—-¿↦ \mathlig-‘⇀ \mathlig ¿↝ \mathlig=¿⇒ \mathlig—=⊨ \mathlig ∼ \mathlig¿=≥ \mathlig¡=≤ \mathlig¡=¿⇔ \mathlig-*\sepimp \mathlig-¿→ \mathlig—[⟦ \mathlig—]⟧ \mathlig!=≠
A separation logic for sequences
in pointer programs and its decidability
Abstract
Separation logic and its variants can describe various properties on pointer programs. However, when it comes to properties on sequences, one may find it hard to formalize. To deal with properties on variable-length sequences and multilevel data structures, we propose sequence-heap separation logic which integrates sequences into logical reasoning on heap-manipulated programs. Quantifiers over sequence variables and singleton heap storing sequence (sequence singleton heap) are new members in our logic. Further, we study the satisfiability problem of two fragments. The propositional fragment of sequence-heap separation logic is decidable, and the fragment with 2 alternations on program variables and 1 alternation on sequence variables is undecidable. In addition, we explore boundaries between decidable and undecidable fragments of the logic with prenex normal form.
Index Terms:
separation logic, predicate logic, higher-order, sequence, decidabilityI Introduction
The classical separation logic proposed by Reynolds[1] is widely used to describe and verify various properties on heap-manipulated programs. It has evolved in many versions: object-oriented separation logic[2], quantitative separation logic [3], higher-order separation logic[4], separation logic with inductive predicates[5], etc. Its separating conjunction and separating implication provides much succincter expressions on mutable data structures.
Sequences are also widely used in programs. Many data structures can be abstracted to sequences, including in C++, and in Java. There are many string solvers on sequences, such as CVC4[6] and Z3str3[7]. Sequence predicate logic[8] introduces sequence variables and sequence functions, and allows quantifiers over sequence variables. With sequence variables, sort function can be defined elegantly.
However, to our best knowledge, there is no integral formal systems on logical reasoning of programs with both heap and sequence. The example proposed in [1] provides a way to formally verify whether a program implements list reversal. The program aims to reverse the sequence in and put it into . The invariant of this program is written as follows:
| (1) |
where denotes reversal of the sequence , and the term denotes the concatenation of the two sequences and . The predicate denotes a singly-linked list starting from , which can be inductively defined as follows:
| (2) | ||||
The property defined in Equation 1 can be attributed to properties on variable-length sequences in pointer programs. These properties can be found in many commonly-used mutable data structures, such as in stacks, queues, and graphs. Besides, variable-length sequences also appear in multilevel data structures, such as paging on operating systems, and file systems. It is necessary to introduce a logic to describe and verify these kind of properties.
In this paper, we aim to establish a logical foundation for variable-length sequences and multilevel data structures in pointer programs, especially on definition, expressiveness and decidability. We propose sequence-heap separation logic to integrate sequences into logical reasoning in pointer programs. The logic is an extension of both classical separation logic proposed in [1], and sequence predicate logic proposed in [8].
Sequence-heap separation logic can be seen as a fragment of higher-order separation logic proposed in [4]. Quantifiers over sequences can be reduced to those over predicates (or over sets). Sequence-heap separation logic is less expressive than higher-order separation logic, but can be used in many scenarios on sequences in pointer programs, and has better deciability results.
In terms of definition for sequence-heap separation logic, we define the heap model as a finite partial mapping from locations to sequences, which is similar to the block model defined in [9]. The model can be written as , compared to the model defined in the classical separation logic.
We also define sequence singleton heap as the term to adapt more scenarios on variable-length sequences. The term can be used to denote stack, queue, variadic arguments, trees with variable-length branches, graphs with unbounded out-degree, etc. We take stack as an example.
In the classical separation logic, one has to describe stack with the inductive predicate defined in Equation 2, where and denote the top pointer and contents of the stack respectively. However, with sequence singleton heap defined in sequence-heap separation logic, one can use this formula to denote stack without inductive predicate.
The definition of sequence singleton heap can help us to get a decidable result. We prove that the fragment with sequence singleton heap is decidable, compared to the undecidable result on fragment in [10] where the list predicate , separating conjunctions, and separating implications are defined.
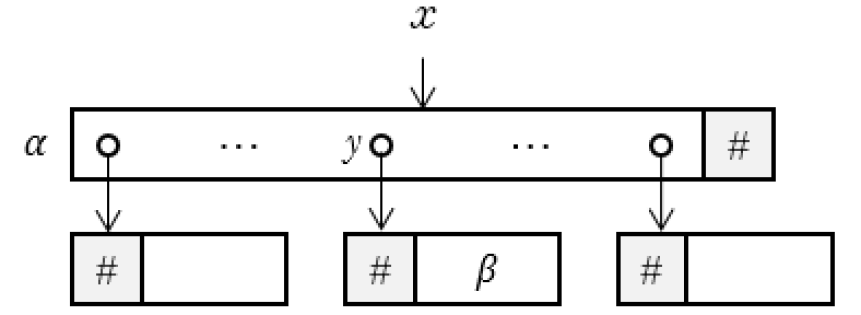
Besides, properly defining the form of can help the logic to describe multilevel data structures. For example, if is of the form (where denotes the sequence of locations, denotes the sequence of contents, and separates these two sequences), one can describe two-tier data structures[9] in block-based cloud storage systems in the following way.
| (3) |
where denotes the block location, denotes the sequence of content location, and denotes contents in each location of . The term denotes appears in , which is defined as follows:
Equation 3 can be illustrated by Fig. (1).
We notice that sequence predicate logic proposed in [8] is also capable of describing various properties on variable-length sequences. However, the logic cannot be directly used to describe sequences in pointer programs. sequence-heap separation logic is more than just the combination of sequence predicate logic and separation logic. The logic enriches the composition of the two.
