A State-Vector Framework for Dataset Effects
Abstract
The impressive success of recent deep neural network (DNN)-based systems is significantly influenced by the high-quality datasets used in training. However, the effects of the datasets, especially how they interact with each other, remain underexplored. We propose a state-vector framework to enable rigorous studies in this direction. This framework uses idealized probing test results as the bases of a vector space. This framework allows us to quantify the effects of both standalone and interacting datasets. We show that the significant effects of some commonly-used language understanding datasets are characteristic and are concentrated on a few linguistic dimensions. Additionally, we observe some “spill-over” effects: the datasets could impact the models along dimensions that may seem unrelated to the intended tasks. Our state-vector framework paves the way for a systematic understanding of the dataset effects, a crucial component in responsible and robust model development.
1 Introduction
In recent years, data-driven systems have shown impressive performance on a wide variety of tasks and massive, high-quality data is a crucial component for their success (Brown et al., 2020; Hoffmann et al., 2022). Currently, the availability of language data grows much more slowly than the computation power (approximately at Moore’s law), raising the concern of “data exhaustion” in the near future (Villalobos et al., 2022). This impending limitation calls for more attention to study the quality and the effects of data.
The data-driven systems gain linguistic abilities on multiple levels ranging from syntax, semantics, and even some discourse-related abilities during the training procedures (Liu et al., 2021). The training procedures almost always include multiple datasets – usually there is a “pre-training” phase and a “fine-tuning” phase, where the model developers apply different datasets. Model developers use large corpora that may include multiple existing datasets (Sun et al., 2021; Wei et al., 2021; Brown et al., 2020). How these data relate to the progress in linguistic ability is not systematically studied yet. Each dataset has desired effects, but does it have some under-specified effects? When using multiple datasets together, do they have undesired, interaction effects? These questions become more contingent as the engineering of datasets becomes more essential, yet no existing framework allows convenient quantification of these dataset effects.

Probing provides convenient frameworks to study the linguistic abilities of DNN systems from multiple perspectives. Probing analyses show how the components of DNNs demonstrate linguistic abilities (Tenney et al., 2019; Rogers et al., 2020; Belinkov, 2021; Niu et al., 2022). The probing results are relevant to the model’s ability to the extent that the probing accuracies can predict the model’s downstream performance (Zhu et al., 2022a). These findings make probing classification a promising candidate for setting up a framework to describe the effects of datasets.
In this paper, we set up a state-vector framework for describing the dataset effects. We formalize idealized probes, which give the true linguistic ability of the DNN model in a state of training. Then, we derive two terms, individual and interaction effects, that describe the dataset effects along multiple dimensions of linguistic abilities. A benefit of our state-vector framework is that it allows a convenient setup of statistical tests, supporting a rigorous interpretation of how the datasets affect the models.
The state framework allows us to frame transitions and set up experiments efficiently. Many frequently-used datasets have “spill-over” effects besides the purposes they are originally collected to achieve. Additionally, the interaction effects are concentrated and characteristic. Our framework provides a systematic approach to studying these effects of the datasets, shedding light on an aspect of model developments that deserves more attentions. All scripts, data, and analyses are available at our GitHub repository.
2 Related Works
Understanding the datasets
Recent work has investigated various properties of datasets. Swayamdipta et al. (2020) used the signals of the training dynamics to map individual data samples onto “easy to learn”, “hard to learn”, and “ambiguous” regions. Ethayarajh et al. (2022) used an aggregate score, predictive -information (Xu et al., 2020), to describe the difficulty of datasets. Some datasets can train models with complex decision boundaries. From this perspective, the complexity can be described by the extent to which the data samples are clustered by the labels, which can be quantified by the Calinski-Habasz index. Recently, Jeon et al. (2022) generalized this score to multiple datasets. We also consider datasets in an aggregate manner but with a unique perspective. With the help of probing analyses, we are able to evaluate the effects of the datasets along multiple dimensions, rather than as a single difficulty score.
Multitask fine-tuning
Mosbach et al. (2020) studied how fine-tuning affects the linguistic knowledge encoded in the representations. Our results echo their finding that fine-tuning can either enhance or remove some knowledge, as measured by probing accuracies. Our proposed dataset effect framework formalizes the study in this direction. Aroca-Ouellette and Rudzicz (2020) studied the effects of different losses on the DNN models and used downstream performance to evaluate the multidimensional effects. We operate from a dataset perspective and use the probing performance to evaluate the multidimensional effects. Weller et al. (2022) compared two multitask fine-tuning settings, sequential and joint training. The former can reach higher transfer performance when the target dataset is larger in size. We use the same dataset size on all tasks, so either multitask setting is acceptable.
3 A State-Vector framework
This section describes the procedure for formulating a state-vector framework for analyzing dataset effects in multitask fine-tuning.
An abstract view of probes
There have been many papers on the theme of probing deep neural networks. The term “probing” contains multiple senses. A narrow sense refers specifically to applying post-hoc predictions to the intermediate representations of DNNs. A broader sense refers to examination methods that aim at understanding the intrinsics of the DNNs. We consider an abstract view, treating a probing test as a map from multi-dimensional representations to a scalar-valued test result describing a designated aspect of the status of the DNN. Ideally, the test result faithfully and reliably reflects the designated aspect. We refer to the probes as idealized probes henceforth.
Idealized probes vectorize model states
Training DNN models is a complex process consisting of a sequence of states. In each state , we can apply a battery of idealized probes to the DNN and obtain a collection of results describing the linguistic capabilities of the model’s state at timestep . In this way, the state of a DNN model during multitask training can be described by a state vector .
Without loss of generality, we define the range of each probing result in . Empirically, many scores are used as probing results, including correlation scores (Gupta et al., 2015), usable -information (Pimentel and Cotterell, 2021), minimum description length (Voita and Titov, 2020), and combinations thereof (Hewitt and Liang, 2019). Currently, the most popular probing results are written in accuracy values, ranging from 0 to 1. We do not require the actual choice of probing metric as long as all probing tasks adopt the same metric.
From model state to dataset state
Now that we have the vectorized readout values of the states, how is the state determined? In general, there are three factors: the previous state, the dataset, and the training procedure applied to the model since the previous state. We can factor out the effects of the previous state and the training procedure.
