A symmetric matrix-variate normal local approximation for the Wishart distribution and some applications
Abstract
The noncentral Wishart distribution has become more mainstream in statistics as the prevalence of applications involving sample covariances with underlying multivariate Gaussian populations as dramatically increased since the advent of computers. Multiple sources in the literature deal with local approximations of the noncentral Wishart distribution with respect to its central counterpart. However, no source has yet developed explicit local approximations for the (central) Wishart distribution in terms of a normal analogue, which is important since Gaussian distributions are at the heart of the asymptotic theory for many statistical methods. In this paper, we prove a precise asymptotic expansion for the ratio of the Wishart density to the symmetric matrix-variate normal density with the same mean and covariances. The result is then used to derive an upper bound on the total variation between the corresponding probability measures and to find the pointwise variance of a new density estimator on the space of positive definite matrices with a Wishart asymmetric kernel. For the sake of completeness, we also find expressions for the pointwise bias of our new estimator, the pointwise variance as we move towards the boundary of its support, the mean squared error, the mean integrated squared error away from the boundary, and we prove its asymptotic normality.
keywords:
asymmetric kernel, asymptotic statistics, density estimation, expansion, local approximation, matrix-variate normal, multivariate associated kernel, normal approximation, smoothing, total variation, Wishart distributionMSC:
[2020]Primary: 62E20 Secondary: 62H10, 62H12, 62B15, 62G05, 62G071 Introduction
Let be given. Define the space of (real) symmetric matrices of size and the space of (real symmetric) positive definite matrices of size as follows:
| (1) | |||
| (2) |
For and , the density function of the distribution is defined by
| (3) |
where is the number of degrees of freedom, is the scale matrix, and
| (4) |
denotes the Euler gamma function. The mean and covariance matrix for the vectorization of , namely
| (5) |
( is the operator that stacks the columns of the upper triangular portion of a symmetric matrix on top of each other) are well known to be:
| (6) |
and
| (7) |
where is the identity matrix of order , is a transition matrix (see Gupta and Nagar [25, p.11] for the precise definition), and denotes the Kronecker product.
Multiple sources in the literature deal with local approximations of the noncentral Wishart distribution with respect to the (central) Wishart distribution, see, e.g., Steyn and Roux [54], Tan and Gupta [55], Kollo and von Rosen [37], Kocherlakota and Kocherlakota [34]. However, no source has yet developed explicit local approximations for the (central) Wishart distribution in terms of a normal analogue, which is important since Gaussian distributions are at the heart of the asymptotic theory for many statistical methods.
The main goal of our paper (Theorem 1) is to establish an asymptotic expansion for the ratio of the Wishart density (3) to the symmetric matrix-variate normal (SMN) density with the same mean and covariances. According to Gupta and Nagar [25, Eq.(2.5.8)], the density of the distribution is
| (8) |
where the last equality follows from Gupta and Nagar [25, Eq.(1.2.18)], and
| (9) |
Rewritings of the density (8) are provided on page 71 of Gupta and Nagar [25] using the vectorization operators and . For example, we can rewrite in terms of as follows:
| (10) |
To give a bit of practical motivations for the SMN distribution (8), note that noise in the estimate of individual voxels of diffusion tensor magnetic resonance imaging (DT-MRI) data has been shown to be well modeled by the distribution in [44, 6, 45]. The SMN voxel distributions were combined into a tensor-variate normal distribution in [7, 23], which could help to predict how the whole image (not just individual voxels) changes when shearing and dilation operations are applied in image wearing and registration problems, see Alexander et al. [3]. In [49], maximum likelihood estimators and likelihood ratio tests are developed for the eigenvalues and eigenvectors of a form of the SMN distribution with an orthogonally invariant covariance structure, both in one-sample problems (for example, in image interpolation) and two-sample problems (when comparing images) and under a broad variety of assumptions. This work extended significantly previous results of Mallows [41]. In [49], it is also mentioned that the polarization pattern of cosmic microwave background (CMB) radiation measurements can be represented by positive definite matrices, see the primer by Hu and White [30]. In a very recent and interesting paper, Vafaei Sadr and Movahed [56] presented evidence for the Gaussianity of the local extrema of CMB maps. We can also mention [22], where finite mixtures of skewed SMN distributions were applied to an image recognition problem.
