A Study of Third-party Resources Loading on Web
Abstract.
This paper performs a large-scale study of dependency chains in the web, to find that around 50% of first-party websites render content that they did not directly load. Although the majority (84.91%) of websites have short dependency chains (below 3 levels), we find websites with dependency chains exceeding 30. Using VirusTotal, we show that 1.2% of these third-parties are classified as suspicious — although seemingly small, this limited set of suspicious third-parties have remarkable reach into the wider ecosystem. We find that 73% of websites under-study load resources from suspicious third-parties, and 24.8% of first-party webpages contain at least three third-parties classified as suspicious in their dependency chain. By running sandboxed experiments, we observe a range of activities with the majority of suspicious JavaScript codes downloading malware.
1. Introduction
In the modern web ecosystem, websites often load resources from a range of third-party domains such as ad providers, tracking services and analytics services. This is a well known design decision that establishes an explicit trust between websites and the domains providing such services. However, often overlooked is the fact that these third-parties can further load resources from other domains, creating a dependency chain. This results in a form of implicit trust between first-party websites and any domains loaded further down the chain.
Consider the bbc.com webpage, an hypothetical example, which loads JavaScript program from widgets.com, which, upon execution loads additional content from another third-party, say ads.com. Here, bbc.com as the first-party website, explicitly trusts widgets.com, but implicitly trusts ads.com. This can be represented as a simple dependency chain in which widgets.com is at level 1 and ads.com is at level 2. Past work tends to ignore this, instead collapsing these levels into a single set of third-parties (Falahrastegar et al., 2014).
In this work, we study the dependency chains in the web ecosystem by focusing on the implicitly loaded resources.
2. Dependency Dataset
First, we obtain the resource dependencies of the Alexa top-200K websites’ main pages using the method described in (Ikram et al., 2019). This Chromium-based Headless (Google, 2018) crawler renders a given website and tracks resource dependencies by recording network requests sent to third-party domains. The requests are then used to reconstruct the dependency chains between each first-party website and its third-party URLs. Note that each first-party can trigger the creation of multiple dependency chains (to form a tree structure). From the Alexa Top-200k websites, we collect 11,287,230 URLs which consist of 6,806,494 unique external resources that correspond to 68,828 and 196,940, respectively, unique second level domains of third- and first-parties.
The next challenge is to classify domains as suspicious vs. innocuous. For this we use VirusTotal (Inc, 2019) — an online solution which aggregates the scanning capabilities provided by 68 Anti-Virus (AV) tools, scanning engines and datasets. It has been commonly used in the academic literature to detect malicious apps, executables, software and domains (Zhao et al., 2019; Ikram et al., 2016; Ikram and Kaafar, 2017). For each domain, we use the VirusTotal report API to obtain the VTscore for each third-party domain. This VTscore represents the number of AV tools that flagged the website as malicious (max. 68). The reports also contain meta-information such as the first scan date, scan history, and domain category. We further supplement each domain with their WebSense (Websense, 2018) category provided by the VirusTotal’s reports.
3. Exploring the Chains
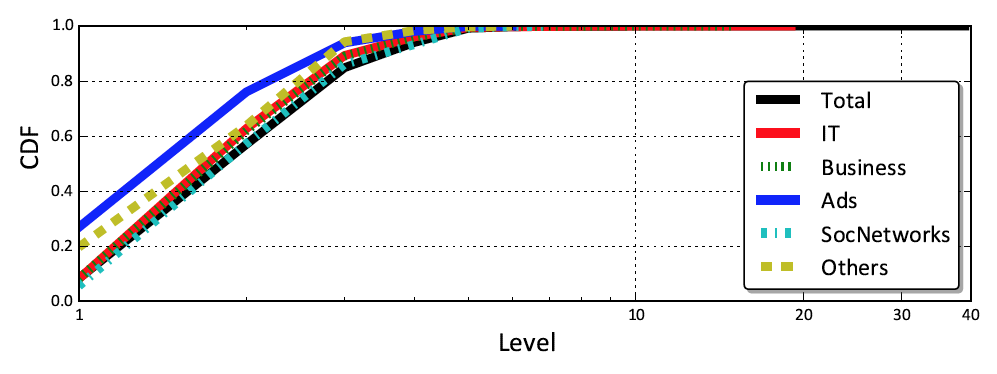
We begin by inspecting how extensive dependency chains are across the Alexa’s top-200K. We confirm their prominence, finding that around 50% of websites do include third-parties (e.g., content delivery networks (CDNs) such as akamaihd.net and ad and tracking services such as google-analytics.com) which subsequently load other third-parties to form a dependency chain (i.e., they implicitly trust third-parties they do not directly load). The most common implicitly trusted third-parties are well known operators, e.g., google-analytics.com and doubleclick.net: these are implicitly imported by 68.3% (134,510) and 46.4% (91,380) websites respectively. However, we also observe a wide range of more obtuse third-parties such as pippio.com and 51.la imported by 0.52% (1,146) and 0.51% (1,009) of websites. As depicted in Figure 1a, although the majority (84.91%) of websites have short chains (with levels of dependencies below 3), we find first-party websites with dependency chains exceeding 30 in length. This not only complicates page rendering, but also creates notable attack surface.
