A Semi-Supervised Approach with Error Reflection for Echocardiography Segmentation
Abstract
Segmenting internal structure from echocardiography is essential for the diagnosis and treatment of various heart diseases. Semi-supervised learning shows its ability in alleviating annotations scarcity. While existing semi-supervised methods have been successful in image segmentation across various medical imaging modalities, few have attempted to design methods specifically addressing the challenges posed by the poor contrast, blurred edge details and noise of echocardiography. These characteristics pose challenges to the generation of high-quality pseudo-labels in semi-supervised segmentation based on Mean Teacher. Inspired by human reflection on erroneous practices, we devise an error reflection strategy for echocardiography semi-supervised segmentation architecture. The process triggers the model to reflect on inaccuracies in unlabeled image segmentation, thereby enhancing the robustness of pseudo-label generation. Specifically, the strategy is divided into two steps. The first step is called reconstruction reflection. The network is tasked with reconstructing authentic proxy images from the semantic masks of unlabeled images and their auxiliary sketches, while maximizing the structural similarity between the original inputs and the proxies. The second step is called guidance correction. Reconstruction error maps decouple unreliable segmentation regions. Then, reliable data that are more likely to occur near high-density areas are leveraged to guide the optimization of unreliable data potentially located around decision boundaries. Additionally, we introduce an effective data augmentation strategy, termed as multi-scale mixing up strategy, to minimize the empirical distribution gap between labeled and unlabeled images and perceive diverse scales of cardiac anatomical structures. Extensive experiments on a public echocardiography dataset CAMUS, and a private clinical echocardiography dataset demonstrate the competitiveness of the proposed method.
Index Terms:
Semi-supervised learning, Echocardiography, Image segmentationI Introduction
Transthoracic echocardiography (TTE) possesses characteristics of non-invasiveness, absence of radiation, and cost-effectiveness, rendering it widely applicable in clinical settings. TTE aids the medical team in discerning the nature and extent of lesions in complex congenital heart diseases (CHD) [9]. Segmenting the internal structures from echocardiography can aid clinicians in identifying various cardiac conditions and assessing cardiac functionality. With the advancement of deep learning [8, 12], significant advancements have been made in medical image segmentation [19, 4]. Since then, this technology has been introduced into echocardiography segmentation [10, 18] and achieves promising results. However, training an accurate echocardiography segmentation model usually requires a large amount of labeled data. Data annotation is a time-consuming and labor-intensive task, especially when it comes to annotating medical images, which requires domain-specific knowledge. Semi-supervised learning (SSL) [1] has shown great potential to alleviate annotations scarcity, which typically obtains high-quality segmentation results by learning from a limited amount of labeled data and a large set of unlabeled data directly.
Many recently successful SSL methods typically leverage unlabeled data by performing unsupervised consistency regularization. These approaches base on the smoothness assumption, enforcing consistent predictions through perturbations at the image level [24, 2], feature level [17], or network level [23]. In addition, DTC [13] established task-level regularization, and SASSnet [11] introduced adversarial loss to learn consistent shape representations from the dataset. Image-level data perturbation or augmentation is common yet potent, because pixels in the same map share semantics and are closer, such as CutMix [6], ClassMix [16], and ComplexMix [5]. BCP [2] focused on designing consistent learning strategies for both labeled and unlabeled data. Some studies attempted to introduce semi-supervised methods into echocardiography segmentation [15, 7]. Zhao et al. [25] employed boundary attention and feature consistency constraints to improve the performance of semi-supervised echocardiography segmentation. Wu et al. [22] proposed an adaptive spatiotemporal semantic alignment method for semi-supervised echocardiography video segmentation.
