A Spectral Method for Assessing and Combining Multiple Data Visualizations
Abstract
Dimension reduction and data visualization aim to project a high-dimensional dataset to a low-dimensional space while capturing the intrinsic structures in the data. It is an indispensable part of modern data science, and many dimensional reduction and visualization algorithms have been developed.
However, different algorithms have their own strengths and weaknesses, making it critically important to evaluate their relative performance for a given dataset, and to leverage and combine their individual strengths. In this paper, we propose an efficient spectral method for assessing and combining multiple visualizations of a given dataset produced by diverse algorithms. The proposed method provides a quantitative measure – the visualization eigenscore – of the relative performance of the visualizations for preserving the structure around each data point. Then it leverages the eigenscores to obtain a consensus visualization, which has much improved quality over the individual visualizations in capturing the underlying true data structure. Our approach is flexible and works as a wrapper around any visualizations. We analyze multiple simulated and real-world datasets from diverse applications to demonstrate the effectiveness of the eigenscores for evaluating visualizations and the superiority of the proposed consensus visualization.
Furthermore, we establish rigorous theoretical justification of our method based on a general statistical framework, yielding fundamental principles behind the empirical success of consensus visualization along with practical guidance.
KEY WORDS: data visualization; dimension reduction; high-dimensional data; manifold learning; spectral method.
1 INTRODUCTION
Data visualization and dimension reduction is a central topic in statistics and data science, as it facilitates intuitive understanding and global views of high-dimensional datasets and their underlying structural patterns through a low-dimensional embedding of the data (Donoho, 2017; Chen et al., 2020). The past decades have witnessed an explosion in machine learning algorithms for data visualization and dimension reduction. Many of them, such as Laplacian eigenmap (Belkin and Niyogi, 2003), kernel principal component analysis (kPCA) (Schölkopf et al., 1997), t-SNE (van der Maaten and Hinton, 2008), and UMAP (McInnes et al., 2018), have been regarded as indispensable tools and state-of-art techniques for generating graphics in academic and professional writings (Chen et al., 2007), and for exploratory data analysis and pattern discovery in many research disciplines, such as astrophysics (Traven et al., 2017), computer vision (Cheng et al., 2015), genetics (Platzer, 2013), molecular biology (Olivon et al., 2018), especially in single-cell transcriptomics (Kobak and Berens, 2019), among others.
However, the wide availability and functional diversity of data visualization methods also brings forth new challenges to data analysts and practitioners (Nonato and Aupetit, 2018; Espadoto et al., 2019). On the one hand, it is critically important to determine among the extensive list which visualization method is most suitable and reliable for embedding a given dataset. In fact, even for a single visualization method, such as t-SNE or UMAP, oftentimes there are multiple tuning parameters to be determined by the users, and different tuning parameters may lead to distinct visualizations (Kobak and Linderman, 2021; Cai and Ma, 2021). Thus, for a given dataset, selecting the most suitable visualization method and along with its tuning parameters calls for a method that provides quantitative and objective assessment of different visualizations of the dataset. On the other hand, as different methods are usually based on distinct ideas and heuristics, they would generate qualitatively diverse visualizations of a dataset, each containing important features about the data that are possibly unique to the visualization method. Meanwhile, due to noisiness and high-dimensionality of many real-world datasets, their low-dimensional visualizations necessarily contain distortions from the underlying true structures, which again may vary from one visualization to another. It is therefore of substantial practical interest to combine strengths and reach a consensus among multiple data visualizations, in order to obtain an even better “meta-visualization” of the data that captures the most information and is least susceptible to the distortions. Naturally, a meta-visualization would also save practitioners from painstakingly selecting a single visualization method among many.
In this paper, we propose an efficient spectral approach for simultaneously assessing and combining multiple data visualizations produced by diverse dimension reduction/visualization algorithms, allowing for different settings of tuning parameters for individual algorithms. Specifically, the proposed method takes as input a collection of visualizations, or low-dimensional embeddings of a dataset, hereafter referred as “candidate visualizations,” and summarizes each visualization by a normalized pairwise-distance matrix among the samples. With respect to each sample in the dataset, we construct a comparison matrix from these normalized distance matrices, characterizing the local concordance between each pair of candidate visualizations. Based on eigen-decomposition of the comparison matrices, we propose a quantitative measure, referred as “visualization eigenscore,” that quantifies the relative performance of the candidate visualizations in a sample-wise manner, reflecting their local concordance with the underlying low-dimensional structure contained in the data. To obtain a meta-visualization, the candidate visualizations are combined together into a meta-distance matrix, defined as a row-wise weighted average of those normalized distance matrices, using the corresponding eigenscores as the weights. The meta-distance matrix is then used to produce a meta-visualization, based on an existing method such as UMAP or kPCA, which is shown to be more reliable and more informative compared to individual candidate visualizations. Our method is schematically summarized in Figure 1 and Algorithm 1, and detailed in Section 2.1. The thus obtained meta-visualization reflects a joint perspective aggregating various aspects of the data that are oftentimes captured separately by individual candidate visualizations.
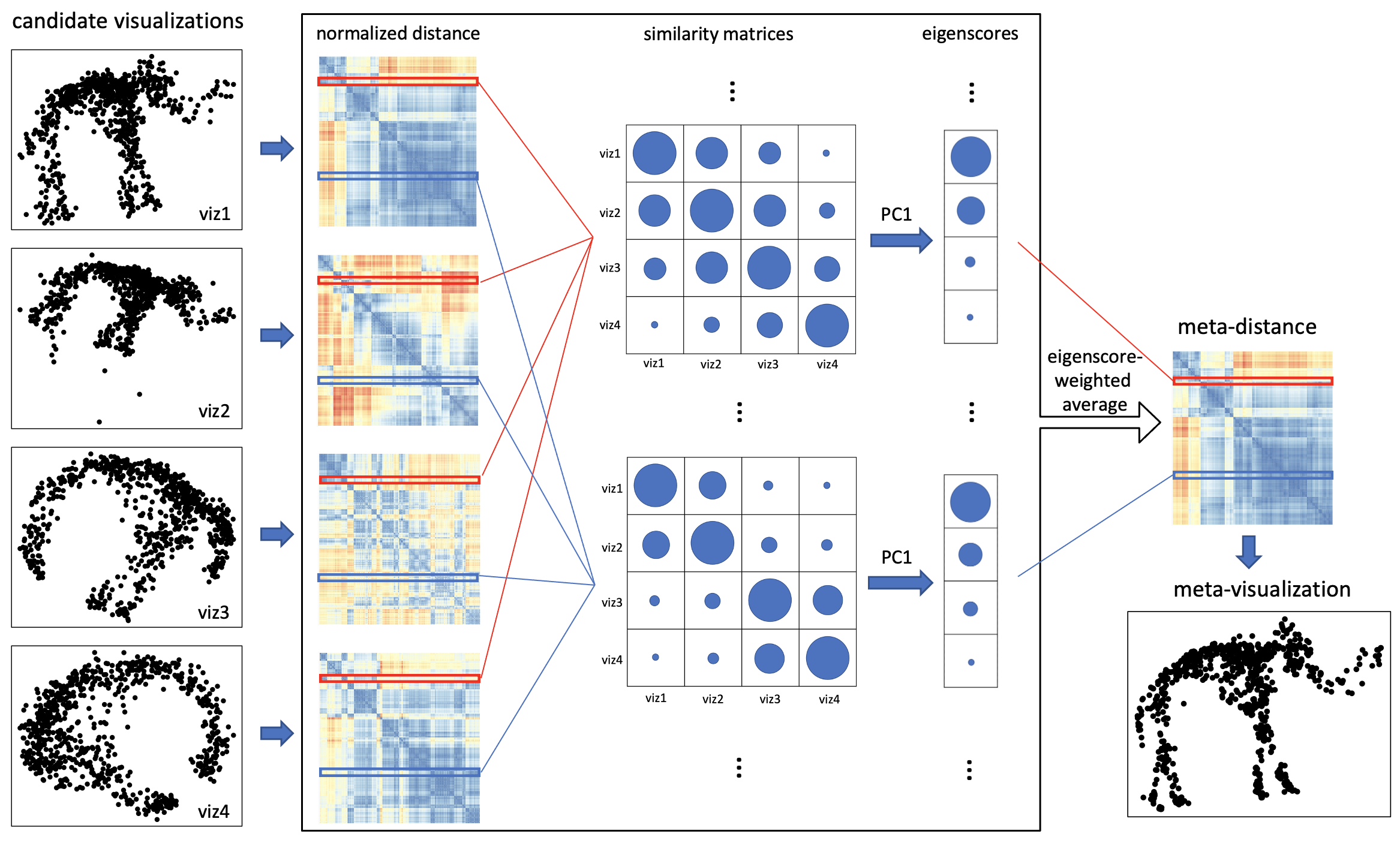
Numerically, through extensive simulations and analysis of multiple real-world datasets with diverse underlying structures, we show the effectiveness of the proposed eigenscores in assessing and ranking a collection of candidate visualizations, and demonstrate the superiority of the final meta-visualization over all the candidate visualizations in terms of identification and characterization of these structural patterns. To achieve a deeper understanding of the proposed method, we also develop a formal statistical framework, that rigorously justifies the proposed scoring and meta-visualization method, providing theoretical insights on the fundamental principles behind the empirical success of the method, along with its proper interpretations, and guidance on practice.
1.1 Related Works
Quantitative assessment of dimension reduction and data visualization algorithms is of substantial practical interests, and have been extensively studied in the past two decades. For example, many evaluation methods are based on distortion measures from metric geometry (Abraham et al., 2006, 2009; Chennuru Vankadara and von Luxburg, 2018; Bartal et al., 2019), whereas some other methods rely on information-theoretic precision-recall measures (Venna et al., 2010; Arora et al., 2018), co-ranking structure (Mokbel et al., 2013), or graph-based criteria (Wang et al., 2021; Cai and Ma, 2021). See also Bertini et al. (2011), Nonato and Aupetit (2018) and Espadoto et al. (2019) for recent reviews. However, most of these existing methods evaluate data visualizations by comparing them directly with the original dataset, without accounting for its noisiness. The thus obtained assessment may suffer from intrinsic bias due to ignorance of the underlying true structures, only approximately represented by the noisy observations; see Section 2.3.5 and Supplementary Figure 21 for more discussions. To address this issue, the proposed eigenscores, in contrast, provide provably consistent assessment and ranking of visualizations reflecting their relative concordances with the underlying noiseless structures in the data.
Compared to the quantitative assessment of data visualizations, there is a scarcity of meta-visualization methods that combine strengths of multiple data visualizations. In Pagliosa et al. (2015), an interactive method is developed that assesses and combines different multidimensional projection methods via a convex combination technique. However, for supervised learning tasks such as classification, there is a long history of research on designing and developing meta-classifiers that combine multiple classifiers (Woods et al., 1997; Tax et al., 2000; Parisi et al., 2014; Liu et al., 2017; Mohandes et al., 2018). Compared with meta-classification, the main difficulty of meta-visualization lies in the identification of a common space to properly align multiple visualizations, or low-dimensional embeddings, whose scales and coordinate bases may drastically differ from one to another (see, for example, Figures 3-5(a)). Moreover, unlike many meta-classifiers, which combines presumably independent classifiers trained over different datasets, a meta-visualization procedure typically relies on multiple visualizations of the same dataset, and therefore has to deal with more complicated correlation structure among the visualizations. The current study provides the first meta-visualization method that can flexibly combine any number of visualizations, and has interpretable and provable performance guarantee.
1.2 Main Contributions
The main contribution of the current study can be summarized as follows:
-
•
We propose a computationally efficient spectral method for assessing and combining multiple data visualizations. The method is generic and easy to implement: it does not require knowledge of the original dataset, and can be applied to a large number of data visualizations generated by diverse methods.
-
•
For any collection of visualizations of a dataset, our method provides a quantitative measure – eigenscore – of the relative performance of the visualizations for preserving the structure around each data point. The eigenscores are useful on their own rights for assessing the local and global reliability of a visualization in representing the underlying structures of the data, and in guiding selection of hyper-parameters.
-
•
The proposed method automatically combines strengths and ameliorates weakness (distortions) of the candidate visualizations, leading to a meta-visualization which is provably better than all the candidate visualizations under a wide range of settings. We show that the meta-visualization is able to capture diverse intrinsic structures, such as clusters, trajectories, and mixed low-dimensional structures, contained in noisy and high-dimensional datasets.
-
•
We establish rigorous theoretical justifications of the method under a general signal-plus-noise model (Section 2.3) in the large-sample limit. We prove the convergence of the eigenscores to certain underlying true concordance measures, the guaranteed performance of the meta-visualization and its advantages over alternative methods, its robustness against possible adversarial candidate visualizations, along with their conditions, interpretations, and practical implications.
The proposed method is described in detail in Section 2.1, and empirically illustrated and evaluated in Section 2.2, through extensive simulation studies and analyses of three real-world datasets with diverse underlying structures. In Section 2.3, we show results from our theoretical analysis, which unveils fundamental principles associated to the method, such as the benefits of including qualitatively and functionally diverse candidate visualizations.
2 RESULTS
2.1 Eigenscore and Meta-Visualization Methodology
Throughout, without loss of generality, we assume that for visualization purpose the target embedding is two-dimensional, although our discussion applies to any finite-dimensional embedding.
| (2.1) |
| (2.2) |
| (2.3) |
| (2.4) |
We consider visualizing a -dimensional dataset containing samples. From , suppose we obtain a collection of (candidate) visualizations of the data, produced by various visualization methods. We denote these visualizations as two-dimensional embeddings for . Our approach only needs access to the low-dimensional embeddings rather than the raw data ; as a result, the users can use our method even if they don’t have access to the original data, which is often the case.
2.1.1 Measuring Normalized Distances From Each Visualization
In order that the proposed method is invariant to the respective scale and coordinate basis (i.e., directionality) of the low-dimensional embeddings generated from different visualization method, we start by considering the normalized pairwise-distance matrix for each visualization.
Specifically, for each , we define the normalized pairwise-distance matrix
| (2.5) |
where
| (2.6) |
is the un-normalized Euclidean distance matrix, and is a diagonal matrix with its diagonal entries being the -norms of the rows of . As a result, the normalized distance matrix has its rows being unit vectors, and is invariant to any scaling and rotation of the visualization .
The normalized distance matrices summarize the candidate visualizations in a compact and efficient way. Their scale- and rotation-invariance properties are particularly useful for comparing visualizations produced by distinct methods.
2.1.2 Sample-wise Eigenscores for Assessing Visualizations
Our spectral method for assessing multiple visualizations is based on the normalized distance matrices . For each , we define the similarity matrix
| (2.7) |
which summarizes the pairwise similarity between the candidate visualizations with respect to sample . By construction, the entries of are inner-products between unit vectors, each representing the normalized distances associated with sample in a candidate visualization. Naturally, a larger entry indicates higher concordance between the two candidate visualizations. Then, for each , we define the vector of eigenscores for the candidate visualizations with respect to sample as the absolute value of the eigenvector of associated to its largest eigenvalue, that is,
| (2.8) |
where the absolute value function is applied entrywise. As will be explained later (Section 2.3.2), the nonnegative components of quantify the relative performance of candidate visualizations with respect to sample , with higher eigenscores indicating better performance. Consequently, for each candidate visualization , one obtains a set of eigenscores summarizing its performance relative to other candidate visualizations in a sample-wise manner. Ranking and selection among candidate visualizations can be achieved based on various summary statistics of the eigenscores, such as mean, median, or coefficient of variation, depending on the specific applications. In particular, when some candidate visualizations are produced by the same method but under different tuning parameters, the eigenscores can be used to select the most suitable tuning parameters for visualizing the dataset. However, a more substantial application of the eigenscores is to combine multiple data visualizations into a meta-visualization, which has improved signal-to-noise ratio and higher resolution of the structural information contained in the data.
Importantly, as will be shown later (Section 2.3.5), the eigenscores essentially take the underlying true signals rather than the noisy observations as its referential target for performance assessment, making the method easier to implement and less susceptible to the effect of noise in the original data (Section 2.3.5 and Supplement Figure 21).
2.1.3 Meta-Visualization using Eigenscores
Using the above eigenscores, one can construct a meta-distance matrix properly combining the information contained in each candidate visualization. Specifically, for each , we define the vector of meta-distances with respect to sample as the eigenscore-weighted average of all the normalized distances respect to sample , that is,
| (2.9) |
Then, the meta-distance matrix is defined as whose -th row is . To obtain a meta-visualization, we take the meta-distance matrix and apply an existing visualization method that allows for the meta-distance (or its symmetrized version ) as its input.
Intuitively, for each , we essentially apply a principal component (PC) analysis to the normalized distance matrix Specifically, by definition (Jolliffe and Cadima, 2016) the leading eigenvector of is the first PC loadings of , whereas the first PC is defined as the linear combination . Under the condition that the first PC loadings are all nonnegative (which is ensured with high probability under condition (C2) below), the first PC is exactly the meta-distance defined in (2.9) above. When interpreted as PC loadings, the leading eigenvector of contains weights for different vectors so that the final linear combination has the largest variance, that is, summarizes the most information contained in . It is in this sense that the meta-distance is a consensus across .
For our own numerical studies (Section 2.2), we used UMAP for meta-visualizing datasets with cluster structures, and used kPCA for meta-visualizing all the other datasets with smoother manifold structures, such as trajectory, cycle, or mixed structures. The choice of UMAP in the former case was due to its advantage in treating large numbers of clusters without requiring prior knowledge about the number of clusters (McInnes et al., 2018; Cai and Ma, 2021); whereas the choice of kPCA in the latter case was rooted in its advantage in capturing nonlinear smooth manifold structures (Ding and Ma, 2022). In each case, the hyper-parameters used for generating the meta-visualization were determined without further tuning – for example, when using UMAP for meta-visualization, we set the hyper-parameters the same as those associated to the UMAP visualization which achieved higher median eigenscore than other UMAP visualizations. Moreover, while in general UMAP/kPCA works well as a default method for meta-visualization, our proposed algorithm is robust with respect to the choice of this final visualization method. In our numerical analysis (Section 2.2), we observed empirically that other methods such as t-SNE and PHATE could also lead to meta-visualizations with comparably substantial improvement over individual candidate visualizations in terms of the concordance with the underlying true low-dimensional structure of the data (see Supplement Figure 11). In addition, the meta-visualization shows robustness to potential outliers in the data (Figures 4 and 5).
