A Statistically Principled and Computationally Efficient Approach to Speech Enhancement using Variational Autoencoders
Abstract
Recent studies have explored the use of deep generative models of speech spectra based of variational autoencoders (VAEs), combined with unsupervised noise models, to perform speech enhancement. These studies developed iterative algorithms involving either Gibbs sampling or gradient descent at each step, making them computationally expensive. This paper proposes a variational inference method to iteratively estimate the power spectrogram of the clean speech. Our main contribution is the analytical derivation of the variational steps in which the encoder of the pre-learned VAE can be used to estimate the variational approximation of the true posterior distribution, using the very same assumption made to train VAEs. Experiments show that the proposed method produces results on par with the aforementioned iterative methods using sampling, while decreasing the computational cost by a factor 36 to reach a given performance.
3cm(11.1cm,-6.2cm) SUBMITTED TO INTERSPEECH 2019
Index Terms: Speech enhancement, variational autoencoders, variational Bayes, non-negative matrix factorization.
1 Introduction
Speech enhancement is the problem of extracting a speech source from a noisy recording [1, 2]. It is commonly tackled by discriminative methods using deep neural networks (DNNs) to predict time-frequency masks [3, 4], clean power spectrograms[5] or to model the signal variance [6] from spectrograms of mixtures. While the performances of these methods are satisfactory, their generalization capabilities are limited due to their supervised nature. Indeed, DNNs trained this way are specific to a task and a recording condition. Instead, generative approaches do not suffer from this drawback. Once a source model has been learned, the statistical model can account for the different tasks and recording conditions.
Non-negative matrix factorization (NMF) [7] is a popular method for speech enhancement in which power or amplitude spectrograms are approximated as the product of two non-negative matrices. While certain forms of NMF can be interpreted as generative, they suffer from their linearity assumptions. Very recent studies have combined the modelling power of DNN with statistical approaches in order to design unsupervised speech enhancement and source separation methods in both single-channel [8, 9, 10] and multichannel scenarios [11, 12, 13, 14, 15]. The main idea of these studies is to use variational autoencoders (VAEs) [16] to replace the NMF generative model, thus benefiting from DNNs’ representational power. Combined with an observation model, Expectation-Maximization (EM) [17] or Bayesian inference [18] algorithms can be derived to iteratively estimate individual source spectra from a given mixture.
In [8, 9, 10, 11, 12], speech enhancement is performed using a pretrained VAE-based generative model of speech spectra combined with an unsupervised NMF model for the noise. Inference of the clean speech involves using the Metropolis-Hastings algorithm [19] to estimate an intractable distribution over the VAE’s latent space. Similar approaches applied to source separation are developed in [13, 14], where the latent variables are updated using backpropagation. While the algorithms analytically derived in [8, 9, 10, 11, 12, 13, 14, 15] show promising performances, sampling and backpropagation methods are computationally expensive.
In order to train a VAE, an encoder is jointly learned with the generative model. The role of the encoder is to approximate the true, but intractable, posterior. Once the VAE is trained, the encoder could in principle be used to approximate the true posterior. Interestingly, [15] proposes a heuristic algorithm for multichannel source separation based on [13] which uses this property of the encoder to achieve computational efficiency. However this inference algorithm is not statistically principled.
In this study, we present a Bayesian single-channel speech enhancement algorithm in which a VAE is used as generative model of speech spectra, and the noise is modelled using NMF. After unsupervised training of the speech model, the inference constits in iteratively updating the source estimates using Wiener filtering and updating the corresponding latent representation using the encoder. No sampling or backpropagation being required, our method is significantly faster than in [8, 9, 10, 11, 12, 13, 14]. The use of the encoder differs from [15], and, unlike it, it is not heuristic but motivated by the same variational approximation as the one used to train VAEs. To the best of our knowledge, this is the first method to propose a statistically principled approach re-using the probabilistic encoder as a posterior approximator.
We first introduce the VAE framework and its application to spectrogram modelling. We then detail our assumptions and our inference algorithm. Experiments and results will be presented before we finally conclude.
2 Model
Given an observation of clean speech embedded in noise, the goal of speech enhancement is to produce an estimate of the clean speech. Our approach is to use a VAE as the generative model of clean speech spectra to infer this estimate. We will first describe the VAE framework and its training procedure in Section 2.1 and 2.2 before introducing the observation model in Section 2.3.