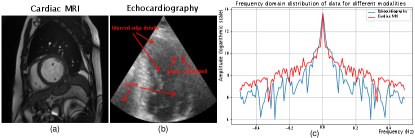
Although existing semi-supervised methods have made significant advancements in image segmentation across various medical imaging modalities, they fail to fully tailor the design to the characteristics of echocardiography. As depicted in Fig.1, spectral analysis comparing echocardiographic and cardiac MR images reveals a reduced presence of high-frequency components in echocardiography. The high-frequency components in an image typically convey information such as edges, fine details, and textures. Therefore, whether from visual perception or spectral analysis, echocardiography typically exhibits poor contrast, blurred edge details and more noise compared to other medical imaging modalities. These characteristics pose challenges to the generation of high-quality fine pseudo-labels from unlabeled images by the teacher network. In the Mean Teacher [20] architecture, the teacher network generates pseudo-labels for the unlabeled images to guide the student network, thereby emphasizing the importance of producing high-quality pseudo-labels.
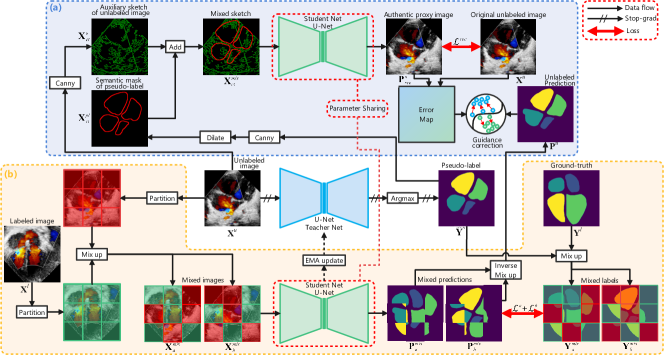
Therefore, we devise an error reflection strategy inspired by human intuition to reflect upon and rectify erroneous practices. When humans encounter erroneously segmented outputs, they may reflect upon the original image and attempt to correct segmentation. Specifically, the strategy is divided into two steps. The first step is called reconstruction reflection. The network is tasked to reconstruct authentic proxy images from the semantic masks of unlabeled images and their auxiliary sketches. If the segmentation is accurate, the reconstructed proxy shall exhibit a high degree of similarity to the original image. Otherwise, the proxy shall manifest deficiencies. The second step is called guidance correction. The error map, generated by discrepancies between original and proxy images, decouples unlabeled image segmentation into reliable and unreliable areas, guiding optimization of potentially unreliable data near decision boundaries with reliable data from high-density regions. The strategy encourages the model to reflect on itself to identify deficiencies in pseudo-labels, thereby enhancing the robustness of pseudo-label generation. In addition, data augmentation in semi-supervised learning is important. We introduce an effective data augmentation strategy, termed as the multi-scale mixing up strategy. Specifically, we improve the strategy of partitioning labeled and unlabeled images into small, variable-sized patches akin to a puzzle, by randomly mixing them while preserving relative positions and varying patch sizes. This facilitates the minimization of the empirical distribution gap between labeled and unlabeled images while enabling the perception of various scales of cardiac anatomical structures. We verify the proposed method on the popular public echocardiography dataset CAMUS [10] and a private clinical echocardiography dataset. Extensive experiments demonstrate the advantages and competitiveness of our method. Our approach notably does not modify the U-Net architecture.
II Method
We define the RGB image of an echocardiography scan as , where , , and respectively represent the width, height, and channels of the image. The goal of semi-supervised segmentation is to predict the semantic label of each pixel , which constitutes into a prediction label map , where represents back-ground, and indicates the cardiac anatomy class. The training set comprises two subsets of different sizes: , where and (). The pipeline of the proposed approach is shown in Fig.2, based on Mean Teacher architecture [20]. The proposed framework consists of the error reflection strategy and the multi-scale mixing up strategy. When training the framework, a mini-batch consists of images . Assuming , each comprises labeled image and unlabeled image , sampled from sets and respectively.
II-A Error reflection strategy
II-A1 Reconstruction reflection step
The workflow of the reconstruction reflection step is as follows: Unlabeled image is fed into the teacher network to obtain prediction map , where represents the number of classes. is processed by argmax function to obtain pseudo-label mask . The sketches are extracted by the Canny operator from the unlabeled image and its pseudo-label mask . Then, is bolded by the dilation morphological operation . Afterwards, and are merged into a new sketch by the addition operation . The mixed sketch is sequentially processed by the student network to reconstruct the authentic proxy image . The whole process can be expressed succinctly as:
| (1) |
| (2) |
| (3) |
The calculation of structural similarity (SSIM) loss for the reconstruction task can be denoted as: , where the unlabeled image serves as the ground truth for . denotes the SSIM loss function.
