Date of publication xxxx 00, 0000, date of current version xxxx 00, 0000. 10.1109/ACCESS.2017.DOI
Corresponding author: Zhaoxiang Liu (e-mail: liuzx178@chinaunicom.cn), Shiguo Lian (e-mail: liansg@chinaunicom.cn) .
A Survey on Unsupervised Anomaly Detection Algorithms for Industrial Images
Abstract
In line with the development of Industry 4.0, surface defect detection/anomaly detection becomes a topical subject in the industry field. Improving efficiency as well as saving labor costs has steadily become a matter of great concern in practice, where deep learning-based algorithms perform better than traditional vision inspection methods in recent years. While existing deep learning-based algorithms are biased towards supervised learning, which not only necessitates a huge amount of labeled data and human labor, but also brings about inefficiency and limitations. In contrast, recent research shows that unsupervised learning has great potential in tackling the above disadvantages for visual industrial anomaly detection. In this survey, we summarize current challenges and provide a thorough overview of recently proposed unsupervised algorithms for visual industrial anomaly detection covering five categories, whose innovation points and frameworks are described in detail. Meanwhile, publicly available datasets for industrial anomaly detection are introduced. By comparing different classes of methods, the advantages and disadvantages of anomaly detection algorithms are summarized. Based on the current research framework, we point out the core issue that remains to be resolved and provide further improvement directions. Meanwhile, based on the latest technological trends, we offer insights into future research directions. It is expected to assist both the research community and industry in developing a broader and cross-domain perspective.
Index Terms:
Industrial Anomaly detection, Unsupervised learning, Deep learning=-15pt
I Introduction
Industry 4.0 is an era of making use of information technology to promote the industrial revolution, that is, the intelligent era. It is the fourth industrial revolution dominated by intelligent manufacturing. Adhere to the development trend of Industry 4.0, it is the general trend to build a smart manufacture system.
Ideally, once a production link deviates from the standard operation, an alarm signal will be sent, and the producer can make positive improvement response in the shortest time. This transparent and efficient information based production process can minimize production costs and also avoid wasting materials. In the long run, smart manufacturing mode based on artificial intelligence technology [1] can reduce the requirements on human decision, such as dependence on technical experts, by mining and depositing relevant knowledge, so that labor costs can be saved.
Material anomaly extensively exists in industrial production [2, 3, 1], and more and more safety problems are caused by material defects. Hence people pay more attention to the detection of material anomalies. There are a lot of defects images in the industrial scene. Examples of surface defects are shown in Fig. 1. The traditional method of surface anomaly detection and localization relies on the manual operation by qualified specialists, which is not only inefficient but also depends on the subjective judgment of operators, making it difficult to ensure the accuracy of detection. The production mode of anomaly detection equipment combined with industrial production line ensures the quality of products, reduces the cost of manual testing, and improves the efficiency of production as well. With the rapid rise of computer image processing technology, many algorithms have been gradually applied to the field of material anomaly detection, improving the accuracy of material anomaly detection. In recent years, deep learning [4, 5] has also been applied to material anomaly detection and achieved extraordinary performance.








Current deep learning-based supervised algorithms have certain limitations. Model training requires a large amount of labeled data [5], while images with defect labels are not easy to obtain. And the lack of defect samples makes it difficult to bring the models online, which also limits the application of deep learning in the industrial detection field. Therefore, a new solution is urgently needed - unsupervised algorithms, which need no labeled data. This paper provides a review of some recently proposed unsupervised methods, whose innovation points and frameworks are described in detail. Note that we only concentrate on industrial vision anomaly detection algorithms. Particularly, the industry uses the terms defect detection, visual anomaly detection, and surface detection, which we all count in our research. Meanwhile, publicly available datasets for industrial anomaly detection are introduced, with experimental results displayed. This review offers different contributions that distinguish it from other reviews.
-
We discuss the inadequacies of the current algorithms and dataset tailored to the requirements of actual industrial scenarios, such as edible oil impurity detection.
-
Based on the current research framework, we suggest that the conflict between FAR (false alarm rate) and MAR (missed alarm rate) is the core issue that remains to be resolved. We also provide further improvement directions to current methods, like integration of diverse technologies.
-
We offer insights into future directions based on the latest technological trends, such as foundation model and multimodal learning.
The subsequent content of the article is organized as follows: related works in Section II, visual anomaly detection methodology in Section III, comparison and analysis of methodologies in Section IV, introduction to industrial datasets in Section V, challenge and discussion of research actuality and future development direction in Section VI, conclusion in Section VII.
II Related works
A. Previous Algorithms
We only focus on the surprising success and dominance of anomaly detection in industrial images but exclude other areas such as action recognition [12] [13] and video anomaly detection [14]. Although some of the strategies have been validated in the above scenario, real industrial images lack prior knowledge of action images and video sequence information, which makes it difficult for models to generalize across different domains.
For some existing methods of visual anomaly detection, the development and changes in technology are introduced below. Initially, anomaly detection relied on statistical methods. Statistical approaches assess the geographic distribution of pixel values by extracting statistical information from defect images. Histogram information [15, 16, 17, 18, 19, 20], co-occurrence matrices [21, 22, 23, 24, 25, 26], and local binary patterns (LBP) [27, 28, 29, 30, 31, 32] have all been presented as statistical methods for defect detection. Statistical approaches can present anomalies in an intuitive and discriminative manner, and they are simple to model, interpret, and display. However, they frequently make assumptions, such as separable defect regions, that cannot be satisfied in all scenarios. Later, hand-extracted features can describe the structure of the image. In structural methods, defect feature is characterized by texture elements [33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43]. As a result, the structural approaches’ goals are to extract the texture elements of defects, which are used to represent the spatial placement rules. The geometrical feature can be found using structural approaches. This approach is easier to implement and better suited to random textured defects. However, the majority of them are sensitive to the shape and size of defects, and defect images should be aperiodic.
In the field of image processing, filter-dependent methods are also used for anomaly detection. Filter-based methods apply some filter banks on defect images and calculate the energy of the filter responses [44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56]. Common filter-based methods include Sobel operator, Canny operator, Gabor operator, Laplacian operator, wavelet transform, and Fourier transform, which can be further divided into spatial domain, frequency domain, and spatial-frequency domain methods. In vision-based anomaly recognition, filter-based approaches are widespread. The cross-domain methods can aid the model in extracting more meaningful information. Furthermore, they are affine transformation invariant and can handle multi-scale defects. While, they may not be appropriate to random textured images, and some of them may be influenced by feature correlations and noises.
With the development of neural networks and machine learning, a large number of supervised algorithms have appeared. Supervised Neural Networks [57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68], Support Vector Machines (SVM) [69, 70, 71] and k-Nearest Neighbors [72, 73, 74, 75, 76, 77, 78] are the most common supervised algorithms. Recently, deep learning-based algorithms are becoming popular. The majority of deep learning-based visual anomaly detection is data-driven. To build the visual anomaly detection model, supervised methods take two means. The first one trains an image-level classification model, which requires a labeled training set including both normal and abnormal samples. The second conducts refined object localization. Containing more information, supervised methods should theoretically yield higher detection rates than semi-supervised and unsupervised methods. However, because of lacking training dataset that covers all defect locations and erroneous labeling, there still exists certain technical difficulties.
B. Previous Surveys
| Tile | Year | Venue | Description | ||||||||||
| Deep learning for anomaly detection [79] | 2020 | KDD |
|
||||||||||
|
2021 |
|
The reviews present a concise overview of traditional and deep learning-based visual anomaly detection techniques. | ||||||||||
|
2021 |
|
|||||||||||
|
2022 |
|
|||||||||||
|
2020 | Sensors | |||||||||||
|
2020 | MLMI | These studies focus only on anomaly detection on particular materials. | ||||||||||
|
2020 |
|
|||||||||||
|
2020 | Sensors | |||||||||||
|
2021 |
|
|
||||||||||
|
2021 | arXiv |
|
||||||||||
|
2022 | Neurocomputing |
|
As an important research area, there have been already many reviews researching it. Table. I enlists some existing surveys in the industrial anomaly detection field, which have different focus from our research. Specifically, the review [79] starts with formulations of the most classical algorithms of different schools. The paper [80] surveys traditional methods, and also introduces deep learning-based methods. For each type of method, the characteristics of each method are listed in a general way. The article [81] represents an introduction to traditional methods, deep learning-based methods, and an introduction to hardware and software devices is involved in the meantime. For the introduction to deep learning-based methods, it mainly focuses on the supervised domain and introduces milestone algorithms by timeline. The survey [82] groups the relevant approaches given their underlying principles and discusses their assumptions, advantages, and disadvantages. The study [83] focuses on specific solutions for visual processing methods and, in particular, visual inspection approaches for metallic, ceramic, and textile surfaces in industrial applications. The methods in literature [84] are divided into categories based on the types of detection materials used. Some studies focus only on anomaly detection on a particular material. A thorough survey [1] is provided of both two-dimensional and three-dimensional surface defect detection systems for various common metal planar material products such as steel, aluminum, copper plates, and strips. The review [85] presents a detailed overview of histogram-based approaches, color-based approaches, image segmentation-based approaches, frequency domain operations, texture-based defect detection, sparse feature-based operations, and image morphology operations for fabric defect detection. The article [86] investigates supervised and semi-supervised deep learning algorithms. As for the unsupervised aspect, more attention is paid to the different network architectures used by different types of algorithms. The article [87] focuses on the intersection of different research fields, providing extended cross-cutting ideas, exhaustively introducing the algorithms and frameworks of some typical methods, de-emphasizing methodological schools and blurring domain boundaries. It intends to bring these fields closer together. The article [88] focuses only on GAN-based algorithms.
In practice, it is more biased towards the needs for the unsupervised domain in the current industrial context. To our best knowledge, no review has been done for the recently emerged unsupervised methods. The article will provide a comprehensive and in-depth summary of the state-of-the-art algorithms for visual industrial anomaly detection, which will be divided into a systematic categorization listed as III-A Reconstruction-based, III-B Normalizing Flow (NF)-based, III-C Representation-based, III-D Data augmentation-based, and III-E Algorithm enhancements. This comprehensive summary is expected to contribute to the implementation and practice of the industrial field.
III Methodology
A large part of the traditional visual anomaly detection algorithms belong to the category of supervised learning [89, 90], which requires collecting enough samples of different defect categories and accurate labeling, such as the category of the image, the location of the defects in the image and the category information of each pixel. However, in many application scenarios, it is difficult to collect a sufficient number of samples [91]. For example, in the surface defect detection task, most of the images collected actually belong to normal defect-free samples, while only a small amount belong to defect samples. With diverse types of defects to be detected, the number of defect samples available for training is very limited.