In Section 2.3, under a generic signal-plus-noise model, we obtain explicit theoretical conditions under which the performance of the proposed spectral method is guaranteed. Specifically, we show the convergence of the eigenscores to a desirable concordance measure between the candidate visualizations and the underlying true pattern, characterized by their associated pairwise distance matrices of the samples. In addition, we show improved performance of the meta-visualization over the candidate visualizations in terms of their concordance with the underlying true pattern, and its robustness against possible adversarial candidate visualizations. These conditions provide proper interpretations and guidance on the application of the method, such as how to more effectively prepare the candidate visualizations (Section 2.3.6). For clarity, we summarize these technical conditions informally as follows, and relegate their precise statements to Section 2.3.
-
(C1’)
The performance of candidate visualizations are sufficiently diverse in terms of their individual distortions from the underlying true structures.
-
(C2’)
The candidate visualizations altogether contains sufficient amount of information about the underlying true structures.
Intuitively, Condition (C1’) concerns diversity of methods in producing candidate visualizations, whereas Condition (C2’) is related to the quality of the candidate visualizations. In practice, Condition (C2’) is satisfied when the signal-to-noise ratio in the data, as described by (2.11), is sufficiently large, so that the adopted visualization methods perform reasonably well on average. On the other hand, from Section 2.3, a sufficient condition for (C1’) is that, at most out of candidate visualizations are very similarly distorted from the true patterns in terms of the normalized distances . This would allow, for example, groups of up to 3 to 4 candidate visualizations out of 10 to 15 visualizations being produced by very similar procedures such as the same method under different hyper-parameters.
2.2 Simulations and Visualization of Real-World Datasets
2.2.1 Simulation Studies: Visualizing Noisy Low-Dimensional Structures
To demonstrate the wide range of applicability and the empirical advantage of the proposed method, we consider visualization of three families of noisy datasets, each containing a distinct low-dimensional structure as its underlying true signal. We assess performance of the eigenscores and the quality of the resulting meta-distance matrix based on 16 candidate visualizations produced by multiple visualization methods.
For a given sample size , we generate -dimensional noisy observations from the signal-plus-noise model where are the underlying noiseless samples (signals), and are the random noises. Specifically, we generate true signals from various low-dimensional structures isometrically embedded in the -dimensional Euclidean space. Each of the low-dimensional structures lie in some -dimensional linear subspace, and is subject to an arbitrary rotation in , so that these signals are generally -dimensional vectors with dense (nonzero) coordinates. Then we generate noise vector from the standard multivariate normal distribution , and use the -dimensional noisy vector as the final observed data. In this way, we simulated noisy observations of an intrinsically -dimensional structure. For our simulations, for some given signal-to-noise ratio (SNR) parameter , we generate uniformly from each of the following three structures:
-
(i)
Finite point mixture with : are independently sampled from the discrete set with equal probability, where ’s are arbitrary orthogonal vectors in with the same length, i.e., for .
-
(ii)
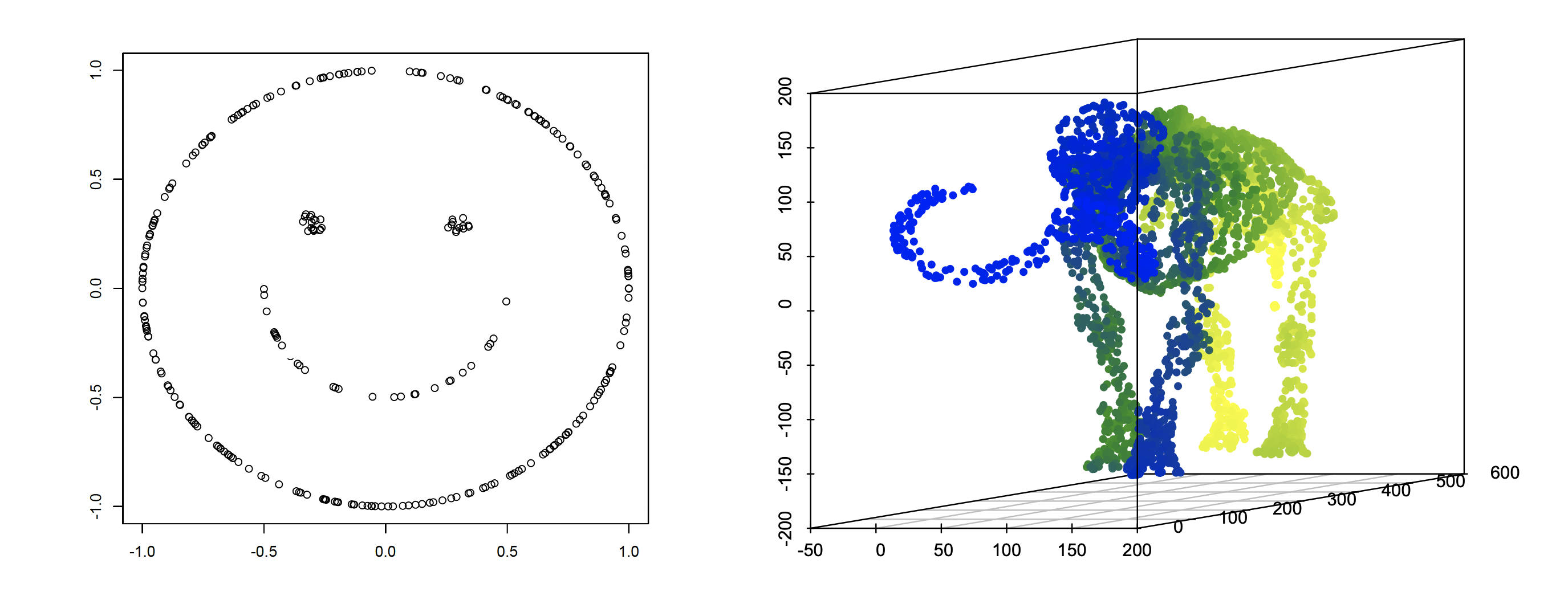
“Smiley face” with : are generated independently and uniformly from a two-dimensional “smiley face” structure (Supplement Figure 6 left) of diameter , isometrically embedded in and subject to an arbitrary rotation.
-
(iii)
“Mammoth” manifold with : are generated independently uniformly from a three-dimensional “mammoth” manifold (Supplement Figure 6 right) of diameter , isometrically embedded in and subject to an arbitrary rotation.
The thus generated datasets cover diverse structures including Gaussian mixture clusters (i), mixed-type nonlinear clusters (ii), and a connected smooth manifold (iii). As a result, the first family of datasets was set to have and , and were obtained by fixing various values of the SNR parameter , and generating from the above setting (i) to obtain the noisy dataset as described above. Similarly, the second and the third families of datasets were obtained by drawing from the above settings (ii) and (iii), respectively, and generating datasets with and , for various values of .
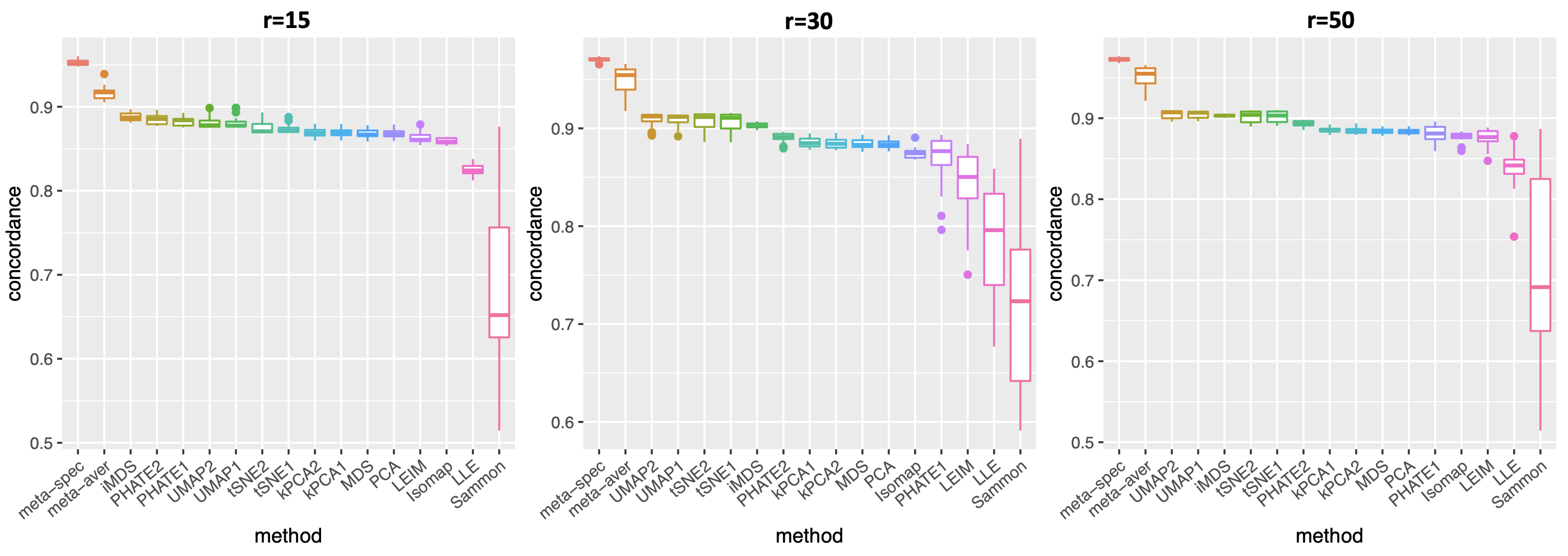
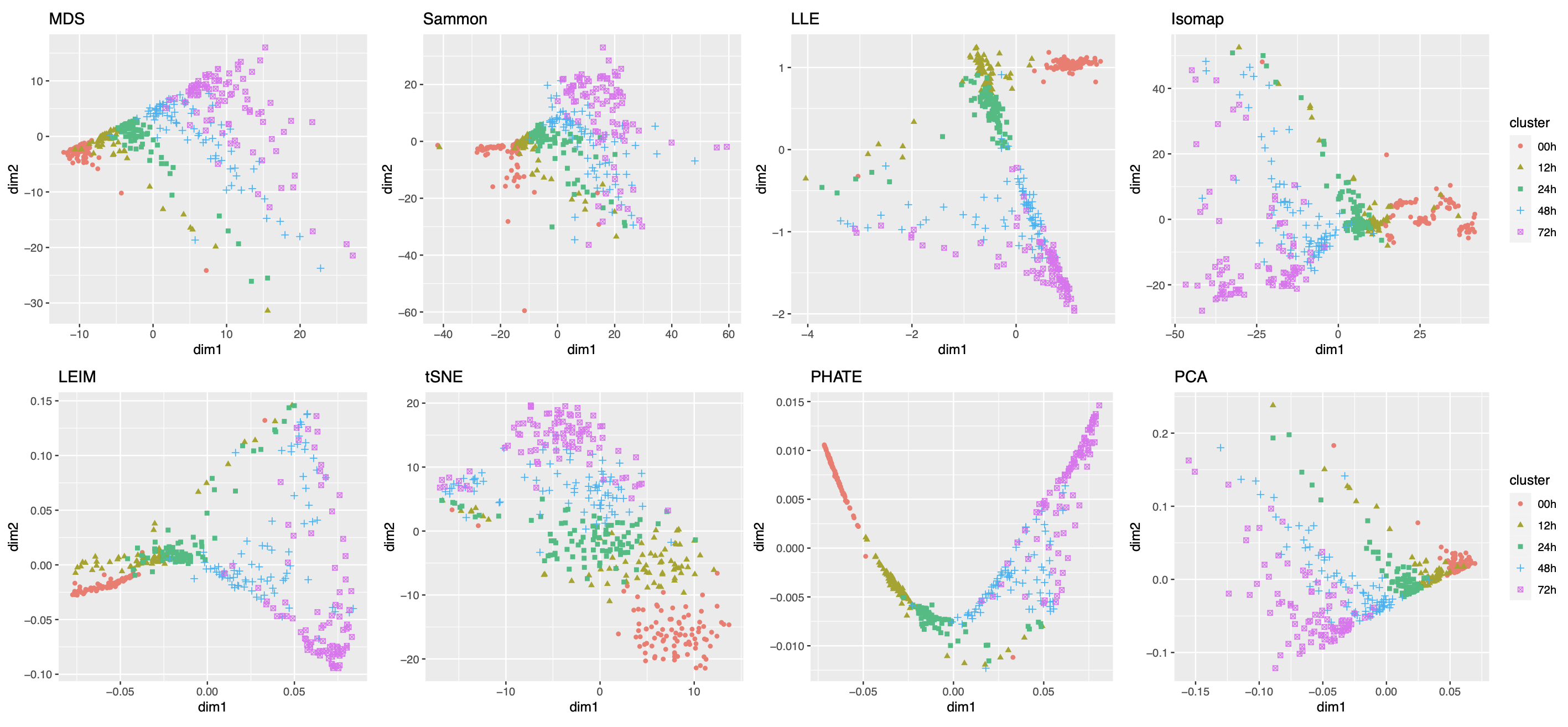
For each dataset , we consider existing data visualization tools including principal component analysis (PCA), multi-dimensional scaling (MDS), Kruskal’s non-metric MDS (iMDS) (Kruskal, 1978), Sammon’s mapping (Sammon) (Sammon, 1969), locally linear embedding (LLE) (Roweis and Saul, 2000), Hessian LLE (HLLE) (Donoho and Grimes, 2003), isomap (Tenenbaum et al., 2000), kPCA, Laplacian eigenmap (LEIM), UMAP, t-SNE and PHATE (Moon et al., 2019). For methods such as kPCA, t-SNE, UMAP and PHATE, that require tuning parameters, we consider two different settings (Section A.2 of the Supplement) of tuning parameters for each method, denoted as “kPCA1” and “kPCA2,” etc. Therefore, for each dataset we obtain candidate visualizations corresponding to different combinations of visualization tools and tuning parameters. Applying our proposed method, we obtain eigenscores for the candidate visualizations. We also compare two meta-distances based on the 16 visualizations, which are, the proposed spectral meta-distance matrix (“meta-spec”) based on the eigenscores, and the naive meta-distance matrix (“meta-aver”) assigning equal weights to all the candidate visualizations, as in (2.13).
| Low-Dimensional Structure | Gaussian mixture | Smiley face | Mammoth |
|---|---|---|---|
| Simulation Setting | |||
| Empirical Mean (SE) | 0.992 () | 0.986 () | 0.990 () |
To evaluate the proposed eigenscores, for each setting and each , we compute , for the angle between the eigenscores and the true local concordance defined as
| (2.10) |
where is the -th row of the normalized distance matrix for the underlying noiseless samples , defined as in (2.5) with ’s replaced by ’s. Table 1 shows empirical mean and standard error (SE) of the averaged cosines , over the family of datasets under the same low-dimensional structure associated with various as shown in Figure 2(a). Our simulations showed that , indicating that the eigenscores essentially characterize the true concordance between the patterns contained in each candidate visualization and that of the underlying noiseless samples, evaluated locally with respect to sample . This justifies the proposed eigenscore as a precise measure of performance of the candidate visualizations in preserving the underlying true signals.