To factor out the effect of the previous state, we introduce the concept of an “initial state”. The initial state is specified by the structures and the parameters of the DNNs. If we study the effects of data in multitask fine-tuning BERT, then the initial state is the BERT model before any fine-tuning. Let us write the initial state as . Based on this initial state, the dataset specifies a training task that leads the model from the initial state to the current state .
To factor out the effect of the training procedure, we assume the dataset , together with the training objective, defines a unique global optimum. Additionally, we consider the training procedure can eventually reach this optimum, which we write as the dataset state, . Practically, various factors in the training procedures and the randomness in the sampled data may lead the models towards some local optima, but the framework considers the global optimum when specifying the dataset state.
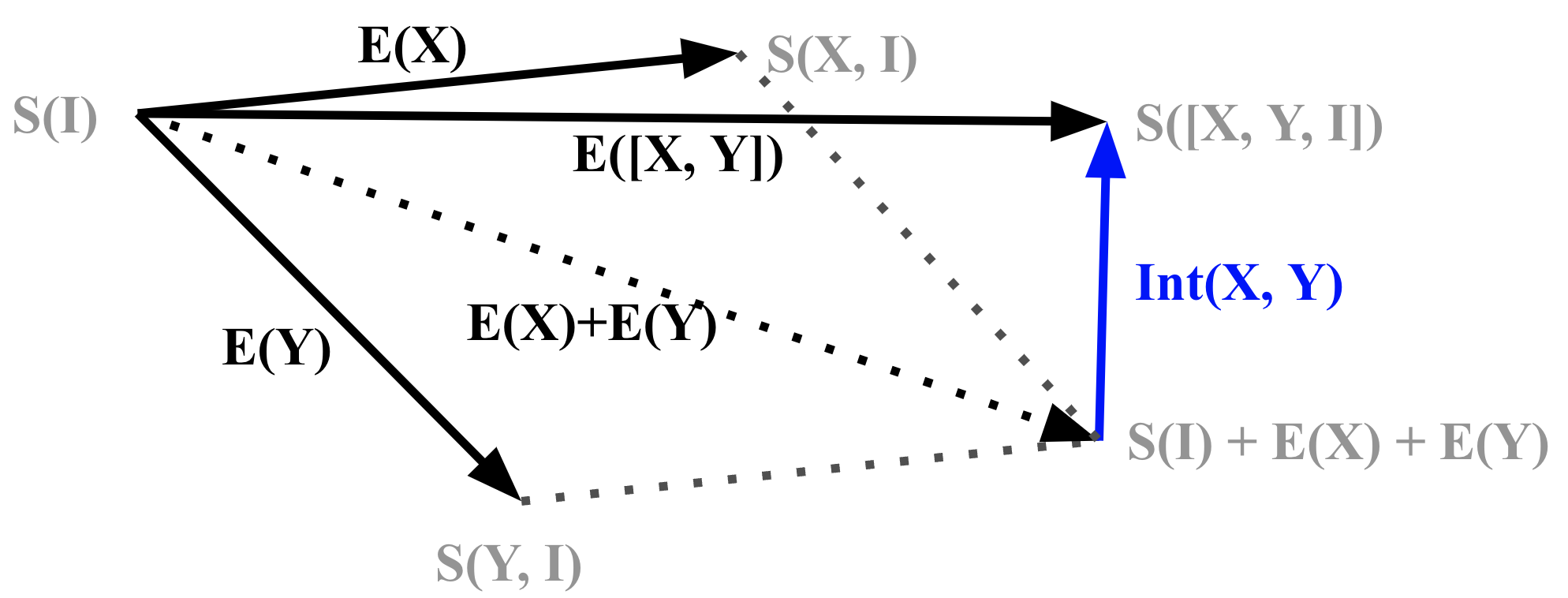
4 Dataset effects
4.1 Individual dataset effect
We define the effect of a dataset as:
| (1) |
Here denotes combining datasets and , and and are the state vectors of the states and respectively. describes how does the linguistic ability of the model shift along the dimensions that we probe. In other words, describes the multi-dimensional fine-tuning effect of the dataset .
Remark 1: The effect of depends on a “reference state” where is used to describe the dataset leading to the reference state . In an edge case, the dataset is a subset of the dataset , so . This can be attributed to the fact that our definition is the global optimum of a model fine-tuned on among all possible training procedures, including re-sampling. Hence, the dataset should have no effect on the model, which can be verified by .
Remark 2: In another scenario, consists of plus only one other data point . Then degenerates to the effect of the data point .
Remark 3: We assume does not overlap with in the rest of this paper. This assumption stands without loss of generality since we can always redefine as the non-overlapping data subset.
Remark 4: The dataset effects form an Abelian group – Appendix §A.3 contains the details.
4.2 Interaction effect
Motivating example
Let us first consider an example of detecting the sentiment polarity. Suppose three abilities can contribute to addressing the sentiment polarity task:
-
A1:
Parsing the structure of the review.
-
A2:
Recognizing the tense of the review.
-
A3:
Detecting some affective keywords such as “good”.
Consider two sentiment polarity datasets, and . In , all positive reviews follow a unique syntax structure where all negative reviews do not. In , all positive reviews are written in the present tense where all negative reviews in the past tense. The problem specified by dataset can be solved by relying on both A1 and A3, and the problem specified by dataset can be solved by relying on both A2 and A3. Imagine a scenario where after training on both and , a model relies solely on A3 to predict the sentiment polarity. This behavior is caused by the interaction between and . Using the terms of our state-vector framework, there is an interaction effect between and with a positive value along the dimension of A3, and a negative value along the dimensions of A1 and A2.
Definition of the interaction effect
Let us define the interaction effect between two datasets, and as:
| (2) |
This is the difference between the dataset effect of ( and combined), and the sum of the effects of and (as if and have no interactions at all).
Remark 1: An equivalent formulation is:
| (3) | ||||
Remark 2: What if and share some common items? This would introduce an additional effect when merging and . An extreme example is when and are the same datasets, where collapses to . Then where it should be . The reason for this counter-intuitive observation is that the “collapse” step itself constitutes a significant interaction. Our “datasets do not overlap” assumption avoids this problem. This assumption goes without loss of generality because we can always redefine and to contain distinct data points.
