A Soft SIMD Based Energy Efficient
Computing Microarchitecture
Abstract
The ever-increasing size and computational complexity of today’s machine-learning algorithms pose an increasing strain on the underlying hardware. In this light, novel and dedicated architectural solutions are required to optimize energy efficiency by leveraging opportunities (such as intrinsic parallelism and robustness to quantization errors) exposed by algorithms. We herein address this challenge by introducing a flexible two-stages computing pipeline. The pipeline can support fine-grained operand quantization through software-supported Single Instruction Multiple Data (SIMD) operations. Moreover, it can efficiently execute sequential multiplications over SIMD sub-words thanks to zero-skipping and Canonical Signed Digit (CSD) coding. Finally, a lightweight repacking unit allows changing the bitwidth of sub-words at run-time dynamically. These features are implemented within a tight energy and area budget. Indeed, experimental results showcase that our approach greatly outperforms traditional hardware SIMD ones both in terms of area and energy requirements. In particular, our pipeline occupies up to 53.1% smaller than a hardware SIMD one supporting the same sub-word widths, while performing multiplication up to 88.8% more efficiently.
Index Terms:
Hardware Software Co-design, Energy Efficient Computing, Single Instruction Multiple Data, Edge Machine Learning.I Introduction
Machine Learning (ML) has fostered a revolution in computing, impacting a plethora of domains ranging from healthcare [1] to finance [2]. Nonetheless, the high computational requirements of ML applications pose a challenge to their deployment, especially when targeting resource-constrained devices [3].
To address the deployment challenges mentioned above, two main optimization avenues have been proposed. They take advantage of a) the high degree of parallelism offered by ML algorithms and b) their robustness towards low-range data representation. Our research contribution also leverages these opportunities, declining them towards the design of a dedicated computing pipeline. The pipeline is optimized for parallel, small-bitwidth arithmetics, which supports flexible Single Instruction Multiple Data (SIMD) formats. It efficiently implements the software SIMD (Soft SIMD [4][5]) computing paradigm and a Canonical Signed Digit (CSD [6] [7]) representation of operands.
Our solution features a fine-grained configurability of the adopted data bitwidths, which can be defined at run-time according to the desired computation precision, e.g., adapting to the robustness of different layers in an ML network [8][9]. It can perform the parallel multiplication of a multiplier value with several multiplicands, the most prominent operation in ML applications. Moreover, it allows seamless transitions among different SIMD formats using a dedicated data packing stage. Our design is extremely parsimonious in terms of area and energy resources, paving the way for its integration as a near-memory accelerator interfacing memory banks [10], hence harnessing the regularity of computations that characterize ML applications.
In summary, our contributions are as follows:
-
•
We introduce a novel two-stage pipeline supporting the Soft SIMD and CSD coding paradigms to support parallel multiplications, as well as data-repacking to bridge between SIMD formats.
-
•
Through detailed post-synthesis analyses, we show that our approach offers superior flexibility and area/energy efficiency with respect to traditional solutions based on hardware SIMD (Hard SIMD). In particular, our design requires up to 53.1 less area than an equivalent Hard SIMD implementation. Moreover, our design consumes up to 88.8 less energy to perform a multiplication.
II Background
II-A Software SIMD
Single Instruction Multiple Data is a well-known approach to enhance parallelism, hence performance, when executing regular computation patterns. Indeed, mainstream Instruction Set Architectures (ISAs) do define SIMD extensions, e.g., in the form of ARM Neon [11], or x86 AVX [12] instructions. Their hardware implementation entails using wide registers hosting a fixed number of sub-words (of fixed bitwidth) and the corresponding parallel functional units performing vector operations among registers.
