robot systems, electrical power systems and chemical processes. Sampled-data control schedules the update of a digital controller output at periodic or aperiodic sampling instances. Input-delay approach [12, 11, 10] is usually adopted to design sampled-data controller for linear systems, while two other methods are mainly used for nonlinear systems, namely controller emulation, involving digital implementation of a continuous-time stabilizing control law, and plant discretization consists of discretizing the plant model and discrete-time control law design [21]. However, the sampled-data control approach may over-sample in some cases and motivates event-triggered control which suggests scheduling update only when necessary and specified by the occurrence of the designated triggering event and may achieve more efficient sampling pattern. Sampled-data and event-triggered have been developed for stabilization and tracking of individual systems, e.g., [26, 19, 25, 18] and cooperative control of networked systems, e.g., [9, 23, 5, 29]. In this paper, these two control methods are uniformly called the sampling control.
The two-step digital emulation, constituting continuous-time control law design and its digital implementation, is a common technique for analysis and design of sampling control systems especially for nonlinear systems. In [14, 22], when the emulation of periodic sampled-data control is formulated in the hybrid system setting, the maximum allowable sampling period (MASP) that guarantees asymptotic stability of sampled-data systems can be explicitly computed. In [4], a new small gain theorem is proposed to reveal the quantitative tradeoff between robustness and sampling bandwidth of the sampled-data control. Emulation is also commonly adopted for the design of event-triggered laws where the continuous-time controller is assumed to ensure dissipativity [21] or the input-to-state stability (ISS) of the closed-loop system with the sampling error as input, see, e.g., [1, 7, 18, 20, 17, 25]. The ISS condition can be specified in a max-form, e.g. [18, 30] or in an ISS-Lyapunov form, e.g. [1, 17, 20, 25] for the closed-loop sampling system and the small gain conditions were then proposed to ensure the stability of the event-triggered system. In [16], the event-triggered technique in [25] was interpreted as a stabilization problem of interconnected hybrid systems for which each subsystem admits an ISS-Lyapunov function and a hybrid small gain condition was proposed. As another variant of small gain theorem, the cyclic small gain theorem has been proved effective for event-triggered control of large-scale systems [7, 17, 18].
Achieving Zeno free sampling and robustness to the disturbance and uncertainties simultaneously is not trivial. In [8], a dynamic output-based event-triggered law is proposed to achieve a finite -gain and a strictly positive lower bound on the inter-event times when the system is subjected to non-vanishing external disturbances. In [18], event-triggered control scheme is designed for systems subject to disturbances. In order to handle the uncertainties, [17] proposed a dynamic event-triggered controller to achieve the stabilization when the system has the dynamic uncertainties whose state is not available for the feedback. The problem is solved in [30] by a static event-triggered controller using a particular small-gain theorem method.
Recently, a few works on the event-triggered adaptive control have been proposed when systems possess parameter uncertainties. Since ISS condition is not guaranteed by the continuous-time stabilization controller and how to design an event-triggered adaptive control scheme is still challenging problem. In [28], an event-triggered adaptive control scheme was proposed for a class of nonlinear systems based on the -modification scheme. -modification scheme results in an ISS Lyapunov function, but only practical stabilization can be achieved, i.e., the trajectories converge to a bounded set in the neighborhood of the origin. The event-triggered law in [28] was improved in [13] in the sense that the adaptation dynamics was also sampled on the assumption of global Lipschitz conditions. In [27], a novel event-triggered adaptive control scheme is proposed for a class of nonlinear systems with unknown control direction and unknown sensor faults, while only practical stabilization is achieved.
In this paper, we propose a novel sampling control framework that can lead to event-triggered and periodic sampling robust and adaptive stabilization of nonlinear systems. The main contribution of this paper is three-fold. First, the paper proposes a sampling control framework where the error caused by the sampling of the actuation is regarded as the auxiliary input to the emulated system. The emulated closed-loop system is first assumed to admit an ISS Lyapunov function when regarding the auxiliary input as the input, while the error dynamics admits an continuously differentiable function whose derivative is bounded by functions of state and sampling errors. The design of periodic sampling and event-triggered control law renders the error dynamics bounded-input-bounded-state (BIBS), when coupled with system dynamics, achieves global or semi-global stabilization. Zeno free behavior is theoretically guaranteed and the system performance is robust to the external disturbances. Second, the proposed framework is then extended to tackle the event-triggered and periodic sampling control for the systems where only partial state is available for the feedback and the system is subject to parameter uncertainties. The proposed controller design combines the method proposed in Section III and changing supply function method. In [18, 17], an auxiliary dynamic system is introduced to estimate the decay rate of immeasurable states and used as the dynamic threshold for the event-triggered law, while the proposed controller is static and easier to design and implement in practice. The periodic sampling control is also proposed here, which is not considered in [18, 17, 30]. Third, the proposed framework is extended to solve two classes of event-triggered adaptive control problems where the emulated closed-loop system does not admit an ISS Lyapunov function. The first class of systems contains linear parameterized uncertainties, and global asymptotical stabilization is achieved without the global Lipschitz condition as often required in [13]. The second class of systems has the uncertainties whose bound is not known and requires adaptive/dynamic gain technique. To author’s best knowledge, the event-triggered dynamic gain control is first time solved in this paper.