A linear regression view
The interaction effect as defined in Eq. 2, equals the coefficient computed by regressing for the state vector along each of the dimensions:
| (4) |
where and are indicator variables, and is the residual. If dataset appears, , and otherwise. The same applies to . is the dimension in the state vector. The correspondence between the indicator variables and as listed in Table 1:
| 0 | 0 | |
| 1 | 0 | |
| 0 | 1 | |
| 1 | 1 |
5 Experiments
5.1 Models
5.2 Fine-tuning
The GLUE benchmark (Wang et al., 2018) consists of 3 types of natural language understanding tasks: single-sentence, similarity and paraphrase, and inference tasks. Two tasks from each category were selected to fine-tune models.
Single-sentence tasks
Similarity and paraphrase tasks
Inference tasks
QNLI (Rajpurkar et al., 2016) takes a sentence-question pair as input and labels whether the sentence contains the answer to the question. RTE (Dagan et al., 2005; Haim et al., 2006; Giampiccolo et al., 2007; Bentivogli et al., 2009) labels whether a given conclusion is implied from some given text.
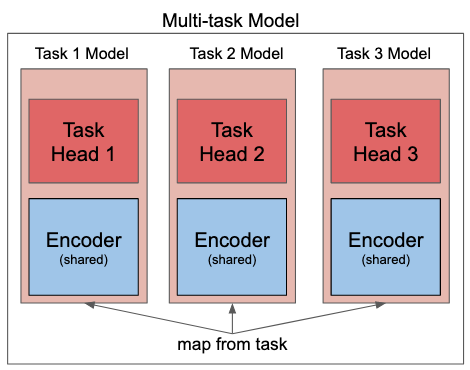
The multitask model resembles that of Radford et al. (2018). It consists of a shared encoder with a separate classification layer per task – Figure 5 shows an illustration. This was made possible by leveraging HuggingFace’s Transformers library (Wolf et al., 2020). Model hyperparameters are the same as those listed in Table 3 of Mosbach et al. (2020), except 3 epochs were used for all experiments. This is valid, as their experiments incorporated both BERT-base-cased and RoBERTa-base models. Model checkpoints were saved every 6 optimization steps, with the final model being the one with the lowest training loss.111Downstream task performance can be accessed in our repository.
To mitigate the effect of train set size per task, train datasets were reduced to 2,490 examples per task, which corresponds to the size of the smallest train dataset (COLA). GLUE benchmarks such as QQP, MNLI, and WNLI (Levesque et al., 2012) were excluded because their train sets were too large (more than 300K examples) or too small (fewer than 1K examples).
5.3 Probing
We use the SentEval suite (Conneau and Kiela, 2018) to build proxies for the idealized probes that vectorize the model states. SentEval contains the following tasks:
-
•
Length: given a sentence, predict what range its length falls within (0: 5-8, 1: 9-12, 2: 13-16, 3: 17-20, 4: 21-25, 5: 26-28).
-
•
WC: given a sentence, predict which word it contains from a target set of 1,000 words.
-
•
Depth: given a sentence, predict the maximum depth of its syntactic tree.
-
•
TopConst: given a sentence, predict its constituent sequence (e.g. NP_VP_.: noun phrase followed by verb phrase).
-
•
BigramShift: given a sentence, predict whether any two consecutive tokens of the original sentence have been inverted.
-
•
Tense: given a sentence, predict whether its main verb is in the past or present tense.
-
•
SubjNumber: given a sentence, predict whether the subject of its main clause is singular or plural.
-
•
ObjNumber: given a sentence, predict whether the direct object of its main clause is singular or plural.
-
•
OddManOut: given a sentence, predict whether any verb or noun of the original sentence was replaced with another form with the same part of speech.
-
•
CoordInv: given a sentence, predict whether two coordinated casual conjoints of the original sentence have been inverted.
For each probing task, we downsample the datasets to 10% of their original sizes or 12K samples per task (10K train, 1K validation, 1K test). This is valid, as datasets of similar sizes usually have sufficient statistical power (Card et al., 2020; Zhu et al., 2022b). WC was removed from consideration, as its performance would have been significantly compromised given that it possesses 1000 ground truths. We built our training pipeline based on the SentEval library and used the default config.222SentEval code and default config are accessible here. The default architecture is a single classification layer on top of the frozen fine-tuned encoder.
5.4 Multitask settings
As the number of tasks increases, the number of combinations increases exponentially. To compute the dataset states in a realistic time, we group the experiments by the format of the tasks (e.g., single-sentence, similarity, inference) and impose selection conditions, reducing the total number of fine-tuning experiments from around 10k to 300 per model. Note that 300 fine-tuning experiments per model are still nontrivial, but they can be completed within two months. Section A.2 in Appendix contains the details.
6 Results
| Dataset | Model | Length | Depth | TopConst | BigramShift | Tense | SubjNumber | ObjNumber | OddManOut | CoordInv |
|---|---|---|---|---|---|---|---|---|---|---|
| COLA | BERT | |||||||||
| SST2 | BERT | |||||||||
| MRPC | BERT | |||||||||
| STSB | BERT | |||||||||
| QNLI | BERT | |||||||||
| RTE | BERT |
| Dataset | Model | Length | Depth | TopConst | BigramShift | Tense | SubjNumber | ObjNumber | OddManOut | CoordInv |
|---|---|---|---|---|---|---|---|---|---|---|
| COLA | RoBERTa | |||||||||
| SST2 | RoBERTa | |||||||||
| MRPC | RoBERTa | |||||||||
| STSB | RoBERTa | |||||||||
| QNLI | RoBERTa | |||||||||
| RTE | RoBERTa |
6.1 Individual dataset effect
Some observations regarding individual dataset effects are noted below. Tables 2 and 3 summarize average individual GLUE dataset effects for BERT and RoBERTa models, respectively. Tables 4 and 9 break down the average individual effects of COLA and SST2, respectively.333Tables for other datasets can be accessed in our repository.
Model choice
Per Tables 2 and 3, there is no consistent agreement between significant dimensions (i.e., dimensions marked as ∗, ∗∗, or ∗∗∗). In fact, of the combined 33 significant individual effects observed in Tables 2 and 3, only 13 () can be confirmed by both BERT and RoBERTa models. This demonstrates that datasets can have different effects depending on model architecture.