We also notice that the model of sequence-heap separation logic is similar to that of block-based separation logic proposed in [9]. However, the sequence singleton heap and quantifiers over sequences in sequence-heap separation logic provide more abstraction, and can be used for wider application scenarios, not just for block-based cloud storage systems.
For example, the combined logic can simplify expressions on describing stack. Besides, sequence predicate logic and separation logic alone cannot describe multilevel data structures shown in Equation 3, but the combined one can do this.
We also study decidability problems of sequence-heap separation logic fragments. This can help us to find algorithms for decidable fragments, as well as to understand expressiveness of the logic intensively. We get the following two main fragments on satisfiability problems. One is a decidable fragment which lays between fragment of the classical separation logic, and the logic involving list predicate. The other is an undecidable fragment where there are two alternations on quantifiers over program variables, and one alternation on quantifiers over sequence variables.
The paper is organized as follows. In Section \@slowromancapii@, we introduce some basic concepts of separation logic and sequence predicate logic. In Section \@slowromancapiii@, we define sequence-heap separation logic and explore its expressiveness. In Section \@slowromancapiv@, we prove that the satisfiability problem of fragment is decidable. In Section \@slowromancapv@, we prove that the satisfiability problem of the fragment with the prenex normal form is undecidable. In addition, we explore boundaries between decidable and undecidable fragments. In Section \@slowromancapvi@, we conclude our work, and propose future work on sequence-heap separation logic.
Related work. Separation logic can express properties on heaps, such as dangling pointers, non-circularity, and memory leakages.[11] However, the logic itself is proved to be undecidable[12]. We investigate the following two categories of fragments: basic fragments without inductive predicates and fragments with inductive predicates.
In basic fragments, there are no user-defined predicates or hard-corded predicates. It is known that the validity problem of fragment is decidable[13], and that of basic fragment with quantifiers and no separation implications is undecidable[13]. If we restrict the size of the heap satisfying in the formulae to be bounded (namely ), then we can get a decidable basic fragment [12]. To get decidable fragments, one can either restrict quantifier alternations in the formulae of prenex normal form, or number of quantified variables. For quantifier alternations, the fragment with 2 quantifier alternations is decidable[14], while the fragment with 3 is undecidable[14]. For quantified variables, the fragment with 1 quantified variable is decidable [15], while the fragment with 2 quantified variables is undecidable [16].
In fragments, it contains separation implications (or its variants) and inductive predicates describing data structures. One basic result is that the satisfiability problem of fragment with lists is undecidable[10]. However, if list predicates are restricted to the list with length at most 2, one can get a decidable fragment [10]. Besides, if we further restrict heap unions in separation model, one can get strong-separation logic[17]. It is proved that the strong-separation fragment with list predicates is decidable.
All fragments mentioned above can be found in TABLE I.
| Fragment | Model | Key connectives and predicates | Decidability |
| separation model | decidable | ||
| undecidable | |||
| decidable | |||
| prenex | decidable | ||
| prenex | undecidable | ||
| 1 quantified variable | decidable | ||
| 2 quantified variables | undecidable | ||
| separation model | undecidable | ||
| separation model | decidable | ||
| strong-separation model | decidable |
Sequence predicate logic is an extension of word equation. Specifically, word equations are fragment or fragment of sequence predicate logic, where there are only quantifiers over sequence variables. It can express many properties on sequences, such as conjugates, and lexicographic ordering on words[18]. On the other hand, it cannot express properties such as ”the primitiveness” and ”the equal length”. It is shown that every Boolean combinations of word equations on free semigroup can be reduced to a single word equation[19].
Different from the classical predicate logic, sequence variables, sequence predicates and sequence functions are defined in sequence predicate logic[8]. The problem of whether there is a solution for word equation is decidable[19]. Namely, the truth of fragment of sequence predicate logic is decidable. Further researches show that the truth of positive formulae (where there is no negations or inequalities) which is of the form [20], [21] or [22] is shown to be undecidable. To get a decidable fragment, one can restrict the formulae of the form to the positive one[22].
There are some works which combine separation logic and sequences. When formalizing cloud storage systems, one can construct a modeling language IMDSS[23], and a proof system based on separation logic[9]. These papers define values of heaps as finite sequences, and describe properties on blocks without using sequence singleton heap. Coq-based proof assistant[24] is implemented based on the logic defined in [9].
II Preliminaries
In this section, we introduce some basic concepts on separation logic and sequence predicate logic.
II-A Separation logic
In this subsection, we mainly focus on definitions and expressiveness of separation logic.
Definition II.1 (Definition of separation logic)
The syntax of separation logic[25] with 1 records is defined as follows:
where denotes constants, denotes variables, denotes -ary functions mapping to , and denotes -ary predicates mapping to .
The underlying model of separation logic consists of a stack and a heap . The set comprises locations excluding . The set comprises symbols of variables, including . The set comprises integer values. The model is defined as follows:
| . |
The semantics of the term can be defined as follows, where is the interpretation of .
The semantics of formulae is inductively defined as follows:
| iff | ||||
| iff | ||||
| iff | ||||
| iff | ||||
| iff | ||||
| iff | ||||
| iff | ||||
| iff | ||||
| iff | ||||
| iff | ||||
| iff | ||||
where denotes the interpretation of .
For convenience, we have the following notation[25] denoting that points to with some fixed .
| (4) |
In some fragments of separation logic, the heap model is defined as with some fixed [25][26]. In this case, Equation 4 will no longer hold. The semantics of the notation is defined as follows:
| iff | ||||
We notice that in either separation logic or one of its fragments (symbolic heap[11][26], strong-separation logic[17], etc.), the singleton heap is defined with some fixed number . It may not be suitable for describing properties on blocks, or graphs where each node is of unbounded out-degrees.
