-3pt plus 3pt minus 2pt
A Unified Framework for Fair Spectral Clustering With Effective Graph Learning
Abstract
We consider the problem of spectral clustering under group fairness constraints, where samples from each sensitive group are approximately proportionally represented in each cluster. Traditional fair spectral clustering (FSC) methods consist of two consecutive stages, i.e., performing fair spectral embedding on a given graph and conducting means to obtain discrete cluster labels. However, in practice, the graph is usually unknown, and we need to construct the underlying graph from potentially noisy data, the quality of which inevitably affects subsequent fair clustering performance. Furthermore, performing FSC through separate steps breaks the connections among these steps, leading to suboptimal results. To this end, we first theoretically analyze the effect of the constructed graph on FSC. Motivated by the analysis, we propose a novel graph construction method with a node-adaptive graph filter to learn graphs from noisy data. Then, all independent stages of conventional FSC are integrated into a single objective function, forming an end-to-end framework that inputs raw data and outputs discrete cluster labels. An algorithm is developed to jointly and alternately update the variables in each stage. Finally, we conduct extensive experiments on synthetic, benchmark, and real data, which show that our model is superior to state-of-the-art fair clustering methods.
Index Terms:
Spectral clustering, graph learning, joint optimization, fairness constraints, spectral embedding.I Introduction
Clustering is an unsupervised task that aims to group samples with common attributes and separate dissimilar samples. It has numerous practical applications, e.g., image processing [1], remote sensing [2], and bioinformatics [3]. Existing clustering methods include means [4], spectral clustering (SC) [5], hierarchical clustering [6]. Among these methods, SC is a graph-based method utilizing the topological information of data and usually obtains better performance when handling complex high-dimensional datasets [5].
Recently, many concerns have arisen regarding fairness when performing clustering algorithms. For example, in loan applications, applicants are grouped into several clusters to support cluster-specific loan policies. However, clustering results could be affected by sensitive factors such as race and gender [7], even if the clustering algorithms do not consider sensitive attributes. Unfair clustering can lead to discriminatory outcomes, such as a specific group being more likely to be denied a loan. Therefore, there is a growing need for fair clustering methods unbiased by sensitive attributes. In the literature, [8] first introduces the notion of group fairness into clustering. As illustrated in Fig.1, given data with sensitive attributes, fair clustering aims to partition the data into clusters, where samples in every sensitive group are approximately proportionally represented in each cluster [8]. In this way, every sensitive group is treated fairly. Following [8], [9] generalizes the definition of fair clustering, [10] proposes a scalable fair clustering algorithm, and [11] applies the variational method to fair clustering. Furthermore, fairness constraints are also incorporated into deep clustering methods that leverage deep neural networks to partition data [12, 13].

Here, we consider the problem of fair spectral clustering (FSC). The first work discussing FSC is [14], which designs a fairness constraint for SC according to the definition of group fairness in [8]. A scalable algorithm is proposed in [15] to solve the model in [14], and [16] considers group fairness of normalized-cut graph partitioning. In [17], individual fairness is considered in SC, which utilizes a representation graph to encode sensitive attributes and requires the neighbors of a node in the graph to be approximately proportionally represented in the clusters. Recently, [18] proposes a fair multi-view SC method. However, existing FSC models are built on a given similarity graph, which may not be available in practice. Thus, before proceeding with FSC algorithms, it is necessary to construct a graph from raw data. That is, a complete FSC method typically consists of three subtasks. First, a similarity graph is constructed from raw data. Second, spectral embedding under fairness constraints is performed on the graph to obtain a continuous cluster indicator matrix. Third, conducting means on the continuous matrix to obtain discrete cluster labels.
Although feasible, the traditional FSC paradigm still has the following problems to be addressed. (i) The quality of the constructed graph inevitably affects subsequent fair clustering performance, but this has not been explored theoretically. Additionally, noisy observations make it more difficult to construct accurate graphs. (ii) The post-processing discretization means is sensitive to the initial cluster centers and could cause far deviation from the true discrete results [19]. (iii) Performing the subtasks separately breaks the connections among graph construction, fair spectral embedding, and discretization, leading to suboptimal fair clustering results. For example, independent graph construction may fail to find the optimal graph for fair clustering [20]. Furthermore, independent spectral embedding is inferior to joint optimization of graph construction and spectral embedding [21].
To address the above issues, we propose a unified FSC model based on group fairness, which is an end-to-end framework that inputs observed data and outputs discrete cluster labels. Specifically, we first theoretically analyze how the estimated graphs affect FSC, demonstrating that accurate graphs are crucial to improve fair clustering performance. Motivated by the analysis, we propose a novel graph construction method to learn graphs from observed data under the smoothness assumption. Our approach incorporates a node-adaptive graph filter to denoise and produce smooth signals from potentially noisy data. Second, we introduce the group fairness constraint into traditional spectral embedding to guarantee fair clustering results. Third, we utilize spectral rotation instead of means as the discretization operation since it can produce discrete results with smaller discrepancies from the true labels. Finally, all subtasks are integrated into a single objective function to avoid the sub-optimality caused by separate optimization.
In summary, the contributions of this study are as follows.
-
We theoretically analyze the impact of the estimated graph on fair clustering errors, justifying the necessity of an accurate graph to improve FSC performance. Motivated by the analysis, we propose a graph construction method to learn accurate graphs as inputs to FSC.
-
We propose a unified FSC model integrating graph construction, fair spectral embedding, and discretization into a single objective function. Our model is an end-to-end framework that inputs observed data and outputs discrete fair clustering results and a similarity graph.
-
We develop an algorithm to solve the objective function of our model. Compared with separate optimization, our algorithm updates all variables jointly and alternately, leading to an overall optimal solution for all subtasks.
-
We conduct extensive experiments on synthetic, benchmark, and real data to test the proposed FSC model. Experimental results demonstrate that our model outperforms state-of-the-art fair clustering models.
Organization: The rest of this paper is organized as follows. Section II presents some related works. Background information is introduced in Section III. We propose our unified FSC framework in Section IV. Then, the proposed algorithm is provided in Section V. We conduct experiments to test the proposed FSC method in Section VI. Finally, concluding remarks are presented in Section VII.
Notations: Throughout this paper, vectors, matrices, and sets are written in bold lowercase, bold uppercase letters, and calligraphic uppercase letters, respectively. Given a matrix , , and denote the -th row, the -th column, and the entry of , respectively. means all elements of are non-negative. Furthermore, and mean converting the diagonal elements of to a vector and setting the diagonal entries of to zeros. The vectors , , and matrix represent all-one vectors, all-zero vectors, and identity matrices, respectively. Moreover, , , and are the Frobenius norm, element-wise norm, and norm of a vector (matrix), respectively. The notations , , and are pseudo inverse, Hadamard product, and trace operator, respectively. Given a set , is the number of elements in . Finally, and are the domain of real values and symmetric matrices whose dimensions depend on the context.
II Related Work
II-A Graph Learning Methods For (Fair) SC
Graph learning (GL) aims to infer the graph topology behind observed data, a prerequisite step for (fair) SC when similarity graphs are unavailable. Traditionally, graphs are constructed via some direct rules, such as -nearest-neighborhood (-NN), -nearest-neighborhood (-NN) [22], and sample correlation methods like Pearson correlation (PC). These methods may be limited in capturing similarity relationships between data pairs [23]. Thus, many works attempt to learn graphs from data adaptively, including the sparse representation (SR) method [24] and the low-rank representation method [25]. The emergence of adaptive neighbourhood graph learning (ANGL) [26] provides a new way that uses the probability of two samples being adjacent to measure the similarity between them. In [27], a possibilistic neighbourhood graph is proposed, an improved version of [26]. Recently, with the rise of graph signal processing (GSP) [28], many works attempt to learn graphs from the perspective of signal processing. One of the widely-used GSP-based GL methods postulates that signals are smooth over the corresponding graphs [29]. Intuitively, a smooth graph signal means the signal values of two connected nodes are similar[30], which is also a fundamental principle of SC [5]. Many methods are dedicated to learning graphs from smooth signals [31]. However, limited to our understanding, applying smoothness-based GL to SC has yet to be thoroughly explored, let alone FSC.