Dataset composition
MRPC and STSB accomplish very similar tasks, but impact different dimensions. Matching significant dimensions for MRPC and STSB amount to 2 of 7 for BERT (see Table 2) and 1 of 5 for RoBERTa (see Table 3). Although they both are paraphrasing tasks, their samples are extracted from different sources and have different ground truths (i.e., MRPC is a binary task, STSB is an ordinal task). Hence, the composition of datasets can affect what individual effects they will contribute.
Dataset type
The inference datasets (QNLI, RTE) do not have much significant impact on the set of probing dimensions. In all cases, both datasets have no more than two significant dimensions (see Tables 2 and 3). This is far fewer than single-sentence tasks (COLA, SST2), whose effects span many more dimensions (see Tables 2 and 3). We hypothesize that this can be attributed to the fact that SentEval probing tasks assess linguistic information captured on the sentence level. By fine-tuning on single-sentence datasets, models are more likely to learn these relevant sentence properties and incorporate them in their embeddings. Inference datasets are more complex and require models to learn linguistic properties beyond the sentence scope, such as semantic relationships between sentences. Similarity and paraphrase datasets fall in between single-sentence and inference datasets with respect to complexity and linguistic scope, which explains why MPRC and STSB impact more dimensions than QNLI and RTE but fewer dimensions than COLA and SST2.
| Dataset | Reference | Model | Length | Depth | TopConst | BigramShift | Tense | SubjNumber | ObjNumber | OddManOut | CoordInv |
|---|---|---|---|---|---|---|---|---|---|---|---|
| COLA | BERT | ||||||||||
| COLA | SST2 | BERT | |||||||||
| COLA | MRPC | BERT | |||||||||
| COLA | STSB | BERT | |||||||||
| COLA | QNLI | BERT | |||||||||
| COLA | RTE | BERT | |||||||||
| COLA | MRPC QNLI | BERT | |||||||||
| COLA | MRPC RTE | BERT | |||||||||
| COLA | STSB QNLI | BERT | |||||||||
| COLA | STSB RTE | BERT | |||||||||
| COLA | RoBERTa | ||||||||||
| COLA | SST2 | RoBERTa | |||||||||
| COLA | MRPC | RoBERTa | |||||||||
| COLA | STSB | RoBERTa | |||||||||
| COLA | QNLI | RoBERTa | |||||||||
| COLA | RTE | RoBERTa | |||||||||
| COLA | MRPC QNLI | RoBERTa | |||||||||
| COLA | MRPC RTE | RoBERTa | |||||||||
| COLA | STSB QNLI | RoBERTa | |||||||||
| COLA | STSB RTE | RoBERTa |
Reference state
In most cases, significant dataset dimensions varied with different reference states. From Table 4, it is clear that significant individual effects of COLA are inconsistent between experiments, besides BigramShift (for both models) and OddManOut (positive effect for RoBERTa only). The same conclusion is valid for datasets other than COLA. This implies that there are inherent interaction effects between datasets that also influence results. Note that if we add a dataset to a large number of varying reference states and observe that there are persistent, significant dimensions across these experiments, then this is a strong empirical indication of a dataset’s effect on this set of dimensions (e.g., see COLA’s effect on BigramShift in Table 4 and SST2’s effect on Length in Table 9). In the case of our experiments, for argument’s sake, we impose that a dataset effect must appear in at least 70% reference states. This lower bound can be adjusted to 60% or 80%, but wouldn’t result in any major adjustments as dataset effects tend to appear in fewer than 50% of our experiments. Table 5 summarizes such instances and supports previous statements made regarding model choice (some effects are only observed on RoBERTa) and dataset type (both datasets are single-sentence tasks). The low number of table entries further justifies that there are other confounding variables, including but not limited to model choice, hyperparameter selection, and dataset interactions.
| Dataset | Dimension | Effect | Model(s) |
|---|---|---|---|
| COLA | BigramShift | + | Both |
| COLA | OddManOut | + | RoBERTa |
| SST2 | Length | - | Both |
| SST2 | TopConst | - | RoBERTa |
| SST2 | BigramShift | - | Both |
Spill-over
We observed that some syntactic datasets have effects along the semantic dimensions and vice-versa. This is odd, as learning sentiment shouldn’t be correlated to e.g., losing the ability to identify the syntactic constituents or swapped word order. We refer to such effects as “spill-over” effects. For instance, Tables 2 and 3 suggest that fine-tuning on COLA (a syntactic dataset) has a positive effect on OddManOut and CoordInv (semantic dimensions). This is unexpected, given OddManOut and CoordInv probing datasets consist of grammatically acceptable sentences, they only violate semantic rules. Conversely, fine-tuning on SST2 (a semantic dataset) hurts TopConst and BigramShift (syntactic or surface-form dimensions). We hypothesize that the spill-over individual effects are likely due to the aforementioned confounding variables inducing false correlations. More rigorous analysis is required to identify these variables and their effects.