The rest of the paper is organized as follows. Section II formulates the sampling control problem for nonlinear systems which will be solved by the sampling control framework proposed in Section III when an ISS condition is assumed. The proposed framework is extended to tackle the event-triggered and periodic sampling control for the systems where only partial state is available for the feedback in Section IV. It is further extended to solve event-triggered adaptive stabilization of two types of uncertain systems in Section V. The numerical simulation is conducted in Section VI and the paper is concluded in Section VII.
Notations. and denote the set of non-negative and positive real numbers, respectively. denotes the real space of dimension , denotes the set of real matrices with dimension , and denotes the set of non-negative integers. Let be the supremum norm of a given signal , over the interval , and be the signal slice of over the interval . Denote a function by if it is a function, by if it is a function, by if it is a smooth positive function and by if it is a smooth non-negative function. A continuous function is said to be a parameterized function if, for each fixed , the function is a function, and for each fixed , the function is non decreasing. For functions and , as means that . Let be a continuously differentiable function. It is called an ISS-Lyapunov function for the system if the derivative of along the -dynamics satisfies, for all , and ,
| (1) |
where . The inequalities in (1) are simplified as . A bounded piecewise continuous function is said to be persistent exciting (PE) if there exist positive constant , , such that,
II Problem Formulation of Sampling Control
Consider the nonlinear system
| (2) |
where is the system state, the output, the control input, and system uncertainty. Suppose the function is a continuously differentiable function satisfying and , and the uncertainty belongs to a compact set . Suppose the equilibrium point of the system can be stabilized by a continuous-time feedback controller
| (3) |
with a continuously differentiable function . It becomes a continuous-time state feedback system when . In this paper, we use the emulation technique to study the sampling version of (3) as follows
| (4) |
where is a sequence of sampling time instances. The sampling instances can be determined by an event-triggered law specified as follows
| (5) |
for some functional representing event occurrence to be designed. A periodic sampling law with sampling period can be considered as a special case of (5) with , i.e., . Note that the error caused by the sampling mechanism is
| (6) |
For the emulation, the closed-loop system composed of the dynamics (2) and a sampling version of feedback controller (4) is put into the impulsive form
| (7) |
The objective of the sampling control is to design the sampling law (5), either periodic sampling or event-triggered law, such that the closed-loop system composed of (2) and (4) achieves two objectives,
-
1.
stabilization: the original system is asymptotically stable at the origin, in particular, , semi-globally or globally;
-
2.
Zeno-free behavior: a finite number of events are triggered in a finite amount of time.
In general, the continuous-time feedback controller in (3) is assumed to ensure that the -subsystem in (7) has some properties such as input-to-state stability (ISS) when regarding sampling error as the input. The motivation of using the sampling error of the actuation rather than state or output measurement is explained in [15]. It is exploited in our previous papers [15, 30] to design event-triggered control law where -dynamics is assumed to have the ISS condition specified in a max-form. As is known, the classic analysis tools developed for the adaptive control rely on the Lyapunov function method, typically along the gradient of a Lyapunov function. In order to solve event-triggered adaptive control in Section V, this paper first considers the ISS condition specified in terms of ISS-Lyapunov function and assumes the existence of a positive function on -subsystem which plays a similar role of a Lyapunov function. As a result, the sampling control framework proposed in next section can be naturally extended to event-triggered adaptive control in Section V where the continuous-time adaptive control does not admit an ISS condition.
Assumption II.1
The -subsystem in (7) has an ISS-Lyapunov function . There exists a continuously differentiable such that the derivative of along the -subsystem, for all , and , satisfies
| (8) |
for some functions , , , .
