A Systematic Exploration of Reservoir Computing for Forecasting Complex Spatiotemporal Dynamics
Abstract
A reservoir computer (RC) is a type of simplified recurrent neural network architecture that has demonstrated success in the prediction of spatiotemporally chaotic dynamical systems. A further advantage of RC is that it reproduces intrinsic dynamical quantities essential for its incorporation into numerical forecasting routines such as the ensemble Kalman filter---used in numerical weather prediction to compensate for sparse and noisy data. We explore here the architecture and design choices for a ‘‘best in class’’ RC for a number of characteristic dynamical systems, and then show the application of these choices in scaling up to larger models using localization. Our analysis points to the importance of large scale parameter optimization. We also note in particular the importance of including input bias in the RC design, which has a significant impact on the forecast skill of the trained RC model. In our tests, the the use of a nonlinear readout operator does not affect the forecast time or the stability of the forecast. The effects of the reservoir dimension, spinup time, amount of training data, normalization, noise, and the RC time step are also investigated. While we are not aware of a generally accepted best reported mean forecast time for different models in the literature, we report over a factor of 2 increase in the mean forecast time compared to the best performing RC model of [1] for the 40 dimensional spatiotemporally chaotic Lorenz 1996 dynamics, and we are able to accomplish this using a smaller reservoir size.
1 Introduction
Chaotic nonlinear dynamical systems are deterministic, but have the property that even small uncertainties in initial conditions lead to exponentially growing errors that limit any forecast of such a system. A typical linear systems analysis (e.g., a fourier transform) of such signals would conclude that the signal is noise, thus missing an essential feature of chaos. An illustrative example of this is the error made by Edwin Colpitts [2] in 1918---who designed and built a nonlinear variable frequency circuit (then made with vacuum tubes, now using bipolar transistors)---in identifying the irregularity in the output of his circuit as ‘‘noise.’’ 76 years later Michael Kennedy [3] recognized this feature to be deterministic chaos.
The original identification of chaotic motion of nonlinear systems was made by Poincare in the 19th century while analyzing the three body problem of classical mechanics. The present era of understanding and insight into the properties of such systems was initiated by Edward Lorenz in 1963 [4]. Lorenz’ simplification of convection in the Earth’s lower atmosphere introduced the idea of deterministic, nonperiodic behavior.
The study of nonlinear dynamical systems typically requires the use of numerical integration methods, as analytic solutions to nonlinear differential equations are not typically available. This is an important contrast to the well established analysis of linear dynamics. The solution to the linear filtering problem with discrete data proposed by Kalman in 1960[5]---now called the Kalman filter---is still the basis for many of the most advanced algorithms for predicting chaotic systems, especially in the highly nonlinear application of numerical weather prediction (NWP) [6].
We do note here that there are also fully nonlinear developments of data assimilation (in contrast with the linearity assumptions in the Kalman filter) in working with the dynamics of the Earth system for weather and climatic studies [7]. The use of these techniques in NWP faces many challenges. However, in other arenas such as the behavior of single biophysical neurons, where the dynamics are many orders of magnitude smaller than NWP, the challenges are smaller and the effectiveness of the tools much greater [8].
One limitation of the linear Kalman filter and its nonlinear descendants is that the technique requires a detailed physical model of the underlying process---something that is usually not known for complicated physical systems. To address this issue, there has been an increasing drive towards replacing the physical model altogether by using a ‘‘data-driven model’’ as the predictor. Such data-driven models fall into the category of machine learning (ML); examples include autoregressive methods (ARMA), the multilayer perceptron (MLP), and the recurrent neural network (RNN) [9].
RNNs are a family of artificial neural networks where the internal state of the network depends explicitly both on the previous internal or ‘hidden’ state and an external driving signal. Thus, there is a natural ordering to the data---we call the order label time---which explicitly allows treatment of an RNN as a dynamical system. In contrast, other forms of artificial neural networks impose no ordering on the data and thus their natural mathematical description is as a function [10].
An RNN takes a -dimensional input sequence , evolves as the -dimensional state , and is asked to predict a value . Equation 10.5 in Deep Learning by Goodfellow, et.al. [9], gives the general discrete time RNN evolution equation
| (1) |
where represents the RNN hyperparameters. This shows the dependence of on the previous RNN state and external driving signal . The output/readout layer of the network then ‘reads’ as containing the information on previous inputs, through the recursive relation, to predict . In other words, the output of the network is a function of the RNN hidden state . The operator defined here is a generic function, and could even be implemented as a neural network. Later we will take to be a linear operator (a matrix). We can thus use as a forecast.
Long short-term memory (LSTM) networks, introduced by Hochreiter and Schmidhuber (1997) [11] and Gers et al. (1999) [12] have been one of the most useful varieties of RNN, as they are capable of maintaining a representation of long-term dependencies. This design helped LSTMs to circumvent a number of difficulties that plagued RNNs regarding exploding and vanishing gradients during optimization using backpropagation. A simplified form of the LSTM was later developed by Kyunghyun Cho et al. in 2014 [13] called the Gated Recurrent Unit (GRU), which has a reduced set of trainable model parameters.
Our purpose here is to systematically explore an alternative form of RNN called a reservoir computer (RC) due to its demonstrated success in the prediction of chaotic dynamics. Through the examination of architectural and procedural choices for the RC design, we present ‘‘best in class’’ results for a wide range of simple dynamical systems. We then explore the method of localization for scaling the RC to larger spatiotemporally chaotic systems. We note that because the structure of the RC is nearly identical to the canonical RNN [14], many of the findings will be relevant for general RNNs as well.
1.1 Background
RC [15, 16] is a general term that encompasses multiple research tracks that developed in different fields in the early 2000’s, in particular Echo State Networks (ESNs) [17, 18, 19] and Liquid State Machines (LSMs) [20]. It is a kind of RNN with a structure consisting of a fixed high-dimensional ‘‘reservoir’’ combined with a single trained output layer. The fixed nature of the reservoir reduces the size of the trained parameter space to a handful of ‘macro-scale’ parameters governing global properties, as well as ‘micro-scale’ parameters that comprise the matrix and vector elements. A key advantage of RC is that the final output or ‘readout’ layer can be formulated as a linear layer and then trained using linear regression. This reduction in the size of the searchable parameter space allows one to easily bypass the exploding/vanishing gradient problems that arise due to the use of backpropagation schemes [21, 22, 23].
In 2007, Schrauwen, Verstraeten, and Campenhout [24] drew the connection between methods proposed by [17] and [20] and the state-of-the-art learning rule for RNNs described by [25]. For example, the recurrent learning rule of Atiya and Parlos (2000) [26] trains the output weights while the internal weights are only globally scaled up or down.
In addition to being easy to use and train, RCs have been shown to be very successful for chaotic time series prediction [27, 28, 29, 1]. For NWP specifically, a major use case of multivariate chaotic time series prediction, Arcomano et.al. (2020) [30] applied RC to a global atmospheric forecast model. Penny et.al. (2021) [31] integrated RC with state-of-the-art data assimilation methods to estimate the forecast error covariance matrix, tangent linear model representation, and other components of the data assimilation process that are typically costly to either formulate or compute. Further computational advantage are afforded by implementing RCs on GPUs or even dedicated hardware [32].
We note that other ML methods have been explored for modeling dynamical systems, with varying degrees of success. While we cannot name them all, we highlight a few examples. Bocquet et al. [33, 34] used NNs and Convolutional NNs [9] to learn ODEs that could then be integrated using traditional numerical methods. As with RC, they have similarly been able to reconstruct the Lyapunov spectrum of simple systems. Convolutional LSTMs have been used in MetNet [35] to predict the evolution of precipitation. Gauthier et.al. [36] introduced a vector autoregression scheme that has shown remarkable success in the prediction of small systems; see, for example, Clark et.al. [37] for an application in neurobiology. Data assimilation has been shown equivalent to feedforward Machine learning [38].
1.2 Why a Systematic Exploration of RC is Needed
Although published guides to the general use of RC exist [39] and there have been multiple studies on specific applications of RC with dynamical systems [40], there has been little guidance on best practices for implementing RC for forecasting chaotic dynamical systems. A practitioner must piece together design decisions by drawing on potentially conflicting information from multiple sources. We intend here to point the researcher or practitioner to strategies that have proven more successful, and to avoid those that we show to be ‘traps’ (i.e., commonly published design decisions that have little or even negative impact on overall performance). Additionally, using ML to forecast chaotic dynamical systems presents a number of its own unique challenges when compared to standard practices in ML. There is a high potential for misunderstanding by practitioners and developers.
This paper aims to lay out in clear terms the problem being solved by RC for the specific task of forecasting chaotic dynamical systems, guidance on how to train and test the RC models, as well as the lessons we have learned in applying these methods over the last several years on the specifics of implementations for particular problems.
1.3 Structure
We proceed as follows:
-
1.
Section 2 gives an overview of the RC implementation.
-
2.
Section 3 explains how an RC works and why it has properties, such as the reproduction of error growth statistics, that may not be well documented in other ML models.
-
3.
Section 4 gives details of the generative models and advice on how to properly test a new RC implementation.
-
4.
Section 5 details the general training procedure and shows experimental results on experimental design choices.
-
5.
Section 6 discusses scaling up the RC to high dimensional systems.
2 RC Definition
In the context of chaotic time series prediction we apply RC to the temporal ML problem where the task is to predict a time series generated from an autonomous dynamical system
| (2) |
where the dot denotes a time derivative and denotes the equations of the dynamical system. The dimension of the input system is . In general is not known, nor does it need to be known for RC to be used. We do assume that exists and that time dependent data can therefore be generated deterministically. The system can describe any physical process and therefore these techniques can be applied in fields such as biology, hydrology, meteorology, oceanography, economics, chemistry, and many others.
Here we use an RC model with the specific form of a simplified ‘‘Elman’’ style[41] RNN. The RC consists of three layers: an input layer , the reservoir itself, and an output layer . The reservoir is composed of nodes that are generally acted upon with simple nonlinear elements e.g., activation functions. The nodes in the network are connected through an adjacency matrix , chosen randomly to have a connection density and non-zero elements uniformly chosen between , scaled such that the maximal eigenvalue of is a number denoted the spectral radius ().
The input layer is an dimensional matrix that maps the input signal from dimensions into the dimensional reservoir space. The elements of are chosen uniformly between . The matrix provides the mapping from the RC reservoir state to the system state as . The reservoir state can be viewed as embedding the information given in the time series in a higher dimensional space, consistent with Takens theorem of time-delay embedding [42]. Takens theorem implies that information from unobserved states of the dynamics is contained in the time delay signal, thus allowing an RC to operate even when not all the information is measured.
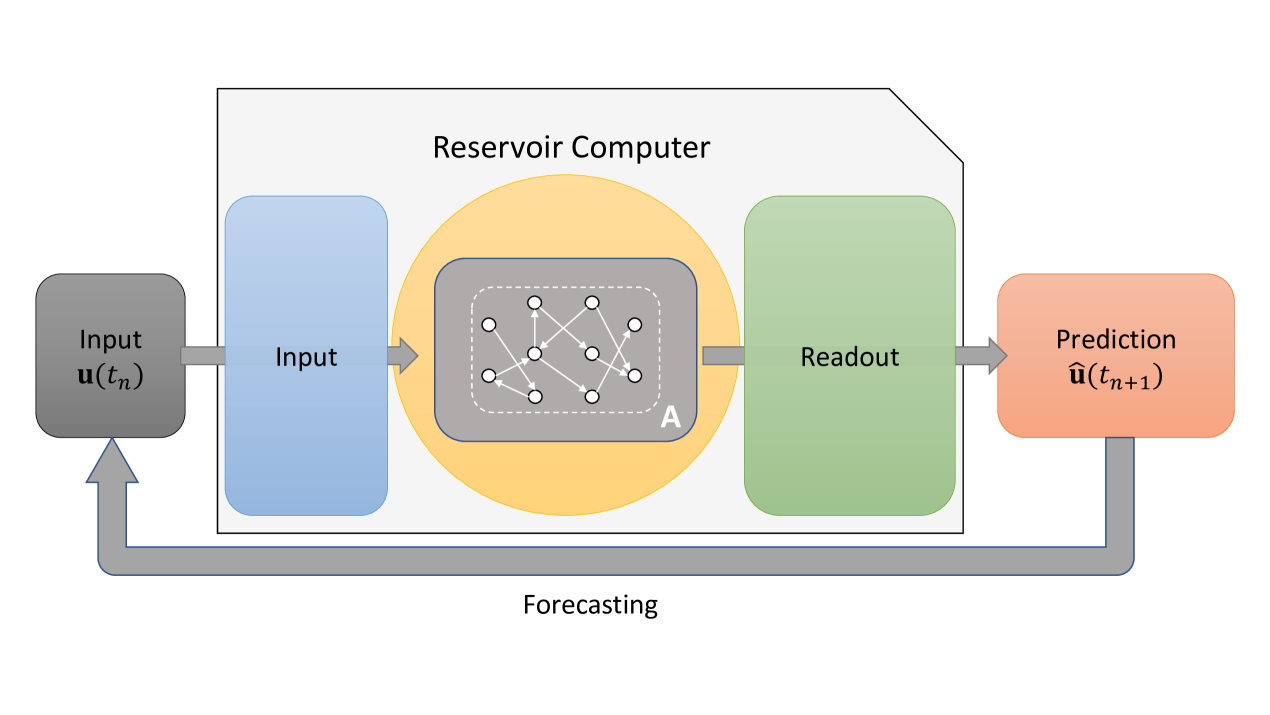
2.0.1 Training
The output layer is a matrix such that chosen during the training phase. The elements of are what we call ‘‘micro-scale’’ parameters---in contrast to the ‘‘macro-scale’’ parameters (, , , N,…) that set overall properties of the RC by adjusting multiple matrix elements at once. An analogy would be that setting the macro-scale parameters is similar to specifying the overall temperature or pressure of a gas, the positions and velocities of each individual particle need not be taken into account, greatly simplifying the problem. The micro-scale parameters that comprise the elements of can be trained at minimal cost using linear regression.
The reservoir dynamics themselves can either be posed in mapping or differential form. The differential form is
| (3) |
with the inverse time constant, the input bias, a vector of 1’s, and .
The mapping form is
| (4) |
with . The notation is as follows; describes the differential form, while describes the mapping form. denotes the ‘driven’ RC, as opposed to ‘autonomous’ (), is the reservoir state vector, and is the state produced by the true dynamics, which is provided as input data. Eqs.(3, 4) are denoted the ‘‘driven RC’’ because enters directly into the reservoir equation of motion.
The mapping form is equivalent to the differential form when the latter is integrated using the Euler method. This can be shown by setting and discretizing Eq.(3) with the Euler discretization scheme. While both the mapping and differential forms can be used interchangeably, this detail must be acknowledged as the integration method may affect the RC accuracy. Alternative forms of the RC have been suggested---see [40] for a review---but so far we have not found any advantages in using those forms.
We determine the micro-scale parameters in by optimizing the loss
| (5) |
where is a matrix containing and is a matrix containing for all in the training dataset, and is a Tikhonov-Miller regularization hyperparameter [43]. This is also known as ridge regression. The solution is
| (6) |
where is the identity matrix. There is an option to add nonlinearity to the readout operator, which is addressed in section 5.5.