II-A2 Guidance correction step
First, the pixel-wise error map between the reconstructed proxy image and the unlabeled original image is computed. As the error decreases continuously during the training process, a fixed error threshold is inappropriate. We devise a simple dynamic error threshold based on to obtain the unreliable segmentation region map . The process can be expressed succinctly as:
| (4) |
| (5) |
where denotes normalization, represents taking the absolute value, and indicates obtaining the maximum value.
The unlabeled image prediction is obtained by mixed predictions and (their generation process is shown in next subsection) through the inverse mixing up operation . Then, and are respectively multiplied by point-by-point to obtain their unreliable prediction regions . Subsequently, the pixel-wise values of and are compared, and a new mask is generated when the predicted probability of is greater than that of . The process is denoted as:
| (6) |
| (7) |
| (8) |
where denotes point-by-point multiplication.
For the unreliable segmented regions and , we leverage the more confident prediction regions in pseudo labels, which tend to occur near high-density regions, to guide the optimization of less confident regions in unlabeled image predictions, which may appear at decision boundaries. , .
We employ L2 loss function to guide the optimization of low-confidence regions, while gradients from high-confidence regions are detached from back-propagation at this stage: , where represents the L2 loss function, and denotes the detachment of gradients for back-propagation.
II-B Multi-scale mixing up strategy
To encourage the model to perceive diverse scales of cardiac anatomical structures and to learn comprehensive common semantics from both labeled and unlabeled images, we implemented multi-scale mixing up strategy. First, we partition and into puzzle patches and , respectively, where , represents the total number of patches, and denotes the relative position of the patch in the image puzzle. We define the partition operation as . During the training phase, can be configured as a variable value, whereby different values of enable the model to perceive cardiac anatomical structures at different scales. Subsequently, puzzle patches and are randomly mixed up while maintaining their original positions, resulting in the creation of two new mixed images, denoted as . The operation of mixing up puzzle patches is denoted as . After being sequentially processed by the student network and the softmax layer , mixed images yield predicted maps . Next, employing the same mixing up method as before, we mix up ground-truth and pseudo-label to obtain mixed labels for supervising and , respectively. The whole process is expressed succinctly as:
| (9) |
| (10) |
The calculation of loss for and is denoted as:
| (11) |
| (12) |
where denote multi-class Cross-Entropy and Dice loss functions respectively.
II-C Training strategy
During the training phase, the parameters of the student network are optimized by stochastic gradient descent (SGD), while the parameters of the teacher network are updated from with exponential moving average (EMA) [20]. update by SGD with loss function at each iteration: , where and are parameters for harmonizing the significance of each loss function. are updated at the ()th iteration: , where represents the smoothing coefficient parameter.
III Experiments and results
III-A Experimental setup
III-A1 Datasets
We evaluated our method on two echocardiography datasets: the public CAMUS (Cardiac Acquisitions for Multi-structure Ultrasound Segmentation) dataset [10] and a private clinical dataset. The CAMUS dataset comprises 3000 echocardiography images (four- and two-chamber views) from 500 patients at the University Hospital of St Etienne, France, aimed at segmenting cardiac substructures like the left ventricle endocardium, epicardium, and left atrium borders. The private dataset consists of 5671 echocardiography images (apical four-chamber view, low parasternal four-chamber view, and parasternal short-axis view of large artery) from 676 patients at Shanghai Children’s Medical Center (P.R.China). Its purpose is to segment the four cardiac chambers: right ventricle, left ventricle, right atrium, and left atrium. This study received ethics approval from the Shanghai Children’s Medical Center Ethics Committee (Approval No. SCMCIRB-W2021058).
III-A2 Evaluation metrics
We evaluate the performance of our method quantitatively by 4 common evaluation metrics follow in BCP [2]: Dice(%), Jaccard(%), the 95% Hausdorff Distance (95HD)(pixel), and the average surface distance (ASD)(pixel).