The paper [9] introduces sequence into separation logic to describe properties on block-based cloud storage systems. The model of the logic is defined as a quintuple of the form , where are assignments of file variables, block variables and location variables respectively, are heaps of blocks and heaps of values respectively. The file stack is a mapping from file variables to a sequence of block addresses, which is denoted as , and is a finite partial mapping from blocks to sequences of locations, which is denoted as . Although and both range over sequences, the logic does not introduce sequence variables, sequence functions, or sequence singleton heap. The logic visits these sequences by existential quantifiers on block variables, and by equality over values of block variables.
II-B Word equations and sequence predicate logic
Word equation can be seen as a special case of sequence predicate logic. It can be defined as follows:
Definition II.2 (Word equation)
Suppose is a free semigroup satisfying with unknowns , where are generators. Word equation is an equality of the form:
where is the equality between two concatenations of sequences. If there is a solution for , then the word equation is satisfied.
The definition of word equation can be enhanced with Boolean combination, as is shown in Definition II.3.
Definition II.3 (Boolean combination of word equations)
Boolean combination of word equations is defined as follows:
where denotes constants, denotes sequence variables, and denotes the concatentation of two sequences and .
Word equation is capable of describing many properties on sequences. Every Boolean combinations of word equations can be reduced to a single word equation followed by Theorem II.1[18].
Theorem II.1
For every Boolean combinations defined above, there exists a single word equation , which is equivalent to . The proof sketch of the theorem can be found in Appendix.
If word equation is enhanced with sequence function, and quantifiers over variables and sequences, then one can get the following definition of sequence predicate logic.
Definition II.4 (Sequence predicate logic)
The syntax of sequence predicate logic[8] can be defined as follows:
The variable denotes individual variables, and denotes sequence variables. The arity of , , and can be either fixed or flexible. When it is fixed, there is no sequence variables on parameters. When it is flexible, it may contain sequence variables.
The structure of the logic is defined as , where is the domain, and is the interpretation on individual and sequence constants, functions and predicates. The assignment of the logic can be defined as , where , , and , .
II-C Expressiveness of sequence predicate logic
We recall properties which can be expressed by sequence predicate logic. They are useful for describing properties with sequence-heap separation logic.
Length. Sequence predicate logic can be used to get the length of a sequence. The function denotes the length of the sequence , which can be inductively defined as follows:
For convenience, we define to denote .
Statistics. Sequence predicate logic can be used to get occurrences of specific terms. The function denotes the occurrences of in sequence , which can be inductively defined as follows:
For convenience, we define to denote .
Lookups. The predicate denotes the -th item of sequence is , which can be expressed as follows:
Note that does not appear as a term in Definition II.4. If so, consider the case where exceeds the length of sequence . A new value should be introduced to denote illegal term, which may complicate the logic. We take to denote for convenience:
Other properties can be expressed with lookups. We list some of them below.
The relationships between items and sequences can be defined as , which means can be found in the sequence :
The -th item of the sequence is equal to the -th item of the sequence :
Unary property. All items in the sequence satisfies the unary property :
Binary property. Each two items with different indices in the sequence satisfies the binary property :
Increment and set-like defined bellow are binary properties.
Increment. The sequence is strictly increasing:
Set-like. Each two items in sequence are distinct:
Segment. The sequence is the consecutive sub-sequence of :
Truncation. The sequence is the consecutive sub-sequence of with indices ranging over :
III sequence-heap separation logic
sequence-heap separation logic is an extension of both classical separation logic and sequence predicate logic. It can describe properties on variable-length sequences, and multilevel data structures. Some properties cannot be expressed easily by the classical separation logic or sequence predicate logic alone.
In this section, we present the definition and expressiveness of sequence-heap separation logic (SeqSL).
III-A Definition of sequence-heap separation logic
Definition III.1 (Syntax of sequence-heap separation logic)
The syntax of the logic can be defined as follows:
Note that other functions and predicates can be defined in SeqSL following the definition in [8], such as comparison between sequence, and picking up an item from a sequence. Most commonly-used predicates and functions can be expressed by the logic defined above.
Definition III.2 (Model of sequence-heap separation logic)
There are three types of variables in the signature of SeqSL: program variables , sequence variables . These sets are all countable. The model can be defined as follows:
| , |
where Loc is the set of locations, Val is the set of values, Atoms is the set of reserved words, denotes the stack, denotes the assignment on sequence variables, and denotes the heap which stores sequence of locations, values, or atoms.
Definition III.3 (Semantics of terms)
The symbol denotes individual term, whose value ranges over Val. The denotational semantics of the term can be inductively defined as follows:
where in Atoms cannot be used as a location, and is used to describe multilevel data structures.
The symbol denotes sequence term, whose value ranges over . The denotational semantics of the term can be inductively defined as follows:
where denotes the concatenation of two sequences and .
Definition III.4 (Semantics of sequence-heap separation logic)
In SeqSL, the indices of sequence items start from 1. We set for convenience. The semantics of SeqSL can be defined as follows:
| iff | ||||
| iff | ||||
| iff | ||||
| iff | ||||
| iff | ||||
| iff | ||||
| iff | ||||
| iff | ||||
| iff | ||||
| iff | ||||
| iff | ||||
| iff | ||||
where and denote substitution of program variable and sequence variable respectively. They are defined as follows.
For convenience, we write to denote , and to denote .
SeqSL can express properties which is widely used in logic reasoning on pointer programs. We list some of them. These notations will be used in this paper.
| septraction | |||
| universal quantifier | |||
III-B Expressiveness of sequence-heap separation logic
In this subsection, we list few examples to show expressiveness of SeqSL. We divide examples into 2 categories: properties on variable-length sequence in programs, and properties on multilevel data structures.