Remark II.1
Note that the existence of the function condition is mild. Due to and thus , the function in (7) is continuously differentiable and satisfies . Applying Lemma 11.1 in [6], one has for some functions , . As a result, Then, it is always possible to find functions , such that the second inequality of (8) holds.
Remark II.2
In [30], a pair of ISS and input-to-output stability (IOS) conditions are given in max-norm form for the closed-loop system (7) where is regarded as the input and as the output. ISS and IOS properties, for any , are stated as follows,
| (9) | ||||
| (10) |
for , where and are functions. Although ISS-Lyapunov function in Assumption II.1 implies (9), (10) and (8) do not necessarily imply each other. Therefore, conditions in Assumption II.1 are different from (9) and (10).
III Sampling Control Design
In this section, periodic sampling and event-triggered control are proposed for the emulation system (7). We first present Theorem III.1 for the design of event-triggered law, which provides a common guideline for periodic sampling control design.
III-A Event-triggered Control
In order to solve the sampling stabilization problem, we apply the changing supply function technique ([24] and Lemma 2.5 of [6]) to the ISS-Lyapunov function in Assumption II.1. Let function be selected such that . If as , the changing supply function technique shows that there exists another ISS Lyapunov function where the functions , can be calculated accordingly. Then, the event-triggered control law is presented as follows.
Theorem III.1
Proof: The closed-loop system consisting of (2) and (4) is put into the form (7). The proof will be divided into three parts. First, the boundedness of all signals is proved. The fact that as implies that it is always possible to find a new supply function and . Integrating both side of (8) in Assumption II.1 gives
which leads to
| (12) |
due to and . It further implies that
| (13) |
where . The sampling law (11) implies , which together with , leads to
| (14) |
Let be the Lyapunov function candidate for the closed-loop system (7). Since and hence are continuous in and is piecewise continuous in and has jump at , one has
by noting . For ,
| (15) |
where the functions and are defined as
As a result, is monotonically decreasing except when and therefore the signals and are bounded for whose bound depends on the initial value . Denote the bound by . The derivative of denoted as is also bounded whose bound is denoted by . The notation will be used instead of for the notation simplicity. Note that for any and .
Then, it will be shown that the event-triggered law is free of Zeno behavior by showing that for some constant possibly depending on the initial condition. Note that as implies that Denote . Due to , one has . For a given , there exists an such that
| (16) |
Denote
| (17) |
As a result
where we used (16). Therefore, the sampling interval can be selected to be lower bounded irrespective of , i.e., for and the bound depends on and thus the initial condition .
Finally, the convergence of the signal to zero, i.e., , is proved. If it is not true, there is a positive constant such that for every , we can find with . It is noted from (15) that and exists and is finite. Since is a uniformly continuous function, applying Barbalat’s lemma we can show that . It will also be shown that the convergence of the signal to zero, i.e., . If it is not true, there is a positive constant such that for every , we can find with . Also, there exists a . Since signals and are bounded and is continuous in , there exists a such that , and for some . Following the proof of Barbalat’s lemma, it causes a contradiction and therefore .
Remark III.1
Remark III.2
Remark III.3
The condition as in Theorem III.1 can be implied by two conditions and as . Note that as implies as . It together with as implies that one can find a such that or equivalently as .
To see we can make as , let and its derivative is calculated as
| (19) |
where we used the bound of in Remark II.1. Then, inequality (8) in Assumption II.1 is satisfied with . Note that in this case and then is satisfied due to .
The conditions and as can be made satisfied during the continuous-time feedback controller design phase. From (19), we can choose the function in (8) to be for some function . Then, if one designs the continuous-time feedback controller that renders and , it leads to and as . Such kind of feedback controller can always be found for a large class of nonlinear systems such as those in strict feedback form and lower-triangular form, to be presented in Section IV and V.
Remark III.4
The following proposition shows that event-triggered control tends to behave like a periodic sampling control as , whose sampling interval approaches a constant.
Proposition III.1
Proof: The proof is similar to that of Proposition 2.1 in our paper [30] and omitted here.
III-B Periodic Sampling Control
In this subsection, the periodic sampling controller is to seek a uniform sampling period, simply denoted as
| (21) |
The constant is called the sampling period and sampling frequency. From Remark III.4, looking for the sampling period amounts to, for all , finding a uniform such that with given in (20), or equivalently, the following inequality must be made satisfied
| (22) |
The theorem of periodic sampling control follows the idea.