2.1 Generative speech model
A common approach to modeling sound sources is to assume the short time Fourier Transform (STFT) coefficients are proper complex Gaussian random variables. With denoting the frequency index and the time-frame index, for all , each source STFT coefficient independently follows
| (1) |
Several frameworks have been used to model the variance of this distribution [20, 2]. To this end, we choose to use the VAE framework, which uses the representational power of DNNs to build generative models. It consists in mapping a zero-mean unit Gaussian random variable through a DNN, into the desired output distribution. In our setting, we use it to represent . The generative model can be written as
| (2) | ||||
| (3) |
where is a non-linear function implemented by a DNN with parameters . Each is one neuron of a F-dimensional output layer of a single DNN.
2.2 VAE training and posterior approximation
The VAE is trained on clean speech data by maximizing the likelihood , with . To do so, we introduce a variational approximation of , , parametrized by . We have
| (4) | ||||
| (5) |
where denotes the Kullback-Leibler (KL) divergence. The KL term on the left hand side of (4) being always positive, is a lower bound of the marginal log-likelihood . We can thus maximize the individual with respect to and in order to maximize the log-likelihood . For all , is defined as in [8]
| (6) |
where and are DNN-based functions parametrized by . Finally, we can use (2), (3) and (6) to write (5) as
| (7) | ||||
where denotes the Itakura-Saito divergence, and denotes equality up to a constant. Using the so-called reparametrization trick [16], we can maximize using gradient descent optimization algorithms [21].
The variational distribution is usually considered as an unwanted by-product of the training procedure of the VAE, only introduced to learn . However, by examining carefully (4), we can see that while maximizing can only increase the log-likelihood, it also decreases the KL divergence between the true posterior and its variational approximation. In other words, in addition to the generative speech model, the VAE provides a variational approximation of the true posterior. This feature will play a key role in the inference algorithm proposed in Section 3.
2.3 Noisy speech model
As in [8], the STFT coefficients of the noise are modelled with a rank- NMF Gaussian model. For all
| (8) |
with , .
Finally, independently for all , the single-channel observation of the noisy speech is modeled by
| (9) |
where and are independent.
3 Inference
Given a noisy speech signal , our goal is now to maximize the likelihood of given the mixture model (9), the generative model of speech (2), (3) and the NMF model (8). With and , we consider to be the set of latent variables and the parameters of the model. We introduce , a variational approximation of . We have
| (10) |
We suppose that the variational distribution factorizes as
| (11) |
We can then iteratively maximize with respect to the factorized distributions and the NMF parameters. The variational distributions’ updates are given by (10.9) in [18]
| (12) | ||||
| (13) |
and can be updated by maximizing the following:
| (14) |
We detail those updates below, and in the supporting document [22].
3.1 E-(s,n) step
We define to make the notation less cluttered. Using (12), we find (see [22])
| (15) |
where and are defined as
| (16) |
with
| (17) |
where are randomly drawn from .
We note and define and to be the diagonal terms of .
3.2 E-z step
3.3 M-step
3.4 Speech Reconstruction
Let and be respectively the set of NMF parameters and the variational distribution estimated by the proposed algorithm. The final estimate of the source is given, as in [8], by
| (23) | ||||
| (24) |
There are three ways to evaluate this estimate.
The straightforward way is to replace in (23) by its variational approximation . The expectation over can also be approximated using the Metropolis Hastings (MH) algorithm as in [8], using the mean of as the initial sample. And finally we can compute the expectation in (24) by replacing by its variational approximation . We will respectively refer to these methods as S-Wiener, MH-Wiener and Z-Wiener for ease of referencing.
Metropolis-Hastings : At the -th iteration of the Metropolis-Hastings algorithm, we draw a random sample for each according to
| (25) |
The acceptance probability can be computed as
| (26) |
We accept the new sample and set only if , drawn from a uniform distribution , is smaller than . We keep only the last samples to compute from (24) and discard the samples drawn during the burn-in period.