2.0.2 Forecasting
When making a forecast, the external forcing is replaced by a feedback loop . Thus the equation for the ‘‘autonomous RC’’ is
| (7) |
One can see that is replaced by and so in prediction we have being an autonomous dynamical system, allowing multi-timestep forecasts via recursion.
| Parameter | Description |
|---|---|
| Spectral radius (max eigenvalue) of the adjacency matrix | |
| Density of the adjacency matrix | |
| N | Degrees-of-Freedom of the reservoir |
| Leak rate (time constant) of the reservoir computer | |
| Strength of input signal | |
| Strength of input bias | |
| Tikhonov regularization parameter |
3 RC Theory
3.1 Stability
Recalling the earliest works on ESNs [17, 18], setting the spectral radius is given as a guarantee of the ‘‘echo state property’’ i.e., generalized synchronization and fading memory---see section 3.3. Over the years the caveats in the original derivation, for example that the condition holds only when is an input, have generally been lost; the claim is therefore that the should always be set to a value less than 1. Despite this statement being proved empirically incorrect [44, 45], it is usually one of the first statements one comes across when studying the RC literature. In the following we give an alternative analysis based on dynamical stability theory.
Intuitively, local stability around a fixed point requires that small perturbations do not result in large movements to the state of the system [46]. If the RC were unstable, a small variation in training data would result in vastly different reservoir states, making finding a readout practically if not theoretically impossible [47]. Therefore finding conditions for local instability can in practice give us conditions on the trainability of the RC.
The fixed points of a nonlinear map are solutions of the equation . Therefore, for our reservoir Eq.(4) we find can find the equilibrium
| (8) |
which has solution when , and .
The stability of the system is governed by the eigenvalues of the Jacobian of the map evaluated at . If the magnitude of the largest eigenvalue is then the system is stable around the fixed point [48]; one caveat is that local stability does not imply global stability where a perturbed orbit will stay in the neighborhood of the unperturbed orbit. The Jacobian of a nonlinear map is . For the RC, taking the derivative of Eq.(4) with respect to
and plugging in from Eq.(8) to simplify, we find
| (9) |
where denotes the formation of a diagonal matrix.
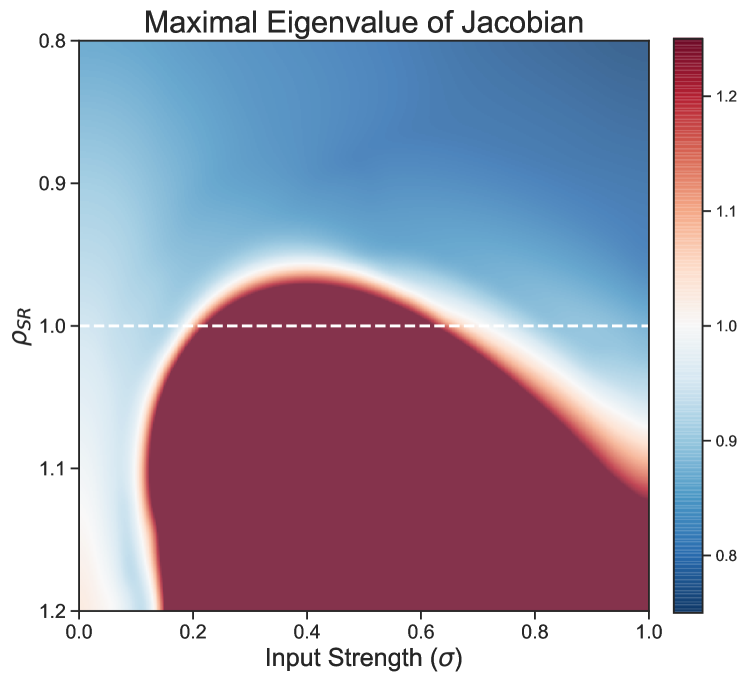
We can use this equation to visualize the areas of stability of the RC. If we assume for small then and we solve for
| (10) |
With the fixed points given we can plot the maximal eigenvalue of . An example is given in Fig.(2). In this example, the RC is stable for values of that are much greater than 1. This also gives a clear example that for nonzero input, there can be regions where is less than one but the RC is unstable.
Having a globally stable RC is most likely necessary, but certainly not a sufficient condition for obtaining a that gives good predictions. For instance, it has been noted many times that the RC operates best at the ‘‘edge of stability’’[47, 49, 50] and in general the RC is sensitive to parameter variation. An unstable RC is, however, rather unlikely to have a linear map between and .
3.2 Attractor Reconstruction and Lyapunov Exponents
The Lyapunov spectrum, composed of a system’s Lyapunov Exponents (LE), is a tool to probe the fundamental characteristics of a dynamical system [51, 52]. For example, one definition of a chaotic system is that there is at least one positive LE [53]. LEs can also be used to estimate the rate of entropy production (Kolmogorov-Sinai Entropy) and the fractal or information dimension [53].
The LEs describe how two points and , separated initially by a distance , evolve in time with respect to one another. More specifically,
with being the largest LE 111it is important to note that this is only actually true when lies exactly along the direction , however for large the largest exponent will dominate.. Therefore if is positive, over time the two initial conditions that at first only differ by a small amount will diverge away from one another exponentially fast in the linearized regime---the definition of chaos. We give a more rigorous definition of LEs in the appendix along with a discussion of how to calculate them---Appendix A.
3.2.1 Application to Reservoir Computing
When the LEs of the autonomous Eq.(7) RC match the LEs of the input data generated from the dynamical system then the RC is said to have ‘‘reconstructed’’ the attractor [28]. A reconstructed attractor is strongly correlated with properties such as the physicality and robustness of forecasts [54]. The LEs of can be estimated from the data with no knowledge of the dynamics [52].
To calculate the LEs of the autonomous reservoir we note that the Jacobian/linear propagator of Eq.(7) is
| (11) |
with diag denoting a diagonal matrix and the constant matrix . This propagator may be used in the algorithms given in Geist et.al., [55] using the procedure given in [28, 1] to calculate the LEs.
3.3 Generalized Synchronization
As described in detail by [28, 54], the RC works by making use of the concept of generalized synchronization (GS) [56]. The definition of GS is: for a drive system and response system , they are synchronized if there exists a function such that [56]. Intuitively this implies that the dynamics of the response system are entirely predictable from the history of the input; in RC, for a contracting system, this property is related to the ‘‘echo state property’’ [17] and ‘‘fading memory’’ [57]. The requirement to find a matrix such that is tantamount to finding a linear approximation to the local inverse of the generalized synchronization function---we call this statement predictive generalized synchronization [54]. We would like to note that the statement of the existence of the inverse of is in general not a global, but a local property due to the necessity of being differentiable [58] for to exist. Grigoryeva et. al., [59, 60] details general conditions for differential GS to exist in an RC. When does not meet these criteria then the RC is untrainable; this statement is connected to the stability criterion explored in section 3.1.
The concept of GS is useful for visualizing the operation of the RC. When and are synchronized, the combined state will lie on an invariant synchronization manifold [61]. This manifold is generally low dimensional [54] and so the dynamics of the RC are taking place on this low dimension structure in phase space. In addition, the concept of synchronization shows that there is a certain amount of ‘‘spinup’’ time needed for the transient initial conditions to contract to the synchronization manifold. The amount of time needed for spinup is directly related to the strength of the conditional Lyapunov exponents (CLEs) [62] of the synchronization manifold---see appendix A for CLEs. The statement of stability of the motion on the manifold [61, 63] is that the contraction normal to the manifold must be larger than the contraction tangential to it [64], thus giving a statement of the stability of the RC.
The CLEs and the constraint that they be negative is in fact closely related to the stability conditions we discuss in section 3.1. If the RC is unstable everywhere, , then the CLEs will always be positive and the RC will not synchronize with the input data. As a last note, it has been observed that RCs work best when at the edge of stability [47, 49, 50]; this edge corresponds to the largest CLE being and [54].
4 Data Generation for Numerical Experiments
We begin with a discussion of the training and testing data used in the following numerical experiments. The use of input data is different for dynamical systems forecasting than for the typical ML use case. Typically in ML there are standard training and testing datasets e.g., MNIST [65], that one can acquire in order to directly test newly proposed models against published results from previous models [66]. For dynamical systems forecasting we instead have certain standard models from which one can generate data. Therefore it is important to make sure one is observing best practices when constructing ones own training, validation and testing sets.
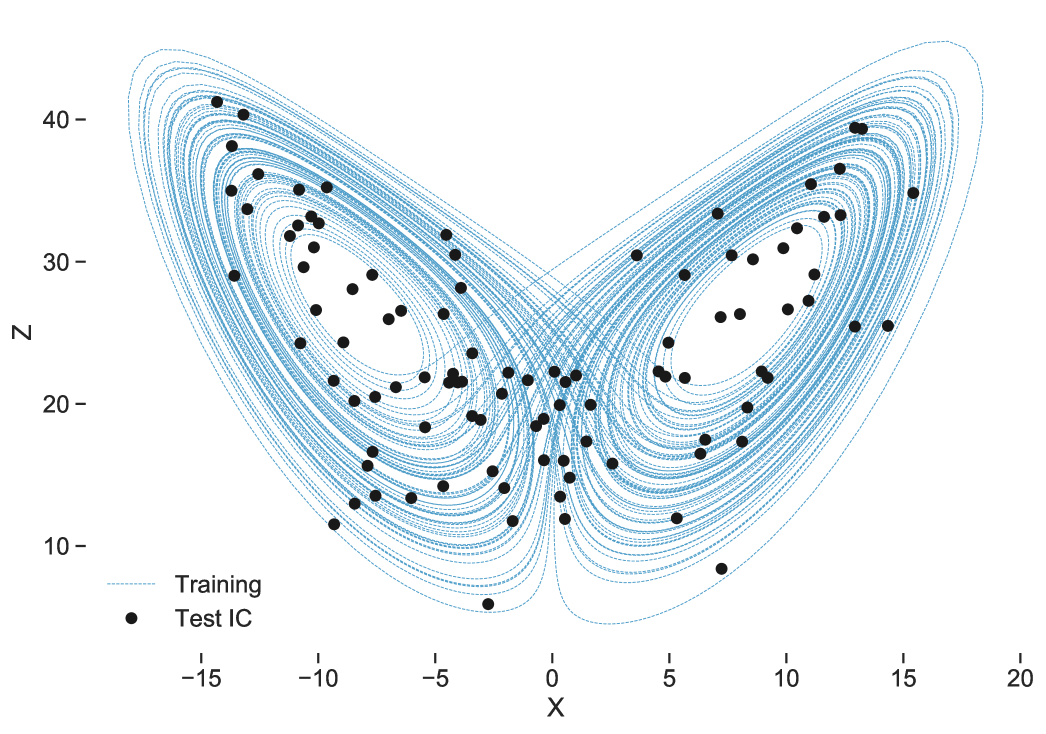
We would like to construct independent training, validation and testing data for training and testing our ML models. In order to be confident in our results, the validation/testing data must be independent from both one another and the training data. Furthermore, we would like the testing data to sample as much of the phase space of as possible, so that we can be confident that the RC generalizes to parts of the input with different properties than which it has been trained on. All data have been generated with these principles in mind Fig.(3).
Additionally, we report forecast times in terms of the Lyapunov timescale of the input dynamical system. This timescale , gives the natural timescale of error growth in the system and is therefore a useful measure of how ‘‘good’’ the forecast is. Not even a perfect model can predict a chaotic dynamical system forever---numerical errors will eventually cause divergence---and therefore gives us a metric of a reasonable timescale for prediction.
4.1 Generative Models
The dynamical models used for data generation have been chosen for their applicability to certain use cases as well as their ability to test particular abilities of reservoir computing. The Rossler system and Colpitt’s oscillator are both 3 dimensional systems with long time scale dynamics---i.e., large, slow error growth rates. The Colpitt’s oscillator is particularly interesting because its dynamical equations of motion include an exponential term, making it the most nonlinear of the models studied here. The degree of nonlinearity of the dynamics can create greater difficulty for prediction with a linear readout operator. The Lorenz attractor (L63) is another 3 dimensional system but with shorter time scale dynamics than Rossler or Collpitts. The Lorenz 1996 system can be defined with arbitrary size so we can use it to look at how our RC scales with system dimension. Finally the Climate Lorenz Model (CL63) is composed of three L63 systems coupled together with multi-timescale dynamics. RCs tend to focus on a particular time scale [15] so it is important to study multi-timescale dynamics for certain applications such as in a weather prediction context [68, 69]. See the appendix for equations and parameters.
| Dataset | Largest LE | Time Scale |
|---|---|---|
| Rossler | 0.065 | 15.4 |
| Colpitts | 0.07 | 14.3 |
| L63 | 0.9 | 1.1 |
| L96-5D | 0.4 | 2.5 |
| L96-10D | 1.1 | 0.9 |
| CL63 | 0.9 | 1.1 |
4.2 Forecast Testing Metric
A common ML benchmark for time series prediction is the one-step prediction mean square error Eq.(5). Indeed this is exactly how we train the micro-scale parameters in to obtain the linear map from . As a method for testing, however, one-step prediction is not an appropriate metric; it overemphasizes the high frequency modes in the data at the expense of the long-term stability of the RC forecast.
As shown by Platt et.al.,[54], the metric that best represents the ideal behavior of the RC---good short-term predictions coupled with ‘‘physical’’ (the forecast RC stays on the synchronization manifold ) long-term forecasts---is best represented by the reproduction of the input system’s LEs. In practice the LEs can be difficult to calculate from high-dimensional experimental data and computationally expensive for the RC. Therefore, a proxy for the reproduction of the LEs has in practice been long-term forecasts [54].
Our standard metric for forecast time is the valid prediction time (VPT) [1]. The VPT is the time when the accuracy of the forecast exceeds a given threshold. For example,
| (12) |
where is the system dimension, is the long term standard deviation of the time series, is an arbitrary threshold, and is the RC forecast. For the results shown in subsequent section a total of 200 test initial conditions are used to report a distribution of VPTs with set arbitrarily to . [1] use in their reported results.
5 RC Training
Training the RC model can be separated into training the macro-scale parameters---e.g., spectral radius, leak rate---and the micro-scale parameters i.e., the elements of . Much of the early guidance on RC training [39] included advice on the intuition behind hand-tuning the macro parameters for a particular problem as hyperparameters. For instance, a widely cited guideline is that the spectral radius must be below 1---see section 3.1---but that is based on many assumptions that do not necessarily hold for a particular RC application. Modern optimization algorithms and increased computational power have decreased the need to hand-tune all of these macro parameters as hyperparameters. Instead, they can be incorporated directly into the objective function for training via optimization. For intuition on the effect of these parameters on the RC we refer the reader to Lukoševičius [39].
We employ a two step optimization approach, described by [29, 31] where one first fixes the macro-scale parameters, trains the micro-scale parameters through linear regression Eq.(6) and then tests the completed RC on a series of long forecasts. For the macro loss function we have had success using the scaled error
with M being the number of forecasts used for comparison. We reiterate that the training for the macro-scale parameters does not use the one-step-ahead prediction error because that is not a good proxy for the reproduction of the LE spectrum. Penny et.al., [31] (Fig.12) examined the effect of increasing numbers of on the cost function landscape and showed that increasing smooths out the loss function landscape and enables better convergence to the global minimum. However, a compromise is necessary as increasing will substantially increase computational complexity. We have empirically found that using 15-20 or so forecasts is generally enough for these simple models, provided that those forecasts are made at statistically independent points. Ideally the data would well sample the input system attractor, but in practice that cannot always be the case.