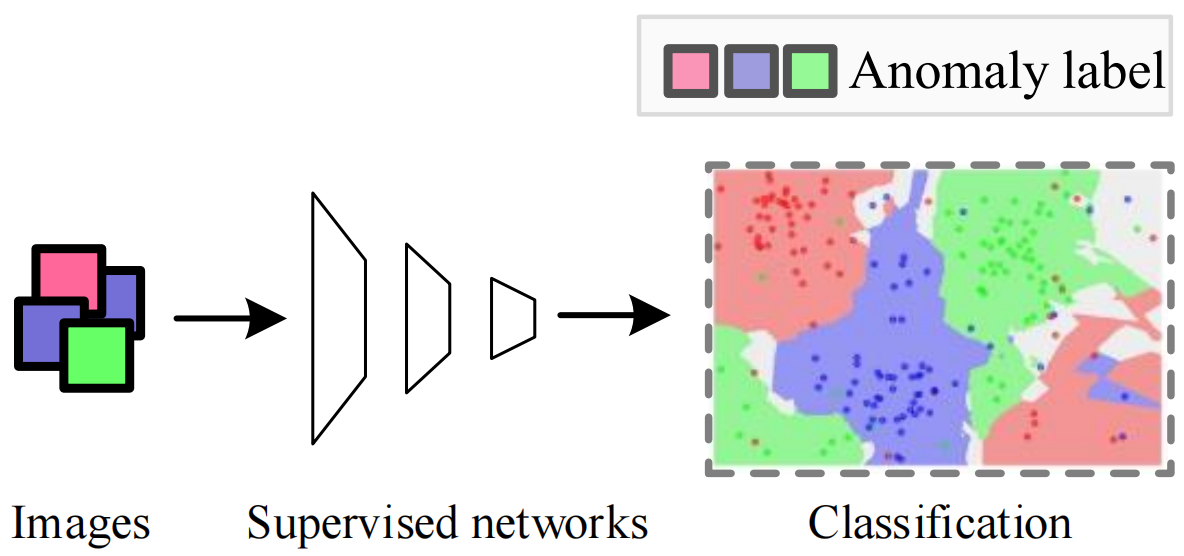
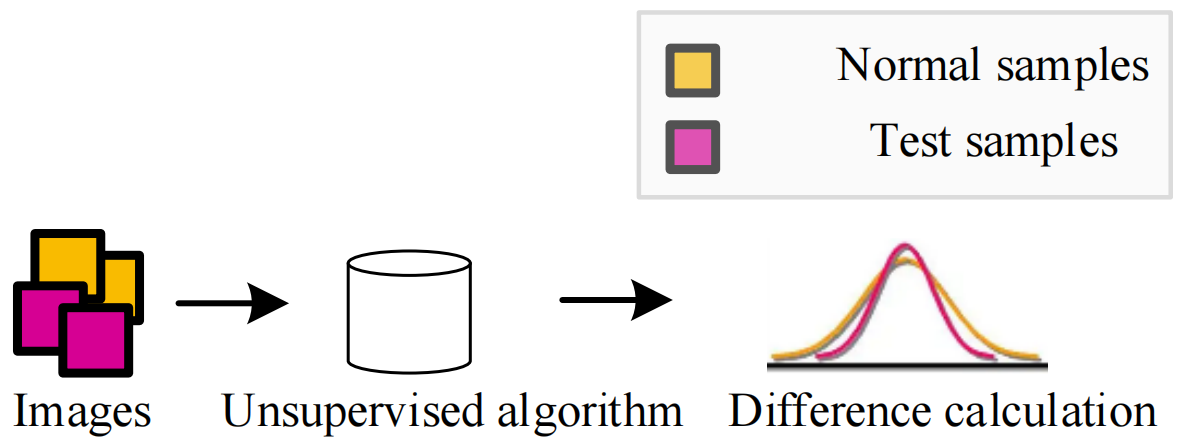
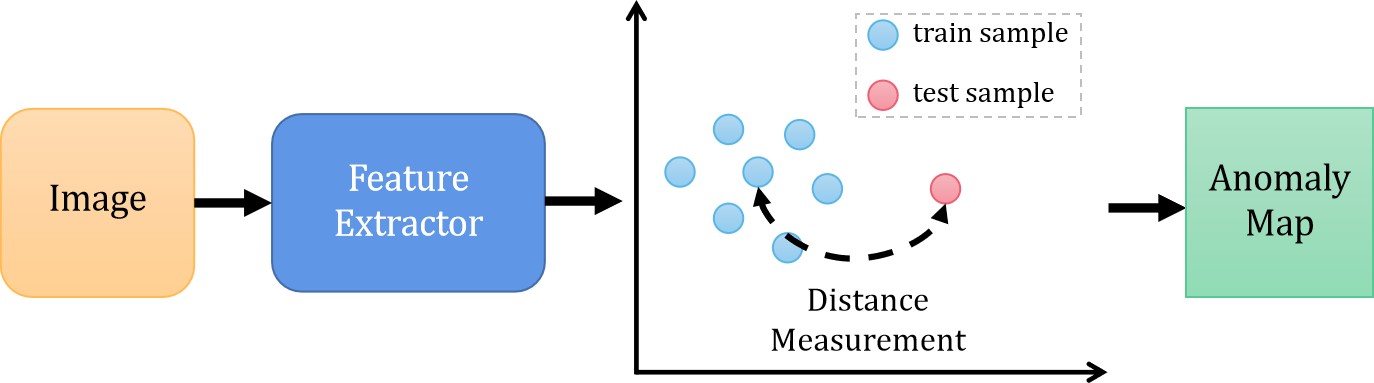
Unsupervised visual anomaly detection algorithms can build detection models without any annotated samples, which makes it very suitable for the scenarios described above. In anomaly detection tasks, the difficulty in collecting normal images is much lower than that of anomalous images, which can significantly reduce the time and labor cost of detection algorithms in practical applications. Moreover, unsupervised visual anomaly detection models detect anomalous samples by analyzing the differences between normal samples and abnormal samples, allowing the algorithm to detect a wide range of abnormal samples, even brand new sorts of flaws. Comparison of framework diagrams of supervised and unsupervised algorithms is shown in Fig. 2.
There are some highlighted approaches worth mentioning among the algorithms with great performance, which will be described in detail in this section. We categorize the existing research into five types: reconstruction-based methods, normalizing flow-based methods, representation-based methods, data augmentation-based methods, and algorithm enhancement. An overview and summary of these categories is listed in Table II.
| Category | Description | Paper | Advantages | Disadvantages |
|---|---|---|---|---|
| Reconstruction-based Methods | The core idea is to conduct encoding and decoding on the input normal images and train the neural network with the aim of reconstruction. Based on the assumption that by training only on normal images, the model will not be able to reconstruct abnormal images correctly, and the anomaly scores will be higher. | Ven.,CAVGA[92]; Liu,UTAD[93]; Yang,DFR[94]; Mo.,STPM[95]; Yamada,RSTPM[96]; Deng,RDOE[97]; Rudolph,AST[98]; Massoli,MOCCA[99]; Liang,OCR-GAN[100]; Mishra,VT-ADL[101]; Li,SOMAD[102] | The algorithm principle is straightforward and comprehensible, while the network architecture is uncomplicated. | Reconstructors like auto-encoders and GANs are highly generalizable and robust, and the anomalous part of the image can be well reconstructed, leading to hypothesis failure. |
| Normalizing Flow (NF)-based Methods | NF is able to learn transformations between data distributions and well-defined probability density functions, which can serve as a suitable estimator of probability densities for the purpose of detecting anomalies. | Rudolph,Differnet[103]; Gudovskiy,CFlow[104]; Rudolph,FCCSF[105]; Yu,FastFlow [106] | NF mapping is bijective and can be evaluated in both directions and inference efficiency is high. | NF-based methods require expensive training computational resources. |
| Representation-based Methods | Deep neural networks are used to extract meaningful vectors describing the image, and the anomaly score is usually represented by distance calculation. | Cohen,SPADE[107]; Defard,PaDIM [108]; Kars.,PatchCore [109]; Wang,GP[110]; Zheng,FYD [111]; Rip.,Gaussian-AD[112]; Yi,Patch SVDD[113]; DisAug CLR[114]; Ki.,Semi-orth[115]; Lee,CFA[116] | Representation-based methods do not call for a dedicated training stage, which introduces no parameters other than the backbone. | Because the backbone is usually biased towards ImageNet, it does not have good generalizability for different domains. |
| Data augmentation-based Methods | Augmentation algorithms are designed to resemble anomalies. | Zav.,DRAEM[117]; Schluter,NSA[118]; Li,CutPaste[119]; Nicolae,SSPCAB[120]; Song,AnoSeg [121] | The approach is uncomplicated and facile to comprehend and execute. | The data augmentation method is unable to fully replicate actual anomalies, resulting in certain generalization issues. |
III-A Reconstruction-based Methods
To learn the distribution pattern of normal images, the core idea is to conduct encoding and decoding on the input normal images and train the neural network with the aim of reconstruction. With the help of the trained networks, the differences between the images before and after reconstruction are analyzed to detect anomalies in the detection stage. With anomaly score usually represented by reconstruction error, the anomalous images are easy to be found because they cannot be reconstructed well. Classical methods based on reconstruction include autoencoders (AE [122, 123]) , variational auto-encoders (VAE [124]) and generative adversarial networks (GAN [125]), which can generate samples from the manifold of the training data. During the training phase, only normal data without anomalies are conventionally modeled. In testing phase, anomaly scores are calculated with the difference between the input image and the reconstructed image. Based on the assumption that by training only on normal images, the model will not be able to reconstruct abnormal images correctly, and the anomaly scores will be higher. The basic flow of reconstruction-based method is shown in Fig. 3.
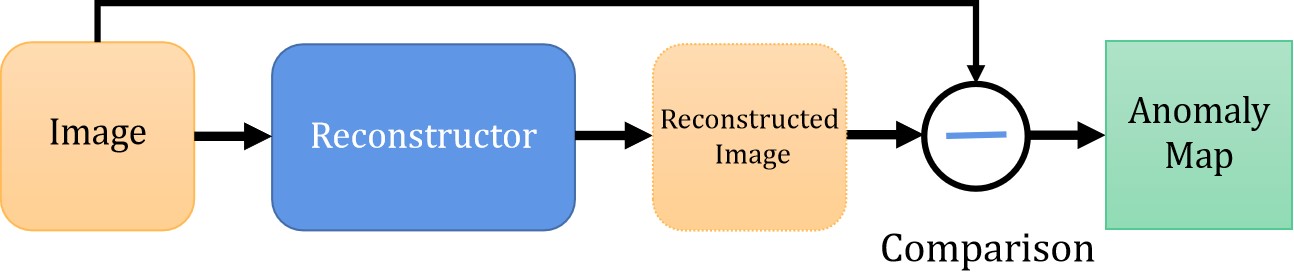
Typical auto-encoder and GAN based anomaly detection approaches mentioned above have some limitations, including:
Uncertain threshold. Autoencoders and GAN based approaches use a thresholded pixel-wise difference between the input and reconstructed image to localize anomalies. However, the use of anomalous training images, which may not be available in real-world situations, is required for these approaches to determine class-specific thresholds.
High computational cost. Autoencoder and GAN based anomaly detection approaches often require large amounts of computational resources to train and evaluate. This can be a bottleneck for real-time applications that require fast anomaly detection.
Difficult to interpret. The representations learned by autoencoders and GANs may be difficult to interpret, making it challenging to understand why a particular instance was classified as an anomaly. This can make it difficult to diagnose and fix problems in the system.
Sensitivity to hyperparameters. The performance of autoencoder and GAN based anomaly detection approaches can be sensitive to the choice of hyperparameters, such as the number of layers, the learning rate, and the batch size. It can be challenging to select the optimal hyperparameters for a given dataset, and the performance can degrade significantly if the hyperparameters are not tuned properly.
To improve the reconstruction ability, in method CAVGA [92], VAE, GAN and other means are combined and an attention mechanism is introduced for the first time into the anomaly detection field. The framework encourages the attention map to cover the entire normal region, while suppressing attention maps corresponding to the anomaly classes in the training images. Two modes of unsupervised and weakly supervised are provided. 1. Unsupervised mode: GAN is used as the overall architecture, VAE is used as the codec and attention map is generated by Grad-CAM. Loss function consists of three parts: VAE, adversarial loss, and attention part. 2. Weakly supervised mode: Compared with mode 1, classifiers are added to distinguish normal and abnormal samples. Loss function consists of four parts: VAE, adversarial loss, complementary guided attention loss, and classification loss. However, one potential drawback is that it relies on the assumption that anomalies in images are always visually distinct from the background or normal regions. This may not always be the case, as certain types of anomalies may be visually similar to the background, making them harder to detect using this method.
Classical methods like GAN and Autoencoder compare the input and its difference from the output to pinpoint the anomaly. However, coarse reconstructions produce excessive image differences, which prevents the detection of anomalies. To address this problem, the approach UTAD [93] proposes an unsupervised visual anomaly detection method for natural images by combining mutual information, GAN, and autoencoder. A two-stage framework (i.e., IE-Net, Expert Net) is utilized to generate high-fidelity and anomaly-free input reconstructions for anomaly detection tasks.
Aiming at the anomalies in small and confined regions of images, DFR method [94] suggests an effective unsupervised anomaly segmentation approach, which utilizes the transformed hierarchical CNN features to build dense discriminative multiscale feature representations for every local region of the images via a specially designed regional feature generator. DFR also proposes to detect possible anomalous regions in images by deep feature reconstruction, i.e. reconstructing the multiscale regional features via a deep yet efficient convolutional autoencoder(CAE). The regional feature generator takes the multi-scale feature maps as input and turns them into a relatively large single feature map, which is then reconstructed by a deep CAE. By calculating the reconstruction error and the anomaly score map, anomalies will be segmented if any score on the anomaly map is greater than the estimated value or a user-defined threshold.
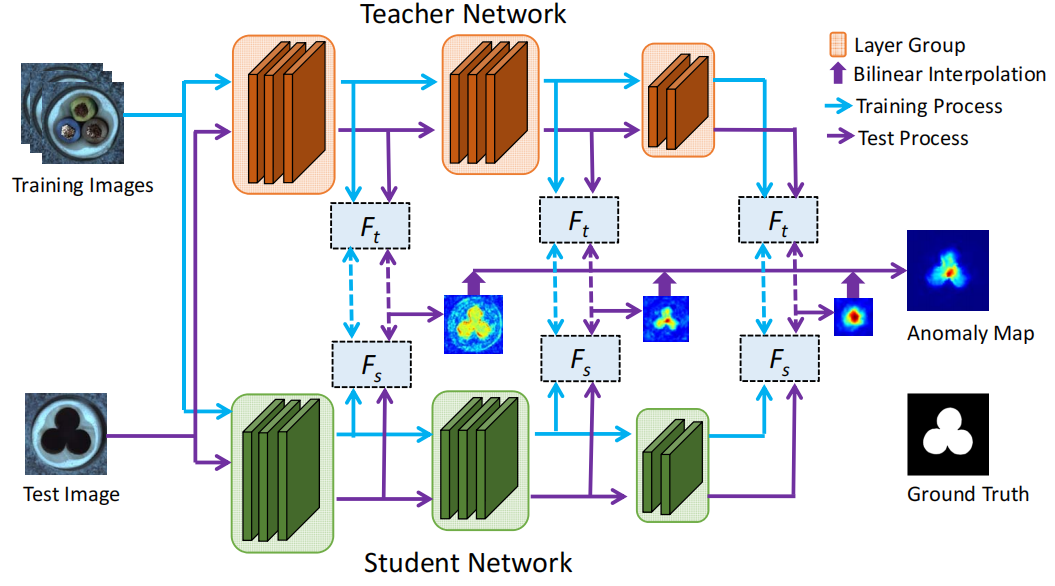
Some attempts utilize pre-trained model of image classification task. Nevertheless, the problem of the incompleteness of transferred knowledge and the complexity of handling scaling has not yet been resolved. Thus, STPM [95] introduces a novel feature pyramid matching technique and incorporates it into the student-teacher anomaly detection framework. Fig. 4 shows the overview of STPM. The algorithm employs multiple layers of features extracted from a powerful network pre-trained for image classification tasks as the teacher to guide a student network with the same structure to learn the distribution of anomaly-free images. The student network learns the distribution of images by matching the features of the anomaly-free images with the pre-trained network, and this step of transmission seeks to retain as much critical information as possible. In the training phase, the teacher network is a mature network trained on ImageNet, and the image input network generates multi-layer feature maps. The student network is trained with a fraction of the training set, approximating the multi-layer feature trained by the teacher network as much as possible. In the testing phase, samples are put into both teacher and student networks, the differential loss between which is computed. A high anomaly score will be assigned if the features of a test image (or pixel) deviate significantly between the two models. If any pixel in the image is anomalous, the image is judged as anomalous.
