A statistical framework for analyzing activity pattern from GPS data
Abstract
We introduce a novel statistical framework for analyzing the GPS data of a single individual. Our approach models daily GPS observations as noisy measurements of an underlying random trajectory, enabling the definition of meaningful concepts such as the average GPS density function. We propose estimators for this density function and establish their asymptotic properties. To study human activity patterns using GPS data, we develop a simple movement model based on mixture models for generating random trajectories. Building on this framework, we introduce several analytical tools to explore activity spaces and mobility patterns. We demonstrate the effectiveness of our approach through applications to both simulated and real-world GPS data, uncovering insightful mobility trends.
Keywords: GPS, nonparametric statistics, kernel density estimation, random trajectory, activity space, mobility pattern
1 Introduction
The rapid advancement of Global Positioning System (GPS) technology has revolutionized various domains, ranging from transportation and urban planning to environmental studies and public health (Papoutsis et al., , 2021; Yang et al., , 2022; Mao et al., , 2023). GPS data provides high-resolution spatial and temporal information, enabling precise tracking of movement and location patterns. With the increasing availability of GPS-equipped devices, such as smartphones, vehicles, and wearable deices, vast amounts of trajectory data are generated every day.
In scientific research, GPS data play a crucial role in understanding human mobility, tracing activity spaces, and analyzing travel behaviors (Barnett and Onnela, , 2020; Andrade and Gama, , 2020; Elmasri et al., , 2023). Researchers leverage GPS data to study commuting patterns, urban dynamics, wildlife tracking, and disaster response. By examining spatial-temporal GPS records, scientists gain insights into mobility patterns of individuals and the dynamics of population movements. Despite the rich information embedded in the GPS data, little is known about how to properly analyze the data from a statistical perspective.
While various methods exist for processing GPS data, a comprehensive statistical framework for analysis is still lacking. Traditional approaches often rely on heuristic methods or machine learning techniques (Newson and Krumm, , 2009; Early and Sykulski, , 2020; Chabert-Liddell et al., , 2023; Burzacchi et al., , 2024) that may lack rigorous statistical foundations. A major challenge in modeling GPS data is that records cannot be viewed as independently and identically distributed (IID) random variables. Thus, a conventional statistical model does not work for GPS records. The absence of a reliable statistical framework hinders cross-disciplinary applications and reduces the potential for scientific applications.
The objective of this paper is to introduce a general statistical framework for analyzing GPS data. We introduce the concept of random trajectories and model GPS records as a noisy measurement of points on a trajectory. Specifically, we assume that on each day, the individual has a true trajectory that is generated from an IID process. Within each day, the GPS data are locations on the trajectory with additive measurement noises recorded at particular timestamps. The independence across different days allow us to use daily-average information to infer the overall patterns of the individual.
1.1 Related work
Our procedure for estimating activity utilizes a weighted kernel density estimator (KDE; Chacón and Duong, 2018; Wasserman, 2006; Silverman, 2018; Scott, 2015). The weights assigned to each observation account for the timestamp distribution while adjusting for the cyclic nature of time, establishing connections to directional statistics (Mardia and Jupp, , 2009; Meilán-Vila et al., , 2021; Pewsey and García-Portugués, , 2021; Ley and Verdebout, , 2017).
Our analysis of activity space builds on the concept of density level sets (Chacón, , 2015; Tsybakov, , 1997; Cadre, , 2006; Chen et al., , 2017) and level sets indexed by probability (Polonik, , 1997; Chen and Dobra, , 2020; Chen, , 2019). Additionally, the random trajectory model introduced in this paper is related to topological and functional data analysis (Chazal and Michel, , 2021; Wang et al., , 2016; Wasserman, , 2018).
Recent statistical research on GPS data primarily focuses on recovering latent trajectories (Early and Sykulski, , 2020; Duong, , 2024; Huang et al., , 2023; Burzacchi et al., , 2024) or analyzing transportation patterns (Mao et al., , 2023; Elmasri et al., , 2023). In contrast, our work aims to develop a statistical framework for identifying an individual’s activity space and anchor locations (Chen and Dobra, , 2020). Activity spaces are the spatial areas an individual visits during their activities of daily living. Anchor locations represent mobility hubs for an individual: they are locations the individual spends a significant amount of their time that serve as origin and destination for many of the routes they follow (Schönfelder and Axhausen, , 2004).
1.2 Outline
This paper is organized as follows. In Section 2, we formally introduce our statistical framework for modeling GPS data. This framework describes the underlying statistical model on how GPS data are generated. Section 3 describes estimators of the key parameters of interest introduced in Section 2. Section 4 presents the associated asymptotic theory. To study human activity patterns, we introduce a simple movement model in Section 5 and present some statistical analysis based on this model. We apply our methodology to a real GPS data in Section 6 and explain the key insights about human mobility gained from our analysis. All codes and data are available on https://github.com/wuhy0902/Mobility_analysis.
2 Statistical framework of GPS data


We consider GPS data recorded from a single individual over several non-overlapping time periods of the same length. In what follows we will consider a time period to be one day, but our results extend to any other similar time periods that can be longer (e.g., weeks, months, weekdays, weekends) or shorter (e.g., daytime hours between 7:00am and 5:00pm).
The GPS data can be represented as random variables
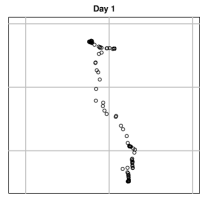
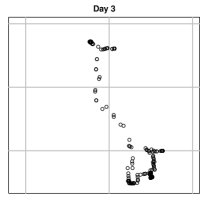
where denotes the day in which the observation was recorded and denotes the sequence of observations for -th day. Here stands for the spatial location of this GPS observation (latitude and longitude), and represents the time when the observation was recorded. Note that for each day , Here is the total number of observations in day . We assume that the timestamps are non-random (similar to a fixed design). Figure 1 provides an example of real GPS data recorded from an individual in four different days (ignoring timestamps).
A challenge in modeling GPS data is that observations within the same day are dependent since each observation can be viewed as a realization of the individual’s trajectory on discrete time point (with some measurement errors). Thus, it is a non-trivial task to formulate an adequate statistical model that accurately captures the nature of GPS data.
2.1 Latent trajectory model for GPS records
To construct a statistical framework for GPS records, we consider a random trajectory model as follows. For -th day, there exists a continuous mapping such that is the actual location of the individual on day and time . We call the (latent) trajectory of -th day.
The observed data is where is independent noises (independent across both and ) with a bounded PDF that are often assumed to be Gaussian. We also write to denote the actual location of the individual at time .
We assume that the latent trajectories where is a distribution of random trajectory. Namely, on each day, the individual follows a random trajectory independent of all other trajectories from . In Section 5, we provide a realistic example on how to generate a random trajectory.
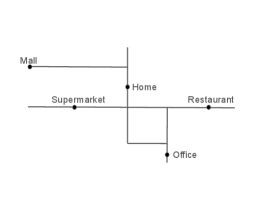
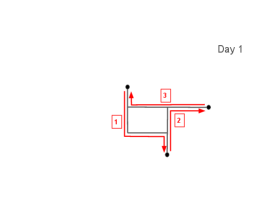
Figure 2 presents an example of the latent trajectory model. The first column presents a map of important locations such as home and office, and the corresponding road networks inside this region. The second column shows random trajectories of two days. The actual trajectory is shown in black lines. The red arrows indicate the direction of the trajectory. Note that the individual might remain at the same location for an extended period of time as indicated as the solid black dots in the second column. The third column presents the observed locations of the GPS records. We note that GPS records mostly follow the individual’s trajectory but may occasionally deviate from it due to measurement errors.

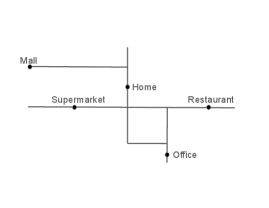

2.2 Activity patterns
The individual’s activity pattern is characterized by the distribution of the random trajectory . Let be a spatial region. The probability is the probability that the individual is in the region at time . The manner in which distribution of changes over time provides us with information about the dynamics of the most likely locations visited by this individual. Let be a random variable independent of . The probability
can be interpreted the proportion of time that the individual spends in the region . Thus, the distribution of tells us the overall activity patterns of the individual.
2.3 GPS densities
The distributions of or are difficult to estimate from the GPS data because of the measurement error . This is known as the deconvolution problem and is a notoriously difficult task. Thus, our idea is to use the distribution of and as surrogates.
Naively, one may consider the the marginal PDF of
| (1) |
as an estimate of the distribution of . This geometric approach (Simon, , 2014) is a convenient way to define density in this case. However, this PDF is NOT the PDF of because it depends on the distribution of the timestamps . Even if the individual’s latent trajectory remains the same, changing the distribution of timestamps will change the distribution of .
Average GPS density. To solve this problem, we consider a time-uniform density of the observation. Let be a uniform random variable for the time interval . Recall that
where and are independent random quantities. can be viewed as the random latent position corrupted by the measurement error . The average behavior of describes the expectation of a random trajectory (with measurement error) that is invariant to the timestamps distribution. With this, we define the average GPS density is the PDF of :
| (2) |
The quantity describes the expectation of a random trajectory with consideration to the measurement error and is invariant to the distribution of timestamps. What influences is the distribution of the latent trajectory and the measurement errors (which are generally small). Thus, is a good quantity to characterize the activity pattern based on GPS records.
Interval-specific GPS density. Sometimes we may be interested in the activity pattern that takes place within a specific time-interval, e.g., the morning or evening rush hours. Let be an interval of interest. The activity patterns within can be described by the following interval-specific GPS density
| (3) | ||||
where is the uniform distribution over the interval .
Conditional GPS density. When the interval is shrinking to a specific point , we obtain the conditional GPS density:
| (4) | ||||
The conditional GPS can be used for predicting individual’s location at time when we have no information about the individual’s latent trajectory. The conditional GPS density and the previous two densities are linked via the following proposition.
Proposition 1
The above three GPS densities are linked by the following equalities:
2.4 Identification of activity patterns from GPS densities
Even if there are measurement errors, the GPS densities still provide useful bound on the distribution of . For simplicity, we assume that the measurement error . Namely, the measurement error is an isotropic Gaussian with variance . Let be the CDF of the distribution.