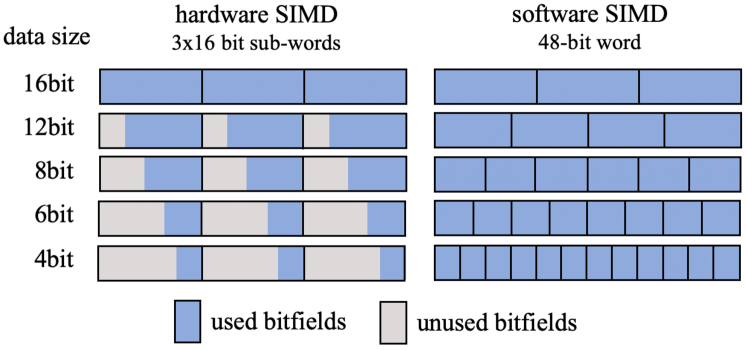
Soft SIMD, proposed in [4][5], challenges this paradigm, allowing arbitrary partitioning of vector registers in sub-words, as illustrated in Figure 1. Soft SIMD formats can then be configured in software at run-time (hence the name), ensuring that operations on a sub-word would not cause side effects on other sub-words, even in the case of positive/negative overflows. Soft SIMD is particularly appealing when a fine-grained control of bitwidths is beneficial, employed bitwidths are small, and/or the desired data representation changes in different computation phases. These features truly characterize ML applications, as discussed in Section I.
Soft SIMD can be embodied along two alternative approaches: reserving bit locations in-between sub-words (guardbits) or adopting configurable carry generation at sub-word boundaries in arithmetic units with low additional hardware cost and timing path increase [4][5][13]. In the implementation presented in this work, we employ a configurable carry generation, but our strategy is also compatible with the approaches using guardbits.
II-B CSD Coding
Our proposed pipeline performs parallel multiplications as a sequence of arithmetic shifts and additions between multiplicands and accumulators, processing one bit of a multiplier operand each time. As detailed in Section III-B, only the shift operation is performed when the multiplier bit is ‘0’. Therefore, multiple shifts can be coalesced in the same clock cycle when processing bit patterns with trailing zeros such as “10”, “100”, etc. To maximize the ensuing performance benefit, we herein adopt a Canonical Signed Digit (CSD) representation for multiplier values [6][7]. Such encoding employs three symbols for each digit: ‘1’, ‘0’, and ‘-’, where the latter indicates that the number should be interpreted as negative. As an example, the number “0-01” in CSD notations equals to . In CSD numbers, of the digits are zeroes, increasing opportunities for coalescing multiple shifts.
III Soft SIMD Microarchitecture
III-A Soft SIMD Arithmetic Pipeline
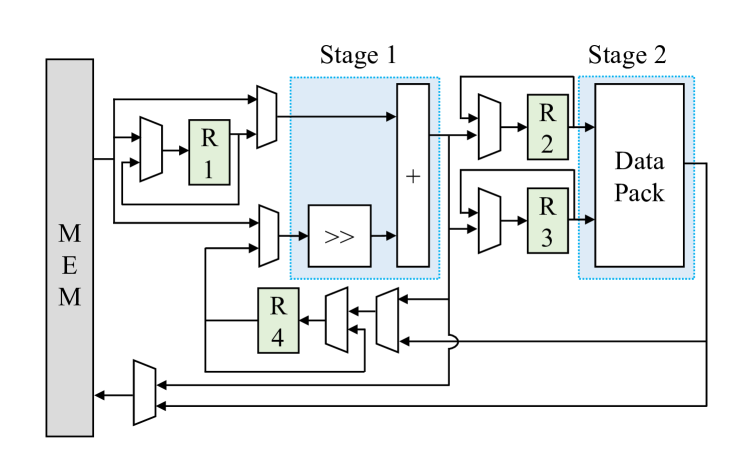
A block scheme of the hardware design is illustrated in Figure 2. It is composed of two pipeline stages. The first one is dedicated to parallel shift-add operations, hence sequentially performing multiplications. As we will show in Section IV, such an approach leads to higher efficiency (especially for small-bitwidth operands) with respect to using combinatorial multipliers because it requires simpler (leaner, faster) logic. The second pipeline stage is instead devoted to data packing, namely, to the translation of values between bitwidths across computation phases adopting different SIMD formats. This second stage can be bypassed if no data conversion is required. Details on datapath stages are provided in the following sub-sections.