II-B Unified SC Models
Many works focus on establishing a unified model for SC, which can be roughly divided into three categories. The first one integrates graph construction and spectral embedding [21, 32, 26]. They use an independent discretization step as post-processing. The second one is based on a given similarity graph. They integrate spectral embedding and discretization [33, 34, 35]. The third category integrates all three stages into a single objective function [20, 23, 36, 37, 38]. Our model differs from these models in two main ways. (i) Our framework utilizes a new graph construction method. (ii) We further consider fairness issues in clustering tasks.
III Background
This section presents background information, including SC under group fairness constraints and spectral rotation.
III-A SC Under Group Fairness Constraints
Given an undirected graph of vertices, where and are the sets of vertices and edges of , respectively, its adjacency matrix is a symmetric matrix with zero diagonal entries and non-negative off-diagonal elements if the graph has non-negative edge weights and no self-loops. The Laplacian matrix of is defined as , where is a diagonal matrix satisfying . Unnormalized SC aims to partition nodes into disjoint clusters , where , and is the set containing nodes in the –th cluster. The problem of unnormalized SC is equivalent to minimizing the objective function [5], i.e.,
| (1) |
where contains all nodes in except those in , and
| (2) |
Let be
| (3) |
Then, minimizing the objective function (1) is equivalent to solving the following problem [5]
| (4) |
Due to the discrete constraint of (3), problem (4) is NP-hard. In practice, problem (4) is usually relaxed to
| (5) |
where is a relaxed continuous clustering label matrix, and is adopted to avoid trivial solutions. The process of solving (5) is called spectral embedding. After obtaining , a common practice is to apply means to the rows of to yield final discrete clustering labels , where is a binary cluster indicator matrix. The only non-zero element of the -th row of indicates the cluster membership of the -th node of .
Fair spectral clustering groups the vertices of by considering fairness. If the nodes of belong to sensitive groups , where contains the nodes of the -th sensitive group, we define the of cluster as [8]
| (6) |
where . The higher the of each cluster, the fairer the clustering [8]. It is not difficult to check that . Thus, this notion of fairness is asking for a clustering where the fraction of different sensitive groups in each cluster is approximately the same as that of the entire dataset [14], which is also called group fairness. To incorporate this fairness notion into SC, a group-membership vector of is defined, where if and otherwise, for and . Then, we have the following lemma.
Lemma 1.
Lemma 1 states that the proportional representation of all sensitive attribute samples in each cluster can be interpreted as a linear constraint . Under this fairness constraint, unnormalized SC is equivalent to the following problem
| (8) |
Similarly, we can relax (8) to
| (9) |
Following traditional SC, existing FSC models perform means on rows of to obtain discrete cluster labels .
III-B Spectral Rotation
Spectral rotation [19] is an alternative to means for obtaining discrete clustering results from continuous labels , which is formulated as
| (10) |
where the set contains all discrete cluster indicator matrices, and is an orthonormal matrix. According to the spectral solution invariance property [19], if is a solution of (5), is another solution. A suitable could facilitate as close to as possible. In contrast, means is performed directly on obtained from spectral embedding, which may far deviate from the real discrete results. Thus, spectral rotation usually achieves superior performance than means [19].
IV Model Formulation
In this section, we first theoretically analyze the impact of the constructed graph on FSC, which justifies an accurate graph for improving FSC performance. Then, we propose a novel graph construction method to learn graphs from potentially noisy observed data. Next, we integrate graph construction, fair spectral embedding, and discretization into an end-to-end framework. Finally, we analyze the connections between our model and existing works.
IV-A Why We Need An Accurate Graph?
We first introduce a variant of the stochastic block model [39] (vSBM) to generate random graphs with cluster structures and sensitive attributes [14]. This model assumes that there are two or more meaningful ground-truth clusterings of the observed data, and only one of them is fair. Assume that comprises sensitive groups and is partitioned into clusters such that , for with . Based on the clusters and sensitive groups, we construct a random graph by connecting two vertices and with a probability that depends on the clusters and sensitive groups of and . We define
| (11) |
where and are two functions that assign a node to one of the clusters and sensitive groups, respectively. Let be the real graph Laplacian matrix generated by the vSBM method and be the Laplacian matrix estimated by any graph construction method. The matrix is used as the input to fair spectral embedding in (9), and spectral rotation is utilized to obtain discrete cluster labels. Our goal is to derive a fair clustering error bound related to the estimation error between and . Let us make some assumptions.
Assumption 1.
Let be a continuous cluster indicator matrix estimated from via (9). For a given constant , the and estimated by spectral rotation satisfies
| (12) |
Assumption 2.
The ground-truth clustering and sensitive partitions of satisfy
| (13) |
Assumption 1 is similar to the approximation of means [40], which provides the estimation accuracy of spectral rotation. Assumption 2 is the same as that in Theorem 1 of [14], which is only made to facilitate theoretical analysis. In practice, Assumption 2 may be violated, which, however, does not affect the effectiveness of FSC algorithms [14]. Based on the two assumptions, we have the following proposition.
Proposition 1.
Let be the real Laplacian matrix of the random graph generated by the vSBM method with satisfying for some , and be the estimated Laplacian matrix from observed data. Assume that we run fair spectral embedding (9) on and perform spectral rotation (10) to obtain discrete cluster labels. Besides, let be the assigned cluster label (after proper permutation) of node , and define as the set of misclassified vertices of cluster . Under Assumptions 1-2, for every , there exist constants and such that if
| (14) |
then with probability at least , the number of misclassified vertices, , is at most
| (15) |
where is a matrix whose columns form the orthonormal basis of the nullspace of .
Proof.
According to [14], the meaning of “the number of misclassified vertices is at most ” is that there exists a permutation of cluster indices such that the clustering results up to this permutation successfully predict all cluster labels but many vertices. Note that the error bound consists of two parts. The first one is caused by the difference between the expected and real graph produced by the vSBM method, which is similar to [14]. The second part is related to the estimation error of graph construction methods. The fair constraint affects clustering performance via , which is a matrix determined by sensitive group-membership matrix . For convenience, is dubbed fair graph. Generally, the error bound in (15) depends on , and . If we divide (15) by , we obtain the bound for the misclassification rate. The first part of the misclassification rate bound tends to zero as goes to infinity, meaning that if is exactly estimated (the second part equals to zero), performing FSC via (9) and spectral rotation is weakly consistent [14]. However, usually cannot be estimated exactly, causing an additional error for subsequent fair clustering results. If the fair graph estimation error does not increase quadratically as , the second part of the misclassification rate bound will also decay to zero. Proposition 1 illustrates that a well-estimated graph , which is close to , brings a small misclassification error bound. Thus, it motivates us to seek a more effective method to construct accurate graphs from observed data.
IV-B The Proposed Graph Construction Method
Given observed data , we need to infer the underlying similarity graph topology as the input to FSC algorithms. However, contaminated data may lead to poor graph estimation performance, as indicated in Proposition 1, which degrades subsequent fair clustering performance. Therefore, we propose a method to learn graphs from potentially noisy data , which is formulated as
| (16) |
where contains all Laplacian matrices. Moreover, and are parameters, and is a vector of adaptive weights. We let , where . Eq.(16) is a joint model of denoising and smoothness-based GL [30].
1) Denoising: If is fixed, the problem (16) becomes
| (17) |
The model is a node-adaptive graph filter, and represents node weights. Specifically, given node weights , we have
| (18) |
Taking the derivative of (18) and setting it to zero, we obtain
| (19) |
We let , which is positive definite and has eigen-decomposition with eigenvalues matrix and eigenvectors matrix . Moreover, , where are the eigenvalues of . From the perspective of graph spectral filtering (GFT) [28], can be interpreted as that the observed graph signals (columns of ) are first transformed to the graph frequency domain via , attenuated GFT coefficients according to , and transformed back to the nodal domain via . It is observed from that the graph filter is low-pass since the attenuation is stronger for larger eigenvalues. Thus, the graph filter can suppress the high-frequency component of raw data , alleviating the noises on the graph to output the “noiseless” signal .
Our graph filter differs from the Auto-Regressive graph filter [41] in that we assign each node an individual weight . The reason for using is that the measurement noise of different nodes may be heterogeneous. If the -th node signal (the -th row of ) has a small noise scale, a large should be assigned to the fidelity term of node in (17) to ensure is are close to the corresponding observation [42]. When we cannot know the noise scale a priori, we can adaptively learn from the data. Specifically, given , the problem (17) becomes
| (20) |
Intuitively, solving (20) will assign a large to node if is close to , as expected.