III-A3 Implementation details
We employ U-Net as the backbone of the architecture, with input image size set to pixels. The parameter N for image puzzle partitions is randomly set to 2 or 3, dividing the image into 4 or 9 small puzzle patches. and in the loss function are both set to 0.01. All experiments, using PyTorch and five-fold cross-validation, are conducted on Nvidia RTX 3080 GPU with SGD optimizer for model optimization.
III-B Quantitative evaluation
| Method | Labeled | Dice | Jaccard | 95HD | ASD |
| U-Net | 5(1%) | 84.99 | 75.01 | 15.02 | 4.97 |
| U-Net | 25(5%) | 88.65 | 80.28 | 8.62 | 3.08 |
| U-Net | 500(All) | 90.67 | 83.40 | 6.84 | 2.47 |
| UA-MT[24] | 5(1%) | 84.46 | 74.23 | 14.26 | 5.10 |
| URPC[14] | 85.22 | 75.25 | 12.35 | 4.29 | |
| MC-Net[23] | 85.54 | 75.76 | 12.69 | 4.32 | |
| CNN_ViT[21] | 85.36 | 75.44 | 12.03 | 4.38 | |
| BCP[2] | 87.26 | 78.18 | 9.20 | 3.30 | |
| DCNet[3] | 86.69 | 77.50 | 9.12 | 3.29 | |
| Ours | 88.28 | 79.21 | 8.94 | 3.18 | |
| UA-MT[24] | 25(5%) | 88.47 | 80.03 | 8.40 | 3.04 |
| URPC[14] | 88.78 | 80.51 | 7.84 | 2.84 | |
| MC-Net[23] | 89.08 | 80.93 | 7.59 | 2.81 | |
| CNN_ViT[21] | 88.24 | 79.57 | 9.45 | 3.39 | |
| BCP[2] | 89.26 | 81.24 | 7.45 | 2.74 | |
| DCNet[3] | 89.21 | 81.30 | 7.44 | 2.75 | |
| Ours | 89.63 | 81.75 | 7.22 | 2.64 |
| Method | Labeled | Dice | Jaccard | 95HD | ASD |
| U-Net | 7(1%) | 69.50 | 59.73 | 62.88 | 9.80 |
| U-Net | 34(5%) | 76.52 | 68.32 | 61.79 | 4.64 |
| U-Net | 676(All) | 78.51 | 72.04 | 75.97 | 2.15 |
| UA-MT[24] | 7(1%) | 69.03 | 59.15 | 67.30 | 9.71 |
| URPC[14] | 69.96 | 60.44 | 64.40 | 6.69 | |
| MC-Net[23] | 70.54 | 61.02 | 65.24 | 7.77 | |
| CNN_ViT[21] | 70.49 | 60.65 | 64.89 | 7.13 | |
| BCP[2] | 70.43 | 60.89 | 65.49 | 7.46 | |
| DCNet[3] | 70.25 | 60.96 | 63.81 | 5.48 | |
| Ours | 71.75 | 61.68 | 63.62 | 5.44 | |
| UA-MT[24] | 34(5%) | 76.49 | 68.29 | 61.92 | 4.69 |
| URPC[14] | 75.95 | 67.78 | 61.60 | 4.10 | |
| MC-Net[23] | 76.75 | 68.68 | 62.14 | 4.40 | |
| CNN_ViT[21] | 76.90 | 68.95 | 62.06 | 4.36 | |
| BCP[2] | 77.08 | 68.85 | 62.32 | 4.69 | |
| DCNet[3] | 77.33 | 69.14 | 61.76 | 4.50 | |
| Ours | 77.90 | 69.95 | 61.44 | 4.03 |
We compare our method with existing ones: UA-MT [24], URPC [14], MC-Net [23], CNN_ViT [21], BCP [2], and DCNet [3]. Results from other compared methods were obtained using the same experimental setting in BCP [2] for fair comparisons. Table I shows the quantitative performance of segmentation results on CAMUS and with 1% and 5% labeled ratios. Our approach outperforms other competitors under the condition of extremely limited labeled images (1%), achieving a 1.02% improvement in Dice score on the private dataset. Furthermore, our method achieves the best performance in the other three metrics. Table II shows the quantitative performance of segmentation results on private clinical dataset with 1% and 5% labeled ratios. Our approach continues to outperform other approaches under the condition of (1%) labeled images, achieving a 1.21% improvement in Dice score on the private clinical dataset. This implies that reflecting upon and enhancing the quality of pseudo-label generation is advantageous for improving the performance and robustness of the network. Surprisingly, the performance of UA-MT appears to be even worse than the lower bound. It is possible that UA-MT failed to address challenges posed by characteristics of echocardiography and failed to generate high-quality pseudo-labels, and thus misled the student network. Visualization and additional analysis are shown in the supplementary material.