III-B Soft SIMD Multiplication
The first pipeline stage allows the multiplication of values represented in fixed-point notation, i.e., with one leading bit for the integer parts and the rest devoted to the fractional part. Operations are performed parallel among a multiplier, encoded in CSD notation, and several multiplicands are represented in 2’s complement notation.
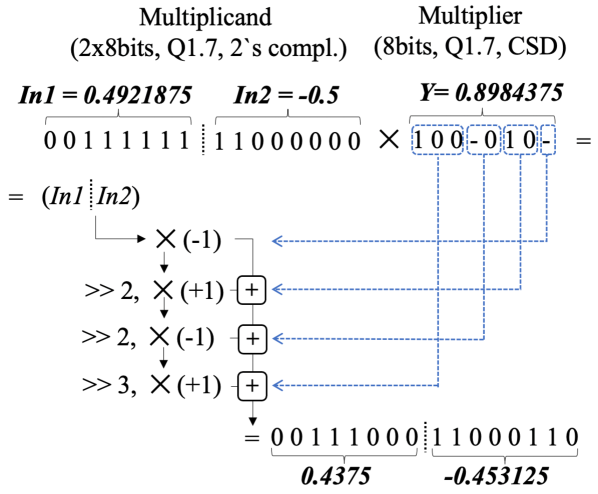
The employed algorithm is shown in Figure 3 using an example of a multiplier and two 8-bit multiplicands stored as Soft SIMD sub-words, themselves represented as values. Notice that since the bitwidth of results and that of the multiplicands are the same, truncation errors can and do occur. Nonetheless, these are negligible even for very constrained bitwidths, e.g., approximately in the shown 8-bit example.
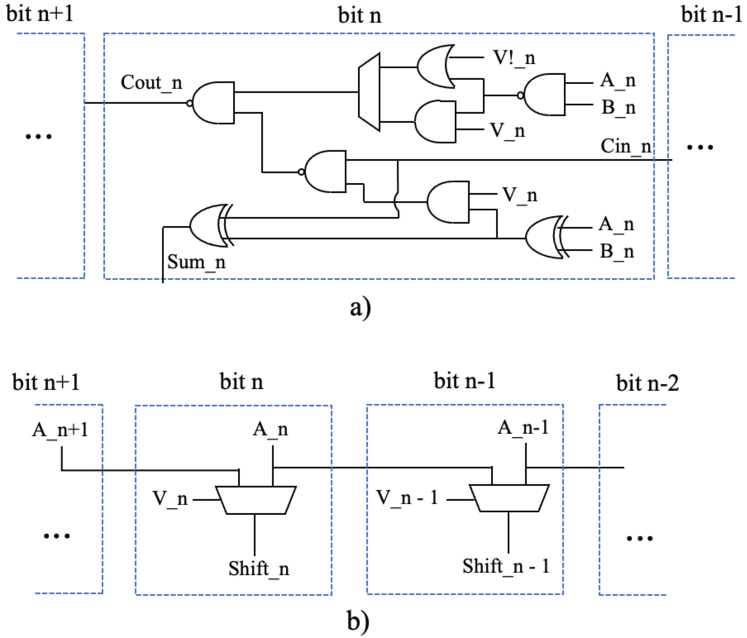
Figure 3 showcases that right shifts, complements (multiplications by ), and additions are required to implement multiplication. Such operations must not result in interference from one sub-word to the next. To this end, sub-word boundaries prevent overflow from passing in additions and provide +1 for the next sub-word in subtractions in our design by expandable control signals. The employed circuit is shown in Figure 4-a. Since the carry logic operation of the multi-bit adder is performed simultaneously, the increase in the time path is very small. As the shift operation, the Most Significant Bit (MSB) of sub-words propagates the corresponding bit position of the input, hence implementing sign extension (Figure 4-b). It has to be noted that muxes can be employed selectively, depending on the supported bitwidths. Indeed, no mux is required if a bit position is never the MSB of a sub-word for all supported Soft SIMD formats. Such a strategy can scale to support multiple shifts by employing further combinatorial stages of 1-bit muxes. In this way, multi-bit patterns with trailing zeros can be processed in a single clock cycle, as shown in Figure 3. In our design, we support up to 3-bit patterns, as more extensive sequences of consecutive zeros are rare and do not justify the additional logic.