2) Graph learning: If we have obtained the “noiseless” signals via the graph filter , the problem (16) becomes
| (21) |
The first Laplacian quadratic term of (21) is equivalent to
| (22) |
which measures the average smoothness of data over the graph [30]. The second term of (21) contains regularizers that endow the learned graphs with desired properties. The -degree term is to control node degree, and the Frobenius norm term is to control graph sparsity. Our model (21) can learn a graph suitable for graph-based clustering tasks for the following reasons. (i) It is observed from (22) that minimizing the smoothness is to seek a graph whose similar vertices (node signals) are closely connected, which is consistent with the fundamental principle of SC. (ii) The -degree term can avoid isolated nodes, which is crucial for SC, especially for normalized SC [5]. (iii) The Frobenius norm term can lead to a sparse graph, which may remove redundant and noisy edges.
The model (21) is similar to the ANGL method [26] since both construct graphs by minimizing the smoothness. The main differences lie in three aspects. (i) Our model removes the sum-to-one constraint in the ANGL method—the degree of each node is forced to be one—since the constraint makes the output graphs sensitive to noisy points [27]. Removing this constraint allows our model to capture more complex similarity relationships. (ii) We add a -degree term to ensure the learned graph has no isolated nodes. (iii) The input data of (21) are those produced by a low-pass graph filter.
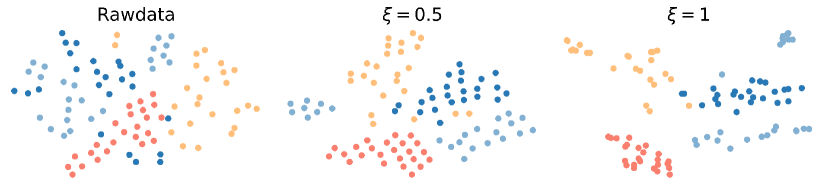
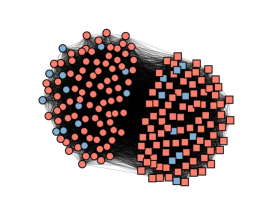
3) Discussion: We try to explain why our method is effective in constructing graphs from observed data. If data have a clustering structure, they should follow the assumption of cluster and manifold, i.e., the data in the same cluster are close to each other. According to [43], smooth signals containing low-frequency parts tend to follow the cluster and manifold assumption. Thus, if accurately represents the graph behind observed data, the denoising part of our model has two functions. First, it filters out the high-frequency components of the observed graph signals that correspond to noises. Second, it produces smooth signals that have a clearer clustering structure, which could facilitate subsequent clustering. To better illustrate the effectiveness of the node-adaptive filter, Fig.2 depicts the t-SNE [44] results of our methods on the MNIST dataset, where four clusters correspond to four randomly selected digits. We can see that raw data are entangled together. In contrast, the denoised data by the graph filter are clearly separated, meaning that the denoising part of our model can produce cluster-friendly signals. From the perspective of GL, our model (21) learns a graph minimizing the smoothness of data, i.e., the nodes corresponding to similar signals are closely connected. Thus, the learned graph can effectively capture similarity relationships between data and preserve clustering structures. Consequently, the denoising operation and the smoothness-based GL can enhance each other collaboratively to bring a high-quality graph for subsequent fair clustering tasks.

IV-C The Unified FSC Model
In this subsection, we build an end-to-end FSC framework that inputs observed data and node attributes and directly outputs discrete cluster labels. As shown in Fig.3, our model consists of four modules, i.e., denoising, graph learning, fair spectral embedding, and discretization. First, we construct graphs from the observed data by the proposed method (16). Once we obtain , the Laplacian matrix together with can be directly used to perform fair spectral embedding (9) to obtain continuous clustering label matrix . Finally, we leverage spectral rotation (10) instead of means to obtain discrete cluster labels. In addition to the reason for superior performance as stated in Section III-B, we utilize spectral rotation since it can be flexibly integrated into an end-to-end framework. Integrating all the above subtasks into a single objective function, we obtain
| (23) |
where and are two parameters. All modules are not simply put together, but are bridged by two Laplacian quadratic terms, i.e., and . First, can be viewed as the graph Tikhonov regularizer of the denoising task (18) to output smooth signals [41]. On the other hand, it measures smoothness in the GL task to capture the similarity relationships between data. Second, together with performs fair spectral embedding as input to the discretization. It is also used to impose structural constraints on the constructed graph, which is discussed in the next subsection. The four modules are coupled with each other to achieve the overall optimal results for all subtasks.
To better understand how the fairness constraint works, we introduce a new variable matrix and let , where is the matrix defined in Proposition 1. The matrix encodes sensitive information, as does . Then, problem (23) can be rephrased in term of as
| (24) |
In (24), the fairness constraint is removed. We conduct spectral embedding on the fair graph , which encodes graph topology and sensitive information simultaneously, instead of to ensure fair clustering. The impact of fairness constraints is discussed in the next subsection.
The basic formulation (23) is flexible and has many possible extensions. Here are some examples. (i) We can replace spectral rotation with improved spectral rotation [45] to further improve discretization performance. (ii) We can introduce self-weighted features into (23) to determine the importance of different features in assigning cluster labels [46]. (iii) We can extend (23) from unnormalized SC (5) to normalized SC [47]. (iv) We can also incorporate individual fairness [17] into our unified model. We place the details of these extensions in the supplementary material for completeness.
Remark 1.
The above extensions may improve fair clustering performance. However, we focus on the basic formulation (23) since our primary goal is to demonstrate the advantages of the proposed graph construction method and the unified framework rather than to propose a complex FSC model.
IV-D Connections to Existing Works
1) Connections to community-based GL models: If we only focus on GL and fair spectral embedding, Eq.(24) becomes
| (25) |
where is regarded as the “noiseless” data here. According to Ky Fan’s theorem [48], we have , where is the smallest eigenvalue of . Thus, the problem (25) can be rephrased as
| (26) |
Note that is a semi-positive definite matrix, i.e., . Minimizing (26) is equivalent to forcing if is large enough. That is, (26) encourages the fair graph to have connected components. Therefore, (26) can be viewed as the community-based GL model, which has been widely studied. For example, [49] lets the first smallest eigenvalues of Laplacian matrices be zero to obtain the community structures, which can be relaxed to the last term in (26). The works [50, 26] force the rank of Laplacian matrices to , which can also be interpreted as minimizing the sum of the first eigenvalues. Furthermore, [51] adds a term to impose community constraints, where contains the value 1 for within-community edges only and 0 everywhere else. Although closely related, (25) differs from existing community-based GL models in two key aspects. First, the basic GL models are different. Our model is based on the smoothness-based GL, while [49, 51] are based on statistical GL models like Graphical Lasso. Besides, [50, 26] are based on the ANGL method. Second, our model imposes the community constraint on the fair graph instead of on like existing works. Thus, the fairness constraint may affect the topology of the learned graph to obtain fair clustering. We will test the impact of the fairness constraint in the experimental section.
2) Connections to unified SC models: If we remove the denoising module and fairness constraint, our model becomes
| (27) |
Again, is treated as the observed data. The model (27) is an end-to-end SC model. Here, we discuss the connections between our model and those unified SC models integrating graph construction, spectral embedding, and discretization. As stated in Remark 1, we focus on basic formulations without additional extensions. The first model we compare is [20]
| (28) |
where , and are constant parameters. Moreover, is the set containing all adjacency matrices. This is a unified SC model that leverages the sparse representation method [24] to construct graphs, which is different from our GL method.
Another unified SC model [23, 36] is concluded as
| (29) |
where , and are constant parameters. The graph construction method in (29) is the ANGL method [26]. We have discussed the difference between our graph construction method and the ANGL in the previous subsection.
In summary, our model (27) differs from the existing unified SC models (28)-(29) mainly in the graph construction method. As Proposition 1 states, an accurate GL method can boost fair clustering performance. In the experimental section, we develop fair versions of (28)-(29) and compare them with our model (23) to illustrate the superiority of our model.