Proposition 2 (Anchor point identification)
Let be a uniform random variable. Suppose is a location such that Then and
Proposition 2 shows that if the location has a probability mass, the average GPS density will also be a non-trivial number. A location with a high probability mass of means that on average, the individual has spent a substantial amount of time staying there. This is generally a location of interest and is called an anchor location if the individual has spent a lot of time there on a daily basis. The home and work place are good examples of anchor locations.
Proposition 2 can be generalized to a region. Let be the -neighboring region around the set . Then we have the following result.
Proposition 3 (High activity region)
Let be a uniform random variable. Suppose is a regions where Then
Proposition 3 shows that if the random trajectories had spent some time in the region , the average GPS density will also be a non-small number around . The CDF of a distribution is due to the measurement error being an isotropic two-dimensional Gaussian. If the measurement error has a different distribution, this quantity has to be modified.
Finally, a region with a high average GPS probability will imply its neighborhood has more activities.
Proposition 4 (GPS density to activity)
Let be a uniform random variable.
Suppose is a regions where Then
for any .
The lower bound in Proposition 2 is meaningful only if . This proposition shows that if the density is high, we will expect some high probability around of around .
3 Estimating the GPS densities
In this section, we study the problem of estimating the GPS densities. Recall that our data are where is the indicator of different days and is the indicator of the time at each day. Our method is based on the idea of kernel smoothing. We will show that after properly reweighting the observations according to the timestamp, a 2D kernel density estimator (KDE) can provide a consistent estimator of the GPS densities.
Naively, one may drop the timestamps and apply the kernel density estimation, which leads to
| (5) |
where is the smoothing bandwidth and is the kernel function such as a Gaussian and is the total number of observations. One can easily see that is a consistent estimator of (marginal density of ), not . So this estimator is in general inconsistent.
3.1 Time-weighted estimator
To estimate , we consider a very simple estimator by weighting each observation by its time difference. For observation , we use the two mid-points to the before and after timestamps: and . The time difference between these two mid-points is which will be used as the weight of observation .
For the first time and the last time , we use the fact that the time at and are the same. So we set as if the last timestamp occurs before the first timestamp and as if the first timestamp occurs after the last timestamp. This also leads to the summation . We then define the time-weighted estimator as
| (6) |
This is essentially a weighted 2D KDE with the weight representing the amount of time around . While this estimator is just simply weighting each observation by the time, it is a consistent estimator of (Theorem 5).
If we want to estimate the interval-specific GPS density, we can restrict observations only to the those within the time interval of interest and adjust the weights accordingly.
3.2 Conditional GPS density estimator
To estimate the conditional GPS density, we can simply use the conditional kernel density estimator (KDE):
| (7) |
where and are the smoothing bandwidth and is a kernel function for the time and
measures the time difference correcting for the fact that the time and are the same time. The time interval is not just simply an interval but its two ends and are connected, making it a cyclic structure. Thus, measures the distance in terms of time. Alternatively, one may map the time into a “degree” in as if it is on a clock and use a directional kernel to preserve the cyclic structure of the time (Nguyen et al., , 2023; Mardia and Jupp, , 2009; Meilán-Vila et al., , 2021).
While this estimator seem to be similar to the naive estimator , it turns out that this estimator is consistent for . Moreover, the conditional KDE can be used to estimate the average GPS density by integrating over :
| (8) | ||||
Similar to , the estimator is also a weighted 2D KDE. This integrated conditional KDE is a consistent estimator of . Note that we can convert to an interval-specific GPS density estimator by integrating over the interval of interest. In Appendix A.1, we discuss some numerical techniques for quickly computing the estimator .
Remark (daily average estimator). Here is an alternative estimator for the conditional GPS by averaging daily conditional GPS density estimators. Let
be a conditional KDE for day . One can see that when and are properly shrinking to , this estimator will be a consistent estimator of conditional GPS density at day . We can then simply average over all days to get an estimator of This estimator is also consistent but we experiments show that its performance is not as good as .
4 Asymptotic theory
In this section, we study the asymptotic theory of these estimators. Recall that our data consist of the collections for and such that where are IID random trajectories and are IID mean noises. We assume a fixed design scenario where the timestamps are non-random. All relevant assumptions are given in Appendix C.
For simplicity, we assume that the number of observation of each day is a fixed and non-random quantity. Since random trajectories are IID across different days, the observations in day are independent to the observations in day .
Special case: even-spacing design. When comparing our results to a conventional nonparametric estimation rate, we will consider an even-spacing design such that and Namely, all timestamps are evenly spacing on the interval . Under this scenario we will re-write our convergence rate in terms of , making it easy to compare to a conventional rate. The analysis under the even-spacing design allows us to investigate the effect of smoothing bandwidth in a clearer way.
4.1 Time-weighted estimator
We first derive the convergence rate of the time-weighted estimator .
Theorem 5 describes the convergence rate of the time-weighted estimator. The first term is the conventional smoothing bias. The second term is a bias due to the timestamps differences. The third quantity is a stochastic errors due to the fluctuations in weights . The last quantity is the usual convergence rate due to averaging over independent day’s data.
While Theorem 5 shows a pointwise convergence rate, it also implies the rate for mean integrated square error (MISE):
| (9) | ||||
when the support of is a compact set. We show the connection between this convergence rate and the rate of usual nonparametric estimators in the even-spacing design scenario.
4.1.1 Even-spacing design and bandwidth selection
To make a meaningful comparison to conventional rate of a KDE, we consider the even-spacing design with . In this case,
Thus,
| (10) | ||||
In the case of MISE, equation (10) becomes
| (11) |
This is a reasonable rate. The first quantity is the conventional smoothing bias in a KDE. The second quantity is the bias due to the ‘resolution’ of each day’s observation. The last term is the variance (stochastic error) of a 2D KDE when the effective sample size is . In our estimator, we are averaging over days and each day has observations, so the total number of random elements we are averaging is , which is the effective sample size here.
Choosing the optimal bandwidth is a non-trivial problem because and there are three terms in equation (11). We denote
so that the term (B) represents the temporal resolution bias and the term (S) represents the variance.
Proposition 6
Proposition 6 shows that the critical rate to balance between the errors is . When , the temporal resolution bias (B) is larger than the stochastic error (S) and we obtain a convergence rate of , which is dominated by the resolution bias. On the other hand, is the case where (S) dominates (B), so the convergence rate is , which is the stochastic error.
4.2 Conditional GPS density estimator
In this section, we study the convergence of the conditional GPS density estimator .
Theorem 7
The corresponding MISE rate will be the square of the rate in Theorem 7. Each term in Theorem 7 has a correspondence to the term in Theorem 5. The first term is the smoothing bias. The second term is the resolution bias due to the fact that observed may be away from the time point of interest . A high level idea on how the linear term occurs is that the difference when the velocity of the trajectory is bounded from the above. The third term is the stochastic error of the estimator. The last term is the stochastic error due to different weights of each day;this quantity corresponds to the term .
4.2.1 Even-spacing design and bandwidth selection
We now investigate the scenario of even-spacing, which provides us insights into the convergence rate and bandwidth selection problem. When is the same and the timestamps are evenly spacing, we immediate obtain for every .
Moreover, the summation is associated with the KDE of the time :
where is the approximation error. This implies that
| (12) |
Similarly, the summation in the numerator of the second term of equation (7)
| (13) | ||||
where is a uniform random variable over and is a constant and is another approximation error. Note that in the second equality of equation (13), we replace with because when , only those matters and in this case, .
Now, putting equations (12) and (13) into Theorem 7, we obtain
and the corresponding MISE rate is
| (14) |
The first quantity is the conventional smoothing bias. The second bias is the resolution bias. In contrast to the time-weighted estimator, this resolution bias is in a different form and is due to the fact that observations with a high weights will be within neighborhood of in terms of time. In the worst case, the actual location on the trajectory can differ by the same order, leading to this rate. The third quantity is the bias when we approximate a uniform integral with a dense even-spacing grid. The fourth term is the conventional variance part of the estimator and the last one is just the variance due to distinct days.
Equation (14) also provides the convergence rate of the estimator because is a finite integral. So the MISE convergence rate of is the same as in equation (14).
The bandwidth selection under equation (14) is straightforward. The optimal choice will be of the rate
| (15) |
which corresponds to the convergence rate
One can clearly see that the convergence rate is dominated by the second term because of the resolution bias and the approximation bias at each day. Since both quantity are not stochastic errors, increasing the number of days will not affect them.
Under the optimal smoothing bandwidth, we also have
Comparing this to the time-weighted estimator in Proposition 6, the two rates are the same when the number of days is not much larger than the number of observation per day , which is the typical case. When we have , has a MISE of rate when is large, which is slightly faster than . This is because the time-weighted estimator does not require an estimator on the conditional density, so there is no smoothing on the time, making the estimator more efficient.
5 Simple movement model
All the above analysis can be applied to GPS data recorded from a human being but also from other living creatures whose spatial trajectories are studied in the literature (e.g., elk, whales, turtles, fish). However, human activity patterns are very different from rest because they are generally very regular (Hägerstrand, , 1963, 1970). To tailor our analysis on humans, we study a special class of random trajectories that we call simple movement model (SMM). In spite of its simplicity, it provides a model that generates a trajectory similar to an actual trajectory of a person. Our simulation studies are all based on this model.
Let be a collection of locations that an individual visits very often. The set includes the so-called anchor locations such as the home, office location as well as other places such as restaurants and grocery stores. Let be a random element that takes the form of
such that are the location where the individual stay stationary. The vector is called an action vector since it describes the actions being taken in a single day. The quantity is a road/path connecting to , which describes the road that the individual takes to move from location to .