4 Experimental evaluation
4.1 Experimental settings
Dataset: As in [8, 9], we use the the TIMIT corpus [24] to train the clean speech model. At inference time, we mix speech signals from the TIMIT test set with noise signals from the DEMAND corpus [25] at 0dB signal-to-noise ratio, according to the file provided in in the original implementation of [8] 111https://gitlab.inria.fr/sileglai/mlsp2018. Note that both speakers and utterances are different from those in the training set.
VAE’s architecture and training: The architecture of the VAE is the same as in [8]. The hyperbolic tangent of an input 128-dimensional linear layer passes through two L-dimensional linear layers to estimate and , from which is sampled using the reparametrization trick. is then fed to a 128-dimensional linear layer with hyperbolic tangent activation followed by an linear output layer predicting . For training, we computed the STFT of the utterances with a 1024-points sine window and a hop size of 256 points. 20 of the training set is held for validation. A VAE with is trained with the Adam optimizer [26], using a learning rate of and a batch size of 128. Training stops if no improvement is seen on the validation loss for 10 epochs.
Baseline methods: We compare our method to two baselines. The first baseline, developed in [8], shares the same statistical assumptions made in Section 2 except for the inclusion of a gain factor in (9). The inference is performed using a Monte Carlo Expectation-Maximization (MCEM) algorithm in which MH sampling is used to estimate the true posterior. We will refer to this method as MCEM. The second baseline is a heuristic we introduce to evaluate the impact of the covariance term in (20) on the convergence of the algorithm. We simply remove from (20) and the rest of the algorithm remains unchanged. Note that this is similar to the heuristic developped in [15] for determined multichannel source separation, only adapted to single-channel speech enhancement.
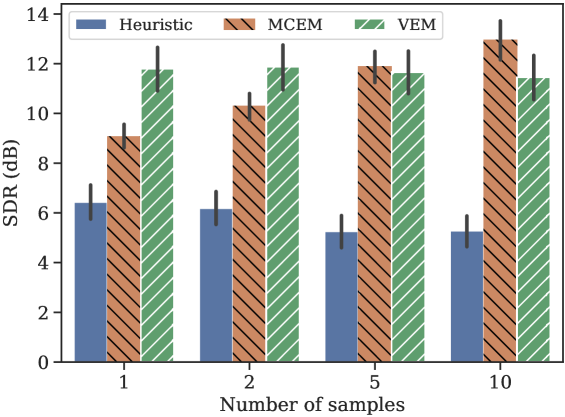
Inference Setting: For fair comparaison, we use the same settings for the three methods : the rank of the NMF model is set to , the latent dimension of the VAE is set to and the same stopping criterion is used as in [8]. is initialized based on and for the final speech estimate, equation (24) is approximated using the last 25 samples of a 100-iteration MH sampling with . In [8], for samples used, the total number of draws is . The methods will be compared for a same number of samples actually used to estimate the expected values : if samples are used to evaluate (17), samples will be drawn in the MCEM case.
4.2 Results
Experiment 1: We first compare the performances of the three methods on the test set described above, in terms of Signal to Distorsion Ration (SDR) [27], computed using the mir_eval222https://github.com/craffel/mir_eval toolbox. The comparison is done for different numbers of samples . As can be seen in Fig. 1, the heuristic algorithm consistently performs worse than both other methods, proving the importance of the covariance term in (20). We also see that the performances of the proposed algorithm do not depend on the number of samples drawn to approximate (17), contrary to the MCEM algorithm which presents poor performances for and outperforms the proposed method for . The superiority of the MCEM algorithm for a large number of samples is not surprising due to the approximation involved in the VEM approach.