V Model Optimization
In this section, we first propose an algorithm for solving (23), followed by convergence and complexity analyses.
V-A Optimization Algorithm
Our algorithm alternately updates , , , and in (23), i.e., updating one with the others fixed. For clarity, we omit the iteration index here. The following derivations are the updates in one iteration.
1) Update : The sub-problem of updating is
| (30) |
The problem can be rewritten in terms of
| (31) |
where
| (32) |
and . By the definition of , the free variables of are the upper triangle elements. Thus, we define a vector , satisfying that , where is a function that converts the upper triangular elements of a matrix into a vector. Then, the problem (31) is equivalent to
| (33) |
where ), is a linear operator satisfying [30]. The problem (33) is convex, and we employ the algorithm in [52] to solve the problem. The complete algorithm flow is presented in the supplementary materials. After obtaining the estimated , we let , where is the inverse operation. The operation converts into an adjacency matrix, where corresponds to the upper triangle elements of . Finally, we calculate the Laplacian matrix from and feed it into subsequent updates of other variables.
2) Update : The sub-problem of updating is
| (34) |
Like (24), (34) can be cast into a problem of variable
| (35) |
This is a typical quadratic optimization problem with orthogonal constraints. Let be the objective function of (35). We have that is differential, and . Thus, the problem can be efficiently solved via the algorithm in [53]. After obtaining , we let .
3) Update : The sub-problem of updating is
| (36) |
It is the orthogonal Procrustes problem with a closed-form solution [54]. Assuming that and are the left and right matrices of SVD of , the solution to (36) is [54]
| (37) |
5) Update : The sub-problem of updating is (17), which has a closed solution (19). However, matrix inversion is computationally expensive with complexity . Fortunately, is symmetric, sparse, and positive definite. We can hence solve (17) efficiently using conjugate gradient (CG) algorithm without matrix inverse [55].
6) Update : The sub-problem of updating is (20). Taking the derivative of (20) and setting it to zero, we have
| (40) |
It is observed that the updates of , , , , , and are coupled with each other. Updating one variable depends on the other variables, leading to an overall optimal solution. The complete procedure is presented in Algorithm 1.
V-B Convergence and Complexity Analysis
1) Convergence analysis: It is challenging to obtain a globally optimal solution to (23) since it is not jointly convex for all variables. However, our algorithm for solving each sub-problem can reach its optimal solution. Specifically, when we update , the problem (32) is convex, and the corresponding algorithm is guaranteed to converge to the global optimum [52]. When updating , we use the algorithm in [53] to solve the problem (35), which can converge to the global optimum [53]. The updates of , and have closed-form solutions. Despite updating via (18) has a closed solution, we update using CG, which is guaranteed to converge [55]. In summary, the update of each variable converges in our algorithm. In reality, the whole algorithm converges well, which is verified experimentally in Section VI.
2) Complexity analysis: In one iteration, our algorithm consists of six parts, which we analyze one by one below. As stated in [52], the update of requires costs, where is the average number of iterations of updating . The computational cost can be further reduced if the average number of neighbors per node is fixed; see [56] and analysis therein. The computational complexity of our algorithm for updating is according to [53], where is the average number of iterations of the algorithm in [53]. When updating , we perform SVD on , which costs . The updates of and require and , respectively. Finally, the complexity of using CG to update is , where is the average number of iterations of the CG algorithm.
VI Experiments
In this section, we test our proposed model using synthetic, benchmark, and real-world data. First, some experimental setups are introduced.
VI-A Experimental Setups
1) Graph generation: For synthetic data, we leverage the vSBM method to generate random graphs with sensitive attributes. Specifically, we let , and . After obtaining connections among nodes, we assign each edge a random weight between . Finally, we normalize the edge weights to satisfy .
2) Signal generation: We generate observed signals from the following Gaussian distribution [29]
| (41) |
where and is the noise scale of the -th node. As stated in [29], signals generated in this way are smooth over the corresponding graph.
3) Evaluation metrics: In topology inference, determining whether two vertices are connected can be regarded as a binary classification problem. Thus, we employ the F1-score () to evaluate classification results
| (42) |
where is true positive rate, is true negative rate, is false positive rate, and is false negative rate. We also use the estimation error () to evaluate the learned graph
| (43) |
For a fair comparison of , we normalize the learned graphs to . For fair clustering, we use the same two metrics as in [14]: clustering error () and Balance ()
| (44) |
where is the estimated cluster label of node (after proper permutation), and is the ground-truth. The metric measures the average balance of all clusters.
4) Baselines: The comparison baselines are list in Table.I. The model Fairlets is the fair version of median [8]. Models 3-5 are the implementations of [14] using different graph construction methods. FGLASSO [57] is the only model that jointly performs graph construction and fair spectral embedding. FSRSC and FJGSED are the fair versions of unified SC models (28) and (29). The formulations and algorithms for the two models are placed in the supplementary material.
| Index | Models | Graph-based | Fair | End-to-End | GL method |
| 1 | means | ✗ | ✗ | — | — |
| 2 | Fairlets | ✗ | ✓ | ✗ | — |
| 3 | CorrFSC | ✓ | ✓ | ✗ | PC |
| 4 | KNNFSC | ✓ | ✓ | ✗ | -NN |
| 5 | NNFSC | ✓ | ✓ | ✗ | -NN |
| 6 | FGLASSO | ✓ | ✓ | ✗ | GLASSO |
| 7 | FJGSED | ✓ | ✓ | ✓ | ANGL |
| 8 | FSRSC | ✓ | ✓ | ✓ | SR |
5) Determination of parameters: For our model, we first grid-search and corresponding to the best in the range for the graph learning task. Then, parameters and are selected as those achieving the best in the range . All parameters of baselines are also selected as those achieving the best values.
| means | — | — | 0.671 | 0.191 | — | — | 0.687 | 0.149 | — | — | 0.635 | 0.161 | — | — | 0.667 | 0.145 |
| Fairlets | — | — | 0.658 | 0.485 | — | — | 0.665 | 0.457 | — | — | 0.611 | 0.355 | — | — | 0.623 | 0.348 |
| CorrFSC | 0.472 | 2.858 | 0.567 | 0.482 | 0.441 | 3.016 | 0.578 | 0.705 | 0.630 | 2.529 | 0.104 | 0.874 | 0.596 | 2.511 | 0.156 | 0.859 |
| KNNFSC | 0.105 | — | 0.687 | 0.829 | 0.103 | — | 0.703 | 0.626 | 0.113 | — | 0.729 | 0.628 | 0.098 | — | 0.682 | 0.731 |
| EpsNNFSC | 0.086 | — | 0.729 | 0.380 | 0.094 | — | 0.739 | 0.333 | 0.091 | — | 0.718 | 0.652 | 0.065 | — | 0.724 | 0.369 |
| FGLASSO | 0.482 | 3.902 | 0.411 | 0.616 | 0.450 | 3.724 | 0.406 | 0.646 | 0.587 | 3.971 | 0.291 | 0.657 | 0.574 | 3.533 | 0.271 | 0.908 |
| FJGSED | 0.271 | 28.159 | 0.724 | 0.359 | 0.263 | 22.626 | 0.734 | 0.240 | 0.325 | 23.576 | 0.604 | 0.579 | 0.293 | 31.552 | 0.734 | 0.247 |
| FSRSC | 0.374 | 5.222 | 0.724 | 0.619 | 0.355 | 9.671 | 0.733 | 0.607 | 0.345 | 5.049 | 0.729 | 0.766 | 0.512 | 10.024 | 0.739 | 0.663 |
| Ours | 0.501 | 2.375 | 0.286 | 0.845 | 0.474 | 2.414 | 0.390 | 0.801 | 0.715 | 1.691 | 0.052 | 0.960 | 0.674 | 2.174 | 0.142 | 0.870 |
-
•
means that higher value is better and means that lower value is better.