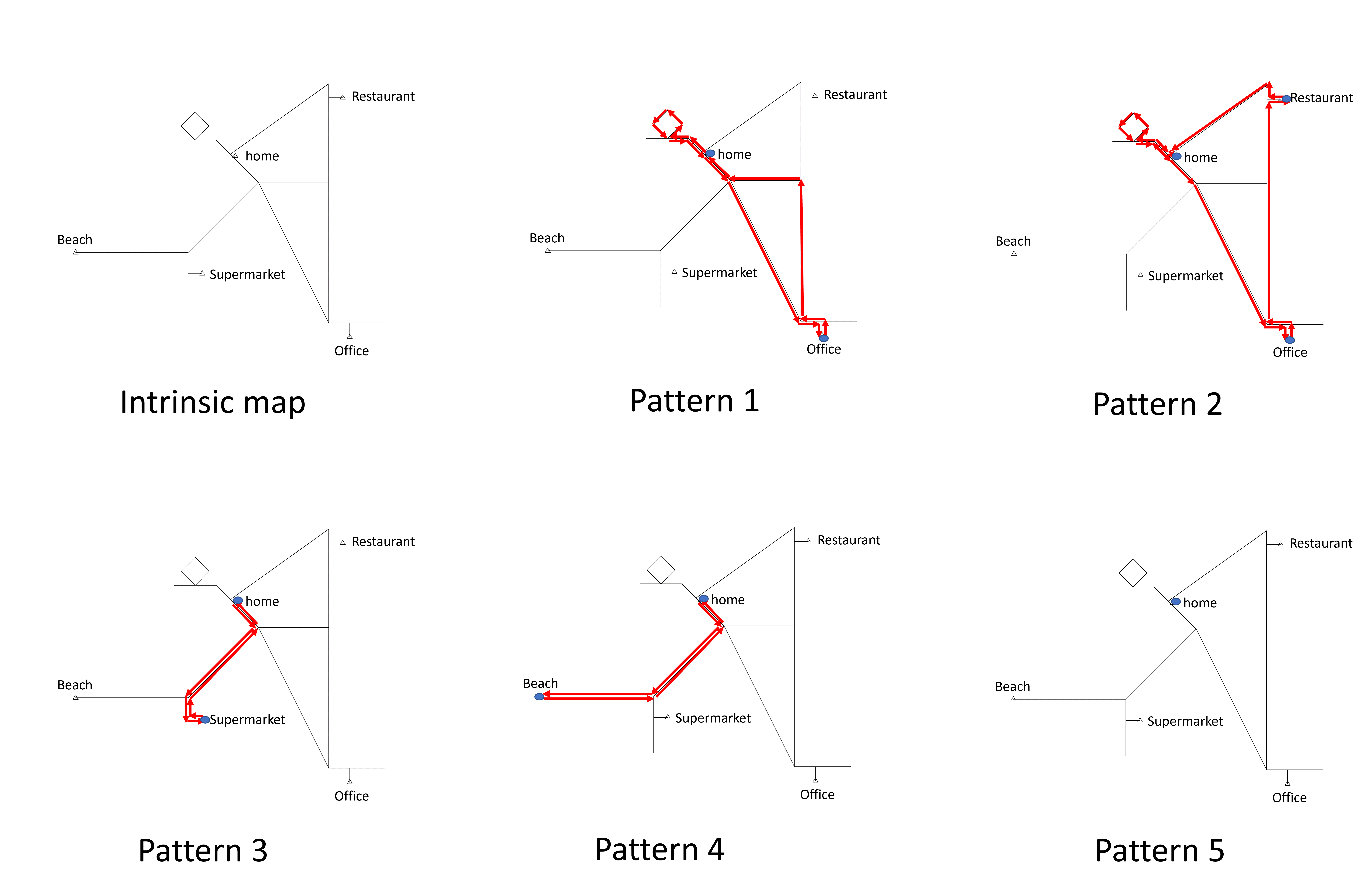
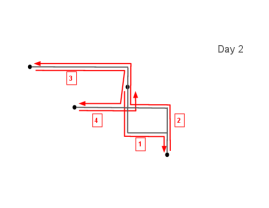
Figure 3 provides an example of the SMM. In this case, there are five possible patterns that the action vector can be. The first pattern is the following action vector
The road is from home directly to the office and is a road from office to home. The road is where the individual goes to the park in the top region and then goes home without staying. Pattern 3 is the simplest one as it involves only a trip to the local grocery store:
The randomness of the action vector reflects that the individual may follow different activity patterns in a day. Also, even if all the locations are the same, the individual may take a different road to move between them. In this construction, we would assume that all possible outcomes of is a finite set, meaning that the the distribution of can be described by a probability mass function.
The action vector only describes the actions (stationary at a location or moving from one to another) of the individual. It does not include any information about the time. Thus, we introduce another random variable conditioned on such that is a random partition of the interval such that for , is the amount of time that the individual spend on while is the amount of time that the individual is on the road . One can think of as a (2k+1)-simplex. When the individual is on the road, we assume that the individual moves between locations with constant velocity. One may use the Dirichlet distribution or truncated Gaussian distribution to generate .
To illustrate the idea, we consider again the example in Figure 3. When , there are a total of elements in the action vector. So is a 7-simplex. Suppose . This means that the individual leaves home at 9 am and spends 1 hour on the road to office. The individual then spends 8 hours in the office and drives home for 1 hour. After a 2-hour stay at home, the individual goes to the park and takes a round trip back home for 1-hour and stays at home for the rest of the day. Note that the vector will be a 5-simplex since pattern 3 only has 5 possible actions.
Once we have randomly generate , we can easily obtain the corresponding random trajectory . Since this model consider a simplified movement of an individual, we call it simple movement model. Although it is a simplified model, it does capture the primary activity of an individual that can be captured by the GPS data. Under SMM, the distribution can be characterized by a PMF of and the PDF of . Since the action vector only have finite number of possible outcome, the implied trajectories can be viewed as generating from a mixture model where the action vector acts as the indicator of the component.
5.1 Recovering anchor locations
In the SMM, we may define the the anchor locations as for some given threshold . The threshold is the proportion of the time that the individual spend at the location in a day. For instance, the threshold should give us the home location as we expect people to spend more than 8 hours in the home in a day. may correspond to both the home and the work place.
Suppose that the measurement noise is isotropic Gaussian with variance that is known to us, Proposition 2 show that for any with we have This implies that any anchor location will satisfy
Let be an estimated GPS density, either from the time-weighted approach or the conditional GPS method. We may use the estimated upper level set
| (16) |
as an estimator for possible locations of . As a result, the level sets of provide useful information on the anchor locations.
In addition to the level sets, the density local modes of can be used as an estimator of the anchor locations. Under SMM, anchor locations are where there are probability mass of . On a regular road , there is no probability mass (only a 1D probability density along the road). This property implies that the GPS density will have local modes around each anchor point (when the measurement noise is not very large). Thus, the local modes within can be used to recover the anchor location:
where is the largest eigenvalue of the matrix and is the Hessian matrix of .
5.2 Detecting activity spaces
The activity space is a region where the individual spends most of her/his time in a regular day. This region is unique to every individual and can provide key information such as how the built-environment influences the individual (Sherman et al., , 2005). We show how GPS data can be used to determine an individual’s acvity space.
Suppose we know the true GPS density , a simple approach to quantify the activity space is via the level set indexed by the probability (Polonik, , 1997), also known as the density ranking (Chen and Dobra, , 2020; Chen, , 2019):
| (17) | ||||
Because the level set are nested when changing , can be recovered by varying until we have an exactly amount of probability within the level set.
The set has a nice interpretation: it is the smallest region where the individual spends at least a proportion of time in it. As a concrete example, is where the individual has spent of the time on average. Thus, can be used as statistical entity of the activity space. Interestingly, can also be interpreted as a prediction region of the individual.
5.2.1 Estimating the activity space
Estimating from the data can be done easily by the plug-in estimator approach. A straightforward idea is to use
While this estimator is valid, it may be expansive to compute it because of the integral in the estimator.
Here is an alternative approach to estimating without the evaluation of the integral. First, the integral , where is the corresponding CDF of . When the timestamps are even-spacing, can be estimated by the empirical distribution of . When the timestamps are not even-spacing, we can simply weight each observation by the idea of time-weighting estimator. In more details, a time-weighted estimator of is
where if we are using and
if we are using . can be viewed as a time-weighted EDF. A feature of is that when integrating over any region , we have
It is the time-weighted proportion of inside the region . With this, we obtain the estimator
| (18) | ||||
note that can be either or . We provide a fast numerical method for computing in Appendix A.2.
5.3 Clustering of trajectories
In the SMM, the action vector is assumed to take a finite number of possible outcomes. While the actual time of each movement under this model may vary a bit according to the random vector , resulting in a slightly different trajectory with the same , the main structure of the trajectory remain similar. This implies that the individual’s trajectories can be clustered into groups according to the action vector .
While we do not directly observe , we may use the estimated GPS densities at each day as a noisy representation of and cluster different days according to the estimated GPS densities.
Here we describe a simple approach to cluster trajectories. Let
be the estimated time-weighted GPS density of day , where is defined in equation (8). While we may use the pairwise distance matrix among different days as a distance measure, we recommend using a scaled log-density, i.e.,
| (19) |
for some small constant to stabilize the log-density. Our empirical studies find that equation (19) works much better in practice because the GPS density is often very skew due to the fact that when the individual is not moving, the density is highly concentrated at a location.
With the distance matrix , we can perform cluster analysis based on hierarchical cluster or spectral clustering (Von Luxburg, , 2007) to obtain a cluster label for every day. We may also detect outlier activity by examining the distance matrix.
5.3.1 Recovering dynamics after clustering
Once we have done clustering of the data, we obtain a label for every day, indicating what cluster the day belongs to. In SMM, trajectories in the same cluster are likely to be from the same action vector . If we focus on the data of a cluster, we may perform inference on anchor locations or activity space (Sections 5.1 and 5.2) specifically for the corresponding action vector.
Under SMM, trajectories in the same cluster are likely to have the same action vector (but different temporal distribution ). We will expect that the conditional density on the days from the same clusters to be similar. The average behavior of these conditional densities in the same cluster provides us useful information about the latent action vector.
Let for every be the cluster label. For a cluster , we compute the cluster conditional GPS density
| (20) |
How the conditional distribution changes over time informs us the movement of this individual under this action vector.
Estimating the conditional center. Since trajectories in the same cluster are similar, we expect the cluster conditional GPS density to be uni-modal and the mean of this density will be a good representation of its center. Thus, a simple way to track how this distribution moves over time is to study the movement of the mean location, which can be written as
| (21) |
Note that this is like a kernel regression with two ‘outcome variables’ (coordinates). For two time points , the difference in the center can be interpreted as the average movement in the distribution within the time interval . Thus, the function describes the overall dynamics of the trajectories. Note that we may use a local polynomial regression method (Fan, , 2018) to estimate the velocity as well.