In general, we know that the Gaussian distribution is an attractor for sums of i.i.d. random variables with finite variance, which makes many estimators in statistics asymptotically normal. Similarly, we expect the SMN distribution (8) to be an attractor for sums of i.i.d. random symmetric matrices with finite variances, thus including many estimators such as sample covariance matrices and score statistics for symmetric matrix parameters. In particular, if a given statistic or estimator is a function of the components of a sample covariance matrix for i.i.d. observations coming from a multivariate Gaussian population, then we could study its large sample properties (such as its moments) using Theorem 1 (for example, by turning a Wishart-moments estimation problem into a Gaussian-moments estimation problem).
In Section 3, we use our asymptotic expansion (Theorem 1) to find the pointwise variance of a new density estimator on the space of positive definite matrices with a Wishart asymmetric kernel (Section 3.1), and we derive an upper bound on the total variation between the probability measures on induced by (3) and (8) (Section 3.2). These are two examples of applications, but it is clear that there could be many others under the proper context.
Remark 1 (Notation).
Throughout the paper, means that as (or as or as in Section 3.1, depending on the context), where is a universal constant. Whenever might depend on some parameter, we add a subscript (for example, ). Similarly, means that , and subscripts indicate which parameters the convergence rate can depend on. The notation will denote the trace operator for matrices and their determinant. For a matrix that is diagonalizable, will denote its eigenvalues, and we let .
In Section 3.1 and the related proofs, the symbol over an arrow ‘’ will denote the convergence in distribution (or law). We will also use the shorthand in several places. Finally, the bandwidth parameter will always be implicitly a function of the number of observations, the only exceptions being in Theorem 2 and the related proof.
2 Main result
Below, we prove an asymptotic expansion for the ratio of the Wishart density to the symmetric matrix-variate normal (SMN) density with the same mean and covariances. This result is (much) stronger than the result found, for example, in [4, Theorem 3.6.2] or [20, Theorem 2.5.1], which says that for a sequence of i.i.d. multivariate Gaussian observations with and , the scaled and recentered sample covariance matrix of converges in law to a SMN distribution, specifically,
| (11) |
The result in Theorem 1 is stronger than (11) since it is well known that in this context.
Theorem 1.
Let and be given. Pick any and let
| (12) |
denote the bulk of the Wishart distribution. Then, as and uniformly for , we have
| (13) | ||||
Furthermore,
| (14) | ||||
As a direct consequence of Theorem 1, we obtain expansions for the ratio and log-ratio of the density function for a multivariate bijective mapping applied to a Wishart random matrix to the density function of the same mapping applied to the corresponding SMN random matrix. In particular, the corollary below provides an asymptotic expansion for the density of a bijective mapping applied to a sample covariance matrix for i.i.d. observations coming from a multivariate Gaussian population.
Corollary 1.
Let and be given, and let and . Let be a one-to-one mapping from an open subset of onto a subset of . Assume further that has continuous partial derivatives on and its Jacobian determinant is non-zero for all . Define
| (15) |
and denote by and the density functions of and , respectively. Fix any , then we have, as , and uniformly for such that ,
| (16) | ||||
and
| (17) | ||||
Under the conditions of Corollary 1, we know from the multivariate delta method (see, e.g., [20, Theorem 2.5.2]) that the random vectors and both converge in distribution, as , to
where and
Therefore, it would have been neat to extend Corollary 1 by expanding the log-ratio . However, this would most likely require an expansion for the log-ratio , and it is unclear which restrictions we should impose on to progress in that direction. This question is left open for future research.
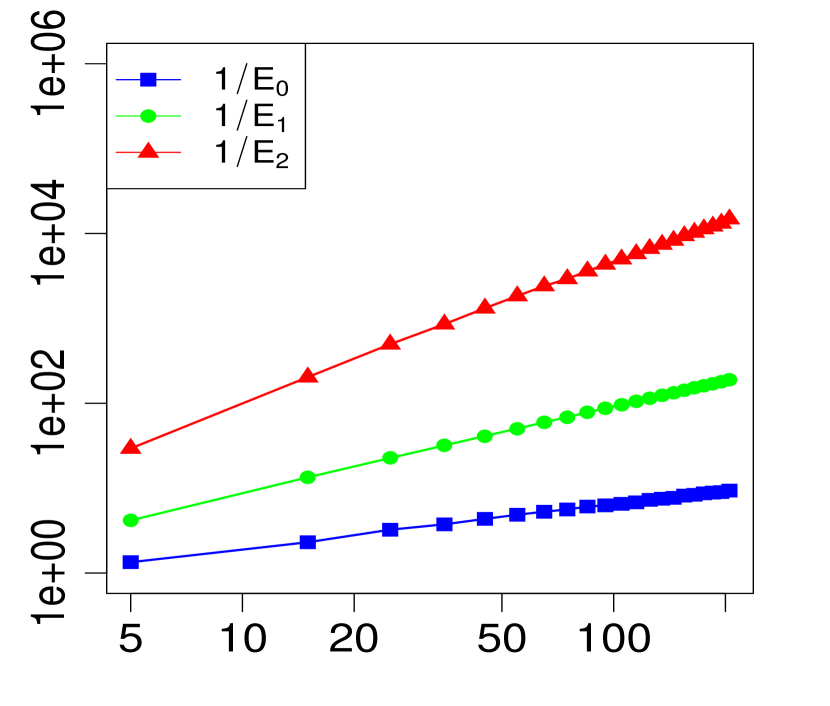
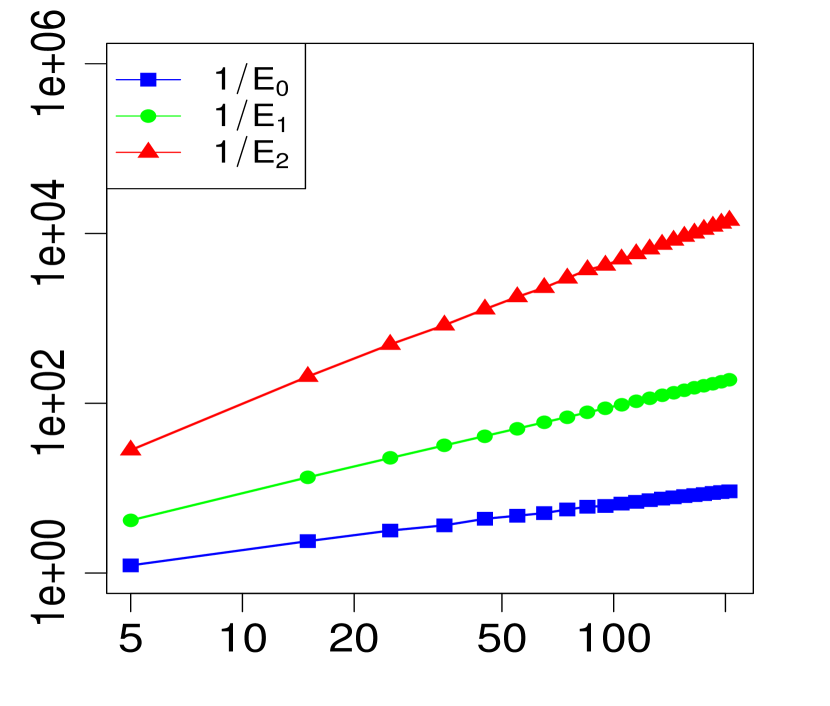
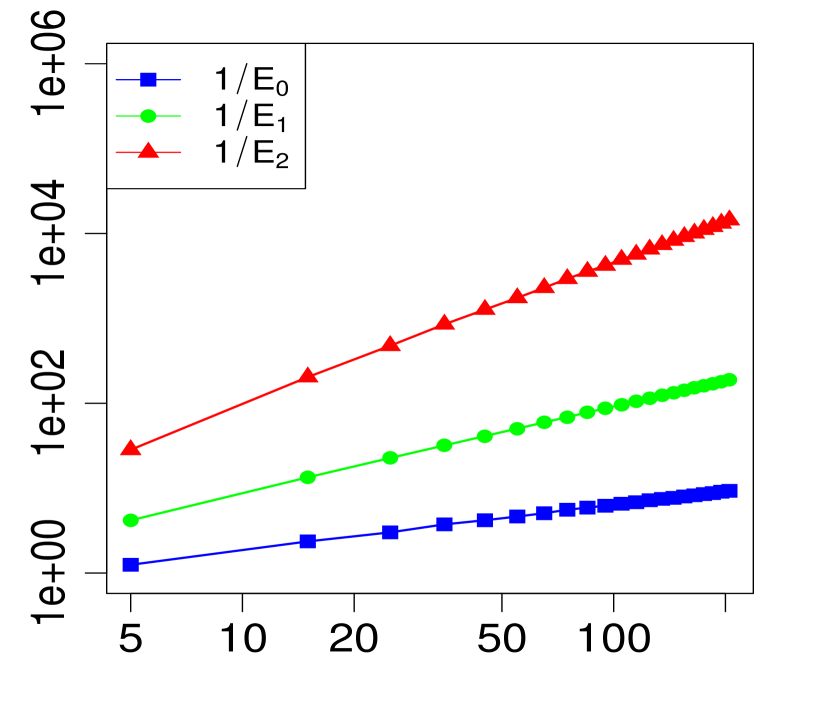
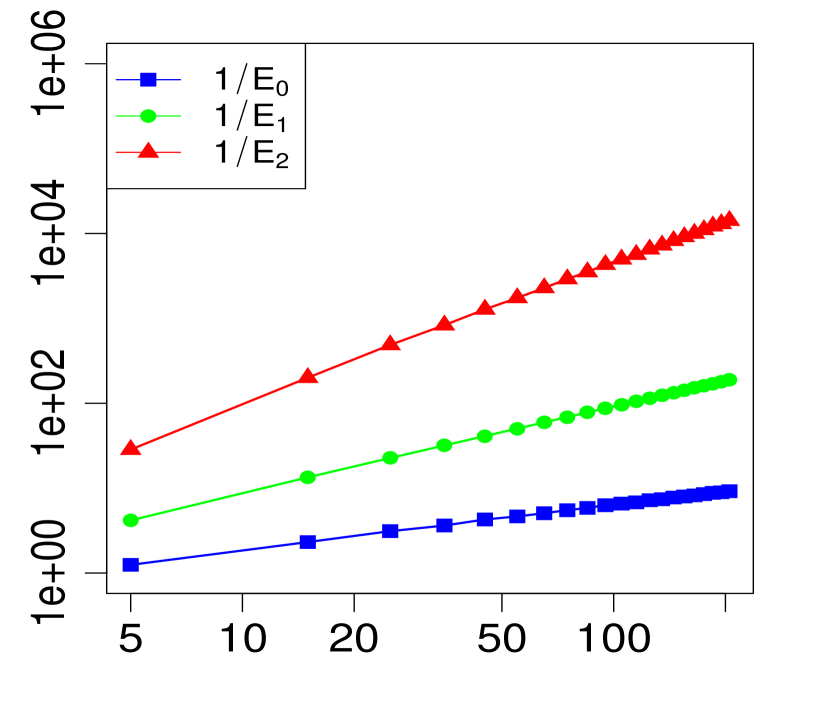
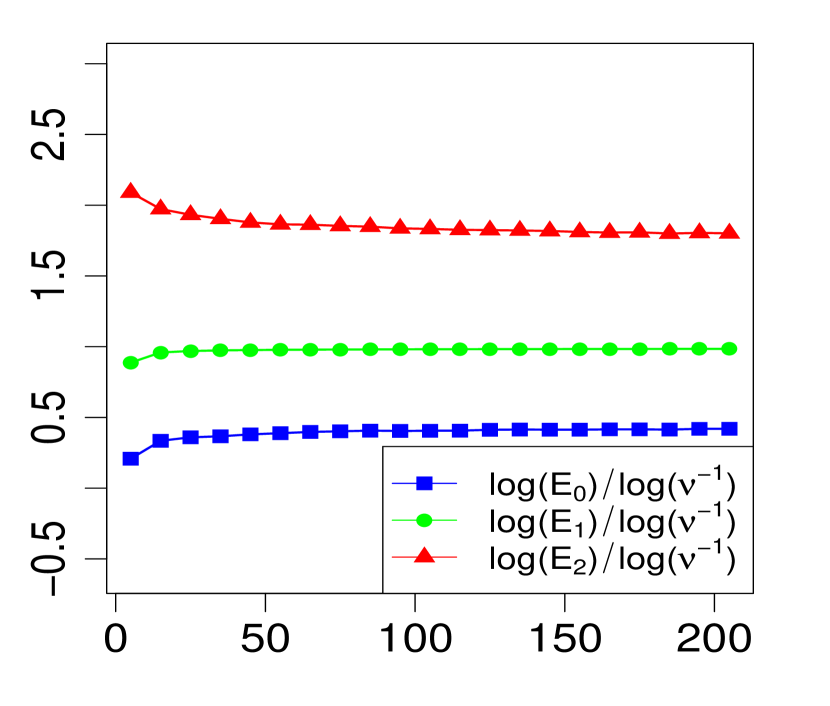
Below, we provide numerical evidence (displayed graphically) for the validity of the expansion in Theorem 1 when . We compare three levels of approximation for various choices of . For any given , define
| (18) | ||||
| (19) | ||||
| (20) |
In order to avoid numerical errors in part due to the gamma functions in , we have to work a bit to get an expression for which is numerically more stable. By taking the expression for in (54) and dividing by the expression for on the right-hand side of (8), we get
| (21) |
so that
| (22) | ||||
In R, we used this last equation to evaluate the log-ratios inside , and .
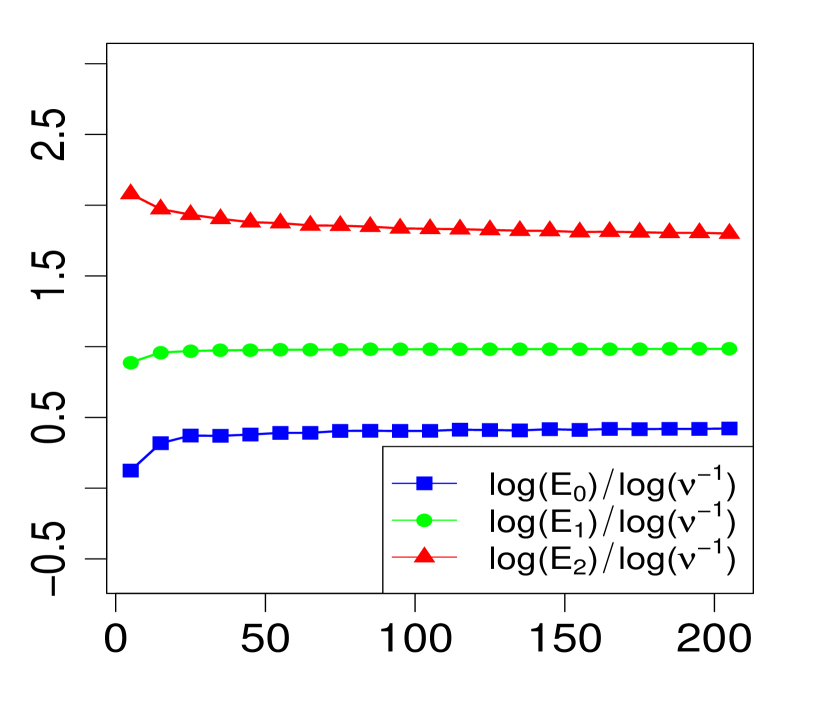
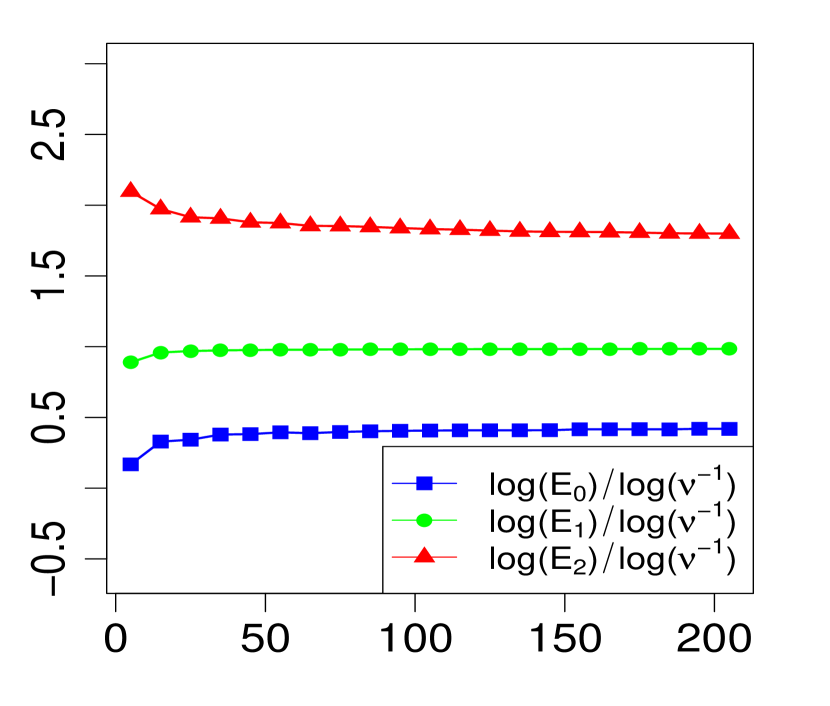
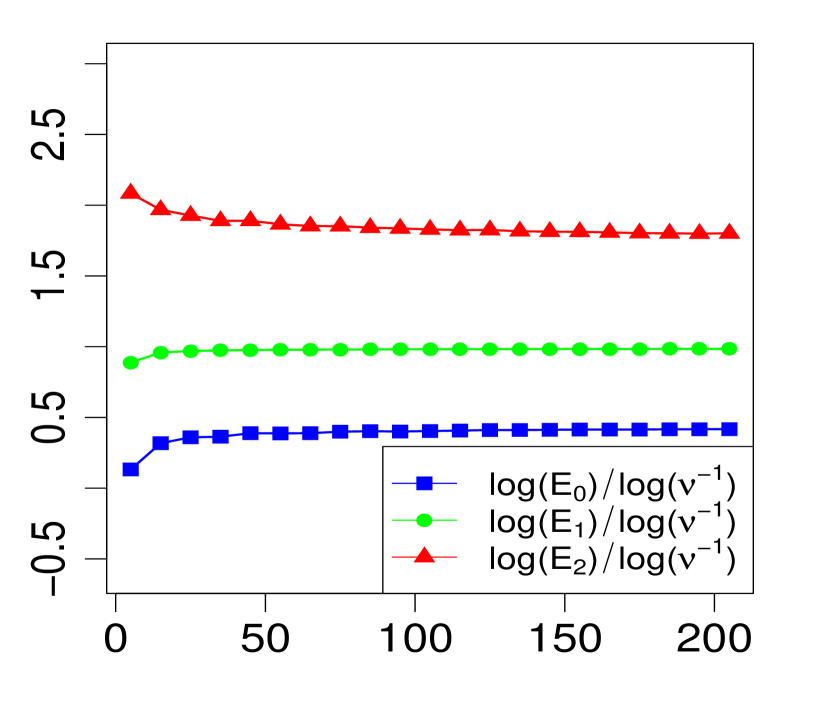
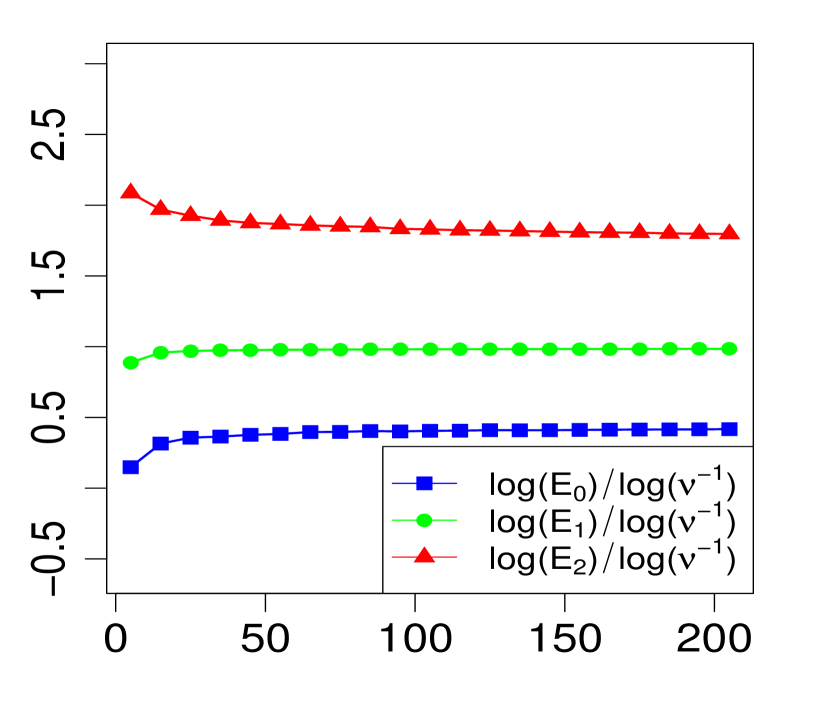
Note that implies for all , so we expect from Theorem 1 that the maximum errors above (, and ) will have the asymptotic behavior
| (23) |
or equivalently,
| (24) |
The property (24) is verified in Fig. 2 below, for various choices of . Similarly, the corresponding the log-log plots of the errors as a function of are displayed in Fig. 1. The simulations are limited to the range . The R code that generated Fig. 1 and Fig. 2 can be found in C.