5.1 Bayesian Optimization
Rather than hand-tune each macro-scale parameter as a hyperparameter, we suggest instead using an optimization procedure such as the two step optimization routine described above. While any global search algorithm can be used e.g., differential evolution, we use a Bayesian optimization technique using surrogate modeling. Bayesian optimization is a protocol for optimizing expensive nonlinear functions that works by “minimiz[ing] the expected deviation from the extremum” of a target loss function [70]. We have found success with the efficient global optimization algorithm of Jones et.al., [71] as implemented by [72]. This algorithm evaluates the loss function over a number of sampled points and then a Gaussian process regression is fit to the surface produced. One can then optimize over this interpolated ‘‘surrogate’’ model to identify promising regions of parameter space and then iterate by reevaluating the loss function in these regions. Given that we need only train a few macro-scale parameters, this surrogate optimization technique renders the optimization problem computationally tractable.
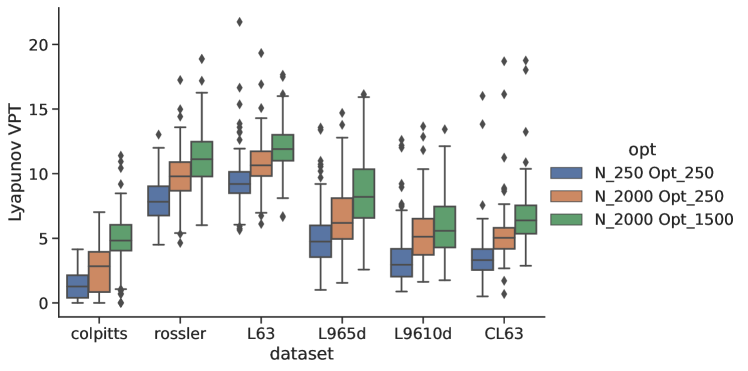
With these algorithms, one can jettison the hand-tuning of hyperparameters and simply optimize all the macro-scale RC parameters for a given problem. This procedure produces good performance for a wide range of simple dynamical models Fig.(4) in a reasonable amount of time.
We will now go into greater detail on the choices that must be made outside of the optimization routine (by definition hyperparameters) and how they can affect the solution to the RC problem. The experiments are conducted by fixing/varying a particular hyperparameter or macro-scale parameter from table 1 and then optimizing over the rest of the macro-scale parameters. It will be stated if we are not optimizing over the un-varied parameters.
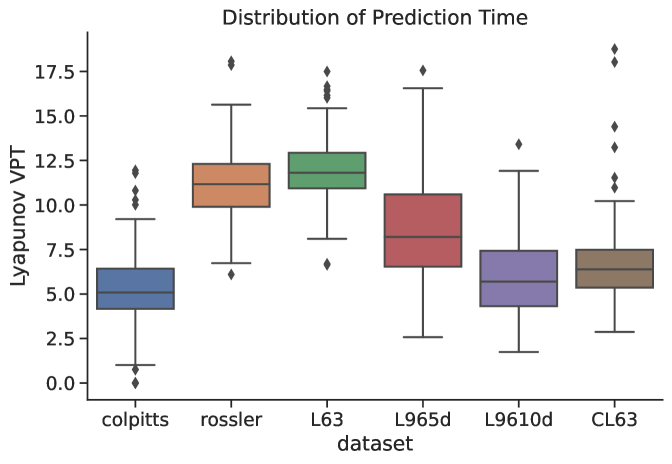
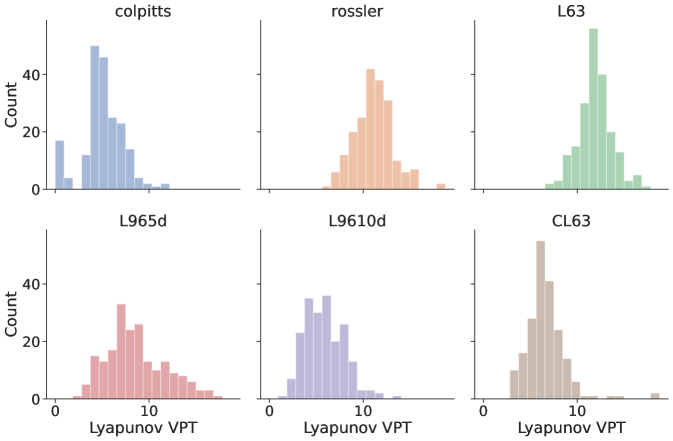
(right) Histogram view of the distribution of VPT for the different models. The distributions are close to Gaussian but with heavier tails. The outliers correlate with the FTLEs of the input system. When the FTLEs are low negative values, meaning the input data is very stable, then prediction times can be extremely long and vice versa. While some of the variability in prediction time is caused by randomness and training in the RC, other variability is intrinsic to the dynamics we are attempting to predict.
5.2 Reservoir Dimension
The reservoir dimension of the RC is related to the memory capacity of the network [18, 39]. Larger reservoirs do tend to produce more accurate forecasts with longer VPTs than smaller networks. However, there are diminishing returns where ever larger reservoirs are needed for ever smaller improvements in predictability. For example, consider the L63 system in Fig.(5). Using a reservoir size of just nodes, we see a VPT only a couple Lyapunov time scales less than when using a reservoir of size . Therefore if our application only requires a few Lyapunov time scales of prediction skill, then it is possible to use a much smaller and more computationally efficient RC.
Because optimization routines are far more computationally intensive than forecasting with the RC, it is practical to ask whether one can optimize/train using a smaller reservoir and then scale up to larger reservoir to generate a forecast. The answer is that one can indeed train a small reservoir and then use those same macro-scale parameters with a larger reservoir to see substantial improvement in prediction skill. This strategy was used by [31]. However, an RC optimized at the larger size will tend to produce more accurate forecasts. If computational resources allow, it is appropriate to perform a final optimization using the reservoir size that will be used for the production RC. The left side of Fig.(5) shows the effect of increasing the reservoir dimension without re-optimizing parameters. The RC performance tends to saturate as the reservoir dimension increases.
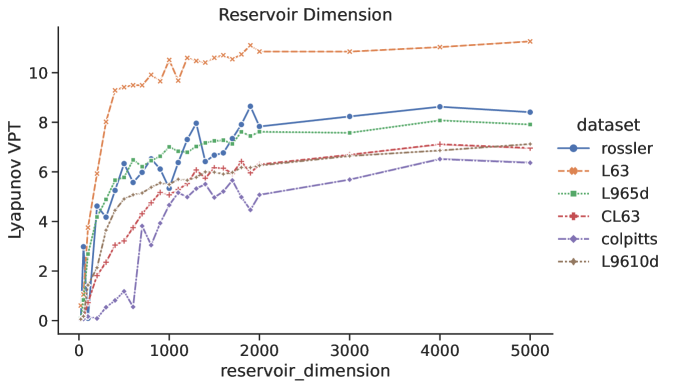
(right) VPT for a 3 different RCs 1) small RC optimized at 2) an RC with identical global parameters to 1, but with a dimension scaled up to 3) an RC with optimized for .
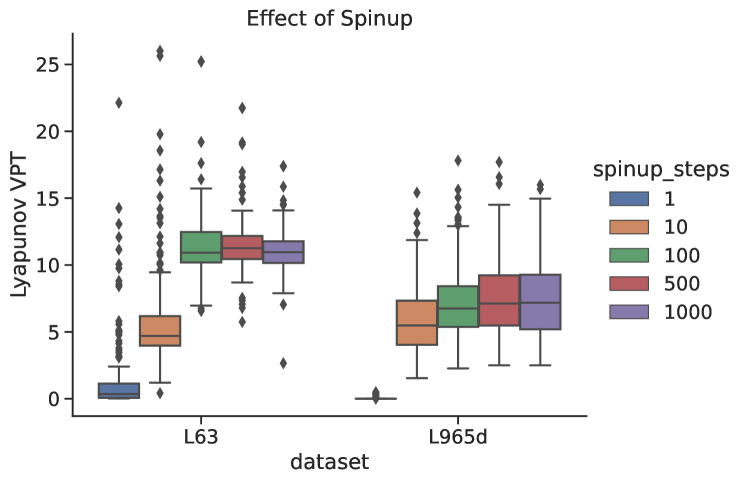
5.3 Spinup Time
The spinup time is the time it takes for a trained RC to converge from its initial condition (usually either set to zero or randomly chosen) onto the synchronization manifold to which it is driven by the input data. The number of steps needed for spinup is related to:
-
1.
How far the initial condition of the RC is from the synchronization manifold.
-
2.
The CLEs of the generalized synchronization manifold; these are related to the ‘‘echo state property’’ and the spectral radius of the adjacency matrix .
-
3.
The RC approaches the synchronization manifold asymptotically so while the error tolerance is also important, it probably does not need to converge to within . Convergence during spinup and error growth during prediction are both governed by with giving the negative CLEs for spinup or the positive LEs for forecasting.
In practice it is easy to tell empirically how much time is needed---see Fig.(6)---usually for these small models only time steps are necessary. For larger systems the spinup time can be significantly higher.
5.4 Input Bias
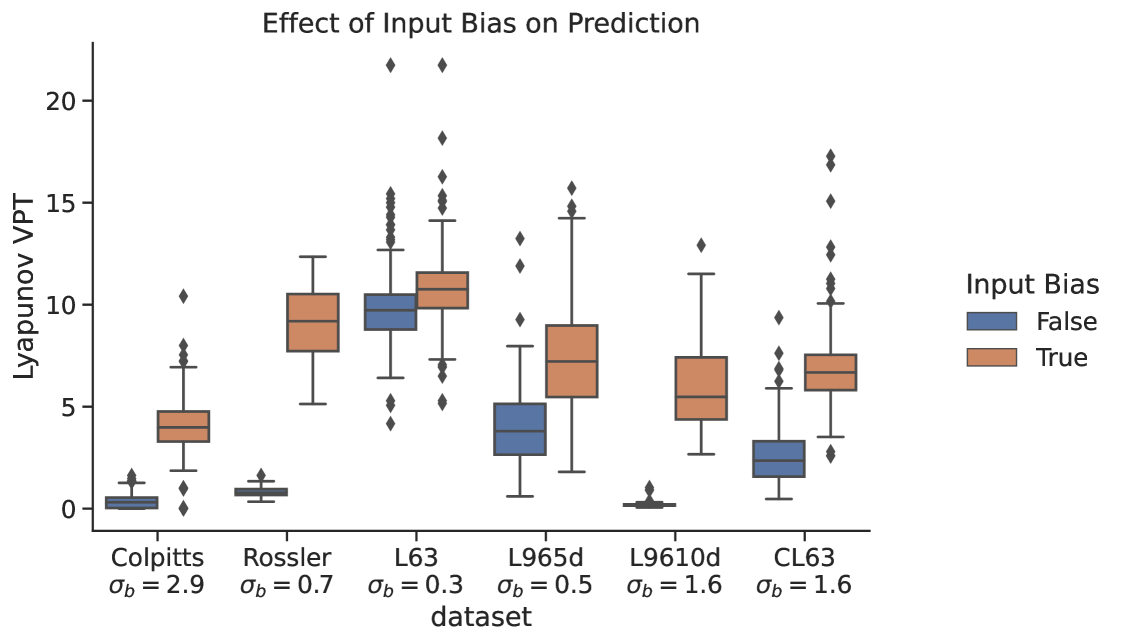
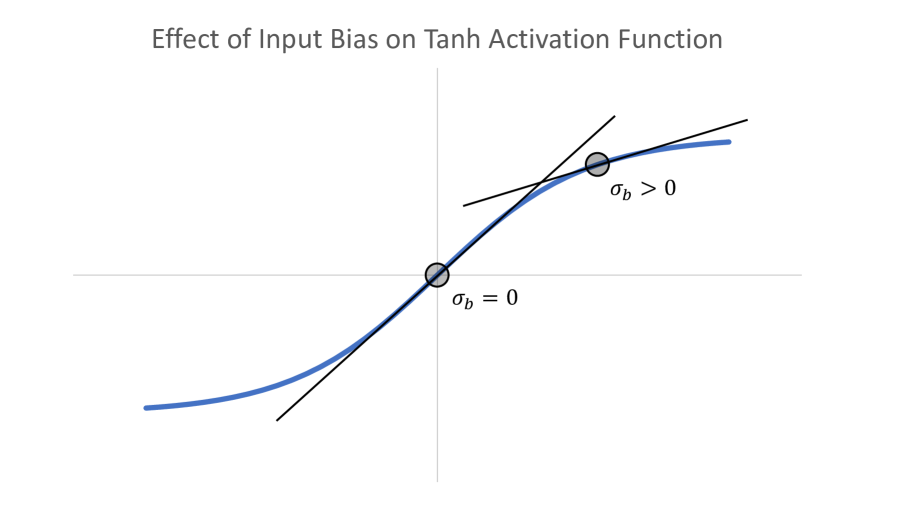
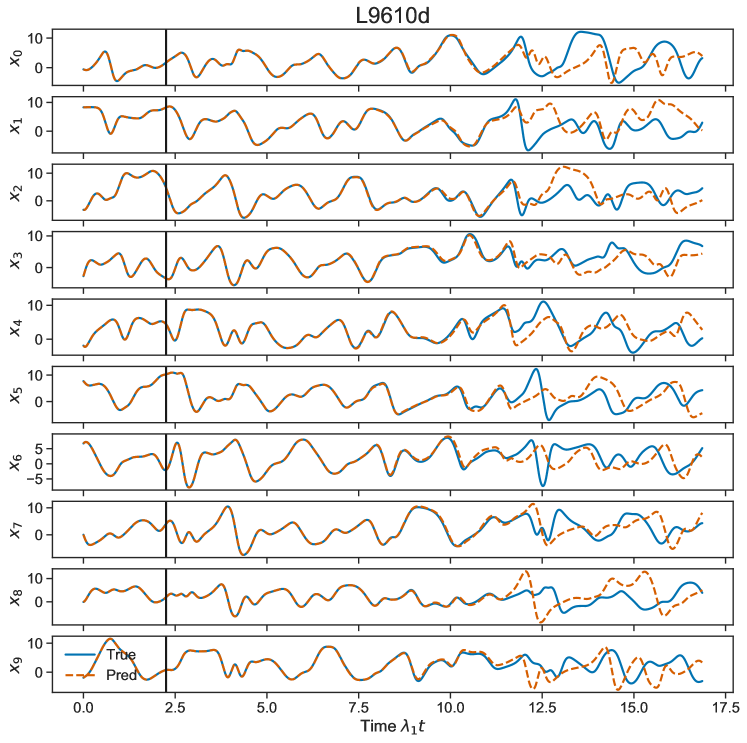
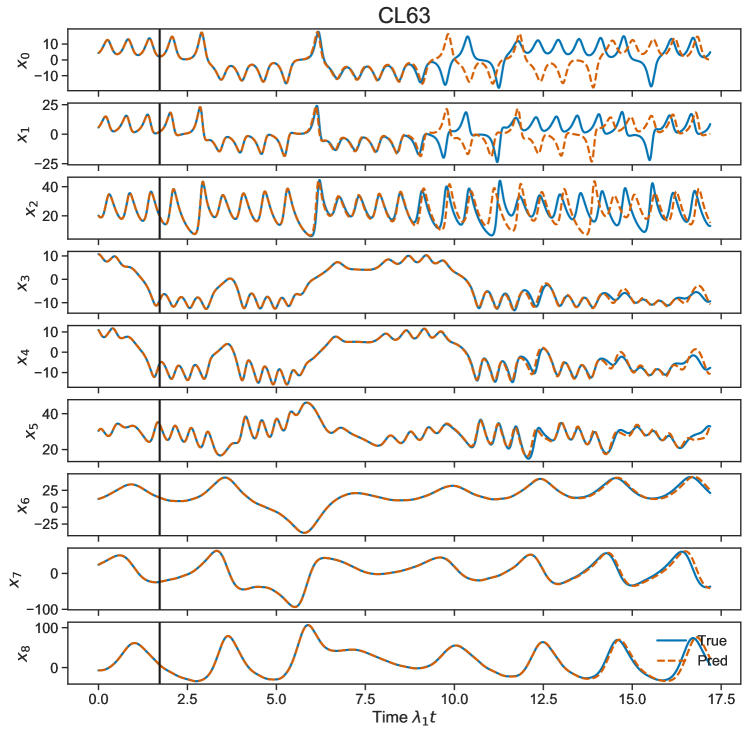
The input bias can have a significant impact on RC prediction skill, but it has consistently been left out of most published RC studies focused on forecasting chaotic dynamics. We see in Fig.(7) that if we do not include this term in the RC when optimizing macro-scale parameters then for almost all models the forecast skill is negligible. The input bias sets the extent of the ‘nonlinearity’ in the reservoir Fig.(8); corresponds to the reservoir operating mostly in the linear part of the tanh function around 0, while a high bias term corresponds to the RC operation being in a more nonlinear part of the regime.
