A Study of Using Cepstrogram for Countermeasure Against Replay Attacks
Abstract
This study investigated the cepstrogram properties and demonstrated their effectiveness as powerful countermeasures against replay attacks. A cepstrum analysis of replay attacks suggests that crucial information for anti-spoofing against replay attacks may be retained in the cepstrogram. When building countermeasures against replay attacks, experiments on the ASVspoof 2019 physical access database demonstrate that the cepstrogram is more effective than other features in both single and fusion systems. Our LCNN-based single and fusion systems with the cepstrogram feature outperformed the corresponding LCNN-based systems without the cepstrogram feature and several state-of-the-art single and fusion systems in the literature.
Index Terms— Cepstrogram, cepstrum, anti-spoofing, replay attacks, automatic speaker verification
1 Introduction
Various speech-related applications use automatic speaker verification (ASV) to verify the identity of speakers. Despite the convenience it brings to people’s lives, ASV systems are vulnerable to spoofing attacks [1, 2], such as synthesized speech, converted speech, and replay attacks [3, 4, 5]. Therefore, we require practical countermeasures against spoofing attacks.
Recently, a series of ASVspoof challenges have been conducted [6, 7, 8, 9]. The challenge encourages developing effective countermeasures to protect ASV systems from unforeseen spoofing attacks [6]. It initially focused on synthesized speech [6], while trials of replay attacks were later added to the challenge of evaluating the performance of anti-spoofing [7]. Because ASVspoof 2019 [8], the challenge is further divided into logical access (LA) and physical access (PA) scenarios. The LA scenario includes synthesized and converted speech, and the PA scenario includes replay attacks. The anti-spoofing task has been the subject of growing research, and methods can be roughly divided into three types: front-end [10, 11, 12, 13, 14], back-end [3, 4, 5, 15, 16, 17], and joint optimization of front-end and back-end [18, 19, 20, 21]. Front-end methods derive discriminative features, while back-end methods design effective models to distinguish between real and deceptive speech.
This study focused on the front-end processing for anti-spoofing purposes. We first analyzed the impact of replay attacks in the quefrency domain and investigated a common quefrency-domain representation of speech signals: the cepstrogram. The cepstrogram was obtained using the discrete cosine transform (DCT) to the spectrogram, which was obtained by applying the short-time Fourier transform (STFT) to the speech waveform. Our investigations showed that the cepstrogram is more discriminative than the spectrogram when comparing real and deceptive speech data. We further examined the cepstrogram properties through experiments, which showed that the cepstrogram indeed carries key information for constructing countermeasures against replay attacks.
The remainder of this study is organized as follows. Section 2 reviews the related studies on anti-spoofing. Section 3 describes the proposed front-end method for countermeasures. Section 4 discusses the experimental setup and results. In section 5, we provide concluding remarks regarding this study.
2 Related Work
This section reviews related works, including common front-end and back-end methods for anti-spoofing tasks.
2.1 Front-ends
Front-end processing in anti-spoofing systems derives discriminative features for distinguishing between real and spoofed speech signals. This section reviews several speech features computed in the frequency and quefrency domains for anti-spoofing.
2.1.1 Frequency-domain Features
Spectrogram and CQTgram are frequency-domain features common in anti-spoofing systems [5, 15, 16]. Spectrogram and CQTgram are obtained using STFT and constant Q transform (CQT), respectively, to speech signals [12, 13]. Phase information can be extracted from the spectrogram and CQTgram using several techniques such as the modified group delay function (MGD) and product spectrum (PS) to achieve high replay attack detection performance [18, 19, 22, 23]. However, state-of-the-art anti-spoofing results on recent datasets are obtained by directly using the magnitude representations of the frequency-domain features [5].
2.1.2 Quefrency-domain Features
Linear frequency cepstral coefficients (LFCC) [10, 11] and constant Q cepstral coefficients (CQCC) [12, 13] are quefrency-domain acoustic features commonly used in anti-spoofing systems [5, 7, 8, 16]. The extraction of cepstral coefficients involves using cepstrum analysis of speech signals [24, 25], where a set of linear filter banks is applied to the spectral features before transforming them into the quefrency domain. Although using linear filter banks may cause some loss of detail in the cepstrum, LFCC remains a popular quefrency-domain acoustic feature that achieves excellent performance in spoofed speech detection tasks [5, 16].
2.2 Back-ends
The back end of the anti-spoofing system refers to different classification models. This section reviews two representative models: the Gaussian mixture model (GMM) and the deep neural network (DNN).
2.2.1 Gaussian mixture model
GMM-based classifiers are a classical method for countermeasures against replay attacks [7, 8, 10, 11] that determine whether a given speech signal is spoofed by calculating its likelihood. In such a system, one GMM calculates the likelihood that the speech is spoofed, and the other GMM calculates the likelihood that the speech is real. The two likelihoods are then compared to determine whether the speech is spoofed or real. Because the likelihood is calculated by averaging over all frames, the GMM does not exploit the temporal information of the speech features, resulting in limited detection performance.