-
•
, means that the noise scale of the -th node is from the uniform distribution








VI-B Synthetic Data
1) Model performance: We first compare our model with all baselines in four cases. We let , and . As listed in Table II, our model outperforms means and Fairlets on clustering metrics because it exploits structured information behind raw data. The graphs established by KNNFSC and EpsNNFSC methods are not evaluated by since no edge weights are assigned. Among Models 3-5, CorrFSC achieves the best GL performance () as well as the best clustering performance (). However, the graph construction performance of the three methods is inferior to our model, leading to unsatisfactory fair clustering results. Furthermore, compared with the three methods, our model unifies all seprate stages into a single optimization objective, avoiding suboptimality caused by separate optimization. The reason why our model outperforms FGLASSO could be that FGLASSO separately uses means to obtain final cluster labels. Besides, our method could learn better graphs than FGLASSO. Although FJGSED and FSRSC also perform fair clustering in an end-to-end manner, our model obtains superior fair clustering performance due to more accurate graphs constructed by our method. Finally, our model has a node-adaptive graph filter to denoise observed signals. Thus, our model obtains the best graph construction performance under different levels of noise contamination.
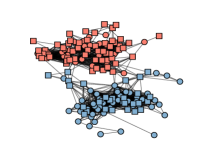
We visualize the learned graphs of different methods in Fig.4. We see that EpsNNFSC fails to capture the clustering structure, resulting in the worst fair clustering performance. The graph of KNNFSC tends to have imbalanced node degrees, and the graph of FSRSC has small edge weights. Compared with CorrFSC, FGLASSO, and FJGSED, the graph of our model has fewer noisy edges and clearer cluster structures.
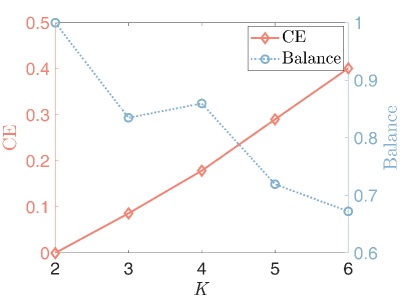
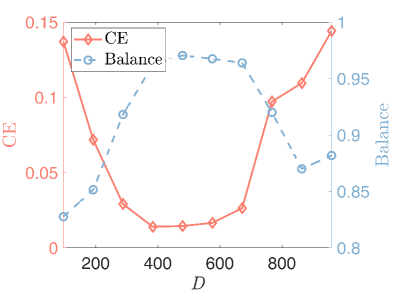
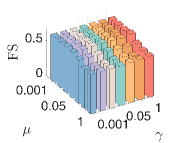
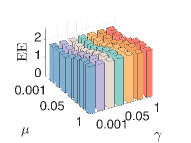
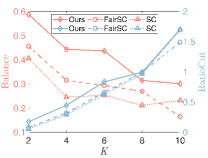
2) The effect of and : We set . In the first case, we fix and vary from 2 to 6. In the second case, we fix and vary from 2 to 6. Fig.5 displays that the fair clustering performance degrades with the increase of ( increases and decreases), which is consistent with Proposition 1. On the other hand, the fair clustering performance is less affected by .
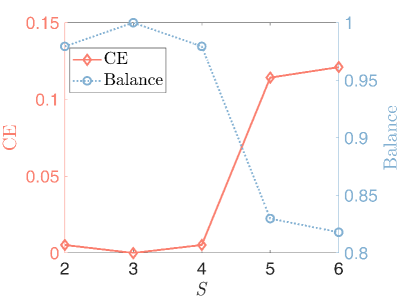
3) The effect of : We let and . As depicted in Fig.6, for a fixed data size, first decreases and then increases as . The reason may be that, as stated in Proposition 1, the misclassification rate of FSC algorithms on the graph generated by the vSBM method decreases as if the underlying graph is exactly estimated. However, the quality of the estimated graph declines for large if is fixed. Thus, the second part of the error bound in Proposition 1 worsens. If the performance improvement brought by increasing is smaller than the degradation caused by the graph estimation error, fair clustering performance decreases when is large.
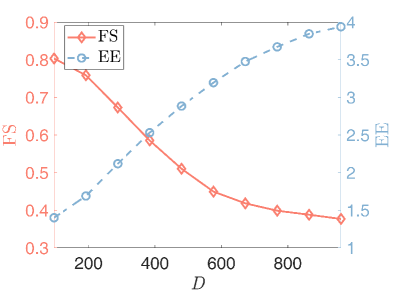
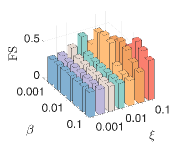
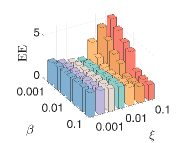
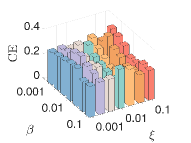
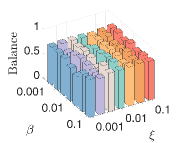
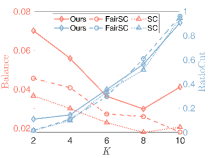
4) The sensitivity of parameters: We let , and . First, we fix and and vary and from to . We then fix and and vary and from to . As shown in Fig.8, our model can achieve consistent GL and fair clustering performance except when is too small and is too large. Moreover, GL performance is more sensitive to than . There exist combinations of and that achieve satisfactory and simultaneously.
5) The effect of the fairness constraint: We consider a special case where the real graph contains two clusters, each consisting of samples from the same sensitive group. In this case, the of real clustering is zero. We then perform clustering using our FSC model and a variant where the fairness constraint is removed. As shown in Fig.7, if we remove the fairness constraint, our model can exactly group all samples. However, some samples are misclassified to improve fairness in our model due to the effect of the fairness constraint. We list the corresponding model performance in Table III. Our model achieves a significantly higher value at the cost of reduced clustering accuracy. Furthermore, the GL performance of our model is also degraded due to the fairness constraint. Thus, if the underlying graph has only one meaningful cluster that is highly unbalanced, fairness constraints may degrade GL and clustering performance.
| w/o fairness | 0.734 | 1.211 | 0 | 0 |
| Ours | 0.719 | 1.353 | 0.484 | 0.867 |


6) Ablation study: Three cases are taken into consideration. (i) We construct graphs using (16), conduct fair spectral embedding, and discretize using spectral rotation separately to test the benefit of a unified model (Ours-Sep). (ii) We construct graphs using (17) and conduct fair spectral embedding jointly. After obtaining continuous results, we exploit means as the discretization step to test the benefit of spectral rotation (Ours-means). (iii) We remove the denoising module in our model to test the benefit of the node-adaptive graph filter (Ours-noDN). We let , and , and the results are listed in Table IV. Our model outperforms Ours-Sep, demonstrating the benefit of a unified model. Although the graph of Ours-means is well estimated, it obtains the worst due to the poor performance of means. Our model outperforms Ours-noDN because it has a low-pass filter to enhance graph construction.
| Ours-Sep | 0.637 | 2.333 | 0.250 | 0.704 |
| Ours-means | 0.635 | 2.320 | 0.549 | 0.353 |
| Ours-noDN | 0.623 | 2.354 | 0.276 | 0.694 |
| Ours | 0.658 | 2.203 | 0.167 | 0.782 |
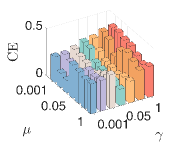
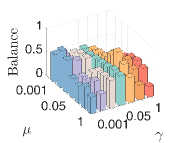
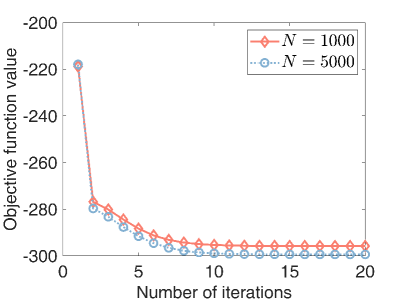
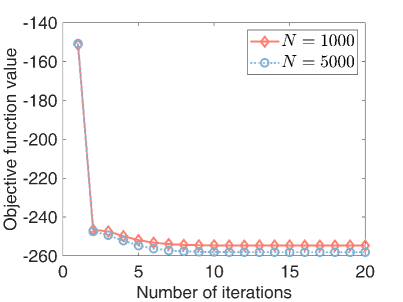

7) Convergence: Finally, we test the convergence of our algorithm. We let . As shown in Fig.9, the objective function values monotonically decrease as the number of iterations. Besides, our algorithm converges within a few iterations, indicating its fast convergence.