6 Real data analysis
We analyze GPS data recorded for a single individual from a longitudinal study of exposure to a cognitive-impairing substance. Participants in this study have been recruited from several cities in a major metropolitan area in the US. The survey data collected comprise one month of GPS tracking with a GPS-enabled smartphone carried by each study participant. The protocol of the study required that the smartphones recorded point locations (latitude, longitude, timestamp) on the spatiotemporal trajectories followed by study participants every minute using a commercially available software. The study participant whose GPS locations are used to illustrate our proposed methodology has been selected at random from the study cohort which comprises more than 150 individuals with complete survey data. In order to preserve any disclosure of private, sensitive information related to this study participant, the latitude and longitude coordinates have been shifted and scaled. The timestamps have been mapped to the unit interval.
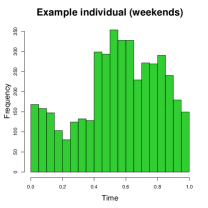
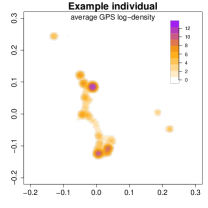
The GPS data for the selected example individual consists of a total of 14,972 observations recorded over days, averaging approximately observations per day. Although the study protocol specified that a new GPS observation should be recorded every minute, the actual recorded timestamps are not regularly distributed over the entire observation window, as illustrated in the first two panels of Figure 4. Consequently, a naive estimation approach would be biased, so we should use either or for density estimation. We choose because it allows for conditional density estimation at any given time. The smoothing bandwidths are set to (longitude/latitude degrees) and (approximately 30 minutes). The third panel in Figure 4 displays the GPS log-density . Several high-density regions emerge, suggesting potential anchor locations for the individual.
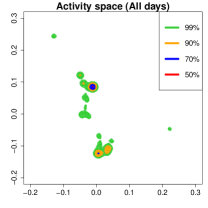
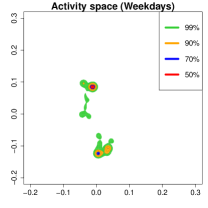
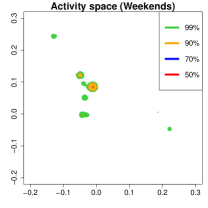
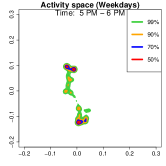
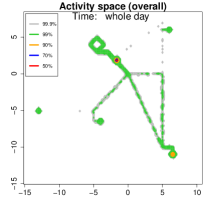
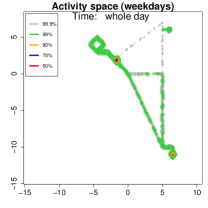
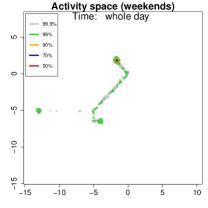
Activity space analysis. Figure 5 presents the individual’s activity space under three scenarios: all days, weekdays, and weekends. The contour region represents the area where the individual spends proportion of their time. For instance, (green) covers 99% of their time. More than 50% of the time is spent at home, as it includes nighttime. On weekdays (middle panel), 90% of the activities (orange contour) are concentrated at home or the office. To further analyze mobility, we separate the data into weekdays and weekends and examine hourly density variations.
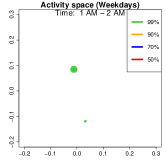
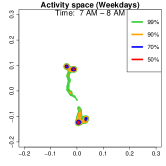
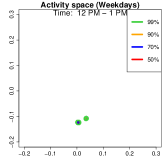
Analysis on the weekdays patterns. Weekday Patterns Figure 6 depicts GPS density distributions across four weekday time windows: 1-2 AM (sleep time), 7-8 AM (morning rush hour), 12-1 PM (noon), and 5-6 PM (evening rush hour). The top row shows the logarithm of the hourly GPS density to mitigate skewness. The bottom row presents the activity space contours for 99% (green), 90% (orange), 70% (blue), and 50% (red) of the time. From Figure 6, we identify five likely anchor locations: one main living place (highest density region in first column) and other two close locations the person may also visit at night (two high-density regions at bottom in the first column) and two office locations (identified in the third panel as high-density regions during midday). By further cluster analysis, we find that there is a main living location (corresponding to the highest density region at night), and an alternative living place close to a park that the example individual sometimes walks inside. The second and fourth columns capture rush-hour mobility, illustrating connectivity between anchor locations.
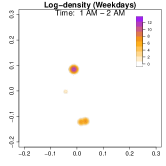
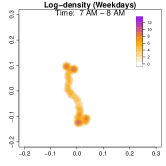
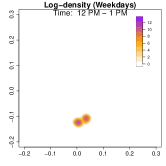
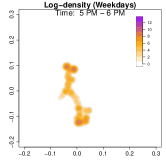
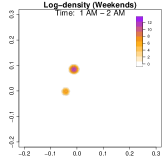
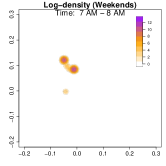
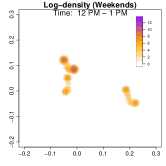
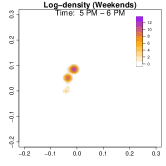
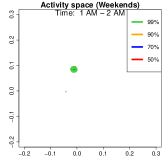
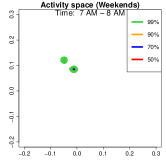
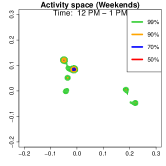
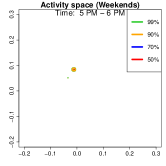
Analysis on the weekends patterns. Figure 7 shows the GPS density during weekends, revealing distinct mobility patterns compared to weekdays. Notably, the office locations (bottom two spots in the third column of Figure 6) show no density. Additional high-density spots appear, likely representing leisure locations (e.g., parks, malls, or beaches). The fourth column indicates a frequent weekend location near home, which is a plaza containing some restaurants and shops. Comparing Figures 6 and 7, we observe a more dispersed mobility pattern on weekends, with multiple high-density regions, whereas weekdays exhibit a concentrated movement pattern, consistent with regular commuting behavior.
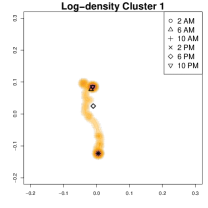
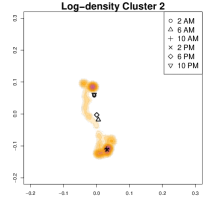
Cluster Analysis on Weekday Mobility.
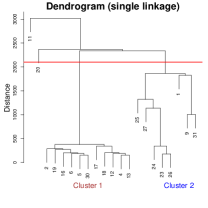
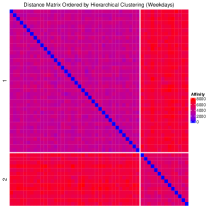
Given the structured weekday patterns, we conduct a cluster analysis to further investigate mobility trends. The results are presented in Figure 8. For each day, we use the same smoothing bandwidths ( and ) and compute pairwise distances via the integrated squared difference between log-densities:
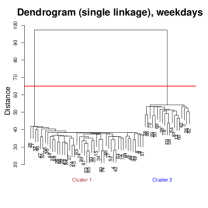
Applying single-linkage hierarchical clustering, the dendrogram (first panel of Figure 8) identifies four clusters, separated by the red horizontal line. Cluster 3 contains Day 11 exclusively. All GPS records on Day 11 are located at home, which corresponds to a wildfire event in the individual’s region that forced he or she to remain indoors throughout the day. So we classify it as an outlier. And cluster 4 also consists of one day (Day 20). On this day, the individual made an additional stop when going back home from office, visiting an entertainment venue that was only recorded once in the entire dataset.
We focus on clusters 1 and 2, comparing their average GPS densities and conditional centers at six different time points. Although both clusters represent commuting patterns, they exhibit distinct anchor locations around the workplace and different evening behaviors. In the lower part of the second and third panels of Figure 8, Cluster 1 shows two high-density regions in the evening, primarily at home and near the office, whereas Cluster 2 contains additional high-density area representing an alternative place to stay overnight (to the right of the main office location) and a park nearby. In particular, on days in Cluster 2, the individual sometimes stays in an alternative home overnight after leaving office rather than returning to the primary home, or visits the park, in the evening (e.g., for a walk) after staying in the alternative home for about 2 hours (and then goes back to the alternative home after visiting the park) By contrast, in Cluster 1, the individual tends to commute directly between home and office without these additional stops.
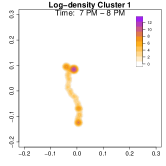
To highlight these differences, Figure 9 compares log-density estimates for four specific time intervals: 7-8 AM (morning rush hour), 5-6 PM (evening rush hour), 7-8 PM (post-work activities), and 9-10 PM (late evening). The top row (Cluster 1) exhibits only 2 high-density regions in the evening, while the bottom row (Cluster 2) shows 4 high-density regions (home, office, park and alternative apartment). As a result, Cluster 2’s pattern emphasizes extended or alternative routines after work including returning to the alternative home or a visit to the park near the work place. The clustering analysis uncovers two distinct weekday mobility patterns: Cluster 1: The individual commutes directly between home and office. Cluster 2: The individual has two options after working: the individual goes back home, otherwise, the individual goes back to the alternative home (sometimes also containing the visit to park after working). This method effectively reveals hidden mobility structures in the data, demonstrating the utility of GPS density estimation in understanding individual movement behavior.
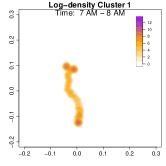
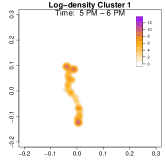
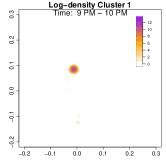
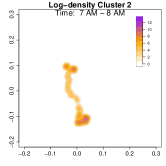
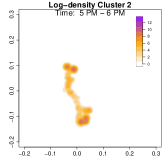
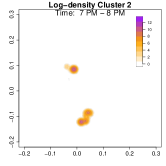
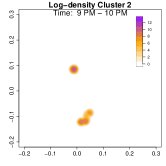
7 Discussion and future directions
In this paper, we introduced a statistical framework for analyzing GPS data. The general framework presented in Section 2 applies to GPS data collected from various entities, extending beyond human mobility. For studying human activity patterns, we developed the SMM in Section 5. Despite its simplicity, the SMM effectively captures major movement patterns within a single day and enables meaningful analyses. Our framework lays the foundation for numerous future research directions.