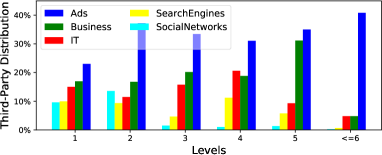
We also inspect the categories of third-party domains hosting these resources. Figure 1b presents the make-up of third-party categories at each level in the chain. It is clear that, across all levels, advertisement domains make up the bulk of third-parties. We also notice other highly demanded third-party categories such as search engines, Business and IT. Figure 1b also reveals that the distributions of categories vary across each dependency level. For example, 23.1% of all loaded resources at level 1 come from advertisement domains, 37.3% at level 2, and 46.2% at level 3. In other words, the proportion increases across dependency levels. In contrast, social network third-parties (e.g., Facebook) are mostly presented at level 1 (9.58%) and 2 (13.57%) with a significant drop at level 3. The dominance of advertisements is not, however, caused by a plethora of ad domains: there are far fewer ad domains than business or IT. Instead, it is driven by the large number of requests to advertisements: Even though ad domains only make-up 1.5% of third-parties, they generate 25% of resource requests. Importantly, these popular providers can trigger further dependencies; for example, doubleclick.com imports 16% of its resources from further implicitly trusted third-party websites. This makes such domains an ideal propagator of malicious resources for any other domains having implicit trust in it (Lauinger et al., 2017).
4. Finding Suspicious Chains
With the above in mind, we then proceed to inspect if suspicious or even potentially malicious third-parties are loaded via these long dependency chains. We do not limit this to just traditional malware, but also include third-parties that are known to mishandle user data and risk privacy leaks (Masood et al., 2018; Su et al., 2018; Hashmi et al., 2019).
Using the VirusTotal service API, we classify third-party domains into innocuous vs. suspicious. When using a classification threshold (i.e., VTscore 10, we find that 1.2% of third-parties are classified as suspicious. Although seemingly small, we find that this limited set of suspicious third-parties have remarkable reach. 73% of websites under-study load resources from suspicious third-parties, and 24.8% of first-party webpages contain at least 3 third-parties classified as suspicious in their dependency chain. This, of course, is impacted by many considerations which we explore — most notably, the power-law distribution of third-party popularity, which sees a few major players on a large fraction of websites.
5. Characterizing Suspicious JavaScript Resources
In our past research (Ikram et al., 2019), we inspected the prevalence of dependency chains in the web. Here, we build on these past findings to focus on what activities are undertaken within the dependency chains. Hence, we sandbox all suspicious JavaScript programs to monitor their activities. We build a sandbox and perform tests executing suspicious JavaScript codes. We find that JavaScript codes loaded at higher levels in the dependency chain (2) generated a larger number of HTTP requests. This is worrying as resources loaded at higher levels in the dependency chain are the most opaque to the website operator (i.e., they rely on implicit trust). The activities of these scripts are diverse. For example, we find evidence of first-party websites performing malicious search poisoning activities when (implicitly) loading some JavaScript codes. The most typical purpose of the suspicious JavaScript code is downloading dropfiles. Dropfiles are executables (e.g., malware, Exploitkits, Trojans, etc) exploiting the browser to download and execute code without user consent. We also observe instances of very active JavaScript codes, e.g., the most active (at level 4) downloads 129 files.
It is also interesting to observe that the resources at level 2 tend to have higher VTscores, indicating that their activities are blocked by a large number of virus checkers. The actual content of the files are quite diverse. We exclude the 8% which are encrypted, and therefore cannot be examined. The vast majority of remaining files (98.62%) are Adware and Click bots, suggesting that these types of financial gain are a major driving force in this domain. The remainder are Potentially Unwanted Programs (0.52%), Exploitkits (0.36%), Adware and Click Bots (98.62%), and Trojan (0.50%). For instance, videowood.tv/assets/js/poph.js uses and exploits eval() — JavaScript’s dynamic loading method — to download and execute 1832-fc204a9bcefeab3d.exe (with VTscore=5). This then enables the attacker to take over web browser for displaying a wide range of adverts and garner fraudulent clicks.