III-C Data Packing Unit
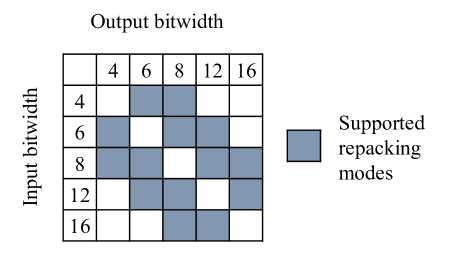
The role of the data packing unit is to bridge across SIMD formats. To this end, a crossbar [14] is employed to connect bits in different bit ranges of the Stage2 inputs (registers R2, R3 in Figure 2) to the Stage2 output (registers R4 or write back to memory). The hardware resources required by the crossbar depend on the width of the datapath and the set of employed Soft SIMD formats. In the design investigated in Section IV, we considered a 48-bits datapath and sub-words of 4, 6, 8, 12, and 16 bits. We support many conversions between modes, as indicated in Figure 5. Finally, the entire stage can be bypassed if no change in sub-word format is required.
IV Experiment and Result
IV-A Experiment Setup
Across experiments, we target a 48-bit pipeline. To investigate its performance, we compare its efficiency with that of Hard SIMD solutions employing combinatorial multipliers. The first baseline Hard SIMD architecture supports sub-word configurations 4, 6, 8, 12, and 16 bits, while the other only supports 8 and 16 bits. In all cases, timing, area, and energy characterizations are performed on post-synthesis data based on a 28nm technology library under varying timing constraints.
IV-B Area Evaluation
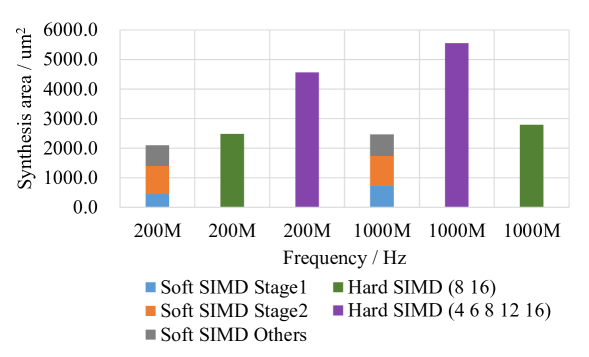
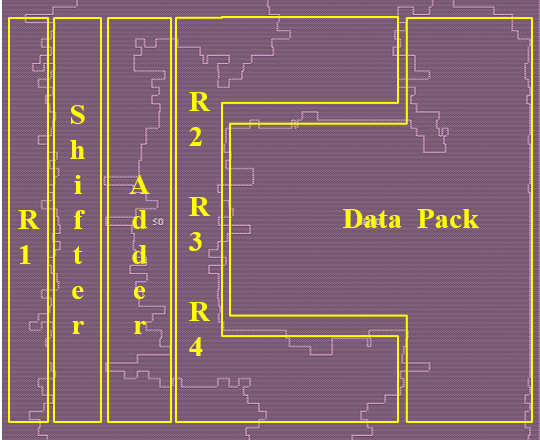
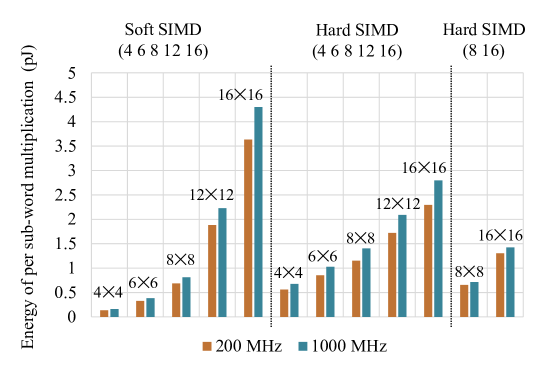
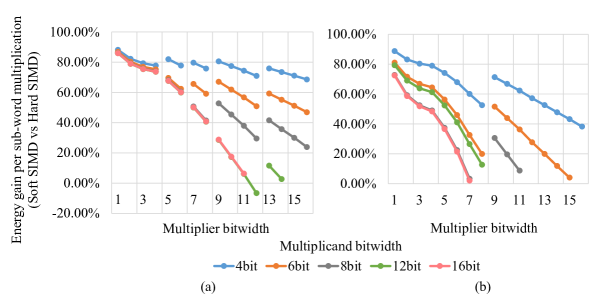
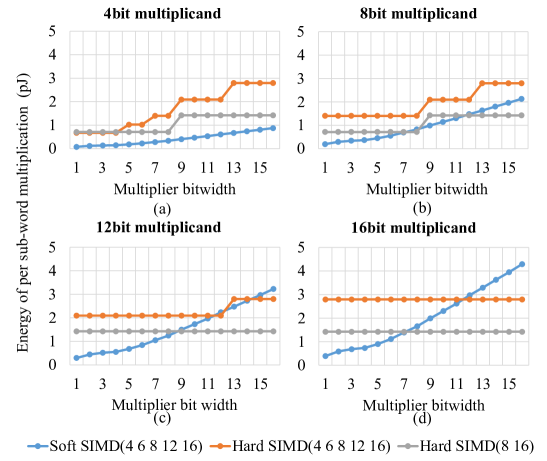
Figure 6 compares the area of Hard SIMD and Soft SIMD solutions. As expected, as Soft SIMD does not require a resource-hungry combinatorial multiplier, its area requirements are markedly lower with respect to Hard SIMD for the same supported bitwidths (less than half across different timing constraints). Moreover, the area efficiency of Soft SIMD is not matched by Hard SIMD even when only 8- and 16-bit sub-words are supported in the latter, which still remains more than 10% larger in all cases. In addition, stage 2 of Soft SIMD remains basically constant at different frequencies while stage 1 and other parts (registers, etc.) grow with frequency. The design layout is presented in Figure 7.