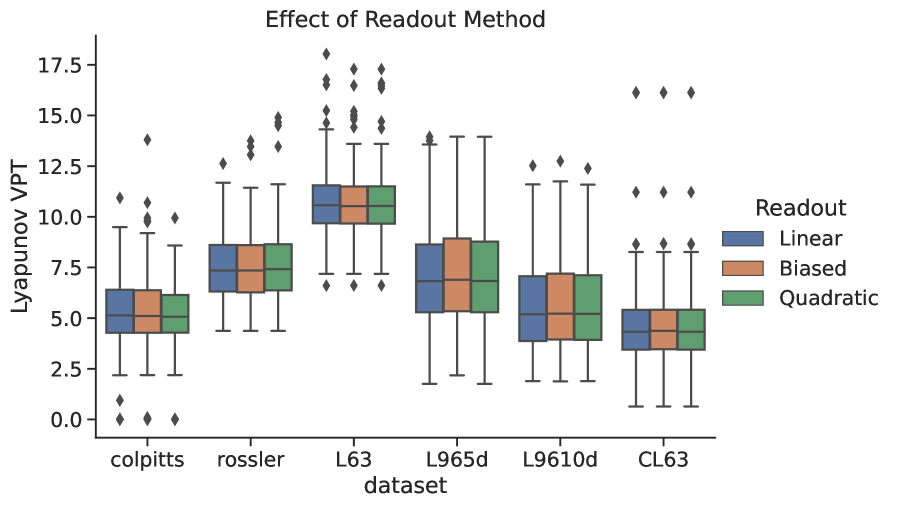
5.5 Readout Functions: Linear, Biased, Quadratic
We generalize the readout to for some function . An example in the literature is by Lu et.al., [28] who use a quadratic readout function . As another example, [39] recommended a biased output where so the previous input is fed directly into . We have tested a number of options and found that the readout does not have much impact on the quality of the forecasts made by the RC Fig.(9) as long as the parameters are well optimized and the input bias is not set to 0. While these results seemingly contradict those reported and used in the previously cited studies, we note that when the bias term is not included---see Fig.(7)---then changing the readout layer does indeed improve the predictions. We speculate that the readout in this case is injecting a certain amount of nonlinearity, essential for good predictions, into a system that is operating around the linear regime of the activation function.
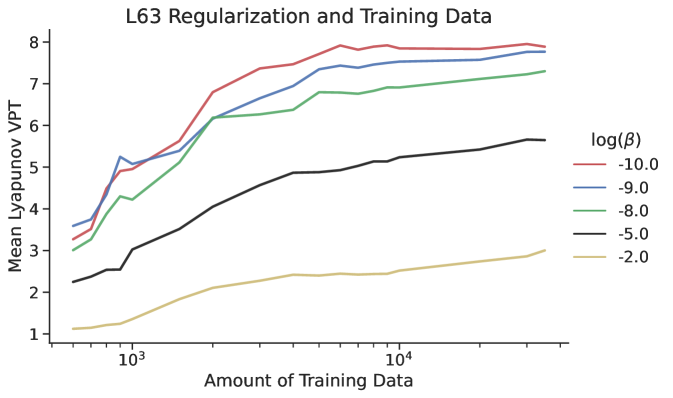
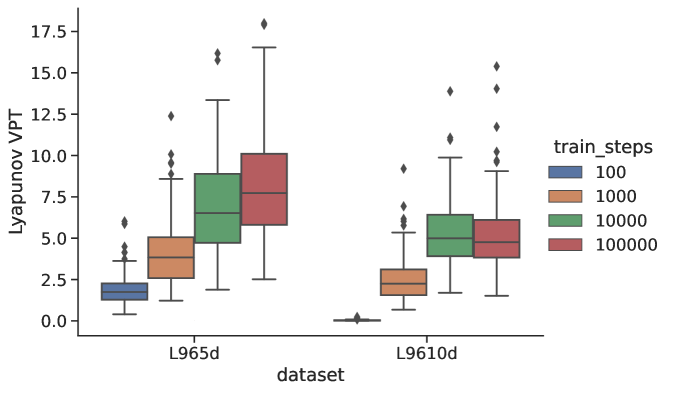
5.6 Amount of Training Data
The data are used differently in the two steps of the training routine---see Eq.(5). The data should be separated into the long forecasts that are used to compute the loss and the data used to train in Eq.(6). More and longer test forecasts for the global loss will help guarantee 1) the generalizability of the RC to segments of the data the RC might not have seen, 2) stability of the trained RC, and 3) the optimality of the global parameters found during training. The amount of data that is used for the micro-scale loss function governs the accuracy of the linear map . Experiments indicate diminishing returns, where increasing the size of the training data leads to diminishing improvements in forecast skill Fig.(10).
5.7 Normalization
Normalization is a standard practice in ML. Applying normalization is usually among the first suggestions to anyone analyzing a new dataset [9]. We must emphasize, however, that when forecasting dynamical systems the standard methods for normalizing datasets can have deleterious effects. To illustrate, we introduce two normalization schemes,
-
1.
Normalize each variable separately by subtracting the mean and dividing by the standard deviation
-
2.
Normalize the variables by the joint mean and max/min of the variables
We assume that the variables in the dynamical system have been nondimensionalized. The statistical functions mean, max, and min are calculated from all the training data and thus represent ‘‘climatological’’ statistics. The VPTs resulting from both normalization schemes are shown in Fig.(11).
As shown in Figure 11, normalization scheme 2 vastly outperforms scheme 1. Our hypothesis is that normalizing each variable separately (particularly subtracting the mean) destroys the cross-variable information necessary to reconstruct the relationships in the dynamical system. There is a significant amount of information stored in the relationships between the variables as well as their magnitudes. The second scheme compensates for the normalization via and to preserve all the information in the data while the first scheme destroys that information.
It is possible that we could recover the prediction skill by a skillful selection of . If we optimized the inputs () for each column of separately as well as , that would help the RC to compensate for the normalization. However, this introduces additional global parameters that must be optimized.
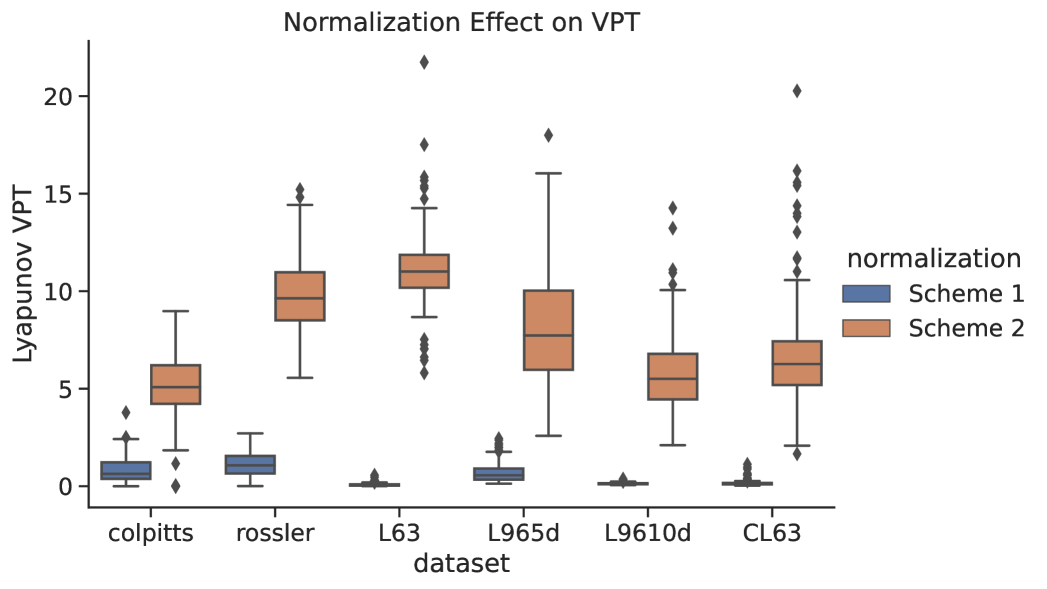
Generally, we recommend not normalizing the variables when the data is nondimensionalized, as is the case for the dynamical models examined here. We note that [31] used no normalization and still produced successful predictions with the RC models. In a realistic setting, however, when the data is collected from sensors and there are many different unit scales, one has to do some kind of normalization in order for the methods to be numerically stable. We discuss this point further with a simple example in appendix B. Because we have shown that normalization can be detrimental when using data to forecast dynamical systems, we emphasize that care must be taken when normalizing any data prior to training.
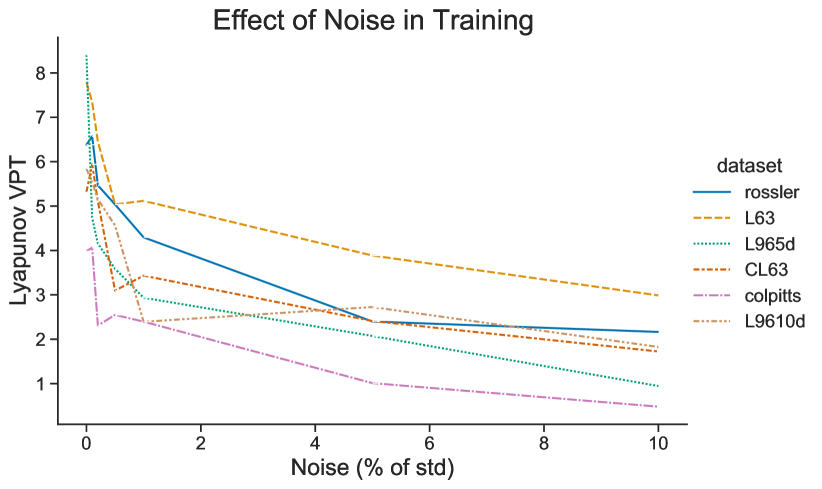
5.8 Effect of Noise
The RC is quite sensitive to additive noise Fig.(12). There is a sharp decrease in prediction quality with even a small amount of noise, meaning that any slight perturbation to the training of causes the errors to multiply rapidly. This is consistent with our observation that even casting double precision floating point numbers in to single precision can cause similar degradation.
We must address a phenomenon reported by [1] that sometimes a small amount of noise can help predictions. This observation held true when we normalized the data using scheme 1 rather than scheme 2---see the previous section. We note, however, that even with the small observed increase in predictive skill, the VPT was still far below that reported with the scheme 2. While [1] speculated that the noise could regularize the data, we find this is not true in general.
5.8.1 Sparse in Time
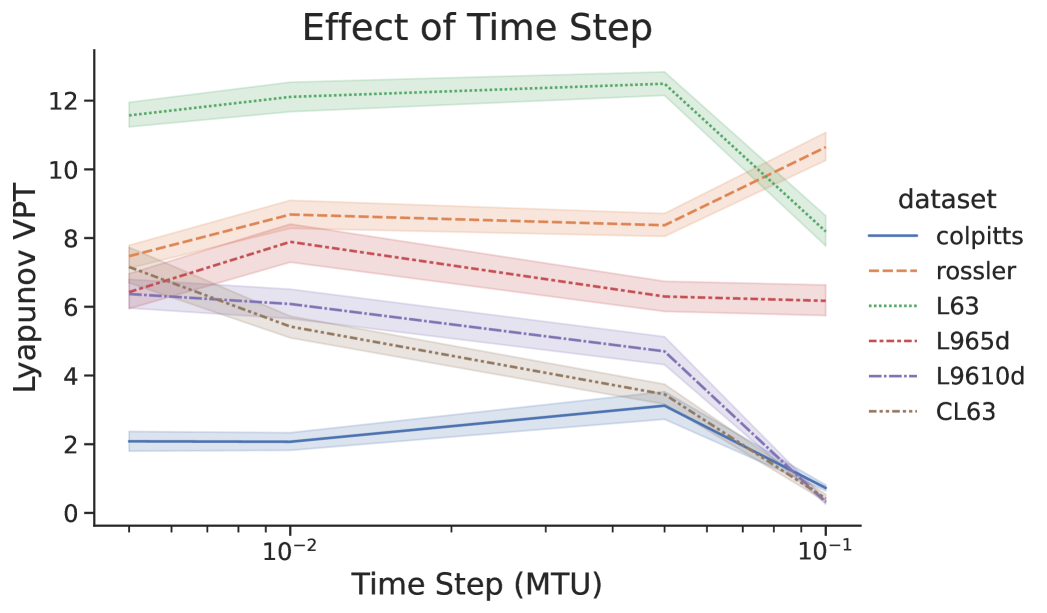
RC can be quite sensitive to the time step of the input data i.e., how sparse the measurements are in time. In Fig.(13) we tested the RC for different time steps , reoptimizing the RC each time. The total time of the training data for number of steps, did not change. We call attention to the result that finer training data does not always increase the prediction time of the RC and that certain models had an optimal time step. In practice one may want to interpolate the input data to try to match the optimal time step.
5.9 Sparsity of the Adjacency Matrix
The sparsity of the adjacency matrix in general makes very little difference to the predictive capability of the RC---this is described by [39] and matches our experience. The benefit of using a very sparse matrix comes from taking advantage of sparse matrix representations in scientific computing software packages to vastly increase computational speed. We have found a set value of 98% or 99% sparsity, to be sufficient for all applications, provided the resulting matrix is full rank.
Of course there is a limit to this guideline---if the matrix is too sparse (i.e., has no nonzero values) then the RC will not work. In addition, when using small reservoirs of say less than = then the randomness of the selection of can have a significant impact on the quality of predictions [15]. Slightly larger reservoirs seem to be more robust to random variations in connectivity.