Similar to the classical separation logic, sequence-heap separation logic does not make differences between locations and values in formulae. To adjust more scenarios in practice, we use the atom to manually separate locations and values. The sequence singleton heap can thus be written as , where denotes sequence of locations, and denotes sequence of values.
III-B1 Properties on variable-length sequences in programs
we list some properties on graphs to show the expressiveness of SeqSL on describing variable-length sequences in programs. These properties include: out-degree and reachability.
Out-degree. The out-degree of node can be denoted as . The formula means the out-degree of node is . It is defined as follows:
| (5) | ||||
Note that the reserved word nil might be in . It does not affect the truth of the definition, because nil can be viewed as location 0. Its out-degree is 0, and in-degree is not necessarily be 0.
Reachability. First, we define one-step reachability , which means there exists an edge from to .
Then we define , which means there exists a path from to . The length of the path is ().
Finally we define , which means there exists a path from to , whose length is larger or equal than 0.
Note that defined in SeqSL is different from defined in the separation logic fragments on shape analysis. The former can describe reachability on graphs without restrictions on out-degree of each nodes, while the latter can only describe reachability on linked lists.
III-B2 Properties on multilevel data structures
we list some properties on two kinds of storage systems to show expressiveness of SeqSL on describing multilevel data structures.
Different from SeqSL, the model of SeqSL describing storage systems should be interpreted in disk, not in memory.
Properties on Windows storage systems. The structure of Windows storage systems based on trees can be expressed by SeqSL. The indices of files are stored in the location . The file is stored in the location .
| (6) | ||||
Note that the sub-formula can not be replaced by . The reason is that, is a finite sequence. When exceeds the length of , it falsifies . So we have to restrict with .
We apply in Equation 6 to describe two-tier data structures. The first tier merely stores locations , while the second tier merely stores data . These two different forms of contents prevent the location in the second tier from pointing to the location in the first tier.
With Equation 6 in hand, we can describe properties of files. We list two of them.
A file can be found by its index :
The content can be found in the file :
In addition, we can apply to describe n-th tier of multilevel data structure. This is useful for describing multilevel pointers in C++, multilevel paging, multilevel addressing, etc.
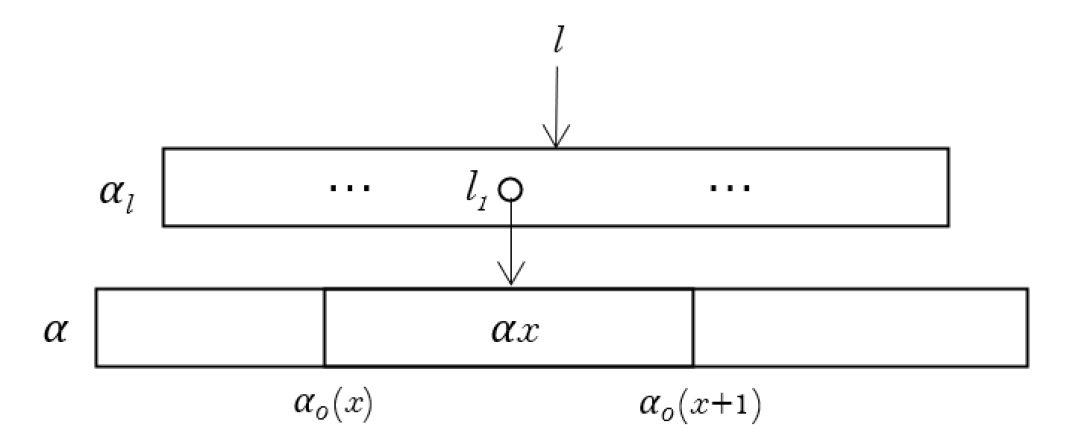
Properties on block-based cloud storage systems. SeqSL can be used to describe blocks in cloud storage systems. Generally speaking, the sequence in the formula can be viewed as a block. With a relative address , the content can be found.
For convenience, we define the predicate , which means with length is strictly increasing. The first item of is 1, and the last is .
A big file stored in location is divided into smaller blocks and is stored in disk. The indices of the file are stored in location . The function can be used to locate these blocks. The sequence variable in the following formula represents the sequence of division points, which should make the predicate to be true. The length of each block can be additionally fixed to 64 by tahe formula .
The formula defined above can be illustrated by Fig. (2).
IV Decidable fragments
In this section, we consider a decidable fragment of SeqSL. It contains sequence singleton heap, separating conjunction, separating implication, equality and concatenation on sequences. We present the following main result of this section.
Theorem IV.1 (Decidable fragment of SeqSL)
The satisfiability problem of the language is decidable when it is restricted as follows:
The model of the fragment is the same as that of SeqSL, which is defined in Definition III.2.
We call the above fragment the fragment of separation logic (PSeqSL, where the alphabet ’P’ means propositional). PSeqSL is a non-trivial fragment for the following reasons:
-
•
The expressiveness of PSeqSL is stronger than that of the fragment of the classical separation logic proposed in [1], because the former can express properties on variable-length sequences and on multilevel data structures.
-
•
The heap stores variable-length sequences in PSeqSL. The models of a formula in PSeqSL may have more possibilities than that of a formula in the classical separation logic.
-
•
Sequences and heap operations in the fragment are not independent. Their satisfiability may affect each other. For instance, to decide whether the formula is true, we need to consider both conditions on heap, and the implicit condition on sequences. To decide whether the formula is true, we need to consider the implicit condition .
-
•
PSeqSL can describe some of the formulae consisting of existential quantifiers in SeqSL. The property in SeqSL can be expressed in PSeqSL as:
We prove Theorem IV.1 following these three steps:
-
1.
prove the following problem is decidable: given the formula in PSeqSL, and a part of the model , decide whether there exists , such that .