Population study. While this paper primarily focuses on analyzing the activity patterns of a single individual, extending our framework to a population-level analysis remains an open challenge. One key difficulty lies in the variation of anchor locations across individuals, as each person has distinct home and workplace locations. To accommodate population-level studies, modifications to the SMM are necessary to generalize anchor locations and account for heterogeneous mobility patterns. Also, a population-level study will lead to an additional asymptotic regime where the number of individual increases. Together with the two asymptotic regimes of the current framework (number of days and temporal resolution), we encounter a scenario with three asymptotics. The convergence rate and choice of tuning parameters will require adjustments.
Connections to functional data. Our framework transforms GPS data into a density map, establishing interesting connections with functional data analysis (Ramsay and Silverman, , 2002; Wang et al., , 2016). In particular, the daily average GPS density for an individual can be viewed as independent and identically distributed (IID) 2D functional data under the assumption that timestamps are generated in an IID setting. Existing functional data analysis techniques may therefore be applicable, offering new perspectives on GPS-based modeling. Notably, methods introduced in Section 5 suggest potential links between structural assumptions in the SMM and those in functional data analysis. In addition, when the sampling frequency is high, the two coordinates in the GPS data can be separated viewed as two functional data with a common but irregular spacing (Gervini, , 2009). Under this point of view, we may directly apply methods from functional data to handle GPS data. This alternative perspective may lead to a different framework for analyzing GPS data. Further exploration of these connections is an important research direction.
Limiting regime of measurement errors. Our current analysis considers asymptotic limits where the number of days and the temporal resolution . Another intriguing limit involves the measurement noise level, where , reflecting advancements in GPS technology. However, as measurement errors vanish, the density function becomes ill-defined. In this noiseless scenario, the distribution of a random trajectory point consists of a mixture of point masses (at anchor locations) and 1D distributions representing movement along trajectories. Addressing the challenges posed by singular measures (Chen and Dobra, , 2020; Chen, , 2019) in this regime is a crucial area for future investigation.
Alternative random trajectory models. While the SMM proposed in Section 5 provides practical utility and meaningful insights, it does not precisely model an individual’s movement. Specifically, the SMM assumes a constant velocity when an individual is in motion, leading to a step-function velocity profile with abrupt jumps at transitions between movement and stationary states. This assumption deviates from realistic human mobility patterns. Developing more sophisticated models that accurately capture velocity dynamics and movement variability remains an open problem for future research.
Topological data analysis. Topological data analysis (TDA; Wasserman, 2018; Chazal and Michel, 2021) is a data analysis technique to study the shape of features inside data. A common application of TDA is to study the morphology of the probability density function. The TDA can be applied to analyze GPS data in two possible ways. The first application is to use TDA to analyze the morphology of GPS density functions. This allows us to further understand the activity space. The second applications is to use TDA to investigate the latent trajectories generated the GPS data. The common/persistent features of trajectories informs us important characteristics of the individual’s activity patterns.
References
- Andrade and Gama, (2020) Andrade, T. and Gama, J. (2020). Identifying points of interest and similar individuals from raw gps data. In Mobility Internet of Things 2018: Mobility IoT, pages 293–305. Springer.
- Barnett and Onnela, (2020) Barnett, I. and Onnela, J.-P. (2020). Inferring mobility measures from gps traces with missing data. Biostatistics, 21(2):e98–e112.
- Burzacchi et al., (2024) Burzacchi, A., Bellanger, L., Gall, K. L., Stamm, A., and Vantini, S. (2024). Generating synthetic functional data for privacy-preserving gps trajectories. arXiv preprint arXiv:2410.12514.
- Cadre, (2006) Cadre, B. (2006). Kernel estimation of density level sets. Journal of multivariate analysis, 97(4):999–1023.
- Chabert-Liddell et al., (2023) Chabert-Liddell, S.-C., Bez, N., Gloaguen, P., Donnet, S., and Mahévas, S. (2023). Auto-encoding gps data to reveal individual and collective behaviour.
- Chacón, (2015) Chacón, J. E. (2015). A population background for nonparametric density-based clustering. Statistical Science, 30(4):518–532.
- Chacón and Duong, (2018) Chacón, J. E. and Duong, T. (2018). Multivariate kernel smoothing and its applications. Chapman and Hall/CRC.
- Chacón et al., (2011) Chacón, J. E., Duong, T., and Wand, M. P. (2011). Asymptotics for general multivariate kernel density derivative estimators. Statistica Sinica, 21(2):807–840. Accessed 5 Mar. 2025.
- Chazal and Michel, (2021) Chazal, F. and Michel, B. (2021). An introduction to topological data analysis: fundamental and practical aspects for data scientists. Frontiers in artificial intelligence, 4:667963.
- Chen, (2019) Chen, Y.-C. (2019). Generalized cluster trees and singular measures. The Annals of Statistics, 47(4):2174–2203.
- Chen and Dobra, (2020) Chen, Y.-C. and Dobra, A. (2020). Measuring human activity spaces from GPS data with density ranking and summary curves. The Annals of Applied Statistics, 14(1):409 – 432.
- Chen et al., (2017) Chen, Y.-C., Genovese, C. R., and Wasserman, L. (2017). Density level sets: Asymptotics, inference, and visualization. Journal of the American Statistical Association, 112(520):1684–1696.
- Duong, (2024) Duong, T. (2024). Using iterated local alignment to aggregate trajectory data into a traffic flow map. arXiv preprint arXiv:2406.17500.
- Early and Sykulski, (2020) Early, J. J. and Sykulski, A. M. (2020). Smoothing and interpolating noisy gps data with smoothing splines. Journal of Atmospheric and Oceanic Technology, 37(3):449–465.
- Elmasri et al., (2023) Elmasri, M., Labbe, A., Larocque, D., and Charlin, L. (2023). Predictive inference for travel time on transportation networks. The Annals of Applied Statistics, 17(4):2796–2820.
- Fan, (2018) Fan, J. (2018). Local polynomial modelling and its applications: monographs on statistics and applied probability 66. Routledge.
- Gervini, (2009) Gervini, D. (2009). Detecting and handling outlying trajectories in irregularly sampled functional datasets. The Annals of Applied Statistics, pages 1758–1775.
- Hägerstrand, (1963) Hägerstrand, T. (1963). Geographic measurements of migration. In Sutter, J., editor, Human Displacements: Measurement Methodological Aspects. Monaco.
- Hägerstrand, (1970) Hägerstrand, T. (1970). What about people in regional science? Papers of the Regional Science Association, 24:7–21.
- Huang et al., (2023) Huang, Y., Abdelhalim, A., Stewart, A., Zhao, J., and Koutsopoulos, H. (2023). Reconstructing transit vehicle trajectory using high-resolution gps data. In 2023 IEEE 26th International Conference on Intelligent Transportation Systems (ITSC), pages 5247–5253. IEEE.
- Ley and Verdebout, (2017) Ley, C. and Verdebout, T. (2017). Modern directional statistics. Chapman and Hall/CRC.
- Mao et al., (2023) Mao, J., Liu, L., Huang, H., Lu, W., Yang, K., Tang, T., and Shi, H. (2023). On the temporal-spatial analysis of estimating urban traffic patterns via gps trace data of car-hailing vehicles. arXiv preprint arXiv:2306.07456.
- Mardia and Jupp, (2009) Mardia, K. V. and Jupp, P. E. (2009). Directional statistics. John Wiley & Sons.
- Meilán-Vila et al., (2021) Meilán-Vila, A., Francisco-Fernández, M., Crujeiras, R. M., and Panzera, A. (2021). Nonparametric multiple regression estimation for circular response. TEST, 30(3):650–672.
- Newson and Krumm, (2009) Newson, P. and Krumm, J. (2009). Hidden markov map matching through noise and sparseness. In 17th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems (ACM SIGSPATIAL GIS 2009), November 4-6, Seattle, WA, pages 336–343.
- Nguyen et al., (2023) Nguyen, T. D., Pham Ngoc, T. M., and Rivoirard, V. (2023). Adaptive warped kernel estimation for nonparametric regression with circular responses. Electronic Journal of Statistics, 17(2):4011–4048.
- Papoutsis et al., (2021) Papoutsis, P., Fennia, S., Bridon, C., and Duong, T. (2021). Relaxing door-to-door matching reduces passenger waiting times: A workflow for the analysis of driver gps traces in a stochastic carpooling service. Transportation Engineering, 4:100061.
- Pewsey and García-Portugués, (2021) Pewsey, A. and García-Portugués, E. (2021). Recent advances in directional statistics. Test, 30(1):1–58.
- Polonik, (1997) Polonik, W. (1997). Minimum volume sets and generalized quantile processes. Stochastic processes and their applications, 69(1):1–24.
- Ramsay and Silverman, (2002) Ramsay, J. O. and Silverman, B. W. (2002). Applied functional data analysis: methods and case studies. Springer.
- Schönfelder and Axhausen, (2004) Schönfelder, S. and Axhausen, K. W. (2004). On the variability of human activity spaces. In Koll-Schretzenmayr, M., Keiner, M., and Nussbaumer, G., editors, The Real and Virtual Worlds of Spatial Planning, pages 237–262. Springer Verlag, Berlin, Heidelberg.
- Scott, (2015) Scott, D. W. (2015). Multivariate density estimation: theory, practice, and visualization. John Wiley & Sons.
- Sherman et al., (2005) Sherman, J. E., Spencer, J., Preisser, J. S., Gesler, W. M., and Arcury, T. A. (2005). A suite of methods for representing activity space in a healthcare accessibility study. International Journal of Health Geographics, 4:24–24.
- Silverman, (2018) Silverman, B. W. (2018). Density estimation for statistics and data analysis. Routledge.
- Simon, (2014) Simon, L. (2014). Introduction to Geometric Measure Theory. Cambridge University Press.