6 Scaling to Higher Dimensional Systems
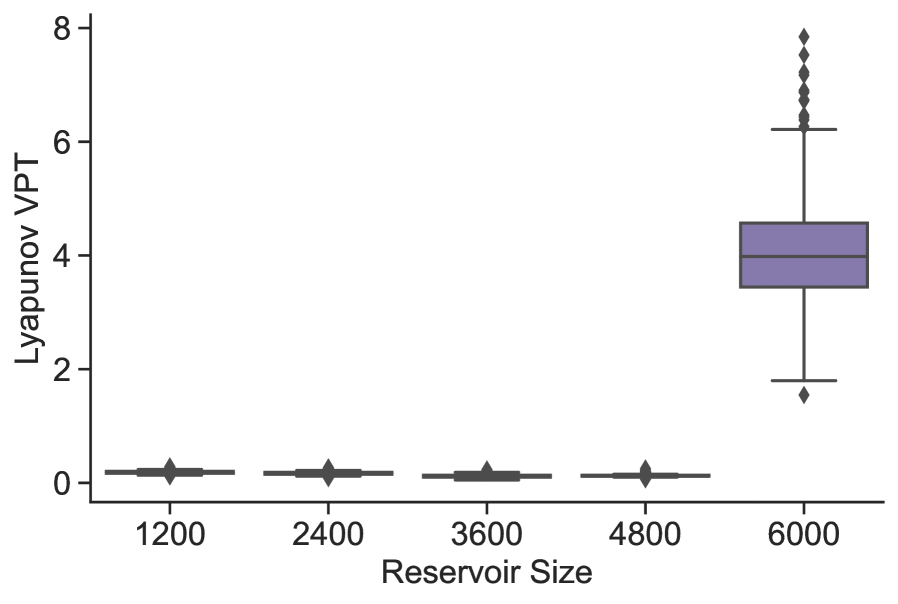
Up to this point we have considered systems with a state dimension , and a single RC model has been sufficient to predict their time evolution. However, systems with larger state spaces will require larger reservoirs to make adequate predictions. We highlight this situation in Figure 14, which shows the VPT of RC models with increasing reservoir dimension on the Lorenz96 system with 40 nodes. Note that we use a leading Lyapunov exponent of to represent the timescale for this system following [1]. There is no prediction skill until a certain minimum reservoir size is attained, somewhere between 4,800 and 6,000. For systems with even larger state spaces, the reservoir size will have to increase beyond the amount of Random Access Memory (RAM) available and parallelization schemes will have to be considered.
To address these issues, [27] introduced a parallelization strategy which has been used in numerous high dimensional applications, e.g. [30, 1, 31]. In this localization scheme, multiple reservoirs work semi-independently, each making predictions of a subset of the system state. More precisely, the elements of the system state are split up into groups, such that each group is assigned an individual RC model that predicts of the state vector nodes, with . At each time step, each group receives of the neighboring state vector values, such that a system with a single spatial dimension has an input dimension for each RC model of . With this architecture one must decide how to choose and . Our goal in this section is to explore these choices within the framework outlined in Sections 4 & 5.
6.1 Varying the halo size and output dimension
Figure 15(a) shows the performance of localized RC models with varying output size, and halo size, . For output dimensions 2 and 4 (color), we see that the RC model shows its best performance when the halo size is 2. These RC models show no prediction skill with halos smaller than 2, and exhibit diminishing performance as the halo size increases beyond this point. These results suggest that for this particular system, the optimal configuration has a halo size of 2. For the Lorenz96 system, this is unsurprising since we know that the time evolution for each individual node requires information of neighboring states up to 2 nodes away, equation (C.0.4). For halo sizes smaller than 2, the known interactions between neighboring grid points are not represented. As the halo size increases, the RC model must effectively ‘learn’ the length scale across which the underlying dynamical interactions occur.
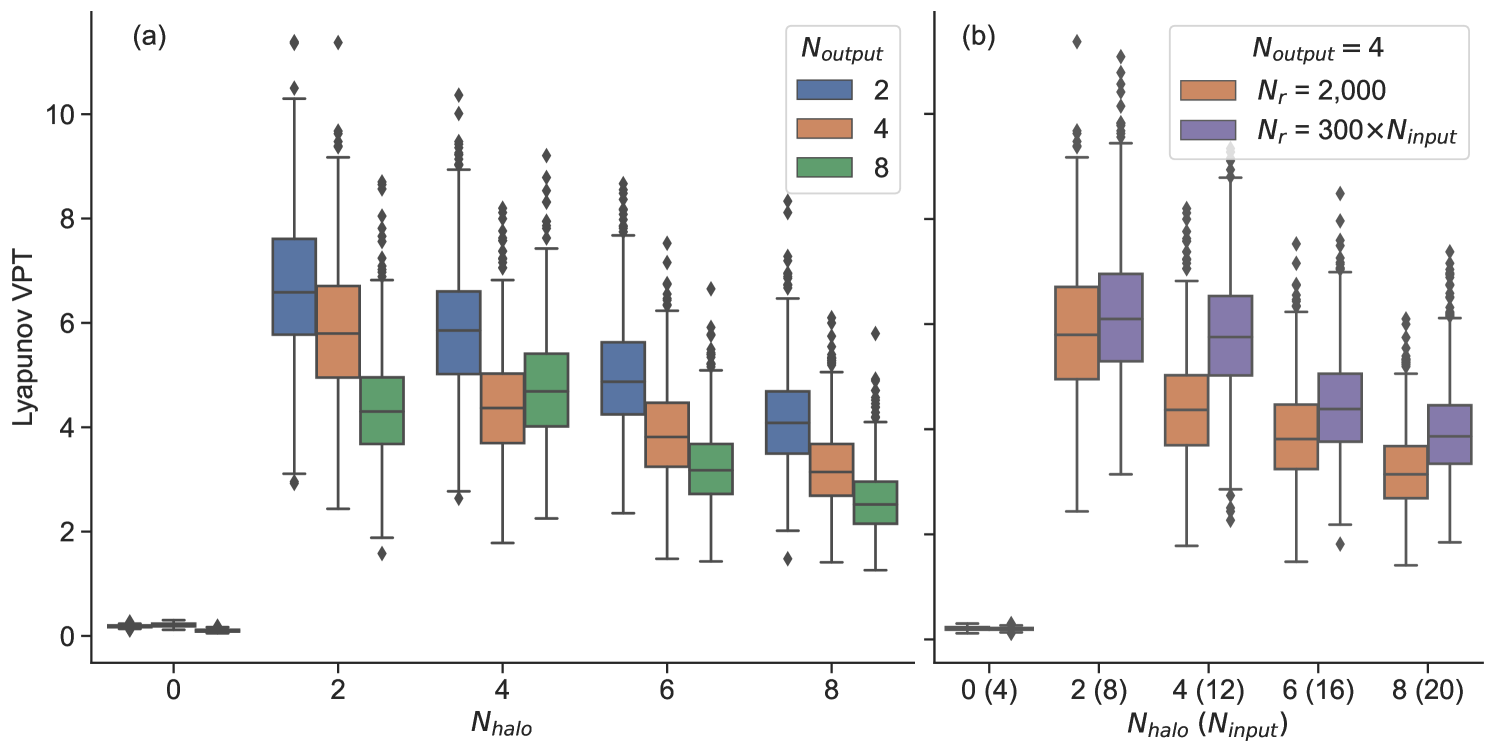
The results suggests that the optimal halo size should be set to a ‘‘minimum length scale’’ relevant to the time evolution of the dynamical system. This value is obviously system dependent, and will require knowledge of how the training data are acquired. If the data arise from a numerical model, the halo size could be related to the numerical stencil used in time integration (e.g. finite difference or finite element scheme). In the case of observed data, approximating the minimum length scale will require knowledge of the system dynamics.
As the output dimension for each local reservoir increases we see a similar effect as increasing the halo size: the prediction skill decreases. Taken together, prediction skill is optimal when the reservoir ‘‘stencil’’ is as small as possible: each local RC model is trained with exactly the amount of information it needs. This result is in some ways a restatement of [27] (their Figure 5b), who show that prediction performance improves as the number of local reservoirs increases with a fixed system dimension. Using more local reservoirs requires more computational resources, and the benefits must be weighed against the increase in computational cost.
6.2 Increasing the reservoir size with input dimension
The previous section showed that prediction skill decreases as the input dimension increases. Here, we test the impact of increasing the reservoir size in order compensate for this reduction in performance. Figure 15(b) shows the result of this test for , comparing performance with a fixed reservoir size (orange) against models where . For , the median VPT increases by 1.4 (32%) as a result of increasing the reservoir size from 2,000 to 3,600 (80%). For larger values of , the payoff from increasing the reservoir size is even smaller. For example, , the median VPT increases by 0.6 (15%) but requires a reservoir size that is 4,800 (140% larger). The results highlight what is shown in Section 5.2 (Figure 5). After a certain level of performance is obtained for a given problem size, increasing the reservoir size provides diminishing returns for prediction skill.
6.3 Input bias at scale
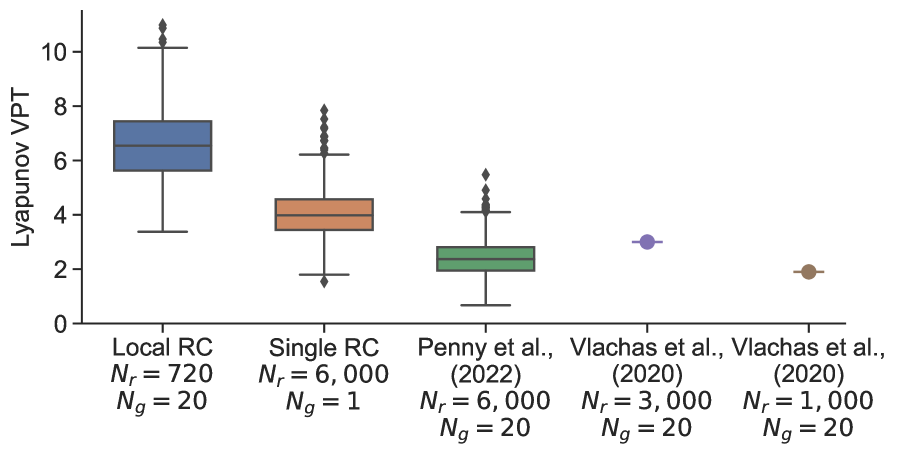
Finally, we emphasize the importance of the bias term in the RC architecture, which is accentuated in high dimensional systems. Figure 16 compares the performance of two RC models that use an optimized value for (‘‘Local RC’’ and ‘‘Single RC’’) against two RC models that use (from [31] and [1]). The RC configuration from [31] uses local reservoirs, each with an output dimension of 2, halo size 4, and reservoir size of 6,000. Even with all other parameters optimized, the VPT is roughly half that of a single RC model with reservoir size 6,000 when an optimized (nonzero) bias term is used. When 20 local reservoirs are used with an optimized bias term and , the VPT is approximately tripled.
Penny et al. (2021) [31] found it necessary to increase the local reservoir dimension to 6,000 in order to attain reasonable prediction skill. The results in this section show that this was essentially a brute force solution to overcome an inactive bias term. This is an important takeaway for forecasting high dimensional systems, which may have such a large number of localized RC models that increasing the reservoir size to overcome this inactive bias term would become prohibitive.
7 Conclusion and Discussion
Reservoir computing is a powerful machine learning method that can be used to successfully predict chaotic time series data. While not as flexible as other RNN methods, the RC has a number of properties that make it a good method of choice for these kinds of tasks. The ability to set the macro-scale properties of the network and the quick training of the micro-scale parameter through linear regression couple together to allow the RC to be trained and deployed quickly and easily. Additionally, the RC has been shown not only to give good predictions but also to react like a physical model to perturbations in the system state (shown as the reproduction of the LEs) [28, 54, 31]. This property is crucial for applications in numerical weather prediction and other fields where it is important to produce both a forecast as well as an uncertainty estimate of that forecast. RCs can also be scaled up to large systems while being accelerated on dedicated hardware for vast speedups [32], thus making them an exciting candidate for the simulation of high dimensional systems.
We present in this paper an exploration of the options needed to for RCs to be trained successfully for chaotic time series forecasting. Almost all the results presented here involve the reoptimization of parameters through the outlined Bayesian optimization procedure for every experiment. The complex effects of the macro-scale parameters on the predictability of the RC and the correlations between these parameters preclude drawing many conclusions from simply varying each one of the parameters individually. When the data, RC training method, or one parameter is changed then a full re-optimization is necessary to compensate. This is one reason why the results presented here differ from those presented in previous literature.
The bias term in the RC equation is found to be criticaly important Fig.(7), for all but the L63 system, and we emphasize that this is generally neglected in the current literature. Indeed predictions were practically impossible for many of the models without the addition of this term. We additionally show that the form of the readout has little impact on the skillful forecast time, at least for the given dynamical models. While this may be surprising given that the inclusion of an term in the readout has become a standard practice [28, 27, 1], we note that without the inclusion of bias, the nonlinear readout does have some positive impact (results not shown).
Our further exploration included showing the deleterious effects of a standard ML normalization procedure where each dimension of the input is recentered and rescaled separately [9]. This procedure is important in deep learning where the stability of the optimization procedure using backpropagation can be compromised. Centering all of the data around 0, however, destroys the important relationships between the variables, leading to a very poor predictive capacity for the RC. The RC is not trained through backpropagation, therefore it is advisable to avoid this kind of normalization when attempting to predict chaotic time series.
We also examine the effect of the reservoir dimension , the amount of training data as well as the time step of the data on the performance of an RC. A general ‘‘law of diminishing returns’’ is exhibited in regards to RC size and the amount of data. This effect can be partially mitigated by re-optimizing the RC using a larger reservoir size instead of scaling up directly. We suggest that more effort should be dedicated to increasing the robustness of the RC to noise, since in real applications this will be a limitation on the usefulness of the method.
Finally, we show how to scale up the method to larger systems through localization, examining the effect of halo size and output dimension. We present results on the 40 dimensional Lorenz system. Comparing to state of the art results for the RC [1, 31], the reported architecture in this paper increases the VPT while decreasing the computational cost. Vlachas et al. (2020) [1] noted ‘‘that RC...have slightly lower VPT than GRU and LSTM but require significantly lower training times.’’ Our results now give a clear advantage of RC over the LSTM and GRU in pure predictive capacity as well as training time; additionally the RC has the advantage of reproducing the LEs of the input data, enabling the reproduction of the climatalogical attractor [28]. We hope that this work, by collecting a number of different characteristic models together, gives a clear set of standards to compare as a benchmark when developing new RC techniques.
8 Acknowledgements
J.A. Platt, S.G. Penny, and H.D.I. Abarbanel acknowledge support from the Office of Naval Research (ONR) grants N00014-19-1-2522 and N00014-20-1-2580. S.G. Penny and T.A. Smith acknowledge support from NOAA grant NA20OAR4600277. T.-C. Chen is supported by the NOAA Cooperative Agreement with CIRES, NA17OAR4320101. S.G. Penny and J.A. Platt jointly proposed and guided the research study. J.A. Platt conducted the majority of the investigation. T.A. Smith conducted the study of localization and scaling to larger systems. Coauthors Penny, Platt, Smith, and Chen all contributed to the development of the software used to conduct the experiments in this study.