Theorem III.2
Suppose the system composed of (2) and (4) satisfies Assumption II.1. Let functions , , , and be defined in the proof of Theorem III.1. Let be a compact set and where is the closure of . Find for (21) such that
| (23) |
the equilibrium point of the system is asymptotically stable for any initial condition . Moreover, where is positive invariant and .
The proof of Theorem III.2 is given in Appendix which will show that the condition (23) implies (22).
Remark III.5
For a given set and thus , Zeno freeness proof in Theorem III.1 shows that satisfying condition (23) can always be found. Note that is determined by the initial state set and needs to be known, therefore the periodic sampling law in Theorem III.2 achieve semi-global stabilization rather than the global stabilization. Similarly, for a given , one can also find such that the condition (23) is satisfied. Then, Theorem III.2 can be interpreted in another way. That is, given a sampling limitation in terms of the fastest sampling speed , the best stabilization performance can be achieved in terms of the estimated region of attraction, i.e., . Note that the best estimated periodic sampling interval is sometimes called maximum allowable sampling period. If the function can be specified as a function, i.e., , then the condition can be refined as . In this case, can be found as
where is the asymptotic sampling period of the event-triggered in Proposition III.1 as approaches infinity. In a word, as the system trajectory approaches equilibrium point, the periodic sampling is no better than event-triggered control in terms of saving the sampling times.
III-C Robustness Issue
Now, let us consider the robustness of the sampling control when the uncertainties also includes non-vanishing external disturbance. In this case, we suppose the emulated system (7) satisfies the external-disturbance version of Assumption II.1.
Assumption III.1
Suppose the -subsystem in (7) has an ISS-Lyapunov function , i.e., where . There exists a continuously differentiable such that the derivative of along the -subsystem, for all , and , and for some , , , .
Then, we present the following corollary for event-triggered law whose proof is given in the Appendix and the result for periodic sampling is similar and not presented.
Corollary III.1
Suppose the system composed of (2) and (4). Suppose conditions of Theorem III.1 are satisfied except that Assumption II.1 is replaced by Assumption III.1. Let be the bound of external disturbance , i.e., for . If the event-triggered law is designed as in Theorem III.1, then the trajectories of closed-loop system is ultimately bounded, i.e., there exists a possibly depending on the initial condition such that
for some , , , and Zeno-behavior is avoided.
IV Robust Sampling Control
In this section, we will apply the sampling control method proposed in Section III to solve the sampling robust stabilization problem of a class of nonlinear systems, called strict feedback systems of a relative degree one, as follows,
| (24) |
where and are state variables, is the input and is the uncertainties belonging to a compact set . The functions and are sufficiently smooth with and for all . Note that the state is assumed to be not available for feedback control and thus the -dynamics is called dynamic uncertainty. A common assumption on -dynamics is given to make the problem tractable.
Assumption IV.1
The -subsystem in (24) has an ISS-Lyapunov function and functions and satisfy
The sampling robust stabilization problem is to design sampling controller such that . Since is a sufficiently smooth function, one has
| (25) |
for some sufficiently smooth functions depending on the size of . For the continuous-time stabilization of the system, a high-gain controller can be adopted to dominate the uncertainties when the size of is known. The case that the size of is unknown will be handled using dynamic gain technique in Section V. The continuous-time controller usually takes the form of with the high-gain term to be specified. We adopt the method developed in Section III and propose the sampling controller as follows
| (26) |
for . Define the sampling error as Then, the sampled-data closed-loop system is rewritten as
| (27) |
The event-triggered robust stabilization can be solved by applying Theorem III.1.
Theorem IV.1
Proof: Denote . Let us first consider the -dynamics. Let . By changing supply function technique, there exists another ISS Lyapunov function for -dynamics, for some functions , , and , that can be calculated accordingly. Let
and the Lyapunov function candidate be . The calculation of the derivative of , along the trajectory of -dynamics, obtains
Now, let us examine the -dynamics. Note that where . Let and decompose to be where and . As a result, for some function . Let . We claim that
| (29) |
with some functions . In fact, one possible calculation of the derivative of is given below
where and are selected as
Let us choose and . Then, (29) is satisfied.
Let function . Since there exists an ISS Lyapunov function for (27), by changing supply function method, there exists another ISS Lyapunov function for some functions , , and , that are calculated accordingly. Moreover, . Select function as
| (30) |
Let be the Lyapunov function candidate for the system (27). We can check that conditions of Theorem III.1 is satisfied. Moreover,
| (31) |
Applying Theorem III.1 completes the proof.