The RSTPM [96] approach is a generalization of the Student-Teacher framework method STPM, which was developed previously. The new approach differs from prior STPM in three ways: student network for reconstruction, an attention mechanism from the teacher network to the student network, and a different teacher network structure from the original STPM.
T-S model typically uses similar or identical architectures. To improve the T-S model’s representation diversity on unknown, out-of-distribution samples, a novel T-S model [97] with a teacher encoder and student decoder is suggested, along with a straightforward yet powerful reverse distillation paradigm. Instead of receiving raw images directly, the student network takes the teacher model’s one-class embedding as input and targets to restore the teacher’s multiscale representations. It is the first approach to adopt an encoder and a decoder to construct the T-S model. This strategy differs from existing ones due to the heterogeneity of the teacher and student networks and reversed data flow in knowledge distillation.
Previous methods suffer from the similarity of student and teacher architecture, such that the distance is undesirably small for anomalies. To tackle this problem, AST [98] proposes asymmetric student-teacher networks, which train a normalizing flow for density estimation as a teacher and a conventional feed-forward network as a student to trigger large distances for anomalies.
Explicitly leveraging the networks’ multi-layer composition, MOCCA [99] exploits the output of a deep model at different depths to detect anomalous input in the one-class setting. With MOCCA, the training technique is split into two stages in which the autoencoder is trained on the reconstruction task only, and then only the encoder is utilized to detect anomalies by exploiting a one-class-like objective applied to different layers of the network.
OCR-GAN [100] reconsiders the distinction between normal and abnormal images from the frequency domain perspective and proposes a novel framework for anomaly detection based on omni-frequency reconstruction. Specifically, FD module is proposed to decouple the input image into various frequencies and model the reconstruction process as a combination of parallel omni-frequency image restorations.
VT-ADL [101] combines the classic reconstruction-based methods with the benefits of a patch-based approach. Visual transformer networks contribute to preserving the spatial information of the embedded patches, which is later coped with a Gaussian mixture density network to localize the anomalous areas.
Self-organizing map for anomaly detection (SOMAD) [102] makes use of pre-trained CNN to extract the features of patches and leverages the SOM to maintain the neighborhood relationship of embedding vectors in topology space. It greatly reduces the search space by mapping the normal feature space into 2-dimensional space through SOM.
III-B Normalizing Flow (NF)-based Methods
Normalizing Flows (NF) [126] are neural networks that are able to learn transformations between data distributions and well-defined probability density functions. Their special property is that their mapping is bijective and they can be evaluated in both directions. The property of normalizing flows to serve as a suitable estimator of probability densities for the purpose of detecting anomalies has not drawn much attention yet. Here we summarize some recently emerged NF-based visual anomaly detection algorithms to provide ideas for future study.
There are methods [103, 104] adopting normalizing flow to estimate distribution through a trainable process that maximizes the log-likelihood of normal image features. Normal image features are embedded into standard normal distribution and the probability is used to identify and locate anomalies. The basic flow of the Normalizing Flow (NF)-based method is shown in Fig. 5.
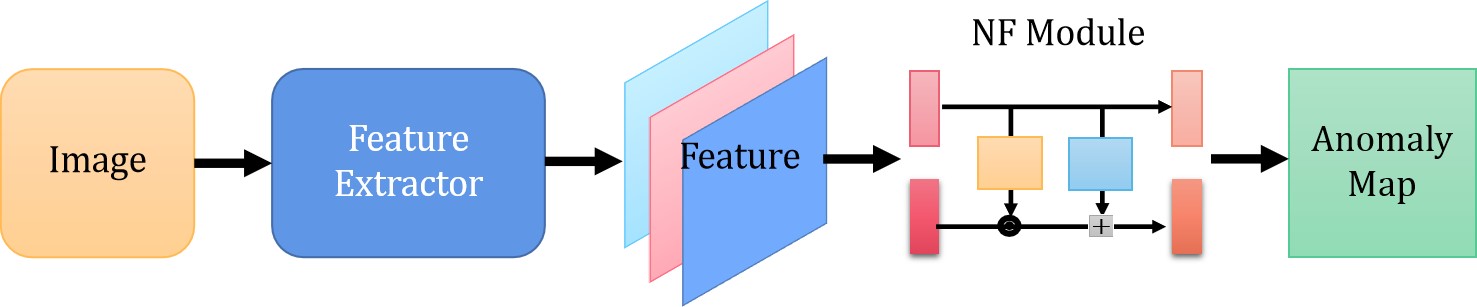
The method [105] detects and locates defects based on density estimates of feature maps extracted from input images of different sizes. Cross-connections between scales are made by jointly processing multiscale feature maps using a fully convolutional normalizing flow.
However, in order to estimate the distribution, the original one-dimensional normalizing flow model must flatten the two-dimensional input feature into a one-dimensional vector, which destroys the inherent spatial positional relationship implied by the two-dimensional image and constrains the NF model. FastFlow [106] expands the original normalizing flow model to two-dimensional space to address the concerns mentioned above.
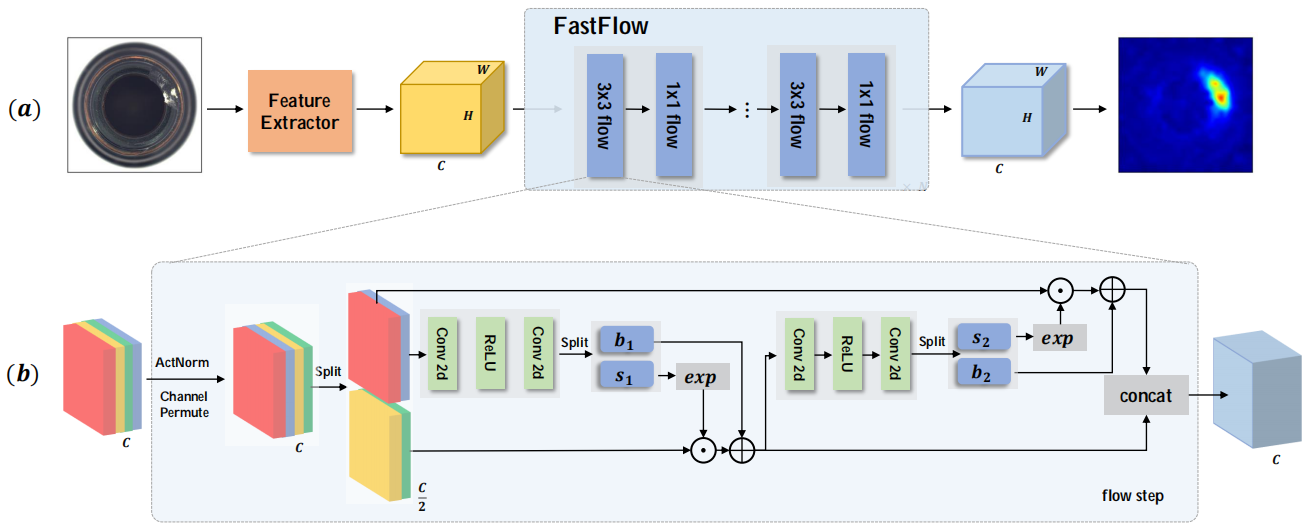
As shown in Fig. 6, the algorithm is summarized: the visual features are first extracted by a feature extractor and then fed into FastFlow to estimate the probability density. In the training phase, FastFlow is trained with normal images to transform the original distribution into a standard normal distribution in a 2D manner. In inference phase, the probability value of each position on the 2D feature is employed as the anomaly score.
III-C Representation-based Methods
For representation-based methodology, deep neural networks are used to extract meaningful vectors describing the entire image, and the anomaly score is usually represented by the distance between the embedded vectors of the test images and the reference vector representing normality from the training dataset. The basic flow of representation-based method is shown in Fig. 7. The core idea is to train a deep neural network as a feature extractor to make the distribution of feature vectors extracted from normal images as compact as possible, i.e., the intra-class distance of the samples is reduced as much as possible. Contrary to reconstruction-based algorithms, representation-based methods do not call for a dedicated training stage, which introduces no parameters other than the backbone. The concept of distance metric learning techniques is comparable to clustering.
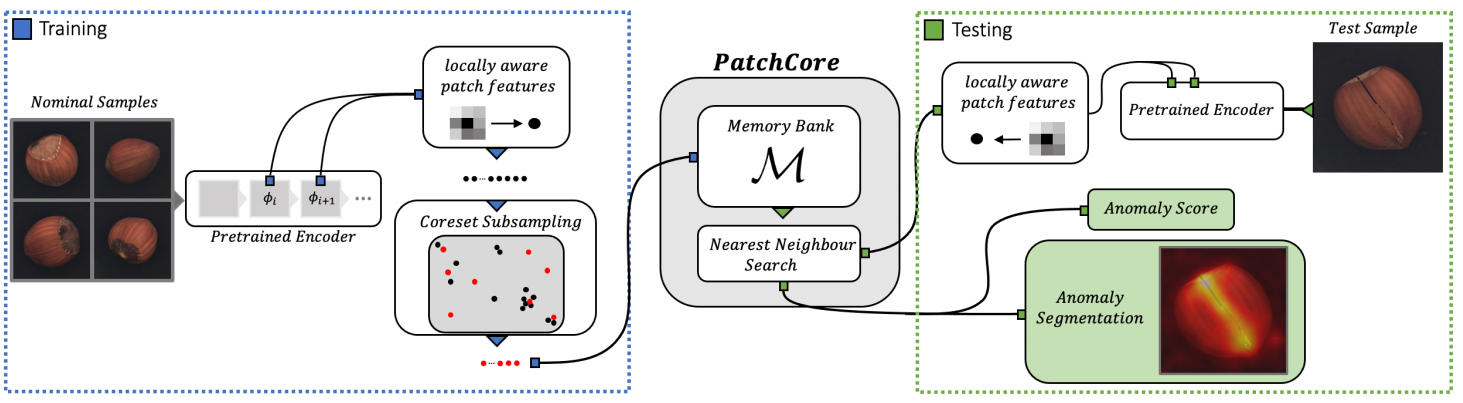
In the testing phase, most methods calculate the distance between the features of the sample to be tested and the normal features as a metric to perform anomaly detection. Typical algorithms mainly include SPADE [107], PaDIM [108], PatchCore [109], GP [110], etc. To record anomaly score and generate a score map, all these approaches employ different distance measurements (loss functions).
PatchCore uses a maximally representative memory bank of nominal patch-features to integrate embeddings from ImageNet models with an outlier detection model. The framework of PatchCore [109] is shown in Fig. 8
PaDiM makes use of a pre-trained convolutional neural network (CNN) for patch embedding, and multivariate Gaussian distributions to get a probabilistic representation of the normal class. It also exploits the correlations between different semantic levels of the CNN to better locate the anomalies.
Based on alignment between an anomalous image and a constant number of similar normal images, SPADE [107] uses KNN and multiscale feature pyramid for defect detection and localization of anomalies. The following steps make up SPADE algorithm: i) image feature extraction ii) K-nearest-neighbor normal image retrieval iii) pixel alignment with deep feature pyramid correspondences.
With a coarse-to-fine alignment technique, FYD method [111] seeks to learn dense and compact distribution of normal images. In both picture and feature levels, the coarse alignment stage normalizes the pixel-level position of objects. After that, the fine alignment stage maximizes the similarity of features across all corresponding locations in a batch.
In terms of the scale of image processing, the methods can be divided into image level, patch level and pixel level. Gaussian-AD [112] extracts discriminative feature vectors from normal images. Algorithms like Patch SVDD [113], PatchCore [109] and PaDIM [108] extract discriminative feature vectors from normal image patches. SPADE [107] extracts discriminative features which are used for pixel-level image alignment. From different process levels, these methods extract features of normal images and model the distribution with statistical methods. Based on the assumption that abnormal samples have different distributions, more promising results for anomaly detection are yielded.