6. Conclusion
Inspired by the lack of prior work focusing on how resources are loaded, we explored dependency chains in the web ecosystem and found that over 50% of websites do rely on implicit trust. Although the majority (84.91%) of websites have short chains (with levels of dependencies below 3), we found first-party websites with chains exceeding 30 levels. The most common implicitly trusted third-parties are well known operators (e.g., doubleclick.net), but we also observed various less known implicit third-parties. We hypothesised that this might create notable attack surfaces. To confirm this, we classified the third-parties using VirusTotal to find that 1.2% of third-parties are classified as potentially malicious. Worryingly, our “confidence” in the classification actually increases for implicitly trusted resources (i.e., trust level 2), where 78% of suspicious JavaScript resources have a VTscore . In other words, more implicitly trusted JavaScript resources have high VTscores than explicitly trusted ones. These resources have remarkable reach — largely driven by the presence of highly central third-parties, e.g., google-analytics.com. With this in mind, we performed sandbox experiments on the suspicious JavaScript codes to understand their actions. We witnessed extensive download activities, much of which consist of downloading dropfiles and malware. It was particularly worrying to see that JavaScript resources loaded at level 2 in the dependency chain tended to have more aggressive properties, particularly as exhibited by their higher VTscore. This exposes the need to tighten the loose control over indirect resource loading and implicit trust: it creates exposure to risks such as malware distribution, search engine optimization (SEO) poisoning, malvertising and exploit kit redirection. We argue that ameliorating this can only be achieved through transparency mechanisms that allow web developers to better understand the resources on their webpages (and the related risks). To foster future research, we share all our datasets, experimental testbed code and scripts with the wider research community: https://wot19submission.github.io.
References
- (1)
- Falahrastegar et al. (2014) Marjan Falahrastegar, Hamed Haddadi, Steve Uhlig, and Richard Mortier. 2014. Anatomy of the third-party web tracking ecosystem. Traffic Measurements Analysis Workshop (TMA) (2014).
- Google (2018) Google. 2018. Headless chromium. https://chromium.googlesource.com/chromium/src/+/lkgr/headless/README.md.
- Hashmi et al. (2019) Saad Sajid Hashmi, Muhammad Ikram, and Mohamed Ali Kaafar. 2019. A longitudinal analysis of online ad-blocking blacklists. In 2019 IEEE 44th LCN Symposium on Emerging Topics in Networking (LCN Symposium). IEEE, 158–165.
- Ikram and Kaafar (2017) Muhammad Ikram and Mohamed Ali Kaafar. 2017. A first look at mobile ad-blocking apps. In Network Computing and Applications (NCA), 2017 IEEE 16th International Symposium on. IEEE, 1–8.
- Ikram et al. (2019) Muhammad Ikram, Rahat Masood, Gareth Tyson, Mohamed Ali Kaafar, Noha Loizon, and Roya Ensafi. 2019. The Chain of Implicit Trust: An Analysis of the Web Third-party Resources Loading. In Web Conference.
- Ikram et al. (2016) Muhammad Ikram, Narseo Vallina-Rodriguez, Suranga Seneviratne, Mohamed Ali Kaafar, and Vern Paxson. 2016. An Analysis of the Privacy and Security Risks of Android VPN Permission-enabled Apps. In IMC.
- Inc (2019) VirusTotal Inc. 2019. VirusTotal Public API. https://www.virustotal.com/en/documentation/public-api/.
- Lauinger et al. (2017) Tobias Lauinger, Abdelberi Chaabane, Sajjad Arshad, William Robertson, Christo Wilson, and Engin Kirda. 2017. Thou Shalt Not Depend on Me: Analysing the Use of Outdated JavaScript Libraries on the Web. In NDSS.
- Masood et al. (2018) Rahat Masood, Dinusha Vatsalan, Muhammad Ikram, and Mohamed Ali Kaafar. 2018. Incognito: A method for obfuscating web data. In Proceedings of the 2018 world wide web conference. 267–276.
- Su et al. (2018) Jingxiu Su, Zhenyu Li, Stephane Grumbach, Muhammad Ikram, Kave Salamatian, and Gaogang Xie. 2018. Web Tracking Cartography with DNS Records. In IEEE 37th International Performance Computing and Communications Conference (IPCC).
- Websense (2018) Websense. 2018. Real-time Threat Analysis with CSI: ACE Insight. https://csi.websense.com/.
- Zhao et al. (2019) Benjamin Zi Hao Zhao, Muhammad Ikram, Hassan Jameel Asghar, Mohamed Ali Kaafar, Abdelberi Chaabane, and Kanchana Thilakarathna. 2019. A decade of mal-activity reporting: A retrospective analysis of internet malicious activity blacklists. In Proceedings of the 2019 ACM Asia Conference on Computer and Communications Security. 193–205.