- Tsybakov, (1997) Tsybakov, A. B. (1997). On nonparametric estimation of density level sets. The Annals of Statistics, 25(3):948–969.
- Von Luxburg, (2007) Von Luxburg, U. (2007). A tutorial on spectral clustering. Statistics and computing, 17:395–416.
- Wang et al., (2016) Wang, J.-L., Chiou, J.-M., and Müller, H.-G. (2016). Functional data analysis. Annual Review of Statistics and its application, 3(1):257–295.
- Wasserman, (2006) Wasserman, L. (2006). All of nonparametric statistics. Springer Science & Business Media.
- Wasserman, (2018) Wasserman, L. (2018). Topological data analysis. Annual Review of Statistics and Its Application, 5(1):501–532.
- Yang et al., (2022) Yang, Y., Jia, B., Yan, X.-Y., Li, J., Yang, Z., and Gao, Z. (2022). Identifying intercity freight trip ends of heavy trucks from gps data. Transportation Research Part E: Logistics and Transportation Review, 157:102590.
SUPPLEMENTARY MATERIAL
- Numerical techniques (Section A):
-
We provide some useful numerical techniques for computing our estimators.
- Simulations (Section B):
-
We provide a simulation study to investigate the performance of our method.
- Assumptions (Section C):
-
All technical assumptions for the asymptotic theory are included in this section.
- Proofs (Section D):
-
The proofs of the theoretical results are given in this section.
- Data and R scripts:
-
See the online supplementary file.
Appendix A Numerical techniques
A.1 Conditional estimator as a weighted estimator
Recall that the estimator in equation (8) is
and the conditional PDF in equation (7),
where
is a local weight at time . So both estimators are essentially the weighted 2D KDE with different weights. This allows us to quickly compute the estimator using existing kernel smoothing library such as the ks library in R.
Moreover, the weights are connected by the integral
If we are interested in only the time interval , we just need to adjust the weight to be
and rerun the weighted 2D KDE. In practice, we often perform a numerical approximation to the integral based on a dense grid of . Computing the weights can be done easily by using only the grid points inside the interval .
A.2 A fast algorithm for the activity space
Recall that the -activity space is
Numerically, the minimization in is not needed. Since the time-weight EDF is a distribution function with a probability mass of on . Therefore, the summation remains the same when we vary without including any observation . Using this insight, let be the estimated density at . We then ordered all observations (across every day) according to the estimated density evaluated at each point
and let be the corresponding location and weight from . Note that is total number of observations.
In this way, if we choose , the level set will cover all observations of indices , leading to the proportion of being covered inside . Note that the division of is to account for the summation over days. As a result, for a given proportion , we only need to find the largest index such that the upper cumulative sum of is above :
| (22) |
With this, the choice leads to the set
| (23) |
Appendix B Simulation
B.1 Design of simulations
| Pattern | Probability |
|
Actions | ||||
| Pattern 1 | 15/28 | 9 | 0.15 | 0.5 | At home | ||
| 0.5 | 0.08 | 0.25 | Home to office | ||||
| 8 | 0.15 | 0.5 | At office | ||||
| 0.6 | 0.08 | 0.25 | Office to home | ||||
| 2 | 0.2 | 0.6 | At home | ||||
| 1 | 0.06 | 0.15 | Home to park to home | ||||
| 2.9 | Home | ||||||
| Pattern 2 | 5/28 | 8.5 | 0.15 | 0.5 | Home | ||
| 0.5 | 0.08 | 0.25 | Home to office | ||||
| 8 | 0.15 | 0.5 | At office | ||||
| 0.75 | 0.08 | 0.25 | Office to restaurant | ||||
| 1 | 0.08 | 0.25 | At restaurant | ||||
| 0.4 | 0.08 | 0.25 | Restaurant to home | ||||
| 0.95 | 0.1 | 0.3 | At home | ||||
| 1 | 0.06 | 0.15 | Home to park to home | ||||
| 2.9 | At home | ||||||
| Pattern 3 | 4/28 | 11 | 0.3 | 1 | At home | ||
| 0.75 | 0.15 | 0.45 | Home to supermarket | ||||
| 2.5 | 0.3 | 1 | At supermarket | ||||
| 0.75 | 0.15 | 0.45 | Supermarket to home | ||||
| 9 | At home | ||||||
| Pattern 4 | 1/28 | 10 | 0.3 | 1 | At home | ||
| 0.8 | 0.3 | 0.7 | Home to beach | ||||
| 5.7 | 0.35 | 1 | Beach | ||||
| 0.8 | 0.3 | 0.7 | Beach to home | ||||
| 6.7 | At home | ||||||
| Pattern 5 | 3/28 | 24 | At home |
To evaluate the performance of the proposed activity density estimators, we construct a simplified scenario involving a single fictitious individual residing in a small-scale world. This world contains five anchor points: home, office, restaurant, beach, and supermarket connected by several routes (Figure 3, the first panel).
Activity patterns.
We design five distinct daily activity patterns for this individual, illustrated in the 2nd to 6th panel in Figure 3. Specific details including the order of visits, the expected time spent at each location, and the probability of selecting each pattern are summarized in Table 1. Each day, the individual randomly chooses one of these five patterns.
For each location in a chosen pattern, the duration is drawn from a truncated normal distribution:
where and are the mean and standard deviation, and sets a reasonable range for the duration. The duration of final location in each pattern is computed as whatever time remains in the 24-hour day once all previous locations have been visited.
There are two reasons we use a truncated Gaussian distribution for the duration of each position:
-
•
First, controlling variance: By adjusting , we can reflect realistic scenarios; for example, weekday departures from home tend to be less variable than weekend departures for a beach visit. Hence, we set the variance of duration of the first position higher on weekends.
-
•
Second, ensuring a reasonable time distribution: Truncation avoids unrealistic time of visiting for some places (for example, a restaurant stay should not exceed typical operating hours).
Our ultimate goal is to estimate and over the time interval , which corresponds to the morning rush hour between 8 AM and 10 AM.
Timestamp generation. For simplicity, we assume that every day has equal number of observations, i.e., , and we choose as
such choice of reflects one week, one month, and three months of GPS observation data. The choices of correspond to one observation every 9 minutes, 3 minutes, or 1 minute on average.
To investigate estimator performance under both regular and irregular frequencies of observations, we generate timestamps in two different ways:
-
1.
Even-spacing: In each simulated day, the timestamps are evenly spaced at intervals of minutes. Then, the GPS observations are recorded every minutes.
-
2.
Realistic: To generate non-uniform timestamps which align with the realistic recording, We use real GPS data described in Section 6 in the following procedure:
-
(a)
Randomly select one individual from the real dataset.
-
(b)
For each day, randomly choose one day from that individual.
-
(c)
If the chosen day has fewer than real timestamps, generate the additional timestamps by sampling from a Gaussian kernel density estimate of that day’s timestamp distribution (using Silverman’s rule of thumb for bandwidth). If the chosen day has more than real timestamps, randomly remove timestamps until timestamps remain, where the probability of removal for each observation is the same.
This process yields timestamps per simulated day, preserving the original non-uniformity found in the selected individual’s data. The real data’s timestamp distribution is possibly very skew. This procedure preserves the original day-to-day skew and clustering patterns of timestamps found in real data. Figure 4 illustrates an example of a highly skewed timestamp distribution for one individual.
-
(a)
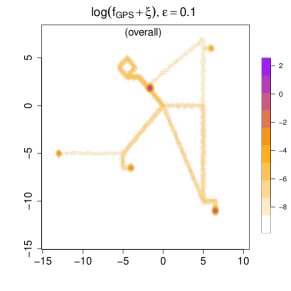
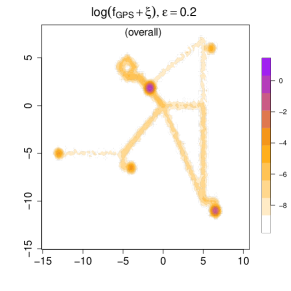
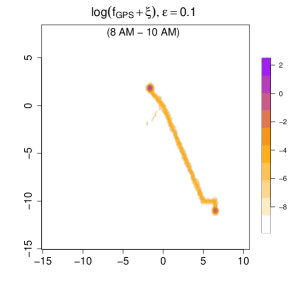
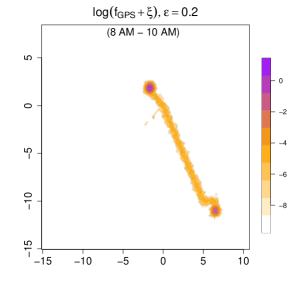
Measurement errors. We introduce measurement errors by drawing from a Gaussian noise distribution with or . The corresponding is shown in Figure 10, where is set as 0.0001. Note that we use a log-scale because the anchor locations (home and office) have a very high , which would otherwise dominate the scale so that we cannot see the overall pattern well. In the top panels, we display while in the bottom panel, we focus on the density during the morning rush hour (8 AM to 10 AM).
Compared with the real-data analysis in Section 6, here we choose a smaller . This adjustment is caused by the scale of coordinates. The density value will be lower if the data is in a larger spatial region. This smaller ensures low-frequency or low-duration regions, such as the route between home and the beach, remain distinguishable from truly unvisited areas in both visualization and the further analysis such as clustering. As a result, in subsequent clustering analyses, the reduced value helps more clearly separate visited versus unvisited locations, thereby improving the distinctiveness among different mobility patterns.
Bandwidth selection. After preliminary experiments using mean integrated squared error (MISE) as a performance measure, we found the following reference rule for the spatial and temporal smoothing bandwidth:
where
Here, denotes the spatial coordinates of the -th observation on day , and is its (normalized) timestamp within day . The weights ensure proper normalization over the total number of days and allow for variable sampling rates within a day.
Compared with standard bandwidth heuristics such as Silverman’s rule of thumb for multivariate kernels Chacón et al., (2011), our scale constants are noticeably smaller. This discrepancy arises because Silverman’s rule is often derived under assumptions of (approximately) unimodal or smooth data distributions. In contrast, our simulated environment exhibits strongly localized activity peaks due to prolonged stays at a small number of anchor points (e.g., home and office). As a result, the density near these anchor points is extremely high compared with other regions. A smaller bandwidth helps avoid oversmoothing these sharp peaks, thereby reducing bias and improving local accuracy of the estimated density. From a MISE perspective, capturing these density spikes precisely is critical, since errors around densely occupied points can contribute disproportionately to the integrated error. Consequently, a smaller scale constant not only accommodates the multimodal nature of the data but also minimizes MISE by enhancing resolution in areas with concentrated activity.