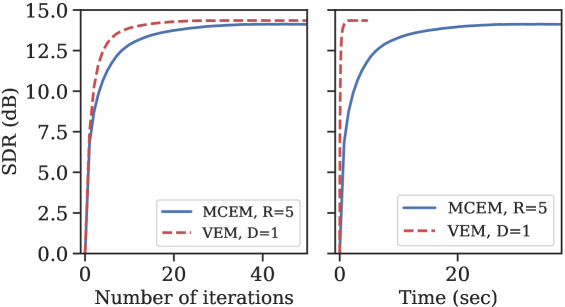
Experiment 2: We then compare the SDR achieved by the MCEM and VEM methods as a function of the computational time, in terms of number of iteration and absolute time. The number of samples was set to 1 for the VEM, and to 5 for the MCEM so as to achieve a similar SDR at convergence (see Fig. 1). At each iteration of both methods, we estimate the speech spectra by approximating (24) with MH sampling and we compute the SDR. This is done for each test utterance. Each individual SDR curve is then padded with the SDR obtained at the last iteration and all SDR curves are averaged to produce the left graph in Fig. 2. We observe that the proposed method converges faster which suggests that using the encoder allows for bigger jumps in the latent space than the sampling method with a small number of samples. On a 4-core i7-8650U CPU, one iteration takes on average 55 ms and 753 ms for the VEM and the MCEM algorithm respectively. Using these numbers, we can convert the SDR as a function of the number of iterations to the SDR as a function of time. This is shown in the right part of Fig. 2 where the superiority of the proposed algorithmm in terms of absolute speed is clear. To compare the execution times, for each utterance and for both algorithms we compute the number of iteration needed to reach the final SDR up to 0.5dB tolerance. The ratio between the number of iterations multiplied by the time per iteration ratio yields an average computational cost decrease factor of 36 to reach the same performance.
Experiment 3: In this experiment, we compare the three different ways of computing the source STFT coefficients in (23). We present the mean SDR after convergence for the three possible methods in Table 1. We can see that MH sampling consistently outperforms the other methods, suggesting that a better posterior approximation benefits to the quality of the reconstruction.
| MH-Wiener | S-Wiener | Z-Wiener | |
|---|---|---|---|
| VEM | 11.8 | 11.4 | 11.4 |
| Heuristic | 6.4 | 5.8 | 5.8 |
| MCEM | 11.9 | / | / |
5 Conclusion
In this paper, we proposed a speech enhancement method based on a variational EM algorithm. Our main contribution is the analytical derivation of the variational steps in which the encoder of the pre-learned VAE can be used to estimate the variational approximation of the true posterior distribution, using the very same assumption made to train VAEs. Experimental results showed that the principled approach outperforms its heuristic counterpart, and produces results on par with the algorithm proposed by Leglaive et al. [8] in which the true posterior is approximated using MH sampling. Additionally, the proposed algorithm converges 36 times faster. Future work includes multichannel and multisource extension of this work. The use of other statistical models of speech spectra [28, 29, 30] will also be explored.
References
- [1] P. C. Loizou, Speech Enhancement: Theory and Practice, 2nd ed. Boca Raton, FL, USA: CRC Press, Inc., 2013.
- [2] E. Vincent, T. Virtanen, and S. Gannot, Audio Source Separation and Speech Enhancement. Wiley, Aug. 2018.
- [3] F. Weninger, J. R. Hershey, J. L. Roux, and B. W. Schuller, “Discriminatively trained recurrent neural networks for single-channel speech separation,” 2014 IEEE Global Conference on Signal and Information Processing (GlobalSIP), pp. 577–581, 2014.
- [4] J. R. Hershey, Z. Chen, J. Le Roux, and S. Watanabe, “Deep clustering: Discriminative embeddings for segmentation and separation,” 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Mar 2016.
- [5] X. Lu, Y. Tsao, S. Matsuda, and C. Hori, “Speech enhancement based on deep denoising autoencoder,” in INTERSPEECH, 2013.
- [6] A. A. Nugraha, A. Liutkus, and E. Vincent, “Multichannel audio source separation with deep neural networks,” IEEE/ACM Transactions on Audio Speech and Language Processing, vol. 24, no. 9, pp. 1652–1664, 2016.
- [7] A. Ozerov and C. Fevotte, “Multichannel nonnegative matrix factorization in convolutive mixtures for audio source separation,” IEEE Transactions on Audio, Speech and Language Processing, vol. 18, no. 3, pp. 550–563, 2010.
- [8] S. Leglaive, L. Girin, and R. Horaud, “A variance modeling framework based on variational autoencoders for speech enhancement,” in Proc. IEEE Int. Workshop on Machine Learning for Signal Processing (MLSP), 2018.
- [9] S. Leglaive, U. Simsekli, A. Liutkus, L. Girin, and R. Horaud, “Speech enhancement with variational autoencoders and alpha-stable distributions,” in IEEE International Conference on Acoustics Speech and Signal Processing (ICASSP). Brighton, United Kingdom: IEEE, 2019, pp. 1–5.