Based on distribution-augmented contrastive learning, DisAug CLR algorithm [114] first learns self-supervised representations from one-class data, and then builds one-class classifiers on learned representations.
The method Semi-orthogonal [115] is a generalization of the prior work’s random feature selection method PaDIM [108]. It extends the random feature selection to semi-orthogonal embedding as a low-rank approximation of precision matrix for the Mahalanobis distance.
Albeit simple and efficient, most of these methods require manual specification of feature centers in advance, and additional tasks need to be designed in the training stage to avoid model degradation. The approach of setting only one global feature centroid imposes some constraints on the image context. In the changeable scenes of medical images or natural images, it may be challenging to map all images to the same target point under the condition of guaranteeing generalization ability.
Previous studies focused on approximating the distribution or extracting features with pre-trained CNNs of normal data, which may make the normality of abnormal features overestimated. CFA [116] performs transfer learning on the target dataset as a solution to alleviate this problem. CFA first acquires multiscale feature maps with biased CNN to generate a patch memory bank. Through transfer learning and the feature adaptation of patch descriptor associated with the memory bank, CFA achieved successful target-oriented anomaly detection.
III-D Data augmentation-based Methods
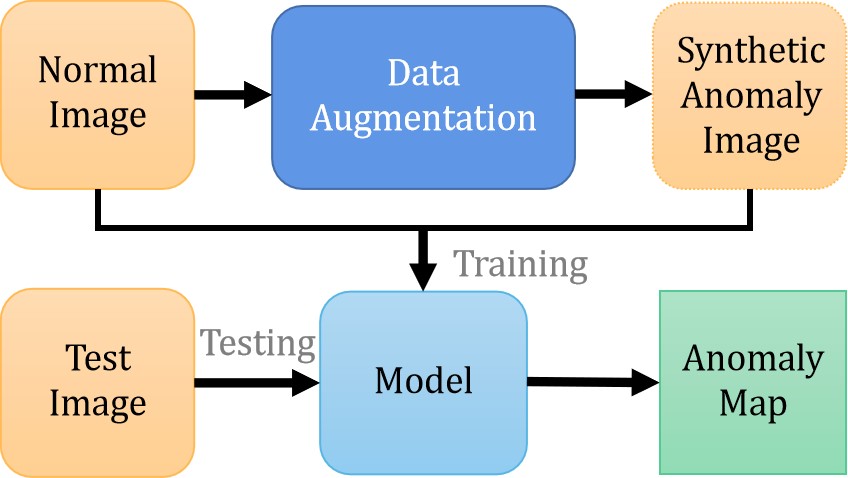
In the unsupervised setting, the training data are all anomaly-free data. Hence, there are some algorithms [114, 117, 118, 119, 121] that adopt the method of creating anomalies. To overcome the limitation of insufficient data, augmentation algorithms [127, 128] have been widely used in deep learning scheme. The basic flow of the data augmentation-based method is shown in Fig. 9.
In DRAEM [117] method, noise generation method is adopted to create anomalies and superimpose them on normal images. The proposed method learns a joint representation of a normal image and its synthetic anomalous image, while simultaneously learns a decision boundary between normal and anomalous examples.
The method NSA [118] is a naturally synthetic anomaly approach that proposes a way to create anomalies by selecting patches of different sizes at different locations and blending them into anomaly-free images. Specifically, it is a self-supervised task to create diverse and realistic synthetic anomalies with Poisson image editing to seamlessly blend multiscale patches of various sizes in different images. This produces a wide range of synthetic anomalies, which are more similar to natural sub-image irregularities.
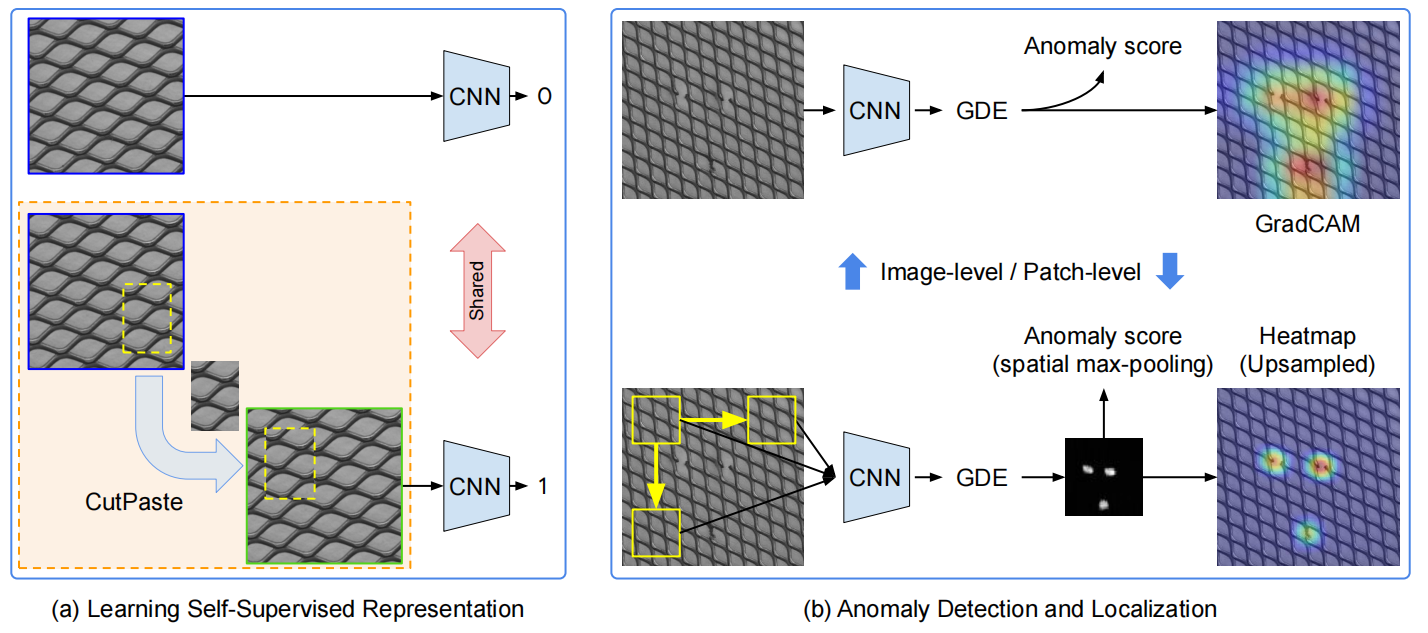
CutPaste [119] is also an synthetic anomaly method designed to produce augmentations to synthesize anomalous samples by operating on normal image patches, including cropping, rotating, transforming and overlaying. The distance between the normal samples and the generated anomalous samples is then measured. An overview of CutPaste method for anomaly detection and localization is shown in Fig. 10.
The method [120] proposes a self-supervised predictive convolutional attentive block (SSPCAB), which can be easily incorporated into various state-of-the-art anomaly detection methods, such as DRAEM [117] and CutPaste [119]. It aims at reconstructing masked information with contextual information, so as to realize performance improvements.
AnoSeg [121] is a segmentation model which combines three techniques: self-supervised learning with hard augmentation, adversarial learning, and coordinate channel connectivity. It is directly trained for anomaly segmentation tasks with synthetic anomaly data generated by hard augmentation. In addition, anomaly regions sensitive to positional relationships are more easily to be detected by means of coordinate vectors representing the pixel position information.
III-E Algorithm enhancements
Some algorithms provide some enhancements [129, 113, 130, 131], such as improved loss functions or interpretability.
IGD [129] employs reverse-interpolated training samples to train a class of Gaussian anomaly classifiers that describe representative normal samples for effective normality. Current state-of-the-art models learn a compact normality description by hyper-sphere minimization, but they are prone to overfitting. To solve this problem, interpolated Gaussian descriptor (IGD) approach is introduced. Methods that can locate anomalies generally are suitable for a specific anomaly size and structure, which may result in missing anomalies outside of that size and structure range. To avoid this problem, IGD is designed to detect multiscale structural and non-structural anomalies to improve the accuracy of anomaly localization.
Classical unsupervised anomaly detection algorithms such as support vector data description (SVDD [132]) and Deep-SVDD (DSVDD [133]) can hardly explain why an image is anomalous. Therefore, FCDD [130] explores converting the final comparison vector of the previous DSVDD model into a two-dimensional matrix (explanation heatmap) to enhance the interpretability of the algorithm. For most traditional fully connected convolutional networks, images are mapped to the feature map of . It is mentioned in this paper that an important attribute of the convolution layer is that a pixel of the feature map only has a fixed receptive field corresponding to the input. A heatmap upsampling algorithm is proposed in this paper, so that the abnormal score of the feature map can be mapped back to the position of the original image, i.e., spatial information is reserved.
A new loss function is proposed which can overcome failure modes of both center-loss and contrastive-loss methods [131]. Furthermore, it is combined with a confidence-invariant center loss, which replaces the Euclidean distance used in previous work, i.e., a distance that is sensitive to prediction confidence. The improvements yield a new anomaly detection approach, based on mean-shifted contrastive loss, which is both more accurate and less sensitive to catastrophic model collapse than previous methods.
In the field of anomaly detection, attention mechanisms [134, 92] are often used for algorithm improvement. Another kind of methodology utilizes multiscale features to enrich semantic information capture [105, 104, 108, 112, 103, 107, 95, 99, 94].
There are other methods try brand new ways to solve anomaly detection task. For the first time, RFS Energy algorithm [135] solves the challenge of unsupervised anomaly detection using keypoint detection and an energy model.
IV Comparison and Analysis
| Model | FPS | A.d. Time (ms) | A.d. Params (M) | ||
|---|---|---|---|---|---|
|
5.88 | 159 | 0 | ||
|
14.9 | 56 | 81.6 | ||
|
100 | 43.8 | 124 |
Both supervised and unsupervised algorithms are used in the field of anomaly detection, and the advantages and disadvantages of each are summarized in Table III. Although the supervised approach possesses high accuracy, there are limitations in the acquisition of labeled data, which requires a large amount of work, and sometimes it is impossible to acquire enough labeled defect samples. The process of training the network also has many parameters to optimize, which leads to inefficiency. Classification is not possible for defects that do not appear in the training set. The classes of methods introduced above in this paper are all unsupervised algorithms that do not require category labels, which can save a lot of cost and effort in practical applications. NF-based methods require expensive training computational resources, while undefined defect detection is supported and inference efficiency is high. Reconstruction-based methods require expensive training for the related task and deep generative models are not robust enough, and their performances for anomaly detection are not stable whereas the model has good generalization ability. Representation-based methods do not need to introduce parameters other than backbone, which is beneficial for efficiency. However, because backbone is usually biased towards ImageNet, it does not have good generalizability for some images, such as medical images. Data augmentation-based methods are designed to resemble the anomalies, which are data-dependent and non-automatic.
As far as complexity is concerned, we take time complexity and memory complexity into account. Time complexity. For representation-based algorithms, the training time complexity scales linearly with the dataset size. However, contrary to the methods that require training deep neural networks like reconstruction-based methods, representation-based algorithms use a pre-trained CNN, and, thus, no deep learning training is required which is often a complex procedure. Hence, it is very fast and easy to train on small datasets like MVTec AD. Conversely, take SPADE as an example, it computes and stores in the memory before testing all the embedding vectors of the normal training images. Those vectors are the inputs of a KNN algorithm which makes SPADE’s inference speed very slow. While for reconstruction-based methods, after training stage, their inference phase can be quite fast. NF-based methods avoid the time-consuming k-nearest-neighbor-search process, while it still needs to perform a more complex inference phase than reconstruction-based methods. Memory complexity. Representation-based algorithms like SPADE and Patchcore perform KNN clustering between each test feature of each image patch and the gallery features of normal image patches, and they do not need to introduce parameters other than backbone. But they require large memory allocation for gallery features.
We make an efficiency analysis of some representative methods from aspects of inference speed, additional inference time and additional model parameters, “additional” refers to not considering the backbone itself. The hardware configuration of the machine used for testing is Intel(R) Xeon(R) CPU E5-2680 V4@2.4GHZ and NVIDIA GeForce GTX 1080Ti. The analysis results are shown in Table IV.
V Datasets
Datasets are the base for research work. A good dataset is more conducive to the discovery and summary of problems, so as to facilitate the solution. There are now some quality inspection/anomaly detection datasets in the industry field.