2.2.2 Deep neural network
Compared with GMM-based anti-spoofing classifiers, DNN-based classifiers usually require only one model to detect spoofed speech [3, 5, 15, 16, 18, 19, 27]. Most DNN-based classifiers use 2D convolutional layers in their model architecture to detect spoofing attacks with entire sequences of speech features, rather than single frames. In this manner, the spatiotemporal information in speech features can be more effectively characterized, thereby improving the countermeasure performance against replay attacks [5, 16, 18, 19].
3 Cepstrogram
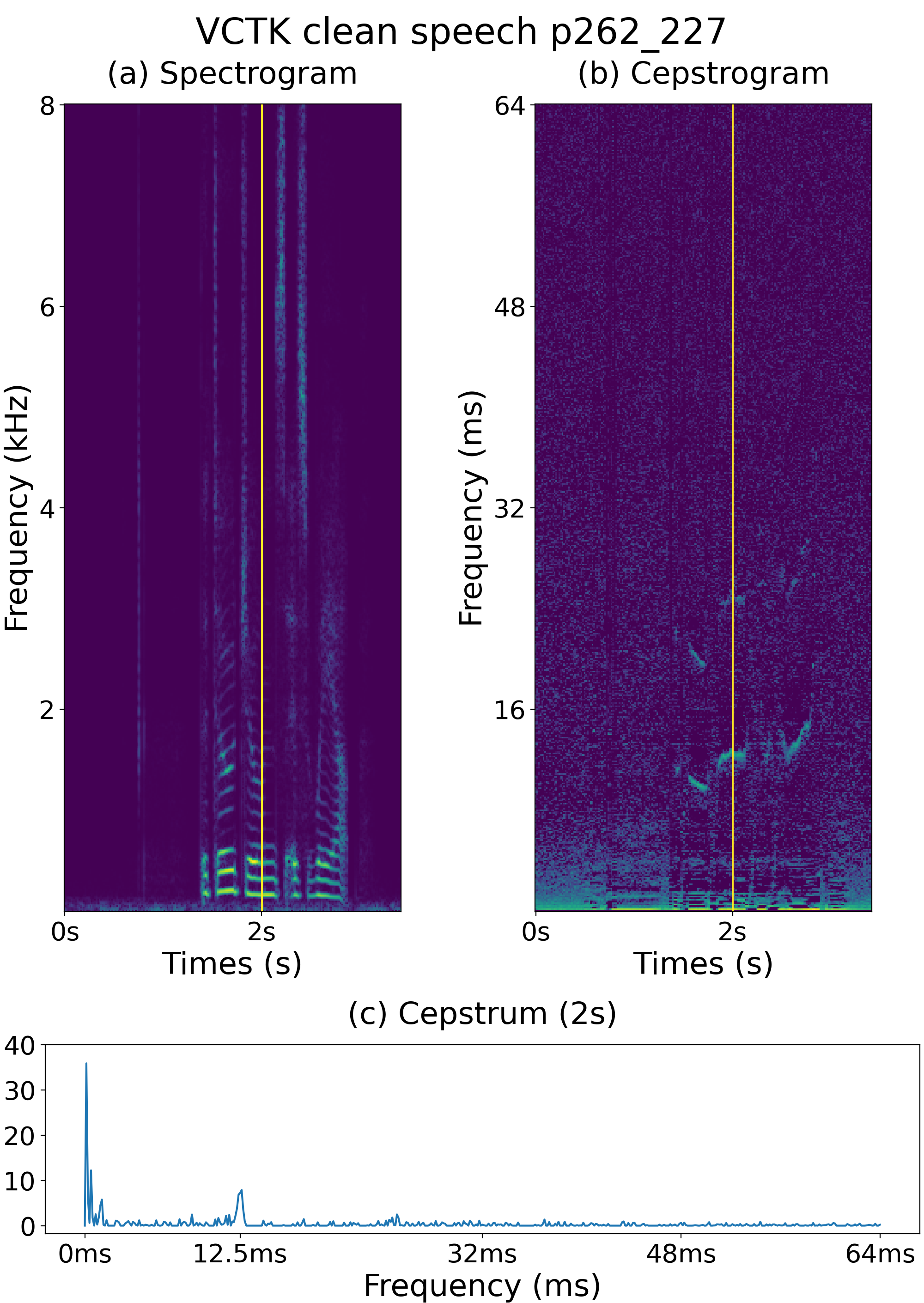
A cepstrogram is a time-quefrency representation of a speech signal, that is, its cepstrum changes gradually, while a spectrogram is a time-frequency representation of a speech signal, that is, its spectrum changes gradually. Fig. 1 (a) and (b) present the spectrogram and cepstrogram, respectively, of a clean speech signal from the VCTK database [26]. For both plots, the vertical axis represents the time index, and the horizontal axis represents the frequency (for spectrogram) and quefrency (for cepstrogram). Colors represent signal amplitudes on the log1p (natural logarithm of (1 + input)) scale [28, 29].