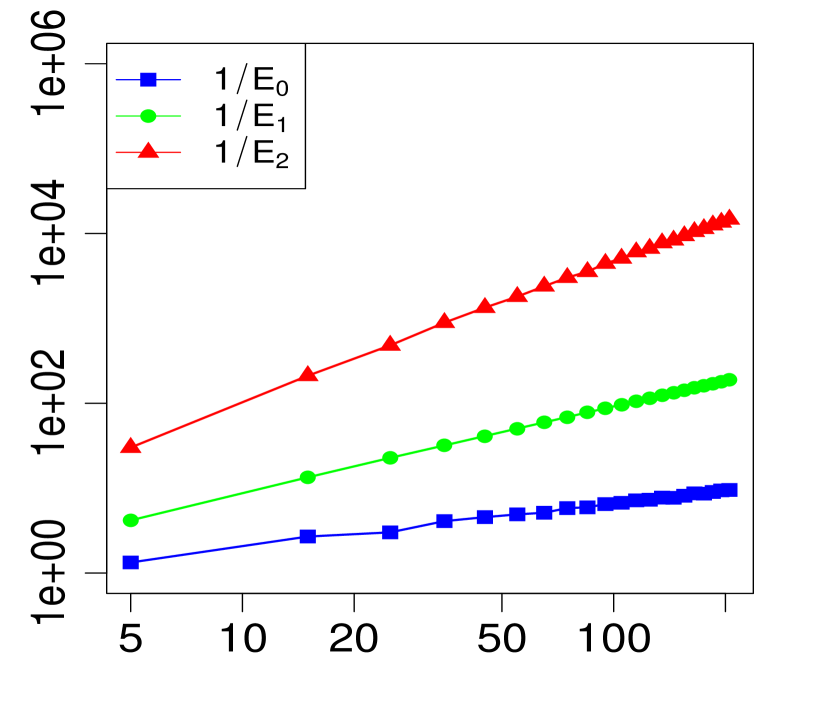
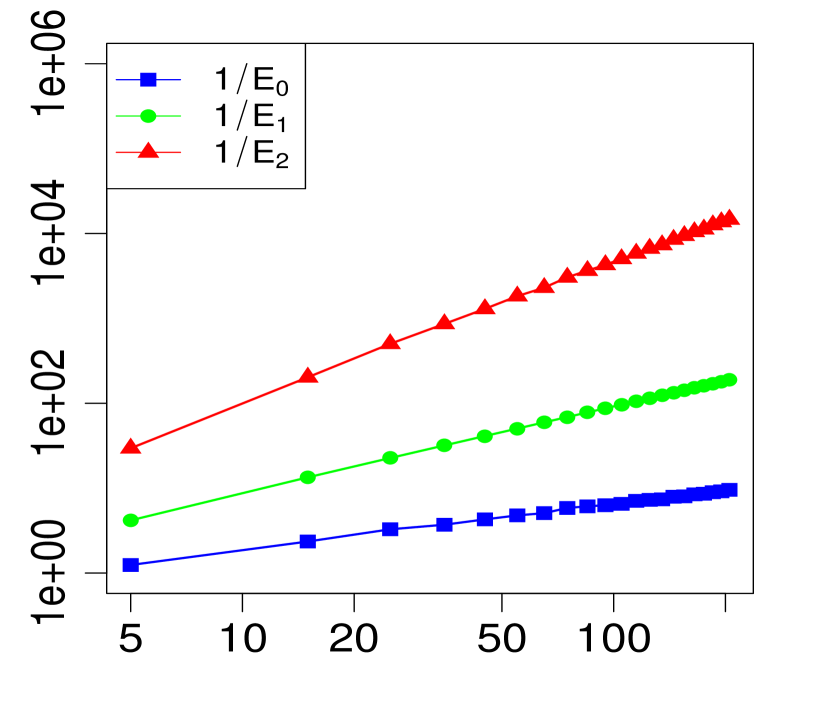
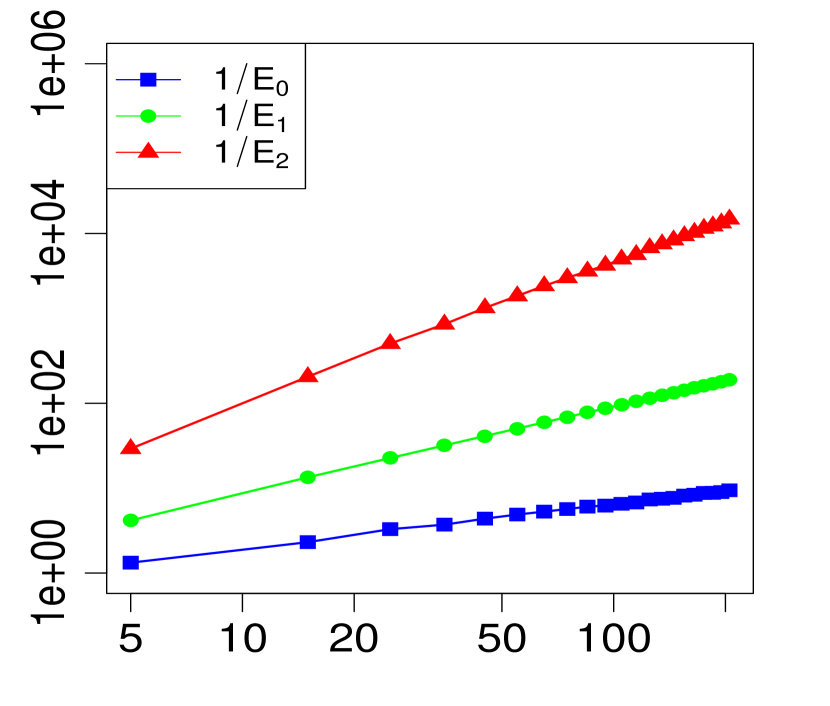
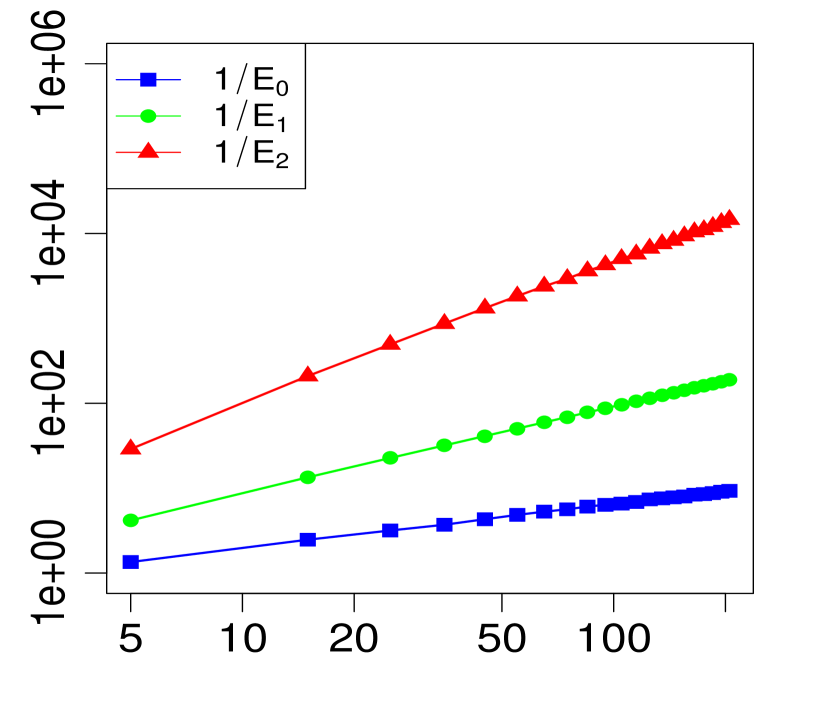
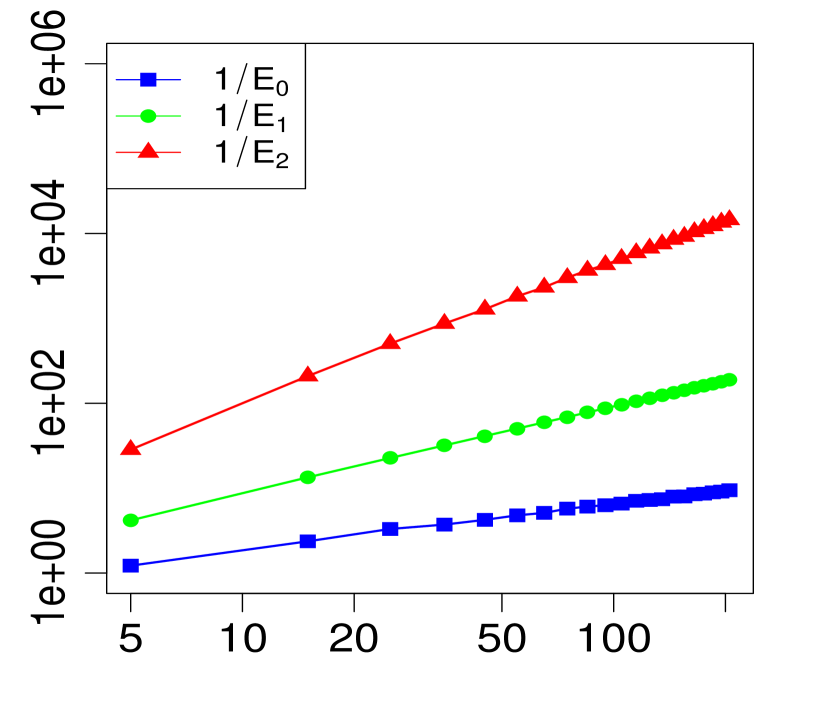
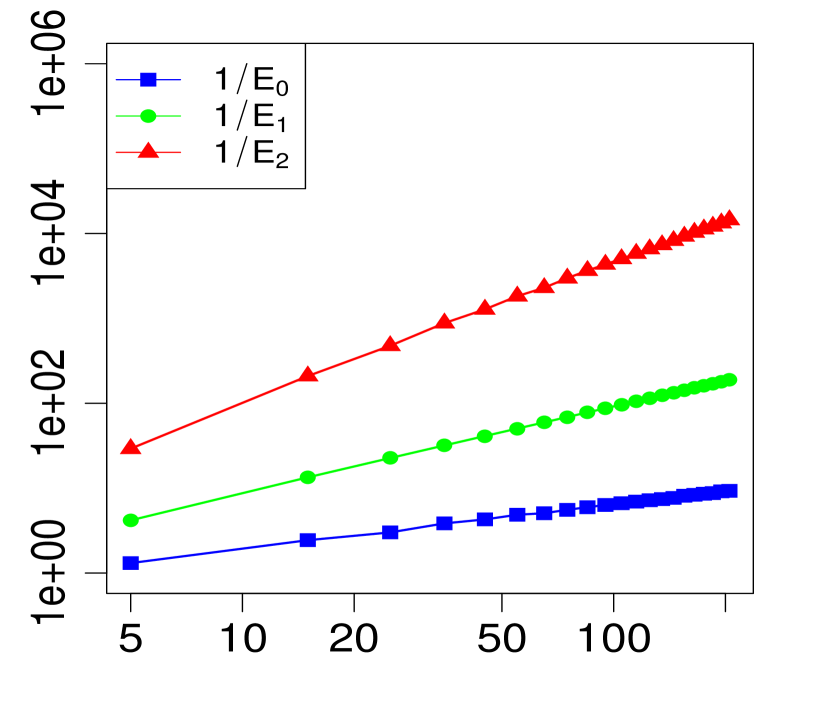
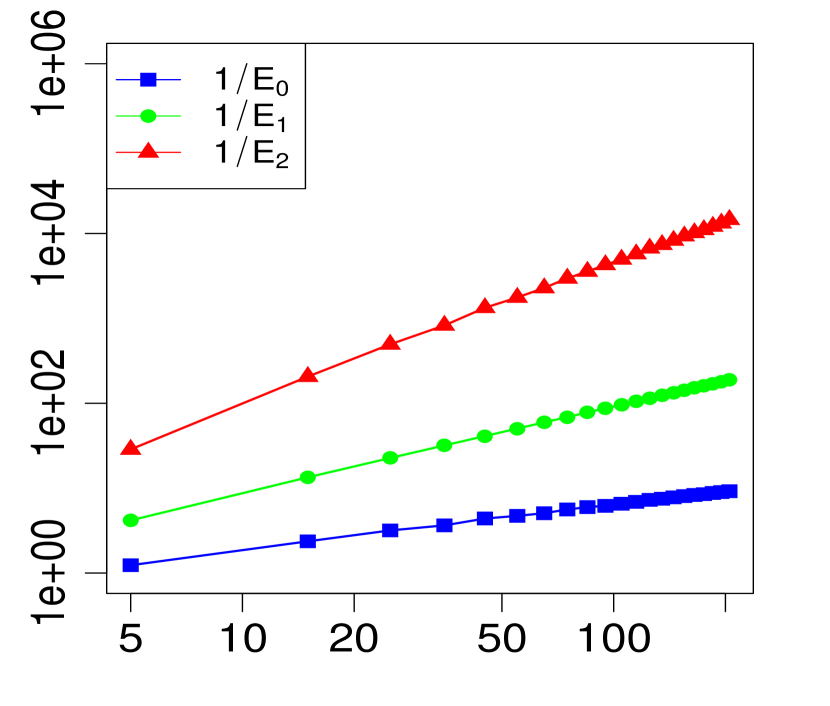
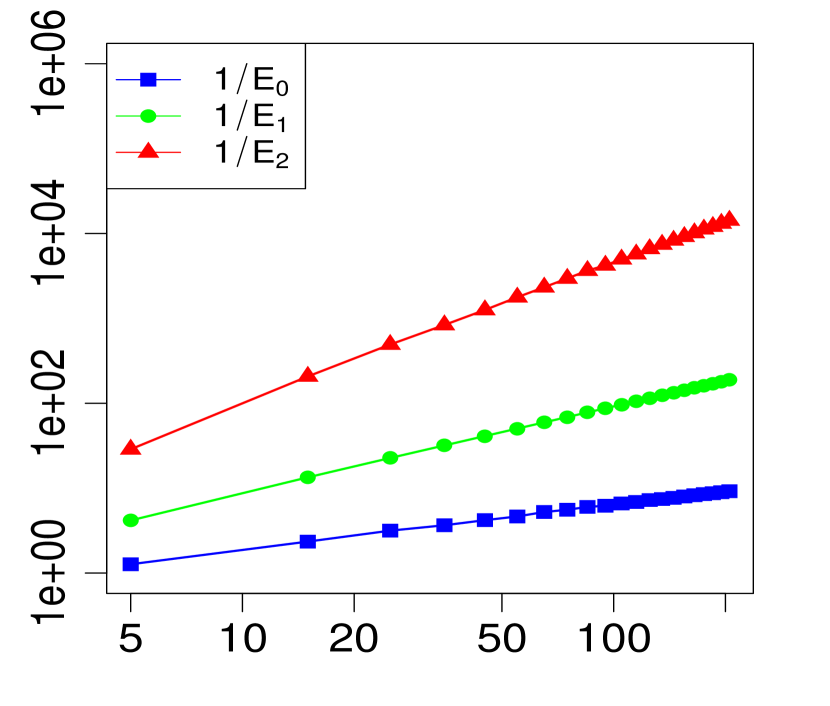
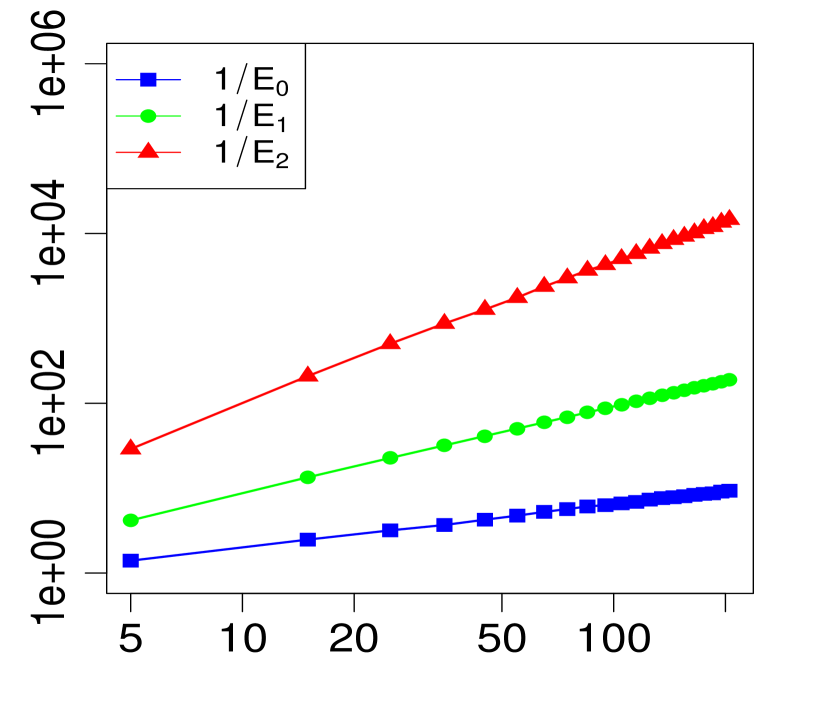
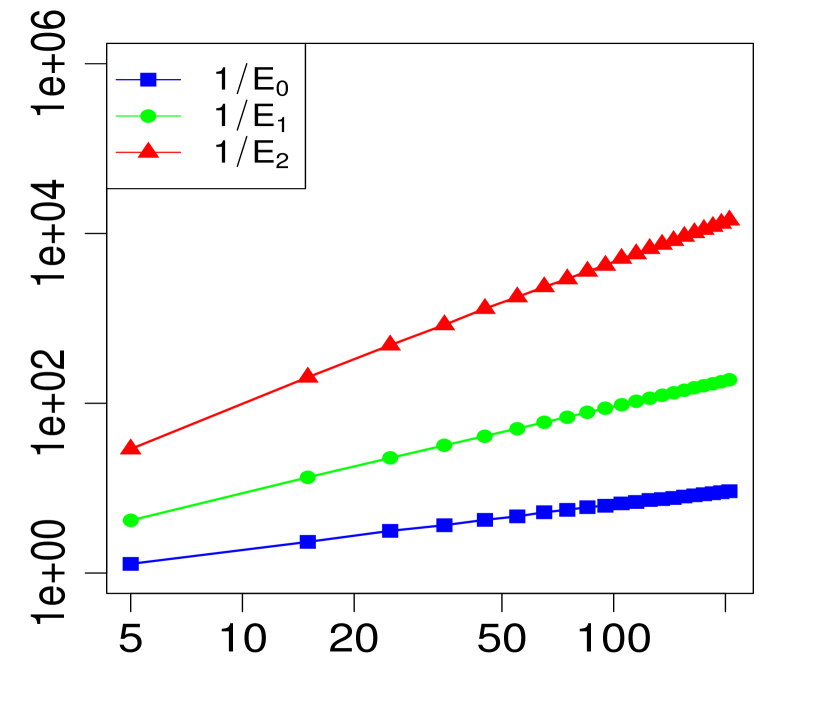
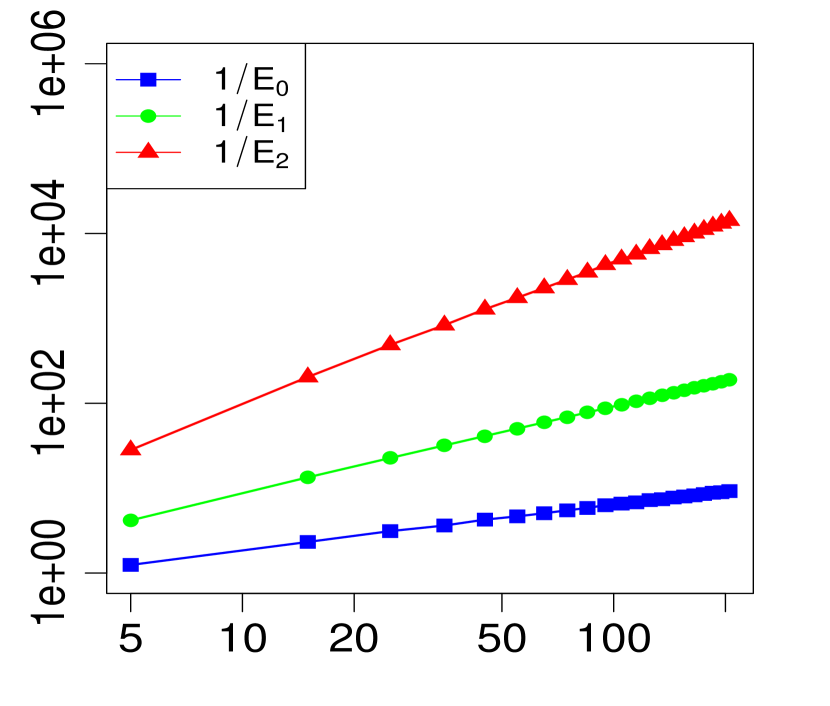
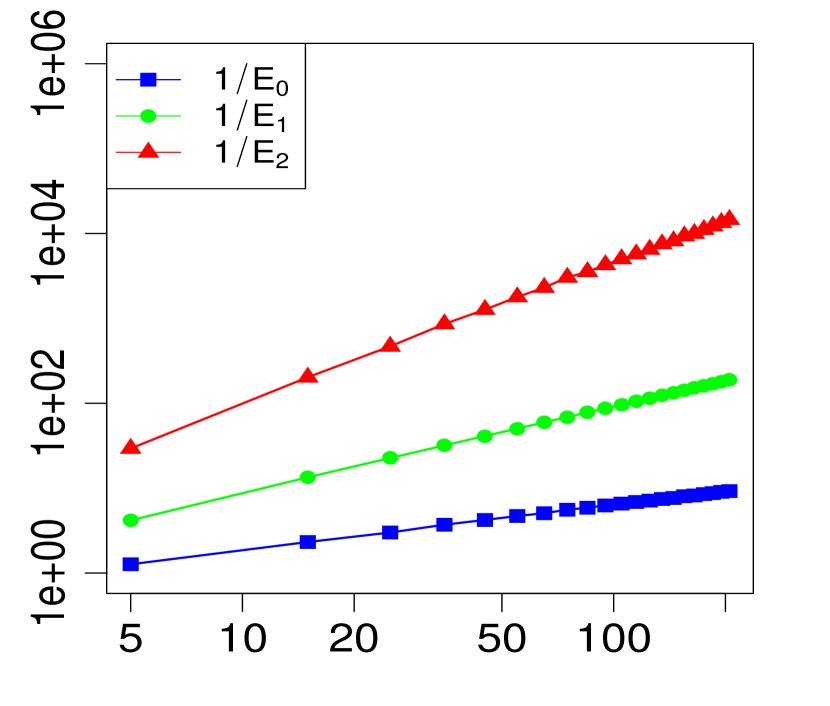
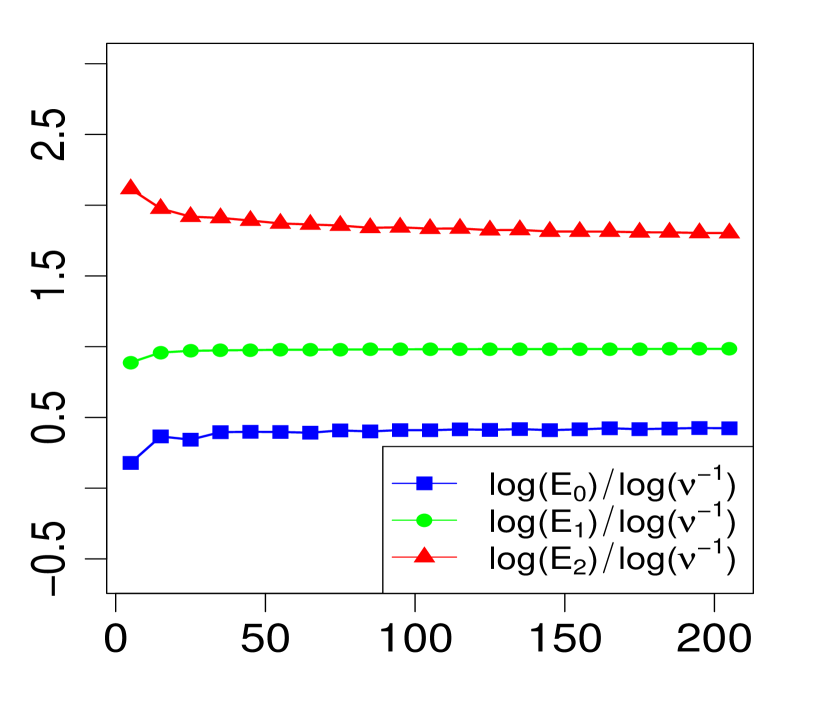
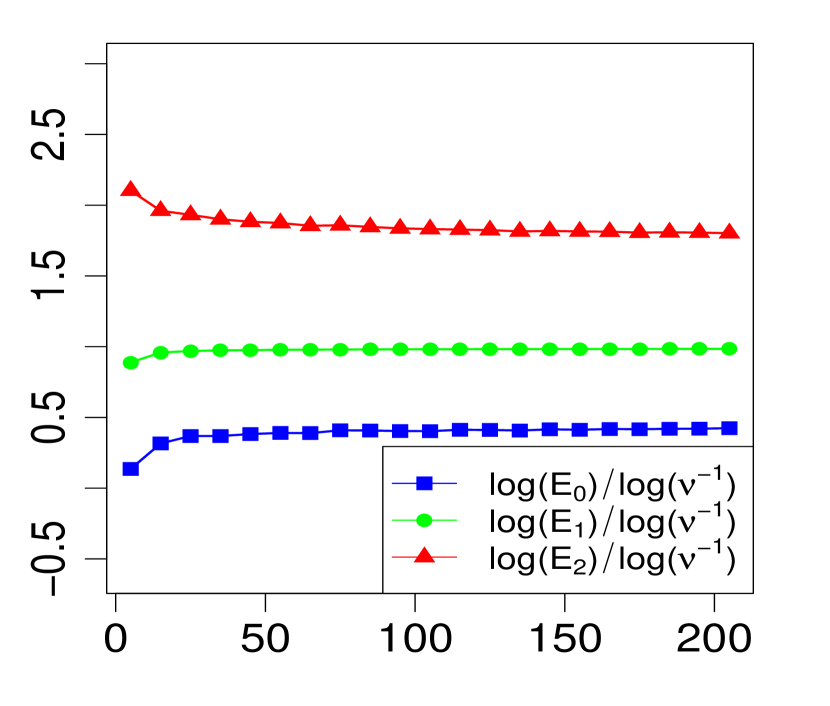
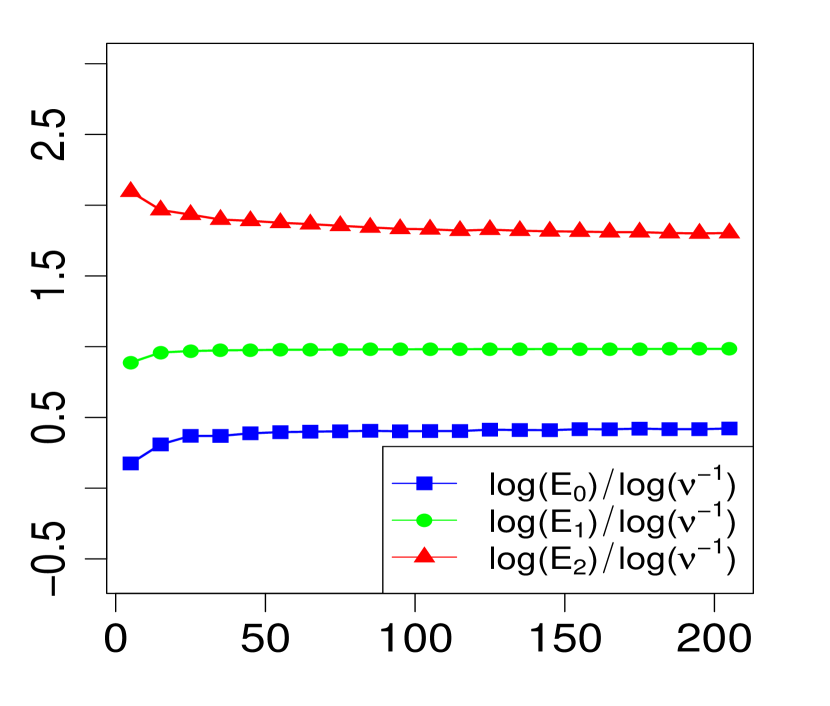
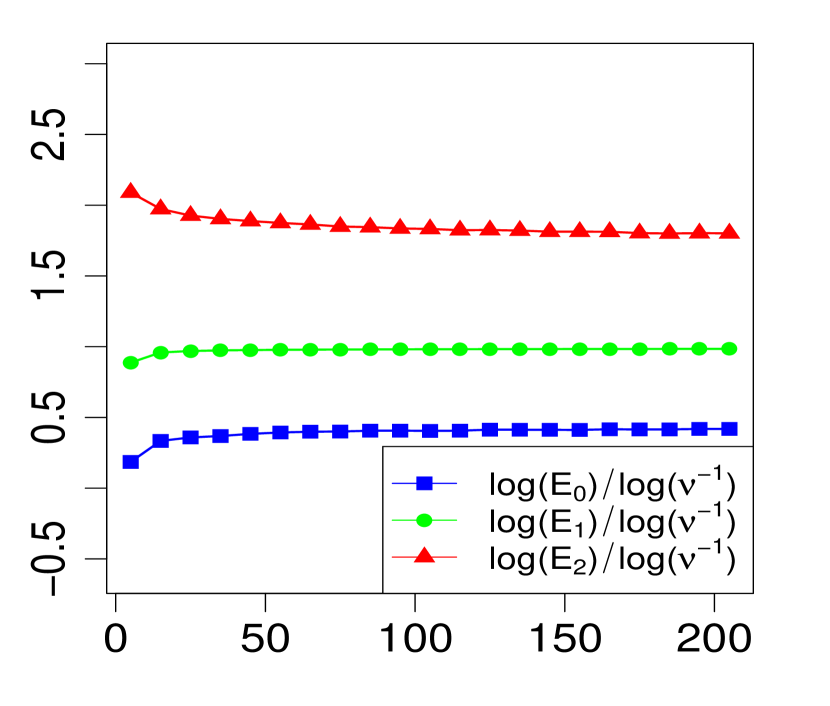
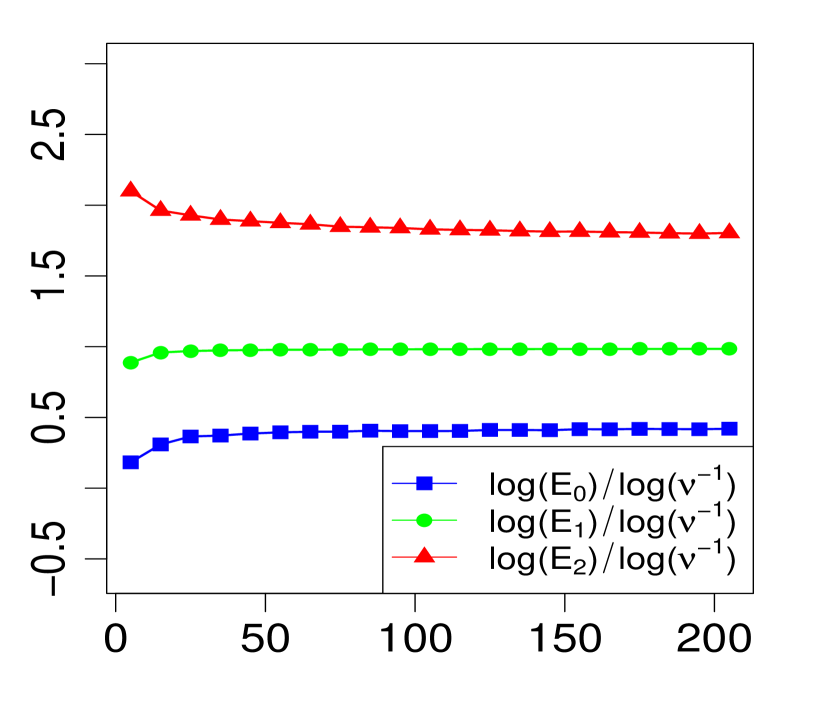
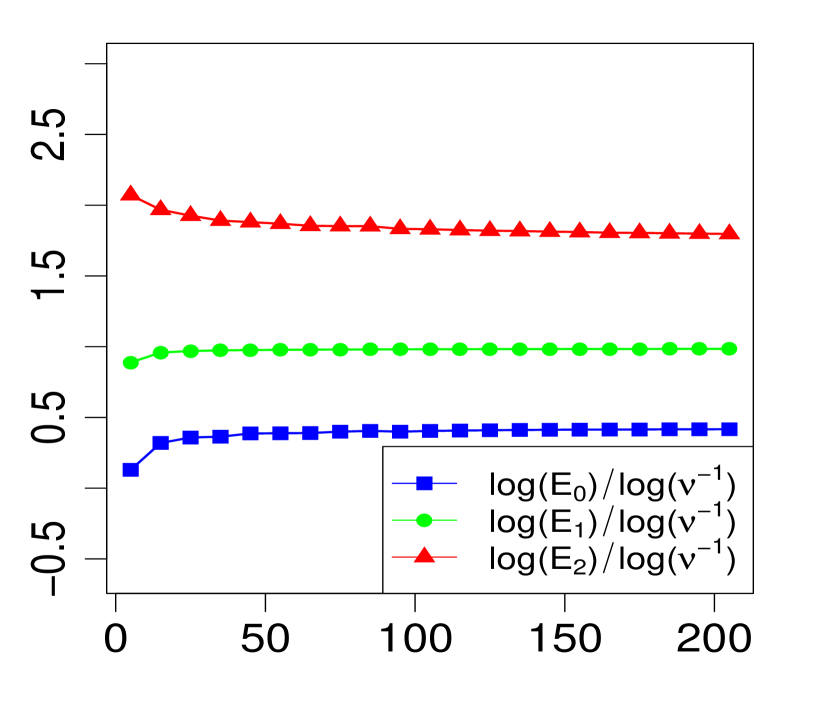
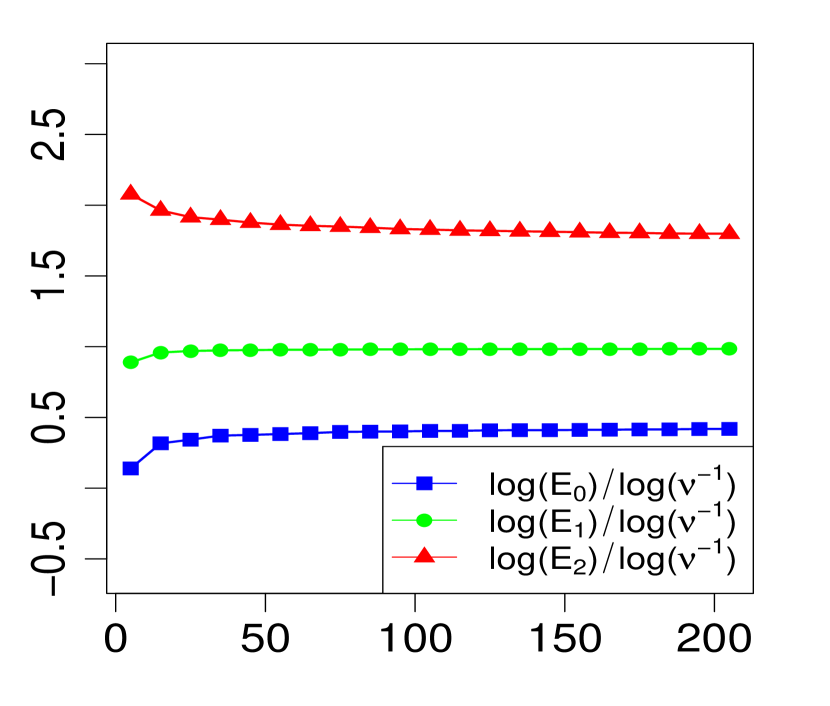
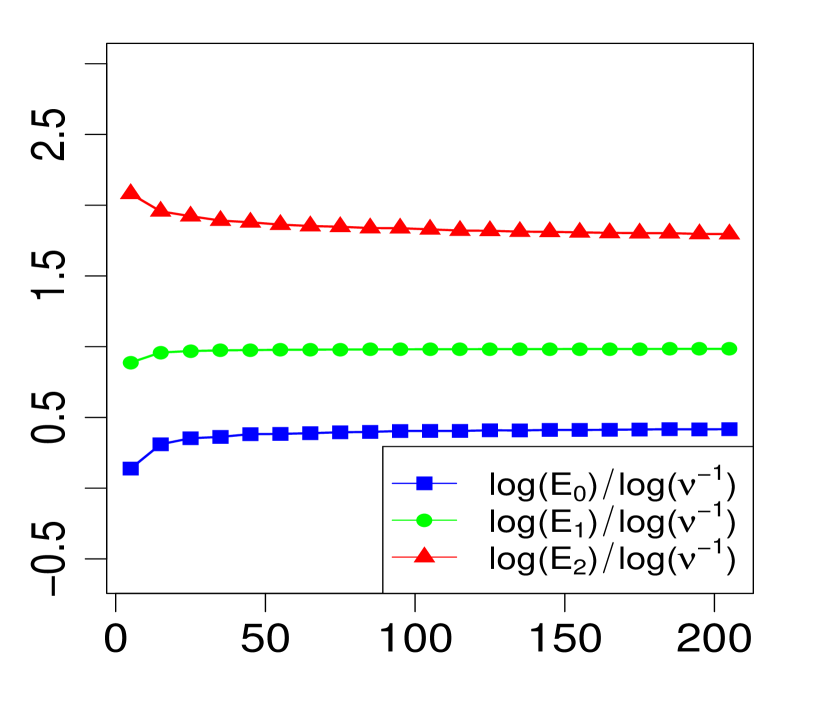
3 Applications
3.1 Asymptotic properties of Wishart asymmetric kernel estimators
Symmetric positive definite (SPD) matrix data are prevalent in modern statistical applications. As pointed out by Hadjicosta [26] and Hadjicosta and Richards [27], where goodness-of-fit tests for the Wishart distribution were developed based on integral transforms, factor analysis, diffusion tensor imaging, CMB radiation measurements, volatility models in finance, wireless communication systems and polarimetric radar imaging are just a few areas where SPD matrix data might be observed. Some articles have dealt with methods of density estimation on this space but the