We evaluated the efficiency of the proposed pipeline in terms of the energy (pico-Joules) required to perform a multiplication among multiplicands and multipliers of varying bitwidths. In all cases, the bitwidth of the result matches that of the multiplicand. Absolute energy results for selected configurations are shown in Figure 8, highlighting that Soft SIMD achieves better energy efficiency for widths smaller than 8 bits. Moreover, Soft SIMD can seamlessly support a large number of data widths, while in the Hard SIMD case, flexibility comes at a hefty cost in terms of efficiency, as the comparison between the two Hard SIMD solutions in the and configurations highlights.
A comprehensive view of the efficiency of our proposed pipeline and that of the compared baseline designs is presented in Figure 9. This figure plots the energy gain of Soft SIMD with respect to the two Hard SIMD implementations when executing multiplications of different multiplicands and multipliers widths. These results show that import gains are obtained, especially for small bitwidths. Moreover, in these comparisons, the plotted series present discontinuities when the multiplicand width exceeds the size of the Hard SIMD sub-words, i.e., between 8 and 9 bits in Figure 9, on the left side.
Finally, as Figure 10 shows, the benefits of Soft SIMD derive from its graceful scaling to different bitwidths in terms of energy requirements. Conversely, even though Hard SIMD often enables the support of many SIMD formats, this flexibility does not lead to efficiency increases. In fact, the Hard SIMD (4 6 8 12 16) solution consistently underperformed the simpler Hard SIMD (8 16) option in our experiments.