As has been done in Section III, the periodic sampling law can be found by following the idea of Theorem IV.1. The proof is straightforward and omitted here.
Proposition IV.1
The discussion in Remark III.5 shows that the initial condition of the signal must be known for the design of periodic sampling. Although the signal is not available for the feedback, Proposition IV.1 requires the initial condition of the signal or at least its bound be known, which is used to estimate in (32).
Remark IV.1
In [18, 17], the decay rate of immeasurable states is estimated by an auxiliary dynamic system and then used for constructing the event-triggered law. In comparison, a static sampling controller is proposed in Theorem IV.1, that is easier to design and implement in practice. Moreover, our method can also be used to derive the periodic sampling control law when the initial bound of the signal is known.
V Even-triggered Adaptive Control
In this section, we will solve two types of classical adaptive control problem in the event-triggered setting exploiting the sampling control scheme proposed in Section III.
V-A Adaptive Control with Uncertain Parameters
We consider the event-triggered adaptive stabilization problem of a class of nonlinear systems with unknown parameters, as follows,
| (33) |
where is the state and is an unknown constant parameter vector. Note that function does not necessarily vanish at . Without loss of generality, we assume and is bounded.
Assumption V.1
(1) The unknown parameter is bounded with a known bound , i.e., ; (2) .
In this case, the argument in Remark II.1 does not apply and inequality (8) in Assumption II.1 might not hold. Therefore, the development of the controller design in Section III must be modified to suit the problem. Similar to the continuous-time adaptive control for the system (33), we propose the event-triggered controller as follows,
| (34) |
where , is a diagonal matrix and , functions are to be designed. Note that the term does not appear in traditional continuous-time adaptive control and is introduced particularly for the event-triggered control. In this paper, we do not consider the challenging case where the adaptation dynamics is sampled and it remains our future research direction. Define the sampling error as Then, the closed-loop system is rewritten as
| (35) |
where is estimation error. Based on the event-triggered controller design in Section III, the following theorem is obtained.
Theorem V.1
Suppose the system composed of (33) and (34) satisfies Assumption V.1. Then, there exists smooth positive functions , for the controller (34) and such that the event-triggered law is designed as
| (36) |
then Zeno-behavior is avoided and the equilibrium point is globally asymptotically stable. Moreover, The algorithm of event-triggered adaptive controller design is summarized in Algorithm 1.
Proof: First, let us consider the -dynamics. Denote and Note that
Decompose as where depends on satisfying and is a constant vector. Decompose as where depends on satisfying and is a scalar possibly depending on . Denote , , , and . Note that . As a result,
| (37) |
Since and , and for some functions . Select two smooth positive functions and as
| (38) |
Moreover, is bounded when signals and are bounded. As a result, it follows from (37) that
| (39) |
It should be noted that the selection of only depends on the function and not on function in -dynamics. In other words, can be selected to be dependent on .
Then, let us consider the -dynamics. Let . The derivative of along the -dynamics is
Following changing supply function lemma (in Lemma 2.5 of [6]), for , there exists a non-decreasing function such that
| (40) |
and a new supply function such that its derivative along the -dynamics satisfies
| (41) |
for some . Since is not dependent on , so is function . Then, one can choose and in (34) to be
| (42) |
Now, let us consider the -dynamics. Let and its derivative along -dynamics becomes
Denote . Letting leads to
| (43) |
By the selection of and in (42), the inequality (39) further becomes
| (44) |
where
| (45) |
Finally, the event-triggered law design is presented. Let
| (46) |
where is given in (41). One has
which together with event-triggered law (36) implies
Let be the Lyapunov function candidate for the closed-loop system (35). As a result,
Therefore, is monotonically decreasing and all signal , and are bounded. So, there exists a positive constant depending on the bound of , and such that . Moreover, there exists a such that
and noting (36) shows Therefore, it is Zeno free.
The convergence of the signal to zero follows similar argument in the proof of Theorem III.1. When and , it shows that . Because is PE, it is proved that or by Lemma 2.4 of [6].
1. Select smooth positive functions and to satisfy (38);
3. Choose and to be in (42);
5. Construct the event-triggered law in (36).
Remark V.1
In [13], the event-triggered adaptive control problem is solved when the global Lipschitz condition is assumed on the function , while it is not required in our method. It would be very interesting to consider that the adaptation dynamics is also sampled as in [13] in our future work. Compared with the development in Section III, the derivative of is upper bounded as in (39) which is more complicated than (8) in Assumption II.1. Therefore, the event-triggered law in (36) is also more involved and not merely determined by but also and .