VI-C Benchmark Data
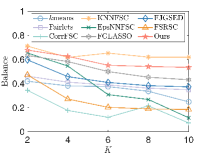
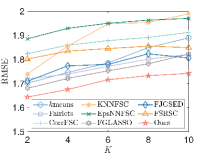
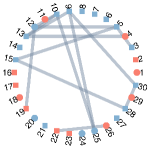
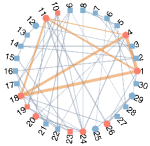
In this section, we test the performance of our model on the commonly used benchmark datasets of FSC [14]. The first dataset is a high school friendship network named FACEBOOKNET111http://www:sociopatterns:org/datasets/high-school-contact-and-friendshipnetworks/. The dataset contains a graph with vertices representing high school students and edges representing connections between students on Facebook. After data preprocessing, we obtain 155 students split into male and female groups. In this dataset, gender is considered a sensitive attribute. All vertices are divided into two groups, i.e., male and female. The second dataset, DRUGNET, is a network encoding acquaintanceship between drug users in Hartford 222 https://sites:google:com/site/ucinetsoftware/datasets/covert-networks/drugnet. After data preprocessing, we obtain 193 vertices. We use ethnicity as a sensitive attribute and split the vertices into three groups: African Americans, Latinos, and others. Note that previous FSC work [14] is based on a given graph, and the two datasets only contain ground-truth graphs and no observed signals. However, one of the primary advantages of our model is that we can group observed data without the real graph structures. Thus, we generate data via (41) based on the ground-truth networks. We then use our model to group vertices via the observed data. For comparison, we apply the FSC algorithm in [14] (FairSC) and unnormalized spectral clustering (SC) to the real networks to cluster vertices. We aim to demonstrate that our model can achieve competitive fair clustering performance even without real graphs. Referring to [14], we use and as evaluation metrics since we have no real labels. We let and . As displayed in 10 (a)-(b), for the two datasets, our model achieves almost the same as FairSC and SC—which are based on the ground-truth networks—even though we do not know the underlying graphs. However, compared with FSC and SC, our model can improve at a moderate sacrifice of . Figures 10 (c)-(d) depict the real FACEBOOKNET graph and the graph learned by our model when . Fewer edges are learned between two clusters, suggesting that our model may tend to learn a graph that is more suitable for clustering. Furthermore, two clusters are observed from our learned graph, meaning our model can fairly partition the nodes from the observed data even if we have no real graphs.
VI-D Real Data
1) MovieLens 100K dataset: We employ MovieLens 100K dataset333http://www.grouplens.org to group movies by their ratings. This dataset contains ratings of 1682 movies by 943 users in the range , which is sparse as many movies have few ratings. To alleviate the impact of sparsity, we select the top 200 most-rated movies from 1682 movies. Therefore, we have a who-rated-what matrix . The matrix can be used to construct a movie-movie similarity graph strongly correlated with how users explicitly rate items [58]. Therefore, we can perform clustering on the similarity graph to group movies with similar attributes. However, as stated in [57], old movies tend to obtain higher ratings because only masterpieces have survived. To obtain fair results unbiased by production time, we consider movie year as a sensitive attribute. Movies made before 1991 are considered old, while others are considered new. To evaluate clustering results, we conduct traditional item-based collaborative filtering (CF) on each cluster, termed cluster CF, to predict user ratings of movies. As claimed in [57], if the obtained clusters accurately contain a set of similar items, cluster CF can better predict user ratings of movies. Therefore, we follow [57] and use root mean square error () between the predicted and true ratings as an evaluation metric in addition to [57, 58]. Figures 11 (a)-(b) depict fair clustering results of different models. Our model obtains the highest except KNNFSC. However, KNNFSC performs poorly on , indicating unsatisfactory clustering results. This may be caused by the fact that the graph constructed by KNNFSC hardly characterizes the similarity relationships between movies. In contrast, our model achieves the best since it better reveals similarity relationships behind observed data. In Fig.11(c)-(d), we provide the learned sub-graphs and clustering results of the top 30 rated movies when . The graph learned by KNNFSC has isolated nodes since they are connected to the movies outside the top 30 rated movies. In our graph, nodes 1, 4, 11, and 18 are closely connected because they belong to the Star Wars series. However, in Fig.11(c), they are not connected. Moreover, our model successfully groups the four nodes into the same cluster.
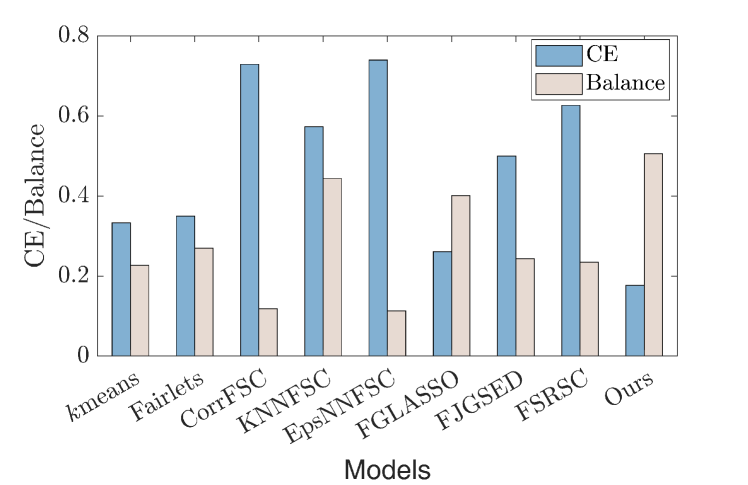
2) MNIST-USPS dataset: The second dataset we employ is MNIST-USPS dataset 444http://yann.lecun.com/exdb/mnist, https://www.kaggle.com/bistaumanga/usps-dataset, which contains two sub-datasets, i.e., MNIST and USPS. The two sub-datasets contain images of handwritten digits from 0 to 9. We cluster these images and use digits as the ground-truth cluster labels. Specifically, we randomly select 48 images from each sub-dataset, which contains four digits and twelve pictures for each digit. We finally obtain 96 images and resize each image to a matrix. We take each image as a node in a graph and flatten the corresponding matrix as the node signals. Therefore, the observed data are . We take the domain source of images—images from MNIST or USPS—as a sensitive attribute. Thus, we have and . We use and as evaluation metrics since we have real labels but no ground-truth graphs. As shown in Fig.12, our model achieves the best fair clustering performance for both and , indicating its superiority. The reason for CorrFSC, KNNFSC, EpsFSC, and FSRSC achieving unsatisfactory may be that the corresponding graphs for this dataset cannot reflect the real topological similarity.
VII Conclusion
In this paper, we theoretically analyzed the impact of similarity graphs on FSC performance. Motivated by the analysis, we proposed a graph construction method for FSC tasks as well as an end-to-end FSC framework. Then, we designed an efficient algorithm to alternately update the variables corresponding to each submodule in our model. Extensive experiments showed that our approach is superior to state-of-the-art (fair) SC models. Future research directions may include developing more scalable FSC algorithms.
Appendix A Proof of Proposition 1
We first provide the following lemma.
Lemma 2.
For any and any two matrices such that with and , let be a approximation of using spectral rotation as Assumption 1, and . Then, for any , define , , and we have
| (45) |
Proof.
First, by the procedure of spectral rotation, we have
| (46) |
Then, based on Assumption 1, we can obtain that
| (47) |
It is not difficult to obtain the following inequalities
| (48) |
The first inequality holds due to the basic inequality, and the second one holds due to (47). Finally, according to the definition of , we can obtain the conclusion (45). ∎
We start our proof of Proposition 1, which is inspired by [14]. To incorporate the fairness constraint into the objective function of (9), we let , where contains the eigenvectors of corresponding to the smallest eigenvalues. Suppose that contains the eigenvectors of corresponding to the smallest eigenvalues, where is the expected Laplacian matrix of the graphs generated by the vSBM method. We apply spectral rotation on estimated from by solving (9). For any satisfying , it is not difficult to obtain
| (49) |
Therefore, we have
| (50) |
The first inequality holds due to [14] and how we generate the ground-truth graph, and the second inequality holds due to norm inequality. On the other hand, we have
| (51) |
As in Lemma 6 of [14], we can choose in such a way that , where if the vertices and are in the same cluster and if the vertices and are not in the same cluster. Futhermore, multiplying by will not change the properties of since is a orthogonal matrix. Finally, according to Lemma 2, if we let , then in Lemma 2 is equivalent to . Furthermore, according to Lemma 5.3 in [40], if , we have
| (52) |
Let , we have
| (53) |
The first term is the difference between the expected Laplacian matrix and the real matrix, which has been derived in [14]. Specifically, for any and some satisfying , with probability at least , we have that there exist a constant such that
| (54) |
The second term of (53) is the error between the Laplacian estimated by our model and the real one. Bringing (54) to (53), we finally complete the proof.