References
- [1] P.R. Vlachas et al. ‘‘Backpropagation algorithms and Reservoir Computing in Recurrent Neural Networks for the forecasting of complex spatiotemporal dynamics’’ In Neural Networks 126, 2020, pp. 191–217 DOI: https://doi.org/10.1016/j.neunet.2020.02.016
- [2] Edwin H. Colpitts ‘‘Oscillation Generation’’, 1918
- [3] M.P. Kennedy ‘‘Chaos in the Colpitts oscillator’’ In IEEE Transactions on Circuits and Systems I: Fundamental Theory and Applications 41.11, 1994, pp. 771–774 DOI: 10.1109/81.331536
- [4] Edward N. Lorenz ‘‘Deterministic Nonperiodic Flow’’ In Journal of the Atmospheric Sciences 20.2, 1963, pp. 130–141 DOI: 10.1175/1520-0469(1963)020<0130:DNF>2.0.CO;2
- [5] R.. Kalman ‘‘A New Approach to Linear Filtering and Prediction Problems’’ In Journal of Basic Engineering 82.1, 1960, pp. 35–45 DOI: 10.1115/1.3662552
- [6] Geir Evensen ‘‘Data Assimilation: The Ensemble Kalman Filter’’ Springer, 2009
- [7] H... Abarbanel ‘‘The Statistical Physics of Data Assimilation and Machine Learning’’ Cambridge University Press, 2022, pp. 284
- [8] Anna Miller et al. ‘‘Statistical Data Assimilation: Formulation and Examples From Neurobiology’’ In Frontiers in Applied Mathematics and Statistics 4, 2018 DOI: 10.3389/fams.2018.00053
- [9] Ian Goodfellow, Yoshua Bengio and Aaron Courville ‘‘Deep Learning’’ http://www.deeplearningbook.org MIT Press, 2016
- [10] Zachary Chase Lipton ‘‘A Critical Review of Recurrent Neural Networks for Sequence Learning’’ In CoRR abs/1506.00019, 2015 arXiv:1506.00019
- [11] Sepp Hochreiter and Jürgen Schmidhuber ‘‘Long Short-Term Memory’’ In Neural Computation 9.8, 1997, pp. 1735–1780
- [12] F.. Gers, J. Schmidhuber and F. Cummins ‘‘Learning to Forget: Continual Prediction with LSTM’’ In Neural Computation 12.10, 2000, pp. 2451–2471
- [13] Kyunghyun Cho et al. ‘‘Learning Phrase Representations using RNN Encoder--Decoder for Statistical Machine Translation’’ In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP) Doha, Qatar: Association for Computational Linguistics, 2014, pp. 1724–1734 DOI: 10.3115/v1/D14-1179
- [14] Jeffrey L. Elman ‘‘Finding Structure in Time’’ In Cognitive Science 14.2, 1990, pp. 179–211 DOI: https://doi.org/10.1207/s15516709cog1402\_1
- [15] M. Lukoševicius and H. Jaeger ‘‘Reservoir computing approaches to recurrent neural network training’’ In Comput. Sci. Rev. 3, 2009, pp. 127–149
- [16] Herbert Jaeger ‘‘Long Short-Term Memory in Echo State Networks: Details of a Simulation Study’’, Jacobs University Technical Reports 27, 2012
- [17] Herbert Jaeger ‘‘The "echo state" approach to analysing and training recurrent neural networks-with an erratum note’’ In Bonn, Germany: German National Research Center for Information Technology GMD Technical Report 148, 2010, pp. 1–47
- [18] Herbert Jaeger ‘‘Short term memory in echo state networks. GMD-Report 152’’ In GMD - German National Research Institute for Computer Science, 2002
- [19] Herbert Jaeger and Harald Haas ‘‘Harnessing Nonlinearity: Predicting Chaotic Systems and Saving Energy in Wireless Communication’’ In Science 304 American Association for the Advancement of Science, 2004, pp. 78–80 DOI: 10.1126/science.1091277
- [20] Wolfgang Maass, Thomas Natschläger and Henry Markram ‘‘Real-Time Computing Without Stable States: A New Framework for Neural Computation Based on Perturbations’’ In Neural Computation 14, 2002, pp. 2531–2560
- [21] S. Hochreiter, Y. Bengio, P. Frasconi and J. Schmidhuber ‘‘Gradient flow in recurrent nets: the difficulty of learning long-term dependencies’’ In A Field Guide to Dynamical Recurrent Neural Networks IEEE Press, 2001
- [22] Y. Bengio, P. Frasconi and P. Simard ‘‘The problem of learning long-term dependencies in recurrent networks’’ In IEEE International Conference on Neural Networks, 1993, pp. 1183–1188 vol.3
- [23] Razvan Pascanu, Tomas Mikolov and Yoshua Bengio ‘‘On the difficulty of training recurrent neural networks’’ 28.3, Proceedings of Machine Learning Research Atlanta, Georgia, USA: PMLR, 2013, pp. 1310–1318
- [24] Benjamin Schrauwen, David Verstraeten and Jan Van Campenhout ‘‘An overview of reservoir computing: Theory, applications and implementations’’ In ESANN’2007 proceedings - European Symposium on Artificial Neural Networks Bruges (Belgium), 25-27 April 2007, 2007, pp. 471–482
- [25] J.J. Steil ‘‘Backpropagation-decorrelation: online recurrent learning with O(N) complexity’’ In 2004 IEEE International Joint Conference on Neural Networks (IEEE Cat. No.04CH37541) 2, 2004, pp. 843–848 vol.2 DOI: 10.1109/IJCNN.2004.1380039
- [26] A.F. Atiya and A.G. Parlos ‘‘New results on recurrent network training: unifying the algorithms and accelerating convergence’’ In IEEE Transactions on Neural Networks 11.3, 2000, pp. 697–709 DOI: 10.1109/72.846741
- [27] Jaideep Pathak et al. ‘‘Model-Free Prediction of Large Spatiotemporally Chaotic Systems from Data: A Reservoir Computing Approach’’ In Physical Review Letters 120, 2018, pp. 024102
- [28] Zhixin Lu, Brian R. Hunt and Edward Ott ‘‘Attractor reconstruction by machine learning’’ In Chaos: An Interdisciplinary Journal of Nonlinear Science 28.6, 2018, pp. 061104 DOI: 10.1063/1.5039508
- [29] Aaron Griffith, Andrew Pomerance and Daniel J. Gauthier ‘‘Forecasting chaotic systems with very low connectivity reservoir computers’’ In Chaos: An Interdisciplinary Journal of Nonlinear Science 29.12, 2019, pp. 123108 DOI: 10.1063/1.5120710
- [30] Troy Arcomano et al. ‘‘A Machine Learning-Based Global Atmospheric Forecast Model’’ In Geophysical Research Letters 47.9, 2020, pp. e2020GL087776 DOI: https://doi.org/10.1029/2020GL087776
- [31] Stephen G. Penny et al. ‘‘Integrating Recurrent Neural Networks with Data Assimilation for Scalable Data-Driven State Estimation’’, 2021 arXiv:2109.12269 [cs.LG]
- [32] Daniel Canaday, Aaron Griffith and Daniel J. Gauthier ‘‘Rapid time series prediction with a hardware-based reservoir computer’’ In Chaos 28, 2018, pp. 123119
- [33] Marc Bocquet, Julien Brajard, Alberto Carrassi and Laurent Bertino ‘‘Bayesian inference of chaotic dynamics by merging data assimilation, machine learning and expectation-maximization’’ In Foundations of Data Science 2.1, 2020, pp. 55–80
- [34] Marc Bocquet, Alban Farchi and Quentin Malartic ‘‘Online learning of both state and dynamics using ensemble Kalman filters’’ In Foundations of Data Science 3.3, 2021, pp. 305–330
- [35] Casper Kaae Sønderby et al. ‘‘MetNet: A Neural Weather Model for Precipitation Forecasting’’, 2020 arXiv:2003.12140 [cs.LG]
- [36] Daniel J. Gauthier, Erik Bollt, Aaron Griffith and Wendson A.. Barbosa ‘‘Next generation reservoir computing’’ In Nature Communications 12.1, 2021 DOI: 10.1038/s41467-021-25801-2
- [37] Randall E Clark, Lawson Fuller, Jason Platt and Henry Abarbanel ‘‘Reduced Dimension, Biophysical Neuron Models Constructed From Observed Data’’ In bioRxiv Cold Spring Harbor Laboratory, 2021 DOI: 10.1101/2021.12.03.471194
- [38] H... Abarbanel, P.. Rozdeba and Sasha Shirman ‘‘Machine Learning; Deepest Learning as Statistical Data Assimilation Problems’’ In Neural Computation MIT Press, 2018, pp. 2025–2055
- [39] Mantas Lukoševičius ‘‘A Practical Guide to Applying Echo State Networks’’ Springer, 2012, 2012, pp. 659–686 DOI: 10.1007/978-3-642-35289-8_36
- [40] Gouhei Tanaka et al. ‘‘Recent advances in physical reservoir computing: A review’’ In Neural Networks 115, 2019, pp. 100–123 DOI: https://doi.org/10.1016/j.neunet.2019.03.005
- [41] Jeffrey L. Elman ‘‘Finding structure in time’’ In Cognitive Science 14.2, 1990, pp. 179–211 DOI: https://doi.org/10.1016/0364-0213(90)90002-E
- [42] Allen Hart, James Hook and Jonathan Dawes ‘‘Embedding and approximation theorems for echo state networks’’ In Neural Networks 128, 2020, pp. 234–247 DOI: https://doi.org/10.1016/j.neunet.2020.05.013
- [43] A.. Tikhonov and V.. Arsenin ‘‘Solutions of Ill-Posed Problems’’ Wiley:New York, 1977
- [44] D. Verstraeten, B. Schrauwen and D. Stroobandt ‘‘Reservoir-based techniques for speech recognition’’ In The 2006 IEEE International Joint Conference on Neural Network Proceedings, 2006, pp. 1050–1053 DOI: 10.1109/IJCNN.2006.246804
- [45] Junjie Jiang and Ying-Cheng Lai ‘‘Model-free prediction of spatiotemporal dynamical systems with recurrent neural networks: Role of network spectral radius’’ In Phys. Rev. Research 1 American Physical Society, 2019, pp. 033056 DOI: 10.1103/PhysRevResearch.1.033056
- [46] Steven H. Strogatz ‘‘Nonlinear Dynamics and Chaos: With Applications to Physics, Biology, Chemistry and Engineering’’ Westview Press, 2000
- [47] David Verstraeten and Benjamin Schrauwen ‘‘On the Quantification of Dynamics in Reservoir Computing’’ In Artificial Neural Networks -- ICANN 2009 Berlin, Heidelberg: Springer Berlin Heidelberg, 2009, pp. 985–994
- [48] Guanrong Chen ‘‘Stability of Nonlinear Systems’’, 2005 DOI: 10.1002/0471654507.eme413
- [49] Joschka Boedecker et al. ‘‘Information processing in echo state networks at the edge of chaos’’ In Theory in biosciences = Theorie in den Biowissenschaften 131.3, 2012, pp. 205–213 DOI: 10.1007/s12064-011-0146-8
- [50] T.. Carroll ‘‘Do reservoir computers work best at the edge of chaos?’’ In Chaos: An Interdisciplinary Journal of Nonlinear Science 30.12, 2020, pp. 121109 DOI: 10.1063/5.0038163
- [51] A.. LYAPUNOV ‘‘The general problem of the stability of motion’’ In International Journal of Control 55.3 Taylor Francis, 1992, pp. 531–534 DOI: 10.1080/00207179208934253
- [52] H... Abarbanel ‘‘The Analysis of Observed Chaotic Data’’ Springer-Verlag, New York, 1996
- [53] J.-P. Eckmann and D. Ruelle ‘‘Ergodic theory of chaos and strange attractors’’ In Rev. Mod. Phys. 57 American Physical Society, 1985, pp. 617–656 DOI: 10.1103/RevModPhys.57.617
- [54] Jason A. Platt et al. ‘‘Robust forecasting using predictive generalized synchronization in reservoir computing’’ In Chaos 31, 2021, pp. 123118 URL: https://doi.org/10.1063/5.0066013
- [55] Karlheinz Geist, Ulrich Parlitz and Werner Lauterborn ‘‘Comparison of Different Methods for Computing Lyapunov Exponents’’ In Progress of Theoretical Physics 83.5, 1990, pp. 875–893 DOI: 10.1143/PTP.83.875
- [56] M.. Sushchik, N. Rul’kov, L.. Tsimring and H... Abarbanel ‘‘Generalized Synchronization of Chaos in Directionally Coupled Chaotic Systems’’ In Physical Review E 51, 1995, pp. 980–994
- [57] S. Boyd and L.O. Chua ‘‘Fading memory and the problem of approximating nonlinear operators with Volterra series’’ In IEEE Trans. Circuits Syst., CAS-32 11, 1985, pp. 1150–1161
- [58] Brian R. Hunt, Edward Ott and James A. Yorke ‘‘Differentiable generalized synchronization of chaos’’ In Phys. Rev. E 55 American Physical Society, 1997, pp. 4029–4034 DOI: 10.1103/PhysRevE.55.4029
- [59] Lyudmila Grigoryeva, Allen Hart and Juan-Pablo Ortega ‘‘Chaos on compact manifolds: Differentiable synchronizations beyond the Takens theorem’’ In Phys. Rev. E 103 American Physical Society, 2021, pp. 062204 DOI: 10.1103/PhysRevE.103.062204
- [60] Lyudmila Grigoryeva, Allen Hart and Juan-Pablo Ortega ‘‘Learning strange attractors with reservoir systems’’, 2021 arXiv:2108.05024 [math.DS]
- [61] Louis M. Pecora et al. ‘‘Fundamentals of synchronization in chaotic systems, concepts, and applications’’ In Chaos: An Interdisciplinary Journal of Nonlinear Science 7.4, 1997, pp. 520–543 DOI: 10.1063/1.166278
- [62] Louis M. Pecora and Thomas L. Carroll ‘‘Synchronization in chaotic systems’’ In Phys. Rev. Lett. 64 American Physical Society, 1990, pp. 821–824 DOI: 10.1103/PhysRevLett.64.821
- [63] Lou Pecora et al. ‘‘Synchronization Stability in Coupled Oscillator Arrays: Solution for Arbitrary Configurations’’ In International Journal of Bifurcation and Chaos 10.02, 2000, pp. 273–290 DOI: 10.1142/S0218127400000189
- [64] Ljupco Kocarev, Ulrich Parlitz and Reggie Brown ‘‘Robust synchronization of chaotic systems’’ In Phys. Rev. E 61 American Physical Society, 2000, pp. 3716–3720 DOI: 10.1103/PhysRevE.61.3716
- [65] Li Deng ‘‘The mnist database of handwritten digit images for machine learning research’’ In IEEE Signal Processing Magazine 29.6 IEEE, 2012, pp. 141–142
- [66] ‘‘List of datasets for machine-learning research’’, 2021 URL: https://en.wikipedia.org/wiki/List_of_datasets_for_machine-learning_research
- [67] H.D.I. Abarbanel, R. Brown and M.B. Kennel ‘‘Local Lyapunov exponents computed from observed data’’ In Journal of Nonlinear Science 2, 1992, pp. 343–365 DOI: https://doi.org/10.1007/BF01208929
- [68] Eugenia Kalnay ‘‘Atmospheric Modeling, Data Assimilation and Predictability’’ Cambridge University Press, 2002 DOI: 10.1017/CBO9780511802270
- [69] M. Pe˜na and E. Kalnay ‘‘Separating fast and slow modes in coupled chaotic systems’’ In Nonlinear Processes in Geophysics 11.3, 2004, pp. 319–327 DOI: 10.5194/npg-11-319-2004
- [70] J. Močkus ‘‘On bayesian methods for seeking the extremum’’ In Optimization Techniques IFIP Technical Conference Novosibirsk, July 1--7, 1974 Berlin, Heidelberg: Springer Berlin Heidelberg, 1975, pp. 400–404
- [71] Donald Jones, Matthias Schonlau and William Welch ‘‘Efficient Global Optimization of Expensive Black-Box Functions’’ In Journal of Global Optimization 13, 1998, pp. 455–492 DOI: 10.1023/A:1008306431147
- [72] Mohamed Amine Bouhlel et al. ‘‘A Python surrogate modeling framework with derivatives’’ In Advances in Engineering Software 135, 2019, pp. 102662 DOI: https://doi.org/10.1016/j.advengsoft.2019.03.005
- [73] James D. Bjorken and Sidney David Drell ‘‘Relativistic Quantum Mechanics’’ McGraw-Hill, 1964
- [74] V.. Oseledec ‘‘A multiplicative ergodic theorem. Lyapunov characteristic numbers for dynamical systems’’ In Trudy Mosk. Mat. Obsc. 19, 1968, pp. 197–
- [75] Leslie E. Matson ‘‘The Malkus–Lorenz water wheel revisited’’ In American Journal of Physics 75.12, 2007, pp. 1114–1122 DOI: 10.1119/1.2785209
- [76] Lucas Illing, Rachel F. Fordyce, Alison M. Saunders and Robert Ormond ‘‘Experiments with a Malkus–Lorenz water wheel: Chaos and Synchronization’’ In American Journal of Physics 80.3, 2012, pp. 192–202 DOI: 10.1119/1.3680533
- [77] O.E. Rössler ‘‘An equation for continuous chaos’’ In Physics Letters A 57.5, 1976, pp. 397–398 DOI: https://doi.org/10.1016/0375-9601(76)90101-8
- [78] Edward N Lorenz ‘‘Predictability: A problem partly solved’’ In Predictability of weather and climate Cambridge, 2006
- [79] Mark Kostuk ‘‘Synchronization and Statistical Methods for the Data Assimilation of HVC Neuron Models’’, 2012 URL: http://escholarship.org/uc/item/2fh4d086
Appendix A Lyapunov Exponents
Given an N-dimensional dynamical system 222 defines a dynamical system with external forcing. Formally, the LEs calculated for this system are called conditional Lyapunov exponents (CLE). If does not depend explicitly on time then it is an autonomous system and we are just calculating LEs.
| (13) |
with the state, the dynamics and denoting the spectrum of LEs can be computed as follows. First we find the linearization of the system. We derive the variational equations, which describe the evolution of the tangent vectors, by taking on both sides of eq (13). Applying the chain rule we find
which we rewrite as
| (14) |
with being the variational matrix and being the Jacobian. The general solution to Eq.(14) involves the matrix exponential
with and being the time ordering operator [73] for two operators (here matrices) and that are not commutative,
is important because the Jacobian matrices are not commutative i.e.,
The variational equation is much easier to work with in discrete time where it appears as
and .