V-B Event-triggered Stabilization with Dynamic Gain
In this subsection, we consider the dynamic system
| (47) |
where and are state variables, is the input and is the uncertainties belonging to a compact set . The functions and are sufficiently smooth with and for all . In contrast to Section IV, the size of and controller gain are not known and a dynamic gain technique is required. The state is also assumed to be not available for feedback control and thus -dynamics is dynamic uncertainty. A few Assumptions are list as follows.
Assumption V.2
for some known constant .
Assumption V.3
The -subsystem in (24) has an ISS-Lyapunov function and functions and satisfy Moreover, the functions are known and the function is known up to a constant factor in the sense that there exist an unknown constant and a known function ς such that .
Note that the system (47) differs from that studied in Section IV in some aspects. First, in Section IV, since the controller gain is unity, we can apply sufficient high gain specified by to dominate uncertainties and stabilize the system. Here, the controller gain is not known. Although the upper bound of is known, it is still not possible to calculate the controller gain that is sufficiently high to stabilize the system. Second, although the -subsystem in (47) admits an ISS-Lyapunov function, the input gain is only known to a constant factor. Third, since the size of is unknown, by Corollary 11.1 in [6], there exists a positive number , which depends on the size of and is also unknown, and two positive and sufficiently smooth known functions and , such that
| (48) |
These three differences call for the dynamic gain stabilization technique.
For the continuous-time stabilization of the system (47), dynamic gain controller using universal adaptive control technique is proposed in [6]. It takes the form of
| (49) |
where is to be specified. The second equation of (49) is the adaptation dynamics for dynamic gain. For the event-triggered control, we adopt the method developed in Section III and propose the controller as follows
| (50) |
Define the sampling error as Then, the event-triggered closed-loop system is rewritten as
| (51) |
Theorem V.2
Proof: Denote and . First, let us examine -dynamics. By changing supply function method, for , there exists another ISS Lyapunov function, for some functions , , and a smooth function , that are calculated accordingly. Let where is a positive number to be specified later. Define the Lyapunov function candidate as
| (53) |
The calculation of the derivative of , along the trajectory of (51), shows that
| (54) |
where is to be specified. Let be
and
As a result, one has
| (55) |
Next, the -dynamics is examined as follows
where . Let and decompose to be where and . As a result, for some function . Let and one has
Let
| (56) |
where and are unknown. As a result, one has
which further leads to
| (57) |
where is an unknown constant, and
Let where is given in (53) and its derivative also satisfies By Parameterized Changing Supply in Lemma .1, for any smooth function and , there exists a new supply function such that
| (58) |
for some sufficiently smooth functions , and unknown constant . Note that and we specify to be . It leads to
| (59) |
Now, it is ready to design the event-triggered law. Let
where is given in (56) and is given in (58). One has
which together with event-triggered law (52) (similar to the proof of Theorem III.1) implies
Let be the Lyapunov function candidate for the closed-loop system (51). As a result,
Therefore, is monotonically decreasing and all signal , , and are bounded. The convergence and Zeno freeness can be proved similar to that of Theorem III.1 and IV.1 and are omitted here.
VI Numerical Examples
Example VI.1
(Event-triggered Adaptive Stabilization with Uncertain Parameters) Consider the uncertain system
where is an unknown parameter whose bounds is . We propose the sampling controller as follows,
with and to be designed and to be specified. Let the sampling error be . Let and the inequality (44) is satisfied with where and . Let and . Let and thus in (40) should be and Then, and in (34) is and . As a result, is selected to make (45) satisfied. Then, can be selected as with . Finally, the event-triggered law is designed according to Theorem V.1, as follows,
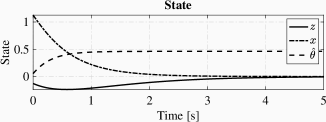
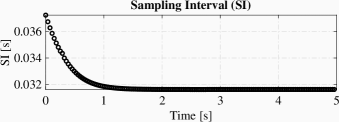
The simulation result is illustrated in Fig 1, which includes figures for state trajectories, input signal and sampling intervals. Note that the estimated value converges to the real value of and the trajectories of system converge to the origin.