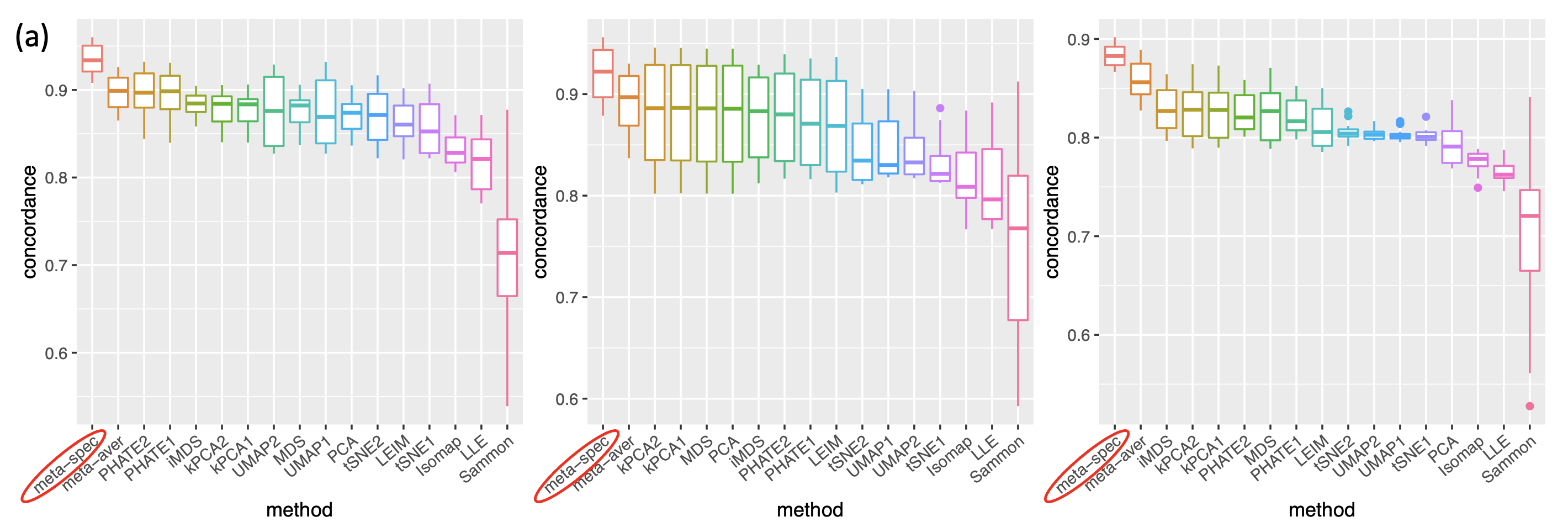
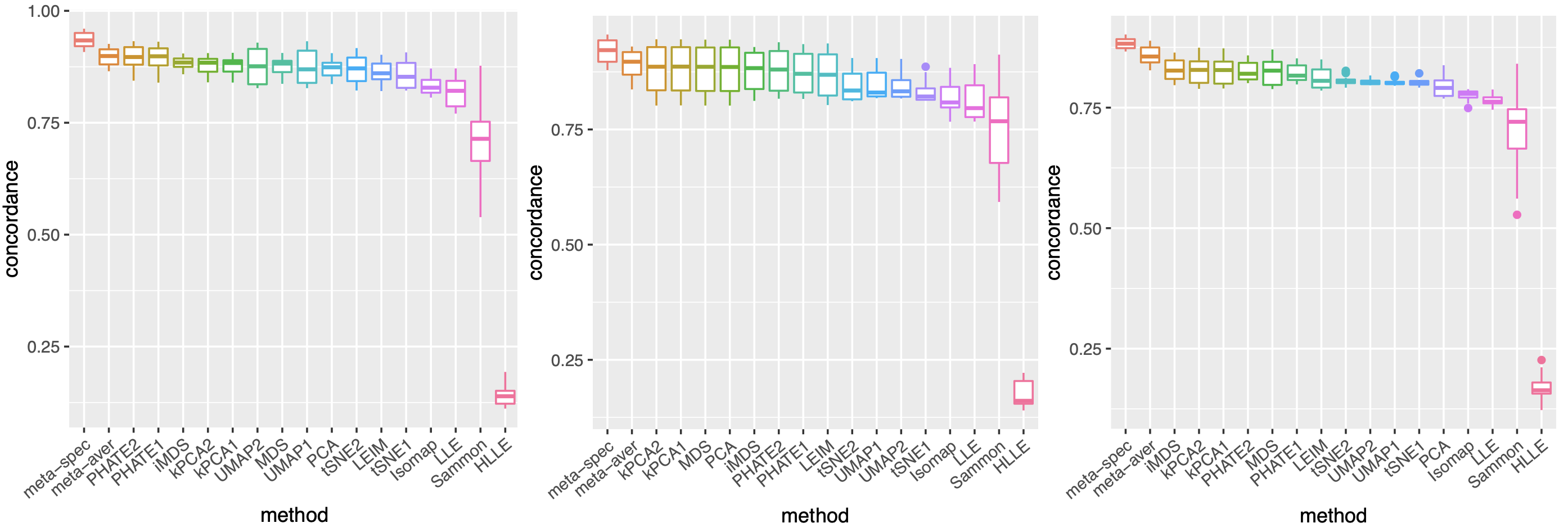
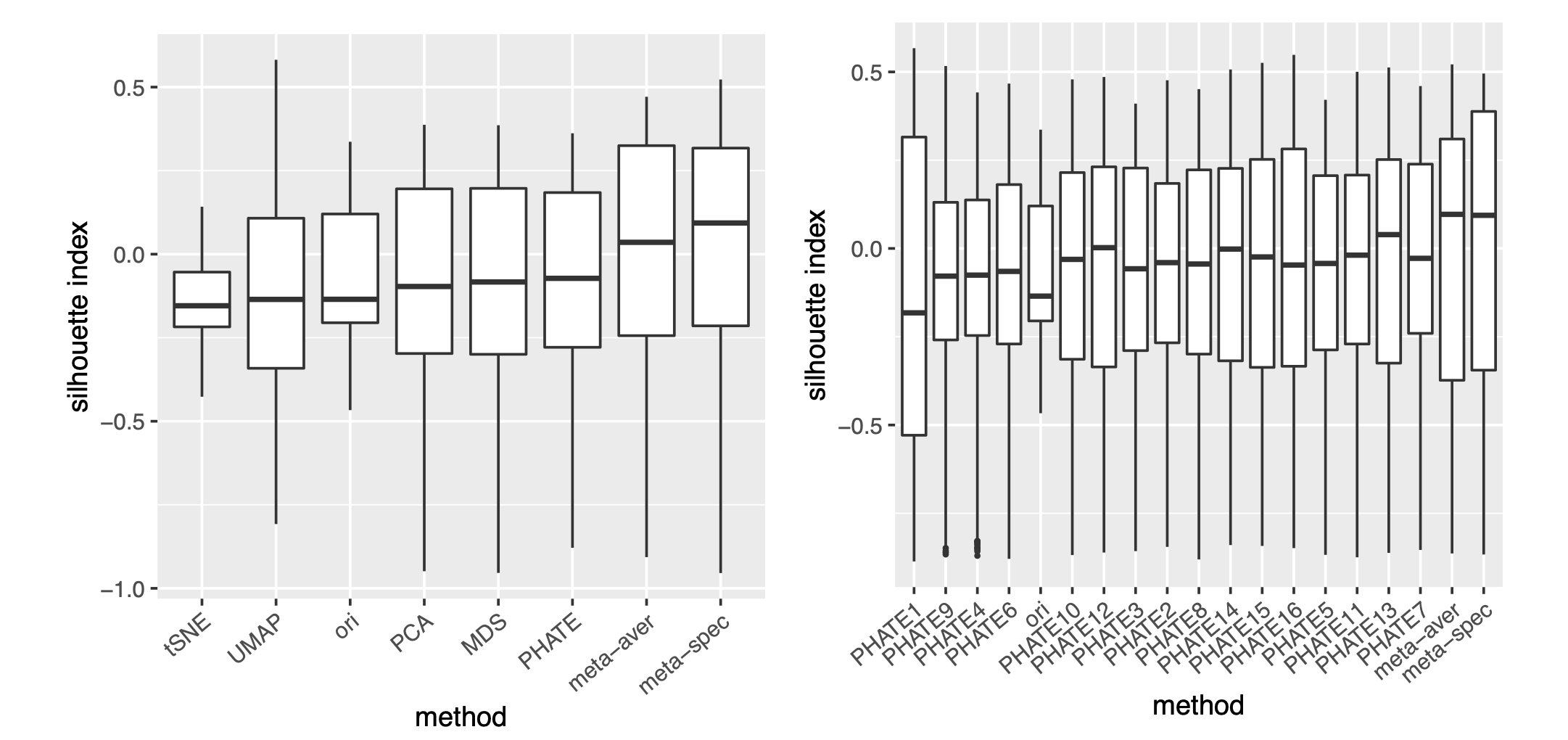
To assess the quality of two meta-distance matrices, for each dataset, we compare the mean concordance between the normalized distance of each candidate visualization and that of the underlying noiseless samples, and the mean concordance between the obtained meta-distance and that of the underlying noiseless samples. Figure 2(a) and Supplement Figure 7 show boxplots of these mean concordances for the 16 candidate visualizations and the two meta-distances under each setting of underlying structures across various values of . We observe that for each of the three structures, our proposed meta-distance is substantially more concordant with the underlying true patterns, than every candidate visualization and the naive meta-distance, indicating the superiority of the proposed meta-distance. To further demonstrate the advantage of the spectral meta-distance and its benefits to the final meta-visualization, we compared our proposed meta-visualization using UMAP, and candidate visualizations of a dataset under setting (i) with , and present their sample-wise concordance for each , and of the proposed meta-distance (Figure 2(b) and Supplement Figure 8). We observe that, while each individual method may capture some clusters in the dataset but misses others, the proposed meta-visualization is able to combine strengths of all the candidate visualizations in order to capture all the underlying clusters. Finally, to demonstrate the flexibility of our method with respect to higher intrinsic dimension , under the setting (i), we further evaluated the performance of different methods for . Supplement Figure 9 shows consistent and superior performance of the proposed method compared to the other approaches.
2.2.2 Visualizing Clusters of Religious and Biblical Texts
Cluster data are ubiquitous in scientific research and industrial applications. Our first real data example concerns fragments of text, extracted from English translations of eight religious books or sacred scripts including Book of Proverb (BOP), Book of Ecclesiastes (BOE1), Book of Ecclesiasticus (BOE2), Book of Wisdom (BOW), Four Noble Truth of Buddhism (BUD), Tao Te Ching (TTC), Yogasutras (YOG) and Upanishads (UPA) (Sah and Fokoué, 2019). All the text were pre-processed using natural language processing into a Document Term Matrix that counts frequency of 8265 atomic words, such as truth, diligent, sense, power, in each text fragment. In other words, each text fragment was treated as a bag of words, represented by a vector with features. The word counts were centred and normalized before downstream analysis.
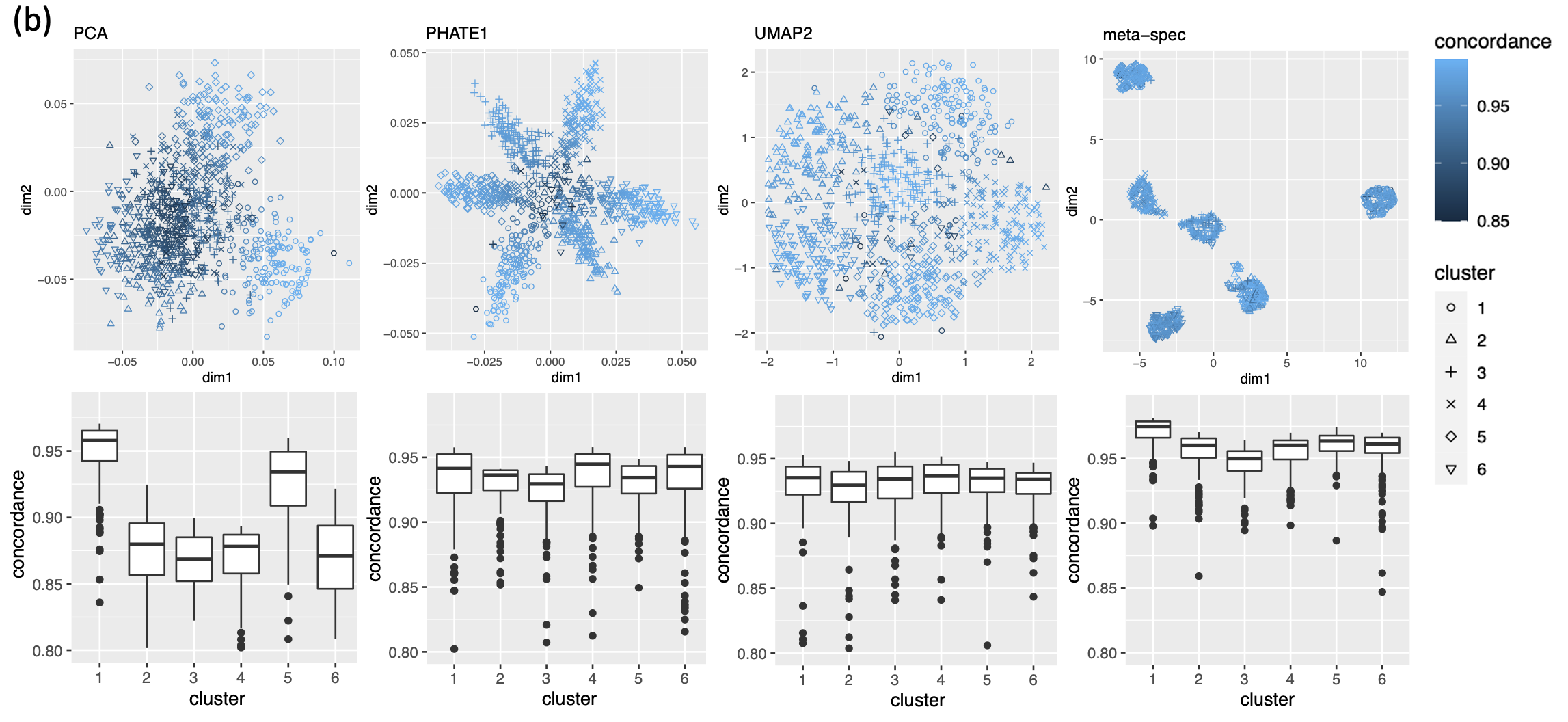
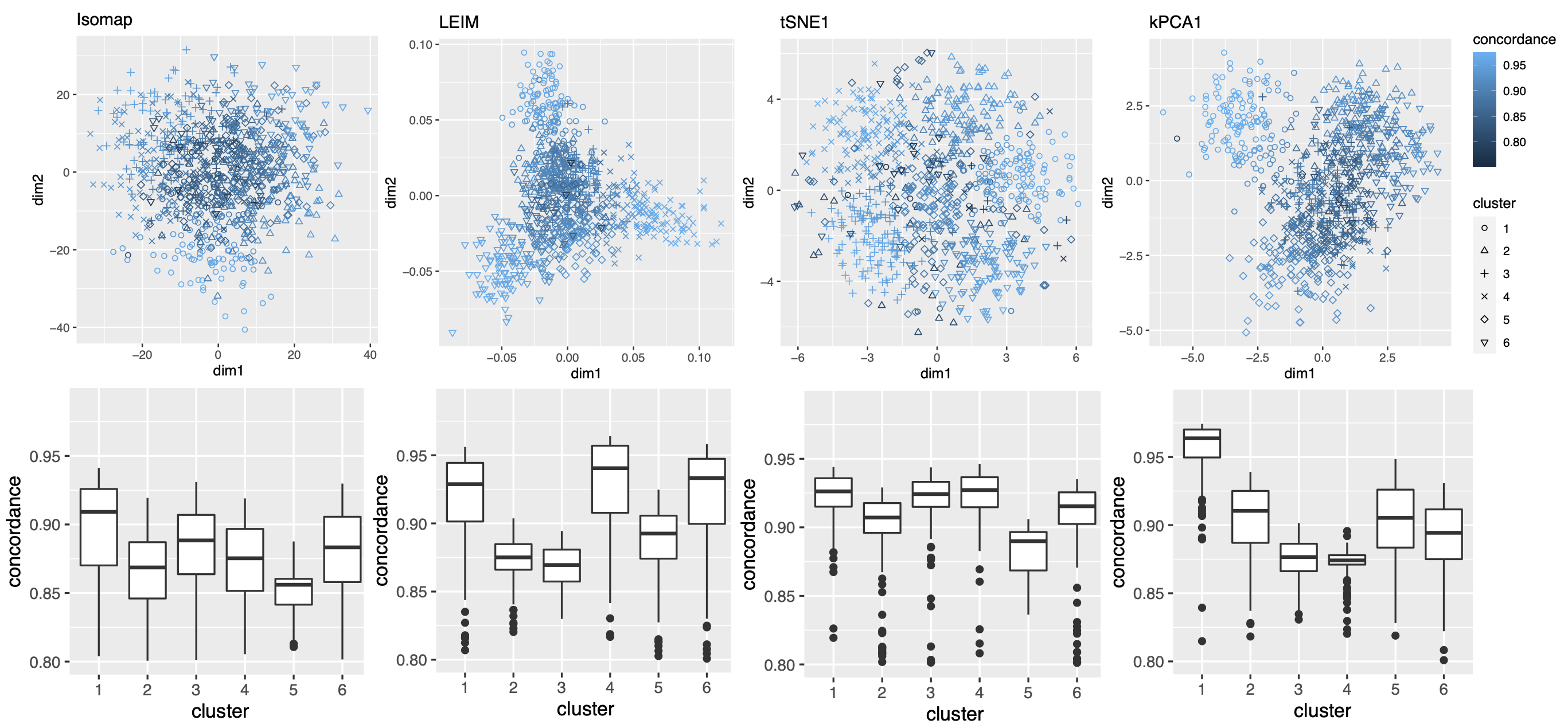
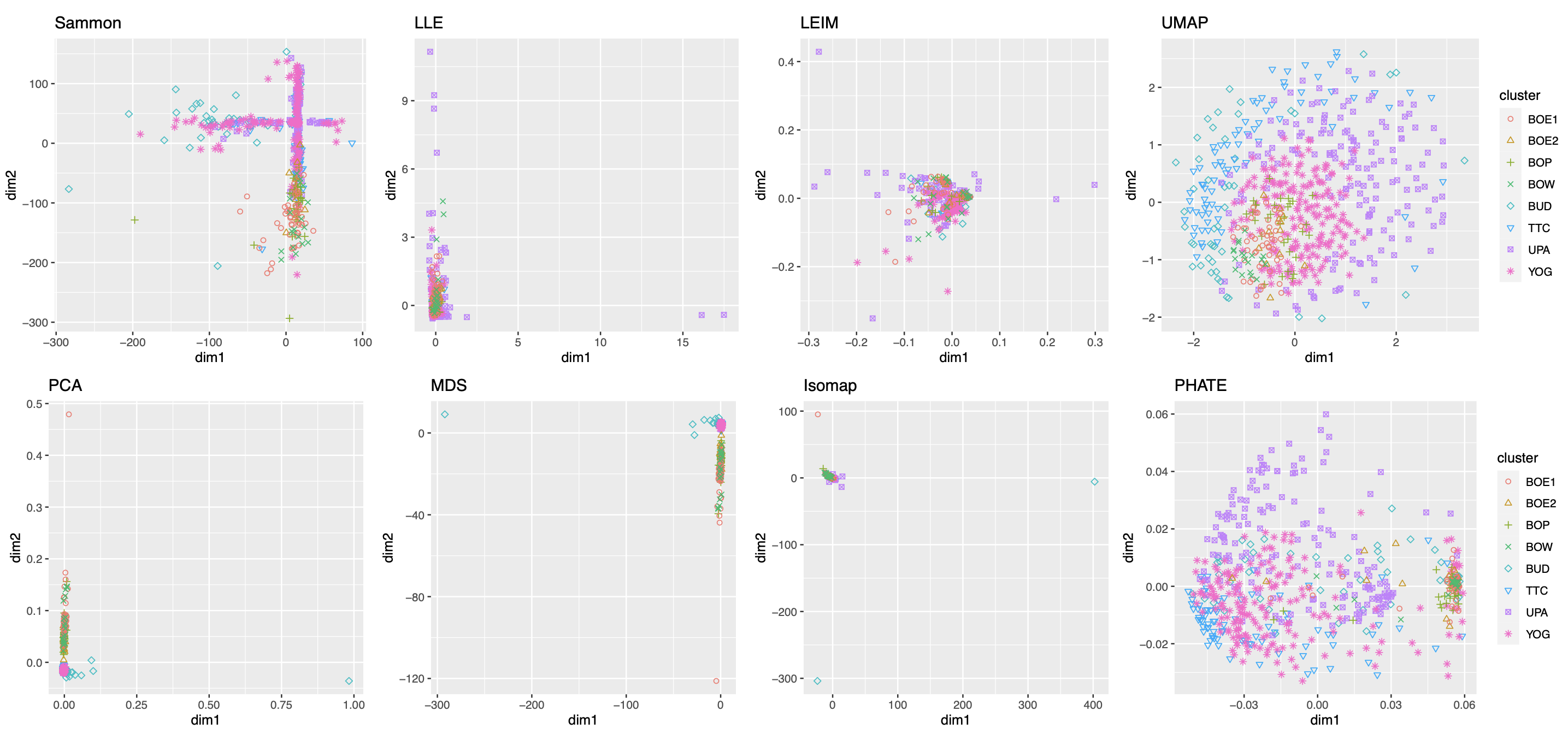
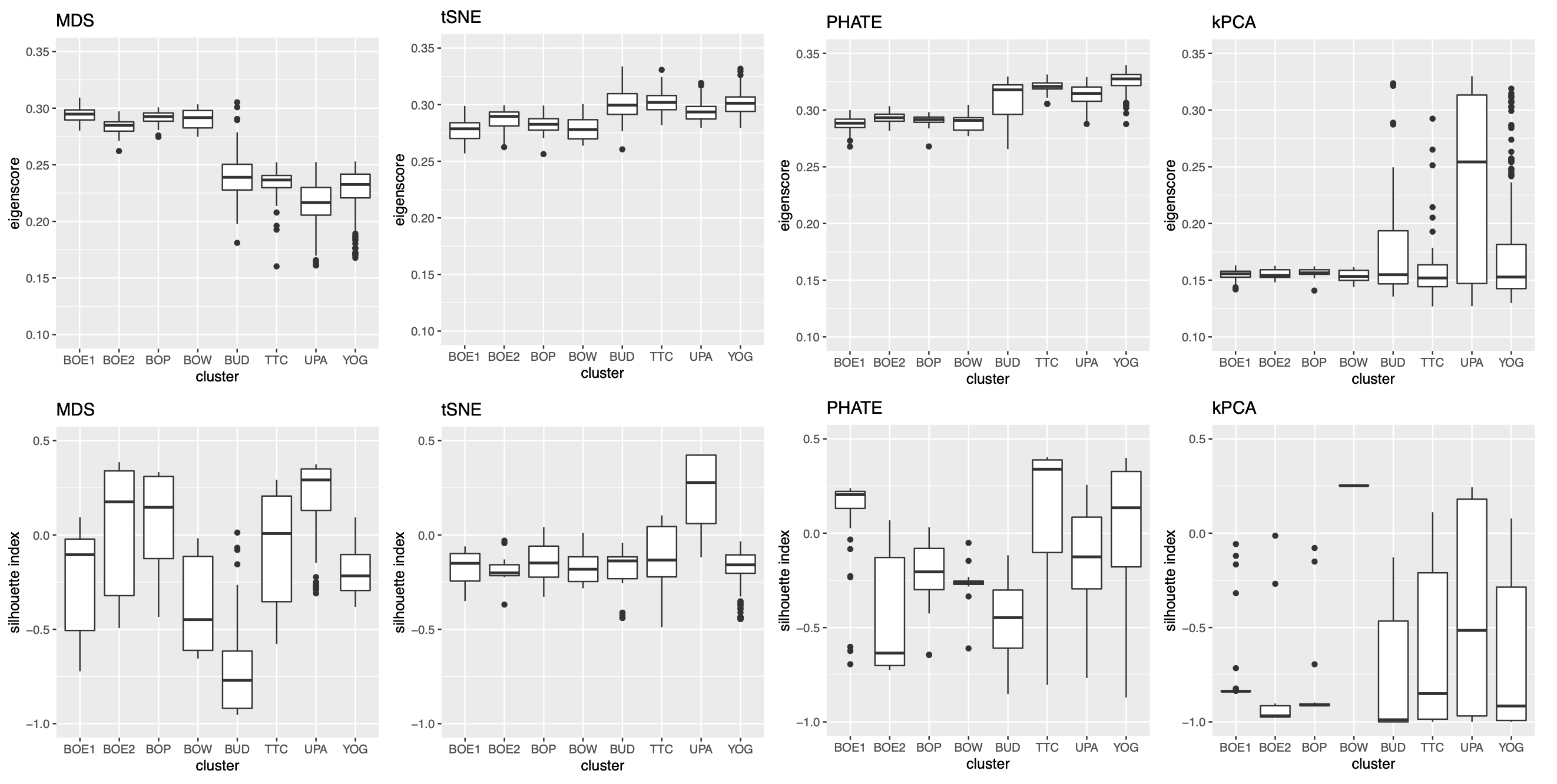
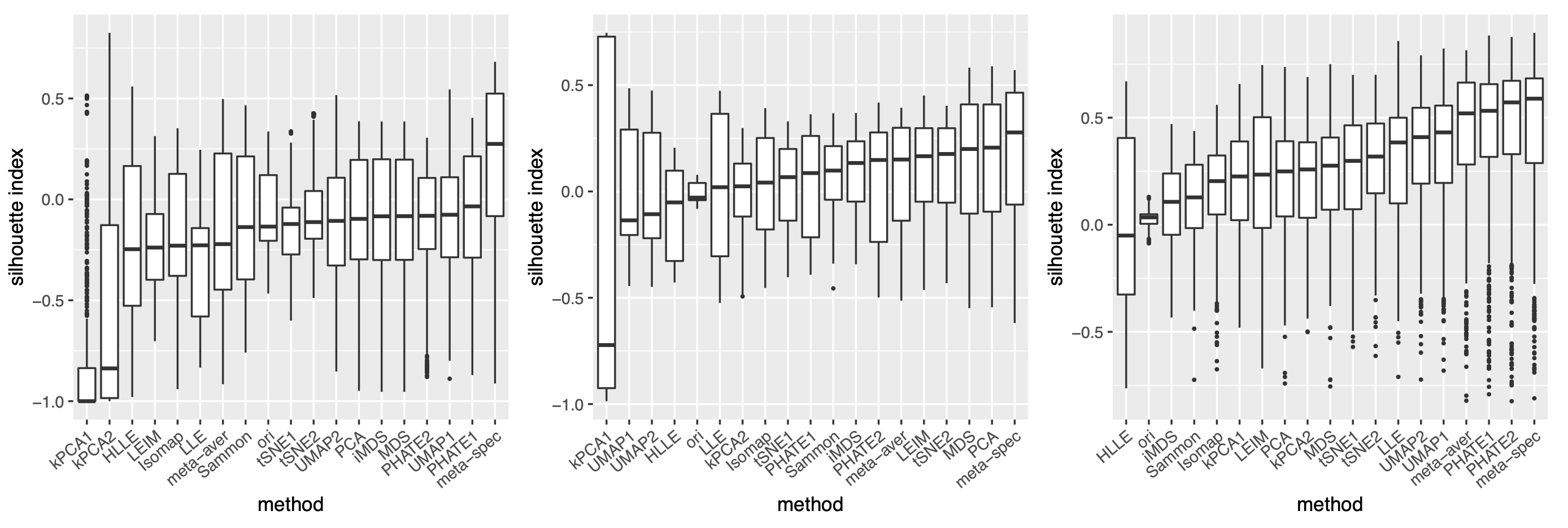
As in our simulation studies, we still consider candidate visualizations generated by 12 different methods with various tuning parameters (see Section A.2 of the Supplement for implementation details). Figure 3(a) contains examples of candidate visualizations obtained by PHATE, t-SNE, and kPCA, whose median eigenscores were ranked top, middle and bottom among all the visualizations (Figure 3(b)), respectively. More examples are included in Supplement Figure 10. In each visualization, the samples (text fragments) were colored by their associated books, showing how well the visualization captures the underlying clusters of the samples. The usefulness and validity of the eigenscores in Figure 3(b) can be verified empirically, by visually comparing the clarity of cluster patterns demonstrated by each candidate visualizations in Figure 3(a) and in Supplement Figure 10. Figure 3(c) is the proposed meta-visualization111With a slight abuse of notation, we used “meta-spec” and “meta-aver” hereafter to refer to the final meta-visualizations rather than the meta-distance matrices as in Section 2.2.1. of the samples by applying UMAP to the meta-distance matrix, which shows substantially better