Then the solution for is the product of Jacobians
| (15) | |||||
The matrix describes how small perturbations to a state propagate to the state at . Given equations (13) and (14) one can solve them concurrently to find Oseledec’s matrix
The eigenvalues of the of for large times
| (16) |
are the global Lyapunov Exponents; the eigenvalues are by definition real and the eigenvectors orthogonal since is a symmetric matrix. We order the LEs . The matrix is ill-conditioned, so accurately evaluating all of its eigenvalues requires a stable algorithm, for example as provided by [53, 52].
Oseledec’s multiplicative ergodic theorem [74] states that all LEs of a dynamical system (a) exist, (b) are independent of the initial starting point , and (c) are invariant under smooth coordinate transformations 333The statement of invariance under coordinate transformation is important when attempting to recover the LEs from a time delay embedding.. The finite time Lyapunov exponents (FTLE) [67], Eq.(16) evaluated for finite , are not independent of nor are they invariant under a smooth coordinate transformation. Furthermore, for a continuous time dynamical system one of the LEs must be 0, and In Hamiltonian systems the spectrum of LEs is symmetric around 0 and thus a natural statement of phase space volume conservation guaranteed by Liouville’s theorem.
Appendix B Malkus Water Wheel
For physical applications, determining the correct normalization scheme can be more difficult when the state variables have different units e.g., temperature, pressure, velocity,…. All of the source models that we used in this study were nondimensionalized. In practice we may instead have data measured in quantities with different units. There are two solutions that we propose:
-
1.
Nondimensionalize the state variables using physical parameters of the system. This does not require knowledge of the full equations of motion, only basic knowledge of the physics involved.
-
2.
Allow the RC to learn the correct scaling laws by setting a separate and for each unit type. For example, one might have a and a . Note that this replaces the scalar with a vector that has the structure for different units for the state variables.
As an illustrative example, we consider the Malkus water wheel [46, 75, 76]. The chaotic water wheel is a physical model of the L63 equations and thus provides a mixed-units example with which to apply the proposed normalization schemes. Following the notation of [75], the three state variables are , and where is the angular velocity of the water wheel for the angle in the plane of the wheel, and gives the position of the center of mass (COM) also in the plane of the wheel. The equations of motion are
where is the angular acceleration due to gravity per horizontal displacement of the COM, is the time constant for the axle friction and input water drag, is the leakage rate of the water and is the radius of the wheel. We see that also gives the relaxation time constant for the COM. The maximal LE when , , , is giving a time constant of model time units.
To nondimensionalize the system we see that there are two different units for the state variables. has units while and have units . Therefore, if we choose a time scale and length scale , we can nondimensionalize by taking , and . Using knowledge of the physics but without knowing the equations of motion we can write a list of parameters on which the equations may depend---see table 3. Again, no a priori knowledge of the equations of motion is needed.
| axel friction | ||
| moment of inertia | ||
| leak rate | ||
| radius | ||
| gravity at angle | ||
| mass |
We can construct and using this set of candidate parameters. An obvious choice for is , since both have the same units. For we could use or . There is no wrong answer as long as all the parameters with the same units are scaled in the same way and one can measure the parameters needed.
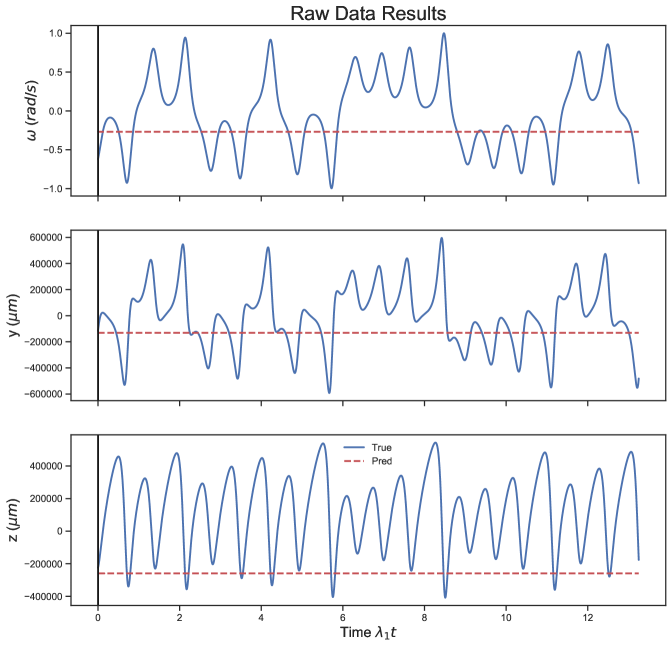
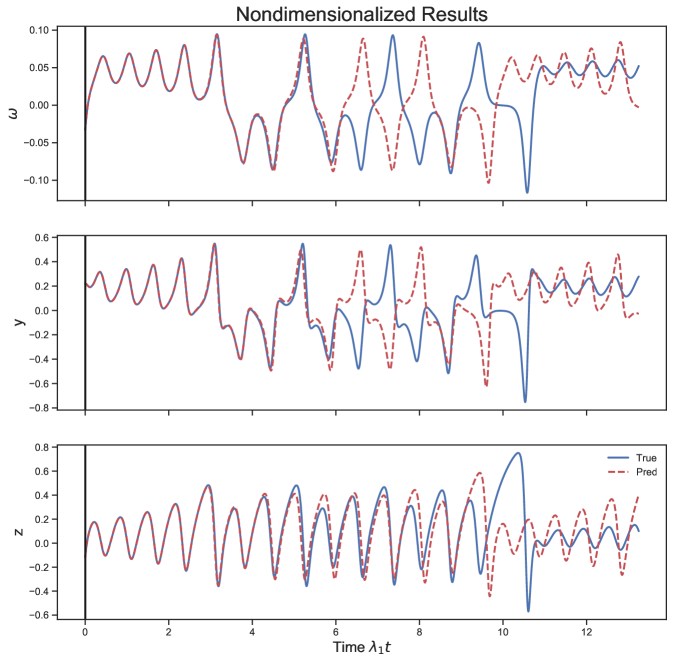
As a (somewhat extreme) example, let us say the distance measurements from our sensor are in , and is measured in . In this case the RC is not able to predict the system at all Fig.(17). This is not really surprising considering the wildly different scales between and the and variables. We correct this by scaling by and and by . This leads to reasonably accurate forecasts. Letting the optimization determine the correct scaling between the variables also leads to accurate forecasts.
Appendix C Details of Datasets
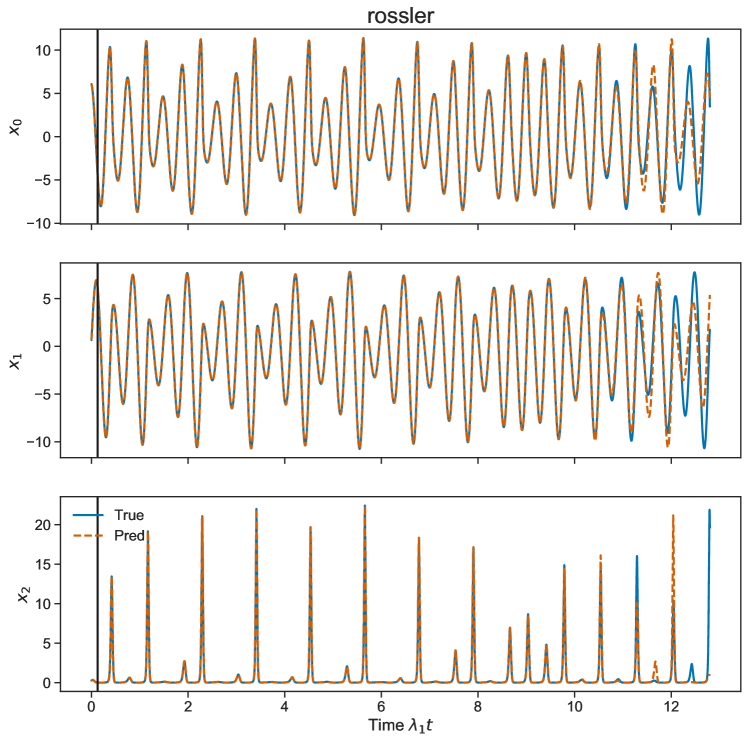
C.0.1 Rossler
The Rossler system [77] was proposed as a simplified form of the L63 system with a single second order nonlinearity and only one lobe of the strange attractor. The equations are
The LEs are .
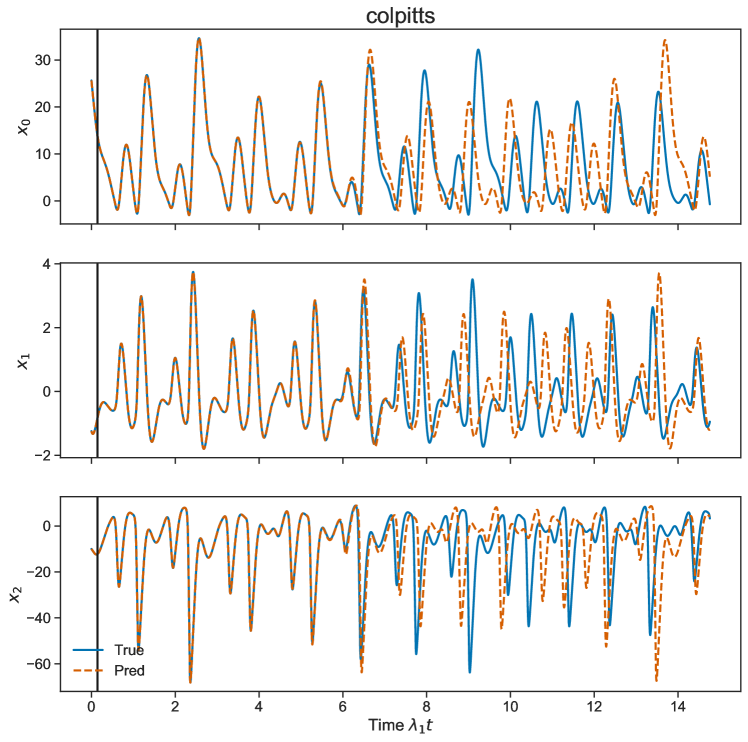
C.0.2 Colpitts
The Colpitts Oscillator [2] is a three dimensional nonlinear dynamical system describing chaos in a nonlinear circuit. The equations of the system are given
with , , and For this circuit has limit cycle oscillations.
The Lyapunov exponents are calculated via the QR decomposition algorithm given by Eckmann and Ruelle [53].
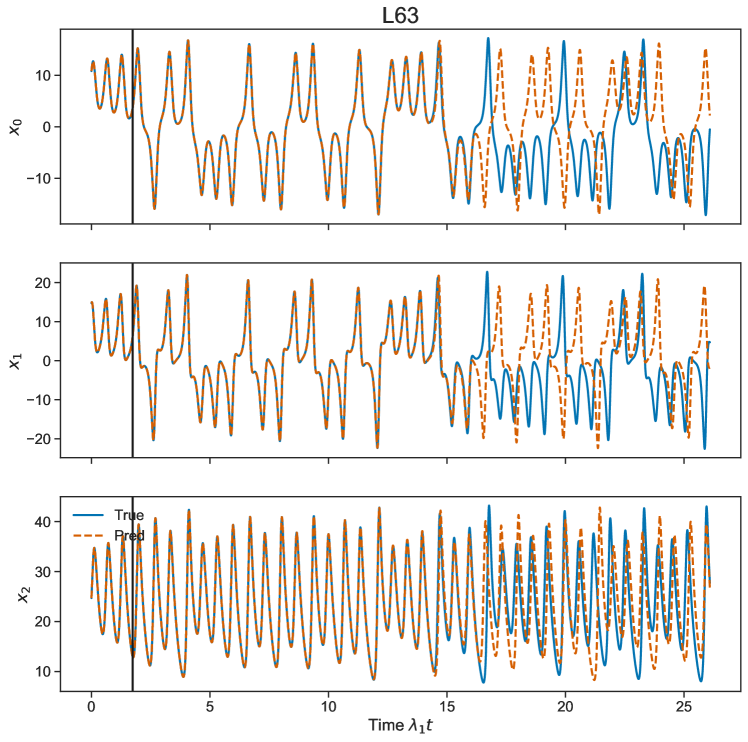
C.0.3 L63
The Lorenz-63 [4] equations form a deterministic nonlinear dynamical system that exhibits chaos for certain ranges of parameters. It was originally found as a three dimensional, reduced, approximation to the partial differential equations for the heating of the lower atmosphere of the Earth by solar radiation. The dynamical equations of motion are
with time independent parameters .
The Lyapunov exponents are calculated using the QR decomposition approach given by Eckmann and Ruelle [53].
C.0.4 L96
These dynamical equations were introduced by [78]:
and ; ; ; . is a fixed parameter that we take to be 8.0 where the solutions to these dynamical equations are chaotic [79]. The equations for the states are meant to describe points on a periodic spatial lattice. We use , and .
The Lyapunov exponents are and
calculated using the QR decomposition approach given by Eckmann and Ruelle [53].