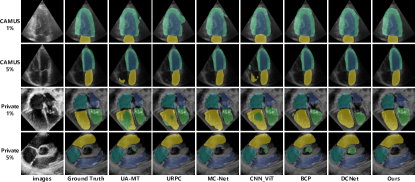
Moreover, we present the visualization of segmentation results in Fig. 3. As shown in the figure, our method achieves a more delicate edge segmentation. Some methods erroneously identify the interior of larger objects (e.g., right ventricle) in certain images as belonging to other categories. Some other methods mistakenly classify unnecessary segmentation areas in some images as a specific object (e.g., aorta).
III-C Ablation studies
| ERS | MMS | L | Dice | 95HD | L | Dice | 95HD |
| 1% | 85.34 | 12.56 | 5% | 88.92 | 7.81 | ||
| ✓ | 86.58 | 9.28 | 89.11 | 7.57 | |||
| ✓ | 87.29 | 9.15 | 89.24 | 7.46 | |||
| ✓ | ✓ | 88.28 | 8.94 | 89.63 | 7.22 |
To validate the effectiveness of our designs, we conduct a series of ablation studies on public dataset CAMUS. First, we evaluate the effectiveness of the error reflection strategy and the multi-scale mixing up strategy in our proposed framework. As shown in Table III, the experimental results demonstrate that the proposed strategies have all contributed to performance gains.
| Method | Labled | Dice | 95HD | Labled | Dice | 95HD |
| All-AS | 5(1%) | 85.67 | 10.12 | 25(5%) | 88.86 | 7.91 |
| All-S1 | 87.64 | 9.11 | 89.39 | 7.42 | ||
| All-S2 | 87.96 | 9.02 | 89.52 | 7.34 | ||
| All | 88.28 | 8.94 | 89.63 | 7.22 |
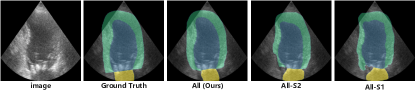
We focus our study on examining whether error reflection strategy can overcome the challenges in pseudo-label generation for semi-supervised echocardiography segmentation posed by the poor contrast, blurred edge details and noise characteristics of echocardiography. In one experiment, we remove the reconstruction reflection step, replace the process of generating the unreliable region map with a simple Softmax function evaluation, and retain the guidance correction step. In another experiment, we retain the reconstruction reflection step but remove the guidance correction step. As shown in Table IV, the experimental results indicate that both steps of the error reflection strategy are indispensable for achieving optimal performance. Additionally, we examine the significance of auxiliary sketches: the generation of distorted proxies without auxiliary sketches adversely impacts segmentation quality. As illustrated in Fig. 4, each of our designs contributes to performance enhancement, effectively improving the generation quality of pseudo-labels.
| Labled | Dice | 95HD | Labled | Dice | 95HD | |
| 2 | 5(1%) | 87.39 | 9.07 | 25(5%) | 89.21 | 7.45 |
| 3 | 87.67 | 9.10 | 89.32 | 7.38 | ||
| 4 | 84.75 | 14.52 | 88.48 | 8.41 | ||
| 2/3 | 88.28 | 8.94 | 89.63 | 7.22 |
Furthermore, we study the impact of number (N) of puzzle patches. As shown in Table V, the experimental results reveal that the model performs optimally when N is randomly assigned as either 2 or 3. This suggests that the strategy can effectively improve empirical mismatch between labeled and unlabeled data distribution, and facilitate the perception of cardiac anatomical structures at different scales, thereby enhancing performance.