| Model | Dataset effect dimensions | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Length | Depth | TopConst | BigramShift | Tense | SubjNumber | ObjNumber | OddManOut | CoordInv | |||
| COLA | SST2 | RoBERTa | |||||||||
| COLA | MRPC | RoBERTa | |||||||||
| COLA | STSB | RoBERTa | |||||||||
| COLA | QNLI | RoBERTa | |||||||||
| COLA | RTE | RoBERTa | |||||||||
| SST2 | MRPC | RoBERTa | |||||||||
| SST2 | STSB | RoBERTa | |||||||||
| SST2 | QNLI | RoBERTa | |||||||||
| SST2 | RTE | RoBERTa | |||||||||
| MRPC | STSB | RoBERTa | |||||||||
| MRPC | QNLI | RoBERTa | |||||||||
| MRPC | RTE | RoBERTa | |||||||||
| STSB | QNLI | RoBERTa | |||||||||
| STSB | RTE | RoBERTa | |||||||||
| QNLI | RTE | RoBERTa | |||||||||
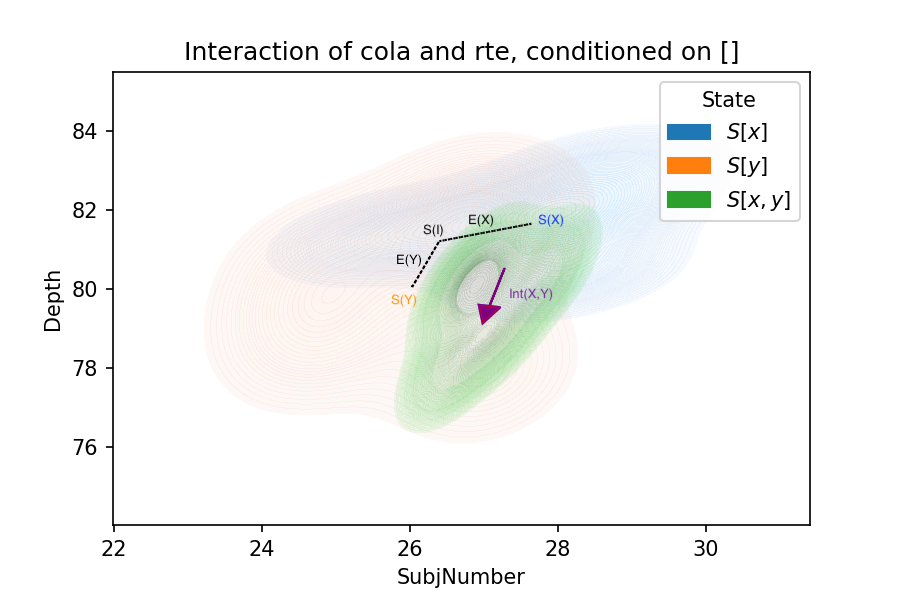
6.2 Interaction effect
The average interaction effects of datasets on RoBERTa and BERT are listed in Table 6 and Table 7, respectively.
Interaction effects are concentrated
The interaction effects are not always significant along the probing dimensions. More specifically, in most (28 out of 30) scenarios listed in Tables 6 and Table 7, the significant interactions concentrate on no more than three dimensions. The remaining two scenarios are both SST2 and RTE (on RoBERTa and BERT, respectively).
Interaction effects can occur with insignificant individual effects
Many interaction effects are observed along the linguistic dimensions where neither of the participating datasets has a significant individual effect. For example, all significant interactions along the “Depth” dimension for BERT have this characteristic. Apparently, even if a dataset does not have a significant individual effect along a dimension, it could still interact with the other dataset along this dimension.
Interaction effects are characteristic
The significant dimensions differ across the datasets. Even the datasets with similar purposes do not demonstrate identical interaction effects with the same “third-party” dataset. For example, both MRPC and STSB target at detecting paraphrasing. When interacting with COLA, STSB has an insignificant effect on the TopConst dimension, while MRPC has a significant negative effect along the same dimension. Can we predict the dimensions of the significant effects, just by analyzing the datasets? Rigorous, systematic studies in the future are necessary to give deterministic answers.
Similar datasets interact less
The interactions of similar datasets appear to interact less significantly than those “less similar” datasets. Among the 30 scenarios in Tables 6 and 7, only two scenarios show no significant interactions along any dimensions: (MRPC, QNLI) and (QNLI, RTE), both on RoBERTa, and both involve strong similarities between the datasets: QNLI and RTE test the same downstream task (infer the textual entailment), and MRPC and QNLI both involve an intricate understanding of the semantics of the text.
| Model | Dataset effect dimensions | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Length | Depth | TopConst | BigramShift | Tense | SubjNumber | ObjNumber | OddManOut | CoordInv | |||
| COLA | SST2 | BERT | |||||||||
| COLA | MRPC | BERT | |||||||||
| COLA | STSB | BERT | |||||||||
| COLA | QNLI | BERT | |||||||||
| COLA | RTE | BERT | |||||||||
| SST2 | MRPC | BERT | |||||||||
| SST2 | STSB | BERT | |||||||||
| SST2 | QNLI | BERT | |||||||||
| SST2 | RTE | BERT | |||||||||
| MRPC | STSB | BERT | |||||||||
| MRPC | QNLI | BERT | |||||||||
| MRPC | RTE | BERT | |||||||||
| STSB | QNLI | BERT | |||||||||
| STSB | RTE | BERT | |||||||||
| QNLI | RTE | BERT | |||||||||
7 Discussion
Checking the effects before using datasets
Considering that the datasets can show spill-over effects when used independently and interaction effects when used jointly, we call for more careful scrutiny of datasets. While the model developers already have a busy working pipeline, we call for model developers to at least be aware of spill-over effects of the datasets. Considering the possibly negative effects to the models’ linguistic abilities, adding datasets to the model’s training might not always be beneficial.
Documentation for datasets
The transparency of model development pipelines can be improved, and better documentation of the data is a crucial improvement area (Gebru et al., 2021; Paullada et al., 2021). Recently, Pushkarna et al. (2022) described some principles for unified documentation of datasets: flexible, modular, extensible, accessible, and content-agnostic. The dataset effect can be a module in the dataset documentation. In addition to documenting the basic properties of the datasets, it would be great to also note how the dataset has potential “spill-over” effects and “interaction effects”. This is better done via a joint effort from the AI community.
From data difficulty to “dataset effects”
While the difficulty of the dataset is a uni-dimensional score, the effect of datasets can be multi-dimensional. Improving the difficulty of datasets (e.g., by identifying adversarial examples and challenging datasets) has been shown to improve performance (Ribeiro et al., 2020; Gardner et al., 2020). The consideration of multi-dimensional dataset effects can potentially introduce similar benefits.
8 Conclusion
We propose a state-vector framework to study dataset effects. The framework uses probing classifiers to describe the effects of datasets on the resulting models along multiple linguistic ability dimensions. This framework allows us to identify the individual effects and the interaction effects of a number of datasets. With extensive experiments, we find that the dataset effects are concentrated and characteristic. Additionally, we discuss how the state-vector framework to study dataset effects can improve the dataset curation practice and responsible model development workflow.
9 Limitations
Probing tests may not be idealized
When formulating the framework, we consider idealized probes – 100% valid and reliable. In reality, probing tests are unfortunately not ideal yet. We follow the common practice of setting up the probing classifiers to allow fair comparison with their literature. We run the probing experiments on multiple random seeds to reduce the impacts of randomness.