Cepstrum is an effective representation that exploits homomorphic information of speech for various tasks, such as speech recognition [29], speaker recognition [30], speech emotion recognition [31], pitch detection [32] and anti-spoofing [12, 13, 16, 19]. Further details on the properties of the cepstrum can be found in [24].
To demonstrate the advantages of cepstrum analysis, we consider a scenario in which the signal involves an echo, in which the overall signal can be expressed as
| (1) |
The magnitude spectrum of the overall signal is
| (2) |
After obtaining the logarithm of the magnitude spectrum, the overall spectrum can be further separated into two components
| (3) |
Based on Eq. (3), we can view as the original signal with an additive periodic component . By applying the DCT to , we obtain the cepstrogram of the signal . Periodic patterns can be easily observed in the cepstrogram, and therefore, it is argued that cepstrogram can be a powerful feature for replay attacks.
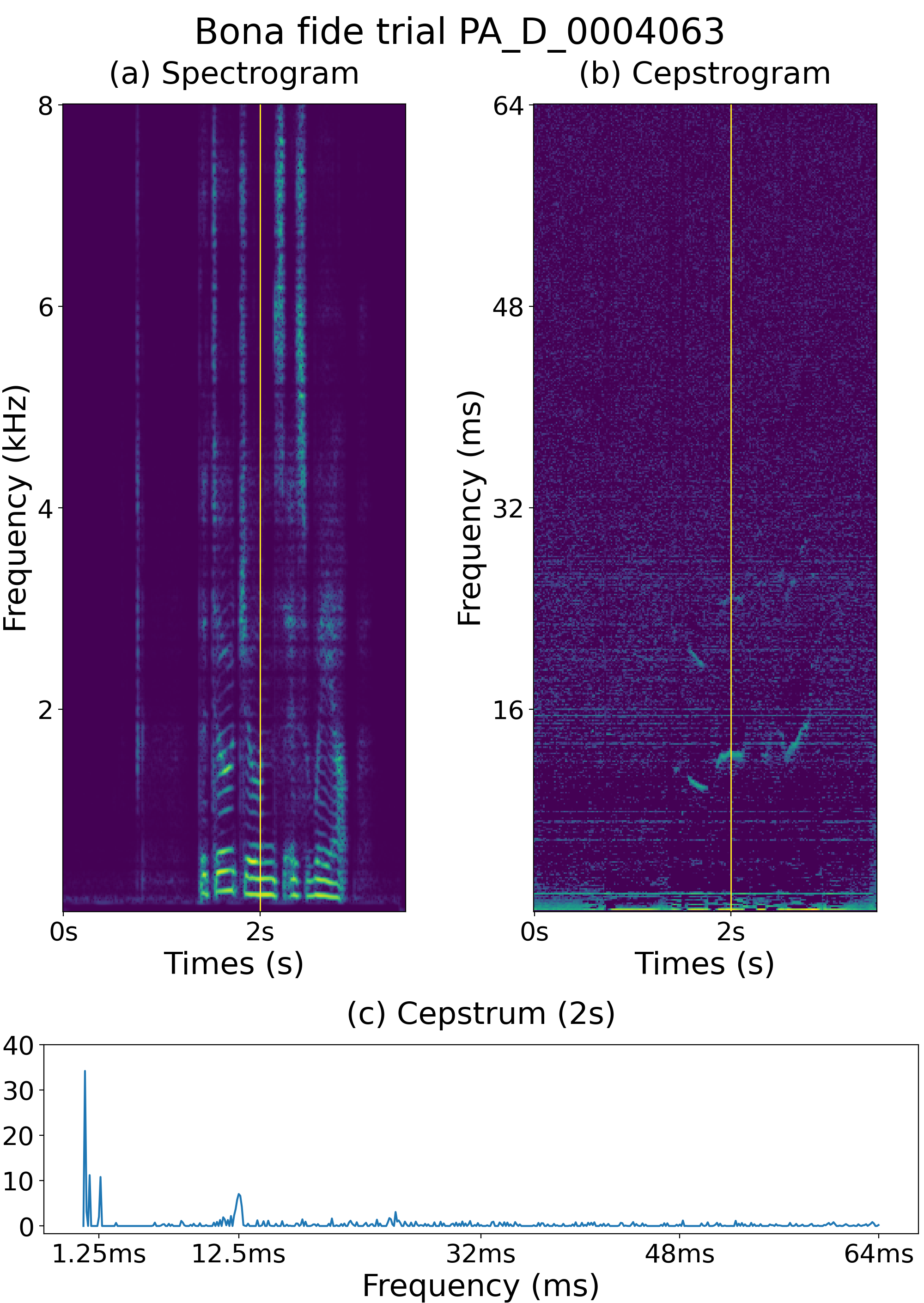
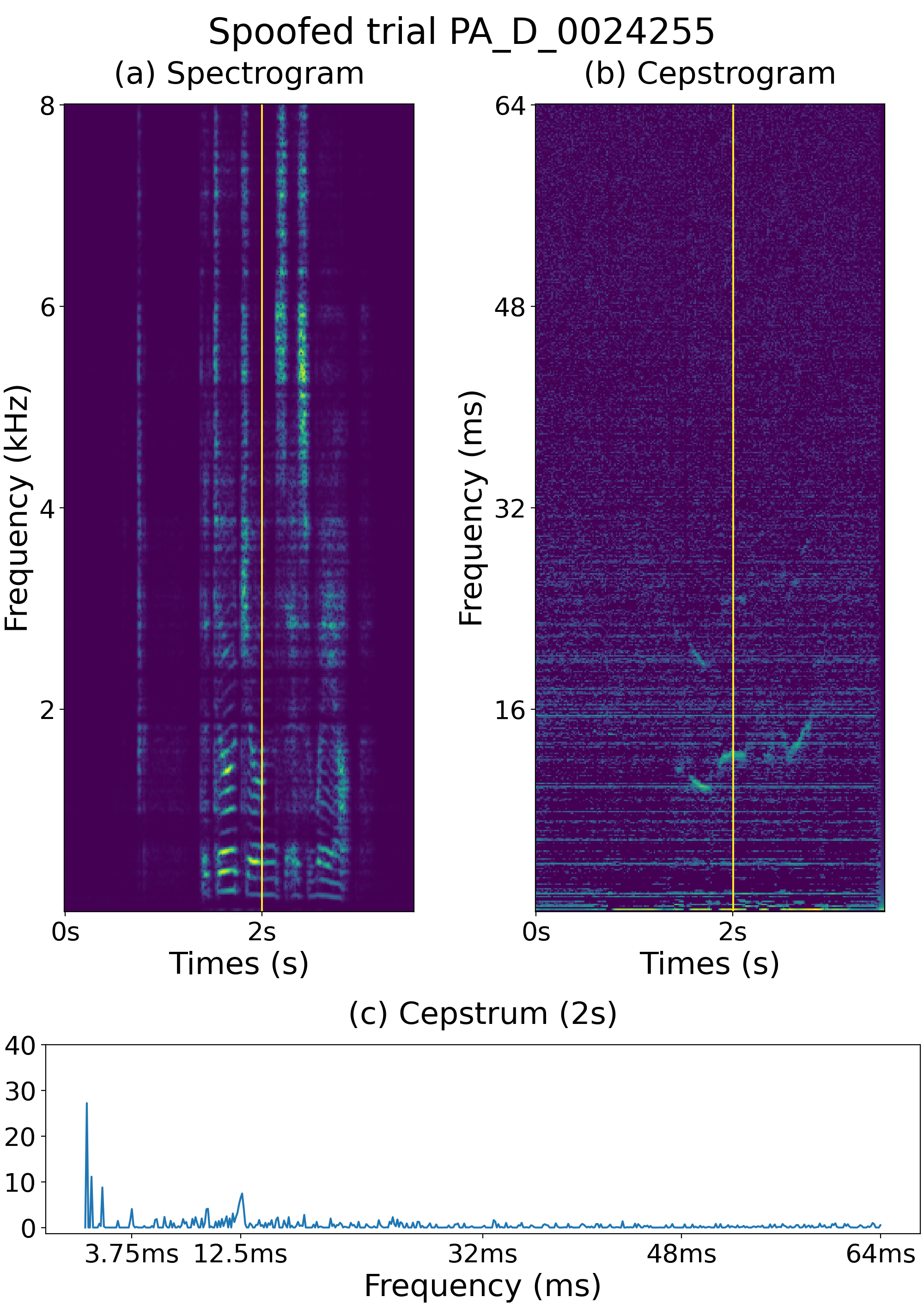