IV Conclusion
In this paper, we reflect upon the characteristics of poor contrast, blurred edge details and noise in echocardiography, and propose an error reflection strategy for semi-supervised segmentation of echocardiography. The strategy, consisting of a reconstruction reflection step and a guidance correction step, aims to improve the quality of pseudo-label generation, thereby improving the model performance. Additionally, we introduce a data augmentation strategy, namely multi-scale mixing up strategy, to reduce the distribution mismatch between labeled and unlabeled images and facilitate the perception of various scales of cardiac anatomical structures. Experimental results on a public echocardiography dataset and a private clinical echocardiography dataset verify the superiority of the proposed method.
Acknowledgment
We thank Qiming Huang, a Ph.D. student from the University of Birmingham, for insights. This work was partially supported by the National Natural Science Foundation of China (Grant No. 62071285), Sanya Science and Technology Innovation Program (Grant No. 2022KJCX41), and Pediatric Medical Consortium Scientific Research Project of Shanghai Children’s Medical Center affiliated to Shanghai Jiao Tong University School of Medicine.
References
- [1] W. Bai, O. Oktay, M. Sinclair, H. Suzuki, M. Rajchl, G. Tarroni, B. Glocker, A. King, P. M. Matthews, and D. Rueckert, “Semi-supervised learning for network-based cardiac mr image segmentation,” in Medical Image Computing and Computer-Assisted Intervention- MICCAI 2017: 20th International Conference, Quebec City, QC, Canada, September 11-13, 2017, Proceedings, Part II 20. Springer, 2017, pp. 253–260.
- [2] Y. Bai, D. Chen, Q. Li, W. Shen, and Y. Wang, “Bidirectional copy-paste for semi-supervised medical image segmentation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 11 514–11 524.
- [3] F. Chen, J. Fei, Y. Chen, and C. Huang, “Decoupled consistency for semi-supervised medical image segmentation,” in International Conference on Medical Image Computing and Computer-Assisted Intervention. Springer, 2023, pp. 551–561.
- [4] J. Chen, Y. Lu, Q. Yu, X. Luo, E. Adeli, Y. Wang, L. Lu, A. L. Yuille, and Y. Zhou, “Transunet: Transformers make strong encoders for medical image segmentation,” arXiv preprint arXiv:2102.04306, 2021.
- [5] Y. Chen, X. Ouyang, K. Zhu, and G. Agam, “Complexmix: Semi-supervised semantic segmentation via mask-based data augmentation,” in 2021 IEEE International Conference on Image Processing (ICIP). IEEE, 2021, pp. 2264–2268.
- [6] G. French, S. Laine, T. Aila, M. Mackiewicz, and G. Finlayson, “Semi-supervised semantic segmentation needs strong, varied perturbations,” arXiv preprint arXiv:1906.01916, 2019.
- [7] Z. Guo, Y. Zhang, Z. Qiu, S. Dong, S. He, H. Gao, J. Zhang, Y. Chen, B. He, Z. Kong et al., “An improved contrastive learning network for semi-supervised multi-structure segmentation in echocardiography,” Frontiers in cardiovascular medicine, vol. 10, p. 1266260, 2023.
- [8] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 770–778.
- [9] G. S. Hillis and P. Bloomfield, “Basic transthoracic echocardiography,” Bmj, vol. 330, no. 7505, pp. 1432–1436, 2005.
- [10] S. Leclerc, E. Smistad, J. Pedrosa, A. Østvik, F. Cervenansky, F. Espinosa, T. Espeland, E. A. R. Berg, P.-M. Jodoin, T. Grenier et al., “Deep learning for segmentation using an open large-scale dataset in 2d echocardiography,” IEEE transactions on medical imaging, vol. 38, no. 9, pp. 2198–2210, 2019.
- [11] S. Li, C. Zhang, and X. He, “Shape-aware semi-supervised 3d semantic segmentation for medical images,” in Medical Image Computing and Computer Assisted Intervention–MICCAI 2020: 23rd International Conference, Lima, Peru, October 4–8, 2020, Proceedings, Part I 23. Springer, 2020, pp. 552–561.