Model training may not be optimal
Empirically, the datasets included in our analyses are limited to the fine-tuning stage. Previous work found distinct “stages” during the training of DNNs where the DNNs respond to the data samples differently. For example, Shwartz-Ziv and Tishby (2017) referred to the stages as “drift phase” and the “diffusion phase”. The means of the gradients are drastically different between the two stages. Tänzer et al. (2022) identified a “second stage” where the models do not overfit to noisy data labels. In the framework of this paper, we consider the ideal model training, where our states are defined as the global optimum where the model arrives.
Interaction effects of more than two tasks
The interaction effect is defined between two tasks. We believe this framework can generalize to more than two tasks, but the empirical verification is left to future work.
Coverage of experiments
As the number of datasets we consider increases, the number of experiments in total grows exponentially. It is unrealistic to go through the set of all combinations in our experiments, so we picked some experiments and organized them given the categories of the desired effects (instead of the observed effects) of the datasets. Additional experiments that test the exact interaction effects are left to future works. Also, we only considered classification-type tasks in the experiments. While this state-vector framework naturally generalizes to other tasks, including cloze and next-sentence prediction, the empirical observations are left to future works as well. We consider the fine-tuning setting in the experiments. Another setting, language model pre-training, also involves classification-type tasks and usually has larger sets of labels. Our theoretical framework generalizes to the pre-training setting as well.
References
- Aroca-Ouellette and Rudzicz (2020) Stéphane Aroca-Ouellette and Frank Rudzicz. 2020. On Losses for Modern Language Models. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 4970–4981, Online. Association for Computational Linguistics.
- Belinkov (2021) Yonatan Belinkov. 2021. Probing Classifiers: Promises, Shortcomings, and Alternatives. arXiv:2102.12452.
- Bentivogli et al. (2009) Luisa Bentivogli, Peter Clark, Ido Dagan, and Danilo Giampiccolo. 2009. The fifth pascal recognizing textual entailment challenge. TAC, 7:8.
- Brown et al. (2020) Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel Ziegler, Jeffrey Wu, Clemens Winter, Chris Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. 2020. Language Models are Few-Shot Learners. In Advances in Neural Information Processing Systems, volume 33, pages 1877–1901.
- Card et al. (2020) Dallas Card, Peter Henderson, Urvashi Khandelwal, Robin Jia, Kyle Mahowald, and Dan Jurafsky. 2020. With Little Power Comes Great Responsibility. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 9263–9274, Online. Association for Computational Linguistics.
- Cer et al. (2017) Daniel Cer, Mona Diab, Eneko Agirre, Iñigo Lopez-Gazpio, and Lucia Specia. 2017. SemEval-2017 task 1: Semantic textual similarity multilingual and crosslingual focused evaluation. In Proceedings of the 11th International Workshop on Semantic Evaluation (SemEval-2017), pages 1–14, Vancouver, Canada. Association for Computational Linguistics.
- Conneau and Kiela (2018) Alexis Conneau and Douwe Kiela. 2018. SentEval: An evaluation toolkit for universal sentence representations. In Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC 2018), Miyazaki, Japan. European Language Resources Association (ELRA).
- Dagan et al. (2005) Ido Dagan, Oren Glickman, and Bernardo Magnini. 2005. The pascal recognising textual entailment challenge. In Machine learning challenges workshop, pages 177–190. Springer.
- Devlin et al. (2019) Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4171–4186, Minneapolis, Minnesota. Association for Computational Linguistics.
- Dolan and Brockett (2005) William B. Dolan and Chris Brockett. 2005. Automatically constructing a corpus of sentential paraphrases. In Proceedings of the Third International Workshop on Paraphrasing (IWP2005).
- Ethayarajh et al. (2022) Kawin Ethayarajh, Yejin Choi, and Swabha Swayamdipta. 2022. Understanding dataset difficulty with -usable information. In Proceedings of the 39th International Conference on Machine Learning, volume 162 of Proceedings of Machine Learning Research, pages 5988–6008. PMLR.
- Gardner et al. (2020) Matt Gardner, Yoav Artzi, Victoria Basmova, Jonathan Berant, Ben Bogin, Sihao Chen, Pradeep Dasigi, Dheeru Dua, Yanai Elazar, Ananth Gottumukkala, et al. 2020. Evaluating models’ local decision boundaries via contrast sets. arXiv preprint arXiv:2004.02709.
- Gebru et al. (2021) Timnit Gebru, Jamie Morgenstern, Briana Vecchione, Jennifer Wortman Vaughan, Hanna Wallach, Hal Daumé Iii, and Kate Crawford. 2021. Datasheets for datasets. Communications of the ACM, 64(12):86–92.
- Giampiccolo et al. (2007) Danilo Giampiccolo, Bernardo Magnini, Ido Dagan, and William B Dolan. 2007. The third pascal recognizing textual entailment challenge. In Proceedings of the ACL-PASCAL workshop on textual entailment and paraphrasing, pages 1–9.
- Gupta et al. (2015) Abhijeet Gupta, Gemma Boleda, Marco Baroni, and Sebastian Padó. 2015. Distributional vectors encode referential attributes. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, pages 12–21, Lisbon, Portugal. Association for Computational Linguistics.
- Haim et al. (2006) R Bar Haim, Ido Dagan, Bill Dolan, Lisa Ferro, Danilo Giampiccolo, Bernardo Magnini, and Idan Szpektor. 2006. The second pascal recognising textual entailment challenge. In Proceedings of the Second PASCAL Challenges Workshop on Recognising Textual Entailment, volume 7, pages 785–794.
- Hewitt and Liang (2019) John Hewitt and Percy Liang. 2019. Designing and interpreting probes with control tasks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 2733–2743, Hong Kong, China. Association for Computational Linguistics.
- Hoffmann et al. (2022) Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, et al. 2022. Training compute-optimal large language models. arXiv preprint arXiv:2203.15556.
- Jeon et al. (2022) Hyeon Jeon, Michael Aupetit, DongHwa Shin, Aeri Cho, Seokhyeon Park, and Jinwook Seo. 2022. Sanity check for external clustering validation benchmarks using internal validation measures. arXiv preprint arXiv:2209.10042.
- Levesque et al. (2012) Hector Levesque, Ernest Davis, and Leora Morgenstern. 2012. The winograd schema challenge. In Thirteenth international conference on the principles of knowledge representation and reasoning.