literature remains relatively scarce. Chevallier et al. [17] show how truncated Fourier series can be used for various applications, Kim and Richards [32, 33] and Haff et al. [28] explore the deconvolution of Wishart mixtures, Chevallier et al. [18] adapt the kernel estimator on compact Riemannian manifolds introduced by Pelletier [46] to compact subsets of the space of multivariate Gaussian distributions under the Fisher information metric and the Wasserstein metric, and Asta [5] defines a kernel density estimator on symmetric spaces of non-compact type (similar to Pelletier’s but for which Helgason–Fourier transforms are defined) and proves an upper bound on the convergence rate that is analogous to the minimax rate of classical kernel estimators on Euclidean spaces.
In a recent preprint, Li et al. [39] consider log-Gaussian kernel estimators (based on the logarithm map for SPD matrices) and a variant of the Wishart asymmetric kernel estimator that is slightly different from our definition below in (25). They prove various asymptotic properties for the former and a simulation study compares them both. If we were to apply traditional multivariate kernel estimators to the vectorization (in , recall (5)) of a sequence of i.i.d. random SPD matrices, then these estimators would misbehave near the boundary because of the condition on the eigenvalues (i.e., that they remain positive), and the usual boundary kernel modifications would not be appropriate either since positive definiteness is not a condition that can be translated to individual bounds on the entries of a matrix. To the best of our knowledge, [39] is the only paper that presents estimators on the space of SPD matrices that address (implicitly) the spill over problem of traditional multivariate kernel estimators caused by the boundary condition on the eigenvalues. Similarly to Li et al. [39], we can construct a new density estimator with a Wishart asymmetric kernel that creates a variable smoothing in our space and has a uniformly negligible bias near the boundary of .
In terms of applications, our new density estimation method on could be used, apart from visualization purposes, for nonparametric alternatives to regression and classification (both supervised and unsupervised) in any of the fields mentioned at the beginning of the first paragraph in this section. The favorable boundary properties of our estimator (the proof of Theorem 2 below shows that the pointwise bias is asymptotically uniformly negligible near the boundary) means that it could be particularly useful for scarce data sets and/or data sets with clusters of observations near the boundary of .
Here is the definition of our estimator. Assume that we have a sequence of observations that are independent and distributed ( is unknown), with density supported on for some . Then, for a given bandwidth parameter , let
| (25) |