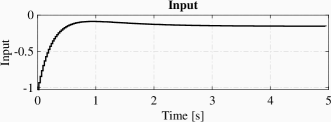
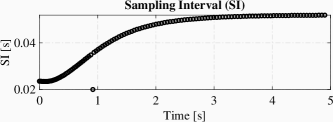
Example VI.2
(Event-triggered Stabilization with Dynamic Gain) Consider the following nonlinear system
where , and are unknown parameters and . Note that when , one has for any unknown constant and thus Assumption V.3 is satisfied. And for some , that is, inequality (48) is verified for and . Then, we propose the sampling controller as in (49) and the closed-loop system is written as
where is the sampling error. Let and Select and Then, . Note that and let . The inequality (57) is satisfied, i.e., where
Note that where . Let and . Let and . Let and . The derivative of becomes
Let
Then, inequality (59) is satisfied with . Then, where . Finally, the event-triggered law is designed according to Theorem V.2, as follows,
The simulation result is illustrated in Fig 2, which includes figures of state trajectories, input signal and sampling intervals showing that the system trajectories converge to the origin without Zeno behavior.
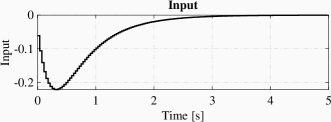
VII Conclusion
In this paper, we propose a novel sampling control framework based on the emulation technique where the sampling error is regarded as the auxiliary input to the emulated system. The design of periodic sampling and event-triggered control law utilizes the supremum norm of sampling error and renders the error dynamics bounded-input-bounded-state (BIBS), when coupled with system dynamics, achieves global or semi-global stabilization. The proposed framework is then extended to tackle the event-triggered and periodic sampling stabilization for systems with dynamic uncertainties. The proposed framework is further extended to solve two classes of event-triggered universal adaptive control problems. It would be very interesting to consider the case where the adaptation dynamics is also sampled and periodic event-triggered control along this research line.
Lemma .1
(Parameterized Changing Supply Functions, Lemma 6.1 in [6]) Consider the system with and . Suppose there exists a supplying function satisfying
for functions , , , a parameterized function , and positive number and . Then, for any smooth function and positive number , there exists a continuously differentiable function satisfying
for a functions , a parameterized function , a function and positive numbers and . Moreover, if the functions , , and are known, so are the functions , and . The positive numbers , , , and are not necessarily known.
Proof of Theorem III.2: It suffices to show condition (23) imply (22) and meanwhile it is guaranteed that the boundedness of signals , i.e., , . From (23), one has . Since and are continuous functions, there exists a sufficiently small such that
It, together with (23), further implies
| (60) |
We will prove that . If this is not true, there exists a finite time such that but . Due to (60) and the periodic sampling law in (21), one have
| (61) |
where . Therefore, (22) is valid for and , where is given in (20). By Remark III.4, results of Theorem III.1 hold, and one has . Due to , one has , that is is a positively invariant set. By Remark III.1, one has which causes a contradiction to . Therefore, . As a result, conducting similar analysis as above for shows that (22) is valid for and using the discussion in Remark III.4 completes the proof.
Proof of Corollary III.1: The fact that as implies it is always possible to find a new supply function for some functions , , and , that can be calculated accordingly. Denote . Following the first proof step of Theorem III.1, one has
Let be the Lyapunov function candidate. Similarly, one has
where functions is selected as and . Note that there exist functions and satisfying
such that . As a result, which implies that any trajectory starting outside will eventually goes inside where . and is satisfied. Similar to the proof of Theorem III.1, Zeno-freeness depends on the condition as and can be proved in the same way.
References
- [1] A. Anta and P. Tabuada. To sample or not to sample: Self-triggered control for nonlinear systems. IEEE Transactions on Automatic Control, 55(9):2030–2042, 2010.
- [2] M. Araki. Recent developments in digital control theory. IFAC Proceedings Volumes, 26(2):951–960, 1993.
- [3] T. Chen and B. A. Francis. Optimal sampled-data control systems. Springer Science & Business Media, 2012.
- [4] Z. Chen and H. Fujioka. Performance analysis of nonlinear sampled-data emulated controllers. IEEE Transactions on Automatic Control, 59(10):2778–2783, 2014.
- [5] Z. Chen, Q.-L. Han, Y. Yan, and Z.-G. Wu. How often should one update control and estimation: review of networked triggering techniques. Science China Information Sciences, 63:150201:1–18, 2020.
- [6] Z. Chen and J. Huang. Stabilization and Regulation of Nonlinear Systems. Springer International Publishing, 2015.
- [7] C. De Persis, R. Sailer, and F. Wirth. On a small-gain approach to distributed event-triggered control. IFAC Proceedings Volumes, 44(1):2401–2406, 2011.