A signal with echoes exhibits rahmonic peaks in the quefrency domain, which reflects its pitch in the cepstrum analysis [24]. We expect speech with simulated reverberation or replay attacks to exhibit rahmonic peaks in the quefrency domain. Fig. 2 shows the spectrogram, cepstrogram, and cepstrum of a single frame of the bona fide trial generated from the speech sample shown in Fig. 1 with the simulated reverberation, while Fig. 3 shows the spectrogram, cepstrogram, and cepstrum of a single frame of the spoofed trial generated from the bona fide trial speech in Fig. 2 for a replay attack. Comparing the cepstrogram of the bona fide trial shown in Fig. 2 (b) and that of the clean speech in Fig. 1 (b), more rahmonic peaks can be observed in the former; for example, in addition to the largest peak at approximately 12.5 ms, a distinct peak at approximately 1.25 ms can also be observed, as shown in Fig. 2 (c). Comparing Fig. 3 (b) in Fig. 2 (b), the replay likely causes more peaks, for instance, there is an additional peak at approximately 3.75 ms in Fig. 3 (c). These figures confirm that whenever a speech signal is simulated with reverberation or replayed, additional rahmonic peaks appear in the quefrency domain. Accordingly, a cepstrogram serves as a powerful feature against replay attacks, causing more harmonic peaks. The next section describes experiments conducted to confirm this conjecture.