-
2.
prove the following problem is decidable: given the formula in PSeqSL, and a part of the model , decide whether there exists , such that .
-
3.
prove the following problem is decidable: given the formula in PSeqSL, decide whether there exists , such that . (Theorem IV.1)
The first step is the main part of the proof. The result on the fragment without separating implications is trivial, because the finiteness of leads to finite possibilities of models satisfying the formula .
Similar to the paper [13], we define the size of the formula as to represent the maximum heap size for deciding whether the formula is true or its negation is true.
Definition IV.1 (Size of formula)
The size of the formula , can be inductively defined as follows:
| . | |
We define free program variables as follows.
Definition IV.2 (Free program variables in PSeqSL)
In PSeqSL, free program variables in the term and free program variables in the term can be inductively defined as follows:
| . | ||
Free program variables in the formula can be inductively defined as follows:
We define the set of sequence terms to collect the terms appearing in the formula. It helps us to get a finite set of all possible heap models which may satisfy the formula.
Definition IV.3 (Set of sequence terms)
The set of sequence terms appearing in the formula can be inductively defined as:
Separating implication involves universal quantifiers over heaps. The paper [13] presents a solution on searching all possible models of the formula in the classical separation logic fragment. They restrict the domain and the range of the heap to finite sets. To deal with sequences, we come up with a different restriction on the range of . The range of involves the set of all sequence terms appearing in the formula, empty sequence , and a fresh sequence term whose value is different from all sequence terms in the formula. Thus, universal quantifiers over heaps can be reduced to those over finite heaps. The reduction preserves satisfiability.
We present the following lemma to show small model property on the formula .
Lemma IV.1
Given the model and formulae satisfying , the set , the set which contains the first values in , the fresh sequence variable satisfying . We define where contains a new assignment for . Let , and . Then, holds, if and only if for all satisfying:
-
•
and ,
-
•
,
-
•
,
the proposition holds, where denotes the range of .
According to Lemma IV.1, we define the reduction function as follows.
Definition IV.4
The reduction function is a mapping from stack , heap , and the PSeqSL formula , to the formula in sequence predicate logic. The reduction can be inductively defined in Fig. (3), \stripsep+2pt
where .
Given and , the formula consists of finitely many terms of the form , because the implicit existential quantifier in separating conjunction does not create new heaps. The formula also consists of finitely many terms of the form according to Lemma IV.1. Moreover, the truth values of the following three formulae , , and can be determined, as well as the value of (which is a sequence). So consists of only and its conjunctions, disjunctions and negations. It can be further reduced to a single word equation followed by Theorem II.1. PSeqSL is thus reduced to the satisfiability problem of sequence predicate logic. The fragment of sequence predicate logic is shown to be decidable in [19].
Lemma IV.2
Given stack and heap . For all assignment and formula , the proposition holds if and only if there exist assignments , such that holds, where and are assignments of program variables and sequence variables respectively, is the reduction from PSeqSL to sequence predicate logic defined by Definition IV.4.
Note that after doing reductions in Definition IV.4 and applying Theorem II.1, one can get a single word equation with constants ( contents for example) and sequence variables ( variables for example). It is easy to show the following fact: there is a solution for if and only if there is a solution for on the free monoid with generators, where the first generators coincide with constants, and the other generators are fresh in .
To give readers some intuitions for Lemma IV.2, we list two examples below.
Example IV.1
Consider whether the formula can be satisfied, given the stack satisfying where and are distinct integer numbers and the heap . The assignment is pending.
Suppose , where , . We have the formula in Fig. (4).
+0.5em
Suppose , where , and . We have:
where
and are the first three values in , the term satisfies:
The domain consists of many finite possibilities. However, there are only two possibilities and which may satisfy the formula. So,
Similarly, we discuss possibilities of models satisfying the formula . Then we have:
So,
We observe that can be satisfied. Hence given , there exists such that holds.
Example IV.2
Consider whether the formula can be satisfied, given .
Following definition Definition 4.4, we have:
We observe that cannot be satisified. Hence given , there does not exist such that holds. We omit the details here.
For the second step of the proof, heap is not given beforehand. The satisfiability problem of the formula in PSeqSL can be reduced to the problem in the first step by the following lemma.
Lemma IV.3
Given stack and the PSeqSL formula , the following problem is decidable: whether there exists and such that .
The above problem is equivalent to the following problem: given , whether there exists such that holds. Thus we can conclude Lemma IV.3.
For the third step, stack is not given. Similar to the paper[13], we need to figure out a finite range of , such that the formula is true on the range if and only if the formula is true on infinite range of .
Definition IV.5
Given two models , the set , and the set . The relation holds, if and only if there exists an isomorphism , such that the following conditions are satisfied:
-
•
for each , we have ,
-
•
, , and for each , we have ,
-
•
for each , we have ,
-
•
for each , we have .
Proposition IV.1
Given two models , and the formula satisfying . If , then .
Lemma IV.4
Given the model and the formula . Let be the first locations in . There exists such that , and .
With Lemmas IV.2, IV.3 and IV.4, we can conclude that the satisfiability problem of PSeqSL is decidable, that is Theorem IV.1 holds.
As we know, the truth of fragment of sequence predicate logic is decidable[19]. As the fragment consists of negations without any restrictions, there is a one-to-one mapping from instances in fragment of sequence predicate logic and those in fragment of sequence predicate logic. Thus we have Corollary IV.1.
Corollary IV.1
The theory of fragment of sequence predicate logic is decidable.
The proof of Theorem IV.1 shows that PSeqSL has small model property. The satisfiability of a formula in PseqSL can be reduced to that of the formula with finite length in fragment sequence logic. According to small model property of PSeqSL and Corollary IV.1, we have Corollary IV.2.