V-A BTAD
BeanTech Anomaly Detection dataset [101] (BTAD111http://avires.dimi.uniud.it/papers/btad/btad.zip) contains a total of 2830 real-world images of 3 industrial products showcasing body and surface defects. The training set consists of only normal images, while the testing set has a mixture of both normal and abnormal images. Product 0, 1, and 2 of this dataset contain 400, 1000, and 399 training images respectively. This dataset is often used for unsupervised defect/anomaly detection. The AUROC (area under the receiver operator curve) metrics of the SOTA methods on this dataset are summarized in Table V, where the bold parts are the best-performing results.
| Methods | Product0 | Product1 | Product2 | Average |
|---|---|---|---|---|
| VT-ADL [101] | 0.990 | 0.940 | 0.770 | 0.900 |
| AE MSE [136] | 0.490 | 0.920 | 0.950 | 0.787 |
| AE MSE+SSIM [137] | 0.530 | 0.960 | 0.890 | 0.793 |
| FastFlow [106] | 0.950 | 0.960 | 0.990 | 0.967 |
| BGAD [138] | 0.972 | 0.967 | 0.996 | 0.978 |
| BGAD-FAS [138] | 0.980 | 0.977 | 0.998 | 0.985 |
| FYD [111] | 0.961 | 0.953 | 0.997 | 0.970 |
V-B Solar panel dataset: ELPV
The dataset ELPV222https://github.com/zae-bayern/elpv-dataset [6, 7, 8] contains 2624 8-bit grayscale image samples of 300 x 300 pixel functional and defective solar cells, with varying degrees of degradation extracted from 44 different solar modules. Defects in annotated images are internal or external types of defects known to reduce the power efficiency of solar modules. With every image annotated with a defect probability (a floating point value between 0 and 1), this dataset can be used to solve unsupervised tasks.
V-C Fabric defect dataset: AITEX
The collection AITEX333http://www.aitex.es/afid/ [10] contains photos of seven different fabric textures with a resolution of 4096 × 256 pixels. There are 140 defect-free images in the dataset, 20 images for each type of fabric. In addition, there are 105 images of 12 different types of fabric defects commonly found in the textile industry. It can be used to solve unsupervised tasks. The AUROC metrics of the SOTA methods on ELPV dataset and AITEX dataset are summarized in Table VI, where the bold parts are the best-performing results.
V-D MTD-Surface defect saliency
In magnetic brick surface defect dataset444https://github.com/abin24/Magnetic-tile-defect-datasets. [9], a total of 1344 images are taken, the ROI (region of interest) of the tiles is cropped and classified into six subsets according to defect type, which are respectively porosity, crack, wear, fracture, non-uniformity (caused by the grinding process) and free (defect-free), each with a pixel-level label. To simulate the manufacturing process on an actual assembly line, images are captured under a variety of lighting conditions for each given brick. It can be used to solve unsupervised tasks. The experiment results of AUROC on this dataset are summarized in Table VII, where the bold parts are the best-performing results.
V-E KolektorSDD
KolektorSDD [151] consists of 399 images of electrical commutators, where 52 defected images are annotated for microscopic fractions or cracks on the surface of the plastic embedding in electrical commutators. The dataset represents a real-world problem of surface-defect detection for an industrial semi-finished product where the number of defective items available for the training is limited. Table VIII shows AUROC performance on KolektorSDD dataset in terms of several SOTA algorithms.
| Methods | AUROC |
|---|---|
| skipGAN [152] | 0.551 |
| Puzzle AE [153] | 0.554 |
| DifferNet [103] | 0.849 |
| InTra [134] | 0.701 |
| CutPaste [119] | 0.602 |
| Draem [117] | 0.859 |
| OCR-GAN [100] | 0.914 |
| Uninformed student [154] | 0.896 |
| PaDiM [108] | 0.945 |
| Semi-orthogonal [115] | 0.960 |
| Methods | Average |
|---|---|
| skipGAN [152] | 0.558 |
| Puzzle AE [153] | 0.593 |
| CutPaste [119] | 0.665 |
| DifferNet [103] | 0.746 |
| Draem [117] | 0.980 |
| OCR-GAN [100] | 0.993 |
| f-AnoGAN [155] | 0.575 |
| Uninformed student [154] | 0.864 |
| Staar [156] | 0.830 |
| PatchSVDD [113] | SPADE [107] | CutPaste [119] | PatchCore [109] | AST [98] | CFA [116] | CFlow [104] | FastFlow [106] | |
|---|---|---|---|---|---|---|---|---|
| carpet | (92.9,92.6) | (98.6,97.5) | (100.0,98.3) | (98.7,98.9) | (97.5,-) | (97.3,-) | (100.0,99.3) | (100.0,99.4) |
| grid | (94.6,96.2) | (99.0,93.7) | (96.2,97.5) | (98.2,98.7) | (99.1,-) | (99.2,-) | (97.6,99.0) | (99.7,98.3) |
| leather | (90.9,97.4) | (99.5,97.6) | (95.4,99.5) | (100.0,99.3) | (100.0,-) | (100.0,-) | (97.7,99.7) | (100.0,99.5) |
| tile | (97.8,91.4) | (89.8,87.4) | (100.0,90.5) | (98.7,95.6) | (100.0,-) | (99.4,-) | (98.7,98.0) | (100.0,96.3) |
| wood | (96.5,90.8) | (95.8,88.5) | (99.1,95.5) | (99.2,95.0) | (100.0,-) | (99.7,-) | (99.6,96.7) | (100.0,97.0) |
| bottle | (98.6,98.1) | (98.1,98.4) | (99.9,97.6) | (100.0,98.6) | (100.0,-) | (100.0,-) | (100.0,99.0) | (100.0,97.7) |
| cable | (90.3,96.8) | (93.2,97.2) | (100.0,90.0) | (99.5,98.4) | (98.5,-) | (99.8,-) | (100.0,97.6) | (100.0,98.4) |
| capsule | (76.7,95.8) | (98.6,99.0) | (98.6,97.4) | (98.1,98.8) | (99.7,-) | (97.3,-) | (99.3,99.0) | (100.0,99.1) |
| hazelnut | (92.0,97.5) | (98.9,99.1) | (93.3 ,97.3) | (100.0.98.7) | (100.0,-) | (100.0,-) | (96.8,98.9) | (100.0,99.1) |
| meta nut | (94.0,98.0) | (96.9,98.1) | (86.6,93.1) | (100.0,98.4) | (98.5,-) | (100.0,-) | (91.9,98.6) | (100.0,98.5) |
| pill | (86.1,95.1) | (96.5,96.5) | (99.8,95.7) | (96.6,97.1) | (99.1,-) | (97.9,-) | (99.9,99.0) | (99.4,99.2) |
| screw | (81.3,95.7) | (99.5,98.9) | (90.7,96.7) | (98.1,99.4) | (99.7,-) | (97.3,-) | (99.7,98.9) | (97.8,99.4) |
| toothbrush | (100.0,98.1) | (98.9,97.9) | (97.5 ,98.1) | (100.0,98.7) | (96.6,-) | (100.0,-) | (95.2,99.0) | (94.4,98.9) |
| transistor | (91.5,97.0) | (81.0,94.1) | (99.8,93.0) | (100.0,96.3) | (99.3,-) | (100.0,-) | (99.1,98.0) | (99.8,97.3) |
| zipper | (97.9,95.1) | (98.8,96.5) | (99.9,99.3) | (98.8,98.8) | (99.1,-) | (99.6,-) | (98.5,99.1) | (99.5,98.7) |
| Average | (92.1,95.7) | (96.2,96.5) | (97.1,96.0) | (99.1,98.1) | (99.2,95.0) | (99.2,98.2) | (98.3,98.6) | (99.4,98.5) |

| BTAD | ELPV | AITEX | MTD-Surface | KolektorSDD | DAGM | MVTec AD | |
|---|---|---|---|---|---|---|---|
| Small amount of anomalous data | ✓ | ✓ | |||||
| Small size of defects | ✓ | ✓ | |||||
| Object appearance variability | ✓ | ✓ | ✓ | ||||
| Texture differences | ✓ | ✓ |
V-F DAGM
DAGM555https://conferences.mpi-inf.mpg.de/dagm/2007/prizes.html [157] is a well-known benchmark dataset for surface defect detection. It contains images of various surfaces with artificially generated defects. Surfaces and defects are split into 10 classes of various difficulties, such as scratches or spots. It is a weakly supervised dataset, and there are 8,050 training and testing sets each, and the ratio of positive and negative samples for each type is approximately 1:7. The experiment results of AUROC on this dataset averaged over ten categories are summarized in Table IX, where the bold part is the best-performing result.
V-G MVTec AD
MVTec AD dataset666http://www.mvtec.com/company/research/datasets [11] has a total of 15 categories, with 5 of them being distinct types of textures and the remaining 10 being different sorts of objects. In total, 3629 photos are utilized for training and verification, while 1725 images are used for testing in this dataset. The training set contains solely non-defective images, whereas the test set contains both non-defective and defective images of various types. This dataset is often used for unsupervised defect/anomaly detection. Example images of MVTec AD dataset are shown in Fig. 11. Under the metrics of image-level AUROC and pixel-level AUROC, the detailed comparison results of all categories are shown in Table X.
V-H Summary
There are many challenges in visual industrial anomaly detection scenarios. Take the datasets we listed for example, as shown in Table XI, there are problems such as small amount of anomalous data, small size of defects, object appearance variability, texture differences, etc.












VI Challenges and Discussion
Lack of comprehensive open datasets. Currently, the existing open datasets merely cover a limited number of scenarios, which is not comprehensive enough. The actual industrial scenarios are rich and diverse, resulting in a domain gap with the scenarios presented by the open datasets. Although the AUROC of existing methods on open datasets is high, it is not sufficiently instructive. In industrial quality inspection scenarios, defects are complex and diverse, and the current study is only the tip of the iceberg. In the actual industrial scenario, there are also cases such as edible oil impurities, wine impurities, bearing defects, engine lining defects (3D internal), etc., as shown in Fig. 12. There are still some problems that are not well solved by current methods. Taking abnormal detection of edible oil in the actual industrial scene as an example, we verify the anomaly detection of image level with existing SOTA algorithm Patchcore and AST as shown in Table. XII, but the experimental results are not ideal and far from the results reported on MVTec benchmark. It further explains that the data in the actual industrial scenario is more complex, and the benchmark data is too simple and not rich enough. On the other hand, the lack of types and quantities of testing samples can not fully verify the proposed model is reliable, which hinders the generalization ability of the model. Therefore, it is necessary to launch richer datasets with diverse scenarios and testing samples.
| Patchcore-single | Patchcore-3model | AST | |
| detection AUROC | 92.2 | 94.4 | 91.8 |
Conflict between FAR and MAR. In industrial applications there are intractably practical problems, FAR and MAR being a pair of contradictions. Correspondingly, the algorithm should be optimized to achieve a reduction in both false alarm rate and missed alarm rate. Otherwise missed alarms can lead to the production of inferior products, which will cause commercial loss, whereas a high rate of false alarms can lead to increased costs for manual confirmation.
Combination of data distribution learning and data augmentation. Normalizing flow (NF)-based methods transform a simple distribution, such as a Gaussian distribution, into a more complex distribution by applying a series of invertible transformations. For unsupervised anomaly detection, NF is used to learn the distribution of normal samples [106]. There are other approaches [158] also based on the idea of learning data distribution. Considering the idea of learning data distribution in combination with data augmentation, NF can also be used to learn the distribution of artificially augmented defective samples. The joint learning of normal and artificial anomaly samples is beneficial to improve the generalization ability of the model.
Further research on foundation model. Represention-based methods apply a pre-trained model to extract image features for anomaly detection, which demonstrates the effectiveness of the pre-trained model. As data volume and model scale evolve, foundation model [159] [160] shows great potential as a member of pre-trained models. Foundation models are trained on massive amounts of data, which enables them to capture a broad range of patterns and relationships. By fine-tuning the model on specific tasks, it can quickly adapt to new domains and produce high-quality representation. The foundation model has striking strengths in representing ability and adaptation efficiency, and it has been started to be utilized in the field of computer vision [161] [162]. While the relevant research in the field of industrial anomaly detection still needs further exploration.
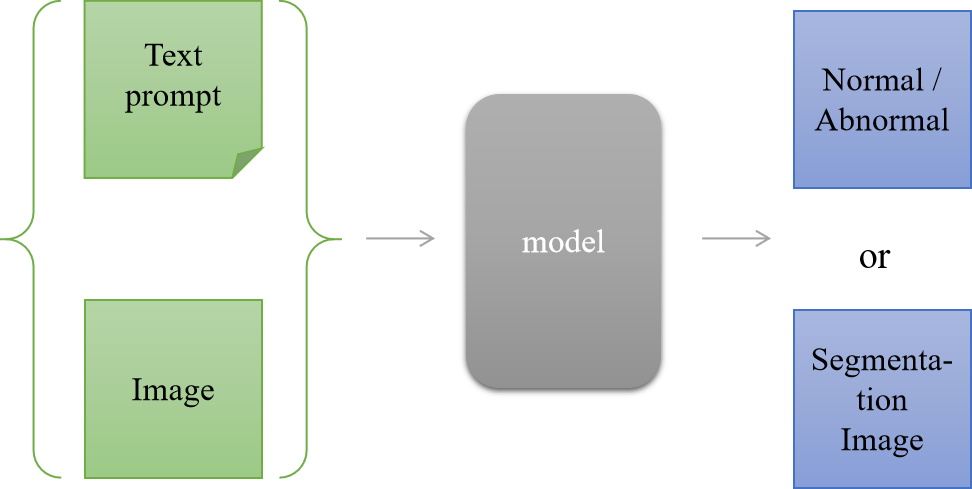
Multimodal industrial anomaly detection. Multimodal learning can facilitate deeper understanding by providing multiple perspectives and facilitating connections between different modalities. With the development of multimodal learning, models have shown great potential in dealing with image and text modalities, like GPT-4 [163], CLIP [164], stable diffusion [165], SAM [166], OFA [167] and Unified-IO [168]. In future research on industrial anomaly detection, it is expected to accept image and text prompt inputs and produce specified results, such as normal/abnormal classification or defect segmentation, as shown in Fig. 13.