4 Experimental Setup and Results
Experiments confirm that the cepstrogram is an effective feature for a replay attack spoofing task. Thus far, we experimented under the ASVspoof 2019 PA scenario and used the anti-spoofing system of the then-winning team T45 as the benchmark system to test the effectiveness of the cepstrogram feature. The ASVspoof 2019 PA task provides the largest database for replay attack detection [33]. The T45 system performed best on the ASVspoof 2019 PA task with LFCC as one of the front-ends. Because we have front-ends other than LFCC that represent signals in different domains, our goal was to compare these front-ends with a fixed back-end. The results were evaluated in terms of the equal error rate (EER) and minimum tandem detection cost function (min-tDCF), which are standard metrics used in the ASVspoof 2019 challenge [34].
4.1 Experimental setup
The T45 system uses a light convolutional neural network (LCNN) architecture as the back-end and the CQTgram, LFCC, and spectrogram via DCT (termed DCT) as the front-ends. Specifically, three single systems with different front-ends, namely LCNN-CQT, LCNN-LFCC, and LCNN-DCT, were first built on the training set. The development set determines the best models for testing the performance of the evaluation set. The scores from the three single systems are combined to generate the final score (for the fusion system). For a fair comparison, we followed the same setup as the T45 system to build the back end of our system while testing the new front end. In our experiments, CQTgram and LFCC were generated using the codes provided by the challenge organizer, and the other features were extracted using our codes. Table 1 presents the performance of the T45 system reported in [8, 16] (upper four rows) and the proposed implementation (lower four rows). The table shows that our implementations yield slightly better performance than those reported in [8, 16]. This might be due to the dropout layer setting. The setting of the dropout layers of the T45 system was not specified in the corresponding study [16], and we only performed one dropout on the flatten layer to prevent overfitting. For more details on our implementation, please visit our repository 111https://github.com/shihkuanglee/RD-LCNN. In the following discussion, we use our implementation for comparison.
4.2 Results
Table 2 lists the results of the systems using the LCNN as the back-end with five different front-ends: CQT, LFCC, DCT, Spec (spectrogram), and Ceps (cepstrogram). It is evident from the table that Ceps performs the best, confirming its effectiveness. Next, we incorporate the single system LCNN-Ceps into the fusion systems. As shown in Table 3, all fusion systems with the cepstrogram front-end performed better than their counterparts without the cepstrogram front-end. For example, the system using Ceps+CQT reduces the EER from 0.514 to 0.149 compared to the system using CQT, while the system using Ceps+LFCC+CQT+Spec reduces the EER from 0.177 to 0.094 compared to the system using LFCC+CQT+Spec.
Finally, we compared our systems with the proposed Ceps feature with the state-of-the-art systems. The top and bottom panels in Table 4 show the results for the single and fusion systems, respectively. It is evident from the table that our system performs best in both single-system and fusion-system categories with the cepstrogram as the front-end. Our fusion system using CQT+LFCC+Spec (system LCNN-CQT+LFCC+Spec) achieves a 38% (0.287 to 0.177) EER reduction on the evaluation set compared to the best fusion system that uses the same features (Res2Net-CQT+LFCC+Spec [5]); the fusion system using CQT+LFCC+Spec+Ceps (system LCNN-CQT+LFCC+Spec+Ceps) can further reduce the EER to 0.094, which is the new state-of-the-art performance on the evaluation set of the ASVspoof 2019 PA task.