- [10] Y. Bando, M. Mimura, K. Itoyama, K. Yoshii, and T. Kawahara, “Statistical speech enhancement based on probabilistic integration of variational autoencoder and non-negative matrix factorization,” in 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, apr 2018, pp. 716–720.
- [11] S. Leglaive, L. Girin, and R. Horaud, “Semi-supervised multichannel speech enhancement with variational autoencoders and non-negative matrix factorization,” no. 3, 2018.
- [12] K. Sekiguchi, Y. Bando, K. Yoshii, and T. Kawahara, “Bayesian Multichannel Speech Enhancement with a Deep Speech Prior,” Apsipa, no. November, pp. 1233–1239, 2018.
- [13] H. Kameoka, L. Li, S. Inoue, and S. Makino, “Semi-blind source separation with multichannel variational autoencoder,” aug 2018.
- [14] S. Seki, H. Kameoka, L. Li, T. Toda, and K. Takeda, “Generalized Multichannel Variational Autoencoder for Underdetermined Source Separation,” sep 2018.
- [15] L. Li, H. Kameoka, and S. Makino, “Fast MVAE Joint separation and classification of mixed sources based on multichannel variational autoencoder with auxiliary classifier,” CoRR, vol. abs/1812.0, 2018.
- [16] D. P. Kingma and M. Welling, “Auto-encoding variational bayes,” in ICLR, 2014.
- [17] G. Wei and M. Tanner, “A monte carlo implementation of the em algorithm and the poor man’s data augmentation algorithms,” Journal of the American Statistical Association, vol. 85, no. 411, pp. 699–704, 1 1990.
- [18] C. M. Bishop, Pattern Recognition and Machine Learning. Springer, 2006.
- [19] C. P. Robert and G. Casella, Monte Carlo Statistical Methods. Springer-Verlag New York, Inc., Secaucus, NJ, USA, 2005.
- [20] E. Vincent, M. G. Jafari, S. A. Abdallah, M. D. Plumbley, and M. E. Davies, “Probabilistic modeling paradigms for audio source separation,” in Machine Audition: Principles, Algorithms and Systems, W. Wang, Ed. IGI Global, 2010, pp. 162–185.
- [21] S. Ruder, “An overview of gradient descent optimization algorithms,” arXiv preprint arXiv:1600.04747, 2016.
- [22] M. Pariente, A. Deleforge, and E. Vincent, “A statistically principled and computationally efficient approach to speech enhancement using variational autoencoders : Supporting document,” Inria, Tech. Rep. RR-9268, 2019. [Online]. Available: https://hal.inria.fr/hal-02089062
- [23] C. Fevotte, N. Bertin, and J. Durrieu, “Nonnegative Matrix Factorization with the Itakura-Saito Divergence: With Application to Music Analysis,” Neural Computation, vol. 21, no. 3, pp. 793–830, 2009.
- [24] J. S. Garofolo, L. F. Lamel, W. M. Fisher, J. G. Fiscus, D. S. Pallett, N. L. Dahlgren, and V. Zue, “Timit acoustic phonetic continuous speech corpus,” Linguistic data consortium, 1993.
- [25] J. Thiemann, N. Ito, and E. Vincent, “The diverse environments multi-channel acoustic noise database (DEMAND): A database of multichannel environ- mental noise recordings,” Proc. Int. Cong. on Acoust., 2013.
- [26] D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” arXiv preprint arXiv:1412.6980, 2014.
- [27] E. Vincent, R. Gribonval, and C. Fevotte, “Performance measurement in blind audio source separation,” IEEE Transactions on Audio, Speech, and Language Processing, vol. 14, no. 4, pp. 1462–1469, July 2006.
- [28] A. A. Nugraha, K. Sekiguchi, and K. Yoshii, “A deep generative model of speech complex spectrograms,” arXiv preprint arXiv:1903.03269, 2019.
- [29] P. Magron and T. Virtanen, “Bayesian anisotropic gaussian model for audio source separation,” in 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), April 2018, pp. 166–170.
- [30] A. Liutkus, C. Rohlfing, and A. Deleforge, “Audio source separation with magnitude priors: The beads model,” in 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), April 2018, pp. 56–60.