be the (or a) Wishart asymmetric kernel estimator for the density function , where is defined in (3). The estimator can be seen as a continuous example in the broader class of multivariate associated kernel estimators introduced by Kokonendji and Somé [35, 36]. It is also a natural generalization of a slight variant of the (unmodified) Gamma kernel estimator introduced by Chen [16] because the Wishart distribution (recall (3)) is a matrix-variate analogue of the Gamma distribution. In [16, 12, 19, 9, 10, 11, 58, 8, 29], many asymptotic properties for Gamma kernel estimators of density functions supported on the half-line were studied, among other things: pointwise bias, pointwise variance, mean squared error, mean integrated squared error, asymptotic normality and uniform strong consistency. Also, bias reduction techniques were explored by Igarashi and Kakizawa [31] and Funke and Kawka [21], and adaptative Bayesian methods of bandwidth selection were presented by Somé [52] and Somé and Kokonendji [53].
Below, we show how some of the asymptotic properties of can be studied using the asymptotic expansion developed in Theorem 1. Assume that is Lipschitz continuous and bounded on . (To make sense of this assumption, note that is an open and convex subset in the space of symmetric matrices of size , which itself is isomorphic to .) Then, straightforward calculations show that, for any given ,
| (26) |
where
| (27) |
By applying this last estimate in (26), we obtain the pointwise variance.
Proposition 1 (Pointwise variance).