VII Conclusion
Deep learning has inspired a surge of interest in the visual industrial anomaly detection problem in recent years, resulting in a wide range of creative solutions. We present a complete review of newly proposed methodologies for visual industrial anomaly detection in the literature in this study. We categorize the relevant approaches based on their fundamental principles and describe their assumptions, benefits, and drawbacks, which may be of interest to practitioners as well as academic researchers. We hope to assist academics in better understanding the common principles of visual industrial anomaly detection systems and identifying interesting research directions in this area. The unsupervised anomaly detection algorithm is still under continuous research and development, and we will continue to track the progress in the follow-up work.
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/feb149c4-0663-46dc-88e0-0a6b08ed4b57/cui.png) |
YAJIE CUI received the B.S. degree in computer science and technology from Northeastern University, Shenyang, China, in 2018 and the M.S. degree in computer science and technology from Tianjin University, Tianjin, China, in 2021. Since 2021, she has been an Deep Learning Algorithm Engineer of AI Innovation and Appliaction Center, China Unicom Digital Technology Co., Ltd, Beijing, China. Her research interest includes anomaly detection in computer vision, machine learning and deep learning. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/feb149c4-0663-46dc-88e0-0a6b08ed4b57/liu.png) |
ZHAOXIANG LIU received the B.S. and Ph.D. degrees from the College of Information and Electrical Engineering, China Agricultural University, Beijing, China, in 2006 and 2011, respectively. He joined VIA Technologies, Inc., Beijing, in 2011. From 2012 to 2016, he was a Senior Researcher of the Central Research Institute, Huawei Technologies, Beijing. He was a Senior Manager of CloudMinds Technologies Inc., Beijing, from 2016 to 2019. Since 2019, he has been a director of AI Innovation and Appliaction Center, China Unicom Digital Technology Co., Ltd, Beijing, China. His current research interests include computer vision, deep learning, robotics, and human-computer interaction. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/feb149c4-0663-46dc-88e0-0a6b08ed4b57/lian.png) |
SHIGUO LIAN (M’04) received the Ph.D. degree from the Nanjing University of Science and Technology, China. He was a Research Assistant with the City University of Hong Kong, Hong Kong, in 2004. From 2005 to 2010, he was a Research Scientist with France Telecom Research and Development Beijing, Beijing, China. He was a Senior Research Scientist and the Technical Director of the Huawei Central Research Institute, Beijing, from 2010 to 2016. He was a Senior Director of CloudMinds Technologies Inc., Beijing, from 2016 to 2019. Since 2019, he has been the Chief AI Scientist of China Unicom Digital Technology Co., Ltd and the General Manager of AI Innovation and Appliaction Center, China Unicom Digital Technology Co., Ltd, Beijing, China. He has authored over 80 refereed international journal articles covering topics of articial intelligence, multimedia communication, and human-computer interface. He has authored or coedited over ten books. He holds over 50 patents. Dr. Lian is on the editor board of several refereed international journals. |
References
- [1] X. Fang, Q. Luo, B. Zhou, C. Li, and L. Tian, “Research progress of automated visual surface defect detection for industrial metal planar materials,” Sensors, vol. 20, no. 18, p. 5136, 2020.
- [2] X. Xie, “A review of recent advances in surface defect detection using texture analysis techniques,” ELCVIA: electronic letters on computer vision and image analysis, pp. 1–22, 2008.
- [3] T. Zhang, Y. Liu, Y. Yang, X. Wang, and Y. Jin, “Review of surface defect detection based on machine vision,” J. Science Technology and Engineering, vol. 20, no. 35, pp. 14 366–14 376, 2020.
- [4] J. Cao, G. Yang, and X. Yang, “A pixel-level segmentation convolutional neural network based on deep feature fusion for surface defect detection,” IEEE Transactions on Instrumentation and Measurement, vol. 70, pp. 1–12, 2020.
- [5] G. Pang, C. Shen, L. Cao, and A. V. D. Hengel, “Deep learning for anomaly detection: A review,” ACM computing surveys (CSUR), vol. 54, no. 2, pp. 1–38, 2021.
- [6] S. Deitsch, V. Christlein, S. Berger, C. Buerhop-Lutz, A. Maier, F. Gallwitz, and C. Riess, “Automatic classification of defective photovoltaic module cells in electroluminescence images,” Solar Energy, vol. 185, pp. 455–468, Jun. 2019.
- [7] C. Buerhop-Lutz, S. Deitsch, A. Maier, F. Gallwitz, S. Berger, B. Doll, J. Hauch, C. Camus, and C. J. Brabec, “A benchmark for visual identification of defective solar cells in electroluminescence imagery,” in European PV Solar Energy Conference and Exhibition (EU PVSEC), 2018.
- [8] S. Deitsch, C. Buerhop-Lutz, E. Sovetkin, A. Steland, A. Maier, F. Gallwitz, and C. Riess, “Segmentation of photovoltaic module cells in uncalibrated electroluminescence images,” vol. 32, no. 4.
- [9] Y. Huang, C. Qiu, and K. Yuan, “Surface defect saliency of magnetic tile,” The Visual Computer, vol. 36, no. 1, pp. 85–96, 2020.
- [10] J. Silvestre-Blanes, T. Albero Albero, I. Miralles, R. Pérez-Llorens, and J. Moreno, “A public fabric database for defect detection methods and results,” Autex Research Journal, vol. 19, no. 4, pp. 363–374, 2019.
- [11] P. Bergmann, M. Fauser, D. Sattlegger, and C. Steger, “Mvtec ad–a comprehensive real-world dataset for unsupervised anomaly detection,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 9592–9600.
- [12] L. Wang and P. Koniusz, “Self-supervising action recognition by statistical moment and subspace descriptors,” in Proceedings of the 29th ACM International Conference on Multimedia, 2021, pp. 4324–4333.
- [13] P. Koniusz, L. Wang, and A. Cherian, “Tensor representations for action recognition,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 44, no. 2, pp. 648–665, 2021.
- [14] L. Wang, D. Q. Huynh, and M. R. Mansour, “Loss switching fusion with similarity search for video classification,” in 2019 IEEE International Conference on Image Processing (ICIP). IEEE, 2019, pp. 974–978.
- [15] P.-H. Chen, Y.-C. Yang, and L.-M. Chang, “Automated bridge coating defect recognition using adaptive ellipse approach,” Automation in Construction, vol. 18, no. 5, pp. 632–643, 2009.
- [16] S. Lee, L.-M. Chang, and M. Skibniewski, “Automated recognition of surface defects using digital color image processing,” Automation in Construction, vol. 15, no. 4, pp. 540–549, 2006.
- [17] R. Manish, A. Venkatesh, and S. D. Ashok, “Machine vision based image processing techniques for surface finish and defect inspection in a grinding process,” Materials Today: Proceedings, vol. 5, no. 5, pp. 12 792–12 802, 2018.
- [18] M. Chu, R. Gong, S. Gao, and J. Zhao, “Steel surface defects recognition based on multi-type statistical features and enhanced twin support vector machine,” Chemometrics and Intelligent Laboratory Systems, vol. 171, pp. 140–150, 2017.
- [19] H.-F. Ng, “Automatic thresholding for defect detection,” Pattern recognition letters, vol. 27, no. 14, pp. 1644–1649, 2006.
- [20] M. Aminzadeh and T. Kurfess, “Automatic thresholding for defect detection by background histogram mode extents,” Journal of Manufacturing Systems, vol. 37, pp. 83–92, 2015.
- [21] J. Kumar, S. Srivastava, R. Anand, P. Arvind, S. Bhardwaj, and A. Thakur, “Glcm and ann based approach for classification of radiographics weld images,” in ICIIS, 2018, pp. 168–172.
- [22] M. A. Shabir, M. U. Hassan, X. Yu, and J. Li, “Tyre defect detection based on glcm and gabor filter,” in INMIC, 2019, pp. 1–6.
- [23] S. Sadaghiyanfam, “Using gray-level-co-occurrence matrix and wavelet transform for textural fabric defect detection: A comparison study,” in EBBT, 2018, pp. 1–5.
- [24] N. T. Deotale and T. K. Sarode, “Fabric defect detection adopting combined glcm, gabor wavelet features and random decision forest,” 3D Research, vol. 10, no. 1, pp. 1–13, 2019.
- [25] X. YongHua and W. Jin-Cong, “Study on the identification of the wood surface defects based on texture features,” Optik-International Journal for Light and Electron Optics, vol. 126, no. 19, pp. 2231–2235, 2015.
- [26] S.-W. Yang, C.-S. Lin, S.-K. Lin, and H.-T. Chiang, “Automatic defect recognition of tft array process using gray level co-occurrence matrix,” Optik, vol. 125, no. 11, pp. 2671–2676, 2014.
- [27] V. A. Sindagi and S. Srivastava, “Domain adaptation for automatic oled panel defect detection using adaptive support vector data description,” International Journal of Computer Vision, vol. 122, no. 2, pp. 193–211, 2017.
- [28] K. Song and Y. Yan, “A noise robust method based on completed local binary patterns for hot-rolled steel strip surface defects,” Applied Surface Science, vol. 285, pp. 858–864, 2013.
- [29] S. Fekri-Ershad and F. Tajeripour, “Multi-resolution and noise-resistant surface defect detection approach using new version of local binary patterns,” Applied Artificial Intelligence, vol. 31, no. 5-6, pp. 395–410, 2017.
- [30] Z. Liu, L. Yan, C. Li, Y. Dong, and G. Gao, “Fabric defect detection based on sparse representation of main local binary pattern,” International Journal of Clothing Science and Technology, 2017.
- [31] S. Li, D. Li, and W. Yuan, “Wood defect classification based on two-dimensional histogram constituted by lbp and local binary differential excitation pattern,” IEEE Access, vol. 7, pp. 145 829–145 842, 2019.
- [32] K. Yan, Q. Dong, T. Sun, M. Zhang, and S. Zhang, “Weld defect detection based on completed local ternary patterns,” in Proceedings of the International Conference on Video and Image Processing, 2017, pp. 6–14.
- [33] A. Chondronasios, I. Popov, and I. Jordanov, “Feature selection for surface defect classification of extruded aluminum profiles,” The International Journal of Advanced Manufacturing Technology, vol. 83, no. 1, pp. 33–41, 2016.
- [34] R. Ma, S. Deng, H. Sun, and Y. Qi, “An algorithm for fabric defect detection based on adaptive canny operator,” in ICICAS, 2019, pp. 475–481.
- [35] Y. Zhang, T. Li, and Q. Li, “Defect detection for tire laser shearography image using curvelet transform based edge detector,” Optics & Laser Technology, vol. 47, pp. 64–71, 2013.
- [36] X. Hou and H. Liu, “Welding image edge detection and identification research based on canny operator,” in International Conference on Computer Science and Service System, 2012, pp. 250–253.
- [37] M. Halim, N. Ruhaiyem, E. Fauzi, A. Mohamed et al., “Automatic laser welding defect detection and classification using sobel-contour shape detection,” Journal of Telecommunication, Electronic and Computer Engineering (JTEC), vol. 8, no. 6, pp. 157–160, 2016.
- [38] C. Taştimur, M. Karaköse, E. Akın, and İ. Aydın, “Rail defect detection with real time image processing technique,” in INDIN, 2016, pp. 411–415.
- [39] J. Zhang, Z. Guo, T. Jiao, and M. Wang, “Defect detection of aluminum alloy wheels in radiography images using adaptive threshold and morphological reconstruction,” Applied Sciences, vol. 8, no. 12, p. 2365, 2018.
- [40] J. Hu, Z. He, G. Weng, L. Sun, B. Zuo, and C. Wang, “Detection of chemical fabric defects on the basis of morphological processing,” The Journal of The Textile Institute, vol. 107, no. 2, pp. 233–241, 2016.
- [41] V. Jayashree and S. Subbaramn, “Hybrid approach using correlation and morphological approaches for gfdd of plain weave fabric,” in IEEE Control and System Graduate Research Colloquium, 2012, pp. 197–202.
- [42] A. Rebhi, S. Abid, and F. Fnaiech, “Fabric defect detection using local homogeneity and morphological image processing,” in IPAS, 2016, pp. 1–5.
- [43] T.-C. Su and M.-D. Yang, “Application of morphological segmentation to leaking defect detection in sewer pipelines,” Sensors, vol. 14, no. 5, pp. 8686–8704, 2014.
- [44] I. Pastor-López, B. Sanz, J. G. d. l. Puerta, and P. G. Bringas, “Surface defect modelling using co-occurrence matrix and fast fourier transformation,” in International Conference on Hybrid Artificial Intelligence Systems, 2019, pp. 745–757.