References
- [1] T. Lei, X. Jia, Y. Zhang, S. Liu, H. Meng, and A. K. Nandi, “Superpixel-based fast fuzzy c-means clustering for color image segmentation,” IEEE Trans. Fuzzy Syst., vol. 27, no. 9, pp. 1753–1766, 2018.
- [2] H. Xie, A. Zhao, S. Huang, J. Han, S. Liu, X. Xu, X. Luo, H. Pan, Q. Du, and X. Tong, “Unsupervised hyperspectral remote sensing image clustering based on adaptive density,” IEEE Geosci. Remote S., vol. 15, no. 4, pp. 632–636, 2018.
- [3] V. Y. Kiselev, T. S. Andrews, and M. Hemberg, “Challenges in unsupervised clustering of single-cell rna-seq data,” Nat. Rev. Genet., vol. 20, no. 5, pp. 273–282, 2019.
- [4] A. Likas, N. Vlassis, and J. J. Verbeek, “The global k-means clustering algorithm,” Pattern Recognit., vol. 36, no. 2, pp. 451–461, 2003.
- [5] U. Von Luxburg, “A tutorial on spectral clustering,” Stat. Comput., vol. 17, pp. 395–416, 2007.
- [6] W.-B. Xie, Y.-L. Lee, C. Wang, D.-B. Chen, and T. Zhou, “Hierarchical clustering supported by reciprocal nearest neighbors,” Inf. Sci., vol. 527, pp. 279–292, 2020.
- [7] A. Chouldechova and A. Roth, “The frontiers of fairness in machine learning,” arXiv:1810.08810, 2018.
- [8] F. Chierichetti, R. Kumar, S. Lattanzi, and S. Vassilvitskii, “Fair clustering through fairlets,” Proc. Adv. Neural Inf. Process. Syst., vol. 30, 2017.
- [9] S. Bera, D. Chakrabarty, N. Flores, and M. Negahbani, “Fair algorithms for clustering,” Proc. Adv. Neural Inf. Process. Syst., vol. 32, 2019.
- [10] A. Backurs, P. Indyk, K. Onak, B. Schieber, A. Vakilian, and T. Wagner, “Scalable fair clustering,” in Proc. Int. Conf. Mach. Learn. PMLR, 2019, pp. 405–413.
- [11] I. M. Ziko, J. Yuan, E. Granger, and I. B. Ayed, “Variational fair clustering,” in Proc. Natl. Conf. Artif. Intell., vol. 35, no. 12, 2021, pp. 11 202–11 209.
- [12] P. Zeng, Y. Li, P. Hu, D. Peng, J. Lv, and X. Peng, “Deep fair clustering via maximizing and minimizing mutual information: Theory, algorithm and metric,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2023, pp. 23 986–23 995.
- [13] P. Li, H. Zhao, and H. Liu, “Deep fair clustering for visual learning,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2020, pp. 9070–9079.
- [14] M. Kleindessner, S. Samadi, P. Awasthi, and J. Morgenstern, “Guarantees for spectral clustering with fairness constraints,” in Proc. Int. Conf. Mach. Learn. PMLR, 2019, pp. 3458–3467.
- [15] J. Wang, D. Lu, I. Davidson, and Z. Bai, “Scalable spectral clustering with group fairness constraints,” in Proc. Int. Conf. Artif. Intell. Stat., AISTATS. PMLR, 2023, pp. 6613–6629.
- [16] J. Li, Y. Wang, and A. Merchant, “Spectral normalized-cut graph partitioning with fairness constraints,” arXiv:2307.12065, 2023.
- [17] S. Gupta and A. Dukkipati, “Protecting individual interests across clusters: Spectral clustering with guarantees,” arXiv: 2105.03714, 2021.
- [18] Y. Wang, J. Kang, Y. Xia, J. Luo, and H. Tong, “ifig: Individually fair multi-view graph clustering,” in 2022 IEEE International Conference on Big Data (Big Data). IEEE, 2022, pp. 329–338.
- [19] J. Huang, F. Nie, and H. Huang, “Spectral rotation versus k-means in spectral clustering,” in Proc. Natl. Conf. Artif. Intell., vol. 27, no. 1, 2013, pp. 431–437.
- [20] Z. Kang, C. Peng, Q. Cheng, and Z. Xu, “Unified spectral clustering with optimal graph,” in Proc. Natl. Conf. Artif. Intell., vol. 32, no. 1, 2018.
- [21] Z. Kang, C. Peng, and Q. Cheng, “Twin learning for similarity and clustering: A unified kernel approach,” in Proc. Natl. Conf. Artif. Intell., vol. 31, no. 1, 2017.
- [22] J. Huang, F. Nie, and H. Huang, “A new simplex sparse learning model to measure data similarity for clustering,” in Int. Joint Conf. Artif. Intell., 2015.
- [23] Y. Peng, W. Huang, W. Kong, F. Nie, and B.-L. Lu, “Jgsed: An end-to-end spectral clustering model for joint graph construction, spectral embedding and discretization,” IEEE Trans. Emerg. Topics Comput. Intell., 2023.
- [24] E. Elhamifar and R. Vidal, “Sparse subspace clustering: Algorithm, theory, and applications,” IEEE Trans. Pattern Anal. Mach. Intell, vol. 35, no. 11, pp. 2765–2781, 2013.
- [25] G. Liu, Z. Lin, S. Yan, J. Sun, Y. Yu, and Y. Ma, “Robust recovery of subspace structures by low-rank representation,” IEEE Trans. Pattern Anal. Mach. Intell, vol. 35, no. 1, pp. 171–184, 2012.
- [26] F. Nie, X. Wang, and H. Huang, “Clustering and projected clustering with adaptive neighbors,” in Proc. ACM SIGKDD Int. Conf. Knowl. Discov. Data Min., 2014, pp. 977–986.
- [27] C. Gao, Y. Wang, J. Zhou, W. Ding, L. Shen, and Z. Lai, “Possibilistic neighborhood graph: A new concept of similarity graph learning,” IEEE Trans. Emerg. Topics Comput. Intell., 2022.
- [28] D. I. Shuman, S. K. Narang, P. Frossard, A. Ortega, and P. Vandergheynst, “The emerging field of signal processing on graphs: Extending high-dimensional data analysis to networks and other irregular domains,” IEEE Signal Process. Mag., vol. 30, no. 3, pp. 83–98, 2013.
- [29] X. Dong, D. Thanou, P. Frossard, and P. Vandergheynst, “Learning Laplacian matrix in smooth graph signal representations,” IEEE Trans. Signal Process., vol. 64, no. 23, pp. 6160–6173, 2016.
- [30] V. Kalofolias, “How to learn a graph from smooth signals,” in Proc. Int. Conf. Artif. Intell. Stat., AISTATS. PMLR, 2016, pp. 920–929.
- [31] X. Dong, D. Thanou, M. Rabbat, and P. Frossard, “Learning graphs from data: A signal representation perspective,” IEEE Signal Process. Mag., vol. 36, no. 3, pp. 44–63, 2019.
- [32] F. Nie, D. Wu, R. Wang, and X. Li, “Self-weighted clustering with adaptive neighbors,” IEEE Trans. Neural Netw. Learn. Syst., vol. 31, no. 9, pp. 3428–3441, 2020.
- [33] Y. Pang, J. Xie, F. Nie, and X. Li, “Spectral clustering by joint spectral embedding and spectral rotation,” IEEE Trans. Cybern., vol. 50, no. 1, pp. 247–258, 2018.
- [34] Y. Yang, F. Shen, Z. Huang, and H. T. Shen, “A unified framework for discrete spectral clustering.” in IJCAI, 2016, pp. 2273–2279.
- [35] W. Huang, Y. Peng, Y. Ge, and W. Kong, “A new kmeans clustering model and its generalization achieved by joint spectral embedding and rotation,” PeerJ Comput. Sci., vol. 7, p. e450, 2021.