clustering of the text fragments in accordance with their sources. In addition, the meta-visualization also reflected deeper relationship between the eight religious books, such as the similarity between the two Hinduism books YOG and UPA, the similarity between Buddhism (BUD) and Taoism (TTC), the similarity between the four Christian books BOE1, BOE2, BOP, and BOW, as well as the general discrepancy between Asian religions (Hinduism, Buddhism, Taoism) and non-Asian religions (Christianity). All of these important phenomena, while salient in our meta-visualization, only appeared vaguely in very few candidate visualizations such as those produced by PHATE (Figure 3(a)) and UMAP (Supplement Figure 10).
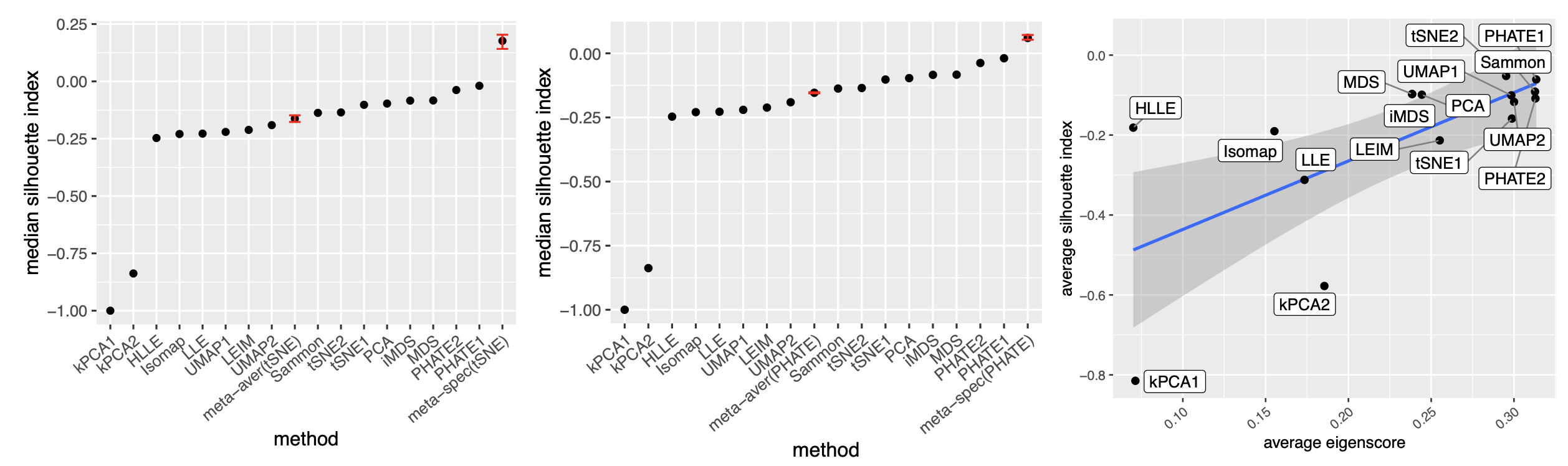
To quantitatively evaluate the preservation of the underlying clustering pattern, we computed for each visualization the Silhouette indices (Rousseeuw, 1987) with respect to the underlying true cluster membership, based on the normalized pairwise-distance matrices of the embeddings defined in (2.5). The Silhouette index (see Section A.2 of the Supplement for its definition), defined for each individual sample in a visualization, measures the amount of discrepancy between the within-class distances and the inter-class distances with respect to a given sample. As a result, for a given visualization, its Silhouette indices altogether indicate how well the underlying cluster pattern is preserved in a visualization, and higher Silhouette indices indicate that the underlying clusters are more separate. Empirically, we observed a notable correlation () between the median Silhouette indices and the median eigenscores across the candidate visualizations (Supplement Figure 11). In addition, for each candidate visualization, we found that samples with higher Silhouette index tend to have higher eigenscores (Supplement Figure 12), demonstrating the effectiveness of eigenscores, and its benefits on the final meta-visualization. In Figure 3(d), we show that, even taking into account the stochasticity of the visualization method (UMAP) applied to the meta-distance matrix, our meta-visualization had the median Silhouette index much higher than those of the candidate visualizations, as well as that of the meta-visualization “meta-aver” based on the naive meta-distance. It is of interest to note that “meta-spec” was the only visualization with a positive median Silhouette index, showing its better separation of clusters compared with other visualizations. Importantly, the proposed meta-visualization was not sensitive to the specific visualization method applied to the meta-distance matrices – similar results were obtained when we replaced UMAP by PHATE, the method having the highest median eigenscore in Figure 3(c), or t-SNE, for meta-visualization (Supplement Figure 11).
2.2.3 Visualizing Cell Cycles
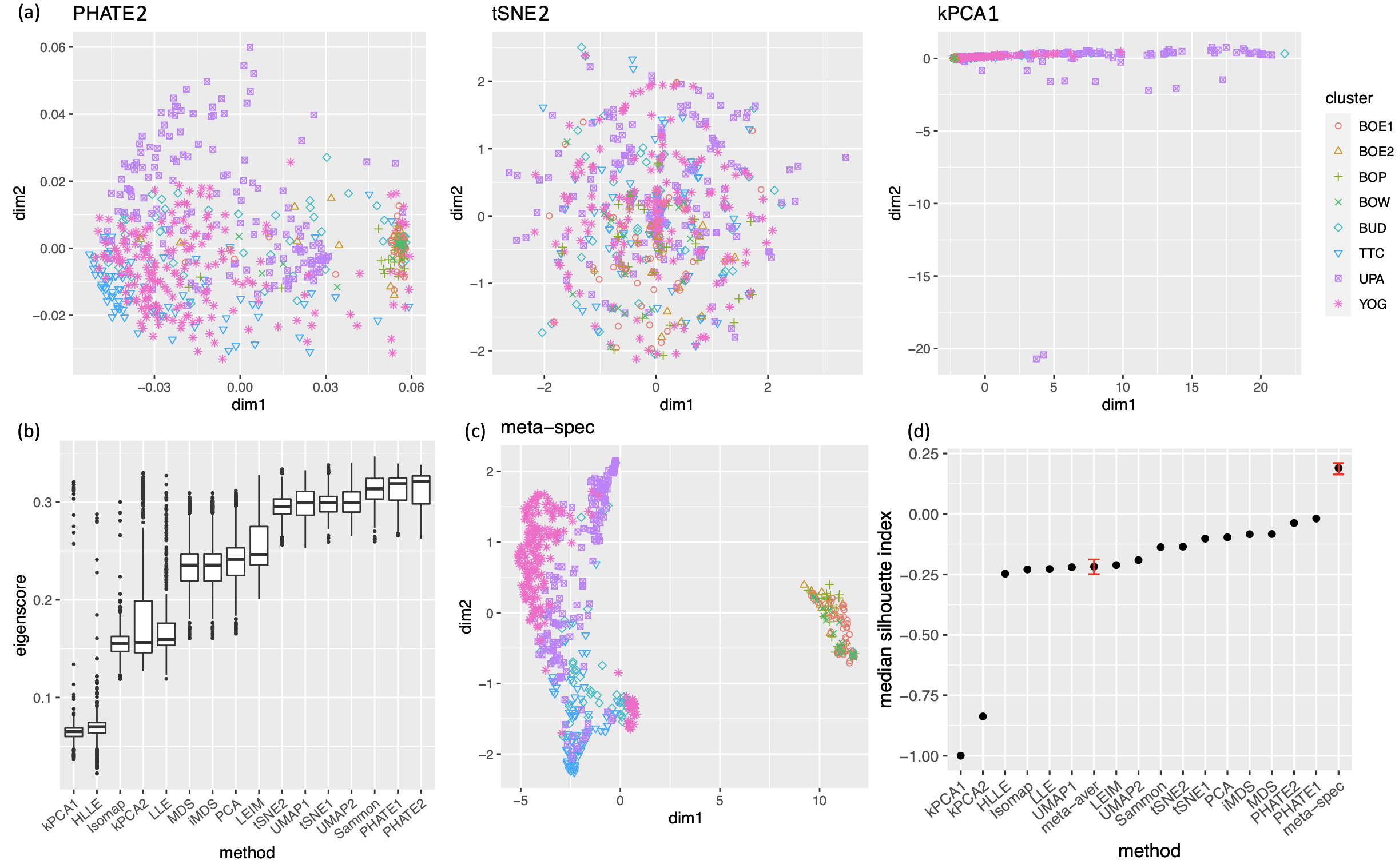
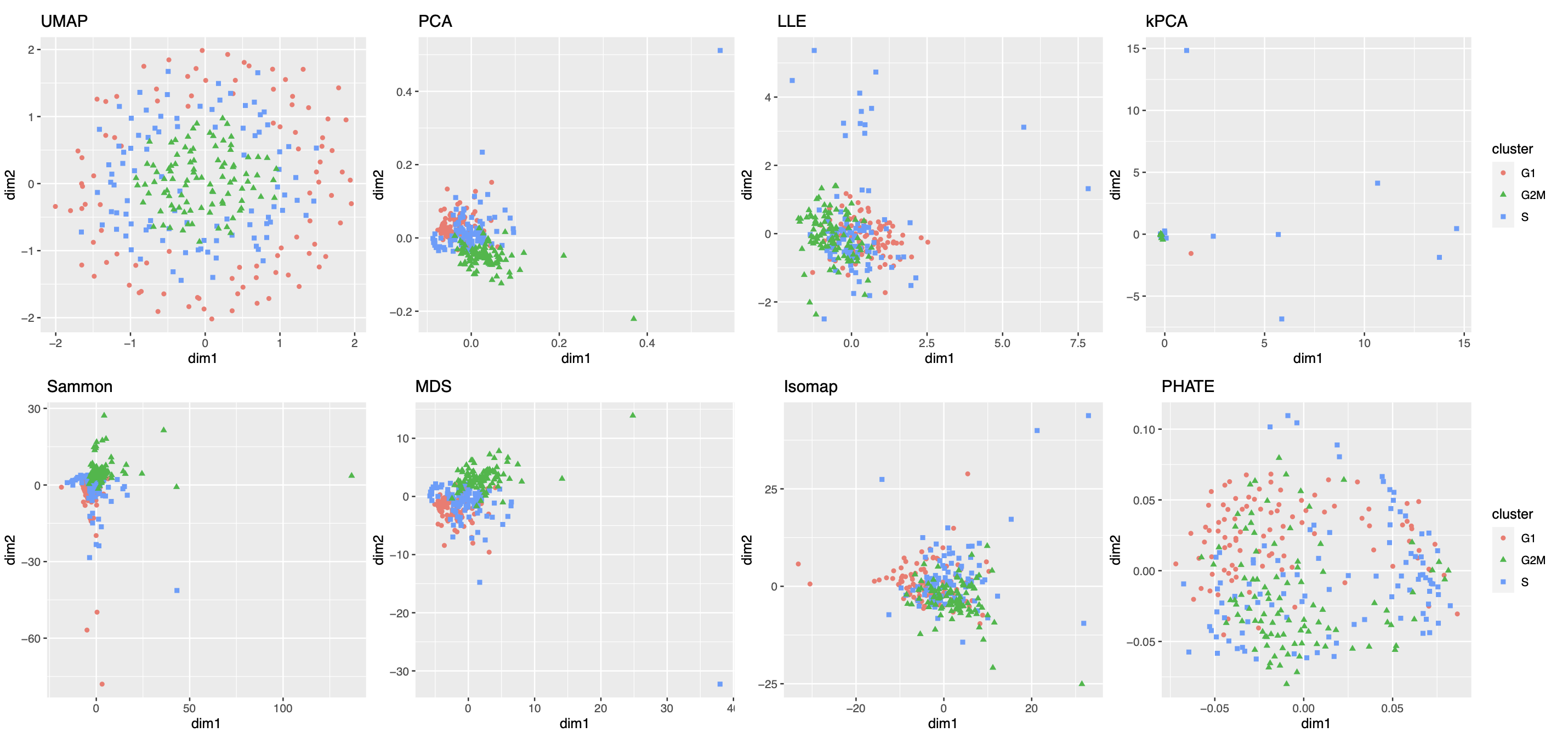
Our second real data example concerns visualization of a different low-dimensional structure, namely, a mixture of cycle and clusters, contained in the gene expression profile of a collection of mouse embryonic stem cells, as a result of the cell cycle mechanism. The cell cycle, or cell-division cycle, is the series of events that take place in a cell that cause it to divide into two daughter cells222https://en.wikipedia.org/wiki/Cell_cycle. Identifying the cell cycle stages of individual cells analyzed during development is important for understanding its wide-ranging effects on cellular physiology and gene expression profiles. Specifically, our dataset contains mouse embryonic stem cells, whose underlying cell cycle stages were determined using flow cytometry sorting (Buettner et al., 2015). Among them, one-third (96) of the cells are in the G1 stage, one-third in the S stage, and the rest in the G2M stage. The raw count data were preprocessed and normalized, leading to a dataset consisting of standardized expression levels of cell-cycle related genes for the 288 cells (see Section A.2 of the Supplement for implementation details of our data preprocessing).