- [45] X. Bai, Y. Fang, W. Lin, L. Wang, and B.-F. Ju, “Saliency-based defect detection in industrial images by using phase spectrum,” IEEE Transactions on Industrial Informatics, vol. 10, no. 4, pp. 2135–2145, 2014.
- [46] P. Kumaresan, “Defect detection in texture by fourier analysis approach,” International Journal of Engineering, Science and Mathematics, vol. 6, no. 3, pp. 124–130, 2017.
- [47] S. Ajithaprasad, R. Velpula, and R. Gannavarpu, “Defect detection using windowed fourier spectrum analysis in diffraction phase microscopy,” Journal of Physics Communications, vol. 3, no. 2, p. 025006, 2019.
- [48] G.-H. Hu, “Automated defect detection in textured surfaces using optimal elliptical gabor filters,” Optik, vol. 126, no. 14, pp. 1331–1340, 2015.
- [49] J.-W. Wang, W.-Y. Chen, and J.-S. Lee, “Singular value decomposition combined with wavelet transform for lcd defect detection,” Electronics letters, vol. 48, no. 5, pp. 266–267, 2012.
- [50] C. Yang, P. Liu, G. Yin, H. Jiang, and X. Li, “Defect detection in magnetic tile images based on stationary wavelet transform,” Ndt & E International, vol. 83, pp. 78–87, 2016.
- [51] J. Liu, G. Xu, L. Ren, Z. Qian, and L. Ren, “Defect intelligent identification in resistance spot welding ultrasonic detection based on wavelet packet and neural network,” The International Journal of Advanced Manufacturing Technology, vol. 90, no. 9, pp. 2581–2588, 2017.
- [52] P. Li, H. Zhang, J. Jing, R. Li, and J. Zhao, “Fabric defect detection based on multi-scale wavelet transform and gaussian mixture model method,” The Journal of The Textile Institute, vol. 106, no. 6, pp. 587–592, 2015.
- [53] J. Jing, P. Yang, P. Li, and X. Kang, “Supervised defect detection on textile fabrics via optimal gabor filter,” Journal of Industrial Textiles, vol. 44, no. 1, pp. 40–57, 2014.
- [54] L. Tong, W. K. Wong, and C. K. Kwong, “Differential evolution-based optimal gabor filter model for fabric inspection,” Neurocomputing, vol. 173, pp. 1386–1401, 2016.
- [55] X. Yang, D. Qi, and X. Li, “Multi-scale edge detection of wood defect images based on the dyadic wavelet transform,” in International Conference on Machine Vision and Human-machine Interface, 2010, pp. 120–123.
- [56] V. Vijaykumar and S. Sangamithirai, “Rail defect detection using gabor filters with texture analysis,” in ICSCN, 2015, pp. 1–6.
- [57] Y. Li, W. Zhao, and J. Pan, “Deformable patterned fabric defect detection with fisher criterion-based deep learning,” IEEE Transactions on Automation Science and Engineering, vol. 14, no. 2, pp. 1256–1264, 2016.
- [58] Y. Wang, M. Liu, P. Zheng, H. Yang, and J. Zou, “A smart surface inspection system using faster r-cnn in cloud-edge computing environment,” Advanced Engineering Informatics, vol. 43, p. 101037, 2020.
- [59] Y.-t. LIU, Y.-n. YANG, W. Chao, X.-y. XU, and T. ZHANG, “Research on surface defect detection based on semantic segmentation,” DEStech Transactions on Computer Science and Engineering, no. aicae, 2019.
- [60] D. Weimer, B. Scholz-Reiter, and M. Shpitalni, “Design of deep convolutional neural network architectures for automated feature extraction in industrial inspection,” CIRP Annals, vol. 65, no. 1, pp. 417–420, 2016.
- [61] Y. Li and C. Zhang, “Automated vision system for fabric defect inspection using gabor filters and pcnn,” SpringerPlus, vol. 5, no. 1, pp. 1–12, 2016.
- [62] S. S. Kumar, D. M. Abraham, M. R. Jahanshahi, T. Iseley, and J. Starr, “Automated defect classification in sewer closed circuit television inspections using deep convolutional neural networks,” Automation in Construction, vol. 91, pp. 273–283, 2018.
- [63] D. Brackenbury, I. Brilakis, and M. DeJong, “Automated defect detection for masonry arch bridges,” in ICSIC, 2019, pp. 3–9.
- [64] C. Sacco, A. B. Radwan, R. Harik, and M. Van Tooren, “Automated fiber placement defects: Automated inspection and characterization,” in SAMPE, 2018.
- [65] Y. Yang, L. Pan, J. Ma, R. Yang, Y. Zhu, Y. Yang, and L. Zhang, “A high-performance deep learning algorithm for the automated optical inspection of laser welding,” Applied Sciences, vol. 10, no. 3, p. 933, 2020.
- [66] Y. Liu, J. Geng, Z. Su, W. Zhang, and J. Li, “Real-time classification of steel strip surface defects based on deep cnns,” in Proceedings of 2018 Chinese Intelligent Systems Conference, 2019, pp. 257–266.
- [67] L. Song, W. Lin, Y.-G. Yang, X. Zhu, Q. Guo, and J. Xi, “Weak micro-scratch detection based on deep convolutional neural network,” IEEE Access, vol. 7, pp. 27 547–27 554, 2019.
- [68] Y. Liu, K. Xu, and J. Xu, “Periodic surface defect detection in steel plates based on deep learning,” Applied Sciences, vol. 9, no. 15, p. 3127, 2019.
- [69] R. F. Pereira, C. M. Medeiros, and P. P. Rebouças Filho, “Goat leather quality classification using computer vision and machine learning,” in IJCNN, 2018, pp. 01–08.
- [70] S. Tural and R. Samet, “Automated defect detection on surface of militarz cartridges,” J. Mod. Technol. Eng, vol. 4, pp. 178–189, 2019.
- [71] M. P. Samy, S. Foong, G. S. Soh, and K. S. Yeo, “Automatic optical & laser-based defect detection and classification in brick masonry walls,” in TENCON, 2016, pp. 3521–3524.
- [72] F. López, J.-M. Valiente, and J.-M. Prats, “Surface grading using soft colour-texture descriptors,” in Iberoamerican Congress on Pattern Recognition, 2005, pp. 13–23.
- [73] F. López, J. M. Valiente, R. Baldrich, and M. Vanrell, “Fast surface grading using color statistics in the cie lab space,” in Iberian conference on pattern recognition and image analysis, 2005, pp. 666–673.
- [74] F. Pernkopf, “Detection of surface defects on raw steel blocks using bayesian network classifiers,” Pattern Analysis and Applications, vol. 7, no. 3, pp. 333–342, 2004.
- [75] C. Mandriota, M. Nitti, N. Ancona, E. Stella, and A. Distante, “Filter-based feature selection for rail defect detection,” Machine Vision and Applications, vol. 15, no. 4, pp. 179–185, 2004.
- [76] K. Wiltschi, A. Pinz, and T. Lindeberg, “An automatic assessment scheme for steel quality inspection,” Machine Vision and Applications, vol. 12, no. 3, pp. 113–128, 2000.
- [77] C.-h. Chan and G. K. Pang, “Fabric defect detection by fourier analysis,” IEEE transactions on Industry Applications, vol. 36, no. 5, pp. 1267–1276, 2000.
- [78] A. Latif-Amet, A. Ertüzün, and A. Erçil, “An efficient method for texture defect detection: sub-band domain co-occurrence matrices,” Image and Vision computing, vol. 18, no. 6-7, pp. 543–553, 2000.
- [79] R. Wang, K. Nie, Y. Chang, X. Gong, T. Wang, Y. Yang, and B. Long, “Deep learning for anomaly detection,” in KDD, 2020, pp. 3569–3570.
- [80] Y. Gao, X. Li, X. V. Wang, L. Wang, and L. Gao, “A review on recent advances in vision-based defect recognition towards industrial intelligence,” Journal of Manufacturing Systems, 2021.
- [81] X. Zheng, S. Zheng, Y. Kong, and J. Chen, “Recent advances in surface defect inspection of industrial products using deep learning techniques,” The International Journal of Advanced Manufacturing Technology, vol. 113, no. 1, pp. 35–58, 2021.
- [82] J. Yang, R. Xu, Z. Qi, and Y. Shi, “Visual anomaly detection for images: A systematic survey,” Procedia Computer Science, vol. 199, pp. 471–478, 2022.
- [83] T. Czimmermann, G. Ciuti, M. Milazzo, M. Chiurazzi, S. Roccella, C. M. Oddo, and P. Dario, “Visual-based defect detection and classification approaches for industrial applications—a survey,” Sensors, vol. 20, no. 5, p. 1459, 2020.
- [84] S. Qi, J. Yang, and Z. Zhong, “A review on industrial surface defect detection based on deep learning technology,” in MLMI, 2020, pp. 24–30.
- [85] A. Rasheed, B. Zafar, A. Rasheed, N. Ali, M. Sajid, S. H. Dar, U. Habib, T. Shehryar, and M. T. Mahmood, “Fabric defect detection using computer vision techniques: A comprehensive review,” Mathematical Problems in Engineering, vol. 2020, 2020.
- [86] P. M. Bhatt, R. K. Malhan, P. Rajendran, B. C. Shah, S. Thakar, Y. J. Yoon, and S. K. Gupta, “Image-based surface defect detection using deep learning: A review,” Journal of Computing and Information Science in Engineering, vol. 21, no. 4, 2021.
- [87] M. Salehi, H. Mirzaei, D. Hendrycks, Y. Li, M. H. Rohban, and M. Sabokrou, “A unified survey on anomaly, novelty, open-set, and out-of-distribution detection: Solutions and future challenges,” arXiv preprint arXiv:2110.14051, 2021.
- [88] X. Xia, X. Pan, N. Li, X. He, L. Ma, X. Zhang, and N. Ding, “Gan-based anomaly detection: a review,” Neurocomputing, 2022.
- [89] N. Görnitz, M. Kloft, K. Rieck, and U. Brefeld, “Toward supervised anomaly detection,” Journal of Artificial Intelligence Research, vol. 46, pp. 235–262, 2013.
- [90] Y. Kawachi, Y. Koizumi, and N. Harada, “Complementary set variational autoencoder for supervised anomaly detection,” in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2018, pp. 2366–2370.
- [91] L. Ruff, J. R. Kauffmann, R. A. Vandermeulen, G. Montavon, W. Samek, M. Kloft, T. G. Dietterich, and K.-R. Müller, “A unifying review of deep and shallow anomaly detection,” Proceedings of the IEEE, 2021.
- [92] S. Venkataramanan, K.-C. Peng, R. V. Singh, and A. Mahalanobis, “Attention guided anomaly localization in images,” in European Conference on Computer Vision, 2020, pp. 485–503.
- [93] Y. Liu, C. Zhuang, and F. Lu, “Unsupervised two-stage anomaly detection,” arXiv preprint arXiv:2103.11671, 2021.
- [94] J. Yang, Y. Shi, and Z. Qi, “Dfr: Deep feature reconstruction for unsupervised anomaly segmentation,” arXiv preprint arXiv:2012.07122, 2020.
- [95] M. Zolfaghari and H. Sajedi, “Unsupervised anomaly detection with an enhanced teacher for student-teacher feature pyramid matching,” in CSICC, 2022, pp. 1–4.
- [96] S. Yamada, S. Kamiya, and K. Hotta, “Reconstructed student-teacher and discriminative networks for anomaly detection,” in 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2022, pp. 2725–2732.
- [97] H. Deng and X. Li, “Anomaly detection via reverse distillation from one-class embedding,” in CVPR, 2022, pp. 9737–9746.
- [98] M. Rudolph, T. Wehrbein, B. Rosenhahn, and B. Wandt, “Asymmetric student-teacher networks for industrial anomaly detection,” in Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2023, pp. 2592–2602.
- [99] F. V. Massoli, F. Falchi, A. Kantarci, Ş. Akti, H. K. Ekenel, and G. Amato, “Mocca: Multi-layer one-class classification for anomaly detection,” arXiv preprint arXiv:2012.12111, 2020.
- [100] Y. Liang, J. Zhang, S. Zhao, R. Wu, Y. Liu, and S. Pan, “Omni-frequency channel-selection representations for unsupervised anomaly detection,” arXiv preprint arXiv:2203.00259, 2022.
- [101] P. Mishra, R. Verk, D. Fornasier, C. Piciarelli, and G. L. Foresti, “Vt-adl: A vision transformer network for image anomaly detection and localization,” in ISIE, 2021, pp. 01–06.
- [102] N. Li, K. Jiang, Z. Ma, X. Wei, X. Hong, and Y. Gong, “Anomaly detection via self-organizing map,” in 2021 IEEE International Conference on Image Processing (ICIP). IEEE, 2021, pp. 974–978.
- [103] M. Rudolph, B. Wandt, and B. Rosenhahn, “Same same but differnet: Semi-supervised defect detection with normalizing flows,” in Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2021, pp. 1907–1916.