| Dev | Eval | |||
|---|---|---|---|---|
| System | tDCF | EER | tDCF | EER |
| CQT[16] | 0.0197 | 0.800 | 0.0295 | 1.23 |
| LFCC[16] | 0.0320 | 1.311 | 0.1053 | 4.60 |
| DCT[16] | 0.0732 | 3.850 | 0.560 | 2.06 |
| Fusion[16] | 0.0001 | 0.0154 | 0.0122 | 0.54 |
| CQT | 0.0096 | 0.374 | 0.0130 | 0.514 |
| LFCC | 0.0145 | 0.519 | 0.0299 | 1.061 |
| DCT | 0.0385 | 1.444 | 0.0774 | 2.897 |
| Fusion | 0.0014 | 0.057 | 0.0048 | 0.165 |
| Dev | Eval | |||
|---|---|---|---|---|
| System | tDCF | EER | tDCF | EER |
| CQT | 0.0096 | 0.374 | 0.0130 | 0.514 |
| LFCC | 0.0145 | 0.519 | 0.0299 | 1.061 |
| DCT | 0.0385 | 1.444 | 0.0774 | 2.897 |
| Spec | 0.0148 | 0.556 | 0.0522 | 1.719 |
| Ceps | 0.0039 | 0.129 | 0.0105 | 0.370 |
| Dev | Eval | |||
|---|---|---|---|---|
| System | tDCF | EER | tDCF | EER |
| CQT | 0.0096 | 0.374 | 0.0130 | 0.514 |
| Ceps+CQT | 0.0024 | 0.094 | 0.0043 | 0.149 |
| LFCC | 0.0145 | 0.519 | 0.0299 | 1.061 |
| Ceps+LFCC | 0.0030 | 0.109 | 0.0074 | 0.254 |
| DCT | 0.0385 | 1.444 | 0.0774 | 2.897 |
| Ceps+DCT | 0.0013 | 0.074 | 0.0066 | 0.242 |
| CQT+LFCC | 0.0037 | 0.166 | 0.0079 | 0.283 |
| Ceps+CQT+LFCC | 0.0022 | 0.074 | 0.0042 | 0.150 |
| CQT+DCT | 0.0048 | 0.205 | 0.0111 | 0.475 |
| Ceps+CQT+DCT | 0.0015 | 0.059 | 0.0034 | 0.128 |
| LFCC+DCT | 0.0042 | 0.183 | 0.0089 | 0.321 |
| Ceps+LFCC+DCT | 0.0012 | 0.039 | 0.0040 | 0.143 |
| LFCC+CQT+DCT | 0.0014 | 0.057 | 0.0048 | 0.165 |
| Ceps+LFCC+CQT+DCT | 0.0008 | 0.052 | 0.0029 | 0.104 |
| LFCC+CQT+Spec | 0.0009 | 0.039 | 0.0045 | 0.177 |
| Ceps+LFCC+CQT+Spec | 0.0004 | 0.022 | 0.0027 | 0.094 |
| Dev | Eval | |||
| Single System | tDCF | EER | tDCF | EER |
| T45-LCNN-CQT[16] | 0.0197 | 0.800 | 0.0295 | 1.23 |
| T28-ResNeWt-MFbank+CQT[19] | 0.0093 | 0.41 | 0.0134 | 0.52 |
| LCNN-CQT | 0.0096 | 0.375 | 0.0130 | 0.514 |
| Res2Net-CQT[5] | 0.0086 | 0.329 | 0.0116 | 0.459 |
| LCNN-Ceps | 0.0039 | 0.129 | 0.0105 | 0.370 |
| Dev | Eval | |||
| Fusion System | tDCF | EER | tDCF | EER |
| T45-Fusion[16] | 0.0001 | 0.0154 | 0.0122 | 0.54 |
| T28-Fusion[19] | 0.0049 | 0.20 | 0.0096 | 0.39 |
| Res2Net-CQT+LFCC+Spec[5] | 0.0028 | 0.096 | 0.0075 | 0.287 |
| LCNN-CQT+LFCC+Spec | 0.0009 | 0.039 | 0.0045 | 0.177 |
| LCNN-CQT+LFCC+DCT | 0.0014 | 0.057 | 0.0048 | 0.165 |
| LCNN-CQT+LFCC+DCT+Ceps | 0.0008 | 0.052 | 0.0029 | 0.104 |
| LCNN-CQT+LFCC+Spec+Ceps | 0.0004 | 0.022 | 0.0027 | 0.094 |
5 Discussion
The experiments confirm that the cepstrogram provides key information for anti-spoofing against replay attacks. As described in [24], a signal with echoes exhibits rahmonic peaks in the quefrency domain. This inspired us to investigate whether the replayed speech also had rahmonic peaks in the cepstrum. From Fig. 3 (b), additional rahmonic peaks can be observed in the replay attack trial. For the LFCC feature, the spectral envelope became blurred owing to filter banks, causing such peaks to disappear. As shown in Table 2, the Ceps-based single system outperforms single systems using other features, including LFCC. As shown in Table 3, a fusion system using the cepstrogram feature constantly outperforms its counterpart without using the cepstrogram feature. The fusion system of LFCC-LCNN and LCNN-Ceps also results in performance improvement in contrast to single systems, although both are quefrency-domain features, and we leave it as future work and focus on the properties of the cepstrogram in this study.
6 Conclusions
This qualitatively analyzed the properties of the cepstrogram, a time-quefrency representation of a speech signal, and then applied it to anti-spoofing against replay attacks. The analysis shows that the cepstrogram shows additional rahmonic peaks associated with the specific echo patterns and thus serves as a powerful feature for replay attack detection. Our extensive experiments on the ASVspoof 2019 PA task also quantitatively confirmed the effectiveness of the cepstrogram against replay attacks. Using the cepstrogram as a front-end, our systems achieved state-of-the-art performance in both the single-system and fusion-system categories.
References
- [1] Sung-Hyun Yoon, Min-Sung Koh, Jae-Han Park, and Ha-Jin Yu, “A new replay attack against automatic speaker verification systems,” IEEE Access, vol. 8, pp. 36080–36088, 2020.
- [2] Pavol Partila, Jaromir Tovarek, Gokhan Hakki Ilk, Jan Rozhon, and Miroslav Voznak, “Deep learning serves voice cloning: How vulnerable are automatic speaker verification systems to spoofing trials?,” IEEE Communications Magazine, vol. 58, no. 2, pp. 100–105, 2020.