Assume that is Lipschitz continuous and bounded on . For any given , we have
| (28) |
From this, other asymptotic expressions can be derived such as the mean squared error and the mean integrated squared error, and we can also optimize the bandwidth parameter with respect these expressions to implement a plug-in selection method exactly as we would in the setting of traditional multivariate kernel estimators, see, e.g., Scott [50, Section 6.5] or Chacón and Duong [14, Section 3.6]. The expressions for the mean squared error and the mean integrated squared error (away from the boundary) are provided below in Corollary 2 and Theorem 4, respectively, together with the corresponding optimal choice of . For the sake of completeness, we also provide results on the pointwise bias of our estimator (see Theorem 2), its pointwise variance as we move towards the boundary of (see Theorem 3) and its asymptotic normality (see Theorem 5).
For each result in the remainder of this section, one of the following two assumptions will be used:
| The density is Lipschitz continuous and bounded on . | (29) | |||
| The density and its first order partial derivatives are continuous and bounded on , | (30) | |||
| and the second order partial derivatives of are uniformly continuous and bounded on . | (31) |
Remark 2.
Again, to make sense of the above assumptions, note that is an open and convex subset in the space of symmetric matrices of size , denoted by , which itself is isomorphic to .
We denote the expectation of by
| (32) |
Alternatively, notice that if , then we also have the representation
| (33) |
The asymptotics of the pointwise bias and variance were first computed by Chen [15, 16] for Beta and Gamma kernel estimators, by Ouimet and Tolosana-Delgado [43] for the Dirichlet kernel estimator of Aitchison and Lauder [2], and by Kokonendji and Somé [35, 36] for multivariate associated kernel estimators. The next two theorems below extend the (unmodified) Gamma case to our multidimensional setting.
Theorem 2 (Pointwise bias).
Assume that (31) holds. Then as , and for all , we have
| (34) |
where
| (35) |
and where denotes the Kronecker product, and means that we select the entry in the matrix.
Theorem 3 (Pointwise variance near and away from the boundary of ).
Assume that (29) holds. Furthermore, let be independent of and assume that it diagonalizes as . Pick any subset and assume that
| (36) |
In particular, with this choice of , note that . Then we have, as ,
| (37) |
where
| (38) |
The above theorem means that the pointwise variance is away from the boundary of and it gets multiplied by a factor everytime one of the eigenvalues approaches zero at a linear rate with respect to . If eigenvalues approach zero as , then the pointwise variance is .
By combining Theorem 2 and Proposition 1 (equivalently, Theorem 3 for ), we can compute the mean squared error of our estimator and optimize the choice of the bandwidth parameter .
Corollary 2 (Mean squared error).
Assume that (31) holds. Then, as and , and for any given , we have
| (39) | ||||
In particular, if , the asymptotically optimal choice of , with respect to , is
| (40) |
with
| (41) |
More generally, if as and for some , then
| (42) |
By integrating the MSE on the following subset of ,
| (43) |
we obtain the next result.
Theorem 4 (Mean integrated squared error on ).
A straightforward verification of the Lindeberg condition for double arrays yields the asymptotic normality.
Theorem 5 (Asymptotic normality).
Remark 3.
The rate of convergence for the traditional -dimensional kernel density estimator with i.i.d. data and bandwidth is in Theorem 3.1.15 of Prakasa Rao [48], whereas converges at a rate of . Hence, the relation between the bandwidth of and the bandwidth of the traditional multivariate kernel density estimator is .
3.2 Total variation and other probability metrics upper bounds between the Wishart and SMN distributions
Our second application of Theorem 1 is to compute an upper bound on the total variation between the probability measures induced by (3) and (8). Given the relation there is between the total variation and other probability metrics such as the Hellinger distance (see, e.g., Gibbs and Su [24, p.421]), we obtain several other upper bounds automatically. For the uninitiated reader, the utility of having total variation or Hellinger distance bounds between two measures is discussed by Pollard [47].
Theorem 6.
Let and be given. Let be the law of the distribution defined in (8), and let be the law of the distribution defined in (3). Then, as , we have
| (52) |
where is a universal constant, denotes the Hellinger distance, and can be replaced by any of the following probability metrics: Total variation, Kolmogorov (or Uniform) metric, Lévy metric, Discrepancy metric, Prokhorov metric.
4 Proofs
Proof of Theorem 1.
First, note that
| (53) |
so we can rewrite (3) as
| (54) |
Using the Taylor expansion
| (55) |
and Stirling’s formula,
| (56) |
see, e.g., Abramowitz and Stegun [1, p.257], we have
| (57) |
and
| (58) |
By taking the logarithm in (54) and using the expressions found in (4) and (58), we obtain (also using the fact that for all ):
| (59) | ||||
By the Taylor expansion in (55) and the fact that for all , we have, uniformly for ,
| (60) |
Therefore,
| (61) | ||||
With the expression for the symmetric matrix-variate normal density in (8), we can rewrite the above as
| (62) | ||||
which proves (13). To obtain (14) and conclude the proof, we take the exponential on both sides of the last equation and we expand the right-hand side with
| (63) |
For large enough and uniformly for , the right-hand side of (62) is , so we get
| (64) | ||||
This ends the proof. ∎
Proof of Theorem 2.
Assume that (31) holds, and let
| (65) |
(Recall the notation .) By a second order mean value theorem, we have
| (66) | ||||
for some random matrix on the line segment joining and in . (The mean value theorem is applicable because the subspace is open and convex in the space of symmetric matrices of size , recall Remark 2.) If we take the expectation in the last equation, and then use the estimates in (6) and (7), we get
| (67) |
where for any given , the real number is such that
| (68) |
uniformly for . (We know that such a number exists because the second order partial derivatives of are assumed to be uniformly continuous on .) Equations (68) and (7) then yield, together with the Cauchy-Schwarz inequality,
| (69) |
The second order partial derivatives of are also assumed to be bounded, say by some constant . Furthermore, implies that at least one component of is larger than , so a union bound over followed by concentration bounds for the marginals of the Wishart distribution (the diagonal entries of a Wishart random matrix are chi-square distributed while the off-diagonal entries are variance-gamma distributed) yield
| (70) |
where is a large enough constant that depends only on and . If we choose a sequence that goes to as slowly enough that , for example, then in (4) is by (69) and (70). This ends the proof. ∎
Proof of Theorem 3.
Assume that (29) holds. First, note that we can write
| (71) |
where the random variables
| (72) |
Hence, if , then
| (73) | ||||
| (74) |
where
| (75) |
and where the last line in (73) follows from the Lipschitz continuity of , the Cauchy-Schwarz inequality and the analogue of (7) for :
| (76) |
Now, by Stirling’s formula,
| (77) |
Therefore,
| (78) | ||||
where the last equality follows from the fact that for all . By our assumption on , note that , so we get the general expression in (37) by combining (73) and (78). This ends the proof. ∎
Proof of Theorem 4.
Proof of Theorem 5.
Assume that (31) holds. By (71), the asymptotic normality of will be proved if we verify the following Lindeberg condition for double arrays (see, e.g., Section 1.9.3 in [51]): For every ,
| (80) |
where and . From Lemma 3 with and , we know that
| (81) |
and we also know that when is Lipschitz continuous and bounded, by the proof of Theorem 3. Therefore, whenever as (and ), we have
| (82) |
Under this condition, Equation (80) holds (since for any given , the indicator function is equal to for large enough, independently of ) and thus
| (83) |
This ends the proof. ∎
Proof of Theorem 6.
By the comparison of the total variation norm with the Hellinger distance on page 726 of Carter [13], we already know that
| (84) |
Then, by applying a union bound followed by large deviation bounds on the eigenvalues of the Wishart matrix, we get, for large enough,
| (85) |
By Theorem 1, we have
| (86) | ||||
On the right-hand side, the first and third lines are estimated using Lemma 1, and the second line is bounded using Lemma 2. We find
| (87) |
Putting (85) and (86) together in (84) gives the conclusion. ∎
Appendix A Technical computations
Below, we compute the expectations for the trace of powers (up to ) of a normalized Wishart matrix. The lemma is used to estimate some trace moments and the errors in (86) of the proof of Theorem 6, and also as a preliminary result for the proof of Lemma 2.
Lemma 1.
Proof of Lemma 1.
Let . It was shown by Letac and Massam [38, p.308-310] (another source could be de Waal and Nel [57, p.66], or Lu and Richards [40, Theorem 3.2], although the latter is less explicit) that
| (90) | ||||
| (91) | ||||
| (92) | ||||
| (93) |
from which we deduce the following:
| (94) | ||||
| (95) | ||||
| (96) | ||||
| (97) |
By the linearity of expectations, we have
| (98) |
The conclusion follows. ∎
We can also estimate the moments of Lemma 1 on various events. The lemma below is used to estimate the errors in (86) of the proof of Theorem 6.
Lemma 2.
Let and be given, and let be a Borel set. If according to (3), then, for large enough,
| (99) | |||
| (100) |
where recall .
Proof of Lemma 2.
In the next lemma, we bound the density of the distribution from (3) when .
Lemma 3.
If and , then
| (103) |
Appendix B Acronyms
| CMB | cosmic microwave background |
| i.i.d. | independent and identically distributed |
| SMN | symmetric matrix-variate normal |
| SPD | symmetric positive definite |
Appendix C Simulation code
Supplementary material related to this article can be found online at https://doi.org/10.1016/j.jmva.2021.104.
Acknowledgments
First, I would like to thank Donald Richards for his indications on how to calculate the moments in Lemma 1. I also thank the Editor, the Associate Editor and the referees for their insightful remarks which led to improvements in the presentation of this paper. The author is supported by postdoctoral fellowships from the NSERC (PDF) and the FRQNT (B3X supplement and B3XR).
References
- Abramowitz and Stegun [1964] M. Abramowitz, I. A. Stegun, Handbook of Mathematical Functions with Formulas, Graphs, and Mathematical Tables, volume 55 of National Bureau of Standards Applied Mathematics Series, For sale by the Superintendent of Documents, U.S. Government Printing Office, Washington, D.C., 1964. MR0167642.
- Aitchison and Lauder [1985] J. Aitchison, I. J. Lauder, Kernel density estimation for compositional data, J. Roy. Statist. Soc. Ser. C 34 (1985) 129–137. doi:10.2307/2347365.
- Alexander et al. [2001] D. C. Alexander, C. Pierpaoli, P. J. Basser, J. C. Gee, Spatial transformations of diffusion tensor magnetic resonance images, IEEE Trans. Med. Imaging 20 (2001) 1131–1139. doi:10.1109/42.963816.
- Anderson [2003] T. W. Anderson, An Introduction to Multivariate Statistical Analysis, Wiley Series in Probability and Statistics, Wiley-Interscience [John Wiley & Sons], Hoboken, NJ, third edition, 2003. MR1990662.
- Asta [2021] D. M. Asta, Kernel density estimation on symmetric spaces of non-compact type, J. Multivariate Anal. 181 (2021) 104676, 10. MR4172886.
- Basser and Jones [2002] P. J. Basser, D. K. Jones, Diffusion-tensor MRI: theory, experimental design and data analysis - a technical review, NMR Biomed. 15 (2002) 456–467. doi:10.1002/nbm.783.
- Basser and Pajevic [2003] P. J. Basser, S. Pajevic, A normal distribution for tensor-valued random variables: applications to diffusion tensor MRI, IEEE Trans. Med. Imaging 22 (2003) 785–794. doi:10.1109/TMI.2003.815059.