In summary, Soft SIMD achieves significant energy gains (up to 88.8%) for multiplications with small bit-width operands compared to traditional Hard SIMD alternatives. Such characteristics are of great interest for algorithms amenable to aggressive quantization, such the machine learning ones.
V Conclusion
V-A Energy Efficiency Evaluation
This paper presents a novel computing pipeline, leveraging the Soft SIMD paradigm and CSD encoding to achieve ultra-high energy efficiency when performing arithmetic operations among aggressively quantized values. The pipeline features the skipping of trailing ’0’ digits in multiplier operands, seamless support of a wide range of quantization levels, and a repacking unit to bridge across SIMD formats.
Experiments showcase that our Soft SIMD design greatly outperforms Hard SIMD alternatives when executing multiplications among small-bitwidth operands, highlighting energy gains of up to 88.8% in energy, while requiring fewer hardware resources.
References
- [1] A. Qayyum, J. Qadir, M. Bilal, and A. Al-Fuqaha, “Secure and robust machine learning for healthcare: A survey,” IEEE Reviews in Biomedical Engineering, vol. 14, pp. 156–180, 2020.
- [2] A. M. Ozbayoglu, M. U. Gudelek, and O. B. Sezer, “Deep learning for financial applications: A survey,” Applied Soft Computing, vol. 93, p. 106384, 2020.
- [3] M. S. Murshed, C. Murphy, D. Hou, N. Khan, G. Ananthanarayanan, and F. Hussain, “Machine learning at the network edge: A survey,” ACM Computing Surveys (CSUR), vol. 54, no. 8, pp. 1–37, 2021.
- [4] S. Kraemer, R. Leupers, G. Ascheid, and H. Meyr, “Softsimd-exploiting subword parallelism using source code transformations,” in 2007 Design, Automation & Test in Europe Conference & Exhibition. IEEE, 2007, pp. 1–6.
- [5] F. Catthoor, P. Raghavan, A. Lambrechts, M. Jayapala, A. Kritikakou, and J. Absar, Ultra-low energy domain-specific instruction-set processors. Springer Science & Business Media, 2010.
- [6] A. K. Oudjida, “Binary arithmetic for finite-word-length linear controllers: Mems applications,” Ph.D. dissertation, Besançon, 2014.
- [7] S. Nigam and A. Mishra, “Hardware implementation of canonical signed digit adder-subtractor circuit,” in 2022 3rd International Conference on Electronics and Sustainable Communication Systems (ICESC). IEEE, 2022, pp. 151–154.
- [8] F. Ponzina, M. Rios, G. Ansaloni, A. Levisse, and D. Atienza, “A flexible in-memory computing architecture for heterogeneously quantized cnns,” in 2021 IEEE Computer Society Annual Symposium on VLSI (ISVLSI). IEEE, 2021, pp. 164–169.
- [9] S. I. Young, W. Zhe, D. Taubman, and B. Girod, “Transform quantization for cnn compression,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 44, no. 9, pp. 5700–5714, 2021.
- [10] C. Sudarshan, M. H. Sadi, L. Steiner, C. Weis, and N. Wehn, “A critical assessment of dram-pim architectures-trends, challenges and solutions,” in International Conference on Embedded Computer Systems. Springer, 2022, pp. 362–379.
- [11] V. G. Reddy, “Neon technology introduction,” ARM Corporation, vol. 4, no. 1, pp. 1–33, 2008.
- [12] D. Kusswurm, “Advanced vector extensions (avx),” in Modern X86 Assembly Language Programming. Springer, 2014, pp. 327–349.
- [13] G. Psychou, R. Fasthuber, F. Catthoor, J. Hulzink, and J. Huisken, “Sub-word handling in data-parallel mapping,” in ARCS 2012. IEEE, 2012, pp. 1–7.
- [14] P. Raghavan, S. Munaga, E. R. Ramos, A. Lambrechts, M. Jayapala, F. Catthoor, and D. Verkest, “A customized cross-bar for data-shuffling in domain-specific simd processors,” in International Conference on Architecture of Computing Systems. Springer, 2007, pp. 57–68.