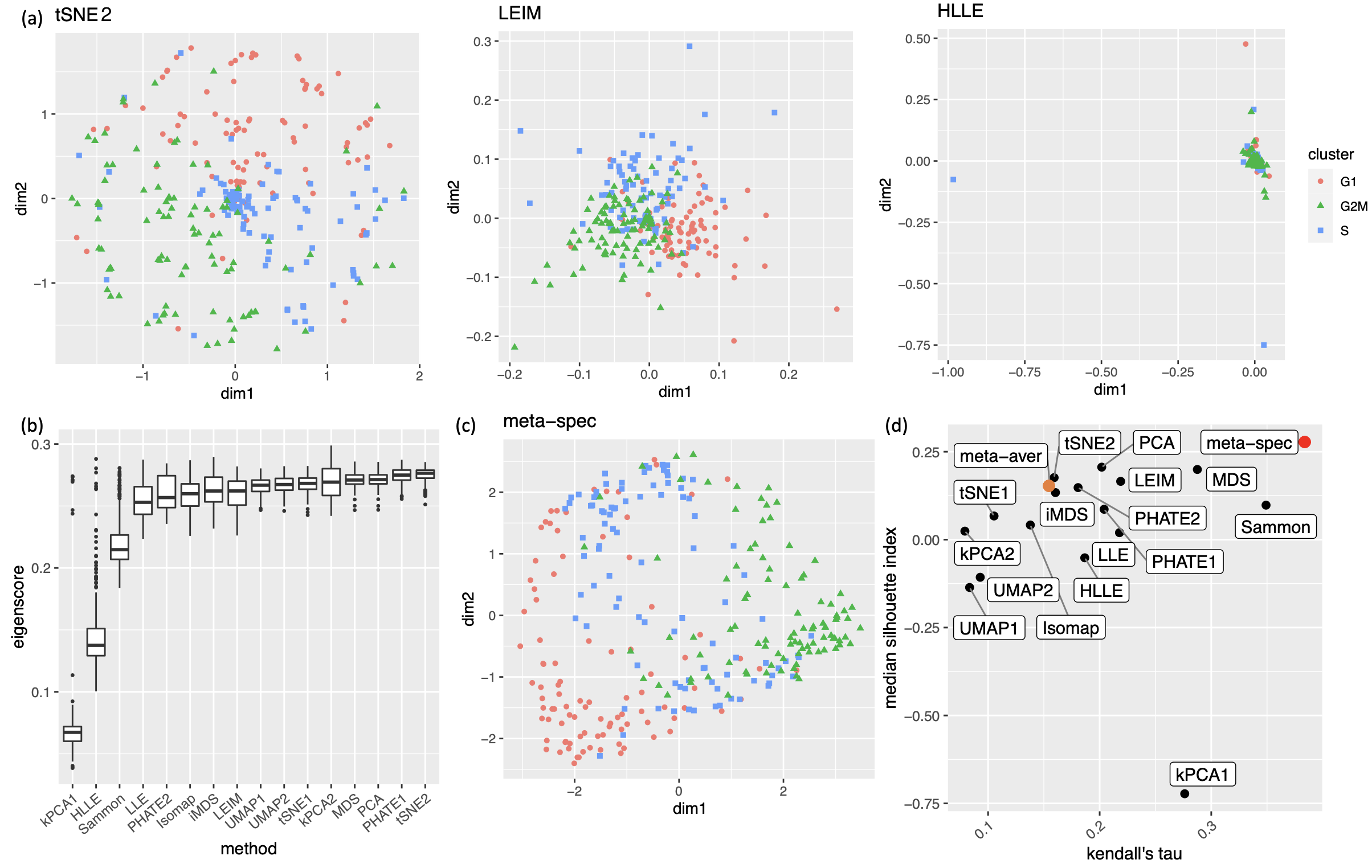
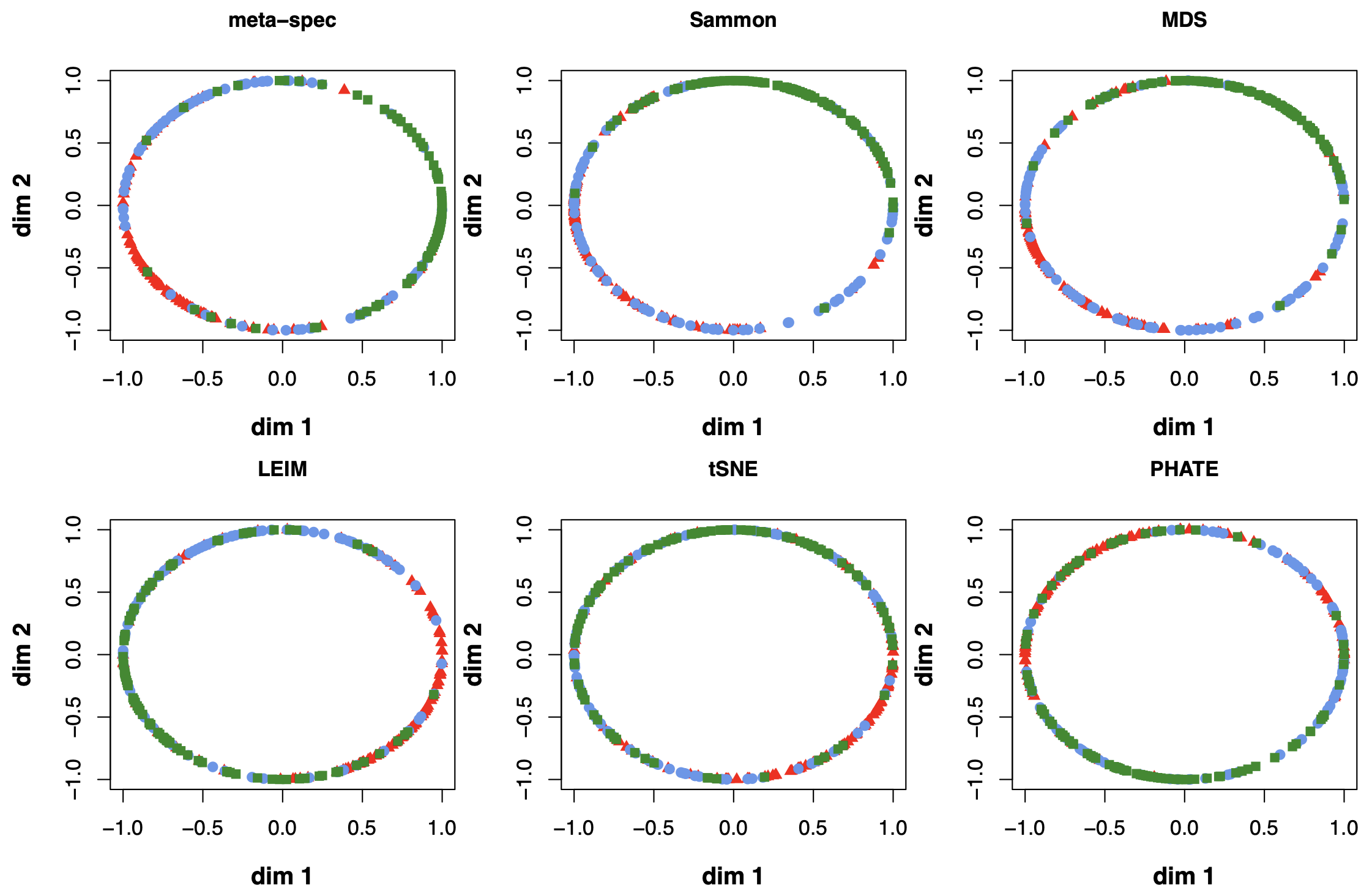
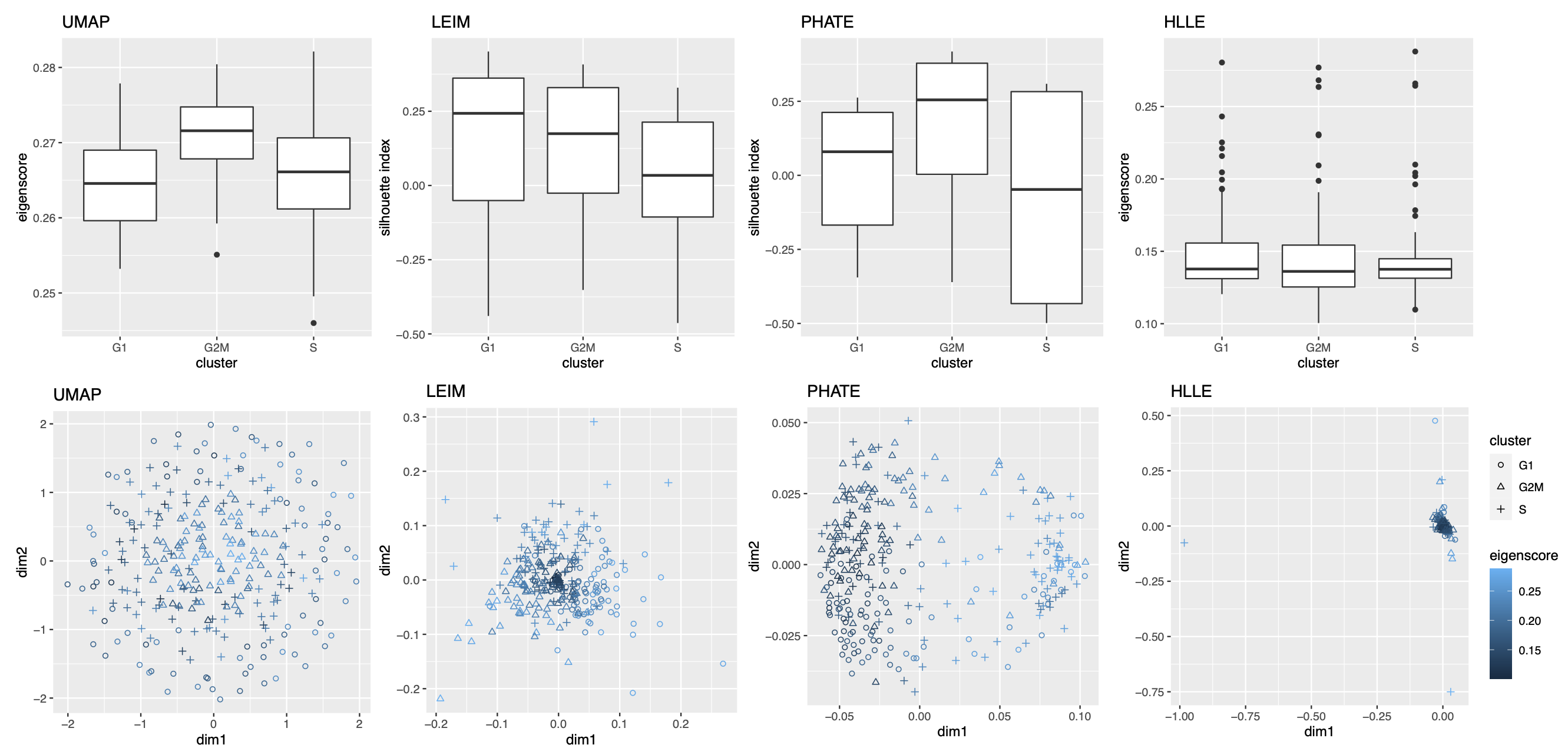
We obtained 16 candidate visualizations as before, and applied our proposed method. Figure 4(a) contains examples of candidate visualizations obtained by t-SNE, LEIM, and kPCA, whose median eigenscores were ranked top, middle and bottom among all the visualizations, respectively, and the cells were colored according to their true cell cycle stages. Figure 4(b) contains the boxplots of eigenscores for the candidate visualizations, indicating the overall quality of each visualization. The variation of eigenscores within each candidate visualization suggests that different visualizations have their own unique features and strengths to be contributed to the meta-visualization (Supplement Figure 16). Figure 4(c) is the proposed meta-visualization by applying kPCA to the meta-distance matrix. Comparing with Figure 4(a), the proposed meta-visualization showed better clustering of the cells according to their cell cycle stages, as well as a more salient cyclic structure underlying the three cell cycle stages (Supplement Figure 15). To quantify the performance of each visualization in terms of these two underlying structures (cluster and cycle), we considered two distinct metrics, namely, the median Silhouette index with respect to the underlying true cell cycle stages, and the Kendall’s tau statistic (Kendall, 1938) between the inferred relative order of the cells and their true orders on the cycle. Specifically, to infer the relative order of cells, we projected the coordinates of each visualization to the two-dimensional unit circle centred at the origin (Supplement Figure 15), and then determined the relative orders based on the cells’ respective projected positions on the unit circle. Figure 4(d) shows that the proposed meta-visualization was significantly better than all the candidate visualizations and the naive meta-visualization in representing both aspects of the data.
2.2.4 Visualizing Trajectories of Cell Differentiation
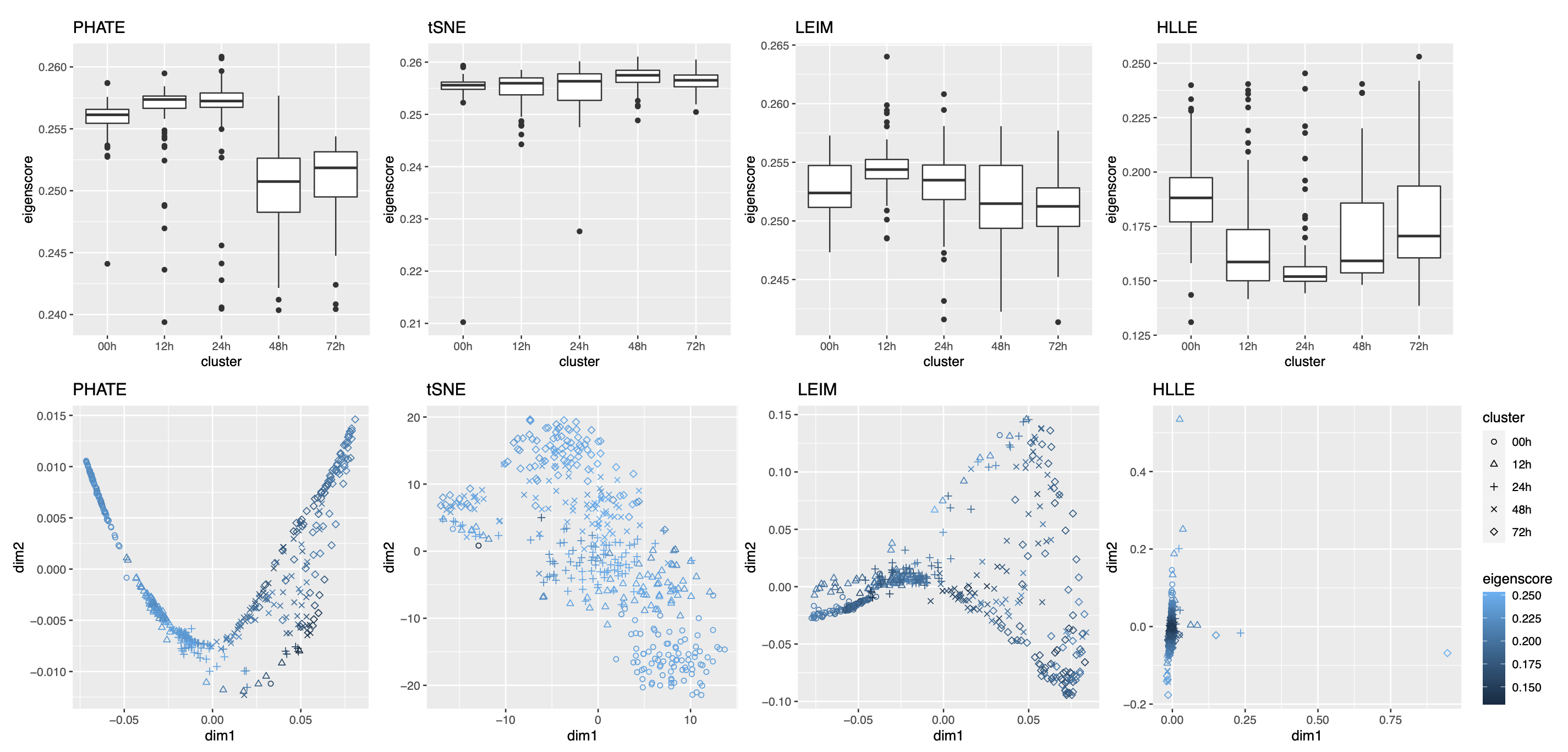
Our third real data example concerns visualization of a mixed pattern of a trajectory and clusters underlying the gene expression profiles of a collection of cells undergoing differentiation (Hayashi et al., 2018). Specifically, 421 mouse embryonic stem cells were induced to differentiate into primitive endoderm cells. After the induction of differentiation, the cells were dissociated and individually captured at 12- or 24-hour intervals (0, 12, 24, 48 and 72 h), and each cell was sequenced to obtain the final total RNA sequencing reads using the random displacement amplification sequencing technology. As a result, at each of the five time points, there were about 70 to 90 cells captured and sequenced. The raw count data were preprocessed and normalized (see Section A.2 of the Supplement for implementation details), leading to a dataset consisting of standardized expression levels of most variable genes for the 421 cells.