- [3] Guang Hua, Andrew Beng Jin Teoh, and Haijian Zhang, “Towards end-to-end synthetic speech detection,” IEEE Signal Processing Letters, vol. 28, pp. 1265–1269, 2021.
- [4] Hemlata Tak, Jose Patino, Massimiliano Todisco, Andreas Nautsch, Nicholas Evans, and Anthony Larcher, “End-to-end anti-spoofing with rawnet2,” in ICASSP 2021 - 2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2021, pp. 6369–6373.
- [5] Xu Li, Na Li, Chao Weng, Xunying Liu, Dan Su, Dong Yu, and Helen Meng, “Replay and synthetic speech detection with res2net architecture,” in ICASSP 2021 - 2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2021, pp. 6354–6358.
- [6] Zhizheng Wu, Tomi Kinnunen, Nicholas Evans, Junichi Yamagishi, Cemal Hanilçi, Md. Sahidullah, and Aleksandr Sizov, “ASVspoof 2015: the first automatic speaker verification spoofing and countermeasures challenge,” in Proc. Interspeech 2015, 2015, pp. 2037–2041.
- [7] Tomi Kinnunen, Md. Sahidullah, Héctor Delgado, Massimiliano Todisco, Nicholas Evans, Junichi Yamagishi, and Kong Aik Lee, “The ASVspoof 2017 Challenge: Assessing the Limits of Replay Spoofing Attack Detection,” in Proc. Interspeech 2017, 2017, pp. 2–6.
- [8] Massimiliano Todisco, Xin Wang, Ville Vestman, Md. Sahidullah, Héctor Delgado, Andreas Nautsch, Junichi Yamagishi, Nicholas Evans, Tomi H. Kinnunen, and Kong Aik Lee, “ASVspoof 2019: Future Horizons in Spoofed and Fake Audio Detection,” in Proc. Interspeech 2019, 2019, pp. 1008–1012.
- [9] Junichi Yamagishi, Xin Wang, Massimiliano Todisco, Md Sahidullah, Jose Patino, Andreas Nautsch, Xuechen Liu, Kong Aik Lee, Tomi Kinnunen, Nicholas Evans, and Héctor Delgado, “ASVspoof 2021: accelerating progress in spoofed and deepfake speech detection,” in Proc. 2021 Edition of the Automatic Speaker Verification and Spoofing Countermeasures Challenge, 2021, pp. 47–54.
- [10] Md. Sahidullah, Tomi Kinnunen, and Cemal Hanilçi, “A comparison of features for synthetic speech detection,” in Proc. Interspeech 2015, 2015, pp. 2087–2091.
- [11] Hemlata Tak, Jose Patino, Andreas Nautsch, Nicholas Evans, and Massimiliano Todisco, “Spoofing Attack Detection Using the Non-Linear Fusion of Sub-Band Classifiers,” in Proc. Interspeech 2020, 2020, pp. 1106–1110.
- [12] Massimiliano Todisco, Héctor Delgado, and Nicholas Evans, “A New Feature for Automatic Speaker Verification Anti-Spoofing: Constant Q Cepstral Coefficients,” in Proc. The Speaker and Language Recognition Workshop (Odyssey 2016), 2016, pp. 283–290.
- [13] Massimiliano Todisco, Héctor Delgado, and Nicholas Evans, “Constant q cepstral coefficients: A spoofing countermeasure for automatic speaker verification,” Computer Speech & Language, vol. 45, pp. 516–535, 2017.
- [14] Yuxiang Zhang, Wenchao Wang, and Pengyuan Zhang, “The Effect of Silence and Dual-Band Fusion in Anti-Spoofing System,” in Proc. Interspeech 2021, 2021, pp. 4279–4283.
- [15] Galina Lavrentyeva, Sergey Novoselov, Egor Malykh, Alexander Kozlov, Oleg Kudashev, and Vadim Shchemelinin, “Audio Replay Attack Detection with Deep Learning Frameworks,” in Proc. Interspeech 2017, 2017, pp. 82–86.
- [16] Galina Lavrentyeva, Sergey Novoselov, Andzhukaev Tseren, Marina Volkova, Artem Gorlanov, and Alexandr Kozlov, “STC Antispoofing Systems for the ASVspoof2019 Challenge,” in Proc. Interspeech 2019, 2019, pp. 1033–1037.
- [17] Xin Wang and Junichi Yamagishi, “A Comparative Study on Recent Neural Spoofing Countermeasures for Synthetic Speech Detection,” in Proc. Interspeech 2021, 2021, pp. 4259–4263.
- [18] Francis Tom, Mohit Jain, and Prasenjit Dey, “End-To-End Audio Replay Attack Detection Using Deep Convolutional Networks with Attention,” in Proc. Interspeech 2018, 2018, pp. 681–685.