B.2 Results on the MISE
Estimating the average GPS density. For each combination of , we report the averaged mean integrated squared error (MISE) over a grid averaged over 100 repetitions, where each cell has area . The results for estimating appear in Tables 2–3.
| Even-spacing | |||||||
|---|---|---|---|---|---|---|---|
| 7 | 159 | 0.0839 | 0.0812 | 0.0839 | 0.8571 | 0.8482 | 0.8571 |
| 7 | 479 | 0.0619 | 0.0599 | 0.0619 | 0.6426 | 0.6353 | 0.6426 |
| 7 | 1439 | 0.0456 | 0.0438 | 0.0456 | 0.4442 | 0.4375 | 0.4442 |
| 30 | 159 | 0.0473 | 0.045 | 0.0473 | 0.5967 | 0.5874 | 0.5967 |
| 30 | 479 | 0.0359 | 0.0341 | 0.0359 | 0.4321 | 0.4249 | 0.4321 |
| 30 | 1439 | 0.0209 | 0.0197 | 0.0209 | 0.268 | 0.2623 | 0.268 |
| 90 | 159 | 0.0368 | 0.0344 | 0.0368 | 0.4592 | 0.4495 | 0.4592 |
| 90 | 479 | 0.0225 | 0.021 | 0.0225 | 0.3109 | 0.3041 | 0.3109 |
| 90 | 1439 | 0.0113 | 0.0105 | 0.0113 | 0.1729 | 0.1675 | 0.1729 |
| Realistic | |||||||
|---|---|---|---|---|---|---|---|
| 7 | 159 | 0.113 | 0.0844 | 0.1457 | 0.9321 | 0.8747 | 1.0424 |
| 7 | 479 | 0.097 | 0.0622 | 0.1192 | 0.7135 | 0.6473 | 0.819 |
| 7 | 1439 | 0.0925 | 0.0489 | 0.1017 | 0.5616 | 0.4736 | 0.642 |
| 30 | 159 | 0.0708 | 0.0472 | 0.0934 | 0.6512 | 0.5873 | 0.7415 |
| 30 | 479 | 0.0575 | 0.0325 | 0.0787 | 0.4859 | 0.4143 | 0.5773 |
| 30 | 1439 | 0.0462 | 0.0219 | 0.0642 | 0.349 | 0.2801 | 0.4359 |
| 90 | 159 | 0.0562 | 0.0337 | 0.0778 | 0.5228 | 0.4529 | 0.6108 |
| 90 | 479 | 0.0415 | 0.0224 | 0.0641 | 0.3734 | 0.3119 | 0.4677 |
| 90 | 1439 | 0.0286 | 0.0106 | 0.0432 | 0.2358 | 0.1751 | 0.3172 |
In Tables 2 (even-spacing), we see that all methods work well with the conditional method that performs slightly better than the others. And the marginal method has almost same MISE as naive method . Because timestamps are recorded at uniform intervals, each observation naturally represents a comparable portion of the day, thus reducing the penalty from ignoring time differences. A similar conclusion holds if timestamps are generated uniformly in .
In contrast, when timestamps are drawn from the real dataset, the results change significantly. Real-world GPS records are often non-uniform in time, so the naive estimator which assumes each data point is equally representative suffers from a pronounced bias. This effect is especially evident in the last row of Table 3, where exhibits a substantially higher MISE than either of the proposed estimators. Notably, both and handle irregular sampling much more effectively, resulting in significantly lower MISE.
Estimating the interval-specific GPS density. In addition to the average GPS densities, we also consider the case of estimating the GPS density during the morning rush hour (8 AM - 10 AM). Tables 4 and 5 present the results for this interval-specific density.
The performance trends mirror those observed for daily averages (Table 4): all three estimators remain consistent, and the conditional method has a slight edge over the other two. The naive and weighted methods show comparable MISE values.
Table 5 shows the MISE of three estimators when we generate the timestamps from a realistic distribution. As with the daily density estimation, the real (irregular) distribution of timestamps reveals a clear advantage for . The naive approach again shows higher MISE, though in this specific morning interval, the difference between and is smaller than in the full-day scenario. This arises because the distribution of the real data timestamps between 8 AM and 10 AM are not as severely skewed as the distribution of timestamps in the whole day, so the advantage of is somewhat diminished.
Overall, the results confirm that both and more robustly handle uneven timestamp distributions compared to the naive approach, and that typically offers the best performance in terms of MISE across a variety of sampling settings.
| Realistic | |||||||
|---|---|---|---|---|---|---|---|
| 7 | 159 | 0.1802 | 0.1212 | 0.1794 | 1.2959 | 0.8483 | 1.2935 |
| 7 | 479 | 0.1287 | 0.0917 | 0.1281 | 0.9944 | 0.6345 | 0.9922 |
| 7 | 1439 | 0.1184 | 0.0789 | 0.1184 | 0.8261 | 0.4762 | 0.8253 |
| 30 | 159 | 0.0971 | 0.0676 | 0.0964 | 0.864 | 0.5967 | 0.8615 |
| 30 | 479 | 0.0787 | 0.0548 | 0.0783 | 0.6974 | 0.436 | 0.6955 |
| 30 | 1439 | 0.0498 | 0.0333 | 0.0497 | 0.4488 | 0.2693 | 0.4482 |
| 90 | 159 | 0.0777 | 0.0545 | 0.0772 | 0.7083 | 0.4752 | 0.7058 |
| 90 | 479 | 0.049 | 0.0341 | 0.0489 | 0.4616 | 0.3144 | 0.46 |
| 90 | 1439 | 0.038 | 0.0204 | 0.0379 | 0.3093 | 0.1817 | 0.3089 |
| Realistic | |||||||
|---|---|---|---|---|---|---|---|
| 7 | 159 | 0.1489 | 0.1099 | 0.1522 | 1.0886 | 0.816 | 1.1085 |
| 7 | 479 | 0.1064 | 0.0812 | 0.1123 | 0.8289 | 0.582 | 0.8495 |
| 7 | 1439 | 0.0909 | 0.0749 | 0.1006 | 0.6751 | 0.4664 | 0.7054 |
| 30 | 159 | 0.0894 | 0.065 | 0.0902 | 0.7808 | 0.5702 | 0.7857 |
| 30 | 479 | 0.0637 | 0.0463 | 0.0651 | 0.5714 | 0.3954 | 0.5776 |
| 30 | 1439 | 0.0542 | 0.0424 | 0.0573 | 0.4103 | 0.3121 | 0.4225 |
| 90 | 159 | 0.0616 | 0.0482 | 0.0627 | 0.5631 | 0.4508 | 0.568 |
| 90 | 479 | 0.046 | 0.0357 | 0.0486 | 0.3906 | 0.3136 | 0.4013 |
| 90 | 1439 | 0.0286 | 0.0162 | 0.0304 | 0.2301 | 0.1587 | 0.2373 |
B.3 Applications based on the simple movement model
In our simulation setup, Pattern 1 and Pattern 2 correspond to typical weekday schedules (containing the office as an anchor point), whereas Pattern 3, Pattern 4, and Pattern 5 represent potential weekend routines (not containing office as anchor point). We separately analyze the data in weekdays and weekends using the framework of Section 5. Throughout this subsection, we fix the measurement error at and assume evenly spaced timestamps with 479 GPS observations per day. We generate a total of 90 simulated days under these conditions.
B.3.1 Anchor location recovering
From Table 1, we identify three anchor locations for weekdays (home, office, restaurant) and another set of three for weekends (home, supermarket, beach). Across the entire 90 days, these yield five un anchor points overall.
Using the method described in Section 5.1 with , we recover all anchor locations accurately, whether we consider:
1. All 90 days combined,
2. Weekdays only (Patterns 1 and 2), or
3. Weekends only (Patterns 3, 4, and 5).
Figure 11 compares the true anchor points with the detected ones in each of these scenarios. Under a suitably chosen threshold, and assuming sufficient time spent at each anchor point, the technique in Section 5.1 locates the simulated individual’s anchor sites with high accuracy.
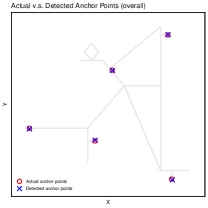
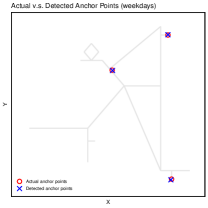
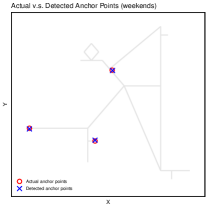
B.3.2 Analysis on activities
Figure 12 depicts the contour region , which encloses the spatial area where the individual spends a proportion of their time. We show contours for in three scenarios:
-
1.
All Days (Left Panel): Over 90 days, 90% of the individual’s time (orange contour) is concentrated at home and office, consistent with Patterns 1 and 2 being selected more frequently.
-
2.
Weekdays (Middle Panel): On weekdays alone, the same 90% region again focuses heavily on home and office, indicating most weekday hours are spent in these two anchor locations.
-
3.
Weekends (Right Panel): On weekends (Patterns 3 to 5), more than 90% of time is spent at home, reflecting fewer trips away from the house (with occasional visits to the supermarket or beach).
B.3.3 Clustering of trajectories
Clustering of days. A key aspect of our study is to cluster the simulated individual’s weekday days (Patterns 1 and 2) and weekend days (Patterns 3, 4, and 5) based on their GPS trajectories. To do so, we separately analyze the weekday observations and the weekend observations.
For each day, we compute the smoothed conditional density (using the bandwidths and determined earlier) and measure pairwise distances via the integrated squared difference between log-densities:
where is the estimated conditional density for day , and for day . Same as the log-density visualization in Figure 10, here, is set as 0.0001.
Figure 13 further illustrates the structure of the clusters by showing the re-ordered distance matrices for weekdays (left panel) and weekends (right panel). In both cases, we see a pronounced block structure, indicating clear separations between the different activity patterns measured based on our proposed density estimation method.