Corollary IV.2
The satisfiability and validity problem of fragment of PSeqSL is decidable, where fragment of PSeqSL is of the form , and is quantifier-free.
V Undecidable fragments
In this section, we mainly focus on an undecidable fragment of the form . It is the conjunction of formula in and formula , where denotes there are 0 or more existential quantifiers over sequence variables, and denotes there are 0 or more existential quantifiers over program variables. The meaning of and are similar. We present the following main result of this section.
Theorem V.1 (Undecidable fragment of SeqSL)
The satisfiability problem of the language is undecidable when it is restricted as follows:
where is a sentence.
The model of the fragment is defined in Definition III.2.
We reduce the problem from halting problem of two-counter Minsky machine. Before getting into details of the reduction, we recall the definition of two-counter Minsky machine.
Definition V.1 (Two-counter Minsky machine)
Let be a Minsky machine with instructions. The machine has two counters and . The instructions are defined as follows:
-
1.
goto ,
-
2.
if , then goto , else (; goto ),
-
3.
halt,
where and . Machine halts if there is a run of the form
such that , , and . The run follows the instructions defined above.
The set of instructions with type 1 (denoted by ) consists of tuples , and those with type 2 (denoted by ) consists of tuples , where denotes the current pointer, denote two counters (), and denote the next pointers.
The problem of deciding whether a machine halts is known to be undecidable[28].
We first show the undecidable fragment defined in Theorem V.1 is not that easy to get. In general, decidability results of both sequence logic fragments and separation logic fragments restrict the form of undecidable fragments of SeqSL.
Decidability results in free semigroup show that, the theory of fragment[21], the positive theory of fragment[20] and fragment[20] of word equations are undecidable. The results in separation logic show that, the satisfiability problem of fragment of separation logic is undecidable. In this case, We can get V.1.
Fact V.1
In the fragment of SeqSL with prenex normal form, if there are 3 or more alternations of quantifiers over program variables, or 2 or more over sequence variables, then the satisfiability problems of resulting fragments are undecidable. For instance, the satisfiability problems of , , are undecidable.
In order to get a non-trivial undecidable fragment of SeqSL with negations, we have to restrict the alternations of quantifiers over program variables to be less than 3, and those over sequence variables to be less than 2.
To prove Theorem V.1, we first discuss the encoding of the reduction. The general structure is sapling, which is shown in Fig. (5).
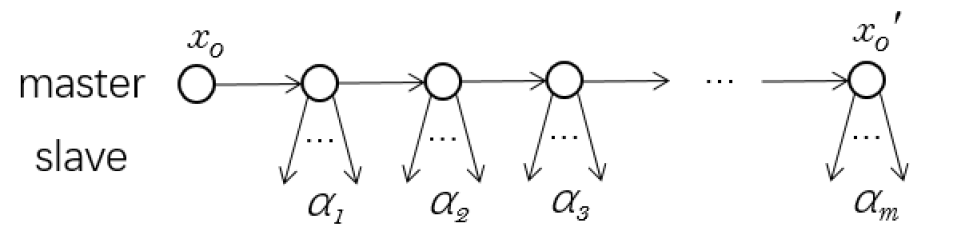
We consider the encoding for sapling. Sapling is a fishbone-like structure with ’bones’ going in opposite directions. Sapling consists of a master branch and several slave branches attached to nodes in the master branch. The depth of each slave branch is 1, and the end points of them does not point to any nodes in master branch. Similar to the encoding for the list defined in [12] and fishbone heap defined in [16], we encode the sapling in the following ways:
-
1.
There are smaller or equal than 1 predecessor of each node. It is denoted by the formula ,
-
2.
There is no predecessor on the first master node. It is denoted by the formula ,
-
3.
The first master node is allocated, and the last node does not point to the next master node. It is denoted by the formula (it is not necessary to make the predecessor of the last node to be 1),
-
4.
For each node except for the last node, there is another allocated node which follows the node. It is denoted by the formula .
The sapling from node to node (assume here that ) can be expressed by
| (7) |
where , and are defined in Fig. (4).
+0.5em
It can be easily shown that the predicate is of the form .
Note that the encoding in Equation 7 is just a general idea. It does not prevent contents in slave nodes from pointing to other nodes. However, this does not have impacts on the main result, because these contents only consist of which will be shown in Equation 8.
Note also that the predicate not only encodes the graph consisting of only one sapling, but also graphs consisting of both one sapling and circles. It is not necessary to remove all these circles, because it does not have impacts on correctness of the reduction. It is shown in Lemma V.1.
Lemma V.1
Given the predicate defined in Equation 7, it can be satisfied by a model if and only if there exists a model that satisfies , and there are no circles in .
The proof of Lemma V.1 can be found in Appendix. Now we prove Theorem V.1.
Proof:
We go into details of the reduction, which is shown in Fig. (7).
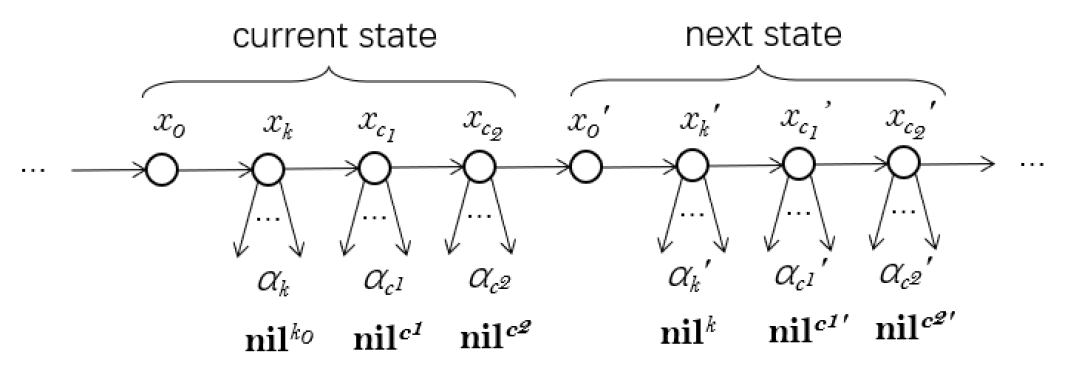
The master branch is the longest path from the beginning master node to the end master node. Each master node points to 0 or more slave nodes . The master nodes have the period of 4. Each period represents a state of the run. In the -th period (), the first master node represents a deliminator which separates each state of the run. There is no slave node attached to it. The second to the fourth master nodes represent the -th triple satisfying . The slave nodes pointed from these 3 nodes are respectively. The first period represents the initial state, while the last represents the final state.