- [36] Y. Han, L. Zhu, Z. Cheng, J. Li, and X. Liu, “Discrete optimal graph clustering,” IEEE Trans. Cybern., vol. 50, no. 4, pp. 1697–1710, 2018.
- [37] C. Tang, Z. Li, J. Wang, X. Liu, W. Zhang, and E. Zhu, “Unified one-step multi-view spectral clustering,” IEEE Trans. Knowl. Data Eng., vol. 35, no. 6, pp. 6449–6460, 2022.
- [38] F. Zhang, J. Zhao, X. Ye, and H. Chen, “One-step adaptive spectral clustering networks,” IEEE Signal Process. Lett., vol. 29, pp. 2263–2267, 2022.
- [39] P. W. Holland, K. B. Laskey, and S. Leinhardt, “Stochastic blockmodels: First steps,” Soc. Networks, vol. 5, no. 2, pp. 109–137, 1983.
- [40] J. Lei and A. Rinaldo, “Consistency of spectral clustering in stochastic block models,” Ann. Stat., vol. 43, no. 1, 2015.
- [41] Q. Li, X.-M. Wu, H. Liu, X. Zhang, and Z. Guan, “Label efficient semi-supervised learning via graph filtering,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2019, pp. 9582–9591.
- [42] Y. Y. Pilavcı, P.-O. Amblard, S. Barthelmé, and N. Tremblay, “Graph tikhonov regularization and interpolation via random spanning forests,” IEEE Trans. Signal. Inf. Process. Netw., vol. 7, pp. 359–374, 2021.
- [43] E. Pan and Z. Kang, “Multi-view contrastive graph clustering,” Proc. Adv. Neural Inf. Process. Syst., vol. 34, pp. 2148–2159, 2021.
- [44] L. Van der Maaten and G. Hinton, “Visualizing data using t-sne.” J. Mach. Learn. Res., vol. 9, no. 11, 2008.
- [45] G. Zhong and C.-M. Pun, “Self-taught multi-view spectral clustering,” Pattern Recognit., vol. 138, p. 109349, 2023.
- [46] F. Nie, S. Shi, and X. Li, “Semi-supervised learning with auto-weighting feature and adaptive graph,” IEEE Trans. Knowl. Data Eng., vol. 32, no. 6, pp. 1167–1178, 2019.
- [47] J. Shi and J. Malik, “Normalized cuts and image segmentation,” IEEE Trans. Pattern Anal. Mach. Intell, vol. 22, no. 8, pp. 888–905, 2000.
- [48] K. Fan, “On a theorem of weyl concerning eigenvalues of linear transformations i,” Proc. of the Nat. Academy. of Sci., vol. 35, no. 11, pp. 652–655, 1949.
- [49] S. Kumar, J. Ying, J. V. de Miranda Cardoso, and D. P. Palomar, “A unified framework for structured graph learning via spectral constraints.” J. Mach. Learn. Res., vol. 21, no. 22, pp. 1–60, 2020.
- [50] D. Wu, F. Nie, J. Lu, R. Wang, and X. Li, “Effective clustering via structured graph learning,” IEEE Trans. Knowl. Data Eng., 2022.
- [51] E. Pircalabelu and G. Claeskens, “Community-based group graphical lasso,” J. Mach. Learn. Res., vol. 21, no. 1, pp. 2406–2437, 2020.
- [52] S. S. Saboksayr and G. Mateos, “Accelerated graph learning from smooth signals,” IEEE Signal Process. Lett., vol. 28, pp. 2192–2196, 2021.
- [53] Z. Wen and W. Yin, “A feasible method for optimization with orthogonality constraints,” Math. Program., vol. 142, pp. 397–434, 2013.
- [54] P. H. Schönemann, “A generalized solution of the orthogonal procrustes problem,” Psychometrika, vol. 31, no. 1, pp. 1–10, 1966.
- [55] O. Axelsson and G. Lindskog, “On the rate of convergence of the preconditioned conjugate gradient method,” Numer. Math., vol. 48, pp. 499–523, 1986.
- [56] V. Kalofolias and N. Perraudin, “Large scale graph learning from smooth signals,” in Int. Conf. Learn. Representations, 2019.
- [57] D. A. Tarzanagh, L. Balzano, and A. O. Hero, “Fair structure learning in heterogeneous graphical models,” arXiv:2112.05128, 2021.
- [58] H. Wang, N. Wang, and D.-Y. Yeung, “Collaborative deep learning for recommender systems,” in Proc. ACM SIGKDD Int. Conf. Knowl. Discov. Data Min., 2015, pp. 1235–1244.
- [59] X. Chen, G. Yuan, F. Nie, and Z. Ming, “Semi-supervised feature selection via sparse rescaled linear square regression,” IEEE Trans. Knowl. Data Eng., vol. 32, no. 1, pp. 165–176, 2018.
- [60] L. Hagen and A. B. Kahng, “New spectral methods for ratio cut partitioning and clustering,” IEEE Trans. Comput. Aided Des. Integr. Circuits Syst., vol. 11, no. 9, pp. 1074–1085, 1992.
Supplementary Materials
A-A Several Extensions to The Proposed Model
1) Improved spectral rotation: Improved spectral rotation is an improved version of (10), which is formulated as [45]:
| (55) |
The improved spectral rotation can output a discrete label matrix that are closer to since , i.e., and are in the same space [45]. If we employ the improved spectral rotation in (23), the model becomes
| (56) |
2) Self-weighted feature importance: To improve clustering performance, some works define feature weights to determine the importance of different features in assigning cluster labels [46, 59]. Specifically, given data matrix , we define weight matrix , where and . The weighted -th feature is . The weights can be directly learned from data. Thus, our model (23) with self-weighted feature importance is formulated as
| (57) |
3) Normalized spectral clustering: The model (23) is a unified framework based on unnormalized SC [60]. Here, we extend (23) to normalized SC [47]. The standard normalized spectral embedding is
| (58) |
The fair constraint also holds for normalized SC [14]. Thus, our model based on the normalized SC is
| (59) |
4) Individual fairness: Our model is based on group fairness, which induces the fairness constraint . The work [17] introduces individual fairness into SC, which induces a new fairness constraint , where is a graph representing individual sensitive attributes. Our unified model based on individual fairness is
| (60) |
A-B The Complete Algorithm Flow for Updating (33)
We use the algorithm in [52] to solve problem (33). The complete algorithm flow is presented in Algorithm 2.
A-C The Formulation and Algorithm for FJGSED
The model FJGSED is formulated as
| (61) |
The framework of our algorithm for sloving (61) is the same as Algorithm 1, which alternately updates , and . The update of , , and is the same as Algorithm 1. The main difference is updating /, and hence we discuss the update of here. The corresponding sub-problem is
| (62) |
We can rewrite the problem as
| (63) |
Let , and the problem (63) can be optimized for each row, i.e. for ,
| (64) |
It defines a squared Euclidean distance on a simplex constraint. Inspired by [23], we update as
| (65) |
where is a hyper-parameter determining the number of neighbor nodes of the learned graphs. We select instead of as the model parameters.
We iteratively update , , and until convergence. The complete algorithm is shown in Algorithm 3
A-D The Formulation And Algorithm For FSRSC
The model FSRSC is formulated as
| (66) |
The framework of our algorithm for (66) is the same as Algorithm 1, which alternately updates , and . The update of , , and is the same as Algorithm 1. The main difference is updating , and hence we discuss the update of here. The corresponding sub-problem is
| (67) |
We use the augmented Lagrange multiplier (ALM) type of method to solve the problem (67). Let us first introduce an auxiliary variable here
| (68) |
The augmented Lagrangian function of the problem is
| (69) |
where is the Lagrangian constant. In the ALM algorithm, we update , and in an alternating manner. We first fix and update . Let , the optimization problem is
| (70) |
which can be updated elementwise as
| (71) |
Then, we fix and update . Let , and we have
| (72) |
which is equivalent to
| (73) |
where is the pair-wise distance matrix of . For every column of , we have the following problem
| (74) |
We calculate the derivative of and have
| (75) |
Let , and we obtain
| (76) |
After updating all columns of , we project into the constraints .
Finally, we fix and update , i.e., .