- [19] Xingliang Cheng, Mingxing Xu, and Thomas Fang Zheng, “Replay detection using cqt-based modified group delay feature and resnewt network in asvspoof 2019,” in 2019 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), 2019, pp. 540–545.
- [20] Zhenzong Wu, Rohan Kumar Das, Jichen Yang, and Haizhou Li, “Light Convolutional Neural Network with Feature Genuinization for Detection of Synthetic Speech Attacks,” in Proc. Interspeech 2020, 2020, pp. 1101–1105.
- [21] Yang Xie, Zhenchuan Zhang, and Yingchun Yang, “Siamese Network with wav2vec Feature for Spoofing Speech Detection,” in Proc. Interspeech 2021, 2021, pp. 4269–4273.
- [22] Hema A. Murthy and Bayya Yegnanarayana, “Group delay functions and its applications in speech technology,” Sadhana, vol. 36, pp. 745–782, 2011.
- [23] Joao Monteiro and Jahangir Alam, “Development of Voice Spoofing Detection Systems for 2019 Edition of Automatic Speaker Verification and Countermeasures Challenge,” in 2019 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), 2019, pp. 1003–1010.
- [24] A.V. Oppenheim and R.W. Schafer, “From frequency to quefrency: a history of the cepstrum,” IEEE Signal Processing Magazine, vol. 21, no. 5, pp. 95–106, 2004.
- [25] Alan V. Oppenheim and Ronald W. Schafer, Discrete-Time Signal Processing, Prentice Hall Press, USA, 3rd edition, 2009.
- [26] Christophe Veaux, Junichi Yamagishi, and Kirsten MacDonald, “CSTR VCTK Corpus: English Multi-speaker Corpus for CSTR Voice Cloning Toolkit,” Tech. Rep., University of Edinburgh, The Centre for Speech Technology Research (CSTR), 2017.
- [27] Andreas Nautsch, Xin Wang, Nicholas Evans, Tomi H. Kinnunen, Ville Vestman, Massimiliano Todisco, Héctor Delgado, Md Sahidullah, Junichi Yamagishi, and Kong Aik Lee, “Asvspoof 2019: Spoofing countermeasures for the detection of synthesized, converted and replayed speech,” IEEE Transactions on Biometrics, Behavior, and Identity Science, vol. 3, no. 2, pp. 252–265, 2021.
- [28] Shang-Yi Chuang, Hsin-Min Wang, and Yu Tsao, “Improved lite audio-visual speech enhancement,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 30, pp. 1345–1359, 2022.
- [29] S. Davis and P. Mermelstein, “Comparison of parametric representations for monosyllabic word recognition in continuously spoken sentences,” IEEE Transactions on Acoustics, Speech, and Signal Processing, vol. 28, no. 4, pp. 357–366, 1980.
- [30] K.S.R. Murty and B. Yegnanarayana, “Combining evidence from residual phase and mfcc features for speaker recognition,” IEEE Signal Processing Letters, vol. 13, no. 1, pp. 52–55, 2006.
- [31] Kunxia Wang, Ning An, Bing Nan Li, Yanyong Zhang, and Lian Li, “Speech emotion recognition using fourier parameters,” IEEE Transactions on Affective Computing, vol. 6, no. 1, pp. 69–75, 2015.
- [32] Li Su, “Between homomorphic signal processing and deep neural networks: Constructing deep algorithms for polyphonic music transcription,” in 2017 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), 2017, pp. 884–891.
- [33] Xin Wang, Junichi Yamagishi, Massimiliano Todisco, Héctor Delgado, Andreas Nautsch, Nicholas Evans, Md Sahidullah, Ville Vestman, Tomi Kinnunen, Kong Aik Lee, Lauri Juvela, Paavo Alku, Yu-Huai Peng, Hsin-Te Hwang, Yu Tsao, Hsin-Min Wang, Sébastien Le Maguer, Markus Becker, Fergus Henderson, Rob Clark, Yu Zhang, Quan Wang, Ye Jia, Kai Onuma, Koji Mushika, Takashi Kaneda, Yuan Jiang, Li-Juan Liu, Yi-Chiao Wu, Wen-Chin Huang, Tomoki Toda, Kou Tanaka, Hirokazu Kameoka, Ingmar Steiner, Driss Matrouf, Jean-François Bonastre, Avashna Govender, Srikanth Ronanki, Jing-Xuan Zhang, and Zhen-Hua Ling, “Asvspoof 2019: A large-scale public database of synthesized, converted and replayed speech,” Computer Speech & Language, vol. 64, pp. 101114, 2020.
- [34] Tomi Kinnunen, Kong Aik Lee, Hector Delgado, Nicholas Evans, Massimiliano Todisco, Md Sahidullah, Junichi Yamagishi, and Douglas A. Reynolds, “t-DCF: a Detection Cost Function for the Tandem Assessment of Spoofing Countermeasures and Automatic Speaker Verification ,” in Proc. The Speaker and Language Recognition Workshop (Odyssey 2018), 2018, pp. 312–319.