C.0.5 CL63
The climate Lorenz 63 system[69] consist of three L63 systems coupled together with multiple time scales. The three layers are an extratropical atmosphere, a tropical atmosphere, and a tropical ocean system. The presence of multiple time scales often creates a challenge for RC models.
| Extratropical atmosphere system | ||
| Tropical atmosphere system | ||
| Tropical ocean system | ||
Appendix D Parameters
| dataset | N | readout | ||||||
|---|---|---|---|---|---|---|---|---|
| CL63 | 0.007 | 1.00 | 0.01 | 2.201375e-08 | 2000 | 0.66 | linear | 0.98 |
| L63 | 0.084 | 0.60 | 0.80 | 8.493901e-08 | 2000 | 1.60 | linear | 0.98 |
| L9610d | 0.005 | 0.72 | 0.21 | 7.640822e-09 | 2000 | 1.47 | linear | 0.98 |
| L96-5D | 0.060 | 0.70 | 0.58 | 6.332524e-09 | 2000 | 1.59 | linear | 0.98 |
| colpitts | 0.100 | 1.00 | 1.20 | 1.000000e-08 | 2000 | 2.00 | linear | 0.98 |
| rossler | 0.066 | 0.47 | 0.50 | 2.101845e-09 | 2000 | 1.23 | linear | 0.98 |
| dataset | N | readout | ||||||
|---|---|---|---|---|---|---|---|---|
| CL63 | 0.002 | 0.84 | 0.53 | 1.033811e-07 | 250 | 1.31 | linear | 0.98 |
| CL63 | 0.007 | 1.00 | 0.01 | 2.201375e-08 | 2000 | 0.66 | biased | 0.98 |
| L63 | 0.024 | 0.96 | 0.64 | 1.339452e-08 | 250 | 1.63 | biased | 0.98 |
| L63 | 0.084 | 0.60 | 0.80 | 8.493901e-08 | 2000 | 1.60 | quadratic | 0.98 |
| L9610d | 0.005 | 0.51 | 0.68 | 2.844557e-10 | 250 | 1.37 | biased | 0.98 |
| L9610d | 0.005 | 0.72 | 0.21 | 7.640822e-09 | 2000 | 1.47 | biased | 0.98 |
| L96-5D | 0.022 | 0.85 | 0.34 | 5.756201e-08 | 250 | 0.41 | biased | 0.98 |
| L96-5D | 0.060 | 0.70 | 0.58 | 6.332524e-09 | 2000 | 1.59 | biased | 0.98 |
| colpitts | 0.100 | 1.00 | 0.01 | 3.548470e-09 | 250 | 0.00 | biased | 0.98 |
| colpitts | 0.100 | 1.00 | 1.20 | 1.000000e-08 | 2000 | 2.00 | linear | 0.98 |
| rossler | 0.100 | 1.00 | 1.20 | 1.000000e-08 | 250 | 2.00 | quadratic | 0.98 |
| rossler | 0.066 | 0.47 | 0.50 | 2.101845e-09 | 2000 | 1.23 | quadratic | 0.98 |
| dataset | N | readout | ||||||
|---|---|---|---|---|---|---|---|---|
| CL63 | 0.004 | 0.98 | 0.66 | 5.216114e-10 | 1200 | 1.57 | linear | 0.98 |
| CL63 | 0.014 | 0.88 | 0.01 | 1.572121e-05 | 1200 | 0.00 | linear | 0.98 |
| L63 | 0.011 | 0.49 | 0.59 | 1.115693e-10 | 1200 | 0.28 | linear | 0.98 |
| L63 | 0.014 | 0.89 | 1.02 | 2.390891e-08 | 1200 | 0.00 | linear | 0.98 |
| L9610d | 0.017 | 0.95 | 0.10 | 1.443850e-09 | 1200 | 1.59 | linear | 0.98 |
| L9610d | 0.001 | 0.41 | 0.92 | 4.553807e-03 | 1200 | 0.00 | linear | 0.98 |
| L96-5D | 0.100 | 1.00 | 0.05 | 1.012426e-10 | 1200 | 0.55 | linear | 0.98 |
| L96-5D | 0.096 | 0.80 | 0.40 | 4.087443e-08 | 1200 | 0.00 | linear | 0.98 |
| colpitts | 0.100 | 0.55 | 1.87 | 2.836222e-09 | 1200 | 2.85 | linear | 0.98 |
| colpitts | 0.022 | 0.91 | 1.11 | 3.177257e-07 | 1200 | 0.00 | linear | 0.98 |
| rossler | 0.042 | 0.89 | 0.79 | 1.006571e-08 | 1200 | 0.71 | linear | 0.98 |
| rossler | 0.028 | 0.48 | 0.81 | 1.000000e-08 | 1200 | 0.00 | linear | 0.98 |
| dataset | N | readout | Train Data | ||||||
|---|---|---|---|---|---|---|---|---|---|
| L9610d | 0.001 | 0.68 | 1.01 | 2.202428e-02 | 1000 | 1.40 | linear | 0.98 | 100 |
| L9610d | 0.003 | 0.85 | 0.43 | 1.043649e-09 | 1000 | 1.04 | linear | 0.98 | 1000 |
| L9610d | 0.006 | 1.00 | 0.01 | 1.769733e-10 | 1000 | 1.15 | linear | 0.98 | 10000 |
| L9610d | 0.008 | 0.22 | 0.02 | 9.382122e-08 | 1000 | 1.33 | linear | 0.98 | 100000 |
| L96-5D | 0.012 | 0.96 | 1.26 | 1.236301e-09 | 1000 | 3.00 | linear | 0.98 | 100 |
| L96-5D | 0.023 | 0.83 | 0.31 | 2.517159e-09 | 1000 | 1.23 | linear | 0.98 | 1000 |
| L96-5D | 0.039 | 0.69 | 0.85 | 1.349428e-08 | 1000 | 1.08 | linear | 0.98 | 10000 |
| L96-5D | 0.066 | 0.60 | 0.66 | 1.319216e-09 | 1000 | 1.04 | linear | 0.98 | 100000 |
| dataset | N | readout | normalization | ||||||
|---|---|---|---|---|---|---|---|---|---|
| CL63 | 0.007 | 0.28 | 0.40 | 6.630623e-03 | 1512.0 | 1.44 | quadratic | 0.98 | Scheme 1 |
| CL63 | 1.566 | 1.00 | 0.01 | 2.201375e-08 | 2000.0 | 0.69 | biased | 0.98 | Scheme 2 |
| L63 | 0.002 | 0.17 | 1.16 | 3.530047e-03 | 1833.0 | 2.36 | biased | 0.98 | Scheme 1 |
| L63 | 5.985 | 0.60 | 0.80 | 8.493901e-08 | 2000.0 | 1.71 | quadratic | 0.98 | Scheme 2 |
| L9610d | 0.005 | 0.40 | 0.75 | 2.292198e-01 | 1550.0 | 0.44 | biased | 0.98 | Scheme 1 |
| L9610d | 0.116 | 0.72 | 0.21 | 7.640822e-09 | 2000.0 | 1.57 | biased | 0.98 | Scheme 2 |
| L96-5D | 0.004 | 0.87 | 0.14 | 1.972360e-08 | 1739.0 | 3.12 | biased | 0.98 | Scheme 1 |
| L96-5D | 1.017 | 0.70 | 0.58 | 6.332524e-09 | 2000.0 | 1.73 | biased | 0.98 | Scheme 2 |
| colpitts | 0.527 | 0.19 | 0.44 | 1.780703e-03 | 1897.0 | 1.19 | biased | 0.98 | Scheme 1 |
| colpitts | 10.184 | 1.00 | 1.20 | 1.000000e-08 | 2000.0 | 2.00 | linear | 0.98 | Scheme 2 |
| rossler | 0.712 | 0.67 | 0.68 | 1.533086e-02 | 1595.0 | 4.30 | quadratic | 0.98 | Scheme 1 |
| rossler | 2.204 | 0.47 | 0.50 | 2.101845e-09 | 2000.0 | 1.23 | quadratic | 0.98 | Scheme 2 |
| dataset | N | readout | time step | ||||||
|---|---|---|---|---|---|---|---|---|---|
| CL63 | 0.002 | 0.64 | 0.43 | 3.963368e-09 | 1500 | 1.63 | linear | 0.98 | 0.005 |
| CL63 | 0.004 | 0.96 | 0.28 | 8.664170e-07 | 1500 | 0.96 | linear | 0.98 | 0.010 |
| CL63 | 0.008 | 0.94 | 0.03 | 7.266341e-08 | 1500 | 1.85 | linear | 0.98 | 0.050 |
| CL63 | 0.004 | 0.61 | 1.55 | 1.322695e-02 | 1500 | 3.06 | linear | 0.98 | 0.100 |
| L63 | 0.020 | 1.00 | 1.10 | 3.671288e-08 | 1500 | 1.34 | linear | 0.98 | 0.005 |
| L63 | 0.034 | 0.92 | 0.69 | 1.294075e-08 | 1500 | 1.28 | linear | 0.98 | 0.010 |
| L63 | 0.056 | 0.79 | 0.18 | 5.401025e-10 | 1500 | 1.02 | linear | 0.98 | 0.050 |
| L63 | 0.040 | 0.79 | 0.05 | 1.436348e-07 | 1500 | 0.19 | linear | 0.98 | 0.100 |
| L9610d | 0.012 | 0.54 | 0.91 | 7.059347e-07 | 1500 | 1.82 | linear | 0.98 | 0.005 |
| L9610d | 0.020 | 0.51 | 0.87 | 4.387346e-08 | 1500 | 1.74 | linear | 0.98 | 0.010 |
| L9610d | 0.025 | 0.89 | 0.10 | 1.180616e-08 | 1500 | 2.37 | linear | 0.98 | 0.050 |
| L9610d | 0.003 | 0.61 | 0.75 | 1.237630e-02 | 1500 | 0.38 | linear | 0.98 | 0.100 |
| L96-5D | 0.014 | 0.95 | 1.64 | 1.604735e-07 | 1500 | 1.26 | linear | 0.98 | 0.005 |
| L96-5D | 0.066 | 0.90 | 1.31 | 1.672450e-09 | 1500 | 2.23 | linear | 0.98 | 0.010 |
| L96-5D | 0.025 | 0.67 | 0.07 | 1.654891e-10 | 1500 | 1.28 | linear | 0.98 | 0.050 |
| L96-5D | 0.100 | 0.69 | 0.03 | 1.903574e-08 | 1500 | 0.12 | linear | 0.98 | 0.100 |
| colpitts | 0.059 | 0.41 | 1.84 | 2.170770e-04 | 1500 | 1.69 | linear | 0.98 | 0.005 |
| colpitts | 0.100 | 0.83 | 2.00 | 5.228608e-05 | 1500 | 4.00 | linear | 0.98 | 0.010 |
| colpitts | 0.043 | 0.62 | 0.30 | 6.942212e-09 | 1500 | 0.15 | linear | 0.98 | 0.050 |
| colpitts | 0.100 | 0.98 | 1.95 | 1.000000e+00 | 1500 | 1.88 | linear | 0.98 | 0.100 |
| rossler | 0.050 | 0.66 | 0.23 | 8.252811e-09 | 1500 | 0.58 | linear | 0.98 | 0.005 |
| rossler | 0.030 | 1.00 | 1.52 | 2.060958e-08 | 1500 | 0.95 | linear | 0.98 | 0.010 |
| rossler | 0.035 | 0.43 | 2.00 | 2.999644e-10 | 1500 | 4.00 | linear | 0.98 | 0.050 |
| rossler | 0.081 | 0.60 | 1.48 | 1.025288e-10 | 1500 | 2.64 | linear | 0.98 | 0.100 |
| readout | |||||||
|---|---|---|---|---|---|---|---|
| 0.001 | 0.71 | 0.93 | 9.988696e-01 | 1200 | 0.01 | linear | 0.98 |
| 0.002 | 0.32 | 0.78 | 5.411962e-02 | 2400 | 1.50 | linear | 0.98 |
| 0.002 | 0.21 | 0.80 | 9.887132e-01 | 3600 | 1.29 | linear | 0.98 |
| 0.001 | 0.90 | 1.50 | 1.000000e+00 | 4800 | 2.00 | linear | 0.98 |
| 0.001 | 1.00 | 0.07 | 1.758120e-07 | 6000 | 0.63 | linear | 0.98 |
| readout | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| 2 | 0 | 0.001 | 1.00 | 1.50 | 3.655278e-01 | 2000 | 1.11 | linear | 0.98 |
| 2 | 2 | 0.027 | 0.67 | 1.18 | 1.221827e-08 | 2000 | 1.54 | linear | 0.98 |
| 2 | 4 | 0.017 | 1.00 | 0.16 | 3.432201e-07 | 2000 | 0.75 | linear | 0.98 |
| 2 | 6 | 0.005 | 0.94 | 0.46 | 6.443480e-07 | 2000 | 0.58 | linear | 0.98 |
| 2 | 8 | 0.006 | 0.74 | 0.71 | 1.801521e-07 | 2000 | 1.23 | linear | 0.98 |
| 4 | 0 | 0.004 | 0.45 | 0.39 | 2.475150e-01 | 2000 | 0.29 | linear | 0.98 |
| 4 | 2 | 0.021 | 0.77 | 1.03 | 1.372422e-08 | 2000 | 1.27 | linear | 0.98 |
| 4 | 4 | 0.003 | 0.99 | 0.64 | 4.054118e-07 | 2000 | 1.17 | linear | 0.98 |
| 4 | 6 | 0.003 | 0.99 | 0.64 | 4.054118e-07 | 2000 | 1.17 | linear | 0.98 |
| 4 | 8 | 0.003 | 0.99 | 0.64 | 4.054118e-07 | 2000 | 1.17 | linear | 0.98 |
| 8 | 0 | 0.001 | 0.44 | 0.90 | 1.000000e+00 | 2000 | 1.74 | linear | 0.98 |
| 8 | 2 | 0.003 | 0.99 | 0.64 | 4.054118e-07 | 2000 | 1.17 | linear | 0.98 |
| 8 | 4 | 0.001 | 0.74 | 0.17 | 1.000000e-08 | 2000 | 0.72 | linear | 0.98 |
| 8 | 6 | 0.003 | 0.99 | 0.64 | 4.054118e-07 | 2000 | 1.17 | linear | 0.98 |
| 8 | 8 | 0.003 | 0.99 | 0.64 | 4.054118e-07 | 2000 | 1.17 | linear | 0.98 |
| readout | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| 4 | 0 | 0.004 | 0.45 | 0.39 | 2.475150e-01 | 2000 | 0.29 | linear | 0.98 |
| 4 | 2 | 0.021 | 0.77 | 1.03 | 1.372422e-08 | 2000 | 1.27 | linear | 0.98 |
| 4 | 4 | 0.003 | 0.99 | 0.64 | 4.054118e-07 | 2000 | 1.17 | linear | 0.98 |
| 4 | 6 | 0.003 | 0.99 | 0.64 | 4.054118e-07 | 2000 | 1.17 | linear | 0.98 |
| 4 | 8 | 0.003 | 0.99 | 0.64 | 4.054118e-07 | 2000 | 1.17 | linear | 0.98 |
| 4 | 0 | 0.004 | 0.45 | 0.39 | 2.475150e-01 | 1200 | 0.29 | linear | 0.98 |
| 4 | 2 | 0.005 | 1.00 | 1.50 | 1.000000e-08 | 2400 | 2.00 | linear | 0.98 |
| 4 | 4 | 0.005 | 0.36 | 0.48 | 1.000000e-08 | 3600 | 0.93 | linear | 0.98 |
| 4 | 6 | 0.003 | 0.99 | 0.64 | 4.054118e-07 | 4800 | 1.17 | linear | 0.98 |
| 4 | 8 | 0.003 | 0.99 | 0.64 | 4.054118e-07 | 6000 | 1.17 | linear | 0.98 |