We observe that the values of two counters in the sapling are greater than the real values of the counters in the run by 1. It is because we need to distinguish these nodes from the first node of each period, to which there is no slave nodes attached.
In general, The reduction formula consists of the following three parts.
-
1.
Construct the basic structure of sapling, which is denoted by the formula .
-
2.
Initialize the initial and the final state, which is denoted by the formula .
-
3.
Encode the transition from one state to the other following the current instruction, which is denoted by the formula .
The formula is of the form
| (8) | ||||
or
The detailed construction can be found in Appendix.
For each two-counter Minsky machine M, let be the formula of the form defined in Equation 8. If the machine M halts, then there is a finite run. It can be easily shown that there is a finite sapling from the first period encoding the first state to the final one encoding the final state, and each state except for the final state can be transformed to the next state by the corresponding instruction.
For the other side of the proof, we suppose that the formula of the form defined in Equation 8 is satisfied. The model of may consist of circles. We can get a model satisfying in which there is no circles according to Lemma V.1. ∎
VI Conclusion
In this paper, we propose sequence-heap separation logic which combines sequence predicate logic and separation logic. It is capable of describing the following properties which sequence predicate logic or separation logic alone cannot describe or cannot easily describe.
-
•
sequence operations in programs, such as list reversal, and lookups.
-
•
properties corresponding to variable-length sequences in programs, such as stack, queue, and graphs with unbounded out-degree.
-
•
multilevel data structures in programs, such as data structure in Windows storage systems, and in block-based cloud storage systems.
Besides, we find a boundary between decidable and undecidable SeqSL fragments, which are both of the prenex normal form. We prove the following two decidable results: the satisfiability problem of fragment and fragment is decidable, and that of is undecidable. As corollaries, fragments with either 3 quantifier alternations over program variables or 2 quantifier alternations over sequence variables are undecidable.
We will do the following work in the future.
-
•
Find other boundaries between decidable and undecidable fragments of sequence-heap separation logic, such as boundaries on numbers of quantified variables, and on inductive predicates.
-
•
Investigate deeply on expressiveness of sequence-heap separation logic.
-
•
Construct a proof system for sequence-heap separation logic.
-
•
Implement formal verification tools for sequence-heap separation logic fragments.
References
- [1] J. C. Reynolds, “Separation logic: A logic for shared mutable data structures,” in Proceedings 17th Annual IEEE Symposium on Logic in Computer Science (LICS). IEEE, 2002, pp. 55–74.
- [2] M. J. Parkinson and G. M. Bierman, “Separation logic, abstraction and inheritance,” ACM SIGPLAN Notices, vol. 43, no. 1, pp. 75–86, 2008.
- [3] K. Batz, B. L. Kaminski, J.-P. Katoen, C. Matheja, and T. Noll, “Quantitative separation logic: a logic for reasoning about probabilistic pointer programs,” Proceedings of the ACM on Programming Languages (POPL), vol. 3, no. POPL, pp. 1–29, 2019.
- [4] B. Biering, L. Birkedal, and N. Torp-Smith, “Bi-hyperdoctrines, higher-order separation logic, and abstraction,” ACM Transactions on Programming Languages and Systems (TOPLAS), vol. 29, no. 5, pp. 24–es, 2007.
- [5] J. Brotherston, C. Fuhs, J. A. N. Pérez, and N. Gorogiannis, “A decision procedure for satisfiability in separation logic with inductive predicates,” in Proceedings of the Joint Meeting of the Twenty-Third EACSL Annual Conference on Computer Science Logic (CSL) and the Twenty-Ninth Annual ACM/IEEE Symposium on Logic in Computer Science (LICS), 2014, pp. 1–10.
- [6] C. Barrett, C. L. Conway, M. Deters, L. Hadarean, D. Jovanović, T. King, A. Reynolds, and C. Tinelli, “Cvc4,” in International Conference on Computer Aided Verification (CAV). Springer, 2011, pp. 171–177.
- [7] M. Berzish, V. Ganesh, and Y. Zheng, “Z3str3: A string solver with theory-aware heuristics,” in 2017 Formal Methods in Computer Aided Design (FMCAD). IEEE, 2017, pp. 55–59.
- [8] T. Kutsia and B. Buchberger, “Predicate logic with sequence variables and sequence function symbols,” in International Conference on Mathematical Knowledge Management (MKM). Springer, 2004, pp. 205–219.
- [9] Z. Jin, B. Zhang, T. Cao, Y. Cao, and H. Wang, “Reasoning about block-based cloud storage systems via separation logic,” Theoretical Computer Science (TCS), vol. 936, pp. 43–76, 2022.
- [10] S. Demri, É. Lozes, and A. Mansutti, “The effects of adding reachability predicates in propositional separation logic,” in International Conference on Foundations of Software Science and Computation Structures (FoSSaCS). Springer, 2018, pp. 476–493.