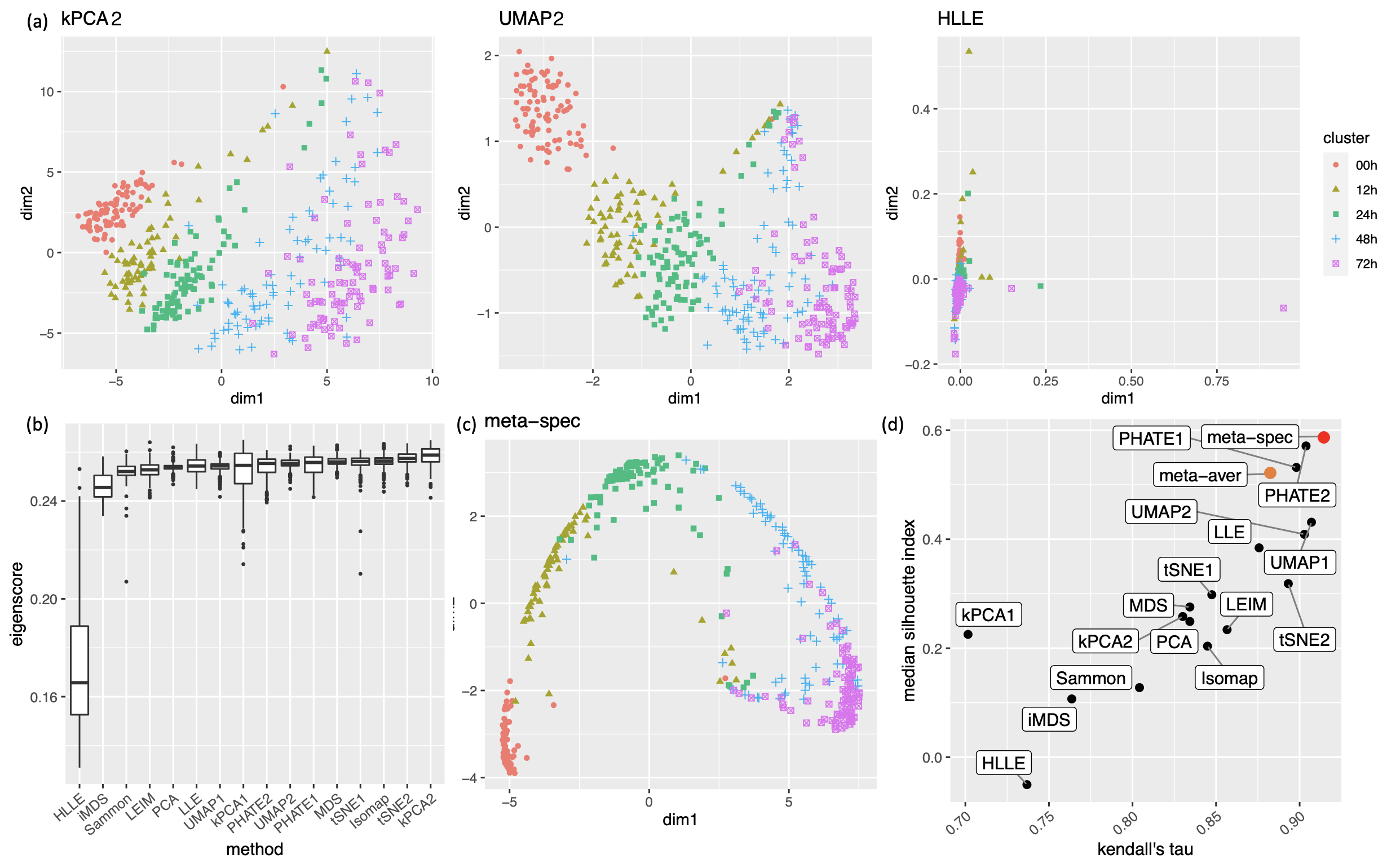
Again, we obtained 16 candidate visualizations as before, and applied our proposed method. In Figure 5(a)-(c) we show examples of candidate visualizations, boxplots of the eigenscores, and the meta-visualization using kPCA. The global (Figure 5(b)) and local (Supplement Figure 18) variation of eigenscores demonstrated contribution of different visualizations to the final meta-visualization according to their respective performance. We observed that some candidate visualizations such as kPCA, UMAP (Figure 5(a)) and PHATE (Supplement Figure 17) to some extent captured the underlying trajectory structure consistent with the time course of the cells. However, the meta-visualization in Figure 5(c) showed much more salient patterns in terms of both the underlying trajectory and the cluster pattern among the cells, by locally combining strengths of the individual visualizations (Supplement Figure 18). We quantified the performance of visualizations from these two aspects using the median Silhouette index with respect to the underlying true cluster membership (i.e., batches of time course) and Kendall’s tau statistic between the inferred cell order and the true order along the progression path. To infer the relative order of the cells from a visualization, we ordered all the cells based on the two-dimensional embedding along the direction that explained the most variability of the cells. In Figure 5(d), we observed that, the proposed meta-visualization had the largest median Silhouette index as well as the largest Kendall’s tau statistic, compared with all the candidate visualizations and the naive meta-visualization, showing the superiority of the proposed meta-visualization in both aspects.
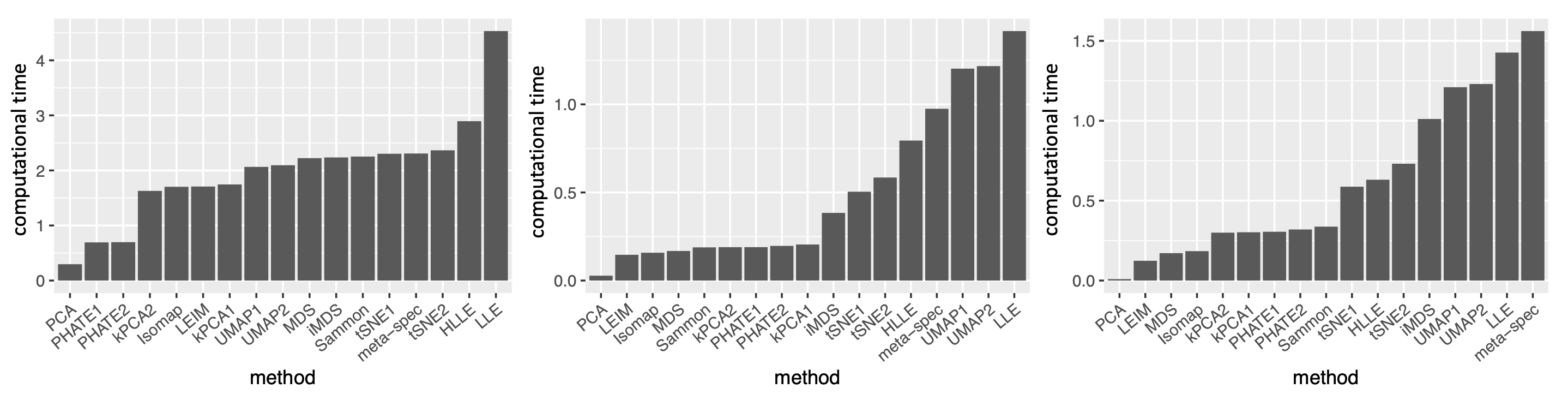
2.2.5 Computational Cost
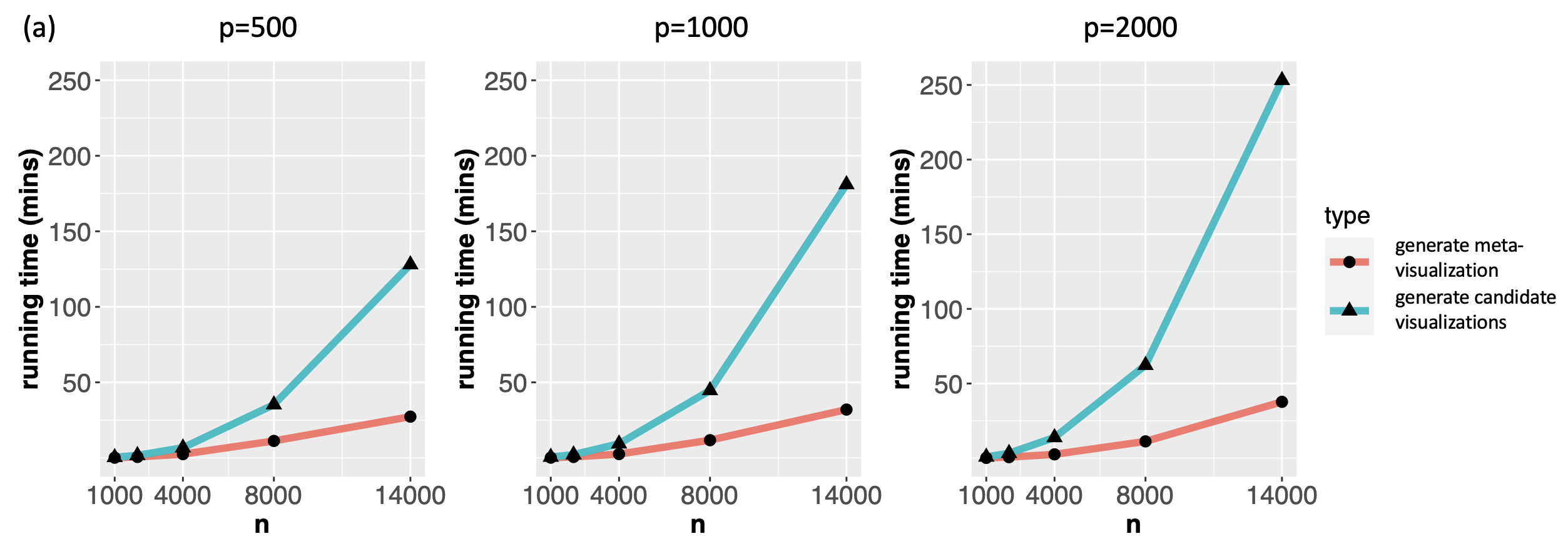
For datasets of moderate size as the ones analyzed in the previous sections, the proposed method had a computational cost comparable to that of t-SNE or UMAP for generating a single candidate visualization (Supplement Figure 19). As for very large and high-dimensional datasets, there are a few features of the proposed algorithm that make it readily scalable. First, although our method relies on computing the leading eigenvector of generally non-sparse matrices, these matrices (i.e., in Algorithm 1) are of dimension , where – the number of candidate visualizations – is usually much smaller compared to the sample size or dimensionality of the original data. Thus, for each sample , the computational cost due to the eigendecomposition is mild. Second, given the candidate visualizations, our proposed algorithm is independent of the dimensionality () of the original dataset, as it only requires as input a set of low-dimensional embeddings produced by different visualization methods. Third, since our algorithm computes the eigenscores and the meta-distance with respect to each sample individually, the algorithm can be easily parallelized and carried out in multiple cores to further reduce time cost.
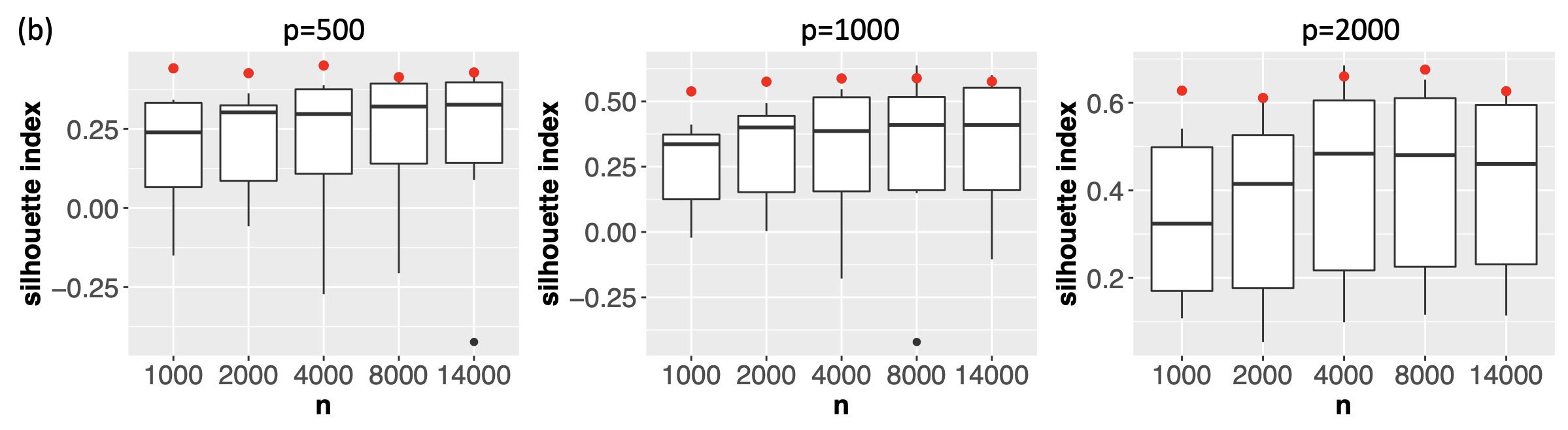
To demonstrate the computational efficiency of the proposed method for large and high-dimensional datasets, we evaluated the proposed method on real single-cell transcriptomic datasets (Buckley et al., 2022) of various sample sizes ( cells of nine different cell types from the neurogenic regions of mice) and dimensions ( genes). For each dataset, we obtained 11 candidate visualizations and applied Algorithm 1 to generate the final meta-visualization (see Section A.2 of the Supplement for implementation details). Supplement Figure 20(b) contains boxplots of median Silhouette indices for each candidate visualizations and the meta-visualization (highlighted in red) with respect to the underlying true cell types, showing the stable and superior performance of the proposed method under various sample sizes and dimensions. In Supplement Figure 20(a), we compared the running time for generating the 11 candidate visualizations, and that for generating the meta-visualizations based on Algorithm 1, on a MacBook Pro with 2.2 GHz 6-Core Intel Core i7. In general, as became large, the running time of the proposed algorithm also increased, but remained much less than that for generating the candidate visualizations. The difference in time cost became more significant as increased, demonstrating that for very large and high-dimensional datasets the computational cost essentially comes from generating candidate visualizations, rather than from the meta-visualization step. In particular, for dataset of sample size as large as and of dimension , it took about 60 mins to generate all the 11 candidate visualizations, and took about additional 12 mins to generate the meta-visualization. Moreover, Supplement Figure 20(a) also demonstrated that, for each , when increased, the running time for generating the candidate visualizations was longer, but the time cost for meta-visualization remained about the same (difference less than one minute). We also note that users often create multiple visualizations for data exploration, and our approach can simply reuse these visualizations with little additional computational cost.
2.3 Theoretical Justifications and Fundamental Principles
2.3.1 General Model for Multiple Visualizations
We develop a general and flexible theoretical framework, to investigate the statistical properties of the proposed methods, as well as the fundamental principles behind its empirical success333Throughout, we adopt the following notations. For a matrix , we define its spectral norm as . For sequences and , we write or if , and write if there exists constants such that for all .. As can be seen from Section 2.1, there are two key ingredients of our proposed method, namely, the eigenscores for evaluating the candidate visualizations, and the meta-distance matrix that combines multiple candidate visualizations to obtain a meta-visualization.
To formally study their properties, we introduce a generic model for the collection of candidate visualizations produced by multiple visualization methods, with possibly different settings of tuning parameters for a single method as considered in previous sections. Specifically, we assume are generated as
| (2.11) |
where are the underlying noiseless samples and are the random noises. Recall that are the distance matrices associated to the candidate visualizations. Then, for the candidate visualizations, we consider a scaled signal-plus-noise expression
| (2.12) |
induced by (2.11), where is a global scaling parameter, is the -th row of the pairwise distance matrix of the underlying noiseless samples, and is a random vector characterizing the relative distortion of associated to the -th candidate visualization, from the underlying true pattern . Before characterizing the distributions of , we point out that, in principle, the relative distortions are jointly determined by the random noises in (2.11), and the features and relations between of the specific visualization methods. Importantly, in line with what is often encountered in practice, equation (2.12) allows for flexible and possibly distinct scaling and directionality for different candidate visualizations, by introducing the visualization-specific parameter , and by focusing on the pairwise distance matrices, rather than the low-dimensional embeddings themselves.
To quantitatively describe the variability of the distortions across candidate visualizations, we assume
-
(C1a)
are identically distributed sub-Gaussian vectors with parameter , that is, for any deterministic unit vector , we have , and that with high probability444An event holds with high probability if there exists some , such that for all for some large constant . for some constant .
This assumption makes (2.12) a generative model for with ground truth and random distortions, where the variance parameter describes the average level of the distortions of candidate visualizations from the truth after proper scaling. In relation to (2.11), such a condition can be satisfied when the signal structure is finite, the noise is sub-Gaussian, and the dimension reduction map underlying the candidate visualization is bounded and sufficiently smooth. See Section B.2 of the Supplement for details. In addition, we also need to characterize the correlations among these random distortions, not only because the candidate visualizations are typically obtained from the same dataset , but also because of the possible similarity between the adopted visualization methods, such as MDS and iMDS, or t-SNE under different tuning parameters. Specifically, for any , we define the cross-visualization covariance , and quantify the level of dependence between a pair of candidate visualizations by . By Condition (C1a), we have for all . For all correlation parameters , we assume
-
(C1b)
The matrix satisfies .