- [8] V. S. Dolk, D. P. Borgers, and W. P. M. H. Heemels. Output-based and decentralized dynamic event-triggered control with guaranteed - gain performance and zeno-freeness. IEEE Transactions on Automatic Control, 62(1):34–49, 2017.
- [9] Y. Fan, G. Feng, Y. Wang, and C. Song. Distributed event-triggered control of multi-agent systems with combinational measurements. Automatica, 49(2):671–675, 2013.
- [10] E. Fridman, M. Dambrineb, and N. Yeganefar. On input-to-state stability of systems with time-delay: A matrix inequalities approach. Automatica, 44:2364–2369, 2008.
- [11] E. Fridman, A. Seuret, and J.P. Richard. Robust sampled-data stabilization of linear systems: an input delay approach. Automatica, 40(8):1441–1446, 2004.
- [12] E. Fridman, R. Shaked, and V. Suplin. Input/output delay approach to robust sampled-data h-infty control. Systems & Control Letters, 54(3):271–282, 2005.
- [13] J. Huang, W. Wang, C. Wen, and G. Li. Adaptive event-triggered control of nonlinear systems with controller and parameter estimator triggering. IEEE Transactions on Automatic Control, 65(1):318–324, 2019.
- [14] I. Karafyllis and C. Kravaris. Global stability results for systems under sampled-data control. International Journal of Robust and Nonlinear Control, 19(10):1105–1128, 2009.
- [15] G. D. Khan, Z. Chen, and L. Zhu. A new approach for event-triggered stabilization and output regulation of nonlinear systems. IEEE Transactions on Automatic Control, 65(8):3592–3599, 2020.
- [16] D. Liberzon, D. Nešić, and A. R. Teel. Lyapunov-based small-gain theorems for hybrid systems. IEEE Transactions on Automatic control, 59(6):1395–1410, 2014.
- [17] T. Liu and Z. P. Jiang. Event-based control of nonlinear systems with partial state and output feedback. Automatica, 53:10–22, 2015.
- [18] T. Liu and Z. P. Jiang. A small-gain approach to robust event-triggered control of nonlinear systems. IEEE Transactions on Automatic Control, 60(8):2072–2085, 2015.
- [19] N. Marchand, S. Durand, and J. F. G. Castellanos. A general formula for event-based stabilization of nonlinear systems. IEEE Transactions on Automatic Control, 58(5):1332–1337, 2013.
- [20] M. Mazo, A. Anta, and P. Tabuada. An ISS self-triggered implementation of linear controllers. Automatica, 46(8):1310–1314, 2010.
- [21] R. Moheimani. Perspectives in robust control, volume 268. Springer Science & Business Media, 2001.
- [22] D. Nesic, A. R. Teel, and D. Carnevale. Explicit computation of the sampling period in emulation of controllers for nonlinear sampled-data systems. IEEE Transactions on Automatic Control, 54(3):619–624, 2009.
- [23] G. S. Seyboth, D. V. Dimarogonas, and K. H. Johansson. Event-based broadcasting for multi-agent average consensus. Automatica, 49(1):245–252, 2013.
- [24] E. Sontag and A. Teel. Changing supply function in input/state stable systems. IEEE Transactions on Automatic Control, 40:1476–1478, 1995.
- [25] P. Tabuada. Event-triggered real-time scheduling of stabilizing control tasks. IEEE Transactions on Automatic Control, 52(9):1680–1685, 2007.
- [26] P. Tallapragada and N. Chopra. On event triggered tracking for nonlinear systems. IEEE Transactions on Automatic Control, 58(9):2343–2348, 2013.
- [27] C. Wang, C. Wen, and Q. Hu. Event-triggered adaptive control for a class of nonlinear systems with unknown control direction and sensor faults. IEEE Transactions on Automatic Control, 65(2):763–770, 2019.
- [28] L. Xing, C. Wen, Z. Liu, H. Su, and J. Cai. Event-triggered adaptive control for a class of uncertain nonlinear systems. IEEE Transactions on Automatic Control, 62(4):2071–2076, 2016.
- [29] X. Yi, K. Liu, D.V. Dimarogonas, and K. H. Johansson. Dynamic event-triggered and self-triggered control for multi-agent systems. IEEE Transactions on Automatic Control, 64(8):3300–3307, 2018.
- [30] L. Zhu, Z. Chen, D.J. Hill, and S. Du. Event-triggered controllers based on the supremum norm of sampling-induced error. Automatica, 128:109532, 2021.