- [12] Y. Liu, X. Han, T. Liang, B. Dong, J. Yuan, M. Hu, Q. Liu, J. Chen, Q. Li, and Y. Zhang, “Edmae: An efficient decoupled masked autoencoder for standard view identification in pediatric echocardiography,” Biomedical Signal Processing and Control, vol. 86, p. 105280, 2023.
- [13] X. Luo, J. Chen, T. Song, and G. Wang, “Semi-supervised medical image segmentation through dual-task consistency,” in Proceedings of the AAAI conference on artificial intelligence, vol. 35, no. 10, 2021, pp. 8801–8809.
- [14] X. Luo, W. Liao, J. Chen, T. Song, Y. Chen, S. Zhang, N. Chen, G. Wang, and S. Zhang, “Efficient semi-supervised gross target volume of nasopharyngeal carcinoma segmentation via uncertainty rectified pyramid consistency,” in Medical Image Computing and Computer Assisted Intervention–MICCAI 2021: 24th International Conference, Strasbourg, France, September 27–October 1, 2021, Proceedings, Part II 24. Springer, 2021, pp. 318–329.
- [15] A. Madani, J. R. Ong, A. Tibrewal, and M. R. Mofrad, “Deep echocardiography: data-efficient supervised and semi-supervised deep learning towards automated diagnosis of cardiac disease,” NPJ digital medicine, vol. 1, no. 1, pp. 1–11, 2018.
- [16] V. Olsson, W. Tranheden, J. Pinto, and L. Svensson, “Classmix: Segmentation-based data augmentation for semi-supervised learning,” in Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2021, pp. 1369–1378.
- [17] Y. Ouali, C. Hudelot, and M. Tami, “Semi-supervised semantic segmentation with cross-consistency training,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 12 674–12 684.
- [18] N. Painchaud, N. Duchateau, O. Bernard, and P.-M. Jodoin, “Echocardiography segmentation with enforced temporal consistency,” IEEE Transactions on Medical Imaging, vol. 41, no. 10, pp. 2867–2878, 2022.
- [19] O. Ronneberger, P. Fischer, and T. Brox, “U-net: Convolutional networks for biomedical image segmentation,” in Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, October 5-9, 2015, Proceedings, Part III 18. Springer, 2015, pp. 234–241.
- [20] A. Tarvainen and H. Valpola, “Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results,” Advances in neural information processing systems, vol. 30, 2017.
- [21] Z. Wang, T. Li, J.-Q. Zheng, and B. Huang, “When cnn meet with vit: Towards semi-supervised learning for multi-class medical image semantic segmentation,” in European Conference on Computer Vision. Springer, 2022, pp. 424–441.
- [22] H. Wu, J. Liu, F. Xiao, Z. Wen, L. Cheng, and J. Qin, “Semi-supervised segmentation of echocardiography videos via noise-resilient spatiotemporal semantic calibration and fusion,” Medical Image Analysis, vol. 78, p. 102397, 2022.
- [23] Y. Wu, M. Xu, Z. Ge, J. Cai, and L. Zhang, “Semi-supervised left atrium segmentation with mutual consistency training,” in Medical Image Computing and Computer Assisted Intervention–MICCAI 2021: 24th International Conference, Strasbourg, France, September 27–October 1, 2021, Proceedings, Part II 24. Springer, 2021, pp. 297–306.
- [24] L. Yu, S. Wang, X. Li, C.-W. Fu, and P.-A. Heng, “Uncertainty-aware self-ensembling model for semi-supervised 3d left atrium segmentation,” in Medical Image Computing and Computer Assisted Intervention–MICCAI 2019: 22nd International Conference, Shenzhen, China, October 13–17, 2019, Proceedings, Part II 22. Springer, 2019, pp. 605–613.
- [25] Y. Zhao, K. Liao, Y. Zheng, X. Zhou, and X. Guo, “Boundary attention with multi-task consistency constraints for semi-supervised 2d echocardiography segmentation,” Computers in Biology and Medicine, vol. 171, p. 108100, 2024.