- [104] D. Gudovskiy, S. Ishizaka, and K. Kozuka, “Cflow-ad: Real-time unsupervised anomaly detection with localization via conditional normalizing flows,” in Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2022, pp. 98–107.
- [105] M. Rudolph, T. Wehrbein, B. Rosenhahn, and B. Wandt, “Fully convolutional cross-scale-flows for image-based defect detection,” in CVPR, 2022, pp. 1088–1097.
- [106] J. Yu, Y. Zheng, X. Wang, W. Li, Y. Wu, R. Zhao, and L. Wu, “Fastflow: Unsupervised anomaly detection and localization via 2d normalizing flows,” arXiv preprint arXiv:2111.07677, 2021.
- [107] N. Cohen and Y. Hoshen, “Sub-image anomaly detection with deep pyramid correspondences,” arXiv preprint arXiv:2005.02357, 2020.
- [108] T. Defard, A. Setkov, A. Loesch, and R. Audigier, “Padim: a patch distribution modeling framework for anomaly detection and localization,” in International Conference on Pattern Recognition, 2021, pp. 475–489.
- [109] K. Roth, L. Pemula, J. Zepeda, B. Schölkopf, T. Brox, and P. V. Gehler, “Towards total recall in industrial anomaly detection,” in CVPR 2022. IEEE, 2022, pp. 14 298–14 308.
- [110] S. Wang, L. Wu, L. Cui, and Y. Shen, “Glancing at the patch: Anomaly localization with global and local feature comparison,” in CVPR, 2021, pp. 254–263.
- [111] Y. Zheng, X. Wang, R. Deng, T. Bao, R. Zhao, and L. Wu, “Focus your distribution: Coarse-to-fine non-contrastive learning for anomaly detection and localization,” in ICME, 2022, pp. 1–6.
- [112] O. Rippel, P. Mertens, and D. Merhof, “Modeling the distribution of normal data in pre-trained deep features for anomaly detection,” in ICPR, 2021, pp. 6726–6733.
- [113] J. Yi and S. Yoon, “Patch svdd: Patch-level svdd for anomaly detection and segmentation,” in Proceedings of the Asian Conference on Computer Vision, 2020.
- [114] K. Sohn, C. Li, J. Yoon, M. Jin, and T. Pfister, “Learning and evaluating representations for deep one-class classification,” in ICLR, 2021.
- [115] J.-H. Kim, D.-H. Kim, S. Yi, and T. Lee, “Semi-orthogonal embedding for efficient unsupervised anomaly segmentation,” arXiv preprint arXiv:2105.14737, 2021.
- [116] S. Lee, S. Lee, and B. C. Song, “Cfa: Coupled-hypersphere-based feature adaptation for target-oriented anomaly localization,” IEEE Access, vol. 10, pp. 78 446–78 454, 2022.
- [117] V. Zavrtanik, M. Kristan, and D. Skočaj, “Draem-a discriminatively trained reconstruction embedding for surface anomaly detection,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 8330–8339.
- [118] H. M. Schlüter, J. Tan, B. Hou, and B. Kainz, “Self-supervised out-of-distribution detection and localization with natural synthetic anomalies (nsa),” arXiv preprint arXiv:2109.15222, 2021.
- [119] C.-L. Li, K. Sohn, J. Yoon, and T. Pfister, “Cutpaste: Self-supervised learning for anomaly detection and localization,” in CVPR, 2021, pp. 9664–9674.
- [120] N. Ristea, N. Madan, R. T. Ionescu, K. Nasrollahi, F. S. Khan, T. B. Moeslund, and M. Shah, “Self-supervised predictive convolutional attentive block for anomaly detection,” in CVPR, 2022, pp. 13 566–13 576.
- [121] J. Song, K. Kong, Y.-I. Park, S.-G. Kim, and S.-J. Kang, “Anoseg: Anomaly segmentation network using self-supervised learning,” arXiv preprint arXiv:2110.03396, 2021.
- [122] Y. LeCun et al., “Generalization and network design strategies,” Connectionism in perspective, vol. 19, pp. 143–155, 1989.
- [123] M. Rudolph, B. Wandt, and B. Rosenhahn, “Structuring autoencoders,” in Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, 2019, pp. 615–623.
- [124] D. P. Kingma and M. Welling, “Auto-encoding variational bayes,” in ICLR, 2014.
- [125] I. J. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. C. Courville, and Y. Bengio, “Generative adversarial networks,” CoRR, vol. abs/1406.2661, 2014.
- [126] D. J. Rezende and S. Mohamed, “Variational inference with normalizing flows,” in ICML 2015, ser. JMLR Workshop and Conference Proceedings, vol. 37, 2015, pp. 1530–1538.
- [127] X. Wang, K. Wang, and S. Lian, “A survey on face data augmentation for the training of deep neural networks,” Neural Computing and Applications, pp. 1–29, 2020.
- [128] N. Ishida, Y. Nagatsu, and H. Hashimoto, “Unsupervised anomaly detection based on data augmentation and mixing,” IECON 2020 The 46th Annual Conference of the IEEE Industrial Electronics Society, pp. 529–533, 2020.
- [129] Y. Chen, Y. Tian, G. Pang, and G. Carneiro, “Deep one-class classification via interpolated gaussian descriptor,” in AAAI, 2022, pp. 383–392.
- [130] P. Liznerski, L. Ruff, R. A. Vandermeulen, B. J. Franks, M. Kloft, and K. Müller, “Explainable deep one-class classification,” in ICLR, 2021.
- [131] T. Reiss and Y. Hoshen, “Mean-shifted contrastive loss for anomaly detection,” arXiv preprint arXiv:2106.03844, 2021.
- [132] D. M. Tax and R. P. Duin, “Support vector data description,” Machine learning, vol. 54, no. 1, pp. 45–66, 2004.
- [133] L. Ruff, R. Vandermeulen, N. Goernitz, L. Deecke, S. A. Siddiqui, A. Binder, E. Müller, and M. Kloft, “Deep one-class classification,” in ICML, 2018, pp. 4393–4402.
- [134] J. Pirnay and K. Chai, “Inpainting transformer for anomaly detection,” in Image Analysis and Processing(ICIAP), ser. Lecture Notes in Computer Science, vol. 13232, 2022, pp. 394–406.
- [135] A. M. Kamoona, A. K. Gostar, A. Bab-Hadiashar, and R. Hoseinnezhad, “Anomaly detection of defect using energy of point pattern features within random finite set framework,” arXiv preprint arXiv:2108.12159, 2021.
- [136] G. E. Hinton and R. R. Salakhutdinov, “Reducing the dimensionality of data with neural networks,” science, vol. 313, no. 5786, pp. 504–507, 2006.
- [137] P. Bergmann, S. Löwe, M. Fauser, D. Sattlegger, and C. Steger, “Improving unsupervised defect segmentation by applying structural similarity to autoencoders,” in VISIGRAPP, 2019, pp. 372–380.
- [138] X. Yao, C. Zhang, and R. Li, “Explicit boundary guided semi-push-pull contrastive learning for better anomaly detection,” CoRR, vol. abs/2207.01463, 2022.
- [139] M. Salehi, N. Sadjadi, S. Baselizadeh, M. H. Rohban, and H. R. Rabiee, “Multiresolution knowledge distillation for anomaly detection,” in CVPR, 2021, pp. 14 902–14 912.
- [140] G. Pang, C. Ding, C. Shen, and A. van den Hengel, “Explainable deep few-shot anomaly detection with deviation networks,” CoRR, vol. abs/2108.00462, 2021.
- [141] T. Lin, P. Goyal, R. B. Girshick, K. He, and P. Dollár, “Focal loss for dense object detection,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 42, no. 2, pp. 318–327, 2020.
- [142] J. Tack, S. Mo, J. Jeong, and J. Shin, “CSI: novelty detection via contrastive learning on distributionally shifted instances,” in NeurIPS, 2020.
- [143] W. Liu, W. Luo, Z. Li, P. Zhao, S. Gao et al., “Margin learning embedded prediction for video anomaly detection with a few anomalies.” in IJCAI, 2019, pp. 3023–3030.
- [144] C. Ding, G. Pang, and C. Shen, “Catching both gray and black swans: Open-set supervised anomaly detection,” in CVPR, 2022, pp. 7388–7398.
- [145] I. Golan and R. El-Yaniv, “Deep anomaly detection using geometric transformations,” Advances in neural information processing systems, vol. 31, 2018.
- [146] S. Akcay, A. Atapour-Abarghouei, and T. P. Breckon, “Ganomaly: Semi-supervised anomaly detection via adversarial training,” in Asian conference on computer vision, 2018, pp. 622–637.
- [147] S. Zhai, Y. Cheng, W. Lu, and Z. Zhang, “Deep structured energy based models for anomaly detection,” in ICML, 2016, pp. 1100–1109.
- [148] T. S. Nazare, R. F. de Mello, and M. A. Ponti, “Are pre-trained cnns good feature extractors for anomaly detection in surveillance videos?” arXiv preprint arXiv:1811.08495, 2018.
- [149] H. Cheng, H. Liu, F. Gao, and Z. Chen, “Adgan: A scalable gan-based architecture for image anomaly detection,” in ITNEC, vol. 1, 2020, pp. 987–993.
- [150] J. Andrews, T. Tanay, E. J. Morton, and L. D. Griffin, “Transfer representation-learning for anomaly detection,” 2016.
- [151] D. Tabernik, S. Šela, J. Skvarč, and D. Skočaj, “Segmentation-Based Deep-Learning Approach for Surface-Defect Detection,” Journal of Intelligent Manufacturing, May 2019.
- [152] S. Akçay, A. Atapour-Abarghouei, and T. P. Breckon, “Skip-ganomaly: Skip connected and adversarially trained encoder-decoder anomaly detection,” in IJCNN, 2019, pp. 1–8.
- [153] M. Salehi, A. Eftekhar, N. Sadjadi, M. H. Rohban, and H. R. Rabiee, “Puzzle-ae: Novelty detection in images through solving puzzles,” arXiv preprint arXiv:2008.12959, 2020.
- [154] P. Bergmann, M. Fauser, D. Sattlegger, and C. Steger, “Uninformed students: Student-teacher anomaly detection with discriminative latent embeddings,” in CVPR, 2020, pp. 4183–4192.
- [155] T. Schlegl, P. Seeböck, S. M. Waldstein, G. Langs, and U. Schmidt-Erfurth, “f-anogan: Fast unsupervised anomaly detection with generative adversarial networks,” Medical image analysis, vol. 54, pp. 30–44, 2019.
- [156] B. Staar, M. Lütjen, and M. Freitag, “Anomaly detection with convolutional neural networks for industrial surface inspection,” Procedia CIRP, vol. 79, pp. 484–489, 2019.
- [157] M. Wieler and T. Hahn, “Weakly supervised learning for industrial optical inspection,” in DAGM symposium in, 2007.
- [158] A. Makhzani, J. Shlens, N. Jaitly, I. Goodfellow, and B. Frey, “Adversarial autoencoders,” arXiv preprint arXiv:1511.05644, 2015.
- [159] R. Bommasani, D. A. Hudson, E. Adeli, R. Altman, S. Arora, S. von Arx, M. S. Bernstein, J. Bohg, A. Bosselut, E. Brunskill et al., “On the opportunities and risks of foundation models,” arXiv preprint arXiv:2108.07258, 2021.
- [160] K. He, X. Chen, S. Xie, Y. Li, P. Dollár, and R. Girshick, “Masked autoencoders are scalable vision learners,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 16 000–16 009.
- [161] T. Xi, Y. Sun, D. Yu, B. Li, N. Peng, G. Zhang, X. Zhang, Z. Wang, J. Chen, J. Wang et al., “Ufo: Unified feature optimization,” in Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part XXVI. Springer, 2022, pp. 472–488.
- [162] C. Riquelme, J. Puigcerver, B. Mustafa, M. Neumann, R. Jenatton, A. Susano Pinto, D. Keysers, and N. Houlsby, “Scaling vision with sparse mixture of experts,” Advances in Neural Information Processing Systems, vol. 34, pp. 8583–8595, 2021.
- [163] OpenAI, “GPT-4 technical report,” CoRR, vol. abs/2303.08774, 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2303.08774
- [164] A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark et al., “Learning transferable visual models from natural language supervision,” in International conference on machine learning. PMLR, 2021, pp. 8748–8763.
- [165] R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer, “High-resolution image synthesis with latent diffusion models,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 10 684–10 695.
- [166] A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. C. Berg, W.-Y. Lo et al., “Segment anything,” arXiv preprint arXiv:2304.02643, 2023.
- [167] P. Wang, A. Yang, R. Men, J. Lin, S. Bai, Z. Li, J. Ma, C. Zhou, J. Zhou, and H. Yang, “Ofa: Unifying architectures, tasks, and modalities through a simple sequence-to-sequence learning framework,” in International Conference on Machine Learning. PMLR, 2022, pp. 23 318–23 340.
- [168] J. Lu, C. Clark, R. Zellers, R. Mottaghi, and A. Kembhavi, “Unified-io: A unified model for vision, language, and multi-modal tasks,” arXiv preprint arXiv:2206.08916, 2022.