We perform single-linkage hierarchical clustering, producing dendrograms of weekday and weekend data (Figure 14). After comparing with the known activity pattern for each day, we find that hierarchical clustering achieves 100% accurate day-level classifications, perfectly matching the original activity patterns used to generate the data.
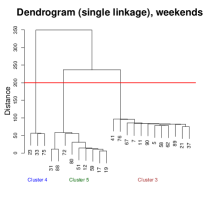
Conditional density on clustered days. To further illustrate how the discovered clusters differ in their spatiotemporal patterns, we compare conditional densities at specific times of day.
Figure 15 shows the estimated conditional density at 6:00 PM for each weekday cluster (i.e., Patterns 1 and 2). The densities differ markedly: in Pattern 1, the individual leaves the office and goes directly home, whereas in Pattern 2, they stop at a restaurant (top-right anchor) before returning home.
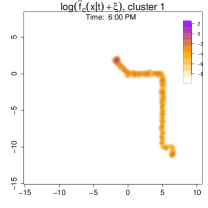
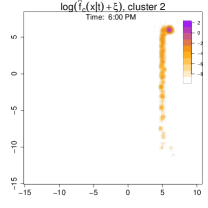
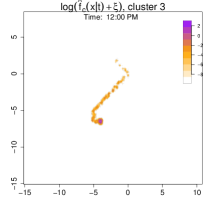
Figure 16 displays the conditional density at 12:00 PM for each weekend cluster. In Pattern 3, the individual is often near the supermarket around noon; in Pattern 4, they might be found at the beach; and in Pattern 5, they remain at home throughout the day.
Centers on each cluster. Given these day-level clusters, we also estimate a cluster-specific center representing the average location for each cluster at time . Figure 17 shows the computed centers at six time points (from 6:00 AM to 9:00 PM) for each cluster. The first (top-left) panel shows the combined data (all days), and the remaining panels correspond to each of the five clusters.
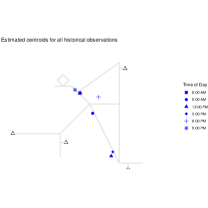
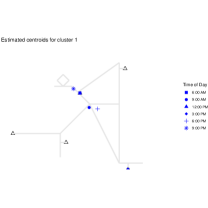
On weekdays, for four of the six time points 6:00 AM, 12:00 PM, 3:00 PM, and 9:00 PM, both clusters have roughly the same center (reflecting time spent at home or in the office). However, at 9:00 AM, the Cluster 1 center is closer to home, whereas the Cluster 2 center is closer to the office, consistent with the expected earlier departure in the weekdays’ morning under Pattern 2 in Table 1. At 6:00 PM, Cluster 1 centers near home, while Cluster 2 centers near the restaurant, mirroring the aforementioned difference in post-work behavior.
Each weekend pattern displays a distinct midday center, aligning with the anchor points for each pattern on weekends: supermarket for Pattern 3, beach for Pattern 4, and home for Pattern 5.
Appendix C Assumptions
Assumption 1 (Property of the kernel function)
The 2-dimensional kernel function satisfies the following properties:
(a) for any ;
(b) is symmetric, i.e. for any satisfying , we have ;
(c) ;
(d) .
(e) have Lipchitz property: there exists constant such that, for any , we have
Assumption 1 are standard assumptions on the kernel functions (Wasserman, , 2006). The additional requirement is the Lipchitz condition (e) but it is a very mild condition.
Assumption 2
Any random trajectory is Lipschitz, i.e., there exists a such that for any .
The Lipschitz condition in Assumption 2 allows the case where the individual suddenly start moving. It also implies that the velocity of the individual is finite (the Lipschitz constant).
Assumption 3
The density of measurement error is bounded in the sense that , , and are uniformly bounded by a constant for every .
The Assumption 1 is the common assumption for kernel density estimation, and most common kernel functions can satisfy it. When the distribution of measurement error is fixed, then the Assumption 3 is automatically satisfied.
By the convolution theory, Assumptions 3 implies that the GPS density has bounded second derivative.
Assumption 4
The kernel function is a symmetric PDF and and is Lipschitz.
Assumption 4 is for the kernel function on the time. It will be used when we analyze the asymptotic properties of the conditional estimator.
Appendix D Proofs
D.1 Proof of Proposition 1
D.2 Proof of Proposition 2
For regular GPS density , we have
Moreover, the right-hand-side in the above inequality can further be bound by
Note that we use the fact that is an isotropic Gaussian with a variance , so
D.3 Proof of Proposition 3
Proof. We can write as
D.4 Proof of Proposition 4
Proof. A straight forward calculation shows that
Given , a necessary condition to is that . Thus,
Putting this into the long inequality shows that
which is the desired result after rearrangements.
D.5 Proof of Theorem 5
Let is the estimated density of th day observations, i.e.
Since the latent trajectories across different days are IID, this estimator will be IID quantities in different days if the timestamps are the same for every . Since the time-weighted estimator can be written as the mean of each day, i.e.,
we can investigate the bias of by investigating the bias of versus . The following lemma will be useful for this purpose.
Lemma 8 (Riemannian integration approximation of GPS density)
Assume assumptions 1 to 3. For any and a trajectory , there are constants such that depends on the maximal velocity of and depends on the distribution of with
| (24) |
for every .
Proof.[Proof of Lemma 8] Since , without loss of generality, we only need to derive (24) under . Then, for , we can decompose (24) to the following two terms:
| (25) | ||||
To simplify in (25), we use to denote , i.e. the expection of at time given latent trajectory .
Term (I): Then, by , Term (I) in (25) can be written as
For the weights of first and last observation, note that,
We have
| (26) |
Term (II): Note that , then Term (II) in the (25) can be decomposed to
| (27) |
Namely, we decompose (II) into each interval so that we can easily compare it with term (I).
Combining (26) and (27), (25) can be written as:
| (28) |
In RHS of (28), the term (III) represents the error caused by the approximation using GPS observations. The source of the term (IV) and (V) is due to our design of circular weights for the first and last observation in each day.
Before deriving the convergence rate of term (III), (IV) and (V) in (28), note that, by Assumption 2 (velocity assumption) and Assumption 1 (Lipchitz property of the kernel function ), for every the term in the further analysis can be bounded in the following way:
| (29) |
where
Term (III): For the convergence rate of the term (III) in (28), we find that
| (30) | ||||
In (30), for every and corresponding to each integral of the summation, we have Hence, by applying (29), the term (III) in (28) can be bounded by
| (31) |
for some constant .
Term (IV): For term (IV):
| (32) |
Since two parts in (32) have same form, we only need to focus on the first term for RHS of (32). Recall , then, for , . Thus,
| (33) |
Similarly, for the second term of RHS of (32), we have
| (34) |
Term (V): For term (V):
| (35) |
Similar as the procedure of deriving convergence rate of term (IV), the two parts in RHS of (35) have same form, we only need to focus on the first term for RHS of (35), for , . Thus,
| (36) |
Similarly,
| (37) |
Proof. For any , can be decomposed to the following three terms:
Term (I): ; For any , we have
By Assumption 3, is twice differentiable,
By Assumption 1 and Assumption 3, , , is bounded. Hence,
| (38) |
Term (II): . Recall that to is the estimated density contributed by the observations in th day, i.e.
Then, we can decompose the expectation of the density estimator:
Note that
Hence, term (II) can be written as
Then, by Lemma 8, for any and , there is uniform constant such that
for every . Hence,
Term (III). Note that the term (III) is the variance of :
by the independence among . To simplify, we only need to consider . Then we calculate
| (39) | ||||
For the first term of the RHS of (39), note that are IID,
Note that, for any , only depends on the measurement error that is independent at each timestamp. Then,
By Assumption 1 and 3, and is bounded, we have
| (40) |
For the second term in RHS of (39), by
| (41) | ||||
we consider in (41) first. For any :
For any , is upped-bounded by , then the RHS of (41) can be upper-bounded by
By Assumption 3, is uniformly bounded by some constant. Hence,
| (42) |
Hence, the convergence rate of Term (III) is
Combining the convergence rate of 3 terms derived above, we have
D.6 Proof of Proposition 6
Proof. From equation (11), we have
Since the temporal resolution bias (B) is the dominating term, we should choose to optimize with respect to this, which leads to when . This leads to the inequality when we put into the inequality .
On the other hand, (S) dominates (B) when and in this case, the optimal smoothing bandwidth is . By putting this into , we obtain the inequality .
The convergence rates are obtained by simply plug-in these optimal smoothing bandwidth.
Note that at the critical point , we have , so the two choices coincide.
D.7 Proof of Theorem 7
We use to denote the th day’s contribution to , i.e.
Recall that , then, for any , we define in the following way:
For any , we define as
| (43) |
With the above definitions, and can be written as
| (44) |
Our analysis begins with a lemma controlling the error for a given trajectory .
Lemma 9
Proof. By the independence among , WLOG, we can just let .
Bias: We first derive the bias of , for any , by variable changing , and (43), we have
Then, by Assumption 3, we apply Taylor expansion on :
By Assumption 4, , then
Hence,
for any
Step 2 (Variance): As for the variance, for any ,
| (47) |
In (47), by Assumption 3, is upper-bounded by some constant , then for every
| (48) |
for any , where the last inequality is derived by Assumption 3 that is bounded. Plugging (48) to (47), we obtain
for any .
Now we formally state our proof of Theorem 7.
Proof. Recall that we use to denote the th day’s contribution to , i.e.
Then, can be written as
where represents the kernel-sum weight for each day. Note that for every .
Bias: The expectation of is
where, for any :
And can be written as
By the (45) in Lemma 9, for any ,
So,
Furthermore, by Assumption 2 and Assumption 3, note that there exists constant and such that
hold for any , and . Then,
| (49) |
Variance: By the independence of mobility among each day,
By , for every , we have
| (50) |
WLOG, we can simply let .
For the term in RHS of (50), for any , by (46) in Lemma 9, we have
So, by Assumption 4 (boundness of ), we have
| (51) | ||||
For the term in the RHS of (50), for any , by Assumption 3, is bounded by some constant , we have
Hence,
| (52) |
Combining (51) and (52), we have
| (53) |
Combining (49) and (53), we get