- Liu et al. (2021) Leo Z. Liu, Yizhong Wang, Jungo Kasai, Hannaneh Hajishirzi, and Noah A. Smith. 2021. Probing Across Time: What Does RoBERTa Know and When? arXiv:2104.07885 [cs].
- Liu et al. (2019) Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. 2019. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv:1907.11692 [cs].
- Mosbach et al. (2020) Marius Mosbach, Anna Khokhlova, Michael A. Hedderich, and Dietrich Klakow. 2020. On the Interplay Between Fine-tuning and Sentence-level Probing for Linguistic Knowledge in Pre-trained Transformers. In Findings of the Association for Computational Linguistics: EMNLP 2020, pages 2502–2516, Online. Association for Computational Linguistics.
- Niu et al. (2022) Jingcheng Niu, Wenjie Lu, and Gerald Penn. 2022. Does BERT rediscover the classical NLP pipeline? In Proceedings of the 29th International Conference on Computational Linguistics. International Committee on Computational Linguistics.
- Paullada et al. (2021) Amandalynne Paullada, Inioluwa Deborah Raji, Emily M. Bender, Emily Denton, and Alex Hanna. 2021. Data and its (dis)contents: A survey of dataset development and use in machine learning research. Patterns, 2(11):100336.
- Pimentel and Cotterell (2021) Tiago Pimentel and Ryan Cotterell. 2021. A Bayesian framework for information-theoretic probing. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 2869–2887, Online and Punta Cana, Dominican Republic. Association for Computational Linguistics.
- Pushkarna et al. (2022) Mahima Pushkarna, Andrew Zaldivar, and Oddur Kjartansson. 2022. Data Cards: Purposeful and Transparent Dataset Documentation for Responsible AI. arXiv preprint arXiv:2204.01075.
- Radford et al. (2018) Alec Radford, Karthik Narasimhan, Tim Salimans, Ilya Sutskever, and others. 2018. Improving language understanding by generative pre-training. Publisher: OpenAI.
- Rajpurkar et al. (2016) Pranav Rajpurkar, Jian Zhang, Konstantin Lopyrev, and Percy Liang. 2016. SQuAD: 100,000+ questions for machine comprehension of text. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, pages 2383–2392, Austin, Texas. Association for Computational Linguistics.
- Ribeiro et al. (2020) Marco Tulio Ribeiro, Tongshuang Wu, Carlos Guestrin, and Sameer Singh. 2020. Beyond Accuracy: Behavioral Testing of NLP Models with CheckList. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 4902–4912, Online. Association for Computational Linguistics.
- Rogers et al. (2020) Anna Rogers, Olga Kovaleva, and Anna Rumshisky. 2020. A Primer in BERTology: What We Know About How BERT Works. Transactions of the Association for Computational Linguistics, 8:842–866.
- Shwartz-Ziv and Tishby (2017) Ravid Shwartz-Ziv and Naftali Tishby. 2017. Opening the black box of deep neural networks via information. arXiv preprint arXiv:1703.00810.
- Socher et al. (2013) Richard Socher, Alex Perelygin, Jean Wu, Jason Chuang, Christopher D. Manning, Andrew Ng, and Christopher Potts. 2013. Recursive deep models for semantic compositionality over a sentiment treebank. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, pages 1631–1642, Seattle, Washington, USA. Association for Computational Linguistics.
- Sun et al. (2021) Yu Sun, Shuohuan Wang, Shikun Feng, Siyu Ding, Chao Pang, Junyuan Shang, Jiaxiang Liu, Xuyi Chen, Yanbin Zhao, Yuxiang Lu, and others. 2021. ERNIE 3.0: Large-scale knowledge enhanced pre-training for language understanding and generation. arXiv preprint arXiv:2107.02137.
- Swayamdipta et al. (2020) Swabha Swayamdipta, Roy Schwartz, Nicholas Lourie, Yizhong Wang, Hannaneh Hajishirzi, Noah A. Smith, and Yejin Choi. 2020. Dataset cartography: Mapping and diagnosing datasets with training dynamics. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 9275–9293, Online. Association for Computational Linguistics.
- Tänzer et al. (2022) Michael Tänzer, Sebastian Ruder, and Marek Rei. 2022. Memorisation versus generalisation in pre-trained language models. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 7564–7578, Dublin, Ireland. Association for Computational Linguistics.
- Tenney et al. (2019) Ian Tenney, Dipanjan Das, and Ellie Pavlick. 2019. BERT Rediscovers the Classical NLP Pipeline. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 4593–4601, Florence, Italy. Association for Computational Linguistics.
- Villalobos et al. (2022) Pablo Villalobos, Jaime Sevilla, Lennart Heim, Tamay Besiroglu, Marius Hobbhahn, and Anson Ho. 2022. Will we run out of data? An analysis of the limits of scaling datasets in Machine Learning.
- Voita and Titov (2020) Elena Voita and Ivan Titov. 2020. Information-theoretic probing with minimum description length. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 183–196, Online. Association for Computational Linguistics.
- Wang et al. (2018) Alex Wang, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel Bowman. 2018. GLUE: A multi-task benchmark and analysis platform for natural language understanding. In Proceedings of the 2018 EMNLP Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP, pages 353–355, Brussels, Belgium. Association for Computational Linguistics.
- Warstadt et al. (2018) Alex Warstadt, Amanpreet Singh, and Samuel R Bowman. 2018. Neural network acceptability judgments. arXiv preprint arXiv:1805.12471.
- Wei et al. (2021) Jason Wei, Maarten Bosma, Vincent Y Zhao, Kelvin Guu, Adams Wei Yu, Brian Lester, Nan Du, Andrew M Dai, and Quoc V Le. 2021. Finetuned language models are zero-shot learners. arXiv preprint arXiv:2109.01652.
- Weller et al. (2022) Orion Weller, Kevin Seppi, and Matt Gardner. 2022. When to use multi-task learning vs intermediate fine-tuning for pre-trained encoder transfer learning. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 272–282, Dublin, Ireland. Association for Computational Linguistics.
- Wolf et al. (2020) Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Remi Louf, Morgan Funtowicz, Joe Davison, Sam Shleifer, Patrick von Platen, Clara Ma, Yacine Jernite, Julien Plu, Canwen Xu, Teven Le Scao, Sylvain Gugger, Mariama Drame, Quentin Lhoest, and Alexander Rush. 2020. Transformers: State-of-the-art natural language processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages 38–45, Online. Association for Computational Linguistics.