Condition (C1b) covers a wide range of correlation structures among the candidate visualizations, allowing in particular for a subset of highly correlated visualizations possibly produced by very similar methods. The parameter characterizes the overall correlation strength among the candidate visualizations, which is assumed to be not too large. As a comparison, note that a set of pairwise independent candidate visualizations implies that , whereas a set of identical candidate visualizations have . In particular, the requirement can be satisfied if, for example, among candidate visualizations, there are subsets of at most visualizations that are produced by very similar procedures, such as by the same method under different tuning parameters, so that . When Condition (C1b) fails, as all the candidate visualizations are essentially similarly distorted from truth, combination of them will not be substantially more informative than each individual visualization.
2.3.2 Convergence of Eigenscores
Under Condition (C1a), it holds that . Hence, we can use the quantity to characterize the overall SNR in the candidate visualizations as modelled by (2.12), which reflects the average quality of the candidate visualizations in preserving the underlying true patterns around sample . Before stating our main theorems, we first introduce our main assumption on the minimal SNR requirement, that is,
-
(C2)
For defined in (C1a) and (C2b), it holds that and as .
Our algorithm is expected to perform well if is small relative to the overall SNR. The condition is easily satisfied for a sufficiently large dataset.
Recall that The following theorem concerns the convergence of eigenscores to the true concordance , and is proved in Section B.3 of the Supplement.
Theorem 1.
Under Conditions (C1a) (C1b) and (C2), for each , it holds that in probability as .
Theorem 1 implies that, as long as the candidate visualizations contain sufficient amount of information about the underlying true structure, and are not terribly correlated, the proposed eigenscores are quantitatively reliable, as they converge to the actual quality measures asymptotically. In other words, the eigenscores provide a point-wise consistent estimation of the concordance between the candidate visualizations as summarized by and the underlying true patterns , justifying the empirical observations in Table 1. Importantly, Condition (C2) suggests that our proposed eigenscores may benefit from a larger number of candidate visualizations, or a smaller overall correlation , that is, a collection of functionally more diverse candidate visualizations; see further discussions in Section 2.3.6.
2.3.3 Theoretical Guarantee for Meta-Visualization
Our second theorem concerns the guaranteed performance of our proposed meta-distance matrix and its improvement upon the individual candidate visualizations in the large-sample limit.
Theorem 2.
Under Conditions (C1a) (C1b) and (C2), for each , it holds that in probability as . Moreover, for any constant , there exist a constant such that, whenever , we have in probability as .
Theorem 2 is proved in Section B.4 of the Supplement. In addition to the point-wise consistency of as described by in probability, Theorem 2 also ensures that the proposed meta-distance is in general no worse than the individual candidate visualizations, suggesting a competitive performance of the meta-visualization. In particular, if in addition to Conditions (C1a) (C1b) and (C2) we also have , that is, the magnitude of the random distortions from the true structure is relatively large, then each candidate visualization necessarily has at most mediocre performance, i.e., in probability. In such cases, the proposed meta-distances is still consistent and thus strictly better than all candidate visualizations. Theorem 2 justifies the superior performance of the spectral meta-visualization demonstrated in Section 2.2, compared with 16 candidate visualizations.
Among the three conditions required for the consistency of the proposed meta-distance matrix, Condition (C2) is most critical as it describes the minimal SNR requirement, that is, how much information the candidate visualizations altogether should contain about the underlying true structure of the data. In this connection, our theoretical analysis indicates that, in fact, such a signal strength condition is also necessary, not only for the proposed method, but for any possible methods. More specifically, in Section B.6 of the Supplement, we proved (Theorem 4) that, it’s impossible to construct a meta-distance matrix that is consistent when Condition (C2) is violated. This result shows that the settings where our meta-visualization algorithm works well is essentially the most general setting possible.
2.3.4 Robustness of Spectral Weighting against Adversarial Visualizations
In Section 2.2, in addition to the proposed meta-visualization, we also considered the meta-visualization based on the naive meta-distance matrix , whose rows are
| (2.13) |
which is a simple average across all the candidate visualizations. We observed in all our real-world data analyses that, such a naive meta-visualization only had mediocre performance compared to the candidate visualizations (Figures 3, 4 and 5), much worse than the proposed spectral meta-visualization. The empirical observations suggest the advantage of informative weighting for combining candidate visualizations.
The empirically observed suboptimality of the non-informative weighting procedure can justified rigorously by theory. Our next theorem concerns the behavior of the proposed meta-distance matrix and the naive meta-distance matrix when combining a mixture of well-conditioned candidate visualizations, as characterized by our assumptions (C1a) (C1b) and (C2), and some adversarial candidate visualizations whose pairwise-distance matrices does not contain any information about the true structure. Specifically, we suppose among all the candidate visualizations, there is a collection of well-conditioned candidate visualizations for some small , and a collection of adversarial candidate visualizations.
Theorem 3.
For any , suppose among all the candidate visualizations, there is a collection of candidate visualizations for some small satisfying Conditions (C1a) (C1b) and (C2), and a collection of adversarial candidate visualizations such that for all . Then, for the proposed meta-distance , we still have in probability as . However, for the naive meta-distance , even if , we have in probability as .
Theorem 3 is proved in Section B.5 of the Supplement. By Theorem 3, on the one hand, even when there are a small portion of really poor (adversarial) candidate visualizations to be combined with other relatively good visualizations, the proposed method still perform well thanks to the consistent eigenscore weighting in light of Theorem 1. On the other hand, no matter how strong the SNR is for those well-conditioned candidate visualizations, the method based on non-informative weighting is strictly sub-optimal. Indeed, when , although we have in probability for all , the non-informative weighting would suffer from the non-negligible negative effects from the adversarial visualizations in , causing a strict deviation from ; see, for example, Figures 3-5(b)(d) for empirical evidences from real-world data.
2.3.5 Limitations of Original Noisy High-Dimensional Data
The proposed eigenscores provide an efficient and consistent way of evaluating the performance of the candidate visualizations. As mentioned in Section 1, a number of metrics have been proposed to quantify the distortion of a visualization by comparing the low-dimensional embedding directly with the original high-dimensional data. Such metrics essentially treat the original high-dimensional data as the ground truth, and do not take into account the noisiness of the high-dimensional data. However, for many datasets arising from real-world applications, the observed datasets, as modelled by (2.11), are themselves very noisy, which may not make an ideal reference point for evaluating a visualization that probably has already significantly denoised the data through dimension reduction. For example, the three real-world datasets considered in Section 2.2 are all high-dimensional and contain much more features than number of samples. In each case, there are some underlying clusters among the samples, but the original datasets showed significantly weaker cluster structure compared to most of the 16 candidate visualizations (Supplement Figure 21), suggesting that directly comparing a visualization with the noisy high-dimensional data may be misleading. In this respect, our theorems indicate that the proposed spectral method is able to precisely assess and effectively combine multiple visualizations to better grasp the underlying noiseless structure , without referring to the original noisy datasets, making it more robust, flexible, and computationally more efficient.
2.3.6 Benefits of Including More Functionally Diverse Visualizations
Our theoretical analysis implies that the proposed meta-visualization may benefit from a large number (larger ) of functionally diverse (small ) candidate visualizations. To empirically verify this theoretical observation, we focused on the religious and biblical text data and the mouse embryonic stem cells data considered in Section 2.2, and obtained spectral meta-visualizations based on a smaller but relatively diverse collection of 5 candidate visualizations, produced by arguably the most popular methods, namely, t-SNE, PHATE, UMAP, PCA and MDS, respectively. Compared with the 16 candidate visualizations considered in Section 2.2, here we have presumably similar but much smaller . As a result, for the religious and biblical texts data, the meta-visualization had a median Silhouette index 0.187 (Supplement Figure 13), which was smaller than the median Silhouette index 0.275 based on the 16 candidate visualizations as in Figure 3(d); for the cell cycle data, the meta-visualization had a median Silhouette index -0.062 and a Kendall’s tau statistic 0.313, both smaller than the respective values based on the 16 candidate visualizations as in Figure 4(d). On the other hand, we also evaluated the effect when is increased but remains fixed. Specifically, we obtained 16 candidate visualizations, all produced by PHATE with varying nearest neighbor parameters, the final spectral meta-visualization had a median Silhouette index 0.094, which was even lower than the above meta-visualization based on five distinct methods, although being still slightly better than the 16 PHATE-based candidate visualizations (Supplement Figure 13). These empirical evidences were in line with our theoretical predictions, suggesting benefits of including more diverse visualizations.
3 DISCUSSION
We developed a spectral method in the current study to assess and combine multiple data visualizations. The proposed meta-visualization combines candidate visualizations through an arithmetic weighted average of their normalized distance matrices, by their corresponding eigenscores. Although the proposed method was shown both in theory and numerically to outperform the individual candidate visualizations and their naive combination, it is still unclear whether there exists any other forms of combinations that lead to even better meta-visualizations. For example, one could consider constructing a meta-distance matrix using the geometric or harmonic (weighted) average, or an average based on barycentric coordinates (Floater, 2015). We plan to investigate such problems concerning how to optimally combining multiple visualizations in a subsequent work.
Although originally developed for data visualization, the proposed method can be useful for other supervised and unsupervised machine learning tasks, such as combining multiple algorithms for clustering, classification, or prediction. For example, for a given dataset, if one has a collection of predicted cluster memberships produced by multiple clustering algorithms, one could construct cluster membership matrices with -th entry being 0 if sample and are not assigned to the same cluster and being 1 otherwise. Then we may define the similarity matrix as in (2.7), obtain the eigenscores for the candidate clusterings, and a meta-clustering using (2.9). It is of interest to know its empirical performance and if the fundamental principles unveiled in the current work continue to hold for such broader range of learning tasks.
Data Availability
The religious and biblical text data (Sah and Fokoué, 2019) was downloaded from UCI Machine Learning Repository 555https://archive.ics.uci.edu/ml/datasets/A+study+of++Asian+Religious+and+Biblical+Texts. The cell cycle analysis was based on the mouse embryonic stem cell data (Buettner et al., 2015) downloaded from EMBL-EBI with accession code E-MTAB-2805. The cell trajectory analysis was based on the mouse embryonic stem single cell data (Hayashi et al., 2018) downloaded from Gene Expression Omnibus with accession code GSE98664. The single-cell transcriptomic dataset (Buckley et al., 2022) used for evaluating computational cost is accessible at BioProject PRJNA795276.
Code Availability
The R codes of the method, and for reproducing our simulations and data analyses are available at our GitHub page https://github.com/rongstat/meta-visualization.
References
- Abraham et al. (2006) Abraham, I., Y. Bartal, and O. Neiman (2006). Advances in metric embedding theory. In Proceedings of the thirty-eighth annual ACM symposium on Theory of computing, pp. 271–286.
- Abraham et al. (2009) Abraham, I., Y. Bartal, and O. Neiman (2009). On low dimensional local embeddings. In Proceedings of the Twentieth Annual ACM-SIAM Symposium on Discrete Algorithms, pp. 875–884. SIAM.
- Arora et al. (2018) Arora, S., W. Hu, and P. K. Kothari (2018). An analysis of the t-SNE algorithm for data visualization. In Conference on Learning Theory, pp. 1455–1462. PMLR.
- Bartal et al. (2019) Bartal, Y., N. Fandina, and O. Neiman (2019). Dimensionality reduction: theoretical perspective on practical measures. Advances in Neural Information Processing Systems 32.
- Belkin and Niyogi (2003) Belkin, M. and P. Niyogi (2003). Laplacian eigenmaps for dimensionality reduction and data representation. Neural Computation 15(6), 1373–1396.
- Bertini et al. (2011) Bertini, E., A. Tatu, and D. Keim (2011). Quality metrics in high-dimensional data visualization: An overview and systematization. IEEE Transactions on Visualization and Computer Graphics 17(12), 2203–2212.
- Bhatia (2013) Bhatia, R. (2013). Matrix Analysis, Volume 169. Springer Science & Business Media.
- Buckley et al. (2022) Buckley, M. T., E. Sun, B. M. George, L. Liu, N. Schaum, L. Xu, J. M. Reyes, M. A. Goodell, I. L. Weissman, T. Wyss-Coray, et al. (2022). Cell type-specific aging clocks to quantify aging and rejuvenation in regenerative regions of the brain. bioRxiv.
- Buettner et al. (2015) Buettner, F., K. N. Natarajan, F. P. Casale, V. Proserpio, A. Scialdone, F. J. Theis, S. A. Teichmann, J. C. Marioni, and O. Stegle (2015). Computational analysis of cell-to-cell heterogeneity in single-cell rna-sequencing data reveals hidden subpopulations of cells. Nature Biotechnology 33(2), 155–160.
- Cai et al. (2021) Cai, T. T., H. Li, and R. Ma (2021). Optimal structured principal subspace estimation: Metric entropy and minimax rates. J. Mach. Learn. Res. 22, 46–1.
- Cai and Ma (2021) Cai, T. T. and R. Ma (2021). Theoretical foundations of t-sne for visualizing high-dimensional clustered data. arXiv preprint arXiv:2105.07536.
- Cai and Zhang (2018) Cai, T. T. and A. Zhang (2018). Rate-optimal perturbation bounds for singular subspaces with applications to high-dimensional statistics. The Annals of Statistics 46(1), 60–89.
- Chen et al. (2007) Chen, C.-h., W. K. Härdle, and A. Unwin (2007). Handbook of Data Visualization. Springer Science & Business Media.
- Chen et al. (2020) Chen, M., H. Hauser, P. Rheingans, and G. Scheuermann (2020). Foundations of Data Visualization. Springer.
- Cheng et al. (2015) Cheng, J., H. Liu, F. Wang, H. Li, and C. Zhu (2015). Silhouette analysis for human action recognition based on supervised temporal t-SNE and incremental learning. IEEE Transactions on Image Processing 24(10), 3203–3217.
- Chennuru Vankadara and von Luxburg (2018) Chennuru Vankadara, L. and U. von Luxburg (2018). Measures of distortion for machine learning. Advances in Neural Information Processing Systems 31.
- Ding and Ma (2022) Ding, X. and R. Ma (2022). Learning low-dimensional nonlinear structures from high-dimensional noisy data: An integral operator approach. arXiv preprint arXiv:2203.00126.
- Donoho (2017) Donoho, D. (2017). 50 years of data science. Journal of Computational and Graphical Statistics 26(4), 745–766.
- Donoho and Grimes (2003) Donoho, D. L. and C. Grimes (2003). Hessian eigenmaps: Locally linear embedding techniques for high-dimensional data. Proceedings of the National Academy of Sciences 100(10), 5591–5596.
- Espadoto et al. (2019) Espadoto, M., R. M. Martins, A. Kerren, N. S. Hirata, and A. C. Telea (2019). Toward a quantitative survey of dimension reduction techniques. IEEE Transactions on Visualization and Computer Graphics 27(3), 2153–2173.
- Floater (2015) Floater, M. S. (2015). Generalized barycentric coordinates and applications. Acta Numerica 24, 161–214.
- Hayashi et al. (2018) Hayashi, T., H. Ozaki, Y. Sasagawa, M. Umeda, H. Danno, and I. Nikaido (2018). Single-cell full-length total rna sequencing uncovers dynamics of recursive splicing and enhancer rnas. Nature Communications 9(1), 1–16.
- Jolliffe and Cadima (2016) Jolliffe, I. T. and J. Cadima (2016). Principal component analysis: a review and recent developments. Philosophical Transactions of the Royal Society A: Mathematical, Physical and Engineering Sciences 374(2065), 20150202.
- Kendall (1938) Kendall, M. G. (1938). A new measure of rank correlation. Biometrika 30(1/2), 81–93.
- Kobak and Berens (2019) Kobak, D. and P. Berens (2019). The art of using t-SNE for single-cell transcriptomics. Nature Communications 10(1), 1–14.
- Kobak and Linderman (2021) Kobak, D. and G. C. Linderman (2021). Initialization is critical for preserving global data structure in both t-SNE and UMAP. Nature Biotechnology 39(2), 156–157.
- Kruskal (1978) Kruskal, J. B. (1978). Multidimensional Scaling. Number 11. Sage.
- Liu et al. (2017) Liu, Z.-G., Q. Pan, J. Dezert, and A. Martin (2017). Combination of classifiers with optimal weight based on evidential reasoning. IEEE Transactions on Fuzzy Systems 26(3), 1217–1230.
- McInnes et al. (2018) McInnes, L., J. Healy, and J. Melville (2018). Umap: Uniform manifold approximation and projection for dimension reduction. arXiv preprint arXiv:1802.03426.
- Mohandes et al. (2018) Mohandes, M., M. Deriche, and S. O. Aliyu (2018). Classifiers combination techniques: A comprehensive review. IEEE Access 6, 19626–19639.
- Mokbel et al. (2013) Mokbel, B., W. Lueks, A. Gisbrecht, and B. Hammer (2013). Visualizing the quality of dimensionality reduction. Neurocomputing 112, 109–123.
- Moon et al. (2019) Moon, K. R., D. van Dijk, Z. Wang, S. Gigante, D. B. Burkhardt, W. S. Chen, K. Yim, A. v. d. Elzen, M. J. Hirn, R. R. Coifman, et al. (2019). Visualizing structure and transitions in high-dimensional biological data. Nature Biotechnology 37(12), 1482–1492.
- Nonato and Aupetit (2018) Nonato, L. G. and M. Aupetit (2018). Multidimensional projection for visual analytics: Linking techniques with distortions, tasks, and layout enrichment. IEEE Transactions on Visualization and Computer Graphics 25(8), 2650–2673.
- Olivon et al. (2018) Olivon, F., N. Elie, G. Grelier, F. Roussi, M. Litaudon, and D. Touboul (2018). Metgem software for the generation of molecular networks based on the t-SNE algorithm. Analytical Chemistry 90(23), 13900–13908.
- Pagliosa et al. (2015) Pagliosa, P., F. V. Paulovich, R. Minghim, H. Levkowitz, and L. G. Nonato (2015). Projection inspector: Assessment and synthesis of multidimensional projections. Neurocomputing 150, 599–610.
- Parisi et al. (2014) Parisi, F., F. Strino, B. Nadler, and Y. Kluger (2014). Ranking and combining multiple predictors without labeled data. Proceedings of the National Academy of Sciences 111(4), 1253–1258.