- Bouezmarni et al. [2011] T. Bouezmarni, A. El Ghouch, M. Mesfioui, Gamma kernel estimators for density and hazard rate of right-censored data, J. Probab. Stat. (2011) Art. ID 937574, 16 pp. MR2801351.
- Bouezmarni and Rombouts [2008] T. Bouezmarni, J. V. K. Rombouts, Density and hazard rate estimation for censored and -mixing data using gamma kernels, J. Nonparametr. Stat. 20 (2008) 627–643. MR2454617.
- Bouezmarni and Rombouts [2010a] T. Bouezmarni, J. V. K. Rombouts, Nonparametric density estimation for multivariate bounded data, J. Statist. Plann. Inference 140 (2010a) 139–152. MR2568128.
- Bouezmarni and Rombouts [2010b] T. Bouezmarni, J. V. K. Rombouts, Nonparametric density estimation for positive time series, Comput. Statist. Data Anal. 54 (2010b) 245–261. MR2756423.
- Bouezmarni and Scaillet [2005] T. Bouezmarni, O. Scaillet, Consistency of asymmetric kernel density estimators and smoothed histograms with application to income data, Econom. Theor. 21 (2005) 390–412. MR2179543.
- Carter [2002] A. V. Carter, Deficiency distance between multinomial and multivariate normal experiments, Ann. Statist. 30 (2002) 708–730. MR1922539.
- Chacón and Duong [2018] J. E. Chacón, T. Duong, Multivariate Kernel Smoothing and Its Applications, volume 160 of Monographs on Statistics and Applied Probability, CRC Press, Boca Raton, FL, 2018. MR3822372.
- Chen [1999] S. X. Chen, Beta kernel estimators for density functions, Comput. Statist. Data Anal. 31 (1999) 131–145. MR1718494.
- Chen [2000] S. X. Chen, Probability density function estimation using gamma kernels, Ann. Inst. Statist. Math 52 (2000) 471–480. MR1794247.
- Chevallier et al. [2014] E. Chevallier, A. Chevallier, J. Angulo, Computing histogram of tensor images using orthogonal series density estimation and Riemannian metrics, in: 22nd International Conference on Pattern Recognition, pp. 900–905. doi:10.1109/ICPR.2014.165.
- Chevallier et al. [2017] E. Chevallier, E. Kalunga, J. Angulo, Kernel density estimation on spaces of Gaussian distributions and symmetric positive definite matrices, SIAM J. Imaging Sci. 10 (2017) 191–215. MR3606419.
- Fernandes and Monteiro [2005] M. Fernandes, P. K. Monteiro, Central limit theorem for asymmetric kernel functionals, Ann. Inst. Statist. Math. 57 (2005) 425–442. MR2206532.
- Fujikoshi et al. [2010] Y. Fujikoshi, V. V. Ulyanov, R. Shimizu, Multivariate Statistics, Wiley Series in Probability and Statistics, John Wiley & Sons, Inc., Hoboken, NJ, 2010. MR2640807.
- Funke and Kawka [2015] B. Funke, R. Kawka, Nonparametric density estimation for multivariate bounded data using two non-negative multiplicative bias correction methods, Comput. Statist. Data Anal. 92 (2015) 148–162. MR3384258.
- Gallaugher and McNicholas [2018] M. P. B. Gallaugher, P. D. McNicholas, Finite mixtures of skewed matrix variate distributions, Pattern Recognit. 80 (2018) 83–93. doi:10.1016/j.patcog.2018.02.025.
- Gasbarra et al. [2017] D. Gasbarra, S. Pajevic, P. J. Basser, Eigenvalues of random matrices with isotropic Gaussian noise and the design of diffusion tensor imaging experiments, SIAM J. Imaging Sci. 10 (2017) 1511–1548. doi:10.1137/16M1098693.
- Gibbs and Su [2002] A. L. Gibbs, F. E. Su, On choosing and bounding probability metrics, Int. Stat. Rev. 70 (2002) 419–435. doi:10.2307/1403865.
- Gupta and Nagar [1999] A. K. Gupta, D. K. Nagar, Matrix Variate Distributions, Chapman and Hall/CRC, first edition, 1999.
- Hadjicosta [2019] E. Hadjicosta, Integral Transform Methods in Goodness-of-Fit Testing, PhD thesis, Pennsylvania State University, 2019.
- Hadjicosta and Richards [2020] E. Hadjicosta, D. Richards, Integral transform methods in goodness-of-fit testing, II: the Wishart distributions, Ann. Inst. Statist. Math. 72 (2020) 1317–1370. MR4169380.
- Haff et al. [2011] L. R. Haff, P. T. Kim, J.-Y. Koo, D. S. P. Richards, Minimax estimation for mixtures of Wishart distributions, Ann. Statist. 39 (2011) 3417–3440. MR3012414.
- Hirukawa and Sakudo [2015] M. Hirukawa, M. Sakudo, Family of the generalised gamma kernels: a generator of asymmetric kernels for nonnegative data, J. Nonparametr. Stat. 27 (2015) 41–63. MR3304359.
- Hu and White [1997] W. Hu, M. White, A CMB polarization primer, New Astronomy 2 (1997) 323–344. doi:10.1016/S1384-1076(97)00022-5.
- Igarashi and Kakizawa [2018] G. Igarashi, Y. Kakizawa, Generalised gamma kernel density estimation for nonnegative data and its bias reduction, J. Nonparametr. Stat. 30 (2018) 598–639. MR3843043.
- Kim and Richards [2008] P. T. Kim, D. S. P. Richards, Diffusion tensor imaging and deconvolution on spaces of positive definite symmetric matrices, in: 2nd MICCAI Workshop on Mathematical Foundations of Computational Anatomy, New York, United States, 2008, pp. 140–149. inria-00632882.
- Kim and Richards [2011] P. T. Kim, D. S. P. Richards, Deconvolution density estimation on the space of positive definite symmetric matrices, in: Nonparametric statistics and mixture models, World Sci. Publ., Hackensack, NJ, 2011, pp. 147–168. MR2838725.
- Kocherlakota and Kocherlakota [1999] S. Kocherlakota, K. Kocherlakota, Approximations for central and noncentral bivariate chi-square distributions, Commun. Stat. - Simul. Comput. 28 (1999) 909–930. doi:10.1080/03610919908813585.
- Kokonendji and Somé [2018] C. C. Kokonendji, S. M. Somé, On multivariate associated kernels to estimate general density functions, J. Korean Statist. Soc. 47 (2018) 112–126. MR3760293.
- Kokonendji and Somé [2021] C. C. Kokonendji, S. M. Somé, Bayesian bandwidths in semiparametric modelling for nonnegative orthant data with diagnostics, Stats 4 (2021) 162–183. doi:10.3390/stats4010013.
- Kollo and von Rosen [1995] T. Kollo, D. von Rosen, Approximating by the Wishart distribution, Ann. Inst. Statist. Math. 47 (1995) 767–783. MR1370289.
- Letac and Massam [2004] G. Letac, H. Massam, All invariant moments of the Wishart distribution, Scand. J. Statist. 31 (2004) 295–318. MR2066255.
- Li et al. [2020] D. Li, Y. Lu, E. Chevallier, D. Dunson, Density estimation and modeling on symmetric spaces, Preprint (2020) 1–41. arXiv:2009.01983.
- Lu and Richards [2001] I.-L. Lu, D. S. P. Richards, MacMahon’s master theorem, representation theory, and moments of Wishart distributions, Adv. in Appl. Math. 27 (2001) 531–547. MR1868979.
- Mallows [1961] C. L. Mallows, Latent vectors of random symmetric matrices, Biometrika 48 (1961) 133–149. MR131312.
- Minc and Sathre [6465] H. Minc, L. Sathre, Some inequalities involving , Proc. Edinburgh Math. Soc. (2) 14 (1964/65) 41–46. MR162751.
- Ouimet and Tolosana-Delgado [2022] F. Ouimet, R. Tolosana-Delgado, Asymptotic properties of Dirichlet density estimators, J. Multivariate Anal. 187 (2022) 104832, 25 pp. doi:10.1016/j.jmva.2021.104832.
- Pajevic and Basser [1999] S. Pajevic, P. J. Basser, Parametric description of noise in diffusion tensor MRI, in: 8th Annual Meeting of the ISMRM, Philadelphia, p. 1787.
- Pajevic and Basser [2003] S. Pajevic, P. J. Basser, Parametric and non-parametric statistical analysis of DT-MRI data, J. Magn. Reson. 161 (2003) 1–14. doi:10.1016/s1090-7807(02)00178-7.
- Pelletier [2005] B. Pelletier, Kernel density estimation on Riemannian manifolds, Statist. Probab. Lett. 73 (2005) 297–304. MR2179289.
-
Pollard [2005]
D. Pollard, Total variation distance between
measures, in: Asymptopia, version: 15feb05,
2005, pp. 1–15.
[URL] http://www.stat.yale.edu/ pollard/Courses/607.spring05/handouts/Totalvar.pdf. - Prakasa Rao [1983] B. L. S. Prakasa Rao, Nonparametric Functional Estimation, Probability and Mathematical Statistics, Academic Press, Inc. [Harcourt Brace Jovanovich, Publishers], New York, 1983. MR0740865.
- Schwartzman et al. [2008] A. Schwartzman, W. F. Mascarenhas, J. E. Taylor, Inference for eigenvalues and eigenvectors of Gaussian symmetric matrices, Ann. Statist. 36 (2008) 2886–2919. MR2485016.
- Scott [2015] D. W. Scott, Multivariate Density Estimation, Wiley Series in Probability and Statistics, John Wiley & Sons, Inc., Hoboken, NJ, second edition, 2015. MR3329609.
- Serfling [1980] R. J. Serfling, Approximation Theorems of Mathematical Statistics, Wiley Series in Probability and Mathematical Statistics, John Wiley & Sons, Inc., New York, 1980. MR0595165.
- Somé [2020] S. M. Somé, Bayesian selector of adaptive bandwidth for gamma kernel density estimator on : simulations and applications, Communications in Statistics - Simulation and Computation (2020) 1–11. doi:10.1080/03610918.2020.1828921.
- Somé and Kokonendji [2021] S. M. Somé, C. C. Kokonendji, Bayesian selector of adaptive bandwidth for multivariate gamma kernel estimator on , Journal of Applied Statistics (2021) 1–22. doi:10.1080/02664763.2021.1881456.
- Steyn and Roux [1972] H. S. Steyn, J. J. J. Roux, Approximations for the non-central Wishart distribution, South African Statist. J. 6 (1972) 165–173. MR326925.
- Tan and Gupta [1982] W. Y. Tan, R. P. Gupta, On approximating the noncentral Wishart distribution by central Wishart distribution: a Monte Carlo study, Comm. Statist. B—Simulation Comput. 11 (1982) 47–64. MR648656.
- Vafaei Sadr and Movahed [2021] A. Vafaei Sadr, S. M. S. Movahed, Clustering of local extrema in Planck CMB maps, MNRAS 503 (2021) 815–829. doi:10.1093/mnras/stab368.
- de Waal and Nel [1973] D. J. de Waal, D. G. Nel, On some expectations with respect to Wishart matrices, South African Statist. J. 7 (1973) 61–67. MR347003.
- Zhang [2010] S. Zhang, A note on the performance of the gamma kernel estimators at the boundary, Statist. Probab. Lett. 80 (2010) 548–557. MR2595129.