- Xu et al. (2020) Yilun Xu, Shengjia Zhao, Jiaming Song, Russell Stewart, and Stefano Ermon. 2020. A theory of usable information under computational constraints. ICLR.
- Zhu et al. (2022a) Zining Zhu, Soroosh Shahtalebi, and Frank Rudzicz. 2022a. Predicting fine-tuning performance with probing. In EMNLP.
- Zhu et al. (2022b) Zining Zhu, Jixuan Wang, Bai Li, and Frank Rudzicz. 2022b. On the data requirements of probing. In Findings of the Association of Computational Linguistics. Association for Computational Linguistics.
.
Appendix A Appendix
A.1 Figure illustrating the experimental setup
A.2 Additional details on multitask settings
Consider the number of different multitask fine-tuning settings possible assuming a constant random seed. If we fine-tune encoders task-by-task (e.g., first COLA, then MRPC) such that order matters, then this problem is equivalent to the number of ordered subsets that can be formed from the set COLA, SST2, MRPC, STSB, QNLI, RTE. This computes to models per encoder, or total models. Note the lower bound of the summation is 0, as the empty set corresponds to the baseline model (i.e., no fine-tuning).
If we discount ordering effects, then the problem reduces to the number of subsets contains. This evaluates to models per encoder or total models, which results in far fewer experiments. Ordering effects can be discounted by aggregating training samples of each task, then randomly sampling from this combined dataset when training. Each sample will have a tag indicating which task it pertains to, so it can be redirected to the correct classification head during training.
Note that we initially assume a constant random seed. Later, we expanded to five random seeds (42, 1, 1234, 123, 10) to allow statistical significance testing. This increases total models to , which requires excessive compute resources. There is also the need to organize experiments better to illustrate potential individual and interaction effects clearly.
To address these issues, we impose the following condition: experiments must constitute of equal task counts per task group OR all tasks must belong to the same task group. Recall the task groups from Section 5.2 to be single-sentence, similarity and paraphrase, and inference. This enables us to organize the experiments by marking the states as follows:
-
•
: The initial state.
-
•
: The model is trained on one dataset.
-
•
: The model is trained on two datasets from the same group.
-
•
: The model is trained on two datasets from different groups.
-
•
: The model is trained on three datasets from different groups.
-
•
: The model is trained on four tasks from two groups (two per group).
-
•
: The model is trained on six tasks from three groups (two per group)
As demonstrated in Table 8, the total number of models we need to train is reduced to .
| Marker | N. Groups | N. Tasks | N. Experiments |
|---|---|---|---|
| 0 | 0 | 1 | |
| 1 | 1 | 6 | |
| 1 | 2 | 3 | |
| 2 | 1 | 12 | |
| 3 | 1 | 8 | |
| 2 | 2 | 3 | |
| 3 | 2 | 1 |
Designing experiments this way allows framing the dataset effects.
The individual effects can be framed as transitions between marked states (i.e. adding some task to one state yields another state). For example, can reflect the individual effect of a dataset, conditioned on the “no-fine-tuning initial state” . denotes the individual effect of a dataset , conditioned on the initial state that contains a dataset (), where is in the same group as .
The interaction effects can be framed as combinations between multiple states. For example, two states labeled (with dataset and , respectively) and a state labeled (with datasets ) can jointly define the interaction between the datasets and . This can be written as .
This labeling mechanism of the states can support the following effects:
-
•
Individual effects: , , ,
-
•
Interaction effects: , , , , , ,
Note that although it is possible to compute interaction effects of more than two datasets, we chose not to focus on these cases as it adds an extra layer of complexity. Hence, we only consider the following interaction effects: , . This means we don’t need to train models for states and , reducing total experiments to .
A.3 Additional math motivation
Here we provide some additional mathematical motivations for the proposed state-vector framework: dataset effects form an Abelian group.
Given a reference state , the collection of all possible dataset effects forms an additive Abelian group. Here we show that satisfies the requirements.
Existence of zero. We already know that the identity element is . Intuitively, the identity element corresponds to “no effect” for this dataset.
Existence and closure of addition. The addition operation refers to the vector addition. Since is defined under , it is closed under addition. Note that due to the interaction effect, addition does not refer to applying two datasets together to the “bucket” of data for multitask training.
Existence and closure of negation. The negation operation refers to flipping the direction of a vector in . Empirically, negating involves a counterfactual query of the effect of a dataset: if were not applied, what would have been the effect on the state of the model?
Associativity and commutativity. Vector addition satisfies associativity: and commutativity: .
A.4 On the equivalence between formulations of interaction effects
Plugging in the indicator variables into Eq. 4 yields the following equation (writing in matrix form):
| (5) |
The standard variable elimination operations give us an expression for the expression for the interaction effect parameter :
| (6) |
which exactly recovers the definition for using the equivalent formulation (Eq. 3).
A.5 Additional experiment results
| Dataset | Reference | Model | Length | Depth | TopConst | BigramShift | Tense | SubjNumber | ObjNumber | OddManOut | CoordInv |
|---|---|---|---|---|---|---|---|---|---|---|---|
| SST2 | BERT | ||||||||||
| SST2 | COLA | BERT | |||||||||
| SST2 | MRPC | BERT | |||||||||
| SST2 | STSB | BERT | |||||||||
| SST2 | QNLI | BERT | |||||||||
| SST2 | RTE | BERT | |||||||||
| SST2 | MRPC QNLI | BERT | |||||||||
| SST2 | MRPC RTE | BERT | |||||||||
| SST2 | STSB QNLI | BERT | |||||||||
| SST2 | STSB RTE | BERT | |||||||||
| SST2 | RoBERTa | ||||||||||
| SST2 | COLA | RoBERTa | |||||||||
| SST2 | MRPC | RoBERTa | |||||||||
| SST2 | STSB | RoBERTa | |||||||||
| SST2 | QNLI | RoBERTa | |||||||||
| SST2 | RTE | RoBERTa | |||||||||
| SST2 | MRPC QNLI | RoBERTa | |||||||||
| SST2 | MRPC RTE | RoBERTa | |||||||||
| SST2 | STSB QNLI | RoBERTa | |||||||||
| SST2 | STSB RTE | RoBERTa |