- Platzer (2013) Platzer, A. (2013). Visualization of snps with t-SNE. PloS One 8(2), e56883.
- Rousseeuw (1987) Rousseeuw, P. J. (1987). Silhouettes: a graphical aid to the interpretation and validation of cluster analysis. Journal of Computational and Applied Mathematics 20, 53–65.
- Roweis and Saul (2000) Roweis, S. T. and L. K. Saul (2000). Nonlinear dimensionality reduction by locally linear embedding. Science 290(5500), 2323–2326.
- Sah and Fokoué (2019) Sah, P. and E. Fokoué (2019). What do asian religions have in common? an unsupervised text analytics exploration. arXiv preprint arXiv:1912.10847.
- Sammon (1969) Sammon, J. W. (1969). A nonlinear mapping for data structure analysis. IEEE Transactions on Computers 100(5), 401–409.
- Schölkopf et al. (1997) Schölkopf, B., A. Smola, and K.-R. Müller (1997). Kernel principal component analysis. In International Conference on Artificial Neural Networks, pp. 583–588. Springer.
- Tax et al. (2000) Tax, D. M., M. Van Breukelen, R. P. Duin, and J. Kittler (2000). Combining multiple classifiers by averaging or by multiplying? Pattern Recognition 33(9), 1475–1485.
- Tenenbaum et al. (2000) Tenenbaum, J. B., V. d. Silva, and J. C. Langford (2000). A global geometric framework for nonlinear dimensionality reduction. Science 290(5500), 2319–2323.
- Traven et al. (2017) Traven, G., G. Matijevič, T. Zwitter, M. Žerjal, J. Kos, M. Asplund, J. Bland-Hawthorn, A. R. Casey, G. De Silva, K. Freeman, et al. (2017). The galah survey: classification and diagnostics with t-SNE reduction of spectral information. The Astrophysical Journal Supplement Series 228(2), 24.
- van der Maaten and Hinton (2008) van der Maaten, L. and G. Hinton (2008). Visualizing data using t-SNE. Journal of Machine Learning Research 9(Nov), 2579–2605.
- Venna et al. (2010) Venna, J., J. Peltonen, K. Nybo, H. Aidos, and S. Kaski (2010). Information retrieval perspective to nonlinear dimensionality reduction for data visualization. Journal of Machine Learning Research 11(2).
- Vershynin (2018) Vershynin, R. (2018). High-dimensional probability: An introduction with applications in data science, Volume 47. Cambridge University Press.
- Wang et al. (2021) Wang, Y., H. Huang, C. Rudin, and Y. Shaposhnik (2021). Understanding how dimension reduction tools work: An empirical approach to deciphering t-sne, umap, trimap, and pacmap for data visualization. Journal of Machine Learning Research 22, 1–73.
- Woods et al. (1997) Woods, K., W. P. Kegelmeyer, and K. Bowyer (1997). Combination of multiple classifiers using local accuracy estimates. IEEE Transactions on Pattern Analysis and Machine Intelligence 19(4), 405–410.
- Yu et al. (2015) Yu, Y., T. Wang, and R. J. Samworth (2015). A useful variant of the davis–kahan theorem for statisticians. Biometrika 102(2), 315–323.
Acknowledgement
The authors would like to thank the edit and two anonymous reviewers for their suggestions and comments, which have resulted in a significant improvement of the manuscript. R.M. would like to thank David Donoho and Rui Duan for helpful discussions. J.Z. is supported by NSF CAREER 1942926, NIH P30AG059307, 5RM1HG010023 and grants from the Chan-Zuckerberg Initiative and the Emerson Collective. R.M. is supported by David Donoho at Stanford University.
Supplement to “A Spectral Method for Assessing and Combining Multiple Data Visualizations”
Rong Ma1, Eric D. Sun2 and James Zou2
Department of Statistics, Stanford University1
Department of Biomedical Data Science, Stanford University2
Appendix A Supplementary Results and Figures from Real Data Analysis
A.1 Silhouette Index
Consider a partition , of samples into non-overlapping subsets, with each cluster containing at least samples, being the true cluster membership of samples. Let be the distance between samples and in certain vector space. For each sample for some , we define
| (A.1) |
as the mean distance between sample and all other samples in cluster , and define
| (A.2) |
as the smallest mean distance of to all samples in any other cluster, of which sample is not a member. Then the Silhouette index of sample is defined as
| (A.3) |
By definition, we have , and a higher indicates better concordance between the distances and the underlying true cluster membership.
A.2 Implementation Details and Supplementary Figures
Simulations.
For each simulation setting, we let the diameter of the underlying structure vary within a certain range so that the final results are comparable across different structures. The final boxplots in Figure 2(a), and Figures 7 and 9 summarize the simulation results across 20 equispaced diameter values for each underlying structure.
For the 16 candidate visualizations, they were obtained by the following R functions:
-
•
PCA: the fast SVD function svds from R package rARPACK with embedding dimension k=2.
-
•
MDS: the basic R function cmdscale with embedding dimension k=2.
-
•
Sammon: the R function sammon from R package MASS with embedding dimension k=2.
-
•
LLE: the R function lle from R package lle with parameters m=2, k=20, reg=2.
-
•
HLLE: the R function embed from R package dimRed with parameters method="HLLE", knn=20, ndim=2.
-
•
Isomap: the R function embed from R package dimRed with parameters method="Isomap", knn=20, ndim=2.
-
•
kPCA1&2: the R function embed from R package dimRed with parameters method="kPCA", kpar=list(sigma=width), ndim=2, where we set width=0.01 for kPCA1 and width=0.001 for kPCA2.
-
•
LEIM: the R function embed from R package dimRed with parameters ndim=2 and method = "LaplacianEigenmaps".
-
•
UMAP1&2: the R function umap from R package uwot with parameters n_neighbors=n, n_components=2, where we set n=30 for UMAP1 and width=50 for UMAP2.
-
•
tSNE1&2: the R function embed from R package dimRed with parameters method="tSNE", perplexity=n, ndim=2, where we set n=10 for tSNE1 and n=50 for tSNE2.
-
•
PHATE1&2: the R function phate from R package phateR with parameters knn=n, ndim=2, where we set n=30 for PHATE1 and n=50 for PHATE2.
Religious and Biblical Texts Data.
Each visualization method was applied to the Document Term Matrix, with 8265 centred and normalized features and 590 samples (text fragments). For the 16 candidate visualizations, they were obtained by the following R functions with the same tuning parameters as described above for the simulation studies. For the 16 PHATE-based candidate visualizations obtained in Figure 13, we consider 16 values of nearest neighbor parameter knn ranging from 2 to 150 with equal space.
Cell Cycle Data.
The raw count data were preprocessed, normalized, and scaled by following the standard procedure (R functions CreateSeuratObject, NormalizeData and ScaleData under default settings) as incorporated in the R package Seurat666https://cran.r-project.org/web/packages/Seurat/index.html. We also applied the R function FindVariableFeatures in Seurat to identify most variable genes for subsequent analysis. The final cell-cycle related genes were selected based on two-sample t-tests. The 16 candidate visualizations were generated the same way as in the previous example, with the same set of tuning parameters.
Cell Differentiation Data.
The raw count data were preprocessed, normalized, and scaled using Seurat package by following the same procedure as described previously. The 16 candidate visualizations were generated the same way as in the previous examples, with the same set of tuning parameters.
Computational Cost.
We considered the single-cell transcriptomic dataset of Buckley et al. (2022) that contains more than 20,000 cells of different cell types from the neurogenic regions of 28 mice. For each , we randomly select cells of nine different cell types, and selected subsets of genes to obtain an count matrix. After normalizing the count matrix, we applied various visualization methods (PCA, HLLE, kPCA, LEIM, UMAP, t-SNE and PHATE) that are in general scalable to large datasets (i.e., cost less than one minute for visualizing samples of dimension ), to generate 11 candidate visualizations (with two different parameter settings for kPCA, t-SNE, UMAP and PHATE). Then we ran our proposed algorithm to obtain the final meta-visualization.
Appendix B Proof of Main Theorems
B.1 Notations
For a vector , we denote as the diagonal matrix whose -th diagonal entry is , and define the norm and the norm . For a matrix , we define its Frobenius norm as , and its spectral norm as ; we also denote as its -th column and as its -th row. For sequences and , we write or if , and write , or if there exists a constant such that for all . We write if and .
B.2 Sufficient Condition for (C1a)
We provide a sufficient condition in light of the signal-plus-noise model (2.11) of the main text with some intuitions that implies the sub-Gaussian condition (C1a) for in (2.12). In general, the distortion vector is jointly determined by the noise , the noiseless samples and the dimension reduction map associated to the -th visualization method. Accordingly, our sufficient condition for (C1a) essentially involves regularity of the signal structure and the dimension reduction (DR) maps for , and sub-Gaussianity of the noise vector . We first state precisely our sufficient condition.
-
(C01)
(Regularity of the signal and DR map) The noiseless samples lie on a bounded manifold embedded in , and the DR map and its first-order derivative are bounded in the sense that for all
(B.1) almost surely for some constants and .
-
(C02)
(Sub-Gaussian noise) The noise vectors are sub-Gaussian random vectors.
Intuitively, (C01) requires that the underlying signal structure is finite and that the DR map is also finite and sufficiently smooth. In particular, we allow that is random in itself, as in the cases of randomized algorithms such as t-SNE and UMAP. The sub-Gaussian condition (C02) on the noise vector is mild and allows for wide range of noise structures.
Below we show that Conditions (C01) and (C02) jointly imply the sub-Gaussianity of . Firstly, note that by definition Then for each , we can define the pairwise distance for the noiseless samples associated with the -th visualization method as
| (B.2) |
Recall that Then, by (2.12), it follows that
| (B.3) | ||||
| (B.4) |
where in (B.3) we used Taylor expansion of at with being some point between and , and in (B.4) we used Taylor expansion of at with being some point between and .
For each , since is a parameter that accounts for the possible scaling difference caused by the dimension reduction map , without loss of generality, we can take . Under Condition (C01), it follows that in (B.4) is bounded and therefore a sub-Gaussian random variable. Similarly, for the random variable
| (B.5) |
in (B.4), under Condition (C01), we also have the boundedness of and . By Proposition 2.5.2 of Vershynin (2018), these along with the boundedness of and , and the sub-Gaussianity of and from (C02), imply that (B.5) is also a sub-Gaussian random variable. Thus, we have verified that the sub-Gaussianity of under Conditions (C01) and (C02). In particular, the sub-Gaussian parameter in (C1a) is jointly determined by the underlying manifold , the scale () and the smoothness () of the DR map.
B.3 Eigenscore Consistency: Proof of Theorem 1
For simplicity, we omit the dependence on and hereafter denote , , , , and . Therefore, model (2.12) in the main paper can be rewritten as
| (B.6) |
We denote
| (B.7) |
and define the matrix of normalized vectors
Then
where is the -th column of , so that
For any , it follows that
This implies that
| (B.8) |
where
We denote
| (B.9) |
Let the singular value decomposition of be
where and . Then we have
| (B.10) |
and
| (B.11) |
Therefore, we have
where Now we derive estimates of the random quantities , , and to obtain an upper bound of the last term in the above inequality. Consider the decomposition (B.9) and the first equation of (B.10). Firstly, by Weyl’s inequality (e.g., Corollary III.2.6 of Bhatia 2013), we have
| (B.12) |
and
| (B.13) |
Secondly, by Davis-Kahan’s perturbation theorem (e.g., Theorem 1 of (Yu et al., 2015)), we have
| (B.14) |
Thus, if we denote , by (B.12) and (B.13), if , we have
and by (B.14), we have
Therefore, if , we have
| (B.15) |
If , we further have
| (B.16) |
The rest of the proof is devoted to the stochastic upper bound of . Since by the elementary inequality and triangle inequality, we have
| (B.17) |
Then it follows that
| (B.18) |
Hence, it suffices to obtain an upper bound for and a lower bound for .
Upper bound of .
Since
| (B.19) |
we have
| (B.20) |
The following lemma gives the upper bound of , which is proved in Section B.7 below.
Lemma 1.
Under the conditions of Theorem 1, it holds that with probability at least for some universal constants .
Now for
note that
By Condition (C1a), we have
for any small constant , and that
Since , we have
in probability, for some .
In other words, we have
| (B.21) |
in probability, for some non-negative sequence . This implies
| (B.22) |
in probability.
Lower bound of .
By similar argument that leads to (B.21), we have
| (B.23) |
in probability for some non-negative sequence .
Completing the proof.
Combining the above results, we have
where the last inequality follows from . Thus, under Condition (C2), for sufficiently large , we always have , and therefore by (B.16), we have
| (B.24) |
Finally, note that for any , we have
| (B.25) |
in probability. By Condition (C2), whenever the right-hand side of the above inequality is strictly positive. In other words, in probability, is a strictly positive vector. Thus, for , under the same event it holds that
| (B.26) |
This along with (B.24) implies
| (B.27) |
B.4 Guarantee of Meta-Visualization: Proof of Theorem 2
We still use the notation defined at the beginning of the proof of Theorem 1. In addition, we denote , and define
| (B.28) |
where . To begin with, note that
and
Then
Similarly, we have
We first prove some auxiliary results. Since
we have, for sufficiently large ,
| (B.29) |
in probability, according to Lemma 1, and
| (B.30) |
| (B.31) |
for some non-negative sequence as , in probability. In addition, by (B.23) and (B.21), we have
| (B.32) |
in probability for some . Now we show that
| (B.33) |
To see this, since
| (B.34) |
and as in (B.28), we have
| (B.35) |
Hence
Note that by Theorem 1, we have in probability. Then it suffices to show that
| (B.36) |
To see this, since
| (B.37) |
Note that
| (B.38) |
By Condition (C2), whenever , we have
in probability, which implies
in probability, where the last inequality follows from (B.21) and (B.23). On the one hand, we have
Thus, we have
| (B.39) |
which along with (B.37) implies (B.36). This completes our proof of (B.33). Finally, we note that
so that
Now in order to prove the theorem, we show that, on the one hand,
| (B.40) |
and on the other hand, under the additional assumption that for some sufficiently small constant,
| (B.41) |
for some constant .
B.5 Robustness of Spectral Weighting: Proof of Theorem 3
For the first statement concerning , firstly, we note that by the proof of Theorem 2, we have under the conditions of Theorem 1, as the effects of the adversarial candidate visualizations vanish in (B.28). Therefore, it suffices to show that under such an adversarial setting, we still have in probability.
To see this, by the proof of Theorem 2, it suffices to show that in probability, or,
| (B.43) |
By the proof of Theorem 1, we have
where we denote with for all . For any , it follows that
where . This implies that
| (B.44) |
where
and
In other words,
| (B.45) |
Note that by definition
then we can treat the above decomposition as a low-rank matrix plus a noise matrix . In this respect, the Davis-Kahan’s perturbation theorem applies similarly as in the proof of Theorem 1, only with therein replaced by
Note that by definition we have
| (B.46) |
whereas by (B.23) we have
| (B.47) |
Then, as long as
| (B.48) |
we have
and the rest argument leading to (B.43) follows as in the proof of Theorem 2. Finally, note that a sufficient condition for (B.48) is
| (B.49) |
for some sufficiently large . This completes the first part of the proof.
As for the second statement concerning , note that by (B.25), whenever for some sufficiently large , all the candidate visualizations are concordant with the true structure in probability, that is for all . In particular, we have
in probability for some constant . Without loss of generality, we assume , and for all . Thus, it follows that
and
in probability. If is chosen such that , then we have
in probability.
B.6 Necessity of the Signal Strength Condition (C2)
In this part, we show that the signal strength condition (C2) required by the proposed method is in fact asymptotically sharp and optimal, in the sense that it is essentially required for any possible method in order to achieve consistent estimation of the true structure .
Specifically, we consider the settings where the following two conditions hold:
(C1c) are identically distributed Gaussian random vectors with mean zero and covariance matrix .
(C1d) The matrix satisfies .
Note that Conditions (C1c) and (C1d) are sufficient conditions for Conditions (C1a) and (C1b), respectively, so that Conditions (C1a) and (C1b) are satisfied throughout our discussion below.
Using the previous notations, we can rewrite our model for given as
where by (C1c) are identically distributed Gaussian vectors with mean zero and covariance matrix , and is defined similarly as in the main paper describing the correlation structure among . We consider the parameter space for the model parameters as
for some sufficiently large universal constant . Define a subset of as
From our previous analysis (Theorem 2), it follows that as long as , the proposed method satisfies
| (B.50) |
for all . Now we show the following minimax lower bound result, which shows that consistent estimation of is never possible over the parameter space for any estimator whenever for some large constant .
Theorem 4.
Under Conditions (C1c) and (C1d), there exists some absolute constant such that, as long as , we have
| (B.51) |
for some absolute constant .
Proof.
To see this, note that
| (B.52) |
Over the parameter space , the model reduces to
| (B.53) |
which is rank-one matrix denoising model, where and has rows drawn from . The estimation of the direction of is thus equivalent to estimation of the right singular vector of the rank-one matrix . Now we recall the following lemma concerning the minimax lower bound for singular vector estimation in the low-rank matrix denoising model, proved by Cai et al. (2021).
Lemma 2.
Let . There exists some constants such that
| (B.54) |
for sufficiently large .
As a result, since by Lemma 1 of Cai and Zhang (2018), we have
| (B.55) |
Then, it follows that implies . Therefore, whenever we choose a constant sufficiently large so that , we have
| (B.56) |
which implies
| (B.57) |
This completes the proof of the theorem. ∎
B.7 Proof of Auxiliary Lemma 1
We need the following lemma, proved in Cai and Zhang (2018), to obtain the upper bound.
Lemma 3.
For any , denote as the -dimensional unit ball in the Euclidean space. Suppose is a random matrix. Then we have for ,
By Lemma 3, for , it follows that
| (B.58) |
For any and , we have
| (B.59) |
where is Hilbert-Schmidt norm for matrices. Now define be , so that its -th block is . By Conditions (C1a) and (C1b) and the definition of , we have
where for . In particular, we have
| (B.60) |
To see this, if we denote , then
Now by (B.60), we have
| (B.61) |
By properties of sub-Gaussian vectors, it holds that
| (B.62) |
Combining (B.62) and (B.58), we have
Setting for some sufficiently large , we have
| (B.63) |