- [11] J. Berdine, C. Calcagno, and P. W. O’hearn, “A decidable fragment of separation logic,” in International Conference on Foundations of Software Technology and Theoretical Computer Science (FSTTCS). Springer, 2004, pp. 97–109.
- [12] R. Brochenin, S. Demri, and E. Lozes, “On the almighty wand,” Information and Computation (IANDC), vol. 211, pp. 106–137, 2012.
- [13] C. Calcagno, H. Yang, and P. W. O’hearn, “Computability and complexity results for a spatial assertion language for data structures,” in International Conference on Foundations of Software Technology and Theoretical Computer Science (FSTTCS). Springer, 2001, pp. 108–119.
- [14] A. Reynolds, R. Iosif, and C. Serban, “Reasoning in the bernays-schönfinkel-ramsey fragment of separation logic,” in International Conference on Verification, Model Checking, and Abstract Interpretation (VMCAI). Springer, 2017, pp. 462–482.
- [15] S. Demri, D. Galmiche, D. Larchey-Wendling, and D. Méry, “Separation logic with one quantified variable,” Theory of Computing Systems, vol. 61, no. 2, pp. 371–461, 2017.
- [16] S. Demri and M. Deters, “Two-variable separation logic and its inner circle,” ACM Transactions on Computational Logic (TOCL), vol. 16, no. 2, pp. 1–36, 2015.
- [17] J. Pagel and F. Zuleger, “Strong-separation logic,” ACM Transactions on Programming Languages and Systems (TOPLAS), vol. 44, no. 3, pp. 1–40, 2022.
- [18] J. Karhumäki, F. Mignosi, and W. Plandowski, “The expressibility of languages and relations by word equations,” Journal of the ACM (JACM), vol. 47, no. 3, pp. 483–505, 2000.
- [19] G. S. Makanin, “The problem of solvability of equations in a free semigroup,” Matematicheskii Sbornik, vol. 145, no. 2, pp. 147–236, 1977.
- [20] V. G. Durnev, “Undecidability of the positive 3-theory of a free semigroup,” Siberian Mathematical Journal, vol. 36, no. 5, pp. 917–929, 1995.
- [21] J. D. Day, V. Ganesh, P. He, F. Manea, and D. Nowotka, “The satisfiability of word equations: Decidable and undecidable theories,” in International Conference on Reachability Problems (RP). Springer, 2018, pp. 15–29.
- [22] J. M. Važenin and B. V. Rozenblat, “Decidability of the positive theory of a free countably generated semigroup,” Mathematics of the USSR-Sbornik, vol. 44, no. 1, p. 109, 1983.
- [23] Y. Jing, H. Wang, Y. Huang, L. Zhang, J. Xu, and Y. Cao, “A modeling language to describe massive data storage management in cyber-physical systems,” Journal of Parallel and Distributed Computing (JPDC), vol. 103, pp. 113–120, 2017.
- [24] B. Zhang, Z. Jin, H. Wang, and Y. Cao, “Tool for verifying cloud block storage based on separation logic,” Journal of Software, vol. 33, no. 6, pp. 2264–2287, 2022.
- [25] J. C. Reynolds, “Intuitionistic reasoning about shared mutable data structure,” Millennial perspectives in computer science, vol. 2, no. 1, pp. 303–321, 2000.
- [26] J. Berdine, C. Calcagno, and P. W. O’hearn, “Symbolic execution with separation logic,” in Asian Symposium on Programming Languages and Systems (APLAS). Springer, 2005, pp. 52–68.
- [27] T. Kutsia, “Solving equations with sequence variables and sequence functions,” Journal of Symbolic Computation (JSC), vol. 42, no. 3, pp. 352–388, 2007.
- [28] M. Minsky, Computation: Finite and Infinite Machines. JSTOR, 1968.
Appendix
Proof sketch of Theorem II.1: For every Boolean combinations defined in Definition II.3, there exists a single word equation , which is equivalent to in the following inductive way:
where is generator set, and
Proof sketch of Lemma V.1:
The ’if’ part of the lemma is straightforward. For the ’only if’ part, we suppose that . It is sufficient to show the following two facts.
-
•
It is impossible that all connected components in are circles,
-
•
If there are one or more circles in , then let be the model with only one sapling in and without circles. We can get .
First we prove the first fact. We suppose that all connected components in are circles. We can imply that each master node has one predecessor. It contradicts which claims there are no predecessors on the first node .
Then we prove the second fact. According to the first fact, there exists one sapling in . The sapling does not intersect with other circles according to which claims that each master node has no more than 2 predecessors. Let be the sapling in , and be all circles in . We can have . So, the proposition is true, because removing circles does not affect the truth of , and .
Construction in Theorem 5.1. The formula in part 1 is exactly of the form defined in eq. 7. It can be written in the following way:
| (9) |
The formula in part 2 can be written in the following way.
| (10) | ||||
The predicate encodes the initial state (which corresponds to slave nodes on three master nodes in Fig. (7) ), and
encodes the final state . The state corresponds to slave nodes on three master nodes in Fig. (7). These two predicates are defined as follows:
| (11) | ||||
Note that is fixed when the two-counter Minsky machine is given.
Before constructing the formula , we need to formalize some additional properties shown below.
The sequence is of the form :
| (12) |
The sequence of the form is one element longer than sequence of the same form:
With the idea in , we can construct as follows:
| (13) | ||||
In , the predicate represents the current state beginning from the master node which has no slave nodes, represents the final state which has been defined in Equation 11, and represents the transition from one state to the other. The formula encodes the following fact: for each current state except for the final state, there exists a next state which can be transitioned from the current state. The predicates and are defined as follows:
where the predicate is defined as follows. The predicate has been defined in Equation 12.
The predicate is defined as follows:
In the formula , the set and have been defined in Definition V.1. The reduction can be done following Equations 8, 9, 10 and 13.